William Collins
HarperCollins出版社的印记
伦敦桥街1号
伦敦 SE1 9GF
HarperCollins出版社
爱尔兰都柏林4区,Ringsend路,Watermarque大厦1楼
本电子书于2021年首次在英国由William Collins出版
版权所有 © Daniel Kahneman, Olivier Sibony 和 Cass R. Sunstein 2021
封面图片 © Shutterstock
Daniel Kahneman, Olivier Sibony 和 Cass R. Sunstein 声明拥有被认定为本作品作者的精神权利
本书的目录记录可从英国图书馆获得
根据国际和泛美版权公约保留所有权利。通过支付所需费用,您已获得在屏幕上访问和阅读本电子书文本的非独占、不可转让权利。未经HarperCollins明确书面许可,不得以任何形式或任何方式(无论是电子还是机械方式,无论是现在已知还是今后发明的)复制、传输、下载、反编译、逆向工程或存储在任何信息存储和检索系统中或引入此类系统的任何部分文本
来源ISBN:9780008309039
电子书版本 © 2021年5月 ISBN:9780008309015
版本:2022-05-31
《星期日泰晤士报》畅销书
《纽约时报》畅销书
“学术性和清晰写作的杰作”
《纽约时报》
“这是一本不朽的、扣人心弦的书。它也令人振奋。几乎没有专家、公司或机构能够毫发无损。三位作者改变了我们思考世界的方式。他们深入观察了我们做决定和组织生活的方式。作为《思考,快与慢》的某种续作,这是朝着更复杂、更现实地把握人类事务方向迈出的进一步步骤,正在取代近来粗糙的简化。杰出之作”
布莱恩·阿普尔亚德,《星期日泰晤士报》
“正如你对其作者的期望,这是对一个重要话题的严谨方法…有很多令人惊讶和娱乐的内容。任何发现cognitive biases文献重要的人都会发现这是对他们知识的宝贵补充”
丹尼·芬克尔斯坦,《泰晤士报》
“Noise无处不在且严重干扰。作者们提出了一个大胆的解决方案。这本书是一次令人满意的旅程,穿越一个重大但并非无法解决的问题,沿途有大量引人入胜的案例研究”
玛莎·吉尔,《标准晚报》
“这是一个关于不准确性的谦逊教训…他们令人信服地论证了《Noise》的主题与《思考,快与慢》的主题同等重要”
《金融时报》
“研究充分、令人信服且实用的书…由全明星团队撰写…细节和证据将满足严格和苛刻的读者,正如它提供的关于noise的多重观点一样。每个学者、政策制定者、领导者和顾问都应该读这本书。有能力和毅力应用《Noise》中见解的人将做出更人道和公平的决定,拯救生命,防止时间、金钱和才能的浪费”
罗伯特·萨顿,《华盛顿邮报》
“《Noise》可能是我十多年来读过的最重要的书。一个真正新颖的想法,如此极其重要,你会立即将其付诸实践。一部杰作”
安吉拉·达克沃斯,《坚毅》作者
“《Noise》是对一个一直隐藏在众目睽睽之下的巨大社会问题的绝对精彩调查”
史蒂文·莱维特,《魔鬼经济学》合著者
“在《Noise》中,作者们出色地将他们对人类判断缺陷的独特而新颖的见解应用到人类努力的每个领域…《Noise》是一项杰出成就,是心理学领域的里程碑”
菲利普·E·泰特洛克,《超级预测》合著者
“行为科学书籍的黄金标准是提供新颖见解、严谨证据、引人入胜的写作和实际应用。很少有书能涵盖其中两个以上方面,但《Noise》四个方面都做到了——这是一个全垒打。准备好让世界上一些最伟大的思想帮助你重新思考如何评估人、做决定和解决问题”
亚当·格兰特,《重新思考》畅销书作者及TED播客《WorkLife》主持人
“Kahneman、Sibony和Sunstein发现了一个像大象一样巨大的问题:noise。在这本重要的书中,他们向我们展示了为什么noise很重要,为什么我们意识到的noise比实际的要少得多,以及如何减少它。实施他们的建议将给我们带来更有利可图的企业、更健康的公民、更公平的法律系统和更幸福的生活”
乔纳森·海特,《正义的心》作者
“无效政策的最大来源往往不是偏见、腐败或恶意,而是三个I:直觉(Intuition)、无知(Ignorance)和惰性(Inertia)。这本书精彩地展示了为什么三个I如此普遍,以及我们能做什么来对抗它们。一本必读的、开眼界的书”
埃丝特·迪弗洛,2019年诺贝尔奖获得者及《艰难时期的好经济学》合著者
“《Noise》完成了始于《思考,快与慢》和《助推》的三部曲。它们共同突出了所有领导者需要知道的,以改善自己的决策,更重要的是,改善整个组织的决策…我鼓励你尽快阅读《Noise》,在noise在你的组织中破坏更多决策之前”
马克斯·H·巴泽曼,《更好,而非完美》作者
《噪音》的影响应该是震撼性的,因为它探索了人类判断中一个根本但被严重低估的危险。深化其必读地位的是,它提供了减少决策威胁的可行方法。
罗伯特·西奥迪尼,《影响力》和《预推动》作者
“对人类思维的电击式探索,这本书将永久改变我们对偏见规模和范围的思考方式”
大卫·拉米,托特纳姆选区议员,《部落》作者
献给诺加、奥里和吉莉—DK
献给范汀和莱莉娅—OS
献给萨曼莎—CRS
封面
标题页
版权页
赞誉
献词
引言:两种错误
第一部分:发现噪音
犯罪与噪音处罚
噪音系统
单一决定
第二部分:你的大脑是一个测量仪器
判断问题
测量错误
噪音分析
场合噪音
群体如何放大噪音
第三部分:预测性判断中的噪音
判断与模型
无噪音规则
客观无知
正常的山谷
第四部分:噪音如何产生
启发式、偏见与噪音
匹配操作
量表
模式
噪音的来源
第五部分:改善判断
更好的法官带来更好的判断
去偏见与决策卫生
法医学中的信息排序
预测中的选择与聚合
医学指南
绩效评级中的量表定义
招聘中的结构
中介评估协议
第六部分:最优噪音
降噪成本
尊严
规则还是标准?
回顾与结论:认真对待噪音
尾声:一个更少噪音的世界
附录A:如何进行噪音审计
附录B:决策观察者检查清单
附录C:修正预测
注释
索引
致谢
关于作者
丹尼尔·卡尼曼、奥利维尔·西博尼和卡斯·R·桑斯坦的其他作品
关于出版社
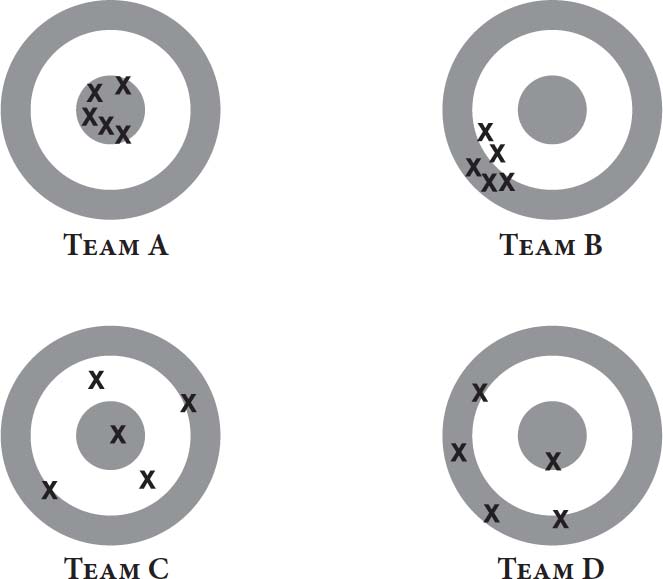
想象四个朋友小队去了射击游戏厅。每队由五人组成;他们共用一支步枪,每人射击一发。图1显示了他们的结果。
在理想世界中,每一枪都应该命中靶心。
图1:四个小队
A队几乎做到了这一点。该队的射击紧密聚集在靶心周围,接近完美模式。
我们称B队为有偏见的,因为其射击系统性地偏离目标。如图所示,偏见的一致性支持预测。如果该队的一名成员再射击一次,我们会押注它落在与前五发相同的区域。偏见的一致性也引发因果解释:也许该队步枪的瞄准镜弯曲了。
我们称C队为噪音的,因为其射击广泛分散。没有明显的偏见,因为弹着点大致以靶心为中心。如果该队的一名成员再射击一次,我们对其可能命中的位置知之甚少。此外,没有有趣的假设来解释C队的结果。我们知道其成员是糟糕的射手。我们不知道为什么他们如此充满噪音。
D队既有偏见又有噪音。像B队一样,其射击系统性地偏离目标;像C队一样,其射击广泛分散。
但这不是一本关于射击的书。我们的主题是人类错误。偏见和噪音——系统性偏差和随机散布——是错误的不同组成部分。靶子说明了这种差异。
射击场是人类判断中可能出现问题的隐喻,特别是在人们代表组织做出的各种决策中。在这些情况下,我们会发现图1所示的两种错误类型。一些判断是有偏差的;它们系统性地偏离目标。其他判断是有噪音的,因为本应达成一致的人最终却在目标周围的不同点上产生分歧。不幸的是,许多组织都同时受到偏差和噪音的困扰。
图2说明了偏差和噪音之间的重要区别。它显示了如果你只看到各队射击目标的背面,而没有任何他们瞄准的靶心指示,你在射击场会看到什么。
从目标背面看,你无法判断A队还是B队更接近靶心。但你一眼就能看出C队和D队是有噪音的,而A队和B队没有。实际上,你对散布程度的了解和图1中一样多。噪音的一般特性是,你可以识别和测量它,而无需了解目标或偏差。
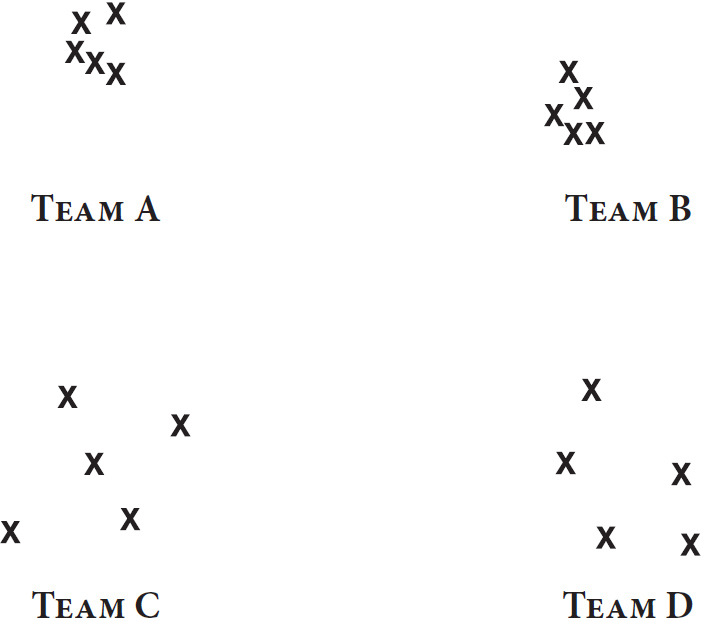
图2:从目标背面观察
刚才提到的噪音的一般特性对本书的目的至关重要,因为我们的许多结论都来自于真实答案未知甚至不可知的判断。当医生对同一患者提供不同诊断时,我们可以在不知道患者病情的情况下研究他们的分歧。当电影高管估算一部电影的市场前景时,我们可以在不知道这部电影最终收入多少,甚至不知道它是否真的被制作出来的情况下,研究他们答案的可变性。我们不需要知道谁是对的就能测量同一案例的判断变化程度。测量噪音所需要做的就是观察目标的背面。
要理解判断中的错误,我们必须理解偏差和噪音。正如我们将看到的,有时噪音是更重要的问题。但在关于人类错误的公共讨论中,以及在世界各地的组织中,噪音很少被认识到。偏差是主角。噪音是配角,通常在台下。偏差话题已在数千篇科学文章和数十本通俗书籍中讨论过,其中很少有书籍甚至提到噪音问题。这本书是我们纠正这种平衡的尝试。
在现实世界的决策中,噪音的数量往往高得令人震惊。以下是一些在准确性至关重要的情况下令人担忧的噪音数量的例子:
医学是有噪音的。 面对同一患者,不同医生对患者是否患有皮肤癌、乳腺癌、心脏病、肺结核、肺炎、抑郁症和大量其他疾病做出不同判断。在精神病学中噪音特别高,那里主观判断显然很重要。然而,在可能不被期待的领域也发现了相当大的噪音,比如在X光片的阅读中。
儿童监护权决定是有噪音的。 儿童保护机构的案例管理员必须评估儿童是否有受虐待的风险,如果有,是否将他们安置在寄养家庭。系统是有噪音的,因为一些管理员比其他人更可能将孩子送到寄养家庭。多年后,更多被这些严厉管理员分配到寄养家庭的不幸儿童有着糟糕的生活结果:更高的犯罪率、更高的青少年生育率和更低的收入。
预测是有噪音的。 专业预测者对新产品的可能销售、失业率的可能增长、陷入困境公司破产的可能性以及几乎所有其他事情提供高度可变的预测。他们不仅彼此不同意,而且与自己也不一致。例如,当同一软件开发人员在两个不同的日子被要求估算同一任务的完成时间时,他们预测的小时数平均相差71%。
庇护决定是有噪音的。 寻求庇护者是否会被允许进入美国取决于类似抽奖的事情。一项对随机分配给不同法官的案例的研究发现,一位法官批准了5%的申请人,而另一位批准了88%。这项研究的标题说明了一切:“难民轮盘赌”。(我们将看到很多轮盘赌。)
人事决定是有噪音的。 求职候选人的面试官对同一人做出广泛不同的评估。同一员工的绩效评级也高度可变,更多地取决于做评估的人而不是被评估的绩效。
保释决定是有噪音的。 被告是否获得保释或在审判前被送进监狱,部分取决于最终听取案件的法官的身份。一些法官比其他人宽松得多。法官在评估哪些被告逃跑或再犯风险最高方面也存在显著差异。
法医学是有噪音的。 我们被训练认为指纹识别是绝对可靠的。但指纹检查员有时在决定犯罪现场发现的指纹是否与嫌疑人的指纹匹配时存在分歧。专家不仅意见不一致,而且同一专家在不同场合面对同一指纹时有时会做出不一致的决定。在其他法医学学科中也记录了类似的可变性,甚至DNA分析也是如此。
专利授权决策存在噪音。 一项专利申请领域权威研究的作者强调了其中涉及的噪音:“专利局是授权还是拒绝专利,很大程度上与指派哪位审查员处理申请这一偶然因素有关。”从公平角度来看,这种可变性显然令人担忧。
所有这些存在噪音的情况只是巨大冰山的一角。无论你在哪里观察人类判断,都可能发现噪音。要提高我们判断的质量,我们需要克服噪音和偏见。
本书分为六个部分。在第一部分中,我们探讨噪音和偏见之间的区别,并证明公共和私人组织都可能存在噪音,有时程度令人震惊。为了理解这个问题,我们从两个领域的判断开始。第一个涉及刑事量刑(因此涉及公共部门)。第二个涉及保险(因此涉及私人部门)。乍一看,这两个领域截然不同。但在噪音方面,它们有很多共同点。为了确立这一点,我们引入了噪音审计的概念,旨在衡量组织内专业人员在考虑相同案例时存在多少分歧。
在第二部分中,我们研究人类判断的本质,并探讨如何衡量准确性和错误。判断容易受到偏见和噪音的影响。我们描述了两种错误类型作用的惊人等价性。场合噪音(occasion noise)是同一人或群体在不同场合对同一案例判断的可变性。令人惊讶的是,群体讨论中产生了大量场合噪音,这是由于一些看似无关的因素,比如谁先发言。
第三部分深入探讨了一种已被广泛研究的判断类型:预测性判断。我们探讨了规则、公式和算法在做出预测时相对于人类的关键优势:与普遍观念相反,主要不是规则的卓越洞察力,而是它们的无噪音性。我们讨论了预测性判断质量的最终限制——对未来的客观无知——以及它如何与噪音共同作用来限制预测质量。最后,我们解决一个你到那时几乎肯定会问自己的问题:如果噪音如此普遍,那么你为什么之前没有注意到它?
第四部分转向人类心理学。我们解释噪音的核心原因。这些包括由各种因素产生的人际差异,包括个性和认知风格;在权衡不同考虑因素时的特殊变化;以及人们对相同量表的不同使用方式。我们探讨为什么人们对噪音视而不见,并且经常对他们根本无法预测的事件和判断不感到惊讶。
第五部分探讨如何改善判断和防止错误这一实践问题。(主要对噪音减少实际应用感兴趣的读者可能会跳过第三和第四部分关于预测挑战和判断心理学的讨论,直接进入这一部分。)我们研究在医学、商业、教育、政府和其他领域应对噪音的努力。我们介绍了几种噪音减少技术,我们将其归纳为决策卫生的标签。我们提供了五个领域的案例研究,这些领域存在大量记录在案的噪音,人们已经做出持续努力来减少噪音,成功程度各不相同,具有启发性。案例研究包括不可靠的医疗诊断、绩效评级、法医学、招聘决策和一般预测。我们最后提供了一个我们称之为中介评估协议的系统:一种评估选项的通用方法,它融合了决策卫生的几个关键实践,旨在产生更少噪音和更可靠的判断。
什么是合适的噪音水平?第六部分转向这个问题。也许有违直觉的是,合适的水平不是零。在某些领域,完全消除噪音是不可行的。在其他领域,这样做成本太高。在另一些领域,减少噪音的努力会损害重要的竞争价值。例如,消除噪音的努力可能会破坏士气,让人们感觉自己被当作机器中的齿轮对待。当算法是答案的一部分时,它们会引起各种反对意见;我们在这里解决其中一些问题。尽管如此,目前的噪音水平是不可接受的。我们敦促私人和公共组织进行噪音审计,并以前所未有的严肃态度,加强减少噪音的努力。如果它们这样做,组织可以减少普遍的不公平——并在许多领域降低成本。
怀着这种愿望,我们在每章结尾都会以引用的形式提出几个简短的命题。你可以原样使用这些陈述,或者将它们调整用于任何对你重要的问题,无论涉及健康、安全、教育、金钱、就业、娱乐还是其他方面。理解噪音问题并试图解决它,是一项正在进行的工作和集体努力。我们所有人都有机会为这项工作做出贡献。写这本书是希望我们能够抓住这些机会。
I对于相似的人员,因同样的罪名被定罪,却最终得到截然不同的刑期——比如一个判五年监禁,另一个只是缓刑——这是不可接受的。然而在许多地方,类似的情况确实在发生。诚然,刑事司法系统也充斥着偏见。但我们在第1章的重点是噪音——特别是,当一位知名法官引起人们对此问题的关注,发现其令人震惊,并发起了一场在某种意义上改变了世界(但还不够)的运动时所发生的事情。我们的故事涉及美国,但我们确信类似的故事可以(也将会)在许多其他国家被讲述。在其中一些国家,噪音问题可能比在美国更严重。我们使用量刑的例子部分是为了说明噪音可能产生巨大的不公正。
刑事量刑具有特别高的戏剧性,但我们也关心私营部门,那里的利害关系也可能很大。为了说明这一点,我们在第2章转向一家大型保险公司。在那里,核保人的任务是为潜在客户设定保险费,理赔调整员必须判断理赔的价值。你可能会预测这些任务简单而机械化,不同的专业人员会得出大致相同的金额。我们进行了一个精心设计的实验——噪音审计——来测试这个预测。结果令我们惊讶,但更重要的是,它们让公司领导层感到震惊和沮丧。正如我们了解到的,噪音的庞大数量正在给公司造成大量的经济损失。我们使用这个例子来说明噪音可能产生巨大的经济损失。
这两个例子都涉及对大量人员做出大量判断的研究。但许多重要的判断是单一的而非重复的:如何处理一个看似独特的商业机会,是否推出一个全新的产品,如何应对大流行病,是否雇用一个不符合标准概况的人。在这样的独特情况决策中能找到噪音吗?人们很容易认为在那里不存在噪音。毕竟,噪音是不需要的变异性,你如何在单一决策中产生变异性?在第3章中,我们试图回答这个问题。即使在看似独特的情况下,你做出的判断也是可能性云中的一个。你在那里也会发现很多噪音。
从这三章中出现的主题可以用一句话总结,这将是本书的一个关键主题:无论哪里有判断,哪里就有噪音——而且比你想象的更多。 让我们开始了解有多少。
S假设有人因犯罪被定罪——商店盗窃、持有海洛因、袭击或武装抢劫。刑期可能是什么?
答案不应该取决于案件碰巧被分配给的特定法官,不应该取决于外面是热还是冷,也不应该取决于当地体育队前一天是否获胜。如果三个相似的人因同样的犯罪被定罪,却受到截然不同的惩罚:一个缓刑,另一个判两年监禁,第三个判十年监禁,这将是令人愤慨的。然而这种愤慨在许多国家都能找到——不仅在遥远的过去,今天也是如此。
在世界各地,法官长期以来在决定适当刑期方面拥有很大的自由裁量权。在许多国家,专家们赞美这种自由裁量权,并将其视为既公正又人道的。他们坚持认为,刑事判决不仅应该基于犯罪,还应该基于涉及被告品格和情况的诸多因素。个性化定制是当时的准则。如果法官受到规则约束,罪犯就会受到非人化对待;他们不会被视为有权引起人们关注其情况细节的独特个体。在许多人看来,正当法律程序的概念本身似乎要求开放式的司法自由裁量权。
在1970年代,对司法自由裁量权的普遍热情开始因为一个简单的原因而崩溃:令人震惊的噪音证据。1973年,一位知名法官马文·弗兰克尔引起了公众对这个问题的关注。在他成为法官之前,弗兰克尔是言论自由的捍卫者和充满激情的人权倡导者,他帮助创立了人权律师委员会(现在被称为人权第一组织)。
弗兰克尔可能很激烈。而对于刑事司法系统中的噪音,他感到愤怒。以下是他描述其动机的方式:
如果一个联邦银行抢劫被告被定罪,他或她可能面临最高25年的刑期。这意味着从0到25年的任何刑期。而我很快意识到,刑期的设定,与其说取决于案件或个别被告,不如说取决于个别法官,即取决于法官的观点、偏好和偏见。因此,同一个被告在同一个案件中可能会根据哪个法官处理案件而得到大不相同的刑期。
Frankel并未提供任何统计分析来支持他的论点。但他确实提供了一系列有力的轶事,显示了在对待相似人员时不合理的差异。两名男子都没有犯罪记录,因兑现伪造支票分别被定罪,金额分别为58.40美元和35.20美元。第一名男子被判十五年,第二名被判30天。对于彼此相似的挪用公款行为,一名男子被判117天监禁,而另一名被判20年。指出众多此类案例,Frankel谴责他所称的联邦法官”几乎完全不受制约和全面的权力”,导致”每日犯下的任意残酷行为”,他认为这在”法律而非人治的政府”中是不可接受的。
Frankel呼吁国会结束这种”歧视”,他用这个词来描述那些任意的残酷行为。通过这个术语,他主要指的是噪音,即判刑中无法解释的变化。但他也关心偏见,即种族和社会经济差异的形式。为了对抗噪音和偏见,他敦促不应允许对刑事被告的不同待遇,除非这些差异能够”通过相关测试来证明合理,这些测试能够以足够的客观性进行表述和应用,以确保结果不仅仅是特定官员、法官或其他人的特殊专制令”。(术语特殊专制令有些深奥;Frankel的意思是个人法令。)更进一步,Frankel主张通过”详细的档案或因素清单来减少噪音,该清单应尽可能包括某种形式的数字或其他客观评分”。
在1970年代初写作时,他并没有完全为他所称的”用机器取代人”进行辩护。但令人惊讶的是,他很接近这一点。他相信”法治要求一套非个人化的规则,普遍适用,对法官和其他所有人都有约束力”。他明确主张使用”计算机作为判刑中有序思考的辅助工具”。他还建议创建一个判刑委员会。
Frankel的书成为整个刑法史上最具影响力的著作之一——不仅在美国,也在全世界范围内。他的工作确实存在一定程度的非正式性。它具有毁灭性但印象派的特点。为了测试噪音的现实性,几个人立即跟进,探索刑事判刑中的噪音水平。
这种类型的早期大规模研究于1974年进行,由Frankel法官本人主持。来自各个地区的50名法官被要求为在相同的判刑前报告中总结的假设案件中的被告设定刑期。基本发现是”缺乏共识是常态”,刑罚的变化”令人震惊”。海洛因贩子可能被监禁一到十年,取决于法官。对银行抢劫犯的惩罚从五年到十八年监禁不等。研究发现,在一个敲诈案件中,刑期从惊人的二十年监禁和65,000美元罚款到仅仅三年监禁且无罚款不等。最令人震惊的是,在二十个案件中的十六个案件中,对于是否适合任何监禁都没有一致意见。
这项研究之后进行了一系列其他研究,所有这些研究都发现了类似令人震惊的噪音水平。例如,1977年,William Austin和Thomas Williams对四十七名法官进行了调查,要求他们对相同的五个案件做出回应,每个案件都涉及低级别犯罪。所有案件描述都包括法官在实际判刑中使用的信息摘要,如指控、证词、以前的犯罪记录(如果有)、社会背景和与品格相关的证据。关键发现是”实质性差异”。例如,在涉及盗窃的案件中,推荐的刑期从五年监禁到仅仅三十天(外加100美元罚款)不等。在涉及持有大麻的案件中,一些法官建议监禁;其他人建议缓刑。
1981年进行的一项更大规模的研究涉及208名联邦法官,他们面对相同的十六个假设案件。其核心发现令人震惊:
在16个案件中,只有3个案件在判处监禁刑期上达成一致同意。即使在大多数法官同意监禁刑期合适的情况下,推荐的监禁刑期长度也存在实质性变化。在一个平均监禁刑期为8.5年的欺诈案件中,最长刑期是终身监禁。在另一个案件中,平均监禁刑期为1.1年,但推荐的最长监禁刑期是15年。
尽管这些研究很有启发性,但这些涉及严格控制实验的研究几乎肯定低估了刑事司法现实世界中噪音的严重程度。现实生活中的法官接触到的信息比这些实验中精心指定的小故事中研究参与者收到的信息要多得多。当然,其中一些额外信息是相关的,但也有充分证据表明,以小的和看似随机因素形式出现的无关信息可能在结果中产生重大差异。例如,研究发现法官在一天开始时或食物休息后比在此类休息前更可能批准假释。如果法官饿了,他们会更严厉。
一项对数千份少年法庭判决的研究发现,当地方橄榄球队在周末比赛失利时,法官会在周一做出更严厉的判决(在一定程度上,这种影响会延续到本周剩余时间)。黑人被告不成比例地承受了这种加重处罚的冲击。另一项研究分析了三十年来150万份司法判决,同样发现法官在当地城市橄榄球队失利后的日子里比获胜后的日子更严厉。
一项对法国法官十二年来600万份判决的研究发现,被告在生日当天会得到更宽大的处理。(这里指的是被告的生日;我们怀疑法官在自己生日时可能也会更宽容,但据我们所知,这个假设尚未得到验证。)甚至室外温度这样无关的因素也能影响法官。一项对四年来207,000份移民法庭判决的审查发现,日常温度变化有显著影响:天气炎热时,人们获得庇护的可能性较小。如果你在祖国遭受政治迫害并希望在别处获得庇护,你应该希望甚至祈祷你的听证会安排在凉爽的日子。
在1970年代,Frankel的论点以及支持这些论点的实证发现引起了Edward M. Kennedy的注意,他是遇害总统John F. Kennedy的兄弟,也是美国参议院最有影响力的成员之一。Kennedy感到震惊和愤慨。早在1975年,他就提出了量刑改革立法;但没有通过。但Kennedy坚持不懈。他指出证据,年复一年地继续推动该立法的通过。1984年,他成功了。为了回应不合理变异性的证据,国会通过了1984年《量刑改革法》。
新法律旨在通过减少”法律赋予负责施加和执行刑罚的法官和假释当局的不受限制的自由裁量权“来减少系统中的噪音。特别是,国会议员提到了”不合理的巨大”量刑差异,具体引用了在纽约地区,相同实际案件的刑罚可能从三年到二十年监禁不等的发现。正如Frankel法官所建议的,该法律创建了美国量刑委员会,其主要职责很明确:发布旨在强制执行的量刑指导原则,为刑事判决建立限制范围。
次年,委员会建立了这些指导原则,通常基于对一万个实际案例分析中类似犯罪的平均刑期。最高法院大法官Stephen Breyer深度参与了这一过程,他为使用过往实践进行辩护,指出委员会内部存在难以调和的分歧:“为什么委员会不坐下来真正理性化这件事,而不只是采用历史做法?简单的答案是:我们做不到。我们做不到,因为到处都有很好的论据指向相反的方向……试着按可惩罚程度将所有犯罪列成排序表……然后收集你朋友们的结果,看看是否都匹配。我告诉你,它们不会匹配。”
根据指导原则,法官必须考虑两个因素来确定刑期:犯罪和被告的犯罪史。犯罪根据严重程度被分配为43个”犯罪等级”中的一个。被告的犯罪史主要指被告以往定罪的数量和严重程度。一旦犯罪和犯罪史结合起来,指导原则提供相对狭窄的量刑范围,授权范围的上限超过下限的幅度为六个月或25%中的较大者。法官可以根据他们认为的加重或减轻情节完全偏离这个范围,但偏离必须向上诉法院说明理由。
尽管指导原则是强制性的,但它们并非完全僵化。它们远没有达到Frankel法官想要的程度。它们为法官提供了重要的操作空间。尽管如此,几项使用不同方法、关注不同历史时期的研究得出了相同的结论:指导原则减少了噪音。更技术性地说,它们”减少了归因于量刑法官身份偶然性的刑期净变异“。
最详尽的研究来自委员会本身。它比较了1985年(指导原则生效前)银行抢劫、可卡因分销、海洛因分销和银行挪用案件的刑期与1989年1月19日至1990年9月30日之间施加的刑期。罪犯在指导原则下被认为与量刑相关的因素方面进行了匹配。对于每种犯罪,后期(《量刑改革法》实施后)各法官之间的变异都要小得多。
根据另一项研究,法官之间刑期长度的预期差异在1986年和1987年为17%,或4.9个月。这个数字在1988年至1993年间降至11%,或3.9个月。一项独立研究涵盖了不同时期,在减少法官间差异方面发现了类似的成功,法官间差异被定义为案件负荷相似的法官之间平均刑期的差异。
尽管有这些发现,指导原则却遭遇了激烈的批评风暴。一些人,包括许多法官,认为某些刑期过于严厉——这是关于偏见而非噪音的观点。对我们来说,一个更有趣的反对意见来自众多法官,他们认为指导原则极不公平,因为这些原则禁止法官充分考虑案件的具体情况。降低噪音的代价是让决策变得不可接受地机械化。耶鲁法学院教授凯特·斯蒂思和联邦法官何塞·卡布拉内斯写道:“需要的不是盲目,而是洞察力,是公平”,这”只能通过考虑个案复杂性的判决来实现”。
这种反对意见引发了对指导原则的激烈挑战,有些基于法律,有些基于政策。这些挑战都失败了,直到2005年,由于与这里总结的辩论完全无关的技术原因,最高法院废除了指导原则。法院裁决的结果是,指导原则仅变成建议性的。值得注意的是,大多数联邦法官在最高法院决定后更加满意。75%的法官偏爱建议性制度,而只有3%认为强制性制度更好。
将指导原则从强制性改为建议性产生了什么影响?哈佛法学院教授杨晶晶调查了这个问题,她没有使用实验或调查,而是使用了涉及近40万名刑事被告的大规模实际判刑数据集。她的核心发现是,通过多项衡量标准,法官间的差异在2005年后显著增加。当指导原则是强制性时,被相对严厉的法官判刑的被告比被平均法官判刑要多2.8个月。当指导原则仅变成建议性时,这种差异翻了一倍。杨教授的话听起来很像40年前的弗兰克尔法官,她写道:“我的发现引发了重大的公平关切,因为指定判刑法官的身份显著导致了对犯相似罪行的相似罪犯的不同待遇”。
指导原则变成建议性后,法官更可能基于个人价值观做出判刑决定。强制性指导原则既减少偏见也减少噪音。最高法院决定后,非裔美国人被告和犯相同罪行的白人之间的刑期差异显著增加。同时,女性法官比男性法官更可能行使她们增加的自由裁量权倾向于宽大处理。民主党总统任命的法官也是如此。
弗兰克尔2002年去世三年后,废除强制性指导原则产生了回到更像他噩梦般情况的结果:没有秩序的法律。

弗兰克尔法官为判刑指导原则而战的故事让我们一窥本书将涵盖的几个关键要点。首先,判断是困难的,因为世界是一个复杂、不确定的地方。这种复杂性在司法界显而易见,在大多数其他需要专业判断的情况下也是如此。广义上,这些情况包括医生、护士、律师、工程师、教师、建筑师、好莱坞高管、招聘委员会成员、图书出版商、各类企业高管和体育队经理做出的判断。在涉及判断的地方,分歧是不可避免的。
其次,这些分歧的程度远比我们预期的要大。虽然很少有人反对司法自由裁量的原则,但几乎每个人都不赞成它产生的差异程度。系统噪音,即理想情况下应该相同的判断中的不必要变异性,可能造成猖獗的不公正、高昂的经济成本和各种错误。
第三,噪音可以减少。弗兰克尔倡导并由美国判刑委员会实施的方法——规则和指导原则——是成功减少噪音的几种方法之一。其他方法更适合其他类型的判断。一些采用的减少噪音的方法可以同时减少偏见。
第四,减少噪音的努力经常引发反对意见并遇到严重困难。这些问题也必须得到解决,否则对抗噪音的斗争将失败。
“实验显示法官对相同案件推荐的刑期存在巨大差异。这种变异性不可能是公平的。被告的刑期不应该取决于案件碰巧分配给哪个法官。”
“刑事判决不应该取决于法官在听证期间的情绪,或外界温度。”
“指导原则是解决这个问题的一种方法。但许多人不喜欢它们,因为它们限制了司法自由裁量权,而这可能是确保公平和准确性所必需的。毕竟,每个案件都是独特的,不是吗?”
我们与噪音的初次接触,以及最初引发我们对这个话题兴趣的,远没有与刑事司法系统打交道那么戏剧性。实际上,这次接触有点像是意外,涉及一家保险公司,该公司聘请了我们两人所隶属的咨询公司。
当然,保险这个话题并不是每个人都感兴趣的。但我们的研究发现显示,在一个盈利性组织中,噪声问题的严重程度令人震惊,这种组织会因为充满噪声的决策而遭受巨大损失。我们与这家保险公司的合作经验有助于解释为什么这个问题往往被忽视,以及可以采取什么措施来解决它。
这家保险公司的高管们正在权衡提高一致性的潜在价值——即减少代表公司做出重大财务决策的人员判断中的噪声。每个人都同意一致性是理想的。每个人也都同意这些判断永远不可能完全一致,因为它们是非正式的,部分是主观的。一些噪声是不可避免的。
当涉及到噪声的程度时,分歧出现了。高管们怀疑噪声能否成为他们公司的实质性问题。然而,值得赞扬的是,他们同意通过我们称之为噪声审计的简单实验来解决这个问题。结果让他们感到惊讶。这也成为了噪声问题的完美例证。
任何大公司中的许多专业人士都被授权做出约束公司的判断。例如,这家保险公司雇用了众多承保人,他们为金融风险报价,比如为银行承保因欺诈或流氓交易造成的损失。它还雇用了许多理赔调整员,他们预测未来理赔的成本,并在出现争议时与申请人谈判。
公司的每个大分支机构都有几名合格的承保人。当收到报价请求时,任何恰好有空的人都可能被指派准备报价。实际上,将确定报价的特定承保人是通过抽签选择的。
报价的确切值对公司有重大影响。如果报价被接受,高保费是有利的,但这样的保费有失去客户给竞争对手的风险。低保费更可能被接受,但对公司来说不太有利。对于任何风险,都有一个恰到好处的金发姑娘价格——既不太高也不太低——大量专业人士的平均判断很可能不会偏离这个金发姑娘数字太远。高于或低于这个数字的价格都是代价高昂的——这就是充满噪声的判断变异性如何损害底线的。
理赔调整员的工作也影响公司的财务状况。例如,假设代表一名在工业事故中永久失去右手使用能力的工人(申请人)提交了理赔申请。一名调整员被分配到这个案件——就像承保人被分配一样,因为她恰好有空。调整员收集案件事实并提供其对公司最终成本的估算。同一名调整员然后负责与申请人的代表谈判,以确保申请人获得保单中承诺的福利,同时也保护公司免于过度支付。
早期估算很重要,因为它为调整员在与申请人的未来谈判中设定了一个隐含目标。保险公司在法律上也有义务为每项理赔的预测成本预留资金(即有足够的现金能够支付)。在这里,从公司的角度来看,也有一个金发姑娘价值。和解并不能保证,因为对方有申请人的律师,如果提议过于吝啬,他们可能选择上法庭。另一方面,过于慷慨的预留可能给调整员太多自由度来同意无理要求。调整员的判断对公司来说是重要的——对申请人来说更加重要。
我们使用抽签这个词来强调机会在选择一名承保人或调整员中的作用。在公司的正常运营中,一名专业人士被分配到一个案件,没有人能够知道如果选择了另一位同事会发生什么。
抽签有其存在的意义,它们不一定是不公正的。可接受的抽签被用来分配”好处”,比如一些大学的课程,或”坏处”,比如军队征兵。它们服务于目的。但我们谈论的判断抽签不分配任何东西。它们只是产生不确定性。想象一家保险公司,其承保人是无噪声的并设定最优保费,但然后一个机会装置介入来修改客户实际看到的报价。显然,这样的抽签没有任何理由。对于一个结果取决于随机选择做出专业判断的人身份的系统,也没有任何理由。
选择特定法官确立刑事判决或单一射手代表团队的抽签创造了变异性,但这种变异性仍然不被看见。噪声审计——比如对联邦法官量刑进行的审计——是揭示噪声的一种方式。在这样的审计中,同一个案件由许多个人评估,他们反应的变异性变得可见。
承保人和理赔调整员的判断特别适合这种练习,因为他们的决策基于书面信息。为了准备噪声审计,公司高管构建了每组(承保人和调整员)五个代表性案例的详细描述。员工被要求独立评估两到三个案例。他们没有被告知研究的目的是检查他们判断的变异性。
在继续阅读之前,您可能想要思考一下以下问题的答案:在一家运营良好的保险公司中,如果您随机选择两名合格的承保人或理赔调节员,您认为他们对同一案例的估计会有多大差异?具体来说,两个估计之间的差异占其平均值的百分比是多少?
我们询问了该公司的众多高管,在随后的几年中,我们从不同行业的各种人员那里获得了估计。令人惊讶的是,有一个答案明显比其他答案更受欢迎。大多数保险公司高管猜测是10%或更少。当我们询问来自各个行业的828名CEO和高级管理人员,他们预期在类似的专家判断中会发现多少变异时,10%也是中位数答案和最频繁的答案(第二受欢迎的是15%)。10%的差异意味着,例如,两名承保人中的一名设定了9,500美元的保费,而另一名报价10,500美元。这不是一个可以忽略的差异,但是一个组织可以容忍的差异。
我们的噪声审计发现了更大的差异。根据我们的测量,承保中的中位数差异是55%,大约是大多数人(包括公司高管)预期的五倍。这个结果意味着,例如,当一名承保人设定9,500美元的保费时,另一名并不会设定为10,500美元——而是报价16,700美元。对于理赔调节员,中位数比率是43%。我们强调这些结果是中位数:在一半的案例对中,两个判断之间的差异甚至更大。
我们向其报告噪声审计结果的高管们很快意识到,噪声的绝对数量带来了一个昂贵的问题。一位高级管理人员估计,公司在承保中的年度噪声成本——包括因过高报价而失去的业务和因定价过低合同而产生的损失——达到数亿美元。
没有人能准确说出有多少错误(或多少偏差),因为没有人能确切知道每个案例的最适值。但没有人需要看到靶心来测量靶背面的散布,并意识到这种变异性是一个问题。数据显示,客户被要求支付的价格在令人不安的程度上取决于挑选处理该交易的员工的抽签。至少可以说,如果客户听说他们在未经同意的情况下被签署了这样的抽签,他们不会高兴。更一般地说,与组织打交道的人期望一个能可靠地提供一致判断的系统。他们不期望系统噪声。
系统噪声的一个定义特征是它是不受欢迎的,我们应该在这里强调,判断中的变异性并不总是不受欢迎的。
考虑偏好或品味的问题。如果十个电影评论家观看同一部电影,如果十个品酒师评价同一款酒,或者如果十个人阅读同一本小说,我们不期望他们有相同的意见。品味的多样性是受欢迎的,完全在预期之内。没有人愿意生活在一个每个人都有完全相同喜好和厌恶的世界中。(嗯,几乎没有人。)但是如果个人品味被误认为是专业判断,品味的多样性可能有助于解释错误。如果一个电影制片人决定推进一个不寻常的项目(比如说,关于旋转电话的兴衰),因为她个人喜欢剧本,如果没有其他人喜欢它,她可能犯了一个重大错误。
在竞争情况下,判断中的变异性也是预期的和受欢迎的,在这种情况下,最好的判断将得到奖励。当几家公司(或同一组织中的几个团队)竞争为同一客户问题生成创新解决方案时,我们不希望他们专注于同一种方法。当多个研究团队攻击科学问题时也是如此,比如疫苗的开发:我们非常希望他们从不同角度来看待它。即使是预测者有时也表现得像竞争对手。正确预测其他人都没有预料到的经济衰退的分析师肯定会获得声誉,而从不偏离共识的分析师仍然默默无闻。在这样的环境中,想法和判断的变异性再次受到欢迎,因为变异只是第一步。在第二阶段,这些判断的结果将相互竞争,最好的将获胜。在市场中如同在自然界中,没有变异就无法进行选择。
品味问题和竞争环境都提出了有趣的判断问题。但我们的重点是变异性不受欢迎的判断。系统噪声是系统的问题,系统是组织,而不是市场。当交易员对股票价值做出不同评估时,其中一些人会赚钱,其他人则不会。分歧创造市场。但是如果其中一位交易员被随机选择代表她的公司做出评估,如果我们发现她在同一公司的同事会产生非常不同的评估,那么公司就面临系统噪声,这就是一个问题。
一个关于该问题的优雅说明出现在我们向一家资产管理公司的高级经理展示我们的发现时,这促使他们进行了自己的探索性噪音审计。他们要求公司内四十二名经验丰富的投资者估算一只股票的公允价值(投资者对买入或卖出无差异的价格)。投资者基于一页商业描述进行分析;数据包括过去三年的简化损益表、资产负债表和现金流量表,以及未来两年的预测。以与保险公司相同方式测量的中位数噪音为41%。同一公司内投资者之间使用相同估值方法却存在如此巨大差异,这不可能是好消息。
当做出判断的人从同等资格的个体池中随机选择时,就像这家资产管理公司、刑事司法系统和前面讨论的保险公司的情况一样,噪音就是一个问题。系统噪音困扰着许多组织:实际上随机的分配过程往往决定了医院里哪位医生为你看病、法庭上哪位法官审理你的案件、哪位专利审查员审查你的申请、哪位客服代表听取你的投诉等等。这些判断中不必要的变异性可能导致严重问题,包括金钱损失和猖獗的不公平。
关于判断中不必要变异性的一个常见误解是它并不重要,因为随机错误据说会相互抵消。当然,对同一案例判断中的正面和负面错误往往会相互抵消,我们将详细讨论如何利用这一特性来减少噪音。但噪音系统不会对同一案例进行多次判断。它们对不同案例进行噪音判断。如果一份保险单定价过高而另一份定价过低,定价平均看起来可能是对的,但保险公司犯了两个代价高昂的错误。如果两个本应被判五年监禁的重罪犯分别被判三年和七年,平均而言并没有实现正义。在噪音系统中,错误不会相互抵消。它们会累积。
几十年来的大量文献已经记录了专业判断中的噪音。因为我们了解这些文献,保险公司噪音审计的结果并没有让我们感到惊讶。然而,让我们惊讶的是高管们对我们报告发现的反应:公司里没有人预期到我们观察到的噪音程度。没有人质疑审计的有效性,也没有人声称观察到的噪音程度是可接受的。然而,噪音问题——及其巨大成本——对组织来说似乎是一个新问题。噪音就像地下室的漏水。它被容忍不是因为被认为可以接受,而是因为它一直未被注意到。
这怎么可能?同一角色和同一办公室的专业人士如何能够彼此差异如此之大而不自知?高管们如何未能做出这一观察,而他们理解这对公司业绩和声誉构成重大威胁?我们开始认识到系统噪音问题在组织中经常不被认识,对噪音的普遍忽视与其普遍性一样有趣。噪音审计表明,受人尊敬的专业人士——以及雇用他们的组织——在日常专业判断中实际上存在分歧时却保持着一致性的幻觉。
要开始理解一致性的幻觉是如何产生的,把自己置于承保人正常工作日的处境中。你有超过五年的经验,你知道自己在同事中备受推崇,你尊重并喜欢他们。你知道自己擅长工作。在彻底分析金融公司面临的复杂风险后,你得出20万美元的保费是合适的。问题很复杂,但与你每天解决的问题并无太大不同。
现在想象被告知你的办公室同事已经得到相同信息并评估了相同风险。你能相信他们中至少一半人设定的保费要么高于25.5万美元要么低于14.5万美元吗?这个想法很难接受。事实上,我们怀疑那些听说噪音审计并接受其有效性的承保人从未真正相信其结论适用于他们个人。
我们大多数人在大多数时候都带着一个不被质疑的信念生活,即世界看起来是这样是因为它就是这样。从这个信念到另一个信念只有一小步:“其他人看世界的方式与我大致相同。”这些被称为朴素现实主义的信念对我们与他人共享的现实感至关重要。我们很少质疑这些信念。我们在任何时候都持有对周围世界的单一解释,通常很少努力为其生成合理的替代方案。一种解释就足够了,我们体验它为真实。我们不会在生活中想象看待所见事物的替代方式。
在专业判断的情况下,认为他人看待世界的方式与我们大体相同的信念每天都在多种方式下得到强化。首先,我们与同事共享一套通用的语言和规则,这些规则关于在我们的决策中应该重要的考虑因素。我们也有与他人就违反这些规则的判断的荒谬性达成一致的令人安心的经历。我们将与同事偶尔的分歧视为他们判断上的失误。我们很少有机会注意到我们一致认同的规则是模糊的,足以排除一些可能性,但不足以对特定案例指定共同的积极回应。我们可以与同事舒适地共事,而从未注意到他们实际上并不像我们那样看待世界。
我们采访的一位核保人员描述了她在部门中成为资深人员的经历:“当我是新人时,我会与我的主管讨论75%的案例…几年后,我不需要了——我现在被认为是专家…随着时间推移,我对自己的判断变得越来越自信。”像我们中的许多人一样,这个人主要通过行使判断来培养对判断的信心。
这个过程的心理学是被充分理解的。信心通过判断的主观体验得到培养,这些判断是以越来越流畅和轻松的方式做出的,部分原因是它们类似于过去在类似案例中做出的判断。随着时间推移,当这位核保人员学会与她过去的自己达成一致时,她对自己判断的信心增加了。她没有表明——在最初的学徒阶段后——她学会了与他人达成一致,检查了她在多大程度上确实与他们达成一致,或者甚至试图防止她的做法偏离同事的做法。
对保险公司而言,一致性的错觉只有通过噪音审计才被打破。公司的领导者怎么会对他们的噪音问题一直不知情?这里有几个可能的答案,但在许多情况下似乎起重要作用的一个答案就是对分歧的不适感。大多数组织更喜欢共识和和谐,而不是异议和冲突。现有的程序似乎明确设计来最小化接触实际分歧的频率,当这种分歧发生时,则将其解释掉。
明尼苏达大学心理学教授、绩效预测领域的leading研究者Nathan Kuncel与我们分享了一个说明这个问题的故事。Kuncel在帮助一所学校的招生办公室审查其决策过程。首先一个人阅读申请文件,给出评分,然后连同评分一起传递给第二个阅读者,第二个阅读者也会给出评分。Kuncel建议——出于在本书中将变得明显的原因——最好屏蔽第一个阅读者的评分,以免影响第二个阅读者。学校的回复:“我们过去这样做,但这导致了太多分歧,所以我们转换到了现在的系统。”这所学校不是唯一一个认为避免冲突至少与做出正确决策同样重要的组织。
考虑许多公司求助的另一种机制:对不幸判断的事后分析。作为学习机制,事后分析是有用的。但如果真的犯了错误——在判断远离专业规范的意义上——讨论它不会有挑战性。专家们会容易得出判断远离共识的结论。(他们也可能将其作为罕见例外而搁置。)糟糕的判断比好的判断更容易识别。指出恶劣错误和边缘化糟糕同事的做法不会帮助专业人士意识到在做出广泛可接受的判断时他们有多么不同意。相反,对糟糕判断的轻松共识甚至可能强化一致性的错觉。关于系统噪音普遍性的真正教训永远不会被学到。
我们希望你开始分享我们的观点,即系统噪音是一个严重问题。它的存在并不令人惊讶;噪音是判断非正式性质的结果。然而,正如我们将在本书中看到的,当组织认真审视时观察到的噪音量几乎总是令人震惊。我们的结论很简单:凡是有判断的地方,就有噪音,而且比你想象的更多。
“我们依赖专业判断的质量,包括核保人员、理赔调整员和其他人的判断。我们将每个案例分配给一位专家,但我们在错误假设下运作,即另一位专家会产生类似的判断。”
“系统噪音比我们想象的——或者比我们能容忍的——要大五倍。没有噪音审计,我们永远不会意识到这一点。噪音审计打破了一致性的错觉。”
“系统噪音是一个严重问题:它使我们损失数亿美元。”
“凡是有判断的地方,就有噪音——而且比我们想象的更多。”
我们迄今讨论的案例研究涉及重复做出的判断。对被判定盗窃罪的人什么是正确的刑期?对特定风险什么是正确的保费?虽然每个案例在某种意义上都是独特的,但像这些这样的判断是重复性决策。医生诊断病人、法官审理假释案例、招生官员审查申请、会计师准备税表——这些都是重复性决策的例子。
重复决策中的噪音可以通过噪音审计来证明,就像我们在前一章中介绍的那些。当可互换的专业人员在类似案例中做决策时,不必要的变异性很容易定义和测量。但是,将噪音的概念应用到我们称为单一决策的判断类别似乎要困难得多,或者甚至可能是不可能的。
例如,考虑世界在2014年面临的危机。在西非,许多人死于埃博拉病毒。由于世界是相互关联的,预测表明感染将迅速传播到世界各地,并特别严重地冲击欧洲和北美。在美国,有坚持要求关闭来自受影响地区的航空旅行并采取积极措施关闭边境的呼声。朝这个方向行动的政治压力很大,著名且消息灵通的人士支持这些措施。
巴拉克·奥巴马总统面临着他总统任期内最困难的决策之一——一个他以前从未遇到过,也再也没有遇到过的决策。他选择不关闭任何边境。相反,他派遣了三千人——卫生工作者和士兵——前往西非。他领导了一个多元化的国际国家联盟,这些国家并不总是能很好地合作,利用他们的资源和专业知识在源头解决问题。
像总统的埃博拉应对这样只做一次的决策是单一的,因为它们不是由同一个人或团队重复做出的,它们缺乏预设的响应,并且具有真正独特的特征。在处理埃博拉问题时,奥巴马总统和他的团队没有真正的先例可以借鉴。重要的政治决策通常是单一决策的好例子,军事指挥官最重要的选择也是如此。
在私人领域,你在选择工作、买房或求婚时做出的决策具有相同的特征。即使这不是你的第一份工作、第一套房子或第一次结婚,尽管无数人之前都面临过这些决策,但对你来说这个决策感觉是独特的。在商业中,公司负责人经常被要求做出对他们来说似乎是独特的决策:是否推出一个可能改变游戏规则的创新,在疫情期间关闭多少业务,是否在外国开设办事处,或者是否向寻求监管他们的政府投降。
可以说,单一决策和重复决策之间存在连续性,而不是类别差异。承保人可能会处理一些他们认为非常不寻常的案例。相反,如果你是第四次买房,你可能已经开始将买房视为重复决策。但极端的例子清楚地表明这种差异是有意义的。开战是一回事;进行年度预算审查是另一回事。
单一决策传统上被视为与大型组织中可互换员工例行做出的重复判断截然不同。虽然社会科学家处理重复决策,但高风险的单一决策一直是历史学家和管理大师的领域。对这两种类型决策的方法截然不同。对重复决策的分析通常采用统计倾向,社会科学家评估许多类似的决策以识别模式、确定规律性并测量准确性。相比之下,对单一决策的讨论通常采用因果观点;它们在事后进行,专注于识别所发生事情的原因。历史分析,就像管理成功和失败的案例研究一样,旨在理解本质上独特的判断是如何做出的。
单一决策的性质为噪音研究提出了一个重要问题。我们将噪音定义为对同一问题判断中的不良变异性。由于单一问题从未完全重复,这个定义不适用于它们。毕竟,历史只运行一次。你永远无法将奥巴马在2014年向西非派遣卫生工作者和士兵的决策与其他美国总统在那个特定时间处理那个特定问题时做出的决策进行比较(尽管你可以推测)。你可能同意将你与那个特别的人结婚的决策与像你这样的其他人的决策进行比较,但那种比较对你来说不会像我们在同一案例上承保人报价之间进行的比较那么相关。你和你的配偶是独特的。没有直接的方法来观察单一决策中噪音的存在。
然而,单一决策并不免于在重复决策中产生噪音的因素。在射击场上,C队(噪音队)的射手可能正在向不同方向调整他们步枪上的瞄准器,或者他们的手可能只是不稳定。如果我们只观察团队中的第一个射手,我们不会知道团队有多嘈杂,但噪音的来源仍然存在。同样,当你做单一决策时,你必须想象另一个决策者,即使是和你一样有能力并且分享相同目标和价值观的人,也不会从相同的事实得出相同的结论。作为决策者,你应该认识到,如果情况或决策过程的某些无关方面有所不同,你可能会做出不同的决策。
换句话说,我们无法衡量单一决策中的噪音,但如果我们反事实地思考,我们确信噪音就在那里。正如射手颤抖的手暗示单次射击可能落在其他地方一样,决策者和决策过程中的噪音暗示单一决策可能会有所不同。
考虑影响单一决策的所有因素。如果负责分析埃博拉威胁和制定应对计划的专家是不同的人,具有不同的背景和生活经历,他们向奥巴马总统提出的建议会是一样的吗?如果相同的事实以稍微不同的方式呈现,对话会以同样的方式展开吗?如果关键人物当时心情不同或在暴风雪中开会,最终决策会完全相同吗?从这个角度看,单一决策似乎并不那么确定。根据我们甚至没有意识到的许多因素,决策很可能会有所不同。
作为反事实思考的另一个练习,考虑不同国家和地区如何应对COVID-19危机。即使病毒大致在同一时间以类似方式袭击它们,应对措施也存在巨大差异。这种变化为不同国家决策中的噪音提供了明确证据。但如果疫情只袭击了一个国家呢?在那种情况下,我们不会观察到任何变化。但我们无法观察到变化并不会使决策变得不那么嘈杂。
这种理论讨论很重要。如果单一决策与反复决策一样嘈杂,那么减少反复决策中噪音的策略也应该提高单一决策的质量。
这是一个比看起来更违反直觉的处方。当你需要做出独一无二的决策时,你的本能可能是将其视为独一无二的。有些人甚至声称概率思维的规则与在不确定性下做出的单一决策完全无关,这样的决策需要完全不同的方法。
我们这里的观察建议相反的建议。从噪音减少的角度来看,单一决策是只发生一次的反复决策。无论你只做一次决策还是一百次,你的目标都应该是以减少偏见和噪音的方式做出决策。减少错误的做法在你独一无二的决策中应该与在重复决策中一样有效。
“你处理这个不寻常机会的方式使你暴露于噪音中。”
“记住:单一决策是只做一次的反复决策。”
“塑造你成为现在的你的个人经历与这个决策并不真正相关。”
无论在日常生活还是科学中,测量都是使用仪器在量表上为物体或事件分配数值的行为。你使用卷尺以英寸为单位测量地毯的长度。你通过查看温度计以华氏度或摄氏度测量温度。
做出判断的行为是相似的。当法官确定犯罪的适当刑期时,他们在量表上分配一个数值。承保人为风险设定保险金额时也是如此,医生做出诊断时也是如此。(量表不必是数字的:“排除合理怀疑的有罪”、“晚期黑色素瘤”和”建议手术”也是判断。)
因此,判断可以被描述为以人类思维为仪器的测量。测量概念中隐含的目标是准确性——接近真相并最小化错误。判断的目标不是给人留下深刻印象,不是表明立场,不是说服。重要的是要注意,我们在这里使用的判断概念借用自技术心理学文献,它是一个比日常语言中同一词汇更狭窄的概念。判断不是思考的同义词,做出准确判断不是具有良好判断力的同义词。
正如我们定义的,判断是可以用一个词或短语总结的结论。如果情报分析师写了一份长报告,得出政权不稳定的结论,只有结论是判断。判断,像测量一样,既指做出判断的心理活动,也指其产物。我们有时会使用判断者作为技术术语来描述做出判断的人,即使他们与司法部门无关。
虽然准确性是目标,但即使在科学测量中也从未实现这一目标的完美,更不用说在判断中了。总是有一些错误,其中一些是偏见,一些是噪音。
为了体验噪音和偏见如何导致错误,我们邀请你玩一个不到一分钟的游戏。如果你有一部带秒表的智能手机,它可能有圈数功能,使你能够在不停止秒表甚至不看显示器的情况下测量连续的时间间隔。你的目标是在不看手机的情况下产生五个连续的正好十秒的圈数。你可能想在开始之前观察几次十秒间隔。开始。
现在查看记录在手机上的圈数时长。(手机本身并非完全没有噪音,但噪音很少。)你会看到这些圈数并非都是准确的十秒,而是在相当大的范围内变化。你试图准确重现相同的计时,但无法做到。你无法控制的变异性就是噪音的一个实例。
这个发现并不令人惊讶,因为噪音在生理学和心理学中是普遍存在的。个体间的变异性是生物学的既定事实;豆荚中没有两颗豌豆是真正相同的。在同一个人内部,也存在变异性。你的心跳并不完全规律。你无法以完美的精确度重复相同的手势。当听力学家为你检查听力时,会有一些声音太轻你永远听不到,另一些声音太响你总是能听到。但也会有一些声音你有时能听到,有时听不到。
现在看看手机上的五个数字。你看到某种模式了吗?比如,所有五个圈数都短于十秒,这种模式表明你的内在时钟运行得很快?在这个简单的任务中,偏差是你的圈数平均值与十秒之间的差值,可正可负。噪音构成了你结果的变异性,类似于我们之前看到的射击散布。在统计学中,变异性最常见的度量是标准差,我们将用它来测量判断中的噪音。
我们可以将大多数判断,特别是预测性判断,视为类似于你刚才进行的测量。当我们做预测时,我们试图接近一个真实值。经济预测师的目标是尽可能接近明年国内生产总值增长的真实值;医生的目标是做出正确的诊断。(请注意,本书技术意义上使用的预测一词并不意味着预测未来:就我们的目的而言,对现有医疗状况的诊断就是一种预测。)
我们将大量依赖判断与测量之间的类比,因为它有助于解释噪音在错误中的作用。做预测性判断的人就像瞄准靶心的射手或努力测量粒子真实重量的物理学家一样。他们判断中的噪音意味着错误。简单来说,当判断瞄准真实值时,两个不同的判断不可能都是正确的。像测量仪器一样,在特定任务中,有些人通常比其他人表现出更多错误——也许是因为技能或训练的不足。但是,像测量仪器一样,做判断的人永远不会完美。我们需要理解和测量他们的错误。
当然,大多数专业判断比时间间隔的测量要复杂得多。在第4章中,我们定义了不同类型的专业判断,并探索它们的目标。在第5章中,我们讨论如何测量错误以及如何量化系统噪音对错误的贡献。第6章更深入地探讨系统噪音并识别其组成部分,即不同类型的噪音。在第7章中,我们探索这些组成部分之一:场合噪音。最后,在第8章中,我们展示群体如何经常放大判断中的噪音。
从这些章节中得出一个简单的结论:像测量仪器一样,人类大脑是不完美的——它既有偏差又有噪音。为什么?程度如何?让我们来找出答案。
本书讨论的是广义理解的专业判断,并假设做出此类判断的人是有能力的,目标是做对。然而,判断这个概念本身包含着一种不情愿的承认,即你永远无法确定判断是正确的。
考虑”判断问题”或”这是一个判断调用”这样的短语。我们不认为太阳明天会升起或氯化钠的分子式是NaCl是判断问题,因为理性的人在这些问题上应该完全一致。判断问题是指对答案有某种不确定性,我们允许理性和有能力的人可能不同意的可能性。
但可接受的分歧是有限度的。事实上,判断这个词主要用于人们认为应该达成一致的地方。判断问题不同于观点或品味问题,在后者中,未解决的分歧是完全可以接受的。对噪音审计结果感到震惊的保险公司高管们,如果理赔调整员在甲壳虫乐队和滚石乐队的相对优劣,或者鲑鱼和金枪鱼的比较上存在严重分歧,他们不会有任何问题。
判断问题,包括专业判断,占据了一个空间,一边是事实或计算问题,另一边是品味或观点问题。它们由有界分歧的期望来定义。
在判断中到底多少分歧是可以接受的,这本身就是一个判断调用,取决于问题的难度。当判断是荒谬的时候,达成一致特别容易。在常规欺诈案件中在量刑上差异很大的法官会一致认为一美元罚款和终身监禁都是不合理的。葡萄酒比赛的评委在哪些葡萄酒应该获得奖牌上分歧很大,但经常对被淘汰的酒一致表示蔑视。
在我们进一步讨论判断体验之前,现在请你自己做一个判断。如果你完成这个练习并将其执行到底,你将从本章剩余部分中获得更多收获。
想象你是一个团队的成员,负责评估一家面临日益激烈竞争的中等成功地区金融公司首席执行官职位的候选人。你被要求评估以下候选人在工作两年后成功的概率。 成功 被简单定义为候选人在两年结束时仍然保持CEO职位。请在0(不可能)到100(确定)的范围内表达概率。
Michael Gambardi今年37岁。自从他12年前从Harvard Business School毕业以来,他担任过几个职位。早期,他是两家初创公司的创始人和投资者,这些公司在没有吸引到太多财务支持的情况下失败了。然后他加入了一家大型保险公司,并迅速升至欧洲地区首席运营官职位。在那个职位上,他发起并管理了一项重要的及时解决索赔问题的改进。同事和下属将他描述为有效但也专横和粗暴,在他任职期间高管流失率很高。同事和下属也证明了他的诚信和承担失败责任的意愿。在过去的两年里,他担任一家中等规模金融公司的CEO,该公司最初面临失败风险。他稳定了公司,在那里他被认为是成功的,尽管很难共事。他表示有兴趣继续前进。几年前面试他的人力资源专家在创造力和活力方面给了他优秀的评级,但也将他描述为傲慢的,有时是专制的。
回想一下,Michael是一家中等成功且面临日益激烈竞争的地区金融公司CEO职位的候选人。如果雇用Michael,他在两年后仍然在职的概率是多少?请在继续阅读之前决定一个0到100范围内的具体数字。如果需要,请重新阅读描述。
如果你认真参与了这项任务,你可能发现它很困难。有大量信息,其中很多似乎不一致。你必须努力形成做出判断所需的连贯印象。在构建那个印象时,你专注于一些看似重要的细节,你很可能忽略了其他细节。如果被要求解释你选择的数字,你会提到一些突出的事实,但不足以完全解释你的判断。
你经历的思维过程说明了我们称为判断的心理操作的几个特征:
由于复杂判断过程中的这三个步骤都包含一些变异性,我们不应该对Michael Gambardi案例的答案中出现大量噪音感到惊讶。如果你让几个朋友阅读这个案例,你可能会发现你们对他成功概率的估计分布很广。当我们向115名MBA学生展示这个案例时,他们对Gambardi成功概率的估计范围从10到95。这是大量的噪音。
顺便说一下,你可能已经注意到秒表练习和Gambardi问题说明了两种类型的噪音。秒表连续试验判断的变异性是单个判断者(你自己)内部的噪音,而Gambardi案例判断的变异性是不同判断者之间的噪音。在测量术语中,第一个问题说明人内可靠性,第二个说明人间可靠性。
您对Gambardi问题的答案是一个预测性判断,正如我们定义的那个术语。然而,它与我们称为预测性的其他判断在重要方面有所不同,包括明天曼谷的最高气温、今晚足球比赛的结果,或下一届总统选举的结果。如果您与朋友在这些问题上存在分歧,您将在某个时候发现谁是对的。但如果您对Gambardi存在分歧,时间不会告诉我们谁是对的,原因很简单:Gambardi并不存在。
即使问题涉及一个真实的人,我们也知道结果,单一的概率判断(除了0或100%之外)也无法被证实或反驳。结果并不能揭示事前概率是什么。如果一个被分配90%概率的事件没有发生,概率判断并不一定是错误的。毕竟,只有10%可能发生的结果确实有10%的时间会发生。Gambardi练习是不可验证预测性判断的一个例子,有两个不同的原因:Gambardi是虚构的,答案是概率性的。
许多专业判断都是不可验证的。除非有严重错误,承保人永远不会知道,例如,某项特定保单是定价过高还是定价过低。其他预测可能因为它们是有条件的而不可验证。“如果我们开战,我们将被击败”是一个重要的预测,但它很可能仍然未经检验(我们希望如此)。或者预测可能过于长期,以至于做出预测的专业人士无法对此负责——例如,对21世纪末平均气温的估计。
Gambardi任务的不可验证性质是否改变了您处理它的方式?例如,您是否问过自己Gambardi是真实的还是虚构的?您是否想过结果是否会在文本后面揭示?您是否思考过这样一个事实:即使是这样,揭示也不会给您所面临问题的答案?可能没有,因为当您回答问题时,这些考虑似乎并不相关。
可验证性并不改变判断的体验。在某种程度上,您可能会对答案很快就会揭示的问题思考得更加深入,因为害怕暴露会集中注意力。相反,您可能拒绝对过于假设以至于荒谬的问题给予太多思考(“如果Gambardi有三条腿并且会飞,他会成为更好的CEO吗?”)。但总的来说,您处理一个合理的假设问题的方式与您处理真实问题的方式大致相同。这种相似性对心理学研究很重要,其中大部分使用虚构的问题。
由于没有结果——您可能甚至没有问过自己是否会有结果——您并不试图相对于那个结果最小化错误。您试图得到正确的判断,找到一个您有足够信心使其成为您答案的数字。当然,您对那个答案并不完全确信,就像您完全确信四乘六等于二十四那样。您意识到一些不确定性(正如我们将看到的,可能比您认识到的更多)。但在某个时刻,您决定不再取得进展,满足于一个答案。
是什么让您觉得您得到了正确的判断,或者至少足够正确以成为您的答案?我们认为这种感觉是判断完成的内部信号,与任何外部信息无关。如果您的答案似乎与证据足够舒适地匹配,它就会感觉正确。0或100的答案不会给您那种匹配感:它暗示的信心与提供的混乱、模糊、冲突的证据不一致。但无论您选择的数字是什么,它都给了您所需的连贯感。正如您所体验的,判断的目标是实现连贯的解决方案。
这个内部信号的基本特征是连贯感是判断体验的一部分。它不依赖于真实的结果。因此,内部信号对不可验证的判断和对真实、可验证的判断一样可用。这解释了为什么对像Gambardi这样的虚构角色做出判断感觉与对现实世界做出判断非常相似。
可验证性不会改变判断发生时的体验。然而,它确实改变了事后的评估。
可验证的判断可以由客观观察者根据一个简单的错误度量来评分:判断与结果之间的差异。如果天气预报员说今天的最高气温将是七十华氏度,而实际是六十五度,预报员就犯了正五度的错误。显然,这种方法不适用于像Gambardi问题这样的不可验证判断,它们没有真实的结果。那么,我们如何决定什么构成好的判断?
