

高效程序员

权威指南
Jason Brittain 和 Ian F. Darwin 著 Neal Ford 著
David Bock 作序
Beijing • Cambridge • Farnham • Köln • Sebastopol • Taipei • Tokyo
高效程序员
作者:Neal Ford
版权所有 © 2008 Neal Ford。保留所有权利。
美国印刷。
由 O’Reilly Media, Inc. 出版,地址:1005 Gravenstein Highway North, Sebastopol, CA 95472。
O’Reilly 图书可用于教育、商业或销售推广用途。大多数书目也提供在线版本(http://safari.oreilly.com)。如需更多信息,请联系我们的企业/机构销售部门:(800) 998-9938 或 corporate@oreilly.com。
编辑: Mike Loukides 索引: Fred Brown
制作编辑: Loranah Dimant 封面设计: Mark Paglietti
文字编辑: Emily Quill 内页设计: David Futato
校对: Loranah Dimant 插图: Robert Romano
摄影师: Candy Ford
出版历史:
2008年7月:第一版。
O’Reilly 标志是 O’Reilly Media, Inc. 的注册商标,相关商业外观是 O’Reilly Media, Inc. 的商标。
制造商和销售商用于区分其产品的许多名称被声明为商标。当这些名称出现在本书中,且 O’Reilly Media, Inc. 知晓商标声明时,这些名称以大写或首字母大写形式印刷。
在准备本书时已采取了一切预防措施,但出版商和作者对错误或遗漏,或因使用本书所含信息而造成的损害不承担任何责任。
TM
本书使用 RepKover™,这是一种耐用且灵活的平装装订。
ISBN: 978-0-596-51978-0
[C]
1213991395
前言 vii
序言 ix
1 引言 1
为什么要写一本关于程序员生产力的书? 2
本书讲什么 3
接下来去哪里? 5
第一部分 机制
2 加速 9
启动台 10
加速器 18
宏 33
小结 35
3 专注 37
消除干扰 38
搜索胜过导航 40
查找困难目标 42
使用根视图 44
使用粘性属性 46
使用基于项目的快捷方式 47
增加显示器 48
使用虚拟桌面隔离工作区 48
小结 50
4 自动化 51
不要重复造轮子 53
本地缓存内容 53
自动化与网站的交互 54
与 RSS 订阅交互 54
将 Ant 用于非构建任务 56
将 Rake 用于常见任务 57
使用 Selenium 遍历网页 58
使用 Bash 收集异常计数 60
用 Windows Power Shell 替换批处理文件 61
使用 Mac OS X Automator 删除旧下载 62
驯服命令行 Subversion 62
用 Ruby 构建 SQL 分割器 64
自动化的合理性 65
iii
不要剃牦牛 67
小结 68
5 规范性 69
DRY 版本控制 70
使用规范构建机器 72
间接性 73
使用虚拟化 80
DRY 阻抗不匹配 80
DRY 文档 88
小结 93
第二部分 实践
6 测试驱动设计 97
演进测试 99
代码覆盖率 105
7 静态分析 109
字节码分析 110
源代码分析 112
使用 Panopticode 生成度量 113
动态语言的分析 116
8 良好公民 119
破坏封装 120
构造函数 121
静态方法 121
犯罪行为 126
9 YAGNI 129
10 古代哲学家 135
亚里士多德的本质属性和偶然属性 136
奥卡姆剃刀 137
得墨忒耳定律 140
软件传说 141
11 质疑权威 143
愤怒的猴子 144
流畅接口 145
反对象 147
12 元编程 149
Java 和反射 150
使用 Groovy 测试 Java 151
编写流畅接口 152
元编程的未来 154
13 组合方法和 SLAP 155
组合方法实战 156
iv 目录
SLAP 160
14 多语言编程 165
我们如何到达这里?这里到底是哪里? 166
我们要去哪里?我们如何到达那里? 169
Ola 的金字塔 173
15 寻找完美工具 175
寻求完美编辑器 176
候选者 179
为工作选择正确的工具 180
放弃错误的工具 186
16 结论:继续对话 189
附录:构建块 191
索引 199
目录 v
在我们的行业中,程序员的个人生产力差异很大。大多数人可能需要一周才能完成的工作,有些人一天就能完成。为什么会这样?简短的答案是关于对开发者可用工具的掌握程度。详细的答案是关于对工具能力的真正认识以及使用它们的思维过程的掌握。真相介于方法论和哲学之间,这正是 Neal 在本书中所捕捉的内容。
本书的种子是在 2005 年秋天,在返回机场的路上播下的。Neal 问我:“你认为世界需要另一本关于正则表达式的书吗?”从那里开始,
我的职业生涯转向了关于我们希望存在的书籍的话题讨论。我回想起职业生涯中的一个节点,在那里我感觉自己从仅仅是优秀跃升到了非常高效,以及这是如何发生的以及为什么会发生。我说:“我不知道这本书的标题是什么,但副标题应该是’将命令行用作集成开发环境’。”当时我将生产力的提升归功于使用 bash shell 带来的加速,但不仅如此——更重要的是我对这个工具越来越熟悉,不再需要费力去做事情,而是可以直接完成它们。我们花了一些时间讨论那种超高生产力以及如何将其提炼出来。经过数年时间、无数次对话和一系列讲座之后,Neal 在这个主题上创作了一部权威著作。
在他的著作《Programming Perl》(O’Reilly出版)中,Larry Wall 将程序员的三大美德描述为”懒惰、急躁和傲慢”。懒惰,因为你会付出努力来减少总体必要的工作量。急躁,因为如果你浪费时间做一些计算机可以更快为你完成的事情,这会让你感到愤怒。而傲慢,因为过度的自豪感会促使你编写其他人不会说坏话的程序。这本书没有使用这些词中的任何一个(我用 grep 检查过),但当你继续阅读时,你会发现这种情感在内容中得到了呼应和扩展。
有几本书对我的职业生涯产生了巨大影响,改变了我看待世界的方式。我希望10年前就能拿到这本书;我确信它会对阅读它的人产生深远的影响。
—David Bock 首席顾问 CodeSherpas
多年前,我为正在学习新技术(如 Java)的经验丰富的开发者教授培训课程。学生之间的生产力差异总是令我震惊:有些人的效率要高出几个数量级。我指的不是他们使用的工具:我指的是他们与计算机的总体交互方式。我曾经对几个同事开玩笑说,班上的一些人不是在”运行”他们的计算机,而是在”遛”计算机。顺着这个逻辑结论,这让我质疑自己的生产力。我是否从我正在运行(或遛)的计算机中获得了最高效的使用?
快进多年后,David Bock 和我就这件事展开了对话。我们的许多年轻同事从未真正使用过命令行工具,不理解它们如何可能比当今精巧的 IDE 提供更高的生产力。正如 David 在本书前言中所述,我们就此进行了交谈,并决定写一本关于更有效使用命令行的书。我们联系了一家出版商,并开始从朋友和同事那里收集我们能找到的所有命令行技巧。
然后,发生了几件事。David 创办了自己的咨询公司,他和妻子有了他们的第一个孩子:三胞胎!好吧,David 现在显然有太多事情要处理了。与此同时,我得出了一个结论,即一本纯粹关于命令行技巧的书可能是有史以来最无聊的书。大约在那个时候,我在班加罗尔的一个项目上工作,我的结对编程伙伴 Mujir 正在谈论代码模式(pattern)以及如何识别它们。这个想法像一吨砖头一样击中了我。我一直在我收集的所有技巧中看到模式。与其写一本大量命令行技巧的合集,不如讨论如何识别是什么让开发者更高效。这就是你现在手中拿着的东西。
这不是一本面向最终用户想要更有效地使用计算机的书。这是一本关于程序员生产力的书,这意味着我可以对读者做很多假设。开发者是终极高级用户,所以我不会在基础内容上花太多时间。精通技术的用户当然应该能学到东西(尤其是在第一部分),但目标读者仍然是开发者。
本书没有明确的顺序,所以可以随意浏览或从头到尾阅读。主题之间的联系只会以意想不到的方式出现,所以从头到尾阅读可能有轻微的优势,但不足以建议这是唯一的阅读方式。
本书使用以下排版约定:
斜体表示新术语、URL、电子邮件地址、文件名和文件扩展名。
等宽字体用于程序清单,以及在段落中引用程序元素,如变量或函数名、数据库、数据类型、环境变量、语句和关键字。
等宽粗体显示用户应该逐字输入的命令或其他文本。
等宽斜体显示应该由用户提供的值或由上下文确定的值替换的文本。
本书旨在帮助您完成工作。通常,您可以在您的程序和文档中使用本书中的代码。除非您复制了代码的重要部分,否则您无需联系我们以获得许可。例如,编写一个使用本书中几个代码块的程序不需要许可。销售或分发包含 O’Reilly 书籍示例的 CD-ROM 需要许可。通过引用本书并引用示例代码来回答问题不需要许可。将本书中大量示例代码合并到产品文档中需要许可。
我们感谢但不要求署名。署名通常包括标题、作者、
出版商和ISBN。例如:“The Productive Programmer by Neal Ford. Copyright 2008 Neal Ford, 978-0-596-51978-0.”
如果您认为您对代码示例的使用超出了合理使用范围或上述授权,请随时通过 permissions@oreilly.com 联系我们。
请将有关本书的评论和问题发送至出版商:
O’Reilly Media, Inc. 1005 Gravenstein Highway North Sebastopol, CA 95472 800-998-9938 (美国或加拿大) 707-829-0515 (国际或本地) 707 829-0104 (传真)
我们为本书建立了一个网页,在那里我们列出勘误表、示例和任何附加信息。您可以访问此页面:
http://www.oreilly.com/catalog/9780596519780
如需对本书发表评论或提出技术问题,请发送电子邮件至:
有关我们的图书、会议、资源中心和O’Reilly网络的更多信息,请访问我们的网站:
当您在您最喜爱的技术书籍封面上看到Safari® Enabled图标时,这意味着该书可以通过O’Reilly Network Safari Bookshelf在线获取。
Safari提供了一个比电子书更好的解决方案。它是一个虚拟图书馆,让您可以轻松搜索数千本顶级技术书籍,剪切和粘贴代码示例,下载章节,并在需要最准确、最新信息时快速找到答案。在 http://safari.oreilly.com 免费试用。
这是本书中我的非技术朋友们会阅读的唯一部分,所以我最好写好它。我的整个生活支持系统在这个漫长的写书过程中给了我极大的帮助。首先是我的家人,特别是我的母亲Hazel和父亲Geary,还有我的整个大家庭,包括我的继母Sherrie和我的继父Lloyd。No Fluff, Just Stuff的演讲者、参与者和组织者Jay Zimmerman帮助我在许多个月里审查了这些材料,特别是演讲者们让大量的旅行变得值得。特别感谢我的ThoughtWorks同事们:一群让我感到非常荣幸能与之共事的人。我从未见过一家公司如此致力于革新人们编写软件的方式,拥有如此高度智慧、热情、专注、无私的人。我认为这至少部分归功于非凡的Roy Singham,ThoughtWorks的创始人,我对他有点崇拜。感谢我所有的邻居(无论是非车库的还是荣誉车库的),他们不了解也不关心任何这些技术内容,特别是Kitty Lee、Diane和Jamie Coll、Betty Smith,以及所有其他现在和以前的Executive Park邻居(是的,Margie,这包括你)。特别感谢我现在遍布全球的朋友们:Masoud Kamali、Frank Stepan、Sebastian Meyen和S&S团队的其他成员。当然,还有那些我只能在其他国家见到的人,比如Michael Li,以及虽然他们只住在五英里外,但我们的时间表很少能对上的Terry Dietzler和他的妻子Stacy。感谢(虽然他们读不懂这个)Isabella、Winston和Parker,他们不关心技术,但真的很在意关注(当然是按他们的条件)。感谢我的朋友Chuck,他越来越少的来访仍然能让我的一天变得轻松愉快。最后,把最重要的留在最后,我美好的妻子Candy。我所有的演讲朋友都说她是个圣人,允许我环游世界,演讲和写软件。她慷慨地纵容我这个无所不包的职业,因为她知道我热爱它,但没有像爱她那样。她耐心地等待,直到我退休或厌倦这一切,这样我就可以把所有时间都花在她身上。

生产力被定义为单位时间内完成的有用工作量。 生产力更高的人在给定的时间间隔内比生产力较低的人完成更多有效的工作。本书全面讲述如何在执行软件开发所需任务时变得更有生产力。它与语言和操作系统无关:我提供了多种语言的技巧,涵盖三大主流操作系统:Windows(各种版本)、Mac OS X和*-nix(Unix和Linux替代品)。
本书讲的是个人程序员的生产力,而不是团队生产力。为此,我不讨论方法论(好吧,也许会在这里那里提一点,但总是在边缘地带)。我也不讨论影响整个团队的生产力提升。我的使命是为个人程序员提供工具和理念,让他们在单位时间内完成更多有用的工作。
我在ThoughtWorks工作,这是一家国际咨询公司,约有1,000名员工分布在6个国家。由于我们是旅行顾问(特别是在美国),我们在人口统计学上是一家非常年轻的公司。在我们公司的一次聚会上(有饮料供应),我开始与一位人力资源部门的人聊天。她问我多大了,我告诉了她。然后,她给了我一个不经意的赞美(?): “哇,你的年龄足以为公司增添多样性!” 这引发了一些思考。我从事软件开发已经很多年了(想起那句感伤的话”在我那个年代,我们有煤油驱动的计算机…“)。在那段时间里,我观察到一个有趣的现象:
开发者的效率正在下降,而不是提高。在远古时代(在计算机时间里就是几十年前),运行计算机是一项困难的工作,编程就更不用说了。你必须是一个真正聪明的开发者才能从这些笨重的机器中获得任何有用的东西。这个熔炉锻造出了真正聪明的家伙(Really Smart Guys),他们开发出各种高效的方法来与那个时代难以驾驭的计算机交互。
慢慢地,由于程序员的辛勤工作,计算机变得更容易使用了。这种创新实际上是为了让用户不再那么多抱怨。真正聪明的家伙们为自己感到自豪(就像所有程序员在能让用户安静下来时所做的那样)。然后一件有趣的事情发生了:整整一代开发者出现了,他们不再需要聪明的技巧和狡猾的智慧来让计算机做他们想做的事情。开发者们,就像最终用户一样,沉浸在更易用的计算机中。那么,这有什么问题吗?毕竟,生产力是一件好事,对吧?
这要看情况。对用户来说高效的东西(漂亮的图形用户界面、鼠标、下拉菜单等)实际上可能会阻碍那些试图从计算机获得最佳性能的人。“易于使用”和”高效”很少重叠。在图形用户界面(好吧,我就直说了:Windows)中长大的开发者不知道过去真正聪明的家伙们许多很酷、高效的技巧。今天的开发者不是在运行他们的计算机,而是在遛它们。我打算解决这个问题。
这里有一个简单的例子:你一天要访问多少个网站?它们中的大多数以”www.”开头,以”.com”结尾。所有现代浏览器都存在一个鲜为人知的快捷方式:地址补全。地址补全使用热键组合自动在你在浏览器地址栏中输入的字符串前面添加”www.”,在末尾添加”.com”。不同的浏览器支持略有不同的语法。(请注意,这与让浏览器自动提供前缀和后缀不同。所有现代浏览器也都这样做。)区别在于效率。为了自动补全前缀和后缀,浏览器会访问网络并查找具有”裸”名称的站点。如果找不到,它会尝试使用前缀和后缀,这需要再次访问网络。使用快速连接时,你甚至可能不会注意到延迟,但你正在用所有这些错误的访问减慢整个互联网的速度!
Internet Explorer (IE) 使输入包含标准前缀和后缀的地址变得更容易。使用 Ctrl-Enter 键在地址前面添加”www.”,在末尾添加”.com”。
相同的 Internet Explorer 快捷方式也适用于 Windows 版本的 Firefox。对于 Macintosh,Apple-Enter 做同样的事情。Firefox 更进一步:对于它支持的所有平台,Alt-Enter 在末尾放置”.org”。
Firefox 还有其他方便的快捷键,似乎没有人利用。要直接转到某个标签页,你可以在 Windows 中使用 Ctrl + 数字,或在 OS X 中使用 Apple + 数字。
好吧,这个快捷方式每个网页只节省了八次按键。但想想你每天访问的网页数量,每页这八个字符开始累积起来。这是加速(acceleration)原则的一个例子,在第2章中定义。
但每个网页节省八次按键并不是这个例子的重点。我对我认识的所有开发者进行了非正式调查,发现不到20%的人知道这个快捷方式。这些人都是铁杆计算机专家,但他们甚至没有利用最简单的生产力提升。我的使命是纠正这一点。
《高效程序员》分为两部分。第一部分讨论生产力的机制,以及在你进行软件开发的物理活动时使你更高效的工具及其用途。第二部分讨论生产力的实践,以及你如何利用自己和他人的知识更快地生产出更好的软件。在这两个部分中,你可能会遇到一些你已经知道的东西,以及一些你以前从未想过的东西。
你可以把这本书当作命令行和其他生产力技巧的食谱书,仍然会受益。但是,如果你理解为什么某件事能提高生产力,你就可以在周围认出它。创建模式来描述某件事会创建术语:一旦你给某件事命名,当你再次看到它时就更容易识别。本书的目标之一是定义一组生产力原则,以帮助你定义自己的生产力技术。就像所有模式一样,一旦它们有了名字,就更容易识别它们。知道为什么某件事能加快你的速度,可以让你更快地识别其他能帮助你更快工作的事情。
这不仅仅是一本关于如何更有效地使用计算机的书(尽管这是一个副作用)。它专注于程序员的生产力。为此,我不涵盖许多对普通用户甚至高级用户来说显而易见的东西(尽管,作为证明规则的例外,前面的”浏览器中的地址补全”部分确实展示了一个显而易见的技巧)。程序员代表了计算机用户的独特子集。我们应该能够比任何人更有效地让计算机服从我们的意愿,因为我们最了解它们的真正工作方式。这本书主要是关于你可以用计算机做什么以及对计算机做什么来使你的工作更容易、更快、更高效。但是,我也讨论了一些可以让你更高效的容易实现的改进(low-hanging fruit)。
第一部分涵盖了我能发明、收集、从朋友那里逼问或阅读到的所有生产力技巧。
最初,我的目标是创建世界上最棒的生产力方法集合。我不知道是否实现了这个目标,但你仍然会在这里找到一个相当令人印象深刻的方法集合。
当我开始整理所有这些很酷的生产力技巧时,我注意到了一些模式的出现。在研究这些技巧时,我开始为程序员的生产力制定分类。最终,我创建了程序员生产力原则(Principles of Programmer Productivity),坦白说,我想不出一个更自命不凡的名字了。这些原则是加速(acceleration)、专注(focus)、自动化(automation)和规范化(canonicality)。它们描述了让程序员变得更高效的实践。
显然,如果一个人在特定任务上更快,那么这个人在该任务上比做同样事情但速度较慢的人更有生产力。加速原则的绝佳例子是本书中出现的众多键盘快捷键。加速涵盖了诸如启动应用程序、管理剪贴板以及搜索和导航等内容。
它讨论了减少环境混乱(包括物理和虚拟环境)的方法、如何高效搜索以及如何避免分心。
第1章:简介
让计算机为你执行额外的工作显然会让你更有生产力。
你每天执行的许多任务可以(并且应该)自动化。本章提供了让你的计算机为你工作的示例和策略。
规范化实际上只是应用DRY原则(Don’t Repeat Yourself,不要重复自己)的一个花哨术语,该原则首次由Andy Hunt和Dave Thomas在《程序员修炼之道》(The Pragmatic Programmer, Addison-Wesley)中提出。DRY原则建议程序员找到信息重复的地方,并为这些信息创建单一来源。《程序员修炼之道》雄辩地描述了这一原则,在第5章”规范化”中,我展示了应用它的具体示例。
第二部分:实践(哲学)
作为一名开发者,我在咨询工作上度过了大部分资深岁月。相比年复一年在同一代码库上工作的开发者,咨询顾问有一些优势。我们可以看到许多不同的项目和许多不同的方法。当然,我们也看到了不少失败的项目(咨询顾问很少被叫去”修复”健康的项目)。我们可以看到软件开发的广泛范围:从头开始构建项目、在中途提供建议,以及拯救严重损坏的项目。随着时间的推移,即使是最不善于观察的人也能感受到什么有效、什么无效。
第二部分是我所见过的那些能让开发者更有生产力或降低其生产力的事物的提炼。我将它们或多或少按随机顺序捆绑在一起(尽管你可能会惊讶于同样的想法以不同的形式出现的频率)。这不是要成为让开发者高效的终极大全;相反,这是我观察到的事物清单,只是所有可能性的一小部分。
现在该去哪里?
本书的两个部分是独立的,所以你可以按任何顺序阅读;然而,第二部分更具叙事性,可能会出现意想不到的联系。不过,其中大部分材料是非顺序的:你可以按任何你喜欢的顺序阅读。
有一点警告。如果你对基本的命令行操作(管道、重定向等)不太熟悉,你应该快速查看一下附录A。它涵盖了如何设置适合使用第一部分中讨论的许多技巧和技术的环境。我保证,这很轻松。
机制
第一部分”机制”处理的是(没错,你猜对了)生产力的机制。这些工具中的许多不一定是开发者工具,而是可以帮助任何高级用户的工具。当然,开发者应该是终极的高级用户,充分利用本书这一部分列出的几乎所有工具类别。
加速
使用计算机需要相当多的仪式和繁文缛节。你必须启动它,你必须知道如何启动应用程序,并且你必须理解交互模型,这在不同应用程序之间可能有所不同。你与计算机的交互越少,速度就越快。换句话说,消除繁文缛节可以让你有更多时间去关注问题的本质。你花在漫长的文件系统层次结构中查找内容的时间,本可以用来提高生产力。计算机是工具,你在工具的维护上花费的时间越多,完成的工作就越少。科幻作家道格拉斯·亚当斯(Douglas Adams)有一句名言:“我们被技术所困,而我们真正想要的只是能用的东西。”
注意
专注于本质,而非繁文缛节。
本章全是关于如何加快你与计算机的交互,无论是更快地启动应用程序、更快地查找文件,还是更少地使用鼠标。
启动板
看看你计算机的应用程序列表。如果你使用的是Windows,点击”开始”
并选择程序。你有多少列?两列?三列?四列!?随着硬盘容量越来越大,应用程序种类(以及我们必须使用的工具)变得越来越复杂,我们使用的应用程序数量也呈爆炸式增长。当然,有了常见的 100 GB 硬盘,我们可以在系统中安装大量软件。但数量是有代价的。
[应用程序列表的有用性与其长度成反比。]
列表越长,就越不实用。在 Windows 中有三列,或者在 Mac OS X 中 dock 将图标压缩到微观尺寸,找到我们需要的东西变得越来越困难。这对开发者的影响尤其严重,因为我们有很多偶尔使用的应用程序:那些我们可能一个月只运行一天的专用工具,但当那一天到来时,我们又迫切需要它们。
[启动器(Launchers)]
启动器是一种应用程序,允许你输入应用程序(或文档)名称的前几个字符来启动它。大多数情况下,这是一种更高效的启动应用程序的方式。
[花哨的界面看起来很好,但并不实用。]
[10][ 第 2 章:] [加速]
如果你知道你要找的东西的名称(比如应用程序的名称),为什么不直接告诉计算机你想要什么,而不是在一个庞大的列表中排序或在一堆图标中搜索它?启动器穿透图形化的花哨界面,精确快速地直达你需要的东西。
所有主流操作系统都有开源和免费的启动器,允许你输入想要启动的应用程序的名称(或部分名称)。值得尝试的几个包括 Launchy、Colibri 和 Enso。Launchy 和 Colibri 都是开源的,因此是免费的,它们都允许你打开一个小窗口并开始输入应用程序的名称,它会在列表中弹出。Launchy 目前是最受欢迎的开源启动器。Colibri 试图复制一个名为 Quicksilver 的 Mac OS X 实用工具[(在即将到来的”Mac OS X”部分讨论)]。
Enso 是一个具有一些有趣附加功能的启动器。它也是免费的(但不是开源的),由 Humanized 公司创建,该公司由 Jef Raskin 创立,他是 Mac 早期的用户界面设计师之一。Enso 封装了他的许多(有时略显激进的)用户界面观点,但它非常有效。例如,Raskin 推广的一个想法是准模式键(Quasimode keys)的概念,它像 Shift 键一样工作(换句话说,按住时改变键盘的模式)。Enso 接管了相当无用的 Caps Lock 键,并使用它来启动应用程序和执行其他任务。你按住 Caps Lock 键并开始输入命令,比如 OPEN FIREFOX,它会打开 Firefox。当然,这样输入很麻烦,所以另一个 Enso 命令是 LEARN AS FF FIREFOX,它教会 Enso 使用 FF 命令启动 Firefox。Enso 不仅仅是启动应用程序。如果你在文档中有一个数学表达式,比如 4+3,你可以突出显示它并调用 CALCULATE 命令,Enso 会用计算的值替换你突出显示的文本。Enso 值得尝试,看看 Raskin 关于启动的观点是否符合你的需求。
如果你使用 Windows Vista,它包含了这些启动器应用程序的启动功能。当你调用开始菜单时,随后出现的菜单底部有一个搜索字段,允许你输入想要的应用程序名称,使用增量搜索。但它有一个缺点(可能是一个 bug),而上面提到的启动器没有:如果你输入一些不存在的内容,Windows Vista 需要很长时间才能返回并告诉你找不到它。在这个过程中,你的机器基本上跟砖头一样没用。希望这只是当前版本的一个怪癖,很快就会被修复。
[下载地址 ][http://www.launchy.net.]
[下载地址 ][http://colibri.leetspeak.org.]
[下载地址 ][http://www.humanized.com.]
[启动面板 ] [11]
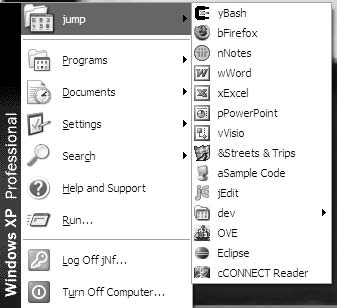
[图 2-1. 自定义启动器窗口]
[创建 Windows 启动面板]
你可以轻松利用 Windows 中的文件夹基础设施来创建自己的启动面板。在开始按钮下创建一个文件夹,其中包含你每天使用的应用程序的快捷方式。你可以将这个文件夹命名为”jump”,并使用”j”作为其快捷键,这样你就可以通过输入 Windows-J 来访问它。图 2-1 中显示了这样一个”jump”窗口的示例。注意,每个菜单项都包含一个在文件夹内唯一的单字母前缀,这有助于快速启动应用程序。启动文件夹中的每个应用程序只需两次按键即可访问:Windows-J[字母] 启动应用程序。
这只是一个目录,所以你可以在其中嵌套其他目录来创建你自己的应用程序迷你层次结构。对于我的大多数工作机器,26 个条目是不够的,所以我倾向于创建一个 dev 启动文件夹,其中包含所有开发工具。我有意将一个层次结构替换为另一个,但有一个很大的区别:我对这个组织有完全的控制权,不像 Windows 中的程序组。我经常重新组织这个文件夹,因为一些应用程序不再受欢迎,新的应用程序取代了它们。
创建启动文件夹非常简单,但这取决于你拥有的开始按钮的类型。Windows XP 和 Vista 支持两种”开始”配置:“经典”(从 Windows 95 到 2000 的风格)和”现代”(Windows XP 和 Vista)。对于”经典”Windows,创建启动文件夹极其简单。右键单击开始按钮,选择打开(如果你只想为当前登录的用户添加启动菜单)或打开所有用户(为所有人更改它)。这将打开控制开始菜单的底层文件夹。
你想要打开的内容,都在”开始”菜单中,你可以随心所欲地添加快捷方式。
或者,你可以进入开始菜单所在的位置,在当前用户的 Documents and Settings 目录结构下。一个简单的方法是从庞大的程序菜单中选择你一直需要的程序,然后右键拖动到启动文件夹中,创建快捷方式的副本,这样就能用你经常使用的内容填满启动菜单。
[第2章:加速]
如果你使用”现代”的 Windows 开始菜单,创建启动菜单会更困难,但仍然可行。你可以在前面提到的同一目录中创建启动文件夹,但出于某种奇怪的原因,当你按下 Windows 键时它不再立即出现;现在只有在展开程序组后才会出现。这是一个主要的烦恼,因为现在我们加速启动的方式需要额外的按键;然而,有一个解决这个问题的方法。如果你在桌面上创建跳转文件夹并将其拖放到开始菜单上,它将创建一个立即显示的文件夹。“现代”版本的开始菜单剩下的唯一麻烦是热键问题。在”现代”菜单中,不同的应用程序会根据使用情况进出(Windows 会随机化你精心记忆的快速访问路径)。因此,如果你使用”现代”开始菜单,你应该为启动菜单选择一个不会冲突的首字符,比如 ~ 或 ( 键。
因为这很麻烦,我倾向于只使用”经典”版本的开始按钮。你可以在 Windows XP 或 Vista 中通过任务栏的属性从”现代”切换到”经典”,如图 2-2 所示。
Microsoft 发布(但不支持)一组名为 PowerToys 的实用程序,§ 包括 Tweak UI,它允许你通过图形界面对 Windows 注册表进行更改。我的文档(My Documents)通常位于令人费解的位置 c:\Documents and Settings\<your login name>\My Documents(在 Windows Vista 中简化为直接在根目录下的 Documents)。Tweak UI 允许你更改我的文档的默认位置,以便将其移动到更合理的位置,如 c:\Documents(Windows Vista 默认将文档放在这里)。
但要小心:如果你要移动我的文档,应该在操作系统安装的早期进行。许多 Windows 应用程序依赖于该目录中的文件,如果你在一个已经建立的 Windows 机器上这样做,将会破坏许多应用程序。
如果你不想走得这么远,你可以选择一个文件夹(如我的文档),右键单击以获取属性对话框,并告诉 Windows 重新定位它。它会将你的所有我的文档文件复制到新位置。你也可以使用古老的 subst 命令(允许你用一个文件夹替换另一个文件夹),但它会破坏许多应用程序,所以请谨慎使用。如果你使用 NTFS 文件系统,Junction 实用程序可以让你真正地用一个目录替换另一个目录,效果更好。详见第5章中的”间接引用”。
§ 下载地址:http://www.microsoft.com/windowsxp/downloads/powertoys/xppowertoys.mspx.
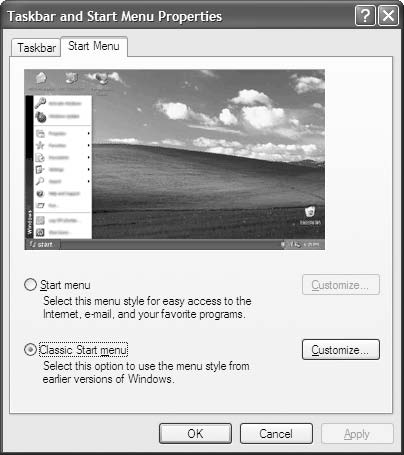
图 2-2. 切换回经典菜单
Windows 确实有一个快速简便的机制来启动几个应用程序:快速启动栏(Quick Launch bar)。这是出现在任务栏上的快捷方式区域,通常在开始按钮旁边。如果你看不到它,你需要通过右键单击任务栏并选择快速启动栏来打开它。你可以在这里拖放快捷方式并将其用作启动器。而且,因为这是一个目录(像其他所有东西一样),你可以直接将内容放在快速启动文件夹中。就像所有其他快捷方式一样,你可以为这些项目分配操作系统范围的键加速器(key accelerators),但现有的应用程序加速器会干扰它们。
注意
输入比导航更快。
Windows Vista 对快速启动栏有一个略微不同的改进。你可以通过 Windows 键加数字键来运行与快捷方式关联的应用程序。换句话说,Windows-1 选择并按下第一个快速启动项,Windows-2 启动第二个,依此类推。这个机制很好用…只要你经常使用的应用程序不超过10个!虽然这不能像真正的启动器那样容纳那么多应用程序,但它可能是放置几个非常重要的应用程序的便捷位置。
所有主要操作系统都允许你创建键盘加速器(即热键)来启动应用程序。那么,为什么不只是定义一个加速器列表,然后完成所有这些启动工作呢?将热键映射到应用程序启动在你总是将桌面作为当前焦点时效果很好。但开发人员几乎从来没有只打开桌面(或文件系统资源管理器)。通常,开发人员会打开20个专用工具,每个工具都有自己的神奇键盘组合。尝试使用操作系统的热键来启动应用程序会造成这种巴别塔效应(Tower of Babel effect)。几乎不可能找到不会与至少某些当前打开的应用程序冲突的热键。虽然使用操作系统级热键听起来是个有吸引力的想法,但在实际使用中会失效。
Mac OS X 的 Dock 结合了 Windows 中快速启动菜单和任务按钮的实用性。它鼓励你将常用的应用程序放在 Dock 上,并将其他应用程序拖出去
空间(当它们消失时会有令人满意的”噗”的一声)。就像快速启动栏一样,有限的屏幕空间限制了你:在dock上放置足够数量的应用程序会让它膨胀到变得笨重的地步。这催生了Mac OS X替代启动器的细分市场。尽管一些知名的启动器已经存在多年,但今天大多数高级用户已经迁移到Quicksilver。
Quicksilver是任何人最接近创建图形化命令行的尝试。就像bash提示符一样,Quicksilver允许你启动应用程序、执行文件维护以及许多其他操作。Quicksilver本身以浮动窗口的形式出现,通过可自定义的热键调用(Quicksilver的一切都是可自定义的,包括浮动窗口的外观和感觉)。一旦它出现,你可以在”目标”面板中执行操作。
Quicksilver目前免费,可从 http://quicksilver.blacktree.com/ 下载。Quicksilver的创建者正在积极鼓励开发者为其构建更多插件。已经有Subversion、PathFinder、Automator等核心操作系统和第三方应用程序的插件。
Quicksilver绝对让人上瘾。比任何其他软件都更能从根本上改变我与计算机交互的方式。Quicksilver代表了软件中最稀有的特质:简单优雅。第一次看到它时,你会想”没什么大不了的,只是启动应用程序的新方式。“然而,你用得越多,就会看到越多的微妙之处,它的强大功能会逐渐展现出来。
Quicksilver可以通过热键和几个按键轻松启动应用程序。Quicksilver中有三个面板:顶部用于文件或应用程序(“名词”),中间用于操作(“动词”),第三个(如有必要)用于操作的目标(“直接宾语”)。当你在Quicksilver中搜索项目时,它会将你输入的所有内容视为具有通配符。例如,如果你在Quicksilver中输入”shcmem”,它将找到名为ShoppingCartMemento.java的文件。
Quicksilver不仅仅是启动应用程序。它允许你对任何文件应用任何(上下文相关的)命令。在图2-3中,我选择了一个名为acceleration_quicksilver_regex.tiff的文件,并指定了Move To…操作。第三个面板允许我选择移动的目标位置,方式与我在目标面板中选择文件名的方式相同(即使用前面描述的特殊通配符行为)。
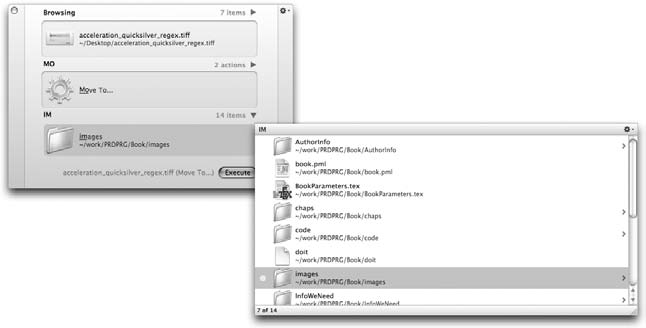
为什么这对开发者来说如此重要?Quicksilver通过插件工作,并且存在相当数量的以开发者为中心的插件。例如,Quicksilver具有出色的Subversion集成。你可以更新仓库、提交更改、获取状态以及许多其他功能。虽然不如命令行Subversion强大(确实没有什么能与之相比),但它为你提供了一种快速的图形化方式,只需几个按键就能完成常见任务。
关于Quicksilver还有一点值得一提:触发器(trigger)。触发器是名词-动词-直接宾语的组合,就像你通过正常用户界面所做的那样,永久存储在热键下。例如,我有几个项目一直使用相同的按键序列:
我经常这样做,所以我为它分配了一个触发器。现在,只需按一个键(在我的例子中是Alt-1),我就可以调用这个命令序列。触发器旨在让你将常见的Quicksilver操作保存在单个热键下。我还使用触发器来启动和停止servlet引擎(如Tomcat和Jetty)。确实非常有用。
我只是触及了Quicksilver功能的皮毛。你可以启动应用程序、对一个或多个文件应用命令、在iTunes中切换歌曲等等。它改变了你使用操作系统的方式。使用Quicksilver,你可以将dock仅用作任务管理器,显示当前运行的应用程序,并使用Quicksilver作为启动器。Quicksilver的自定义通过已发布的插件API进行(有关如何下载Quicksilver及其插件的信息,请参阅前面的”获取Quicksilver”侧边栏)。
Quicksilver是一个很好的例子,说明一个应用程序在首次安装时看起来太简单而无用。许多朋友对我说过”我安装了Quicksilver,现在该做什么?“为此,我和一些朋友创建了一个关于Mac上通用生产力主题的博客,名为PragMactic-OSXer (http://pragmactic-osxer.blogspot.com)。
Quicksilver的功能与Spotlight(Mac OS X上的内置搜索工具)重叠。但Quicksilver不仅仅是快速搜索。它允许你基本上替换Mac OS X Finder,因为在Quicksilver中可以更快地完成所有典型的文件操作(打字比导航更快)。Quicksilver允许你指定要编目的项目(不像Spotlight索引整个硬盘),这使Quicksilver在其索引中查找文件更快。而且Quicksilver使用很酷的”每个字符之间的正则表达式”方式来指定搜索项,而Spotlight没有。我实际上不再使用Finder了。所有文件操作(以及几乎与计算机的所有交互)都通过Quicksilver完成。我变得如此依赖它,以至于如果
如果它崩溃了(虽然很少发生但确实会发生;毕竟它仍处于测试阶段),就好像我的机器突然瘫痪了一样。与我使用过的任何其他实用工具相比,它改变了我的工作方式。
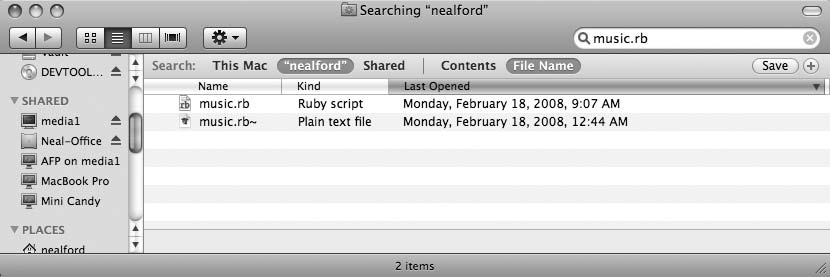
Leopard版本的Spotlight比以前的版本快得多,但这两个工具并不互斥。在Leopard版本的Spotlight中,您现在可以跨多台机器进行搜索(Quicksilver无法做到这一点)。要实现此功能,您必须登录到另一台机器(出于明显的安全原因)。现在,当您执行Spotlight搜索时,可以在工具栏上选择要搜索的机器。在示例中[图2-4],我从笔记本电脑登录到桌面机器(名为Neal-office)并选择了主目录(名为nealford)。当我执行Spotlight搜索时,可以在顶部工具栏中选择目标。文件music.rb仅存在于桌面机器上。
不幸的是,Windows和Linux世界还没有像Quicksilver这样出色的工具。前面提到的Colibri实现了Quicksilver功能的一小部分(主要是其启动功能,但不包括图形化命令行部分)。希望最终有人能将Quicksilver移植到其他平台或创建一个令人信服的克隆版本。它是所有操作系统中最先进的启动器。
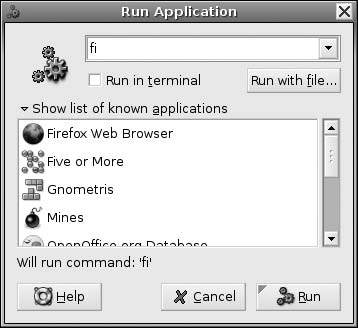
大多数桌面Linux运行GNOME或KDE。两者都具有从Windows借鉴的类似任务栏风格的用户界面。然而,自定义它们的启动选项要困难得多,因为它们的菜单结构不像简单的目录条目那样存在。现代版本的GNOME包含一个相当实用的启动器,默认绑定到Alt-F2快捷键。它显示可运行应用程序的列表,并允许您通过输入来精确选择。[在图2-5中,列表通过两个字母”fi”缩小了范围。]
注意优先使用键盘而不是鼠标。
开发人员本质上是专门的数据录入员。我们输入到计算机中的数据不是来自某个外部来源,而是来自我们的大脑。但数据录入操作员的经验教训仍然适用。按输入信息量获得报酬的数据录入工作者知道,使用鼠标会使他们的速度降低几个数量级。开发人员可以从中学到重要的一课。
经典的”无需鼠标”应用程序是VI编辑器。观看有经验的VI用户令人敬畏。光标似乎跟随他们的眼睛。不幸的是,要达到那个水平需要大约两年的每日VI使用,因为学习曲线非常陡峭。如果您每天使用它1年零364天,仍然会感到吃力。另一个经典的Unix编辑器是Emacs,它也非常以键盘为中心。不过,Emacs是原型IDE(集成开发环境):通过其插件架构,它不仅仅是编辑文件。VI用户轻蔑地将Emacs称为”一个具有有限文本编辑功能的伟大操作系统”。
VI和Emacs都支持一个非常重要的加速器:永远不要把手从字符键上移开。即使是伸手去按键盘上的方向键也会降低您的速度,因为您必须回到基准行键才能再次输入字符。真正有用的编辑器让您的手保持在最佳位置,同时进行输入和导航。
除了学习VI之外,您可以弄清楚如何使用加速器来加快与操作系统及其应用程序的交互。本节描述了一些加速使用底层操作系统和IDE等工具的方法。我从操作系统级别开始,逐步向IDE等更高层级的工具发展。
图形化操作系统倾向于便利性(和视觉效果)而不是原始效率。命令行仍然是与计算机交互的最有效方式,因为用户和期望结果之间几乎没有障碍。尽管如此,大多数现代操作系统仍支持大量键盘快捷键和其他导航辅助工具来帮助加快您的工作。
注意地址栏是最高效的Windows资源管理器界面。
命令行上的一个重要导航辅助功能是自动补全(autocompletion),您按Tab键,shell会自动补全当前目录中的匹配元素。如果出现多个匹配项,它会生成公共部分并允许您添加更多字符来完成完整的名称(目录、文件名等)。现在所有主要操作系统的命令行都具有补全功能,通常使用Tab字符。
尽管Windows 2000默认情况下不在命令行执行Tab文件名补全,但只需简单调整注册表即可实现。要在Windows 2000中启用文件名补全:
许多开发人员没有意识到Windows资源管理器的地址栏也提供Tab文件名补全,就像命令提示符一样。进入地址栏的键盘快捷键是Alt-D;从那里,您可以开始输入目录的一部分,按Tab,资源管理器将为您补全名称。
Mac OS X包含大量键盘快捷键,每个应用程序都有一组自己的快捷键
自己的配置。讽刺的是,考虑到苹果对可用性的普遍关注,OS X 应用程序的一致性不如大多数 Windows 应用程序。微软在创建和执行通用标准方面做得很出色,键盘映射可能是其最大的成功。尽管如此,Mac OS X 还是有一些不错的内置键盘快捷键和其他不那么明显的快捷键。就像 Mac 周围的许多事物一样,需要有人向你展示这些快捷键,你才能发现它们。
这方面的一个完美例子是 Finder 和打开/保存对话框中的键盘导航。在 Windows 资源管理器中,地址栏很明显。但在 Finder 中,你可以使用 Tab 补全来导航到任何文件夹(就像在资源管理器中使用地址栏一样),方法是按 Apple-Shift-G,这会显示一个对话框,你可以在其中输入位置。
你不应该只使用 Finder 或终端(参见本章后面的”触手可及的命令提示符”)。它们可以很好地相互配合。你可以将文件夹从 Finder 拖到终端,快速执行 cd 命令。你还可以使用 open 命令从终端打开文件,而不是在 Finder 中双击它们。这完全取决于上下文和学习手头工具的功能,以便你能够适当地应用这些功能。
注意
花时间学习你的世界中所有隐藏的键盘快捷键。
Windows 用户在 Mac OS X 上最怀念的快捷键是应用程序的 Alt 键加速器。Mac OS 有它们,但它们基于增量搜索而不是显式的键关系。Ctrl-F2 键将焦点移动到菜单栏,你可以输入所需菜单项的第一部分。当它被高亮显示时,按回车键并开始增量输入包含的菜单项。听起来很复杂,但它运行得很好,而且适用于所有应用程序。你还可以使用 Ctrl-F8 将焦点移动到菜单栏的最右侧,那里有所有服务图标。
我最大的问题是调用 Ctrl-F2 需要繁琐的操作,所以我使用标准的 Mac OS X 键盘快捷键对话框将其重新映射到 Ctrl-Alt-Apple-空格键(这听起来更糟糕,但它们都排成一行,所以很容易按下这个组合)。另外,我的 Quicksilver 调用器映射到 Apple-回车键,所以我所有的”元”导航都映射到差不多相同的区域。
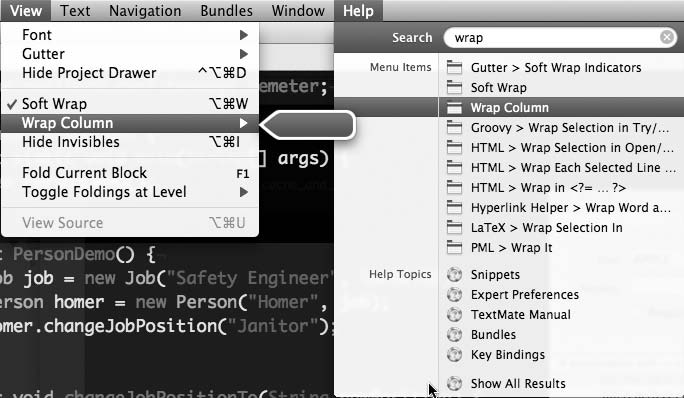
如果你使用最新版本的 Mac OS X,选择菜单项会更容易。Leopard 的帮助功能之一是在你输入名称(或名称的一部分)时为你查找菜单项。这是访问位于深层嵌套菜单中的菜单项的好方法,这些菜单项的名称你记得但位置却想不起来,以及你认为应用程序应该做但不知道功能在哪里的事情。如果你按 Apple-? 键,帮助搜索选项将出现。输入你想要的菜单项名称的任何部分,Leopard 会为你高亮显示它,如果你按回车键就会调用它。与许多键盘魔法一样,这比做起来更难解释(图 2-6)。
有时令人惊讶的是我们能倒退多远。过去的两个传奇编辑器(VI 和 Emacs)都有多个剪贴板(也称为寄存器)。然而,两大主要操作系统将我们限制在一个可怜的单一剪贴板上。你会认为剪贴板是一种稀缺的自然资源,必须小心分配,以免有一天我们用完。这是一个完美的例子,说明由于不同开发人员群体之间的知识传承不足,我们在一代又一代中失去了多少有用的信息。我们不断地一遍又一遍地重新发明相同的东西,因为我们没有意识到十年前已经有人解决了这个问题。
注意
上下文切换消耗时间。
拥有多个剪贴板可能看起来不是一个很大的生产力提升。但是一旦你习惯了拥有它们,它就会改变你的工作方式。例如,如果一个任务需要从一个文件复制并粘贴几个不连续的项目到另一个文件,大多数开发人员会复制、跳转到另一个文件、粘贴、跳回第一个文件,然后反复进行。显然,这不是一种高效的工作方式。你最终会花太多时间在打开的应用程序之间进行上下文切换。然而,如果你有一个剪贴板栈,你可以从第一个文件中收集所有的值——将它们堆叠在你的剪贴板上——然后跳转一次到目标文件,并将它们一次一个地粘贴到适当的位置。
注意
批量剪贴比串行剪贴更快。
有趣的是,如此简单的机制需要时间来内化。即使你安装了一个多剪贴板实用程序,也需要一段时间才能意识到它适用的所有情况。太多时候,你安装了它,然后很快就忘记了它的存在。就像本书中的许多生产力提示一样,你必须保持积极的心态才能利用这些技巧。认识到其中一种技巧适用的适当情况是成功的一半。我经常使用剪贴板历史;我现在无法想象没有它的生活。
幸运的是,Windows 和 Mac OS X 都有各种剪贴板增强工具,包括开源和商业版本。Windows 中一个不错的、简单的开源替代品是 CLCL,它为你提供了一个可配置的剪贴板栈,并允许你分配自己的键盘快捷键。对于 Mac OS X,JumpCut 是一个简单的开源剪贴板栈。对于更精细的(商业)产品,jClip 非常不错,不仅允许你
剪贴板堆栈,还支持配置多个独立的剪贴板。拥有独立的剪贴板非常有用,当你需要复制大量内容时,可以避免污染主剪贴板堆栈。
不过,当你习惯使用剪贴板堆栈后要小心。你可能会兴奋地向某个穿凉鞋的Unix老手谈论这个功能,结果引来他长达一小时的演讲,讲述他从你上小学时就开始使用多剪贴板了,以及那些有20年历史的文本编辑器在其他方面有多厉害。
注意记住历史的人,不必重复输入。
所有shell都有历史记录机制(history mechanism),允许你调用之前的命令并重复执行,必要时还可以修改。这是shell相比图形界面的巨大优势之一:在图形环境中很难轻松重复执行带有细微变化的操作。因此,学会在命令提示符下执行操作意味着你在自己和机器之间建立了更高效的通信层。
历史记录通常绑定到上下方向键,这是一种获取之前命令的暴力方法。但正如我之前所说,搜索比导航更高效。你可以搜索历史记录来找到目标命令,这比逐个扫描每条记录要快得多。
在Windows中,输入之前命令的开头部分,然后按F8键。Shell会在之前的命令中向后搜索与你刚输入的开头部分匹配的命令。你可以继续按F8键在匹配命令列表中向上移动。如果想查看命令历史,按F7键,会显示最近的历史记录列表,你可以用上下方向键选择命令。
在基于Unix的系统(包括Cygwin)中,你可以选择命令行快捷键语法类型,可以是Emacs(通常是默认)或VI。如我之前提到的,VI是一个超强大的导航快捷键集,但从零开始学习非常困难。你可以在*-nix环境中通过在~/.profile文件中添加以下内容来设置VI模式:
set -o vi设置VI模式后,可以按Escape键(进入命令模式),然后按/进入搜索模式。输入搜索文本,按Enter。第一个匹配结果将是最近匹配搜索字符串的命令。如果不是你想要的,按/然后按Enter搜索下一个。在bash中,如果你最近执行过某个命令,可以按!加上该命令的首字母来重新运行它。!让你可以直接访问历史记录。如果想查看命令行历史,执行history命令,它会提供一个按逆序排列的已执行命令编号列表(换句话说,最近的命令在列表底部)。你可以使用感叹号(!)加上想要执行的命令的历史编号来执行历史记录中的命令。当你有一些想要重新执行的复杂命令时,这非常有用。
作为开发者,我们经常在文件系统中跳转。我们总是需要获取一个JAR文件,查找一些文档,复制一个程序集,或者在某处安装某个东西。因此,我们必须磨练导航和定位技能。正如我在本章中一直强调的,图形浏览器和查找器不太适合这种跳转(因为这从来不只是跳转…而是为了处理一些小任务往返某处,因为我们必须回到起点)。
隐藏的ALT-TAB条目
Windows中的Alt-Tab查看器只能容纳21个项目。一旦超过这个数量,它们就不再显示(即使应用程序仍在运行)。你可以控制Explorer的生成,或者使用以下两种涉及Windows PowerToys的解决方案。第一种是Tweak UI,允许你配置Alt-Tab对话框中显示的项目数量。另一种解决方案是通过Virtual Desktop PowerToy安装多个桌面,我在第3章的”用虚拟桌面隔离工作空间”中讨论过。
Mac OS X允许你在Apple-Tab切换时关闭应用程序实例…只需在目标应用程序获得焦点时按Q键,它就会关闭。类似地,如果你使用应用程序管理器Witch,可以在窗口获得焦点时按W键关闭单个窗口,这对于关闭左右两边的Finder窗口非常有用。当然,如果你使用Quicksilver,就不需要那么多Finder窗口了。
一些老式命令行工具提供了很好的替代方案,不用每次需要跳转到另一个位置时都生成新的Explorer。它们允许你临时导航到另一个位置,完成需要做的事情,然后返回起点。pushd执行两个操作:它将你放入作为参数传递的目录中,并将当前目录推入内部堆栈。因此pushd是更基础的cd命令的替代方案。完成工作后,执行popd命令返回原始位置。
pushd和popd在目录堆栈上工作。这是计算机科学意义上的堆栈(stack),意味着它作为FILO(先进后出)列表(经典的比喻是自助餐厅里的盘子堆)。因为它是堆栈,你可以”push”任意多次,它们会按相反的顺序”pop”回来。
所有Unix系统都有pushd和popd命令(包括Mac OS X)。但是,它们不是
某些仅限Cygwin的Windows附加工具。
[jNf| ~/work]=> pushd ~/Documents/
~/Documents ~/work
[jNf| ~/Documents]=> pushd /opt/local/lib/ruby/1.8
/opt/local/lib/ruby/1.8 ~/Documents ~/work
[jNf| /opt/local/lib/ruby/1.8]=>在这个例子中,我从/work目录开始,跳转到/Documents目录,然后转到Ruby安装目录。每次执行pushd命令时,它都会显示栈中已存在的目录。我试过的所有Unix版本都是如此。这个命令的Windows版本只执行上述三个任务中的前两个:它不会给你任何关于栈中当前内容的提示。不过,在使用时这并不是什么大问题,因为这对命令主要用于快速跳转到另一个位置,然后马上返回。
想象一下你躺在高效程序员的治疗沙发上。“我真的很想多花些时间在命令行上,但我需要做的大部分事情都在资源管理器(Explorer)中。” 好吧,我来帮你。有几种方法可以让你快速轻松地在图形界面视图和命令提示符之间切换。
注意嵌入式命令提示符让你能够充分利用两个世界的优点。
对于Windows,命令提示符资源管理器栏是一个很棒的开源工具,它允许你使用键盘快捷键Ctrl-M在当前资源管理器视图底部打开一个命令提示符。在图2-7中可以看到这个工具的实际效果。这个工具的一个很棒的可用性特性是它与附加的资源管理器视图中显示的目录的”粘性”。当你在资源管理器中更改目录时,下面命令提示符中的目录会自动更改。不幸的是,这种关系不是双向的:在命令提示符窗口中更改目录不会改变资源管理器视图中的目录。尽管如此,它仍然是一个有用的工具。
不幸的是,Mac OS X没有任何原生能力来执行这个技巧。然而,商业Finder替代品Path Finder可以实现这一点,如图2-8所示。这个终端就像Mac OS X中的任何其他终端窗口一样(它读取你的主配置文件等),并且可以使用键盘快捷键Alt-Apple-B启动。一旦你习惯了如此容易访问终端(或命令提示符),你往往会更多地将它用于适当的任务。
目录结构的图形视图(资源管理器、Finder)也可以通过拖放的相关但不明显的方式与命令行视图(命令提示符、终端)交互。
在Windows和Mac OS X中,你都可以将目录拖到命令行视图中以复制路径。因此,如果你想在命令提示符中切换到某个目录,并且你在Windows资源管理器中打开了父文件夹(或任何可以抓取目标目录的地方),输入cd,然后将目录拖到命令提示符,它将填充目录名称。你也可以使用下一节讨论的”在此处打开命令提示符”功能。
在Mac OS X中还有一个很酷的技巧。如果你在Finder中复制文件,你可以通过执行粘贴操作(Apple-V)在终端窗口中访问它们;Mac OS X会带上完整路径和文件名。你还可以使用pbcopy(将内容复制到剪贴板)和pbpaste(将内容从剪贴板粘贴到命令行)与剪贴板进行管道操作交互。但是,请注意pbpaste只粘贴文件名,而不是整个路径。
注意将命令提示符嵌入资源管理器,使上下文切换更容易。
在这个加速工具系列中我还有最后一个条目。如果你花时间和精力在Windows资源管理器中导航漫长曲折的路径到达某个目录,你不想在命令提示符中再走一遍相同的路径。幸运的是,微软PowerToys中的一个工具可以帮助你:在此处打开命令提示符(Command Prompt Here)。安装这个PowerToy会对注册表进行一些调整,并添加一个上下文(即右键)菜单,正如你可能猜到的,叫做”在此处打开命令提示符”。执行此命令会在你选择的目录中打开一个命令提示符。
Microsoft发布(但不支持)一系列称为PowerToys的实用程序。这些PowerToys为Windows添加了各种有趣的功能,可以追溯到Windows 95,而且它们都是免费的。其中很多(如Tweak UI)实际上只是对注册表项进行特殊调整的对话框。一些PowerToys包括:
Tweak UI 允许你控制Windows的各种视觉方面,比如桌面上出现哪些图标、鼠标行为和其他隐藏功能。
TaskSwitch 改进的任务切换器(绑定到Alt-Tab,显示正在运行的应用程序的缩略图)。
Virtual Desktop Manager Windows的虚拟桌面(参见第3章中的”使用虚拟桌面隔离你的工作空间”)。
Microsoft不支持这些小工具。如果你从未玩过它们,去看看列表吧。很可能你一直希望Windows为你做的某些事情已经在那里了。
不甘示弱,你可以通过从Cygwin运行chere来获得”Bash在此处”上下文菜单,
这会在该位置打开一个 Cygwin bash shell,而不是命令提示符。这两个工具配合得很好,所以你可以同时安装它们,并根据具体情况决定是使用命令提示符还是 bash shell。命令:
[chere ][-i]
安装”Bash Here”上下文菜单,而:
[chere ][-u][-s][ bash]
卸载它。实际上,chere 工具还可以通过以下命令安装 Windows 命令提示符的”Command Prompt Here”上下文菜单(就像 Windows PowerToy 一样):
[‖] [下载地址:][http://www.microsoft.com/windowsxp/downloads/powertoys/xppowertoys.mspx.]
[28][ 第 2 章:] [加速]
[chere ][-i][-s][ cmd]
所以,如果你有 Cygwin,就不需要下载”Command Prompt Here” PowerToy,只需使用 chere。
Mac OS X 中的 Path Finder 也有一个”Open in Terminal”上下文菜单选项,它会打开另一个终端窗口(不是图 2-8 中描述的抽屉版本,而是一个完整的独立窗口)。Quicksilver 有一个名为”Go to the directory in Terminal”的操作。
小测验:屏幕上最大的可点击目标是什么?就是光标正下方的那个,这就是为什么右键菜单应该包含最重要的内容。鼠标下方的目标实际上是无限大的。第二个问题:第二大的目标是什么?是屏幕的边缘,因为你可以尽可能快地加速到边缘而不会越过它。这表明真正重要的内容应该位于屏幕边缘。这些观察结果来自菲茨定律(Fitt’s Law),该定律指出用鼠标点击目标的难易程度是你必须移动的距离和目标大小的组合。
Mac OS X 的设计者了解这一定律,这就是为什么菜单栏位于屏幕顶部。当你使用鼠标点击其中一个菜单项时,可以将鼠标指针推到屏幕顶部,你就到达了想要的位置。而 Windows 在每个窗口顶部都有一个标题栏。即使窗口最大化,你仍然必须小心地找到目标,加速到顶部,然后使用一些精确的鼠标操作来命中目标。
对于某些 Windows 应用程序,有一种方法可以缓解这个问题。Microsoft Office 套件有一个”全屏”模式,它可以去掉标题栏并将菜单放在顶部,就像 Mac OS X 一样。开发人员也有帮助。Visual Studio 具有相同的全屏模式,IntelliJ 对 Java 开发人员也是如此。如果你要使用鼠标,在全屏模式下使用应用程序会更容易命中菜单。
但加快鼠标的使用并不是我真正提倡的。编程(除了用户界面设计)是一项基于文本的活动,因此你应该努力让双手尽可能多地放在键盘上。
注意 [编码时,始终优先使用键盘而不是鼠标。]
你整天使用 IDE 来创建代码,而 IDE 有大量的键盘快捷键。学会它们全部!在源代码中使用键盘导航总是比使用鼠标快。但键盘快捷键的数量之多可能令人生畏。学习它们的最佳方法是有意识地努力将它们内化。阅读长长的列表并没有帮助,因为快捷键没有上下文。Eclipse IDE 有一个很好的快捷键,可以显示特定视图的所有其他快捷键:Ctrl-Shift-L。这是一个很好的记忆方法,因为它已经在适当的上下文中。学习键盘快捷键的最佳时机是当你需要执行该活动时。当你打开菜单时,注意上面的键盘快捷键。然后,不要选择菜单项,记住快捷键,关闭菜单,然后在键盘上执行。这将加强任务和键盘快捷键之间的关联。不管你信不信,大声说出快捷键也有帮助,因为它会强制将其放入大脑的更多部分。当然,你的同事可能会认为你疯了,但你很快就能在键盘操作上超过他们。
我的一位同事有一种很好的教授键盘快捷键的方法。每当你与他结对编程时,如果你使用鼠标选择菜单或工具按钮,他会让你撤消操作,然后使用键盘执行三次。是的,一开始会让你慢下来,但这种强化(加上当你忘记时他的邪恶眼神)是学习快捷键的压力锅。
注意 [在上下文中学习 IDE 键盘快捷键,而不是阅读长列表。]
另一种记住快捷键的好方法是让某人(或某物)不断提醒你。IntelliJ 有一个很棒的插件叫 Key Promoter。每次你使用菜单选择某些内容时,都会弹出一个对话框,告诉你本可以使用的快捷键以及你已经做错了多少次(见图 2-9)。Eclipse 也有相同的工具,叫做 Key Prompter。Key Prompter 更进一步:你可以设置一种模式,忽略菜单选择,强制你使用快捷键!
不幸的是,许多很棒的快捷键根本不存在于菜单项上:它们被埋在可能的键盘快捷键的超长列表中。你应该为你使用的 IDE 找出很酷的快捷键。表 2-1 是 IntelliJ 和 Eclipse for Windows 中一些很酷的、隐藏的键盘快捷键的简短列表,供 Java 开发人员参考。