答案是有第二种评估判断的方法。这种方法既适用于可验证的判断,也适用于不可验证的判断。它包括评估判断的过程。当我们谈到好的或坏的判断时,我们可能在谈论输出(例如,您在Gambardi案例中产生的数字)或过程——您为得出那个数字所做的事情。
评估判断过程的一种方法是观察该过程在大量案例中的表现。例如,考虑一位政治预测者为大量地方选举候选人分配获胜概率。他描述其中一百名候选人有70%的获胜可能性。如果其中七十人最终当选,我们就有了该预测者使用概率量表技能的良好指标。这些判断作为整体是可验证的,尽管没有单一的概率判断可以被宣布为对或错。同样,对特定群体的偏见最好通过检查大量案例的统计结果来确定。
关于判断过程可以提出的另一个问题是,它是否符合逻辑或概率论的原则。大量关于判断认知偏见的研究都属于这一类。
专注于判断过程而非结果,使得评估不可验证判断的质量成为可能,比如对虚构问题或长期预测的判断。我们可能无法将它们与已知结果进行比较,但我们仍然可以判断它们是否做出了错误判断。当我们转向改进判断而不仅仅是评估判断的问题时,我们也会专注于过程。我们在本书中推荐的所有减少偏见和噪音的程序,都旨在采用能在类似案例集合中最小化错误的判断过程。
我们对比了评估判断的两种方式:通过将其与结果比较和通过评估导致判断的过程质量。请注意,当判断是可验证的时,这两种评估方式在单个案例中可能得出不同的结论。一个熟练而谨慎的预测者使用最佳工具和技术,在进行季度通胀预测时经常会错过正确数字。同时,在某个季度,一只投掷飞镖的黑猩猩有时会是对的。
决策学者们为解决这种矛盾提供了明确建议:专注于过程,而不是单个案例的结果。然而,我们认识到这并非现实生活中的标准做法。专业人士通常根据他们的判断与可验证结果的匹配程度来评估,如果你问他们在判断中追求什么,他们会回答密切匹配。
总之,人们在可验证判断中通常声称追求的是与结果匹配的预测。无论可验证性如何,他们实际上试图实现的是案例事实与判断之间一致性所提供的内在完成信号。而从规范角度来说,他们应该试图实现的是能在类似案例集合中产生最佳判断的判断过程。
到目前为止,在本章中,我们专注于预测性判断任务,我们将讨论的大多数判断都属于这种类型。但第1章讨论了Frankel法官和联邦法官量刑中的噪音,检验了另一种判断类型。对重犯量刑不是预测。这是一种评价判断,旨在使刑罚与犯罪严重程度相匹配。葡萄酒博览会的评委和餐厅评论家做出评价判断。为论文打分的教授、花样滑冰比赛的评委以及向研究项目授予资助的委员会都做出评价判断。
另一种评价判断出现在涉及多个选项及其权衡的决策中。考虑在候选人中选择雇用对象的管理者、必须决定战略选项的管理团队,甚至选择如何应对非洲流行病的总统。可以肯定的是,所有这些决策都依赖于提供输入的预测性判断——例如,候选人在第一年的表现如何,股市对特定战略举措的反应如何,或者如果不加控制,流行病传播的速度如何。但最终决策需要在各种选项的利弊之间进行权衡,这些权衡通过评价判断来解决。
与预测性判断一样,评价判断包含有限分歧的期望。没有一个自尊的联邦法官可能会说:“这是我最喜欢的惩罚,我一点也不在乎同事们的其他想法。”从几个战略选项中选择的决策者期望拥有相同信息并分享相同目标的同事和观察者同意他们的观点,或者至少不要过分不同意。评价判断部分取决于做出判断者的价值观和偏好,但它们不仅仅是品味或观点问题。
因此,预测性和评价性判断之间的界限是模糊的,做出判断的人往往意识不到这一点。设定刑期的法官或为论文打分的教授认真思考他们的任务,努力寻找”正确”答案。他们对自己的判断和为此提供的理由产生信心。当判断是预测性的(“这个新产品会卖得怎么样?”)和评价性的(“我的助手今年表现如何?”)时,专业人士的感受、行为和为自己辩护的言论大致相同。
在预测性判断中观察到噪声总是表明出了问题。如果两位医生对诊断意见不一致,或者两名预测者对下一季度销售额有分歧,那么至少其中一人必然犯了错误。错误可能是因为其中一人技能较差,因此更容易出错,或者是由于其他噪声源造成的。无论原因如何,未能做出正确判断可能对依赖这些个人诊断和预测的人产生严重后果。
评价性判断中的噪声会因不同原因而产生问题。在任何假设法官可以互换并准随机分配的系统中,对同一案件的巨大分歧违背了公平性和一致性的期望。如果对同一被告的量刑存在巨大差异,我们就进入了法官弗兰克尔谴责的”任意残酷”领域。即使是相信个性化量刑价值并且对抢劫犯量刑有分歧的法官也会同意,将判决变成彩票的分歧程度是有问题的。当对同一篇文章给出截然不同的分数,对同一家餐厅给出不同的安全评级,对同一名滑冰运动员给出不同的分数时,情况也是如此(尽管不那么戏剧性)——或者当一个患有抑郁症的人获得社会保障残疾福利,而另一个患有相同疾病的人却什么都得不到时。
即使不公平只是一个次要关切,系统噪声也会带来另一个问题。受评价性判断影响的人期望这些判断反映的价值观是系统的价值观,而不是个别法官的价值观。如果一个客户抱怨笔记本电脑有缺陷获得全额退款,而另一个客户只得到道歉;或者如果一名在公司工作五年的员工要求升职并如愿以偿,而另一名表现完全相同的员工被礼貌地拒绝,那么一定是出了大问题。系统噪声就是不一致性,而不一致性会损害系统的可信度。
我们测量噪声所需要的只是对同一问题的多次判断。我们不需要知道真实值。正如引言中射击场故事所说明的,当我们看靶子背面时,靶心是看不见的,但我们可以看到弹孔的散布。一旦我们知道所有射手都在瞄准同一个靶心,我们就可以测量噪声。这就是噪声审计所做的事情。如果我们要求所有预测者估算下一季度的销售额,他们预测的散布就是噪声。
偏差和噪声之间的这种区别对于改进判断的实际目的至关重要。声称我们可以在无法验证判断是否正确的情况下改进判断似乎是矛盾的。但我们可以——如果我们从测量噪声开始。无论判断的目标是纯粹的准确性还是价值观之间更复杂的权衡,噪声都是不受欢迎的,而且通常是可以测量的。一旦测量了噪声,正如我们将在第5部分讨论的,通常可以减少它。
“这是判断问题。你不能期望人们完全同意。”
“是的,这是判断问题,但有些判断太离谱了,它们是错误的。”
“你在候选人之间的选择只是品味的表达,不是严肃的判断。”
“一个决定需要预测性和评价性判断。”
一致性偏差显然会产生代价高昂的错误。如果一个秤总是给你的体重加上一个固定数值,如果一个热情的经理总是预测项目只需要实际所需时间的一半,或者如果一个胆小的高管年复一年地对未来销售过度悲观,结果将是大量严重的错误。
我们现在已经看到噪声也会产生代价高昂的错误。如果一个经理通常预测项目只需要最终实际所需时间的一半,偶尔预测需要实际时间的两倍,说这个经理”平均”是对的是没有帮助的。不同的错误会累积;它们不会相互抵消。
因此,一个重要问题是偏差和噪声如何以及在多大程度上导致误差。本章旨在回答这个问题。其基本信息很直接:在各种专业判断中,只要准确性是目标,偏差和噪声在整体误差计算中发挥相同作用。在某些情况下,偏差的贡献会更大;在其他情况下是噪声(这些情况比人们预期的更常见)。但在每种情况下,减少噪声对整体误差的影响与减少同等程度的偏差相同。因此,噪声的测量和减少应该与偏差的测量和减少具有同样高的优先级。
这一结论基于一种特定的误差测量方法,该方法有着悠久的历史,在科学和统计学中得到普遍接受。在本章中,我们提供了这一历史的入门概述和基本推理的概要。
开始想象一家名为GoodSell的大型零售公司,该公司雇佣了许多销售预测员。他们的工作是预测GoodSell在各个地区的市场份额。也许在阅读了一本关于噪音主题的书后,GoodSell预测部门主管Amy Simkin进行了一次噪音审计。所有预测员都对同一地区的市场份额产生了独立估计。
图3显示了噪音审计的(令人难以置信的平滑)结果。Amy可以看到预测呈现熟悉的钟形曲线分布,也称为正态分布或高斯分布。钟形曲线峰值代表的最频繁预测是44%。Amy还可以看到公司的预测系统相当嘈杂:这些预测如果都准确的话应该是相同的,但却在相当大的范围内变化。
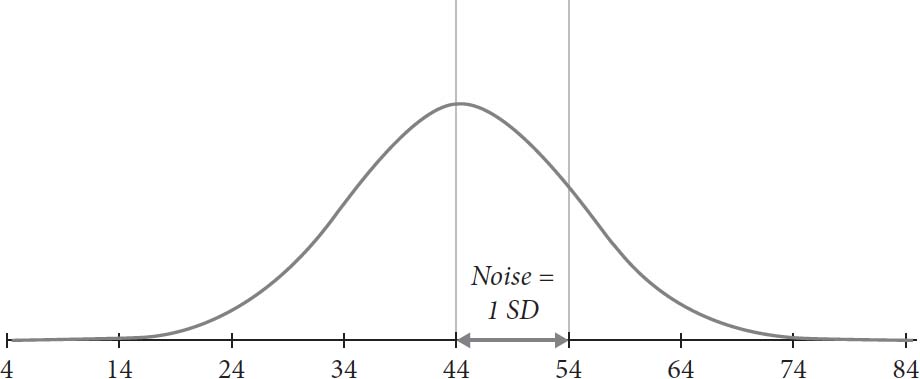
图3:GoodSell某一地区市场份额预测分布
我们可以为GoodSell预测系统中的噪音量附上一个数字。就像您使用秒表测量圈数时所做的那样,我们可以计算预测的标准差。顾名思义,标准差代表与均值的典型距离。在这个例子中,它是10个百分点。对于每个正态分布都是如此,大约三分之二的预测包含在均值两侧一个标准差内——在这个例子中,介于34%和54%的市场份额之间。Amy现在对市场份额预测中的系统噪音量有了估计。(更好的噪音审计会使用几个预测问题来获得更稳健的估计,但一个对我们这里的目的来说就足够了。)
就像第2章中真实保险公司的高管们一样,Amy对结果感到震惊并想要采取行动。不可接受的噪音量表明预测员在执行他们应该遵循的程序时缺乏纪律性。Amy要求获得聘请噪音顾问的权限,以在她的预测员工作中实现更多的统一性和纪律性。不幸的是,她没有得到批准。她老板的回复似乎足够明智:他问,当我们不知道我们的预测是对还是错时,我们如何能减少错误?他说,当然,如果预测中存在大的平均误差(即大的偏差),解决它应该是优先事项。他总结说,在承担任何改善预测的工作之前,GoodSell必须等待并找出它们是否正确。
在原始噪音审计一年后,预测员试图预测的结果已知。目标地区的市场份额结果是34%。现在我们也知道每个预测员的误差,这简单地是预测与结果之间的差异。对于34%的预测误差是0,对于44%的平均预测误差是10%,对于24%的低估预测误差是-10%。
图4显示了误差分布。它与图3中的预测分布相同,但从每个预测中减去了真实值(34%)。分布的形状没有改变,标准差(我们的噪音测量)仍然是10%。
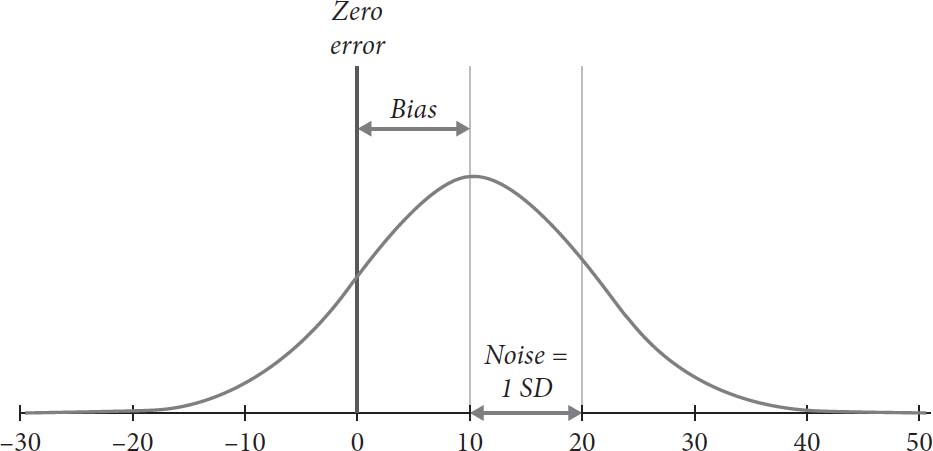
图4:GoodSell某一地区预测误差分布
图3和图4之间的差异类似于从靶子背面和正面看到的射击模式之间的差异(见引言中的图1和图2)。了解靶子的位置对于观察射击中的噪音并不必要;同样,了解真实结果对于已知的预测噪音没有任何增加。
Amy Simkin和她的老板现在知道了他们之前不知道的事情:预测中的偏差量。偏差简单地是误差的平均值,在这种情况下也是10%。因此,在这组数据中,偏差和噪音恰好在数值上相同。(需要明确的是,噪音和偏差的这种相等性绝不是一般规律,但偏差和噪音相等的情况更容易理解它们的作用。)我们可以看到大多数预测员犯了乐观错误——也就是说,他们高估了将要实现的市场份额:他们大多数在零误差垂直线的右手边犯错。(事实上,使用正态分布的性质,我们知道84%的预测都是这种情况。)
正如Amy的老板几乎毫不掩饰满意地指出,他是对的。预测中确实存在很多偏差!确实,现在很明显减少偏差将是一件好事。但是,Amy仍然想知道,一年前减少噪音会是一个好主意吗——现在减少噪音会是一个好主意吗?这种改善的价值与减少偏差的价值相比如何?
要回答Amy的问题,我们需要一个误差的”评分规则”,一种将个别误差加权并合并成总体误差单一测量的方法。幸运的是,这样的工具存在。它是最小二乘法,由Carl Friedrich Gauss在1795年发明,他是1777年出生的著名数学神童,在十几岁时就开始了重大发现的职业生涯。
Gauss提出了一个评分个别误差对总体误差贡献的规则。他的总体误差测量——称为均方误差(MSE)——是各个测量误差平方的平均值。
Gauss关于他测量总体误差方法的详细论证远超出本书的范围,他的解决方案并不是立即显而易见的。为什么使用误差的平方?这个想法似乎是任意的,甚至是奇怪的。然而,正如您将看到的,它建立在您几乎肯定分享的直觉之上。
为了理解原因,让我们转向一个看似完全不同但实际上是同一个问题的情况。想象你拿到一把尺子,被要求测量一条线的长度,精确到最近的毫米。你可以进行五次测量。图5中向下指向的三角形代表这些测量值。
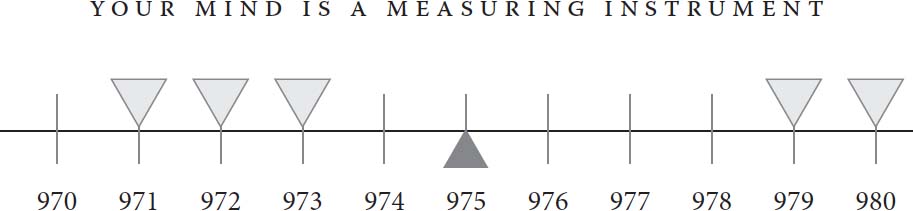
图5:对同一长度的五次测量
如你所见,五次测量都在971到980毫米之间。你对线条真实长度的最佳估计是什么?有两个明显的候选答案。一种可能是中位数,即位于两个较短测量值和两个较长测量值之间的测量值,是973毫米。另一种可能是算术平均值,通俗称为平均数,在这个例子中是975毫米,用向上指向的箭头表示。你的直觉可能倾向于平均值,而你的直觉是正确的。平均值包含更多信息;它受数字大小的影响,而中位数只受其顺序影响。
在这个你有清晰直觉的估计问题与我们在此关心的整体误差测量问题之间,存在着紧密的联系。实际上,它们是同一枚硬币的两面。这是因为最佳估计是能最小化可用测量值整体误差的估计。因此,如果你关于平均值是最佳估计的直觉是正确的,那么你用来测量整体误差的公式应该是一个以算术平均值作为误差最小化值的公式。
MSE具有这个特性——而且它是唯一具有这个特性的整体误差定义。在图6中,我们为线条真实长度的十个可能整数值计算了五次测量中MSE的值。例如,如果真实值是971,五次测量的误差将是0、1、2、8和9。这些误差的平方和为150,平均值是30。这是一个很大的数字,反映了一些测量值远离真实值的事实。你可以看到MSE随着我们接近975——平均值——而减少,超过这一点后又增加。平均值是我们的最佳估计,因为它是使整体误差最小的值。
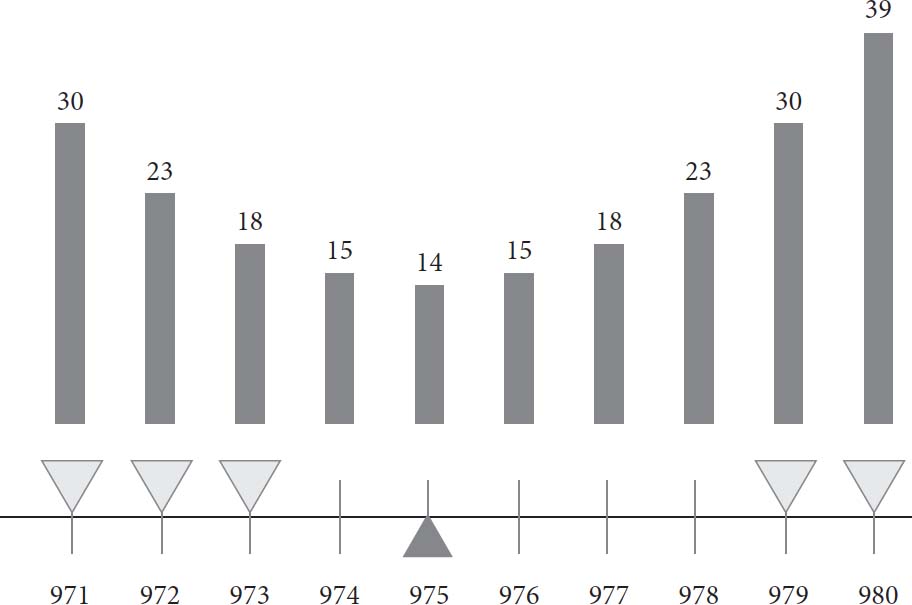
图6:真实长度十个可能值的均方误差(MSE)
你还可以看到,当你的估计偏离平均值时,整体误差会迅速增加。例如,当你的估计仅增加3毫米,从976到979时,MSE翻倍。这是MSE的一个关键特征:平方运算给大误差的权重远大于给小误差的权重。
现在你明白为什么Gauss测量整体误差的公式被称为均方误差,为什么他的估计方法被称为最小二乘法。误差的平方是其核心思想,没有其他公式能与你关于平均值是最佳估计的直觉相兼容。
Gauss方法的优势很快被其他数学家认识到。在他的众多成就中,Gauss使用MSE(和其他数学创新)解决了一个困扰欧洲最优秀天文学家的谜题:重新发现Ceres,这颗小行星在1801年消失在太阳的眩光中之前只被短暂追踪过。天文学家们一直试图估计Ceres的轨道,但他们计算望远镜测量误差的方法是错误的,这颗行星没有在他们的结果所建议的位置附近重新出现。Gauss使用最小二乘法重新进行了计算。当天文学家们将望远镜对准他指示的位置时,他们找到了Ceres!
不同学科的科学家很快采用了最小二乘法。两个多世纪后,它仍然是在以准确性为目标的任何地方评估误差的标准方法。按误差平方加权是统计学的核心。在所有科学学科的绝大多数应用中,MSE占主导地位。正如我们即将看到的,这种方法有着令人惊讶的含义。
偏差和噪声在误差中的作用可以用两个我们称为误差方程的表达式来轻松总结。第一个方程将单次测量中的误差分解为你现在熟悉的两个组成部分:偏差——平均误差——和剩余的”噪声误差”。当误差大于偏差时,噪声误差为正;当误差小于偏差时,噪声误差为负。噪声误差的平均值为零。第一个误差方程没有新内容。
第二个误差方程是我们现在介绍的整体误差测量MSE的分解。使用一些简单的代数,可以证明MSE等于偏差和噪声的平方和。(回想一下,噪声是测量值的标准差,与噪声误差的标准差相同。)因此:
这个方程的形式——两个平方数的和——可能会让你想起高中时期的一个最爱,勾股定理。正如你可能记得的,在直角三角形中,两条较短边的平方和等于最长边的平方。这提示了误差方程的一个简单可视化,其中MSE、Bias²和Noise²是直角三角形三边上三个正方形的面积。图7显示了MSE(较深正方形的面积)如何等于其他两个正方形面积的和。在左图中,噪声多于偏差;在右图中,偏差多于噪声。但MSE是相同的,误差方程在两种情况下都成立。

图7:MSE的两种分解
正如数学表达式和其可视化表示都暗示的那样,偏差和噪声在误差方程中扮演着相同的角色。它们彼此独立,在决定总体误差时权重相等。(注意,当我们在后面章节中分析噪声的组成部分时,我们将使用类似的分解为平方和的方法。)
误差方程为Amy提出的实际问题提供了答案:以相同程度减少噪声或偏差,将如何影响总体误差?答案很直接:偏差和噪声在误差方程中是可互换的,无论减少这两者中的哪一个,总体误差的减少都是相同的。在图4中,偏差和噪声恰好相等(都是10%),它们对总体误差的贡献是相等的。
误差方程还为Amy Simkin最初尝试减少噪声的冲动提供了明确的支持。每当你观察到噪声时,你都应该努力减少它!方程显示Amy的老板错了,当他建议GoodSell等待测量其预测中的偏差,然后再决定做什么时。就总体误差而言,噪声和偏差是独立的:减少噪声的好处是相同的,无论偏差的数量是多少。
这个概念高度违反直觉但至关重要。为了说明这一点,图8显示了以相同程度减少偏差和噪声的效果。为了帮助你理解两个面板中所取得的成果,原始的误差分布(来自图4)用虚线表示。
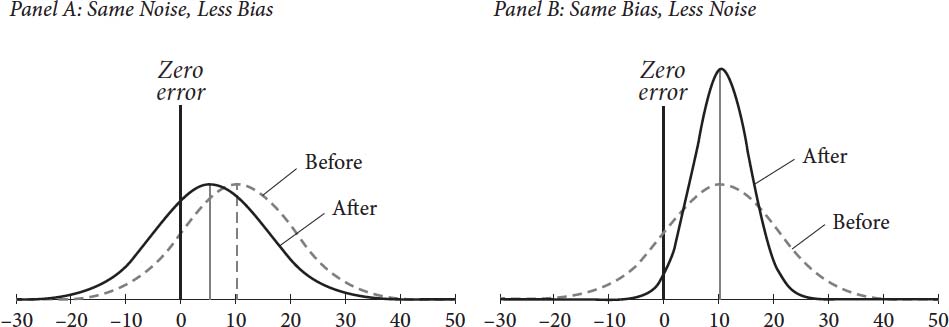
图8:偏差减半与噪声减半时的误差分布
在面板A中,我们假设Amy的老板决定按他的方式做事:他找出了偏差是什么,然后设法将其减少了一半(也许通过向过度乐观的预测者提供反馈)。对噪声没有采取任何措施。改善是可见的:整个预测分布已经向真实值靠近。
在面板B中,我们展示了如果Amy赢得争论会发生什么。偏差保持不变,但噪声减少了一半。这里的悖论是噪声减少似乎让事情变得更糟。预测现在更加集中(噪声更少)但不更准确(偏差不更少)。而84%的预测在真实值的一侧,现在几乎所有(98%)都朝着超过真实值的方向出错。噪声减少似乎让预测更加精确地错误——这很难说是Amy希望的那种改善!
然而,尽管表面如此,总体误差在面板B中的减少与面板A中的减少一样多。面板B中恶化的错觉源于对偏差的错误直觉。偏差的相关度量不是正负误差的不平衡。而是平均误差,即钟形曲线峰值与真实值之间的距离。在面板B中,这个平均误差从原始情况没有改变——仍然很高,为10%,但没有更糟。确实,偏差的存在现在更加突出,因为它占总体误差的更大比例(80%而不是50%)。但这是因为噪声已经减少。相反,在面板A中,偏差已经减少,但噪声没有。净结果是两个面板中的MSE是相同的:以相同程度减少噪声或偏差对MSE有相同的效果。
正如这个例子所说明的,MSE与关于预测判断评分的常见直觉相冲突。要最小化MSE,你必须专注于避免大误差。例如,如果你测量长度,将误差从11厘米减少到10厘米的效果比从1厘米误差到完美命中的效果大21倍。不幸的是,人们在这方面的直觉几乎与应该的相反:人们非常热衷于获得完美命中,对小误差高度敏感,但对两个大误差之间的差异几乎毫不关心。即使你真诚地相信你的目标是做出准确的判断,你对结果的情感反应可能与科学定义的准确性成就不兼容。
当然,这里最好的解决方案是同时减少偏差和噪声。由于偏差和噪声是独立的,没有理由在Amy Simkin和她的老板之间选择。在这方面,如果GoodSell决定减少噪声,噪声减少让偏差更加可见——确实,不可能忽视——的事实可能会是一个福音。实现噪声减少将确保偏差减少是公司议程上的下一个项目。
诚然,如果偏差远大于噪声,那么减少噪声的优先级就会降低。但GoodSell的例子提供了另一个值得强调的教训。在这个简化模型中,我们假设噪声和偏差相等。鉴于误差方程的形式,它们对总误差的贡献也是相等的:偏差占总误差的50%,噪声也占50%。然而,正如我们注意到的,84%的预测者犯同样方向的错误。需要这么大的偏差(七个人中有六个人犯同样方向的错误!)才能产生与噪声相同的影响。因此,我们发现噪声大于偏差的情况也就不足为奇了。
我们演示了误差方程在单个案例中的应用,即GoodSell公司领土的一个特定区域。当然,对多个案例同时进行噪声审计总是可取的。没有什么改变。误差方程适用于单独的案例;通过对各案例的MSE、偏差平方和噪声平方取平均值来获得总体方程。Amy Simkin最好能够获得几个区域的多个预测,无论是来自同一个还是不同的预测者。平均结果将使她更准确地了解GoodSell预测系统中的偏差和噪声。
误差方程是本书的理论基础。它为减少预测判断中系统噪声的目标提供了理论依据,这个目标在原则上与减少统计偏差同样重要。(我们应该强调,统计偏差不是社会歧视的同义词;它只是一组判断中的平均误差。)
误差方程以及我们从中得出的结论依赖于使用MSE作为总体误差的衡量标准。这个规则适用于纯粹的预测性判断,包括预测和估计,所有这些都旨在以最大准确性(最少偏差)和精确性(最少噪声)接近真实值。
然而,误差方程不适用于评价性判断,因为误差概念依赖于真实值的存在,在评价性判断中很难应用。此外,即使能够确定误差,其代价也很少是对称的,并且不太可能与其平方精确成比例。
例如,对于制造电梯的公司来说,估计电梯最大载重量时出现误差的后果显然是不对称的:低估代价高昂,但高估可能是灾难性的。在决定何时离家赶火车时,平方误差同样不相关。对于这个决定,晚一分钟或晚五分钟的后果是一样的。当第2章的保险公司为保单定价或估计理赔价值时,两个方向的误差都是昂贵的,但没有理由假设它们的代价是等价的。
这些例子突出了在决策中明确预测性判断和评价性判断作用的必要性。良好决策制定的一个广泛接受的格言是,你不应该混合你的价值观和事实。良好的决策制定必须基于客观准确的预测性判断,这些判断完全不受希望和恐惧、偏好和价值观的影响。对于电梯公司,第一步应该是在不同工程解决方案下对电梯最大技术载荷进行中性计算。安全只有在第二步才成为主要考虑因素,此时评价性判断决定选择可接受的安全边际来设定最大容量。(当然,这种选择也将在很大程度上取决于涉及该安全边际成本和收益的事实判断。)同样,决定何时前往车站的第一步应该是客观确定不同旅行时间的概率。错过火车和在车站浪费时间的各自代价只有在你选择愿意接受的风险时才变得相关。
同样的逻辑适用于更重要的决策。军事指挥官在决定是否发起攻势时必须权衡许多考虑因素,但领导者依赖的大部分情报都是预测性判断的问题。应对健康危机(如大流行病)的政府必须权衡各种选择的利弊,但如果没有对每个选择可能后果的准确预测(包括什么都不做的决定),就不可能进行评估。
在所有这些例子中,最终决策都需要评价性判断。决策者必须考虑多个选择并应用他们的价值观来做出最优选择。但这些决策依赖于潜在的预测,这些预测应该是价值中性的。它们的目标是准确性——尽可能接近靶心——MSE是误差的适当衡量标准。只要程序不会在更大程度上增加偏差,减少噪声的程序就会改善预测性判断。
“奇怪的是,将偏差和噪声减少相同的量对准确性具有相同的效果。”
“减少预测判断中的噪声总是有用的,无论你对偏差了解多少。”
“当判断在高于和低于真实值之间的分割比例为84比16时,存在很大的偏差——这时偏差和噪声相等。”
“预测性判断涉及每个决策,准确性应该是它们唯一的目标。将你的价值观和事实分开。”
前一章讨论了单个案例测量或判断中的变异性。当我们关注单个案例时,判断的所有变异性都是错误,而错误的两个组成部分是偏差和噪声。当然,我们正在检查的判断系统,包括那些涉及法院和保险公司的系统,都是为了处理不同案例并对它们进行区分而设计的。如果联邦法官和理赔员对所有遇到的案例都做出相同判断,他们将毫无用处。不同案例判断中的大部分变异性是有意的。
然而,同一案例判断中的变异性仍然是不良的——这是系统噪声。正如我们将要展示的,在噪声审计中,同一批人对多个案例做出判断,这允许对系统噪声进行更详细的分析。
为了说明多案例的噪声分析,我们转向一项关于联邦法官量刑的极其详细的噪声审计。该分析于1981年发表,是我们在第1章中描述的量刑改革运动的一部分。该研究狭义地关注量刑决定,但它提供的教训是普遍的,并且适用于其他专业判断。噪声审计的目标是超越弗兰克尔法官和其他人收集的关于噪声的生动但轶事性证据,更系统地”确定量刑差异的程度”。
研究作者开发了十六个假设案例,其中被告已被裁定有罪并将被判刑。这些简短描述描绘了抢劫案或欺诈案,并在其他六个维度上有所不同,包括被告是犯罪的主犯还是从犯,他是否有犯罪记录,是否(对于抢劫案)使用了武器等等。
研究人员组织了与208名在职联邦法官的全国样本进行的精心结构化访谈。在九十分钟的过程中,法官们被提供了所有十六个案例并被要求确定刑期。
为了理解从这项研究中可以学到什么,你会发现可视化练习很有帮助。想象一个大表格,有十六列用于犯罪,从A到P标记,208行用于法官,从1到208标记。每个单元格,从A1到P208,显示特定法官为特定案例设定的监禁期限。图9说明了这个3,328个单元格的表格看起来会是什么样子。为了研究噪声,我们将想要关注十六列,每一列都是一个单独的噪声审计。
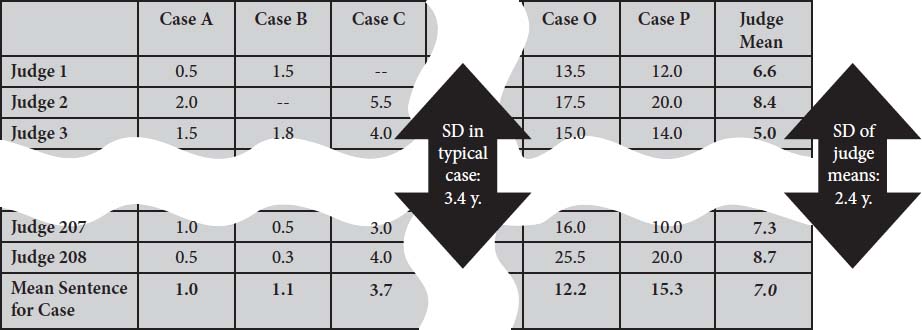
图9:量刑研究的表示
没有客观的方法来确定特定案例刑期的”真实价值”是什么。在下文中,我们将每个案例的208个刑期的平均值(平均刑期)视为该案例的”公正”刑期。正如我们在第1章中指出的,美国量刑委员会在使用过去案例的平均做法作为制定量刑指导原则的基础时做出了同样的假设。这个标签假设每个案例的平均判断具有零偏差。
我们完全意识到,实际上,这个假设是错误的:某些案例的平均判断相对于其他高度相似案例的平均判断很可能是有偏差的,例如由于种族歧视。案例间偏差的方差——一些积极,一些消极——是错误和不公平的重要来源。令人困惑的是,这种方差通常被称为”偏差”。我们在本章——以及本书中——的分析专注于噪声,这是一个不同的错误来源。弗兰克尔法官强调了噪声的不公正,但也引起了对偏差(包括种族歧视)的关注。同样,我们对噪声的关注不应被视为减少了测量和对抗共同偏差的重要性。
为了方便起见,每个案例的平均刑期在表格的底行标出。案例按严重程度递增排列:案例A的平均刑期为1年;案例P为15.3年。所有十六个案例的平均监禁期限为7年。
现在想象一个完美的世界,其中所有法官都是正义的完美测量仪器,量刑是无噪声的。在这样的世界中,图9会是什么样子?显然,案例A列中的所有单元格都将是相同的,因为所有法官都会给案例A中的被告完全相同的一年刑期。所有其他列也是如此。当然,每行中的数字仍然会有所不同,因为案例是不同的。但每一行都与上面和下面的行相同。案例之间的差异将是表格中变异性的唯一来源。
不幸的是,联邦司法的世界并不完美。法官们并不相同,列内的变异性很大,表明每个案例的判断中存在噪声。刑期的变异性比应有的更大,研究的目的是分析它。
从我们上面描述的完美世界图景开始,在这个世界中,所有案件都会从每个法官那里得到相同的刑罚。每一列都是一系列208个相同的数字。现在,通过沿着每一列向下并在这里和那里改变一些数字来添加噪音——有时通过增加刑期到平均刑期,有时通过从中减去。因为你所做的改变并不完全相同,它们在列内创造了变异性。这种变异性就是噪音。
这项研究的本质结果是在每个案件的判决内观察到的大量噪音。每个案件内噪音的衡量标准是分配给该案件的刑期的标准差。对于平均案件,平均刑期是7.0年,围绕该平均值的标准差是3.4年。
虽然你可能很熟悉标准差这个术语,但你可能会发现具体描述很有用。想象你随机选择两名法官并计算他们对一个案件判决的差异。现在重复,对所有法官对和所有案件,并平均结果。这个衡量标准,平均绝对差异,应该让你感受到联邦法庭中被告面临的抽签。假设判决是正态分布的,它是标准差的1.128倍,这意味着同一案件两个随机选择的刑期之间的平均差异将是3.8年。在第3章中,我们谈到了需要保险公司专业承保的客户面临的抽签。毫不夸张地说,刑事被告的抽签后果更为严重。
当平均刑期是7.0年时,法官之间3.8年的平均绝对差异是一个令人不安的,在我们看来,不可接受的结果。然而,有充分的理由怀疑在实际司法管理中存在更多的噪音。首先,噪音审计的参与者处理的是人工案件,这些案件异常容易比较并且是连续呈现的。现实生活并没有提供如此多的支持来维持一致性。其次,法庭上的法官比他们在这里拥有更多的信息。新信息,除非是决定性的,为法官彼此不同提供了更多机会。由于这些原因,我们怀疑被告在实际法庭中面临的噪音量甚至比我们在这里看到的更大。
在分析的下一步中,作者将噪音分解为单独的组成部分。噪音的第一个解释可能出现在你的脑海中——正如它出现在弗兰克尔法官的脑海中一样——是噪音是由于法官在设定严厉刑期的倾向上的变化造成的。正如任何辩护律师会告诉你的,法官有声誉,一些被称为严厉的”绞刑法官”,他们比平均法官更严厉,另一些被称为”心软法官”,他们比平均法官更宽容。我们将这些偏差称为水平错误。(再次:这里的错误被定义为与平均值的偏差;如果平均法官是错误的,错误实际上可能纠正不公正。)
水平错误的变异性将在任何判断任务中发现。例子包括绩效评估中一些主管比其他人更慷慨,市场份额预测中一些预测者比其他人更乐观,或背部手术建议中一些骨科医生比其他人更激进。
图9中的每一行显示一名法官设定的刑期。每名法官设定的平均刑期,显示在表格的最右列,是法官严厉程度的衡量标准。事实证明,法官在这个维度上差异很大。最右列数值的标准差是2.4年。这种变异性与正义无关。相反,正如你可能怀疑的那样,平均量刑的差异反映了法官在其他特征上的变异——他们的背景、生活经历、政治观点、偏见等等。研究人员检查了法官对一般量刑的态度——例如,他们是否认为量刑的主要目标是使其失去能力(将罪犯从社会中移除)、康复或威慑。他们发现,认为主要目标是康复的法官倾向于分配更短的监禁刑期和更多的监督时间,而不是指向威慑或使其失去能力的法官。另外,位于美国南部的法官分配的刑期明显比其他地区的同行更长。毫不奇怪,保守意识形态也与刑期严厉程度相关。
总体结论是,量刑的平均水平起着人格特质的作用。你可以使用这项研究将法官安排在从非常严厉到非常宽容的量表上,就像人格测试可能衡量他们的外向性或宜人性程度一样。像其他特质一样,我们预期量刑严厉程度会与遗传因素、生活经历和人格的其他方面相关。这些都与案件或被告无关。我们使用术语水平噪音来表示法官平均判决的变异性,这与水平错误的变异性相同。
如图9中黑色箭头所示,水平噪音是2.4年,系统噪音是3.4年。这种差异表明系统噪音不仅仅是个别法官平均严厉程度的差异。我们将称这种噪音的其他组成部分为模式噪音。
要理解模式噪音,请再次考虑图9,并专注于一个随机选择的单元格——比如说单元格C3。案例C的平均刑期显示在该列的底部;如你所见,是3.7年。现在,查看最右边的列,找到法官3在所有案例中给出的平均刑期。是5.0年,比总体平均值少2.0年。如果法官严厉程度的差异是第3列噪音的唯一来源,你会预测单元格C3的刑期是3.7 - 2.0 = 1.7年。但单元格C3的实际条目是4年,表明法官3在判决该案例时特别严厉。
同样的简单加法逻辑可以让你预测表格中每一列的每个刑期,但实际上你会发现大多数单元格都偏离了这个简单模型。横向查看一行,你会发现法官在判决所有案例时并不是同等严厉的:在某些案例中他们比个人平均水平更严厉,在其他案例中更宽松。我们称这些残余偏差为模式错误。如果你在表格的每个单元格中写下这些模式错误,你会发现对于每个法官(行)它们加起来为零,对于每个案例(列)也加起来为零。然而,模式错误在对噪音的贡献上并不会相互抵消,因为在计算噪音时所有单元格的值都要平方。
有一个更简单的方法来确认判决的简单加法模型并不成立。你可以在表格中看到,每列底部的平均刑期从左到右稳步增加,但在行内并非如此。例如,法官208对案例O中的被告设定的刑期比对案例P中的被告要高得多。如果个别法官按照他们认为合适的监禁时间对案例进行排名,他们的排名不会相同。
我们使用术语模式噪音来描述我们刚刚识别的变异性,因为这种变异性反映了法官对特定案例态度的复杂模式。例如,一个法官可能总体上比平均水平更严厉,但对白领犯罪相对更宽松。另一个可能倾向于轻判,但当罪犯是累犯时更严厉。第三个可能接近平均严厉程度,但当罪犯只是共犯时表示同情,当受害者是老年人时则严厉。(我们使用术语模式噪音是为了便于阅读。模式噪音的正确统计术语是法官×案例交互作用——读作”法官乘以案例”。我们为给有统计训练的人士强加翻译负担而道歉。)
在刑事司法的背景下,对案例的一些特异性反应可能反映法官个人的判决哲学。其他反应可能源于法官几乎没有意识到的联想,比如一个被告让他想起某个特别可恨的罪犯,或者看起来像他的女儿。无论其起源如何,这些模式不是纯粹的偶然:如果法官再次看到同一个案例,我们预期它们会重现。但因为模式噪音在实践中难以预测,它为已经不可预测的判决彩票增加了不确定性。正如研究作者所指出的,“法官在犯罪/罪犯特征影响方面的模式化差异”是”刑期差异的额外形式”。
你可能已经注意到,将系统噪音分解为水平噪音和模式噪音遵循与前一章错误方程相同的逻辑,该方程将错误分解为偏差和噪音。这次,该方程可以写成如下形式:
这个表达式可以用与原始错误方程相同的方式进行视觉表示(图10)。我们将三角形的两边表示为相等。这是因为,在判决研究中,模式噪音和水平噪音对系统噪音的贡献大致相等。
模式噪音是普遍存在的。假设医生正在决定是否让人住院,公司正在决定雇用谁,律师正在决定提起哪些案件,或者好莱坞高管正在决定制作哪些电视节目。在所有这些情况下,都会有模式噪音,不同的判断者对案例产生不同的排名。
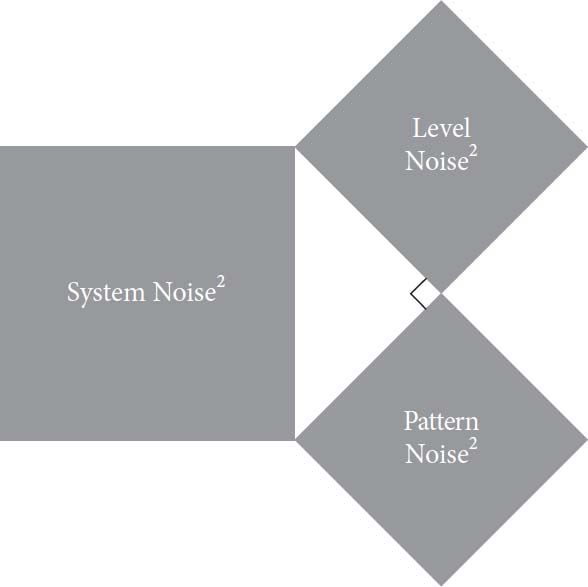
图10:分解系统噪音
我们对模式噪音的处理掩盖了一个重要的复杂性:随机错误的可能贡献。
回想秒表练习。当你试图重复测量十秒钟时,你的结果从一次到下一次都有变化;你表现出个人内部变异性。同样,如果法官被要求在另一个场合再次判决这十六个案例,他们不会设定完全相同的刑期。实际上,正如我们将看到的,如果原始研究在同一周的另一天进行,他们不会设定相同的刑期。如果法官因为女儿发生了好事,或者因为喜欢的运动队昨天赢了,或者因为今天是个美好的日子而心情很好,她的判决可能比其他情况下更宽松。这种个人内部变异性在概念上区别于我们刚刚讨论的稳定的个人间差异——但很难将这些变异性来源区分开来。我们将由于短暂效应引起的变异性称为场合噪音。
在这项研究中,我们有效地忽略了偶然噪音,选择将法官在噪音审计中的特殊判决模式解释为表明稳定态度的指标。这个假设当然是乐观的,但有独立的理由相信偶然噪音在这项研究中没有起到重要作用。参与研究的经验丰富的法官肯定带来了关于犯罪和被告人各种特征重要性的既定观念。在下一章中,我们将更详细地讨论偶然噪音,并展示如何将其与模式噪音的稳定成分分离。
总结一下,我们讨论了几种类型的噪音。系统噪音是多个个体对同一案例判断的不理想变异性。我们已经识别了它的两个主要组成部分,当同一个体评估多个案例时可以将其分离:
 水平噪音是不同法官判决平均水平的变异性。
水平噪音是不同法官判决平均水平的变异性。
模式噪音是法官对特定案例反应的变异性。
在目前的研究中,水平噪音和模式噪音的数量大致相等。然而,我们识别为模式噪音的组成部分肯定包含一些偶然噪音,这可以被视为随机误差。
我们使用司法系统中的噪音审计作为例证,但同样的分析可以应用于任何噪音审计——在商业、医学、政府或其他地方。水平噪音和模式噪音(包括偶然噪音)都对系统噪音有贡献,随着我们的进展,我们将反复遇到它们。
“水平噪音是指法官表现出不同的严厉程度。模式噪音是指他们对哪些被告人应该受到更严厉或更宽松的待遇意见不一致。模式噪音的一部分是偶然噪音——即法官与自己的意见不一致。”
“在一个完美的世界中,被告人会面对正义;在我们的世界中,他们面对的是一个有噪音的系统。”
一名职业篮球运动员正在准备罚球。他站在罚球线上。他集中精神——然后投篮。这是他已经练习过无数次的精确动作序列。他会投中吗?
我们不知道,他也不知道。在美国国家篮球协会,球员通常能投中大约四分之三的尝试。显然,一些球员比其他球员更好,但没有球员能100%命中。历史最佳球员的罚球命中率略高于90%。(在撰写本文时,他们是斯蒂芬”库里”·库里、史蒂夫·纳什和马克·普莱斯。)历史最差的大约为50%。(例如,伟大的沙奎尔·奥尼尔只投中了大约53%的投篮。)尽管篮筐总是恰好十英尺高、十五英尺远,球总是重二十二盎司,但重复投篮所需的精确手势序列的能力并不容易获得。变异性是预期的,不仅存在于球员之间,也存在于球员内部。罚球是一种彩票形式,如果投手是库里而不是奥尼尔,成功的几率会高得多,但它仍然是一种彩票。
这种变异性从何而来?我们知道无数因素可以影响罚球线上的球员:长时间比赛的疲劳、比分胶着的心理压力、主场的欢呼声,或者对方球队球迷的嘘声。如果像库里或纳什这样的球员投失了,我们会援引这些解释之一。但实际上,我们不太可能知道这些因素所起的确切作用。投手表现的变异性是一种噪音形式。
罚球或其他物理过程的变异性并不令人惊讶。我们习惯了身体的变异性:我们的心率、血压、反射、声音的音调,以及手的颤抖在不同时候都是不同的。无论我们多么努力地产生相同的签名,每张支票上的签名仍然略有不同。
观察我们思维的变异性不那么容易。当然,我们都有过改变想法的经历,即使没有新信息。昨晚让我们大笑的电影现在看起来平庸且容易忘记。我们昨天严厉评判的人现在似乎值得我们宽容。我们曾经不喜欢或不理解的论点现在渗透进来,看起来很重要。但正如这些例子所示,我们通常将这种变化与相对次要且在很大程度上主观的事情联系起来。
实际上,我们的观点确实会无明显理由地改变。这一点甚至适用于专业专家的仔细、深思熟虑的判断。例如,当同一位医生两次面对同一病例时,获得明显不同的诊断是常见的(见第22章)。当美国一次重要葡萄酒比赛的葡萄酒专家两次品尝同样的葡萄酒时,他们只对18%的葡萄酒给出了相同的评分(通常是最差的那些)。法医专家在仅仅几周后再次检查同样的指纹时,可能得出不同的结论(见第20章)。经验丰富的软件顾问在两次不同场合可能对同一任务的完成时间提供明显不同的估计。简单地说,就像篮球运动员从不以完全相同的方式投球两次一样,当我们在两次场合面对相同事实时,我们并不总是产生相同的判断。
我们已经描述了选择承销商、法官或医生的过程,这是一个产生系统噪音的抽签过程。场合噪音是第二次抽签的产物。这次抽签选择专业人士做出判断的时刻、专业人士的情绪、脑海中仍然清晰的案例序列,以及场合的无数其他特征。第二次抽签通常比第一次更加抽象。我们可以看到第一次抽签如何可能选择了不同的承销商,但所选承销商实际回应的替代方案是抽象的反事实。我们只知道确实发生的判断是从一团可能性中挑选出来的。场合噪音是这些看不见的可能性之间的变异性。
测量场合噪音并不容易——原因与其存在一旦确立,常常让我们感到惊讶的原因大致相同。当人们形成经过深思熟虑的专业意见时,他们会将其与证明其观点的理由联系起来。如果被要求解释他们的判断,他们通常会用他们认为令人信服的论据来为其辩护。如果他们第二次遇到相同的问题并认出它,他们会重现之前的答案,既为了减少努力,也为了保持一致性。考虑教学职业中的这个例子:如果老师给学生论文一个优秀的成绩,然后在看到原始成绩后一周后重新阅读同一篇论文,他不太可能给出截然不同的成绩。
因此,每当案例容易记住时,很难获得场合噪音的直接测量。例如,如果你向承销商或刑事法官展示他们之前决定的案例,他们可能会认出该案例并重复他们之前的判断。一项关于专业判断变异性的研究综述(技术上称为重测信度,或简称信度)包括许多研究,其中专家在同一次会话中做出两次相同的判断。毫不奇怪,他们倾向于与自己保持一致。
我们上面提到的实验通过使用专家不会认出的刺激来绕过这个问题。葡萄酒评判员参加了盲品。指纹检验员被展示他们已经看过的指纹对,软件专家被询问他们已经处理过的任务——但是几周或几个月后,并且没有被告知这些是他们已经检验过的案例。
还有另一种不太直接的方法来确认场合噪音的存在:使用大数据和计量经济学方法。当可以获得大量过去专业决策样本时,分析师有时可以检查这些决策是否受到特定场合的、无关因素的影响,例如一天中的时间或外部温度。这些无关因素对判断的统计显著影响是场合噪音的证据。现实地说,没有希望发现场合噪音的所有外在来源,但那些可以找到的说明了这些来源的巨大多样性。如果我们要控制场合噪音,我们必须尝试理解产生它的机制。
想想这个问题:世界上有多少百分比的机场在美国?当你思考它时,答案可能出现在你的脑海中。但它不是以你记住你的年龄或电话号码的方式出现的。你意识到你刚刚产生的数字是一个估计。它不是一个随机数字——1%或99%显然是错误的答案。但你想出的数字只是你不会排除的一系列可能性中的一个。如果有人在你的答案上加减1个百分点,你可能不会发现结果猜测比你的猜测可信度低多少。(顺便说一下,正确答案是32%。)
两位研究者Edward Vul和Harold Pashler有了一个想法,要求人们回答这个问题(以及许多类似的问题)不是一次而是两次。受试者第一次不被告知他们必须再次猜测。Vul和Pashler的假设是两个答案的平均值会比单独的任何一个答案更准确。
数据证明他们是对的。一般来说,第一次猜测比第二次更接近真相,但最好的估计来自两次猜测的平均值。
Vul和Pashler从著名的群体智慧效应现象中获得了灵感:平均不同人的独立判断通常会提高准确性。1907年,达尔文的表兄弟、著名博学家Francis Galton要求乡村集市上的787名村民估计一头获奖公牛的重量。没有村民猜中公牛的实际重量,公牛重1,198磅,但他们猜测的平均值是1,200,仅差2磅,中位数(1,207)也非常接近。村民们是一个”聪明的群体”,意思是虽然他们的个人估计相当嘈杂,但他们是无偏的。Galton的演示让他感到惊讶:他对普通人的判断没有什么尊重,尽管如此,他敦促说他的结果”比预期的更能证明民主判断的可信性”。
在数百种情况下都发现了类似的结果。当然,如果问题非常困难,只有专家才能接近答案,那么群体未必会很准确。但是,当人们被要求猜测透明罐子里的果冻豆数量、预测一周后所在城市的温度,或者估计州内两个城市之间的距离时,大量人群的平均答案很可能接近真相。原因是基本的统计学:将几个独立的判断(或测量)进行平均会产生一个新的判断,这个判断虽然偏差不会减少,但噪音会比个人判断更少。
Vul和Pashler想要找出同样的效应是否适用于场合噪音:你能否通过结合同一个人的两次猜测来更接近真相,就像结合不同人的猜测一样?如他们所发现的,答案是肯定的。Vul和Pashler给这一发现起了一个生动的名字:内在的群体。
对同一个人的两次猜测进行平均,其改善判断的效果不如寻求独立的第二意见。正如Vul和Pashler所说,“向自己问同一个问题两次所获得的收益,大约是从别人那里获得第二意见收益的1/10。”这不是一个大的改善。但是你可以通过等待一段时间再进行第二次猜测来大大增强这种效果。当Vul和Pashler让三周时间过去后再向受试者询问同一个问题时,收益提升到了第二意见价值的三分之一。对于一种不需要任何额外信息或外部帮助的技术来说,这已经相当不错了。这个结果确实为给决策者的古老建议提供了理论依据:“先睡一觉,明天早上再想想。”
德国研究人员Stefan Herzog和Ralph Hertwig独立于Vul和Pashler但在大约同一时间,提出了同一原理的不同实施方法。他们不是简单地要求受试者产生第二个估计,而是鼓励人们生成一个尽可能与第一个不同但仍然合理的估计。这个要求需要受试者积极思考他们第一次没有考虑到的信息。给参与者的指示如下:
首先,假设你的第一个估计是错误的。其次,想几个可能的原因。哪些假设和考虑可能是错误的?第三,这些新的考虑意味着什么?第一个估计是过高还是过低?第四,基于这个新的视角,做出第二个替代估计。
像Vul和Pashler一样,Herzog和Hertwig然后对这样产生的两个估计进行平均。他们的技术被称为辩证自举法,在准确性方面比简单地在第一次估计后立即要求第二次估计产生了更大的改善。因为参与者强迫自己从新的角度考虑问题,他们采样了另一个更不同的自己版本——“内在群体”中两个相距更远的”成员”。结果,他们的平均值产生了对真相更准确的估计。两个紧接着的”辩证”估计在准确性方面的收益大约是第二意见价值的一半。
正如Herzog和Hertwig总结的,对决策者来说,结论是程序之间的简单选择:如果你能从他人那里获得独立意见,就去做——这种真正的群体智慧很可能改善你的判断。如果不能,就自己再做一次同样的判断来创造一个”内在群体”。你可以在一段时间过去后这样做——让自己与第一个意见保持距离——或者通过积极尝试反驳自己来找到问题的另一个视角。最后,无论是哪种类型的群体,除非你有非常强的理由给其中一个估计更多权重,否则你最好的选择是对它们进行平均。
除了实用建议,这一研究路线证实了关于判断的一个基本洞察。正如Vul和Pashler所说,“受试者做出的反应是从内部概率分布中采样的,而不是基于受试者拥有的所有知识确定性地选择的。”这一观察呼应了你在回答美国机场问题时的经历:你的第一个答案没有捕捉到你的所有知识,甚至不是最好的知识。答案只是你的大脑可能生成的可能答案云中的一个点。我们在同一个人对同一问题的判断中观察到的变异性不是在少数高度专业化问题中观察到的偶然现象:场合噪音一直影响着我们所有的判断。
至少有一个我们都注意到的场合噪音来源:情绪。我们都经历过自己的判断如何依赖于感觉——我们也确实意识到他人的判断也会随着他们的情绪而变化。
情绪对判断的影响一直是大量心理学研究的主题。让人们暂时感到快乐或悲伤,并测量这些情绪被诱发后他们判断和决策的变异性,这是非常容易的。研究人员使用各种技术来做到这一点。例如,参与者有时被要求写一段回忆快乐记忆或悲伤记忆的文字。有时他们只是观看从喜剧电影或催泪电影中截取的视频片段。
几位心理学家花费数十年时间研究情绪操控的影响。其中最为多产的可能是澳大利亚心理学家约瑟夫·福加斯(Joseph Forgas)。他在情绪研究领域发表了大约一百篇科学论文。
福加斯的一些研究证实了你已经知道的:心情好的人通常更积极。他们更容易回忆起快乐的记忆而不是悲伤的,他们对人更认可,更慷慨和乐于助人,等等。消极情绪产生相反的效果。正如福加斯所写:“同一个微笑,心情好的人会认为是友好的,但心情不好的观察者可能会判断为尴尬;讨论天气,心情好的人可能觉得得体,但心情不好时会觉得无聊。”
换句话说,情绪对你的思维有可测量的影响:你在环境中注意到什么,你从记忆中提取什么,你如何理解这些信号。但情绪还有另一个更令人惊讶的效果:它也会改变你如何思考。在这里,效果并不是你可能想象的那样。心情好是一把双刃剑,坏心情也有其好处。不同情绪的成本和收益是具体情况而定的。
例如,在谈判情况下,好心情有帮助。心情好的人更合作,能引起对方的回应。他们往往比不开心的谈判者取得更好的结果。当然,成功的谈判也会让人开心,但在这些实验中,情绪不是由谈判中发生的事情引起的;而是在人们谈判之前就被诱发的。此外,在谈判过程中从好心情转为愤怒的谈判者往往能取得好结果——这是你面对顽固对手时需要记住的!
另一方面,好心情让我们更可能接受第一印象为真,而不去质疑它们。在福加斯的一项研究中,参与者阅读一篇简短的哲学文章,文章后附有作者的照片。一些读者看到的是典型的哲学教授——中年男性,戴着眼镜。其他人看到的是一位年轻女性。正如你可以猜到的,这是对读者刻板印象脆弱性的测试:当文章归属于中年男性时,人们是否会比认为是年轻女性写的时候给出更高的评价?他们确实如此。但重要的是,在好心情条件下这种差异更大。心情好的人更可能让偏见影响他们的思维。
其他研究测试了情绪对轻信的影响。戈登·彭尼库克(Gordon Pennycook)及其同事进行了许多研究,观察人们对无意义的伪深刻陈述的反应,这些陈述是通过从流行大师的话语中随机选择名词和动词组装成语法正确的句子而产生的,比如”整体性平息无限现象”或”隐藏的意义转化无与伦比的抽象美”。在这种陈述中寻找意义的倾向是一种被称为废话接受性(bullshit receptivity)的特质。(废话(Bullshit)自普林斯顿大学哲学家哈里·法兰克福(Harry Frankfurt)发表了一本富有洞察力的著作《论废话》以来,已经成为某种技术术语,在书中他区分了废话和其他类型的歪曲。)
确实,有些人比其他人更容易接受废话。他们可能被”看似令人印象深刻的断言所打动,这些断言被呈现为真实和有意义的,但实际上是空洞的”。但在这里,这种轻信不仅仅是永久、不变倾向的函数。诱发好心情会让人们更容易接受废话,总体上更轻信;他们不太容易发现欺骗或识别误导性信息。相反,接触误导性信息的目击者在心情不好时更能够忽视这些信息——并避免虚假证词。
即使道德判断也受到情绪的强烈影响。在一项研究中,研究人员让受试者面对人行天桥问题,这是道德哲学中的一个经典问题。在这个思想实验中,五个人即将被失控的电车撞死。受试者要想象自己站在人行天桥上,电车很快就会从下面经过。他们必须决定是否将一个大个子推下天桥到轨道上,这样他的身体就会阻止电车。如果他们这样做,他们被告知,这个大个子会死,但五个人会得救。
人行天桥问题说明了道德推理方法之间的冲突。与英国哲学家杰里米·边沁(Jeremy Bentham)相关的功利主义计算表明,失去一个生命比失去五个生命更可取。与伊曼努尔·康德(Immanuel Kant)相关的义务论伦理学禁止杀害某人,即使是为了拯救其他几个人。人行天桥问题明显包含个人情感的突出元素:身体上将一个人推下桥进入迎面而来的电车路径是一个特别令人厌恶的行为。做出将人推下桥的功利主义选择需要人们克服对陌生人进行身体暴力行为的厌恶。只有少数人(在这项研究中,不到十分之一)通常说他们会这样做。
然而,当受试者处于积极情绪中——通过观看五分钟视频片段诱导——他们说会把那个人推下桥的可能性增加了三倍。无论我们将”不可杀人”视为绝对原则,还是愿意杀死一个陌生人来拯救五个人,都应该反映我们最深层的价值观。然而我们的选择似乎取决于我们刚刚观看的视频片段。
我们详细描述了这些情绪研究,因为我们需要强调一个重要的真理:你在任何时候都不是同一个人。 随着你的情绪变化(这是你当然意识到的),你的认知机制的某些特征也会随之变化(这是你并不完全意识到的)。如果你面对一个复杂的判断问题,当时的情绪可能会影响你处理问题的方法和得出的结论,即使你认为你的情绪没有这种影响,即使你能自信地为你找到的答案辩护。简而言之,你是有噪音的。
许多其他偶然因素会在判断中引起场合噪音。在不应该影响专业判断但确实会影响的外部因素中,有两个主要嫌疑犯:压力和疲劳。例如,一项对近七十万次初级医疗访问的研究表明,医生在漫长一天结束时开阿片类药物的可能性显著增加。当然,没有理由认为下午4点预约的患者比上午9点来的患者疼痛更严重。医生落后于预定时间表这一事实也不应该影响处方决定。事实上,其他疼痛治疗的处方,如非甾体抗炎药和物理治疗转诊,并没有显示类似的模式。当医生面临时间压力时,他们显然更倾向于选择快速解决方案,尽管它有严重的缺点。其他研究表明,在一天结束时,医生更可能开抗生素处方,而较少开流感疫苗处方。
甚至天气对专业判断也有可测量的影响。由于这些判断通常在空调房间内做出,天气的影响可能是通过情绪”中介”的(也就是说,天气不直接影响决定,而是改变决策者的情绪,进而确实改变了他们的决策方式)。恶劣天气与改善记忆有关;当外面很热时,司法判决往往更严厉;股票市场表现受到阳光影响。在某些情况下,天气的影响不太明显。Uri Simonsohn 表明,大学招生官员在阴天更关注候选人的学术属性,在晴天对非学术属性更敏感。他报告这些发现的文章标题很令人难忘:“云层让书呆子看起来很好”。
判断中随机变异的另一个来源是案例的审查顺序。当一个人在考虑一个案例时,紧接在它之前的决定作为隐含的参考框架。连续做出一系列决定的专业人士,包括法官、贷款官员和棒球裁判,倾向于恢复某种平衡形式:在一连串或一系列朝同一方向的决定之后,他们更可能朝相反方向决定,超过严格合理的程度。因此,错误(和不公平)是不可避免的。例如,美国的庇护法官在前两个案例被批准时,批准申请人庇护的可能性降低19%。如果前两个申请被拒绝,一个人可能会被批准贷款,但如果前两个申请被批准,同一个人可能会被拒绝。这种行为反映了一种被称为赌徒谬误的认知偏见:我们倾向于低估连胜偶然发生的可能性。
相对于总系统噪音,场合噪音有多大?虽然没有一个数字适用于所有情况,但出现了一个一般规律。就其大小而言,我们在本章中描述的影响小于个体在其判断水平和模式上的稳定差异。
如前所述,例如,如果听证会跟在同一法官的两次成功听证会之后,庇护申请人在美国被接纳的机会下降19%。这种变异性确实令人担忧。但与法官之间的变异性相比就相形见绌了:在迈阿密的一个法院,Jaya Ramji-Nogales 和她的合著者发现,一位法官会批准88%申请人的庇护,而另一位只批准5%。(这是真实数据,不是噪音审计,所以申请人是不同的,但他们是准随机分配的,作者检查了原籍国差异不能解释这些差异。)鉴于如此差异,将这些数字之一减少19%似乎不是什么大事。
同样,指纹检验员和医生有时与自己意见不一致,但他们这样做的频率比与他人意见不一致的频率要低。在我们审查的每个可以测量场合噪音在总系统噪音中所占比例的案例中,场合噪音都是比个体间差异更小的贡献者。
或者换句话说,你并不总是同一个人,你的时间一致性比你想象的要差。但令人稍感安慰的是,你与昨天的自己更相似,而不是与今天的另一个人更相似。
情绪、疲劳、天气、顺序效应:许多因素都可能引发同一个人对同一案例判断的不必要变化。我们可能希望构建一个设置,其中所有影响决策的外在因素都是已知的和可控的。至少在理论上,这样的设置应该能减少时机噪音。但即使这样的设置也可能不足以完全消除时机噪音。
Michael Kahana和他在宾夕法尼亚大学的同事们研究记忆表现。(按照我们的定义,记忆不是判断任务,但它是一个认知任务,其条件可以被严格控制,表现变化也容易测量。)在一项研究中,他们要求79名受试者参与对其记忆表现的异常彻底分析。受试者在不同日子进行了23次测试,每次测试中他们必须回忆24个不同列表中的单词,每个列表包含24个单词。回忆单词的百分比定义了记忆表现。
Kahana和他的同事们并不关心受试者之间的差异,而是关心每个受试者表现变化的预测因子。表现会受到受试者感觉多么警觉的影响吗?会受到前一晚睡眠时间的影响吗?会受到一天中时间的影响吗?他们的表现会随着从一次测试到下一次测试的练习而提高吗?会在每次测试中因为疲倦或无聊而恶化吗?某些单词列表会比其他列表更容易记忆吗?
所有这些问题的答案都是肯定的,但影响不大。一个包含所有这些预测因子的模型只能解释给定受试者表现变化的11%。正如研究人员所说,“在移除我们预测变量的影响后,仍然存在如此多的变化,这让我们感到震惊。”即使在这种严格控制的设置中,究竟什么因素驱动时机噪音仍然是一个谜。
在研究人员研究的所有变量中,预测受试者在特定列表上表现的最强预测因子不是外部因素。一个单词列表的表现最好通过受试者在紧接着的前一个列表上的表现来预测。一个成功的列表很可能被另一个相对成功的列表跟随,一个平庸的列表被另一个平庸的列表跟随。表现不是从一个列表到另一个列表随机变化的:在每次测试中,它随着时间起伏波动,没有明显的外部原因。
这些发现表明,记忆表现在很大程度上是由Kahana和合著者所说的”控制记忆功能的内源性神经过程的效率”驱动的。换句话说,大脑效能的时刻变化不仅仅是由外部影响驱动的,比如天气或分散注意力的干预。这是我们大脑本身功能方式的一个特征。
大脑功能的内在变化很可能也会以我们无法希望控制的方式影响我们判断的质量。大脑功能的这种变化应该让任何认为可以消除时机噪音的人停下来思考。与篮球运动员在罚球线上的类比并不像最初看起来那么简单:就像运动员的肌肉永远不会执行完全相同的动作一样,我们的神经元也永远不会以完全相同的方式运作。如果我们的心智是一个测量工具,它永远不会是完美的。
然而,我们可以努力控制那些可以控制的不当影响。当判断是在群体中做出时,这样做尤其重要,正如我们将在第8章中看到的。
“判断就像罚球:无论我们多么努力地精确重复它,它永远不会完全相同。”
“你的判断取决于你的心情,你刚刚讨论过的案例,甚至天气如何。你在任何时候都不是同一个人。”
“虽然你可能不是上周的那个人,但你与上周的’你’的差异比你与今天其他人的差异要小。时机噪音不是系统噪音的最大来源。”
个人判断中的噪音已经够糟糕了。但群体决策为这个问题增加了另一个层面。群体可以朝各种方向发展,部分取决于应该无关紧要的因素。谁先发言,谁最后发言,谁自信地发言,谁穿着黑色,谁坐在谁旁边,谁在合适的时刻微笑、皱眉或做手势——所有这些因素,以及更多因素,都会影响结果。每天,相似的群体都会做出非常不同的决定,无论问题涉及招聘、晋升、办公室关闭、沟通策略、环境法规、国家安全、大学录取还是新产品发布。
强调这一点可能看起来很奇怪,因为我们在前一章中指出,汇总多个个体的判断会减少噪音。但由于群体动力学,群体也可能增加噪音。存在”智慧群体”,其平均判断接近正确答案,但也存在追随暴君的群体、推动市场泡沫的群体、相信魔法的群体,或处于共同幻象影响下的群体。微小的差异可能导致一个群体倾向于坚定的”是”,而一个本质上相同的群体倾向于强烈的”否”。由于群体成员之间的动力学——这是我们这里的重点——噪音水平可能很高。无论我们谈论的是相似群体之间的噪音,还是单一群体在重要事务上的坚定判断应该被视为只是众多可能性中的一种,这个命题都是成立的。
为了寻找证据,我们从一个看似不太可能的地方开始:Matthew Salganik和他的合著者进行的一项大规模音乐下载研究。在这项研究的设计中,实验者创建了一个由数千人组成的对照组(一个相当受欢迎网站的访问者)。对照组成员可以听取并下载72首新乐队歌曲中的一首或多首。这些歌曲都有生动的名字:“Trapped in an Orange Peel”、“Gnaw”、“Eye Patch”、“Baseball Warlock v1”和”Pink Aggression”。(一些标题听起来与我们这里关注的问题直接相关:“Best Mistakes”、“I Am Error”、“The Belief Above the Answer”、“Life’s Mystery”、“Wish Me Luck”和”Out of the Woods”。)
在对照组中,参与者没有被告知其他任何人说了什么或做了什么。他们只能对自己喜欢并希望下载的歌曲做出独立判断。但Salganik和他的同事还创建了另外八个组,数千名其他网站访问者被随机分配到这些组中。对于这些组的成员,一切都是相同的,只有一个例外:人们可以看到他们特定组中有多少人之前下载了每首单独的歌曲。例如,如果”Best Mistakes”在一个组中非常受欢迎,其成员会看到这一点,如果没有人下载它也是如此。
由于各个组在任何重要维度上都没有差异,这项研究本质上是在运行八次历史。你很可能会预测,最终好歌总是会升到顶部,坏歌总是会沉到底部。如果是这样,各个组最终会得到相同或至少相似的排名。在各组之间,不会有噪音。确实,这正是Salganik和他的合著者想要探索的确切问题。他们正在测试噪音的一个特定驱动因素:社会影响。
关键发现是群体排名存在巨大差异:在不同群体之间,存在大量噪音。在一个群体中,“Best Mistakes”可能是一个巨大的成功,而”I Am Error”可能失败。在另一个群体中,“I Am Error”可能表现得非常好,而”Best Mistakes”可能是一场灾难。如果一首歌受益于早期受欢迎程度,它可能表现得很好。如果它没有得到这种益处,结果可能会非常不同。
当然,最差的歌曲(由对照组确定)从未最终升到最顶端,最好的歌曲从未最终沉到最底部。但除此之外,几乎任何事情都可能发生。正如作者强调的,“在社会影响条件下的成功水平比在独立条件下更不可预测。”简而言之,社会影响在群体之间创造了显著的噪音。如果你仔细想想,你会发现个别群体也是嘈杂的,从某种意义上说,他们对某首歌的支持或反对判断很容易就会不同,这取决于它是否吸引了早期的受欢迎程度。
正如Salganik和他的合著者后来证明的那样,群体结果可以相当容易地被操控,因为受欢迎程度是自我强化的。在一个有些恶毒的后续实验中,他们颠倒了对照组中的排名(换句话说,他们谎报了歌曲的受欢迎程度),这意味着人们看到最不受欢迎的歌曲是最受欢迎的,反之亦然。研究人员然后测试网站访问者会做什么。结果是大多数不受欢迎的歌曲变得相当受欢迎,而大多数受欢迎的歌曲表现得很差。在非常大的群体中,受欢迎和不受欢迎会滋生更多相同的情况,即使研究人员误导人们哪些歌曲受欢迎。唯一的例外是对照组中最受欢迎的歌曲确实随着时间的推移而受欢迎程度上升,这意味着颠倒的排名无法压制最好的歌曲。然而,在大多数情况下,颠倒的排名有助于确定最终排名。
很容易看出这些研究如何关系到一般的群体判断。假设一个由十个人组成的小群体正在决定是否采用某个大胆的新举措。如果一两个倡导者首先发言,他们很可能会将整个房间推向他们偏好的方向。如果怀疑者首先发言,情况也是如此。至少如果人们相互影响的话是这样——而他们通常确实如此。出于这个原因,原本相似的群体可能最终做出非常不同的判断,仅仅因为谁先发言并启动了相当于早期下载的行为。“Best Mistakes”和”I Am Error”的受欢迎程度在各种专业判断中都有密切的类似物。如果群体没有听到这种歌曲受欢迎程度排名的类似物——比如说,对那个大胆举措的强烈热情——这个举措可能不会有任何进展,仅仅因为支持它的人没有表达他们的意见。
如果你持怀疑态度,你可能会认为音乐下载的案例是独特的或至少是特殊的,它对其他群体的判断没有太多启发。但在许多其他领域也观察到了类似的现象。例如,考虑英国公投提案的受欢迎程度。在决定是否支持公投时,人们当然必须判断这是否是一个好主意,综合考虑所有因素。其模式与Salganik和他的合著者观察到的相似:最初的人气爆发是自我强化的,如果一个提案在第一天获得很少支持,它基本上就注定失败了。在政治中,如在音乐中一样,很大程度上取决于社会影响,特别是人们是否看到其他人被吸引或排斥。
直接基于音乐下载实验,康奈尔大学社会学家Michael Macy和他的合作者询问,其他人的可见观点是否能突然使可识别的政治立场在民主党人中受欢迎而在共和党人中不受欢迎——或反之亦然。简短的答案是肯定的。如果在线群体中的民主党人看到某个特定观点在民主党人中获得初步人气,他们会支持那个观点,最终导致相关群体中的大多数民主党人支持它。但如果不同在线群体中的民主党人看到完全相同的观点在共和党人中获得初步人气,他们会拒绝那个观点,最终导致相关群体中的大多数民主党人拒绝它。共和党人的行为类似。简而言之,政治立场可能就像歌曲一样,它们的最终命运可能取决于初始人气。正如研究人员所说,“少数早期推动者的偶然变化”可能对大规模人群产生重大影响——并让共和党人和民主党人都接受一系列实际上彼此毫无关系的观点。
或者考虑一个直接关系到群体决策的问题:人们如何判断网站上的评论。耶路撒冷希伯来大学教授Lev Muchnik和他的同事在一个显示各种故事并允许人们发表评论的网站上进行了实验,这些评论可以被点赞或点踩。研究人员自动且人为地给某些故事评论一个即时点赞——这是评论将收到的第一票。你可能会认为在数百或数千名访问者和评分之后,对评论的单个初始投票不可能有影响。这是一个合理的想法,但它是错误的。在看到初始点赞后(记住这完全是人为的),下一个查看者给出点赞的可能性增加了32%。
值得注意的是,这种效应持续了很长时间。五个月后,单个积极的初始投票人为地将评论的平均评分提高了25%。单个积极早期投票的效应是噪音的配方。无论那票的原因是什么,它都可能在整体受欢迎程度上产生大规模转变。
这项研究提供了群体如何转变以及为什么它们是嘈杂的线索(再次在类似群体可以做出非常不同的判断,单个群体可以做出仅仅是可能性云中之一的判断的意义上)。成员经常处于通过表示同意、中立或异议来提供早期点赞(或点踩)功能等价物的位置。如果一个群体成员给出了即时批准,其他成员也有理由这样做。毫无疑问,当群体朝着某些产品、人物、运动和想法的方向发展时,这可能不是因为它们的内在优点,而是因为早期点赞的功能等价物。当然,Muchnik自己的研究涉及非常大的群体。但同样的事情可能在小群体中发生,实际上甚至更戏剧性,因为初始点赞——支持某个计划、产品或判决——经常对其他人产生很大影响。
还有一个相关要点。我们已经指出了群体智慧:如果你询问一大群人一个问题,平均答案很可能接近目标。聚合判断可能是减少噪音进而减少错误的绝佳方式。但如果人们在互相倾听会发生什么?你可能会认为他们这样做可能会有帮助。毕竟,人们可以相互学习,从而弄清楚什么是正确的。在有利的环境下,人们分享他们所知道的,深思熟虑的群体确实可以做得很好。但独立性是群体智慧的先决条件。如果人们不做自己的判断而是依赖其他人的想法,群体可能不会那么明智。
研究已经揭示了这个确切的问题。在简单的估计任务中——城市犯罪数量、指定时期内的人口增长、国家间边界长度——只要群体独立记录他们的观点,群体确实是明智的。但如果他们了解其他人的估计——例如,十二人群体的平均估计——群体做得更差。正如作者所说,社会影响是一个问题,因为它们减少了”群体多样性而不减少集体错误”。具有讽刺意味的是,虽然多个独立意见,适当聚合,可能出人意料地准确,但即使一点社会影响也可能产生一种破坏群体智慧的羊群效应。
我们描述的一些研究涉及信息级联。这种级联现象无处不在。它们帮助解释了为什么商业、政府和其他领域的相似群体可能会走向不同的方向,以及为什么微小的变化会产生如此不同的结果,从而产生噪声。我们只能看到历史实际发生的样子,但对于许多群体和群体决策来说,存在着无数种可能性,其中只有一种得以实现。
为了了解信息级联是如何运作的,想象十个人在一个大办公室里,决定为一个重要职位雇佣谁。有三个主要候选人:Thomas、Sam和Julie。假设小组成员按顺序发表他们的观点。每个人都会合理地关注他人的判断。Arthur是第一个发言的。他建议最佳选择是Thomas。Barbara现在知道了Arthur的判断;如果她对Thomas也很有热情,她当然应该同意他的观点。但假设她不确定谁是最佳候选人。如果她信任Arthur,她可能会简单地同意:Thomas是最好的。因为她足够信任Arthur,所以她支持他的判断。
现在转向第三个人Charles。Arthur和Barbara都说他们想雇佣Thomas,但Charles基于他所知道的有限信息,自己的观点是Thomas不适合这份工作,Julie才是最佳候选人。尽管Charles持有这种观点,但他很可能会忽略自己所知道的,简单地跟随Arthur和Barbara。如果是这样,原因不是Charles胆小。而是因为他是一个尊重他人的倾听者。他可能简单地认为Arthur和Barbara都有支持他们热情的证据。
除非David认为自己的信息确实比前面那些人的更好,否则他应该也会跟随他们的领导。如果他这样做了,David就处于级联中。的确,如果他有非常强有力的理由认为Arthur、Barbara和Charles错了,他会抵制。但如果他缺乏这些理由,他很可能会跟随他们。
重要的是,Charles或David可能拥有关于Thomas(或其他候选人)的信息或见解——Arthur和Barbara不知道的信息或见解。如果这些信息被分享了,这些私人信息可能会改变Arthur或Barbara的观点。如果Charles和David先发言,他们不仅会表达对候选人的看法,还会贡献可能影响其他参与者的信息。但由于他们最后发言,他们的私人信息很可能仍然是私人的。
现在假设Erica、Frank和George也要表达他们的观点。如果Arthur、Barbara、Charles和David之前都说Thomas是最好的,他们每个人很可能会说同样的话,即使他们有充分理由认为另一个选择会更好。当然,如果不断增长的共识明显是错误的,他们可能会反对。但如果决定不明确呢?这个例子的关键在于Arthur的初始判断启动了一个过程,通过这个过程,几个人被引导参与级联,导致群体一致选择Thomas——即使一些支持他的人实际上没有观点,即使其他人认为他根本不是最佳选择。
当然,这个例子是高度人工化的。但在各种群体中,类似的事情经常发生。人们从他人那里学习,如果早期发言者似乎喜欢某样东西或想做某事,其他人可能会同意。至少在他们没有理由不信任他们,也没有充分理由认为他们错了的情况下是如此。
对于我们的目的而言,最重要的一点是信息级联使群体间的噪声成为可能,甚至是很可能的。在我们给出的例子中,Arthur首先发言并支持Thomas。但假设Barbara首先发言并支持Sam。或者假设Arthur感觉稍有不同并偏爱Julie。在合理的假设下,群体会转向Sam或Julie,不是因为他们更好,而是因为级联就是这样发展的。这是音乐下载实验(及其类似实验)的核心发现。
注意,人们参与信息级联不一定是非理性的。如果人们不确定雇佣谁,他们跟随他人可能是明智的。随着持有相同观点的人数增加,依赖他们变得更加明智。尽管如此,仍有两个问题。首先,人们倾向于忽视这样的可能性:群体中的大多数人也处于级联中——并且没有做出自己的独立判断。当我们看到三个、十个或二十个人接受某个结论时,我们很可能低估了他们都在跟随前辈的程度。我们可能认为他们的共同认同反映了集体智慧,即使它只反映了少数人的初始观点。其次,信息级联可能将人群引向真正糟糕的方向。毕竟,Arthur可能对Thomas的看法是错误的。
当然,信息不是群体成员相互影响的唯一原因。社会压力也很重要。在公司或政府中,人们可能会保持沉默,以免显得不合群、好斗、迟钝或愚蠢。他们想成为团队合作者。这就是他们跟随他人观点和行动的原因。人们认为他们知道什么是正确的或可能正确的,但他们仍然会跟随群体的明显共识,或早期发言者的观点,以保持在群体中的良好地位。
除了细微的变化外,刚才讲述的招聘故事可以以同样的方式进行,这不是因为人们彼此学习托马斯的优点,而是因为他们不想显得令人讨厌或愚蠢。阿瑟早期支持托马斯的判断可能会引发一种跟风效应(bandwagon effect),最终对埃里卡、弗兰克或乔治施加强大的社会压力,仅仅因为其他人都支持托马斯。就像信息级联一样,社会压力级联也是如此:人们很可能会夸大那些在他们之前发言的人的信念。如果人们支持托马斯,他们这样做可能不是因为他们真的偏爱托马斯,而是因为早期发言者或有权势的人支持了他。然而,团队成员最终会将自己的声音加入到共识中,从而增加社会压力的水平。这在公司和政府办公室中是一个熟悉的现象,它可能导致对一个完全错误的判断产生信心和一致支持。
在各个群体中,社会影响也会产生噪音。如果有人在会议开始时支持公司方向的重大改变,那个人可能会引发一场讨论,导致群体一致支持这种改变。他们的同意可能是社会压力的产物,而不是信念的产物。如果其他人开始会议时表达了不同的观点,或者如果最初的发言者决定保持沉默,讨论可能会朝着完全不同的方向发展——原因也是一样的。非常相似的群体可能会因为社会压力而走向不同的地方。
在美国和许多其他国家,刑事案件(和许多民事案件)通常由陪审团审理。人们希望通过他们的审议,陪审团能做出比组成这些审议机构的个人更明智的决定。然而,对陪审团的研究发现了一种独特的社会影响,这也是噪音的来源:群体极化。基本思想是,当人们彼此交谈时,他们往往会在符合其原始倾向的方向上走向更极端的立场。例如,如果七人小组中的大多数人倾向于认为在巴黎开设新办公室是个不错的主意,那么经过讨论后,该小组很可能会得出结论,认为开设该办公室将是个绝妙的主意。内部讨论往往会产生更大的信心、更大的团结和更大的极端主义,通常表现为增加的热情。碰巧的是,群体极化不仅发生在陪审团中;做出专业判断的团队也经常变得极化。
在一系列实验中,我们研究了在产品责任案件中判决惩罚性赔偿的陪审团决定。每个陪审团的决定都是一个货币金额,旨在惩罚公司的不当行为并对其他人起到威慑作用。(我们将在第15章回到这些研究并更详细地描述它们。)就我们这里的目的而言,考虑一个比较现实世界审议陪审团和”统计陪审团”的实验。首先,我们向研究中的899名参与者展示了案例小故事,并要求他们对这些案例做出自己独立的判断,使用七度量表来表达他们的愤怒和惩罚意图,以及用美元量表来表示货币奖励(如果有的话)。然后,在计算机的帮助下,我们使用这些个人回应创建了数百万个统计陪审团,即虚拟的六人小组(随机组装)。在每个统计陪审团中,我们将六个个人判断的中位数作为判决。
简而言之,我们发现这些统计陪审团的判断要一致得多。噪音大大减少了。低噪音是统计聚合的机械效应:独立的个人判断中存在的噪音总是通过平均化来减少的。
然而,现实世界的陪审团不是统计陪审团;他们会面并讨论他们对案件的看法。你可能会合理地想知道审议陪审团是否实际上倾向于得出其中位数成员的判断。为了找出答案,我们用另一个实验跟进了第一个实验,这个实验涉及三千多名符合陪审团资格的公民和五百多个六人陪审团。
结果很直接。看同一个案件,审议陪审团比统计陪审团嘈杂得多——这清楚地反映了社会影响噪音。审议的效果是增加噪音。
还有另一个有趣的发现。当六人小组的中位数成员只是适度愤怒并支持宽松惩罚时,审议陪审团的判决通常最终更加宽松。相反,当六人小组的中位数成员相当愤怒并表达严厉的惩罚意图时,审议陪审团通常最终更加愤怒和更加严厉。当这种愤怒表达为货币奖励时,有一种系统性的倾向是得出比陪审团中位数成员更高的货币奖励。实际上,27%的陪审团选择的奖励与其最严厉成员的奖励一样高,甚至更高。审议陪审团不仅比统计陪审团更嘈杂,而且还强化了组成它们的个人的意见。
回顾群体极化的基本发现:人们相互交谈后,通常会在符合其原始倾向的方向上走向更极端的立场。我们的实验说明了这种效应。进行审议的陪审团经历了向更大宽容的转变(当中位数成员宽容时)和向更大严厉的转变(当中位数成员严厉时)。同样,倾向于施加金钱惩罚的陪审团最终施加的惩罚比其中位数成员所偏好的更严厉。
群体极化的解释与级联效应的解释相似。信息起着主要作用。如果大多数人支持严厉惩罚,那么群体将听到许多支持严厉惩罚的论据——而相反方向的论据较少。如果群体成员相互倾听,他们将向主导趋势方向转变,使群体更加统一、更加自信、更加极端。如果人们关心他们在群体内的声誉,他们将向主导趋势方向转变,这也会产生极化。
群体极化当然可能产生错误。而且经常如此。但我们这里的主要关注点是变异性。正如我们所见,判断的聚合将减少噪音,为此目的,判断越多越好。这就是统计陪审团比个体陪审员噪音更小的原因。同时,我们发现审议陪审团比统计陪审团噪音更大。当类似情况的群体最终产生分歧时,群体极化往往是原因。由此产生的噪音可能非常大。
在商业、政府和其他各处,级联和极化可能导致面对同一问题的群体之间出现巨大差异。结果对少数个体判断的潜在依赖——那些首先发言或具有最大影响力的人——在我们探索了个体判断可能有多么嘈杂之后,应该特别令人担忧。我们已经看到,水平噪音和模式噪音使群体成员之间的意见差异比应有的更大(也比我们预期的更大)。我们还看到场合噪音——疲劳、情绪、比较点——可能影响第一个发言的人的判断。群体动态可以放大这种噪音。因此,审议群体往往比仅仅平均个体判断的统计群体更嘈杂。
由于商业和政府中许多最重要的决策都是在某种审议过程后做出的,因此对这种风险保持警觉尤为重要。组织及其领导者应采取措施控制其个体成员判断中的噪音。他们还应以可能减少而非放大噪音的方式管理审议群体。我们将提出的降噪策略旨在实现这一目标。
“一切似乎都取决于早期的受欢迎程度。我们最好努力确保我们的新发布有一个出色的第一周。”
“正如我一直怀疑的,关于政治和经济的想法很像电影明星。如果人们认为其他人喜欢它们,这样的想法就能走得很远。”
“我一直担心当我的团队聚在一起时,我们最终会变得自信和统一——并坚定地致力于我们选择的行动方案。我想我们的内部流程中有些地方进展得不太好!”
许多判断都是预测,由于可验证的预测可以被评估,我们可以通过研究它们来了解很多关于噪音和偏见的知识。在本书的这一部分,我们专注于预测性判断。
第9章比较了专业人士、机器和简单规则所做预测的准确性。我们的结论——专业人士在这场竞争中排名第三——不会令您感到惊讶。在第10章中,我们探讨了这一结果的原因,并表明噪音是人类判断劣势的主要因素。
为了得出这些结论,我们必须评估预测的质量,为此,我们需要一个预测准确性的衡量标准,一种回答这个问题的方法:预测与结果的共变程度如何?例如,如果HR部门定期评估新员工的潜力,我们可以等几年看看员工的表现如何,看看潜力评级与绩效评估的共变程度。预测的准确性程度等于那些在雇用时潜力被评为高的员工在工作中也获得高评价的程度。
一个捕捉这种直觉的衡量标准是一致百分比(PC),它回答一个更具体的问题:假设你随机选择一对员工。潜力得分较高的员工在工作中表现也更好的概率是多少?如果早期评级的准确性是完美的,PC将是100%:按潜力对两名员工的排名将是对他们最终按绩效排名的完美预测。如果预测完全无用,一致性只会偶然发生,“高潜力”员工表现更好的可能性与否一样:PC将是50%。我们将在第9章讨论这个已被广泛研究的例子。对于一个更简单的例子,成年男性脚长和身高的PC是71%。如果你看两个人,先看他们的头,然后看他们的脚,有71%的机会较高的人脚也较大。
PC是一个直观的协变性测量指标,这是它的一大优势,但它不是社会科学家使用的标准测量指标。标准测量指标是相关系数 (r),当两个变量正相关时,它的值在0和1之间变化。在前面的例子中,身高和脚长之间的相关性约为.60。
理解相关系数有很多种方式。这里是一种足够直观的方式:两个变量之间的相关性是它们共同决定因素的百分比。例如,想象某个特征完全由基因决定。我们预期在有50%共同基因的兄弟姐妹之间发现该特征的.50相关性,在有25%共同基因的表兄弟姐妹之间发现.25相关性。我们也可以将身高和脚长之间.60的相关性理解为,决定身高的因果因素中有60%也决定了鞋码。
我们描述的两种协变性测量指标彼此直接相关。表1展示了各种相关系数值对应的PC。在本书的其余部分,当我们讨论人类和模型的表现时,我们总是同时展示这两种测量指标。
| 表1: 相关系数和一致性百分比(PC) | |
|---|---|
| 相关系数 | 一致性百分比(PC) |
| .00 | 50% |
| .10 | 53% |
| .20 | 56% |
| .30 | 60% |
| .40 | 63% |
| .60 | 71% |
| .80 | 79% |
| 1.00 | 100% |
在第11章中,我们讨论了预测准确性的一个重要限制:大多数判断都是在我们称之为客观无知的状态下做出的,因为未来所依赖的许多事情根本无法知晓。令人惊讶的是,大多数时候,我们设法对这种局限性视而不见,并满怀信心(实际上是过度自信)地做出预测。最后,在第12章中,我们表明客观无知不仅影响我们预测事件的能力,甚至影响我们理解事件的能力——这是解释为什么噪音往往不可见这一谜题的重要部分。
许多人对预测人们在工作中的未来表现感兴趣——包括他们自己和他人的表现。因此,表现预测是专业预测性判断的一个有用例子。比如,考虑一家大公司的两名高管。Monica和Nathalie在被雇用时接受了专业咨询公司的评估,在领导力、沟通、人际交往技能、工作相关技术技能和对下一个职位的动机方面获得了1到10分的评分(表2)。你的任务是预测她们在被雇用两年后的绩效评估,同样使用1到10分的量表。
| 表2: 两位高管职位候选人 | ||||||
|---|---|---|---|---|---|---|
| ** ** | 领导力 **沟 | 通能力** **人际交往 | 技能** 技术技能 **动 | 机** 你的预测 | ||
| Monica | 4 | 6 | 4 | 8 | 8 | |
| Nathalie | 8 | 10 | 6 | 7 | 6 |
大多数人面对这类问题时,只是快速浏览每一行并做出快速判断,有时在心理计算分数平均值后。如果你刚才就是这样做的,你可能得出结论认为Nathalie是更强的候选人,她和Monica之间的差距是1或2分。
你对这个问题采取的非正式方法被称为临床判断。你考虑信息,也许进行快速计算,咨询你的直觉,然后得出判断。实际上,临床判断就是我们在本书中简单描述为判断的过程。
现在假设你作为实验参与者执行预测任务。Monica和Nathalie是从几年前雇用的数百名经理的数据库中抽取的,他们在五个独立维度上获得了评分。你使用这些评分来预测经理们在工作中的成功。现在可以获得他们在新角色中的表现评估。这些评估与你对他们潜力的临床判断的一致性如何?
这个例子大致基于一项实际的绩效预测研究。如果你曾是该研究的参与者,你可能不会对其结果感到满意。由一家国际咨询公司雇佣的博士级心理学家进行此类预测,与绩效评估的相关性仅达到0.15(PC = 55%)。换句话说,当他们评定一位候选人比另一位更强时——就像你对Monica和Nathalie所做的评定一样——他们偏爱的候选人最终获得更高绩效评级的概率为55%,仅略好于随机猜测。至少可以说,这不是一个令人印象深刻的结果。
也许你认为准确性很差是因为你看到的评级对预测毫无用处。因此我们必须问,候选人的评级实际包含多少有用的预测信息?如何将它们组合成一个预测分数,以便与绩效有尽可能高的相关性?
一个标准的统计方法回答了这些问题。在本研究中,它产生了0.32的最佳相关性(PC = 60%),远非令人印象深刻,但比临床预测取得的结果高出很多。
这种技术称为多元回归,产生一个预测分数,该分数是预测变量的加权平均值。它找到最佳权重集,选择这些权重是为了最大化复合预测与目标变量之间的相关性。最佳权重使预测的MSE(均方误差)最小化——这是最小二乘法原理在统计学中占主导地位的一个典型例子。正如你可能期望的那样,与目标变量最密切相关的预测变量获得较大权重,而无用的预测变量权重为零。权重也可能是负数:候选人未缴交通罚单的数量可能作为管理成功的预测变量获得负权重。
多元回归的使用是机械预测的一个例子。机械预测有很多种类,从简单规则(“雇用任何完成高中学业的人”)到复杂的AI模型。但线性回归模型是最常见的(它们被称为”判断和决策制定研究的主力”)。为了减少术语,我们将线性模型称为简单模型。
我们用Monica和Nathalie说明的研究是临床预测和机械预测众多比较中的一个,它们都具有简单的结构:
一组预测变量(在我们的例子中,是候选人的评级)用于预测目标结果(同一人群的工作评估);
人类判断者进行临床预测;
一个规则(如多元回归)使用相同的预测变量产生同一结果的机械预测;
比较临床预测和机械预测的整体准确性。
当人们了解临床预测和机械预测时,他们想知道两者如何比较。相对于公式,人类判断有多好?
这个问题以前就有人问过,但直到1954年才引起广泛关注,当时明尼苏达大学心理学教授Paul Meehl发表了一本题为临床vs统计预测:理论分析和证据回顾的书。Meehl回顾了二十项研究,这些研究中临床判断与机械预测在学术成功和精神病学预后等结果上进行了较量。他得出了强有力的结论:简单的机械规则通常优于人类判断。Meehl发现,临床医生和其他专业人士在他们通常视为独特优势的能力上表现得令人沮丧地薄弱:整合信息的能力。
要理解这一发现有多令人惊讶,以及它与噪音的关系,你必须理解简单机械预测模型的工作原理。其定义特征是对所有案例应用相同的规则。每个预测变量都有一个权重,该权重不会因案例而异。你可能认为这种严格约束使模型相对于人类判断者处于极大劣势。在我们的例子中,也许你认为Monica的动机和技术技能的结合将是一项重要资产,可以抵消她在其他领域的局限性。也许你还认为,考虑到Nathalie的其他优势,她在这两个领域的弱点不会是严重问题。隐含地,你想象了两位女性成功的不同路径。这些合理的临床推测有效地为两个案例中的相同预测变量分配了不同权重——这种微妙之处超出了简单模型的能力范围。
简单模型的另一个限制是,预测因子增加1个单位总是产生相同的效果(而增加2个单位的效果是前者的两倍)。临床直觉经常违反这条规则。例如,如果你对娜塔莉在沟通技能上的满分10分印象深刻,并决定这个分数值得提升你的预测,你做了简单模型不会做的事情。在加权平均公式中,10分和9分之间的差异必须与7分和6分之间的差异相同。临床判断不遵循这个规则。相反,它反映了一种常见的直觉,即同样的差异在一种情况下可能无关紧要,而在另一种情况下却至关重要。你可能想要检查一下,但我们怀疑没有简单模型能够完全解释你对莫妮卡和娜塔莉的判断。
我们用于这些案例的研究是Meehl模式的一个明确例子。正如我们所指出的,临床预测与工作表现的相关性为.15(PC = 55%),但机械预测达到了.32的相关性(PC = 60%)。想想你在比较莫妮卡和娜塔莉案例相对优点时所体验到的信心。Meehl的结果强烈表明,你对自己判断质量的任何满意都是一种错觉:有效性错觉。
有效性错觉在任何进行预测性判断的地方都能找到,因为人们普遍无法区分预测任务的两个阶段:根据可用证据评估案例和预测实际结果。你通常可以非常自信地评估两个候选人中哪一个看起来更好,但猜测他们中哪一个实际上会更好则完全是另一回事。可以安全地断言,例如,娜塔莉看起来比莫妮卡是更强的候选人,但断言娜塔莉将是比莫妮卡更成功的高管则一点也不安全。原因很简单:你知道评估这两个案例所需的大部分信息,但凝视未来充满了深度的不确定性。
不幸的是,这种差异在我们的思维中变得模糊。如果你发现自己对案例和预测之间的区别感到困惑,你并不孤单:每个人都觉得这种区别令人困惑。然而,如果你对预测的信心与对案例评估的信心一样,你就是有效性错觉的受害者。
临床医生也不能免受有效性错觉的影响。你肯定可以想象临床心理学家对Meehl发现的反应——简单的公式,如果持续应用,会超越临床判断。这种反应结合了震惊、不信和对这种浅薄研究的蔑视,这种研究假装研究临床直觉的奇迹。这种反应很容易理解:Meehl的模式与判断的主观体验相矛盾,我们大多数人会相信自己的经验而不是学者的声明。
Meehl本人对自己的发现持矛盾态度。由于他的名字与统计学优于临床判断相关联,我们可能会想象他是人类洞察力的无情批评者,或者如我们今天所说的量化分析之父。但那将是一种漫画化的描述。Meehl除了学术生涯外,还是一名执业精神分析师。弗洛伊德的照片挂在他的办公室里。他是一个博学者,不仅教授心理学课程,还教授哲学和法律课程,并写作形而上学、宗教、政治科学,甚至超心理学。(他坚持认为”心灵感应是有道理的。“)这些特征都不符合顽固数字专家的刻板印象。Meehl对临床医生没有恶意——远非如此。但正如他所说,机械方法在结合输入方面的优势证据是”大量且一致的”。
“大量且一致”是一个公平的描述。2000年对136项研究的回顾明确证实,机械聚合优于临床判断。文章中调查的研究涵盖了广泛的主题,包括黄疸诊断、军事服务适应性和婚姻满意度。机械预测在63项研究中更准确,另外65项研究被宣布为统计平局,临床预测在8个案例中获胜。这些结果低估了机械预测的优势,它也比临床判断更快、更便宜。此外,在许多这些研究中,人类判断者实际上具有不公平的优势,因为他们可以获得没有提供给计算机模型的”私人”信息。这些发现支持一个直白的结论:简单模型胜过人类。
Meehl的发现提出了重要问题。确切地说,为什么公式更优越?公式做得更好的是什么?事实上,一个更好的问题是问人类做得更差的是什么。答案是人们在许多方面都不如统计模型。他们的一个关键弱点是他们是嘈杂的。
为了支持这个结论,我们转向关于简单模型的不同研究流,它始于俄勒冈州的小城市尤金。Paul Hoffman是一位富有且有远见的心理学家,对学术界感到不耐烦。他创立了一个研究所,在一个屋檐下聚集了几位非常有效的研究人员,他们将尤金变成了人类判断研究的世界著名中心。
其中一位研究者是刘易斯·戈德伯格(Lewis Goldberg),他因在人格五大因素模型发展中的领导作用而最为知名。在20世纪60年代末,戈德伯格在霍夫曼早期工作的基础上,研究了描述个体判断的统计模型。
构建一个判断者模型就像构建一个现实模型一样容易。使用的是相同的预测变量。在我们最初的例子中,预测变量是对经理绩效的五项评分。使用的也是相同的工具——多元回归。唯一的区别是目标变量。公式不是用来预测一组真实结果,而是用来预测一组判断——例如,你对莫妮卡、娜塔莉和其他经理的判断。
将你的判断建模为加权平均的想法可能看起来完全奇怪,因为这不是你形成观点的方式。当你对莫妮卡和娜塔莉进行临床思考时,你并没有对两个案例应用相同的规则。事实上,你根本没有应用任何规则。判断者模型并不是对判断者实际如何判断的现实描述。
然而,即使你实际上没有计算线性公式,你仍然可能好像你在这样做一样进行判断。专业台球选手表现得好像他们解决了描述特定击球力学的复杂方程,即使他们根本没有做这样的事情。同样,你可能像使用简单公式一样生成预测——即使你实际所做的要复杂得多。一个能够合理准确预测人们行为的”好像”模型是有用的,即使它作为过程的描述显然是错误的。这就是简单判断模型的情况。一项判断研究的全面回顾发现,在237项研究中,判断者模型与判断者临床判断之间的平均相关性为0.80(PC = 79%)。虽然远非完美,但这种相关性足够高,可以支持”好像”理论。
驱动戈德伯格研究的问题是,判断者的简单模型在预测真实结果方面表现如何。由于模型是判断者的粗略近似,我们可以合理地假设它不能表现得那么好。当模型取代判断者时,会损失多少准确性?
答案可能会让你惊讶。当模型生成预测时,预测并没有失去准确性。它们得到了改善。在大多数情况下,模型的预测超过了它所基于的专业人员。替代品比原产品更好。
这个结论已经在许多领域的研究中得到证实。戈德伯格工作的早期复制涉及对研究生学术成功的预测。研究人员要求98名参与者根据十个线索预测90名学生的GPA。基于这些预测,研究人员为每个参与者的判断建立了一个线性模型,并比较了参与者和参与者模型预测GPA的准确性。对于98名参与者中的每一个,模型都比参与者表现得更好!几十年后,一项对50年研究的回顾得出结论,判断者模型始终优于它们所建模的判断者。
我们不知道这些研究中的参与者是否收到了关于他们表现的个人反馈。但你当然可以想象,如果有人告诉你,一个对你判断的粗糙模型——几乎是一个漫画——实际上比你更准确,你会有多么沮丧。对我们大多数人来说,判断活动之所以复杂、丰富和有趣,正是因为它不符合简单的规则。当我们发明和应用复杂规则,或者有一个洞察使个别案例与其他案例不同时——简而言之,当我们做出不能简化为简单加权平均操作的判断时,我们对自己和我们做出判断的能力感觉最好。判断者模型研究强化了米尔的结论,即微妙性在很大程度上是浪费的。复杂性和丰富性通常不会导致更准确的预测。
为什么会这样?要理解戈德伯格的发现,我们需要了解是什么导致了你和你的模型之间的差异。是什么造成了你的实际判断与预测它们的简单模型输出之间的差异?
你判断的统计模型不可能在它们包含的信息中添加任何东西。模型所能做的就是减法和简化。特别是,你判断的简单模型不会代表你始终遵循的任何复杂规则。如果你认为沟通技能评分中10和9之间的差异比7和6之间的差异更重要,或者在所有维度上都得到稳定7分的全面候选人比以明显的优势和显著弱点达到相同平均分的候选人更可取,那么你的模型不会再现你的复杂规则——即使你以完美的一致性应用它们。
当你的微妙性有效时,未能再现你的微妙规则将导致准确性的损失。例如,假设你必须从两个输入——技能和动机——预测困难任务的成功。加权平均不是一个好公式,因为再多的动机也不足以克服严重的技能缺陷,反之亦然。如果你使用两个输入的更复杂组合,你的预测准确性将得到增强,并将高于未能捕捉到这种微妙性的模型所达到的准确性。另一方面,复杂规则往往只会给你有效性的错觉,实际上会损害你判断的质量。有些微妙性是有效的,但许多不是。
此外,一个简单的你的模型无法代表你判断中的模式噪音。它无法复制由你对特定案例可能产生的任意反应而引起的正面和负面错误。该模型也无法捕捉瞬时情境的影响以及你在做出特定判断时的心理状态。很可能,这些嘈杂的判断错误与任何事物都没有系统性的关联,这意味着在大多数情况下,它们可以被视为随机的。
从你的判断中消除噪音的效果总是会提高你的预测准确性。例如,假设你的预测与结果之间的相关性是.50(PC = 67%),但你判断中50%的变异由噪音组成。如果你的判断能够做到无噪音——正如你的模型那样——它们与同一结果的相关性将跃升至.71(PC = 75%)。机械地减少噪音能够提高预测判断的有效性。
简而言之,用你的模型替代你会产生两个效果:它消除了你的微妙性,也消除了你的模式噪音。“判断者的模型比判断者本身更有效”这一稳健发现传达了一个重要信息:人类判断中微妙规则的收益——当它们存在时——通常不足以补偿噪音的有害影响。你可能认为自己比你思维的线性简化更微妙、更有洞察力、更细致入微。但实际上,你主要是更嘈杂。
为什么复杂的预测规则会损害准确性,尽管我们强烈感觉它们汲取了有效的洞察?首先,人们发明的许多复杂规则可能并不普遍正确。但还有另一个问题:即使复杂规则在原则上是有效的,它们也不可避免地适用于很少观察到的条件。例如,假设你得出结论认为特别原创的候选人值得雇用,即使他们在其他维度上的得分平庸。问题是,按定义,特别原创的候选人特别罕见。由于对原创性的评估可能不可靠,该指标上的许多高分都是偶然的,而真正的原创人才往往未被发现。能够确认”原创者”最终成为超级明星的绩效评估也是不完美的。两端的测量误差不可避免地削弱了预测的有效性——而罕见事件特别容易被遗漏。真正微妙性的优势很快就被测量误差淹没了。
Martin Yu和Nathan Kuncel的一项研究报告了Goldberg演示的一个更激进版本。这项研究(这是Monica和Nathalie例子的基础)使用了一家国际咨询公司的数据,该公司雇用专家评估847名高管职位候选人,分为三个独立样本。专家对七个不同评估维度的结果进行评分,并使用他们的临床判断为每人分配一个总体预测分数,结果相当不令人印象深刻。
Yu和Kuncel决定不是将判断者与他们自己的最佳简单模型进行比较,而是与随机线性模型进行比较。他们为七个预测变量生成了一万组随机权重,并应用这一万个随机公式来预测工作表现。
他们的惊人发现是,任何线性模型,当一致地应用于所有案例时,都可能在从相同信息预测结果方面超越人类判断者。在三个样本中的一个,77%的一万个随机加权线性模型比人类专家表现更好。在另外两个样本中,100%的随机模型超越了人类。或者,直白地说,在那项研究中,生成一个比专家表现更差的简单模型几乎是不可能的。
这项研究得出的结论比我们从Goldberg关于判断者模型的工作中得出的结论更强——实际上这是一个极端例子。在这种情况下,人类判断者在绝对意义上表现非常差,这有助于解释为什么甚至不太出色的线性模型都能超越他们。当然,我们不应该得出任何模型都能击败任何人类的结论。不过,机械地遵循简单规则(Yu和Kuncel称之为”无思维的一致性”)能够在困难问题中显著改善判断这一事实,说明了噪音对临床预测有效性的巨大影响。
这次快速浏览展示了噪音如何损害临床判断。在预测性判断中,人类专家很容易被简单公式超越——现实模型、判断者模型,甚至随机生成的模型。这一发现支持使用无噪音方法:规则和算法,这是下一章的主题。
“人们相信他们在做判断时捕捉了复杂性并增加了微妙性。但复杂性和微妙性大多是浪费的——通常它们并不能增加简单模型的准确性。”
“在Paul Meehl的书出版六十多年后,机械预测优于人类的观点仍然令人震惊。”
“判断中有如此多的噪音,以至于判断者的无噪音模型比实际判断者实现了更准确的预测。”
近年来,人工智能(AI),特别是机器学习技术,使机器能够执行许多以前被认为是典型人类任务的工作。机器学习算法可以识别面孔、翻译语言和读取放射影像。它们可以解决计算问题,例如同时为数千名司机生成驾驶路线,速度和准确性令人惊叹。它们还执行困难的预测任务:机器学习算法预测美国最高法院的决定,确定哪些被告更可能逃保,并评估哪些致电儿童保护服务的电话最紧急需要案例工作者的访问。
尽管如今这些是我们听到算法一词时想到的应用,但这个术语有更广泛的含义。在一本词典的定义中,算法是”在计算或其他问题解决操作中要遵循的过程或规则集,特别是由计算机执行的”。根据这个定义,我们在前一章中描述的简单模型和其他形式的机械判断也是算法。
事实上,许多类型的机械方法,从几乎可笑地简单的规则到最复杂和不可理解的机器算法,都可以超越人类判断。这种超越表现的一个关键原因——尽管不是唯一原因——是所有机械方法都是无噪声的。
为了研究不同类型的基于规则的方法,并了解每种方法如何以及在什么条件下有价值,我们从第9章的模型开始我们的旅程:基于多元回归(即线性回归模型)的简单模型。从这个起点,我们将在复杂程度的光谱上向两个相反的方向前进——首先寻求极端简单性,然后增加更大的复杂性(图11)。

图11:四种类型的规则和算法
Robyn Dawes是1960和1970年代研究判断的俄勒冈州尤金明星团队的另一名成员。1974年,Dawes在预测任务的简化方面取得了突破。他的想法令人惊讶,几乎是异端的:他提议给所有预测因子相等的权重,而不是使用多元回归来确定每个预测因子的精确权重。
Dawes将等权重公式标记为不当线性模型。他的惊人发现是,这些等权重模型与”正当”回归模型一样准确,并且远优于临床判断。
即使是不当模型的支持者也承认这种说法是不可信的,“违反统计直觉”。确实,Dawes和他的助手Bernard Corrigan最初在科学期刊上发表他们的论文时遇到了困难;编辑们根本不相信他们。如果你想想前一章中Monica和Nathalie的例子,你可能相信某些预测因子比其他因子更重要。例如,大多数人会给领导力比技术技能更高的权重。一个直接的非加权平均值怎么能比精心加权的平均值或专家的判断更好地预测某人的表现呢?
今天,在Dawes突破的许多年后,这个如此令他的同时代人惊讶的统计现象已经得到很好的理解。如本书前面所解释的,多元回归计算”最优”权重以最小化平方误差。但多元回归在原始数据中最小化误差。因此,公式调整自身以预测数据中的每个随机异常。例如,如果样本包括几个技术技能高且由于无关原因表现异常出色的经理,模型将夸大技术技能的权重。
挑战在于,当公式应用于样本外时——即当它用于预测不同数据集中的结果时——权重将不再是最优的。原始样本中的异常不再存在,正是因为它们是异常;在新样本中,技术技能高的经理并非都是超级明星。新样本有不同的异常,公式无法预测。模型预测准确性的正确衡量是其在新样本中的表现,称为交叉验证相关性。实际上,回归模型在原始样本中过于成功,交叉验证相关性几乎总是低于原始数据中的相关性。Dawes和Corrigan在几种情况下比较了等权重模型与多元回归模型(交叉验证)。他们的一个例子涉及预测伊利诺伊大学90名心理学研究生的第一年GPA,使用与学术成功相关的十个变量:能力测试分数、大学成绩、各种同伴评级(如外向性)和各种自我评级(如责任心)。标准多元回归模型达到了.69的相关性,在交叉验证中缩减到.57(PC = 69%)。等权重模型与第一年GPA的相关性大致相同:.60(PC = 70%)。类似的结果在许多其他研究中也得到了验证。
交叉验证中准确性的损失在原始样本较小时最为严重,因为在小样本中偶然性因素的影响更大。Dawes指出的问题是,社会科学研究中使用的样本通常都很小,以至于所谓最优权重的优势消失了。正如统计学家Howard Wainer在一篇关于适当权重估计的学术文章副标题中令人难忘地写道:“这根本不重要”。或者,用Dawes的话说:“我们不需要比我们的测量更精确的模型。”等权重模型表现良好,因为它们不容易受到抽样偶然性的影响。
Dawes工作的直接含义值得被广泛了解:你可以在没有关于要预测结果的先验数据的情况下做出有效的统计预测。你所需要的只是一组你相信与结果相关的预测变量。
假设你必须预测那些在多个维度上被评分的高管的表现,就像第9章的例子一样。你相信这些分数衡量了重要的品质,但你没有关于每个分数如何预测表现的数据。你也没有等待几年来跟踪大量管理者样本表现的奢侈。尽管如此,你仍然可以采用这七个分数,进行所需的统计工作来对它们进行等权重处理,并将结果用作你的预测。这个等权重模型会有多好?它与结果的相关性为.25(PC = 58%),远优于临床预测(r = .15, PC = 55%),并且肯定与交叉验证回归模型非常相似。而且它不需要任何你没有的数据或任何复杂的计算。
用Dawes的话说,这在判断研究的学生中已经成为一个模因,等权重具有”稳健的美感“。介绍这一想法的开创性文章的最后一句话提供了另一个简洁的总结:”整个诀窍就是决定要看什么变量,然后知道如何相加。”
另一种简化风格是通过节俭模型或简单规则。节俭模型是看起来像荒谬简化的、粗略估算的现实模型。但在某些情况下,它们可以产生惊人的良好预测。
这些模型建立在多元回归的一个大多数人都觉得令人惊讶的特征之上。假设你使用两个对结果有强预测性的预测变量——它们与结果的相关性分别为.60(PC = 71%)和.55(PC = 69%)。还假设这两个预测变量彼此相关,相关性为.50。当这两个预测变量以最优方式组合时,你认为你的预测会有多好?答案相当令人失望。相关性为.67(PC = 73%),比之前高,但高得不多。
这个例子说明了一个普遍规则:两个或更多相关预测变量的组合比它们中最好的单独使用时的预测性几乎没有提高。因为在现实生活中,预测变量几乎总是彼此相关的,这个统计事实支持使用节俭的预测方法,即使用少量预测变量。与使用更多预测变量的模型相比,可以在很少或不需要计算的情况下应用的简单规则在某些情况下产生了令人印象深刻的准确预测。
一个研究团队在2020年发布了一项大规模努力,将节俭方法应用于各种预测问题,包括保释法官在决定是否释放或拘留等待审判的被告时面临的选择。这个决定是对被告行为的隐含预测。如果错误地拒绝保释,那个人将被不必要地拘留,对个人和社会都造成重大成本。如果向错误的被告批准保释,那个人可能在审判前逃跑,甚至犯下另一项罪行。
研究人员建立的模型只使用两个已知高度预测被告逃跑可能性的输入:被告的年龄(年龄较大的人逃跑风险较低)和过去错过的法庭日期数量(以前未出庭的人往往会再犯)。该模型将这两个输入转换为若干分数,可以用作风险评分。计算被告的风险不需要计算机——实际上,甚至不需要计算器。
在对真实数据集进行测试时,这个节俭模型的表现与使用更多变量的统计模型一样好。节俭模型在预测逃跑风险方面比几乎所有人类保释法官都做得更好。
同样的节俭方法,使用最多五个特征,用小整数(-3到+3之间)加权,被应用于各种任务,如从乳房X光摄影数据确定肿瘤的严重程度、诊断心脏病和预测信用风险。在所有这些任务中,节俭规则的表现与更复杂的回归模型一样好(尽管通常不如机器学习好)。
在简单规则力量的另一个演示中,另一个研究团队研究了一个类似但不同的司法问题:累犯预测。仅使用两个输入,他们能够匹配使用137个变量评估被告风险水平的现有工具的有效性。毫不奇怪,这两个预测变量(年龄和以前定罪的次数)与保释模型中使用的两个因素密切相关,它们与犯罪行为的关联是有充分记录的。
简约规则的吸引力在于它们透明且易于应用。此外,这些优势相对于更复杂的模型在准确性方面的损失相对较小。
在我们旅程的第二部分,让我们现在朝着复杂性光谱的相反方向前进。如果我们能够使用更多的预测因子,收集关于每个因子的更多数据,发现人类无法检测到的关系模式,并建模这些模式以实现更好的预测,会怎么样?这本质上就是AI的承诺。
非常大的数据集对于复杂分析至关重要,这种数据集日益增加的可用性是近年来AI快速发展的主要原因之一。例如,大数据集使得机械化处理”断腿例外”成为可能。这个有些神秘的短语可以追溯到Meehl想象的一个例子:考虑一个设计用来预测人们今晚去看电影概率的模型。无论你对模型有多大信心,如果你碰巧知道某个特定的人刚刚摔断了腿,你可能比模型更清楚他们的晚上会是什么样子。
当使用简单模型时,断腿原则为决策者提供了重要教训:它告诉他们何时应该推翻模型,何时不应该。如果你有模型无法考虑的决定性信息,那就有一个真正的断腿情况,你应该推翻模型的建议。另一方面,即使你缺乏这种私人信息,有时你也会不同意模型的建议。在那些情况下,你推翻模型的冲动反映了你正在将个人模式应用于相同的预测因子。由于这种个人模式很可能是无效的,你应该克制推翻模型的冲动;你的干预很可能会使预测变得不够准确。
机器学习模型在预测任务中成功的原因之一是它们能够发现这样的断腿情况——比人类能想到的多得多。给定关于大量案例的大量数据,一个跟踪电影观众行为的模型实际上可以学习到,例如,在他们常规电影日去过医院的人不太可能在那个晚上看电影。以这种方式改善罕见事件的预测减少了对人类监督的需求。
AI所做的不涉及魔法也不涉及理解;它仅仅是模式发现。虽然我们必须赞赏机器学习的力量,但我们应该记住,AI可能需要一些时间才能理解为什么摔断腿的人会错过电影之夜。
大约在前面提到的研究团队将简单规则应用于保释决定问题的同时,另一个由Sendhil Mullainathan领导的团队训练了复杂的AI模型来执行同样的任务。AI团队可以访问更大的数据集——758,027个保释决定。对于每个案例,团队可以访问法官也能获得的信息:被告的当前罪名、犯罪记录和之前的缺席记录。除了年龄之外,没有其他人口统计信息被用来训练算法。研究人员也知道每个案例中被告是否被释放,如果是,该个人是否未能出庭或被重新逮捕。(74%的被告被释放,其中15%未能出庭,26%被重新逮捕。)利用这些数据,研究人员训练了一个机器学习算法并评估了其性能。由于模型是通过机器学习构建的,它不限于线性组合。如果它在数据中检测到更复杂的规律性,它可以使用这种模式来改善其预测。
该模型被设计为产生量化为数值分数的逃跑风险预测,而不是保释/不保释决定。这种方法认识到最大可接受风险阈值,即超过该风险水平就应该拒绝保释的水平,需要模型无法做出的评估性判断。然而,研究人员计算出,无论风险阈值设在哪里,使用他们模型的预测分数都会比人类法官的表现有所改善。如果风险阈值设置得使被拒绝保释的人数与法官决定时保持相同,Mullainathan的团队计算出,犯罪率可以减少多达24%,因为被关押的人将是最有可能再犯的人。相反,如果风险阈值设置为在不增加犯罪的情况下尽可能减少被拒绝保释的人数,研究人员计算出被拘留的人数可以减少多达42%。换句话说,机器学习模型在预测哪些被告是高风险方面比人类法官表现得更好。
通过机器学习构建的模型也比使用相同信息的线性模型成功得多。原因很有趣:“机器学习算法在可能被忽略的变量组合中发现了重要信号。”算法发现其他方法容易错过的模式的能力在算法分类为最高风险的被告中尤其明显。换句话说,数据中的一些模式虽然罕见,但强烈预测高风险。这一发现——算法捕捉到罕见但决定性的模式——将我们带回到断腿概念。
研究人员还使用该算法构建了每位法官的模型,类似于我们在第9章中描述的法官模型(但不局限于简单的线性组合)。将这些模型应用于整个数据集,使团队能够模拟法官在看到相同案件时会做出的决定,并比较这些决定。结果表明,保释决定中存在相当大的系统噪音。其中一些是水平噪音:当法官按宽松程度排序时,最宽松的五分之一(即释放率最高的20%的法官)释放了83%的被告,而最不宽松的五分之一法官只释放了61%。法官在判断哪些被告具有更高逃跑风险方面也有非常不同的模式。一个被某位法官视为低逃跑风险的被告,可能被另一位法官认为是高逃跑风险,而后者总体上并不更严格。这些结果清楚地证明了模式噪音的存在。更详细的分析显示,案件间的差异占方差的67%,系统噪音占33%。系统噪音包括一些水平噪音,即平均严厉程度的差异,但大部分(79%)是模式噪音。
最后,幸运的是,机器学习程序更高的准确性并不以牺牲法官可能追求的其他可识别目标为代价——特别是种族公平。理论上,尽管算法不使用种族数据,但程序可能无意中加剧种族差异。如果模型使用与种族高度相关的预测因子(如邮政编码),或者如果训练算法的数据源存在偏见,就可能出现这些差异。例如,如果使用过往逮捕次数作为预测因子,而过往逮捕受到种族歧视的影响,那么由此产生的算法也会产生歧视。
虽然这种歧视在原则上确实是一种风险,但该算法的决定在重要方面比法官的决定种族偏见更少,而不是更多。例如,如果设置风险阈值以达到与法官决定相同的犯罪率,那么算法将少关押41%的有色人种。在其他情况下也发现了类似的结果:准确性的提高不一定会加剧种族差异——正如研究团队也显示的那样,算法可以很容易地被指示减少这些差异。
另一项在不同领域的研究说明了算法如何能够同时提高准确性和减少歧视。Columbia Business School教授Bo Cowgill研究了一家大型科技公司的软件工程师招聘。Cowgill开发了一个机器学习算法来筛选候选人简历,而不是使用(人工)简历筛选员来选择谁能获得面试机会,并用公司收到和评估的三十多万份申请对其进行训练。算法选择的候选人在面试后获得工作机会的可能性比人工选择的候选人高14%。当候选人收到录用通知时,算法组接受录用的可能性比人工选择组高18%。算法还选择了在种族、性别和其他指标方面更多样化的候选人群体;它更有可能选择”非传统”候选人,如那些不是精英学校毕业的、缺乏先前工作经验的,以及没有推荐的候选人。人类倾向于偏爱那些符合软件工程师”典型”档案所有条件的简历,但算法给予每个相关预测因子适当的权重。
需要明确的是,这些例子并不能证明算法总是公平、无偏见或非歧视性的。一个常见的例子是,一个算法本应预测求职候选人的成功,但实际上是在过去晋升决定的样本上训练的。当然,这样的算法会复制过去晋升决定中的所有人类偏见。
构建一个延续种族或性别差异的算法是可能的,而且可能过于容易,已经有许多报告的算法案例就是这样做的。这些案例的可见性解释了人们对算法决策中偏见日益增长的担忧。然而,在对算法得出一般性结论之前,我们应该记住,一些算法不仅比人类法官更准确,而且更公平。
总结这次对机械决策制定的简短巡览,我们回顾了各种规则优于人类判断的两个原因。首先,如第9章所述,所有机械预测技术,不仅仅是最新和最复杂的技术,都代表了对人类判断的显著改进。个人模式和场合噪音的结合对人类判断质量的影响如此沉重,以至于简单性和无噪音性是相当大的优势。仅仅是合理的简单规则通常比人类判断做得更好。
其次,数据有时足够丰富,能让复杂的AI技术检测到有效模式,并远远超越简单模型的预测能力。当AI以这种方式成功时,这些模型相对于人类判断的优势不仅仅是没有噪音,还有利用更多信息的能力。
考虑到这些优势以及支持它们的大量证据,值得思考的是,为什么算法在我们本书讨论的专业判断类型中没有得到更广泛的应用。尽管人们对算法和机器学习有热烈的讨论,尽管在特定领域有重要的例外情况,但它们的使用仍然有限。许多专家忽视临床与机械判断的辩论,更愿意相信自己的判断。他们对自己的直觉有信心,怀疑机器能做得更好。他们认为算法决策的想法是非人性化的,是对自己责任的推卸。
例如,在医疗诊断中使用算法尚未成为常规做法,尽管取得了令人印象深刻的进展。很少有组织在招聘和晋升决策中使用算法。好莱坞制片厂高管根据自己的判断和经验批准电影项目,而不是根据公式。图书出版商也是这样做的。如果迈克尔·刘易斯(Michael Lewis)的畅销书《点球成金》中关于痴迷统计数据的奥克兰运动家棒球队的故事产生了如此深刻的印象,那正是因为算法的严谨性长期以来一直是体育团队决策过程中的例外,而不是常规。即使在今天,教练、经理和与他们一起工作的人经常相信自己的直觉,并坚持认为统计分析不可能取代良好的判断。
在1996年的一篇文章中,Meehl和一位合著者列出了(并反驳了)精神病医生、医生、法官和其他专业人士对机械判断的不少于十七种类型的反对意见。作者们得出结论,临床医生的抗拒可以用社会心理因素的组合来解释,包括他们对”技术性失业的恐惧”、“教育不足”和”对计算机的普遍厌恶”。
从那时起,研究人员已经确定了导致这种抗拒的其他因素。我们在这里的目标不是对这项研究进行全面回顾。我们在本书中的目标是为改善人类判断提供建议,而不是像Frankel法官所说的那样,争论”用机器取代人”。
但是关于驱动人类对机械预测抗拒的一些发现与我们对人类判断的讨论相关。最近研究中出现的一个关键洞察是:人们并非系统性地怀疑算法。例如,当在接受人类建议和算法建议之间做选择时,他们经常更喜欢算法。对算法的抗拒,或者说算法厌恶,并不总是表现为彻底拒绝采用新的决策支持工具。更多时候,人们愿意给算法一个机会,但一旦看到它犯错误就停止信任它。
在某种程度上,这种反应似乎是合理的:为什么要费心使用一个你不能信任的算法呢?作为人类,我们敏锐地意识到自己会犯错误,但这是一个我们不准备分享的特权。我们期望机器是完美的。如果这种期望被违反,我们就会抛弃它们。
然而,由于这种直觉期望,人们很可能不信任算法并继续使用自己的判断,即使这种选择产生明显较差的结果。这种态度根深蒂固,在达到近乎完美的预测准确性之前不太可能改变。
幸运的是,使规则和算法更好的许多方面可以在人类判断中复制。我们无法希望像AI模型那样高效地使用信息,但我们可以努力模仿简单模型的简单性和无噪声性。在我们能够采用减少系统噪声的方法的程度上,我们应该看到预测判断质量的改善。如何改善我们的判断是第5部分的主要主题。
“当有大量数据时,机器学习算法会比人类做得更好,也比简单模型做得更好。但即使是最简单的规则和算法也比人类判断者有很大优势:它们没有噪声,也不试图应用关于预测变量的复杂的、通常无效的洞察。”
“既然我们缺乏关于必须预测结果的数据,为什么不使用等权重模型呢?它几乎会做得和合适的模型一样好,肯定会比逐案人类判断做得更好。”
“你不同意模型的预测。我理解。但这里有断腿的情况吗,还是你只是不喜欢这个预测?”
“算法当然会犯错误。但如果人类判断者犯更多错误,我们应该信任谁?”
我们经常有这样的经历:与高管听众分享前两章的材料,其中包含关于人类判断有限成就的发人深省的发现。我们要传达的信息已经存在了半个多世纪,我们怀疑很少有决策者没有接触过它。但他们确实能够抗拒它。
我们听众中的一些高管自豪地告诉我们,他们更相信自己的直觉而不是任何数量的分析。许多其他人不那么直率,但持相同观点。管理决策制定的研究表明,高管,特别是更资深和经验丰富的高管,广泛求助于各种被称为直觉、直觉感受或简单的判断(与我们在本书中使用的意义不同)的东西。
简而言之,决策者喜欢相信自己的直觉,而且大多数人似乎对听到的声音很满意。这引发了一个问题:这些拥有权威和极强自信的人,到底从他们的直觉中听到了什么?
关于管理决策中直觉的一项评述将其定义为”对特定行动方案的判断,这种判断伴随着正确性或合理性的光环或信念,但没有明确阐述的理由或依据——本质上是’知道’但不知道为什么。“我们认为,这种不知道为什么却知道的感觉实际上就是我们在第4章中提到的判断完成的内在信号。
内在信号是一种自我奖励,当人们在判断上达到结论时,他们会努力(有时不那么努力)去获得这种奖励。这是一种令人满意的情感体验,一种令人愉悦的连贯感,在这种感觉中,所考虑的证据和得出的判断感觉是正确的。拼图的所有碎片似乎都能拼合。(我们稍后会看到,这种连贯感往往通过隐藏或忽略不合适的证据片段来得到加强。)
使内在信号重要——且具有误导性——的是,它被理解为一种信念而不是一种感觉。这种情感体验(“证据感觉正确”)被伪装成对自己判断有效性的理性信心(“我知道,即使我不知道为什么”)。
然而,信心并不能保证准确性,许多自信的预测结果证明是错误的。虽然偏见(bias)和噪音(noise)都会导致预测错误,但这种错误的最大来源并不是预测判断实际上有多好的限制。而是它们可能有多好的限制。这个限制,我们称之为客观无知,是本章的重点。
如果你发现自己在做重复的预测性判断,这里有一个你可以问自己的问题。这个问题可以适用于任何任务——比如选股,或者预测职业运动员的表现。但为了简单起见,我们选择第9章使用的同一个例子:工作候选人的选择。想象一下,你多年来评估了一百名候选人。现在你有机会评估你的决策有多好,通过比较你当时做出的评估与候选人此后客观评估的表现。如果你随机选择一对候选人,你的事前判断和事后评估有多少次是一致的?换句话说,在比较任意两名候选人时,你认为更有潜力的那个人实际上表现更好的概率是多少?
我们经常非正式地就这个问题调查高管群体。最常见的答案在75-85%的范围内,我们怀疑这些回答受到谦逊和不想显得自夸的愿望的约束。私人的一对一谈话表明,真正的信心感往往更高。
由于你现在已经熟悉了一致性百分比统计,你可以很容易地看出这种评估带来的问题。80%的PC大致对应于0.80的相关性。这种预测能力水平在现实世界中很少能够达到。在人员选择领域,最近的一项评述发现,人类判断者的表现远未达到这个数字。平均而言,他们实现的预测相关性为0.28(PC = 59%)。
如果你考虑人员选择的挑战,令人失望的结果并不那么令人惊讶。今天开始新工作的人将遇到许多挑战和机遇,机遇将以多种方式介入改变她生活的方向。她可能遇到一个相信她的主管,创造机会,推广她的工作,建立她的自信和动机。她也可能不那么幸运,无缘无故地以令人沮丧的失败开始她的职业生涯。在她的个人生活中,也可能有影响她工作表现的事件。这些事件和情况今天都无法预测——不是你,不是其他任何人,也不是世界上最好的预测模型能够预测的。这种难以处理的不确定性包括在此时无法了解的关于你试图预测的结果的一切。
此外,关于候选人的许多情况原则上是可以知道的,但在你做出判断时却是未知的。就我们的目的而言,这些知识空白是来自缺乏足够预测性的测试,还是来自你认为获取更多信息的成本不合理的决定,或者来自你在事实发现中的疏忽,都无关紧要。无论如何,你都处于信息不完善的状态。
难以处理的不确定性(不可能知道的)和不完善的信息(可以知道但不知道的)都使完美预测变得不可能。这些未知数不是你判断中的偏见或噪音问题;它们是任务的客观特征。这种对重要未知数的客观无知严重限制了可实现的准确性。我们在这里采用了术语上的自由,用无知替代了常用的不确定性。这个术语有助于限制不确定性(关于世界和未来)与噪音(应该相同的判断中的变异性)之间混淆的风险。
在某些情况下比其他情况下有更多信息(更少的客观无知)。大多数专业判断都相当好。对于许多疾病,医生的预测是出色的,对于许多法律争议,律师可以非常准确地告诉你法官可能如何裁决。
然而,一般来说,你可以放心地期待从事预测任务的人会低估他们的客观无知。过度自信是记录最充分的认知偏见之一。特别是,对自己进行精确预测能力的判断,即使是基于有限信息,也是出了名的过度自信。我们对预测判断中噪音所说的话同样适用于客观无知:哪里有预测,哪里就有无知,而且比你想象的要多。
我们的一位好朋友,心理学家Philip Tetlock,怀着对真理的坚定承诺和顽皮的幽默感。2005年,他出版了一本名为《专家政治判断》的书。尽管标题听起来中性,但这本书实际上是对专家准确预测政治事件能力的毁灭性攻击。
Tetlock研究了近三百名专家的预测:知名记者、受人尊敬的学者和国家领导人的高级顾问。他询问他们的政治、经济和社会预测是否成真。这项研究跨越了二十年;要找出长期预测是否正确,你需要耐心。
Tetlock的关键发现是,在对重大政治事件的预测中,所谓的专家表现令人震惊地不佳。这本书因其引人注目的妙语而闻名:“普通专家的准确性大致相当于一只投掷飞镖的黑猩猩。”这本书信息的更精确表述是,以”评论或提供建议政治和经济趋势”为生的专家并不比记者或《纽约时报》的专心读者在”解读”新兴形势方面”更好”。当然,专家们讲述了精彩的故事。他们可以分析形势,描绘一幅令人信服的发展图景,并在电视演播室里以极大的信心反驳那些与他们意见不合的人的反对意见。但他们真的知道会发生什么吗?几乎不知道。
Tetlock通过切入叙事得出了这个结论。对于每个问题,他要求专家为三种可能的结果分配概率:维持现状、某事物增加或减少。投掷飞镖的黑猩猩会以相同的概率——三分之一——“选择”这些结果中的每一个,不管现实如何。Tetlock的专家几乎没有超过这个非常低的标准。平均而言,他们为发生的事件分配的概率略高于未发生的事件,但他们表现最显著的特征是对自己预测的过度自信。拥有关于世界如何运作的清晰理论的专家最自信,也最不准确。
Tetlock的发现表明,对特定事件的详细长期预测根本是不可能的。世界是一个混乱的地方,小事件可能产生重大后果。例如,考虑这样一个事实:在受孕的瞬间,历史上每个重要人物(以及不重要的人物)都有一半的机会以不同的性别出生。不可预见的事件必然会发生,这些不可预见事件的后果也是不可预见的。因此,当你展望未来越远时,客观无知会稳步积累。专家政治判断的限制不是由预测者的认知局限性设定的,而是由他们对未来难以处理的客观无知设定的。
因此,我们的结论是,专家不应该因为他们远期预测的失败而受到指责。然而,他们确实应该因为尝试一项不可能的任务以及相信他们能够成功而受到一些批评。
在震撼性地发现许多长期预测的无效性几年后,Tetlock与他的配偶Barbara Mellers合作,研究当人们被要求预测相对短期的世界事件时——通常少于一年——他们的表现如何。研究团队发现,短期预测是困难的,但并非不可能,一些人,Tetlock和Mellers称之为超级预测者,在这方面始终比大多数其他人表现更好,包括情报界的专业人士。用我们在这里使用的术语,他们的新发现与这样的观念相符:当我们展望未来越远时,客观无知会增加。我们在第21章回到超级预测者的话题。
Tetlock的早期研究证明了人们在长期政治预测方面普遍无能为力。即使找到一个拥有清晰水晶球的人也会完全改变结论。只有在许多可信的参与者尝试并失败后,一项任务才能被认为是不可能的。正如我们已经表明的,信息的机械聚合通常优于人类判断,规则和算法的预测准确性为结果的内在可预测性或不可预测性提供了更好的测试。
前面的章节可能给你留下了算法压倒性地优于预测判断的印象。然而,这种印象是误导性的。模型始终比人类表现更好,但好得不多。本质上没有证据表明存在人类表现很差而模型在相同信息下表现很好的情况。
在第9章中,我们提到了对136项研究的综述,该综述证明了机械聚合相对于临床判断的优越性。虽然这种优越性的证据确实是”大量且一致的”,但性能差距并不大。综述中的93项研究专注于二元决策,并测量了临床医生和公式的”命中率”。在中位数研究中,临床医生正确率为68%,公式为73%。35项研究的较小子集使用相关系数作为准确性衡量标准。在这些研究中,临床医生与结果的中位相关性为.32(PC = 60%),而公式达到.56(PC = 69%)。在这两个指标上,公式始终优于临床医生,但机械预测的有限效度仍然令人震惊。模型的性能并没有改变可预测性天花板相当低的情况。
那么人工智能呢?正如我们所指出的,AI通常比更简单的模型表现更好。然而,在大多数应用中,其性能仍远非完美。例如,考虑我们在第10章讨论的保释预测算法。我们注意到,在保持被拒绝保释人数不变的情况下,该算法可以将犯罪率降低多达24%。这是对人类保释法官预测的显著改进,但如果算法能够完美准确地预测哪些被告会再次犯罪,它可以更大幅度地降低犯罪率。《少数派报告》中对未来犯罪的超自然预测之所以是科幻小说,是有原因的:在预测人类行为方面存在大量客观无知。
另一项由Sendhil Mullainathan和Ziad Obermeyer领导的研究模拟了心脏病发作的诊断。当患者出现可能心脏病发作的征象时,急诊科医生必须决定是否开具额外检查。原则上,只有当心脏病发作风险足够高时才应该对患者进行检查:因为检查不仅成本高昂,而且具有侵入性和风险性,对低风险患者来说是不理想的。因此,医生决定开具检查需要评估心脏病发作风险。研究人员构建了一个AI模型来进行这种评估。该模型使用超过2400个变量,基于大量案例样本(440万次Medicare就诊,涉及160万患者)。有了这样的数据量,该模型可能接近客观无知的极限。
不出所料,AI模型的准确性明显优于医生。为了评估模型的性能,考虑模型将其置于风险最高十分位的患者。当这些患者接受检查时,其中30%的人确实发生了心脏病发作,而风险分布中等的患者中有9.3%经历了心脏病发作。这种判别水平令人印象深刻,但也远非完美。我们可以合理地得出结论,医生的表现至少与客观无知的限制一样受到其判断不完善的限制。
通过坚持完美预测的不可能性,我们似乎在陈述显而易见的事实。诚然,断言未来是不可预测的很难算得上是概念突破。然而,这一事实的显而易见性只能与它被忽视的规律性相匹配,正如关于预测过度自信的一致发现所证明的那样。
过度自信的普遍性为我们对信任直觉决策者的非正式调查shed了新的光芒。我们注意到,人们经常将他们的主观自信感误认为是预测效度的指标。例如,在你回顾了第9章关于Nathalie和Monica的证据后,当你达到一致判断时感受到的内在信号给了你信心,认为Nathalie是更强的候选人。然而,如果你对那个预测很有信心,你就陷入了效度幻觉:在给定信息的情况下,你能达到的准确性是相当低的。
那些相信自己能够达到不可能高水平预测准确性的人不仅仅是过度自信。他们不仅否认其判断中噪音和偏见的风险。他们也不仅仅认为自己优于其他凡人。他们还相信实际上不可预测的事件的可预测性,含蓄地否认不确定性的现实。用我们在这里使用的术语来说,这种态度相当于对无知的否认。
对无知的否认为困扰Meehl及其追随者的谜题增加了一个答案:为什么他的信息在很大程度上仍然被忽视,为什么决策者继续依赖他们的直觉。当他们倾听内心时,决策者听到内在信号并感受到它带来的情感奖励。这种达到良好判断的内在信号是自信的声音,是”不知道为什么就知道”。但对证据真正预测力的客观评估很少能证明那种自信水平是合理的。
放弃直觉确定性的情感奖励并不容易。值得注意的是,领导者说他们特别可能在他们认为高度不确定的情况下诉诸直觉决策。当事实否认了他们渴望的理解感和自信时,他们转向直觉来提供这种感觉。当无知是巨大的时候,对无知的否认更加诱人。
对无知的否认也解释了另一个困惑。当面对我们在此提出的证据时,许多领导者得出了一个看似矛盾的结论。他们认为,基于直觉的决策可能并不完美,但如果更系统化的替代方案也远非完美,那就不值得采用。例如,回想一下人类评判者的评分与员工绩效之间的平均相关性是.28(PC = 59%)。根据同一研究,并且与我们回顾的证据一致,机械预测可能做得更好,但好不了多少:其预测准确性是.44(PC = 65%)。一位高管可能会问:为什么要费这个事?
答案是,在像决定雇用谁这样重要的事情上,这种有效性的增加具有很大的价值。同样的高管会为了获得远不及此的收益而定期对其工作方式进行重大改变。理性地说,他们理解成功永远无法保证,而更高的成功机会正是他们在决策中努力追求的。他们也理解概率。如果能以同样的价格购买一张中奖机会为65%的彩票,他们中没有人会购买中奖机会只有59%的彩票。
挑战在于这种情况下的”价格”并不相同。直觉判断带来了它的奖励——内在信号。人们准备信任一个达到很高准确度水平的算法,因为它给他们一种确定感,这种确定感与内在信号提供的相匹配或超越。但当替代方案是某种甚至不声称具有高有效性的机械过程时,放弃内在信号的情感奖励是一个很高的代价。
这一观察对改进判断有重要意义。尽管有所有支持机械和算法预测方法的证据,尽管理性计算清楚地显示了预测准确性递增改进的价值,许多决策者仍将拒绝那些剥夺他们运用直觉能力的决策方法。只要算法不接近完美——而且在许多领域,客观无知决定了它们永远不会完美——人类判断就不会被取代。这就是为什么必须改进它。
“哪里有预测,哪里就有无知,而且可能比我们想象的更多。我们是否检查过我们信任的专家是否比投掷飞镖的黑猩猩更准确?”
“当你因为内在信号而信任直觉时,而不是因为你真正知道的任何东西,你就是在否认自己的客观无知。”
“模型比人做得更好,但好不了多少。大多数情况下,我们发现平庸的人类判断和稍好一些的模型。尽管如此,更好就是好,模型更好。”
“我们可能永远不会对使用模型做这些决定感到舒适——我们只是需要内在信号有足够的信心。所以让我们确保我们有最好的决策过程。”
我们现在转向一个更广泛的问题:在一个许多问题很容易但许多其他问题被客观无知主导的世界中,我们如何获得安慰?毕竟,在客观无知严重的地方,我们应该在一段时间后意识到水晶球在人类事务中的徒劳性。但这不是我们对世界的通常体验。相反,正如前一章所暗示的,我们保持着一种不知悔改的意愿,即从很少有用的信息中对未来做出大胆预测。在本章中,我们探讨了一种普遍且错误的观念:无法预测的事件仍然可以被理解。
这种信念真正意味着什么?我们在两种背景下提出这个问题:社会科学的实施和日常生活事件的体验。
2020年,由萨拉·麦克拉纳汉和马修·萨尔加尼克领导的112名研究人员小组(两人都是普林斯顿大学社会学教授)在《美国国家科学院院刊》上发表了一篇不寻常的文章。研究人员旨在弄清楚社会科学家对社会脆弱家庭的生活轨迹中将要发生的事情实际了解多少。知道他们所知道的,社会科学家能多好地预测家庭生活中的事件?具体来说,专家在使用社会学家通常收集和应用在其研究中的信息来预测生活事件时,能达到什么水平的准确性?用我们的术语来说,这项研究的目的是测量在社会学家完成工作后,这些生活事件中仍然存在的客观无知水平。
作者们从脆弱家庭和儿童福祉研究(Fragile Families and Child Wellbeing Study)中获取资料,这是一项大规模纵向调查,追踪儿童从出生到十五岁的成长过程。这个庞大的数据库包含近五千名儿童家庭的数千项信息,其中大部分儿童出生于美国大城市的未婚父母家庭。数据涵盖了儿童祖父母的教育和就业情况、所有家庭成员的健康详情、经济和社会地位指标、多份问卷调查的答案,以及认知能力和人格测试。这是一个非凡的信息财富,社会科学家们充分利用了这些资料:基于脆弱家庭研究数据已发表了750多篇科学论文。其中许多论文使用儿童及其家庭的背景数据来解释诸如高中成绩和犯罪记录等生活结果。
由普林斯顿团队领导的研究专注于预测儿童十五岁时观察到的六个结果的可预测性,包括最近驱逐事件的发生、儿童的GPA以及家庭物质环境的综合衡量指标。组织者使用了他们称为”共同任务法”的方法。他们邀请研究团队竞争,利用脆弱家庭研究中每个家庭的大量可用数据,准确预测六个选定的结果。这种挑战在社会科学中很新颖,但在计算机科学中很常见,团队经常被邀请参与诸如标准文本集的机器翻译或大型照片集中动物检测等任务的竞争。这些竞赛中获胜团队的成就定义了某个时间点的技术水平,而这个水平总是在下一次竞赛中被超越。在社会科学预测任务中,由于不期望快速改进,使用竞赛中达到的最准确预测作为这些数据结果可预测性的衡量标准是合理的——换句话说,客观无知的剩余水平。
这个挑战在研究人员中引起了相当大的兴趣。最终报告展示了从更大的国际申请者池中选出的160个高素质团队的结果。大部分入选的竞争者自称为数据科学家并使用机器学习。
在竞赛的第一阶段,参与团队可以访问总样本一半的所有数据;数据包括六个结果。他们使用这些”训练数据”来训练预测算法。然后将他们的算法应用于未用于训练算法的对照样本家庭。研究人员使用MSE衡量准确性:每个案例的预测误差是真实结果与算法预测之间差值的平方。
获胜模型的表现如何?在大数据集上训练的复杂机器学习算法当然超越了简单线性模型的预测(并且推而广之,会超过人类判断者的预测)。但AI模型相对于非常简单模型的改进很微小,其预测准确性仍然令人失望地低。在预测驱逐时,最佳模型达到了.22的相关性(PC = 57%)。其他单一事件结果也发现了类似结果,比如主要照护者是否被解雇或参加过职业培训,以及儿童在自我报告的”毅力”衡量指标上的得分——这是一个结合了对特定目标的坚持和激情的人格特质。对于这些,相关性在.17到.24之间(PC = 55 – 58%)。
六个目标结果中有两个是综合指标,这些更容易预测。预测相关性为.44(PC = 65%)对应儿童的GPA,.48(PC = 66%)对应前十二个月物质困难的综合衡量指标。这个衡量指标基于十一个问题,包括”你曾经饿过吗?“和”你的电话服务被取消了吗?“众所周知,综合衡量指标比单一结果的衡量指标更具预测性和可预测性。这项挑战的主要结论是,大量预测信息不足以预测人们生活中的单一事件——甚至综合指标的预测也相当有限。
这项研究观察到的结果是典型的,社会科学家报告的许多相关性都在这个范围内。一项涵盖25,000项研究、涉及800万受试者、跨越一百年的社会心理学研究的广泛综述得出结论:“社会心理学效应通常产生的r值[相关系数]等于.21。”更高的相关性,比如我们之前提到的成人身高和脚长之间的.60,在物理测量中很常见,但在社会科学中非常罕见。一项涵盖行为和认知科学708项研究的综述发现,只有3%的报告相关性为.50或更高。
如果你习惯于阅读被描述为”统计显著”甚至”高度显著”的发现,这样低的相关系数可能会让你感到惊讶。统计术语对外行读者来说往往具有误导性,“显著”可能是最糟糕的例子。当一个发现被描述为”显著”时,我们不应该得出它描述的效应是强效应的结论。这只是意味着该发现不太可能仅仅是偶然的产物。有了足够大的样本,一个相关性可以同时非常”显著”但又小到不值得讨论。
在挑战研究中单一结果的有限可预测性传达了一个关于理解与预测之间差异的令人不安的信息。脆弱家庭研究被认为是社会科学的宝库,正如我们所见,它的数据已被用于大量研究。产生这些研究的学者们肯定觉得他们的工作推进了对脆弱家庭生活的理解。不幸的是,这种进步感并未伴随着对个体生活中个别事件进行精确预测的能力。关于脆弱家庭挑战的多作者报告的引言摘要包含了一个严厉的警告:“研究人员必须调和这样一个观念:他们理解生活轨迹,但事实上没有一个预测是非常准确的。”
这一悲观结论背后的逻辑需要一些阐述。当脆弱家庭挑战的作者们将理解等同于预测(或将一个的缺失等同于另一个的缺失)时,他们在特定意义上使用理解这个词。这个词还有其他含义:如果你说你理解一个数学概念或你理解什么是爱,你可能并不是在暗示能够做出任何具体预测的能力。
然而,在社会科学的话语中,以及在大多数日常对话中,声称理解某事就是声称理解什么导致了那件事。收集和研究脆弱家庭研究中数千个变量的社会学家们在寻找他们观察到的结果的原因。理解患者病情的医生声称他们诊断出的病理是他们观察到的症状的原因。理解就是描述因果链。做出预测的能力是衡量这种因果链是否确实被识别出来的标准。而相关性,即预测准确性的度量,是我们能够解释多少因果关系的度量。
如果你接触过基础统计学并记得经常重复的警告”相关性并不意味着因果关系”,这最后一个陈述可能会让你感到惊讶。例如,考虑儿童鞋码和数学能力之间的相关性:显然,一个变量不会导致另一个。相关性产生于这样一个事实:鞋码和数学知识都随着孩子的年龄增长而增加。相关性是真实的,并支持一个预测:如果你知道一个孩子脚大,你应该预测比你知道孩子脚小时更高的数学水平。但你不应该从这种相关性推断出因果关系。
然而,我们必须记住,虽然相关性并不意味着因果关系,但因果关系确实意味着相关性。在有因果关系的地方,我们应该发现相关性。如果你发现成年人的年龄和鞋码之间没有相关性,那么你可以安全地得出结论:青春期结束后,年龄不会使脚变大,你必须在别处寻找鞋码差异的原因。
简而言之,有因果关系的地方就有相关性。因此,有因果关系的地方,我们应该能够预测——而相关性,即这种预测的准确性,是我们理解多少因果关系的度量。因此普林斯顿研究人员的结论是:社会学家预测驱逐等事件的程度,以0.22的相关性来衡量,表明了他们对这些家庭生活轨迹理解的多少——或多么少。客观无知不仅为我们的预测设定了上限,也为我们的理解设定了上限。
那么,当大多数专业人士自信地声称理解他们的领域时,他们的意思是什么?他们如何能够就他们正在观察的现象的原因做出声明,并对它们提供自信的预测?简而言之,为什么专业人士——以及我们所有人——似乎都低估了我们对世界的客观无知?
如果在阅读本章第一部分时,你问自己是什么驱动了脆弱家庭中的驱逐和其他生活结果,你就参与了与我们描述的研究人员同样的思维。你应用了统计思维:你关注的是集合,如脆弱家庭的人口,以及描述他们的统计数据,包括平均值、方差、相关性等等。你没有专注于个别案例。
一种不同的思维模式,这里称为因果思维,它更自然地进入我们的头脑。因果思维创造故事,其中具体的事件、人和物体相互影响。要体验因果思维,想象你是一名跟踪许多贫困家庭案例的社会工作者。你刚刚听说其中一个家庭——琼斯一家——被驱逐了。你对这一事件的反应取决于你对琼斯一家的了解。碰巧的是,家庭经济支柱杰西卡·琼斯几个月前被解雇了。她找不到另一份工作,从那以后,她一直无法全额支付房租。她付了部分房租,多次向楼房经理求情,甚至要求你介入(你确实这样做了,但他仍然无动于衷)。在这种背景下,琼斯一家的驱逐是悲伤的,但并不令人惊讶。事实上,这感觉像是一系列事件的逻辑结局,一个注定悲剧的不可避免的结局。
当我们屈服于这种不可避免性的感觉时,我们就失去了对事情本可以多么容易不同的洞察力——在每个人生分岔路口,命运本可以走向不同的道路。Jessica本可以保住她的工作。她本可以很快找到另一份工作。亲戚本可以来帮助她。你,这位社会工作者,本可以成为更有效的倡导者。大楼管理员本可以更加理解并允许这家人几周的缓解时间,使Jessica能够找到工作并补上房租。
这些替代性叙述与主要叙述一样不令人意外——如果结果是已知的。无论结果如何(被驱逐或没有),一旦它发生了,因果思维使它感觉完全可以解释,确实是可以预测的。
对这一观察有心理学解释。有些事件是令人惊讶的:致命的大流行病、对双子塔的攻击、一个明星对冲基金原来是庞氏骗局。在我们的个人生活中也是如此,有偶尔的冲击:与陌生人坠入爱河、年轻兄弟姐妹的突然死亡、意外的遗产。其他事件是积极预期的,比如二年级学生在约定时间从学校回来。
但大多数人类经验介于这两个极端之间。我们有时处于积极期待特定事件的状态,有时我们会感到惊讶。但大多数事情发生在正常的广阔谷地中,事件既不完全预期也不特别令人惊讶。例如,此时此刻,你对下一段会出现什么没有具体的期待。如果我们突然切换到土耳其语,你会感到惊讶,但有广泛的事情我们可以说而不会让你震惊。
在正常谷地中,事件就像Jones一家的驱逐一样展开:它们在事后看来正常,尽管它们没有被预期,尽管我们无法预测它们。这是因为理解现实的过程是回顾性的。一个没有被积极预期的事件(Jones一家的驱逐)触发对记忆的搜索以寻找候选原因(艰难的就业市场、不灵活的管理者)。当找到一个好的叙述时搜索就停止了。给定相反的结果,搜索会产生同样令人信服的原因(Jessica Jones的坚韧、理解型的管理者)。
正如这些例子所说明的,正常故事中的许多事件实际上是自我解释的。你可能已经注意到驱逐故事两个版本中的大楼管理员实际上不是同一个人:第一个是不同情的,第二个是善良的。但你对管理员性格的唯一线索是他的性格所表现出的行为。鉴于我们现在对他的了解,他的行为看起来是连贯的。正是事件的发生告诉你它的原因。
当你以这种方式解释一个意外但不令人惊讶的结果时,最终到达的目的地总是有意义的。这就是我们所说的理解一个故事的意思,这就是使现实在事后看来可预测的原因。因为事件在发生时解释了自己,我们产生了它本可以被预期的错觉。
更广泛地说,我们对理解世界的感觉取决于我们构建解释我们观察到的事件的叙述的非凡能力。对原因的搜索几乎总是成功的,因为原因可以从关于世界的事实和信念的无限储备中提取。正如任何收听晚间新闻的人都知道的,例如,很少有股市的大幅波动得不到解释。同样的新闻流可以”解释”指数的下跌(紧张的投资者担心新闻!)或上涨(乐观的投资者保持乐观!)。
当寻找明显原因失败时,我们的首要手段是通过填补我们世界模型中的空白来产生解释。这就是我们推断以前不知道的事实的方式(例如,管理员是一个异常善良的人)。只有当我们的世界模型无法调整以产生结果时,我们才将这个结果标记为令人惊讶并开始寻找更详细的解释。真正的惊讶只有在常规事后洞察失败时才会发生。
这种对现实的持续因果解释就是我们”理解”世界的方式。我们对生活展开的理解感觉包括正常谷地中事后洞察的稳定流动。这种感觉从根本上是因果的:新事件一旦被知道,就消除了替代方案,叙述几乎没有给不确定性留下空间。正如我们从关于事后洞察的经典研究中知道的,即使主观不确定性确实存在一段时间,当不确定性得到解决时,对它的记忆在很大程度上被抹去了。
我们对比了思考事件的两种方式:统计性思维和因果性思维。因果模式通过实时将事件分类为正常或异常来节省大量费力的思考。异常事件会迅速调动昂贵的努力去搜索相关信息,无论是在环境中还是在记忆中。主动期望——专注地等待某事发生——也需要努力。相比之下,正常谷地中的事件流需要很少的心理工作。当你们的路径相交时,你的邻居可能会微笑,或者可能显得心事重重,只是点头——如果这两种事件在过去都相当频繁,它们都不会引起太多注意。如果微笑异常宽泛或点头异常敷衍,你很可能会发现自己在记忆中搜索可能的原因。因果思维避免了不必要的努力,同时保持了检测异常事件所需的警觉性。
相比之下,统计思维是费力的。它需要只有系统2——与缓慢、深思熟虑的思考相关的思维模式——才能带来的注意力资源。超出基础水平,统计思维还需要专门的训练。这种思维从整体开始,将个体案例视为更广泛类别的实例。琼斯一家的被驱逐不被视为一连串特定事件的结果,而是被视为统计上可能(或不太可能)的结果,基于对与琼斯一家共享预测特征的案例的先前观察。
这两种观点之间的区别是本书的一个重复主题。依赖对单个案例的因果思维是可预测错误的来源。采用统计观点,我们也称之为外部观点,是避免这些错误的一种方式。
在这一点上,我们只需要强调因果模式对我们来说更加自然。即使是应该被正确视为统计的解释也很容易转化为因果叙述。考虑诸如”他们失败是因为缺乏经验”或”他们成功是因为有一个杰出的领导者”这样的断言。你很容易想到反例,其中缺乏经验的团队成功了,杰出的领导者失败了。经验和才华与成功的相关性充其量是中等的,可能很低。然而,因果归因很容易做出。在因果关系看似合理的地方,我们的大脑很容易将一个相关性,无论多么低,转化为因果和解释力量。杰出的领导力被接受为成功的令人满意的解释,缺乏经验被接受为失败的解释。
依赖有缺陷的解释也许是不可避免的,如果替代方案是放弃理解我们的世界。然而,因果思维和理解过去的错觉导致对未来过度自信的预测。正如我们将看到的,对因果思维的偏好也导致忽视噪音作为错误的来源,因为噪音本质上是一个统计概念。
因果思维帮助我们理解一个远不如我们想象的那么可预测的世界。它也解释了为什么我们将世界视为比实际更可预测的。在正常的谷地中,没有惊喜,没有不一致。未来似乎和过去一样可预测。噪音既听不到也看不见。
“大约0.20的相关性(PC = 56%)在人类事务中相当常见。”
“相关性不意味着因果关系,但因果关系确实意味着相关性。”
“大多数正常事件既不被期望也不令人惊讶,它们不需要解释。”
“在正常的谷地中,事件既不被期望也不令人惊讶——它们只是自我解释。”
“我们认为我们理解这里发生的事情,但我们能预测到它吗?”