[#] [下载地址:][http://www.mousefeed.com.]
[30][ 第 2 章:] [加速]
[表 2-1. IntelliJ 和 Eclipse 的精选键盘快捷键]
[描述] [IntelliJ] [Eclipse]
[转到类] [Ctrl-N] [Ctrl-Shift-T]
[符号列表] [Alt-Ctrl-Shift-N] [Ctrl-O]
[增量搜索] [Alt-F3] [Ctrl-J]
[最近编辑的文件/打开的文件] [Ctrl-E] [Ctrl-E]
[引入变量] [Ctrl-Alt-V] [Alt-Shift-L]
[逐级扩展选择] [Ctrl-W] [Alt-Shift-Up Arrow]
这几个条目需要进一步说明。最近编辑的文件/打开的文件这个条目在两个 IDE 中的工作方式不同:在 IntelliJ 中,它提供一个你最近编辑过的文件列表,按访问的相反顺序排列(因此最近的文件在顶部)。在 Eclipse 中,这个键盘快捷键提供打开的缓冲区列表。这对开发者很重要,因为我们倾向于经常在一小组文件中工作,所以快速访问这个小组很有帮助。
引入变量从技术上讲是一个重构功能,但我经常用它来为我输入表达式的左侧。在两个 IDE 中,你可以输入表达式的右侧(比如 [Calendar.getInstance();]),然后让 IDE 提供左侧(在这个例子中是 [Calendar calendar = ])。IDE 几乎可以和你一样好地提供变量名,而且这样可以减少很多输入和思考如何命名变量的时间。(这个快捷键让我在用 Java 编码时特别懒。)
最后一个特殊条目是逐级扩展选择。它的工作方式是这样的。当你将光标放在某个地方并调用这个命令时,它会将选择扩展一级到下一个更高的语法元素。下次你按这个键时,它会将选择扩大到下一个更大的语法元素组。因为 IDE 理解 Java 语法,它知道什么是标记(token)、代码块、方法等。你不需要创建六个快捷键来选择每个元素,而是可以反复使用同一个按键来逐渐扩大选择范围。这描述起来很麻烦,但试试看,你会很快爱上它。
这里是学习和内化你在大量键盘快捷键列表中看到的真正酷的快捷键的方法。再读一遍列表,但把你不知道的真正有用的快捷键复制到一个单独的文件(甚至纸上!)。试着记住这个功能存在,下次需要时,看看你的备忘单。这代表了从”我知道可以这样做”到”这是怎么做的”之间缺失的环节。
IDE 生产力的另一个关键是实时模板(live templates)。这些是代码片段,代表你一直使用的某些代码块。大多数 IDE 允许你参数化你的模板,在模板在编辑器中展开时填充值。例如,这是 IntelliJ 中的一个参数化模板,允许你在 Java 中遍历数组:
for(int $INDEX$ = 0; $INDEX$ < $ARRAY$.length; $INDEX$++) {
$ELEMENT_TYPE$ $VAR$ = $ARRAY$[$INDEX$];
$END$
}当这个模板展开时,IDE 首先将光标放在第一个用 []分隔的值上,允许你输入索引名称,然后按tab键跳到下一个参数。在这个模板语言中,[END$] 标记是所有展开完成后光标的位置。
每个 IDE 对此有不同的语法,但几乎每个值得使用的 IDE 都支持这个概念。学习你的 IDE 中的模板语言并尽可能多地使用它。出色的模板支持是 TextMate 和 E-Text 编辑器流行的原因之一。模板不会打错字,为复杂的语言结构准备模板可以节省你编码时的时间和精力。
注意
当你第二次输入一个复杂的结构时,把它做成模板。
代码层次结构也变得太深而失去了实用性。一旦达到一定规模,文件系统、包结构和其他分层系统就会变得太深而无法有效导航。大型 Java 项目受此影响,因为包结构与目录结构绑定。即使对于一个小项目,你也必须在树中挖掘——边走边展开节点——来找到一个文件,即使你已经知道它的名字。如果你发现自己在这样做,说明你为你的电脑工作得太辛苦了。
现代 Java IDE 允许你通过在 Windows 上输入 Ctrl-N 或在 Mac 上输入 Apple-N(对于 IntelliJ)和 Ctrl-Shift-T(对于 Eclipse)快速找到当前项目中的任何 Java 源文件。图 2-10 中显示的示例来自 IntelliJ;它在编辑器中打开一个文本框,允许你输入你想要的文件名。

图 2-10. IntelliJ 的”查找文件”文本框
输入整个名字(甚至其中的大部分)很麻烦。如果 IDE 对你指定名字的方式更智能就好了。事实上它就是这样。你不需要输入文件的名字,如果你开始输入大写字母,它会查找具有相同大写字母模式的名字。例如,如果你在查找文件 ShoppingCartMemento,你可以输入 SCM,IDE 会忽略中间的小写字母并找到匹配的大写字母模式,如图 2-11 所示。

图 2-11. IntelliJ 对名称的智能模式匹配
这个文件查找魔法也适用于非 Java 源文件(在 IntelliJ 中给其他键加上 Shift,或在 Eclipse 中使用 Ctrl-Shift-R)。这是”查找资源”文本框,它的工作方式就像”查找文件”一样。不要再在庞大的源文件树中艰难前行:你知道你想要什么,所以直接去找它。
对于 .NET 开发者,常用的环境是 Visual Studio 2005(在其当前版本中)
化身版本)。虽然它的键盘快捷键数量中等,但你可以通过商业版 Resharper(来自 JetBrains,IntelliJ Java IDE 的创建者)来增强它。许多开发者认为 Resharper 主要关注添加重构支持,但精明的开发者意识到它还添加了大量键盘快捷键(包括前面描述的”查找文件”功能)。
宏是记录下来的与计算机交互的片段。通常,每个工具都有自己的宏录制器(因为只有工具本身知道它如何处理按键)。这当然意味着没有标准的宏语法,有时甚至在同一产品的不同版本之间也不同。多年来,Microsoft Word 和 Excel 的宏语法非常不同,尽管它们来自同一家公司并且在同一个 Office 套件中。直到 Office 2000,微软才最终统一了单一语法。尽管工具之间存在语言混乱的情况,宏仍然可以帮助解决你每天面临的非常具体的问题。
注意对于多行文本的任何对称操作,找到一个模式并录制一个宏。
你多久发现自己在按照某种模式工作?你从 XML 文档中剪切和粘贴了一些信息,现在你必须删除真实数据周围的所有 XML 冗余内容来清理它。宏曾经在开发者中风靡一时,但最近似乎失宠了。我怀疑大多数现代 IDE 的实时模板功能已经消除了对宏的一些需求。
但是,无论你多么依赖实时模板,录制宏仍然有用武之地。常见场景是前面强调的:对某些信息进行一次性处理,要么从另一种格式中去除冗余,要么为某些其他工具的使用添加冗余。如果你能转换对任务的看法,将其视为一系列可重复的步骤,你会发现宏可以用于很多琐事。
注意你对一块文本执行特定操作的次数越多,将来再次执行的可能性就越大。
即使你使用 Eclipse(它没有宏录制器),你也可以随时跳到文本编辑器并使用它的宏录制器来完成这项工作。文本编辑器的一个重要选择标准是其宏录制功能和录制宏的格式。如果宏能够生成某种可读的代码,你可以手动调整,创建一个以后可以使用的可重用资产,那就更好了。毕竟,如果你曾经将某些内容从一种格式剪切并粘贴到另一种格式,很有可能你以后还要再做一次。
虽然编辑器中的正式宏非常适合处理文本、代码和转换,但另一类宏工具可以在日常工作中帮助你。所有主要操作系统都有开源和/或商业按键宏工具。按键宏工具在后台运行,等待文本模式展开。它们允许你输入缩写而不是完整的文本。大多数情况下,这些工具会做一些事情,比如自动输入电子邮件地址的称呼。但是,作为开发者,我们在没有实时模板的地方(如命令行或网页浏览器中)输入大量重复文本。
注意不要一遍又一遍地输入相同的命令。
我一直要执行的任务之一是向人们展示如何使用 Selenium 的远程控制功能。要使其工作,你必须启动一个代理服务器并发出神秘的命令来给它指令,这些基本上只是命令行上的咒语。我不在 IDE 中,所以我不能使用实时模板甚至宏。我甚至不能使用批处理或 shell 脚本:我正在针对一个交互式代理运行。我很快意识到应该将这些命令保存在我的按键宏工具中:
cmd=getNewBrowserSession&1=*firefox&2=8080
cmd=open&1=/art_emotherearth_memento/welcome&sessionId=这行丑陋的代码是在我为 Selenium 启动代理服务器后发出的,采用 Remote Control Selenium 要求的非常特殊的格式。如果你不了解 Selenium,这些命令就不会有意义。但理解命令并不是这个例子的重点。这只是我必须时不时输入的可怕命令字符串之一。每个开发者最终都会遇到这些,它们脱离上下文就没有意义(即使在上下文中也经常勉强有意义)。但现在,我不再从某处复制粘贴,我只需输入 rcsl1 来生成第一行,输入 rcsl2 来生成第二行,依此类推,输入我需要向人们展示的 10 个命令。
一些按键宏工具允许你在操作系统级别录制按键并播放它们(有时甚至捕获鼠标点击和其他交互)。其他工具要求你输入要与特定宏关联的命令。在这两种情况下,你都是以一种易于重用的格式捕获一些你必须重复执行的操作系统级交互。
按键宏工具也非常适合你必须反复输入的常用短语。在 Word 中为项目状态消息输入的文本怎么样?或者在时间和费用系统中输入工时?按键宏工具属于这样一类工具:有一天你甚至不知道它的存在,第二天就进入了”没有它我怎么活”的类别。
Windows 最流行的按键宏工具是 AutoHotKey(开源)。Mac OS X 有几个”商业但价格低廉”的类别,如 TextExpander 和 Typinator。
本章介绍了多种通过消除低效率和不必要的干扰来增强专注力的方法。 你可能在工作中遭受很多干扰,既来自计算机本身,也来自外部世界。在这里,你将学习如何使用特定工具和方法来增强你与计算机交互时的专注力,以及如何让同事不打扰你,这样你就可以停止敲打石头,完成一些工作。目标是让你回到那种刚刚攀登完虚拟山峰后迷茫但快乐的状态。
你是一名知识工作者,这意味着你的报酬来自你产生的创造性和创新性想法。处理持续不断的干扰,无论是在你的办公桌还是在你的桌面上,都可能威胁到你对项目的最佳贡献。开发者渴望一种被称为心流(flow)的状态,在很多地方都有讨论(甚至有一整本书专门讨论它,由Csikszentmihalyi撰写)。所有开发者都知道这种状态:当你如此专注以至于时间消失,你与机器和你正在攻克的问题之间发展出一种几乎共生的关系。这就是你说”哇,已经过了四个小时了吗?我都没注意到”时所处的状态。心流的问题在于它很脆弱。一次干扰就会把你拉出来,而且需要努力才能重新进入。它还受到惯性的影响。在一天的晚些时候,你必须更努力地战斗才能回到那种状态,而且你被突然拉出的次数越多,就越难回到那种状态。干扰会扼杀你对手头问题的专注,使你的生产力降低。幸运的是,你可以通过几种简单的方法有效地阻止干扰。
注意 [专注度越高,想法越密集。]
专注很难维持,特别是当你的计算机似乎决心把你的注意力从工作中拖走时。阻止视觉和听觉干扰有助于你保持良好的、专注的心流状态。对于听觉干扰(特别是如果你没有一个可以关门的办公室),你可以戴耳机(即使你没有听音乐)。当其他人看到你戴着耳机时,他们不太可能打扰你。如果你的办公室不允许戴耳机,考虑在你的隔间入口处挂一个”请勿打扰”的标志。这应该会让人们在闯入之前三思而行。
对于视觉干扰,关闭机器上所有打断你专注力的东西。电子邮件通知非常有害,因为它会制造人为的紧迫感。在一天中你收到的电子邮件中,有多少真的需要立即回复?关闭你的电子邮件客户端,分批查看邮件,当你的工作达到一个自然的中断点时再查看。这让你可以决定何时想要打断你的思路。
Windows中的气球提示(balloon tips)和Mac OS X上的Growl通知也会拖走你的注意力。在Mac OS X上,Growl是可定制的,所以你可以只打开你需要看到的通知来完成工作。不幸的是,Windows中的气球提示是全有或全无的。而且气球提示传递的许多消息都没有用。你真的想停止工作来清理桌面上未使用的图标吗?你还会收到关于Windows自动调整虚拟内存大小的消息。我不想知道那个,我特别不想为了看它而中断我的工作。Windows有时看起来像一个被宠坏的三岁小孩,总是吵着要关注。
有两种方法可以关闭气球提示。如果你已经有Tweak UI PowerToy,其中一个设置可以禁用气球提示,如图3-1所示。另一种方法涉及一点
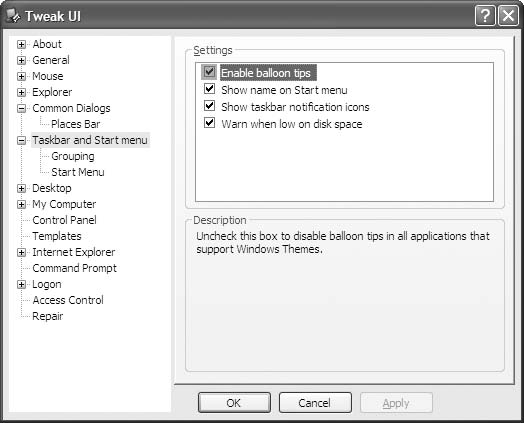
注册表编辑(这就是 PowerToy 在后台所做的全部工作):
运行 regedit。
查找 HKEY_CURRENT_USER 。
创建一个名为 EnableBalloonTips 的 DWORD 值(如果已存在则编辑它),值设为 0。
注销并重新登录。
如果你工作时倾向于创建大量重叠窗口,这些窗口也会分散注意力。有几个免费工具可以”遮蔽”背景,让所有你未使用的应用程序淡出。这样可以让你的注意力紧密聚焦在手头的任务上。
对于 Windows,JediConcentrate 应用程序可以完成这项工作。对于 Mac OS X,淡出应用程序叫做 Doodim。它们的工作方式相同,允许你自定义背景变暗的程度。
如果你在一个有很多其他开发人员的办公室工作,可以考虑设立”安静时间”,例如从上午 9 点到 11 点以及下午 3 点到 5 点。在此期间,每个人都关闭电子邮件,不开会,除非有紧急情况(比如你被阻塞无法完成正在尝试解决的问题),否则禁止打电话或找人交谈。我在我工作过的一家咨询办公室尝试过这个方法,效果惊人。办公室里的每个人都发现,我们在这四个小时内完成的工作比实施这项政策之前一整天完成的还要多。所有开发人员都开始期待这段时间;这是每个人一天中最喜欢的时光。
我认识的另一个开发团队会定期在他们的共享日历中预订会议。这个”会议”实际上只是完成工作的时间。公司的其他人可以从共享日历中看到每个人都在”开会”,因此知道不要打扰他们。悲哀的是,办公环境如此妨碍生产力,以至于员工不得不钻系统的空子来完成工作。有时你必须跳出盒子(或隔间)的思维来完成工作,尽管环境不利。
注意草堆越大,找到针就越难。
项目变得越来越大,随之而来的还有包和命名空间。当层次结构变大时很难导航:它们太深了。在 200 MB 存储空间下运行良好的文件系统在达到 200 GB 时就会出现问题。文件系统已经变成了巨大的草堆,而我们不断地在其中进行硬目标搜索以寻找针。花时间翻找文件会让你偏离应该关注的问题。
幸运的是,新的搜索工具帮助你几乎完全摆脱繁琐的文件系统导航。
最近,强大的搜索应用程序出现在操作系统级别:Mac OS X 中的 Spotlight 和 Vista 中的 Windows Search。这些搜索应用程序不同于以前 Windows 版本中那些古怪的搜索功能(其唯一的实际用途是显示一只狗的动画)。这种新型搜索工具会索引整个硬盘的有趣部分,使搜索速度极快。它们不仅仅查看文件名:还会索引文件内容。
对于 Vista 之前的 Windows,存在几个桌面搜索附加组件。我目前最喜欢的是免费的 Google Desktop Search。开箱即用时,它只搜索”普通”文件(如电子表格、Word 文档、电子邮件等)。Google Desktop Search 最好的部分之一是其插件 API,允许开发人员添加搜索插件。例如,Larry’s Any Text File Indexer 允许你为源文件配置 Google Desktop Search。
安装 Larry’s Any Text File Indexer 并允许它索引你的硬盘(它在后台的空闲时间进行索引)后,你可以搜索文件内容的片段。例如,在 Java 中,文件名必须与公共类的名称匹配。在大多数其他语言(如 C#、Ruby、Python)中,文件名通常与类名匹配。或者,如果你正在查找使用特定类的所有文件,可以搜索你知道存在的代码片段。例如:
new OrderDb();
可以找到所有创建 OrderDb 类实例的类。
按内容搜索非常强大。即使你记不住文件的确切名称,几乎总能记住至少一些内容。
注意用搜索替代文件层次结构。
索引搜索工具让你摆脱文件系统的束缚。使用像 Google Desktop Search 这样的搜索工具需要适应,因为你可能有手动搜索文件的习惯。你不需要这种级别的搜索来检索源文件(你的 IDE 已经为你处理了)。然而,你经常需要访问文件所在的位置,对其执行某些操作,如版本控制、差异比较或从不同项目引用某些内容。Google Desktop Search 允许你右键单击找到的文件并打开包含的文件夹。
Mac OS X 中的 Spotlight 也可以做同样的事情。当你找到一个文件时,如果按 Enter,它会在关联的应用程序中打开文件。如果按 Apple-Enter,它会打开包含的文件夹。就像 Google Desktop Search 一样,你可以下载 Spotlight 插件,允许它索引
您的源文件。例如,您可以从 Apple 网站下载 Spotlight 插件,将 Ruby 代码添加为索引目标。
Spotlight 现在允许您在搜索中添加搜索过滤器。例如,您可以在搜索字符串中添加 kind:email,Spotlight 将仅限于搜索电子邮件。这预示着搜索的未来趋势,即通过可自定义属性进行搜索的能力(参见下一个侧边栏”近期未来:通过属性搜索”)。
仅通过标题搜索文件并不是很有用。记住确切的标题和记住文件放在哪里一样困难。通过内容搜索更好,因为您更有可能至少记得文件的一部分内容。
一个更强大的变体正在出现在前沿软件中:基于可自定义属性搜索文件的能力。例如,假设您有一些属于同一项目的文件:Java 源文件、SQL 架构、项目笔记和跟踪电子表格。将这些项目放在文件层次结构中是有意义的,因为它们都与同一个项目相关。但是,如果某些文件需要在多个项目之间共享怎么办?搜索允许您根据它们参与的事物来找到它们,而不是根据它们的物理位置。
最终,我们将获得”理解”这一理念的文件系统,即您可以用任意属性标记文件。您现在可以在 Mac OS X 中使用 Spotlight 注释来实现这一点,它允许您标记属于同一逻辑项目的文件,而不必担心它们的物理位置。Windows Vista 也提供了类似的功能。如果您的操作系统提供此功能,请使用它!这是组织文件组的更好方法。
注意在诉诸”硬目标”搜索之前,请尝试简单搜索。
当您知道某些内容时,Google Desktop Search、Spotlight 和 Vista 的搜索非常适合查找文件。但有时您需要更复杂的搜索功能。上述工具都不支持正则表达式,这很遗憾,因为正则表达式已经存在很长时间了,并提供了极其强大的搜索机制。您越有效地找到某些东西,就越能更快地将注意力重新集中到手头的问题上。
所有版本的 Unix(包括 Mac OS X、Linux,甚至 Windows 中的 Cygwin)都包含一个名为 find 的实用程序。Find 负责从给定目录向下查找文件,递归遍历目录结构。Find 接受大量参数,允许您优化搜索,包括文件名的正则表达式。例如,这是一个 find 调用,它定位所有在文件扩展名之前带有”Db”的 Java 源文件:
find . -regex ".*Db\.java"此搜索告诉 find 从当前目录(“.”)开始,查找所有在字符串”Db”之前有零个或多个字符(“.*”)的文件,该字符串位于”.”(必须转义,因为”.”通常表示”任何单个字符”)之前,后跟 Java 的文件扩展名。
find 本身就非常有用,但当您将它与 grep 结合使用时,您就拥有了一个真正强大的组合。find 的选项之一是 -exec,它执行后面的命令,并可以选择将找到的文件名作为参数传递。换句话说,find 将找到符合您条件的所有文件,然后将每个文件(在发现时)传递给 -exec 右侧的命令。考虑这个命令(在表 3-1 中解释):
find . -name "*.java" -exec grep -n -H "new .*Db.*" {} \;表 3-1. 解码 find 命令
| 字符 | 它的作用 |
|---|---|
| find | 执行 find 命令。 |
| . | 从当前目录开始。 |
| -name | 匹配”*.java”的名称(注意这不是正则表达式,而是文件系统”通配符”,其中 * 表示所有匹配)。 |
| -exec | 对每个找到的文件执行以下命令。 |
| grep | grep 命令,用于在文件中搜索字符串的强大 Unix 实用程序。 |
| -n | 显示匹配的行号。 |
| -H | 显示匹配的文件名。 |
| “new .*Db.*” | 匹配正则表达式,表示”所有具有任意数量字符,后跟字母 Db,然后后跟任意字符的文件”。 |
| {} | find 找到的文件名的占位符。 |
| \; | 终止 -exec 后的命令。因为这是 Unix 命令,您可能希望将结果通过管道传递给另一个命令,find 命令必须知道”exec”何时完成。 |
虽然这需要大量工作,但您可以看到这些命令组合的强大功能(有关此特定命令组合的两个不同但等效的版本,请查看附录 A 中的”命令行”)。一旦您学会了语法,您就可以真正查询您的代码库。这是另一个稍微复杂一点的示例:
find -name "*.java" -not -regex ".*Db\.java" -exec grep -H -n "new .*Db" {} \;您可以在代码审查期间使用 find + grep 的组合,事实上,这个示例来自我在代码审查期间进行的查询。我们正在编写一个遵循典型分层应用程序设计的应用程序,包括模型、控制器和视图层。所有访问数据库的类都以”Db”结尾,规则是除了在控制器中,您不应该构造这些类。发出 find 命令使我能够准确找到所有边界类被构造的位置,并在问题变严重之前将其解决。
有人做错了什么。
这里有另一个查找东西的小命令行技巧。如果你想进入路径中某个应用程序所在的目录怎么办?例如,假设你想临时进入可执行命令 java 所在的目录。你可以结合使用 pushd 和 which 命令来实现:
pushd `which java`/..记住,反引号(` 字符)中的任何命令都会在其余命令之前执行。在这种情况下,which 命令(用于查找路径中应用程序的位置)会找到 java 的位置。但 java 是一个应用程序,而不是目录。因此,我们获取该位置并返回到父目录,然后 pushd 到它。这是 *-nix 命令可组合性的一个很好的例子。
根视图是以特定子目录为根的目录结构视图,你只能看到从根目录向下的内容。如果你正在处理某个特定项目,你不关心其他项目的文件。根视图允许你消除不相关文件的干扰,只关注当前需要处理的文件集。所有主要平台都支持这个概念,但实现方式不同。
根 Explorer 视图(“根”在 c:\work\sample code\art\art_emotherearth_memento 文件夹)如图 3-2 所示。
这是一个普通的 Explorer 窗口,使用以下参数打开:
explorer /e,/root,c:\\work\\cit根视图仅影响 Explorer 的这个实例。如果使用常规方式启动另一个 Explorer 窗口,你将看到 Explorer 的普通实例。要利用根视图,请创建带有上述根视图参数的 Explorer 快捷方式。根视图适用于所有 Windows 版本,从 Windows 95 到 Windows Vista。
第 3 章:专注 第 44 页
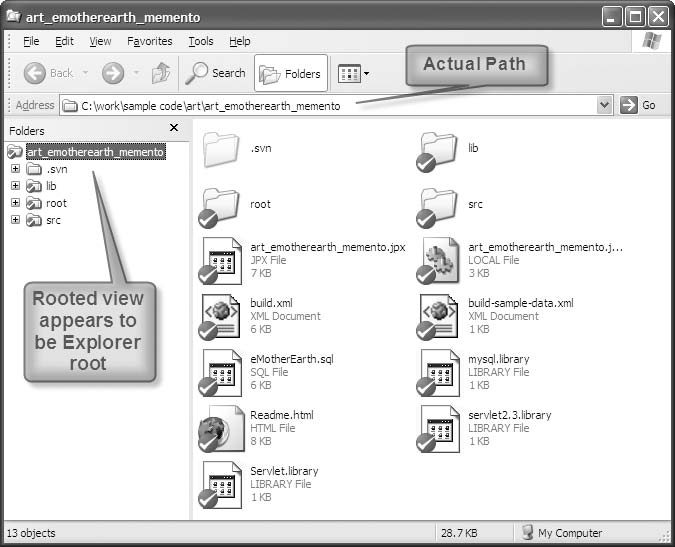
图 3-2. Windows 中的根视图
注意
根视图将 Explorer 转变为项目管理工具。
根视图特别适合项目工作,尤其是如果你使用基于文件或文件夹的版本控制系统(如 Subversion 或 CVS)。就 Explorer 的根实例而言,你的项目文件和文件夹构成了整个世界。你可以通过在根视图中点击的任何位置访问插件 Tortoise(Explorer 的 Subversion 管理工具)。更重要的是,你消除了一堆与你正在处理的项目无关的文件夹和文件所造成的干扰。
根视图在 Mac OS X 中的工作方式略有不同。虽然你无法像在 Windows Explorer 中那样创建唯一专注于单个目录结构的 Finder 视图,但你仍然可以创建专门的根视图来浏览大量目录结构。在 Finder 中,你可以通过将目录拖到侧边栏或程序坞来创建目录快捷方式。这允许你直接从 Finder 打开该目录,如图 3-3 所示。
从 http://tortoisesvn.tigris.org/ 下载。
使用根视图 第 45 页
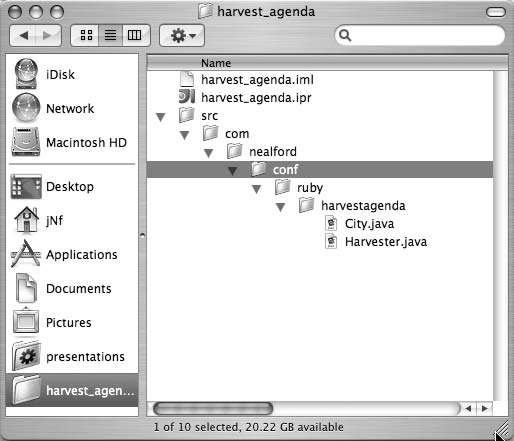
图 3-3. Finder 中的根视图
Windows 中的命令行有一个默认开启的讨厌功能,叫做快速编辑模式(Quick Edit Mode)。这是在命令窗口属性中设置的一个开关,允许你使用鼠标选择要复制的文本。窗口内的任何点击都会启动拖动操作,突出显示矩形文本区域,准备将其复制到剪贴板(奇怪的是,标准键盘快捷键 Ctrl-C 在这里不起作用;你必须按 Enter 键)。问题就在这里。因为你正在控制台窗口中选择文本,一旦开始拖动鼠标,它就会冻结所有活动(即占用该窗口的所有进程和线程)。这是有道理的:试图复制一些主动滚动离开你视线的东西会很烦人。通常,在窗口环境中,点击窗口中的任何位置使其获得焦点是完全安全的。但如果你点击命令提示符窗口,你无意中启动了拖动操作,这会冻结所有进程。讽刺的是,将焦点设置到窗口可能会意外破坏手头工作的专注,因为你开始想”为什么那个窗口什么都没发生?“你可以使用粘性属性来修复这个”功能”。
第 3 章:专注 第 46 页
注意
利用内置的专注功能(如颜色)。
Windows 通过窗口标题跟踪命令提示符中的自定义设置。当你在 Windows 中关闭命令提示符时,它会询问你是否要为所有具有相同标题的命令提示符保存这些设置(从而使它们”粘性”)。你可以利用这一点来创建专门的命令提示符。创建一个启动具有特定标题的窗口的快捷方式,设置一些选项,并在关闭窗口时保存该窗口的选项。对于开发工作,你需要一个具有以下特征的命令提示符:
• 几乎无限的滚动。默认值是可怜的 300 行,在做一些有趣的事情时很容易滚动掉。将其设置为 9999 行(并忽略 1990 年代的警告,即你的命令提示符现在将占用宝贵的 2 MB 内存)。
• 屏幕支持的最宽宽度,不需要水平滚动。在命令提示符中阅读换行的行既乏味又容易出错。
• 设置位置。如果这是一个具有单一用途的命令窗口(如 servlet 引擎或 Ant/Nant/Rake 窗口),让它始终出现在已知位置。你会很快记住该位置,这样你甚至不用看就知道这个命令提示符的用途。
• 设置独特的前景色和背景色。对于常见的命令提示符(如 servlet 引擎),颜色成为识别窗口用途的重要线索。你可以快速识别青色背景配黄色文本是 Tomcat 窗口,而蓝色背景配绿色文本是 MySQL 提示符窗口。当你在打开的命令提示符之间切换时,颜色(和位置)比阅读文字更快地告诉你这个窗口的用途。
• 当然,还要关闭快速编辑模式。
所有主流操作系统都有某种别名、链接或快捷方式机制。使用它来创建项目管理工作空间。通常,你的项目文档分散在硬盘的各个地方:需求/用例/故事卡在一个位置,源代码在另一个位置,数据库定义又在另一个位置。在所有这些文件夹之间导航是浪费时间。与其强制将项目的所有文件放在一个位置,不如虚拟地将它们组合在一起。创建一个基于项目的文件夹,包含整个项目的快捷方式和链接。你会发现花在文件系统中搜寻的时间大大减少。
使用链接创建虚拟项目管理文件夹。
将你的项目管理文件夹放在 Windows 的快速启动按钮或 Mac OS X 的 Dock 中。这两个区域不支持大量项目,但仅用于几个项目整合文件夹是有意义的。
显示器已经变得便宜,开发者可以利用额外的屏幕空间。不给开发者配备超快的计算机和双显示器是因小失大。知识工作者每盯着沙漏看的时刻都是纯粹的生产力浪费。在拥挤的显示器上费力管理所有重叠的窗口也会浪费时间。
多显示器让你可以在一个屏幕上编写代码,在另一个屏幕上调试。或者在编码的同时保持文档可见。不过,拥有多显示器只是第一步,因为你还可以使用虚拟桌面将双工作空间分隔成一堆专门的视图。
虚拟桌面整理你堆积的窗口。
Unix 世界的一个酷炫功能是虚拟桌面。虚拟桌面就像你的常规桌面,窗口按特定方式排列,但”虚拟”部分表示你可以拥有多个。你可以为每个逻辑活动组创建单一用途的桌面,而不是在一个大杂烩桌面上放置 IDE、数据库控制台以及所有电子邮件、即时消息、浏览器等。桌面上大量堆积的窗口会分散你的注意力,因为你必须不断地整理窗口。
虚拟桌面过去只存在于高端 Unix 工作站上(它们有足够的图形处理能力支持这种功能)。但现在它们存在于所有主流平台上。在 Linux 上,GNOME 和 KDE 都内置了虚拟桌面。
Mac OS X 的 Leopard 版本(10.5版)添加了这个功能,称为 Spaces。但之前的 Mac OS X 用户也没有被遗漏:存在几个开源和商业虚拟桌面,如 VirtueDesktops。它提供复杂的功能,如将应用程序”固定”到特定桌面(意味着该应用程序只会出现在该桌面上,如果你选择该应用程序,焦点将切换到该桌面)。这对于开发者来说是一个很棒的功能,他们通常为特定目的设置特定的桌面(开发、文档、调试等)。
下载地址:http://virtuedesktops.info/
我最近的一个项目是 Ruby on Rails 工作,我们在 Mac Mini(比面包盒还小的机器,你购买时不带显示器或键盘)上结对编程。它们是非常好的开发机器,特别是配备两个键盘、鼠标和显示器时。不过,让它们成为出色环境的是虚拟桌面。我们以相同的方式设置每台机器(以便在交换搭档时保持理智),所有开发工具在一个桌面上,文档在另一个桌面上,运行的应用程序(一个以调试模式运行 web 服务器的终端窗口和浏览器)在第三个桌面上。每个桌面都是完全独立的,当我们切换应用程序时,相应的桌面会旋转到视图中。这个环境让我们能够始终将特定桌面的所有窗口保持在同一位置,几乎不需要平铺和层叠。在我上一份工作中,我在 Windows 上独自编码,但我仍然设置了”通信”、“文档”和”开发”桌面,这减少了混乱并帮助我保持理智。
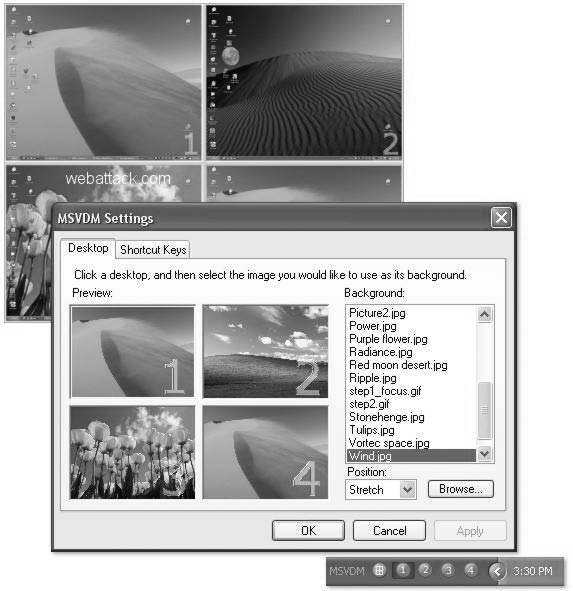
Windows 有一个名为虚拟桌面管理器的 PowerToy,可以在 Windows 2000 和 Windows XP 中启用虚拟桌面(见图3-4)。它允许你管理最多四个虚拟桌面,每个都有任务栏控制器、独特的壁纸和热键支持。虚拟桌面并不是对底层操作系统的根本改变;它只是在后台管理各种窗口的外观和状态。
虚拟桌面提供了一种管理注意力的绝佳方式。它们在你需要的时候恰好提供你需要的信息或工具,没有多余的细节。我倾向于根据我正在做的工作类型灵活地创建虚拟桌面。Spaces 和虚拟桌面管理器的一个不错的功能是能够获取
所需的应用程序并将它们全部移动到一个桌面。这样,我就可以专注于
这个项目,与我机器上运行的其他所有内容隔离开来。事实上,
我正在 Desktop 2 上编写本章!
总结
本章涵盖了专注力的几个不同方面:寻找方法来调整你的
环境以减少干扰、让你的计算机减少干扰的方法,以及
增强专注力的工具。希望你现在能明白为什么我决定围绕
生产力原则来组织这些主题:如果没有专注力这个统一元素,这些主题看起来彼此毫无关联。
在现代环境中很难实现专注。然而,要充分发挥你的潜力,你必须
在你的特定环境中找到一种方法来开辟一个可行的空间和环境。
这样做最终会大大提高你的生产力。