噪音——以及偏见——的起源是什么?什么心理机制产生了我们判断的可变性和影响它们的共同错误?简而言之,我们对噪音心理学了解什么?这些是我们现在要转向的问题。
首先,我们描述快速的系统1思维的一些操作如何导致许多判断错误。在第13章中,我们介绍了系统1广泛依赖的三个重要判断启发式。我们展示这些启发式如何导致可预测的方向性错误(统计偏见)以及噪音。
第14章关注匹配——系统1的一个特殊操作——并讨论它可能产生的错误。
在第15章中,我们转向所有判断中不可或缺的附件:进行判断的尺度。我们展示选择适当的尺度是良好判断的先决条件,定义不清或不充分的尺度是噪音的重要来源。
第16章探索可能是最有趣的噪音类型的心理来源:不同人对不同案例的反应模式。像个人性格一样,这些模式不是随机的,在时间上大多是稳定的,但它们的影响不容易预测。
最后,在第17章中,我们总结了我们对噪音及其组成部分的了解。这种探索使我们能够为我们之前提出的谜题提出答案:为什么噪音尽管无处不在,却很少被视为重要问题?
这本书延续了半个世纪以来关于人类直觉判断的研究,即所谓的启发式与偏见(heuristics and biases)项目。这个研究项目的前四十年在《思考,快与慢》中得到了回顾,该书探讨了既能解释直觉思维奇迹也能解释其缺陷的心理机制。这个项目的核心思想是,当人们被问及一个困难问题时,会使用称为启发式(heuristics)的简化操作。一般来说,启发式由快速、直觉思维产生,也被称为系统1思维(System 1 thinking),它们非常有用并能产生充分的答案。但有时它们会导致偏见,我们将其描述为系统性的、可预测的判断错误。
启发式与偏见项目关注的是人们的共性,而不是他们的差异。它表明,导致判断错误的过程是广泛共享的。部分由于这段历史,熟悉心理偏见概念的人往往假设它总是产生统计偏见(statistical bias),这是我们在本书中用来指主要偏离真相同一方向的测量或判断的术语。确实,当心理偏见被广泛共享时,它们会产生统计偏见。然而,当评判者以不同方式或在不同程度上存在偏见时,心理偏见会产生系统噪音。当然,无论它们是否造成统计偏见或噪音,心理偏见总是会产生错误。
判断偏见通常通过参考真实值来识别。如果错误主要朝一个方向而不是另一个方向,那么预测性判断中就存在偏见。例如,当人们预测完成一个项目需要多长时间时,他们估计的平均值通常远低于实际需要的时间。这种熟悉的心理偏见被称为计划谬误(planning fallacy)。
然而,通常没有可以与判断进行比较的真实值。鉴于我们强调统计偏见只有在已知真实值时才能被检测到,你可能想知道当真相未知时如何研究心理偏见。答案是,研究人员通过观察到不应该影响判断的因素确实对其产生统计效应,或者应该影响判断的因素没有产生影响,来确认心理偏见。
为了说明这种方法,让我们回到射击场的类比。想象团队A和B已经开了枪,我们正在看靶子的背面(图12)。在这个例子中,你不知道靶心在哪里(真实值未知)。因此,你不知道两个团队相对于靶心的偏见程度。然而,你被告知,在面板1中,两个团队瞄准的是同一个靶心,在面板2中,团队A瞄准一个靶心,团队B瞄准不同的靶心。
尽管没有靶子,两个面板都提供了系统性偏见的证据。在面板1中,两个团队的射击结果不同,尽管它们应该是相同的。这种模式类似于你在实验中看到的情况,其中两组投资者阅读内容基本相同但用不同字体印刷在不同纸张上的商业计划书。如果这些不相关的细节在投资者的判断中产生差异,那就存在心理偏见。我们不知道被时尚字体和光滑纸张打动的投资者是否过于积极,或者阅读粗糙版本的投资者是否过于消极。但我们知道他们的判断不同,尽管它们不应该不同。

图12:在测试偏见的实验中查看靶子背面
面板2说明了相反的现象。由于团队瞄准不同的靶子,射击群应该是不同的,但它们集中在同一个点上。例如,想象两组人被问及你在第4章中被问及的关于迈克尔·甘巴尔迪(Michael Gambardi)的同一个问题,但有所变化。一组被问及,就像你一样,估计甘巴尔迪两年后仍在其职位上的概率;另一组被问及估计他三年后仍在其职位上的概率。两组应该得出不同的结论,因为显然在三年内失去工作的方式比在两年内更多。然而,证据表明两组的概率估计几乎没有差异,如果有的话。答案应该明显不同,但它们不是,这表明应该影响判断的因素被忽略了。(这种心理偏见被称为范围不敏感性(scope insensitivity)。)
系统性判断错误已在许多领域得到证明,偏见(bias)一词现在在许多领域中使用,包括商业、政治、政策制定和法律。正如这个词的常见用法,其含义很广泛。除了我们在这里使用的认知定义(指心理机制和这种机制通常产生的错误)之外,这个词经常用来暗示某人对某个群体有偏见(例如,性别偏见或种族偏见)。它也可以意味着某人偏爱特定的结论,比如当我们读到某人因利益冲突或政治观点而有偏见时。我们在讨论判断错误心理学时包括这些类型的偏见,因为所有心理偏见都会造成统计偏见和噪音。
我们强烈反对一种用法。在这种用法中,代价高昂的失败被归因于未明确的”偏见”,而对错误的承认伴随着”努力消除我们决策中的偏见”的承诺。这些陈述的意思不过是”犯了错误”和”我们将努力做得更好”。当然,一些失败确实是由与特定心理偏见相关的可预测错误造成的,我们相信干预措施能够减少判断和决策中的偏见(和噪音)是可行的。但将每一个不良结果都归咎于偏见是一种毫无价值的解释。我们建议将偏见一词保留用于特定的、可识别的错误以及产生这些错误的机制。
为了体验启发式过程,请尝试回答以下问题,这个问题说明了启发式和偏见方法的几个基本主题。像往常一样,如果你提出自己的答案,你会从这个例子中获得更多收获。
比尔三十三岁。他聪明但缺乏想象力,强迫性格,总体上缺乏生气。在学校里,他数学很强,但在社会研究和人文学科方面很弱。
以下是比尔当前情况的八种可能性列表。
请浏览列表并选择你认为最有可能的两项。
比尔是一名医生,以打扑克为爱好。
比尔是一名建筑师。
比尔是一名会计师。
比尔以演奏爵士乐为爱好。
比尔以冲浪为爱好。
比尔是一名记者。
比尔是一名以演奏爵士乐为爱好的会计师。
比尔以爬山为爱好。
现在,重新浏览列表并选择比尔最像该类别中典型人物的两个类别。你可以选择与之前相同或不同的类别。
我们几乎可以确定你选择的最高概率类别和最相似类别是相同的。我们如此自信的原因是多项实验表明人们对这两个问题给出相同的答案。但相似性和概率实际上是相当不同的。例如,问问你自己,以下哪个陈述更有意义?
比尔符合我对以演奏爵士乐为爱好的人的想法。
比尔符合我对以演奏爵士乐为爱好的会计师的想法。
这些陈述都不是很好的匹配,但其中一个显然比另一个没那么糟糕。比尔与一个以演奏爵士乐为爱好的会计师有更多共同点,而不是与一个以演奏爵士乐为爱好的人。现在考虑这个:以下哪个更有可能?
比尔以演奏爵士乐为爱好。
比尔是一名以演奏爵士乐为爱好的会计师。
你可能会倾向于选择第二个答案,但逻辑不允许这样做。比尔以演奏爵士乐为爱好的概率必须高于他是一名演奏爵士乐的会计师的概率。记住你的Venn图!如果比尔是一名爵士乐演奏者和会计师,他当然是一名爵士乐演奏者。向描述中添加细节只能使其概率降低,尽管它可以使其更具代表性,因此更好地”匹配”,如在当前情况下。
判断启发式理论提出,人们有时会在回答更难的问题时使用更容易问题的答案。那么,哪个问题更容易回答:“比尔与典型的业余爵士乐演奏者有多相似?”还是”比尔是业余爵士乐演奏者的概率有多大?“毫无疑问,相似性问题更容易,这使得当被要求评估概率时,人们很可能回答的是这个问题。
你现在已经体验了启发式和偏见计划的基本思想:回答困难问题的启发式方法是找到更容易问题的答案。用一个问题替代另一个问题会导致可预测的错误,称为心理偏见。
这种偏见在比尔的例子中表现明显。当用相似性判断替代概率判断时,必然会出现错误,因为概率受到特殊逻辑的约束。特别是,Venn图只适用于概率,不适用于相似性。因此,许多人犯的可预测逻辑错误。
作为另一个被忽视统计属性的例子,回想一下你在第4章中如何思考Gambardi问题。如果你像大多数人一样,你对Michael Gambardi成功机会的评估完全基于案例告诉你的关于他的情况。然后你试图将他的描述与成功CEO的形象相匹配。
你是否想过考虑一个随机选择的CEO两年后仍然担任同一职位的概率?可能没有。你可以将这种基准率信息视为CEO生存难度的衡量标准。如果这种方法看起来奇怪,考虑一下你如何估计特定学生通过考试的概率。当然,未能通过考试的学生比例是相关的,因为它给你一个考试难度的指示。同样,CEO生存的基准率与Gambardi问题相关。这两个问题都是采用我们所说的外部视角的例子:当你采用这种视角时,你将学生或Gambardi视为类似案例类别的成员。你对这个类别进行统计思考,而不是对焦点案例进行因果思考。
采用外部视角可以产生巨大差异并防止重大错误。几分钟的研究就会发现,美国公司CEO离职率的估计大约在每年15%左右。这一统计数据表明,新上任的CEO在两年后仍在职的概率大约为72%。当然,这个数字只是一个起点,Gambardi案例的具体情况会影响你的最终估计。但如果你只专注于你被告知的关于Gambardi的信息,你就忽略了一个关键信息。(全面披露:我们编写Gambardi案例是为了说明噪音判断;我们花了几周时间才意识到它也是我们在这里描述的偏见的一个典型例子,这种偏见被称为基础率忽视。对本书作者来说,思考基础率并不比其他人更自动。)
用一个问题替代另一个问题不仅限于相似性和概率。另一个例子是用易于想起实例的印象来替代对频率的判断。例如,在飞机坠毁或飓风等事件被广泛报道后,人们对这些事件风险的感知会短暂上升。理论上,风险判断应该基于长期平均值。实际上,最近的事件被给予更多权重,因为它们更容易想起。用判断例子容易想起的程度来替代对频率的评估被称为可得性启发式。
用简单判断替代困难判断不仅限于这些例子。事实上,这非常常见。回答一个更简单的问题可以被认为是回答一个可能难倒你的问题的通用程序。考虑我们倾向于如何通过使用更简单的替代来回答以下每个问题:
我相信气候变化吗?
我信任那些说它存在的人吗?
我认为这位外科医生是否称职?
这个人说话是否充满信心和权威?
项目会按时完成吗?
它现在按时进行吗?
核能是必要的吗?
我对核能这个词感到畏缩吗?
我对整体生活满意吗?
我现在的心情如何?
无论问题如何,用一个问题替代另一个问题都会导致答案没有给证据的不同方面以适当的权重,而证据的错误权重不可避免地导致错误。例如,对生活满意度问题的完整回答显然需要咨询的不仅仅是你当前的心情,但证据表明心情实际上被过度权重了。
同样,用相似性替代概率导致忽视基础率,而基础率在判断相似性时确实是恰当无关的。商业计划文档美学方面的无关变化等因素在评估公司价值时应该给予很少或没有权重。它们对判断的任何影响都可能反映证据的错误权重并会产生错误。
在第三部星球大战电影《绝地归来》剧本开发的关键时刻,该系列的策划者乔治·卢卡斯与他的伟大合作者劳伦斯·卡斯丹进行了激烈的辩论。卡斯丹强烈建议卢卡斯:“我认为你应该杀死卢克,让莱娅接管。”卢卡斯立即拒绝了这个想法。卡斯丹建议如果卢克活着,另一个主要角色应该死去。卢卡斯再次不同意,并补充道:“你不能到处杀人。”卡斯丹用关于电影本质的真诚声明作出回应。他向卢卡斯解释说”如果在途中失去你爱的人,电影会有更多情感分量;旅程会有更大影响。”
卢卡斯的回应迅速而明确:“我不喜欢那样,我也不相信那样。”
这里的思维过程看起来与你思考比尔这个爵士乐演奏会计师时经历的过程截然不同。再读一遍卢卡斯的回答:“不喜欢”先于”不相信”。卢卡斯对卡斯丹的建议有一个自动反应。这种反应帮助激发了他的判断(即使最终是正确的)。
这个例子说明了一种不同类型的偏见,我们称之为结论偏见或预判。像卢卡斯一样,我们经常在判断过程开始时就倾向于得出特定结论。当我们这样做时,我们让快速、直觉的系统1思维建议一个结论。要么我们跳到那个结论并简单地绕过收集和整合信息的过程,要么我们调动系统2思维——进行深思熟虑的思考——来想出支持我们预判的论证。在那种情况下,证据将是选择性的和扭曲的:由于确认偏见和期望偏见,我们倾向于选择性地收集和解释证据,以分别支持我们已经相信的或希望为真的判断。
人们经常会为自己的判断想出看似合理的理由,并且实际上认为这些理由就是他们信念的原因。检验预判作用的一个好方法是想象一下,如果那些看似支持我们信念的论据突然被证明是无效的会怎样。例如,卡斯丹很可能会向卢卡斯指出,“你不能到处杀人”这个理由几乎没有说服力。《罗密欧与朱丽叶》的作者不会同意卢卡斯的观点,如果《黑道家族》和《权力的游戏》的编剧们决定不包含杀戮情节,这两部剧很可能在第一季就被取消了。但我们可以确信,强有力的反驳论据不会改变卢卡斯的想法。相反,他会想出其他论据来支持自己的判断。(例如,“《星球大战》是不同的。”)
无论我们看向哪里,预判都是显而易见的。就像卢卡斯的反应一样,它们通常带有情感成分。心理学家保罗·斯洛维奇将此称为情感启发式(affect heuristic):人们通过咨询自己的感受来决定他们的想法。我们喜欢所支持政治家的大部分方面,而我们甚至不喜欢所讨厌政治家的长相和声音。这就是为什么聪明的公司如此努力地将积极情感与其品牌联系起来的原因之一。教授们经常注意到,在他们获得高教学评分的年份,学生们也会给课程材料高分。在学生不太喜欢教授的年份,他们会给相同的指定阅读材料低分。即使在不涉及情感的情况下,同样的机制也在起作用:无论你信念的真正原因是什么,你都倾向于接受任何似乎支持它的论据,即使推理是错误的。
结论偏见的一个更微妙的例子是锚定效应(anchoring effect),这是指一个任意数字对必须做出定量判断的人们产生的影响。在一个典型的演示中,你可能会看到一些价格不容易猜测的物品,比如一瓶不熟悉的葡萄酒。你被要求写下社会保障号的最后两位数字,并表示是否愿意为这瓶酒支付那个金额。最后,你被要求说出你愿意为它支付的最高金额。结果显示,以你的社会保障号为锚定点会影响你的最终购买价格。在一项研究中,社会保障号产生高锚定值(超过八十美元)的人表示他们愿意支付的金额大约是低锚定值(少于二十美元)的人的三倍。
显然,你的社会保障号不应该对你判断一瓶葡萄酒价值的影响如此之大,但事实确实如此。锚定是一个极其稳健的效应,经常在谈判中被故意使用。无论你是在集市上讨价还价还是坐下来进行复杂的商业交易,你可能在先开价方面具有优势,因为锚定的接受者会不自觉地被吸引去思考你的报价如何可能是合理的。人们总是试图理解他们听到的内容;当他们遇到一个不合理的数字时,他们会自动想到能够减少其不合理性的考虑因素。
这里有另一个实验,将帮助你体验第三种类型的偏见。你将阅读一个高管职位候选人的描述。该描述由四个形容词组成,每个都写在一张卡片上。这副卡片刚刚被洗过。前两张卡片有这两个描述符:
聪明,坚持不懈。
在信息完整之前暂停判断是合理的,但这不是已经发生的事情:你已经对候选人有了评价,而且是积极的。这种判断就这样发生了。你对这个过程没有控制权,暂停判断不是一个选项。
接下来,你抽取最后两张卡片。现在完整的描述是:
聪明,坚持不懈,狡猾,无原则。
你的评价不再有利,但它没有足够的改变。作为比较,考虑以下描述,这是洗牌的另一种结果可能产生的:
无原则,狡猾,坚持不懈,聪明。
第二个描述由相同的形容词组成,然而——由于它们被引入的顺序——它显然比第一个描述要糟糕得多。当狡猾跟在聪明和坚持不懈之后时,它只是轻微的负面,因为我们仍然(毫无理由地)相信这位高管的意图是好的。然而当它跟在无原则之后时,狡猾这个词就很糟糕了。在这种情况下,坚持不懈和聪明不再是正面的:它们让一个坏人变得更加危险。
这个实验说明了过度一致性(excessive coherence):我们快速形成连贯的印象,并且很慢才改变它们。在这个例子中,我们根据很少的证据立即对候选人产生了积极态度。确认偏见——当我们有预判时,导致我们完全忽视冲突证据的同样倾向——使我们对后续数据的重要性给予了应有程度以下的重视。(描述这种现象的另一个术语是光环效应(halo effect),因为候选人在第一印象的积极”光环”中被评价。我们将在第24章看到光环效应是招聘决策中的一个严重问题。)
这里是另一个例子。在美国,公共官员要求连锁餐厅包含卡路里标签,以确保消费者能看到与芝士汉堡、汉堡包和沙拉等食物相关的卡路里。看到这些标签后,消费者会改变他们的选择吗?证据存在争议且结果复杂。但在一项很有启发性的研究中,研究人员发现,如果卡路里标签放在食物项目的左侧而不是右侧,消费者更容易受到影响。当卡路里在左侧时,消费者首先接收到这个信息,显然会想”卡路里很多!“或”卡路里不算多!“,然后才看到食物项目。他们最初的积极或消极反应极大地影响了他们的选择。相比之下,当人们先看到食物项目时,他们显然会想”美味!“或”不太好!“,然后才看到卡路里标签。在这里,他们最初的反应同样极大地影响了他们的选择。作者的发现支持了这个假设:对于从右到左阅读的希伯来语使用者来说,如果卡路里标签在右侧而不是左侧,其影响会显著更大。
总的来说,我们倾向于草率下结论,然后坚持这些结论。我们认为自己的观点基于证据,但我们考虑的证据以及对证据的解释很可能被扭曲,至少在某种程度上是为了符合我们最初的快速判断。因此,我们维持了在脑海中形成的整体故事的连贯性。当然,如果结论是正确的,这个过程是好的。然而,当最初的评估是错误的时候,面对矛盾证据仍坚持错误判断的倾向很可能会放大错误。这种效应很难控制,因为我们听到或看到的信息是不可能忽略的,而且往往难以忘记。在法庭上,法官有时会指示陪审员忽略他们听到的不可采信的证据,但这不是一个现实的指示(尽管在陪审团讨论中可能有所帮助,因为明确基于这种证据的论点可以被拒绝)。
我们简要介绍了以不同方式运作的三种偏见:替代偏见,导致对证据的错误权重;结论偏见,导致我们要么绕过证据,要么以扭曲的方式考虑证据;以及过度连贯性,这放大了最初印象的影响并减少了矛盾信息的冲击。当然,这三种类型的偏见都可能产生统计偏见。它们也可能产生噪音。
让我们从替代开始。大多数人通过比尔的档案与刻板印象的相似性来判断他是会计师的概率:在这个实验中,结果是一个共同的偏见。如果每个受访者都犯同样的错误,就没有噪音。但替代并不总是产生这样的一致性。当”是否存在气候变化?“这个问题被替换为”我是否信任那些说这是真实的人?“时,很容易看出答案会因人而异,取决于那个人的社交圈、首选信息来源、政治倾向等等。同样的心理偏见创造了可变的判断和人际间噪音。
替代也可能是时机噪音的来源。如果一个关于生活满意度的问题通过咨询一个人的即时情绪来回答,那么对同一个人来说,答案不可避免地会因时而异。快乐的早晨可能接着痛苦的下午,随时间变化的情绪可能导致对生活满意度的非常不同的报告,这取决于采访者何时恰好打电话。在第7章中,我们回顾了可以追溯到心理偏见的时机噪音的例子。
偏见也会产生偏见和噪音。回到我们在引言中提到的一个例子:法官接受庇护寻求者百分比的惊人差异。当一个法官接受5%的申请者,而同一法院的另一个法官接受88%时,我们可以相当确定他们朝着不同方向存在偏见。从更广阔的角度来看,偏见的个体差异可能导致巨大的系统噪音。当然,如果大多数或所有法官都有类似的偏见,系统也可能存在偏见。
最后,过度连贯性可能产生偏见或噪音,这取决于信息序列和赋予信息的意义对所有(或大多数)法官是否相同。例如,考虑一个外表具有吸引力的候选人,其美貌在大多数招聘人员中创造了早期的积极印象。如果外表与候选人所考虑的职位无关,这种积极的光晕效应将导致共同错误:一种偏见。
另一方面,许多复杂决策需要汇编以基本随机顺序到达的信息。考虑第2章的理赔调整员。关于理赔的数据变得可用的顺序在不同调整员之间以及不同案例之间随机变化,导致最初印象的随机变化。过度连贯性意味着这些随机变化将在最终判断中产生随机扭曲。效果将是系统噪音。
简而言之,心理偏见作为一种机制是普遍的,它们经常产生共同错误。但当偏见存在巨大个体差异(不同的偏见)或当偏见的影响取决于环境(不同的触发因素)时,就会有噪音。
偏见和噪音都会产生错误,这表明任何能够减少心理偏见的方法都会改善判断。我们将在第5部分回到去偏见或消除偏见的话题。但现在,我们继续探索判断过程。
“我们知道自己有心理偏见,但我们应该抵制将每个错误都归咎于未指明的’偏见’的冲动。”
“当我们用一个更容易的问题来替代我们应该回答的问题时,错误必然会发生。例如,当我们通过相似性来判断概率时,我们会忽略基础概率。”
“预判和其他结论偏见导致人们扭曲证据以支持他们的初始立场。”
“我们快速形成印象,即使出现矛盾信息也会坚持这些印象。这种倾向被称为过度一致性。”
“如果许多人共享相同的偏见,心理偏见会导致统计偏见。然而,在许多情况下,人们的偏见各不相同。在这些情况下,心理偏见会产生系统噪音。”
看看天空。两小时内下雨的可能性有多大?
你可能毫不费力地回答了这个问题。你做出的判断——例如,“很可能”很快就会下雨——是毫不费力地产生的。不知何故,你对天空阴暗程度的评估被转换成了概率判断。
你刚才执行的是匹配的一个基本例子。我们已经将判断描述为一种将值分配到刻度上以对应主观印象(或印象的某个方面)的操作。匹配是该操作的重要组成部分。当你回答”在1到10的刻度上,你的心情有多好?“或”请为你今天上午的购物体验给出一到五颗星”时,你在进行匹配:你的任务是在判断刻度上找到一个与你的心情或体验相匹配的值。
你在上一章中遇到了Bill,他又出现了:“Bill三十三岁。他聪明但缺乏想象力,强迫症且总体上毫无生气。在学校里,他数学很强但在社会研究和人文学科方面很弱。”我们要求你估计Bill从事各种职业和爱好的概率,我们看到你通过用相似性判断替代概率判断来回答这个问题。你并没有真正问Bill是会计师的可能性有多大,而是问他与该职业的刻板印象有多相似。我们现在转向一个我们没有回答的问题:你是如何做出那个判断的。
评估Bill的描述与职业和爱好刻板印象的匹配程度并不困难。Bill显然不如典型的爵士乐手那样像会计师,他甚至更不像冲浪者。这个例子说明了匹配的非凡多样性,这在关于人的判断中特别明显。你可以回答关于Bill的问题几乎没有限制。例如,如果和他一起被困在荒岛上,你会有什么感觉?根据提供的少量信息,你可能立即有了直觉答案。然而,我们有消息要告诉你:我们所知道的Bill,恰好是一个经验丰富的探险家,具有非凡的生存技能。如果这让你惊讶(很可能会),你刚刚经历了无法实现一致性的失败。
这种惊讶是强烈的,因为新信息与你之前构建的Bill形象不兼容。现在想象一下,如果Bill的才能和生存技能包含在原始描述中。你最终会对这个人有不同的整体印象,也许是一个只有在户外才会变得生动的人。对Bill的整体印象会不那么一致,因此更难匹配到职业或爱好类别,但你经历的认知失调会比刚才少得多。
冲突的线索使得实现一致感和找到令人满意的匹配判断变得更加困难。冲突线索的存在是复杂判断的特征,我们预期在其中会发现大量噪音。Gambardi问题,其中一些指标是积极的,其他是消极的,就是这样的判断。我们在第16章回到复杂判断。在本章的其余部分,我们专注于相对简单的判断——特别是那些在强度刻度上做出的判断。
我们表达判断的一些刻度是定性的:职业、爱好和医学诊断是例子。它们的特点是刻度的值没有排序:红色既不比蓝色多也不比蓝色少。
然而,许多判断是在定量强度刻度上做出的。尺寸、重量、亮度、温度或响度的物理测量;成本或价值的测量;概率或频率的判断——所有这些都是定量的。更抽象刻度上的判断也是如此,如信心、力量、吸引力、愤怒、恐惧、不道德或惩罚的严重程度。
这些量化维度共有的显著特征是,对于同一维度上的任何一对数值,都可以回答”哪个更多?“这个问题。你可以判断鞭打比轻拍手腕是更严厉的惩罚,或者你更喜欢《哈姆雷特》而不是《等待戈多》,就像你可以判断太阳比月亮更亮,大象比仓鼠重,迈阿密的平均温度比多伦多高一样。
人们有一种非凡的直觉能力,能够通过将一个强度量表映射到另一个强度量表上,来匹配不相关维度之间的强度。你可以将对不同歌手的喜爱程度与你所在城市建筑物的高度相匹配。(例如,如果你认为鲍勃·迪伦特别棒,你可能会将对他的热情程度与你城市中最高的建筑物相匹配。)你可以将你国家当前的政治分歧程度与你熟悉城市的夏季温度相匹配。(如果政治非常和谐,你可能会将其与纽约夏日微风习习的70度天气相匹配。)如果有人要求你通过比较小说长度而不是通常的1到5星评级来表达对餐厅的欣赏,这个要求会让你觉得相当奇怪,但绝不是不可行的。(你最喜欢的餐厅可能就像《战争与和平》。)在每种情况下,奇怪的是——你的意思都很清楚。
在日常对话中,量表的数值范围是上下文的函数。“她一直在存很多钱”这句话,在为一位成功的投资银行家的退休干杯时与在祝贺一个一直在做保姆的青少年时,有着不同的含义。而像大和小这样的词的含义完全取决于参照框架。例如,我们可以理解”大老鼠跑上了小象的鼻子”这样的陈述。
以下谜题既说明了匹配的力量,也说明了与之相关的系统性判断错误。
朱莉是一名大学毕业生。阅读以下关于她的信息,然后猜测她的GPA(标准量表为0.0到4.0):
朱莉在四岁时就能流利地阅读。
她的GPA是多少?
如果你熟悉美国的平均成绩点数系统,一个数字很快就出现在你的脑海中,它可能接近3.7或3.8。关于朱莉GPA的猜测如何瞬间出现在你脑海中,说明了我们刚刚描述的匹配过程。
首先,你评估了朱莉作为读者有多早熟。这个评估很容易,因为朱莉阅读得异常早,这种早熟将朱莉放在了某个量表的某个类别中。如果你必须描述你使用的量表,你可能会说它的最高类别是”异常早熟”之类的,而你会注意到朱莉并不完全属于那个类别(有些孩子在两岁前就会阅读)。朱莉可能属于下一个类别,即”异常但不是极度早熟”的儿童群体。
在第二步中,你将对GPA的判断与对朱莉的评价相匹配。虽然你没有意识到这样做,但你一定在寻找一个也符合”异常但不是极度”标签的GPA值。当你听到朱莉的故事时,一个匹配预测似乎凭空出现在你的脑海中。
刻意执行完成这些评估和匹配任务所需的计算需要相当长的时间,但在快速的系统1思维中,判断是快速且毫不费力地实现的。我们在这里讲述的关于猜测朱莉GPA的故事涉及一个复杂的、多阶段的心理事件序列,无法直接观察。匹配的心理机制的特异性在心理学中是不寻常的——但支持它的证据异常确凿。从许多类似的实验中,我们可以确定,当向不同群体的人提出以下两个问题时,会引出完全相同的数字:
朱莉班上有百分之几的学生比她阅读得更早?
朱莉班上有百分之几的学生的GPA比她高?
第一个问题本身是可以处理的:它只是要求你评估你得到的关于朱莉的证据。第二个问题需要远距离预测,肯定更难——但通过回答第一个问题来回答它在直觉上是诱人的。
我们关于朱莉的两个问题类似于我们在早期讨论有效性错觉时描述为普遍令人困惑的两个问题。关于朱莉的第一个问题要求你评估你拥有的关于她情况的信息的”强度”。第二个问题询问预测的强度。我们怀疑它们仍然难以区分。
对朱莉GPA的直觉预测是我们在第13章中描述的心理机制的一个案例:用简单问题替代困难问题。你的系统1通过回答一个容易得多的问题来简化困难的预测问题:朱莉作为四岁阅读者的成就有多令人印象深刻?需要额外的匹配步骤才能直接从以年为单位测量的阅读年龄转到以点数测量的GPA。
当然,只有当可用信息相关时,替代才会发生。如果你对朱莉的了解只是她是个快跑者或平庸的舞者,你就没有任何信息。但任何可以被解释为智力合理指标的事实都可能是可接受的替代品。
用一个问题替代另一个问题,当两个问题的真实答案不同时,不可避免地会产生错误。用阅读年龄替代GPA,虽然看似合理,但实际上是荒谬的。要理解为什么,请想想自朱莉四岁以来可能发生的事情。她可能遭遇了可怕的事故。她的父母可能经历了创伤性离婚。她可能遇到了一位对她产生重大影响的启发性老师。她可能怀孕了。这些事件以及其他许多事件都可能影响她在大学的表现。
匹配预测只有在阅读早慧性和大学GPA完全相关的情况下才能得到证明,而这显然不是事实。另一方面,完全忽略朱莉阅读年龄的信息也是错误的,因为她的阅读年龄确实提供了一些相关信息。最佳预测必须介于完美知识和零知识这两个极端之间。
当你对一个案例一无所知时,你了解什么——只知道它所属的类别?这个问题的答案就是我们所说的案例的外部视角。如果我们被要求预测朱莉的GPA但没有得到关于她的任何信息,我们肯定会预测平均值——也许是3.2。这就是外部视角预测。对朱莉GPA的最佳估计必须高于3.2且低于3.8。估计的精确位置取决于信息的预测价值:你越信任阅读年龄作为GPA的预测因子,估计就越高。在朱莉的案例中,这个信息确实相当薄弱,因此最合理的预测会相应地更接近平均GPA。有一种技术性但相当容易的方法来纠正匹配预测的错误;我们在附录C中详细说明。
尽管它们导致统计上荒谬的预测,匹配证据的预测很难抗拒。销售经理经常假设去年比销售团队其他成员更成功的销售人员将继续表现出色。高级管理人员有时会遇到一个异常有才华的候选人,并想象新员工将如何升至组织的顶层。制片人通常预期一位导演的下一部电影会和他之前的热门电影一样成功。
这些匹配预测的例子更可能以失望告终。另一方面,在情况最糟糕时做出的匹配预测更可能过于消极。匹配证据的直觉预测过于极端,无论是乐观的还是悲观的。(这种预测错误的技术术语是它们是非回归的,因为它们未能考虑一种称为均值回归的统计现象。)
然而,应该注意的是,替代和匹配并不总是支配预测。用两个系统的语言来说,直觉的系统1在问题出现时提出快速的联想解决方案,但这些直觉必须得到更反思的系统2的认可才能成为信念。匹配预测有时会被拒绝,转而支持更复杂的反应。例如,人们更不愿意将预测匹配到不利证据而非有利证据。我们怀疑如果朱莉是一个晚读者,你会犹豫是否对低等大学表现做出匹配预测。当有更多信息可用时,有利和不利预测之间的不对称性消失。
我们提供外部视角作为对各种直觉预测的纠正。例如,在之前关于迈克尔·甘巴迪未来前景的讨论中,我们建议将你对迈克尔成功概率的判断锚定在相关的基本率上(新任CEO的两年成功率)。在诸如朱莉GPA等定量预测的情况下,采用外部视角意味着将你的预测锚定在平均结果上。只有在非常简单的问题中,当可用信息支持能够完全自信地做出的预测时,外部视角才能被忽略。当需要严肃判断时,外部视角必须是解决方案的一部分。
我们在强度量表上区分类别的有限能力限制了匹配操作的准确性。诸如大或富有这样的词为规模或财富维度上的一系列值分配相同的标签。这是一个潜在的重要噪音来源。
即将退休的投资银行家肯定配得上富有这个标签,但她有多富有?我们有许多形容词可供选择:小康、富裕、舒适、有钱、超级富有等等。如果你得到一些个人财富的详细描述,并且必须为每个人附加一个形容词,你能形成多少个不同的类别——而不需要诉诸案例间的详细比较?
我们在强度量表上能够区分的类别数量在心理学史上一篇经典文章的标题中给出,该文章发表于1956年:“神奇数字七,正负二。”超出这个限制,人们往往开始犯错误——例如,将A分配到比B更高的类别,而实际上在直接比较中他们会给B比A更高的评级。
想象一组四条不同长度的线段,长度在2到4英寸之间,每条线段都比下一条长相同的长度。你每次看到一条线段,需要说出1到4之间的一个数字,其中1对应最短的线段,4对应最长的线段。这个任务很容易。现在假设你看到五条不同长度的线段,需要重复这个任务,说出1到5的数字。仍然很容易。什么时候你会开始出错?大约在神奇数字七条线段的时候。令人惊讶的是,这个数字几乎不依赖于线段长度的范围:如果线段的间距在2到6英寸之间,而不是2到4英寸之间,你仍然会在超过七条线段时开始出错。当你听到不同响度的音调,或看到不同亮度的光线时,也会得到基本相同的结果。人们在某个维度上给刺激分配不同标签的能力确实存在限制,这个限制大约是七个标签。
这种判别能力的限制很重要,因为我们在强度维度之间匹配数值的能力不可能超过我们在这些维度上分配数值的能力。匹配操作是快速系统1思维的多功能工具,也是许多直觉判断的核心,但它是粗糙的。
神奇数字不是绝对限制。人们可以通过分层分类训练来做出更精细的区分。例如,我们确实可以在千万富翁中区分几个财富类别,法官可以在多个犯罪类别中区分严重程度,这些类别本身也按严重程度排序。然而,要使这种精细化过程起作用,类别必须预先存在,其边界必须清晰。在给一组线段分配标签时,你不能决定将较长的线段与较短的线段分开,并将它们视为两个独立的类别。当你处于快速思维模式时,分类不受意志控制。
有一种方法可以克服形容词量表分辨率有限的问题:不使用标签,而使用比较。我们比较案例的能力远胜于将它们放在量表上的能力。
考虑一下,如果要求你使用二十分制的质量量表来评估大量餐厅或歌手,你会怎么做。五星制很容易管理,但你不可能在二十分制下保持完美的可靠性。(Joe’s Pizza值三颗星,但它是十一分还是十二分?)这个问题的解决方案很简单,虽然耗时。你首先使用五分制评级量表对餐厅或歌手进行评分,将它们分为五个类别。然后对每个类别内的案例进行排名,这通常只会有少数并列:你可能知道自己更喜欢Joe’s Pizza还是Fred’s Burgers,或者更喜欢Taylor Swift还是Bob Dylan,即使你将他们分配到同一类别。为了简化,你现在可以在五个类别中的每个类别内区分四个级别。你甚至可以在最不喜欢的歌手中区分不同程度的鄙视。
这个练习的心理学原理很直接。对判断对象进行明确比较比逐个评估对象支持更精细的区分。线段长度的判断也说明了类似的情况:你比较连续显示的线段长度的能力远好于标记长度的能力,当同时看到线段进行比较时,你会更加准确。
比较判断的优势适用于许多领域。如果你对人们的财富有大致了解,比较同一范围内的个人会比单独标记他们的财富做得更好。如果你批改作文,从最好到最差排名会比逐篇阅读和评分更精确。比较或相对判断比分类或绝对判断更敏感。正如这些例子所示,它们也更费力和耗时。
在明确比较性的量表上单独评估对象保留了比较判断的一些好处。在某些情况下,特别是在教育中,对候选人录取或晋升的推荐通常要求推荐者将候选人定位在某个指定群体的”前5%“或”前20%“中,如”你教过的学生”或”具有相同经验水平的程序员”。这些评级很少值得照单全收,因为无法让推荐者对正确使用量表负责。在某些情况下可以问责:当管理者评估员工或分析师评估投资时,将90%的案例分配到”前20%“类别的人可以被识别和纠正。使用比较判断是我们将在第5部分讨论的减少噪音的补救措施之一。
许多判断任务需要将个别案例匹配到量表上的类别(例如,七分制同意量表)或使用有序的形容词集合(例如,在评估事件概率时使用”不太可能”或”极不可能”)。这种匹配很有噪音,因为它很粗糙。即使在判断实质内容上达成一致,个人对标签的理解也可能不同。强制进行明确比较判断的程序可能会减少噪音。在下一章中,我们将进一步探讨使用错误量表如何增加噪音。
“我们都说这部电影很好,但你似乎比我享受得少得多。我们使用相同的词汇,但我们使用的是相同的量表吗?”
“我们以为这个系列的第二季会和第一季一样精彩。我们做了相同的预测,结果错了。”
“在评估这些论文时很难保持一致性。你应该尝试对它们进行排名吗?”
想象你是一个民事审判的陪审员。你已经听到了下面总结的证据,并且需要对此做出一些判断。
琼·格洛弗诉一般援助公司案
六岁女童琼·格洛弗摄入了大量Allerfree(一种非处方过敏药)药片,需要长期住院治疗。由于过量服用削弱了她的呼吸系统,她在余生中将更容易患哮喘和肺气肿等呼吸相关疾病。Allerfree药瓶使用了设计不当的防儿童安全帽。
Allerfree的制造商是一般援助公司,这是一家大公司(年利润1亿至2亿美元),生产各种非处方药物。联邦法规要求所有药瓶都必须使用防儿童安全帽。一般援助公司系统性地忽视了这项法规的意图,使用的防儿童安全帽失效率远高于行业内其他公司。一份公司内部文件称”这个愚蠢、不必要的联邦法规是浪费我们的钱”,并声明被处罚的风险很低。该文件还补充说,无论如何,“违反法规的处罚极其轻微;基本上我们只会被要求在未来改进安全帽。”尽管美国食品药品监督管理局官员就其安全帽问题发出了警告,该公司仍决定不采取任何纠正措施。
接下来我们要求你做出三个判断。请放慢速度选择你的答案。
| 愤怒程度: | ||||||
|---|---|---|---|---|---|---|
| 以下哪项最能表达你对被告行为的看法?(请圈出你的答案。) | ||||||
| 完全可以接受 | 令人反感 | 令人震惊 | 绝对令人愤怒 | |||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 惩罚意向: | ||||||
|---|---|---|---|---|---|---|
| 除了支付补偿性损害赔偿外,被告应该受到多大程度的惩罚?(请圈出最能表达你对适当惩罚水平意见的数字。) | ||||||
| 不予惩罚 | 轻微惩罚 | 严厉惩罚 | 极其严厉惩罚 |
损害赔偿: 除了支付补偿性损害赔偿外,被告应被要求支付多少惩罚性损害赔偿(如有)作为惩罚,并阻止被告和其他人在未来采取类似行为?(请在下面的空白处写下您的答案。)
$ ……
Joan Glover的故事是我们其中两人(Kahneman和Sunstein,以及我们的朋友和合作者David Schkade)在1998年报告的一项研究中使用的案例的略缩版本。我们在本章中详细描述了这项研究,我们希望您体验该研究包含的任务之一,因为我们现在将其视为噪音审计的一个有启发性的例子,它重现了本书的许多主题。
本章重点关注反应量表作为噪音普遍来源的作用。人们可能在判断上存在分歧,不是因为他们在实质内容上不同意,而是因为他们以不同的方式使用量表。如果您要评估员工的表现,您可能会说在0到6的量表上,表现是4分——在您看来,这相当不错。其他人可能会说在同一量表上,员工的表现是3分——在他看来,这也相当不错。量表措辞的模糊性是一个普遍问题。关于由”超出合理怀疑”、“明确和令人信服的证据”、“出色表现”和”不太可能发生”等模糊表达引起的沟通困难,已经进行了大量研究。用这些短语表达的判断不可避免地是嘈杂的,因为说话者和听者对它们的解释不同。
在为Joan Glover案例编写的研究中,我们观察到模糊量表在具有严重后果的情况下的影响。研究的主题是陪审团裁决惩罚性损害赔偿中的噪音。正如您可以从关于Joan Glover案例的第三个问题推断的那样,美国法律(以及其他一些国家)允许民事案件中的陪审团对行为特别恶劣的被告施加惩罚性损害赔偿。惩罚性损害赔偿是对补偿性裁决的补充,后者旨在使受伤的人恢复原状。当像Glover例子中那样,产品造成了伤害,原告成功起诉了公司时,他们将获得金钱来支付医疗费用和任何损失的工资。但他们也可能获得惩罚性裁决,旨在向被告和类似公司发出警告。General Assistance在此案中的行为显然是应受谴责的;它属于陪审团可以合理施加惩罚性损害赔偿的行为范围。
对惩罚性损害赔偿制度的一个主要担忧是其不可预测性。同样的不当行为可能被从非常温和到巨额不等的损害赔偿所惩罚。使用本书的术语,我们会说这个系统是嘈杂的。惩罚性损害赔偿的请求经常被拒绝,即使被批准,裁决也经常没有对补偿性损害赔偿增加太多。然而,有一些显著的例外,陪审团有时裁决的非常大的金额看起来令人惊讶和任意。一个经常被提及的例子是对一家汽车经销商施加的400万美元惩罚性裁决,因为其未披露原告的新BMW已被重新喷漆的事实。
在我们的惩罚性损害赔偿研究中,899名参与者被要求评估Joan Glover的案例和其他九个类似案例——所有这些案例都涉及遭受某种伤害并起诉据称负责的公司的原告。与您不同,参与者只回答所有十个案例的三个问题中的一个(愤怒、惩罚意图或美元金额)。参与者进一步分为较小的组,每组被分配到每个案例的一个版本。不同版本改变了原告遭受的伤害和被告公司的收入。总共有二十八个场景。我们的目标是测试关于惩罚性损害赔偿心理学的理论,并调查货币量表(这里是美元)作为这一法律制度中噪音主要来源的作用。
如何确定公正的惩罚几个世纪以来一直是哲学家和法律学者辩论的问题。然而,我们的假说是,哲学家认为困难的问题对普通人来说相当容易,他们通过用简单的问题替代困难的问题来简化任务。简单的问题是,当您被问及General Assistance应该受到多少惩罚时立即回答的”我有多愤怒?“然后,预期惩罚的强度将与愤怒的强度相匹配。
为了测试这一愤怒假设,我们要求不同组的参与者回答惩罚意图问题或愤怒问题。然后,我们比较了研究中使用的二十八个场景在这两个问题上获得的平均评分。正如替代想法所预期的那样,愤怒和惩罚意图平均评分之间的相关性接近完美的0.98(PC = 94%)。这种相关性支持愤怒假设:愤怒情绪是惩罚意图的主要决定因素。
愤怒是惩罚意图的主要驱动力,但不是唯一的。你在Joan的故事中有没有注意到,当你评估惩罚意图时比评估愤怒时更引起注意的东西?如果有的话,我们怀疑那是她遭受的伤害。你可以在不知道后果的情况下判断一种行为是否令人愤怒;在这个例子中,General Assistance的行为无疑是令人愤怒的。相比之下,关于惩罚意图的直觉具有报复性方面,这在以眼还眼原则中得到了粗糙的表达。对报复的冲动解释了为什么法律和陪审团对蓄意谋杀和谋杀的处理不同;一个幸运地没有击中目标的潜在杀手会受到较轻的惩罚。
为了弄清楚伤害是否确实在惩罚意图中产生影响但在愤怒中不产生影响,我们向不同组的受访者展示了Joan Glover案例和其他几个案例的”严重伤害”和”轻微伤害”版本。严重伤害版本就是你看到的那个。在轻微伤害版本中,Joan”不得不在医院住了几天,现在对任何种类的药丸都有深度创伤。当她的父母试图让她服用甚至是有益的药物,如维生素、阿司匹林或感冒药时,她会无法控制地哭泣,并说她很害怕。“这个版本描述了孩子的创伤经历,但比你读到的第一个版本中描述的长期医疗损害伤害程度要低得多。正如预期的那样,严重伤害版本(4.24)和轻微伤害版本(4.19)的愤怒平均评分几乎相同。只有被告的行为对愤怒有影响;其后果则没有。相比之下,惩罚意图的评分在严重伤害情况下平均为4.93,在轻微伤害情况下为4.65,这是一个小但统计上可靠的差异。中位数货币奖励在严重伤害版本中为200万美元,在较轻版本中为100万美元。其他几个案例也获得了类似的结果。
这些发现突出了判断过程的一个关键特征:判断任务对证据不同方面权重的微妙影响。评估惩罚意图和愤怒的参与者并不知道他们在哲学问题上表明立场,即正义是否应该是报复性的。他们甚至没有意识到为案例的各种特征分配权重。尽管如此,他们在评估愤怒时给伤害分配了接近零的权重,而在确定惩罚时给同一因素分配了显著的权重。回想一下,参与者只看到了故事的一个版本;他们对更严重伤害分配更高惩罚并不是明确的比较。这是两种条件下匹配自动操作的结果。参与者的反应更多地依赖快速思维而非缓慢思维。
研究的第二个目标是找出为什么惩罚性损害赔偿是有噪音的。我们的假设是,陪审员在他们希望被告受到多严厉惩罚方面普遍达成一致,但在如何将他们的惩罚意图转化为美元量表方面存在很大差异。
研究的设计使我们能够比较在三个量表上对相同案例判断的噪音数量:愤怒、惩罚意图和美元损害赔偿。为了测量噪音,我们应用了第6章中用于分析联邦法官噪音审计结果的方法。我们假设,就像我们在那个分析中所做的那样,案例个人判断的平均值可以被视为无偏的、公正的价值。(这是用于分析目的的假设;我们强调它可能是错误的。)在理想世界中,所有使用特定量表的陪审员在每个案例的判断上都会达成一致。任何偏离平均判断的情况都算作错误,这些错误是系统噪音的来源。
正如我们在第6章中也注意到的,系统噪音可以分解为水平噪音和模式噪音。在这里,水平噪音是陪审员在一般严厉程度上的变异性。模式噪音是给定陪审员对特定案例的反应相对于该陪审员自己平均水平的变异性。因此,我们可以将判断的总体方差分解为三个要素:
判断方差 = 公正惩罚方差 + (水平噪音)² + (模式噪音)²
这个分析,将判断方差分解为三项,分别对愤怒、惩罚意图和美元奖励的三种判断进行。
图13显示了结果。噪音最小的量表是惩罚意图,其中系统噪音占方差的51%——噪音和正义大约相等。愤怒量表明显更有噪音:71%的噪音。而美元量表是迄今为止最糟糕的:判断方差的94%完全是噪音!
这些差异是惊人的,因为三个量表在内容方面几乎相同。我们之前看到,愤怒和惩罚意图的公正价值几乎完全相关,正如愤怒假设所暗示的那样。惩罚意图的评分和美元奖励回答了完全相同的问题——General Assistance应该受到多严厉的惩罚——只是单位不同。我们如何解释图13中看到的巨大差异?
我们大概可以同意,愤怒并不是一个非常精确的量表。确实,存在”完全可以接受”的行为,但如果对通用援助公司或其他被告的愤怒程度有一个上限,那么这个上限是相当模糊的。一个行为”绝对令人愤慨”意味着什么?量表上端缺乏清晰度使得一些噪音不可避免。
惩罚意图更为具体。“严厉惩罚”比”绝对令人愤慨”更加精确,因为”极其严厉的惩罚”受到法律规定的最高限度约束。你可能希望对罪犯”依法严惩”,但你不能,比如说,建议判处通用援助公司CEO及其整个执行团队死刑。(我们希望如此。)惩罚意图量表不那么模糊,因为其上限被更清楚地规定了。正如我们所预期的,它也更少噪音。
图13:判断差异的组成部分
愤怒和惩罚意图都是在类似的评级量表上测量的,通过言语标签或多或少清楚地定义。美元量表属于一个不同的族群,问题要大得多。
我们学术论文的标题表达了其核心信息:“共同愤怒和反复无常的裁决:惩罚性赔偿的心理学。”我们的实验陪审员在惩罚意图评级方面有相当程度的一致性;评级主要由愤怒来解释。然而,美元度量最接近法庭情况的模拟,而且它的噪音大得无法接受。
原因并不神秘。如果你在琼·格洛弗案中实际产生了具体的损害赔偿金额,你肯定体验过这样的感觉:你选择的数字基本上是任意的。任意性的感觉传达了重要信息:它告诉你其他人会做出极其不同的任意决定,判断将会非常嘈杂。这原来是美元裁决所属量表族群的一个特征。
传奇的哈佛心理学家S. S. Stevens发现了一个令人惊讶的事实:人们对许多主观体验和态度的强度比率有着强烈的共同直觉。他们可以调节一盏灯,使其看起来比另一盏”亮两倍”,他们同意十个月监禁的情感意义远不及一个月刑期的十倍那么糟糕。Stevens称利用这种直觉的量表为比率量表。
你可以从我们轻松理解”萨拉得到了60%的加薪!“或”我们的富邻居一夜之间失去了一半财富”这样的表达中看出,我们对金钱的直觉是用比率表达的。惩罚性赔偿的美元量表是衡量惩罚意图的比率量表。像其他比率量表一样,它有一个有意义的零点(零美元)并且在顶端是无界的。
Stevens发现比率量表(如美元量表)可以通过单一的中间锚点(术语是模量)固定下来。在他的实验室里,他会让观察者看到某种亮度的光,指示”将那道光的亮度称为10(或50,或200),并相应地为其他亮度分配数字。“正如预期的那样,观察者分配给不同亮度光线的数字与他们被指示采用的任意锚点成正比。以数字200为锚点的观察者会做出比锚点为10时高20倍的判断;观察者判断的标准差也与锚点成正比。
在第13章中,我们描述了一个有趣的锚定例子,人们对某个物品的支付意愿受到这样一个问题的强烈影响:首先询问他们是否愿意支付(以美元计)其社会安全号码的最后两位数字。一个更引人注目的结果是,初始锚点也影响了他们对整个其他物品清单的支付意愿。被诱导同意为无线轨迹球支付大量金额的参与者,也同意为无线键盘支付相应更大的金额。看起来人们对可比商品的相对价值比对其绝对价值敏感得多。该研究的作者将单一锚点的持续影响命名为”连贯的任意性”。
为了理解琼·格洛弗案中任意锚点的影响,假设本章开头的文本包含以下信息:
在涉及另一家制药公司的类似案例中,一个受害的小女孩遭受了中度心理创伤(如你之前读到的轻微伤害版本)。惩罚性赔偿被设定为150万美元。
注意到为通用援助公司设定惩罚的问题突然变得容易多了。实际上,一个金额可能已经浮现在你脑海中。美元裁决有一个乘数(或比率),对应于对琼造成的严重伤害与另一个小女孩遭受的轻微伤害之间的对比。此外,你读到的单一锚点(150万美元)足以固定整个惩罚的美元量表。现在很容易为比迄今为止考虑的两个案例更严重和更轻微的案例设定损害赔偿。
如果在比率量表上做判断需要锚点,那么当人们没有给定锚点时会发生什么?Stevens报告了答案。在缺乏实验者指导的情况下,人们在首次使用量表时被迫做出任意选择。从那时起,他们一致地做出判断,将他们的第一个答案作为锚点。
您可能会认识到,在为琼·格洛弗案设定损害赔偿时面临的任务是一个没有锚点的缩放实例。就像史蒂文斯实验室中没有锚点的观察者一样,您对一般援助的正确惩罚做出了任意决定。我们惩罚性损害赔偿研究中的参与者面临同样的问题:他们也被迫对看到的第一个案例做出初始的任意决定。然而,与您不同的是,他们不只是做出一个任意决定:他们继续为其他九个案例设定惩罚性损害赔偿。这九个判断并非任意的,因为它们可以与初始锚定判断保持一致,因此彼此之间也保持一致。
史蒂文斯实验室的发现表明,个体产生的锚点应该对其后续美元判断的绝对值产生很大影响,但对十个案例的相对位置没有任何影响。较大的初始判断会使所有其他判断按比例变大,而不影响它们的相对大小。这种推理导致一个令人惊讶的结论:尽管美元判断看起来毫无希望地嘈杂,但实际上反映了法官的惩罚意图。要发现这些意图,我们只需要用相对分数替换绝对美元值。
为了测试这个想法,我们在用每个美元奖励在个体十个判断中的排名替换后,重复了噪音分析。最高的美元奖励得分为1,次高的得分为2,以此类推。这种将美元奖励转换为排名的转换消除了所有水平错误,因为1到10的排名分布对每个人都是相同的,除了偶尔的并列。(如果您想知道的话,问卷有多个版本,因为每个人判断了二十八个情景中的十个。我们对回应相同十个情景的每组参与者分别进行分析,并报告平均值。)
结果令人震惊:判断中的噪音比例从94%下降到49%(图14)。将美元奖励转换为排名揭示了陪审员在不同案例的适当惩罚方面实际上有很大共识。实际上,美元奖励的排名噪音比原始惩罚意图评级的噪音略少。
图14:价值噪音与排名噪音
结果与我们概述的理论一致:所有案例的美元奖励都锚定在每个陪审员为他们看到的第一个案例选择的任意数字上。案例的相对排名相当准确地反映了态度,因此不是很嘈杂,但美元奖励的绝对值本质上是无意义的,因为它们取决于第一个案例中选择的任意数字。
讽刺的是,陪审员在真实审判中评估的案例是他们看到的第一个也是唯一一个。美国法律实践要求民事陪审团为一个案例设定美元奖励,没有任何指导锚点的好处。法律明确禁止向陪审团传达其他案例中惩罚性奖励大小的任何信息。法律中隐含的假设是,陪审员的正义感会直接引导他们从考虑犯罪到正确的惩罚。这个假设在心理学上是无稽之谈——它假设了人类不具备的能力。司法机构应该承认管理它的人的局限性。
惩罚性损害赔偿的例子是极端的;专业判断很少在如此毫无希望模糊的尺度上表达。尽管如此,模糊的尺度很常见,这意味着惩罚性损害赔偿研究有两个一般教训,适用于商业、教育、体育、政府和其他领域。首先,尺度的选择可以在判断噪音量上产生很大差异,因为模糊的尺度是嘈杂的。其次,在可行的情况下,用相对判断替换绝对判断可能会减少噪音。
“我们的判断中有很多噪音。这可能是因为我们对尺度的理解不同吗?”
“我们能否就一个锚定案例达成一致,将其作为尺度上的参考点?”
“为了减少噪音,也许我们应该用排名替换我们的判断?”
还记得朱莉,那个早熟的孩子,您在第14章中试图猜测她的大学GPA吗?这里是更完整的描述。
朱莉是独生女。她的父亲是一名成功的律师,母亲是一名建筑师。朱莉大约三岁时,她的父亲患上了一种自身免疫疾病,迫使他在家工作。他花了很多时间和朱莉在一起,耐心地教她阅读。她四岁时就能流利地阅读了。她爸爸也试图教她算术,但她觉得那个主题很困难。朱莉在小学是一个好学生,但她情感上需要关注,相当不受欢迎。她花了很多时间独处,在与她最喜欢的叔叔一起观鸟后,成为了一个热情的观鸟者。
她父母在她十一岁时离婚了,朱莉很难接受离婚。她的成绩一落千丈,在学校经常发脾气。在高中,她在一些学科上表现很好,包括生物学和创意写作。她在物理学上的优异表现让每个人都感到惊讶。但她忽视了大部分其他学科,以B等学生的身份从高中毕业。
朱莉没有被她申请的名校录取,最终就读于一所不错的州立大学,主修环境研究。在大学的前两年里,她延续了频繁情感纠葛的模式,并且经常吸食大麻。然而,在第四学期,她强烈希望进入医学院,开始更加认真地对待学业。
你对朱莉毕业时GPA的最佳猜测是什么?
显然,这个问题(我们称之为朱莉2.0)变得困难得多。关于朱莉1.0,你所知道的只是她四岁时就能阅读。仅凭一个线索,匹配的力量发挥了作用,对她GPA的直觉估计很快浮现在脑海中。
如果你有几个指向同一总体方向的线索,匹配仍然有效。例如,当你读到比尔——那个演奏爵士乐的会计师的描述时,你拥有的所有信息(“缺乏想象力”、“数学能力强”、“社会研究较弱”)描绘了一个连贯的、刻板印象的画面。同样,如果朱莉2.0生活中的大多数事件都与早熟和卓越成就的故事一致(也许只有少数几个数据点表明”平均”表现),你不会发现这个任务如此困难。当可获得的证据描绘出连贯画面时,我们快速的系统1思维毫不费力地理解它。像这样的简单判断问题很容易解决,大多数人对其解决方案达成一致。
朱莉2.0的情况并非如此。使这个问题困难的是多个冲突线索的存在。有能力和动机的迹象,但也有性格弱点和平庸成就的表现。这个故事似乎杂乱无章。它不容易理解,因为这些元素无法融入一个连贯的解释中。当然,这种不连贯并不使故事不现实或甚至不可信。生活往往比我们喜欢讲述的故事更复杂。
多个冲突的线索创造了定义困难判断问题的模糊性。模糊性也解释了为什么复杂问题比简单问题更嘈杂。规则很简单:如果有不止一种方式看待任何事物,人们看待它的方式就会有所不同。人们可以选择不同的证据片段来构成他们叙述的核心,因此有许多可能的结论。如果你发现很难构建一个能够理解朱莉2.0的故事,你可以相当确定其他读者将构建不同的故事来证明与你不同的判断。这就是产生模式噪音的变异性。
你何时对一个判断感到自信?必须满足两个条件:你相信的故事必须全面连贯,并且不能有吸引人的替代方案。当所选解释的所有细节都与故事吻合并相互强化时,就实现了全面连贯。当然,你也可以通过忽略或解释掉任何不符合的东西来实现连贯,尽管不那么优雅。替代解释也是如此。“解决”了判断问题的真正专家不仅知道为什么她的解释性故事是正确的;她同样能够流利地解释为什么其他故事是错误的。在这里,一个人可以通过未能考虑替代方案或主动抑制它们来获得同等强度但质量较差的信心。
这种信心观点的主要含义是,对自己判断的主观信心绝不能保证准确性。此外,替代解释的抑制——一个在感知中有充分记录的过程——可能诱发我们所称的一致性错觉(见第2章)。如果人们无法想象他们结论的可能替代方案,他们自然会认为其他观察者也必须得出相同的结论。当然,我们很少有幸对所有判断都高度自信,我们所有人都有过不确定的经历,也许就在你阅读朱莉2.0时。我们并非一直都高度自信,但大多数时候我们比应有的更自信。
我们将模式错误定义为个人对案例判断中无法用案例和法官各自效应之和来解释的错误。一个极端例子可能是通常宽大的法官在判处特定类型被告(比如犯交通违法的人)时异常严厉。或者说,通常谨慎的投资者在看到令人兴奋的初创企业计划时放弃了他惯常的谨慎。当然,大多数模式错误并不极端:我们在宽大的法官处理累犯时没有平常那么宽大,或者在判处年轻女性时甚至比平常更宽大时,观察到适度的模式错误。
模式错误源于短暂和永久因素的结合。短暂因素包括我们描述为场合噪音来源的那些,比如法官在相关时刻的好心情或最近发生的一些不幸事件正在法官心中。其他因素更持久——例如,雇主对就读某些大学的人的异常热情,或医生对推荐肺炎患者住院的异常倾向。我们可以写一个简单的方程来描述单个判断中的错误:
由于稳定模式误差和瞬时(偶然)误差是独立且不相关的,我们可以扩展上述方程来分析它们的方差:
正如我们对其他误差和噪音成分所做的那样,我们可以用图形表示这个方程,作为直角三角形各边上的平方和(图15):
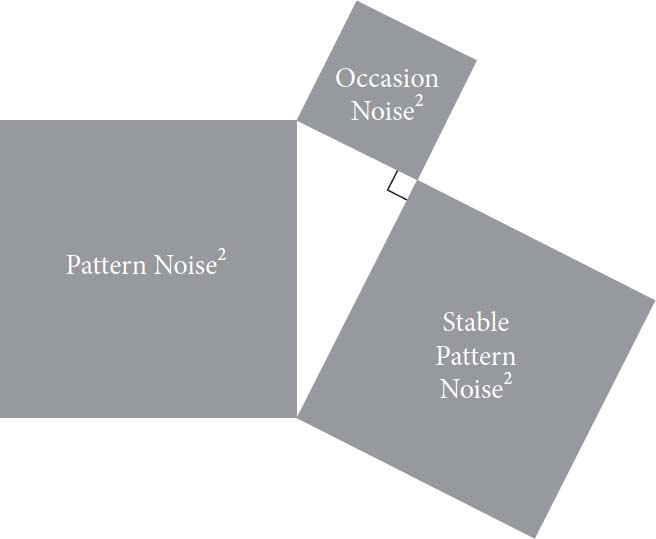
图15:分解模式噪音
关于稳定模式噪音的一个简单例子,考虑根据一系列评级来预测高管未来表现的招聘人员。在第9章中,我们谈到了”评判者模型”。个人招聘人员的模型为每个评级分配权重,这对应于该评级在该招聘人员判断中的重要性。不同招聘人员的权重各不相同:对一个招聘人员来说领导力可能更重要,对另一个来说沟通技巧更重要。这种差异在招聘人员对候选人的排名中产生变异性——这是我们所说的稳定模式噪音的一个例子。
对个别案例的个人反应也可能产生稳定但高度特定的模式。考虑是什么让你比其他方面更关注Julie故事的某些方面。案例的一些细节可能与你的生活经历产生共鸣。也许Julie的某些方面让你想起一个亲近的亲戚,这个人总是几乎成功但最终失败,因为你认为自青少年时期就明显存在的深层性格缺陷。相反,Julie的故事可能唤起对一位密友的回忆,这位朋友在经历了困扰的青春期后,确实进入了医学院,现在是一位成功的专科医生。Julie在不同人身上唤起的联想是特异的和不可预测的,但它们很可能是稳定的:如果你上周读到Julie的故事,你会想起同样的人,并会以同样独特的个人视角看待她的故事。
判断质量的个体差异是模式噪音的另一个来源。想象一个拥有水晶球力量的预测者,但没有人知道这一点(包括她自己)。她的准确性会使她在许多情况下偏离平均预测。在缺乏结果数据的情况下,这些偏差会被视为模式误差。当判断无法验证时,卓越的准确性看起来就像模式噪音。
模式噪音还来自于对案例不同维度做出有效判断能力的系统性差异。考虑职业运动队的选拔过程。教练可能专注于比赛各个方面的技能,医生关注受伤的易感性,心理学家关注动机和韧性。当这些不同的专家评估同样的球员时,我们可以预期相当大的模式噪音。同样,担任同一通才角色的专业人士可能在判断任务的某些方面比其他方面更熟练。在这种情况下,模式噪音更好地描述为人们所知道的变异性,而不是误差。
当专业人士独自做决定时,技能的变异性仅仅是噪音。然而,当管理层有机会构建团队来共同做出判断时,技能的多样性就成为潜在的资产,因为不同的专业人士将涵盖判断的不同方面并相互补充。我们在第21章讨论这个机会——以及捕捉它所需要的条件。
在前面的章节中,我们谈到了保险公司客户或被分配审判他的法官的被告所面临的两种抽签。我们现在可以看到,第一种抽签从一群同事中选择一个专业人士,选择的远不止该专业人士判断的平均水平(水平误差)。抽签还选择了一个万花筒般的价值观、偏好、信念、记忆、经验和联想的组合,这些对这个特定的专业人士来说是独特的。每当你做出判断时,你也带着自己的包袱。你带着在工作中形成的思维习惯和从导师那里获得的智慧。你带着建立信心的成功和小心避免重复的错误。在你的大脑某处存在着你记住的正式规则、忘记的规则,以及你学到的可以忽略的规则。在所有这些方面,没有人完全像你;你的稳定模式误差对你来说是独特的。
第二种抽签选择你做出判断的时刻、你的心情,以及其他不应该影响你的判断但确实会影响的无关环境。这种抽签产生偶然噪音。例如,想象在你阅读Julie的案例之前不久,你读了一篇关于大学校园毒品使用的报纸文章。这篇文章讲述了一个有天赋的学生的故事,他决心进入法学院并努力学习——但无法弥补他在大学早期使用毒品时积累的缺陷。因为这在你的脑海中很新鲜,这个故事会让你在评估Julie的整体机会时更加关注她的吸食大麻习惯。然而,如果你在几周后遇到关于Julie的问题,你可能不会记得这篇文章(如果你昨天阅读了这个案例,你显然不会知道它)。阅读报纸文章的影响是瞬时的;它是偶然噪音。
正如这个例子所示,稳定的模式噪音和我们称之为情境噪音的不稳定变异之间并没有明显的不连续性。主要区别在于一个人对案例某些方面的独特敏感性本身是永久的还是暂时的。当模式噪音的触发因素根植于我们的个人经历和价值观时,我们可以期待这种模式是稳定的,反映了我们的独特性。
特定的人对某些特征或特征组合的独特反应这一想法并不是立即直观的。为了理解它,我们可以考虑另一个我们都很熟悉的复杂特征组合:我们周围人们的个性。事实上,法官对案例做出判断的事件应该被视为一个更广泛主题的特殊情况,这个主题是个性研究的领域:一个人在某种情况下如何行动。从对这个更广泛主题几十年的深入研究中,我们可以学到一些关于判断的东西。
心理学家长期以来一直试图理解和测量个性的个体差异。人们在许多方面彼此不同;早期扫描词典寻找可能描述一个人的术语的尝试发现了一万八千个词。今天,占主导地位的个性模型——大五模型,将特质组合为五个群组(外向性、宜人性、尽责性、经验开放性、神经质),大五中的每一个都涵盖一系列可区分的特质。个性特质被理解为实际行为的预测因子。如果某人被描述为尽责的,我们期望观察到一些相应的行为(准时到达、遵守承诺等等)。如果Andrew在攻击性测量上的得分比Brad高,我们应该观察到,在大多数情况下,Andrew比Brad表现得更有攻击性。然而,事实上,广泛特质预测特定行为的有效性是相当有限的;0.30的相关性(PC = 60%)会被认为是高的。
常识表明,虽然行为可能由个性驱动,但它也受到情境的强烈影响。在某些情况下没有人会有攻击性,而在其他情况下每个人都会有。当安慰一个失去亲人的朋友时,Andrew和Brad都不会表现得有攻击性;然而,在足球比赛中,两人都会表现出一些攻击性。简而言之——而且不出所料——行为是个性和情境的函数。
使人们独特且永远有趣的是,个性和情境的这种结合不是一个机械的、添加性的函数。例如,触发更多或更少攻击性的情境对所有人来说并不相同。即使Andrew和Brad平均来说同样有攻击性,他们也不一定在每种情境下都表现出同等的攻击性。也许Andrew对同伴有攻击性但对上级温顺,而Brad的攻击性水平对等级层级不敏感。也许Brad在受到批评时特别容易有攻击性,在受到身体威胁时异常克制。
这些对情境的标志性反应模式可能在时间上是相当稳定的。它们构成了我们认为的某人个性的大部分,尽管它们不适合用广泛的特质来描述。Andrew和Brad可能在攻击性测试上有相同的分数,但他们在对攻击性触发因素和情境的反应模式上是独特的。共享一个特质水平的两个人——例如,如果他们同样固执或同样慷慨——应该用两个具有相同平均值但不一定在不同情境下有相同反应模式的行为分布来描述。
现在你可以看到这个关于个性的讨论和我们提出的判断模型之间的平行关系。法官之间的水平差异对应于个性特质分数之间的差异,后者代表在多种情况下行为的平均值。案例类似于情境。一个人对特定问题的判断只能从那个人的平均水平中适度预测,就像特定行为只能从个性特质中适度预测一样。个体在判断上的排名在不同案例之间变化很大,因为人们对他们在每个案例中发现的特征和特征组合的反应不同。做出判断和决策的个体的标志是对特征的独特敏感性模式以及相应的案例判断中的独特模式。
个性的独特性通常是值得庆祝的原因,但这本书关注的是专业判断,在这里变异是有问题的,噪音就是错误。这个类比的要点是,判断中的模式噪音不是随机的——即使我们几乎没有希望解释它,即使做出独特判断的个体也无法解释它们。
“你似乎对你的结论很有信心,但这不是一个容易的问题:有指向不同方向的线索。你是否忽略了证据的其他解释?”
“你和我面试了同一个候选人,通常我们都是同样严格的面试官。然而我们有完全不同的判断。这种模式噪音来自哪里?”
“人们个性的独特性使他们能够创新和创造,并且简单地说,与他们在一起是有趣和令人兴奋的。然而,当涉及到判断时,这种独特性并不是一种资产。”
我们希望到现在为止,你已经同意无论在哪里有判断,就有噪声。我们也希望对你来说,噪声不再比你想象的更多。这个关于噪声的箴言在我们开始项目时激励着我们,但在多年的研究过程中,我们对这个话题的思考已经发生了演变。我们现在回顾一下关于噪声组成部分的主要经验教训,以及它们在噪声总体图景中的相对重要性,以及噪声在判断研究中的地位。
图16提供了我们在第5章、第6章和第16章中介绍的三个等式的综合图形表示。该图说明了误差的三个连续分解:
现在你可以看到MSE如何分解为偏差的平方和我们讨论过的三个噪声组成部分的平方。
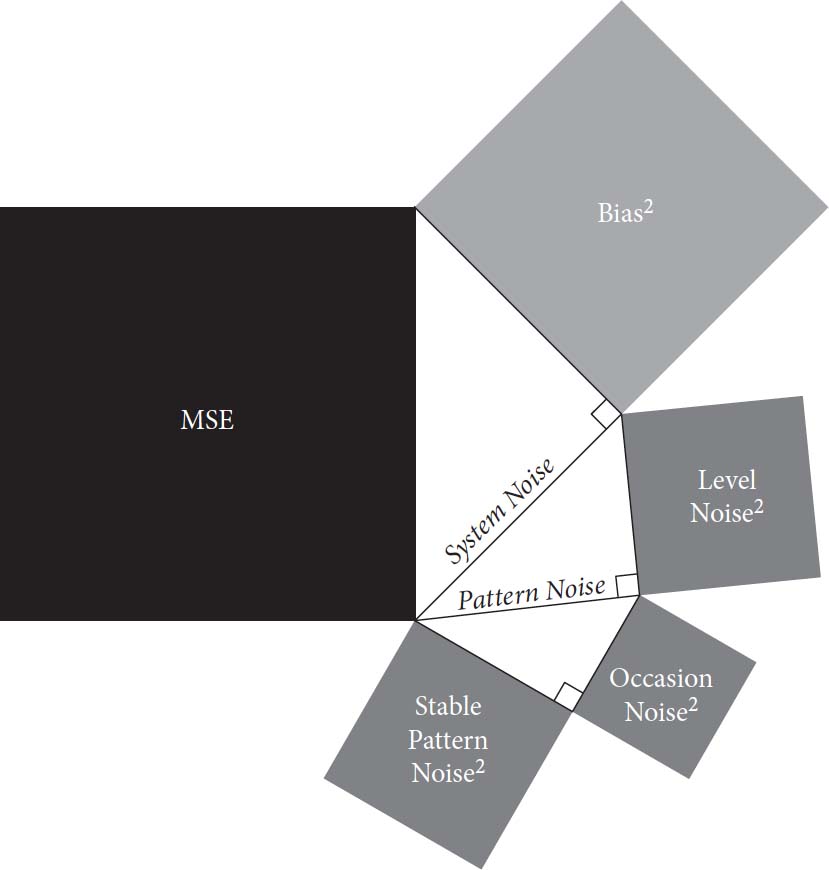
图16:误差、偏差和噪声的组成部分
当我们开始研究时,我们关注的是偏差和噪声在总误差中的相对权重。我们很快得出结论,噪声往往是误差的一个比偏差更大的组成部分,当然非常值得更详细地探索。
我们对噪声构成的早期思考受到复杂噪声审计结构的指导,在这种审计中,多个人对多个案例做出个人判断。联邦法官的研究就是一个例子,惩罚性赔偿的研究是另一个例子。来自这些研究的数据提供了水平噪声的可靠估计。另一方面,因为每个参与者都判断每个案例,但只判断一次,无法判断我们称为模式误差的残差误差是暂时的还是稳定的。在统计分析的保守精神下,残差误差通常被标记为误差项并被视为随机的。换句话说,对模式噪声的默认解释是它完全由场合噪声组成。
这种将模式噪声解释为随机误差的传统理解在很长时间内限制了我们的思考。关注水平噪声似乎是自然的——严厉和宽松法官之间的一致差异,或者乐观和悲观预测者之间的一致差异。我们也对证据感兴趣,这些证据表明无关的暂时环境对判断的影响,这些环境产生了场合噪声。
证据逐渐让我们意识到,不同人做出的噪声判断很大程度上由既不是个人的一般偏差也不是暂时和随机的东西决定:特定个人对众多特征的持续个人反应,这决定了他们对特定案例的反应。我们最终得出结论,我们关于模式噪声暂时性质的默认假设应该被放弃。
虽然我们要小心不要从仍然有限的例子选择中过度概括,但我们收集的研究总的来说表明,稳定模式噪声实际上比系统噪声的其他组成部分更重要。因为我们很少在同一项研究中对误差组成部分有全面的了解,需要一些三角测量来形成这个暂定结论。简而言之,这就是我们知道的——以及我们不知道的。
首先,我们有几个关于水平噪声和模式噪声相对权重的估计。总的来说,模式噪声似乎比水平噪声贡献更多。例如,在第2章的保险公司中,承保人在他们设定的保费平均值上的差异只占总系统噪声的20%;其余80%是模式噪声。在第6章的联邦法官中,水平噪声(平均严重程度的差异)占总系统噪声的略少于一半;模式噪声是更大的组成部分。在惩罚性赔偿实验中,系统噪声的总量根据使用的量表(惩罚意图、愤怒或美元赔偿)差异很大,但模式噪声在总量中的份额大致恒定:在研究中使用的三个量表中,它分别占总系统噪声的63%、62%和61%。我们将在第5部分回顾的其他研究,特别是关于人事决策的研究,与这个暂定结论一致。
这些研究中水平噪音通常不是系统噪音的最大组成部分,这一事实本身就是一个重要信息,因为水平噪音是组织在不进行噪音审计的情况下(有时)能够监控的唯一噪音形式。当案例或多或少随机分配给个别专业人员时,他们决策平均水平的差异就提供了水平噪音的证据。例如,对专利局的研究观察到审查员授予专利的平均倾向存在很大差异,这对这些专利诉讼的发生率产生了后续影响。同样,儿童保护服务的案例官员在将儿童安置到寄养家庭的倾向上也存在差异,这对儿童的长期福利产生了影响。这些观察仅基于对水平噪音的估计。如果模式噪音比水平噪音更多,那么这些已经令人震惊的发现至少低估了噪音问题的严重程度两倍。(这个初步规则有例外。庇护法官决策中令人震惊的变异性几乎肯定更多是由于水平噪音而非模式噪音,我们怀疑模式噪音也很大。)
下一步是通过分离模式噪音的两个组成部分来分析模式噪音。有充分理由假设稳定模式噪音,而不是场合噪音,是主导组成部分。对联邦法官判刑的审计说明了我们的推理。从所有模式噪音都是瞬时的这个极端可能性开始。在这种假设下,判刑将在时间上不稳定和不一致,达到我们认为不太可能的程度:我们必须预期同一法官对同一案件在不同场合的判决之间的平均差异是约2.8年。法官之间平均判刑的变异性已经令人震惊。同一法官在不同场合判刑的相同变异性将是荒谬的。得出法官在对不同被告和不同犯罪的反应上存在差异,且这些差异是高度个人化但稳定的结论似乎更合理。
为了更精确地量化模式噪音中有多少是稳定的,有多少是场合噪音,我们需要同一法官对每个案例进行两次独立评估的研究。正如我们所指出的,在判断研究中获得两个独立判断通常是不可能的,因为很难保证对案例的第二次判断真正独立于第一次判断。特别是当判断复杂时,个人很可能会识别出问题并重复原始判断。
普林斯顿的一组研究人员在Alexander Todorov的领导下,设计了巧妙的实验技术来克服这个问题。他们从Amazon Mechanical Turk招募参与者,这是一个个人提供短期服务(如回答问卷)并获得报酬的网站。在一个实验中,参与者观看面部图片(由计算机程序生成,但与真人面孔完全无法区分)并在各种属性上对其评分,如喜爱度和可信度。实验在一周后重复进行,使用相同的面孔和相同的受访者。
公平地说,在这个实验中期望的共识会比专业判断(如判刑法官的判断)中的共识更少。每个人可能都同意某些人极其有吸引力,而其他人极其没有吸引力,但在很大范围内,我们期望对面孔的反应主要是特异的。确实,观察者之间几乎没有一致性:例如,在可信度评分上,图片之间的差异仅占判断方差的18%。剩余的82%方差是噪音。
在这些判断中期望较少的稳定性也是公平的,因为在线付费回答问题的参与者所做判断的质量通常远低于专业环境中的质量。尽管如此,噪音的最大组成部分是稳定模式噪音。噪音的第二大组成部分是水平噪音——即观察者在可信度平均评分上的差异。场合噪音虽然仍然很大,但是最小的组成部分。
当研究人员要求参与者做出其他判断时——例如对汽车或食物的偏好,或者更接近我们所称的专业判断的问题——得出了相同的结论。例如,在第15章讨论的惩罚性损害赔偿研究的复制中,参与者在相隔一周的两个不同场合对十个人身伤害案例的惩罚意图进行评分。在这里,稳定模式噪音再次是最大的组成部分。在所有这些研究中,个人通常彼此不同意,但他们在判断中保持相当稳定。研究人员称之为”没有共识的一致性”,这提供了稳定模式噪音的明确证据。
稳定模式作用的最有力证据来自我们在第10章提到的保释法官大型研究。在这项卓越研究的一个部分中,作者创建了一个统计模型,模拟每位法官如何使用可用线索来决定是否批准保释。他们为173名法官构建了定制模型。然后他们应用这些模拟法官对141,833个案例做出决定,每个案例产生173个决定——总共超过2400万个决定。应我们的要求,作者慷慨地进行了一项特殊分析,将判断方差分解为三个组成部分:“真实”的每个案例平均决定方差、由法官间批准保释倾向差异产生的水平噪音,以及剩余的模式噪音。
这一分析与我们的论点相关,因为在这项研究中测量的模式噪音完全是稳定的。机会噪音的随机变异性没有被体现,因为这是对预测法官决定的模型的分析。只包括了可验证的稳定的个体预测规则。
结论是明确的:这种稳定的模式噪音几乎是水平噪音的四倍(稳定模式噪音占总方差的26%,水平噪音占7%)。能够识别出的稳定的、特质性的个体判断模式比全面严厉程度的差异大得多。
所有这些证据都与我们在第7章回顾的机会噪音研究一致:虽然机会噪音的存在令人惊讶甚至令人不安,但没有迹象表明个人内部变异性大于个人间差异。系统噪音最重要的组成部分是我们最初忽视的那个:稳定的模式噪音,即法官在特定案例判断中的变异性。
鉴于相关研究相对稀少,我们的结论是暂定的,但它们确实反映了我们对噪音思考方式的改变——以及如何解决噪音问题。至少在原则上,水平噪音——或法官间简单的全面差异——应该是一个相对容易测量和解决的问题。如果存在异常”严厉”的评分者、“谨慎”的儿童监护官员或”风险规避”的贷款员,雇用他们的组织可以努力均衡他们判断的平均水平。例如,大学在要求教授遵守每个班级预定的成绩分布时就在解决这个问题。
不幸的是,正如我们现在意识到的,关注水平噪音遗漏了个体差异的很大一部分。噪音主要不是水平差异的产物,而是相互作用的产物:不同法官如何处理特定被告、不同教师如何处理特定学生、不同社会工作者如何处理特定家庭、不同领导者如何处理对未来的特定愿景。噪音主要是我们独特性的副产品,是我们”判断个性”的副产品。减少水平噪音仍然是一个值得追求的目标,但仅仅实现这个目标会让系统噪音问题的大部分没有解决方案。
我们对噪音有很多话要说,但这个话题几乎完全缺席于公众意识和关于判断与错误的讨论中。尽管有证据表明其存在以及产生它的多种机制,噪音很少被提及为判断中的主要因素。这怎么可能?为什么我们从不援引噪音来解释糟糕的判断,而我们却例行公事地责怪偏见?为什么很少去深入思考噪音作为错误来源,尽管它无处不在?
这个谜题的关键在于,尽管错误的平均值(偏见)和错误的变异性(噪音)在错误方程中起着等同的作用,我们对它们的思考方式却截然不同。我们理解周围世界的普通方式使得几乎不可能认识到噪音的作用。
在本书前面,我们注意到我们容易在事后理解事件,尽管在事件发生前我们无法预测它们。在正常谷地中,事件是不令人惊讶的且容易解释的。
判断也是如此。像其他事件一样,判断和决定大多发生在正常谷地中;它们通常不会让我们惊讶。一方面,产生满意结果的判断是正常的,很少受到质疑。当被选中主罚任意球的射手进球得分时,当心脏手术成功时,或当初创公司繁荣发展时,我们假设决策者做出选择的理由一定是正确的。毕竟,他们已经被证明是对的。像任何其他不令人惊讶的故事一样,成功故事一旦结果已知就能自我解释。
然而,我们确实感到需要解释异常结果:糟糕的结果,偶尔还有令人惊讶的好结果——比如令人震惊的商业赌博获得回报。诉诸错误或特殊天赋的解释远比它们应得的更受欢迎,因为过去的重要赌博一旦结果已知就容易变成天才或愚蠢的行为。一个有充分记录的心理偏见叫做基本归因错误(fundamental attribution error),是一种强烈倾向,即将责任或功劳归咎于行为者的行动和结果,而这些行动和结果更好地用运气或客观环境来解释。另一个偏见,后见之明,扭曲了判断,使得无法预期的结果在回顾中显得容易预见。
对判断错误的解释并不难找到;找到判断的理由,甚至比找到事件的原因更容易。我们总是可以援引做出判断的人的动机。如果这还不够,我们可以责怪他们的无能。近几十年来,对糟糕判断的另一种解释变得很常见:心理偏见。
心理学和行为经济学的大量研究已经记录了一长串心理偏见:规划谬误、过度自信、损失厌恶、禀赋效应、现状偏见、对未来的过度贴现(“当下偏见”),以及许多其他偏见——当然包括对各类人群的偏见。我们对每种偏见可能影响判断和决策的条件了解很多,对于允许决策观察者实时识别偏见思维的知识也了解相当多。
如果偏见可以提前预测或实时检测,那么心理偏见就是判断错误的合理因果解释。仅在事后才识别出的心理偏见,如果它也对未来提供预测,仍然可以提供有用的(尽管是试探性的)解释。例如,一位强势女性候选人意外被拒绝某个职位,可能暗示了性别偏见的更一般假设,未来同一委员会的任命将证实或反驳这一假设。相比之下,考虑一个仅适用于单一事件的因果解释:“在那种情况下他们失败了,所以他们一定是过于自信了。”这种陈述完全是空洞的,但它提供了一种理解的错觉,这种错觉可能相当令人满意。商学院教授Phil Rosenzweig令人信服地论证了,在商业结果的讨论中,用偏见进行的空洞解释很常见。它们的流行证明了对使经验变得有意义的因果故事的普遍需求。
正如我们在第12章中指出的,我们正常的思维方式是因果性的。我们自然地关注特定事物,遵循并创造关于个别案例的因果连贯故事,其中失败往往归因于错误,错误归因于偏见。糟糕判断可以轻易解释的事实,在我们对错误的解释中没有为噪音留下空间。
噪音的不可见性是因果思维的直接后果。噪音本质上是统计性的:只有当我们对类似判断的集合进行统计思考时,它才变得可见。事实上,这时它就变得难以忽视:它是关于量刑决定和承保保费的回顾性统计中的变异性。它是当你和其他人考虑如何预测未来结果时的可能性范围。它是目标上击中点的散布。从因果角度看,噪音无处可寻;从统计角度看,它无处不在。
不幸的是,采用统计观点并不容易。我们毫不费力地为观察到的事件援引原因,但对它们进行统计思考必须学习,而且仍然很费力。原因是自然的;统计是困难的。
结果是我们如何看待偏见和噪音作为错误来源存在明显的不平衡。如果你接触过任何心理学入门课程,你可能记得那些插图,其中一个显著且细节丰富的图形从模糊的背景中突出出来。即使图形相对于背景很小,我们的注意力也牢牢固定在图形上。图形/背景演示是我们对偏见和噪音直觉的恰当隐喻:偏见是一个引人注目的图形,而噪音是我们不关注的背景。这就是我们在很大程度上没有意识到我们判断中的重大缺陷的原因。
“我们很容易看到判断平均水平的差异,但我们看不到的模式噪音有多大?”
“你说这个判断是由偏见引起的,但如果结果不同,你还会说同样的话吗?你能分辨出是否存在噪音吗?”
“我们正确地专注于减少偏见。让我们也担心减少噪音。”
一个组织如何改善其专业人员做出的判断?特别是,一个组织如何减少判断噪音?如果你负责回答这些问题,你会如何着手?
必要的第一步是让组织认识到专业判断中的噪音是一个值得关注的问题。为了达到这一点,我们推荐进行噪音审计(详细描述见附录A)。在噪音审计中,多个个体判断同样的问题。噪音就是这些判断的变异性。会有一些情况,这种变异性可以归因于无能:一些判断者知道他们在说什么,另一些则不知道。当存在这样的技能差距时(无论是总体上,还是在某些类型的案例上),优先级当然应该是改善缺陷技能。但是,正如我们所看到的,即使在胜任且训练有素的专业人员的判断中,也可能存在大量噪音。
如果系统噪音的数量值得解决,那么用规则或算法替代判断是一个你应该考虑的选择,因为它将完全消除噪音。但规则有其自身的问题(我们将在第6部分看到),即使是AI最热心的支持者也同意,算法不是,也不会很快成为人类判断的通用替代品。改善判断的任务比以往任何时候都更加紧迫,这正是本书这一部分的主题。
提高判断质量的一个明智方法当然是选择最好的人类评判者。在射击场上,有些射手的瞄准能力特别好。在任何专业判断任务中也是如此:技能最高的人既不会那么嘈杂,偏见也更少。如何找到最佳评判者有时很明显;如果你想解决一个象棋问题,应该询问大师,而不是本书的作者。但在大多数问题中,优秀评判者的特征更难辨别。这些特征是第18章的主题。
接下来,我们讨论减少判断错误的方法。心理偏见与统计偏见和噪声都有关联。正如我们在第19章中看到的,人们已经进行了许多对抗心理偏见的尝试,有一些明显的失败,也有一些明显的成功。我们简要回顾了去偏见策略,并提出了一种有前景的方法,据我们所知,这种方法尚未得到系统性探索:指定一名决策观察者来寻找诊断性迹象,这些迹象可以实时表明一个团队的工作正受到一种或几种熟悉偏见的影响。附录B提供了决策观察者可以使用的偏见检查清单示例。
然后我们转向本书这一部分的主要关注点:对抗噪声。我们介绍了决策卫生这一主题,这是我们推荐用来减少人类判断中噪声的方法。我们在五个不同领域中展示案例研究。在每个领域中,我们检查噪声的普遍性以及它产生的一些可怕故事。我们还回顾了减少噪声努力的成功——或缺乏成功。当然,在每个领域中都使用了多种方法,但为了便于阐述,每章都强调单一的决策卫生策略。
我们从第20章的法医学案例开始,它说明了信息排序的重要性。对一致性的追求导致人们基于有限的可用证据形成早期印象,然后确认他们正在形成的偏见。这使得在判断过程的早期不接触无关信息变得重要。
在第21章中,我们转向预测的案例,它说明了最重要的噪声减少策略之一的价值:聚合多个独立判断。“群体智慧”原则基于多个独立判断的平均化,这保证能够减少噪声。除了直接平均之外,还有其他聚合判断的方法,这也通过预测的例子得到说明。
第22章回顾了医学中的噪声以及减少噪声的努力。它指出了我们已经通过刑事量刑例子介绍的一种噪声减少策略的重要性和普遍适用性:判断指导原则。指导原则可以成为强有力的噪声减少机制,因为它们直接减少了评判者之间在最终判断上的变异性。
在第23章中,我们转向商业生活中的一个熟悉挑战:绩效评估。减少那里噪声的努力展示了使用基于外部视角的共享量表的关键重要性。这是一个重要的决策卫生策略,原因很简单:判断需要将印象转换到量表上,如果不同的评判者使用不同的量表,就会产生噪声。
第24章探讨了相关但不同的人员选择主题,这在过去一百年中得到了广泛研究。它说明了一个基本决策卫生策略的价值:结构化复杂判断。通过结构化,我们的意思是将判断分解为其组成部分,管理数据收集过程以确保输入彼此独立,并将整体讨论和最终判断延迟到所有这些输入都已收集完毕。
我们基于从人员选择领域学到的经验教训,在第25章中提出了一种称为中介评估协议(简称MAP)的选项评估通用方法。MAP从”选项就像候选人”这一前提出发,并示意性地描述了如何在典型的决策过程中为重复性和单一性决策引入结构化决策制定以及上述其他决策卫生策略。
在我们开始之前的一个总体要点:能够具体说明,甚至量化各种决策卫生策略在不同情境中可能带来的好处是很有价值的。了解哪种策略最有益以及如何比较它们也很有价值。当信息流得到控制时,噪声会减少到什么程度?如果目标是减少噪声,在实践中应该聚合多少判断?结构化判断可能很有价值,但在不同情境中究竟有多大价值?
由于噪声主题很少受到关注,这些仍然是开放性问题,研究最终可能会解决。出于实用目的,一种或另一种策略的好处将取决于使用它的特定环境。考虑采用指导原则:它们有时会产生巨大收益(正如我们将在一些医学诊断中看到的)。然而,在其他环境中,采用指导原则的好处可能是适度的——也许是因为一开始就没有太多噪声,或者也许是因为即使是最好的指导原则也不能大幅减少错误。在任何给定的情境中,决策者都应该努力更精确地理解每种决策卫生策略可能带来的收益——以及相应的成本,我们在第6部分中讨论这些成本。
迄今为止,我们主要讨论的是人类判断者,而没有对他们进行区分。然而,显而易见的是,在任何需要判断的任务中,一些人会比其他人表现得更好。即使是判断的群体智慧聚合,如果群体由更有能力的人组成,也可能会更好。因此,一个重要的问题是如何识别这些更优秀的判断者。
有三个因素很重要。当做判断的人受过良好训练、更聪明并且具有正确的认知风格时,他们的判断既不那么嘈杂,偏见也更少。换句话说:好的判断取决于你知道什么、你思考得多好,以及你如何思考。好的判断者往往经验丰富且聪明,但他们也往往积极开放并愿意从新信息中学习。
说判断者的技能影响其判断质量几乎是同义反复。例如,技能娴熟的放射科医生更可能正确诊断肺炎,在预测世界事件方面,有”超级预测者”能够可靠地超越他们不那么超级的同行。如果你组建一个由某个法律领域真正专家组成的律师团队,他们很可能对法庭上常见法律纠纷的结果做出相似且准确的预测。高技能的人不那么嘈杂,他们也表现出更少的偏见。
这些人是相关任务的真正专家。由于结果数据的可获得性,他们相对于其他人的优越性是可以验证的。至少在原则上,我们可以根据医生、预测者或律师过去正确的频率来选择他们。(由于显而易见的原因,这种方法在实践中可能很困难;我们不建议你试图让你的家庭医生接受能力考试。)
正如我们也已经注意到的,许多判断是无法验证的。在某些界限内,我们无法轻易知道或无争议地定义判断所针对的真实价值。承保和刑事判决属于这一类别,品酒、论文评分、书籍和电影评论以及无数其他判断也是如此。然而,这些领域中的一些专业人士被称为专家。我们对这些专家判断的信心完全基于他们在同行中享有的尊重。我们称他们为受尊敬专家。
受尊敬专家这个术语并非不敬。一些专家不受其判断准确性评估约束的事实不是批评;这是许多领域的生活现实。许多教授、学者和管理顾问都是受尊敬专家。他们的可信度取决于学生、同行或客户的尊重。在所有这些领域以及更多领域中,一个专业人士的判断只能与同行的判断进行比较。
在缺乏真实价值来确定谁对谁错的情况下,我们经常重视受尊敬专家的意见,即使他们彼此不同意。例如,想象一个小组,其中几位政治分析师对外交危机的成因和发展趋势持截然不同的观点。(这种分歧并不罕见;如果他们都同意,那就不会是一个非常有趣的小组了。)所有分析师都相信存在正确的观点,并且他们自己的观点最接近正确。当你倾听时,你可能会发现几位分析师同样令人印象深刻,他们的论证同样令人信服。你无法知道他们中哪个是正确的(即使后来你也可能不知道,如果他们的分析没有被明确表述为可验证的预测)。你知道至少有些分析师是错误的,因为他们意见不一致。然而你尊重他们的专业知识。
或者考虑一组不同的专家,他们根本不做预测。三位道德哲学家,都受过良好训练,聚集在一个房间里。其中一位追随伊曼努尔·康德(Immanuel Kant);另一位追随杰里米·边沁(Jeremy Bentham);第三位追随亚里士多德(Aristotle)。关于道德要求什么,他们激烈分歧。问题可能涉及是否以及何时撒谎是合法的,或动物权利,或刑事惩罚的目标。你仔细倾听。你可能钦佩他们思维的清晰和精确。你倾向于同意一位哲学家,但你尊重他们所有人。
你为什么这样做?更一般地说,那些本身因判断质量而受到尊重的人,在没有数据客观确立专业知识的情况下,如何决定将某人作为专家来信任?什么造就了受尊敬专家?
答案的一部分是共同规范或专业学说的存在。专家通常从专业社区获得专业资格,并在其组织中接受培训和监督。完成住院医师培训的医生和从资深合伙人那里学习的年轻律师不仅学习其行业的技术工具;他们还被训练使用某些方法并遵循某些规范。
共同规范给专业人士一种感觉,即应该考虑哪些输入以及如何做出和证明他们的最终判断。例如,在保险公司,理赔调整员毫不困难地就应该包含在评估理赔检查清单中的相关考虑因素达成一致并进行描述。
当然,这种一致性并没有阻止理赔调整员在他们的理赔评估中出现巨大差异,因为学说并没有完全规定如何进行。它不是可以机械遵循的配方。相反,学说为解释留下了空间。专家仍然产生判断,而不是计算。这就是为什么噪音不可避免地发生。即使是接受相同训练并在他们所应用的学说上达成一致的专业人士,在应用过程中也会彼此偏离。
除了对共同规范的了解,经验也是必要的。如果你的专业是国际象棋、音乐会钢琴或投掷标枪,你可以成为年轻的天才,因为结果验证你的表现水平。但承保人、指纹鉴定专家或法官通常需要多年经验才能获得可信度。承保领域没有年轻的天才。
受尊敬专家的另一个特征是他们能够自信地做出并解释自己的判断。我们倾向于更信任那些信任自己的人,而不是那些表现出怀疑的人。信心启发式(confidence heuristic)指出这样一个事实:在一个群体中,自信的人比其他人更有分量,即使他们没有理由自信。受尊敬的专家擅长构建连贯的故事。他们的经验使他们能够识别模式,通过与以前案例的类比进行推理,并快速形成和确认假设。他们很容易将看到的事实融入一个能够激发信心的连贯故事中。
培训、经验和信心使受尊敬的专家能够赢得信任。但这些属性并不能保证他们判断的质量。我们如何知道哪些专家可能做出好的判断?
有充分理由相信一般智力可能与更好的判断相关。智力与几乎所有领域的良好表现都相关。在其他条件相同的情况下,它不仅与更高的学术成就相关,还与更高的工作表现相关。
在讨论智力或一般心理能力(GMA,现在使用的术语优于智商或IQ)的测量时,会出现许多争论和误解。关于智力的天生性质存在持续的误解;事实上,测试测量的是已发展的能力,这些能力部分是遗传特征的函数,部分受环境影响,包括教育机会。许多人还担心基于GMA的选择对可识别社会群体的不利影响,以及将GMA测试用于选择目的的合法性。
我们需要将这些对测试使用的担忧与其预测价值的现实分开。自从美国军队一个多世纪前开始使用心理能力测试以来,数千项研究已经测量了认知测试分数与后续表现之间的联系。从这大量研究中得出的信息是明确的。正如一项综述所说,“GMA既能预测所达到的职业水平,也能预测在所选职业中的表现,并且比任何其他能力、特征或倾向都要好,也比工作经验更好。”当然,其他认知能力也很重要(稍后详述)。许多人格特征也是如此——包括尽责性和毅力(grit),定义为在追求长期目标时的坚持不懈和激情。是的,还有各种形式的智力是GMA测试无法测量的,如实用智力和创造力。心理学家和神经科学家区分晶体智力——通过依靠关于世界的知识储备(包括算术运算)来解决问题的能力,和流体智力(fluid intelligence)——解决新问题的能力。
然而,尽管有其粗糙性和局限性,GMA通过包含语言、数量和空间问题的标准化测试来测量,仍然是重要结果的最佳单一预测因子。正如前面提到的综述补充说,GMA的预测力”比心理学研究中发现的大多数都要大”。一般心理能力与工作成功之间关联的强度随着相关工作复杂性的增加而增加,这很合乎逻辑:智力对火箭科学家比对从事简单任务的人更重要。对于高复杂性的工作,标准化测试分数与工作表现之间可观察到的相关性在.50范围内(PC = 67%)。正如我们所指出的,.50的相关性按照社会科学标准表明非常强的预测价值。
特别是在讨论熟练专业判断时,对智力测量相关性的一个重要且频繁的反对意见是,所有做出此类判断的人都可能是高GMA个体。医生、法官或高级承保人比一般人群受教育程度更高,在任何认知能力测量上得分都很可能高得多。你可能合理地认为高GMA在他们中间没有什么区别——它仅仅是进入高成就者群体的入场券,而不是该群体内成就差异的来源。
这种信念虽然广泛存在,但是错误的。毫无疑问,在给定职业中发现的GMA范围在职业范围底部比顶部更宽:在较低级别职业中有高GMA个体,但在律师、化学家或工程师中几乎没有低于平均GMA的人。因此,从这个角度来看,高心理能力显然是获得高地位专业准入的必要条件。
然而,这种衡量方法未能捕捉到这些群体内部的成就差异。即使在认知能力排名前1%的人群中(在13岁时评估),杰出成果与GMA仍然密切相关。与这个前1%群体中排在最后四分之一的人相比,排在前四分之一的人获得博士学位、出版书籍或获得专利的可能性要高出2到3倍。换句话说,GMA的差异不仅在第99百分位与第80或第50百分位之间很重要,而且在第99.88百分位与第99.13百分位之间仍然很重要——非常重要!
在另一个能力与成果关联的显著例证中,2013年的一项研究专注于财富500强公司的CEO和424名美国亿万富翁(按财富计算占美国人口的前0.0001%)。不出所料,研究发现这些超级精英群体由智力最优秀的人组成。但研究还发现,在这些群体内部,更高的教育水平和能力水平与更高的薪酬(CEO)和净资产(亿万富翁)相关。顺便提一下,那些成为亿万富翁的著名大学辍学生,如Steve Jobs、Bill Gates和Mark Zuckerberg,只是掩盖了森林的几棵树:虽然约三分之一的美国成年人获得了大学学位,但88%的亿万富翁都获得了大学学位。
结论很明确。GMA对需要判断力的职业表现质量有重要贡献,即使在高能力个体的群体中也是如此。认为存在一个阈值,超过该阈值GMA就不再产生影响的观点并未得到证据支持。这一结论反过来强烈表明,如果专业判断无法验证但假设要达到一个看不见的靶心,那么高能力人群的判断更可能接近目标。如果你必须选择人来做判断,选择心智能力最高的人很有道理。
但这种推理有一个重要的局限性。由于你无法对每个人进行标准化测试,你必须猜测谁是GMA更高的人。而高GMA在许多方面都能提高表现,包括说服他人你是对的能力。高心智能力的人比其他人更可能做出更好的判断并成为真正的专家,但他们也更可能给同行留下深刻印象,赢得他人信任,并在没有现实反馈的情况下成为受人尊敬的专家。中世纪的占星家必定是当时GMA最高的人群之一。
相信那些看起来和听起来聪明、能够为其判断阐述令人信服理由的人可能是明智的,但这种策略是不够的,甚至可能适得其反。那么,还有其他方法来识别真正的专家吗?拥有最佳判断力的人是否具有其他可识别的特征?
无论心智能力如何,人们在认知风格或判断任务的方法上存在差异。许多工具已被开发来捕捉认知风格。这些测量方法大多与GMA(以及彼此)相关,但它们测量的是不同的东西。
其中一种测量方法是认知反思测试(CRT),因现在无处不在的球和球棒问题而闻名:“一个球棒和一个球总共花费1.10美元。球棒比球贵1.00美元。球的价格是多少?”其他用于测量认知反思的问题包括:“如果你在跑步比赛中超过了第二名,你现在是第几名?”CRT问题试图测量人们是否会推翻首先想到的(错误)答案的可能性(球棒和球问题的”十美分”,赛跑例子的”第一名”)。较低的CRT分数与许多现实世界的判断和信念相关,包括对鬼魂、占星术和超感知觉的信念。这些分数可以预测人们是否会上当受骗于明显不准确的”假新闻”。它们甚至与人们使用智能手机的程度相关。
许多人将CRT视为测量一个更广泛概念的工具:使用反思性与冲动性思维过程的倾向。简单地说,有些人喜欢进行仔细思考,而其他人面对同样的问题时,倾向于相信他们的第一直觉。用我们的术语来说,CRT可以被视为测量人们倾向于依赖缓慢的系统2思维而不是快速的系统1思维的工具。
其他自我评估方法已被开发来测量这种倾向(当然,所有这些测试都是相互关联的)。例如,认知需要量表询问人们有多喜欢努力思考问题。要在该量表上得高分,你必须同意”我倾向于设定只有通过付出相当大的心理努力才能实现的目标”,并不同意”思考不是我的乐趣所在”。认知需要高的人往往不易受到已知认知偏见的影响。一些更奇怪的关联也被报告过:如果你避免带有剧透警告的影评,你可能有很高的认知需要;认知需要量表得分低的人更喜欢被剧透的故事。
由于该量表是自我评估,而且社会认可的答案相当明显,该量表引发了合理的质疑。试图给人留下好印象的人几乎不可能认同”思考不是我的乐趣所在”这个陈述。因此,其他测试试图测量技能,而不是使用自我描述。
一个例子是成人决策能力量表,它测量人们在判断中犯典型错误的倾向,如过度自信或风险感知的不一致性。另一个是Halpern批判性思维评估,它专注于批判性思维技能,包括理性思维倾向和一套可学习的技能。在这个评估中,你会被问到这样的问题:“想象一下,一个朋友向你咨询应该选择两个减肥项目中的哪一个。一个项目报告说客户平均减重25磅,另一个项目报告说他们平均减重30磅。在选择其中一个项目之前,你希望得到哪些问题的答案?”如果你回答说,你想知道有多少人减掉了这么多体重,以及他们是否在一年或更长时间内保持了减重效果,你就会因为运用批判性思维而得分。在成人决策能力量表或Halpern评估中得分较高的人似乎在生活中做出更好的判断:他们因为糟糕选择而经历的不良生活事件更少,比如需要为电影租赁支付滞纳金和意外怀孕。
假设所有这些认知风格和技能的测量——以及许多其他测量——通常都能预测判断力,这似乎是合理的。然而,它们的相关性似乎因任务而异。当Uriel Haran、Ilana Ritov和Barbara Mellers寻找可能预测预测能力的认知风格时,他们发现认知需求并不能预测谁会更努力地寻求额外信息。他们也没有发现认知需求与更高的表现可靠地相关。
他们发现能够预测预测表现的认知风格或人格测量只有另一个量表,由心理学教授Jonathan Baron开发,用来测量”主动开放思维“。主动开放思维是指主动寻找与你既有假设相矛盾的信息。这样的信息包括他人的不同意见以及对新证据与旧信念的仔细权衡。主动开放思维的人同意这样的陈述:”让自己被相反的论证说服是良好品格的标志。“他们不同意”改变想法是软弱的表现”或”直觉是做决定的最佳指南”这样的命题。
换句话说,虽然认知反思和认知需求分数测量的是参与缓慢而仔细思考的倾向,但主动开放思维超越了这一点。这是那些不断意识到自己的判断是一个进行中的工作,并渴望被纠正的人的谦逊。我们将在第21章中看到,这种思维风格是最优秀预测者的特征,他们不断改变想法,根据新信息修正信念。有趣的是,有一些证据表明主动开放思维是一种可教授的技能。
我们在这里并不旨在就如何挑选在特定领域做出良好判断的个人得出硬性结论。但从这个简要回顾中出现了两个一般原则。首先,明智的做法是认识到可以通过与真实值比较来确认专业知识的领域(如天气预报)与属于尊重专家范畴的领域之间的区别。一个政治分析师可能听起来口才好、令人信服,而一个国际象棋大师可能听起来怯懦,无法解释他某些棋步背后的推理。然而,我们可能应该对前者的专业判断比对后者的更加怀疑。
第二,一些判断者会比他们同样合格和有经验的同行更好。如果他们更好,他们偏见或噪音更少。在解释这些差异的许多因素中,智力和认知风格很重要。虽然没有单一的测量或量表能明确预测判断质量,但你可能想寻找这样的人:他们主动寻找可能与其先前信念相矛盾的新信息,在将这些信息整合到当前观点中时有条理,并且愿意,甚至渴望因此改变想法。
具有出色判断力的人的人格可能不符合普遍接受的果断领导者的刻板印象。人们往往倾向于信任和喜欢坚定明确的领导者,他们似乎立即且深深地知道什么是对的。这样的领导者能激发信心。但证据表明,如果目标是减少错误,领导者(和其他人)最好对反驳保持开放,并知道他们可能是错的。如果他们最终变得果断,那是在一个过程的结尾,而不是开始。
“你是专家。但你的判断是可验证的,还是你是一个尊重专家?”
“我们必须在两个意见之间做出选择,而我们对这些个人的专业知识和记录一无所知。让我们遵循更聪明的那个人的建议。”
“然而,智力只是故事的一部分。人们如何思考也很重要。也许我们应该选择最深思熟虑、最开放的人,而不是最聪明的人。”
许多研究人员和组织都致力于消除判断偏差的目标。本章将探讨他们的核心发现。我们将区分不同类型的去偏差干预措施,并讨论一种值得进一步研究的此类干预措施。然后我们将转向减少噪音并介绍决策卫生的概念。
描述两种主要去偏差方法的一个好方法是回到测量类比。假设你知道你的浴室秤平均给你的体重增加了半磅。你的秤是有偏差的。但这并不意味着它毫无用处。你可以通过两种可能的方式来解决它的偏差。你可以通过减去半磅来纠正这个不友善秤子的每一次读数。当然,这可能会有点麻烦(而且你可能会忘记这样做)。另一种选择可能是调整刻度盘,一次性改善仪器的准确性。
这两种去偏差测量的方法在去偏差判断的干预措施中有直接的类比。它们要么事后工作,在判断做出后进行纠正,要么事前工作,在判断或决策之前进行干预。
事后或纠正性去偏差通常是直觉性地进行的。假设你正在监督一个负责项目的团队,该团队估计可以在三个月内完成项目。你可能想在团队成员的判断基础上增加一个缓冲,计划四个月或更长时间,从而纠正你假设存在的偏差(计划谬误)。
这种偏差纠正有时会更系统地进行。在英国,HM Treasury发布了《绿皮书》,这是一本关于如何评估计划和项目的指南。该书敦促规划者通过对项目成本和持续时间的估计应用百分比调整来解决乐观偏差。这些调整理想情况下应该基于组织历史上的乐观偏差水平。如果没有此类历史数据,《绿皮书》建议为每种类型的项目应用通用调整百分比。
事前或预防性去偏差干预措施又分为两大类。一些最有前景的干预措施旨在修改做出判断或决策的环境。这种修改或称为助推,旨在减少偏差的影响,甚至利用偏差来产生更好的决策。一个简单的例子是养老金计划的自动注册。为了克服惰性、拖延和乐观偏差而设计,自动注册确保员工将为退休储蓄,除非他们故意选择退出。自动注册在提高参与率方面被证明是极其有效的。该计划有时伴随着”明天储蓄更多”计划,员工可以同意将其未来加薪的一定百分比用于储蓄。自动注册可以在许多地方使用——例如,绿色能源的自动注册、贫困儿童免费学校餐计划的自动注册,或各种其他福利计划的自动注册。
其他助推作用于选择架构的不同方面。它们可能使正确的决策成为简单的决策——例如,通过减少获得心理健康问题护理的行政负担。或者它们可能使产品或活动的某些特征变得突出——例如,通过使曾经隐藏的费用变得明确和清楚。杂货店和网站可以很容易地设计来助推人们以克服他们的偏差的方式。如果健康食品放在显眼的地方,更多的人可能会购买它们。
不同类型的事前去偏差涉及训练决策者识别他们的偏差并克服它们。其中一些干预措施被称为提升;它们旨在提高人们的能力——例如,通过教授他们统计素养。
教育人们克服偏差是一项光荣的事业,但比看起来更具挑战性。当然,教育是有用的。例如,参加过多年高级统计课程的人在统计推理中犯错误的可能性较小。但教人们避免偏差是困难的。数十年的研究表明,在其专业领域学会避免偏差的专业人士在将所学应用到不同领域时经常遇到困难。例如,天气预报员已经学会避免对其预报过度自信。当他们宣布70%的降雨概率时,大体上确实有70%的时间下雨。然而,当被问及常识性问题时,他们可能和其他人一样过度自信。学习克服偏差的挑战在于认识到新问题与我们在别处见过的问题相似,以及我们在一个地方见过的偏差可能在其他地方出现。
研究人员和教育工作者在使用非传统教学方法促进这种认知方面取得了一些成功。在一项研究中,波士顿大学的Carey Morewedge和他的同事使用了教学视频和”严肃游戏”。参与者学会了识别由确认偏差(confirmation bias)、锚定效应(anchoring)和其他心理偏差造成的错误。在每个游戏结束后,他们收到关于所犯错误的反馈,并学习如何避免再次犯同样的错误。这些游戏(以及在较小程度上的视频)减少了参与者在紧接着的测试中以及八周后被问及类似问题时所犯的错误数量。在另一项研究中,Anne-Laure Sellier和她的同事发现,那些玩过教学视频游戏并学会克服确认偏差的MBA学生,在另一门课程中解决商业案例时应用了这一学习成果。即使他们没有被告知这两个练习之间有任何联系,他们也做到了这一点。
无论是事后纠正偏差,还是通过推动或促进来预防偏差的影响,大多数去偏方法都有一个共同点:它们针对特定的偏差,并假设这种偏差是存在的。这个通常合理的假设有时是错误的。
再次考虑项目规划的例子。你可以合理地假设过度自信会影响一般的项目团队,但你不能确定它是影响特定项目团队的唯一偏差(甚至是主要偏差)。也许团队负责人在类似项目中有过不好的经历,因此学会了在做估计时特别保守。因此团队表现出与你认为应该纠正的错误相反的错误。或者团队可能通过与另一个类似项目的类比来制定预测,并被锚定在完成那个项目所花费的时间上。又或者项目团队预料到你会在其估计中添加缓冲,因此通过使其建议比其真实信念更加乐观来抢先调整。
或者考虑一个投资决策。对投资前景的过度自信确实可能在起作用,但另一个强大的偏差——损失厌恶(loss aversion)——具有相反的效果,使决策者不愿意冒失去初始投资的风险。或者考虑一家在多个项目间分配资源的公司。决策者可能既对新举措的效果过于乐观(再次是过度自信),又过于胆怯而不愿从现有部门转移资源(这是由现状偏差(status quo bias)造成的问题,顾名思义,这是我们对保持现状的偏好)。
正如这些例子所说明的,很难确切知道哪些心理偏差正在影响判断。在任何复杂的情况下,多种心理偏差可能同时起作用,共同在同一方向上增加错误或相互抵消,产生不可预测的后果。
结果是,事后或事前去偏——分别纠正或预防特定心理偏差——在某些情况下是有用的。这些方法在错误的总体方向已知并表现为明显统计偏差的地方有效。预期会有强烈偏差的决策类型可能会从去偏干预中受益。例如,规划谬误(planning fallacy)是一个足够稳健的发现,值得对过度自信的规划进行去偏干预。
问题是在许多情况下,错误的可能方向事先并不知道。这些情况包括心理偏差的影响在评判者之间变化且本质上不可预测的所有情况——导致系统噪音。要在这样的情况下减少错误,我们需要撒更大的网,尝试同时检测不止一种心理偏差。
我们建议既不在决策制定之前也不在之后,而是实时进行这种偏差搜索。当然,人们很少在被偏差误导时意识到自己的偏差。这种缺乏意识本身就是一个已知的偏差,即偏差盲点(bias blind spot)。人们往往比在自己身上更容易识别他人的偏差。我们建议可以训练观察者实时发现一个或几个熟悉偏差正在影响他人决策或建议的诊断性迹象。
为了说明这个过程可能如何运作,想象一个试图做出复杂而重要判断的群体。判断可以是任何类型:政府决定对大流行病或其他危机的可能回应,医生探索治疗有复杂症状患者的最佳方法的病例会议,企业董事会决定重大战略举措。现在想象一个决策观察者,某个观察这个群体并使用检查清单来诊断是否有任何偏差可能将群体推离最佳可能判断的人。
决策观察者不是一个容易扮演的角色,毫无疑问,在某些组织中这是不现实的。如果最终决策者不致力于对抗偏差,那么检测偏差是无用的。实际上,决策者必须是启动决策观察过程并支持决策观察者角色的人。我们当然不建议你让自己成为自任的决策观察者。你既不会赢得朋友也不会影响他人。
然而,非正式的实验表明,这种方法确实可以取得真正的进展。至少,在合适的条件下,这种方法是有帮助的,特别是当组织或团队的领导者真正致力于这项工作,并且决策观察者选择得当——而且不容易受到自身严重偏见影响的时候。
在这些情况下,决策观察者分为三类。在一些组织中,这个角色可以由主管来扮演。主管不仅要监督项目团队提交的提案内容,还可能密切关注制定提案的过程以及团队的动态。这使观察者能够警觉到可能影响提案制定的偏见。其他组织可能会指派每个工作团队的一名成员担任团队的”偏见破坏者”;这位决策过程的守护者会实时提醒队友可能误导他们的偏见。这种方法的缺点是,决策观察者被置于团队内部魔鬼代言人的位置,可能很快就会耗尽政治资本。最后,其他组织可能依赖外部协调员,他们具有中立视角的优势(以及在内部知识和成本方面的相应劣势)。
为了有效工作,决策观察者需要一些培训和工具。其中一个工具就是他们试图检测的偏见清单。依赖清单的理由很明确:清单在高风险环境中改善决策有着悠久的历史,特别适合防止过去错误的重复。
这里有一个例子。在美国,联邦机构在颁布昂贵的法规来清洁空气或水、减少工作场所死亡、增加食品安全、应对公共卫生危机、减少温室气体排放或增强国土安全之前,必须编制正式的监管影响分析。一份名称不太好听的密集技术文件(OMB Circular A-4),长达近五十页,阐述了分析的要求。这些要求明确设计来抵消偏见。机构必须解释为什么需要该法规,考虑更严格和不那么严格的替代方案,考虑成本和收益,以公正的方式呈现信息,并适当地贴现未来。但在许多机构中,政府官员并没有遵守那份密集技术文件的要求。(他们甚至可能没有阅读它。)作为回应,联邦官员制作了一份简单的清单,只有一页半,以降低机构忽略或未能关注任何主要要求的风险。
为了说明偏见清单可能是什么样的,我们在附录B中包含了一个。这个通用清单仅仅是一个例子;任何决策观察者都一定想要开发一个根据组织需求定制的清单,既要增强其相关性,又要促进其采用。重要的是,清单并不是所有可能影响决策的偏见的详尽列表;它旨在关注最频繁和最具影响力的偏见。
配备适当偏见清单的决策观察有助于限制偏见的影响。尽管我们在非正式的小规模努力中看到了一些令人鼓舞的结果,但我们不知道对这种方法效果的任何系统性探索,也不知道部署它的各种可能方式的利弊。我们希望激发更多的实验,无论是从业者还是研究人员,来实践决策观察者的实时去偏见。
偏见是我们通常能够看到甚至解释的错误。它是定向的:这就是为什么轻推(nudge)可以限制偏见的有害影响,或者为什么提升判断的努力可以对抗特定偏见。它也通常是可见的:这就是为什么观察者可以希望在做决策时实时诊断偏见。
另一方面,噪音是我们无法轻易看到或解释的不可预测错误。这就是为什么我们经常忽视它——即使它造成严重损害。出于这个原因,降噪策略之于去偏见,就像预防性卫生措施之于医疗治疗:目标是在潜在错误发生之前预防各种未指定的错误。
我们称这种降噪方法为决策卫生。当你洗手时,你可能不知道确切地在避免哪种细菌——你只知道洗手对各种细菌都是很好的预防措施(特别是但不仅仅在大流行期间)。同样,遵循决策卫生原则意味着你采用减少噪音的技术,而不必知道你正在帮助避免哪些潜在错误。
与洗手的类比是有意的。卫生措施可能很乏味。它们的好处不是直接可见的;你可能永远不知道它们预防了什么问题的发生。相反,当问题确实出现时,它们可能无法追溯到卫生遵守方面的具体故障。出于这些原因,洗手合规性很难执行,即使在充分了解其重要性的医疗专业人员中也是如此。
就像洗手和其他形式的预防措施一样,决策卫生是非常宝贵但却不被感激的。纠正一个明确识别的偏差可能至少会给你一种取得成就的切实感受。但减少噪音的程序不会。从统计学上讲,它们会防止许多错误。然而你永远不会知道哪些错误。噪音是一个隐形的敌人,防止隐形敌人的攻击只能产生隐形的胜利。
考虑到噪音可能造成的巨大损害,这种隐形的胜利仍然值得一战。以下章节介绍了在多个领域使用的几种决策卫生策略,包括法医学、预测、医学和人力资源。在第25章中,我们将回顾这些策略,并展示如何将它们结合到一个减少噪音的综合方法中。
“你知道你正在对抗什么具体的偏差以及它在什么方向上影响结果吗?如果不知道,可能有几种偏差在起作用,很难预测哪一种会占主导地位。”
“在我们开始讨论这个决定之前,让我们指定一个决策观察员。”
“我们在这个决策过程中保持了良好的决策卫生;很可能这个决定已经是最好的了。”
2004年3月,一系列放置在通勤列车上的炸弹在马德里杀死了192人,并造成2000多人受伤。在犯罪现场的塑料袋上发现的指纹通过国际刑警组织传送给了世界各地的执法机构。几天后,美国联邦调查局(FBI)犯罪实验室确定该指纹属于布兰登·梅菲尔德(Brandon Mayfield),一名居住在俄勒冈州的美国公民。
梅菲尔德看起来像一个合理的嫌疑人。他是美国陆军的前军官,娶了一名埃及女子并皈依了伊斯兰教。作为一名律师,他曾代表过被指控(后来被定罪)试图前往阿富汗加入塔利班的男子。他在FBI的监视名单上。
梅菲尔德被置于监视之下,他的房子被窃听和搜查,电话被窃听。当这种审查没有产生任何实质性信息时,FBI逮捕了他。但他从未被正式指控。梅菲尔德十年来没有离开过这个国家。当他被拘留时,西班牙调查人员早已告知FBI他们认为梅菲尔德与塑料袋上的指纹不匹配,并将该指纹与另一名嫌疑人匹配。
梅菲尔德在两周后被释放。最终,美国政府向他道歉,支付了200万美元的和解金,并命令对错误原因进行广泛调查。其主要发现:“错误是人为错误,而非方法论或技术故障。”
幸运的是,这种人为错误很少见。然而它们仍然具有启发性。美国最好的指纹专家怎么会错误地识别指纹为属于一个从未接近过犯罪现场的男子呢?为了找出答案,我们首先需要了解指纹检验是如何工作的,以及它与其他专业判断例子的关系。我们将了解到,我们倾向于认为是精确科学的法医指纹识别,实际上受到检验员心理偏差的影响。这些偏差可能比我们想象的产生更多噪音,从而产生更多错误。我们将看到法医学界如何通过实施一种可以应用于所有环境的决策卫生策略来解决这个问题:严格控制用于做出判断的信息流。
指纹是我们手指的摩擦脊在我们触摸的表面上留下的印记。虽然在古代有使用指纹作为明显识别标记的例子,但现代指纹识别可以追溯到19世纪末,当时苏格兰医生亨利·福尔兹(Henry Faulds)发表了第一篇建议使用指纹作为识别技术的科学论文。
在随后的几十年里,指纹作为犯罪记录中的识别标记获得了关注,逐渐取代了法国警官阿方斯·贝蒂永(Alphonse Bertillon)开发的人体测量技术。贝蒂永本人在1912年编制了一个正式的指纹比较系统。弗朗西斯·高尔顿爵士,我们之前遇到过的群体智慧的发现者,在英国开发了一个类似的系统。(尽管如此,这些创始人很少被赞颂也就不足为奇了。高尔顿认为指纹将是根据种族对个人进行分类的有用工具,而贝蒂永,可能由于反犹太主义的偏见,在1894年和1899年阿尔弗雷德·德雷福斯(Alfred Dreyfus)的审判中提供了决定性的——但有缺陷的——专家证词。)
警察很快发现指纹不仅仅可以作为重复犯罪者的识别标记。1892年,阿根廷警官胡安·武切蒂奇(Juan Vucetich)第一个将犯罪现场留下的潜在指纹与嫌疑人的拇指进行比较。从那时起,收集潜在指纹(在犯罪现场由其所有者留下的指纹)并将其与样本指纹(在受控条件下从已知个人处收集的指纹)进行比较的做法一直是指纹识别最具决定性的应用,并提供了最广泛使用的法医证据形式。
如果您曾经接触过电子指纹读取器(如许多国家的出入境服务使用的设备),您可能认为指纹比对是一项简单直接、机械化且易于自动化的任务。但是,将从犯罪现场收集的潜在指纹与样本指纹进行比较,比匹配两个清晰指纹要复杂得多。当您有意在专门记录指纹印象的读取器上用力按压手指时,会产生整洁、标准化的图像。相比之下,潜在指纹往往是部分的、不清晰的、模糊的或以其他方式扭曲的;它们不能提供在受控专用环境中收集的指纹所具有的相同数量和质量的信息。潜在指纹经常与其他指纹重叠,这些指纹可能来自同一人或其他人,还包括表面上存在的污垢和其他伪影。判断它们是否与嫌疑人的样本指纹匹配需要专家判断。这是人类指纹检验员的工作。
当获得潜在指纹时,检验员通常遵循一个称为ACE-V的程序,代表分析(analysis)、比较(comparison)、评估(evaluation)和验证(verification)。首先,他们必须分析潜在指纹以确定其是否具有足够的比较价值。如果有,他们将其与样本指纹进行比较。比较导致评估,可以产生识别(指纹来自同一人)、排除(指纹不来自同一人)或不确定的决定。识别决定触发第四步:由另一位检验员进行验证。
几十年来,这一程序的可靠性一直未受质疑。尽管目击者证词已被证明极不可靠,甚至供词也可能是虚假的,但指纹被接受为——至少在DNA分析出现之前——最可信的证据形式。直到2002年,指纹证据从未在美国法庭上受到成功挑战。例如,当时的FBI网站非常坚定:“指纹提供了绝对可靠的个人身份识别手段。”在极少数确实发生错误的情况下,这些错误被归咎于无能或欺诈。
指纹证据长期未受挑战的部分原因是难以证明其错误。一组指纹的真实价值,即实际犯罪者的真相,往往是未知的。对于Mayfield和少数类似案例,错误尤为严重。但总的来说,如果嫌疑人对检验员的结论提出异议,指纹证据当然会被认为更可靠。
我们已经注意到,不知道真实价值既不罕见,也不妨碍测量噪音。指纹分析中有多少噪音?或者更准确地说,鉴于指纹检验员不像判刑法官或核保员那样产生数字,而是做出分类判断,他们多久产生分歧一次,为什么?这个问题是伦敦大学学院认知神经科学研究员Itiel Dror首先着手研究的。他进行了在一个假设自己没有噪音问题的领域中相当于一系列噪音审计的研究。
认知科学家——心理学家——挑战指纹检验员可能看起来很奇怪。毕竟,正如您可能在《CSI:犯罪现场调查》等电视节目和CSI系列的后续剧集中看到的那样,这些是戴着乳胶手套、使用显微镜的硬科学类型人员。但Dror意识到检验指纹显然是一个判断问题。作为一名认知神经科学家,他推理出哪里有判断,哪里就必须有噪音。
为了测试这一假设,Dror首先关注场合噪音:同一专家两次查看相同证据时判断之间的变异性。正如Dror所说,“如果专家在他们与自己不一致的意义上不可靠,那么他们判断和专业性的基础就成问题了。”
指纹为场合噪音审计提供了完美的测试平台,因为与医生或法官遇到的案例不同,指纹对不容易记住。当然,必须允许适当的时间间隔过去,以确保检验员不记得指纹。(在Dror的研究中,一些勇敢、开明的专家同意,在接下来的五年中的任何时候,他们将在不知情的情况下参与研究。)此外,实验必须在专家的日常案例工作过程中进行,这样他们就不会意识到他们的技能正在被测试。如果在这些情况下,检验员的判断从一次测试到下一次发生变化,我们就遇到了场合噪音。
在他的两项原始研究中,Dror增加了一个重要的转折。当第二次看到指纹时,一些检验员接触到关于案例的额外偏向性信息。例如,之前发现指纹匹配的指纹检验员这次被告知”嫌疑人有不在场证明”或”枪械证据表明不是他”。其他首先得出嫌疑人无罪或指纹不确定结论的人,第二次被告知”侦探相信嫌疑人有罪”、“目击者识别了他”或”他承认了犯罪”。Dror称这个实验为专家”可偏向性”的测试,因为提供的上下文信息在给定方向上激活了心理偏误(确认偏误)。
确实,检验员们被证明容易受到偏见的影响。当同样的检验员重新考虑他们之前看过的相同指纹时,这次带有偏见信息,他们的判断发生了改变。在第一项研究中,五名专家中有四名在面对强烈的情境信息暗示排除时,改变了他们之前的识别决定。在第二项研究中,六名专家审查了四对指纹;偏见信息导致二十四个决定中的四个发生了改变。诚然,他们的大部分决定没有改变,但对于这类决定,六分之一的变化可以算作很大的。这些发现后来被其他研究人员重复验证。
可以预见的是,当决定一开始就很困难、偏见信息很强烈、以及从确定性决定变为不确定性决定时,检验员更可能改变主意。尽管如此,“专业指纹检验员基于情境而非指纹中包含的实际信息做出决定”仍然令人不安。
偏见信息的影响不仅限于检验员的结论(识别、不确定或排除)。偏见信息实际上改变了检验员感知到的内容,以及如何解释这种感知。在一项单独的研究中,Dror和同事们表明,处于偏见情境中的检验员与未接触偏见信息的检验员字面上看不到相同的东西。当潜在指纹伴随着目标样本指纹时,检验员观察到的细节(称为细节特征)明显少于他们单独查看潜在指纹时的情况。后来的一项独立研究证实了这一结论,并补充说”这是[如何]发生的并不明显。”
Dror为偏见信息的影响创造了一个术语:法医确认偏见。这种偏见后来在其他法医技术中得到记录,包括血液模式分析、纵火调查、骨骼遗骸分析和法医病理学。甚至DNA分析——被广泛认为是法医科学的新黄金标准——也可能容易受到确认偏见的影响,至少当专家必须评估复杂的DNA混合物时是这样。
法医专家对确认偏见的易感性不仅仅是一个理论关切,因为在现实中,没有系统性的预防措施来确保法医专家不接触偏见信息。检验员经常收到此类信息,这些信息包含在伴随提交给他们的证据的传递信函中。检验员也经常与警察、检察官和其他检验员直接沟通。
确认偏见引发了另一个问题。ACE-V程序中内置的一个重要的错误防护措施是在确认识别之前由另一名专家进行独立验证。但大多数情况下,只有识别才会被独立验证。结果是存在强烈的确认偏见风险,因为验证检验员知道初始结论是识别。因此,验证步骤没有提供通常从独立判断聚合中期望的好处,因为验证实际上并不独立。
确认偏见的连锁反应似乎在Mayfield案件中起了作用,在该案件中不是两个而是三个FBI专家都同意了错误的识别。正如后来对错误的调查所指出的,第一个检验员似乎被自动化系统搜索指纹数据库寻找可能匹配时”相关性的力量”所打动。虽然他显然没有接触Mayfield的传记细节,但执行初始搜索的计算机化系统提供的结果,“加上处理极其高调案件的固有压力”,足以产生初始确认偏见。一旦第一个检验员做出错误识别,报告继续说,“后续的检查就被污染了。”由于第一个检验员是一位备受尊敬的主管,“机构中的其他人越来越难以不同意。”初始错误被复制和放大,导致Mayfield有罪的近乎确定性。说明问题的是,甚至一位备受尊敬的独立专家,由法院指定代表Mayfield的辩护检查证据,也同意FBI确认了识别。
同样的现象可能在其他法医学科以及跨学科中起作用。潜在指纹识别被认为是法医学科中最客观的之一。如果指纹检验员可能有偏见,那么其他领域的专家也可能如此。此外,如果枪械专家知道指纹是匹配的,这种知识也可能偏见该专家的判断。如果法医牙科学家知道DNA分析已经识别了嫌疑人,该专家可能不太可能建议咬痕与嫌疑人不匹配。这些例子引发了偏见连锁反应的担忧:就像我们在第8章描述的群体决策一样,由确认偏见引起的初始错误成为影响第二个专家的偏见信息,其判断偏见第三个专家,依此类推。
在确定偏见信息会产生变异性之后,Dror和他的同事们发现了更多场合噪声的证据。即使指纹专家没有接触到偏见信息,他们有时也会改变对之前见过的一组指纹的看法。正如我们所预期的,在没有提供偏见信息时,改变较少发生,但仍然会发生。2012年的一项研究由FBI委托进行,通过要求72名检验员重新查看他们大约7个月前评估过的25对指纹,在更大规模上重现了这一发现。通过对大量高素质检验员的样本研究,该研究证实指纹专家有时容易受到场合噪声的影响。大约十分之一的决定被改变了。大多数改变是与不确定类别之间的转换,没有导致错误识别。该研究最令人不安的含义是,一些导致定罪的指纹识别在另一个时间点可能是不确定的。当同样的检验员在查看同样的指纹时,即使背景环境不是为了偏见他们而是尽可能保持恒定,他们的决定中仍存在不一致性。
这些发现提出的实际问题是司法错误的可能性。我们不能忽视对在法庭上作证的专家可靠性的质疑:有效性需要可靠性,因为很简单,如果你不能与自己保持一致,就很难与现实保持一致。
到底有多少错误是由有缺陷的法医学造成的?对无罪项目(一个致力于推翻错误定罪的非营利组织)获得的350个平反案例的审查得出结论,法医学的误用在45%的案例中是一个促成原因。这个统计数字听起来很糟糕,但对法官和陪审员重要的问题是不同的:要知道他们应该对上台作证的检验员给予多少信任,他们需要知道法医学家(包括指纹检验员)犯重大错误的可能性有多大。
对这个问题最可靠的答案可以在总统科学技术顾问委员会(PCAST)的报告中找到,这是一个由国家顶尖科学家和工程师组成的咨询小组,在2016年发布了刑事法庭法医学的深度评估。该报告总结了关于指纹分析有效性的现有证据,特别是错误识别(假阳性)的可能性,比如涉及Mayfield的案例。
这些证据出人意料地稀少,正如PCAST指出的,直到最近才开始产生这些证据的工作是”令人沮丧的”。最可信的数据来自唯一发表的指纹识别准确性大规模研究,该研究由FBI科学家自己在2011年进行。该研究涉及169名检验员,每人比较大约100对潜在和样本指纹。其核心发现是很少发生错误识别:假阳性率约为六百分之一。
六百分之一的错误率很低,但正如报告所指出的,“远高于普通公众(进而言之,大多数陪审员)基于对指纹分析准确性的长期声称可能相信的水平。”此外,该研究不包含偏见性背景信息,参与的检验员知道他们正在参加测试——这可能导致研究低估了实际案件工作中发生的错误。在佛罗里达州进行的后续研究得出了高得多的假阳性数量。文献中的不同发现表明,我们需要更多关于指纹检验员决定准确性以及如何做出这些决定的研究。
然而,在所有研究中似乎一致的一个令人安慰的发现是,检验员似乎谨慎行事。他们的准确性并不完美,但他们意识到自己判断的后果,并考虑到可能错误的不对称成本。由于指纹识别的极高可信度,错误识别可能产生悲剧性后果。其他类型的错误后果较轻。例如,FBI专家观察到,“在大多数案件工作中,排除与不确定具有相同的操作含义。”换句话说,在凶器上发现指纹足以定罪,但没有该指纹不足以为嫌疑人开脱。
与我们对检验员谨慎性的观察一致,证据表明专家在做出识别决定之前会三思——或者远不止三思。在FBI的识别准确性研究中,不到三分之一的”匹配”对(潜在指纹和样本来自同一人)被(准确地)判断为识别。检验员也产生的假阳性识别远少于假阴性排除。他们容易受到偏见影响,但在两个方向上并不相等。正如Dror指出的,“将法医专家偏向于’不确定’的非承诺性结论比偏向于明确的’识别’结论更容易。”
鉴定专家接受培训时被告知,错误识别是必须不惜一切代价避免的致命错误。值得称赞的是,他们确实按照这一原则行事。我们只能希望他们的谨慎程度能够让错误识别(如Mayfield案例和其他几起备受瞩目的案例中出现的错误)保持极其罕见的状态。
观察到法医学中存在噪音不应被视为对法医学家的批评。这仅仅是我们反复观察到的结果:只要有判断的地方,就有噪音,而且比你想象的要多。像指纹分析这样的任务看起来很客观,以至于我们中的许多人不会自然而然地将其视为一种判断形式。然而,它确实存在不一致、分歧以及偶尔出现错误的空间。无论指纹识别的错误率有多低,它都不是零,正如PCAST指出的,应该让陪审团意识到这一点。
减少噪音的第一步当然必须是承认其可能性。这种承认对指纹社区的成员来说并不自然,他们中的许多人最初对Dror的噪音审计高度怀疑。鉴定专家可能在不知不觉中受到案件信息影响的概念让许多专家感到恼火。在对Dror研究的回复中,指纹学会主席写道:“任何在决策过程中受到任何一方影响的指纹鉴定专家都如此不成熟,他/她应该去迪士尼乐园求职。”一位主要法医实验室的主任指出,获得案件信息——正是这种可能使鉴定专家产生偏见的信息——“提供了一些个人满足感,让鉴定专家能够享受他们的工作,而实际上不会改变他们的判断。”甚至FBI在对Mayfield案例的内部调查中也指出,“潜在指纹鉴定专家例行进行验证时会知道之前鉴定专家的结果,但这些结果不会影响鉴定专家的结论。”这些言论本质上等于否认确认偏见的存在。
即使意识到偏见的风险,法医学家也不能免于偏见盲点:承认他人存在偏见但不承认自己存在偏见的倾向。在对21个国家400名专业法医学家的调查中,71%的人同意”认知偏见是整个法医学领域关注的原因”,但只有26%的人认为他们”自己的判断受到认知偏见的影响”。换句话说,大约一半的法医专业人员认为同事的判断有噪音,但自己的判断没有。噪音可能是一个看不见的问题,即使对那些工作就是看见看不见事物的人来说也是如此。
由于Dror及其同事的坚持,态度正在慢慢改变,越来越多的法医实验室开始采取新措施来减少分析中的错误。例如,PCAST报告赞扬FBI实验室重新设计程序以最大限度降低确认偏见的风险。
必要的方法步骤相对简单。它们说明了一种在许多领域都适用的决策卫生策略:排序信息以限制过早直觉的形成。在任何判断中,有些信息是相关的,有些则不是。更多信息并不总是更好,特别是当它有可能通过引导判断者形成过早直觉而使判断产生偏见时。
本着这种精神,法医实验室部署的新程序旨在通过只在鉴定专家需要时给他们所需的信息来保护鉴定专家判断的独立性。换句话说,实验室尽可能让他们对案件一无所知,只逐步透露信息。为了做到这一点,Dror及其同事编纂的方法被称为线性顺序解掩。
Dror还有另一个建议,说明了同样的决策卫生策略:鉴定专家应该在每个步骤记录他们的判断。他们应该在查看样本指纹以决定是否匹配之前记录他们对潜在指纹的分析。这种步骤顺序帮助专家避免只看到他们正在寻找的东西的风险。他们应该在获得可能使他们产生偏见的背景信息之前记录他们对证据的判断。如果他们在接触背景信息后改变了想法,这些变化及其理由都应该被记录下来。这一要求限制了早期直觉使整个过程产生偏见的风险。
同样的逻辑启发了第三个建议,这是决策卫生的重要组成部分。当不同的鉴定专家被要求验证第一个人做出的识别时,第二个人不应该知道第一个判断。
法医学中噪音的存在当然令人担忧,因为它可能产生生死攸关的后果。但它也很有启发性。我们长期以来完全没有意识到指纹识别中出现错误的可能性,这表明我们对专家人类判断的信心有时可能被夸大,以及噪音审计如何能够揭示意想不到的大量噪音。通过相对简单的过程变化减轻这些缺陷的能力应该鼓励所有关心提高决策质量的人。
本案例所展示的主要决策卫生策略——信息排序——作为对时机噪声的防范措施具有广泛的适用性。正如我们所指出的,时机噪声是由无数触发因素驱动的,包括情绪甚至外界温度。你无法指望控制所有这些触发因素,但你可以尝试保护判断免受最明显触发因素的影响。例如,你已经知道判断可能会被愤怒、恐惧或其他情绪所改变,也许你已经注意到,如果可能的话,在不同的时间点重新审视你的判断是一个好的做法,因为那时触发时机噪声的因素很可能是不同的。
不太明显的是,你的判断可能会被时机噪声的另一个触发因素所改变:信息——即使是准确的信息。正如指纹检查员的例子,一旦你知道别人的想法,确认偏误就会导致你过早形成总体印象,并忽略矛盾的信息。希区柯克两部电影的标题很好地总结了这一点:一个好的决策者应该努力保持”怀疑的阴影”,而不是成为”知道得太多的人”。
“有判断的地方就有噪声——包括读取指纹。”
“我们对这个案例有更多信息,但在专家做出判断之前,我们不要告诉他们我们知道的一切,以免产生偏见。事实上,我们只告诉他们绝对需要知道的内容。”
“如果给出第二意见的人知道第一个意见是什么,那么第二意见就不是独立的。第三个意见更不独立:可能会出现偏见级联。”
“要对抗噪声,他们首先必须承认噪声的存在。”
许多判断都涉及预测。下个季度的失业率可能是多少?明年将销售多少辆电动汽车?2050年气候变化的影响是什么?完成一栋新建筑需要多长时间?某家公司的年收益将是多少?新员工的表现如何?新的空气污染法规的成本是多少?谁会赢得选举?这些问题的答案具有重大后果。私人和公共机构的根本选择往往取决于它们。
预测分析师——分析何时出错以及为什么出错——在偏误和噪声(也称为不一致性或不可靠性)之间做出明确区分。每个人都同意,在某些情况下,预测者是有偏见的。例如,官方机构在预算预测中表现出不现实的乐观主义。平均而言,他们预测不现实的高经济增长和不现实的低赤字。出于实际目的,他们不现实的乐观主义是认知偏误还是政治考虑的产物并不重要。
此外,预测者往往过于自信:如果要求他们将预测表述为置信区间而不是点估计,他们倾向于选择比应该选择的更窄的区间。例如,一项持续的季度调查要求美国公司的首席财务官估计下一年S&P 500指数的年回报率。CFO提供两个数字:一个最小值,他们认为实际回报率低于该值的概率是十分之一;一个最大值,他们认为实际回报率超过该值的概率是十分之一。因此,这两个数字是80%置信区间的边界。然而,实际回报率仅在36%的时间里落在该区间内。CFO对其预测精度过于自信。
预测者也是嘈杂的。参考文本J. Scott Armstrong的《预测原理》指出,即使在专家中,“不可靠性是判断性预测中的错误来源”。事实上,噪声是错误的主要来源。时机噪声很常见;预测者并不总是同意自己的观点。人际噪声也很普遍;预测者彼此不同意,即使他们是专家。如果你要求法学教授预测最高法院的裁决,你会发现大量的噪声。如果你要求专家预测空气污染法规的年度效益,你会发现巨大的可变性,范围例如从30亿美元到90亿美元。如果你要求一群经济学家对失业和增长做出预测,你也会发现很大的可变性。我们已经看到了许多嘈杂预测的例子,关于预测的研究发现了更多。
研究还提供了减少噪声和偏误的建议。我们不会在这里详尽地回顾它们,但我们将重点关注两种具有广泛适用性的降噪策略。一种是我们在第18章中提到的原则的应用:选择更好的判断者产生更好的判断。另一种是最普遍适用的决策卫生策略之一:聚合多个独立估计。
聚合多个预测最简单的方法是对它们求平均。平均在数学上能够保证减少噪音:具体来说,它将噪音除以被平均判断数量的平方根。这意味着如果你对一百个判断求平均,你将减少90%的噪音,如果你对四百个判断求平均,你将减少95%的噪音——基本上消除了噪音。这个统计定律是群体智慧方法的引擎,在第7章中有所讨论。
由于平均并不能减少偏差,它对总误差(MSE)的影响取决于偏差和噪音在其中的比例。这就是为什么群体智慧在判断相互独立时效果最好,因此不太可能包含共同偏差。从经验上看,大量证据表明平均多个预测能大大提高准确性,例如经济预测师或股票分析师的”共识”预测。在销售预测、天气预测和经济预测方面,一组预测师的未加权平均表现优于大多数甚至有时优于所有个体预测。对通过不同方法获得的预测求平均具有同样的效果:在对不同领域三十个经验比较的分析中,组合预测平均减少了12.5%的误差。
直接平均并不是聚合预测的唯一方法。精选群体策略根据最近判断的准确性选择最佳判断者,并对少数判断者(例如五个)的判断求平均,可以与直接平均一样有效。对于尊重专业知识的决策者来说,理解和采用不仅依赖聚合还依赖选择的策略也更容易。
产生聚合预测的一种方法是使用预测市场,在其中个人对可能的结果下注,从而被激励做出正确的预测。大多数时候,预测市场被发现表现非常好,即如果预测市场价格表明事件有70%的可能性发生,它们确实在大约70%的时间里发生。各个行业的许多公司都使用预测市场来聚合不同观点。
另一个聚合不同观点的正式流程被称为德尔菲法。在其经典形式中,这种方法涉及多轮,参与者向主持人提交估计(或投票),彼此保持匿名。在每一轮新的过程中,参与者为他们的估计提供理由并回应其他人给出的理由,仍然保持匿名。这个过程鼓励估计收敛(有时通过要求新判断落在前一轮判断分布的特定范围内来强制收敛)。这种方法既受益于聚合也受益于社会学习。
德尔菲法在许多情况下都很有效,但实施起来可能具有挑战性。一个更简单的版本,迷你德尔菲法,可以在单次会议中部署。也被称为估计-讨论-估计,它要求参与者首先产生单独(且安静)的估计,然后解释和证明它们,最后根据其他人的估计和解释做出新的估计。共识判断是在第二轮中获得的个人估计的平均值。
一些关于预测质量最具创新性的工作,远超我们迄今为止探索的内容,始于2011年,当时三位著名的行为科学家创立了Good Judgment Project。Philip Tetlock(我们在第11章讨论他对政治事件长期预测评估时遇到过);他的配偶Barbara Mellers;以及Don Moore联手改进我们对预测的理解,特别是为什么有些人擅长预测。
Good Judgment Project从招募数万名志愿者开始——不是专家或专业人士,而是来自各行各业的普通人。他们被要求回答数百个问题,例如:
朝鲜会在年底前引爆核装置吗?