自动化
我想用多个工作表打开 Excel,但手动操作很麻烦(而且 Excel 不允许你在命令行传递多个文件)。所以,我花了几分钟编写了以下小 Ruby 脚本:
class DailyLogs
private
@@Home_Dir = "c:\\MyDocuments\\Documents\\"
def doc_list
docs = Array.new
docs << "Sisyphus Project Planner.xls"
docs << "TimeLog.xls"
docs << "NFR.xls"
end
def open_daily_logs
excel = WIN32OLE.new("excel.application")
workbooks = excel.WorkBooks
excel.Visible = true
doc_list.each do |f|
begin
workbooks.Open(@@Home_Dir + f, true)
rescue
puts "Cannot open workbook:", @@Home_Dir + f
end
end
excel.Windows.Arrange(7)
end
end
DailyLogs.daily_logs尽管手动打开文件不需要很长时间,但这点时间仍然是浪费时间,所以我将其自动化了。在这个过程中,我发现你可以在 Windows 上使用 Ruby 来驱动 COM 对象,比如 Excel。
计算机被设计用来快速重复执行简单、重复的任务。然而,一件奇怪的事情正在发生:人们正在计算机上手动执行简单、重复的任务。计算机在深夜聚在一起嘲笑他们的用户。这是怎么发生的?
图形环境旨在帮助新手。微软在 Windows 中创建了”开始”按钮,因为用户在以前的版本中很难知道首先要做什么。(奇怪的是,你也用”开始”按钮关闭计算机。)但是那些让普通用户更高效的东西可能会妨碍高级用户。对于大多数开发任务,你在命令行可以完成比通过图形用户界面更多的工作。过去几十年的一个巨大讽刺是,高级用户在执行常规任务时变得更慢了。过去典型的 Unix 用户效率要高得多,因为他们自动化了一切。
如果你曾经去过一个有经验的木工的车间,你会看到很多专业工具(你可能甚至没有意识到存在激光制导、陀螺平衡的车床)。然而,在大多数项目过程中,木工会使用从地板上捡起的一小块废木料来暂时分开两个东西或将两个东西固定在一起。在工程术语中,这些小废料被称为”夹具(jigs)“或”垫片(shims)“。作为开发人员,我们创建的这些小型一次性工具太少了,通常是因为我们没有以这种方式思考工具。
软件开发有许多明显的自动化目标:构建、持续集成(continuous integration)和文档。本章介绍了一些不太明显但同样有价值的开发任务自动化方法,从单个按键到小型应用程序。
不要重造轮子
通用基础设施设置是每个项目都必须做的事情:设置版本控制、持续集成、用户 ID 等。Buildix 是一个开源项目(由 ThoughtWorks 开发),它大大简化了基于 Java 项目的这一过程。许多 Linux 发行版都带有”Live CD”选项,允许你直接从 CD 试用 Linux 版本。Buildix 的工作方式相同,但预配置了项目基础设施。它本身是一个 Ubuntu Live CD,但预装了软件开发工具。Buildix 包括以下预配置的基础设施:
• Subversion,流行的开源版本控制包 • CruiseControl,开源持续集成服务器 • Trac,开源缺陷跟踪和 wiki • Mingle,ThoughtWorks 的敏捷项目跟踪工具
你从 Buildix CD 启动,就拥有了项目基础设施。或者,你可以将 Live CD 用作现有 Ubuntu 系统的安装 CD。这是一个盒装项目。
本地缓存内容
当你开发软件时,你会不断引用互联网上的资源。无论你的网络连接有多快,当你通过 Web 查看页面时,你仍然会付出速度代价。对于经常引用的材料(如编程 API),你应该在本地缓存内容(这也让你可以在飞机上访问它)。有些内容很容易在本地缓存:只需使用浏览器的”保存页面”功能。然而,很多时候,缓存得到的是一组不完整的网页。
wget 是一个 -nix 实用工具,用于将网页的部分内容缓存到本地。它在所有 -nix 系统上都可用,在 Windows 上作为 Cygwin 的一部分提供。wget 有很多选项来获取页面。最常用的是 mirror,它可以将整个站点镜像到本地。例如,要有效地镜像一个网站,执行以下命令:
wget --mirror -w 2 --html-extension --convert-links -P c:\wget_files\example1*下载地址:http://buildix.thoughtworks.com/
这个命令有点复杂。表 4-1 给出了详细说明。
表 4-1. 使用 wget 命令
| 字符 | 作用 |
|---|---|
| wget | 命令本身。 |
| –mirror | 镜像网站的命令。wget 会递归地跟踪站点上的链接并下载所有必需的文件。默认情况下,它只获取自上次镜像操作以来更新的文件,以避免无用的工作。 |
| –html-extension | 许多网页文件即使最终生成 HTML 文件也具有非 HTML 扩展名(如 cgi 或 PHP)。此标志告诉 wget 将这些文件转换为 HTML 扩展名。 |
| –convert-links | 页面上的所有链接都转换为本地链接,修复页面中包含绝对 URI 的问题。wget 将所有链接转换为本地资源。 |
| -P c:_files | 您希望将站点放置在本地的目标目录。 |
可能有一些网站需要登录或其他步骤才能访问内容,您希望从中提取信息。cURL 允许您自动化这种交互。cURL 是另一个开源工具,适用于所有主流操作系统。它类似于 wget,但专门用于与页面交互以检索内容或获取资源。例如,假设您有以下 Web 表单:
<form method="GET" action="junk.cgi">
<input type="text" name="birthyear">
<input type="submit" name="press" value="OK">
</form>cURL 允许您在提供两个参数后获取结果页面:
curl "www.hotmail.com/when/junk.cgi?birthyear=1905&press=OK"您还可以使用”-d”命令行选项与需要 HTML POST 而不是 GET 的页面交互:
curl -d "birthyear=1905&press=%20OK%20" www.hotmail.com/when/junk.cgicURL 的真正优势在于通过各种协议(如 HTTPS)与安全站点交互。cURL 网站对此主题进行了详细介绍。这种导航安全协议和其他 Web 现实的能力使 cURL 成为与站点交互的绝佳工具。它在 Mac OS X 和大多数 Linux 发行版上默认提供;您可以在 http://www.curl.org 下载 Windows 版本。
Yahoo! 有一个服务(目前永久处于 beta 版)叫做 Pipes。Pipes 服务允许您操作 RSS feeds(如博客),组合、过滤和处理结果以创建网页结果或另一个 RSS feed。它使用基于 Web 的拖放界面创建从一个 feed 到另一个 feed 的”管道”,借用了 Unix 命令行管道的隐喻。从可用性的角度来看,它很像 Mac OS X Automator,其中每个命令(或管道阶段)产生输出供下一个管道使用。
例如,图 4-1 中显示的管道从 No Fluff, Just Stuff 会议站点获取博客聚合器,其中包括最近的博客文章。博客文章以”博客作者 - 博客标题”的形式出现,但我只想在输出中显示作者,所以我使用正则表达式管道将作者-标题替换为仅作者姓名。
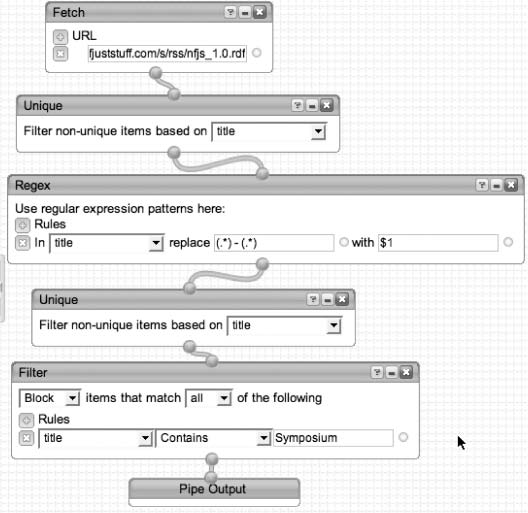
图 4-1. 正则表达式管道实战
管道的输出是另一个 HTML 页面或另一个 RSS feed(每当您刷新 feed 时都会执行管道)。
RSS 是一种越来越流行的开发者信息格式,Yahoo! Pipes 允许您以编程方式操作它以优化结果。不仅如此,Pipes 正在逐步增加对从网页中提取信息并放入管道的支持,使您能够自动检索各种基于 Web 的信息。
注意
在适当的时候将工具用于其原始上下文之外。
批处理文件和 bash 脚本允许您在操作系统级别自动化工作。但两者都有挑剔的语法,有时命令笨拙。例如,如果您需要对大量文件执行操作,使用批处理文件和 bash 脚本中的原始命令很难检索到您想要的文件列表。为什么不使用已经为此目的设计的工具呢?
我们现在用作开发工具的典型 make 命令已经知道如何获取文件列表、过滤它们并对它们执行操作。对于必须对文件组进行操作的任务,Ant、Nant 和 Rake 的语法比批处理和脚本文件友好得多。
这是一个将 Ant 用于某些工作的例子,这些工作在批处理文件中如此困难,以至于我永远不会费心去做。我过去教过很多编程课,在课堂上即兴编写示例。由于提问,我经常会根据需要自定义应用程序。在一周结束时,每个人都想要我编写的自定义应用程序的副本。但在编写它们的过程中,堆积了很多额外的东西(输出文件、JAR 文件、临时文件等),所以我必须清理所有无关文件并为他们创建一个漂亮的 ZIP 存档。我没有手动执行此操作,而是创建了一个 Ant 文件来完成它。好处在于
关于使用 Ant 的一个内置优势是对一组文件的感知能力:
[[name][=]["clean-all"] [depends][=]["init"][>]]
[[verbose][=]["true"] [includeEmptyDirs][=]["true"][>] [[dir][=]["${clean.dir}"][>]]]
[[name][=]["**/*.war"][ />]]
[[name][=]["**/*.ear"][ />]]
[[name][=]["**/*.jar"][ />]]
[[name][=]["**/*.scc"][ />]]
[[name][=]["**/vssver.scc"][ />]]
[[name][=]["**/*.*~"][ />]]
[[name][=]["**/*.~*~"][ />]]
[[name][=]["**/*.ser"][ />]]
[[name][=]["**/*.class"][ />]]
[[expression][=][".*~$"][ />]]
[]
[]
[[verbose][=]["true"] [includeEmptyDirs][=]["true"][ >]]
[[dir][=]["${clean.dir}"] [defaultexcludes][=]["no"][>]]
[[refid][=]["generated-dirs"][ />]]
[]
[]
[]
使用 Ant 让我能够编写一个高级任务来执行之前手动完成的所有步骤:
[[name][=]["zip-samples"] [depends][=]["clean-all"][ >]]
[[file][=]["${class-zip-name}"][ />]]
[[message][=]["Your file name is ${class-zip-name}"][ />] [[destfile][=]["${class-zip-name}.zip"] [basedir][=]["."] [compress][=]["true"] [excludes][=]["*.xml,*.zip, *.cmd"][ />]]]
[]
用批处理文件编写这个任务将是一场噩梦!即使用 Java 编写也会很麻烦:Java 没有内置的匹配模式文件集的感知能力。使用构建工具时,你不需要创建 [main] 方法或构建工具已经提供的任何其他基础设施。
Ant 最糟糕的地方在于它依赖 XML,这种格式难以编写、难以阅读、难以重构,也难以比较差异。一个不错的替代方案是 Gant。它提供了与现有 Ant 任务交互的能力,但你可以用 Groovy 编写构建文件,这意味着你现在使用的是一种真正的编程语言。
Rake 是 Ruby 的 make 工具(用 Ruby 编写)。Rake 是替代 shell 脚本的绝佳选择,因为它为你提供了 Ruby 的全部表达能力,同时让你能够轻松地与操作系统交互。
这是我一直在使用的一个例子。我在开发者大会上做了很多演讲,这意味着我有大量的幻灯片和相应的示例代码。很长一段时间,我会启动演示文稿,然后想起我必须启动的所有其他工具和示例。我总会忘记一个,然后不得不在演讲过程中四处寻找缺失的示例。后来我明智地将这个过程自动化了:
[require ][File][.dirname(][__FILE__][) + ]['][/../base]['] [TARGET][ = ][File][.dirname(][__FILE__][)]
[FILES][ = []
["#{][PRESENTATIONS][}][/building_dsls.key]["][,] ["#{][DEV][}][/java/intellij/conf_dsl_builder/conf_dsl_builder.ipr]["][,] ["#{][DEV][}][/java/intellij/conf_dsl_logging/conf_dsl_logging.ipr]["][,] ["#{][DEV][}][/java/intellij/conf_dsl_calendar_stopping/conf_dsl_calendar_stopping.ipr]["][,] ["#{][DEV][}][/thoughtworks/rbs/intarch/common/common.ipr]["]
[]]
[APPS][ = []
["#{][TEXTMATE][}] [#{][GROOVY][}][/dsls/]["][,]
["#{][TEXTMATE][}] [#{][RUBY][}][/conf_dsl_calendar/]["][,] ["#{][TEXTMATE][}] [#{][RUBY][}][/conf_dsl_context]["]
[]]
这个 rake 文件列出了我需要打开的所有文件以及演讲所需的所有应用程序。Rake 的一个优点是它能够使用 Ruby 文件作为辅助文件。这个 rake 文件本质上只是声明。实际工作由一个名为 base 的基础 rake 文件完成,所有单独的 rake 文件都依赖于它。
[require ]['][rake][']
[require ][File][.dirname(][__FILE__][) + ]['][/locations][']
[require ][File][.dirname(][__FILE__][) + ]['][/talks_helper][']
[task ][:open] [do]
[TalksHelper][.new(][FILES][, ][APPS][).open_everything]
[end]
注意在文件顶部我引入了一个名为 talks_helper 的文件:
[class ][TalksHelper]
[attr_writer] [:openers][, ][:processes]
[ def ][initialize][(openers, processes)]
[@openers][, ][@processes][ = openers, processes]
[ end]
[ def ][open_everything]
[@openers][.each { |][f][| ][`][open ][#{][f.gsub ][/\s/][, ]['][\\ ]['}`][ } ][unless] [@openers][.nil?] [@processes][.each ][do][ |][p][|]
[pid = ][fork][ {system p}]
[Process][.detach(pid)]
[end] [unless] [@processes][.nil?]
[ end]
[end]
这个辅助类包含了执行实际工作的代码。这种机制让我可以为每个演讲准备一个简单的 rake 文件,并自动启动我需要的内容。Rake 的巨大优势在于你可以轻松地与底层操作系统交互。当你用反引号字符(`)分隔字符串时,它会自动将其作为 shell 命令执行。包含 [`open #{f.gsub /\s/, '\\ '}`] 的代码行实际上从底层操作系统执行 open 命令(在本例中是 Mac OS X;你可以在 Windows 中替换为 start),使用我上面定义的变量作为参数。使用 Ruby 驱动底层操作系统比编写 bash 脚本或批处理文件要容易得多。
Selenium 是一个用于 Web 应用程序的开源用户验收测试(user acceptance testing)工具。它允许你通过 JavaScript 自动化浏览器来模拟用户操作。Selenium 完全用浏览器技术编写,因此可以在所有主流浏览器中运行。无论使用什么技术创建 Web 应用程序,它都是测试 Web 应用程序的极其有用的工具。
但我在这里不是要讨论将 Selenium 用作测试工具。Selenium 的一个附属项目是名为 Selenium IDE 的 Firefox 浏览器插件。Selenium IDE 允许你
将你与 Web 应用的交互记录为 Selenium 脚本,你可以通过 Selenium 的 TestRunner 或 Selenium IDE 本身来回放。虽然这在创建测试时很有用,但如果你需要自动化与 Web 应用的交互,这就变得非常宝贵。
[‡] [下载地址:][http://www.openqa.org.]
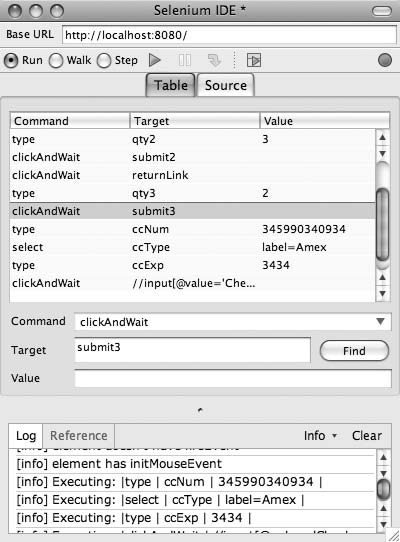
[图 4-2. Selenium IDE 中已准备运行的脚本]
这里有一个常见场景。你正在构建向导式 Web 应用的第四个页面。前三个页面已经完成,这意味着它们的所有交互都能正常工作(包括验证之类的功能)。为了调试第四个页面的行为,你必须一遍又一遍地走过前三个页面。一遍又一遍。你总是想:“好吧,这应该是最后一次需要走过这些页面了,因为我确信这次已经修复了这个 bug。” 但从来都不是最后一次!这就是为什么你的测试数据库里有很多 Fred Flintstone、Homer Simpson 和那个 ASDF 家伙的条目。
使用 Selenium IDE 来帮你完成这些步骤。第一次你需要走过应用来到达第四个页面时,使用 Selenium IDE 记录下来,看起来会很像图 4-2。现在,下次你需要走到第四个页面,并且每个字段都有有效值时,只需回放 Selenium 脚本即可。
Selenium 的另一个出色的开发者用途也浮现出来了。当你的 QA 部门发现一个 bug 时,他们通常会用一些原始的方式报告 bug 是如何产生的:部分的操作列表、模糊的屏幕截图,或者类似的不太有用的东西。让他们用 Selenium IDE 记录他们发现 bug 的过程并报告给你。然后,你可以自动重复他们的确切场景,一遍又一遍,直到你修复 bug。这既节省时间又减少挫败感。Selenium 本质上创建了一个可执行的用户与 Web 应用交互的描述。好好利用它!
注意
不要花时间手动做那些可以自动化的事情。
这里有一个你可能在典型项目中遇到的使用 bash 的例子。我曾在一个已经进行了六年的大型 Java 项目中工作(我只是这个项目的访客,在第六年到达并待了大约八个月)。我的一项任务是清理一些定期发生的异常。我做的第一件事是问”正在抛出什么异常以及频率如何?” 当然,没人知道,所以我的第一个任务就是回答这个问题。
问题是这个应用每周都会产生 2 GB 的日志,包含了我需要分类的异常,以及大量其他噪音。我很快意识到用文本编辑器打开这个文件是浪费时间。所以,我坐下来花了一点时间,最终得到了这个:
#!/bin/bash
for X in $(egrep -o "[A-Z]\w*Exception" log_week.txt | sort | uniq) ; do
echo -n -e "processing $X\t"
grep -c "$X" log_week.txt
done表 4-2 展示了这个方便的小 bash 脚本的作用。
表 4-2. 用于统计异常数量的复杂 bash 命令
| 字符 | 作用 |
|---|---|
| egrep -o | 在日志文件中查找所有在”Exception”之前有一些文本的字符串,对它们排序,并获取一个不重复的列表 |
| “[A-Z]Exception” | 定义异常看起来像什么的模式 |
| log_week.txt | 巨大的日志文件 |
| | sort | 将结果通过 sort 管道传递,创建异常的排序列表 |
| | uniq | 消除重复的异常 |
| for X in $(. . .) ; | 对上面生成的列表中的每个异常执行循环中的代码 |
| echo -n -e “processing $X\t" | 向控制台输出我正在统计的异常(这样我可以知道它在工作) | | grep -c "$X” log_week.txt | 在巨大的日志文件中查找此异常的数量 |
他们在项目中仍然在使用这个小工具。这是自动化创建有价值项目信息的一个很好的例子,这些信息以前没有人花时间去做。我们可以直接查看并准确找出正在抛出的异常类型,而不是猜测和推测,这使得我们有针对性地修复异常变得更加容易。
作为 Vista 版本 Windows 工作的一部分,微软显著升级了批处理语言。代号是 Monad,但当它发布时变成了 Windows Power Shell。(为了节省每次拼写所需的额外纸张,我将继续称它为”Monad”。)它内置于 Windows Vista,但你也可以通过从微软网站下载在 Windows XP 上使用它。
Monad 从类似 bash 和 DOS 这样的命令 shell 语言中借鉴了很多哲学,你可以将一个命令的输出通过管道传递给另一个命令。最大的区别是 Monad 不使用纯文本(像 bash 那样);相反,它使用对象。Monad 命令(称为 cmdlets)理解一组通用对象,这些对象代表操作系统结构,如文件、目录,甚至像 Windows 事件查看器这样的东西。使用它的语义与 bash 相同(管道操作符甚至是同样的 | 符号),但功能却非常广泛。
这里有一个例子。假设你想将 2006 年 12 月 1 日以来更新的所有文件复制到名为 DestFolder 的文件夹中。Monad 命令如下所示:
dir | where-object { $_.LastWriteTime -gt "12/1/2006" } |
move-item -destination c:\DestFolder因为 Monad cmdlets “理解” 其他 cmdlets 以及它们输出的内容类型,你
与其他脚本语言相比,可以更简洁地编写脚本。这里有一个例子。
假设你需要使用 bash 终止所有使用超过 15 MB 内存的进程:
ps -el | awk '{ if ( $6 > (1024*15)) { print $3 } }'
| grep -v PID | xargs kill非常难看!它使用了五个不同的 bash 命令,包括用 awk 来解析 ps 命令的结果。以下是等效的 Monad 命令:
get-process | where { $_.VS -gt 15M } | stop-process在这里,你可以使用 where 命令来筛选 get-process 输出的特定属性(在这种情况下是 VS 属性,即内存大小)。
Monad 使用 .NET 编写,这意味着你还可以访问标准的 .NET 类型。字符串操作在命令行 shell 中传统上很困难,但它依赖于 .NET 中的 [String] 方法。例如,执行以下 Monad 命令:
get-member -input "String" -membertype method会输出 [String] 类的所有方法。这类似于在 *nix 中使用 man 实用程序。
Monad 相比 Windows 世界之前的工具是一个巨大的进步。它在操作系统级别提供了一流的编程能力。许多过去迫使开发人员求助于 Perl、Python 和 Ruby 等脚本语言的任务,现在可以在 Monad 中轻松完成。因为它是操作系统核心的一部分,所以可以查询和操作系统特定的对象(如事件查看器)。
Mac OS X 有一种称为 Automator 的图形化批处理文件编写方式。在许多方面,它是 Monad 的图形化版本,尽管它比 Monad 早了几年。要创建 Automator 工作流(Mac OS X 版本的脚本),从 Automator 的工作区拖动命令,并将一个命令的输出与另一个命令的输入”连接”起来。每个应用程序在安装时都会向 Automator 注册其功能。你还可以用 ObjectiveC(Mac OS X 的底层开发语言)编写 Automator 片段来扩展它。
这里有一个 Automator 工作流示例,它会删除所有超过两周的旧下载文件。工作流如图 4-3 所示,包含以下步骤:
此工作流比上面的 Monad 脚本做了更多工作,因为在工作流中没有简单的方法来指定你想要所有最近两周未修改的文件。最好的解决方案是抓取最近两周修改过的文件,将它们移到缓存目录(名为 recent)之外,然后删除 downloads 中的所有文件。你永远不会费心手动执行此操作,但因为它是一个自动化实用程序,所以可以做额外的工作。一个替代方案是在 bash 中编写 shell 脚本并将其合并到工作流中(其中一个选项是调用 bash 脚本),但这样你又回到了解析 shell 脚本结果以获取名称的状态。如果你想走那么远,可以将整个过程作为 shell 脚本来完成。
最终,你会到达这样一个点:你无法改造另一个工具或找到一个恰好符合你需求的开源项目。这意味着是时候构建你自己的小工具或垫片(shim)了。
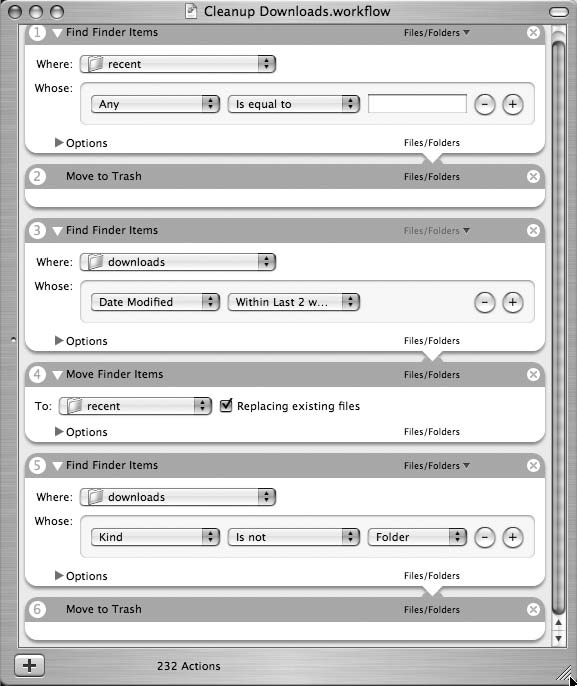
图4-3. Mac OS X Automator 中的”删除旧下载”工作流
本章包含许多构建工具的不同方法;这里有一些在实际项目中使用这些工具解决问题的示例。
我是开源版本控制系统 Subversion 的忠实粉丝。它恰好是强大、简单和易用性的正确组合。Subversion 本质上是一个命令行版本控制系统,但许多开发人员为它创建了前端(我最喜欢的是与 Windows 资源管理器集成的 Tortoise)。然而,Subversion 的真正强大之处在于命令行。让我们看一个例子。
我倾向于小批量地将文件添加到 Subversion。要使用命令行工具,必须指定要添加的每个文件名。如果只有几个文件还不错,但如果你添加了 20 个文件,这就很麻烦了。你可以使用通配符,但你可能会抓取已经在版本控制中的文件(这不会造成任何损害,但你会得到大量错误消息,可能会掩盖其他错误消息)。为了解决这个问题,我编写了一个简短的单行 bash 命令:
svn st | grep '^\?' | tr '^\?' ' ' |
sed 's/[ ]*//' | sed 's/[ ]/\\ /g' | xargs svn add表 4-3 显示了这个单行命令的作用。
表 4-3. svnAddNew 命令序列分析
| 命令 | 结果 |
|---|---|
| svn st | 获取此目录及其所有子目录中所有文件的 Subversion 状态。新文件在开头返回 ?,文件名前有一个制表符。 |
| grep ‘^?’ | 查找所有以 ? 开头的行。 |
| tr ‘^?’ ’ ’ | 将 ? 替换为空格(tr 命令将一个字符转换为另一个字符)。 |
| sed ’s/[ ]*//’ | 使用 sed(基于流的编辑器),将行首部分的空格替换为空。 |
| sed ‘s/[ ]/\ /g’ | 文件名可能包含嵌入的空格,因此再次使用 sed 将任何剩余的空格替换为转义空格字符(前面带有 的空格)。 |
将结果行导入到 svn add 命令中。
这个命令行花了将近15分钟来实现,但从那以后我已经使用这个小工具(或者说是夹具?)数百次了。
我和一位同事正在做一个项目,需要解析一个大型(38,000行)的遗留 SQL 文件。为了让解析工作更容易,我们想把这个庞大的文件分割成每个约1,000行的小块。我们很简短地考虑过手动完成,但决定自动化会更好。我们考虑过用 sed 来做,但看起来会很复杂。我们最终选择了 Ruby,大约一个小时后,我们写出了这段代码:
SQL_FILE = "./GeneratedTestData.sql"
OUTPUT_PATH = "./chunks of sql/"
line_num = 1
file_num = 0
Dir.mkdir(OUTPUT_PATH) unless File.exists? OUTPUT_PATH
file = File.new(OUTPUT_PATH + "chunk " + file_num.to_s + ".sql",
File::CREAT|File::TRUNC|File::RDWR, 0644)
done, seen_1k_lines = false
IO.readlines(SQL_FILE).each do |line|
file.puts(line)
seen_1k_lines = (line_num % 1000 == 0) unless seen_1k_lines
line_num += 1
done = (line.downcase =~ /^\W*go\W*$/ or
line.downcase =~ /^\W*end\W*$/) != nil
if done and seen_1k_lines
file_num += 1
file = File.new(OUTPUT_PATH + "chunk " + file_num.to_s + ".sql",
File::CREAT|File::TRUNC|File::RDWR, 0644)
done, seen_1k_lines = false
end
end这个小 Ruby 程序从原始文件中读取行,直到读取了1,000行。然后,它开始查找包含 GO 或 END 的行。一旦找到这两个字符串中的任何一个,它就完成当前文件并开始另一个文件。
我们计算过,通过手工方式分割这个文件大概需要10分钟,而自动化它花了大约一个小时。我们最终又做了五次,所以几乎收回了我们花在自动化上的时间。但这不是重点。手工执行简单、重复的任务会让你变得更迟钝,它会窃取你的专注力(concentration),而专注力是你最有生产力的资产。
注意
执行简单、重复的任务会浪费你的专注力。
想出一个聪明的方法来自动化任务会让你更聪明,因为你在这个过程中学到了东西。我们花这么长时间完成这个 Ruby 程序的原因之一是我们不熟悉 Ruby 如何处理底层文件操作。现在我们知道了,可以将这些知识应用到其他项目中。而且,我们已经找到了如何自动化项目基础设施的一部分,这使得我们更有可能找到其他方法来自动化简单任务。
注意
找到问题的创新解决方案会让将来解决类似问题变得更容易。
当你部署应用程序时,只需要三个步骤:在数据库上运行”创建表”脚本,将应用程序文件复制到 web 服务器,以及更新配置文件以适应你对应用程序路由所做的更改。简单、容易的步骤。你每隔几天就要做一次。那么,有什么大不了的?这只需要大约15分钟。
如果你的项目持续八个月呢?你将不得不经历这个仪式64次(实际上,当你接近终点线并且必须更频繁地部署时,节奏会加快)。加起来:64次执行这个任务 × 15分钟 = 960分钟 = 16小时 = 2个工作日。两个完整的工作日来一遍又一遍地做同样的事情!这还没有考虑到你不小心忘记执行其中一个步骤的次数,这会在调试和修复上花费更多时间。如果自动化整个过程花费不到两天时间,那么这是理所当然的,因为你可以获得纯粹的时间节省。但如果自动化它需要三天时间——它仍然值得吗?
我遇到过一些系统管理员,他们为执行的每项任务都编写 bash 脚本。他们这样做有两个原因。首先,如果你做一次,你几乎肯定会再做一次。Bash 命令在设计上非常简洁,即使对于经验丰富的开发人员来说,有时也需要几分钟才能做对。但如果你再次执行该任务,保存的命令会节省你的时间。其次,将所有重要的命令行内容保存在脚本中,可以创建你所做工作的活文档(living documentation),以及你执行某项任务的原因。保存你做的每一件事是极端的,但存储非常便宜——比重新创建某些东西所需的时间便宜得多。也许你可以折中一下:不要保存你做的每一件事,但第二次发现自己在做某事时,就自动化它。如果你做两次,很有可能你最终会做100次。
几乎每个在 *-nix 系统上的人都在他们隐藏的 .bash_profile 配置文件中创建别名(aliases),使用常用的命令行快捷方式。以下是一些示例,显示一般语法:
alias catout='tail -f /Users/nealford/bin/apache-tomcat-6.0.14/logs/catalina.out'
alias derby='~/bin/db-derby-10.1.3.1-bin/frameworks/embedded/bin/ij.ksh'
alias mysql='/usr/local/mysql/bin/mysql -u root'任何经常使用的命令都可以出现在这个文件中,使你不必记住一些神奇的咒语。实际上,这个能力与使用键盘快捷键的能力有很大重叠。
宏工具(参见第2章”关键宏工具”)。我倾向于在大多数情况下使用 bash 别名]
(宏展开的开销更小),但有一个关键类别我会使用键盘宏工具。任何包含双引号和单引号混合的命令行都很难通过别名正确转义。键盘宏工具能更好地处理这种情况。
例如,svnAddNew [脚本(如前面”驯服命令行 Subversion”中所示)]
最初是一个 bash 别名,但试图正确处理所有转义让我抓狂。现在它作为键盘宏存在,生活变得简单多了。
注意
自动化的理由在于投资回报率和风险缓解。
你会在项目中看到很多想要自动化的琐事。你必须问自己以下问题(并诚实回答):
• 从长远来看会节省时间吗? • 它是否容易出错(因为有很多复杂步骤),如果做错会浪费时间? • 这个任务会破坏我的专注力吗?(几乎任何任务都会让你离开注意力焦点,使你更难回到专注状态。) • 做错的风险是什么?
66 第4章:自动化
最后一个问题很重要,因为它涉及风险。我曾在一个项目中与一些人共事,他们因为历史原因不想为代码和测试创建单独的输出目录。为了运行测试,我们需要创建三个不同的测试套件,每种测试一个(单元测试、功能测试和集成测试)。项目经理建议我们手动创建测试套件。但我们决定花时间通过反射来自动化创建。手动更新测试套件容易出错;开发人员太容易编写测试后忘记更新测试套件,这意味着他的工作永远不会被执行。我们认为不自动化的风险太大。
当你想要自动化某个任务时,可能会让项目经理担心的一件事是它会失控。我们都有过这样的经历:认为可以在两小时内完成某件事,结果却很快变成了四天。缓解这种风险的最佳方法是时间盒(timebox)你的努力:为探索和事实收集分配确切的时间。在时间盒结束时,客观地重新评估是否可行完全追求这个任务。时间盒开发是关于学习足够的知识来做出现实判断。在时间盒结束时,你可能决定使用另一个时间盒来了解更多。我知道巧妙的自动化任务比你的项目工作更有趣,但要现实一点。你的老板值得得到真实的估算。
注意
对投机性开发使用时间盒。
最后,不要让你的自动化副项目变成剃牦牛(yak shaving)。剃牦牛是计算机科学官方术语文件的一部分。它描述了这种场景:
在某个时刻,你停下来试图记住是什么让你走上这条路。你意识到你正在剃牦牛,然后停下来试图弄清楚剃牦牛与为 Subversion 日志生成文档有什么关系。
不要剃牦牛 67
剃牦牛很危险,因为它会吃掉大量时间。它也解释了为什么任务估算经常出错:完全剃掉一只牦牛需要多长时间?始终记住你想要实现什么,如果开始失控就立即停止。
本章包含了很多自动化方法的例子,但这些例子并不是真正的重点。它们只是用来说明我和其他人想出的自动化常见琐事的方法。计算机的存在就是为了执行简单、重复的任务:让它们工作!注意你每天和每周做的重复性工作,问自己:我能自动化这个吗?这样做可以增加你花在有用问题上的时间,而不是一遍又一遍地解决相同的简单问题。手动执行简单任务会夺走你的一些专注力,因此消除那些烦人的小琐事可以释放你宝贵的脑力用于其他事情。
68 第4章:自动化