俄罗斯会在未来三个月内正式吞并更多乌克兰领土吗?
印度或巴西会在未来两年内成为联合国安理会常任理事国吗?
在明年,会有任何国家退出欧元区吗?
正如这些例子所示,该项目专注于关于世界事件的重大问题。重要的是,努力回答这些问题会引发许多与更平凡预测相同的问题。如果律师询问客户是否会在法庭上获胜,或者如果电视工作室被问及拟议节目是否会大获成功,都涉及预测技能。Tetlock和他的同事想了解是否有些人是特别好的预测者。他们也想了解预测能力是否可以被教授或至少得到改善。
要理解核心发现,我们需要解释 Tetlock 和他的团队用来评估预测者的方法的一些关键方面。首先,他们使用了大量的预测,而不仅仅是一个或几个,因为在少数预测中,运气可能是成功或失败的原因。如果你预测你最喜欢的运动队会赢得下一场比赛,而它确实赢了,你不一定是一个好的预测者。也许你总是预测你最喜欢的队伍会赢:如果这是你的策略,而如果他们只有一半时间获胜,你的预测能力并不特别令人印象深刻。为了减少运气的作用,研究人员检查了参与者在众多预测中的平均表现。
其次,研究人员要求参与者以事件发生概率的形式进行预测,而不是二元的”会发生”或”不会发生”。对许多人来说,预测意味着后者——采取一种或另一种立场。然而,鉴于我们对未来事件的客观无知,制定概率预测要好得多。如果有人在 2016 年说,“希拉里·克林顿有 70% 的可能性当选总统”,他不一定是一个糟糕的预测者。正确地说有 70% 可能性的事情有 30% 的时间不会发生。要知道预测者是否优秀,我们应该询问他们的概率估计是否映射到现实中。假设一个名叫玛格丽特的特定预测者说 500 个不同的事件有 60% 的可能性。如果其中 300 个实际发生了,那么我们可以得出结论,玛格丽特的信心是良好校准的。良好校准是良好预测的一个要求。
第三,作为一个附加改进,Tetlock 和同事们不只是要求他们的预测者对某个事件是否会在比如十二个月内发生做出一个概率估计。他们给了参与者根据新信息持续修订预测的机会。假设你在 2016 年就估计,英国在 2019 年底之前离开欧盟的机会只有 30%。随着新民调的出现,表明”脱欧”投票正在获得支持,你可能会向上修正你的预测。当公投结果已知时,英国是否会在那个时间框架内离开欧盟仍然不确定,但看起来肯定更有可能了。(Brexit 技术上发生在 2020 年。)
随着每条新信息的出现,Tetlock 和他的同事们允许预测者更新他们的预测。为了评分目的,每一次这样的更新都被视为一个新的预测。这样,Good Judgment Project 的参与者被激励监控新闻并持续更新他们的预测。这种方法反映了商业和政府中预测者的期望,他们也应该基于新信息频繁更新他们的预测,尽管有被批评改变主意的风险。(对这种批评的一个著名回应,有时归因于约翰·梅纳德·凯恩斯,是,“当事实改变时,我改变主意。你做什么?”)
第四,为了评分预测者的表现,Good Judgment Project 使用了 Glenn W. Brier 在 1950 年开发的系统。Brier 分数,如它们所知,测量人们预测和实际发生的事情之间的距离。
Brier 分数是一种巧妙的方法来解决与概率预测相关的一个普遍问题:预测者通过从不采取大胆立场来对冲赌注的激励。再想想玛格丽特,我们将她描述为一个校准良好的预测者,因为她将 500 个事件评为 60% 可能,其中 300 个事件确实发生了。这个结果可能没有看起来那么令人印象深刻。如果玛格丽特是一个总是预测 60% 下雨机会的天气预报员,而在 500 天中有 300 个雨天,玛格丽特的预测校准良好但实际上毫无用处。玛格丽特,本质上,是在告诉你,以防万一,你可能想每天都带把伞。将她与尼古拉斯比较,他在下雨的 300 天预测 100% 的下雨机会,在 200 个晴天预测 0% 的下雨机会。尼古拉斯与玛格丽特有相同的完美校准:当任一预测者预测 X% 的天数会下雨时,雨水恰好在 X% 的时间下降。但尼古拉斯的预测更有价值:他没有对冲赌注,而是愿意告诉你是否应该带伞。技术上,尼古拉斯被说成除了良好校准外还有高分辨率。
Brier 分数奖励良好校准和良好分辨率。要产生一个好分数,你不仅要平均正确(即,校准良好),还要愿意采取立场并区分预测(即,有高分辨率)。Brier 分数基于均方误差的逻辑,较低的分数更好:0 分将是完美的。
所以,现在我们知道了他们是如何被评分的,Good Judgment Project 志愿者做得如何?主要发现之一是绝大多数志愿者表现不佳,但大约 2% 脱颖而出。如前所述,Tetlock 称这些表现良好的人为超级预测者。他们并非毫无错误,但他们的预测比机会好得多。值得注意的是,一位政府官员说,该小组的表现”明显优于可以阅读拦截和其他秘密数据的情报界分析师的平均水平”。这种比较值得停下来思考。情报界分析师接受培训以做出准确预测;他们不是业余者。此外,他们可以访问机密信息。然而他们的表现不如超级预测者。
是什么让超级预测者如此出色?与我们在第18章中的论述一致,我们可以合理推测他们具有非同寻常的智力。这种推测并非错误。在GMA测试中,超级预测者确实比优秀判断项目中的普通志愿者表现更好(而普通志愿者已经显著高于全国平均水平)。但这种差异并不算太大,许多在智力测试中表现极其出色的志愿者并不符合超级预测者的标准。除了一般智力之外,我们可以合理预期超级预测者在数学方面异常出色。确实如此。但他们的真正优势不在于数学天赋;而在于他们能够轻松地进行分析性和概率性思考。
考虑超级预测者构建和分解问题的意愿和能力。与其对重大地缘政治问题形成整体性判断(某个国家是否会脱离欧盟,某个地方是否会爆发战争,某位公职人员是否会被暗杀),他们会将问题分解为各个组成部分。他们会问:“答案为是需要什么条件?答案为否需要什么条件?”他们不是提供直觉感受或某种全局性的预感,而是提出并尝试回答一系列辅助性问题。
超级预测者也擅长采用外部视角,他们非常关注基础概率。正如第13章中对Gambardi问题的解释,在关注Gambardi具体情况之前,了解普通CEO在未来两年内被解雇或辞职的概率会很有帮助。超级预测者系统性地寻找基础概率。当被问及明年中国和越南是否会因边界争端发生武装冲突时,超级预测者不会仅仅或立即关注中国和越南目前的关系状况。基于他们阅读的新闻和分析,他们可能对此有直觉。但他们知道对单一事件的直觉通常不是很好的指导。相反,他们首先寻找基础概率:他们询问过去的边界争端有多少次升级为武装冲突。如果这种冲突很少见,超级预测者会首先纳入这一事实,然后才转向中越局势的具体细节。
简而言之,区别超级预测者的不是他们的纯粹智力;而是他们如何运用智力。他们所运用的技能反映了我们在第18章中描述的那种认知风格,这种风格很可能产生更好的判断,特别是高水平的”积极开放的心态”。回想积极开放思维的测试:它包括这样的陈述:“人们应该考虑与他们信念相冲突的证据”和”关注不同意你观点的人比关注同意你观点的人更有用”。显然,在此测试中得分高的人在获得新信息时不会羞于更新他们的判断(不会过度反应)。
为了描述超级预测者的思维风格,Tetlock使用了”永久测试版”这个短语,这是计算机程序员使用的术语,指的是不打算发布最终版本,而是无休止地使用、分析和改进的程序。Tetlock发现”晋升为超级预测者行列的最强预测因子是永久测试版,即一个人对信念更新和自我改进的承诺程度”。正如他所说:“让他们如此出色的不是他们是什么,而是他们做什么——研究的艰苦工作、仔细的思考和自我批评、收集和综合其他观点、细致的判断和无情的更新。”他们喜欢特定的思维循环:“尝试、失败、分析、调整、再试一次”。
此时,你可能会想人们可以被训练成为超级预测者,或至少表现得更像他们。确实,Tetlock和他的合作者一直在努力做到这一点。他们的努力应该被视为理解超级预测者为何表现如此出色以及如何让他们表现得更好的第二阶段。
在一项重要研究中,Tetlock和他的团队将普通(非超级)预测者随机分配到三组,测试不同干预措施对后续判断质量的影响。这些干预措施体现了我们描述的改善判断的三种策略:
训练:几位预测者完成了旨在通过教授概率推理来提高他们能力的教程。在教程中,预测者学习了各种偏差(包括基础概率忽视、过度自信和确认偏差);来自不同来源的多重预测平均化的重要性;以及考虑参考类别。
团队合作(聚合的一种形式):一些预测者被要求在团队中工作,他们可以看到并辩论彼此的预测。团队合作可以通过鼓励预测者处理对立论点和保持积极开放的心态来提高准确性。
选择:所有预测者都根据准确性评分,在整整一年结束时,排名前2%的被指定为超级预测者,并有机会在第二年在精英团队中合作。
事实证明,所有三种干预措施都有效,即它们都改善了人们的Brier分数。训练产生了影响,团队合作产生了更大的影响,而选择产生了更大的效果。
这个重要发现证实了聚合判断和选择优秀判断者的价值。但这并不是全部故事。Ville Satopää与Tetlock和Mellers合作,利用每种干预措施效果的数据,开发了一种复杂的统计技术来准确分析每种干预措施是如何改进预测的。他推理认为,原则上,一些预测者比其他人表现更好或更差有三个主要原因:
他们在寻找和分析环境中与预测相关的数据方面可能更有技能。这种解释指向了信息的重要性。
一些预测者可能对预测的真实值有特定一侧的普遍偏向倾向。如果在数百次预测中,你系统性地高估或低估某些状态改变发生的概率,你可以说是受到了一种偏见(bias)的影响,倾向于变化或稳定。
一些预测者可能不太容易受到噪音(noise)(或随机错误)的影响。在预测中,如同任何判断一样,噪音可能有许多触发因素。预测者可能对特定新闻过度反应(这是我们所称的模式噪音的例子),他们可能受到场合噪音的影响,或者他们在使用概率尺度时可能存在噪音。所有这些错误(以及更多错误)在大小和方向上都是不可预测的。
Satopää、Tetlock、Mellers和他们的同事Marat Salikhov将他们的模型称为BIN(偏见、信息和噪音)预测模型。他们着手测量三个组成部分中每个部分对三种干预措施中每种措施的性能改进贡献了多少。
他们的答案很简单:所有三种干预措施主要通过减少噪音来发挥作用。正如研究人员所说:“每当干预措施提高准确性时,它主要通过抑制判断中的随机错误来发挥作用。奇怪的是,训练干预的最初意图是减少偏见。”
由于训练旨在减少偏见,一个不太超级的预测者会预测偏见减少将是训练的主要效果。然而训练通过减少噪音来发挥作用。这个惊喜很容易解释。Tetlock的训练旨在对抗心理偏见。正如你现在知道的,心理偏见的影响并不总是统计偏见。当它们以不同方式影响不同个体在不同判断上时,心理偏见会产生噪音。这里显然就是这种情况,因为被预测的事件相当多样化。相同的偏见可能导致预测者过度反应或反应不足,这取决于主题。我们不应该期望它们产生统计偏见,即预测者相信事件会或不会发生的一般倾向。因此,训练预测者对抗他们的心理偏见是有效的——通过减少噪音。
团队合作对噪音减少有类似的大效果,但它也显著改善了团队提取信息的能力。这个结果与聚合逻辑一致:几个大脑一起工作比一个大脑更善于寻找信息。如果Alice和Brian在一起工作,Alice发现了Brian遗漏的信号,他们的联合预测会更好。在小组工作时,超级预测者似乎能够避免群体极化和信息级联的危险。相反,他们汇集数据和见解,以他们积极开放的方式充分利用合并的信息。Satopää和他的同事解释了这个优势:“团队合作——不像训练……允许预测者利用信息。”
选择具有最大的总效果。一些改进来自更好地利用信息。超级预测者比其他人更擅长寻找相关信息——可能是因为他们比普通参与者更聪明、更有动机、在做这类预测方面更有经验。但选择的主要效果仍然是减少噪音。超级预测者比普通参与者甚至训练有素的团队噪音更少。这个发现对Satopää和其他研究人员来说也是一个惊喜:“’超级预测者’可能更多地将他们的成功归功于在抑制测量误差方面的卓越纪律,而不是对他人无法复制的新闻的深刻解读。”
超级预测项目的成功突出了两种决策卫生策略的价值:选择(超级预测者确实是超级的)和聚合(当他们在团队中工作时,预测者表现更好)。这两种策略在许多判断中广泛适用。只要可能,你应该努力结合这些策略,通过构建由判断者(例如,预测者、投资专业人士、招聘官员)组成的团队,这些判断者被选择是因为他们既擅长自己的工作又彼此互补。
到目前为止,我们已经考虑了通过平均多个独立判断获得的改进精度,如群体智慧实验中的情况。聚合更高有效性判断者的估计将进一步提高准确性。通过结合既独立又互补的判断,可以获得准确性的另一个提升。想象四个人是犯罪的目击者:当然,确保他们不相互影响是至关重要的。如果此外,他们从四个不同角度看到了犯罪,他们提供的信息质量会好得多。
组建一个专业团队来共同做出判断的任务,类似于组建一系列测试来预测候选人在学校或工作中未来表现的任务。这项任务的标准工具是多元回归(在第9章中介绍)。它通过依次选择变量来工作。最能预测结果的测试首先被选中。然而,接下来要包含的测试不一定是第二有效的。相反,它是通过提供既有效又不与第一个测试冗余的预测,为第一个测试增加最多预测能力的那个。例如,假设你有两个心理能力测试,与未来表现的相关性分别为.50和.45,还有一个人格测试,与表现的相关性只有.30,但与能力测试不相关。最优解决方案是首先选择更有效的能力测试,然后选择人格测试,它带来了更多新信息。
同样,如果你正在组建一个评判团队,你当然应该首先选择最好的评判者。但你的下一个选择可能是一个中等有效但能为团队带来新技能的个体,而不是一个与第一个高度相似但更有效的评判者。以这种方式选择的团队会更优秀,因为当判断彼此不相关时,汇总判断的有效性比冗余时增长得更快。这样的团队中模式噪音会相对较高,因为每个案例的个人判断会有所不同。矛盾的是,这个嘈杂团队的平均值会比一致团队的平均值更准确。
有一个重要的注意事项需要说明。无论多样性如何,聚合只有在判断真正独立时才能减少噪音。正如我们对群体噪音的讨论所强调的,群体deliberation(深思熟虑)通常在偏见方面增加的错误比在噪音方面减少的更多。想要利用多样性力量的组织必须欢迎当团队成员独立达成判断时会出现的分歧。征求和聚合既独立又多样的判断往往是最简单、最便宜、最广泛适用的决策卫生策略。
“让我们取四个独立判断的平均值——这保证能将噪音减少一半。”
“我们应该努力保持永续测试状态,就像超级预测者一样。”
“在我们讨论这种情况之前,相关的基础比率是什么?”
“我们有一个好团队,但我们如何确保更多观点的多样性?”
几年前,我们的一位好朋友(我们叫他Paul)被他的主治医师(我们叫他Jones医生)诊断为高血压。医生建议Paul尝试药物治疗。Jones医生开了利尿剂,但没有效果;Paul的血压仍然很高。几周后,Jones医生用第二种药物——钙通道阻滞剂来应对。它的效果也不明显。
这些结果让Jones医生困惑不解。经过三个月的每周门诊后,Paul的高血压读数略有下降,但仍然过高。下一步该怎么做并不清楚。Paul很焦虑,Jones医生也很困扰,尤其是因为Paul是一个相对年轻且健康状况良好的男性。Jones医生考虑尝试第三种药物。
就在那时,Paul碰巧搬到了一个新城市,在那里他咨询了一位新的主治医师(我们叫他Smith医生)。Paul向Smith医生讲述了他持续与高血压斗争的故事。Smith医生立即回应道:“买一个家用血压计,看看读数是多少。我认为你根本没有高血压。你可能只是有白大褂综合征——你的血压在医生办公室里会升高!”
Paul照做了,果然,他在家里的血压是正常的。从那以后一直正常(在Smith医生告诉他白大褂综合征一个月后,他在医生办公室里的血压也变正常了)。
医生的一个核心任务是做出诊断——决定患者是否患有某种疾病,如果有,就识别它。诊断通常需要某种判断。对于许多病症,诊断是常规的且很大程度上是机械的,有规则和程序来最小化噪音。医生通常很容易确定某人是否有肩关节脱位或脚趾骨折。对于更技术性的问题也可以说类似的话。量化肌腱退化产生很少噪音。当病理学家评估乳腺病变的核心针活检时,他们的评估相对直接,噪音很少。
重要的是,有些诊断完全不涉及判断。医疗保健的进步往往通过消除判断元素来实现——从判断转向计算。对于链球菌性咽喉炎,医生会从患者咽喉的拭子样本开始进行快速抗原检测。在短时间内,检测就能发现链球菌细菌。(没有快速抗原结果,在某种程度上即使有了结果,链球菌性咽喉炎的诊断仍存在噪音。)如果你的空腹血糖水平达到或超过每分升126毫克,或者HbA1c(过去三个月血糖的平均测量值)至少为6.5,你就被认为患有糖尿病。在COVID-19大流行的早期阶段,一些医生最初通过考虑症状后做出的判断来诊断;随着大流行的发展,检测变得更加普遍,检测使判断变得不必要。
许多人都知道,当医生确实需要行使判断时,他们可能会有噪音,也可能会出错;一个标准做法是建议患者获得第二意见。在一些医院,第二意见甚至是强制性的。每当第二意见与第一意见分歧时,我们就有了噪音——当然,可能不清楚哪个医生是对的。一些患者(包括Paul)对第二意见与第一意见的巨大分歧感到震惊。但令人惊讶的不是医疗行业存在噪音,而是其巨大的程度。
我们在本章的目标是详细阐述这一观点,并描述医疗行业使用的一些降噪方法。我们将专注于一种决策卫生策略:诊断指南的制定。我们敏锐地意识到,完全可以写一整本书来讲述医学中的噪音以及医生、护士和医院为解决这一问题而采取的各种步骤。值得注意的是,医学中的噪音绝不仅限于诊断判断中的噪音,这是我们这里关注的重点。治疗也可能有噪音,大量文献也涉及这个话题。如果患者有心脏问题,医生对最佳治疗的判断差异很大,无论问题涉及正确的药物、正确的手术类型,还是是否进行手术。Dartmouth Atlas Project致力于二十多年来记录”医疗资源在美国分配和使用方式的明显差异”。类似的结论在许多国家都成立。然而,就我们的目的而言,简要探讨诊断判断中的噪音就足够了。
关于医学中噪音的文献浩如烟海。虽然大部分文献是实证性的,测试噪音的存在,但其中很多也是规范性的。参与医疗保健的人员继续寻找降噪策略,这些策略有多种形式,是值得在许多领域考虑的想法金矿。
当存在噪音时,一位医生可能明显正确,而另一位可能明显错误(并且可能遭受某种偏见)。正如所预期的,技能很重要。放射科医生肺炎诊断的研究发现了显著的噪音。其中大部分来自技能差异。更具体地说,“技能差异可以解释诊断决策差异的44%”,这表明”改善技能的政策比统一决策指南表现更好”。这里和其他地方一样,培训和选择显然对减少错误以及消除噪音和偏见至关重要。
在一些专科中,如放射学和病理学,医生充分意识到噪音的存在。例如,放射科医生称诊断变异为他们的”致命弱点”。目前尚不清楚放射学和病理学领域的噪音是否受到特别关注,是因为这些领域确实比其他领域有更多噪音,还是仅仅因为在那里更容易记录噪音。我们怀疑记录的便利性可能更重要。在放射学中,进行干净、简单的噪音(有时是错误)测试更容易。例如,你可以重新查看扫描或切片来重新评估之前的评估。
在医学中,人与人之间的噪音,或评分者间信度,通常通过kappa统计量来测量。kappa值越高,噪音越少。kappa值为1反映完全一致;值为0反映的一致性程度与你期望猴子向可能诊断列表投掷飞镖之间的一致性完全相同。在医学诊断的某些领域,通过这个系数测量的可靠性被发现是”轻微的”或”较差的”,这意味着噪音非常高。它经常被发现是”一般的”,这当然更好,但也表明存在显著噪音。关于哪些药物相互作用在临床上重要这一重要问题,全科医生在审查一百个随机选择的药物相互作用时,显示出”较差的一致性”。对于外行人和许多医生来说,肾病各个阶段的诊断可能看起来相对简单。但肾脏病专家只显示对肾病患者评估中使用的标准测试意义的判断”轻微到中等的一致性”。
关于乳腺病变是否为癌性的问题,一项研究发现病理学家之间只有”一般”的一致性。在诊断乳腺增生性病变时,一致性同样只是”一般”。当医生评估MRI扫描中脊柱狭窄程度时,一致性也只是”一般”。这些发现值得我们深思。我们曾说过在某些领域,医学中的噪音水平非常低。但在一些相当技术性的领域,医生远非无噪音的。患者是否会被诊断出严重疾病(如癌症),可能取决于某种抽签,由她碰到的特定医生决定。
让我们再考虑一些来自文献的其他发现,这些发现来自噪音水平似乎特别显著的领域。我们描述这些发现并非为了给出关于当前医疗实践状况的权威声明(医疗实践持续发展和改进,在某些情况下改进很快),而是为了传达噪音普遍存在的一般感受,无论是在相对较近的过去还是现在。
心脏病是美国男性和女性的首要死因。冠状动脉造影术是检测心脏病的主要方法,用于评估急性和非急性情况下心脏动脉的阻塞程度。在非急性情况下,当患者出现反复胸痛时,如果发现一条或多条动脉阻塞超过70%,通常会进行治疗——如支架植入术。然而,解读造影图像存在一定程度的变异性,可能导致不必要的手术。一项早期研究发现31%的时间里,评估造影图的医生对主要血管是否阻塞超过70%存在分歧。尽管心脏病专家广泛意识到读取造影图可能存在变异性,尽管持续努力和采取纠正措施,这个问题仍未得到解决。
子宫内膜异位症是一种通常排列在子宫内侧的子宫内膜组织在子宫外生长的疾病。这种疾病可能很痛苦并导致生育问题。它通常通过腹腔镜检查诊断,即将小型摄像头手术插入体内。三名患者(其中两名患有不同严重程度的子宫内膜异位症,一名没有)的腹腔镜检查数字视频被展示给108名妇科外科医生。要求外科医生判断子宫内膜异位病变的数量和位置。他们的意见存在巨大分歧,在数量和位置方面的相关性都很弱。
结核病(TB)是全世界最广泛传播和最致命的疾病之一——仅2016年就感染了超过1000万人,杀死了近200万人。检测TB的广泛使用方法是胸部X光,它允许检查肺部由TB细菌造成的空洞。TB诊断的变异性已经被充分记录了近七十五年。尽管几十年来有所改进,研究仍然发现TB诊断存在显著变异性,评价者间一致性只有”中等”或仅”一般”。不同国家的放射科医生之间在TB诊断方面也存在变异性。
当病理学家分析皮肤病变是否存在黑色素瘤——最危险的皮肤癌形式时,只有”中等”一致性。审查每个病例的八名病理学家一致或只有一个分歧的时间仅为62%。肿瘤中心的另一项研究发现黑色素瘤的诊断准确率只有64%,意味着医生在三个病变中有一个误诊了黑色素瘤。第三项研究发现纽约大学的皮肤科医生从皮肤活检中未能诊断出黑色素瘤的比例为36%。该研究的作者得出结论“临床上未能正确诊断黑色素瘤对患有这种潜在致命疾病的患者的生存具有严重影响。”
放射科医生在乳腺癌筛查乳房X光检查方面的判断存在变异性。一项大型研究发现,不同放射科医生的假阴性率范围从0%(放射科医生每次都正确)到超过50%(放射科医生超过一半时间错误地将乳房X光片识别为正常)。同样,假阳性率范围从不到1%到64%(意味着近三分之二的时间,放射科医生说乳房X光片显示癌症,而实际上没有癌症)。来自不同放射科医生的假阴性和假阳性确保了噪音的存在。
这些人际噪音的案例在现有研究中占主导地位,但也有场合噪音的发现。放射科医生有时在重新评估同一图像时提供不同观点,因此与自己不一致(尽管比与他人不一致的频率要低)。在评估造影图中的阻塞程度时,二十二名医生与自己一致的时间在63%到92%之间。在涉及模糊标准和复杂判断的领域,所谓的评价者内信度可能很差。
这些研究没有对这种场合噪音提供清晰的解释。但另一项不涉及诊断的研究,识别出了医学中场合噪音的一个简单来源——这一发现对患者和医生都值得牢记。简而言之,医生在上午早些时候比下午晚些时候更有可能下达癌症筛查医嘱。在一个大样本中,乳腺癌和结肠癌筛查检测的医嘱下达率在上午8点最高,为63.7%。整个上午这一比率持续下降,到上午11点降至48.7%。中午时增加到56.2%——然后下降到下午5点的47.8%。由此可见,预约时间较晚的患者接受指南推荐的癌症筛查的可能性较小。
我们如何解释这样的发现?一个可能的答案是,医生在诊所看诊后几乎不可避免地会延误,因为遇到复杂的医疗问题需要超过通常的二十分钟时段。我们已经提到了压力和疲劳作为场合噪音触发因素的作用(见第7章),这些因素似乎在这里起作用。为了跟上他们的时间安排,一些医生跳过了关于预防保健措施的讨论。临床医生疲劳作用的另一个例证是医院轮班结束时适当洗手率的降低。(洗手也被证明是有噪音的。)
不仅对医学,而且对人类知识做出重大贡献的是,在不同医疗问题背景下,对噪音的存在和程度提供全面的说明。我们不知道有任何这样的说明;我们希望它将在适当的时候产生。但即使是现在,现有的发现也提供了一些线索。
在一个极端,某些问题和疾病的诊断本质上是机械性的,不允许判断的余地。在其他情况下,诊断不是机械性的,但很直接;任何有医学训练的人都很可能得出相同的结论。在另一些情况下,一定程度的专业化——比如说,肺癌专家——足以确保噪音存在但很小。在另一个极端,一些病例为判断提供了很大的空间,诊断的相关标准如此开放,以至于噪音将是大量的且难以减少。正如我们将看到的,这在精神病学的很多情况下都是如此。
什么可能有助于减少医学中的噪音?正如我们提到的,训练可以提高技能,技能确实有帮助。多个专家判断的汇总(第二意见等等)也是如此。算法提供了一个特别有前景的途径,医生现在正在使用深度学习算法和人工智能来减少噪音。例如,这样的算法已被用于检测乳腺癌女性的淋巴结转移。已发现其中最好的算法优于最好的病理学家,当然,算法是没有噪音的。深度学习算法也已被用于检测与糖尿病相关的眼部问题,并取得了相当大的成功。而且AI现在在从乳房X光检查中检测癌症方面的表现至少与放射科医生一样好;AI的进一步发展可能会证明其优越性。
医学专业在未来可能会越来越依赖算法;它们有望减少偏差和噪音,并在这个过程中拯救生命和节约资金。但我们这里的重点将是人类判断指南,因为医学领域有助于说明它们如何在某些应用中产生良好甚至优秀的结果,而在其他应用中产生更复杂的结果。
诊断指南最著名的例子也许是Apgar评分,由产科麻醉医师Virginia Apgar于1952年开发。评估新生儿是否处于窘迫状态过去对医生和助产士来说是临床判断的问题。Apgar的评分给了他们一个标准指南。评估者测量婴儿的肤色、心率、反射、肌张力和呼吸努力,有时总结为Apgar姓名的”逆向缩写”:外观(肤色)、脉搏(心率)、grimace(反射)、活动(肌张力)和呼吸(呼吸率和努力)。在Apgar测试中,这五个测量指标各给予0、1或2分。最高可能总分是10分,这很罕见。7分或以上被认为表明健康状况良好(表3)。
表3: Apgar评分指南
| 类别 | 分配点数 |
|---|---|
| 外观(肤色) | 0:全身青紫或苍白 |
| 1:身体颜色良好但手脚青紫 | |
| 2:完全粉红或正常颜色 | |
| 脉搏(心率) | 0:无心率 |
| 1:<100次/分钟 | |
| 2:>100次/分钟 | |
| Grimace(反射) | 0:气道刺激无反应 |
| 1:刺激时做鬼脸 | |
| 2:刺激时做鬼脸并咳嗽或打喷嚏 | |
| 活动(肌张力) | 0:软瘫 |
| 1:手臂和腿部有一些弯曲 | |
| 2:主动运动 | |
| 呼吸 | 0:不呼吸 |
(呼吸频率和努力程度) 1: 哭声微弱(呜咽声、呻吟声) 2: 哭声良好、有力
请注意,心率是评分中唯一严格数字化的组成部分,所有其他项目都涉及一定程度的判断。但由于判断被分解为各个独立要素,每个要素都很容易评估,即使是训练程度不高的从业者也不太可能产生很大分歧——因此Apgar评分产生的噪音很少。
Apgar评分体现了指导原则的工作方式以及它们减少噪音的原因。与规则或算法不同,指导原则并不消除判断的需要:决策不是简单的计算。在每个组成部分以及最终结论上仍可能存在分歧。然而,指导原则成功减少了噪音,因为它们将复杂的决策分解为在预定义维度上的若干更容易的子判断。
当我们从第9章讨论的简单预测模型角度来看待这个问题时,这种方法的益处是显而易见的。临床医生对新生儿健康状况做出判断时,需要依据几个预测线索。场合噪音可能起作用:在某一天而非另一天,或在某种情绪而非另一种情绪下,临床医生可能会关注相对不重要的预测因子或忽略重要的预测因子。Apgar评分使医疗专业人员专注于经验证明重要的五个因子。然后,该评分提供了如何评估每个线索的清晰描述,这大大简化了每个线索层面的判断,从而减少了其噪音。最后,Apgar评分规定了如何机械地权衡预测因子以产生所需的整体判断,而人类临床医生在其他情况下会在分配给线索的权重上有所不同。专注于相关预测因子、简化预测模型和机械汇总——所有这些都减少了噪音。
类似的方法已在许多医学领域得到应用。一个例子是用于指导链球菌性咽喉炎诊断的Centor评分。患者每出现以下症状或体征就得一分(这些术语,如Apgar评分,构成了首次总结该指导原则的Robert Centor及其同事姓氏的逆向缩写):无咳嗽、存在渗出物(喉咙后部的白色斑块)、颈部淋巴结触痛或肿胀,以及体温超过100.4度。根据患者被分配的分数,可能会建议进行咽拭子检查以诊断链球菌性咽炎。使用这个量表进行评估和评分相对直接,它有效减少了接受不必要链球菌性咽喉炎检测和治疗的人数。
同样,已为乳腺癌诊断制定了指导原则,采用乳腺影像报告和数据系统(BI-RADS),该系统减少了乳房X线摄影解读中的噪音。一项研究发现,BI-RADS提高了乳房X线摄影评估的评估者间一致性,证明指导原则在减少变异性显著的领域中的噪音方面是有效的。在病理学方面,已有许多成功的努力将指导原则用于同样的目的。
就噪音而言,精神病学是一个极端案例。当使用相同的诊断标准诊断同一患者时,精神科医生之间经常存在分歧。因此,减少噪音自1940年代以来一直是精神病学界的主要优先事项。正如我们将看到的,尽管不断完善,指导原则在减少噪音方面只提供了适度的帮助。
1964年一项涉及91名患者和10名经验丰富的精神科医生的研究发现,两个意见之间达成一致的可能性仅为57%。另一项早期研究涉及426名州立医院患者,由两名精神科医生独立诊断,发现他们在诊断存在的精神疾病类型时仅有50%的时间达成一致。还有一项涉及153名门诊患者的早期研究发现54%的一致性。在这些研究中,噪音的来源并未明确。然而,有趣的是,发现一些精神科医生倾向于将患者归入特定的诊断类别。例如,一些精神科医生特别容易诊断患者患有抑郁症,而另一些则倾向于诊断焦虑症。
正如我们即将看到的,精神病学中的噪音水平继续保持在高位。为什么会这样?专家们缺乏单一、明确的答案(这意味着噪音的解释本身也是有噪音的)。大量的诊断类别无疑是一个因素。但在初步努力回答这个问题时,研究人员让一名精神科医生先面谈患者,然后在短暂休息后让第二名精神科医生进行另一次面谈。两名精神科医生之后会面,如果他们意见不一致,会讨论为什么不一致。
一个常见原因是”医生的不一致性”:不同的思想流派、不同的训练、不同的临床经验、不同的面谈风格。虽然”具有发展训练背景的临床医生可能将幻觉体验解释为过去虐待的创伤后体验的一部分”,但不同的临床医生”具有生物医学导向的可能将同样的幻觉解释为精神分裂症过程的一部分。“这些差异是模式噪音的例子。
除了医生之间的差异之外,噪音的主要原因是”命名法的不足”。这些观察以及专业人士对精神病学命名法的广泛不满,促成了1980年《精神疾病诊断与统计手册》(DSM-III)第三版的修订。该手册首次包含了诊断精神疾病的明确详细标准,这是引入诊断指南方向上的第一步。
DSM-III导致关于诊断是否存在噪音的研究急剧增加。它在减少噪音方面也证明是有帮助的。但该手册远非完全成功。即使在2000年对第四版DSM-IV(最初于1994年发布)进行重大修订之后,研究显示噪音水平仍然很高。一方面,Ahmed Aboraya和他的同事得出结论:“使用精神疾病诊断标准已被证明能够提高精神病学诊断的可靠性。”另一方面,仍然存在严重风险,即”同一患者的多次入院会显示出对同一患者的多种诊断。”
手册的另一个版本DSM-5于2013年发布。美国精神病学协会希望DSM-5能够减少噪音,因为新版本依赖于更客观、明确分级的标准。但精神科医生仍然表现出显著的噪音。例如,Samuel Lieblich和他的同事发现”精神科医生很难就谁患有或没有患有重度抑郁症达成一致。“DSM-5的现场试验发现”最小程度的一致性”,这”意味着在研究条件下受过高度训练的专科精神科医生仅能在4%到15%的时间里就患者患有抑郁症达成一致。“根据一些现场试验,DSM-5实际上使情况变得更糟,在”所有主要领域”显示噪音增加,“一些诊断,如混合性焦虑抑郁障碍…如此不可靠,在临床实践中显得毫无用处。”
指南成功有限的主要原因似乎是,在精神病学中,“某些疾病的诊断标准仍然模糊且难以操作化。”一些指南通过将判断分解为可减少分歧的标准来减少噪音,但在这些标准相对开放的程度上,噪音仍然可能存在。考虑到这一点,著名提案呼吁更加标准化的诊断指南。这些包括(1)澄清诊断标准,摆脱模糊标准;(2)制定症状及其严重程度的”参考定义”,理论是当”临床医生就症状的存在或不存在达成一致时,他们更可能在诊断上达成一致”;(3)除了开放式对话外,还使用患者的结构化访谈。一个提议的访谈指南包括二十四个筛查问题,允许更可靠地诊断例如焦虑、抑郁和饮食障碍。
这些步骤听起来很有希望,但它们在多大程度上能成功减少噪音还是一个悬而未决的问题。用一位观察者的话说,“对患者主观症状的依赖、临床医生对症状的解释,以及缺乏客观测量(如血液检测),植入了精神疾病诊断不可靠性的种子。”在这个意义上,精神病学可能特别抗拒减少噪音的尝试。
关于这个特定问题,现在做出自信的预测还为时过早。但有一点是清楚的。在医学领域总体上,指南在减少偏见和噪音方面都非常成功。它们帮助了医生、护士和患者,并在此过程中大大改善了公共健康。医学专业需要更多这样的指南。
“在医生中,噪音水平远比我们可能怀疑的要高。在诊断癌症和心脏病——甚至在读X光片时——专家有时会有分歧。这意味着患者得到的治疗可能是抽签的结果。”
“医生喜欢认为无论是周一还是周五,无论是清晨还是下午晚些时候,他们都会做出相同的决定。但事实证明,医生说什么和做什么很可能取决于他们有多累。”
“医学指南可以使医生不太可能以患者为代价犯错。这些指南也可以帮助整个医学专业,因为它们减少了变异性。”
让我们从一个练习开始。想三个你认识的人;他们可能是朋友或同事。在1到5的量表上给他们评分,其中1是最低分,5是最高分,按照三个特征:善良、智力和勤奋。现在请一个很了解他们的人——你的配偶、最好的朋友或最亲密的同事——对同样的三个人做同样的事情。
在某些评分项目上,你和其他评分者很可能会得出不同的数字。如果你(和你的伙伴)愿意的话,请讨论产生差异的原因。你可能会发现答案在于你们如何使用评分标准——我们称之为水平噪声。也许你认为5分需要真正非凡的表现,而另一个评分者认为只需要异常出色的表现即可。或者你们的差异源于对被评分人员的不同看法:你对他们是否善良的理解,以及如何准确定义这种美德,可能与另一个评分者不同。
现在想象一下,对于你评分的三个人,升职或奖金岌岌可危。假设你和另一个评分者正在一家重视善良(或同事友爱)、智慧和勤奋的公司进行绩效评估。你们的评分会有差异吗?差异会像之前的练习中那样大吗?甚至更大?无论这些问题如何回答,政策和评分标准的差异都可能产生噪声。事实上,这正是在各种组织环境的绩效评估中普遍观察到的现象。
在几乎所有大型组织中,绩效都会定期接受正式评估。被评估者并不喜欢这种体验。正如一个新闻标题所说:“研究发现基本上每个人都讨厌绩效评估。”每个人也都知道(我们认为)绩效评估既受到偏见也受到噪声的影响。但大多数人不知道它们有多么嘈杂。
在理想世界中,评估人们的绩效不应该是一个判断任务;客观事实就足以确定人们的表现如何。但大多数现代组织与亚当·斯密的别针工厂几乎没有共同点,在那里每个工人都有可衡量的产出。首席财务官或研究主管的产出会是什么呢?今天的知识工作者需要平衡多个有时相互矛盾的目标。仅仅关注其中一个可能会产生错误的评估并产生有害的激励效应。例如,医生每天接诊的患者数量是医院生产力的重要驱动因素,但你不会希望医生一心专注于这个指标,更不用说仅仅基于这个指标来评估和奖励他们。即使是可量化的绩效指标——比如销售人员的销售额或程序员编写的代码行数——也必须在具体情境中评估:并非所有客户都同样难以服务,也并非所有软件开发项目都相同。鉴于这些挑战,许多人无法完全基于客观绩效指标进行评估。因此基于判断的绩效评估无处不在。
关于绩效评估实践已经发表了数千篇研究文章。大多数研究人员发现这种评估极其嘈杂。这个令人清醒的结论主要来自基于360度绩效评估的研究,在这种评估中,多个评分者对同一被评估人员提供输入,通常是在绩效的多个维度上。当进行这种分析时,结果并不好看。研究经常发现,真实方差,即归因于个人绩效的方差,仅占总方差的不超过20%到30%。评分中其余70%到80%的方差是系统噪声。
这种噪声从何而来?得益于对工作绩效评分方差的多项研究,我们知道系统噪声的所有组成部分都存在。
这些组成部分在绩效评分的背景下很容易想象。考虑两个评分者,Lynn和Mary。如果Lynn宽松而Mary严格,即Lynn平均给所有被评估人员的评分都比Mary高,那么我们就有了水平噪声。正如我们在讨论法官时所指出的,这种噪声可能意味着Lynn和Mary形成了真正不同的印象,或者两个评分者只是使用不同的评分标准来表达相同的印象。
现在,如果Lynn正在评估你,并且恰好对你和你的贡献有明显的负面看法,她的总体宽松可能会被她对你的特殊(和负面)反应所抵消。这就是我们所说的稳定模式:特定评分者对特定被评估人员的反应。因为这种模式是Lynn独有的(以及她对你的判断),所以它是模式噪声的来源。
最后,Mary可能在填写评分表之前刚刚发现有人在公司停车场撞坏了她的车,或者Lynn可能刚刚收到了自己意外丰厚的奖金,这让她在评估你的绩效时心情异常愉快。当然,这些事件可能会产生场合噪声。
不同的研究对系统噪声分解为这三个组成部分(水平、模式和场合)得出不同的结论,我们当然可以想象它应该因组织而异的原因。但所有形式的噪声都是不可取的。这项研究得出的基本信息很简单:大多数绩效评分与被评估人员的实际绩效的关系远比我们希望的要小。正如一项综述总结的那样,“工作绩效与工作绩效评分之间的关系可能很弱,或者充其量是不确定的。”
此外,组织中的评级可能无法反映评估者对员工真实表现感知的原因有很多。例如,评估者实际上可能并不试图准确评估表现,而是可能”策略性地”给人打分。除其他动机外,评估者可能有意夸大评级以避免困难的反馈对话,以偏袒一个正在寻求期待已久晋升的人,或者甚至,矛盾的是,为了摆脱一个表现不佳的团队成员,该成员需要良好的评估才能被允许转移到另一个部门。
这些策略性计算确实会影响评级,但它们并不是噪音的唯一来源。我们知道这一点要感谢一种自然实验:一些360度反馈系统仅用于发展目的。在这些系统中,受访者被告知反馈不会用于评估目的。在评估者实际相信他们被告知内容的程度上,这种方法阻止他们夸大或贬低评级。事实证明,发展性审查确实对反馈质量产生了影响,但系统噪音仍然很高,仍然比被评估人员的表现占更多方差。即使反馈是纯粹发展性的,评级仍然是有噪音的。
如果绩效评级系统如此严重地被破坏,那些测量绩效的人应该注意并改进它们。实际上,在过去几十年中,组织已经尝试了对这些系统进行无数次改革。这些改革采用了我们概述的一些降噪策略。在我们看来,可以做得更多。
几乎所有组织都使用聚合的降噪策略。聚合评级通常与360度评级系统相关联,该系统在1990年代成为大公司的标准。(《人力资源管理》杂志在1993年有一期关于360度反馈的特刊。)
虽然平均来自几个评估者的评级应该有助于减少系统噪音,但值得注意的是,360度反馈系统并不是作为该问题的补救措施而发明的。它们的主要目的是测量比老板看到的更多的内容。当你的同事和下属,而不仅仅是你的老板,被要求为你的绩效评估做出贡献时,所重视内容的性质就改变了。理论是这种转变是更好的,因为今天的工作需要的不仅仅是取悦你的老板。360度反馈的流行兴起与流动的、基于项目的组织的普及同时发生。
一些证据表明360度反馈是一个有用的工具,因为它能预测客观可测量的表现。不幸的是,这种反馈系统的使用产生了自己的问题。随着计算机化使得向反馈系统添加更多问题变得毫不费力,以及多个企业目标和约束的扩散为职位描述增加了维度,许多反馈问卷变得荒谬地复杂。过度设计的问卷比比皆是(一个例子涉及每个评估者和被评估人员在十一个维度上的四十六个评级)。超人般的评估者才能回忆和处理关于在如此多维度上被评估的众多人员的准确、相关事实。在某些方面,这种过于复杂的方法不仅无用,而且有害。正如我们所见,光环效应意味着所谓分离的维度实际上不会被分别对待。对第一个问题的强烈正面或负面评级将倾向于将后续问题的答案拉向同一方向。
更重要的是,360度系统的发展指数级地增加了用于提供反馈的时间量。中层管理者被要求完成关于各级同事的数十份问卷并不罕见——有时还包括其他组织的对应人员,因为许多公司现在要求来自客户、供应商和其他商业伙伴的反馈。无论意图多么良好,对时间受限的评估者提出的要求的爆炸性增长都不能指望改善他们提供信息的质量。在这种情况下,噪音的减少可能不值得成本——这是我们将在第6部分讨论的问题。
最后,360度系统对所有绩效测量系统几乎普遍存在的疾病并不免疫:评级通胀的蔓延。一家大型工业公司曾经观察到98%的管理者被评为”完全达到期望”。当几乎每个人都收到最高可能的评级时,质疑这些评级的价值是公平的。
对评级通胀问题的一个理论上有效的解决方案是在评级中引入一些标准化。一个旨在做到这一点的流行做法是强制排名。在强制排名系统中,评估者不仅被阻止给每个人最高可能的评级,而且被迫遵守预定的分布。强制排名由杰克·韦尔奇在担任通用电气CEO时倡导,作为阻止评级通胀并确保绩效评估中”坦率”的方式。许多公司采用了它,后来又放弃了它,理由是对士气和团队合作产生了不良副作用。
无论排名存在什么缺陷,它们的噪音都比评级要少。我们在惩罚性赔偿的例子中看到,相对判断中的噪音比绝对判断中的噪音要少得多,这种关系在绩效评级中也同样适用。

图 17:绝对和相对评级量表的例子
要理解其中的原因,请看图 17,它显示了两个评估员工的量表例子。面板 A 中,员工在绝对量表上被评级,这需要我们所说的匹配操作:找到最符合你对员工”工作质量”印象的分数。相比之下,面板 B 要求将每个个体与其他一组人在特定维度——安全性上进行比较。主管被要求使用百分位量表,说明员工在指定人群中的排名(或百分位数)。我们可以看到,一位主管在这个通用量表上安排了三名员工。
面板 B 的方法有两个优势。首先,在一个维度上对所有员工进行评级(在这个例子中是安全性)体现了我们将在下一章详细讨论的降噪策略:将复杂判断结构化为几个维度。结构化是试图限制光环效应的尝试,光环效应通常使一个人在不同维度上的评级保持在一个小范围内。(当然,结构化只有在像这个例子中那样对每个维度分别进行排名时才有效:对”工作质量”这样定义不清的综合判断进行排名不会减少光环效应。)
其次,正如我们在第 15 章中讨论的,排名既减少了模式噪音也减少了水平噪音。当你比较团队中两个成员的表现时,比分别给每个人打分更不容易不一致(并产生模式噪音)。更重要的是,排名机制性地消除了水平噪音。如果林恩和玛丽评估同一组二十名员工,林恩比玛丽更宽松,他们的平均评级会不同,但他们的平均排名不会。宽松的排名者和严格的排名者使用相同的排名。
事实上,降噪是强制排名的主要既定目标,它确保所有评估者具有相同的平均值和相同的评估分布。当评级分布被强制规定时,排名就是”强制的”。例如,一个规则可能规定,被评级的人中不超过 20% 可以被归入顶级类别,不少于 15% 可以被归入底级类别。
因此,从原则上讲,强制排名应该带来急需的改进。然而,它经常适得其反。我们在这里不打算回顾它所有可能的不良影响(这些影响往往与实施不当而非原则有关)。但强制排名系统的两个问题提供了一些一般性教训。
第一个问题是绝对绩效和相对绩效之间的混淆。任何公司 98% 的经理不可能都在其同行群体的前 20%、50% 甚至 80% 中,这当然是不可能的。但是,如果这些期望是事先定义的并且是绝对术语,那么他们都”符合期望”并非不可能。
许多高管反对几乎所有员工都能符合期望的观念。他们认为,如果是这样,期望肯定太低了,也许是因为自满的文化。诚然,这种解释可能是有效的,但大多数员工真正符合高期望也是可能的。事实上,这正是我们期望在高绩效组织中发现的。如果你听说成功太空任务中的所有宇航员都完全符合期望,你不会嘲笑美国国家航空航天局绩效管理程序的宽松。
结论是,依赖相对评估的系统只有在组织关心相对绩效时才合适。例如,当无论人们的绝对绩效如何,只有固定百分比的人可以获得晋升时,相对评级可能有意义——想想上校被评估晋升为将军的情况。但是,像许多公司那样,对声称衡量绝对绩效水平的东西强制进行相对排名是不合逻辑的。强制规定一定百分比的员工被评为未达到(绝对)期望不仅残酷,而且荒谬。说军队精英部队的 10% 必须被评为”不满意”是愚蠢的。
第二个问题是,评级的强制分布被假设反映了潜在真实绩效的分布——通常接近正态分布。然而,即使被评级人群中绩效的分布是已知的,在较小的群体中(如单个评估者评估的群体)可能不会再现相同的分布。如果你从几千人的人群中随机挑选十个人,不能保证其中恰好有两个人属于总人群的前 20%。(“不能保证”是轻描淡写:这种情况发生的概率只有 30%。)在实践中,问题甚至更糟,因为团队的组成不是随机的。一些单位可能几乎完全由高绩效者组成,而另一些则由表现不佳的员工组成。
在这种情况下,强制排名不可避免地成为错误和不公平的源头。假设一个评估者的团队由五个绩效无法区分的人组成。对这种无差别的现实强制进行差异化的评级分布不会减少错误,反而会增加错误。
强制排名的批评者经常将攻击重点集中在排名原则上,他们谴责这种做法残酷、不人道,最终适得其反。无论你是否接受这些论点,强制排名的致命缺陷不在于”排名”,而在于”强制”。每当判断被强制套用到不合适的量表上时,无论是因为使用相对量表来衡量绝对绩效,还是因为评判者被迫区分无法区分的事物,量表的选择都会机械地增加噪音。
考虑到组织为改善绩效衡量所做的所有努力,说结果令人失望是一种保守的说法。由于这些努力,绩效评估的成本飙升。2015年,Deloitte计算出每年花费200万小时来评估其6.5万名员工。绩效评估仍然是组织中最令人恐惧的仪式之一,执行评估的人几乎和接受评估的人一样讨厌它。一项研究发现,惊人的90%的经理、员工和HR主管认为他们的绩效管理流程无法提供预期的结果。研究证实了大多数经理所经历的情况。虽然与员工发展计划相关的绩效反馈可以带来改进,但绩效评级在最常见的实践中,抑制动机的频率与激励动机的频率一样高。正如一篇综述文章总结的那样,“无论几十年来尝试了什么来改进[绩效管理]流程,它们继续产生不准确的信息,几乎没有为推动绩效做任何事情。”
绝望之下,越来越多的公司现在正在考虑完全取消评估系统这一激进选择。这场”绩效管理革命”的支持者,包括许多科技公司、一些专业服务机构,以及传统行业的少数公司,旨在专注于发展性、面向未来的反馈,而非评估性、回顾性的评估。一些公司甚至让评估变得无数字化,这意味着他们放弃了传统的绩效评级。
对于那些没有放弃绩效评级的公司(它们是绝大多数),可以做些什么来改善评级呢?一个降噪策略再次与选择正确的量表有关。目标是确保共同的参考框架。研究表明,改进的评级格式和评级者培训的结合可以帮助实现评级者在使用量表时更好的一致性。
至少,绩效评级量表必须基于足够具体的描述符,以便能够一致地解释。许多组织使用行为锚定评级量表,其中量表上的每个等级都对应特定行为的描述。图18的左侧面板提供了一个例子。
然而,证据表明,行为锚定评级量表不足以消除噪音。进一步的步骤,参考框架培训,已被证明有助于确保评级者之间的一致性。在这一步骤中,评级者接受培训以识别绩效的不同维度。他们使用录像小品练习评级绩效,然后了解他们的评级与专家提供的”真实”评级的比较情况。绩效小品充当参考案例;每个小品定义了绩效量表上的一个锚点,从而成为案例量表,如图18右侧面板所示。
使用案例量表,对新个体的每个评级都是与锚定案例的比较。这成为相对判断。因为比较判断比评级更不容易受到噪音影响,案例量表比使用数字、形容词或行为描述的量表更可靠。

图18:行为锚定评级量表(左)和案例量表(右)的示例
参考框架培训已经为人所知几十年,并提供了明显更少噪音和更准确的评级。然而,它却收效甚微。很容易猜测原因。参考框架培训、案例量表和其他追求相同目标的工具复杂且耗时。为了有价值,它们通常需要为公司甚至为进行评估的单位进行定制,并且必须随着工作要求的发展而频繁更新。这些工具要求公司在其已经庞大的绩效管理系统投资基础上增加投入。当前的趋势是相反的方向。(在第6部分中,我们将对降低噪音的成本有更多说明。)
此外,任何组织如果驯服了归因于评级者的噪音,也会降低他们为追求自己目标而影响评级的能力。要求经理接受额外的评级者培训,在评级过程中投入更多努力,并放弃他们对结果的一些控制,肯定会产生相当大的阻力。值得注意的是,迄今为止大多数关于参考框架评级者培训的研究都是在学生身上进行的,而不是在实际的经理身上。
绩效评估这个重大主题引发了许多实际和哲学问题。例如,有些人询问,在当今的组织中,个人绩效这一概念在多大程度上是有意义的,因为结果往往取决于人们如何相互协作。如果我们相信这个概念确实有意义,我们必须思考个人绩效水平在特定组织中的人群分布——比如,绩效是否遵循正态分布,或者是否存在”明星人才”做出极不成比例的巨大贡献。如果你的目标是发挥人们的最佳潜能,你可以合理地询问,衡量个人绩效并使用这种衡量标准通过恐惧和贪婪来激励人们,是否是最佳方法(或者说是否是有效方法)。
如果你正在设计或修订绩效管理系统,你需要回答这些问题以及更多问题。我们在这里的愿望不是要审视这些问题,而是要提出一个更谦逊的建议:如果你确实衡量绩效,你的绩效评级可能已经被系统噪音所渗透,因此,它们可能基本上毫无用处,甚至很可能适得其反。减少这种噪音是一个无法通过简单技术修复解决的挑战。它需要对评级者预期做出的判断进行清晰思考。很可能,你会发现通过澄清评级量表并培训人们始终如一地使用它,可以改善判断。这种降噪策略在许多其他领域都适用。
“我们在绩效评级上花费了大量时间,然而结果是四分之一的绩效和四分之三的系统噪音。”
“我们尝试了360度反馈和强制排名来解决这个问题,但我们可能让事情变得更糟。”
“如果存在如此多的水平噪音,那是因为不同的评级者对’好’或’优秀’的含义有完全不同的想法。只有当我们给他们具体案例作为评级量表的锚点时,他们才会达成一致。”
如果你曾经从事过任何工作,“招聘面试”这几个词可能会唤起一些生动而紧张的回忆。求职面试,即候选人与未来主管或人力资源专业人员会面,是进入许多组织所需的成年礼。
在大多数情况下,面试遵循经过充分排练的例行程序。在交换一些客套话后,面试官要求候选人描述他们的经验或详细说明其特定方面。会询问关于成就和挑战、求职动机或对公司改进想法的问题。面试官经常要求候选人描述他们的个性,并解释为什么他们适合这个职位或公司文化。有时会讨论爱好和兴趣。在面试结束时,候选人通常可以提出几个问题,这些问题会被正式评估其相关性和洞察力。
如果你现在有权雇用员工,你的选择方法可能包括这种仪式的某种版本。正如一位组织心理学家所说,“不经过某种类型的面试就被雇用是罕见的,甚至是不可想象的。”几乎所有专业人士在这些面试中做出招聘决策时都在某种程度上依赖他们的直觉判断。
就业面试的普遍性反映了对判断价值的深层信念,特别是在选择我们将与之合作的人员时。作为一项判断任务,人员选择有一个巨大优势:因为它如此普遍且如此重要,组织心理学家对此进行了非常详细的研究。1917年发表的《应用心理学杂志》创刊号将招聘确定为”最高问题……因为人类能力毕竟是主要的国家资源”。一个世纪后,我们对各种选择技术(包括标准面试)的有效性了解很多。没有复杂的判断任务成为如此多实地研究的焦点。这使其成为一个完美的测试案例,提供了可以推广到许多涉及在多个选项中进行选择的判断的经验教训。
如果你不熟悉关于就业面试的研究,接下来的内容可能会让你感到惊讶。从本质上讲,如果你的目标是确定哪些候选人将在工作中成功,哪些将失败,标准面试(也称为非结构化面试,以区别于我们很快将讨论的结构化面试)信息量并不大。更直白地说,它们往往毫无用处。
为了得出这个结论,无数研究估计了评估者在面试后给候选人的评级与候选人最终在工作中的成功之间的相关性。如果面试评级与成功之间的相关性很高,那么面试——或以同样方式计算相关性的任何其他招聘技术——可以被认为是候选人表现的良好预测指标。
这里需要一个警告。成功的定义是一个非平凡的问题。通常,绩效是基于主管评分来评估的。有时,衡量标准是就业时长。当然,这些衡量标准会引发问题,特别是考虑到绩效评分的可疑有效性,我们在上一章中已经提到了这一点。然而,为了评估雇主在选择员工时判断的质量,使用同一雇主在评估所雇佣员工时做出的判断似乎是合理的。任何对招聘决策质量的分析都必须做出这个假设。
那么这些分析得出了什么结论呢?在第11章中,我们提到了典型面试评分与工作绩效评分之间0.28的相关性。其他研究报告的相关性范围在0.20到0.33之间。正如我们所见,按照社会科学标准,这是一个非常好的相关性——但对于你做决策的基础来说并不是很好。使用我们在第3部分介绍的一致性百分比(PC),我们可以计算一个概率:在前述相关性水平下,如果你对两个候选人的了解仅仅是其中一个在面试中表现更好,那么这个候选人确实会表现更好的机会大约是56%到61%。肯定比抛硬币好一些,但很难说是做重要决策的万无一失的方法。
诚然,面试除了对候选人做出判断外还有其他目的。值得注意的是,它们为向有前途的候选人推销公司和与未来同事建立融洽关系提供了机会。然而,从投入时间和精力进行人才选拔的组织角度来看,面试的主要目的显然是选拔。而在这项任务上,它们并不能算是巨大的成功。
我们可以很容易地看出为什么传统面试在预测工作绩效方面会产生错误。这种错误的一部分与我们所谓的客观无知有关(见第11章)。工作绩效取决于很多因素,包括你雇佣的人适应新职位的速度,或者各种生活事件如何影响她的工作。在招聘时,这些很大程度上是不可预测的。这种不确定性限制了面试的预测效度,实际上也限制了任何其他人员选拔技术的预测效度。
面试也是心理偏见的雷区。近年来,人们已经充分意识到面试官往往会(通常是无意地)偏爱在文化上与他们相似或与他们有共同点的候选人,包括性别、种族和教育背景。许多公司现在认识到偏见带来的风险,并试图通过对招聘专业人员和其他员工进行专门培训来解决这些问题。其他偏见也已经为人所知几十年了。例如,外貌在候选人评估中起很大作用,即使对于那些外貌应该很少重要或根本不重要的职位也是如此。这些偏见被所有或大多数招聘人员所共有,当应用于某个候选人时,往往会产生共同错误——对候选人评估的负面或正面偏见。
你听到还有噪声不会感到惊讶:不同的面试官对同一个候选人有不同的反应并得出不同的结论。两个面试官在面试同一个候选人后产生的评分之间相关性的衡量范围在0.37到0.44之间(PC = 62-65%)。一个原因是候选人与不同面试官的行为可能不完全相同。但即使在小组面试中,几个面试官接触到相同的被面试者行为,他们评分之间的相关性也远非完美。一项元分析估计相关性为0.74(PC = 76%)。这意味着你和另一个面试官在同一个小组面试中看到相同的两个候选人后,仍然会在大约四分之一的时间里对哪个候选人更好产生分歧。
这种变异性很大程度上是模式噪声的产物,即面试官对特定被面试者的特有反应差异。大多数组织完全预期这种变异性,因此要求几个面试官与同一个候选人见面,结果以某种方式汇总。(通常,综合意见是通过讨论形成的,必须达成某种共识——这个程序会产生自己的问题,正如我们已经注意到的。)
一个更令人惊讶的发现是面试中存在大量场合噪声。例如,有强有力的证据表明,招聘建议与面试非正式建立融洽关系阶段形成的印象有关,即前两三分钟你只是友好地聊天让候选人放松的时候。第一印象很重要——非常重要。
也许你认为根据第一印象进行判断是没有问题的。至少我们从第一印象中学到的一些东西是有意义的。我们所有人都知道,在与新相识的人互动的最初几秒钟里,我们确实会学到一些东西。有理由认为这对技能娴熟的面试官来说可能特别真实。但面试的最初几秒钟恰恰反映了你与第一印象相关的那种肤浅品质:早期感知主要基于候选人的外向性和口头技能。甚至握手的质量也是招聘建议的重要预测因子!我们可能都喜欢坚实的握手,但很少有招聘人员会有意识地选择将其作为关键的招聘标准。
为什么第一印象最终会影响一场更长面试的结果?一个原因是在传统面试中,面试官可以自由地按照他们认为合适的方向引导面试。他们可能会问一些确认初始印象的问题。例如,如果候选人看起来害羞内向,面试官可能会想要问一些关于候选人过往团队合作经历的尖锐问题,但对于那些看起来开朗外向的人可能就不会问同样的问题。收集到的关于这两个候选人的证据是不同的。一项追踪面试官行为的研究发现,那些通过简历和测试分数形成积极或消极初始印象的面试官,初始印象对面试进程有深刻影响。例如,有积极第一印象的面试官问的问题更少,并倾向于向候选人”推销”公司。
第一印象的力量并不是面试唯一的问题。另一个问题是,作为面试官,我们希望坐在我们面前的候选人能够说得通(这是我们过度寻求和发现连贯性倾向的表现,在第13章中讨论过)。在一个令人震惊的实验中,研究人员让学生扮演面试官或面试者的角色,并告诉双方面试应该只包含封闭式的是非题。然后他们要求一些面试者随机回答问题。(问题表述的第一个字母决定了他们应该回答是或否。)正如研究人员讽刺地指出:“一些面试者最初担心随机面试会崩溃并被揭露为无意义的。没有发生这样的问题,面试继续进行。”你没看错:没有一个面试官意识到候选人在给出随机答案。更糟糕的是,当被要求评估他们是否”能够在我们共度的时间里推断出关于这个人的很多信息”时,“随机”条件下的面试官与那些遇到诚实回答候选人的面试官一样可能同意。这就是我们创造连贯性的能力。正如我们经常能在随机数据中找到想象的模式或在云朵轮廓中想象出形状一样,我们能够在完全无意义的答案中找到逻辑。
作为一个不那么极端的例证,考虑以下案例。本书作者之一不得不面试一位候选人,他在前一个职位上是一家中型公司的首席财务官。他注意到候选人在几个月后就离开了这个职位,于是问他为什么。候选人解释说原因是与CEO的”战略分歧”。一位同事也面试了这位候选人,问了同样的问题,得到了同样的答案。然而,在随后的汇报中,两位面试官有着截然不同的观点。一个人此前对候选人形成了积极评价,将候选人离开公司的决定视为正直和勇气的表现。另一个人形成了负面的第一印象,将同一事实解释为缺乏灵活性,甚至是不成熟的标志。这个故事说明,无论我们多么希望相信我们对候选人的判断是基于事实的,我们对事实的解释都会被先前的态度所影响。
传统面试的局限性使我们对从中得出任何有意义结论的能力产生严重怀疑。然而在面试中形成的印象是生动的,面试官通常对它们很有信心。当将面试中得出的结论与关于候选人的其他线索结合时,我们倾向于给面试太多权重,而给其他可能更具预测性的数据(如测试分数)太少权重。
一个故事可能有助于让这一观察变得生动。申请教职的教授经常被要求在同行小组面前授课,以确保他们的教学技能符合机构标准。当然,这比普通课堂的风险更高。我们中的一位曾经目睹一位候选人在这个练习中留下糟糕印象,显然是因为情况的压力:候选人的简历上提到了出色的教学评价和几个教学卓越奖。然而,他在一个高度人为情况下失败所产生的生动印象,在最终决定中的权重超过了关于他过往出色教学表现的抽象数据。
最后一点:当面试不是关于候选人信息的唯一来源时——例如,当还有测试、推荐信或其他输入时——这些各种输入必须被结合成一个整体判断。这引出的问题是你现在认识的:应该使用判断(clinical aggregation)还是公式(mechanical aggregation)来结合输入?正如我们在第9章中看到的,mechanical方法在一般情况下和在工作表现预测的具体案例中都是优越的。不幸的是,调查表明绝大多数HR专业人士支持clinical aggregation。这种做法为已经很嘈杂的过程增加了另一个噪音来源。
如果传统面试和基于判断的招聘决策的预测有效性有限,我们能对此做什么?幸运的是,研究也产生了一些关于如何改进人员选拔的建议,一些公司正在关注。
一个已经升级人员选拔实践并报告结果的公司例子是Google。其前人力运营高级副总裁Laszlo Bock在他的书《工作规则!》中讲述了这个故事。尽管专注于招聘最高水平的人才并投入大量资源寻找合适的人选,Google仍在苦苦挣扎。对其招聘面试预测有效性的审计发现”零关系(…) ,完全随机的混乱。“Google为解决这种情况而实施的变化反映了数十年研究中涌现的原则。它们也说明了决策卫生策略。
其中一个策略现在应该很熟悉了:聚合。在这种情况下使用它并不令人惊讶。几乎所有公司都会聚合多个面试官对同一候选人的判断。为了不甘落后,Google有时让候选人经历二十五次面试!Bock审查的结论之一是将这个数字减少到四次,因为他发现额外的面试对前四次面试所达到的预测有效性几乎没有增加。然而,为了确保这种有效性水平,Google严格执行一个并非所有公司都遵守的规则:公司确保面试官在相互沟通之前分别对候选人进行评分。再次强调:聚合有效——但只有在判断独立的情况下才有效。
Google还采用了我们尚未详细描述的决策卫生策略:构建复杂判断。术语结构可能意味着很多事情。正如我们在这里使用的术语,结构化复杂判断由三个原则定义:分解、独立性和延迟整体判断。
第一个原则,分解,将决策分解为组件,或中介评估。这一步的目的与指导原则中子判断的识别相同:它让判断者专注于重要线索。分解充当路线图来指定需要什么数据。并且它过滤掉不相关的信息。
在Google的案例中,分解中有四个中介评估:一般认知能力、领导力、文化契合度(称为”googleyness”)和角色相关知识。(其中一些评估然后被分解为更小的组件。)请注意,候选人的好外表、流利的谈吐、令人兴奋的爱好,以及招聘人员在非结构化面试中可能注意到的任何其他积极或消极方面,都不在列表上。
为招聘任务创建这种结构似乎只是常识。确实,如果你要招聘入门级会计师或行政助理,标准职位描述存在并指定所需的能力。然而,正如专业招聘人员所知,为不寻常或高级职位定义关键评估变得困难,而这一定义步骤经常被忽视。一位著名的猎头指出,以足够具体的方式定义所需能力是一项具有挑战性的、经常被忽视的任务。他强调了决策者”投资于问题定义”的重要性:在遇到任何候选人之前,花费必要的时间预先就清晰详细的职位描述达成一致。这里的挑战是许多面试官使用由共识和妥协产生的冗长职位描述。这些描述是理想候选人应具备的所有特征的模糊愿望清单,它们没有提供校准这些特征或在它们之间进行权衡的方法。
结构化判断的第二个原则,独立性,要求独立收集每个评估的信息。仅仅列出职位描述的组件是不够的:大多数进行传统面试的招聘人员也知道他们在候选人身上寻找的四到五件事。问题是,在进行面试时,他们没有分别评估这些要素。每个评估都会影响其他评估,这使得每个评估都非常嘈杂。
为了克服这个问题,Google精心安排了以事实为基础并彼此独立地进行评估的方法。也许它最显著的举措是引入结构化行为面试。此类面试中面试官的任务不是决定他们是否总体上喜欢候选人;而是收集关于评估结构中每个评估的数据,并在每个评估上为候选人分配分数。为了做到这一点,面试官被要求询问关于候选人在过去情况下行为的预定义问题。他们还必须记录答案并根据预定的评分量表对其进行评分,使用统一的评分标准。评分标准给出了每个问题的平均、良好或优秀答案的例子。这个共享量表(我们在前一章介绍的行为锚定评分量表的一个例子)有助于减少判断中的噪音。
如果这种方法听起来与传统的对话式面试不同,那确实如此。事实上,它可能更像是一场考试或审讯,而不是商业会面,并且有一些证据表明面试者和面试官都不喜欢结构化面试(或者至少更偏好非结构化面试)。关于面试必须包含哪些内容才能称为结构化面试,仍存在持续的争论。尽管如此,面试文献中最一致的发现之一是,结构化面试在预测未来工作表现方面远比传统的非结构化面试更准确。与工作表现的相关性在0.44到0.57之间。使用我们的PC指标,通过结构化面试选择更好候选人的机会在65%到69%之间,相比非结构化面试56%到61%的机会有显著改善。
Google在其关注的某些维度上使用其他数据作为输入。为了测试与工作相关的知识,它部分依赖于工作样本测试,比如要求编程工作的候选人编写一些代码。研究表明,工作样本测试是工作表现的最佳预测指标之一。Google还使用”后门推荐”,这些推荐不是由候选人提名的人提供,而是由与候选人有过接触的Google员工提供。
结构化判断的第三个原则,延迟整体判断,可以用一个简单的建议来概括:不要排除直觉,但要延迟使用它。在Google,最终的招聘建议是由招聘委员会集体做出的,该委员会审查候选人在每次面试中每个评估维度上获得的所有评分的完整档案,以及支持这些评估的其他相关信息。基于这些信息,委员会然后决定是否发出录用通知。
尽管这家公司以数据驱动的文化而闻名,尽管有所有证据表明数据的机械组合优于临床组合,但最终的招聘决定并不是机械的。它仍然是一个判断,委员会考虑所有证据并进行整体权衡,讨论”这个人在Google会成功吗?“这个问题。决定不仅仅是计算出来的。
在下一章中,我们将解释为什么我们认为这种做出最终决定的方法是明智的。但需要注意的是,虽然Google的最终招聘决定不是机械的,但它们基于四位面试官分配的平均分数。它们也以潜在的证据为依据。换句话说,Google只有在收集和分析了所有证据之后,才允许在决策过程中使用判断和直觉。因此,每个面试官(和招聘委员会成员)形成快速直觉印象并急于判断的倾向得到了控制。
这三个原则——再次强调,分解、每个维度的独立评估和延迟整体判断——不一定为所有试图改进选拔流程的组织提供模板。但这些原则与组织心理学家多年来制定的建议大体一致。事实上,这些原则与我们中的一位(Kahneman)早在1956年在以色列军队实施并在《思考,快与慢》中描述的选拔方法有一些相似之处。该流程与Google实施的流程一样,正式化了评估结构(必须评估的人格和能力维度列表)。它要求面试官依次引出与每个维度相关的客观证据,并在转向下一个维度之前对该维度进行评分。它允许招聘人员使用判断和直觉来做出最终决定——但只有在结构化评估完成之后。
有压倒性的证据表明结构化判断流程(包括结构化面试)在招聘中的优越性。有实用建议可以指导想要采用这些方法的高管。正如Google的例子所说明的,正如其他研究人员所指出的,结构化判断方法成本也更低——因为很少有东西比面对面的时间更昂贵。
尽管如此,大多数高管仍然相信非正式的、基于面试的方法具有不可替代的价值。值得注意的是,许多候选人也是如此,他们相信只有面对面的面试才能让他们向潜在雇主展示自己的真正实力。研究人员称这为”幻觉的持续存在”。有一点很清楚:招聘人员和候选人严重低估了招聘判断中的噪音。
“在传统的非正式面试中,我们经常对理解候选人和知道此人是否符合要求有一种不可抗拒的直觉感受。我们必须学会不信任这种感受。”
“传统面试之所以危险,不仅因为偏见,还因为噪音。”
“我们必须为面试增加结构,更广泛地说,为我们的选拔流程增加结构。让我们首先更清楚、更具体地定义我们在候选人身上寻找什么,并确保我们在每个维度上独立评估候选人。”
前段时间,我们两人(Kahneman和Sibony)与我们的朋友Dan Lovallo一起,描述了一种组织决策方法。我们称这种方法为调解评估协议,它主要以噪音缓解为目标而设计,融合了我们在前面章节中介绍的大部分决策卫生策略。该协议可以广泛应用,特别是当对计划或选项的评估需要考虑和权衡多个维度时。它可以被各种类型的组织使用和调整,包括不同的公司、医院、大学和政府机构。
我们在这里用一个风格化的例子来说明该协议,这个例子是几个真实案例的综合:一个我们称之为Mapco的虚构公司。我们将跟随Mapco在研究进行一项重大、变革性收购机会时所采取的步骤,并重点说明这些步骤与公司在此类情况下通常采取的步骤有何不同。正如您将看到的,差异是显著的,但很微妙——一个不细心的观察者甚至可能不会注意到它们。
收购竞争对手Roadco的想法一直在Mapco内部酝酿,并且已经足够成熟,公司领导层正在考虑召开董事会会议来讨论此事。Mapco的CEO Joan Morrison召集了董事会战略委员会会议,初步讨论可能的收购以及应该做什么来改善董事会对此的审议。在会议早期,Joan用一个提议让委员会感到惊讶:
“我想提议我们为将要决定Roadco收购的董事会会议尝试一个新程序。这个新程序有一个不太吸引人的名字,叫调解评估协议,但想法实际上很简单。它的灵感来自于战略选项评估和求职候选人评估之间的相似性。
“你们肯定熟悉研究表明结构化面试比非结构化面试产生更好结果的研究,更广泛地说,你们了解结构化招聘决策能改善决策的想法。你们知道我们的HR部门已经在其招聘决策中采用了这些原则。大量研究表明,面试中的结构化能带来更高的准确性——我们过去实践的非结构化面试甚至无法与之相比。
“我看到候选人评估和重大决策中选项评估之间有明显的相似性:选项就像候选人。这种相似性让我想到我们应该将评估候选人的有效方法适应到我们的任务中,即评估战略选项。”
委员会成员最初对这个类比感到困惑。他们争论说,招聘过程是一个运转良好的机器,做出许多相似的决策,并且不在严重的时间压力下。另一方面,战略决策需要大量的临时工作,必须快速做出。一些委员会成员向Joan明确表示,他们会对任何延迟决策的提议持敌对态度。他们还担心会增加Mapco研究团队的尽职调查要求。
Joan直接回应了这些异议。她向同事们保证,结构化过程不会延迟决策。“这完全是关于为我们将讨论交易的董事会会议设定议程,”她解释道。“我们应该提前决定对交易不同方面的评估清单,就像面试官从工作描述开始,将其作为候选人必须具备的特质或属性的检查清单一样。我们将确保董事会分别讨论这些评估,一个接一个,就像结构化面试中的面试官按顺序评估候选人在不同维度上的表现一样。然后,只有在那之后,我们才会转向讨论是否接受或拒绝交易。这个程序将是利用董事会集体智慧的更有效方式。
“当然,如果我们同意这种方法,它对信息应该如何呈现以及交易团队应该如何准备会议都有影响。这就是为什么我现在想听取你们的想法。”
一位仍然持怀疑态度的委员会成员问Joan,结构化给招聘决策质量带来了什么好处,以及为什么她相信这些好处会转移到战略决策中。Joan向他解释了逻辑。她解释说,使用调解评估协议通过保持评估维度彼此独立来最大化信息价值。“我们通常进行的董事会讨论看起来很像非结构化面试,”她观察到。“我们一直意识到达成决策的最终目标,并根据该目标处理所有信息。我们开始寻求闭合,并尽快实现它。就像非结构化面试中的招聘者一样,我们有使用所有辩论来确认我们第一印象的风险。
“使用结构化方法将迫使我们推迟达成决策的目标,直到我们做出所有评估。我们将把单独的评估作为中间目标。这样,我们将考虑所有可用信息,并确保我们对交易一个方面的结论不会改变我们对另一个不相关方面的解读。”
委员会成员同意尝试这种方法。但是,他们问道,什么是中介评估?Joan心中是否有一个预定义的清单?“没有,”她回答道。“如果我们将该协议应用于常规决策,可能会有这样的清单,但在这种情况下,我们需要自己定义中介评估。这一点至关重要:决定收购的主要方面应该如何评估,这取决于我们。”战略委员会同意第二天再次会面来完成这项工作。
“我们要做的第一件事,”Joan解释道,“是列出一份关于这笔交易的全面独立评估清单。这些将由Jeff Schneider的研究团队进行评估。我们今天的任务是构建评估清单。它应该是全面的,意思是您能想到的任何相关事实都应该找到其位置,并且应该至少影响其中一项评估。我所说的’独立’是指,相关事实最好只影响其中一项评估,以最大限度地减少冗余。”
小组开始工作,生成了一长串看似相关的事实和数据。然后将它们组织成一份评估清单。参与者很快发现,挑战在于使清单简短、全面,并且由不重叠的评估组成。但这项任务是可控的。实际上,小组最终的七项评估清单表面上类似于董事会在常规报告中期望看到的目录,该报告提出收购提案。除了预期的财务建模外,清单还包括,例如,对目标公司管理团队质量的评估以及对预期协同效应能否实现的可能性评估。
一些战略委员会成员对会议没有产生关于Roadco的新颖见解感到失望。但是,Joan解释说,这不是目标。直接目标是向负责研究收购的交易团队进行简报。她说,每项评估都将成为交易团队报告中不同章节的主题,并将由董事会单独讨论。
在Joan看来,交易团队的使命不是告诉董事会他们对整笔交易的看法——至少现在还不是。而是为每项中介评估提供客观、独立的评价。Joan解释说,最终,交易团队报告中的每一章都应该以一个评级结尾,回答一个简单的问题:“撇开我们在最终决策中应该给这个主题多大权重不谈,关于这项评估的证据在多大程度上支持或反对这笔交易?”
负责评估交易的团队负责人Jeff Schneider当天下午召集团队组织工作。与团队通常的工作方式相比,变化并不多,但他强调了这些变化的重要性。
首先,他解释说,团队的分析师应该尽量使他们的分析尽可能客观。评估应该基于事实——这没什么新鲜的——但他们也应该尽可能使用外部视角。由于团队成员不确定他所说的”外部视角”是什么意思,Jeff给了他们两个例子,使用Joan确定的两项中介评估。为了评估交易获得监管批准的概率,他说,他们需要首先找出基准率,即可比较交易获得批准的百分比。这项任务反过来需要他们定义一个相关的参考类别,即一组被认为足够可比的交易。
Jeff然后解释了如何评估目标公司产品开发部门的技术技能——Joan列出的另一项重要评估。“仅仅以基于事实的方式描述公司最近的成就并称其为’好’或’很棒’是不够的。我期望的是类似这样的表述:‘根据其最近产品发布的跟踪记录衡量,该产品开发部门在同行群体中处于第二个五分位数。’”总体而言,他解释说,目标是使评估尽可能具有比较性,因为相对判断比绝对判断更好。
Jeff还有另一个要求。按照Joan的指示,他说,评估应该尽可能彼此独立,以降低一项评估影响其他评估的风险。因此,他将不同的分析师分配给不同的评估,并指示他们独立工作。
一些分析师表示惊讶。“团队合作不是更好吗?”他们问他。“如果你不希望我们沟通,组建团队有什么意义?”
Jeff意识到他需要解释独立性的必要性。“你们可能知道招聘中的光环效应,”他说。“这就是当候选人的总体印象影响你对候选人在特定维度上技能评估时发生的情况。这就是我们试图避免的。”由于一些分析师似乎认为这种效应不是一个严重问题,Jeff使用了另一个类比:“如果你有四名犯罪目击者,你会让他们在作证前互相交谈吗?显然不会!你不希望一名目击者影响其他人。”分析师们并不觉得这个比较特别讨人喜欢,但Jeff认为这传达了信息。
事实上,Jeff没有足够的分析师来实现完全独立评估的目标。团队中经验丰富的成员Jane被分配了两项评估。Jeff选择了两个尽可能不同的评估项目,并指示Jane先完成第一项评估并准备相关报告,然后再转向另一项。另一个担忧是对管理团队质量的评估;Jeff担心他的分析师们难以将对团队内在质量的评估与对公司近期业绩的判断分离开来(团队当然会详细研究这些业绩)。为了解决这个问题,Jeff请了一位外部HR专家来评估管理团队的质量。他认为这样可以获得更独立的意见。
Jeff还有一个团队觉得有些不寻常的指示。每个章节都应专注于一项评估,并如Joan所要求的,以评级形式得出结论。然而,Jeff补充说,分析师应该在每个章节中包含关于该评估的所有相关事实信息。“不要隐瞒任何东西,”他指示他们。“章节的总体基调当然会与建议的评级保持一致,但如果有信息看起来与主要评级不一致甚至矛盾,也不要掩盖任何事情。你们的工作不是推销你们的建议,而是呈现真相。如果情况复杂,那就是复杂的——事实往往如此。”
本着同样的精神,Jeff鼓励分析师们对每项评估的信心水平保持透明。“董事会知道你们没有完美的信息;如果你们告诉他们什么时候真的摸不着头脑,这会对他们有帮助。如果你们遇到真正让你们担忧的事情——一个潜在的交易终结者——你们应该立即报告。”
交易团队按指示进行。幸运的是,他们没有发现重大的交易终结者。他们为Joan和董事会组成了一份报告,涵盖了所有确定的评估。
在阅读团队报告为决策会议做准备时,Joan立即注意到了一个重要的事情:虽然大多数评估都支持进行这项交易,但它们并没有描绘出一个简单、乐观、一切顺利的画面。一些评级很强;其他的则不然。她知道,这些差异是保持评估相互独立的可预测结果。当过度一致性得到控制时,现实并不像大多数董事会报告看起来那么一致。“很好,”Joan想。“这些评估之间的差异会引发问题并触发讨论。这正是我们需要在董事会中进行良好辩论的东西。多样化的结果肯定不会让决策变得更容易——但会让决策变得更好。”
Joan召集董事会会议来审查报告并做出决定。她解释了交易团队遵循的方法,并邀请董事会成员应用同样的原则。“Jeff和他的团队努力保持评估相互独立,”她说,“我们现在的任务也是独立地审查它们。这意味着在我们开始讨论最终决定之前,我们将分别考虑每项评估。我们将把每项评估作为一个独特的议程项目来处理。”
董事会成员知道遵循这种结构化方法会很困难。Joan要求他们在讨论所有评估之前不要形成对交易的整体看法,但他们中的许多人都是行业内部人士。他们对Roadco有看法。不讨论这个感觉有点人为。尽管如此,因为他们理解Joan试图实现的目标,他们同意遵守她的规则,暂时避免讨论他们的整体观点。
令他们惊讶的是,董事会成员发现这种做法非常有价值。在会议期间,他们中的一些人甚至改变了对交易的看法(尽管没人会知道,因为他们一直将观点保留给自己)。Joan主持会议的方式发挥了很大作用:她使用了估算-讨论-估算方法,结合了审议和独立意见平均的优势。
她的做法如下。在每项评估上,Jeff代表交易团队简要总结关键事实(董事会成员事先已详细阅读)。然后Joan要求董事会成员使用手机上的投票应用对评估给出自己的评级——要么与交易团队建议的评级相同,要么不同。评级分布立即投影到屏幕上,不识别评级者身份。“这不是投票,”Joan解释说。“我们只是在每个话题上测试房间的温度。”通过在开始讨论之前立即了解每个董事会成员的独立意见,Joan减少了社会影响和信息级联的危险。
在一些评估上,立即达成了共识,但在其他评估上,这个过程揭示了对立的观点。自然地,Joan管理讨论,在后者上花费更多时间。她确保分歧双方的董事会成员都发言,鼓励他们用事实和论据表达观点,同时也要有细致入微和谦逊的态度。有一次,当一位对交易感觉强烈的董事会成员过于激动时,她提醒他”我们都是理性的人,我们不同意,所以这必须是理性的人可以不同意的主题。”
当一项评估的讨论接近尾声时,Joan要求董事会成员再次对评级进行投票。大多数时候,比起初始轮次,会有更多的一致性。同样的顺序——第一次估计、讨论和第二次估计——在每个评估中重复进行。
最后,是时候对这笔交易得出结论了。为了促进讨论,Jeff在白板上展示了评估清单,每项评估都标有董事会为其分配的评级平均值。董事会成员正在查看交易的概况。他们应该如何决定?
一位董事会成员提出了一个简单的建议:使用评级的直接平均值。(也许他知道机械聚合相对于整体临床判断的优越性,如第9章所讨论的。)然而,另一位成员立即反对,认为在她看来,某些评估应该比其他评估获得更高的权重。第三个人不同意,建议对评估采用不同的等级制度。
Joan打断了讨论。“这不仅仅是计算评估评级的简单组合,”她说。“我们已经延迟了直觉,但现在是使用它的时候了。我们现在需要的是你们的判断。”
Joan没有解释她的逻辑,但她是通过痛苦的经历学到这个教训的。她知道,特别是在重要决策中,人们会拒绝那些束缚他们手脚、不让他们使用判断力的方案。她曾看到决策者在知道将使用公式时如何操纵系统。他们改变评级以达到期望的结论——这违背了整个练习的目的。此外,虽然这里不是这种情况,她仍然警惕可能出现在评估定义中未预料到的决定性考虑因素(第10章讨论的断腿因素(broken-leg factors))。如果出现这样意想不到的交易破坏者(或者相反,交易促成者),基于评估平均值的纯机械决策过程可能导致严重错误。
Joan还知道,让董事会成员在这个阶段使用他们的直觉与让他们在过程早期使用直觉是非常不同的。现在评估已经可用并为所有人所知,最终决策安全地锚定在这些基于事实、经过充分讨论的评级上。一个董事会成员需要提出强有力的理由来反对这笔交易,同时面对大部分支持它的中介评估清单。遵循这个逻辑,董事会讨论了交易并进行了投票,就像所有董事会所做的那样。
我们在一次性、单一决策的背景下描述了中介评估协议。但这个程序也适用于重复决策。想象一下Mapco不是进行单一收购,而是一个对初创公司进行重复投资的风险投资基金。该协议同样适用,故事也基本相同,只是有两个变化,这些变化甚至使其更简单。
首先,初始步骤——定义中介评估清单——只需要做一次。基金有投资标准,适用于所有潜在投资:这些就是评估。不需要每次都重新发明它们。
其次,如果基金做出许多相同类型的决策,它可以利用经验来校准其判断。例如,考虑每个基金都想要进行的评估:评价管理团队的质量。我们建议这种评估应该相对于参考类别进行。也许你同情Mapco的分析师:除了评估特定目标外,收集可比较公司的数据是具有挑战性的。
在重复决策的背景下,比较判断变得容易得多。如果你已经评估了数十甚至数百家公司的管理团队,你可以使用这种共享经验作为参考类别。做到这一点的实用方法是创建由锚点案例定义的案例量表。例如,你可能会说目标管理团队”和我们收购ABC公司时的管理团队一样好”,但不如”DEF公司的管理团队那么好”。锚点案例当然必须为所有参与者所知(并定期更新)。定义它们需要前期时间投入。但这种方法的价值在于相对判断(将这个团队与ABC和DEF的团队进行比较)比在由数字或形容词定义的量表上进行绝对评级要可靠得多。
为了便于参考,我们在表4中总结了中介评估协议所带来的主要变化。
表4: 中介评估协议的主要步骤
| 1. | 在过程开始时,将决策结构化为中介评估。(对于重复判断,这只需要做一次。) |
|---|---|
| 2. | 确保中介评估尽可能使用外部视角。(对于重复判断:使用相对判断,如果可能的话使用案例量表。) |
3. 在分析阶段,尽可能保持各项评估相互独立。 4. 在决策会议中,分别审查每项评估。 5. 对于每项评估,确保参与者独立做出判断;然后使用估计-讨论-估计方法。 6. 为了做出最终决策,延迟直觉,但不要禁止它。
你可能已经在这里认识到了我们在前面章节中提出的几种决策卫生技术的实施:信息排序、将决策结构化为独立评估、使用基于外部观点的共同参考框架,以及汇总多个个体的独立判断。通过实施这些技术,中介评估协议旨在改变决策过程,引入尽可能多的决策卫生。
毫无疑问,这种对过程而非决策内容的强调可能会引起一些质疑。正如我们所描述的,研究团队成员和董事会成员的反应并不罕见。内容是具体的;过程是通用的。使用直觉和判断是有趣的;遵循过程则不然。传统智慧认为,好的决策——尤其是最好的决策——来自伟大领导者的洞察力和创造力。(当我们是所讨论的领导者时,我们特别喜欢相信这一点。)对许多人来说,过程这个词唤起的是官僚主义、繁文缛节和延误。
我们与实施了协议全部或部分组成部分的公司和政府机构的经验表明,这些担忧是错误的。诚然,为已经官僚化的组织的决策过程增加复杂性不会让事情变得更好。但决策卫生不必缓慢,当然也不需要官僚化。相反,它促进挑战和辩论,而不是官僚机构特有的令人窒息的共识。
决策卫生的理由是明确的。商业和公共部门的领导者通常完全没有意识到他们最大和最重要决策中的噪音。因此,他们没有采取具体措施来减少噪音。在这方面,他们就像那些继续依赖非结构化面试作为唯一人员选拔工具的招聘人员:对自己判断中的噪音视而不见,对其有效性过于自信,并且不知道可以改进它的程序。
洗手并不能预防所有疾病。同样,决策卫生也不会防止所有错误。它不会让每个决策都变得出色。但就像洗手一样,它解决了一个无形但普遍存在且具有破坏性的问题。哪里有判断,哪里就有噪音,我们建议将决策卫生作为减少噪音的工具。
“我们有一个结构化的流程来做招聘决策。为什么我们没有一个用于战略决策的流程?毕竟,选项就像候选人。”
“这是一个困难的决策。它应该基于哪些中介评估?”
“我们对这个计划的直觉、整体判断非常重要——但让我们先不讨论它。一旦我们的直觉得到我们要求的单独评估的信息支持,它将为我们提供更好的服务。”
1973年,马文·弗兰克尔法官呼吁持续努力减少刑事量刑中的噪音是正确的。他的非正式、直觉噪音审计,以及随后更正式和系统化的努力,揭示了对相似人员处理中不合理的差异。这些差异是令人愤怒的。它们也是令人震惊的。
本书的大部分内容可以理解为对弗兰克尔论点的概括,并提供对其心理学基础的理解。对一些人来说,刑事司法系统中的噪音似乎是独特的不可容忍,甚至是可耻的。但在无数其他情况下,当私营和公共部门中应该可互换的人在工作中做出不同判断时,这并不完全可以容忍。在保险、员工招聘和评估、医学、法医学、教育、商业和政府中,人际噪音是错误的主要来源。我们也看到,我们每个人都受到场合噪音的影响,即所谓无关的因素可能导致我们在早上和下午,或在周一和周四做出不同的判断。
但正如司法界对量刑指导原则的强烈负面反应所表明的,减噪努力经常遇到严重甚至激烈的反对。许多人认为这些指导原则是僵化的、非人性化的,并以自己的方式不公平。几乎每个人都有过向公司、雇主或政府提出合理请求的经历,却得到”我们真的很想帮助你,但我们的手被束缚了。我们这里有明确的规则”的回应。所讨论的规则可能看起来愚蠢甚至残酷,但它们可能是出于一个好的理由而被采用的:减少噪音(也许还有偏见)。
即便如此,一些减少噪音的努力引起了严重关切,特别是如果这些努力使人们难以或无法获得公平听证。算法和机器学习的使用让这种反对意见呈现出新的视角。没有人举着”算法优先!“的旗帜游行。
一个有影响力的批评来自耶鲁法学院的Kate Stith和联邦法官José Cabranes。他们对量刑指导原则提出了激烈的抨击,从某种意义上说,也对我们这里的核心论点之一提出了质疑。他们的论点仅限于刑事量刑领域,但可以作为对教育、商业、体育和其他各个领域许多噪音减少策略的反对意见。Stith和Cabranes认为,量刑指导原则受到”对行使自由裁量权的恐惧——对判断的恐惧——以及对专家和中央规划的技术官僚信仰”的驱动。他们争辩说,“对判断的恐惧”阻止了对”每个具体案件特殊情况”的考虑。在他们看来,“没有机械化的解决方案能够满足正义的要求。”
这些反对意见值得审视。在涉及各种判断的环境中,人们常常认为”正义的要求”禁止任何形式的机械化解决方案——因此允许甚至要求那些最终保证噪音的过程和方法。许多人呼吁关注”每个具体案件的特殊情况”。在医院、学校以及大大小小的公司中,这种呼吁具有深刻的直觉吸引力。我们已经看到,决策卫生包括减少噪音的多种策略,其中大多数并不涉及机械化解决方案;当人们将问题分解为其组成部分时,他们的判断不必是机械化的。即便如此,许多人不会欢迎使用决策卫生策略。
我们将噪音定义为不需要的变异性,如果某种东西是不需要的,它大概应该被消除。但分析比这更复杂、更有趣。在其他条件相同的情况下,噪音可能是不需要的。但其他条件可能并不相同,消除噪音的成本可能超过收益。即使成本效益分析表明噪音是昂贵的,消除它可能对公共和私人机构产生一系列可怕甚至不可接受的后果。
对减少或消除噪音的努力有七个主要反对意见。
首先,减少噪音可能是昂贵的;可能不值得费力。减少噪音所必需的步骤可能是高度繁重的。在某些情况下,它们甚至可能不可行。
其次,一些为减少噪音而引入的策略可能会产生自己的错误。有时,它们可能产生系统性偏见。如果政府办公室的所有预测者都采用同样不现实的乐观假设,他们的预测就不会有噪音,但他们会是错误的。如果医院的所有医生都为每种疾病开阿司匹林,他们就不会有噪音,但他们会犯很多错误。
我们在第26章探讨这些反对意见。在第27章,我们转向另外五个反对意见,这些反对意见也很常见,在未来几年的许多地方都可能听到,特别是随着对规则、算法和机器学习的日益依赖。
第三,如果我们希望人们感到受到尊重和有尊严的对待,我们可能必须容忍一些噪音。噪音可能是一个不完美过程的副产品,人们最终会接受这个过程,因为这个过程给每个人(员工、客户、申请人、学生、被指控犯罪的人)一个个性化的听证会,一个影响自由裁量权行使的机会,以及一种他们有机会被看到和听到的感觉。
第四,噪音可能对适应新价值观因此允许道德和政治演进是必要的。如果我们消除噪音,当道德和政治承诺朝着新的和意想不到的方向发展时,我们可能会降低我们的应对能力。一个无噪音的系统可能会冻结现有价值观。
第五,一些旨在减少噪音的策略可能会鼓励机会主义行为,允许人们钻系统空子或逃避禁令。一点噪音,或者也许很多噪音,可能是防止不当行为所必需的。
第六,一个有噪音的过程可能是一个好的威慑。如果人们知道他们可能面临小额罚款或大额罚款,他们可能会避免不当行为,至少如果他们是风险厌恶的话。一个系统可能容忍噪音作为产生额外威慑的一种方式。
最后,人们不想被当作仅仅是物品,或某种机器中的齿轮来对待。一些噪音减少策略可能会压制人们的创造力并证明是令人沮丧的。
尽管我们将尽可能同情地处理这些反对意见,但我们绝不赞同它们,至少如果它们被当作拒绝减少噪音总体目标的理由的话。预示一个将贯穿始终的观点:反对意见是否令人信服取决于它意图适用的特定噪音减少策略。例如,你可能反对僵化的指导原则,同时也同意独立判断的聚合是一个好想法。你可能反对使用中介评估协议,同时强烈支持使用基于外部观点的共享量表。考虑到这些要点,我们的总结论是,即使充分考虑了这些反对意见,减少噪音仍然是一个有价值甚至紧迫的目标。在第28章,我们通过探讨人们每天面临的困境来为这个结论辩护,即使他们并不总是意识到这一点。
当要求人们消除噪声时,他们可能会反对,认为必要的步骤太昂贵了。在极端情况下,噪声降低根本不可能。我们在商业、教育、政府和其他地方都听到过这种反对意见。这里确实存在合理的担忧,但这种担忧很容易被夸大,而且往往只是一个借口。
为了让这种反对意见看起来最有吸引力,考虑一个高中教师的情况,他在学年的每一周都要给十年级学生的二十五篇作文打分。如果教师在每篇作文上花费不超过十五分钟,评分可能会有噪声,因此不准确且不公平。教师可能会考虑一点决策卫生,也许通过要求同事也给作文打分来减少噪声,这样两个人都会阅读每一篇论文。也许教师可以通过花更多时间阅读每篇作文、构建相对复杂的评估过程,或通过多次以不同顺序阅读作文来实现同样的目标。使用详细评分指南作为检查清单可能会有帮助。或者教育者可以确保在一天中的同一时间阅读每篇作文,以减少时机噪声。
但如果教师自己的判断相当准确且噪声不是很大,那么不做这些事情中的任何一件可能是明智的。这可能不值得麻烦。教师可能认为使用检查清单或要求同事阅读同样的论文是一种过度行为。要知道是否如此,可能需要有纪律的分析:教师能获得多少更多的准确性,更高的准确性有多重要,以及减少噪声的努力需要多少时间和金钱?我们很容易想象在噪声降低上投资多少的限度。我们同样容易看到,当作文是九年级学生写的或作为高年级论文时,这个限度应该不同,因为大学录取可能岌岌可危,风险更高。
基本分析可能会扩展到各种私人和公共组织面临的更复杂情况,导致它们拒绝一些噪声降低策略。对于某些疾病,医院和医生可能难以识别简单的指导原则来消除变异性。在医学诊断分歧的情况下,减少噪声的努力特别有吸引力;它们可能挽救生命。但这些努力的可行性和成本需要考虑在内。测试可能消除诊断中的噪声,但如果测试是侵入性的、危险的且昂贵的,如果诊断的变异性适中且只有轻微后果,那么要求所有医生让所有患者接受测试可能不值得。
员工评估很少涉及生死问题。但噪声可能导致员工的不公平和公司的高成本。我们已经看到减少噪声的努力应该是可行的。它们值得吗?涉及明显错误评估的案例可能会被注意到,看起来令人尴尬、羞耻或更糟。尽管如此,机构可能认为详细的纠正步骤不值得努力。有时这种结论是短视的、自私的和错误的,甚至是灾难性的。某种形式的决策卫生很可能是值得的。但认为减少噪声成本太高的信念并不总是错误的。
简而言之,我们必须比较噪声降低的好处与成本。这是公平的,这是噪声审计如此重要的原因之一。在许多情况下,审计显示噪声正在产生令人愤怒的不公平水平、非常高的成本,或两者兼而有之。如果是这样,噪声降低的成本很难成为不努力的好理由。
一个不同的反对意见是,一些噪声降低努力本身可能产生不可接受的高错误水平。如果用于减少噪声的工具太钝,这种反对意见可能是令人信服的。事实上,一些减少噪声的努力甚至可能增加偏差。如果Facebook或Twitter等社交媒体平台引入坚定的指导原则,要求删除所有包含某些粗俗词汇的帖子,其决策将不那么嘈杂,但它将删除许多应该被允许保留的帖子。这些假阳性是定向错误——一种偏差。
生活中充满了旨在减少人们自由裁量权和产生噪声的做法的制度改革。许多这样的改革动机良好,但有些治疗方法比疾病更糟糕。在《反应的修辞》中,经济学家Albert Hirschman指出了对改革努力的三种常见反对意见。首先,这些努力可能是反常的,即它们会加剧它们本来要解决的问题。其次,它们可能是徒劳的;它们可能根本不会改变任何事情。第三,它们会危及其他重要价值观(例如当保护工会和组织工会权利的努力据说会损害经济增长时)。反常性、徒劳性和危险性可能被作为反对噪声降低的理由,在这三者中,反常性和危险性的声明往往是最有力的。有时这些反对意见只是修辞——试图破坏实际上会带来很大好处的改革的努力。但一些噪声降低策略可能危及重要价值观,对其他策略来说,反常性的风险可能不容易被忽视。
反对量刑指导原则的法官们正是在指出这种风险。他们非常了解弗兰克尔法官的工作,也不否认自由裁量权会产生噪音。但他们认为,减少自由裁量权会产生更多而非更少的错误。引用瓦茨拉夫·哈维尔的话,他们坚持认为,“我们必须摒弃这种傲慢的信念,即认为世界仅仅是一个有待解决的谜题,一台等待发现使用说明的机器,一堆信息等着被输入计算机,希望迟早会吐出一个通用解决方案。”拒绝通用解决方案理念的一个原因是坚信人类情况高度多样化,优秀的法官会处理这些变化——这可能意味着容忍噪音,或至少拒绝某些降噪策略。
在计算机象棋的早期,一家大型航空公司为国际乘客提供了一个国际象棋程序,邀请他们与计算机对弈。该程序有几个级别。在最低级别,程序使用一个简单规则:只要可能就将对手的国王置于将军状态。该程序没有噪音。它每次都以相同方式下棋;它总是遵循其简单规则。但这个规则确保了大量错误。该程序在国际象棋方面很糟糕。即使是没有经验的象棋玩家也能击败它(这无疑是重点;获胜的航空旅客是快乐的航空旅客)。
或者考虑美国一些州采用的刑事量刑政策,称为”三振出局”。这个想法是,如果你犯了三次重罪,你的刑期就是终身监禁——就这样。该政策减少了来自量刑法官随机分配的变异性。其一些支持者特别关注水平噪音和某些法官对惯犯过于宽松的可能性。消除噪音是三振立法的核心要点。
但即使三振政策在其降噪目标上取得成功,我们也可以合理地反对这种成功的代价过高。一些犯了三次重罪的人不应该被终身监禁。也许他们的犯罪不是暴力性的。或者他们糟糕的生活环境可能帮助导致他们犯罪。也许他们显示出康复的能力。许多人认为终身刑期,不关注特定情况,不仅过于严厉,而且过于僵化,令人无法容忍。因此,这种降噪策略的代价过高。
考虑Woodson v. North Carolina案例,美国最高法院裁定强制死刑违宪,不是因为它过于残忍,而是因为它是一个规则。强制死刑的全部要点是确保防止噪音——在特定情况下,杀人犯必须被处死。援引个性化处理的需要,法院说”不再普遍认为同一法律类别中的每个犯罪都需要相同的惩罚,而不考虑特定罪犯的过去生活和习惯。“根据最高法院,强制死刑的一个严重宪法缺陷是它”将所有被指定犯罪定罪的人不是作为独特的个人,而是作为一个无面孔、无差别群体的成员,盲目地承受死刑的惩罚。”
当然,死刑涉及特别高的风险,但法院的分析可以应用于许多其他情况,其中大多数根本不涉及法律。评估学生的教师、评估患者的医生、评估员工的雇主、设定保险费的承保人、评估运动员的教练——如果他们应用过于僵化的降噪规则,所有这些人都可能犯错误。如果雇主使用简单规则来评估、提升或暂停员工,这些规则可能消除噪音,同时忽略员工绩效的重要方面。一个无噪音的评分系统如果未能考虑重要变量,可能比依赖(有噪音的)个人判断更糟糕。
第27章考虑了将人们视为”独特个体”而非”无面孔、无差别群体成员”的一般想法。现在,我们专注于一个更平凡的要点。一些降噪策略确保了太多错误。它们可能很像那个愚蠢的象棋程序。
尽管如此,这种反对意见似乎比实际更有说服力。如果一种降噪策略容易出错,我们不应该满足于高水平的噪音。我们应该尝试设计更好的降噪策略——例如,聚合判断而不是采用愚蠢的规则,或开发明智的指导原则或规则而不是愚蠢的。为了降噪,大学可以说,例如,考试成绩最高的人将被录取,就这样。如果这个规则似乎太粗糙,学校可以创建一个公式,考虑考试成绩、成绩、年龄、体育成就、家庭背景等等。复杂规则可能更准确——更适应相关因素的全范围。同样,医生有复杂规则来诊断某些疾病。专业人员使用的指导原则和规则并不总是简单或粗糙的,其中许多有助于减少噪音而不产生无法容忍的高成本(或偏见)。如果指导原则或规则不起作用,也许我们可以引入其他形式的决策卫生,适合特定情况;回忆聚合判断或使用结构化过程,如中介评估协议。
噪声削减的潜在高成本经常在算法背景下出现,人们对”算法偏见”的反对声音日渐高涨。正如我们所见,算法消除了噪声,并且通常因此而显得很有吸引力。实际上,这本书的大部分内容可能被理解为支持更多依赖算法的论据,仅仅因为它们是无噪声的。但正如我们也看到的,如果更多依赖算法增加了基于种族和性别的歧视,或者针对弱势群体成员的歧视,那么噪声削减可能会带来无法容忍的代价。
人们普遍担心算法实际上会产生歧视性后果,这无疑是一个严重的风险。在《数学毁灭武器》一书中,数学家Cathy O’Neil敦促依赖大数据和算法决策可能嵌入偏见,加剧不平等,并威胁民主本身。根据另一个持怀疑态度的观点,“潜在有偏见的数学模型正在重塑我们的生活——而负责开发这些模型的公司和政府都无意解决这个问题。”根据ProPublica,一个独立的调查新闻组织,COMPAS——一个在累犯风险评估中广泛使用的算法——对少数族裔成员存在强烈偏见。
没有人应该怀疑创建一个无噪声但也带有种族主义、性别歧视或其他偏见的算法是可能的——甚至是容易的。一个明确使用被告肤色来决定该人是否应该获得保释的算法会产生歧视(在许多国家使用这样的算法是非法的)。一个考虑求职者是否可能怀孕的算法会歧视女性。在这些和其他情况下,算法可以消除判断中不必要的变异性,但也嵌入不可接受的偏见。
原则上,我们应该能够设计一个不考虑种族或性别的算法。实际上,算法可以被设计为完全忽略种族或性别。更具挑战性的问题,现在正受到大量关注,是算法可能产生歧视,并在这个意义上被证明是有偏见的,即使它没有公开使用种族和性别作为预测因子。
正如我们所建议的,算法可能因为两个主要原因而产生偏见。首先,无论是否有意设计,它可能使用与种族或性别高度相关的预测因子。例如,身高和体重与性别相关,人们成长的地方或居住的地方很可能与种族相关。
其次,歧视也可能来自源数据。如果算法在有偏见的数据集上进行训练,它也会有偏见。考虑”预测性执法“算法,它试图预测犯罪,通常是为了改善警察资源的配置。如果关于犯罪的现有数据反映了对某些社区的过度执法或对某些类型犯罪的相对过度报告,那么由此产生的算法将延续或加剧歧视。每当训练数据中存在偏见时,就很可能有意或无意地设计出编码歧视的算法。因此,即使算法不明确考虑种族或性别,它也可能被证明和人类一样有偏见。实际上,在这方面,算法可能更糟:由于它们消除了噪声,它们可能比人类法官更可靠地有偏见。
对许多人来说,一个关键的实际考虑是算法是否对可识别的群体产生不同影响。如何准确测试不同影响,以及如何决定什么构成算法的歧视、偏见或公平,是令人惊讶地复杂的话题,远超出本书的范围。
然而,能够提出这个问题本身就是算法相对于人类判断的一个明显优势。首先,我们建议仔细评估算法,以确保它们不考虑不可接受的输入,并测试它们是否以令人反感的方式产生歧视。对个体人类进行同样的审查要困难得多,他们的判断通常是不透明的;人们有时会无意识地歧视,而且以外部观察者(包括法律系统)难以看到的方式进行歧视。因此在某些方面,算法可以比人类更透明。
毫无疑问,我们需要关注无噪声但有偏见的算法的成本,就像我们需要考虑无噪声但有偏见的规则的成本一样。关键问题是我们是否能够设计出在重要标准组合上比现实世界中的人类法官表现更好的算法:准确性和噪声削减,以及非歧视和公平。大量证据表明,算法可以在我们选择的任何标准组合上超越人类。(注意我们说的是可以而不是将会。)例如,如第10章所述,算法在保释决定方面可以比人类法官更准确,同时比人类产生更少的种族歧视。类似地,简历筛选算法可以选出比人类简历筛选者更好且更多样化的人才库。
这些例子以及许多其他例子都指向一个不可避免的结论:尽管在不确定世界中的预测算法不太可能是完美的,但它可能远比嘈杂且经常有偏见的人类判断更完美。这种优越性在有效性(好的算法几乎总是预测得更好)和辨别性(好的算法可能比人类判断者偏见更少)方面都成立。如果算法比人类专家犯更少的错误,而我们却对人类有直觉偏好,那么我们的直觉偏好应该得到仔细检验。
我们更广泛的结论很简单,并且远远超出了算法这个话题。减少噪音的策略可能成本高昂,这确实如此。但大多数时候,它们的成本只是一个借口——而不是容忍噪音的不公平性和成本的充分理由。当然,减少噪音的努力可能产生其自身的错误,也许以偏见的形式出现。在这种情况下,我们有一个严重的问题,但解决方案不是放弃减少噪音的努力;而是想出更好的方法。
“如果我们试图消除教育中的噪音,我们将不得不花费很多钱。当老师给学生评分时,他们是有噪音的。我们不能让五位老师批改同一份试卷。”
“如果社交网络不依赖人类判断,而是决定无论在什么情况下都不允许任何人使用某些词汇,它将消除噪音,但也会产生很多错误。治疗可能比疾病更糟糕。”
“确实,有一些规则和算法是有偏见的。但人也有偏见。我们应该问的是,我们能否设计出既无噪音又偏见更少的算法?”
“消除噪音可能成本高昂——但这种成本通常值得承担。噪音可能极其不公平。如果减少噪音的一次努力过于粗糙——如果我们最终得到了不可接受的僵化指导原则或规则,或者无意中产生了偏见——我们不应该就此放弃。我们必须再次尝试。”
假设你被拒绝了抵押贷款,不是因为任何人研究了你的情况,而是因为银行有一个严格的规定,即信用评级像你这样的人根本无法获得抵押贷款。或者假设你有出色的资格,面试官对你印象深刻,但你的求职申请被拒绝了,因为你十五年前因毒品犯罪被定罪——而该公司有严格禁止雇用任何有犯罪记录的人的规定。或者也许你被指控犯罪并被拒绝保释,不是在真正的人类面前经过个性化听证,而是因为算法决定具有你特征的人的逃跑风险超过了允许保释的阈值。
在这种情况下,许多人会反对。他们希望被当作个体来对待。他们希望真正的人类来审视他们的特殊情况。他们可能意识到也可能没有意识到个性化待遇会产生噪音。但如果这是这种待遇的代价,他们坚持认为这是值得付出的代价。当人们被对待时,他们可能会抱怨,用最高法院的话说,“不是作为独特的个体,而是作为无面孔、无差别的群体成员,遭受某种刑罚的盲目施加”(见第26章)。
许多人坚持要求个性化听证,摆脱他们所认为的规则暴政,给人们一种被当作个体对待的感觉,因此具有一种尊重。作为日常生活一部分的正当程序概念,似乎需要面对面互动的机会,其中被授权行使自由裁量权的人类考虑广泛的因素。
在许多文化中,这种逐案判断的论证有着深厚的道德基础。它可以在政治、法律、神学甚至文学中找到。莎士比亚的《威尼斯商人》很容易被解读为对无噪音规则的反对和对法律及人类判断中仁慈角色的恳求。因此波西亚的结束论证:
仁慈的品质不是勉强的;
它如天上的甘露
降落在下面的地方。它是双重祝福;
它祝福给予者和接受者:
(…)
它在国王心中登基,
它是上帝本身的属性;
当仁慈调和正义时
尘世的权力最像上帝的权力。
因为它不受规则约束,仁慈是有噪音的。尽管如此,波西亚的恳求可以在许多情况下和无数组织中提出。它经常引起共鸣。员工可能在寻求晋升。准房主可能在申请贷款。学生可能在申请大学。那些对此类案例做决定的人可能拒绝一些减少噪音的策略,尤其是严格的规则。如果他们不这样做,可能是因为他们认为,与波西亚一样,仁慈的品质不是勉强的。他们可能知道自己的方法是有噪音的,但如果它确保人们感到他们受到了尊重的对待,有人倾听了他们,他们可能无论如何都会接受它。
一些减少噪音的策略不会遇到这种反对。如果三个人而不是仅仅一个人在做决定,人们仍然得到个性化听证。指导原则可能为决策者留下重要的自由裁量权。但一些减少噪音的努力,包括僵化的规则,确实消除了这种自由裁量权,可能导致人们反对由此产生的过程冒犯了他们的尊严感。
他们说得对吗?当然,人们往往关心自己是否能得到个性化的听证。获得被倾听的机会具有不可质疑的人文价值。但如果个性化听证导致更多死亡、更多不公平和更高的成本,就不应该被赞美。我们强调过,在招聘、录取和医疗等情况下,一些降噪策略可能会很粗糙;它们可能禁止某些个性化治疗形式,虽然有噪音,但总体上会产生更少的错误。但如果降噪策略很粗糙,那么正如我们所建议的,最好的回应是尝试想出更好的策略——一个适应广泛相关变量的策略。如果这个更好的策略消除了噪音并产生更少的错误,即使它减少或消除了被倾听的机会,它也会比个性化治疗有明显的优势。
我们并不是说对个性化治疗的兴趣无关紧要。但如果这种治疗导致各种可怕的后果,包括明显的不公平,就要付出高昂的代价。
想象一个公共机构成功消除了噪音。比如说,一所大学对”不当行为”进行了定义,使每个教职员工和每个学生都知道它包括什么和不包括什么。或者假设一家大公司准确说明了”腐败”的含义,这样公司里的任何人都知道什么是被允许的,什么是被禁止的。或者想象一个私人机构显著减少了噪音,可能通过声明不会雇用任何没有主修某些科目的人。如果一个组织的价值观发生变化会怎样?一些降噪策略似乎无法为它们留出空间,它们的不灵活性可能是个问题,这与对个性化治疗和尊严的兴趣密切相关。
美国宪法法律中一个著名的令人困惑的决定有助于说明这一点。这个案例于1974年决定,涉及一个学校系统的严格规定,要求怀孕教师在预产期前五个月开始无薪休假。教师Jo Carol LaFleur认为她完全适合教学,这个规定是歧视性的,五个月太过分了。
美国最高法院表示同意。但它没有谈到性别歧视,也没有说五个月一定是过分的。相反,它反对LaFleur没有得到机会证明她个人在身体上没有停止工作的必要。用法院自己的话说:
“教师的医生——或学校董事会的医生——没有对任何特定教师继续工作的能力进行个性化判断。这些规定包含一个不可反驳的身体无能推定,即使关于个别女性身体状况的医学证据可能完全相反,这种推定也适用。”
强制性的五个月休假确实似乎是荒谬的。但法院没有强调这一点。相反,它抱怨”不可反驳的推定”和缺乏”个性化判断”。这样说,法院显然在与Portia一起争论,慈悲的品质不是勉强的,应该要求特定的人看看LaFleur的特殊情况。
但如果没有一些决策卫生,这就是噪音的配方。谁来决定LaFleur的案子?对她的决定会和许多其他类似情况的女性一样吗?无论如何,许多规则都相当于不可反驳的推定。规定的速度限制是不可接受的吗?投票或饮酒的最低年龄?对酒后驾驶的完全禁止?考虑到这些例子,批评者反对说,反对”不可反驳推定”的论点会证明太多——尤其是因为它们的目的和效果是减少噪音。
当时有影响力的评论家通过强调道德价值观随时间变化以及因此需要避免僵硬规则来为法院的决定辩护。他们认为,就女性在社会中的角色而言,社会规范处于巨大的变化状态。他们争辩说,个性化判断在这种情况下特别合适,因为它们将允许纳入那些变化的规范。基于规则的系统可能消除噪音,这是好的,但它也可能冻结现有的规范和价值观,这不太好。
总之,一些人可能坚持认为,噪音系统的一个优势是它将允许人们适应新的和新兴的价值观。随着价值观的变化,如果允许法官行使自由裁量权,他们可能开始对那些被判犯有毒品罪的人给予较轻的刑罚,或对那些被判犯有强奸罪的人给予较重的刑罚。我们强调过,如果一些法官宽大而另一些则不然,那么就会有一定程度的不公平;类似情况的人将受到不同的对待。但如果不公平为新颖或新兴的社会价值观留出空间,可能是可以容忍的。
这个问题并不仅限于刑事司法系统,甚至也不仅限于法律领域。对于许多政策,公司可能会决定在判断和决策中允许一定的灵活性,即使这样做会产生噪音,因为灵活性确保了随着新信念和价值观的出现,他们可以随时改变政策。我们提供一个个人例子:当我们中的一个人几年前加入一家大型咨询公司时,他收到的不太新的欢迎包中规定了他可以申请报销的差旅费用(“安全抵达后的一次回家电话;西装的熨烫费用;给行李员的小费”)。这些规则没有噪音但明显过时了(而且带有性别歧视)。它们很快被能够随时代发展的标准所取代。例如,费用现在必须是”适当和合理的”。
对这种为噪音辩护的第一个回答很简单:一些降噪策略完全不会遇到这种反对意见。如果人们使用基于外部视角的共同标准,他们可以随时间推移响应不断变化的价值观。无论如何,降噪努力既不需要也不应该是永久性的。如果这种努力采取严格规则的形式,制定这些规则的人应该愿意随时间推移做出改变。他们可能会每年重新审视这些规则。他们可能决定由于新的价值观,新规则是必要的。在刑事司法系统中,规则制定者可能会减少某些犯罪的刑期,增加其他犯罪的刑期。他们可能会完全将某些活动非刑罪化——并将之前被认为完全可以接受的活动定为犯罪。
但让我们退一步。有噪音的系统可以为新兴道德价值观让出空间,这可能是一件好事。但在许多领域,用这个论点为高水平的噪音辩护是荒谬的。一些最重要的降噪策略,如聚合判断,确实允许新兴价值观。如果不同的客户因笔记本电脑故障投诉而受到计算机公司的不同对待,这种不一致性不太可能是因为新兴价值观。如果不同的人得到不同的医疗诊断,这很少是因为新的道德价值观。我们可以大大减少噪音甚至消除噪音,同时仍然设计允许价值观演变的过程。
在有噪音的系统中,各种裁判者可以根据情况需要进行调整——并对意外发展做出响应。通过消除适应能力,一些降噪策略可能会产生意想不到的后果,即给人们钻空子的动机。容忍噪音的一个潜在论点是,它可能是私人和公共机构为防止这种钻空子行为而采用方法的副产品。
税法是一个熟悉的例子。一方面,税收系统不应该有噪音。它应该清晰可预测;相同的纳税人不应该受到不同对待。但如果我们消除税收系统中的噪音,聪明的纳税人不可避免地会找到规避规则的方法。在税务专家中,关于最好是有清晰的规则(消除噪音)还是有一定程度的模糊性(允许不可预测性但也减少清晰规则产生机会主义或自私行为的风险)存在激烈辩论。
一些公司和大学禁止人们从事”不当行为”,但没有具体说明这意味着什么。不可避免的结果是噪音,这并不好,甚至可能非常糟糕。但如果有一个具体的不当行为清单,那么没有被清单明确涵盖的可怕行为最终会被容忍。
因为规则有明确的边界,人们可以通过从事技术上被豁免但造成相同或类似损害的行为来规避它们。(每个青少年的父母都知道这一点!)当我们无法轻易设计规则来禁止所有应该被禁止的行为时,我们有一个独特的理由来容忍噪音,或者说反对意见是这样的。
在某些情况下,消除噪音的明确、确定的规则确实会产生规避的风险。这种风险可能是采用其他降噪策略(如聚合)的理由,也许是容忍允许一些噪音的方法。但”可能是”这个词至关重要。我们需要问会有多少规避——以及会有多少噪音。如果只有一点点规避和很多噪音,那么我们最好采用减少噪音的方法。我们将在第28章回到这个问题。
假设目标是威慑不当行为——员工、学生、普通公民的不当行为。一点不可预测性,甚至很多不可预测性,可能不是最糟糕的事情。雇主可能会想,“如果对某些不当行为的惩罚是罚款、停职或解雇,那么我的员工就不会从事这些不当行为。”那些管理刑事司法系统的人可能会想,“如果潜在犯罪分子必须猜测可能的惩罚,我们并不太介意。如果惩罚彩票的前景阻止人们越界,也许由此产生的噪音可以被容忍。”
在抽象层面上,这些论点不能被完全驳回,但它们并不是特别有说服力。乍一看,重要的是惩罚的期望值,50%概率的5,000美元罚款等同于确定的2,500美元罚款。当然,有些人可能会关注最坏情况。风险厌恶者可能更容易被50%概率的5,000美元罚款所威慑——但风险偏好者则不太容易被威慑。要知道噪声系统是否产生更多威慑力,我们需要了解潜在违法者是风险厌恶还是风险偏好。如果我们想增加威慑力,难道不是增加惩罚并消除噪声更好吗?这样做也会消除不公平。
某些降噪努力是否可能抑制动机和参与度?它们是否会影响创造力并阻止人们取得重大突破?许多组织都这么认为。在某些情况下,他们可能是对的。要知道他们是否正确,我们需要明确他们所反对的降噪策略。
回想一下许多法官对量刑指导原则的强烈负面反应。正如一位法官所说:“我们必须重新学会在法庭上信任判断的行使。”一般来说,处于权威地位的人不喜欢他们的自由裁量权被剥夺。他们可能感到被贬低和受约束——甚至感到羞辱。当采取措施减少他们的自由裁量权时,许多人会反抗。他们重视行使判断的机会;他们甚至可能珍视这种机会。如果他们的自由裁量权被剥夺,以至于他们只能做其他人都在做的事,他们可能感觉自己像机器中的齿轮。
简而言之,噪声系统可能对士气有好处,不是因为它有噪声,而是因为它允许人们按照自己认为合适的方式做决定。如果员工被允许以自己的方式回应客户投诉,按照他们认为最好的方式评估下属,或者建立他们认为合适的保费,那么他们可能更享受自己的工作。如果公司采取措施消除噪声,员工可能认为他们自己的能动性受到了损害。现在他们在遵循规则而不是发挥自己的创造力。他们的工作看起来更加机械化,甚至机器人化。谁愿意在一个扼杀你独立决策能力的地方工作?
组织可能不仅因为尊重这些感受而做出回应,还因为他们想给人们空间来提出新想法。如果有规则存在,它可能会减少独创性和发明。
这些观点适用于组织中的许多人,当然不是所有人。不同的任务必须得到不同的评估;对链球菌性咽炎或高血压的噪声诊断可能不是发挥创造力的好地方。但如果噪声能让员工更快乐、更有灵感,我们可能愿意容忍噪声。士气低落本身就是一种成本,并导致其他成本,如表现不佳。可以肯定的是,我们应该能够在减少噪声的同时保持对新想法的接受。一些降噪策略,如结构化复杂判断,正是这样做的。如果我们想在保持良好士气的同时减少噪声,我们可能会选择具有这种结果的决策卫生策略。那些负责的人可能会明确表示,即使有严格的规则存在,也有一个挑战和重新思考这些规则的过程——但不是通过逐案自由裁量来打破它们。
在一系列充满活力的书籍中,杰出的律师和思想家Philip Howard提出了支持允许更灵活判断的类似观点。Howard希望政策不是采用消除噪声的规定性规则的形式,而是一般原则的形式:“要合理”,“谨慎行事”,“不要施加过度风险”。
在Howard看来,现代政府监管世界已经疯狂,仅仅因为它过于僵化。教师、农民、开发商、护士、医生——所有这些专家,以及更多的人,都被告诉他们该做什么以及如何做的规则所负担。Howard认为,允许人们使用自己的创造力来弄清楚如何实现相关目标会更好,无论目标是更好的教育成果、减少事故、更清洁的水还是更健康的患者。
Howard提出了一些有吸引力的论点,但重要的是要询问他偏爱的方法的后果,包括噪声和偏见的潜在增加。大多数人在抽象层面上都不喜欢僵化,但它可能是减少噪声和消除偏见和错误的最佳方式。如果只有一般原则存在,在解释和执行中的噪声将随之而来。这种噪声很可能是无法容忍的,甚至是令人愤慨的。至少,噪声的成本必须得到仔细考虑——而它们通常不会得到考虑。一旦我们看到噪声产生广泛的不公平和自身的高成本,我们通常会得出结论,认为它是不可接受的,我们应该确定不会损害重要价值观的降噪策略。
“人们重视甚至需要面对面的互动。他们希望真正的人类倾听他们的关切和投诉,并有权力让事情变得更好。当然,这些互动将不可避免地产生噪声。但人类尊严是无价的。”
“道德价值观在不断演变。如果我们把一切都锁定,我们就不会为价值观的变化留出空间。一些减少噪声的努力过于僵化;它们会阻止道德变化。”
“如果你想威慑不当行为,你应该容忍一些噪音。如果学生对剽窃的处罚感到不确定,那很好——他们会避免剽窃。以噪音形式出现的一点不确定性可以放大威慑效果。”
“如果我们消除噪音,我们可能最终得到明确的规则,而违法者会找到规避的方法。如果噪音是防止策略性或机会主义行为的一种方式,那么它可能是值得付出的代价。”
“创造性的人需要空间。人不是机器人。无论你的工作是什么,你都应该有一些操作空间。如果你被束缚住,你可能不会制造噪音,但你不会很开心,也无法发挥你的原创想法。”
“最终,大多数为噪音辩护的努力都不令人信服。我们可以尊重人的尊严,为道德演进提供充足空间,并允许人类创造力发挥,而无需容忍噪音的不公平性和代价。”
如果目标是减少噪音或决定如何以及是否这样做(以及在什么程度上),区分两种规范行为的方式是有用的:规则和标准。各种类型的组织经常选择其中一种或两者的某种组合。
在商业中,公司可能会说员工必须在规定时间内上班,任何人不得休超过两周的假期,如果有人向媒体泄露信息,此人将被解雇。或者,它可能会说员工必须在”合理的工作日”上班,假期将”根据具体情况决定,与公司需求保持一致”,泄露”将受到适当惩罚”。
在法律中,规则可能规定任何人不得超过数字化的速度限制,工人不得接触致癌物,或者所有处方药必须附带特定警告。相比之下,标准可能规定人们必须”谨慎”驾驶,雇主必须”在可行范围内”提供安全的工作场所,或者在决定是否为处方药提供警告时,公司必须”合理”行事。
这些例子说明了规则和标准之间的核心区别。规则旨在消除应用者的自由裁量权;标准旨在授予这种自由裁量权。无论何时实施规则,噪音都应该大大减少。那些解释规则的人必须回答一个事实问题:司机开得有多快?工人是否接触了致癌物?药物是否有所需的警告?
在规则下,事实认定本身可能涉及判断,因此产生噪音或受到偏见影响。我们已经遇到了许多例子。但设计规则的人旨在减少这些风险,当规则由数字组成时(“任何人在年满十八岁之前不得投票”或”速度限制是每小时六十五英里”),噪音应该减少。规则有一个重要特征:它们减少了判断的作用。至少在这一点上,法官(理解为包括所有应用规则的人)要做的工作更少。他们遵循规则。无论好坏,他们的操作空间要小得多。
标准完全不同。当标准到位时,法官必须做大量工作来明确开放性术语的含义。他们可能必须做出许多判断来决定什么算作(例如)“合理”和”可行”。除了认定事实外,他们还必须为相对模糊的短语赋予内容。那些制定标准的人实际上将决策权力输出给他人。他们委托权力。
第22章讨论的指导方针类型可能是规则或标准。如果它们是规则,它们会大大限制判断。即使它们是标准,它们也可能远非开放式。Apgar评分是指导方针而不是规则。它们不禁止某些自由裁量权的行使。当指导方针被收紧以消除这种自由裁量权时,它们就变成了规则。算法作为规则而不是标准发挥作用。
从一开始就应该清楚,无论何时公司、组织、社会或团体存在严重分歧,制定标准可能比制定规则容易得多。公司领导可能同意管理者不应该滥用职权,但不知道这种禁令的确切含义。管理者可能反对工作场所的性骚扰,但不决定调情行为是否可以接受。大学可能禁止学生从事剽窃,但不具体说明该术语的确切含义。人们可能同意宪法应该保护言论自由,但不决定是否应该保护商业广告、威胁或淫秽内容。人们可能同意环境监管者应该发布审慎的规则来减少温室气体排放,但不定义什么构成审慎。
在不具体说明细节的情况下设定标准可能导致噪音,这可能通过我们讨论过的一些策略来控制,比如聚合判断和使用调解评估协议。领导者可能想要制定规则,但作为实际问题,可能无法就此达成一致。宪法本身包含许多标准(例如,保护宗教自由)。《世界人权宣言》也是如此(“人人生而自由,在尊严和权利上一律平等”)。
让不同人群就降噪规则达成一致的巨大困难,是采用标准而非规则的原因之一。公司领导可能无法就具体措辞达成一致,来规范员工如何处理客户关系。在这种情况下,标准可能是这些领导能做的最好选择。公共部门也有类似情况。如果这是通过立法的代价,立法者可能会在标准上达成妥协(并容忍由此产生的噪音)。在医学领域,医生们可能会就诊断疾病的标准达成一致;而另一方面,试图制定规则可能会导致难以解决的分歧。
但社会和政治分歧并非人们采用标准而非规则的唯一原因。有时,真正的问题是人们缺乏制定合理规则所需的信息。大学可能无法制定规则来管理是否晋升教员的决定。雇主可能难以预见所有会导致其保留或处分员工的情况。国家立法机构可能不了解空气污染物——颗粒物、臭氧、二氧化氮、铅的合适水平。它能做的最好的事情就是发布某种标准,并依靠可信的专家来明确其含义,即使后果是产生噪音。
规则可能以多种方式存在偏见。规则可能禁止女性成为警察。它可能说爱尔兰人无需申请。即使它们产生很大的偏见,规则也会大幅减少噪音(如果每个人都遵循它们)。如果规则说21岁以上的人都被允许购买酒精饮料,而该年龄以下的人不能这样做,那么可能会有很少的噪音,至少在人们遵循规则的情况下。相比之下,标准会招致噪音。
规则和标准之间的区别对所有公共和私人机构都具有重大意义,包括各种类型的企业。每当委托人试图控制代理人时,就会出现两者之间的选择。如第2章所述,保险承保人努力收取金发姑娘保费(既不太高也不太低)以使其公司受益。他们的老板会给这些承保人标准还是规则来指导他们?公司中的任何领导都可能非常具体地或更一般地指导员工(“运用你的常识”或”运用你的最佳判断”)。医生在向患者提供指导时可能使用其中一种方法。“每天早晚各吃一片药”是规则;“每当你感觉需要时就吃一片药”是标准。
我们已经注意到,像Facebook这样的社交媒体公司不可避免地会关注噪音以及如何减少噪音。公司可能会告诉其员工,当帖子违反明确规则时(比如说,禁止裸体)就删除内容。或者它可能告诉其员工执行标准(如禁止霸凌或明显令人反感的材料)。Facebook的社区标准,首次于2018年公开,是规则和标准的迷人组合,两者兼而有之。它们发布后,Facebook用户提出了大量投诉,他们认为公司的标准产生了过度的噪音(因此造成了错误和不公平)。一个反复出现的担忧是,由于Facebook的数千名审查员必须做出判断,决定可能会高度可变。在决定是否删除他们审查的帖子时,审查员对什么是允许的、什么是禁止的做出了不同的决定。要了解为什么这种可变性是不可避免的,请考虑Facebook 2020年社区标准中的这些话:
我们将仇恨言论定义为基于我们称之为受保护特征——种族、民族、国籍、宗教信仰、性取向、种姓、性别、性别认同、严重疾病或残疾——对人的直接攻击。我们也为移民身份提供一些保护。我们将攻击定义为暴力或非人化言论、自卑陈述,或排斥或隔离的呼吁。
在实施这种定义时,审查员不可避免地会产生噪音。究竟什么算作”暴力或非人化言论”?Facebook意识到了这些问题,为了回应这些问题,它朝着直接规则的方向发展,正是为了减少噪音。这些规则被编录在一个名为实施标准的非公开文档中,包含约12,000个单词,《纽约客》获得了这份文档。在公开的社区标准中,管理图形内容的文本以标准”我们删除美化暴力的内容”开始。(这到底是什么?)相比之下,实施标准列出了图形图像,并明确告诉内容审核员如何处理这些图像。例子包括”烧焦或燃烧的人类”和”非生殖身体部位的分离”。总结一个复杂的故事,社区标准看起来更像标准,而实施标准看起来更像规则。
同样,航空公司可能要求其飞行员遵守规则或标准。问题可能是在跑道上停留90分钟后是否返回登机口,或者确切地说,何时打开安全带指示灯。航空公司可能喜欢规则,因为它们限制了飞行员的自由裁量权,从而减少了错误。但它也可能认为在某些情况下,飞行员应该运用他们的最佳判断。在这些情况下,标准可能比规则好得多,即使它们产生一些噪音。
在所有这些情况以及更多情况下,那些在规则和标准之间做出决定的人必须专注于噪音问题、偏见问题,或者两者兼而有之。无论大小企业,都必须时常做出这样的决定。有时他们凭直觉行事,没有太多框架可循。
标准有各种形式和规模。它们可以基本上没有内容:“在具体情况下做适当的事情。”它们也可以写得接近规则——例如,当适当的内容被具体定义时,以限制法官的自由裁量权。规则和标准也可以混合搭配使用。例如,人事部门可能采用一条规则(“所有申请人必须拥有大学学位”),然后再应用标准(“在这一约束条件下,选择能够出色完成工作的人”)。
我们已经说过,规则应该减少甚至可能完全消除噪音,而标准往往会产生大量噪音(除非采用某种降噪策略)。在私人和公共组织中,噪音往往是未能制定规则的结果。当噪音足够大时——当每个人都能看到处境相似的人没有得到相似对待时——往往会出现向规则方向发展的运动。就像刑事量刑的情况一样,这种运动可能会变成强烈抗议。某种噪音审计通常会在抗议之前出现。
考虑一个重要问题:谁算作残疾人,从而有资格获得为那些无法工作的人保留的经济福利?如果问题是这样表述的,法官将做出临时性决定,这些决定将是嘈杂的,因此是不公平的。在美国,这种嘈杂、不公平的决定曾经是常态,结果令人震惊。两个看似相同的坐轮椅的人或患有严重抑郁症或慢性疼痛的人会受到不同的对待。作为回应,公职人员转向了更像规则的东西——残疾矩阵。该矩阵要求基于教育、地理位置和剩余身体能力做出相对机械的判断。目标是使决定减少噪音。
对这个问题的主要讨论,由法学教授Jerry Mashaw撰写,为消除嘈杂判断的努力起了一个名字:官僚正义。这个术语值得记住。Mashaw赞扬矩阵的创建从根本上是公正的,正是因为它承诺消除噪音。然而,在某些情况下,官僚正义的承诺可能无法实现。每当一个机构转向基于规则的决定时,都存在噪音重新出现的风险。
假设规则在特定情况下产生可怕的结果。如果是这样,法官可能会简单地忽略规则,认为它们太过严厉。因此,他们可能通过一种温和的公民不服从形式行使自由裁量权,这很难监管甚至难以发现。在私人公司中,员工会忽略看起来愚蠢的公司规则。同样,负责保护公共安全和健康的行政机构在法规过于僵化和规则化时可以简单地拒绝执行。在刑法中,陪审团废除指的是陪审团简单地拒绝遵守法律的情况,理由是法律是无意义的僵化和严厉。
每当公共或私人机构试图通过严格规则控制噪音时,它必须始终警惕规则可能会简单地将自由裁量权推向地下的可能性。对于三振出局政策,检察官的常见反应——避免对已被定罪两次的人提出重罪指控——是极其难以控制甚至难以发现的。
当这种情况发生时,会有噪音,但没有人会听到。我们需要监控我们的规则,以确保它们按预期运行。如果它们没有,噪音的存在可能是一个线索,规则应该被修订。
在商业和政府中,规则和标准之间的选择通常是凭直觉做出的,但这可以变得更有条理。作为初步近似,选择取决于两个因素:(1)决定的成本和(2)错误的成本。
对于标准,决定的成本对各种法官来说都可能非常高,仅仅因为他们必须努力给标准赋予内容。行使判断可能是繁重的。如果医生被告知要做出最佳判断,他们可能必须花时间思考每个案例(而且判断很可能是嘈杂的)。如果医生得到明确的指导来决定患者是否患有链球菌性咽喉炎,他们的决定可能是快速和相对直接的。如果限速是每小时六十五英里,警察不必费力思考人们被允许开多快,但如果标准是人们不得”不合理地快速”驾驶,警察必须做更多思考(而且执行几乎肯定是嘈杂的)。对于规则,决定的成本通常要低得多。
尽管如此,这很复杂。规则一旦到位可能很容易应用,但在规则制定之前,必须有人决定它是什么。制定规则可能很困难。有时成本高得令人望而却步。因此,法律系统和私人公司经常使用诸如合理的、谨慎的和可行的等词语。这也是为什么这些术语在医学和工程等领域也发挥同样重要作用的原因。
错误成本是指错误的数量和严重程度。一个普遍的问题是代理人是否具备知识和可靠性,以及他们是否践行决策卫生。如果他们确实如此,那么标准可能运作良好——而且可能几乎没有噪音。委托人需要在有理由不信任其代理人时施加规则。如果代理人不称职或有偏见,并且他们无法切实实施决策卫生,那么他们应该受到规则的约束。明智的组织很清楚,他们给予的自由裁量权数量与他们对代理人的信任程度密切相关。
当然,从完全信任到完全不信任是一个连续体。标准可能导致不那么值得信赖的代理人犯下大量错误,但如果这些错误是轻微的,可能是可以容忍的。规则可能只导致少数错误,但如果这些错误是灾难性的,我们可能需要标准。我们应该能够看到,没有一般性理由认为规则或标准会产生更大的错误成本。当然,如果规则是完美的,它不会产生错误。但规则很少是完美的。
假设法律规定只有21岁或以上才能购买酒类。该法律旨在保护年轻人免受与饮酒相关的各种风险。从这个角度理解,该法律将产生大量错误。一些20岁、19岁、18岁甚至17岁的人完全可以正常饮酒。一些22岁、42岁或62岁的人则不能。如果我们能找到合适的表述形式,并且人们能够准确应用这些词语,标准会产生更少的错误。当然,这很难做到,这就是为什么我们在酒类销售中几乎总是看到基于年龄的简单规则。
这个例子表明了一个更大的观点。每当必须做出大量决策时,很可能会有很多噪音,因此有强有力的理由支持明确的规则。如果皮肤科医生正在治疗大量患有瘙痒皮疹和痣的患者,如果他们的判断受到合理规则的约束,他们可能会犯更少的错误。没有这样的规则,采用开放式标准,决策成本往往变得无法承受。对于重复性决策,朝着机械规则而非临时判断的方向发展具有真正的优势。行使自由裁量权的负担很大,噪音的成本或其造成的不公正可能完全无法容忍。
明智的组织敏锐地意识到这两种行为规范方式的缺点。他们采用规则,或接近规则的标准,作为减少噪音(和偏见)的方式。为了最小化错误成本,他们愿意投入大量时间和注意力,提前确保规则(足够)准确。
在许多情况下,噪音应该是一种丑闻。人们忍受它,但他们不应该这样做。一个简单的回应是从开放式自由裁量权或模糊标准转向规则或接近规则的东西。我们现在了解了什么时候简单回应是正确回应。但即使规则不可行或不是好主意,我们也已经确定了减少噪音的各种策略。
所有这些提出了一个重大问题:法律系统是否应该禁止噪音?简单地回答是会过于简单,但法律应该比现在做得更多来控制噪音。这里有一种思考这个问题的方式。德国社会学家马克斯·韦伯(Max Weber)抱怨”Kadi正义”,他理解为不受一般规则约束的非正式、临时判断。在韦伯看来,Kadi正义令人无法容忍地逐案处理;这违反了法治。正如韦伯所说,法官”恰恰没有根据正式规则和’不考虑个人’进行裁决。[很大程度上恰恰相反];他根据个人的具体品质和具体情况,或根据公平和具体结果的适当性来判决个人。”
韦伯认为,这种方法”不知道理性的决策规则”。我们可以很容易地看出韦伯在抱怨Kadi正义确保的无法容忍的噪音。韦伯赞扬了官僚判断的兴起,这种判断事先受到约束。(回忆官僚正义的概念。)他将专业化、职业化和规则约束的方法视为法律演变的最终阶段。但在韦伯写作很久之后,显然Kadi正义或类似的东西仍然普遍存在。问题是如何应对它。
我们不会说噪音减少应该成为《世界人权宣言》的一部分,但在某些情况下,噪音可以被视为权利侵犯,总的来说,世界各地的法律系统应该为控制噪音做出更大的努力。考虑刑事量刑;民事不当行为罚款;以及庇护、教育机会、签证、建筑许可和职业执照的授予或拒绝。或者假设一个大型政府机构正在雇用数百甚至数千人,其决策没有任何规律可言;存在一片噪音的混乱。或者假设一个儿童监护机构对幼儿的待遇截然不同,这取决于分配给案件的是哪位员工。一个孩子的生活和未来依赖于这种抽签,这怎么能被接受?