距离你向大老板演示还有两小时
关键功能之一在你的机器上无法工作。这不可能。上周它在 Bob 的机器上运行正常。你去 Bob 的机器,果然,它运行得很好。但在你的机器上运行良好的其他一些功能在 Bob 的机器上却无法工作。现在是时候恐慌了。
不久,整个开发团队都站在 Bob 的机器周围,试图弄清楚为什么他构建的东西与其他人构建的不同。在项目的重要里程碑之前是发生这种情况的错误(但不可避免的)时机。事实证明
Bob 的 IDE 中有某个插件的新版本,这改变了应用程序在他环境中的运行方式。当然,在 Bob 的机器上安装相同版本的插件会破坏其他东西。你、Bob 和所有同事都在遭受困扰,因为你们运行着某个重要组件的多个版本,这些版本总是不同步。
规范表示(canonical representation)指的是不丢失信息的最简形式。规范性(canonicality)指的是消除重复的实践。在开创性著作《程序员修炼之道》(The Pragmatic Programmer,Addison-Wesley)中,Andrew Hunt 和 David Thomas 制定了这样的法则:“不要重复自己”(DRY)。这三个词的句子对软件开发产生了深远影响。Glenn Vanderburg 称重复为”软件开发中最具破坏力的单一因素”。想必你已经认同这一点。你如何在软件开发中实现规范性?在很多情况下,甚至很难注意到问题,特别是当非 DRY(潮湿?)是现状时。
本章提供了如何实现规范性的示例。它针对三个常见的非 DRY 来源:数据库对象关系映射、文档和沟通。这里讨论的每个场景都来自真实项目,在每个场景中,开发人员都找到了保持 DRY 的方法。
规范性的一个明显应用已经在大多数开发团队中变得司空见惯:版本控制,它符合规范性的条件,因为”真实”文件存储在版本控制中。使用版本控制具有处理文件版本管理的明显好处。但它也是一个很好的备份机制,将你的源代码保存在安全的地方,远离开发人员机器上的单个实例。
我倾向于使用不锁定文件而是在多个开发人员进行更改时合并内容的版本控制系统(称为乐观修订)。这是一个工具鼓励良好行为并惩罚不良行为的好例子。尽早且频繁地将文件检入版本控制会鼓励你进行小的更改。知道如果对文件进行长期更改就会面临合并冲突,这会鼓励你更频繁地检入。该工具创造了一种有用的张力,以微妙但有益的方式改变你的工作方式。好的工具是那些鼓励良好行为的工具。因此,我喜欢开源的 Subversion 版本控制系统:它非常轻量,是免费的,而且只做它应该做的事情,不做其他事情。
虽然版本控制的使用几乎是普遍的,但通常没有充分发挥其潜力。版本控制可以使你的项目工件尽可能地 DRY。构建项目所需的所有内容都应该存储在版本控制中。这包括二进制文件(库、框架、JAR 文件、构建脚本等)。不应该在版本控制中的唯一内容是由于路径、IP 地址等原因而特定于开发人员机器的配置文件。即使在这种情况下,只有开发人员工作站独有的信息才应该存储在本地文件中。构建工具(如 Ant 和 Nant)允许你外部化特定信息,以便你可以只隔离更改的部分。
为什么要保留二进制文件?当今的项目依赖于大量外部工具和库。假设你正在使用一个流行的日志框架(如 Log4J 或 Log4Net)。如果你不将该日志库的二进制文件作为构建过程的一部分来构建,你应该将其保存在版本控制中。这使你能够继续构建软件,即使相关框架或库消失了(或者更可能的是,在新版本中引入了破坏性更改)。始终将构建软件所需的整个环境保存在版本控制中(除了操作系统,甚至通过虚拟化也是可能的;请参见本章后面的”使用虚拟化”)。你可以通过将二进制文件同时保存在版本控制和共享网络驱动器上来优化保留二进制文件。这样,你不必每小时都处理它们,但如果你需要在一年后重建某些内容,它们会被保存。你永远不知道是否需要重建某些内容。你构建它直到它工作,然后忘记它。当你意识到需要重建两年前的东西却没有所有部件时,会感到恐慌。
注意
将你不构建的所有内容的单个副本保存在版本控制中。
当然,二进制文件会给版本控制增加相当大的膨胀,这可能会导致存储问题(额外空间)和带宽问题(检出项目所需的时间)。存在两种可接受的替代方案。一些版本控制包(如 Subversion)有一个外部选项,允许你从一个项目引用另一个项目。你可以将所有共享库保存在一个从多个其他项目引用的外部项目中。二进制文件仍然存储在版本控制中,但只占用一次空间。这解决了存储问题,但没有解决带宽问题。
另一个解决方案是将库保存在映射的网络驱动器上,由每台开发机器引用。这是一个更可怕的提议,因为你有构建项目所需的文件不再存储在版本控制中。有时这是唯一合理的替代方案。
不可接受的替代方案不幸地成为大多数项目的默认方案:每个开发人员在自己的机器上都有库,有时在不同的目录中。任何经历过这种项目设置的人都知道维护这种潮湿的基础设施是多么噩梦。
在我多年前工作过的一家咨询公司,我们有一个客户的应用程序,几年前我们对其做过一些小改动。之后很长时间我们都没有接触过它。他们的一位内部开发人员一直在维护和增强这个项目。后来他离职去当冲浪者或者”寻找自我”了,结果他们发现除了他的机器之外,无法在任何其他机器上构建这个项目。他们真的花了好几周时间尝试构建项目,但地球上唯一能够成功构建的机器就是这个开发人员的笔记本电脑。最后,他们把笔记本电脑寄给了我们,让我们搞清楚他到底做了什么魔法。结果发现他利用了Java的一个鲜为人知的”特性”——运行时环境中的ext目录,因为他太懒了(或者不知道如何)将其添加到类路径中。当你需要把笔记本电脑寄给咨询公司来弄清楚如何构建你自己的软件时,你就知道配置出了大问题!
使用规范构建机器
每个开发团队都需要的另一个流程是持续集成(Continuous Integration)。持续集成是一个定期构建整个项目、运行测试、生成文档以及执行所有其他软件制作活动的过程(频率越高越好,通常应该在每次向版本控制提交代码时进行构建)。持续集成由同名软件提供支持。理想情况下,持续集成服务器运行在独立的机器上,监控你对版本控制的提交。每次执行代码提交时,持续集成服务器就会启动,运行你指定的构建命令(在类似Ant、Nant、Rake或Make的构建文件中),通常包括执行完整构建、设置测试数据库、运行整套单元测试、运行代码分析以及部署应用程序进行”冒烟测试”。持续集成服务器将构建职责从各个单独机器转移到一个规范的构建位置。
规范构建机器不应该包含你用来创建项目的开发工具,只需要构建应用程序所需的库和其他框架。这可以防止对工具的隐性依赖悄悄渗入你的构建过程。与Bob和他倒霉的同事不同,你要确保每个人构建的都是同样的东西。拥有规范构建服务器使其成为项目唯一的”官方”构建。开发工具的变更不会影响它。
即使是单独的开发人员也能从将持续集成服务器作为唯一构建机器中受益。它可以防止你无意中让工具依赖渗入
第5章:规范性
你的项目。如果你能在独立机器上使用单个命令构建应用程序,显然配置就是正确的。
存在许多持续集成服务器,既有商业的也有开源的。CruiseControl是ThoughtWorks创建的开源项目,它有Java、.NET和Ruby的移植版本。其他持续集成服务器包括Bamboo、Hudson、TeamCity和LuntBuild。
间接层
平台为重要项目提供结构支撑。开发工具通过提供稳定的基础来构建自己的平台,你可以站在这个基础上构建软件。但平台的一部分是基础设施,许多开发工具创建了你无法控制的基础设施。间接层允许你重新获得控制权并提高生产力。
驯服Eclipse插件
注意:使用间接层创建更友好的工作空间。
Eclipse最好的一点是丰富的插件生态系统。Eclipse最糟糕的一点也是这个丰富的插件生态系统!不同的团队成员下载不同版本的插件。通常这不是问题,但偶尔插件版本之间存在不兼容性,突然你就遇到了Bob的不可重现构建问题。这代表了规范性问题。
解决方案是确保项目中的每个人都拥有完全相同的插件集合(精确到次版本号)。开发团队越大,这就越难管理。Eclipse的创建者预见到了这个问题,允许你配置多个插件和特性位置。令人费解的是,这个选项位于帮助菜单下,在软件更新和管理配置中。按照以下步骤创建新配置:
创建一个名为eclipse的新子目录。该目录不应位于Eclipse的默认目录结构内。
在新目录中创建一个名为.eclipseextension的空占位符文件。这是Windows和Eclipse意见不一致的一个例子,你无法在Windows资源管理器中创建此文件,因为它不允许你创建以”.”作为第一个字符的文件。因此,你必须打开命令窗口(Windows shell或bash shell都可以)来创建此文件。在具有该命令的操作系统上,简单的方法就是执行touch .eclipseextension。
在新目录中创建两个(空)目录:features和plugins。
在Eclipse允许你创建指向新目录的新配置之前,你必须执行这些步骤。我不确定为什么Eclipse不直接为你完成这些操作,但它确实不会。无论如何,你现在可以使用产品配置对话框(从
菜单项)。图5-1展示了产品配置对话框,其中定义了两个额外的配置。您可以从那里定义整个工作插件和特性集,包括JDK和所有Eclipse特性(第二个配置位于c:\work\eclipse,包含整个SDK)。您也可以仅指向插件的一个子集(如第三个配置所示,它位于路径c:\work\IVE\eclipse)。
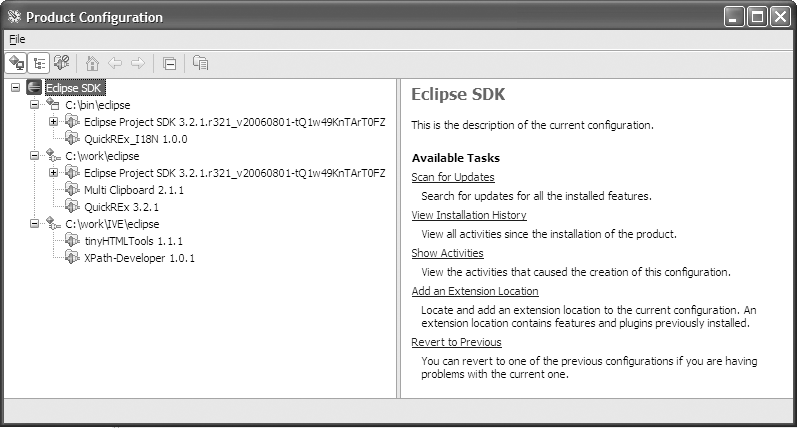
图5-1. Eclipse中的产品配置对话框
在Eclipse中,您可以通过两种不同的方式安装插件和特性。您可以自己下载代码并将相应的文件夹解压到相应的目标位置。在这种情况下,您需要将插件解压到外部配置位置。您也可以使用查找和安装…菜单项,它允许您指向一个定义好的URL并直接下载插件和特性。在这种情况下,Eclipse在下载过程中会提供一个按钮,询问您希望将特性或插件保存在哪个配置中,如图5-2所示。
第5章:规范性
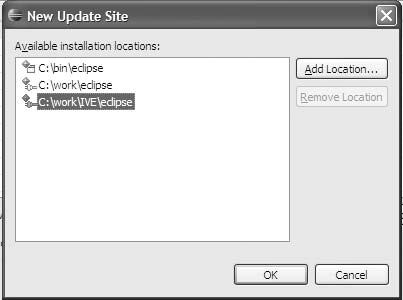
图5-2. 额外配置的更新站点
剩下的很简单:在进入版本控制的目录中创建新的产品配置。为此项目设置所需的插件并执行签入。现在,在其他开发人员的机器上,签出新配置并使用产品配置对话框将Eclipse的全新安装指向它。当一个开发人员工作站上发生更改时,这些更改将在下次进行版本控制更新并重启Eclipse时出现在其他工作站上。
当您创建新配置时,它独立于”主”配置。您还可以选择性地启用和禁用配置。如果您在不同的项目上工作,每个项目都有自己的插件集,这非常方便。更改配置时确实需要重启Eclipse,但这比安装和卸载插件要容易得多。
自从我创建这个解决方案以来,一个名为Pulse的现成解决方案被创建来管理Eclipse插件。这种技术当然仍然有效,但有人认识到这是一个如此重要的问题,以至于他们创建了一个工具来解决它!
我喜欢使用JEdit作为我的通用文本编辑器之一。JEdit的一个不错的特性是它能够记录和保存宏。我在几台不同的机器上工作(家里的各种Windows机器和路上的Macintosh笔记本电脑)。为了保持文档同步,我在互联网上的第三台机器上创建了一个Subversion仓库。该仓库包含我的整个Documents目录(在Windows上保存在我的文档中,在Mac上保存在~/Documents中)。
从http://www.poweredbypulse.com/下载。
在JEdit中,所有宏都保存在目录[用户主目录]\.jedit\macros中,其中”[用户主目录]“是特定机器上用户的主目录。这意味着,在我的情况下,Windows上的主目录是c:\Documents and Settings\nford\,在Mac上是/Users/neal/(或者在Unix中更方便的~/)。主目录不在Documents目录中。这意味着JEdit宏不在Subversion仓库中,因此不会在机器之间同步。
解决方案在于间接引用:让JEdit在您想要的位置查找其宏。在*-nix操作系统(Linux、Mac OS X)中,您可以使用符号链接来实现这一点。不幸的是,如果您使用的是Windows 2000或XP,您无法创建符号链接,快捷方式也不起作用。快捷方式概念不是文件系统的一部分;它是由shell创建的外观。因此,应用程序必须”理解”快捷方式实际上指向其他内容,而JEdit并不是为理解快捷方式而编写的。如果您使用的是较旧版本的Windows,则需要某种符号链接来进行间接引用操作(Windows Vista现在有一个名为mklink的命令,可以创建真正的符号链接)。幸运的是,有一个名为Junction的免费工具可以为您处理这个问题。
Unix、Linux和Mac OS X开发人员的操作系统中内置了链接。Windows用户需要的不仅仅是快捷方式。Junction在文件系统的目录中创建重复条目,允许您创建指向其他目录的指针。它在操作系统层面工作,因此所有应用程序(包括Windows本身)都遵循它创建的指针。
junction是一个命令行工具,允许您创建和删除硬链接。例如,如果您想在当前目录中创建一个名为”myproject”的链接,指向另一个(深度嵌套的)目录,您将发出以下命令:
junction myproject \My Documents\Projects\Sisyphus\NextGen
伪文件夹myproject充当操作系统级别的指针,指向您的\My Documents\Projects\Sisyphus\NextGen文件夹。
现在我们在所有操作系统上都有了真正的间接引用,我可以在Documents中创建一个目录来保存我所有的JEdit宏。在Windows上,我使用junction链接从目录c:\Documents and Settings\nford\.jedit创建一个名为”macros”的指针。同样,在OS X上,我在~/.jedit目录中创建一个名为”macros”的符号链接。junction和符号链接都指向位于Documents目录中的目录(因此也在Subversion仓库中)。图5-3说明了这个解决方案。
第5章:规范性
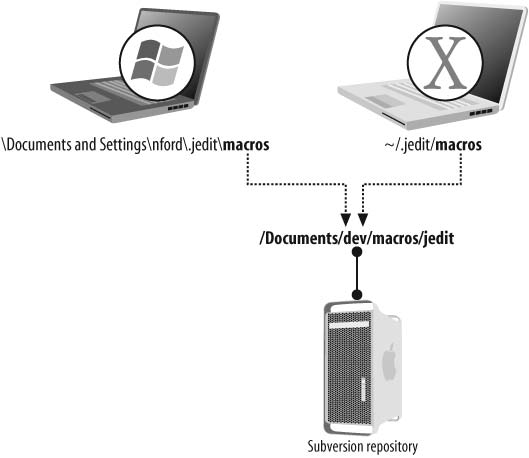
图5-3. 不同操作系统上的JEdit宏位置
现在,我可以在任一台机器上轻松录制宏,并对所有工作进行 Subversion 签入。当我在另一台机器上执行检出时,所有宏都会下载到 Documents 文件夹中,因为我已经”欺骗”了 JEdit,让它查看该文件夹而不是默认位置,所以我录制的所有宏会立即出现。
注意
使用间接引用来保持你的工作同步。
使用间接引用来实现规范化可以嵌套多层。有一次,我同时参与多个项目,每个项目都有自定义的宏。我想使用间接引用原则共享这些宏,但其他团队只对与他们项目相关的宏感兴趣。通过间接引用将 JEdit 宏文件夹中的所有宏发送给他们会违反专注生产力原则,该原则旨在消除干扰。
因为 JEdit 支持在其宏文件夹中创建目录,解决方案很简单:为各个项目在各自的目录中创建链接或联接(junction),并将这些专用目录放在每个版本控制仓库中。JEdit 查看宏的目录仍然是一个链接(或联接),并且它包含指向版本控制中其他外部目录的其他链接/联接。
你可以通过让一个间接引用链接指向另一个间接引用链接来分层间接引用,创建间接引用链。主要限制因素是你使用的工具:如果它依赖于共享资源的单个文件,并且你在 Windows 上,则无法使用此技术。但是,这应该是一个相当短的工具列表,如果你发现自己必须使用过于严格的工具,也许是时候寻找另一个了。
TextMate 是 Mac OS X 上一款功能强大的程序员编辑器。使其如此强大的功能之一是代码片段(snippet)的概念(在其他工具中称为实时模板(live template))。它也以 E Text Editor 的形式移植到了 Windows。
TextMate 中的代码片段保存在 bundle 中,bundle 是 Mac OS X 中以包格式组织的文件集合。Mac OS X 使用此概念为由大量文件组成的应用程序提供安装程序。像 TextMate 这样的应用程序也可以使用 Mac OS X 包概念来管理其 bundle。
TextMate 的一个优秀特性是能够通过在文件系统中找到这些 bundle 并将它们拖到另一个位置(可能是共享网络驱动器上)来共享它们。这些 bundle 存储在 ~/Library/Application Support/TextMate/Bundles 中。一旦你以这种方式提取了 bundle,就可以双击该 bundle 在另一台机器上安装它。换句话说,TextMate 考虑到了共享其 bundle 的需求,并将它们放在允许在另一台机器上自行安装的格式中。向 TextMate 的创建者致敬,感谢他们拥抱《高效程序员》的理想!
但是通过复制粘贴来共享并不是最优的。当你向 bundle 添加新代码片段时会发生什么?该 bundle 的其他副本显然无法利用这些更改。通过复制粘贴来重用是有害的,即使你是在机器之间复制配置。
注意
无论你复制粘贴什么,通过复制粘贴来重用都是有害的。
尽管 bundle 在 OS X 的 Finder 中看起来像单个文件,但它们实际上是文件夹,这意味着你可以通过链接来表示它们。就像前面的 JEdit 示例一样,你可以在 ~/Library/Application Support/TextMate/Bundles 的 Bundles 文件夹中创建一个链接,该链接指向版本控制中的”真实”文件夹。这使开发团队中的每个人都可以访问同一组 bundle,因此当有人创建了一个非常有用的代码片段时,整个团队都可以在下次从版本控制更新时利用它。
让机器以相同的方式设置是项目中的一个长期难题。一些项目采用镜像整个机器的方法,甚至包括操作系统级别(这是某些开发环境的唯一方法;请参阅下一节”使用虚拟化”)。使用间接引用,你可以显著缓解这个问题。
例如,Emacs 将其所有配置信息保存在名为 .emacs 的文件中,该文件位于用户的主目录中。(它将一些历史记录等内容保存在名为 .emacs.d 的目录中。)如果你想在多台机器之间共享该配置怎么办?你可以使用间接引用和符号链接(在 *-nix 机器上)将”真实”的 .emacs 保存在版本控制中,并让 Emacs 指向该链接。不幸的是,你无法在 Windows 2000 或 XP 中使用 Junction 执行此操作,但可以在 Windows Vista 中使用符号链接。
项目中另一个常见的痛点围绕开发人员用于加速编码的代码片段。我之前讨论了如何在 TextMate 中执行此操作,但如果你不使用 TextMate,这并没有太大帮助,对吧?你可以在流行的 IDE 中创建代码片段。不幸的是,没有标准的方法来执行此操作,所以我将介绍如何在几个流行的 Java IDE 中执行此操作:IntelliJ 和 Eclipse。
共享代码片段(在 IntelliJ 中称为实时模板(live template))非常简单,因为它们保存在一个目录中(例如,在 Mac OS X 上,它们位于 /Users/nealford/Library/Preferences/IntelliJIDEA70/templates),每个代码片段都有自己的文件。因此,要共享 IntelliJ 代码片段,只需将代码片段目录的规范版本移动到版本控制中,并从原始位置创建一个符号链接(或联接链接)到版本控制中的新位置。
不幸的是,在 Eclipse 中这样做要困难得多,因为 Eclipse 将代码片段隐藏在 Java 属性文件中。自定义代码片段是其中一个属性的值,以 XML 格式编码为属性值。不,我不是在开玩笑。这几乎就像他们故意让程序化访问变得尽可能困难!这个文件的一小部分看起来像这样(添加了换行):
#Tue Feb 12 09:45:01 EST 2008
org.eclipse.jdt.ui.overrideannotation=true
spelling_locale_initialized=true
org.eclipse.jdt.ui.javadoclocations.migrated=true
proposalOrderMigrated=true
org.eclipse.jdt.ui.formatterprofiles.version=11
useQuickDiffPrefPage=true
org.eclipse.jdt.ui.text.custom_templates=["1.0"][ encoding\=]["UTF-8"][?>["true"][ context\=]["java"][ deleted\=]["false"][ description\=][""][ enabled\=]["true"][ name\=]["my_test"][>][ \@Test public void \${var}() {\n\n}]]
org.eclipse.jdt.ui.text.code_templates_migrated=trueEclipse 确实提供了一种通过首选项对话框导入和导出代码片段的方法。导入和导出本质上是复制粘贴,但这是共享代码片段最简单的方法。另一个复杂之处在于,附加编辑器可能将其代码片段保存在不同的位置:Eclipse 中没有代码片段的标准位置。因为 Eclipse 将其代码片段保存在文本文件中,你可以创建一个脚本定期保存和重新生成属性文件,但这需要大量工作。
注意使用虚拟化来规范化项目的依赖关系。
几年前,我在 .NET 开发中使用了规范性(canonicality)的间接性(indirection)方面来简化开发流程,当时试图重建我们在另一个项目中使用的 Visual Studio 环境。Visual Studio 有一个丰富的第三方组件生态系统。问题在于,使用第三方组件意味着每个应用程序开发环境都略有不同。
客户 A 使用这个组件,但你必须确保不要为客户 B 使用它,因为他们没有该组件的许可证。一旦在开发人员的机器上安装了组件,它们就成为操作系统的一部分。有些客户的环境设置可能需要一周时间才能调整好以便开展工作。问题在于隔离性:你无法在低于操作系统级别的任何层面封装开发环境(或开发的应用程序)。
我们使用操作系统的虚拟实例构建应用程序。当时这方面的主要工具是 VMWare,它刚刚变得非常好用。我们意识到可以采用通用的 Windows 镜像,在 VMWare 映像上安装所有必要的开发工具并在其上进行开发。当时的速度损失并不严重,这使我们能够为每个客户提供纯净的开发环境。当项目的该阶段结束时,我们将 VMWare 映像保存到服务器上。
两年后,当该客户回来请求增强功能时,我们启动了该应用程序的开发环境,就像我们离开时的那天一样。这种方法为我们节省了数天的停机时间,并使为多个客户开发变得轻而易举。客户 A 需要一些小的调整,而我正在处理客户 B 的应用程序。没问题——只需在虚拟机映像之间切换即可。这种方法还提供了其他实际好处。从操作系统和开发工具的全新安装构建开发环境,可以清除操作系统、工具、办公套件等之间的隐藏依赖关系。
你是否经历过带有恼人回声的电话通话?那是阻抗失配(impedance mismatch),当信号不完全同步时就会发生。阻抗失配是一个从电气工程领域泄漏到软件世界的术语,因为它描述了我们的一些问题。
在软件中,阻抗失配是违反 DRY 原则的常见原因之一。阻抗失配发生在两种抽象风格的边界处:基于集合到基于对象,或过程式到面向对象。由于你试图调和这两种抽象风格,最终会在边界周围产生重复。
注意不要让对象关系映射工具(O/R mappers)违反规范性。
我们在处理数据的项目中面临的一个持续头痛问题是关系数据库和面向对象编程语言之间的阻抗失配。解决这种失配问题逐渐引导我们使用 O/R 映射器,如 Hibernate、nHibernate、iBatis 等。使用 O/R 映射器会在项目中引入重复,我们在三个地方拥有本质上相同的信息:在数据库模式中、在 XML 映射文档中以及在类文件中。这代表了对 DRY 原则的两次违反。
这个问题的解决方案是创建单一表示并生成其他两个。第一步是决定谁是这一知识的”官方”持有者。例如,如果数据库是规范来源,则生成 XML 映射和相应的类文件。
在这个例子中,我使用 Groovy(Java 的脚本语言方言)来解决失配问题。在产生这个例子的项目中,开发人员无法控制数据库模式。因此,我决定数据库是数据的规范表示。我使用的是开源的 iBatis SQL 映射工具(它不生成 SQL;它只是处理将类映射到 SQL 结果)。
第一步需要从数据库中获取模式信息:
class GenerateEventSqlMap {
static final SQL =
["sqlUrl":"jdbc:derby:/Users/jNf/work/derby_data/schedule",
"driverClass":"org.apache.derby.jdbc.EmbeddedDriver"][def _file_name]
[def types = [:]]
[def GenerateEventSqlMap(file_name) {]
[_file_name = file_name]
[}]
[[def columnNames() {]]
[Class.forName(SQL["driverClass"])]
[def rs = DriverManager.getConnection(SQL["sqlUrl"]).createStatement().]
[executeQuery(]["select * from event where 1=0"])]
[def rsmd = rs.getMetaData()]
[def columns = []]
[for][ (index in ][1.][.rsmd.getColumnCount()) {]
[‡] [下载地址 ][http://ibatis.apache.org/.]
## DRY 阻抗不匹配
[columns << rsmd.getColumnName(index)]
[types.put(camelize(rsmd.getColumnName(index)),]
[rsmd.getColumnTypeName(index))]
[}]
[return][ columns]
[}]
[[def camelized_columns() {]]
[def cc = []]
[columnNames().each { c][ ->]
[cc << camelize(c)]
[}]
[cc]
[}]
[def camelize(name) {]
[def newName = name.toLowerCase().split(]["_"][).collect() {]
[it.substring(][0][, ][1][).toUpperCase() + it.substring(][1][, it.length())]
[}.join()]
[newName.substring(][0][, ][1][).toLowerCase() +]
[newName.substring(][1][, newName.length())]
[}]
[def columnMap() {]
[def columnMap = [:]]
[for][ (colName in columnNames())]
[columnMap.put(camelize(colName), colName)]
[return][ columnMap]
[}]
[def create_mapping_file() {]
[def writer = ][new][ StringWriter()]
[def xml = ][new][ MarkupBuilder(writer)]
[xml.sqlMap(namespace:]['event'][) {]
[typeAlias(alias:]['Event'][,]
[type]:]['com.nealford.conf.canonicality.Event'][)]
[resultMap(id:]['eventResult'][,][ class]:]['Event'][) {]
[columnMap().each() {key, value][ ->]
[result(property:]"${key}"[, column:]"${value}"[)]
[}}]
[select(id:]['getEvents'][, resultMap:]['eventResult'][,]
['select * from event where id = ?'][)]
[select(id:]["getEvent"][,]
[resultClass][:]["com.nealford.conf.canonicality.Event"][,]
["select * from event where id = #value#"][)]
[}]
[new][ File(_file_name).withWriter { w][ ->]
[w.writeLine(]"${writer.toString()}"[)]
[}]
[}]
[ }]columnNames 方法使用底层 Java
数据库连接(JDBC)从数据库中获取列名。
camelized_columns 返回转换为典型 Java
方法名格式的数据库列名。
create_mapping_file 使用 Groovy 构建器来简化 XML
文档的输出。
使用构建器的优势之一是,与使用 DOM 等方式创建 XML
文档相比,语法更加简洁。你还可以利用循环(这里通过 each
方法)从代码生成 XML。
在 BuildEventSqlMap 类之外,我通过构造该类并让它生成 XML
映射文件来调用它:
[def generator = ][new][ GenerateEventSqlMap(]["/Users/jNf/temp/EventSqlMap.xml"][)]
[generator.create_mapping_file()]这次调用的最终结果是生成映射文件,适合 iBatis 使用:
[[namespace][=]['event']>]]
[[type][=]['com.nealford.conf.canonicality.Event'] [alias][=]['Event'][ />]
[[id][=]['eventResult'] [class][=]['Event']>]]
[[property][=]['description'] [column][=]['DESCRIPTION'][ />]
[[property][=]['eventKey'] [column][=]['EVENT_KEY'][ />]
[[property][=]['start'] [column][=]['START'][ />]
[[property][=]['eventType'] [column][=]['EVENT_TYPE'][ />]
[[property][=]['duration'] [column][=]['DURATION'][ />]]]]]]
[]
[resultMap='eventResult' id='getEvents'>
select * from event where id = ?
]
[resultClass='com.nealford.conf.canonicality.Event' id='getEvent'>
select * from event where id = #value#
]
[]生成 XML SQL
映射解决了我们的一个重复问题(我现在将映射文件直接从数据库模式生成作为构建过程的一部分)。我使用相同的技术来生成类文件。实际上,我可以利用相同的基础设施,因为我已经从数据库中获取了列名。为了生成类文件,我构建了一个
ClassBuilder 类:
[ class][ ClassBuilder {]
[def imports = []]
[def fields = [:]]
[def file_name]
[def package_name]
[def ClassBuilder(imports, fields, file_name, package_name) {]
[this][.imports = imports]
[this][.fields = fields]
[this][.file_name = file_name]
[this][.package_name = package_name]
[}]
[def write_imports(w) {]
[imports.each { i][ ->]
[w.writeLine(]["import ${i};"][)]
[}]
[w.writeLine(][""][)]
[}]
[def write_classname(w) {]
[def class_name_with_extension = file_name.substring(]
[file_name.lastIndexOf(]["/"]) + ][1][, file_name.length());][w.writeLine(]["public class "][ +]
[class_name_with_extension.substring(][0][,]
[class_name_with_extension.length() - ][5][) + ][" {"][)]
[}]
[def write_fields(w) {]
[fields.each { name, type][ ->]
[w.writeLine(]["\t${type} ${name};"][);]
[}]
[w.writeLine(][""][)]
[}]
[[def write_properties(w) {]]
[fields.each { name, type][ ->]
[def cap_name = name.charAt(][0][).toString().toUpperCase() +]
[name.substring(][1][)]
[w.writeLine(]["\tpublic ${type} get${cap_name}() {"][)]
[w.writeLine(]["\t\treturn ${name};\n\t}\n"][);]
[w.writeLine(]["\tpublic void set${cap_name}(${type} ${name}) {"][)]
[w.writeLine(]["\t\tthis.${name} = ${name};\n\t}\n"][)]
[}]
[}]
[def generate_class_file() {]
[new][ File(file_name).withWriter { w][ ->]
[w.writeLine(]["package ${package_name};\n"][)]
[write_imports(w)]
[write_classname(w)]
[write_fields(w)]
[write_properties(w)]
[w.writeLine(]["}"][)]
[}]
[}]
[ }]Groovy 灵活的字符串语法(像 Ruby 一样,它允许你在字符串中使用替换引用成员变量)使得生成标准 Java 构造(如 get/set 方法)变得很容易。
这个方法使用所有辅助函数来生成标准的 Java 类文件。
在脚本中,在我调用方法生成 XML 映射文件后,我调用 [ClassBuilder] 从相同的信息构建相应的类:
TYPE_MAPPING = ["INTEGER" : "int", "VARCHAR" : "String"]
def fields = [:]
generator.camelized_columns().each { name ->
fields.put(name, TYPE_MAPPING[generator.types[name]]);
}
new ClassBuilder(["java.util.Date"], fields,
"/Users/jNf/temp/Event.java", "com.nealford.conf.canonicality").
generate_class_file()这次调用的结果生成了 Java 类文件:
package com.nealford.conf.canonicality;
import java.util.Date;
public class Event {
String description;
int eventKey;
String start;
int eventType;
int duration;
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public int getEventKey() {
return eventKey;
}
public void setEventKey(int eventKey) {
this.eventKey = eventKey;
}
public String getStart() {
return start;
}
public void setStart(String start) {
this.start = start;
}
public int getEventType() {
return eventType;
}
public void setEventType(int eventType) {
this.eventType = eventType;
}
public int getDuration() {
return duration;
}
public void setDuration(int duration) {
this.duration = duration;
}
}当然,这只是一个 DAO(数据访问对象(data access object)),没有行为:它仅仅是 get/set 方法的集合。如果你需要为这个实体添加行为,可以继承这个 DAO 来添加方法。永远不要手动编辑生成的文件,因为下次执行构建时它会被重新生成。
注意通过扩展、开放类或部分类为生成的代码添加行为。
要为生成的代码添加行为,你可以使用继承(在 Java 等语言中)、使用开放类(在 Ruby、Groovy 和 Python 等语言中)或使用部分类(在 C# 等语言中)。
现在,我已经解决了 O/R 映射代码中所有的 DRY 问题。Groovy 脚本作为构建过程的一部分运行,这样每当数据库模式(schema)发生变化时,它会自动生成相应的映射文件和与之映射的 Java 类。
另一个在项目中出现重复的情况也来自代码和 SQL 之间的阻抗不匹配(impedance mismatch)。许多项目将源代码和 SQL 视为完全独立的工件,有时甚至由完全独立的开发人员组创建。然而,为了使源代码正确运行,它必须依赖于特定版本的数据库模式(schema)和数据。有几种方法可以解决这个问题,一种是框架特定的,另一种被设计为跨框架和语言工作。
注意始终保持代码和模式(schemas)同步。
Ruby on Rails Web 开发框架的众多酷炫特性之一是迁移(migrations)的概念。迁移是一个 Ruby 源文件,用于管理数据库模式(schemas)的版本控制,帮助它们与源代码保持同步。可以假设,你会在进行代码更改的同时进行数据库更改(包括模式(schema)和测试数据)。通过迁移管理数据库可以让你同时将两种更改签入版本控制,使版本控制系统成为代码+数据快照的管理者。
Rails 迁移由 Rails 自带的软件工厂(software factories)之一生成,它本质上是一个 Ruby 脚本,创建一个包含两个方法的源文件:[up](你在其中放置对数据库的更改)和 [down](你在其中编写对称操作,即撤销你在 [up] 中所做的任何操作)。每个迁移都使用数字前缀命名(例如,001_create_user_table.rb)。Rails 提供了 Rake 任务,可以按正向顺序执行迁移以进行更改,按反向顺序撤销这些更改。
这是一个创建包含几列的表的 Rails 迁移示例:
class CreateProducts < ActiveRecord::Migration
def self.up
create_table :products do |t|
t.column :title, :string
t.column :description, :text
t.column :image_url, :string
end
end
def self.down
drop_table :products
end
end在这个迁移中,我在 [up] 方法中创建了一个包含三列的 [Product] 表,并在 [down] 方法中删除了它。
迁移允许你通过将模式(schema)信息保存在代码中而不是数据库中来保持 DRY。这种设计的一个附带好处是 Rails 支持多个部署目标。在 Rails 配置文件 database.yml 中,你定义环境(例如,“development”、“test” 和 “production”)。迁移允许你通过针对该环境运行迁移,简单地将任何一个开发环境数据库置于特定状态。
迁移的唯一缺点是它与 Rails 框架紧密绑定,如果你使用 Rails,这很好,但如果你使用其他框架,它对你没有帮助。
然而,如果你不使用 Rails,一切并非没有希望。dbDeploy 是一个开源框架,以平台无关的方式提供了迁移的一些好处。它用 Java 编写,支持广泛(且不断增长)的数据库服务器列表,包括所有主流数据库。
dbDeploy 通过创建数据库的基线 SQL 快照(包括 DDL 和数据)来工作。
随着开发人员对数据进行更改,他们会创建变更脚本,作为按顺序编号的文件来体现这些更改。dbDeploy 帮助管理生成实际要在数据库上运行的 SQL 脚本。它在你添加到数据库的一个数据库(名为 dbdeploy)和表(默认名为 [changelog])中跟踪更改。dbDeploy 为支持的数据库提供了脚本来为你创建 [changelog] 表。为 MS-SQL Server 创建该表的脚本如下所示:
USE dbdeploy
GO
CREATE TABLE changelog (
change_number INTEGER NOT NULL,
delta_set VARCHAR(10) NOT NULL,
start_dt DATETIME NOT NULL,
complete_dt DATETIME NULL,
applied_by VARCHAR(100) NOT NULL,
description VARCHAR(500) NOT NULL
)
GO
ALTER TABLE changelog ADD CONSTRAINT Pkchangelog PRIMARY KEY (change_number, delta_set)
GO注意
使用迁移(migrations)来创建可重复的模式(schema)变更快照。
尽管不如迁移全面,dbDeploy 仍然解决了模式和代码存在于两个完全独立位置的部分问题。允许你以编程方式管理数据库的更改,使你有更好的机会保持两者同步,并避免代码和数据定义之间不可避免的阻抗不匹配。
注意
过时的文档比没有文档更糟糕,因为它会主动误导。
文档是管理层和开发人员之间的经典战场:管理者想要更多文档,而开发人员想要创建更少。这也是反对非规范化表示(noncanonical representations)战争中的一个战场。开发人员应该能够积极地对代码进行更改,以改进其结构并允许它演化。如果你必须为所有代码编写文档,它必须同时演化。但大多数时候,由于进度压力、缺乏动力(因为,面对现实吧,编写代码比编写文档更有趣)和其他因素,它们会不同步。
注意
对于管理者来说,文档是关于风险缓解(risk mitigation)。
过时的文档会带来传播错误信息的风险(这很讽刺,因为它的部分目的是降低风险)。防止文档过时的最佳方法是尽可能多地自动生成文档。本节介绍几种使之成为可能的场景。
在我的一个项目中,我们在传递信息方面遇到了问题。开发人员分散在世界各地的班加罗尔、纽约和芝加哥。我们共享一个单一的源代码控制仓库(repository)(在芝加哥)并在维基(wiki)上跟踪重要决策(我们使用开源的 Instiki)。每天结束时,每个开发人员都要负责更新维基,说明他或她当天做了什么。考虑到每天下班时为了离开办公室赶火车而不可避免地疯狂冲刺,你可以猜到这种做法的效果如何。我们尝试督促开发人员,这只会让每个人都感到恼火。
然后我们意识到,我们实际上违反了规范性(canonicality)原则,因为我们要求开发人员记录他们已经记录过的内容——在他们提交到版本控制时的注释中。所有开发人员都很善于编写描述性注释。我们决定利用这个现有资源,为此我们创建了 SVN2Wiki,一个设计为 Subversion 插件的小工具。当 Subversion 执行操作时,你可以编写它将为你运行的程序。SVN2Wiki 等待 Subversion 在有人签入代码时调用它。然后它收集该开发人员对添加的注释并将它们发布到维基上。
在自动发布注释后,我们意识到我们的维基支持 RSS 订阅。这意味着所有开发人员(事实证明,还有经理)可以订阅维基订阅,以了解自上次查看以来代码库中发生了什么。整个设置如图 5-4 所示。

SVN2Wiki 的代码非常简单。我们用 C# 编写它(应该很容易移植到其他语言)。事实上,SVN2Wiki 中最复杂的代码涉及在带日期的页面上发布条目:
namespace Tools.SVN2Wiki {
public class SVN2Wiki {
private const CONFIG =
"c:/repository/hooks/svn2wiki-config.xml";
private SubversionViewer subversionViewer;
private string revision;
private string repository;
private SVN2WikiConfiguration config;
private Wiki wiki;
private static void Main(string[] args) {
string repository = args[0];
string revision = args[1];
//get configuration
SVN2WikiConfiguration config =
new SVN2WikiConfiguration(CONFIG);
config.loadConfiguration();
Wiki wiki = new WikiUpdates(new HttpInvokerImpl(),
config.WikiURL);
SVN2Wiki svn2wiki = new SVN2Wiki(new SubversionViewerImpl(),
revision, repository, config, wiki);
svn2wiki.processUpdate();
}
public SVN2Wiki(SubversionViewer subversionViewer,
string revision,
string repository,
SVN2WikiConfiguration config,
Wiki wiki) {
this.subversionViewer = subversionViewer;
this.repository = repository;
this.revision = revision;
this.config = config;
this.wiki = wiki;
}
public SVNCommit getCommitData() {
string machine = subversionViewer.svnLook(
"author -r " + revision + " " + repository);
string date = subversionViewer.svnLook(["date -r "][ + revision + ][" "][ + repository);]
[string][ comments = subversionViewer.svnLook(]
["log -r "][ + revision + ][" "][ + repository);]
[string][\[\] dateToParse = date.Split(][' '][);]
[date = dateToParse\[][0][\] + ][" "][ + dateToParse\[][1][\] + ][" "][ + dateToParse\[][2][\];]
[return] [new][ SVNCommit(machine, DateTime.Parse(date), comments);]
[}]
[public] [void][ processUpdate() {]
[SVNCommit commit = getCommitData();]
[//配置文件中的每个更新器]
[foreach][ (UpdaterConfiguration updater ][in][ config.Updaters) {]
[if][ (needToPostSVNCommit(commit, updater)) {]
[Console.WriteLine(]["发布到 "][ + updater.MenuPage);]
[wiki.UpdatesListPage = updater.MenuPage;]
[wiki.UpdatesPageNamePrefix = updater.UpdatePagePrefix;]
[Console.WriteLine(]["发布提交:"][);]
[Console.WriteLine(commit.Machine + ][" "][ +]
[commit.CommittedOn);]
[wiki.postUpdate(commit);]
[}]
[}]
[}]
[public] [bool][ needToPostSVNCommit(SVNCommit commit,]
[UpdaterConfiguration updater) {]
[string][\[\] users = updater.ExcludeUsers.Split(][','][);]
[if][ (arrayContainsString(users, commit.Machine))]
[return] [false][;]
[if][ (updater.ExcludePaths.Length == ][0][)]
[return] [true][;]
[else]
[{]
[string][\[\] paths = updater.ExcludePaths.Split(][','][);]
[string][\[\] changedDirectories =]
[getChangedDirectories(repository, revision);]
[foreach][ (][string][ changedDir ][in][ changedDirectories) {]
[bool][ changedDirInExcludePaths = ][false][;]
[foreach][ (][string][ path ][in][ paths) {]
[Console.WriteLine(]["Path = "][ + path);]
**90** C H A P T E R 5: C A N O N I C A L I T Y(规范性)
[if][ (changedDir.StartsWith(path))]
[changedDirInExcludePaths = ][true][;]
[}]
[if][ (!changedDirInExcludePaths)]
[return] [true][;]
[}]
[}]
[return] [false][;]
[}]
[private] [bool][ arrayContainsString(][string][\[\] array, ][string][ toFind) {]
[foreach][ (][string][ a ][in][ array)]
[if][ (a == toFind) ][return] [true][;]
[return] [false][;]
[}]
[private] [string][\[\] getChangedDirectories(][string][ repository,]
[string][ revision) {]
[return][ subversionViewer.svnLook(]
["dirs-changed -r "][ + revision + ][" "][ + repository).Split(]['\n'][);]
[}]
[}]
[ }]SVN2Wiki 是一个活文档(living documentation)的绝佳例子。大多数项目文档很糟糕,因为它们已经失去了相关性。由于我们在地理位置上非常分散,使用 wiki 被证明是我们项目在记录所有决策和(通过 SVN2Wiki)代码提交方面的最佳选择。我们把项目的所有重要信息都放在那里:会议议程及决策摘要、我们在白板上画的非正式图表然后用数码相机拍摄的照片等。Wiki 允许搜索(我们使用的那个支持正则表达式搜索,所以我们可以随时重新查看决策)。在项目结束时,我们将整个 wiki 导出为 HTML,得到的文档质量如此之好,以至于你几乎可以从中重建整个项目。仔细想想,这正是记录工作的目标:创建一个关于你做了什么以及为什么这样做的可靠来源。
注意
始终保持”活的”文档。
注意
任何需要付出真正努力才能创建的东西都会让其创建者不理性地依恋它。
尽管敏捷开发尽可能保持非正式,但有时你仍然需要图表来说明类或其他工件之间的关系。你可能会倾向于使用一个精巧的工具来绘制图表,但你应该抵制这种诱惑。如果创建某个东西需要任何努力,那就意味着改变它也需要努力。你对一个图表的不理性依恋与创建它所需的努力成正比。如果花了你 15 分钟,你会下意识地试图避免改变,因为在你的潜意识里,你在想着创建它花了多长时间。
注意
白板 + 数码相机胜过 CASE 工具。
因此,低仪式感的工件是最好的,我最喜欢的是在白板上画的简单图画。它几乎不需要任何努力(所以你不介意改变它)。它很容易协作绘制(而大多数工具不允许这样做)。完成后,用数码相机拍张照片,使其成为文档的一部分。你真正需要它只是在将其体现到代码中之前,之后代码就可以自己说话了。
注意
生成所有你能生成的技术文档。
为了让代码自己说话,你应该获得一个从代码生成图表的工具。一个很好的例子是 yDoc,这是一个商业图表工具,可以直接从代码生成带有超链接关系的 UML 图。图 5-5 展示了一个项目的 UML 图示例。一些 IDE(如 Visual Studio)会提供为你生成图表,但它们有时难以自动化。理想情况下,你应该在编译代码的同时生成图表(使用持续集成服务器之类的东西)。这样,你永远不必想”我的图表是最新的吗?“因为它们始终处于最新状态。
注意
永远不要保留同一事物的两个副本(如代码和描述它的图表)。
如果你要先绘制图表,使用工具生成代码。如果你使用白板方法创建非正式图表,之后需要更正式的图表,从代码生成它们。否则,它们总会不同步。
就像类图一样,数据库模式是不必要重复的危险区域。SchemaSpy[§] 是一个开源工具,它对数据库实体/关系图所做的事情就像 yDoc 对代码所做的一样。它连接到数据库并生成表信息(包括
实践
第二部分”实践”提供了许多改进代码的建议。这里的建议大多适用于不同的语言、抽象层次和开发方法论。很可能你已经应用了其中一些或大部分实践。但是,即使你已经严格管理对象的生命周期(良好公民原则),在这里仍然可能看到新的解决方案。如果你认为已经掌握了某些内容,可以略读甚至跳过相关章节。但要注意:我偶尔会加入一些惊喜,只是为了让你保持警觉。
测试驱动设计
单元测试(Unit Testing)已被广泛认可为一种有益的代码卫生实践。经过测试的代码能够更好地确保意图与结果相匹配。测试驱动开发(TDD,Test-Driven Development)更进一步,要求你在编写代码之前先编写测试。当将软件”工程”与其他工程学科进行比较时(这总是需要大量牵强的比喻),会出现重大差异。我们在软件领域没有几个世纪的数学积累可以依靠。软件开发的科学还没有足够长的历史(而且我们可能永远也达不到那种成熟度)。我们也无法利用传统工程中的规模经济效应。例如,金门大桥包含超过1,000,000个铆钉。你可以肯定,设计那座桥的工程师知道那些铆钉的应力特性,并使用该数字乘以1,000,000来了解桥梁应力的重要信息。一个软件也可能有1,000,000个部分,但它们都是不同的。我们无法利用”常规”工程师可以利用的规模和可复制性。但开发人员确实有一个优势:我们可以非常容易地制造组件,并编写代码来验证组件是否按照我们的意图工作。因为编写软件来测试软件的成本极低,我们可以通过各种级别的测试应用我们自己的验证方式:单元测试、功能测试、集成测试和用户验收测试。
注意
测试是软件开发的工程严谨性。
严格应用的TDD还有其他设计上的好处,如此之多以至于我通常将TDD称为测试驱动设计。TDD迫使你以不同的方式思考代码。TDD不是先编写一堆代码然后再为其编写测试,而是迫使你在编写代码之前先思考测试过程。TDD创造了消费意识(Consumption Awareness):当你创建单元测试时,你正在创建正在开发的代码的第一个消费者。这迫使你思考外部世界将如何使用这个类。每个开发人员都有过这样的经验:一次性编写一个类,在此过程中做出各种假设。然后,当真正使用该类时,你意识到一些假设是错误的,不得不重构原始代码。TDD要求你在编写代码之前创建第一个消费者,让你思考其他代码最终将如何使用正在开发的代码。
TDD还迫使你模拟依赖对象。例如,如果你开发一个带有addOrder方法的Customer类,你必须与Order对象协作。如果你在addOrder方法内部创建依赖对象,就需要在测试Customer类之前Order对象已经存在。模拟对象(Mock
Objects)允许你为测试目的创建依赖类的”假”版本。你必须在恰当的时机思考两个对象之间的交互:在开发这两个类中的第一个时。
TDD鼓励你通过字段或参数传递依赖对象,将依赖对象的构造留在其他地方(因为你无法模拟在构造函数中创建的依赖项)。
如果方法触发构造函数本身)。这往往会将对象构造移到定义良好的边界层,使得更容易追踪分配和引用(这样你就不会无意中持有对象的意外引用,从而阻止它们被垃圾回收,因为它们永远不会超出作用域)。TDD 实际上迫使你拥有非常小的、内聚的方法,因为你必须编写只测试一件事的测试。你的方法也往往只做一件事,使它们更严格地遵循 SLAP 原则(在第 13 章中介绍)。
让我们看一个 TDD 带来的设计优势的例子。为了演示这些优势,我们需要一个问题,既不能太琐碎以至于可以随意丢弃,也不能太复杂以至于陷入细节。一个完美的候选(双关语)是完全数查找器。完全数是指其因数(减去数字本身)之和等于该数字的数。例如,6 是一个完全数,因为 6 的因数(1、2、3 和 6)减去 6 后相加等于 6。让我们用 Java 编写一些代码来查找完全数。
以下代码是在没有 TDD 的情况下编写的,仅通过应用简单的逻辑和一些小的数学优化:
public class PerfectNumberFinder {
public static boolean isPerfect(int number) {
// get factors
List factors = new ArrayList();
factors.add(1);
factors.add(number);
for (int i = 2; i < Math.sqrt(number) + 1; i++)
if (number % i == 0) {
factors.add(i);
if (number / i != i)
factors.add(number / i);
}
// sum the factors
int sum = 0;
for (Integer i : factors)
sum += i;
// decide if its perfect
return sum - number == number;
}
}如果你可以成对地收集数字,你只需要计算到该数字的平方根即可。例如,对于数字 28,当你找到因数 2 时,你也可以收集数字 14,即对称因数。
代码 number / i != i
的存在是为了确保不会将同一个数字两次添加到列表中。因为你正在收集对称的数对,当因数相同时会发生什么?例如,在
16 的情况下,当你得到因数 4 时,你只需要将它添加到列表一次。
这段代码有一个静态方法,根据传递的数字是否为完全数返回 true 或
false。第一步获取因数。我知道 1
和数字本身是因数,所以我立即添加它们。然后,我使用 for
循环计算到数字的平方根。这是一个小优化;如果你成对地收集因数,你只需要搜索到平方根。
就目前而言,这只是一大块代码。如果使用 TDD,它看起来会有什么不同?第一个测试应该几乎简单到令人发狂。在这里,我只想获得 1 的因数:
@Test public void factors_for_1() {
int[] expected = new int[] {1};
Classifier c = new Classifier(1);
assertThat(c.getFactors(), is(expected));
}我正在使用 JUnit 4.4 和 Hamcrest 匹配器(Hamcrest
匹配器为匹配器提供了更友好的英语语法,例如
assertThat(expected, is(c.getFactors())))。这怎么可能是一个有用的测试?它似乎太简单了。像这样非常简单的测试实际上并不是真正关于测试,它们是关于正确设置基础设施的。我必须在类路径上有测试库,我需要一个名为
Classifier
的类,我必须解决所有包依赖关系。这是大量的工作!编写一个非常简单的测试使我能够在开始考虑测试实际的难题之前建立所有结构。
一旦我让这个测试通过,我稍微增强它,使它看起来更像预期的真实测试,通过
List 将其更改为可调整大小的列表:
@Test public void factors_for_1() {
List expected = new ArrayList(1);
expected.add(1);
Classifier c = new Classifier(1);
assertThat(c.getFactors(), is(expected));
}一旦我让这个测试通过,我应该保留它吗?是的!我称这些非常简单的测试为金丝雀测试(canary test)。正如矿工将金丝雀带入煤矿以警告即将到来的气体一样,这个测试对你的测试执行持续的现实检查。如果它失败了,你的代码基础设施就有严重问题:JAR 文件被放错位置,代码本身已移动等。这些非常简单的测试可以告诉你是否有什么基础性的东西已经损坏。
[*] 下载地址:http://code.google.com/p/hamcrest/
我想编写的下一个测试检查数字的真实因数:
@Test public void factors_for_6() {
List expected = new ArrayList(
Arrays.asList(1, 2, 3, 6));
Classifier c = new Classifier(6);
assertThat(c.getFactors(), is(expected));
}这是我想编写的测试,但它代表了许多不同的功能:要使这个测试通过,我必须知道一个数字是否是因数,如何计算因数,以及如何收集我找到的因数。这在 TDD 过程中经常发生:一个测试揭示了大量期望的功能。攻克这一令人生畏的工作堆的最佳方法是退后一步,思考实现这个测试的现实需要什么。通过深入研究,我创建了以下测试(以及使它们通过的相应代码):
@Test public void is_factor() {
assertTrue(Classifier.isFactor(1, 10));
assertTrue(Classifier.isFactor(5, 25));
assertFalse(Classifier.isFactor(6, 25));
}
@Test public void add_factors() {
Classifier c = new Classifier(20);[c.addFactor(][2][);]
[c.addFactor(][4][);]
[c.addFactor(][5][);]
[c.addFactor(][10][);]
[List expectation = ][new][ ArrayList(]
[Arrays.asList(][1][, ][2][, ][4][, ][5][, ][10][, ][20][));]
[assertThat(c.getFactors(), is(expectation));]
[}]
对于 [Classifier] 的填充代码,[1] 和数字本身 ([20]) 会自动添加,所以我添加剩余的因数。第一个测试通过了,但在我实现 [Classifier] 中填充 [ArrayList] 的代码后,第二个测试失败了:
[java.lang.AssertionError: Expected: is <[1, 2, 4, 5, 10, 20] got: <[1, 20, 2, 10, 4, 5]> ]
这个意外的结果源于成对收集数字。这引发了一个基本问题:我应该在 [Classifier] 中添加代码来防止重复,还是我使用了错误的抽象?因数没有固有的顺序,它们实际上是一个集合。这表明我应该将 [Classifier] 改为使用 [HashSet] 而不是 [ArrayList]。TDD 擅长帮助尽早发现错误的假设,此时重构的痛苦很小,因为代码还不多。测试示例的一个有趣注释:[addFactor()] 方法实际上在 [Classifier] 中是 [private] 的。我在第12章的”Java和反射”中展示了如何测试这类私有方法。
将这个过程贯彻到其逻辑结论,会产生以下 [Classifier] 的实现:
[public] [class][ Classifier {]
[private] [int][ _number;]
[private][ Set _factors;]
[public][ Classifier(][int][ number) {]
[if][ (number < ][0][) ][throw] [new][ InvalidNumberException();]
[setNumber(number);]
[}]
[public][ Classifier() {}]
[public][ Set getFactors() {]
[return][ _factors;]
[}]
[public] [boolean][ isPerfect() {]
[return][ sumOfFactorsFor(_number) - _number == _number;]
[}]
[public] [void][ calculateFactors() {]
[for][ (][int][ i = ][2][; i < Math.sqrt(_number) + ][1][; i++)]
[addFactor(i);]
[}]
[private] [void][ addFactor(][int][ i) {]
[if][ (isFactor(i)) {]
[_factors.add(i);]
[_factors.add(_number / i);]
[}]
[}]
[private] [int][ sumOfFactorsFor(][int][ number) {]
[calculateFactors();]
[int][ sum = ][0][;]
[for][ (][int][ i : _factors)]
[sum += i;]
[return][ sum;]
[}]
[private] [boolean][ isFactor(][int][ factor) {]
[return][ _number % factor == ][0][;]
[}]
[public] [int][ getNumber() {]
[return][ _number;]
[}]
[public] [void][ setNumber(][int][ value) {]
[_number = value;]
[_factors = ][new][ HashSet();]
[_factors.add(][1][);]
[_factors.add(_number);]
[}]
[}]
如果你比较代码的TDD版本和非TDD版本,你会发现TDD版本有更多的代码,但分布在许多非常小的方法中。许多小方法是好的。如果你阅读方法名,你会对计算完全数所需的原子操作有强烈的认识。事实上,如果你查看原始代码中的注释,相同的功能(甚至更多)会作为方法出现在TDD版本中。
六个月后,当需要修改这段代码时,你可以自信地进行更改。如果出现问题,你会在几行代码内知道问题所在。TDD代码中的方法名描述了原子操作,所以当测试失败时,你能更快地理解破坏了什么。处理具有更长方法的代码时,缩小到错误需要更长的时间,因为你必须理解整个方法的上下文才能对其进行更改。理解三行方法应该完全不需要时间。如果你发现自己在方法内编写嵌入式注释,你的方法应该更精炼。带有大量注释的长方法散发着非组合解决方案的气味。将注释重构为方法以消除它们。
[NOTE]
[将注释重构为方法。]
少数有用的代码指标之一是McCabe的圈复杂度(Cyclomatic Complexity)(参见下一个侧边栏”圈复杂度”)。[PerfectNumberFinder] 类(第一个非TDD版本)的平均圈复杂度是5(这是唯一方法的圈复杂度,因此是类的平均值)。TDD版本的类平均圈复杂度为1.5,这表明其方法(因此类)要简单得多。
Thomas McCabe创建了称为圈复杂度的代码指标来衡量代码的复杂性。公式非常简单:边数 - 节点数 + 2,其中边表示执行路径,节点表示代码行。例如,考虑以下代码:
[public] [void][ doit() {]
[if][ (c1) {]
[f1();]
[} ][else][ {]
[f2();]
[}]
[if][ (c2) {]
[f3();]
[} ][else][ {]
[f4();]
[}]
[}]
如果你像流程图一样绘制此方法(参见图6-1),你会发现8条边和7个节点,这意味着此代码的圈复杂度为3。
存在许多工具来确定圈复杂度(参见第7章的一些开源工具),包括IntelliJ IDE中的分析菜单。
设计影响是TDD设计优势的最后一个指标。假设你贪得无厌的用户突然出现,决定他们不仅想要一个完全数查找器,还想要一个计算盈数(因数之和大于该数的数字)和亏数(因数之和小于该数的数字)的查找器。在完全数查找器的第一个版本中,你必须进行大规模的重构工作,将其分解为类似第二个版本的东西。那么TDD版本呢?只需添加两个
方法:
public boolean isDeficient() {
return sumOfFactorsFor(_number) - _number < _number;
}
public boolean isAbundant() {
return sumOfFactorsFor(_number) - _number > _number;
}所有构建块已经存在。TDD代码往往具有更多可重用元素,因为它迫使你编写超高内聚的方法,而高内聚的方法是真正可重用代码的构建块。
TDD改进了代码设计,提供以下好处:
• 它在代码中强制消费者意识,因为你在创建任何代码之前先创建第一个消费者。
• 对极其简单的初始用例进行测试(并保留测试)可以在你意外破坏关键基础设施时提供警告。
• 测试边缘情况和边界条件至关重要。难以测试的东西应该重构为更简单的东西,或者,如果无法简化它们,无论多么困难都应该严格测试。复杂的东西最需要测试!
• 始终将所有测试保留为构建过程的一部分。软件中最隐蔽的问题是在对完全不相关的代码块进行更改时意外引入的副作用故障。将单元测试作为回归测试运行可以让你立即发现这些副作用。拥有这个单元测试安全网总能节省你的时间和精力。
• 拥有强大的单元测试集可以让你玩”假设”重构游戏(也就是说,你可以进行广泛的更改并运行测试以确定影响)。当我第一次与习惯于拥有强大单元测试的开发人员一起工作时,他们会开始对代码进行更改,这让我感到紧张,因为大规模更改可能会破坏很多东西。但他们会毫不犹豫地这样做,当我意识到拥有测试可以让你有信心进行改进代码的更改时,我最终接受了。
最后一个非常重要的测试主题是代码覆盖率(Code Coverage),它指的是测试执行的代码行和分支。几乎每种语言都存在开源和商业代码覆盖率工具。
对于编译型语言(如Java和C#),代码覆盖率的工作原理是首先在编译的字节码上运行插桩处理器。然后针对插桩代码运行单元测试套件,测量执行了哪些行。详细信息被写入某种中间形式,从中生成报告,显示测试的行和分支覆盖率。如图6-2所示。
对于动态语言,过程略有不同,但最终结果相同:关于测试执行了多少代码的报告。报告显示在IDE中,或以XML或HTML视图显示。
这个指标至关重要,因为它告诉你什么没有被测试。测试是软件的工程严谨性,未测试的代码很可能是bug所在的地方。如果你严格遵守TDD,所有代码都会自动测试,除了不寻常的边缘情况(你应该为此添加测试)。
很多开发人员询问可接受的代码覆盖率水平是多少。我过去对这个数字持乐观态度,将可接受阈值设定为大约80%。然后我注意到一个有趣的现象:只接受80%的覆盖率意味着最需要测试的代码没有得到测试。即使是认真负责的开发人员也会编写一些复杂的代码,运行代码覆盖率报告,然后说”呼!82.3%。我可不想弄清楚如何测试那个怪兽!”
我得出的结论是,任何低于100%的代码覆盖率都是危险的妥协。如果你坚持这个最高标准,你将永远不会有”太复杂而无法测试”的代码。你必须编写更简单的代码,当遇到真正复杂的场景时,你将被迫想出创新的方法来测试它。知道你没有”免于测试”的通行证会让你更加严格地保持代码卫生。
但是,如果你已经有一个没有测试的大型代码库怎么办?想象你可以停止数月的积极开发只是为了加强代码覆盖率是非常不切实际的。首先,设定一个日期,在不久的将来(比如下周四)。然后,让整个开发团队同意,在启动日期之后,你的代码覆盖率将始终增加。这意味着:
• 所有新代码都获得100%覆盖率的单元测试(希望通过TDD开发)。
• 每次修复bug时,都要编写测试。
实现100%代码覆盖率需要付出巨大努力。你将为所有新代码编写测试(这使其更简单),并且在发现bug时编写测试,这意味着bug的可能性将会降低。
就像我刚才说的,在单元测试上实现100%代码覆盖率是一个很难达到的标准。但是,我参与过的一些项目做到了,它总是会改善代码的客观特征(使用静态分析和其他度量进行测量;参见第7章)。

如果你使用的是静态类型语言(如Java或C#),你可以使用一种强大的方法来隔离和发现很难通过其他方式发现的某些类别的bug
代码审查和其他传统方法。静态分析是一种程序化验证机制,工具在代码中查找已知的错误模式。
静态分析工具分为两大类:分析编译产物(即类文件或字节码)的工具和分析源文件的工具。本章我将给出每种工具的示例,使用 Java 作为例子,因为它拥有非常丰富的免费静态分析工具集。然而,这种技术并不局限于 Java 代码;所有主要的静态类型语言都有相应的工具。
字节码分析器在编译后的代码中查找已知的错误模式。这意味着两件事。首先,某些语言已经被充分研究,可以在编译后的字节码中找到常见的错误模式。其次,这些工具无法找到任意错误——它们只能找到已定义模式的错误。这并不意味着这些工具很弱。它们发现的一些错误使用其他方法很难找到(即需要花费许多低效的时间盯着调试器看)。
FindBugs 就是这样一个工具,它是马里兰大学的一个开源项目。FindBugs 以多种不同模式运行:命令行、Ant 任务和图形环境。FindBugs 图形界面如图 7-1 所示。
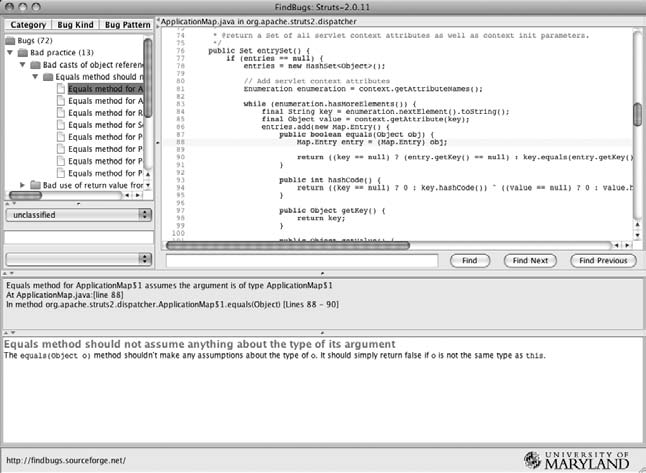
FindBugs 在以下几个类别中查找错误:
正确性(Correctness) 指示可能的错误
不良实践(Bad practice) 违反某些推荐和必要的编码实践(例如,覆盖 equals() 方法但未能同时覆盖 hashCode() 方法)
可疑代码(Dodgy) 令人困惑的代码、奇怪的用法、异常、编写不良的代码
为了演示 FindBugs,我必须选择一个对象,所以我下载了开源的 Struts Web 框架并对其运行 FindBugs。它在”不良实践”类别下发现了一些(可能的)误报,违规名称为”Equals 方法不应对其参数类型做任何假设”。在 Java 中,定义 equals() 方法时的推荐最佳实践是检查传递给该方法的对象的继承关系,以确保相等比较有意义。这是 Struts 中 ApplicationMap.java 文件中的问题代码:
entries.add(new Map.Entry() {
public boolean equals(Object obj) {
Map.Entry entry = (Map.Entry) obj;
return ((key == null) ? (entry.getKey() == null) :
key.equals(entry.getKey())) && ((value == null) ?
(entry.getValue() == null) :
value.equals(entry.getValue()));
}我将此标记为潜在误报的原因与以下事实有关:这是一个匿名内部类定义,也许作者总是知道参数类型。不过,这确实有点可疑。
下面是 FindBugs 发现的一个无可争议的错误。以下代码片段出现在 IteratorGeneratorTag.java 中:
if (countAttr != null && countAttr.length() > 0) {
Object countObj = findValue(countAttr);
if (countObj instanceof Integer) {
count = ((Integer)countObj).intValue();
}
else if (countObj instanceof Float) {
count = ((Float)countObj).intValue();
}
else if (countObj instanceof Long) {
count = ((Long)countObj).intValue();
}
else if (countObj instanceof Double) {
count = ((Long)countObj).intValue();
}仔细看上面代码的最后一行。这属于 FindBugs 的”正确性”类别,违规称为”不可能的类型转换”。上面代码的最后一行总是会生成类转换异常。实际上,无论在什么情况下运行它都会导致问题。开发人员验证 countObj 是 Double 类型,然后立即将其强制转换为 Long。如果你查看前面的 if 语句,你可以清楚地看到发生了什么:复制粘贴错误。这种类型的错误在代码审查中很难发现,因为你往往会直接看过去。显然,Struts 代码库没有触及这一行代码的单元测试,否则它会立即暴露出来。更糟糕的是,这个特定错误在 Struts 代码库中出现了三次:在前面提到的 IteratorGeneratorTag.java 中,以及在 SubsetIteratorTag.java 中出现两次。原因?你猜对了。相同的代码块在这三个地方都是复制粘贴的。(FindBugs 没有发现这一点——我只是注意到问题代码看起来非常相似。)
因为你可以通过 Ant 或 Maven 在构建过程中自动执行 FindBugs,它成为一个非常便宜的保险策略,可以找到它知道的错误。它不能保证代码无缺陷(也不能免除你编写单元测试的责任),但它可以为你找到一些严重的错误。它甚至可以找到通过单元测试难以暴露的错误,比如线程同步问题。
注意
静态分析工具代表了廉价的验证。
顾名思义,源代码分析工具查看你的源代码,搜索错误模式。我在以下代码中使用的工具是 PMD,一个用于 Java 的开源工具。PMD 提供命令行版本、Ant 支持以及所有主要开发环境的插件。它在以下类别中查找问题:
可能的错误例如,空的 try…catch 块
死代码未使用的局部变量、参数和私有变量
次优代码浪费的字符串使用过度复杂的表达式
通过复制粘贴”重用” 重复代码(由一个名为 CPD 的辅助工具支持)
通过复制粘贴”重用”
PMD 介于纯样式检查器(如 CheckStyle,它确保
你的代码遵循特定的样式规范(如缩进),以及FindBugs(用于检查字节码)。作为PMD擅长处理的错误类型示例,请看这个Java方法:
private void insertLineItems(ShoppingCart cart, int orderKey) {
Iterator it = cart.getItemList().iterator();
while (it.hasNext()) {112 第7章:静态分析
CartItem ci = (CartItem) it.next();
addLineItem(connection, orderKey, ci.getProduct().getId(),
ci.getQuantity());
}
}PMD会标记这个方法可以通过将第一个参数(ShoppingCart cart)设为final来改进。通过将参数设为final,你可以让编译器为你做更多工作。因为在Java中所有对象都是按值传递的,所以不可能在方法内给cart分配新的对象引用,尝试这样做表明存在错误。PMD提供了几个这样的提示,使现有工具(如编译器)更高效地运行。
PMD还附带CPD(复制粘贴检测器),它会扫描你的源代码以查找可疑的重复代码(如Struts中复制粘贴的代码)。CPD有一个基于Swing的用户界面,显示状态和有问题的代码,如图7-2所示。当然,这直接关联到第5章讨论的DRY原则。
大多数类似的分析工具都提供自定义API,允许你创建自己的规则集(FindBugs和PMD都有这样的API)。它们通常还提供交互模式,更有价值的是,可以作为自动化流程的一部分运行,比如持续集成。在每次代码签入时运行这些工具,提供了一种极其廉价的方式来避免简单的错误。已经有人完成了识别这些错误的艰苦工作,你只需收获成果。
指标(Metrics)这个主题超出了本书的范围,但高效地生成指标是值得讨论的。对于静态语言(如Java和C#),我非常支持持续的指标收集,以确保能够尽快解决问题。通常,这意味着我有一套指标工具(包括FindBugs和PMD/CPD)作为持续集成的一部分运行。
为每个项目配置所有这些东西很麻烦。就像Buildix一样(参见第4章”不要重新发明轮子”),我希望所有基础设施都是预先配置好的。这就是Panopticode的优势所在。
我的一位同事(Julias Shaw)遇到了同样的问题,但他没有像我一样只是抱怨,而是解决了它。Panopticode* 是一个开源项目,预先配置了许多常用的指标工具。Panopticode的核心是一个Ant构建文件,预先配置了许多开源项目及其JAR文件。你只需提供源代码路径、库路径(即构建项目所需的所有JAR文件)和测试目录,然后运行Panopticode的构建文件。剩下的它会处理。
* 下载地址:http://www.panopticode.org/
使用Panopticode生成指标 113
图7-2. PMD的复制粘贴检测器
Panopticode包含以下预配置的指标工具:
开源代码覆盖率工具(参见第6章”代码覆盖率”)。你可以在Panopticode的构建文件中通过一行更改将其切换为Cobertura(另一个Java开源代码覆盖率工具)。
开源代码样式验证器。你可以在Panopticode的构建文件中通过一个条目提供自己的自定义规则集。
开源指标工具,在包级别收集数值指标。
开源圈复杂度工具(参见第6章”圈复杂度”侧边栏)。
114 第7章:静态分析
商业代码重复查找器。Panopticode附带的版本有15天的许可证;之后你需要付费或将其删除。未来计划使其可与CPD互换。
Panopticode报告以文本和图形形式(使用树状图)显示所有这些指标的结果。
当你运行Panopticode时,它会处理你的代码一段时间,然后生成反映代码指标结果的报告。它还会生成非常漂亮的树状图,这些是复杂的可缩放矢量图形(SVG)图像(大多数现代浏览器都可以显示SVG文件)。树状图提供两个功能:首先,是特定指标值的图形概览。图7-3显示的树状图展示了CruiseControl项目的圈复杂度。阴影区域分别显示特定方法的不同值范围。粗白色分隔线显示包边界,较细的线显示类边界。每个方框代表一个方法。
树状图的第二个优势是交互性。这不仅仅是一张漂亮的图片:它是可交互的。当你在浏览器中显示这个树状图时,点击其中一个方框,它会在右侧显示该特定方法的指标。这些树状图让你能够分析代码,准确找出哪些类和方法存在问题。
Panopticode提供两项重要服务。首先,你不必为每个项目一遍又一遍地配置相同的东西。如果你有一个相当典型的项目结构,你可以在大约五分钟内设置好Panopticode。图形化树状图是第二个优势,因为它们成为出色的信息辐射器(information radiators)。在敏捷项目中,信息辐射器代表放置在显眼位置(如咖啡机附近)的重要项目状态。
团队成员不需要打开电子邮件附件来了解项目状态:他们在去喝咖啡的路上就能偶然发现。
Panopticode 生成的树状图之一显示了代码覆盖率(再次参见第6章中的”代码覆盖率”)。有一个代表你代码覆盖率的巨大黑色斑块是令人沮丧的。当你开始提高代码覆盖率的举措时,找到你能找到的最大彩色打印机,打印出代码覆盖率的树状图(实际上,对于大多数项目,黑白打印机就可以完成第一次打印,因为无论如何它都是全黑的)。把它挂在一个显眼的位置。一旦你达到了一个里程碑,开始编写测试,打印出最新版本并将其挂在第一个旁边。树状图成为你的开发人员无法回避的激励因素:没有人想看到它滑回到过去邪恶的黑暗时代。它还提供了一种很好的、简洁的方式来向你的经理展示你的代码正在获得更多的代码覆盖率。经理们喜欢大型、引人注目的图形。而且这个图形不是没有信息的!
虽然动态语言在许多开发场景中被认为更高效(productive),但它们缺乏静态类型语言所拥有的那种分析工具。为动态语言构建分析工具更加困难,因为你没有类型系统的特性可以依靠。
动态语言领域的大多数努力都集中在循环复杂度(在几乎每种基于块的语言中都是通用的)和代码覆盖率上。例如,在Ruby世界中,rcov是一个常用的代码覆盖率工具。实际上,Ruby on Rails预配置了rcov(你可以在图15-1中看到rcov报告)。对于循环复杂度,你可以使用开源的Saikuro。
† 下载地址:http://saikuro.rubyforge.org/
由于缺乏”传统的”静态分析工具,Ruby开发人员变得很聪明。出现了几个有趣的项目,以非传统方式衡量代码质量。第一个是flog。Flog衡量ABC:赋值(assignments)、分支(branches)和调用(calls),对调用有额外的权重。Flog为方法的每一行分配一个加权值,并像这样报告结果(这是对第15章”为可测试性重构SqlSplitter”中SqlSplitter示例运行flog的结果):
SqlSplitter#generate_sql_chunks: (32.4)
20.8: assignment
7.0: branch
3.4: downcase
3.0: +
2.9: ==
2.8: create_output_file_from_number
2.8: close
2.0: lit_fixnum
1.7: %
1.4: puts
1.4: lines_o_sql
1.2: each
1.2: make_a_place_for_output_files
SqlSplitter#create_output_file_from_number: (11.2)
4.8: +
3.0: |
1.8: to_s
1.2: assignment
1.2: new
0.4: lit_fixnum这个结果表明generate_sql_chunks方法是类中最复杂的,得分为32.4,由下面列出的值得出。方法中最高的复杂度围绕着赋值。因此,要简化这段代码,你应该首先解决方法中大量的赋值问题。
Groovy是一个特殊情况,因为它是一种生成Java字节码的动态语言。这意味着你可以运行标准的Java静态分析工具,前提是它们针对字节码工作。但是,结果可能不令人满意。因为Groovy必须创建大量代理和包装类来实现它的一些魔法,你会得到许多你实际上没有创建的类的引用。Java度量工具的开发人员已经开始考虑Groovy(例如,Cobertura代码覆盖率工具现在对Groovy友好),但仍处于早期阶段。
‡ 下载地址:http://ruby.sadi.st/Flog.html

良好公民性(Good Citizenship)在关于如何改进代码的讨论中似乎是一个奇怪的话题,但良好公民性指的是既意识到自己状态又考虑周围其他对象状态的对象。虽然这看起来很简单,但开发人员通过自动驾驶式编码一直在违反这个原则。本章着眼于几种不同的良好公民性违反者以及成为更负责任公民的方法。
面向对象编程的核心原则之一是封装(encapsulation):保护内部字段免受外部干扰。然而,我见过很多开发人员因为自动驾驶式编码而破坏了封装的意图。
这是一个场景。你创建一个新类,你为它创建一堆私有成员变量,你让IDE生成属性(properties)(在Java中是get/set方法,在C#中是属性),然后你才开始思考。为每个私有字段创建公共属性完全破坏了属性机制的意图。你不如将所有成员变量设为公共的,因为属性根本没有帮助你(事实上,它们只是让你的代码更加密集,没有任何好处)。
例如,假设你有一个Customer类,它有几个地址字段(如典型的addressLine、city、state、zip)。如果你为每个这些字段创建可变属性(mutating properties),
你为某人打开了一扇门,使你的 [Customer] 成为一个不良公民,这意味着它有一个
无效状态。在现实世界中,客户拥有不完整的地址是没有意义的。通常,他们要么拥有完整的地址,要么什么都没有。不要让你的代码将你的客户对象(它应该反映现实世界的客户)置于一个对你的业务没有意义的状态。只读属性可能没问题,但你应该创建一个原子mutator(原子修改器),而不是为每个字段提供一个:
class Customer {
private String _adrLine;
private String _city;
private String _state;
private String _zip;
public void addAddress(String adrLine, String city,
String state, String zip) {
_adrLine = adrLine;
_city = city;
_state = state;
_zip = zip;
}
}拥有原子mutator意味着你的对象可以一步从一个已知的合法状态转移到另一个已知的合法状态。这有几个好处。首先,这意味着你可以跳过后续的验证代码来确保你有一个有效的地址。如果你永远不能创建一个无效的地址,你就不必防范它。其次,它使你的客户抽象更加
120 第8章: 良好公民性
接近你所建模的真实客户。随着真实客户的变化,你的代码可以随之变化,因为它们在语义上如此接近。
与其在创建新类时盲目地创建属性,这里有一个替代策略:仅在需要从其他代码调用它们时才创建属性。这有几个目的。首先,你不会有任何实际上不需要的代码。开发人员创建了太多投机性代码,因为他们认为”我确信以后会需要它,不如现在就创建它。“因为你无论如何都要让工具为你创建属性,所以在需要时创建它们与预先创建它们一样不费功夫。其次,你减少了不必要的代码膨胀。属性在源文件中占用大量空间,阅读所有样板代码会拖慢你的速度。第三,你不必担心为属性编写单元测试。因为你总是从某个使用该属性的其他方法调用它们,所以它们会自动在你的测试中获得代码覆盖率。我从不对属性(Java中的get/set方法,C#中的properties)进行测试驱动开发;相反,我只在真正需要时才让它们出现。
在大多数现代面向对象语言中,我们认为构造函数是理所当然的。我们仅仅把它们看作用于创建新对象的机制。但构造函数有一个更崇高的目的:它们告诉你创建某种类型的有效对象需要什么。构造函数与对象的消费者形成契约关系,指示必须填充哪些字段才能拥有此类型的有效对象。
不幸的是,语言世界的权威人士主张不要有有意义的构造函数。大多数语言实际上坚持所有类都有一个默认构造函数(即不接受任何参数的构造函数)。从公民性的角度来看,这没有任何意义。你有多少次听到业务人员说:“我们需要向这个客户发货,但我们没有任何关于它的信息。”你不能向没有内部状态的客户发货。对象是状态的保持者,拥有一个没有状态的对象是没有意义的。实际上,每个对象都应该至少从一些最小初始状态开始。在你的公司里,可能有一个没有名字的客户吗?
反对默认构造函数很困难。许多框架坚持要求它们,如果你不提供它们就会报错。“必须有默认构造函数”规则甚至在Java中被编入了JavaBeans规范。如果框架或语言标准强制执行这个问题,它会获胜(除非你可以用更友好的替代它)。在这种情况下,将默认构造函数视为异常,就像你有时必须附加到域对象的丑陋序列化杂物一样。
静态方法有一个很好的用途:作为黑盒、独立、无状态的方法。Java中[Math]类的静态方法的使用说明了良好的用法。当你调用[Math.sqrt()]
121 构造函数
方法时,你不会担心后续调用可能会返回立方根而不是平方根,因为[sqrt()]方法内的某些状态发生了变化。当静态方法完全无状态时,它们工作得很好。当你开始混合静态性和状态时,就会遇到麻烦。
多年来,我在一家咨询和培训公司工作,我们教授各种各样的Java主题。我得到了被认为是教学任务中的圣杯:在夏威夷给两组开发人员上两门课。时间安排是我在那里两周(每门课一周),回家三周,然后再去那里两周上第二组课程。当然,我被要求在周末留下来,作为一个好的公司员工,我设法坚持了下来。然而,这是一门艰难的课程,因为所有学生都来自大型机背景。我记得有一个学生无法完全掌握匹配花括号的概念,认为所有编译错误都意味着你需要在文件末尾添加更多花括号。我去帮助这个人,会发现有十几个闭括号,都在一行上。
无论如何,我努力挺过来了,三周后回来上课程的第二部分。我立即受到一位学生的欢迎,他自豪地宣称:“你不在的时候,我们搞懂了Java!”我很震惊,想看看他们一直在写什么样的代码。然后
她给我看的代码。所有代码看起来都差不多是这样的:
public static Hashtable updateCustomer(
Hashtable customerInfo, Hashtable newInfo) {
customerInfo.put("name", newInfo.get("name"));
// . . .
}他们实现了我认为不可能的事情:他们把 Java 变成了一门过程式语言!而且还带有松散的变量类型。不用说,我在接下来的几周里教他们如何不要以这种方式使用 Java。
这个轶事说明了过度使用静态方法表明一种过程式思维。如果你发现自己有很多静态方法,请质疑你的抽象是否正确。
“静态”和”状态”的常见邪恶组合出现在单例设计模式中。单例的目标是创建一个只能实例化一次的类。所有后续尝试创建该类实例的操作都会返回原始实例。单例通常像这样实现(以下是 Java 代码,但在几乎所有语言中看起来都差不多):
public class ConfigSingleton {
private static ConfigSingleton myInstance;
private Point _initialPosition;
public Point getInitialPosition() {
return _initialPosition;
}
private ConfigSingleton() {
Dimension screenSize =
Toolkit.getDefaultToolkit().getScreenSize();
_initialPosition = new Point();
_initialPosition.x = (int) screenSize.getWidth() / 2;
_initialPosition.y = (int) screenSize.getHeight() / 2;
}
public static ConfigSingleton getInstance() {
if (myInstance == null)
myInstance = new ConfigSingleton();
return myInstance;
}
}在这段代码中,getInstance()
方法检查是否已经存在一个实例,如果需要则创建唯一的实例,然后返回对它的引用。请注意,此方法不是线程安全的,但本主题不是关于线程安全的,它只会增加更多复杂性。单例如此邪恶的原因是嵌入的状态,这使得它无法测试。单元测试操作状态,但没有办法操作这个单例对象的状态。因为在
Java
中构造是原子性的,所以无法使用除了从当前屏幕尺寸派生的构造值之外的任何
initialPosition
值来测试这个类。单例是全局变量的面向对象版本,而每个人都知道全局变量是不好的。
注意
不要创建全局变量,即使是对象类型的。
最终,使单例如此糟糕的是一个类有两个不同的职责:管理自身的实例和提供配置信息。任何时候当你有一个具有多个不相关职责的类时,你就有了代码异味(code smell)。
但是只有一个配置对象是有用的。如何在不使用单例的情况下实现这一点?你可以使用一个普通对象加上一个工厂,将各个职责委托给每个对象。工厂负责实例管理,而普通对象(在 Java 中称为 POJO)仅处理配置信息和行为。
以下是作为 POJO 的更新后的配置对象:
public class Configuration {
private Point _initialPosition;
private Configuration(Dimension screenSize) {
_initialPosition = new Point();
_initialPosition.x = (int) screenSize.getWidth() / 2;
_initialPosition.y = (int) screenSize.getHeight() / 2;
}
public int getInitialX() {
return _initialPosition.x;
}
public int getInitialY() {
return _initialPosition.y;
}
}这个类测试起来非常简单。单元测试和工厂都将使用反射来创建类。在 Java
中,private
访问只不过是表明建议用法的文档。在现代语言中,如果需要,你总是可以通过反射绕过它。这代表了一个很好的情况,你不希望任何人实例化这些类之一;因此,构造函数是私有的。
以下列表显示了此类的单元测试,包括通过反射进行实例化以及通过反射访问
private 字段以使用不同值测试类的行为:
public class TestConfiguration {
Configuration c;
@Before public void setUp() {
try {
Constructor cxtor[] =
Configuration.class.getDeclaredConstructors();
cxtor[0].setAccessible(true);
c = (Configuration) cxtor[0].newInstance(
Toolkit.getDefaultToolkit().getScreenSize());
} catch (Throwable e) {
fail();
}
}
@Test
public void initial_position_set_correctly_upon_instantiation() {
Configuration specialConfig = null;
Dimension screenSize = null;
try {
Constructor cxtor[] =
Configuration.class.getDeclaredConstructors();
cxtor[0].setAccessible(true);
screenSize = new Dimension(26, 26);
specialConfig = (Configuration) cxtor[0].newInstance(screenSize);
} catch (Throwable e) {
fail();
}
Point expected = new Point();
expected.x = (int) screenSize.getWidth() / 2;
expected.y = (int) screenSize.getHeight() / 2;
assertEquals(expected.x, specialConfig.getInitialX());
assertEquals(expected.y, specialConfig.getInitialY());
}
@Test
public void initial_postion_can_be_changed_after_instantiation() {
Field f = null;
try {
f = Configuration.class.getDeclaredField("_initialPosition");
f.setAccessible(true);
f.set(c, new Point(10, 10));
} catch (Throwable t) {
fail();
}[Assert.assertEquals(][10][, c.getInitialX());]
[}]
[ }]
[setUp()] 方法通过反射创建 [Configuration] 对象,并调用 [initialize()] 来为大多数测试创建有效的对象。
你可以使用反射访问 [private] 字段 [_initialPosition],以查看如果初始位置不是默认值时,配置类会发生什么。
将 [Configuration] 类设为普通对象可确保它易于测试,并且不会损害它之前的任何功能。
负责创建配置的工厂也简单且可测试;[ConfigurationFactory] 的代码如下所示:
[public] [class][ ConfigurationFactory {]
[private] [static][ Configuration myConfig;]
[public] [static][ Configuration getConfiguration() {]
[if][ (myConfig == ][null][) {]
[try][ {]
[Constructor cxtor[] =]
[Configuration.][class][.getDeclaredConstructors();]
[cxtor[][0][].setAccessible(][true][);]
[myConfig = (Configuration) cxtor[][0][].newInstance(]
[Toolkit.getDefaultToolkit().getScreenSize());]
[} ][catch][ (Throwable e) {]
[throw] [new][ RuntimeException(]["can't construct Configuration"][);]
[}]
[}]
[return][ myConfig;]
[}]
[}]
不出所料,这段代码看起来就像原始单例的创建代码。重要的区别在于这段代码只做一件事:管理 [Configuration] 类的实例。[ConfigurationFactory] 也非常易于测试,如下所示:
[public] [class][ TestConfigurationFactory {]
[@Test]
[public] [void][ creation_creates_a_single_instance() {]
[Configuration config1 = ConfigurationFactory.getConfiguration();]
[assertNotNull(config1);]
[Configuration config2 = ConfigurationFactory.getConfiguration();]
[assertNotNull(config2);]
[assertSame(config1, config2);]
[}]
[ }]
静态方法还有一个陷阱:Java 允许你通过对象实例调用它们,这可能会造成混淆,因为你无法重写静态方法。Java 不会以任何方式警告你正在使用对象(而不是类)作为接收者来调用静态方法。当静态方法与基类和派生类型混合使用时,也会造成混淆,并且可以以令人困惑的方式调用。考虑以下代码:
静态方法 [125]
[ Derived d = ][new][ Derived();]
[ Base b = d;]
[int][ x = d.getNumber();]
[int][ y = b.getNumber();]
[int][ z = ((Base)(][null][)).getNumber();]
[ System.out.println(]["x = "][ + x + ]["][\t][y = "]
[+ y + ]["][\t][z = "][ + z);]
它假设有一个带有 [getNumber()] 方法的 [Base] 类和一个名为 [Derived] 的类继承自 [Base]。你可以合法地以前面显示的所有方式调用相同的 [getNumber()] 方法。
虽然静态方法提供了一些好处,但大量的陷阱表明 Java 也许应该创建一个不同的机制,不会有这么多潜在的麻烦。
当一个反社会的罪犯搬进社区时会发生什么?
[java.util.Calendar] 对 Java 世界中的其他成员表现出许多敌对行为。它让工程纯粹性凌驾于常识之上。定义月份的常量值从 0 开始计数(这是 Java 其余部分的标准),这意味着如果你传递数字 2 来设置月份,它会设置为 [March](三月)。我理解所有内容从 0 开始编号的一致性,但采用一个众所周知的关联(月份数字)并覆盖它是不合理的。
[Calendar] 也无法正确维护自己的内部状态。当你执行以下代码时会发生什么?
[c = Calendar.getInstance();]
[c.set(Calendar.MONTH, Calendar.FEBRUARY);]
[c.set(Calendar.DATE, ][31][);]
[System.out.println(c.get(Calendar.MONTH));]
[System.out.println(c.get(Calendar.DATE));]
输出是 2 和 2,解密后显示它认为正确的日期是 [March](三月)[2nd](2日)。你告诉日历设置日期为 February 31st(二月三十一日),它却默默地返回 [March](三月)[2nd](2日)。你多少次告诉朋友”二月三十一日在那个地方见我”,而你的朋友会说”你是说三月二日,对吧?“[Calendar] 对自己的内部状态一无所知,允许你设置永远不可能实际存在的日期。它不是通过异常来抱怨,而只是默默地给你一个完全不同的日期。对象应该是状态的守护者,但 [Calendar] 似乎对其状态一无所知。
为什么 [Calendar] 会这样表现?问题在于设置单个字段的能力。你应该被强制对日历执行原子更新,同时设置月份、日期和年份,这将允许日历验证它对当前日历有一个真实的日期。然而,[Calendar] 没有这样做,因为方法签名会非常长。原因是什么?[Calendar] 跟踪的信息太多。它不仅保存日期信息,还保存时间信息。你必须设置日期和时间,这将是一个令人烦恼的方法签名。上次有人问你时间时,你说过”等等——我得查一下我的日历”吗?[Calendar] 承担了太多的责任,既损害了对象作为状态守护者的角色,也损害了类的实用性。
当社区监督发现罪犯时会做什么?把他踢出社区!开源的 Joda 库是一个更合理的日历替代品。不要构建表现为不良公民的类,也不要使用它们。试图解决像 [Calendar] 这样的缺陷事物的怪癖,会使你所有的代码变得不必要地更加复杂。
下载地址:[http://joda-time.sourceforge.net/]
不良行为 [127]

[YAGNI]
[YAGNI] [代表] [“][你][不会][需要][它][“](You Ain’t Gonna Need It)。这是敏捷项目开发的战斗口号,用于帮助防止推测性开发(Speculative Development)。推测性开发发生在开发者告诉自己:“我确信以后会需要一些额外功能,所以我现在就提前写好它。”这是一个滑坡。更好的方法是只构建你现在需要的东西。
推测性开发会损害软件,因为它过早地给代码增加了复杂性。正如Andrew Hunt和David Thomas在《程序员修炼之道》(The Pragmatic Programmer,Addison-Wesley出版)中所说,软件会受到熵(Entropy)的影响,这是一个数学术语,表示系统中的复杂度。熵对软件的打击很大,因为复杂性使得代码难以更改、难以理解、难以添加新功能。通常,在物理世界中,事物趋向于简单,除非你添加能量来破坏它。软件则相反:因为创建软件非常容易,它倾向于复杂化(换句话说,创建复杂软件和简单软件所需的物理努力是相同的)。将软件拉回简单需要付出巨大努力。
所有开发者都会掉入镀金陷阱。推测性开发是一个难以打破的习惯。当你在开发高峰期时,很难对自己刚想到的聪明点子保持客观。它会让代码变得更好,还是只是增加更多复杂性?顺便说一下,这就是结对编程(Pair-programming)有效性的一部分。有另一个人在那里对你的绝妙想法提供客观观点是非常宝贵的。开发者很难对自己的想法保持客观,尤其是当这些想法还很新鲜的时候。
无论采取何种形式,如果你沉迷于过多的推测性开发,软件的健康状况就会受损。在最坏的情况下,它会导致框架!框架本身并不坏,但它们说明了推测性开发疾病的一个症状。Java在这种疾病上比任何其他语言都严重。如果你把开发世界中所有其他技术的所有其他框架加起来,Java仍然拥有更多框架。Java甚至有元框架(Meta-frameworks),也就是让构建其他框架变得容易的框架。这种疯狂应该停止了!
只有当框架完全是推测性构建时才是坏的。Java世界中存在几个经典例子:Enterprise JavaBeans(EJB)(版本1和2)和JavaServer Faces(JSF)。两者都被过度设计,使得很难用它们完成实际工作。EJB已成为过度工程的警示故事,因为它太复杂,而且解决的是极少数项目才有的问题。然而,当时Java世界的传统智慧鼓励使用它。JSF的情况有点不同,但同样具有说明性。JSF的一个”特性”是它能够拥有自定义渲染管道,允许你不仅生成HTML,还可以生成WML(无线标记语言,Wireless Markup Language),甚至是原始XML。我还没有遇到过真正使用过这些功能的开发者,但每个使用JSF的人都为它们的存在付出了一些复杂性税。这是象牙塔设计师想出一些酷炫东西并将其添加到框架中的经典例子。阴险的是,这对开发者来说也听起来很酷,使营销工作更容易。然而,归根结底,你不使用的功能只会增加软件的熵。
[130] [第9章:][YAGNI]
[除非绝对必要,否则不要支付复杂性税。]
框架本身并不坏。恰恰相反:它们已成为首选的抽象风格,实现了面向对象开发和组件运动所承诺的大部分代码重用。但是,当框架的功能远超你需要的时候,它们会损害你的项目,因为它们固有地增加了复杂性。最好的框架不是来自象牙塔设计师,试图预测开发者需要什么。最好的框架是从工作代码中提取出来的。有人构建了一个实际工作的应用程序。然后,当需要构建另一个应用程序时,开发者查看第一个应用程序中哪些部分运行良好,提取出来,并将其应用到第二个应用程序中。这就是Ruby on Rails网络框架几乎没有多余包袱的原因之一。它是从工作代码中提取出来的。
YAGNI不是告诫永远不要使用框架,而是承认它们不是银弹。看看框架提供了什么。如果与你需要的功能有很大重叠,它肯定值得使用,因为它代表了你不必自己编写的代码。另一方面,如果有人递给你一个EJB框架,要保持怀疑。
[别说那个词!]
我们有一个小项目需要使用.NET。作为技术负责人,我不想使用像nHibernate或iBatis.net这样成熟的对象关系映射器(O/R Mapper),因为我认为项目规模不需要它。然而,使用.NET的原始数据库库很麻烦,因为它们出了名的难以进行单元测试。我告诉项目经理,我想围绕ADO.NET构建一个非常小的框架,只提供我们需要的功能,但可测试。我以为项目经理要发脾气了。“永远不要在我面前说框架这个词!”他怒吼道。原来他曾经参与过一个项目,最终以追逐框架神话为代价而牺牲了交付软件,他不想再经历那种情况。但是,凭借坚持(以及作为技术负责人的身份),我说服了他这需要完成。
当然,他是对的。我构建了那个小框架(从不在他面前说实际的词),
我们启动了这个项目。在最初的几次使用中,这个框架非常棒:我们非常快速地构建了所需的功能并能够进行测试。然后,不可避免的事情发生了。我们需要构建的某个功能在框架中支持得不太好,所以我不得不添加一些特性。然后这种情况再次发生。不久之后,我花了一半的时间在维护框架上,而项目经理在一旁焦急等待。
我们最终按时完成了项目。早期通过我的神奇框架节省的时间,到最后因为向框架添加功能而消耗的时间连本带利地偿还了。我以为我已经考虑了所有我们需要的东西,但在软件开发中,要预测项目期间将发生的所有细微差别实在太难了。我向项目经理道歉。如果让我重新做一次,我会使用像 nHibernate 或 iBatis 这样已经成熟的框架,因为我们最终构建的只是它们所提供功能的一个小型且有缺陷的子集。
YAGNI 的另一个来源是功能蔓延(creeping featurism),它对商业软件的冲击很大。场景大致是这样的:
市场部:“我们需要 X 功能来对抗竞争对手 Z 的 Y 功能。”
工程部:“嗯,我们的客户真的关心 X 或 Y 吗?”
市场部:“当然关心。这就是我们市场部存在的原因。”
工程部:“好吧。”
这是一个棘手的问题,因为市场部认为他们知道什么是最好的,而且他们可能确实知道。然而,他们并不完全理解向软件添加更多复杂性的影响,以及功能 A 比功能 B 需要多几个数量级的时间来添加,尽管在非开发人员看来它们似乎是一样的。
保持业务驱动者和开发人员之间的沟通渠道畅通非常重要。如果不能满足实际细节,也要愿意提出符合请求精神的建议。大多数时候,用户和业务分析师对功能的工作方式有特定的设想。试着了解功能的核心作用,看看是否存在更简单的解决方案。我在提出既容易实现又能满足相同业务需求的替代建议方面取得了很好的成功。沟通至关重要:没有良好的沟通渠道,你会在被认为咄咄逼人的用户和过于沉默寡言的开发人员之间产生持续的挫败感。记住 Vasa 号船的教训(见下一个侧边栏)。
[软件开发首先是一场沟通游戏。]
[Vasa 号船]
1625 年,瑞典国王古斯塔夫二世·阿道夫委托建造有史以来最好的战舰。他聘请了最好的造船师,种植了一片由最强大的橡树组成的特殊森林,并开始建造 Vasa 号船。国王不断提出要求,让船变得越来越宏伟,到处都是华丽的装饰。在某个时刻,他决定要一艘拥有两层炮甲板的船,这在世界上是独一无二的。他的船将成为海洋上最强大的船。由于外交问题突然出现,他需要立即建成。当然,造船师在设计时只考虑了一层炮甲板,但因为国王要求,他就得到了额外的炮甲板。由于时间紧迫,建造者没有时间进行”倾斜测试”——让一群水手从船的一侧跑到另一侧,以确保船不会摇晃得太厉害(换句话说,不会头重脚轻)。在首航时,Vasa 号在几个小时内就沉没了。在为船添加所有”功能”的过程中,他们设法使它无法在海上航行。Vasa 号一直躺在北海海底,直到 20 世纪初,这艘保存完好的船被打捞上来并放置在博物馆中。
这里有一个有趣的问题:Vasa 号的沉没是谁的错?是国王,因为他要求越来越多的功能?还是建造者,他们建造了他想要的东西,却没有足够大声地表达他们的担忧?看看你目前正在进行的项目:你是在创造另一艘 Vasa 号吗?
专注于为你的软件增加能力而不是复杂性。考虑两个具有相同功能的代码库。一个是严格遵守简单性原则构建的,在每一步都应用 YAGNI。另一个是用虽然不是立即需要但在未来某个时刻可能有合理用途的功能构建的。然而,对于第二个代码库,你开始立即为额外的功能付出代价,这体现在可重构性(refactorability)上,进而影响你在项目中进行更改的速度。你还不需要的功能也会使代码更难以合法的方式维护和扩展。代码的数量很重要。将未使用的代码排除在代码库之外意味着当你更改现有的功能代码时,你需要浏览的内容更少。如果功能是重量,比较将如图 9-1 所示。
努力只构建你现在需要的东西是困难的,但最终你将拥有一个更好的代码库。你不添加的复杂性意味着当你需要进行合法更改或重构代码时,你不必艰难跋涉的复杂性。记住,熵(entropy)会扼杀软件,尽可能不情愿地添加功能。

古代哲学家
古代(以及不那么古代的)哲学家们的思考对构建高质量软件有着直接的影响。
让我们看看几位哲学家对代码有什么看法。
亚里士多德创立了我们今天所知的许多科学分支。事实上,科学研究几乎可以追溯到他。他对自然世界的整个思想领域进行了分类、编目和定义。他还建立了逻辑和形式思维的基础。
亚里士多德定义的逻辑原则之一是本质属性和偶然属性之间的区别。假设你有一组五个单身汉,他们都有棕色的眼睛。未婚是这个群体的本质属性。棕色眼睛是偶然属性。你不能做出所有单身汉都有棕色眼睛的逻辑推论,因为眼睛颜色实际上只是巧合。
好的,那么这与软件有什么关系呢?将这个概念进一步延伸,我们得出了本质复杂性(essential complexity)和偶然复杂性(accidental complexity)的概念。本质复杂性是我们必须解决的问题的核心,它包含软件中真正困难的问题部分。大多数软件问题都包含一些复杂性。偶然复杂性是所有那些不一定直接与解决方案相关,但我们无论如何都必须处理的东西。
我们需要一个例子。假设一个问题的本质复杂性是通过将客户数据从网页放入数据库来跟踪客户数据——一个很好的、直截了当的问题。但是,要让它在你的组织内工作,你必须使用一个驱动程序支持不稳定的旧数据库。当然,你还必须担心获得访问数据库的权限。数据库的某些部分必须与存在于某处大型机中的类似数据进行交叉检查。现在,你必须找出如何连接到大型机并以你可以使用的形式提取数据。结果发现你无法直接获取数据,因为你使用的工具没有连接器技术,所以你必须让某人提取数据并将其放入数据仓库(data warehouse)中,以便你可以访问它。这听起来像你的工作吗?本质复杂性的描述可以用一句话概括。偶然复杂性的描述可能永远说不完。
没有人打算花更多时间处理偶然复杂性而不是本质复杂性。但许多组织最终只是在维护随着时间推移而累积的偶然复杂性层。当前对SOA(面向服务架构)的大部分热潮源于公司试图减轻随着时间推移而积累的偶然复杂性。SOA是一种将不同应用程序绑定在一起以便它们可以通信的架构风格。你很少会将该问题定义为业务的驱动力。然而,如果你周围有许多需要共享信息的无法通信的应用程序,这正是你要做的。在我看来,这听起来像偶然复杂性。SOA架构风格的供应商化是企业服务总线(ESB, Enterprise Service Bus),其主要卖点似乎是中间件问题的解决方案是更多的中间件。增加复杂性会减少复杂性吗?几乎不会。对供应商驱动的解决所有可能问题的方案保持警惕。他们的首要任务是销售他们的产品,他们的第二优先级是(也许)让你的生活更好。
识别是摆脱偶然复杂性的第一步。思考你目前处理的流程、政策和技术迷宫。注意到什么是本质的可能会引导你放弃某些对实际问题的贡献不如它给整体问题带来的复杂性的东西。例如,你可能认为你需要一个数据仓库,但它给整体问题增加的复杂性不值得它可能提供的好处。你永远无法用软件消除所有偶然复杂性,但你可以持续尝试将其最小化。
注意
最大化本质复杂性上的工作;消除偶然复杂性。
奥卡姆的威廉爵士是一位鄙视华丽、复杂解释的修道士。他对哲学和科学的贡献被称为奥卡姆剃刀(Occam’s Razor),它说在对某事的多种解释中,最简单的最有可能是正确的。显然,这与我们对本质复杂性与偶然复杂性的讨论很好地结合在一起。然而,令人惊讶的是这在软件堆栈中延伸得有多远。
作为一个行业,在过去十年左右的时间里,我们一直在进行一项实验。这个实验始于90年代中后期,主要是因为对软件的需求远远超过了能够编写软件的人员供应(这不是一个新问题——自商业软件的想法开始以来,这种情况几乎一直在发生)。实验的目标是:创建工具和环境,使普通和/或平庸的开发人员能够高效工作,无论Fred Brooks等人已经知道的混乱事实如何(参见他的书《人月神话》[Addison-Wesley])。理由是,如果我们能够创建通过限制他们可能造成的损害来让人们远离麻烦的语言,我们就可以生产软件,而不必向那些烦人的软件工匠支付荒谬的金额(即使那样你也可能找不到足够多的人)。这种思维给了我们dBASE、PowerBuilder、Clipper和Access等工具——第四代语言(4GLs, 4th Generation Languages)的兴起,其中包括FoxPro和Access等工具/语言组合。
但问题是你无法在这些环境中完成足够多的工作。它们创建了
我的同事Terry Dietzler称之为Access的”80-10-10法则”(我将其重命名为Dietzler定律):你可以在非常短的时间内完成客户想要的80%的功能。接下来的10%是可能的,但需要大量的努力。最后的10%则完全不可能实现,因为你无法深入所有的工具和框架底层。而用户想要100%他们想要的东西,所以第四代语言让位于通用语言(Visual BASIC、Java、Delphi,以及最终的C#)。Java和C#特别被设计用来让C++更容易使用且更不容易出错,所以开发者为了让普通开发者远离麻烦,内置了一些相当严格的限制。他们创建了自己版本的”80-10-10法则”,只是这次你无法完成的事情要微妙得多。因为这些语言是通用语言,你几乎可以完成任何事情…只要付出足够的努力。
Java不断遇到一些很好但工作量太大的需求,于是框架被构建出来。一个又一个。一个又一个。切面(Aspects)被添加进来。更多的框架被构建。
这里有个例子。考虑以下Java代码,摘自一个广泛使用的开源框架。试着弄清楚它做什么(我稍后会告诉你这个方法的名称):
public static boolean xxXxxxx(String str) {
int strLen;
if (str == null || (strLen = str.length()) == 0) {
return true;
}
for (int i = 0; i < strLen; i++) {
if ((Character.isWhitespace(str.charAt(i)) == false)) {
return false;
}
}
return true;
}你花了多长时间?这实际上是Jakarta Commons框架中的isBlank方法(该框架提供了可能应该内置到Java中的辅助类和方法)。字符串空白的定义有两部分:字符串要么是空的,要么只由空格组成。这段代码是这些条件的一个非常复杂的公式,因为它必须考虑null参数的情况,并遍历所有字符。当然,你必须使用Character类型包装器来确定给定字符是否为空白字符。真糟糕!
这是Ruby中的相同代码:
class String
def blank?
empty? || strip.empty?
end
end这个定义非常接近前面的文字描述。在Ruby中,你可以打开String类并向其添加新方法。blank?方法(Ruby中返回布尔值的方法传统上以问号结尾)检查字符串是否为空,或者在删除所有空格后是否为空。Ruby中方法的最后一行是返回值,因此你可以跳过可选的return关键字。
这段代码在意想不到的地方也能工作。考虑以下单元测试:
class BlankTest < Test::Unit::TestCase
def test_blank
assert "".blank?
assert " ".blank?
assert nil.to_s.blank?
assert ! "x".blank?
end
end在Ruby中,nil是NilClass的一个实例,这意味着它有to_s方法(Ruby等同于Java和C#中的toString方法)。
关键是,用于”企业开发”的主流静态类型语言包含大量的偶然复杂性(accidental complexity)。Java中的原始类型(Primitives)是语言中偶然复杂性的完美例子。虽然在Java刚出现时很有用,但现在它们只是加密我们的代码。自动装箱(Autoboxing)有所帮助,但它导致了其他不寻常的问题。考虑以下内容,这肯定会让你挠头:
public void test_Compiler_is_sane_with_lists() {
ArrayList list = new ArrayList();
list.add("one");
list.add("two");
list.add("three");
list.remove(0);
assertEquals(2, list.size());
}这段代码按预期工作。但考虑这个版本,它从前一个例子中只改变了一个词(ArrayList改为Collection):
public void test_Compiler_is_broken_with_collections() {
Collection list = new ArrayList();
list.add("one");
list.add("two");
list.add("three");
list.remove(0);
assertEquals(2, list.size());
}这个测试失败了,抱怨列表大小仍然是3。怎么回事?这个例子说明了当你用泛型和自动装箱改造一个复杂的库(如集合)时会发生什么。问题在于Collection接口有一个remove方法,但它删除的是匹配内容的项,而不是该索引顺序中的项。在这种情况下,Java将整数2自动装箱为Integer对象,在列表中查找是否有内容为2的元素,未能找到,并且不从列表中删除任何内容。
现代语言的偶然复杂性不但没有让开发者远离麻烦,反而迫使开发者涉足大量复杂的变通方法。这种趋势在构建复杂软件时对生产力产生负面影响。我们真正想要的是第四代语言的生产力,以及强大通用语言的通用性和灵活性。进入使用领域特定语言(DSLs)构建的框架,当前的典范是Ruby on Rails。编写Rails应用程序时,你不会编写太多”纯”Ruby代码(大部分都在模型中,用于业务规则)。大多数情况下,你是在Rails的DSL部分编写代码。这意味着你可以获得巨大的收益:
validates_presence_of :name, :sales_description, :logo_image_url
validates_numericality_of :account_balance
validates_uniqueness_of :name
validates_format_of :logo_image_url,[:with][ => ][%r{][\.(gif|jpg|png)][}i][,] [:message][ => ][”][必须是 GIF、JPG 或 PNG 图片的 URL][”]
通过这一小段代码,你就能获得大量功能。它提供了第四代编程语言(4GL)级别的生产力,但有一个关键区别。在 4GL(以及当前主流的静态类型语言)中,要做真正强大的事情(如元编程)是很麻烦的,甚至是不可能的。而在基于超强大语言构建的领域特定语言(DSL)中,你可以下降一个抽象层次到底层语言,来完成任何你需要完成的事情。
强大的语言 + 领域特定的元层提供了目前可用的最佳方法。生产力来自于在 DSL 中接近问题域的工作;而强大的能力则来自于在表面之下涌动的抽象层。建立在强大语言之上的富有表现力的 DSL 将成为新标准。框架将使用 DSL 编写,而不是建立在具有限制性语法和不必要仪式的静态类型语言之上。注意,这不一定是关于动态语言甚至 Ruby 的争论:静态类型的类型推断语言如果具有合适的语法,也有很大潜力来利用这种编程风格。作为例子,可以看看 Jaskell[*],特别是建立在它之上的构建 DSL,叫做 Neptune.[†] Neptune 执行与 Ant 相同的基本任务,但它是作为 Jaskell 之上的领域特定语言编写的。它展示了你可以在 Jaskell 中使用熟悉的问题域,让代码变得多么可读和简洁。
注意 [Dietzler 法则:即使是通用编程语言也遭受][“80-10-10”规则的影响。]
迪米特法则(Law of Demeter)于 80 年代后期在西北大学开发。它最好用”只与你最亲密的朋友交谈”这句话来概括。其思想是,任何给定的对象都不应该了解与其交互的对象的内部细节。该法则的名称来自罗马农业女神(因此也是食物分配女神)德墨忒尔。虽然她在技术上不是古代哲学家,但她的名字让她听起来像一位!
更正式地说,迪米特法则指出,对于任何对象和方法,应该调用的方法只有以下这些:
• 对象本身的方法 • 方法的参数 • 在方法内创建的任何对象
[*] [下载地址:][http://jaskell.codehaus.org/.]
[†] [下载地址:][http://jaskell.codehaus.org/Neptune.]
[140][ 第 10 章:][古代哲学家]
在大多数现代语言中,你可以使用”任何方法调用永远不要使用超过一个点”的启发式规则,让这个法则变得更简洁。这里有一个例子。
假设你有一个 [Person] 类,有两个字段:姓名和 [Job]。[Job] 也有两个字段:职位和薪水。迪米特法则说,在 [Person] 内部通过 [Job] 调用来获取 [position] 字段是不可接受的,像这样:
[ Job job = ][new][ Job(]["安全工程师"][, ][50000.00][);] [ Person homer = ][new][ Person(]["Homer"][, job);]
[ homer.getJob().setPosition(]["清洁工"][);]
因此,为了使其符合迪米特法则,你可以在 [Person] 上创建一个方法来改变工作,然后让 [Job] 类为你执行工作:
[public][ PersonDemo() {] [Job job = ][new][ Job(]["安全工程师"][, ][50000.00][);] [Person homer = ][new][ Person(]["Homer"][, job);] [homer.changeJobPositionTo(]["清洁工"][);] [}]
[public] [void][ changeJobPositionTo(String newPosition) {] [job.changePositionTo(newPosition);] [}]
这个改变带来了什么好处?首先,注意我们不再调用 [Job] 类上的 [setPosition] 方法,而是使用一个更具描述性的方法,名为 [changePositionTo]。这强调了一个事实,即 [Job] 类外部的任何东西都不知道 position 在 [Job] 内部是如何实现的。虽然现在它看起来像一个 [String],但在内部它可能是一个枚举。这种信息隐藏是主要目的:你不希望依赖对象了解类内部工作的实现细节。迪米特法则通过强制你在类上编写专门隐藏这些细节的方法来防止这种情况。
当严格应用时,你往往会为你的类编写大量小的包装器或代理方法,以防止方法调用中出现多个”点”。你用这些额外代码换来的是类之间更松散的耦合,确保对一个类的更改不会导致对另一个类的更改。有关迪米特法则的更详细示例,请查看(软件传说的一部分)David Bock 的《送报员、钱包和迪米特法则》。[‡]
软件开发者大多对软件传说一无所知。因为技术发展如此之快,开发者必须努力跟上所有的变化。一些古老的(相对而言)技术能告诉我关于我现在需要解决的问题的什么信息呢?
[‡] [下载地址:][http://www.ccs.neu.edu/research/demeter/demeter-method/LawOfDemeter/paper-boy/demeter.pdf.]
软件传说 [141]
当然,如果你只用 Java 或 C# 编写代码,阅读一本关于 Smalltalk 语法的书不会对你有帮助。但并非所有 Smalltalk 书籍中只有语法:它们包含了首次使用全新技术(面向对象语言)的开发者们来之不易的经验教训。
注意 [关注”古老”技术的传说。]
古代哲学家创造的思想在事后看来似乎是显而易见的,但在当时需要巨大的智慧和勇气的飞跃。有时他们遭受了巨大的痛苦,因为他们所说的违背了既定的教条。历史上伟大的反叛者之一是伽利略。
他显然不相信任何人告诉他的事情。他总是必须亲自尝试。
在他那个时代之前被广泛接受的观点认为,较重的物体会比较轻的物体下落得更快。这是基于亚里士多德的思维方式,在那里,对某件事进行深入的逻辑思考比实验更有价值。伽利略不相信这一点,所以他爬上比萨斜塔扔下石头。还用大炮发射石头。他发现,违反直觉的是,所有物体以相同的速率下落(如果你忽略空气阻力的话)。
伽利略所做的就是证明那些看似违反直觉的事情实际上可以是真实的,这至今仍是一个宝贵的教训。一些关于软件开发的来之不易的知识并不符合直觉。你可以预先设计整个软件,然后只需转录它的想法似乎合乎逻辑,但在不断变化的现实世界中它并不奏效。幸运的是,反模式目录(http://c2.com/cgi/wiki?AntiPatternsCatalog)中存在着大量违反直觉的软件知识。这是软件的古老传说。当你的老板强迫你使用低质量代码库时,与其沮丧地咬牙切齿,不如向他指出他正陷入”站在侏儒肩膀上”的反模式,他就会明白你不是唯一一个认为这是个坏主意的人。
理解现有的软件传说,在你被要求做一些你直觉上知道是错误的事情,而某些管理者类型的人却在强制推行时,能为你提供很好的资源。了解过去战斗的历史将为你当前的战斗提供弹药。花些时间阅读那些已经有几十年历史但仍被广泛阅读的软件书籍,如《人月神话》、Hunt和Thomas的《程序员修炼之道》(The Pragmatic Programmer)(Addison-Wesley出版),以及Beck的《Smalltalk最佳实践模式》(Smalltalk Best Practice Patterns)(Prentice Hall出版)。这绝不是详尽的清单,但它们都提供了宝贵的知识。
是一件好事。它使人们能够更容易地阅读彼此的代码,更容易理解习惯用法,并避免疯狂的惯用编码(也许Perl社区除外)。
但盲目遵守标准和完全没有标准一样糟糕。有时标准会阻止有用的偏离。对于你在开发软件时所做的每一件事,确保你知道为什么要这样做。否则,你可能正在遭受愤怒猴子的折磨。
这是我第一次从Dave Thomas在题为”愤怒的猴子和货物崇拜”的主题演讲中听到的故事。我不知道它是否真实(尽管我对此做了相当多的研究),但这无关紧要——它完美地说明了一个观点。
早在20世纪60年代(当时科学家被允许做各种疯狂的事情),行为科学家进行了一项实验,他们将五只猴子放在一个房间里,房间里有一个梯子和一串挂在天花板上的香蕉。猴子们很快就明白它们可以爬上梯子吃香蕉,但每次猴子接近梯子时,科学家就会用冰冷的水浇遍整个房间。你可以猜到这产生了什么:愤怒的猴子。很快,没有猴子再接近梯子了。
然后,科学家用一只新猴子替换了其中一只猴子,这只新猴子没有经受过水的冲击。它做的第一件事就是直奔梯子,所有其他猴子都殴打了它。它不知道为什么它们要殴打它,但它很快就学会了:不要接近梯子。渐渐地,科学家用新猴子替换了原来的猴子,直到他们有了一群从未被冷水浇过的猴子,然而它们仍然会攻击任何接近梯子的猴子。
重点是什么?在软件中,项目中的许多实践之所以存在,是因为”我们一直都是这样做的”。换句话说,是因为愤怒的猴子。
这是我在一个项目中遇到的一个例子。每个人都知道在Java中,方法名应该以小写字母开头,然后使用驼峰命名法(CamelCase),其中单词边界由大写字母表示。这对于常规编码来说很好,但测试名称是不同的。在命名单元测试时,你需要一个好的、长的、描述性的名称,以便你能够知道正在测试什么。不幸的是,长驼峰命名法的名称很难阅读。在这个特定的项目中,我建议我们在测试名称中的单词之间使用下划线,就像这样:
public void testUpdateCacheAndVerifyItemExists() {
}
public void test_Update_cache_and_verify_item_exists() {
}对我来说,带下划线的名称可读性要强得多。观察开发团队对我建议的反应很有趣。一些开发人员立即喜欢这个想法,而另一些开发人员看起来就像愤怒的猴子,只是因为我的建议。我们最终使用了这种风格(技术负责人有时可以成为仁慈的独裁者),发现它产生了更易读的测试名称,特别是在IDE的测试运行器视图中阅读一长串名称时(见图11-1)。
“因为我们一直都是这样做的”不是任何开发习惯的充分理由。如果你理解为什么你一直这样做,并且它是有意义的,那么一定要继续。但你应该始终质疑假设并验证它们的有效性。
流式接口是目前流行的领域特定语言(DSL)风格之一。在流式接口中,你试图将长序列的代码构建成句子,理由是口语中完整的思维块也遵循这种风格。这种编码风格更易读,因为就像英语句子一样,你知道一个想法在哪里结束,下一个在哪里开始。
这里有一个例子,基于我的一个项目。我们构建了一个处理火车车厢的应用程序,每个火车车厢都有营销描述。火车车厢有很多相关的规则和规定,所以正确设置测试场景很困难。我们不得不经常询问业务分析师,我们是否有完全精确的车厢类型定义来进行测试。这是我们展示给他们的简化版本:
Car car = new CarImpl();
MarketingDescription desc = new MarketingDescriptionImpl();
desc.setType("Box");
desc.setSubType("Insulated");
desc.setAttribute("length", "50.5");
desc.setAttribute("ladder", "yes");
desc.setAttribute("lining type", "cork");
car.setDescription(desc);虽然这对Java开发人员来说看起来完全正常,但我们的业务分析师讨厌它。“你为什么给我看Java代码?直接告诉我你的意思。” 当然,翻译总是会引入出错的可能性。为了缓解这个问题,我们创建了一个流式接口,捕获相同的信息,但采用这种形式:
Car car = Car.describedAs()
.box()
.length(50.5)
.type(Type.INSULATED)
.includes(Equipment.LADDER)
.lining(Lining.CORK);我们的业务分析师更喜欢这个。我们成功去除了”正常” Java
API风格中令人反感的冗余。实现非常简单。所有设置属性的方法都返回this而不是void,允许我们通过链接方法调用来创建句子。Car的实现如下:
public class Car {
private MarketingDescription _desc;
public Car() {
_desc = new MarketingDescriptionImpl();
}
public static Car describedAs() {
return new Car();
}
public Car box() {
_desc.setType("box");
return this;
}
public Car length(double length) {
_desc.setLength(length);
return this;
}
public Car type(Type type) {
_desc.setType(type);
return this;
}
public Car includes(Equipment equip) {
_desc.setAttribute("equipment", equip.toString());
return this;
}
public Car lining(Lining lining) {
_desc.setLining(lining);
return this;
}
}这也是被称为表达式构建器的DSL模式的一个例子。Car类隐藏了它实际上在内部构建MarketingDescription对象的事实。表达式构建器在封装的表达式上创建公开接口,以简化流式接口。为了使方法链成为可能,Car的每个修改器方法都返回this。
那么为什么把这个例子放在关于质疑权威的章节中?要编写像Car这样的流式接口,你需要打破Java的一个神圣原则:Car类不再是JavaBean。虽然这看起来不是什么大问题,但Java的大部分基础设施都坚持这个规范。但当你仔细观察JavaBeans规范时,它做了几件损害代码整体质量的事情。
JavaBeans规范坚持每个对象都必须有一个默认构造函数(参见第8章的”构造函数”),但实际上如果没有状态,几乎没有对象是有效的。JavaBeans规范还强制要求Java中丑陋的属性语法,要求访问器使用getXXX()方法,修改器使用setXXX()方法,后者需要void返回类型。我理解这些限制存在的原因(例如,默认构造函数使处理序列化更容易),但Java世界中没有人质疑他们是否应该让对象成为bean。默认做法是跟随其他愤怒的猴子,让一切都成为bean。
质疑权威。让一切都成为bean使得创建流式接口变得不可能。了解你在创建什么,理解它将用于什么,并明智地做出决定。“因为每个人都说应该这样做”很少是正确答案。
有时你应该质疑的权威是你自己对特定问题解决方案的倾向。2006年OOPSLA会议上出现了一篇很棒的论文,名为”协作扩散:编程反对象”。论文作者指出,虽然对象和对象层次结构为大多数问题提供了出色的抽象机制,但这些相同的抽象使某些问题变得更复杂。反对象背后的想法是切换问题的感知前景和背景,解决更简单、不太明显的问题。“前景”和”背景”是什么意思?一个例子会说明。(警告!如果你仍然喜欢玩吃豆人游戏,不要读下面的段落—它们会永远毁掉它!有时知识是有代价的。)
考虑吃豆人游戏机游戏。当它在1970年代问世时,它的计算能力比今天的廉价手机还少。然而,它必须解决一个非常困难的数学问题:
如何让幽灵在迷宫中追逐吃豆人?换句话说:通过迷宫到达移动目标的最短距离是多少?这是一个大问题,特别是当你只有很少的内存或处理器能力可用时。因此吃豆人的开发者并没有解决这个问题,他们使用了反对象方法,将智能构建到迷宫本身中。
吃豆人中的迷宫就像一个自动机(类似康威生命游戏)。每个单元格都有与之关联的简单规则,这些单元格一次执行一个,从左上角开始,一直到右下角。每个单元格都记住一个”吃豆人气味”值。当吃豆人位于一个单元格上时,它具有最大的吃豆人气味。如果他刚刚离开该单元格,它的吃豆人气味值为最大值减1。气味会在几个回合后逐渐减弱,然后消失。然后幽灵就可以变得简单:它们只需嗅探吃豆人的气味,每当遇到气味时,它们就会前往气味更浓的单元格。
这个问题的”显而易见”解决方案是将智能构建到幽灵中。然而,更简单的解决方案是将智能构建到迷宫中。这就是反对象方法:翻转计算的前景和背景。不要陷入认为”传统”建模总是正确解决方案的陷阱。也许某个特定问题在另一种语言中更容易解决。(参见第14章了解这种反对象方法背后的原理。)
元编程的正式定义是编写程序的程序,但实际定义要广泛得多。一般来说,任何在”正常”使用之外操纵代码的解决方案都被认为是元编程。元编程方法往往比传统解决方案(例如库和框架)更复杂,但因为你在更基础的层面上操纵代码,它使困难的事情变得更容易,使不可能的事情变得仅仅是不太可能。
所有主流现代语言都有一定程度的元编程支持。学习你主要语言的元编程功能将为你节省大量精力,并为寻找解决方案开辟新途径。
我在本章中讨论了几个元编程示例,让你了解Java、Groovy和Ruby的特点。每种语言的能力都不同;以下示例只是展示了你可以使用元编程解决的问题类型。
Java的反射功能强大但有限。你当然可以使用方法名称的字符串表示来调用方法,但安全管理器不允许你在运行时定义新方法或覆盖现有方法。你可以使用切面(Aspects)做一些这样的事情,但这可以说不是真正的Java,因为它有自己的语法、编译器等。
你可能想要使用Java反射的一个例子是测试私有方法。当你使用测试驱动开发(TDD)编写代码时,你仍然想使用语言内置的保护机制。使用反射来调用私有方法非常简单,但需要大量语法。
假设你需要在名为Classifier的类上调用名为isFactor的方法(该方法返回一个数字是否是另一个数字的因子)。要调用私有的isFactor方法,你可以在测试类中创建一个辅助方法,如下所示:
private boolean isFactor(int factor, int number) {
Method m;
try {
m = Classifier.class.getDeclaredMethod("isFactor",
int.class);
m.setAccessible(true);
return (Boolean) m.invoke(new Classifier(number), factor);
} catch (Throwable t) {
fail();
}
return false;
}对setAccessible的调用将方法的作用域更改为public。
invoke方法进行实际调用,并对返回值进行必要的类型转换(在这种情况下,会自动装箱回原始的boolean类型)。
无论抛出什么异常,单元测试都会失败,因为出了问题。
然后单元测试变得简单:
@Test public void is_factor() {
assertTrue(isFactor(1, 10));
assertTrue(isFactor(5, 25));
assertFalse(isFactor(6, 25));
}在前面的示例中,你只是吞掉了由于反射代码而发生的任何异常(Java非常担心反射,并要求你捕获许多不同类型的异常)。大多数时候,你可以通过让测试失败来解决问题,因为某些东西就是不工作。然而,在其他情况下,你必须更加小心。这是一个测试类辅助方法的示例,它必须小心处理通过反射调用的方法合理冒出的异常:
private void calculateFactors(Classifier c) {
Method m;
try {
m = Classifier.class.getDeclaredMethod("calculateFactors");
m.setAccessible(true);
m.invoke(c);
} catch (InvocationTargetException t) {
if (t.getTargetException() instanceof InvalidNumberException)
throw (InvalidNumberException) t.getTargetException();
else
fail();
} catch (Throwable e) {
fail();
}
}在这种情况下,你会查看是否关心该异常,如果关心,则重新抛出它并吞掉其他所有异常。
通过反射调用方法的能力使得构建更智能的工厂类成为可能,允许在运行时加载类。大多数插件架构使用
通过反射(reflection)加载类和调用方法的能力,使得人们可以构建符合特定接口的新功能,而无需在编译时拥有具体的类。
Java中的反射(以及其他元编程)功能与动态语言相比较弱。C#具有稍好、更广泛的元编程支持,但它与Java大致处于同一水平。
Groovy是Java的动态语言语法。因此,它可以与Java代码(包括编译后的字节码)无缝交互,为您提供更灵活的语法。Groovy使您能够在Java平台上完成许多使用Java难以或无法完成的工作。
您可以使用Groovy语法调用Java中的标准反射机制,如下面的代码所示,它复制了前面显示的isFactor测试:
@Test public void is_factor_via_reflection() {
def m = Classifier.class.getDeclaredMethod("isFactor", int.class)
m.accessible = true
assertTrue m.invoke(new Classifier(10), 10)
assertTrue m.invoke(new Classifier(25), 5)
assertFalse m.invoke(new Classifier(25), 6)
}如您所见,反射代码非常简洁,我不需要将它放在单独的方法中。Groovy为您处理了繁琐的受检异常,使调用反射方法更容易(或至少更不正式)。Groovy”理解”Java的属性语法,因此调用m.accessible = true等同于Java调用m.setAccessible(true)。Groovy对括号的规则也更宽松。
这里显示的代码测试的代码与上面显示的单元测试完全相同——它实际上使用相同的JAR文件来访问代码。Groovy使为Java代码编写单元测试变得更容易,这是将其”偷偷引入”保守组织的好借口(毕竟,测试代码是基础设施的一部分,不会部署到生产环境,所以谁在乎您使用什么开源库呢,对吧?)。事实上,我强烈主张在非开发人员在场时不要直接称其为”Groovy”。我更喜欢称其为企业业务执行语言(Enterprise Business Execution Language)(使用缩写ebXl——管理人员认为带有大写X的缩写很酷)。
实际上,前面的测试并不是全部。事实证明,在当前版本中,Groovy完全忽略了private关键字,即使某些内容在Java代码中声明为private。因此,前面的测试可以这样编写:
@Test public void is_factor() {
assertTrue new Classifier(10).isFactor(1)
assertTrue new Classifier(25).isFactor(5)
assertFalse new Classifier(25).isFactor(6)
}是的,这是从JAR文件调用Java代码,其中isFactor方法是private的。Groovy方便地忽略了private修饰符,因此您可以直接调用这些方法。Groovy在底层使用反射来调用方法,所以它只是默默地为您调用setAccessible方法。从技术上讲,这是Groovy中的一个bug(从第一天起就存在),但它非常有用,没有人费心去修复它。我希望他们永远不要修复。在任何具有强反射能力的语言中,private关键字只不过是文档:如果需要,我总是可以使用反射来访问它。
这是一个使用Ruby元编程支持编写超越Java能力的流畅接口(fluent interface)的简短示例。显然,关于这个主题可以写一整本书——这只是给您一个尝试。此代码适用于任何版本的Ruby,包括Java平台移植版JRuby。
您想编写一个表示食谱的流畅接口。它应该允许开发人员以看起来像数据格式的方式编写食谱的配料,但在底层它应该构建营养配置文件。封装代码的实际行为是流畅接口的优势之一。以下是目标语法:
recipe = Recipe.new "Spicy bread"
recipe.add 200.grams.of Flour
recipe.add 1.lb.of Nutmeg要使此代码工作,您必须首先向Ruby中的内置Numeric类添加新方法(该类包含整数和浮点数):
class Numeric
def gram
self
end
alias_method :grams, :gram
def pound
self * 453.59237
end
alias_method :pounds, :pound
alias_method :lb, :pound
alias_method :lbs, :pound
endNumeric类已经在类路径上,因此这会重新打开该类以允许添加新方法。
alias_method是Ruby的内置功能,允许您为现有方法创建别名(换句话说,友好名称)。alias_method不是关键字;它是Ruby内置元编程的一部分。
Ruby中的开放类(open
class)允许您向现有类添加新方法。语法非常简单:当您创建类定义时,如果该类已经出现在类路径上,它会打开现有类。内置的Numeric类型显然已经在类路径上,因此此代码向其添加了新方法。我用克来跟踪食谱重量,所以gram方法仅返回数字的值,而pound返回一磅的克数。
对Numeric类的更改使我的食谱流畅接口的第一部分工作。第二部分呢?
class Numeric
def of ingredient
if ingredient.kind_of? String
ingredient = Ingredient.new(ingredient)
end
ingredient.quantity = self[return][ ingredient]
[ end]
[end]
再次重新打开 [Numeric] 允许你向数字添加 [of] 方法。该方法可以处理 [String] 或现有的配料(代码会检查传入的是什么),将 [Ingredient] 对象的数量设置为数字的值,然后返回 [ingredient] 实例(返回并非严格必要;任何 Ruby 方法的最后一行都是方法的返回值,但显式调用使代码更易读)。
[W r i t i n g F l u e n t I n t e r f a c e s ] [153]
这个单元测试验证所有这些更改都能正确工作:
[def ][test_full_recipe]
[ recipe = ][Recipe][.new]
[ expected = [] << ][2][.lbs.of(]["][Flour]["][) << ][1][.gram.of(]["][Nutmeg]["][)][ expected.each {|][i][| recipe.add i}]
[ assert_equal ][2][, recipe.ingredients.size]
[ assert_equal(]["][Flour]["][, recipe.ingredients[][0][].name)][ assert_equal(][2][ * ][453.59237][, recipe.ingredients[][0][].quantity)][ assert_equal(]["][Nutmeg]["][, recipe.ingredients[][1][].name)][ assert_equal(][1][, recipe.ingredients[][1][].quantity)] [end]
在动态语言中构建流畅接口要容易得多,因为它们提供了开放类(open classes)和字面数字作为对象等功能。通过开放类添加方法对 Java 和 C# 开发者来说可能是一种奇怪的问题解决方式,但在 Ruby 和 Groovy 中这是构建代码的自然方式。
[NOTE]
[元编程改变了你的语法词汇表,为你提供了更多表达方式。]
[元编程的未来?]
看到所有这些元编程代码可能会让你感到不安,因为它违反了不编写自修改代码的基本原则。但这正是你应该质疑权威的地方(见第11章)。是的,如果使用不当,这可能很危险。但任何强大的功能都是如此。在 Java 中使用切面(Aspects)也可以做危险的事情,只是更困难而已。但认为强大的语言特性应该如此困难以至于只有大师才能掌握,这是一个糟糕的论点。Java 的许多哲学是通过将 [String] 类设为 [final] 来从开发者手中移除权力。但有趣的事情发生了:在语言中构建限制并没有让差劲的开发者变得更好,反而给最优秀的开发者设置了限制,让他们为了完成工作而跳过荒谬的障碍。现在在 Groovy 中上演的经典例子涉及如何处理 [GString]。[GString] 是 Groovy 中的字符串类,提供的功能比 Java 的 [String] 多得多。因为 Groovy 与 Java 交互如此紧密,能够互换使用 [String] 和 [GString] 会很有帮助,特别是在 Groovy 代码将字符串传递给 Java 代码时。但你做不到。因为 [String] 类被声明为 [final],你甚至不能从 [String] 派生 [GString] 子类,以便 Java 库能够理解它们。[final] 的存在是语言设计者承认他们不信任使用该语言的人。
具有强大元编程支持的语言采取相反的方法:它们赋予开发者非凡的能力,并让他们决定何时使用。
[154][ C H A P T E R 1 2 :] [M E T A - P R O G R A M M I N G]

[组合方法和SLAP]
[SLAP] [代表] [单一] [抽象层次] [原则] [。] 虽然这个概念来自 Kent Beck 的《Smalltalk 最佳实践模式》(Prentice Hall),但我的朋友 Glenn Vanderburg 用这个出色的首字母缩写捕捉到了它的本质。
但在谈论 SLAP 之前,我必须先谈谈 Beck 书中讨论的组合方法(composed method)模式。组合方法要求所有公共方法读起来像执行步骤的大纲。实际步骤以私有方法实现。组合方法是一种分解代码的方式,可以保持代码的内聚性并使其更容易发现代码重用的候选对象。理解组合方法的最佳方式是看它的实际应用。
[组合方法实践]
组合方法鼓励将代码分解(或重构)成小的、内聚的、可读的块。对于我担任技术负责人的项目,我们的经验法则是在 Java 或 C# 中不允许任何方法超过15行代码。对于 Groovy 或 Ruby 等动态语言,规则是5行代码。
这提供了什么好处?考虑以下非组合方法代码,来自一个小型电子商务网站:
[public] [void][ populate() ][throws][ Exception {]
[Connection c = ][null][;]
[try][ {]
[Class.forName(DRIVER_CLASS);]
[c = DriverManager.getConnection(DB_URL, USER, PASSWORD);]
[Statement stmt = c.createStatement();]
[ResultSet rs = stmt.executeQuery(SQL_SELECT_PARTS);]
[while][ (rs.next()) {]
[Part p = ][new][ Part();]
[p.setName(rs.getString(]["name"][));]
[p.setBrand(rs.getString(]["brand"][));]
[p.setRetailPrice(rs.getDouble(]["retail_price"][));]
[partList.add(p);]
[}]
[} ][finally][ {]
[c.close();]
[}]
[}]
这个方法是一个更大类的一部分,该类使用低级 Java 数据库连接(JDBC)从数据库中获取信息。这段代码中没有什么真正突出的地方可以作为重用的候选对象。但它违反了15行准则,而且似乎在做很多事情,所以你应该重构它。
第一步需要重构出看起来像你正在执行的步骤的部分。如果你用英语写出这个方法做什么,你就会很好地了解新方法名应该是什么。经过一次重构后,你得到这样的代码:
[public] [class][ PartDb {]
[private] [static] [final][ String DRIVER_CLASS =]
["com.mysql.jdbc.Driver"][;]
[private] [static] [final][ String DB_URL =]
["jdbc:mysql://localhost/orderentry"][;]
[156][ 第 1 3 章 :] [组合方法与 S L A P]
[private] [static] [final] [int][ DEFAULT_INITIAL_LIST_SIZE = ][40][;] [private] [static] [final][ String SQL_SELECT_PARTS =]
["select name, brand, retail_price from parts"][;]
[private] [static] [final][ Part[] TEMPLATE = ][new][ Part[][0][];] [private][ ArrayList partList;]
[public][ PartDb() {]
[partList = ][new][ ArrayList(DEFAULT_INITIAL_LIST_SIZE);]
[}]
[public][ Part[] getParts() {]
[return][ (Part[]) partList.toArray(TEMPLATE);]
[}]
[public] [void][ populate() ][throws][ Exception {] [Connection c = ][null][;]
[try][ {]
[c = getDatabaseConnection();]
[ResultSet rs = createResultSet(c);]
[while][ (rs.next())]
[addPartToListFromResultSet(rs);]
[} ][finally][ {]
[c.close();]
[}]
[}]
[private][ ResultSet createResultSet(Connection c)]
[throws][ SQLException {]
[return][ c.createStatement().]
[executeQuery(SQL_SELECT_PARTS);]
[}]
[private][ Connection getDatabaseConnection()]
[throws][ ClassNotFoundException, SQLException {]
[Connection c;]
[Class.forName(DRIVER_CLASS);]
[c = DriverManager.getConnection(DB_URL,]
["webuser"][, ]["webpass"][);]
[return][ c;]
[}]
[private] [void][ addPartToListFromResultSet(ResultSet rs)]
[throws][ SQLException {]
[Part p = ][new][ Part();]
[p.setName(rs.getString(]["name"][));]
[p.setBrand(rs.getString(]["brand"][));]
[p.setRetailPrice(rs.getDouble(]["retail_price"][));]
[partList.add(p);]
[}]
[}]
好的,这样更好了。你可以看到 [populate] 方法现在读起来就像所需步骤的大纲:
1. 获取数据库连接。
2. 从连接创建结果集。
3. 对于结果集中的每个项目,将项目添加到 [Part] 列表中。
4. 关闭数据库连接。
[组 合 方 法 实 战 ] [157] [populate] 方法现在遵循了组合方法准则,但注意还发生了什么。[getDatabaseConnection] 方法与 [Parts] 无关:它只是获取数据库连接的通用代码。你可以将它推到继承层次结构的上层,并在其他数据库类中重用它。同样,[createResultSet] 方法唯一与 [Parts] 相关的是 SQL 字符串。我们也可以将其泛化。根据这两个改进,你最终得到两个类—[BoundaryBase] 和 [PartDb]:
[abstract] [public] [class][ BoundaryBase {]
[private] [static] [final][ String DRIVER_CLASS =]
["com.mysql.jdbc.Driver"][;]
[private] [static] [final][ String DB_URL =]
["jdbc:mysql://localhost/orderentry"][;]
[protected][ Connection getDatabaseConnection() ][throws][ ClassNotFoundException,]
[SQLException {]
[Connection c;]
[Class.forName(DRIVER_CLASS);]
[c = DriverManager.getConnection(DB_URL, ]["webuser"][, ]["webpass"][);]
[return][ c;]
[}]
[// . . .]
[BoundaryBase] 类现在有了 [getDatabaseConnection] 方法,它使用的两个常量也随之迁移过来。
要重构 [createResultSet] 方法,可以利用模板方法设计模式(Template Method),这来自经典的四人帮(Gang of Four)著作,Gamma 等人的《设计模式:可复用面向对象软件的基础》(Design Patterns: Elements of Reusable Object-Oriented Software)(Addison-Wesley)。模板方法指出,你应该在父类中创建抽象方法,将实现细节延迟到子类的方法中。这个模式是定义通用算法结构的一种方式,稍后再提供细节。为此,你将 [createResultSet] 方法重构到 [BoundaryBase] 中,同时添加一个抽象方法占位符,强制子类提供 SQL 字符串。在这个例子中,你将 [createResultSet] 方法重构为两个方法,一个保留原来的名称,一个新的抽象方法供子类提供 SQL 字符串([getSqlForEntity]):
[abstract] [protected][ String getSqlForEntity();]
[protected][ ResultSet createResultSet(Connection c) ][throws][ SQLException {]
[Statement stmt = c.createStatement();]
[return][ stmt.executeQuery(getSqlForEntity());]
[}]
好的,这很有趣。让我们看看原始 [populate] 方法中是否还有更多代码可以抽象化。如果你看 [populate] 方法本身,唯一将它与这个特定实体关联的是 [while] 循环的主体,它从结果集中获取项目并填充实体。你可以在这里使用相同的模板方法技巧,将整个 [populate] 方法拖到 [BoundaryBase] 类中:
[abstract] [protected] [void][ addEntityToListFromResultSet(ResultSet rs)]
[throws][ SQLException;]
[public] [void][ populate() ][throws][ Exception {]
[Connection c = ][null][;]
[try][ {]
[158][ 第 1 3 章 :] [组合方法与 S L A P]
[c = getDatabaseConnection();]
[ResultSet rs = createResultSet(c);]
[while][ (rs.next())]
[addEntityToListFromResultSet(rs);]
[} ][finally][ {]
[c.close();]
[}]
[}]
就像之前一样,从结果集中提取数据并将其放入实体列表的算法在许多领域实体中是通用的,所以为什么不让它更通用呢?
现在,看看所有重构之后的 [PartDb] 类:
[public] [class][ PartDb ][extends][ BoundaryBase {]
[private] [static] [final] [int][ DEFAULT_INITIAL_LIST_SIZE = ][40][;] [private] [static] [final][ String SQL_SELECT_PARTS =]
["select name, brand, retail_price from parts"][;]
[private] [static] [final][ Part[] TEMPLATE = ][new][ Part[][0][];] [private][ ArrayList partList;]
[public][ PartDb() {]
[partList = ][new][ ArrayList(DEFAULT_INITIAL_LIST_SIZE);]
[}]
[public][ Part[] getParts() {]
[return][ (Part[]) partList.toArray(TEMPLATE);]
[}]
[protected][ String getSqlForEntity() {]
[return][ SQL_SELECT_PARTS;]
[}]
protected void addEntityToListFromResultSet(ResultSet rs) throws SQLException {
Part p = new Part();
p.setName(rs.getString("name"));
p.setBrand(rs.getString("brand"));
p.setRetailPrice(rs.getDouble("retail_price"));
partList.add(p);
}这个类中唯一剩下的内容直接与 Part 实体相关。所有其他处理从结果集填充实体的机制代码现在都驻留在 BoundaryBase 类中,可以为其他实体重用。
从这个例子中可以看出三点。首先,注意第一版代码看起来似乎不包含任何可重用代码。它只是一堆做一些无趣事情的代码。然而,一旦应用了组合方法(composed method),可重用的资产就显现出来了。缺乏内聚性的方法使得你很难看到可能拥有的任何可重用代码。强迫自己将其分解为原子片段会揭示出你可能从未意识到拥有的可重用代码。
注意
重构为组合方法会揭示隐藏的可重用代码。
组合方法的实际应用 159
其次,你现在在从数据库获取内容的样板机械代码和特定实体所需的实际细节之间有了清晰的分隔。这意味着你拥有了一个简单持久化框架(persistence framework)的雏形。BoundaryBase 类是提取出的处理持久化框架的起点。回想第9章:最好的框架是从工作代码中提取出来的。这个例子包含了一个简单持久化框架的种子。
第三,组合方法暴露了你在不知不觉中重复代码的地方(见第5章)。重复是隐蔽的;它在软件开发中无处不在,即使在你发誓没有重复任何内容的地方也会出现。
关于组合方法的另一点:如果你严格遵守测试驱动开发(TDD)(见第6章),你几乎会自动得到组合方法代码。TDD鼓励,实际上是强迫你编写真正内聚的方法(你可以为其编写测试的最小单元),这有利于组合方法。
注意
TDD有利于组合方法。
SLAP坚持认为方法中的所有代码都应处于相同的抽象级别。换句话说,你不应该有一个方法,其中一部分处理低级数据库连接,另一部分处理高级业务代码,还有一部分处理Web服务管道。当然,这样的方法也会违反Beck的组合方法规则。但即使你有一个内聚的方法,你也应该确保所有代码行共享相同的抽象级别。
这里有个例子。考虑这个方法,取自一个示例JEE电子商务网站(比之前示例中的稍微复杂一些)。这个特定方法接受一个购物车并添加一个订单(进而添加行项目)。为简单起见,它也使用低级JDBC,但这与SLAP讨论无关。
public void addOrder(ShoppingCart cart, String userName,
Order order) throws SQLException {
Connection c = null;
PreparedStatement ps = null;
Statement s = null;
ResultSet rs = null;
boolean transactionState = false;
try {
c = dbPool.getConnection();
s = c.createStatement();
transactionState = c.getAutoCommit();
int userKey = getUserKey(userName, c, ps, rs);
c.setAutoCommit(false);
addSingleOrder(order, c, ps, userKey);
int orderKey = getOrderKey(s, rs);
addLineItems(cart, c, orderKey);
c.commit();160 第13章:组合方法与SLAP
order.setOrderKeyFrom(orderKey);
} catch (SQLException sqlx) {
s = c.createStatement();
c.rollback();
throw sqlx;
} finally {
try {
c.setAutoCommit(transactionState);
dbPool.release(c);
if (s != null)
s.close();
if (ps != null)
ps.close();
if (rs != null)
rs.close();
} catch (SQLException ignored) {
}
}
}这个方法与之前的方法处于不同的抽象级别。
addOrder 方法由一堆设置数据库基础设施的步骤组成,然后转向更高级别的业务领域方法,如 addSingleOrder。这样的代码很难阅读,因为它几乎随机地在抽象级别之间跳跃,基于接下来需要发生的步骤。
稍后进行一次重构,牢记组合方法,产生了同一方法的更清晰版本:
public void addOrder(ShoppingCart cart, String userName,
Order order) throws SQLException {
Connection connection = null;
PreparedStatement ps = null;
Statement statement = null;
ResultSet rs = null;
boolean transactionState = false;
try {
connection = dbPool.getConnection();
statement = connection.createStatement();
transactionState =
setupTransactionStateFor(connection,
transactionState);
addSingleOrder(order, connection,
ps, userKeyFor(userName, connection));
order.setOrderKeyFrom(generateOrderKey(statement, rs));
addLineItems(cart, connection, order.getOrderKey());
completeTransaction(connection);
} catch (SQLException sqlx) {
rollbackTransactionFor(connection);
throw sqlx;
} finally {
cleanUpDatabaseResources(connection,
transactionState, statement, ps, rs);
}
}
private void cleanUpDatabaseResources(Connection connection,
boolean transactionState, Statement s,
PreparedStatement ps, ResultSet rs) throws SQLException {SLAP 161
connection.setAutoCommit(transactionState);
dbPool.release(connection);
if (s != null)
s.close();
if (ps != null)
ps.close();
if (rs != null)
rs.close();
}}
private void rollbackTransactionFor(Connection connection)
throws SQLException {
connection.rollback();
}
private void completeTransaction(Connection c)
throws SQLException {
c.commit();
}
private boolean setupTransactionStateFor(Connection c,
boolean transactionState) throws SQLException {
transactionState = c.getAutoCommit();
c.setAutoCommit(false);
return transactionState;
}如果单行方法能够提升周围代码的抽象级别,那么使用单行方法是可以接受的。
这段代码涵盖了更多方法(包括几个单行方法),但它在不必要地跳跃抽象级别方面做得更好。当然,Java
需要一些前期的样板代码来处理所有初始化,整个方法体必须位于
try...catch 块内以处理发生任何错误时的数据库回滚。现在
addOrder 方法读起来好多了。这体现了组合方法(Composed
Method)的理想状态:公共方法的主体读起来就像所需步骤的大纲,加上一些由
Java 强加的干扰项。
你还能进一步清理这段代码吗?它仍然有相当多的 Java
所需的低级噪音。下面的代码通过将所有管道对象存储在 Map
中,并编写方法从 Map 中接受所有 JDBC
部分而不是单独接受,逐步改进了前一个版本:
public void addOrderFrom(ShoppingCart cart, String userName,
Order order) throws SQLException {
Map db = setupDataInfrastructure();
try {
int userKey = userKeyBasedOn(userName, db);
add(order, userKey, db);
addLineItemsFrom(cart,
order.getOrderKey(), db);
completeTransaction(db);
} catch (SQLException sqlx) {
rollbackTransactionFor(db);
throw sqlx;
} finally {
cleanUp(db);
}
}
private Map setupDataInfrastructure() throws SQLException {
HashMap db = new HashMap();
Connection c = dbPool.getConnection();
db.put("connection", c);
db.put("transaction state",
Boolean.valueOf(setupTransactionStateFor(c)));
return db;
}
private void cleanUp(Map db) throws SQLException {
Connection connection = (Connection) db.get("connection");
boolean transactionState = ((Boolean)
db.get("transation state")).booleanValue();
Statement s = (Statement) db.get("statement");
PreparedStatement ps = (PreparedStatement)
db.get("prepared statement");
ResultSet rs = (ResultSet) db.get("result set");
connection.setAutoCommit(transactionState);
dbPool.release(connection);
if (s != null)
s.close();
if (ps != null)
ps.close();
if (rs != null)
rs.close();
}
private void rollbackTransactionFor(Map dbInfrastructure)
throws SQLException {
((Connection) dbInfrastructure.get("connection")).rollback();
}
private void completeTransaction(Map dbInfrastructure)
throws SQLException {
((Connection) dbInfrastructure.get("connection")).commit();
}
private boolean setupTransactionStateFor(Connection c)
throws SQLException {
boolean transactionState = c.getAutoCommit();
c.setAutoCommit(false);
return transactionState;
}这个版本牺牲了辅助方法的可读性,换取了公共 addOrderFrom
方法的可读性(重命名以使调用更易理解)。最大的变化是将所有逻辑上但语法上不同的数据库字段放在
Map 中传递,简化了方法签名。你还会注意到,我将
dbInfrastructure
的所有参数移到了最后一个参数位置,弱化了管道代码对公共
addOrderFrom 方法可读性的重要性。
通常,为了清晰度和可读性而进行的重构需要权衡。默认情况下存在一定量的本质复杂性,所以问题变成了”复杂性应该在哪里体现?“我更愿意拥有更简单的公共方法,并将复杂性推到私有方法中(在这个例子中,表现为从
Map
打包和解包的形式)。在实现一个类时,你已经沉浸在单行代码的细节中,因此最好在那里处理复杂性。当以后阅读公共方法时,你会更希望不必理解任何细微差别;你只想尽可能简单地理解代码的作用。
注意
将所有实现细节从公共方法中封装起来。
无论你更喜欢第二个还是第三个版本的代码,两者都应用了 SLAP 原则:通过积极的重构,保持方法内的代码行处于相同的抽象级别。
162 第 13 章:组合方法与 SLAP
SLAP 163
164 第 13 章:组合方法与 SLAP

计算机语言就像鲨鱼一样,不能静止不动,否则就会死亡。就像口语一样,计算机语言不断演化(幸运的是,我们没有青少年以他们向英语添加俚语的速度向我们的计算机语言添加俚语)。语言会演化以适应它们所处的不断变化的环境。例如,Java 最近在与 .NET 的持续军备竞赛中添加了泛型(generics)和注解(annotations)。然而,在某个时刻,这会变得适得其反。如果你看看过去的几种语言(Algol 68 或 Ada),你会看到在语言变得笨重并开始在其自身重压下崩溃之前,你可以推动一种语言的极限。
自身重量下崩塌。Java是否已经到了这个地步?如果是,未来会怎样?
本章介绍了多语言编程(polyglot programming)作为Java和.NET平台及其所有热爱者未来的理念。但在深入探讨之前,我们需要了解是如何走到今天这一步的。Java有什么问题,这个新理念将如何解决?
Java是当今企业和其他开发领域根深蒂固的中流砥柱。对于我们这些经历过Java还只是印度尼西亚一个岛屿或一种饮料名称的人来说,见证这一切令人惊叹。但流行并不等同于完美:Java也有其缺陷,主要源于历史包袱(有趣的是,Java作为一门新语言被创建时并没有任何向后兼容性要求)。让我们看看Java是如何走到这里的,以及”这里”究竟是什么地方。
远古时代有一位神话般的人物(我们称他为James)需要为烤面包机和有线电视盒构建一门新语言。他不想使用自己已经熟悉和喜爱的语言(C和C++),因为即使对于热爱它们的人来说,它们也不适合这类工作。当然,你可以因为内存管理问题每天重启电脑几次,但对有线电视盒做同样的事就格外令人恼火了。
有一天,James决定创建一门新语言来解决这些深受喜爱但有缺陷的现有语言的一些问题。他创建了Oak,后来演变为Java。(好吧,我跳过了这个传说的一些部分。)这很好。Java修复了C和C++的许多弊病,并搭上了蓬勃发展的互联网顺风车。Bruce Tate称Java人气的崛起为”完美风暴”:所有正确的条件汇聚在一起,支撑了Java在流行度和使用率上的迅猛增长。
Java刚问世时,互联网和浏览器是所有人的宠儿。Java在那个时代的硬件和操作系统上运行有点慢,但它能实现其他任何技术都做不到的技巧:以applet形式在浏览器中运行。虽然现在看起来很奇怪,但applet正是让Java进入所有人视野的东西。当然,具有讽刺意味的是,事情已经兜了一圈:我们正在编写在浏览器中运行的富客户端应用程序,但现在主要使用JavaScript,它正经历自己的流行复兴。
第14章:多语言编程 第166页
当所有人都意识到在浏览器中运行大型企业应用程序不是个好主意时,服务器端Java已经首次亮相,将servlet和Tomcat等词汇加入到每个人的词汇表中。
Java在正确的时间和正确的地点出现,并不意味着它是完美的解决方案。Java有一些有趣的包袱,考虑到它是一门全新的语言本不必有任何包袱,这就更有趣了。Java中的包袱包括所有那些当你学习Java时对自己说”你一定在开玩笑——它是这样工作的?“的东西。你可能已经忘记了大部分这样的时刻,因为这就是它的工作方式。但让我们回顾一下其中的一些。
考虑一下Java中事物的初始化顺序。初始化是构造函数的工作,对吧?嗯,对也不对。Java允许你创建静态初始化器和实例初始化器。静态初始化器在构造函数之前运行,实例初始化器在构造函数运行前后某个时间运行。而且你可以有任意多个。哦,你还可以在声明对象时调用它们的构造函数。哪个先执行:静态初始化器、实例初始化器,还是已声明(和构造)对象的初始化?困惑了吗?考虑以下代码:
public class LoadEmUp {
private Parent _parent = new Parent();
{
System.out.println("Told you so");
}
static {
System.out.println("Did too");
}
public LoadEmUp() {
System.out.println("Did not");
_parent = new Parent(this);
}
static {
System.out.println("Did not");
}
public static void main(String[] args) {
new LoadEmUp();
System.out.println("Did too");
Parent referee = new Parent();
}
}第167页
class Parent {
public Parent() {
System.out.println("stop fighting!");
}
public Parent(Object owner) {
System.out.println("I told you to stop fighting!");
}
}不参考文档,你能预测消息出现的顺序吗?如果你不确定,这是此应用程序的实际输出:
Did too
Did not
stop fighting!
Told you so
Did not
I told you to stop fighting!
Did too
stop fighting!成为Java神职人员的一部分需要学习这样神秘的、看似武断的事实。
启动行为只是Java奇怪行为的冰山一角。一些奇怪的东西直接编码到语言中,比如数组索引。
…大量使用指针的语言使用者。你有没有问过自己为什么Java中的数组是从零开始的?这毫无意义。当然,Java中的数组从零开始是因为C中的数组从零开始:与Java并不向后兼容的语言保持向后兼容性。
从零开始的数组在C中完全合理,因为C中的数组实际上只是指针运算的简写。考虑图14-1中的图表。C中的数组本质上只是
操作指针和偏移量的语法糖。(可以说,C语言中几乎所有东西都是指针的语法糖,但这是题外话。)
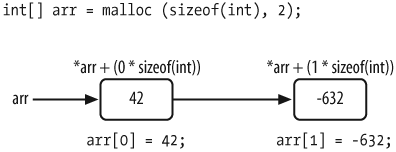
图14-1. C语言中的数组偏移
所以,Java中的数组从零开始是因为C语言中的数组从零开始。虽然从程序员舒适度的角度来看这是有道理的(即,使从C/C++转向Java变得容易),但从语言的角度来看这毫无意义。开发者在转向新语言时很快就会失去旧的习惯用法。如果Java从一开始就包含了foreach关键字,就没有人会关心数组的索引号了。当然,Java最终确实有了foreach运算符(令人困惑的是,它被称为for,就像另一个一样),而这花了整整八年时间!
这种对从零开始的数组的迷恋以及对C语言的盲目向后兼容性,也给了我们(原始的)for语句语法:
for (int i = 0; i < 10; i++) {
// some code
}对于C程序员来说,这就像回家一样。对于从未见过或使用过C语言的开发者(现在这个群体越来越大)来说,这简直太奇怪了。显然,是愤怒的猴子决定了这种语法。
Java包含了令人沮丧的大量奇怪的怪癖和习惯用法,有些是Java创建者新增的,有些是从前世继承的包袱。所有语言都或多或少是这样的。有没有办法逃离这种疯狂呢?
幸运的是,Java的创建者实际上构建了两样东西:Java语言和Java平台。而后者是我们逃离过去包袱的出口。越来越多地,Java被更多地用作平台而不是语言。这一趋势将会持续下去,并在未来几年加速发展。事实上,我们最终都会从事我所说的多语言编程(polyglot programming)。
当我们今天构建Web应用程序时,我们主要使用三种语言(如果算上XML的话是四种)进行开发:Java(或其他一些基础的通用语言)、SQL和JavaScript(以Ajax库的形式)。然而,大多数开发者会说他们是Java(或.NET或Ruby)程序员,忽略了那些渗透到他们”正常”通用语言中的特殊目的语言。
多语言编程是指除了通用语言之外,还使用一种或多种特殊目的语言来构建应用程序。我们已经在这样做了,但这太自然了,我们甚至都没有想过。例如,SQL已经深深植根于应用程序开发中,以至于几乎每个应用程序都会使用它已成为理所当然的事情。
然而,与我们通常使用的通用命令式语言相比,SQL是一种奇怪的东西。SQL完全是关于集合论和数据操作的。因此,它看起来或感觉起来都不像”常规”语言。大多数开发者对这种二分法感到满意。他们愉快地使用SQL(或允许Hibernate为他们生成SQL),调试奇怪的SQL问题,甚至帮助数据库基于分析优化SQL。这是日常软件开发中平凡而自然的一部分。
我们为什么要使用特殊目的语言?嗯,是为了服务于特殊目的。SQL显然属于这一类。JavaScript也是如此,特别是我们今天使用它的方式。尽管这些不同的语言针对不同的平台(虚拟机上的Java,数据库服务器上的SQL,浏览器中的JavaScript),但它们都汇集成一个”应用程序”。
我们应该利用这个想法并更好地使用它。Java平台现在支持大量的语言,其中一些高度专门化于不同的任务。这是我们摆脱Java语言怪异性的”出狱卡”。
Groovy是一种开源语言,它使用动态语言语法和功能更新Java。它生成Java字节码,因此针对Java平台。但是Groovy的语法深受自Java诞生十多年以来出现的语言的影响。Groovy具有闭包(closures)、更松散的类型、“理解”迭代的集合,以及一系列现代语言改进。而且,它可以编译成良好的老式Java字节码。
这里有一个明确的例子。作为一名经验丰富的Java开发者,你的任务是编写一个简单的程序,读取一个文本文件并打印出文本文件的内容,在每行前面添加行号。想一想编写这个应用程序。它可能看起来像这样:
public class LineNumbers {
public LineNumbers(String path) {
File file = new File(path);
LineNumberReader reader = null;
try {
reader = new LineNumberReader(new FileReader(file));
while (reader.ready()) {
out.println(reader.getLineNumber() + ":"
+ reader.readLine());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
reader.close();
} catch (IOException ignored) {
}
}
}
public static void main(String[] args) {
new LineNumbers(args[0]);
}
}这是完成同样功能的完整Groovy应用程序:
def number=0
new File (args[0]).eachLine { line ->
number++
println "$number: $line"
}那个Java解决方案有多少行?在某些时候,Java的语法要求变成了一种约束而不是帮助。Groovy版本的符号比
Java版本有多行代码!如果Java和Groovy生成相同的字节码,为什么还要使用过时的Java语法?
我能听到各地Java开发者的强烈抗议:“Groovy代码的效率不如Java代码!”你说得完全正确:Groovy会给Java字节码增加开销,插入Java所需的声明、构造、异常块和其他固定化元素。Java版本会比Groovy版本快几百毫秒。但那又怎样?开发者生产力比机器周期更重要,而摩尔定律(Moore’s law)(指出处理器性能每18个月翻一倍)将确保这一趋势继续。我们越来越关心用最少的障碍完成工作,而不是代码的原始性能特征。回想一下你写的最近五个应用程序:几乎在每种情况下,网络和数据库延迟不是比语言执行速度更令人担忧吗?
Groovy显然是帮助现代化Java语言陈旧部分的候选者。然而,多语言编程(polyglot programming)这个想法将比仅仅在字节码上加一层Groovy外观要深入得多。我们将越来越多地利用这个想法来实现目前不切实际的应用程序类型。
现在大多数新计算机都配备多个处理器。我正在写作的笔记本电脑有一个双核芯片,这意味着从软件开发的角度来看,它是一台多处理器机器。在具有多个处理器的机器上高效运行应用程序意味着编写良好的线程安全代码。编写良好的线程安全代码极其困难。即使是那些自认为知道自己在做什么的人,在阅读Brian Goetz的《Java并发编程实战》(Java Concurrency in Practice)(Addison-Wesley)后也感到震惊。在他的书中,Brian有效地证明了在Java中(以及推而广之,在任何命令式语言中)编写健壮的线程安全代码确实非常困难。
大约五年前,我们的用户对我们制作的丑陋的、图形化版本的终端窗口Web应用程序完全满意。然后Google那些讨厌的程序员发布了Google Maps和Gmail,向我们的用户展示了Web应用程序不必那么糟糕。我们不得不提升水平,开始构建更好的Web应用程序。并发也会发生同样的事情。我们开发者现在可以对严重的线程问题保持幸福的无知,但总有人会出现并展示有可能以创新的方式利用新机器的能力,我们都将不得不跟上。一场冲突正在逼近,在我们将用应用程序目标定位的机器类型与我们编写在这些机器上有效运行所需代码的能力之间。为什么不利用多语言编程来简化我们的任务?
函数式语言(functional languages)不会遭受命令式语言的许多缺点。函数式语言更严格地遵守数学原理。例如,函数式语言中的函数就像数学中的函数一样工作:输出完全取决于输入。换句话说,函数在工作时不能修改外部状态。纯函数式语言没有变量或状态性的概念。当然,这并不实用。然而,有一些非常好的混合函数式语言具有许多理想的特性,而没有严重的可用性限制。函数式语言的例子包括Haskell、OCaml、erlang、SML等。
特别是,函数式语言处理多线程支持比命令式语言好得多,因为它们不鼓励状态性(statefulness)。其结果是,在函数式语言中编写健壮的线程安全代码比在命令式语言中更容易。
介绍Jaskell,这是运行在Java平台上的Haskell语言版本。换句话说,它是一种编写产生Java字节码的Haskell代码的方法。
这是Jaskell网站上的一个例子。假设你想在Java中实现一个允许安全访问数组元素的类。你可以编写一个类似以下的类:
class SafeArray{
private final Object[] _arr;
private final int _begin;
private final int _len;
public SafeArray(Object[] arr, int len){
_arr = arr;
_begin = begin;
_len = len;
}
public Object at(int i){
if(i < 0 || i >= _len){
throw new ArrayIndexOutOfBoundsException(i);
}
return _arr[_begin + i];
}
public int getLength(){
return _len;
}
}相同的功能可以在Jaskell中编写为元组(tuple),本质上是一个关联数组:
newSafeArray arr begin len = {
length = len;
at i = if i < begin || i >= len then
throw $ ArrayIndexOutOfBoundsException.new[i]
else
arr[begin + i];
}因为元组像关联数组一样工作,调用newSafeArray.at(3)会调用元组的at部分,该部分评估元组那部分定义的代码。尽管Jaskell不是面向对象的,但继承和多态都可以在Jaskell中使用元组来模拟。而且,像使用混入(mixins)这样的理想行为在Jaskell的元组中是可能的,但在核心Java语言中是不可能的。混入提供了接口和继承组合的替代方案,你可以将代码注入类中,而不仅仅是签名,而不使用继承。今天使用Aspects和AspectJ(我们当前多语言混合中的另一种语言)就可以做到这一点。
Haskell(因此也包括 Jaskell)的特点是函数的惰性求值(lazy evaluation),这意味着表达式在需要之前永远不会被执行。例如,这段代码在 Haskell 中完全合法,但在 Java 中永远无法工作:
makeList = 1 : makeList这段代码的意思是”创建一个只有单个元素的列表。如果需要更多元素,则按需求值。“这个函数本质上创建了一个永无止境的
1 列表。
当然,要利用 Haskell 语法(通过 Jaskell),你的开发团队中必须有人理解 Haskell 的工作原理。越来越多地,就像我们现在在项目中有数据库管理员一样,我们将有其他专家来编写具有特殊特性的代码。也许你有一个复杂的调度算法,用 Java 需要 1000 行代码,但用 Haskell 只需要 50 行。为什么不利用 Java 平台,用更适合任务的语言来编写呢?
这种开发方式引入了一系列令人头疼的问题,抵消了它的好处。调试多语言应用程序比调试用单一语言编写的应用程序更困难:问问任何不得不调试 JavaScript 和 Java 之间交互的开发人员就知道了。未来解决这个问题的最简单方案将与现在相同:严格的单元测试,这样可以减少在调试器中花费的时间。
多语言开发方式也将继续引导我们走向领域特定语言(DSL)。在不久的将来,我们的语言格局将看起来非常不同:专门化的语言将被用作构建块,来创建非常特定的 DSL,而这些 DSL 又非常接近我们试图解决的问题域。单一用途的通用语言时代正在接近尾声;我们正在进入一个新的专业化领域。也许是时候拂去大学 Haskell 教科书上的灰尘了!
图 14-2. Ola 金字塔
我的同事 Ola Bini 为多语言编程这个想法增添了一些细节,定义了新的应用程序栈。他对现代开发世界的看法如图 14-2 所示。这个图表表明,我们将使用一种语言(也许是静态类型语言)作为稳定层,使用更高效的语言(可能是动态的,如 JRuby、Groovy 或 Jython)进行日常编码,以及使用领域特定语言(如第 11 章”流畅接口”中所讨论的)使我们的代码更贴近业务分析师和最终用户的需求。我认为 Ola 准确地把握了多语言编程、领域特定语言和动态语言这些不同想法如何结合在一起。
所有医生曾经都是全科医生,但随着他们领域的发展,专业化变得不可避免。软件复杂性正在迅速推动我们走向专业化,这既是因为我们必须编写的应用程序类型,也是因为底层平台。为了应对这个勇敢的新世界,我们应该拥抱多语言编程,为平台提供更专业化的工具,并使用领域特定语言来解决日益困难的问题域。未来五年的软件开发将与今天看起来非常不同!

在本书到目前为止的内容中,我向你展示了如何使用一系列不同的工具来解决各种问题:批处理文件、bash 脚本(包括单行命令和完整脚本)、Windows PowerShell、Ruby、Groovy、sed、awk,以及一整套大眼睛的 O’Reilly 动物。现在关键时刻到了。你已经确定了一个让人头疼的问题,并想通过自动化来解决它:你应该使用哪个工具?你可能首先使用的工具是一个简陋的文本编辑器。所以,我将从讨论这个也许是你武器库中最重要的工具开始。
开发人员仍然花费大量时间处理纯文本。无论我们开发了多少向导和其他魔法工具,大部分编码仍然是纯文本。你保存的大部分信息也应该以纯文本形式存储,因为你永远不知道你正在使用的工具是否会在五年后还存在。可以打赌的是,在接下来的一个世纪左右,你将能够读取纯 ASCII(可能还有 Unicode)。(正如《程序员修炼之道》[Addison-Wesley] 所告诫的:“将知识保存为纯文本。”)
因为我们做的很多事情都围绕着文本,所以找到你的完美文本编辑器是有意义的。这不是关于 IDE;公司政策和你使用的语言通常决定了这一点。IDE 很擅长生成源代码。但它们缺少一些处理普通文本的最佳工具。
我承认我曾经有编辑器癖好。我在机器上安装了半打编辑器,因为我喜欢每个编辑器的不同功能。有一天,我决定创建一个列表,列出我认为完美编辑器应该具备的所有功能,学习每一个细节,并永远摆脱今日编辑器的困扰。
注意:找到你的完美编辑器并彻底学习它。
这是我的列表。这些是我认为完美编辑器应该具备的特性,以及我找到的体现这种理想的编辑器。你的列表可能会有所不同。
在过去的日子里(几十年前),宏是开发人员武器库中最重要的部分之一。我现在仍然几乎每周都会录制至少一个宏。IDE 中实时模板的出现取代了宏的许多基本任务。事实上,
最流行的 Java 开发环境(开源的 Eclipse)仍然没有宏录制功能。如果你告诉一个 1980 年代的 Unix 程序员,存在一个不让你录制宏的开发工具,他会感到震惊。(公平地说,下一版本的 Eclipse 应该会增加这个支持。)
176 第 15 章:寻找完美工具
录制宏用于所有对称的文本操作。
宏仍然是一个强大的工具,但你必须以特定的方式思考问题。当你需要清理从源代码中获取的 HTML,或者用 HTML 标签包装一些代码时,你可以在单行上录制操作,并确保在下一行的相同位置结束。这样你就可以在所有后续行上回放宏。
完美的编辑器应该具有可读的宏语法,这样你就可以保存常用宏并重复使用它们。例如,开源的 JEdit 编辑器使用 BeanShell 编写,这是一种类似 Java 的脚本语言。每次你在 JEdit 中录制宏时,它都会在一个打开的缓冲区中呈现给你保存。这是在 JEdit 中录制的一个宏,它将压缩在单行上的 HTML 术语列表(由于显示间距问题)扩展为每行一个条目:
SearchAndReplace.setSearchString("\"");
SearchAndReplace.setAutoWrapAround(false);
SearchAndReplace.setReverseSearch(false);
SearchAndReplace.setIgnoreCase(true);
SearchAndReplace.setRegexp(true);
SearchAndReplace.setSearchFileSet(new CurrentBufferSet());
SearchAndReplace.find(view);
textArea.goToPrevCharacter(false);
textArea.goToNextWord(false,false);
textArea.goToNextWord(false,false);
textArea.goToNextWord(false,false);如你所见,BeanShell 非常易读,这鼓励你保存有用的录制宏以供将来使用。
从命令行启动
你应该能够从命令行启动编辑器,传递单个或多个文件。TextMate 是我列表中的编辑器之一,它做得更好。当在目录中启动时,它会自动将目录视为项目,在项目抽屉中显示目录及其子目录中的所有文件。
正则表达式搜索和替换
你的编辑器应该对单文件和跨文件搜索和替换都有强大的正则表达式支持。因为我们花了很多时间处理文本,学习正则表达式语法是非常宝贵的。
它有时可以节省几天的工作时间。曾经有一个事件让我确信了正则表达式的力量。我在一个拥有超过 1,000 个企业 JavaBeans(EJB)的项目上工作,决定所有非 EJB 方法(即除了 EJB 强制回调方法之外的所有方法)都需要一个额外的参数。据估计,某人手动完成这项工作需要六天时间(争夺已经开始,谁都不想成为那个人)。团队中的一位开发人员非常了解正则表达式。他坐下来使用他信赖的文本编辑器(Emacs),两小时后,完成了所有
寻找完美编辑器 177
替换。那一天,我决定我也需要非常了解正则表达式语法。
这是专家水管工现象的一个例子。假设你雇了一个水管工来解决大楼里的问题。专家水管工双手插在口袋里走来走去好几天,查看大楼里的所有管道设施。第三天结束时,他爬到某个地方下面,转动一个阀门。“请付 2,000 美元。”你目瞪口呆:“2,000 美元?但你只转了一个阀门!”“是的,”他说。“转阀门 1 美元,知道转哪个阀门 1,999 美元。”
良好的正则表达式知识会让你成为相当于专家水管工的开发人员。在我刚才提到的情况下,开发人员花了 1 小时 58 分钟使语法正确,然后不到两分钟实际运行它。在外行人看来,他大部分时间都不是很有生产力(也就是说,与正则表达式语法作斗争),但最终,他节省了几天的工作。
良好的正则表达式知识可以节省数量级的工作量。
累加剪切和复制命令
令人费解的是,大多数现代 IDE 只有一个包含单个条目的剪贴板。真正好的编辑器不仅提供剪切和复制,还提供复制追加和剪切追加命令,这些命令将文本追加到剪贴板上的现有文本。这允许你在剪贴板上积累内容,而不是在源和目标之间来回切换(我经常看到开发人员复制、切换、粘贴、切换、复制、切换、粘贴等)。在源文件中完成所有复制,然后切换到目标粘贴完整的文本要高效得多。
不要在可以批处理时来回切换。
多个寄存器
具有累加剪切和复制命令的编辑器通常也有多个寄存器。这实际上只是多个剪贴板的老式名称。在完美的编辑器中,你可以获得与键盘上的按键一样多的剪贴板。你可以在操作系统级别创建多个剪贴板(参见第 2 章中的”剪贴板”),但在文本编辑器中也有支持会更好。
跨平台
拥有跨平台编辑器并不影响所有开发人员,但任何必须跨越多个操作系统(有时一天多次)的人都应该有一个可以在任何地方使用的跨平台瑞士军刀。
178 第 15 章:寻找完美工具
以下是一些符合我之前列出的大部分标准的编辑器。这并不是一个详尽的列表,但它是一个很好的起点。
当然,这个编辑器必须上榜。上面提到的许多高级功能都始于这个编辑器及其基础版本。VI 仍然存在并且发展强劲。最流行的跨平台版本叫做 VIM(即”VI Improved”的缩写),适用于所有平台。它唯一稍有不足的地方是可读的宏语法要求。VI 学习起来非常困难;它有一个几乎垂直的学习曲线。但是,一旦你掌握了它,你就是最高效的文本操作者。看着经验丰富的 VI 编辑者工作,人们会说光标就跟随着他们的眼睛移动。当然,VI 和 Emacs 的拥护者之间存在着低级别的争论,但它们实际上是不同的东西:VI 力求成为终极文本操作工具,而 Emacs 力求成为适用于任何语言的 IDE。VI 的支持者说”Emacs 是一个具有基本文本编辑支持的伟大操作系统”。
这是另一个拥有忠实(不,应该说是狂热)追随者的老派编辑器。它支持上面列出的所有功能(如果你把 elisp,即 Emacs 的宏语言,算作”可读的”)。它有 Emacs、XEmacs(在 Windows 等操作系统上的 Emacs 图形界面)和 AquaEmacs(专门为 Mac OS X 设计,除了传统的 Emacs 命令外还使用原生 Mac OS X 命令)等版本。Emacs 有时会让手指扭曲才能完成任务(有些人开玩笑说 Emacs 代表”Escape Meta Alt Control Shift”),但它拥有巨大的功能。它针对不同语言有”模式”,允许复杂的语法高亮、专用工具和许多其他行为。Emacs 实际上是现代 IDE 的原型。
我必须承认这个编辑器甚至让我感到惊讶。我使用 JEdit 好几年,然后就不太用了。但是,当我整理列表时,我重新评估了 JEdit,它满足列表上的所有标准。它已经成为一个非常强大的编辑器,拥有大量插件,允许它利用许多第三方工具(如 Ant)并支持许多语言。它建立在 BeanShell 之上,这意味着它易于自定义和修改,特别是对于 Java 开发人员。
TextMate 是 Mac OS X 的编辑器,赢得了许多人的青睐(包括吸引了一些著名的 Emacs 忠实用户)。它以不引人注目的方式非常强大,支持上面列表中的大部分项目,并且与 Mac OS X 配合得非常好。虽然它最初不符合跨平台要求,但它在 Mac OS X 上变得如此受欢迎,以至于另一家公司正在将其移植到 Windows(称为 eEditor)。
在他的书《选择的悖论》(The Paradox of Choice,Harper Perennial)中,Barry Schwartz 引用了一项研究,表明用户会被太多选择所困扰。他们不但不会因为有很多选择而感到高兴,反而会因为选择太多而感到不舒服。例如,有一家卖果酱的商店,为了让顾客品尝他们的产品,他们摆出了一张桌子,上面放了三罐果酱。果酱的销售额大幅增长,因为顾客喜欢在购买前品尝果酱。店主使用逻辑推理,决定摆出 20 罐果酱供品尝。结果果酱的销售额暴跌。有三罐果酱很好,因为人们喜欢能够品尝。但有 20 罐果酱就变得令人不知所措。人们仍然品尝果酱,但由于选择太多,这使他们的决策过程陷入瘫痪,导致果酱销量减少。
我们软件开发人员在解决问题时也有同样的问题:有太多方法来解决它,我们有时甚至无法开始。例如,在第 4 章”用 Ruby 构建 SQL 分割器”中引用的 SqlSplitter 示例中,与我结对编程的开发人员最初考虑使用 sed、awk、C# 甚至 Perl 来尝试解决问题,但很快意识到这会花费太长时间。考虑到我们有这么多选择,你如何选择?
越来越多地,我一直依赖我所谓的”真正的”脚本语言来完成越来越多的自动化任务。我的意思是支持脚本的通用语言,但具有通用语言的强大支持。你永远不知道一个小”夹具”或”垫片”何时会成长为你项目的真正部分。你有一天创建的用于处理某些小任务的有用小工具有一种坚持存在的方式,随着你需要做更多事情而逐渐增加新功能。在某个时候,它会升级为你项目的真正部分,你会希望对它应用与”真实”代码相同的严格标准(如版本控制、单元测试、重构等)。“真正的”脚本语言的例子包括 Ruby、Python、Groovy、Perl 等。
注意:使用”真正的”脚本语言进行自动化任务。
回到第 4 章的”用 Ruby 构建 SQL 分割器”,我描述了一个将大型 SQL 文件分解为较小块的自动化解决方案,称为 SqlSplitter。我们认为我们只需要执行这个技巧一次,但它”意外地”成为我们项目的重要部分。因为我们用 Ruby 编写它,它很容易从”垫片”过渡到实际资产,包括通常为项目真正部分保留的代码卫生(如单元测试)。对于 SqlSplitter 类,稍微重构一下就可以为它编写单元测试。这是更新后的版本:
class SqlSplitter
attr_writer :sql_linesdef initialize(output_path, input_file)
@output_path, @input_file = output_path, input_file
end
def make_a_place_for_output_files
Dir.mkdir(@output_path) unless @output_path.nil? or File.exists? @output_path
end
def lines_o_sql
@sql_lines.nil? ? IO.readlines(@input_file) : @sql_lines
end
def create_output_file_from_number(file_number)
file = File.new(@output_path + "chunk " + file_number.to_s + ".sql",
File::CREAT|File::TRUNC|File::RDWR, 0644)
end
def generate_sql_chunks
make_a_place_for_output_files
line_num = 1
file_num = 0
file = create_output_file_from_number(1)
found_ending_marker, seen_1k_lines = false
lines_o_sql.each do |line|
file.puts(line)
seen_1k_lines = (line_num % 1000 == 0) unless seen_1k_lines
line_num += 1
found_ending_marker = (line.downcase =~ /^\W*go\W*$/ or
line.downcase =~ /^\W*end\W*$/) != nil
if seen_1k_lines and found_ending_marker
file.close
file_num += 1
file = create_output_file_from_number(file_num)
found_ending_marker, seen_1k_lines = false
end
end
file.close
end
end为 sql_lines 成员变量添加一个
attr_writer。这允许你在构造类之后但在调用任何方法之前向类中注入测试值。
lines_o_sql
方法抽象了成员变量的内部表示,确保它在被调用时始终有值。其他方法都不需要了解
sql_lines 成员变量是如何填充的内部工作原理。
使用该方法来迭代源代码行的集合,允许你注入自己的行数组进行测试,而不是总是依赖于输入文件。
一旦代码被重构,就很容易为其编写单元测试,如下所示:
require "test/unit"
require 'sql_splitter'
require 'rubygems'
require 'mocha'
class TestSqlSplitter < Test::Unit::TestCase
OUTPUT_PATH = "./output4tests/"为工作选择正确的工具 181
private
def lots_o_fake_data
fake_data = Array.new
num_of_lines_of_fake_data = rand(250) + 1
1.upto 250 do
1.upto num_of_lines_of_fake_data do
fake_data << "Lorem ipsum dolor sit amet."
end
fake_data << (num_of_lines_of_fake_data % 2 == 0 ? "END" : "GO")
num_of_lines_of_fake_data = rand(250) + 1
end
fake_data
end
public
def test_mocked_out_dir
ss = SqlSplitter.new("dummy_path", "dummy_file")
Dir.expects(:mkdir).with("dummy_path")
ss.make_a_place_for_output_files_in(dir)
end
def test_that_output_directory_is_created_correctly
ss = SqlSplitter.new(OUTPUT_PATH, nil)
ss.make_a_place_for_output_files
assert File.exists? OUTPUT_PATH
end
def test_that_lines_o_sql_has_lines_o_sql
lines = %w{Lorem ipsum dolor sit amet consectetur}
ss = SqlSplitter.new(nil, nil)
ss.sql_lines = lines
assert ss.lines_o_sql.size > 0
assert_same ss.lines_o_sql, lines
end
def test_generate_sql_chunks
ss = SqlSplitter.new(OUTPUT_PATH, nil)
ss.sql_lines = lots_o_fake_data
ss.generate_sql_chunks
assert File.exists? OUTPUT_PATH
assert Dir.entries(OUTPUT_PATH).size > 0
Dir.entries(OUTPUT_PATH).each do |f|
assert f.size > 0
end
end
def teardown
`rm -fr #{OUTPUT_PATH}` if File.exists? OUTPUT_PATH
end
end这会生成一个看起来有点像 SQL 的数据数组,但具有你需要的标记(即”GO”和”END”)。
这使用 Mocha(Ruby 的 mocking 库)来模拟目录创建以进行测试。
这测试输出目录是否正确创建。
182 第15章:寻找完美工具
这测试 lines_o_sql 方法确实返回一个数组,该数组由传递给
sql_lines 修改器的字符串组成。
这是主要测试。它测试 SqlSplitter
类是否基于解析输入(或看起来像输入的内容)生成输出文件。
此版本测试 SqlSplitter
的所有方面,包括模拟文件系统,以便你可以测试它是否正确地与底层操作系统交互。因为这是
Ruby 代码,我能够运行代码覆盖率工具 rcov 来验证我有 100%
的测试覆盖率(见图
15-1)。这对于脚本来说很重要,尤其是对于偶尔才会出现的边缘情况。
图15-1. SqlSplitter的代码覆盖率
这段代码最初没有测试,但后来被认为足够重要,可以开始将这个小工具视为真正的代码。像 bash、sed、awk 等命令行工具的一个严重缺点是缺乏可测试性。当然,你通常不需要测试这些类型的工具……直到你真的、真的需要测试它们。Ant 的一个主要缺点是当 Ant 文件增长到数千行”代码”时缺乏可测试性(抱歉,我仍然无法让自己称 XML 为代码)。因为 Ant 是 XML,你无法轻松地对其进行差异比较或重构(尽管某些 IDE 支持有限的重构),或者执行”真正”语言中自然而然的任何其他代码卫生操作。
没有什么能阻止人们为 bash 脚本编写单元测试,但这充其量是困难的。没有人会想到测试命令行工具,因为他们认为这些工具
已经足够复杂到值得进行测试了。它们几乎总是从过于简单而无需测试开始,但会逐渐发展成为难以调试但对项目至关重要的庞然大物。
大多数”企业级”开发中普遍存在的一部分是 XML。事实上,某些项目的 XML 代码量与”真实”代码一样多。XML 之所以开始侵入开发世界,有两个原因。首先,它易于解析,有许多标准库可以轻松生成和使用。这是它取代 Unix 风格”小语言”(配置 Unix 各个部分的配置文件)使用的主要原因。第二个原因是人们意识到利用可重用代码的最佳方式之一是通过框架。而框架有两个基本部分:框架代码本身和允许你驱动框架的配置。配置部分通常需要后期绑定(late binding):无需重新编译应用程序即可更改代码的能力。这是早期版本 EJB 的一个巨大卖点,专门的部署专家能够调整你的 EJB 的事务特性。现在听起来有点荒谬,但当时听起来很酷。但保存在后期绑定配置中的配置的有效性仍然是一个有用的想法。
XML 的问题是什么?它不是真正的代码,但它假装是。XML 的重构能力有限,编写起来很困难,尝试对比两个 XML 文件非常糟糕,而且对于我们在计算机语言中认为理所当然的东西(如变量)的支持很弱。
幸运的是,我们可以通过生成 XML 而不是手工编写来解决 XML 的问题。现代动态语言都有标记构建器(markup builders),其中包括专门用于构建 XML 的构建器。这里有个例子。struts-config.xml 文件存在于每个 Struts 项目中(如果你不熟悉 Struts,它是 Java 的一个流行 Web 应用程序框架)。配置文件允许你配置数据库连接池等内容。struts-config 文件的片段如下所示:
<data-source type="com.mysql.jdbc.jdbc2.optional.MysqlDataSource">
<set-property property="url" value="jdbc:mysql://localhost/schedule" />
<set-property property="user" value="root" />
<set-property property="maxCount" value="5" />
<set-property property="driverClass" value="com.mysql.jdbc.Driver" />
<set-property property="minCount" value="1" />
</data-source>如果我们希望最小连接数始终比最大连接数少 5 个怎么办?因为这是 XML,我们没有好的变量机制,所以我们必须手动管理,这当然容易出错。考虑同一 XML 片段的这个版本,但保存在 Groovy 标记构建器中:
def writer = new StringWriter()
def xml = new MarkupBuilder(writer)
def maxCount = 10
def countDiff = 4
xml.'struts-config'() {
'data-sources'() {
'data-source'(type:'com.mysql.jdbc.jdbc2.optional.MysqlDataSource') {
'set-property'(property:'url', value:'jdbc:mysql://localhost/schedule')
'set-property'(property:'user', value:'root')
'set-property'(property:'maxCount', value:"${maxCount}")
'set-property'(property:'driverClass', value:'com.mysql.jdbc.Driver')
'set-property'(property:'minCount', value:"${maxCount - countDiff}")
}
}
}标记构建器允许你编写具有与其生成的 XML 相同层次结构的结构化代码,使用参数和名称/值对来生成 XML 属性和子元素。这更易于阅读,因为它包含的基于 XML 的噪音少得多,比如花括号。但在代码中拥有这种结构的真正好处是可以轻松使用变量创建派生值。在这个例子中,minCount 基于 maxCount,这意味着你永远不必手动同步这些值。使用 Groovy Ant 任务,你可以将此构建器文件作为构建过程的一部分,每次执行构建时自动生成 XML 配置。
好的,但如果你已经有一个 struts-config.xml 文件并且不想重新输入它以将其放入构建器中怎么办?很简单:反构建它。这是获取现有 XML 文件并将其转换为 Groovy 构建器代码的 Groovy 代码:
import javax.xml.parsers.DocumentBuilderFactory
import org.codehaus.groovy.tools.xml.DomToGroovy
def builder = DocumentBuilderFactory.newInstance().newDocumentBuilder()
def inputStream = new FileInputStream("../struts-config.xml")
def document = builder.parse(inputStream)
def output = new StringWriter()
def converter = new DomToGroovy(new PrintWriter(output))
converter.print(document)
println output.toString()Ruby 有类似的构建器,具有相同的功能(实际上,Ruby 构建器受到 Groovy 构建器的启发)。使用构建器生成代码允许你使用开发人员已经习惯的所有功能。永远不要手工编写 XML;始终生成它。当然,生成和反生成 XML 似乎有点愚蠢。(为什么不直接删除中间人 XML,就像 Ruby 所做的那样——Ruby 世界中的大多数配置都是用 Ruby 代码和 YAML 完成的,这实际上是嵌入式 Ruby 代码。)但你不能一夜之间改造 Java 和 C# 等语言中的所有框架以使用真正的代码进行配置。至少你可以编写生成 XML 的代码,获得将行为保留在代码中的好处,并使用
构建者在第一次将其转化为代码时使用。
注意
将行为保持在(可测试的)代码中。
如果你用强大的脚本语言开始所有自动化项目,它允许你在何时添加真正代码的基础设施变得不可或缺时做出判断。这也意味着你不必学习一整套专用工具。现在的脚本语言几乎为你提供了命令行工具的所有功能。
有用的东西往往永远不会消失。它们不断增长,直到成为你流程的重要组成部分。所有小工具都会达到一个临界点,在那里它们变得
[选择合适的工具] 185
重要,因此值得真正关注。如果你从一开始就正确构建它们,当那一天到来时就不必重写它们。尽可能多地将行为保持在代码中(而不是工具或像XML这样的标记语言中)。我们知道各种处理代码的方法:用diff比较版本、重构、健壮的测试库。为什么我们要放弃关于代码的所有积累知识,只是为了某个复杂工具的诱惑?
注意
关注工具的演化。
与选择正确工具同样重要(或许更重要)的是拒绝糟糕的工具。事实上,存在一个描述这种情况的反模式:船锚(boat anchor)。船锚是一种你被迫使用的工具,尽管它对手头的工作完全不适合。通常,这个船锚花费大量金钱,增加了在每种情况下都使用它的政治压力。举一个扭曲但令人沮丧准确的比喻,想象一个木匠被迫使用大锤(无疑很强大)来钉钉子。这种情况下的不适用性是显而易见的,但我们在软件中做出类似甚至更糟糕的决定。
我最近参与了一个大型企业项目的启动。我们向开发人员介绍了许多敏捷原则,他们将其视为新鲜空气。其中一个决定涉及版本控制。基础设施控制代表来与我们交谈,提供了两个选择:Rational ClearCase或Serena Version Manager。如果你不熟悉这两个版本控制软件包,它们都相当昂贵,功能强大(占用空间也相应很大)。我们的选择?以上都不是。我们建议使用Subversion,这个轻量级开源版本控制软件包。我们向基础设施控制人员描述了它,他们同意它听起来非常适合他们的需求。然后出现了一个大问题:“每个用户的许可费用是多少?”当我们告诉他们是免费的时候,他们震惊了。然后,他们反思道:“你知道,我们大约六个月前为另一组开发人员安装了ClearCase,他们似乎不太喜欢它。”
大公司会进入一种收购模式,试图为开发找到一种适合所有情况的工具。对于大公司来说,在基础设施上标准化是有道理的。但在某个时候,标准基础设施变成了阻碍而不是好处。对于过于复杂的工具尤其如此。事实上,我为此创造了一个术语:复杂税(complexitax)。复杂税是你为工具引入的意外复杂性支付的额外成本,这个工具做的比你需要的更多。许多项目淹没在工具带来的复杂性中,讽刺的是,开发人员购买这些工具几乎总是为了提高生产力。
注意
尽可能少地支付复杂税。
186 第15章:寻找完美工具
如何成功对抗船锚和船锚政策?以下是一些攻击不必要复杂性的策略。发起有效的反对开发管制的运动,使第9章涵盖的主题发挥作用。
企业CIO的理由对他来说是有道理的:如果我们能够在一小组工具上标准化,我们就不必做那么多培训,我们可以让人员更容易地跨项目工作,等等。不幸的是,软件供应商用高尔夫郊游(我的一位同事,每次看到角落里闲置的船锚时,总是说:“我希望那是一次愉快的高尔夫郊游”)、无情的销售活动以及其他任何让他购买产品的方法来攻击他。你可以通过展示更简单的东西更适合这个特定项目来成功对抗标准船锚。在旁边启动一个小型秘密项目,展示对于这个简单的web应用程序,Tomcat实际上比Websphere更好,因为我们希望能够编写部署脚本,这在Tomcat上更容易。
有时甚至很难达到可以展示一件事更好的地步,特别是如果需要一段时间才能到位。不要羞于求助于恳求;获得你的方式可以在持续的基础上节省大量时间。
我的一位朋友Jared Richardson有一项艰巨的任务,让世界上最大的软件公司之一变得更敏捷。他环顾四周,注意到每晚构建失败是其最大的问题之一。他没有通过企业层级升级请求,以获得在某些项目上设置CruiseControl的许可,而是找到了一台没人使用的旧台式机,并在上面安装了CruiseControl。他设置它在几个最麻烦的项目上运行持续构建。他设置它在开发人员提交破坏构建的代码时通过电子邮件通知他们。接下来几天,开发人员都开始问他如何关闭构建失败的电子邮件通知。“很简单,”他说,“不要破坏构建。”最终,他们
他们意识到这是阻止骚扰的唯一办法,于是清理了代码。
公司从每月只有三次成功的夜间构建变成了每月只有三次失败的夜间构建。一些精明的经理环顾四周说:“好吧,一定是什么原因导致了这个变化——是什么?”这家公司现在拥有世界上最大的 CruiseControl 安装基数。
柔道是一种鼓励练习者利用对手的重量来对付他们的武术。我们曾在一家大公司的项目中工作,该公司标准化使用一个特别糟糕的版本控制软件包,而且这是全公司范围的政策。我们试过了,但它与我们的开发风格格格不入。我们需要能够非常早期和非常频繁地签入代码,而不锁定文件(这使得激进重构变得困难)。版本控制系统就是无法处理这个问题,所以我们利用这个事实来对付它。它损害了我们的工作流程,因此可衡量地降低了我们的生产力。
我们达成了妥协。他们允许我们使用 Subversion,它非常适合我们的工作。为了遵守公司政策,我们创建了一个计划任务,每晚凌晨 2 点运行,从我们的 Subversion 仓库中检出代码,并将该快照签入企业版本控制系统。他们在标准位置获得了代码,而我们则可以使用最适合我们工作的工具。
虽然供应商是意外复杂性(accidental complexity)的推手,但它也在组织内部滋生。船锚不必是外部工具;它们通常是现有的、自己开发的麻烦。许多项目被不合适的内部框架和工具拖累(站在侏儒肩膀上反模式的受害者)。业务用户在不了解难度数量级的情况下请求”可有可无”的功能。开发人员、架构师和技术负责人必须让用户和管理层理解使用不合适的工具、库和框架所带来的复杂性成本。
被不合适的工具拖累可能看起来是小事(尤其是对非开发人员而言),但它会对开发人员的整体生产力产生巨大影响。口腔顶部的割伤不是致命的,但持续的轻度刺激会让你无法专注于重要的事情。不合适的工具也会做同样的事情。而过于复杂的不合适工具使情况变得更糟,因为你花了太多时间处理工具的无关紧要的东西,无法完成真正的工作。
编程是一种独特的行为,无论我们如何折磨隐喻来将它与其他活动和职业进行比较。它以高度耦合的方式结合了工程和工艺,要求优秀的开发人员展现出广泛的技能:分析思维;对多个层次和美学的极度关注细节;同时意识到宏观和微观层面的关注点;以及对我们正在编写软件来协助的主题的敏锐、细粒度的理解。讽刺的是,开发人员必须比业务的实际从业者在更低的层次上理解业务流程。业务人员可以利用他们的经验在新情况出现时做出即时决策;我们必须将一切编码为算法和显式行为。
《高效程序员》的最初设想是提供一长串提高生产力的方法。它演变成了一本分为两部分的书,第一部分处理生产力的机制,第二部分专注于作为开发人员的生产力实践。在其最终形式中,这本书仍然包含相当数量的方法。但是遵循方法会给你留下美味的菜肴,但没有创造自己方法的能力。识别机械生产力原则(加速、专注、自动化和规范性)为识别我从未想过的新技术提供了一个命名法。本质上,我想创建一本不仅展示如何创造自己方法的食谱书。
第二部分《实践》旨在让你以可能以前没有考虑过的方式思考构建软件。开发人员有时会陷入惯例,需要第三方来指出新的思维方式。希望第二部分做到了这一点。
实际上,这本书的元目标是在机制层面和实践层面创建关于生产力的对话,而不是独白。我想提高我们作为开发人员如何变得更有生产力的意识。同时,我希望其他更聪明的人继续这个对话。总的来说,我们可以想出很多非常酷的东西。
这意味着永远不可能有一本关于生产力任何方面的全面书籍:这是一个不断变化的领域。为了激发基于我刚刚创建的独白的对话,我在 http://productiveprogrammer.com 上托管了一个公共维基。每次你发现能让你更有生产力的东西时,告诉其他所有人。当你发现生产力的模式(或反模式)时,发布它。作为一个群体持续提高我们的生产力的唯一方法是协作、分享战争故事和发现新东西。
过来让我们继续对话吧。
命令行是一个奇妙的工具。如果你知道那些神奇的命令,命令行通常是从意图到执行的最快途径。曾几何时,开发者别无选择——他们必须牢记所有的咒语,计算机杂志上充斥着关于 DOS 如何工作(以及经常不工作)的各种有趣细节。当 Windows 征服了用户的桌面后,开发者也随之而来,只有我们这些”资深”开发者知道如何使用表象之下真正的黑魔法。
尽管 IDE 让新手开发者更有生产力,但最高效的开发者仍然依赖,甚至热衷于这种命令行技巧。通过脚本自动化任务、连接现有工具的输入和输出、对本地和远程文件执行小任务,在闪烁的光标前仍然是最佳选择。但首先,你必须确保你有正确的闪烁光标。如果你使用 Unix 或 Mac OS X,可以跳过下一节。如果你使用 Windows,你迫切需要阅读它。
作为 Windows 用户,你是否曾经嫉妒过 Linux 发行版自带的大量工具?十几种语言的编译器、调试器、文本编辑器、绘图工具、Web 服务器、数据库、发布工具……清单还在继续。你也可以在 Windows 上拥有所有这些——感谢 Cygwin。
Cygwin 是以下几个部分的组合:
首先,从 http://www.cygwin.com 下载 Cygwin 安装器。这不仅仅是一个安装器:它是一个完整的包管理系统。即使在你安装 Cygwin 之后,你也应该保留它;将来你需要用它来安装、更新和删除软件包。你下载的安装器非常小(大约 300k),但这只是冰山一角——根据你决定安装的选项,它将下载大量内容,可能有数百兆字节(你不需要安装那么多来运行本书中的示例)。对于带宽受限的用户,你可以花很少的费用购买安装 CD。
Cygwin 安装器在大多数 Windows 用户眼中有点奇怪。软件包选择屏幕显示了一堆要安装的内容,每个都可以独立选择安装、升级或删除。起初,这有点令人困惑;如果你记住这是一个”包管理器”,而不仅仅是一个”安装器”,会有所帮助。
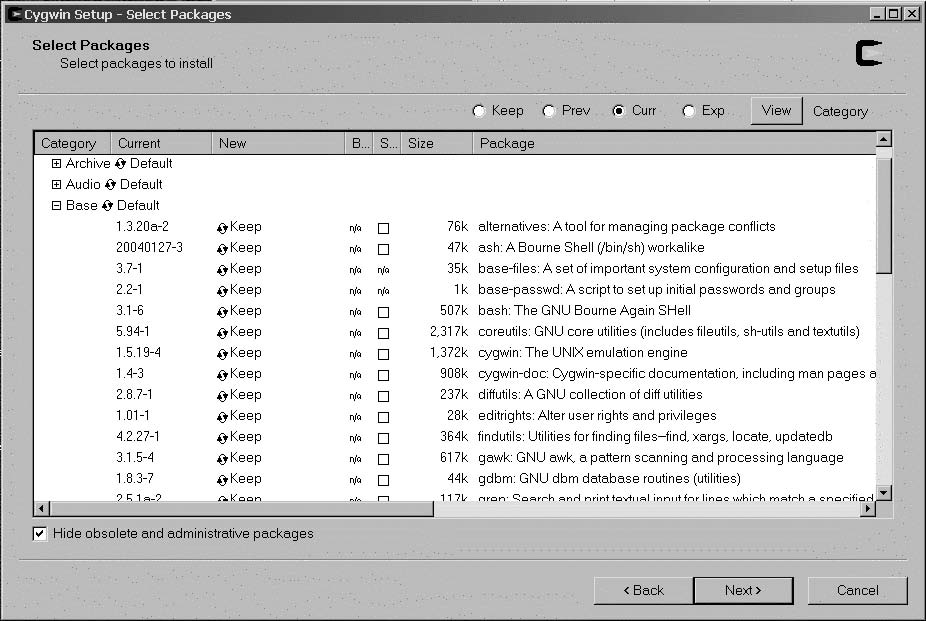
接下来,你必须在 DOS 和 Unix 行尾之间做出选择。对于本书而言,简短的答案是选择 Unix,但原因更加深奥。每行末尾都有不可见字符,这些不可见字符的顺序在 DOS 和 Unix 之间是不同的。由于你正在机器上安装 Unix 工具,现在同一文件系统上将同时存在 DOS 和 Unix 文件。通过在这里选择 Unix,你可能偶尔会打开一个文件,看到每行末尾都有 ‘^M’。但如果你选择 DOS,你将遇到所有这些期望 Unix 行尾的工具可能出现的更奇怪的问题。从实用角度来看,今天的大多数应用程序(除了像 Windows 记事本这样真正糟糕的旧软件)都会为你处理这种区别。
最后,DOS 和 Unix 有不同的路径格式。在 Windows 上,你可能在 c:and Settings找到一个文件,而在 Unix 上,路径看起来像 /home/nford。因为 Cygwin 位于 Windows 文件系统之上,在 Cygwin 中你可能将文件称为 /home/nford/readme.txt,但在 Windows 中它位于 c:.txt。Cygwin 中有将一种路径类型转换为另一种的工具;偶尔程序会期望特定格式,你必须知道如何使它们可互换。
安装 Cygwin 时,你将看到所有可用内容的列表。浏览类别并查看所有好东西。你会发现文本编辑器、数据库、多个 shell、Web 服务器、Ruby 和 Python 等语言,以及大量其他内容。对于本书而言,从默认选项开始(另外确保 wget 也被选中),然后继续。下载和安装所有内容需要一段时间。
完成后,你应该有一个 Cygwin 快捷方式,引导你进入 Windows 版本的 bash shell。
为什么命令行如此有用,特别是在 Unix 世界?为什么所有 Unix 极客谈论它时都会眼含热泪,口水流到他们的勃肯鞋里?这要追溯到 Unix 创造者在命令行中构建的哲学。他们想要一套强大的工具,你可以混合搭配以形成强大的组合。为此,他们围绕一个简单的概念构建了一切:纯文本流。几乎所有 Unix 命令行工具都生成和消费纯文本。甚至文本文件也可以转换为纯文本流(通过 cat 命令),并通过重定向命令 > 放回文件中。
举一个简单的例子,你可以使用 echo 命令获取常规文本,并通过将其从小写转换为大写的工具(使用 tr 或 translate 命令)进行管道传输。
这理解字符类(如 :lower: 和 :upper:),像这样(注意 [$] 不是命令的一部分,而是命令行提示符,留在那里以便您区分输入和输出):
[$ ][echo] ["][productively lazy]["] [|] [tr] ["][[:lower:]]["] ["][[:upper:]]["] [PRODUCTIVELY LAZY]
这里值得注意的概念是管道命令(| 字符)。它获取 echo 命令的输出并将其传递到 tr 命令中,tr 命令会忠实地将小写字符转换为大写字符。所有 Unix 命令都是这样连接的,一个命令的输出成为下一个命令的输入。您还可以通过将此命令的输出重定向到文件来创建包含该内容的文件:
[$ ][echo] ["][productively lazy]["] [|] [tr] ["][[:lower:]]["] ["][[:upper:]]["] [>][pl.txt] [$ ][cat][ pl.txt] [PRODUCTIVELY LAZY]
当然,您可以从一个文件中获取文本,对其进行处理,然后将其放入另一个文件:
[$ ][cat][ pl.txt ][|] [tr] ["][[:upper:]]["] ["][[:lower:]]["] [|] [tr] "["] "["] [>][ plz.txt] [productively laZy]
这里有一个更实用的例子。假设我有一个大型 Java 项目,其中有一堆作为其他类”辅助类”的类,并遵循 Class [Helper] 的命名约定,用于它所帮助的类。我想找到它们全部,即使它们分散在整个项目中:
[$ ][find . ][-name *Helper.java]
我训练有素的助手们忠实地响应:
[ ./src/java/org/sample/domain/DomainHelper.java] [ ./src/java/org/sample/gui/WindowHelper.java] [ ./src/java/org/sample/logic/DocumentHelper.java] [ ./src/java/org/sample/logic/GenericHelper.java]
[194][ 附录:][构建块]
[ ./src/java/org/sample/logic/LoginHelper.java] [ ./src/java/org/sample/logic/PersistenceHelper.java]
好的,您可以在 IDE 的搜索对话框中获得相同的结果。但命令行有趣的地方在于获得这些结果后您可以做什么。在 IDE 中,搜索结果将显示在窗口中,如果幸运的话,您可能可以复制它们并粘贴到某个地方。但从命令行,您可以将该输出通过管道传递到另一个工具。在这种情况下,该工具是 wc。wc 是一个计数工具;它可以计算单词、字符、行和文件:
[$ ][find . ][-name *Helper.java ][|] [wc][-l] [6]
wc -l 行只是计算传递给它的行数:
[这些东西的名称是谁起的?]
Unix 命令非常简洁。毕竟,它们被设计为在电传打字终端上工作,并奖励那些学习其简洁性的人。一旦您学会了它们,只需很少的输入就可以实现很酷的功能。但是 grep 呢?这是从哪里来的?
据传闻,grep 命令来自 ex 编辑器中的搜索命令。ex 编辑器是 VI 的基于行的前身,VI 是传奇的 Unix 编辑器,学习曲线最陡峭。在 ex 中,要执行搜索,您进入命令模式并键入 g 进行全局搜索,用 / 字符开始正则表达式,键入您的正则表达式,用另一个 / 终止它,然后告诉 ex 用 p 打印结果。换句话说,g/re/p。这在 Unix 用户中非常常见,以至于它成为了一个动词。因此,当需要为命令行编写搜索实用程序时,他们已经有了完美的名称:grep。
我知道有些辅助类实际上是其他辅助类的子类。我已经可以使用 find 来查找所有辅助类;现在我想查看这些文件内部,找到那些恰好扩展了其他辅助类的文件。为此,我们使用 grep。我们将查看使用 find 和 grep 组合的三个不同细微版本。第一个使用 find 的扩展选项:
[$ ][find . ][-name *Helper.java ][-exec] [grep][-l] ["][extends .*Helper]["] [{}][ \][;] [./src/java/org/sample/logic/DocumentHelper.java] [./src/java/org/sample/logic/LoginHelper.java]
这个咒语中发生了什么?请参见表 A-1 的分解。
[表 A-1. 解码命令行魔法]
[字符] [它在做什么]
[find] [执行 ][find][ 命令。]
[.] [从当前目录。]
[-name] [匹配名称为 “*Helper.java”。]
命令行 [195]
[字符] [它在做什么]
[-exec] [对每个找到的文件执行以下命令。]
[grep] [grep][ 命令。]
[-l] [显示具有匹配行的文件。]
["extends .*Helper"] [匹配正则表达式,查找匹配 “extends” + 一个空格 + 零个或多个字符 + “Helper” 的行。]
[{}] [find][ 找到的文件名的占位符。]
[\;] [终止 -exec 后的命令。因为这是 Unix 命令,您可能想将结果通过管道传递到另一个命令,] [find][ 命令必须知道 “exec” 何时完成。]
哇,这在一个紧凑的语法中产生了很大的效果。这当然就是重点。为了证明在 Unix 命令行上有很多方法可以做任何事情,这里有一个使用 xargs 命令的替代版本,产生相同的结果:
[$ ][find . ][-name *Helper.java ][|] [xargs] [grep][-l] ["][extends .*Helper]["] [./src/java/org/sample/logic/DocumentHelper.java] [./src/java/org/sample/logic/LoginHelper.java]
这个版本的大部分内容是相同的,除了我们通过 xargs 传递 find 命令的输出,xargs 是一个辅助实用程序,它将从管道获取输入并将其放在其参数的末尾。就像上面的 [{}] 占位符一样,xargs 将获取 find 命令生成的文件名并将它们作为 grep 命令的最后一个参数。您还可以使用 xargs 命令的选项将通过管道传来的参数放在不同的位置
在参数字符串中。例如,以下命令将所有以大写字母开头的文件名复制到目标目录:
$ ls -1d [A-Z]* | xargs -J % cp -rp % destdir-J 标志告诉 xargs 使用 % 作为通过管道传入的输入的占位符。这允许你指定任何你喜欢的替换字符,以确保它不会与目标命令所需的其他字符冲突。
这是我们 find 命令的最后一个版本:
$ grep -l "extends .*Helper" `find . -name *Helper.java`
./src/java/org/sample/logic/DocumentHelper.java
./src/java/org/sample/logic/LoginHelper.java注意那些小反引号字符(`)。我们没有使用管道将一个命令的输出发送到另一个命令——如果我们那样做,grep 只会查看文件名列表,而不是文件本身的内容。用反引号字符(通常在美式键盘的左上角)包装 find 命令会使 find 首先执行,并将输出传递给 grep 作为要搜索的文件列表,而不是要搜索的实际文本。
现在,我将目前看到的所有内容粘合在一起:
$ grep -l "extends .*Helper" `find . -name *Helper.java` | wc -l
2196 附录:构建块
虽然单个命令非常简单,但通过管道和反引号,我可以以原作者可能没有预料到的方式组合它们(这是 Unix 背后的一个主要哲学要点)。掌握大约十几个命令的知识,你也可以看起来像一个 Unix 高级用户。更重要的是,你可以以 IDE 菜单中无法实现的方式对项目进行切片和处理。
在大多数情况下,可以直接从命令行获得帮助,但有时可能有点晦涩或难以找到。在任何类 Unix 系统上获取帮助有两种基本方法。第一种是直接从命令本身获取。在大多数情况下,你只需输入 –help 或 -h,如下所示:
$ ls --help第二种方法是大多数类 Unix 系统中包含的帮助系统”手册页(manpages)“,使用 man 命令访问,如下所示:
$ man wget第三种方法类似于 man 命令,在大多数 Linux 版本上可用,即 info 命令。与 man 一样,你可以只输入你想要获取帮助的命令名称,但与 man 不同的是,你可以在没有特定主题的情况下输入 info 开始浏览。
不幸的是,对于大多数可用的内置帮助,你至少必须知道你要寻求帮助的命令是什么。Unix 命令通常很晦涩,以至于这种情况很少见;例如,你不会想,“我需要知道如何找出哪些文件引用了我的主目录。我知道了——我会输入 man grep!”对于这种帮助,没有什么比好的入门指南、手册或 shell 参考手册更好的了。
命令行 197
符号
80-10-10 法则,137
A
验收测试 web 应用程序,58
偶然属性 Aristotle 论,136
Alt-Tab 查看器(Windows)问题解决,147
Angry Monkey 和 Cargo Cults,144 历史,24
B
数组(参见基于零的数组)论偶然和本质属性,136 检索文件,56
属性,xiii Automator,62 (另见粘性属性)检索文件,56 搜索依据,42
自动完成 Windows 地址栏,20
自动化,52–68 Ant、Nant 和 Rake,56 反对象,147 非构建任务,56
bash shell Cygwin,28
Aristotle 收集异常计数,60
Ant Bash Here 上下文菜单,28
bash shell,60 气球提示(Windows),39
Bini, Ola 论多语言编程,173
批处理文件,61 博客(参见 RSS 订阅)
本地缓存,53 在 Mac OS X 中删除下载,62
199
boat anchor 共享,79
反模式,186 Colibri 应用程序启动器,11
构建机器,72 颜色
Buildix,53 内置焦点,47
bundles 命令行,xiii
TexMate,78 (另见 shells)
字节码分析,110–112 图形化,15
从命令行启动编辑器,177
证明、调整和优化,65–67 RSS 订阅,54 重新发明轮子,53
Selenium 与网页,58 SqlSplitter,64 Subversion,62 网站交互,54 yak shaving,67 Automator(Mac OS X),62
分析(参见字节码分析;源代码分析;静态分析)
二进制文件版本控制,71
行为生成代码,85 可测试代码,185
功率,194–197
设置,47
缓存
Subversion,62
本地,53
命令提示符资源管理器栏(Windows)
日历(Java)
使用,26
公民性,126
命令提示符(Windows),28
日历
“会议”用于安静时间,40
规范性,70–94
构建机器,72
定义,70
DRY 文档,88–92
DRY 阻抗失配,80–88
DRY 版本控制,70
间接性,73–80
虚拟化,80
CheckStyle,114
chere 命令,28
公民性,120–127
Calendar(Java),126
构造函数,121
封装,120
静态方法,121–126
类图,91
CLCL,23
剪贴板栈
软件,23
剪贴板
加速器,21
使用批处理,22
代码
(另见示例;生成代码;可重用代码)
圈复杂度(Cyclomatic Complexity),103
与模式保持同步,86
TDD 与非 TDD 代码,102
XML,183
代码覆盖率
SqlSplitter,183
TDD,105
代码片段
定义,78
命令提示符
使用,25
命令
(另见特定命令)
编辑器中的剪切和复制,178
输入,34
注释
重构为方法,103
编译型语言
代码覆盖率,105
complexitax 原则,186
组合方法(composed method)
(另见重构)
SLAP,156–160
专注
保持,38
配置
规范的,79
构造函数
公民性,121
默认,147
上下文切换
时间消耗者,22
持续集成
定义,72
copy 命令,178
复制和粘贴
邪恶之处,78
功能蔓延(creeping featurism),132
跨平台支持
编辑器,178
cURL,54
cut 命令,178
圈复杂度(Cyclomatic Complexity),103
Cygwin,192
200 索引
(另见 Unix)
间接性,73
bash shell,28
编辑器,176–179
eEditor,179
80-10-10 法则,137
Emacs
数据映射
关于,179
阻抗失配,81–86
配置信息,79
数据库模式,92
Emma,114
dbDeploy
封装
阻抗失配,87
破坏,120
调试
Enso 应用启动器,11
使用 Selenium,60
熵
默认值
定义,130
构造函数,121,147
本质属性
删除
亚里士多德论,136
Mac OS X 中的下载,62
示例
德米特法则(Law of Demeter),140
字节码分析,111
依赖对象
组合方法,156
TDD,98
使用 Groovy 进行数据映射,81
桌面(见虚拟桌面)
dbDeploy,87
图表
Flog,117
(另见类图)
流畅接口(fluent interfaces),146,152–154
创建,91
Groovy 和 XML,185
Dietzler 法则,137
Java 中的初始化,167
干扰,38–40
Jaskell,172
文档
Java 与 Groovy,170
(另见活文档)
Java 的反射,150
DRY,88–92
JEE 电子商务网站,160–164
最新的,88
使用 Rake 启动演示文稿,57
领域特定语言
活文档 wiki,89
多语言(polyglot)风格开发,173
使用 bash 的日志,60
不要重复自己(见 DRY)
使用 Ruby 打开电子表格,52
下载
Rails 迁移,86
Mac OS X 中删除,62
重构 SqlSplitter,180
DRY(不要重复自己)
使用 Ant 检索文件,56
阻抗失配,80–88
单例设计模式,122
版本控制,70
SLAP,160
重复(见规范性)
使用 Ruby 的 SqlSplitter,64
动态语言
Struts,184
代码覆盖率,105
TDD 单元测试,99–105
静态分析,116
XML,184
Excel
电子商务
异常计数
JEE 示例,160–164
bash shell,60
Eclipse
资源管理器(见 Windows)
E Text Editor,78
使用 Ruby 打开电子表格示例,52
Eclipse 插件
键盘快捷键,29
表达式构建器,147
共享代码片段,79
表达式(见正则表达式)
索引 201
视觉效果
与 Java 的关系,170
价值,10
测试 Java,151
Growl(Mac OS X)
通知,39
GString 类,154
因式分解
(另见重构)
组合方法,156
文件层次
硬目标搜索,42–44
与搜索对比,41
热键
find 命令,196
冲突,15
查找工具,43
FindBugs,110
流畅接口
状态,38
阻抗失配,80–88
数据映射,81–86
迁移,86
示例,152–154
间接性,73
使用,145–147
规范配置,79
文件夹
规范性,77
(另见虚拟文件夹)
同步 JEdit 宏,75
启动板,12
TextMate bundles,78
前台
IntelliJ
问题解决,147
Flog,117
与 Spotlight 对比,17
(另见 Eclipse;Emacs;IntelliJ;Selenium)
IDE(集成开发环境)
键盘快捷键,29
流程
Finder(Mac OS X)
键盘快捷键,20
IDE
键盘快捷键,30
框架
推测性开发,130
接口(见流畅接口)
全屏模式(Microsoft Office),29
函数式语言
Jaskell
优势,172
多语言编程(polyglot programming),171
Java
80-10-10 法则,138
生成代码
多语言编程,166–173
原语,139
全局变量
添加行为,85
创建,123
命名约定,144
GNU/Linux(见 Linux;Unix)
反射和元编程,150
Google 桌面搜索,41
搜索与导航,32
图形环境
JavaBeans
对象有效性,147
实用性,52
图形化命令行,15
使用 Groovy 测试,151
grep 命令
JavaScript
与查找工具结合,43
多语言编程,170
Groovy
JEdit 编辑器
关于,179
分析,117
起源,195
JDepend,114
GString 类,154
宏,75
Java 中的反射,152
JEE 电子商务示例,160–164
202 索引
Junction
宏
Windows 链接,76
JEdit,75
使用,33
映射(见树形图)
会议
Key Promoter 插件(IntelliJ),30
用于安静时间,40
键盘
元编程,150–154
使用,29
流畅接口示例,152–154
与鼠标对比,29
Java 和反射,150
[L] [使用 Groovy 测试 Java, 151]
方法
[Larry 的任意文本文件索引器, 41] [命名约定, 144]
[启动器, 10–18] [将注释重构为方法, 103]
[关于, 10] 指标
[Linux, 18] [圈复杂度, 103]
[Mac OS X, 15] [静态分析, 113]
[Windows, 12] 鼠标
从命令行启动 Microsoft Office
[编辑器, 177] [全屏模式, 29]
[Launchy 应用程序启动器, 11] Microsoft Windows(参见 Windows)
[迪茨勒定律;得墨忒耳定律] 数据迁移
法则(参见迪茨勒定律;得墨忒耳定律) [阻抗失配, 86]
长度 镜像
[与实用性的关系, 10] [网站, 53]
库 Monad(参见 Windows Power Shell)
[版本控制, 71] 显示器
[Linux, xiii] [多显示器, 48]
(另见 Unix) 鼠标
[启动器, 18] [与键盘的比较, 29]
[实时模板, xiii] [与打字的比较, 18]
(另见代码片段) [使用, 29]
[IDE, 31] 我的文档(Windows)
活文档 [移动文件夹, 13]
[Subversion, 88]
日志 [N]
[使用 bash 自动化示例, 60]
命名约定
[M] [测试名称与方法名称的比较, 144]
Nant
[Mac OS X, xiii] [非构建任务, 56]
(另见 Finder;Spotlight;Unix) 导航
[命令提示符, 26] [与搜索的比较, 32, 40–42]
[删除下载, 62] [与打字的比较, 14]
在 Apple-Tab 切换时终止应用程序实例, .NET
[24] [框架, 131]
[启动器, 15] [搜索与导航的比较, 33]
[根视图, 45] [Windows Power Shell, 61]
[虚拟桌面, 48] 通知
宏录制器 [关闭, 39]
[编辑器, 176]
索引 [[203]]
对象(参见反对象;依赖对象) Rake
[奥卡姆的威廉爵士, 137–140] [常见任务, 57]
操作系统(参见 Linux;Mac OS X; [数据迁移, 86]
Windows;Unix) [非构建任务, 56]
[乐观修订, 70] 录制器
OS X(参见 Finder;Mac OS X;Spotlight;Unix) [宏, 33]
[重构, xiii]
[P] (另见组合方法) [将注释重构为方法, 103] 吃豆人 [组合方法, 156] 前景和背景问题解决, [148] [SqlSplitter, 180] Panopticode [XML, 183] [静态分析, 113] 反射 [pbcopy 和 pbpaste 命令, 27] [Java 和元编程, 150] [哲学家, 136–142] 寄存器 [亚里士多德, 136] [编辑器, 178] [得墨忒耳定律, 140] 注册表(Windows) [奥卡姆剃刀, 137–140] Windows 2000 自动补全调整, [管道命令, 194] [20] 管道(参见 Yahoo! Pipes) [文件夹, 13] 插件 正则表达式 [Eclipse, 73] [在搜索中, 43] [PMD, 112] [记住历史 shell 功能, 23] [多语言编程, 166–174] 重复(参见规范性) [当前趋势, 169–173] Resharper [Java 起源, 166–169] [搜索与导航的比较, 33] [Ola 金字塔, 173] 可重用代码 [popd 命令, 25] [重构为组合方法, 159] [PowerToys (Windows), xiii] 根视图 (另见虚拟桌面管理器) [使用, 44] [关于, 28] RSS 订阅 [下载位置, 13] [自动化交互, 54] 原始类型 [Ruby, xiii] [Java, 139] (另见 Rake) 编程(参见元编程) [SqlSplitter, 64] 项目管理
[使用根视图, 45] [S]
[虚拟文件夹, 47]
项目 [模式, xiii]
[快捷方式, 47] (另见数据库模式)
[pushd 命令, 25] [与代码保持同步, 86]
[可重复的变更快照, 87]
[Q] 搜索 [编辑器, 177] [Quicksilver, 15] [精确目标搜索, 42–44] 安静时间 [与导航的比较, 32, 40–42] [建立, 40] 服务器
[持续集成, 72] [测试, xiii]
面向服务架构 (SOA) [(另见验收测试;验证)]
[偶然复杂性与本质复杂性, 136] [使用 Groovy 测试 Java, 151]
[Shell, xiii] [命名约定, 144]
(另见 bash shell;Windows Power Shell) [重构 SqlSplitter, 180]
[记住历史功能, 23] [TextMate 包, 78]
快捷方式 [TextMate 编辑器, 179]
[基于项目的, 47] [时间盒开发, 67]
[Simian, 115] 树形图
单一抽象层次原则(参见 SLAP) [使用, 115]
[单例设计模式, 122] 触发器
SLAP(单一抽象层次原则), [Quicksilver, 16]
[156–164] [Tweak UI 工具, 13]
[组合方法, 156–160] 打字
[JEE 电子商务示例, 160–164] [命令, 34]
SOA(面向服务架构) [与鼠标操作的比较, 18]
[偶然复杂性与本质复杂性, 136] [与导航的比较, 14]
[源代码分析, 112–113]
SqlSplitter Unix [Ruby 文件, 64] [命令行之爱, 194] [重构, 180] [历史, 23] 栈(参见剪贴板栈) [pushd 和 popd 命令, 25] [静态分析, 110–117] 实用性 [字节码, 110–112] [与长度的关系, 10] SQL 单元测试 [多语言编程, 169] [TDD, 99–101] [Spotlight (Mac OS X), 17, 42] [U]
[动态语言, 116]
[V]
[指标, 113]
静态方法 [Vasa 沉船, 132]
[公民身份, 121–126] 验证
[粘性属性, 46–47] [静态分析工具, 112]
Subversion VI 编辑器
[命令行, 62] [关于, 179]
[活文档, 88] [历史, 24]
[wiki 示例, 88] 视图(参见根视图)
同步 [虚拟桌面管理器 (Windows), 50]
[JEedit 宏, 75] [虚拟桌面, 48]
虚拟文件夹
[T] [项目管理, 47]
[TDD(测试驱动开发), 98–107] [使用, 80] 虚拟化
[源代码分析, 112–113]
[代码覆盖率, 105] Visual Studio [组合方法, 160] [搜索与导航的比较, 33]
[示例, 99–105]
技术文档(参见文档;活 [W]
文档)
模板(参见代码片段;实时模板) Web 应用程序
测试驱动开发(参见 TDD) [验收测试, 58]
索引 [[205] 网站]
[自动化交互, 54]
[镜像, 53]
[Selenium, 58]
[wget 工具, 53]
Wiki
[Subversion 示例, 88]
[Windows, xiii]
(另见 PowerToys;虚拟桌面
管理器)
[地址栏, 20]
[批处理文件, 61]
[命令提示符资源管理器栏, 26]
history, 23
launchers, 11, 12
rooted views, 44
Windows Power Shell, 61
workspace
indirection, 73
monitors, 48
virtual desktops, 48
XML
refactoring, 183
YAGNI (You Ain’t Gonna Need It), 130–133
Yahoo! Pipes, 54
yak shaving, 67
zero-based arrays
Java, 168
206 索引
Neal Ford 是 ThoughtWorks 的软件架构师和 Meme Wrangler(梗传播者)。ThoughtWorks 是一家全球 IT 咨询公司,专注于端到端的软件开发和交付。在加入 ThoughtWorks 之前,Neal 担任 The DSW Group, Ltd. 的首席技术官,这是一家全国知名的培训和发展公司。Neal 拥有乔治亚州立大学计算机科学学位,专攻语言和编译器,以及数学辅修学位,专攻统计分析。他还是应用程序、教学材料、杂志文章、视频演示的设计者和开发者,著有《Developing with Delphi: Object-Oriented Techniques》(Prentice-Hall)、《JBuilder 3 Unleashed》(Sams) 和《Art of Java Web Development》(Manning) 等书籍。他是《No Fluff, Just Stuff Anthology》(Pragmatic Bookshelf) 2006 年和 2007 年版的编辑和撰稿人。他精通的编程语言包括 Java、C#/.NET、Ruby、Groovy、函数式语言、Scheme、Object Pascal、C++ 和 C。他的主要咨询重点是大型企业应用程序的设计和构建。Neal 曾在国内外为军方和众多财富 500 强公司教授现场课程。他也是国际知名的演讲者,曾在全球 100 多个开发者大会上发表演讲,进行了 600 多次演讲。如果你对 Neal 有着无法满足的好奇心,请访问他的网站 http://www.nealford.com。他欢迎反馈,可以通过 nford@thoughtworks.com 联系他。
封面图片来自 Corbis 的库存照片。正文字体是 Adobe 的 Meridien;标题字体是 ITC Bailey。