在许多情况下,此类决策的变异性明显受到偏见驱动,包括可识别的认知偏见和某些形式的歧视。当情况如此时,人们往往认为这种情况无法容忍,法律可能被用作纠正措施,要求新的和不同的做法。世界各地的组织都将偏见视为恶棍。他们是对的。他们没有以这种方式看待噪音。他们应该这样做。
在许多领域,当前的noise水平远远过高。这造成了巨大的成本并产生了严重的不公平。我们在这里编录的只是冰山一角。法律应该做更多工作来减少这些成本。它应该对抗这种不公平。
“规则简化生活,减少noise。但标准允许人们根据具体情况进行调整。”
“规则还是标准?首先,问问哪种产生更多错误。然后,问问哪种更容易或更繁重地产生或使用。”
“我们经常在应该采用规则时使用标准——仅仅因为我们没有注意到noise。”
“Noise减少不应该成为《世界人权宣言》的一部分——至少现在还不是。但是,noise可能是极其不公平的。世界各地的法律系统都应该考虑采取强有力的措施来减少它。”
Noise是判断的不必要变异性,而且太多了。我们在这里的中心目标是解释为什么会这样,并看看可以做些什么。我们在这本书中涵盖了大量材料,作为结论,我们在这里提供主要观点的简要回顾,以及更广阔的视角。
正如我们使用这个术语,判断不应与”思考”混淆。它是一个更狭窄的概念:判断是一种测量形式,其中工具是人类的思维。像其他测量一样,判断为对象分配分数。分数不必是数字。“玛丽·约翰逊的肿瘤可能是良性的”是一个判断,类似的陈述还有”国民经济非常不稳定”、“弗雷德·威廉姆斯将是雇用为我们新经理的最佳人选”,以及”为这种风险投保的保费应该是12,000美元”。判断非正式地将各种信息整合成总体评估。它们不是计算,也不遵循确切的规则。教师用判断来给论文评分,但不用来给多选题打分。
许多人靠做专业判断谋生,每个人都以重要方式受到这种判断的影响。专业判断者,正如我们在这里称呼他们,包括足球教练和心脏病专家、律师和工程师、好莱坞高管和保险核保人,以及更多其他人。专业判断一直是本书的焦点,既因为它们被广泛研究,也因为它们的质量对我们所有人都有如此巨大的影响。我们相信我们所学到的也适用于人们在生活其他部分做出的判断。
一些判断是预测性的,一些预测性判断是可验证的;我们最终会知道它们是否准确。对于药物效果、疫情进程或选举结果等结果的短期预测,情况通常如此。但许多判断,包括长期预测和对虚构问题的回答,是无法验证的。这种判断的质量只能通过产生它们的思维过程的质量来评估。此外,许多判断不是预测性的而是评估性的:法官设定的判决或绘画在奖项竞赛中的排名不能轻易与客观真实值进行比较。
然而,令人震惊的是,做出判断的人表现得好像真实值存在,无论它是否确实存在。他们思考和行动时,好像有一个看不见的靶心可以瞄准,他们和其他人都不应该错过太多。短语判断性决定既暗示了分歧的可能性,也暗示了分歧将是有限的期望。判断事项的特征是有界分歧的期望。它们占据了计算事项(不允许分歧)和品味事项(除了极端情况外几乎没有一致期望)之间的空间。
当一组判断中的大多数错误都朝同一方向时,我们说存在偏差。偏差是平均错误,例如,当一队射手一致射击目标下方和左侧时;当高管年复一年地对销售过于乐观时;或当公司继续将资金再投资于应该注销的失败项目时。
从一组判断中消除偏差不会消除所有错误。当偏差被移除时,剩余的错误不是共享的。它们是判断的不必要分歧,是我们应用于现实的测量工具的不可靠性。它们是noise。Noise是应该相同的判断中的变异性。我们使用术语系统noise来指在雇用可互换专业人员做决定的组织中观察到的noise,如急诊室的医生、施加刑罚的法官,以及保险公司的核保人。本书的大部分内容都与系统noise有关。
均方误差 (MSE) 两百年来一直是科学测量中准确性的标准。MSE的主要特征是产生样本均值作为总体均值的无偏估计,平等对待正误差和负误差,并且不成比例地惩罚大误差。MSE不能反映判断错误的真实成本,这些成本往往是不对称的。然而,专业决策总是需要准确的预测。对于面临飓风的城市来说,低估和高估威胁的成本显然不同,但你不希望这些成本影响气象学家对风暴速度和轨迹的预测。MSE是做出此类预测性判断的合适标准,其目标是客观准确性。
按MSE衡量,偏差和噪声是独立且叠加的误差来源。显然,偏差总是不好的,减少偏差总是能提高准确性。不太直观的事实是噪声同样有害,减少噪声总是一种改进。散布的最佳量是零,即使判断明显有偏差。当然,目标是最小化偏差和噪声。
可验证判断集合中的偏差由案例的平均判断与相应真实值之间的差异定义。对于不可验证的判断,这种比较是不可能的。例如,承保人为特定风险设定的保费的真实值永远不会知道。我们也不能轻易知道特定犯罪的公正刑期的真实值。缺乏这种知识,一个频繁且方便的(尽管不总是正确的)假设是判断是无偏的,许多判断者的平均值是真实值的最佳估计。
系统中的噪声可以通过噪声审计来评估,这是一个实验,其中几位专业人士对相同案例(真实或虚构)做出独立判断。我们可以在不知道真实值的情况下测量噪声,就像我们从靶子背面可以看到一组射击的散布一样。噪声审计可以测量许多系统中判断的变异性,包括放射科部门和刑事司法系统。它们有时可能会引起对技能或培训缺陷的关注。它们将量化系统噪声——例如,当同一团队的承保人在风险评估上存在分歧时。
在偏差和噪声中,哪个是更大的问题?这取决于情况。答案很可能是噪声。当误差的均值(偏差)等于误差的标准差(噪声)时,偏差和噪声对总体误差(MSE)的贡献相等。当判断分布是正态的(标准钟形曲线)时,当84%的判断高于(或低于)真实值时,偏差和噪声的影响相等。这是一个显著的偏差,在专业环境中通常是可检测的。当偏差小于一个标准差时,噪声是总体误差的更大来源。
在某些判断中,变异性本身并不成问题,甚至是受欢迎的。意见多样性对于产生想法和选择至关重要。逆向思维对创新至关重要。电影评论家之间的多元化意见是一个特点,而不是缺陷。交易者之间的分歧促成了市场。竞争初创公司之间的战略差异使市场能够选择最适合的。然而,在我们称为判断事务中,系统噪声总是一个问题。如果两个医生给你不同的诊断,至少有一个是错误的。
激发这本书的惊喜是系统噪声的巨大规模和它造成的损害程度。这两者都远远超出了常见的预期。我们给出了许多领域的例子,包括商业、医学、刑事司法、指纹分析、预测、人员评级和政治。因此我们的结论是:有判断的地方就有噪声,而且比你想象的要多。
噪声在错误中的重要作用与一个普遍持有的信念相矛盾,即随机错误无关紧要,因为它们会”相互抵消”。这种信念是错误的。如果多次射击分散在目标周围,说平均而言它们击中了靶心是没有帮助的。如果一个求职候选人得到了比她应得的更高的评级,而另一个得到了更低的评级,可能会雇用错误的人。如果一份保险单定价过高而另一份定价过低,两个错误对保险公司来说都是代价高昂的;一个让它失去业务,另一个让它亏钱。
简而言之,如果判断无缘无故地变化,我们可以确定存在错误。即使判断不可验证且错误无法测量,噪声也是有害的。类似情况的人受到不同对待是不公平的,专业判断被视为不一致的系统失去可信度。
系统噪声可以分解为水平噪声和模式噪声。有些法官通常比其他人更严厉,而其他人更宽松;有些预测者对市场前景普遍看涨,而其他人看跌;有些医生比其他医生开更多抗生素。水平噪声是不同个体做出的平均判断的变异性。判断量表的模糊性是水平噪声的来源之一。像可能这样的词或数字(例如,“0到6量表上的4”)对不同的人意味着不同的东西。水平噪声是判断系统中误差的重要来源,也是旨在减少噪声的干预措施的重要目标。
系统噪音包含另一个通常更大的组成部分。无论法官判决的平均水平如何,两名法官对于哪些犯罪应该受到更严厉刑罚的看法可能不同。他们的量刑决定会产生不同的案件排序。我们称这种变异性为模式噪音(技术术语是统计交互作用)。
模式噪音的主要来源是稳定的:它是法官对同一案件的个人、特质化反应的差异。其中一些差异反映了个人遵循的原则或价值观,无论是有意识还是无意识的。例如,一位法官可能对商店扒手特别严厉,对交通违法者异常宽松;另一位法官可能表现出相反的模式。一些潜在的原则或价值观可能相当复杂,法官可能并未意识到它们。例如,一位法官可能对年长的商店扒手相对宽松而不自知。最后,对特定案件高度个人化的反应也可能是稳定的。一个像法官女儿的被告很可能在另一天也会唤起同样的同情感,从而获得宽大处理。
这种稳定的模式噪音反映了法官的独特性:他们对案件的反应与他们的个性一样具有个体特征。人与人之间的微妙差异往往令人愉快和有趣,但当专业人士在假定一致性的系统内工作时,这些差异就变成了问题。在我们研究的案例中,这种个体差异产生的稳定模式噪音通常是系统噪音的最大单一来源。
尽管如此,法官对特定案件的独特态度并非完全稳定。模式噪音也有一个瞬时组成部分,称为场合噪音。当放射科医生在不同日子对同一图像给出不同诊断,或指纹检验员在一次场合确认两个指纹匹配但在另一次场合不认为匹配时,我们就能检测到这种噪音。正如这些例子所示,当法官不认识案件为之前见过的案件时,场合噪音最容易测量。证明场合噪音的另一种方式是显示语境中无关特征对判断的影响,比如法官在他们最喜欢的足球队获胜后更宽大,或医生在下午开更多阿片类药物。
法官的认知缺陷不是预测性判断错误的唯一原因。客观无知往往起着更大的作用。有些事实实际上是不可知的——昨天出生的婴儿七十年后会有多少个孙子孙女,或明年举行的抽奖中中奖彩票的号码。其他的或许是可知的,但法官并不知道。人们对预测判断的过度自信低估了他们的客观无知以及他们的偏见。
我们预测的准确性是有限的,这个限度往往相当低。尽管如此,我们通常对自己的判断感到满意。给我们这种令人满足的信心的是一个内部信号,这是将事实和判断融入连贯故事的自我生成奖励。我们对判断的主观信心不一定与其客观准确性相关。
大多数人听到他们预测判断的准确性不仅很低,而且还不如公式时会感到惊讶。即使是基于有限数据构建的简单线性模型,或可以在信封背面勾画的简单规则,也始终胜过人类法官。规则和模型的关键优势是它们没有噪音。根据我们的主观体验,判断是一个微妙而复杂的过程;我们没有迹象表明这种微妙性可能主要是噪音。我们很难想象无意识地遵守简单规则往往能比我们取得更高的准确性——但这现在是一个充分确立的事实。
心理偏见当然是系统性错误或统计偏差的来源。不太明显的是,它们也是噪音的来源。当偏见不被所有法官共享时,当它们存在的程度不同时,以及当它们的影响取决于外在情况时,心理偏见就会产生噪音。例如,如果做出招聘决定的经理中有一半对女性有偏见,一半偏向她们,就不会有总体偏见,但系统噪音会导致许多招聘错误。另一个例子是第一印象的不成比例影响。这是一种心理偏见,但当证据呈现的顺序随机变化时,这种偏见会产生场合噪音。
我们已经将判断过程描述为对一组线索的非正式整合,以在量表上产生判断。因此,消除系统噪音需要法官在使用线索、分配给线索的权重以及使用量表方面保持一致性。即使撇开场合噪音的随机影响,这些条件也很少得到满足。
在单一维度的判断中,一致性往往相当高。不同的招聘人员经常会在评估两个候选人中哪个更有魅力或更勤奋方面达成一致。跨强度维度的共享直觉匹配过程——比如人们将高GPA与早熟的阅读年龄匹配——通常会产生相似的判断。基于少数指向同一总体方向的线索的判断也是如此。
当判断需要权衡多个相互冲突的线索时,巨大的个体差异就会出现。面对同一位候选人,一些招聘人员会更看重才华或魅力的证据;另一些则更容易受到对勤奋或压力下保持冷静的担忧影响。当线索不一致且无法形成连贯故事时,不同的人必然会更看重某些线索而忽略其他线索。模式噪音由此产生。
噪音不是一个突出的问题。它很少被讨论,其显著性肯定不如偏见。你可能之前没有对此给予太多思考。考虑到它的重要性,噪音的隐蔽性本身就是一个有趣的现象。
认知偏见和其他情感或动机导致的思维扭曲经常被用来解释糟糕的判断。分析师援引过度自信、锚定效应、损失厌恶、可得性偏见和其他偏见来解释最终结果不佳的决策。这种基于偏见的解释令人满意,因为人类大脑渴望因果解释。每当出现问题时,我们寻找原因——而且经常找到。在许多情况下,原因似乎是偏见。
偏见具有一种解释魅力,而噪音缺乏这种魅力。如果我们试图事后解释为什么某个特定决策是错误的,我们很容易找到偏见,却永远找不到噪音。只有统计观点才能让我们看到噪音,但这种观点并非自然而然——我们更喜欢因果故事。我们直觉中缺乏统计思维是噪音比偏见受到更少关注的原因之一。
另一个原因是专业人士很少认为有必要面对自己判断和同事判断中的噪音。经过一段时间的培训后,专业人士通常独立做出判断。指纹专家、经验丰富的承保人和资深专利官很少花时间想象同事可能如何与他们意见不合——他们花更少的时间想象自己可能如何与自己意见不合。
大多数时候,专业人士对自己的判断有信心。他们期望同事会同意他们的观点,却永远不会发现他们是否真的同意。在大多数领域,判断可能永远不会根据真实值进行评估,最多会受到另一位被认为是专业权威的专业人士的审查。只有偶尔,专业人士才会面临令人惊讶的分歧,当这种情况发生时,他们通常会找到理由将其视为孤立案例。组织的例行程序也倾向于忽略或压制其内部专家之间分歧的证据。这是可以理解的;从组织角度来看,噪音是一种尴尬。
有理由相信有些人比其他人做出更好的判断。特定任务技能、智力和某种认知风格——最好描述为积极开放的心态——是最佳判断者的特征。毫不奇怪,优秀的判断者很少犯严重错误。然而,考虑到个体差异的多重来源,我们不应期望即使是最好的判断者在复杂判断问题上也能完全一致。使我们每个人独特的背景、个性和经历的无限多样性,也是使噪音不可避免的原因。
减少错误的一种策略是去偏见化。通常,人们试图通过事后纠正判断或在偏见影响判断之前控制偏见来消除判断中的偏见。我们提出第三种选择,特别适用于群体环境中的决策:通过指定决策观察者来识别偏见迹象,实时检测偏见(见[附录B])。
我们减少判断噪音的主要建议是决策卫生。我们选择这个术语是因为噪音减少,就像健康卫生一样,是对未知敌人的预防。例如,洗手可以防止未知病原体进入我们的身体。同样,决策卫生将防止错误而无需知道它们是什么。决策卫生就像它的名字一样不起眼,肯定不如对抗可预测偏见的胜利那么令人兴奋。防止未知伤害可能没有荣誉,但非常值得做。
组织中的噪音减少努力应始终从噪音审计开始(见附录A)。审计的一个重要功能是获得组织认真对待噪音的承诺。一个重要的好处是评估不同类型的噪音。
我们描述了各个领域噪音减少努力的成功和局限性。我们现在重述定义决策卫生的六个原则,描述它们如何解决导致噪音的心理机制,并展示它们如何与我们讨论的具体决策卫生技术相关。
判断的目标是准确性,而非个人表达。 这一陈述是我们提出的判断中决策卫生第一原则的候选。它反映了我们在本书中定义判断的狭义、具体方式。我们已经表明,稳定的模式噪音是系统噪音的一个重要组成部分,它是个体差异的直接后果,是导致不同人对同一问题形成不同观点的判断个性。这一观察得出一个既不受欢迎又不可避免的结论:判断不是表达你个性的地方。
需要明确的是,个人价值观、个性和创造力在思考和决策的许多阶段都是必需的,甚至是必不可少的,包括目标选择、制定解决问题的新方法以及生成选项。但是,当需要对这些选项做出判断时,个性的表达就成了噪音的来源。当目标是准确性,并且你期望其他人同意你的观点时,你也应该考虑其他称职的判断者如果处在你的位置会怎么想。
这一原则的激进应用是用规则或算法来替代判断。算法评估能够保证消除噪音——实际上,这是唯一能够完全消除噪音的方法。算法已经在许多重要领域得到应用,其作用正在不断增强。但是算法不太可能在重要决策的最后阶段取代人类判断——我们认为这是好消息。然而,通过适当使用算法和采用使决策较少依赖某个专业人士特质的方法,判断是可以改进的。例如,我们已经看到决策指导原则如何帮助约束法官的自由裁量权或促进医生诊断的同质性,从而减少噪音并改善决策。
采用统计思维,从外部视角看待案例。我们说法官对案例采取外部视角,是指她将其视为一类相似案例的成员,而不是独特的问题。这种方法偏离了默认的思维模式,后者紧紧聚焦于手头的案例并将其嵌入因果故事中。当人们运用独特的经验形成对案例的独特看法时,结果就是模式噪音。外部视角是解决这个问题的良方:共享相同参考类别的专业人士将产生更少的噪音。此外,外部视角往往能产生有价值的洞察。
外部视角原则支持将预测锚定在相似案例的统计数据上。它还建议预测应该是适度的(技术术语是回归的;见附录C)。关注过去结果的广泛范围及其有限的可预测性应该有助于决策者校准他们对自己判断的信心。人们不能因为未能预测不可预测的事情而受到指责,但他们可能因为缺乏预测谦逊而受到责备。
将判断结构化为几个独立的任务。这种分而治之的原则是由我们称为过度一致性的心理机制所必需的,这种机制导致人们扭曲或忽略不符合既有或新兴故事的信息。当案例不同方面的印象相互污染时,整体准确性就会受损。类比一下,想想当一组证人被允许相互交流时,他们的证据价值会发生什么。
人们可以通过将判断问题分解为一系列较小的任务来减少过度一致性。这种技术类似于结构化面试的做法,在结构化面试中,面试官一次评估一个特质,在转向下一个特质之前先给出评分。结构化原则启发了诊断指导原则,如Apgar评分。它也是我们称为中介评估协议方法的核心。该协议将复杂的判断分解为多个基于事实的评估,旨在确保每个评估都独立于其他评估进行。只要可能,就通过将评估分配给不同的团队并最小化他们之间的交流来保护独立性。
抵制过早的直觉。我们已经描述了判断完成的内部信号,它给决策者对其判断的信心。决策者不愿意放弃这种有益的信号是抵制使用指导原则、算法和其他约束他们的规则的关键原因。决策者显然需要对他们的最终选择感到舒适,并获得直觉信心的有益感觉。但他们不应该过早地给自己这种奖励。基于对证据平衡和仔细考虑的直觉选择远优于匆忙判断。直觉不必被禁止,但它应该是知情的、有纪律的和延迟的。
这一原则启发了我们对信息排序的建议:做出判断的专业人士不应该被给予他们不需要的、可能使他们产生偏见的信息,即使该信息是准确的。例如,在法医学中,让检验员不知道嫌疑人的其他信息是良好的做法。控制讨论议程是中介评估协议的关键要素,也属于这里。有效的议程将确保问题的不同方面得到单独考虑,整体判断的形成被延迟到评估概况完成之后。
从多个判断者那里获得独立判断,然后考虑汇总这些判断。独立性要求在组织程序中经常被违反,特别是在参与者的意见受到他人影响的会议中。由于级联效应和群体极化,群体讨论往往会增加噪音。在讨论之前收集参与者判断的简单程序既揭示了噪音的程度,又促进了对分歧的建设性解决。
对独立判断进行平均化可以保证减少系统噪音(但不能减少偏见)。单一判断是从所有可能判断总体中抽取的一个样本;增加样本量可以提高估计的精确度。当评判者具有多样化技能和互补的判断模式时,平均化的优势会进一步增强。一个有噪音群体的平均结果可能比一致性判断更准确。
偏向相对判断和相对量表。 相对判断比绝对判断噪音更少,因为我们在量表上对物体进行分类的能力有限,而我们进行配对比较的能力要好得多。要求比较的判断量表比需要绝对判断的量表噪音更少。例如,案例量表要求评判者将案例放在一个由每个人都熟悉的实例定义的量表上。
我们刚刚列出的决策卫生原则不仅适用于重复性判断,也适用于一次性重大决策,或者我们称之为独特决策。独特决策中噪音的存在可能看起来违反直觉:根据定义,如果你只决策一次,就没有可变性可以测量。然而噪音确实存在,会造成错误。如果我们只看到第一个射手在行动,射手团队中的噪音是看不见的,但如果我们看到其他射手,散布就会变得明显。同样,思考独特判断的最佳方法是将它们视为只进行一次的重复性判断。这就是为什么决策卫生也应该改善它们。
执行决策卫生可能是令人沮丧的。噪音是一个看不见的敌人,对看不见敌人的胜利只能是看不见的胜利。但就像身体健康卫生一样,决策卫生是至关重要的。在一次成功的手术后,你喜欢相信是外科医生的技能挽救了你的生命——确实如此——但如果外科医生和手术室里的所有人员没有洗手,你可能已经死了。卫生可能没有太多荣耀可言,但有结果。
当然,对抗噪音并不是决策制定者和组织的唯一考虑。减少噪音可能成本过高:高中可以通过让五位教师阅读每一篇论文来消除评分中的噪音,但这种负担几乎不合理。在实践中,一些噪音可能是不可避免的,是正当程序系统的必要副作用,该系统给每个案例个性化考虑,不把人当作机器中的齿轮对待,并赋予决策制定者代理感。一些噪音甚至可能是可取的,如果它创造的变化使系统能够随时间适应——比如当噪音反映不断变化的价值观和目标,并引发导致实践或法律变化的辩论时。
也许最重要的是,降噪策略可能有不可接受的缺点。许多对算法的担忧被夸大了,但有些是合理的。算法可能产生人类永远不会犯的愚蠢错误,因此失去可信度,即使它们也成功防止了人类确实会犯的许多错误。它们可能因设计不良或在不充分数据上训练而产生偏见。它们的非人性可能激起不信任。决策卫生实践也有其缺点:如果管理不善,它们有官僚化决策的风险,并使感到自主权受到侵犯的专业人士士气低落。
所有这些风险和局限性都值得充分考虑。然而,对降噪的反对是否有意义取决于正在讨论的特定降噪策略。对聚合判断的反对——也许基于成本过高的理由——可能不适用于使用指导原则。可以肯定的是,每当降噪的成本超过其收益时,就不应该追求它。一旦进行成本效益计算,可能会揭示最优的噪音水平不是零。问题是,在没有噪音审计的情况下,人们不知道他们的判断中有多少噪音。在这种情况下,援引减少噪音的困难只不过是不测量它的借口。
偏见导致错误和不公平。噪音也是如此——然而,我们对此做得更少。当判断错误是随机的而不是我们将其归因于某个原因时,它可能看起来更可以容忍;但它并不会减少伤害。如果我们想在重要事情上做出更好的决策,我们应该认真对待降噪。
想象一下,如果组织被重新设计以减少噪音,它们会是什么样子。医院、招聘委员会、经济预测者、政府机构、保险公司、公共卫生当局、刑事司法系统、律师事务所和大学都会敏锐地警觉噪音问题并努力减少它。噪音审计将成为常规;它们可能每年进行一次。
组织的领导者会在比今天更多的领域使用算法来取代或补充人类判断。人们会将复杂判断分解为更简单的中介评估。他们会了解决策卫生并遵循其处方。独立判断会被引出和聚合。会议看起来会非常不同;讨论会更有结构。外部观点会更系统地整合到决策过程中。公开分歧会更频繁,也会得到更建设性的解决。
结果将是一个噪音更少的世界。这将节省大量资金,改善公共安全和健康,增加公平性,并防止许多可避免的错误。我们写这本书的目的是引起人们对这个机会的关注。我们希望您会成为抓住这个机会的人之一。
本附录提供了进行噪音审计的实用指南。您应该从顾问的角度来阅读它,该顾问受组织委托,通过在其某个部门进行噪音审计来检查其员工产生的专业判断质量。
顾名思义,审计的重点是噪音的普遍性。然而,一次精心进行的审计将为偏见、盲点以及员工培训和工作监督中的具体缺陷提供有价值的信息。成功的审计应该刺激该部门运营的变化,包括指导专业人士判断的理论、他们接受的培训、他们用于支持判断的工具以及对其工作的常规监督。如果这项努力被认为是成功的,它可能会扩展到组织的其他部门。
噪音审计需要大量的工作和对细节的关注,因为如果其发现揭示了重大缺陷,其可信度肯定会受到质疑。因此,案例和程序的每个细节都应该在怀有敌意的审查中加以考虑。我们描述的过程旨在通过征集那些是审计最重要潜在批评者的专业人士来成为其作者,从而减少反对。
除了顾问(可能是外部的或内部的)之外,相关的角色包括以下几个:
项目团队。 项目团队将负责研究的所有阶段。如果顾问是内部的,他们将构成项目团队的核心。如果顾问是外部的,内部项目团队将与他们密切合作。这将确保公司内的人员将审计视为他们的项目,并认为顾问起到支持作用。除了管理数据收集、分析结果和准备最终报告的顾问外,项目团队还应包括能够构建评判者将评估的案例的主题专家。项目团队的所有成员都应具有很高的专业可信度。
客户。 噪音审计只有在导致重大变化时才有用,这需要组织领导层的早期参与,这是项目的”客户”。您可以预期客户最初会对噪音的普遍性持怀疑态度。如果这种初始怀疑态度伴随着开放的心态、对审计结果的好奇心以及在顾问的悲观期望得到证实时纠正情况的承诺,那么这种初始怀疑实际上是一个优势。
评判者。 客户将指定一个或多个部门进行审计。选定的部门应该由大量”评判者”组成,即代表公司做出类似判断和决策的专业人士。评判者应该是有效可互换的;即,如果一个人无法处理某个案例,另一个人将被分配到该案例并期望得出类似的判断。引入本书的例子是联邦法官的量刑决定以及保险公司风险保费和理赔准备金的设定。对于噪音审计,最好选择(1)可以基于书面信息完成的,以及(2)用数字表达的(例如,以美元、概率或评级表示)判断任务。
项目经理。 行政人员中的高级经理应被指定为项目经理。该任务不需要特定的专业技能。然而,在组织中的高级职位对于克服行政障碍具有实际意义,也是公司对项目重视程度的体现。项目经理的任务是提供行政支持,以促进项目的所有阶段,包括最终报告的准备和向公司领导层传达其结论。
作为项目团队一部分的主题专家应该在该部门的任务(例如,为风险设定保费或评估可能投资的潜力)方面具有公认的专业技能。他们将负责开发将在审计中使用的案例。设计专业人士在工作中所做判断的可信模拟是一项微妙的任务——特别是考虑到如果研究揭示严重问题,它将受到的审查。团队必须考虑这个问题:如果我们的模拟结果表明噪音水平很高,公司内的人员会接受该部门的实际判断中存在噪音吗?只有当答案是明确的肯定时,噪音审计才值得进行。
有多种方法可以获得积极的回应。第1章描述的量刑噪音审计通过相关属性的简要示意图列表总结每个案例,并在九十分钟内获得了十六个案例的评估。第2章描述的保险公司噪音审计使用了复杂案例的详细且真实的摘要。两种情况下发现的高噪音都提供了可接受的证据,因为如果在简化案例中发现很多分歧,那么在真实案例中噪音只会更严重。
应为每个案例准备一份问卷,以深入了解导致每位评判者对该案例作出判断的推理过程。问卷应在所有案例完成后才进行。它应包括:
当审计中使用的案例材料准备完毕时,应安排一次会议,项目团队将向公司领导层介绍审计。该会议的讨论应考虑研究的可能结果,包括发现不可接受的系统噪音。会议的目的是听取对计划研究的反对意见,并获得领导层对接受研究结果的承诺,无论结果如何:如果没有这样的承诺,就没有必要进入下一阶段。如果提出严重反对意见,项目团队可能需要改进案例材料并重新尝试。
一旦高管接受噪音审计的设计,项目团队应要求他们陈述对研究结果的期望。他们应讨论以下问题:
应记录这些问题的答案,以确保在审计的实际结果出来时能够记住和相信这些答案。
被审计部门的管理者应从一开始就被大致告知他们的部门已被选中进行特别研究。然而,重要的是不要使用噪音审计这个术语来描述项目。应避免使用噪音和嘈杂这些词,特别是作为对人的描述。应使用中性术语,如决策制定研究。
部门管理者将直接负责数据收集,并在项目经理和项目团队成员的参与下负责向参与者介绍任务。应以一般术语向参与者描述练习的意图,如“组织对[决策者]如何得出结论感兴趣。”
必须向参与研究的专业人员保证,个人答案不会被组织内任何人知道,包括项目团队。如有必要,可聘请外部公司对数据进行匿名化处理。同样重要的是强调对该部门不会有具体后果,该部门只是被选为代表组织执行判断任务的部门的代表。为练习分配半个工作日将有助于说服参与者其重要性。
所有参与者应同时完成练习,但应保持物理分离,并要求在研究进行期间不要交流。项目团队将在研究期间回答问题。
项目团队将负责对每位参与者评估的多个案例进行统计分析,包括测量噪音总量及其组成部分、水平噪音和模式噪音。如果案例材料允许,还将识别回应中的统计偏差。项目团队将承担同样重要的任务,即通过检查参与者解释其推理并识别最影响其决策的事实的问卷回应,试图理解判断变异性的来源。主要关注分布两端的极端回应,团队将在数据中寻找模式。它将寻找员工培训、组织程序以及组织向员工提供的信息可能存在缺陷的迹象。
顾问和内部项目团队将共同开发工具和程序,应用决策卫生和去偏见的原则,以改善该部门做出的判断和决策。这一过程步骤可能会持续几个月。与此同时,顾问和专业团队也将准备一份关于该项目的报告,并向组织领导层汇报。
此时,组织将已经在其某个部门进行了样本噪音审计。如果这项工作被认为是成功的,执行团队可能会决定进行更广泛的努力,以评估和改善组织中产生的判断和决策质量。
本附录提供了一个供决策观察者使用的通用检查清单示例(见第19章)。这里提供的检查清单大致遵循导致重要决策的讨论的时间顺序。
每个检查清单项目后面建议的问题提供了额外的澄清。决策观察者在观察决策过程时应该问自己这些问题。
这个检查清单并不是要按原样使用。相反,我们希望它能为决策观察者提供灵感和起点,让他们设计自己的定制偏见观察检查清单。
1. 判断方法
1a. 替换
____“小组对证据的选择和讨论重点是否表明他们用一个更容易的问题替换了分配给他们的困难问题?”
____“小组是否忽略了一个重要因素(或似乎重视了一个不相关的因素)?”
1b. 内部视角
____“小组是否在部分讨论中采用了外部视角,并认真尝试应用比较判断而非绝对判断?”
1c. 观点多样性
____“是否有理由怀疑小组成员共享偏见,这可能导致他们的错误相关?相反,你能想到这个小组中没有代表的相关观点或专业知识吗?
2. 预判和过早结论
2a. 初始预判
____“决策者中是否有人从某个结论中获得的收益比其他结论更多?”
____“是否有人已经承诺某个结论?是否有理由怀疑存在偏见?”
____“反对者是否表达了他们的观点?”
____“是否存在对失败行动路线的承诺升级风险?”
2b. 过早结论;过度一致性
____“在早期讨论的考虑因素选择中是否存在意外偏见?”
____“是否充分考虑了替代方案,是否积极寻求支持这些方案的证据?”
____“是否压制或忽略了令人不适的数据或意见?”
3. 信息处理
3a. 可得性和显著性
____“参与者是否因为事件的近期性、戏剧性或个人相关性而夸大其相关性,即使它不具有诊断价值?”
3b. 对信息质量的忽视
____“判断是否严重依赖轶事、故事或类比?数据是否证实了它们?”
3c. 锚定
____“准确性或相关性不确定的数字是否在最终判断中发挥了重要作用?”
3d. 非回归预测
____“参与者是否做出了非回归外推、估计或预测?”
决策
4a. 规划谬误
____“当使用预测时,人们是否质疑其来源和有效性?是否使用外部视角来质疑预测?”
____“是否对不确定数字使用了置信区间?它们是否足够宽?”
4b. 损失厌恶
____“决策者的风险偏好是否与组织的风险偏好一致?决策团队是否过于谨慎?”
4c. 现在偏见
____“计算(包括使用的折现率)是否反映了组织对短期和长期优先级的平衡?”
匹配预测是由我们对直觉匹配过程的依赖造成的错误(见第14章)。当我们依靠现有信息进行预测并表现得好像这些信息完全(或高度)预测结果时,我们就在做匹配预测。
回想一下Julie的例子,她”四岁时就能流利阅读”。问题是,她的GPA是多少?如果你预测Julie的大学GPA,你直觉地判断四岁的Julie在阅读年龄方面位于同龄人的前10%(尽管不在前3-5%)。然后,你隐含地假设Julie在班级GPA方面也会排在大约第90百分位。这对应3.7或3.8的GPA——因此这些答案很受欢迎。
这种推理在统计学上不正确的原因是它严重夸大了关于Julie的可用信息的诊断价值。一个早熟的四岁儿童并不总是成为学术成就者(幸运的是,最初在阅读方面有困难的孩子也不会永远在班级中垫底)。
事实上,杰出的表现往往会变得不那么杰出。相反,非常糟糕的表现会有所改善。我们很容易想象这种现象背后的社会、心理甚至政治原因,但原因并不是必需的。这种现象纯粹是统计学的。一个方向或另一个方向的极端观察结果往往会变得不那么极端,仅仅因为过去的表现与未来的表现并不完全相关。这种趋势被称为回归均值(因此技术术语非回归用于匹配预测,这些预测未能考虑到这一点)。
从定量角度来说,如果阅读年龄是GPA的完美预测因子,也就是说,如果两个因素之间的相关性为1,那么你对朱莉的判断就是正确的。显然情况并非如此。
有一种统计方法可以做出更准确的判断。它不直观且难以发现,即使对于有一些统计训练的人也是如此。以下是具体步骤。图19以朱莉的例子进行了说明。
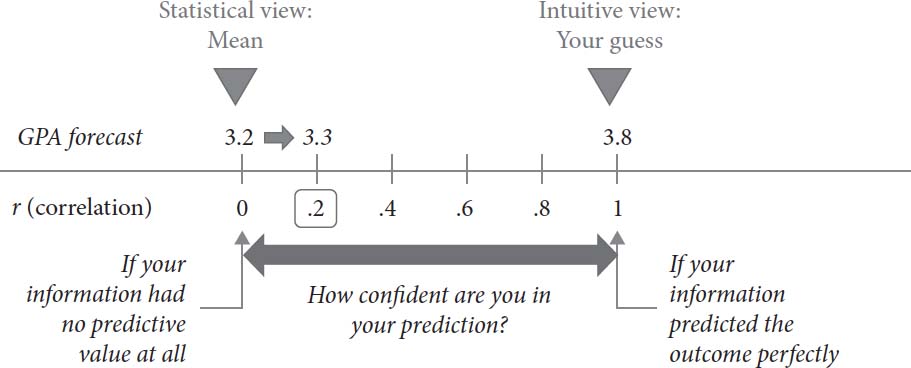
图19:调整直觉预测以适应回归均值
你对朱莉的直觉,或者对你有信息的任何案例的直觉,并非毫无价值。你快速的系统1思维轻松地将你拥有的信息放置在预测的量表上,并为朱莉产生一个GPA分数。这个猜测是如果你拥有的信息完全具有预测性时你会做出的预测。把它写下来。
现在,退一步,暂时忘记你对朱莉的了解。如果你对朱莉完全一无所知,你会如何评价朱莉的GPA?答案当然很直接:在没有任何信息的情况下,你对朱莉GPA的最佳猜测必须是她毕业班级的平均GPA——可能在3.2左右。
这样看待朱莉是我们上面讨论过的更广泛原则的应用,即外部视角。当我们采用外部视角时,我们将所考虑的案例视为一个类别的实例,并从统计角度思考该类别。例如,回想一下对甘巴迪问题采用外部视角如何引导我们询问新CEO的成功基础比率(见第4章)。
这是困难的步骤,你需要问自己:“我拥有的信息的预测价值是什么?”这个问题重要的原因现在应该很清楚了。如果你对朱莉唯一了解的是她的鞋码,你会正确地给这个信息零权重,并坚持平均GPA预测。另一方面,如果你有朱莉在每个科目中获得的成绩清单,这个信息对她的GPA(即它们的平均值)将是完全预测性的。在这两个极端之间有许多灰色地带。如果你有关于朱莉在高中杰出智力成就的数据,这个信息会比她的阅读年龄更具诊断性,但不如她的大学成绩。
你在这里的任务是量化你拥有数据的诊断价值,表示为与你预测结果的相关性。除了极少数情况,这个数字必须是一个粗略的估计。
为了做出合理的估计,请记住我们在第12章中列出的一些例子。在社会科学中,超过.50的相关性非常罕见。许多我们认为有意义的相关性在.20范围内。在朱莉的案例中,.20的相关性可能是上限。
最后一步是你现在产生的三个数字的简单算术组合:你必须从均值调整,朝向你的直觉猜测方向,调整比例与你估计的相关性成正比。
这一步简单地扩展了我们刚才的观察:如果相关性为0,你会坚持均值;如果为1,你会忽视均值并愉快地做出匹配预测。因此,在朱莉的案例中,你能做出的GPA最佳预测是从班级均值出发,朝向她的阅读年龄向你建议的直觉估计方向,移动不超过20%的距离。这个计算导致你预测大约3.3。
我们使用了朱莉的例子,但这种方法同样可以轻松应用于我们在本书中讨论的许多判断问题。例如,考虑一个正在招聘新销售人员的销售副总裁,刚刚与一个绝对杰出的候选人进行了面试。基于这种强烈印象,这位高管估计候选人在工作第一年应该实现100万美元的销售额——是新员工第一年平均销售额的两倍。副总裁如何使这个估计具有回归性?计算取决于面试的诊断价值。在这种情况下,招聘面试对工作成功的预测效果如何?根据我们审查的证据,.40的相关性是一个非常慷慨的估计。因此,对新员工第一年销售额的回归估计最多为50万美元 + (100万美元 − 50万美元) × .40 = 70万美元。
这个过程再次说明,直觉并不总是可靠的。值得注意的是,正如这些例子所说明的,修正后的预测总是比直觉预测更保守:它们永远不会像直觉预测那样极端,而是更接近,往往更接近均值。如果你修正你的预测,你永远不会押注已经赢得十个大满贯冠军的网球冠军会再赢得十个。你也不会预见到一个价值10亿美元的高度成功的初创公司会成为价值数百倍的巨头。修正后的预测不会押注异常值。
这意味着,事后看来,修正后的预测将不可避免地导致一些高度可见的失败。然而,预测并不是在事后进行的。你应该记住,异常值根据定义是极其罕见的。相反的错误要常见得多:当我们预测异常值将保持异常时,它们通常不会,因为会回归到均值。这就是为什么,每当目标是最大化准确性(即最小化MSE)时,修正后的预测优于直觉的、匹配的预测。
目标说明: 瑞士数学家丹尼尔·伯努利使用弓箭而不是枪支,在1778年的一篇关于估计问题的论文中提供了同样的类比。伯努利,“几个不一致观察之间的最可能选择和由此形成的最可能归纳”,Biometrika 48,第1-2期(1961年6月):3-18,https://doi.org/10.1093/biomet/48.1-2.3。
儿童监护权决定: Joseph J. Doyle Jr.,“儿童保护和儿童结果:测量寄养的影响”,American Economic Review 95,第5期(2007年12月):1583-1610。
同样的软件开发人员: Stein Grimstad和Magne Jørgensen,“基于专家判断的软件开发工作量估计的不一致性”,Journal of Systems and Software 80,第11期(2007年):1770-1777。
庇护决定: Andrew I. Schoenholtz,Jaya Ramji-Nogales和Philip G. Schrag,“难民轮盘赌:庇护裁决中的差异”,Stanford Law Review 60,第2期(2007年)。
专利授予决定: Mark A. Lemley和Bhaven Sampat,“审查员特征和专利局结果”,Review of Economics and Statistics 94,第3期(2012年):817-827。另见Iain Cockburn,Samuel Kortum和Scott Stern,“所有专利审查员都相等吗?审查员特征的影响”,工作论文8980,2002年6月,www.nber.org/papers/w8980;以及Michael D. Frakes和Melissa F. Wasserman,“分配给审查专利申请的时间是否诱使审查员授予无效专利?来自微观申请数据的证据”,Review of Economics and Statistics 99,第3期(2017年7月):550-563。
描述了他的动机: Marvin Frankel,Criminal Sentences: Law Without Order, 25 Inst. for Sci. Info. Current Contents / Soc. & Behavioral Scis.: This Week’s Citation Classic 14, 2A-6(1986年6月23日),可在http://www.garfield.library.upenn.edu/classics1986/A1986C697400001.pdf获得。
“几乎完全不受约束”: Marvin Frankel,Criminal Sentences: Law Without Order(纽约:Hill and Wang,1973年),5。
“每天都在犯下的任意残酷行为”: Frankel,Criminal Sentences, 103。
“法律政府,而非人治政府”: Frankel,5。
“特殊的专断法令”: Frankel,11。
“某种形式的数字或其他客观评分”: Frankel,114。
“计算机作为辅助工具”: Frankel,115。
量刑委员会: Frankel,119。
“缺乏共识是常态”: Anthony Partridge和William B. Eldridge,The Second Circuit Sentence Study: A Report to the Judges of the Second Circuit August 1974(华盛顿特区:Federal Judicial Center,1974年8月),9。
“令人震惊”: 美国参议院,“1983年综合犯罪控制法案:美国参议院司法委员会关于S. 1762的报告,以及补充和少数意见”(华盛顿特区:美国政府印刷局,1983年)。报告编号98-225。
一名海洛因贩子: Anthony Partridge和Eldridge,Second Circuit Sentence Study,A-11。
一名银行抢劫犯: Partridge和Eldridge,Second Circuit Sentence Study, A-9。
一起敲诈勒索案: Partridge和Eldridge,A-5–A-7
对四十七名法官的调查: William Austin和Thomas A. Williams III,“法官对模拟法律案件反应的调查:量刑差异的研究笔记”,Journal of Criminal Law & Criminology 68(1977年):306。
一项更大规模的研究: John Bartolomeo等,“量刑决策:判决决定的逻辑以及量刑差异的程度和来源”,Journal of Criminal Law and Criminology 72,第2期(1981年)。(参见第6章的详细讨论。)另见参议院报告,44。
如果法官饿了: Shai Danziger,Jonathan Levav和Liora Avnaim-Pesso,“司法决定中的外在因素”,Proceedings of the National Academy of Sciences of the United States of America 108,第17期(2011年):6889-92。
少年法庭决定: Ozkan Eren和Naci Mocan,“情绪化的法官和不幸的少年”,American Economic Journal: Applied Economics 10,第3期(2018年):171-205。
在败诉次日更加严厉: Daniel L. Chen and Markus Loecher, “Mood and the Malleability of Moral Reasoning: The Impact of Irrelevant Factors on Judicial Decisions,” SSRN Electronic Journal (September 21, 2019): 1–70, http://users.nber.org/dlchen/papers/Mood_and_the_Malleability_of_Moral_Reasoning.pdf.
在生日当天更加宽大: Daniel L. Chen and Arnaud Philippe, “Clash of Norms: Judicial Leniency on Defendant Birthdays,” (2020) available at SSRN: https://ssrn.com/abstract=3203624.
像室外温度这样无关的因素: Anthony Heyes and Soodeh Saberian, “Temperature and Decisions: Evidence from 207,000 Court Cases,” American Economic Journal: Applied Economics 11, no. 2 (2018): 238–265.
“不受约束的自由裁量权”: Senate Report, 38.
“不合理的巨大”量刑差异: Senate Report, 38.
过往做法的使用: Justice Breyer is quoted in Jeffrey Rosen, “Breyer Restraint,” New Republic, July 11, 1994, at 19, 25.
偏离必须有正当理由: United States Sentencing Commission, Guidelines Manual (2018), www.ussc.gov/sites/default/files/pdf/guidelines-manual/2018/GLMFull.pdf.
“减少了净变异”: James M. Anderson, Jeffrey R. Kling, and Kate Stith, “Measuring Interjudge Sentencing Disparity: Before and After the Federal Sentencing Guidelines,” Journal of Law and Economics 42, no. S1 (April 1999): 271–308.
委员会本身: US Sentencing Commission, The Federal Sentencing Guidelines: A Report on the Operation of the Guidelines System and Short-Term Impacts on Disparity in Sentencing, Use of Incarceration, and Prosecutorial Discretion and Plea Bargaining, vols. 1 & 2 (Washington, DC: US Sentencing Commission, 1991).
根据另一项研究: Anderson, Kling, and Stith, “Interjudge Sentencing Disparity.”
一项独立研究: Paul J. Hofer, Kevin R. Blackwell, and R. Barry Ruback, “The Effect of the Federal Sentencing Guidelines on Inter-Judge Sentencing Disparity,” Journal of Criminal Law and Criminology 90 (1999): 239, 241.
“需要的不是盲目…”: Kate Stith and José Cabranes, Fear of Judging: Sentencing Guidelines in the Federal Courts (Chicago: University of Chicago Press, 1998), 79.
最高法院推翻了指导原则: 543 U.S. 220 (2005).
75%的人偏好咨询制度: US Sentencing Commission, “Results of Survey of United States District Judges, January 2010 through March 2010” (June 2010) (question 19, table 19), www.ussc.gov/sites/default/files/pdf/research-and-publications/research-projects-and-surveys/surveys/20100608_Judge_Survey.pdf.
“研究结果引发…”: Crystal Yang, “Have Interjudge Sentencing Disparities Increased in an Advisory Guidelines Regime? Evidence from Booker,” New York University Law Review 89 (2014): 1268–1342; pp. 1278, 1334.
为准备噪音审计: 公司高管构建了代表性案例的详细描述,类似于员工每天处理的风险和索赔。为财产和意外险部门的理赔员准备了六个案例,为专门处理金融风险的承保员准备了四个案例。员工被给予半天假期来评估两到三个案例。他们被指示独立工作,并且没有被告知研究目的是检验他们判断的变异性。总共,我们从四十八名承保员那里获得了八十六个判断,从六十八名理赔员那里获得了一百一十三个判断。
朴素现实主义: Dale W. Griffin and Lee Ross, “Subjective Construal, Social Inference, and Human Misunderstanding,” Advances in Experimental Social Psychology 24 (1991): 319–359; Robert J. Robinson, Dacher Keltner, Andrew Ward, and Lee Ross, “Actual Versus Assumed Differences in Construal: ‘Naive Realism’ in Intergroup Perception and Conflict,” Journal of Personality and Social Psychology 68, no. 3 (1995): 404; and Lee Ross and Andrew Ward, “Naive Realism in Everyday Life: Implications for Social Conflict and Misunderstanding,” Values and Knowledge (1997).
最常见的变异性测量: 一组数字的标准差来自另一个统计量,称为方差。为了计算方差,我们首先获得与均值的偏差分布,然后取每个偏差的平方。方差是这些平方偏差的均值,标准差是方差的平方根。
葡萄酒竞赛的评委: R. T. Hodgson, “An Examination of Judge Reliability at a Major U.S. Wine Competition,” Journal of Wine Economics 3, no. 2 (2008): 105–113.
权衡通过评估性判断来解决: 一些决策研究学者将决策定义为选项之间的选择,并将定量判断视为决策的特例,其中存在连续的可能选择。在这种观点中,判断是决策的特例。我们在这里的方法不同:我们将要求在选项之间进行选择的决策视为源于对每个选项的潜在评估性判断。也就是说,我们将决策视为判断的特例。
发明于1795年: 最小二乘法最早由阿德里安-马里·勒让德于1805年发表。高斯声称他在十年前就首次使用了这种方法,后来他将其与误差理论的发展以及以他命名的正态误差曲线联系起来。这一优先权争议已被广泛讨论,历史学家倾向于相信高斯的说法(Stephen M. Stigler, “Gauss and the Invention of Least Squares,” Annals of Statistics 9 [1981]: 465–474; and Stephen M. Stigler, The History of Statistics: The Measurement of Uncertainty Before 1900 [Cambridge, MA: Belknap Press of Harvard University Press, 1986])。
使用一些简单的代数: 我们将噪声定义为误差的标准差;因此噪声的平方就是误差的方差。方差的定义是”平方的均值减去均值的平方”。由于均值误差是偏差,“均值的平方”就是偏差的平方。因此:噪声² = MSE - 偏差²。
在这方面的直觉: Berkeley J. Dietvorst and Soaham Bharti, “People Reject Algorithms in Uncertain Decision Domains Because They Have Diminishing Sensitivity to Forecasting Error,” Psychological Science 31, no. 10 (2020): 1302–1314.
一项异常详细的研究: Kevin Clancy, John Bartolomeo, David Richardson, and Charles Wellford, “Sentence Decisionmaking: The Logic of Sentence Decisions and the Extent and Sources of Sentence Disparity,” Journal of Criminal Law and Criminology 72, no. 2 (1981): 524–554; and INSLAW, Inc. et al., “Federal Sentencing: Towards a More Explicit Policy of Criminal Sanctions III-4,” (1981).
被要求设定刑期: 刑期可以包括监禁时间、监督时间和罚金的任何组合。为简化起见,我们在这里主要关注刑期的主要组成部分——监禁时间——并暂不讨论其他两个组成部分。
这种方差就是通常所说的…: 在多案例、多法官的设置中,我们在第5章中介绍的误差方程的扩展版本包含一个反映这种方差的项。具体而言,如果我们将总偏差定义为所有案例的平均误差,如果这个误差在各案例中不完全相同,就会存在案例偏差的方差。方程变成:MSE = 总偏差² + 案例偏差方差 + 系统噪声²。
平均监禁期: 本章提到的数字来源于原始研究,具体推导如下。
首先,作者报告犯罪和罪犯的主要效应占总方差的45% (John Bartolomeo et al., “Sentence Decision-making: The Logic of Sentence Decisions and the Extent and Sources of Sentence Disparity,” Journal of Criminal Law and Criminology 72, no. 2 [1981], table 6)。然而,我们在这里更广泛地关注每个案例的效应,包括向法官展示的所有特征——比如被告是否有犯罪记录或在犯罪过程中是否使用了武器。根据我们的定义,所有这些特征都是真实案例方差的一部分,而非噪声。因此,我们将每个案例特征之间的交互作用重新整合到案例方差中(这些占总方差的11%;见Bartolomeo et al., table 10)。结果,我们重新定义了案例方差的份额为56%,法官主效应(水平噪声)为21%,交互作用在总方差中为23%。因此系统噪声占总方差的44%。
公正刑期的方差可以从Bartolomeo et al., 89页列出每个案例平均刑期的表格中计算出来:方差为15。如果这占总方差的56%,那么总方差为26.79,系统噪声的方差为11.79。该方差的平方根是代表性案例的标准差,即3.4年。
法官主效应或水平噪声占总方差的21%。该方差的平方根是归因于法官水平噪声的标准差,即2.4年。
3.4年: 这个值是十六个案例刑期方差平均值的平方根。我们按照前面注释中的说明进行计算。
简单的加法逻辑: 加法假设实际上假定法官的严厉程度会增加恒定的监禁时间。这个假设不太可能正确:法官的严厉程度更可能增加与平均刑期成比例的时间。原始报告忽略了这个问题,没有提供评估其重要性的方法。
“法官之间的模式化差异”: Bartolomeo et al., “Sentence Decision-making,” 23.
大致相等: 以下等式成立:(系统噪声)² = (水平噪声)² + (模式噪声)²。表格显示系统噪声为3.4年,水平噪声为2.4年。因此模式噪声也约为2.4年。这个计算作为例证——由于舍入误差,实际值略有不同。
历史最佳记录:参见 http://www.iweblists.com/sports/basketball/FreeThrowPercent_c.html,2020年12月27日查阅。
沙奎尔·奥尼尔:参见 https://www.basketball-reference.com/players/o/onealsh01.html,2020年12月27日查阅。
葡萄酒专家:R. T. Hodgson,《美国主要葡萄酒比赛中评委可靠性的研究》,《葡萄酒经济学杂志》第3卷第2期(2008年):105-113页。
软件顾问:Stein Grimstad 和 Magne Jørgensen,《基于专家判断的软件开发工作量估计的不一致性》,《系统与软件杂志》第80卷第11期(2007年):1770-1777页。
与自己的观点一致:Robert H. Ashton,《专业判断测试-重测可靠性研究的回顾与分析》,《行为决策杂志》第294卷第3期(2000年):277-294页。顺带一提,作者随后指出,他回顾的41项研究中没有一项是专门设计来评估场合噪音的:“在所有情况下,可靠性的测量都是其他研究目标的副产品”(Ashton,279页)。这一评论表明,对场合噪音的研究兴趣是相对较新的。
正确答案:中央情报局,《世界概况》(华盛顿特区:中央情报局,2020年)。引用的数字包括所有从空中可识别的机场或飞机场。跑道可能是铺装的或未铺装的,可能包括关闭或废弃的设施。
Edward Vul 和 Harold Pashler:Edward Vul 和 Harold Pashler,《内在群体:个体内的概率表征》。
更接近真相:James Surowiecki,《群体的智慧:为什么多数人比少数人更聪明,以及集体智慧如何塑造商业、经济、社会和国家》(纽约:Doubleday出版社,2004年)。
噪音更少:平均判断的标准差(我们的噪音衡量标准)与判断数量的平方根成反比地减少。
“你可以获得”:Vul 和 Pashler,《内在群体》,646页。
Stefan Herzog 和 Ralph Hertwig:Stefan M. Herzog 和 Ralph Hertwig,《三思而后行:在辩证引导中是组合还是选择?》,《实验心理学杂志:学习、记忆与认知》第40卷第1期(2014年):218-232页。
“所做的反应”:Vul 和 Pashler,《测量内在群体》,647页。
Joseph Forgas:Joseph P. Forgas,《情感对人际行为的影响》,《心理学探究》第13卷第1期(2002年):1-28页。
“同样的微笑…”:Forgas,《情感影响》,10页。
情绪转换的谈判者:A. Filipowicz,S. Barsade 和 S. Melwani,《理解情绪转换:谈判中情绪变化的人际后果》,《人格与社会心理学杂志》第101卷第3期(2011年):541-556页。
参与者阅读一篇简短的哲学论文:Joseph P. Forgas,《她看起来就不像哲学家…?情感对印象形成中光环效应的影响》,《欧洲社会心理学杂志》第41卷第7期(2011年):812-817页。
伪深刻陈述:Gordon Pennycook,James Allan Cheyne,Nathaniel Barr,Derek J. Koehler 和 Jonathan A. Fugelsang,《关于伪深刻胡说八道的接受与检测》,《判断与决策制定》第10卷第6期(2015年):549-563页。
论胡说八道:Harry Frankfurt,《论胡说八道》(新泽西州普林斯顿:普林斯顿大学出版社,2005年)。
“看似令人印象深刻的断言”:Pennycook 等,《伪深刻胡说八道》,549页。
更容易受骗:Joseph P. Forgas,《快乐的信徒和悲伤的怀疑者?情感对轻信的影响》,《心理科学当前方向》第28卷第3期(2019年):306-313页。
目击者:Joseph P. Forgas,《情绪对目击者记忆的影响:情感对误导信息易感性的影响》,《实验社会心理学杂志》第41卷第6期(2005年):574-588页。
天桥问题:Piercarlo Valdesolo 和 David Desteno,《情感语境的操纵塑造道德判断》,《心理科学》第17卷第6期(2006年):476-477页。
漫长一天结束时的阿片类药物:Hannah T. Neprash 和 Michael L. Barnett,《初级保健诊所预约时间与阿片类药物处方的关联》,《JAMA网络公开》第2卷第8期(2019年);Lindsey M. Philpot,Bushra A. Khokhar,Daniel L. Roellinger,Priya Ramar 和 Jon O. Ebbert,《一天中的时间与初级保健中腰痛阿片类药物处方相关》,《一般内科医学杂志》第33期(2018年):1828页。
抗生素:Jeffrey A. Linder,Jason N. Doctor,Mark W. Friedberg,Harry Reyes Nieva,Caroline Birks,Daniella Meeker 和 Craig R. Fox,《一天中的时间与抗生素处方决策》,《JAMA内科医学》第174卷第12期(2014年):2029-2031页。
流感疫苗:Rebecca H. Kim,Susan C. Day,Dylan S. Small,Christopher K. Snider,Charles A. L. Rareshide 和 Mitesh S. Patel,《诊所预约时间对流感疫苗接种的变化以及电子健康记录中增加流感疫苗接种的主动选择干预》,《JAMA网络公开》第1卷第5期(2018年):1-10页。
恶劣天气: 关于记忆改善的评论,见Joseph P. Forgas, Liz Goldenberg, and Christian Unkelbach, “Can Bad Weather Improve Your Memory? An Unobtrusive Field Study of Natural Mood Effects on Real-Life Memory,” Journal of Experimental Social Psychology 45, no. 1 (2008): 254–257. 关于阳光的评论,见David Hirshleifer and Tyler Shumway, “Good Day Sunshine: Stock Returns and the Weather,” Journal of Finance 58, no. 3 (2003): 1009–1032.
“阴天让书呆子看起来更好”: Uri Simonsohn, “Clouds Make Nerds Look Good: Field Evidence of the Impact of Incidental Factors on Decision Making,” Journal of Behavioral Decision Making 20, no. 2 (2007): 143–152.
赌徒谬误: Daniel Chen et al., “Decision Making Under the Gambler’s Fallacy: Evidence from Asylum Judges, Loan Officers, and Baseball Umpires,” Quarterly Journal of Economics 131, no. 3 (2016): 1181–1242.
批准庇护: Jaya Ramji-Nogales, Andrew I. Schoenholtz, and Philip Schrag, “Refugee Roulette: Disparities in Asylum Adjudication,” Stanford Law Review 60, no. 2 (2007).
记忆表现: Michael J. Kahana et al., “The Variability Puzzle in Human Memory,” Journal of Experimental Psychology: Learning, Memory, and Cognition 44, no. 12 (2018): 1857–1863.
音乐下载研究: Matthew J. Salganik, Peter Sheridan Dodds, and Duncan J. Watts, “Experimental Study of Inequality and Unpredictability in an Artificial Cultural Market,” Science 311 (2006): 854–856. 另见Matthew Salganik and Duncan Watts, “Leading the Herd Astray: An Experimental Study of Self-Fulfilling Prophecies in an Artificial Cultural Market,” Social Psychology Quarterly 71 (2008): 338–355; 以及Matthew Salganik and Duncan Watts, “Web-Based Experiments for the Study of Collective Social Dynamics in Cultural Markets,” Topics in Cognitive Science 1 (2009): 439–468.
流行度是自我强化的: Salganik and Watts, “Leading the Herd Astray.”
在许多其他领域: Michael Macy et al., “Opinion Cascades and the Unpredictability of Partisan Polarization,” Science Advances (2019): 1–8. 另见Helen Margetts et al., Political Turbulence (Princeton: Princeton University Press, 2015).
社会学家Michael Macy: Michael Macy et al., “Opinion Cascades.”
网站评论: Lev Muchnik et al., “Social Influence Bias: A Randomized Experiment,” Science 341, no. 6146 (2013): 647–651.
研究已经揭示: Jan Lorenz et al., “How Social Influence Can Undermine the Wisdom of Crowd Effect,” Proceedings of the National Academy of Sciences 108, no. 22 (2011): 9020–9025.
一项比较实验: Daniel Kahneman, David Schkade, and Cass Sunstein, “Shared Outrage and Erratic Awards: The Psychology of Punitive Damages,” Journal of Risk and Uncertainty 16 (1998): 49–86.
五百个模拟陪审团: David Schkade, Cass R. Sunstein, and Daniel Kahneman, “Deliberating about Dollars: The Severity Shift,” Columbia Law Review 100 (2000): 1139–1175.
一致性百分比: 一致性百分比(PC)与Kendall’s W密切相关,也称为一致性系数。
身高和脚的大小: Kanwal Kamboj et al., “A Study on the Correlation Between Foot Length and Height of an Individual and to Derive Regression Formulae to Estimate the Height from Foot Length of an Individual,” International Journal of Research in Medical Sciences 6, no. 2 (2018): 528.
表1展示了PC: PC是基于联合分布为双变量正态分布的假设计算的。表中显示的数值是基于该假设的近似值。我们感谢Julian Parris制作了这个表格。
实际的绩效预测研究: Martin C. Yu and Nathan R. Kuncel, “Pushing the Limits for Judgmental Consistency: Comparing Random Weighting Schemes with Expert Judgments,” Personnel Assessment and Decisions 6, no. 2 (2020): 1–10. 专家达到的.15相关性是所研究的三个样本的未加权平均值,总共包括847个案例。真实研究在几个方面与这个简化的描述有所不同。
加权平均: 构建加权平均的前提是所有预测因子必须以可比较的单位进行测量。在我们的介绍性例子中满足了这个要求,其中所有评级都是在0到10的量表上进行的,但情况并非总是如此。例如,绩效的预测因子可能是面试官在0到10量表上的评估、相关经验的年数以及熟练程度测试的分数。多元回归程序在组合之前将所有预测因子转换为标准分数。标准分数衡量观测值与总体均值的距离,以标准差为单位。例如,如果熟练程度测试的均值是55,标准差是8,则+1.5的标准分数对应67的测试结果。值得注意的是,每个人数据的标准化消除了个人判断的均值或方差中任何错误的痕迹。
获得大权重: 多元回归的一个重要特征是每个预测因子的最优权重取决于其他预测因子。如果一个预测因子与另一个高度相关,它不应该得到同样大的权重——这将是一种”重复计算”的形式。
“工作马…”: Robin M. Hogarth and Natalia Karelaia, “Heuristic and Linear Models of Judgment: Matching Rules and Environments,” Psychological Review 114, no. 3 (2007): 734.
简单结构: 在这种情况下被广泛使用的研究框架是判断透镜模型,本讨论基于此模型。参见Kenneth R. Hammond, “Probabilistic Functioning and the Clinical Method,” Psychological Review 62, no. 4 (1955): 255–262; Natalia Karelaia and Robin M. Hogarth, “Determinants of Linear Judgment: A Meta-Analysis of Lens Model Studies,” Psychological Bulletin 134, no. 3 (2008): 404–426.
Paul E. Meehl, 临床预测与统计预测: 理论分析与证据回顾 (Minneapolis: University of Minnesota Press, 1954).
弗洛伊德的照片: Paul E. Meehl, Clinical Versus Statistical Prediction: A Theoretical Analysis and a Review of the Evidence (Northvale, NJ: Aronson, 1996), preface.
博学者: “Paul E. Meehl,” in Ed Lindzey (ed.), A History of Psychology in Autobiography, 1989.
“大量且一致的”: “Paul E. Meehl,” in A History of Psychology in Autobiography, ed. Ed Lindzey (Washington, DC: American Psychological Association, 1989), 362.
2000年的一项综述: William M. Grove et al., “Clinical Versus Mechanical Prediction: A Meta-Analysis,” Psychological Assessment 12, no. 1 (2000): 19–30.
获取”私人”信息: William M. Grove and Paul E. Meehl, “Comparative Efficiency of Informal (Subjective, Impressionistic) and Formal (Mechanical, Algorithmic) Prediction Procedures: The Clinical-Statistical Controversy,” Psychology, Public Policy, and Law 2, no. 2 (1996): 293–323.
在1960年代末: Lewis Goldberg, “Man Versus Model of Man: A Rationale, plus Some Evidence, for a Method of Improving on Clinical Inferences,” Psychological Bulletin 73, no. 6 (1970): 422–432.
绝非如此: Milton Friedman and Leonard J. Savage, “The Utility Analysis of Choices Involving Risk,” Journal of Political Economy 56, no. 4 (1948): 279–304.
这种相关性: Karelaia and Hogarth, “Determinants of Linear Judgment,” 411, table 1.
早期的重复实验: Nancy Wiggins and Eileen S. Kohen, “Man Versus Model of Man Revisited: The Forecasting of Graduate School Success,” Journal of Personality and Social Psychology 19, no. 1 (1971): 100–106.
五十年的综述: Karelaia and Hogarth, “Determinants of Linear Judgment.”
提高预测准确性: 对预测因子不完美可靠性的相关系数修正被称为减弱修正。公式为修正rxy = rxy/√ rxx,其中rxx是可靠性系数(预测因子观察方差中真实方差的比例)。
Martin Yu和Nathan Kuncel的研究: Yu and Kuncel, “Judgmental Consistency.”
随机公式: 我们在下一章中更详细地讨论等权重和随机权重模型。权重被限制在小数字范围内,并且被限制具有正确的符号。
远优于临床判断: Robyn M. Dawes and Bernard Corrigan, “Linear Models in Decision Making,” Psychological Bulletin 81, no. 2 (1974): 95–106. Dawes和Corrigan还提出使用随机权重。第9章描述的管理绩效预测研究是这一想法的应用。
“违背统计直觉”: Jason Dana, “What Makes Improper Linear Models Tick?,” in Rationality and Social Responsibility: Essays in Honor of Robyn M. Dawes, ed. Joachim I. Krueger, 71–89 (New York: Psychology Press, 2008), 73.
类似结果: Jason Dana and Robyn M. Dawes, “The Superiority of Simple Alternatives to Regression for Social Sciences Prediction,” Journal of Educational and Behavior Statistics 29 (2004): 317–331; Dana, “What Makes Improper Linear Models Tick?”
“无关紧要”: Howard Wainer, “Estimating Coefficients in Linear Models: It Don’t Make No Nevermind,” Psychological Bulletin 83, no. 2 (1976): 213–217.
“我们不需要”: Dana, “What Makes Improper Linear Models Tick?,” 72.
与结果的相关性: Martin C. Yu and Nathan R. Kuncel, “Pushing the Limits for Judgmental Consistency: Comparing Random Weighting Schemes with Expert Judgments,” Personnel Assessment and Decisions 6, no. 2 (2020): 1–10. 与前一章一样,报告的相关性是所研究三个样本的未加权平均值。这种比较在三个样本中都成立:临床专家判断的有效性分别为.17、.16和.13,等权重模型的有效性分别为.19、.33和.22。
“稳健的美”: Robyn M. Dawes, “The Robust Beauty of Improper Linear Models in Decision Making,” American Psychologist 34, no. 7 (1979): 571–582.
“全部诀窍”: Dawes and Corrigan, “Linear Models in Decision Making,” 105.
一个研究团队: Jongbin Jung, Conner Concannon, Ravi Shroff, Sharad Goel, and Daniel G. Goldstein, “Simple Rules to Guide Expert Classifications,” Journal of the Royal Statistical Society, Statistics in Society, no. 183 (2020): 771–800.
一个独立团队: Julia Dressel 和 Hany Farid,“预测再犯的准确性、公平性和局限性”,《科学进展》第4卷第1期 (2018): 1–6。
仅两个输入: 这两个例子是基于极少变量集的线性模型(在保释模型的情况下,基于通过舍入方法获得的线性权重近似值,该方法将模型转换为粗略计算)。另一种”不当模型”类型是单变量规则,它只考虑一个预测因子并忽略所有其他因子。参见 Peter M. Todd 和 Gerd Gigerenzer,“让我们变聪明的简单启发法要览”,《行为与脑科学》第23卷第5期 (2000): 727–741。
有据可查: P. Gendreau、T. Little 和 C. Goggin,“成年罪犯再犯预测因子的元分析:什么有效!”,《犯罪学》第34期 (1996)。
非常大的数据集: 这里的规模应理解为观察数与预测因子数的比值。Dawes,“稳健之美”,建议在交叉验证中,该比值必须高达15:1或20:1,最优权重才能比单位权重表现更好。Dana 和 Dawes,“简单替代方案的优越性”,使用了更多案例研究,将标准提高到100:1的比值。
另一个团队: J. Kleinberg、H. Lakkaraju、J. Leskovec、J. Ludwig 和 S. Mullainathan,“人类决策与机器预测”,《经济学季刊》第133期 (2018): 237–293。
训练了一个机器学习算法: 该算法在训练数据子集上进行训练,然后评估其在不同随机选择子集上预测结果的能力。
“机器学习算法发现”: Kleinberg 等,“人类决策”,16。
系统噪声包括: Gregory Stoddard、Jens Ludwig 和 Sendhil Mullainathan,与作者的电子邮件交流,2020年6-7月。
软件工程师招聘: B. Cowgill,“人类和算法中的偏见与生产力:简历筛选的理论与证据”,在史密斯创业研究会议上发表的论文,马里兰州大学公园分校,2018年4月21日。
1996年的一篇文章: William M. Grove 和 Paul E. Meehl,“非正式(主观、印象式)和正式(机械、算法)预测程序的比较效率:临床-统计争议”,《心理学、公共政策与法律》第2卷第2期 (1996): 293–323。
更偏好算法: Jennifer M. Logg、Julia A. Minson 和 Don A. Moore,“算法欣赏:人们更偏好算法而非人类判断”,《组织行为与人类决策过程》第151期 (2018年4月): 90–103。
一旦看到它犯错误: B. J. Dietvorst、J. P. Simmons 和 C. Massey,“算法厌恶:人们在看到算法出错后错误地避免使用算法”,《实验心理学通报》第144期 (2015): 114–126。另见 A. Prahl 和 L. Van Swol,“理解算法厌恶:何时来自自动化的建议被打折?”,《预测杂志》第36期 (2017): 691–702。
如果这种期望被违背: M. T. Dzindolet、L. G. Pierce、H. P. Beck 和 L. A. Dawe,“视觉检测任务中人类和自动化辅助的感知效用”,《人因学:人因工程学会杂志》第44卷第1期 (2002): 79–94;K. A. Hoff 和 M. Bashir,“对自动化的信任:整合影响信任因素的实证证据”,《人因学:人因工程学会杂志》第57卷第3期 (2015): 407–434;以及 P. Madhavan 和 D. A. Wiegmann,“人-人信任与人-自动化信任的相似性和差异:整合性回顾”,《人体工程学理论问题》第8卷第4期 (2007): 277–301。
管理决策制定研究: E. Dane 和 M. G. Pratt,“探索直觉及其在管理决策制定中的作用”,《管理学评论》第32卷第1期 (2007): 33–54;Cinla Akinci 和 Eugene Sadler-Smith,“管理研究中的直觉:历史回顾”,《国际管理评论杂志》第14期 (2012): 104–122;以及 Gerard P. Hodgkinson 等,“组织中的直觉:对战略管理的影响”,《长期规划》第42期 (2009): 277–297。
一项回顾: Hodgkinson 等,“组织中的直觉”,279。
最近的一项回顾: Nathan Kuncel 等,“选拔和录取决策中的机械与临床数据组合:元分析”,《应用心理学杂志》第98卷第6期 (2013): 1060–1072。另见第24章关于人事决策的进一步讨论。
过度自信: Don A. Moore,《完全自信:如何明智地校准你的决策》(纽约:哈珀柯林斯出版社,2020)。
“评论或提供建议”: Philip E. Tetlock,《专家政治判断:有多好?我们如何知道?》(新泽西州普林斯顿:普林斯顿大学出版社,2005),239和233。
136项研究的回顾: William M. Grove 等,“临床与机械预测:元分析”,《心理评估》第12卷第1期 (2000): 19–30。
心脏病发作: Sendhil Mullainathan 和 Ziad Obermeyer,“谁接受心脏病发作检测以及谁应该接受:预测患者风险和医生错误”,2019。NBER工作论文26168,国家经济研究局。
[在他们认为高度不确定的情况下]: Weston Agor, “The Logic of Intuition: How Top Executives Make Important Decisions,” Organizational Dynamics 14, no. 3 (1986): 5–18; Lisa A. Burke and Monica K. Miller, “Taking the Mystery Out of Intuitive Decision Making,” Academy of Management Perspectives 13, no. 4 (1999): 91–99.
[准备信任算法]: Poornima Madhavan and Douglas A. Wiegmann, “Effects of Information Source, Pedigree, and Reliability on Operator Interaction with Decision Support Systems,” Human Factors: The Journal of the Human Factors and Ergonomics Society 49, no. 5 (2007).
[一篇不寻常的文章]: Matthew J. Salganik et al., “Measuring the Predictability of Life Outcomes with a Scientific Mass Collaboration,” Proceedings of the National Academy of Sciences 117, no. 15 (2020): 8398–8403.
[总样本]: 这包括4,242个家庭,由于隐私原因,脆弱家庭研究中的一些家庭被排除在此分析之外。
[相关性为0.22]: 为了评分准确性,竞赛组织者使用了我们在第一部分介绍的相同指标:均方误差(MSE)。为了便于比较,他们还将每个模型的MSE与一种”无用”预测策略进行基准测试:一种一刀切的预测,即每个个案都与训练集的平均值没有差异。为方便起见,我们将他们的结果转换为相关系数。MSE和相关性由表达式r2 = (Var (Y) − MSE) / Var (Y)关联,其中Var (Y)是结果变量的方差,(Var (Y) − MSE)是预测结果的方差。
[社会心理学研究的广泛综述]: F. D. Richard et al., “One Hundred Years of Social Psychology Quantitatively Described,” Review of General Psychology 7, no. 4 (2003): 331–363.
[对708项研究的综述]: Gilles E. Gignac and Eva T. Szodorai, “Effect Size Guidelines for Individual Differences Researchers,” Personality and Individual Differences 102 (2016): 74–78.
[“研究人员必须调和”]: 需要说明一点。按照设计,这项研究使用了一个现有的描述性数据集,该数据集非常庞大,但并非专门为预测特定结果而定制。这与Tetlock研究中的专家有重要区别,那些专家可以自由使用他们认为合适的任何信息。例如,可能可以识别出数据库中没有但可以设想收集到的驱逐预测因子。因此,这项研究并不能证明驱逐和其他结果在本质上有多么不可预测,而是证明了基于这个数据集它们有多么不可预测,而这个数据集被众多社会科学家使用。
[因果链]: Jake M. Hofman et al., “Prediction and Explanation in Social Systems,” Science 355 (2017): 486–488; Duncan J. Watts et al., “Explanation, Prediction, and Causality: Three Sides of the Same Coin?,” October 2018, 1–14, available through Center for Open Science, https://osf.io/bgwjc.
[对我们的大脑来说更自然]: 一个密切相关的区别是对比外延性思维与非外延性或内涵性思维。Amos Tversky and Daniel Kahneman, “Extensional Versus Intuitive Reasoning: The Conjunction Fallacy in Probability Judgment,” Psychological Review 4 (1983): 293–315.
[向后看的]: Daniel Kahneman and Dale T. Miller, “Norm Theory: Comparing Reality to Its Alternatives,” Psychological Review 93, no. 2 (1986): 136–153.
[关于后见之明的经典研究]: Baruch Fischhoff, “An Early History of Hindsight Research,” Social Cognition 25, no. 1 (2007): 10–13, doi:10.1521/soco.2007.25.1.10; Baruch Fischhoff, “Hindsight Is Not Equal to Foresight: The Effect of Outcome Knowledge on Judgment Under Uncertainty,” Journal of Experimental Psychology: Human Perception and Performance 1, no. 3 (1975): 288.
[系统2]: Daniel Kahneman, Thinking, Fast and Slow. New York: Farrar, Straus and Giroux, 2011.
[前四十年]: Daniel Kahneman, Thinking, Fast and Slow (New York: Farrar, Straus and Giroux, 2011).
[证据表明]: 需要说明一点。研究判断偏差的心理学家不满足于每组只有五名参与者,如图10所示,这是有充分理由的:因为判断是有噪音的,每个实验组的结果很少像图11所示的那样紧密聚集。人们在对每种偏差的敏感性上存在差异,并且不会完全忽略相关变量。例如,如果参与者数量非常庞大,你几乎肯定可以确认范围不敏感性是不完美的:分配给Gambardi离开职位的平均概率在三年的情况下比两年的情况下稍微高一点。尽管如此,范围不敏感性的描述是恰当的,因为这种差异只是应有差异的极小部分。
[多项实验]: Daniel Kahneman et al., eds., Judgment Under Uncertainty: Heuristics and Biases (New York: Cambridge University Press, 1982), chap. 6; Daniel Kahneman and Amos Tversky, “On the Psychology of Prediction,” Psychological Review 80, no. 4 (1973): 237–251.
CEO离职率的估计: 例如,参见 Steven N. Kaplan 和 Bernadette A. Minton,“CEO离职率如何变化?”,International Review of Finance 12, no. 1 (2012): 57–87。另见 Dirk Jenter 和 Katharina Lewellen,“业绩导致的CEO离职”,Harvard Law School Forum on Corporate Governance,2020年9月2日,https://corpgov.law.harvard.edu/2020/09/02/performance-induced-ceo-turnover。
在关键时刻: J. W. Rinzler,《星球大战:绝地归来》的制作:权威故事 (纽约:Del Rey出版社,2013年),64页。
剧本的发展: Cass Sunstein,《根据星球大战看世界》 (纽约:HarperCollins出版社,2016年)。
选择性和扭曲性: 我们在这里强调的是判断开始时就存在先入之见的简单情况。事实上,即使在没有这种先入之见的情况下,随着证据的积累,也会产生倾向于特定结论的偏见,这是因为简单性和一致性的倾向。当初步结论出现时,确认偏误会使新证据的收集和解释向有利于该结论的方向倾斜。
即使在推理过程中: 这种观察被称为信念偏误。参见 J. St. B. T. Evans,Julie L. Barson 和 Paul Pollard,“三段论推理中逻辑与信念的冲突”,Memory & Cognition 11, no. 3 (1983): 295–306。
在典型的演示中: Dan Ariely,George Loewenstein 和 Drazen Prelec,“‘一致的任意性’:没有稳定偏好的稳定需求曲线”,Quarterly Journal of Economics 118, no. 1 (2003): 73–105。
在谈判中: Adam D. Galinsky 和 T. Mussweiler,“首次报价作为锚点:角色转换和谈判者焦点的作用”,Journal of Personality and Social Psychology 81, no. 4 (2001): 657–669。
过度一致性: Solomon E. Asch,“人格印象的形成”,Journal of Abnormal and Social Psychology 41, no. 3 (1946): 258–290,首次使用不同顺序的形容词系列来说明这种现象。
在一项揭示性研究中: Steven K. Dallas 等,“不要忽视卡路里标注:菜单项目左侧的卡路里数会导致更低卡路里的食物选择”,Journal of Consumer Psychology 29, no. 1 (2019): 60–69。
一个强度量表到另一个: S. S. Stevens,“关于称为判断的操作”,American Scientist 54, no. 4 (1966年12月): 385–401。我们对匹配一词的使用比Stevens的更广泛,Stevens仅限于比率量表,我们将在第15章回到这个话题。
系统性判断错误: 这个例子首次出现在 Daniel Kahneman,《思考,快与慢》 (纽约:Farrar, Straus and Giroux出版社,2011年)。
完全相同的数字: Daniel Kahneman 和 Amos Tversky,“关于预测心理学”,Psychological Review 80 (1973): 237–251。
“神奇数字七”: G. A. Miller,“神奇数字七,正负二:我们处理信息能力的一些限制”,Psychological Review (1956): 63–97。
迫使比较的量表: R. D. Goffin 和 J. M. Olson,“这一切都是相对的吗?比较判断以及自我评价和他人评价的可能改进”,Perspectives on Psychological Science 6 (2011): 48–60。
1998年报告: Daniel Kahneman,David Schkade 和 Cass Sunstein,“共同愤怒和不稳定裁决:惩罚性损害赔偿的心理学”,Journal of Risk and Uncertainty 16 (1998): 49–86,https://link.springer.com/article/10.1023/A:1007710408413;以及 Cass Sunstein,Daniel Kahneman 和 David Schkade,“评估惩罚性损害赔偿(附法律中认知和评估的注释)”,Yale Law Journal 107, no. 7 (1998年5月): 2071–2153。研究费用由埃克森美孚公司在一次性安排下承担,但该公司没有支付研究人员费用,对数据没有控制权,在学术期刊发表前也不知道结果。
“合理怀疑”: A. Keane 和 P. McKeown,《现代证据法》 (纽约:牛津大学出版社,2014年)。
“不太可能发生”: Andrew Mauboussin 和 Michael J. Mauboussin,“如果你说某事’可能’,人们认为有多大可能?”,Harvard Business Review, 2018年7月3日。
新BMW: BMW诉Gore案,517 U.S. 559 (1996),https://supreme.justia.com/cases/federal/us/517/559。
愤怒情绪: 关于情绪在道德判断中作用的讨论,参见 J. Haidt,“情绪狗及其理性尾巴:道德判断的社会直觉主义方法”,Psychological Review 108, no. 4 (2001): 814–834;Joshua Greene,《道德部落:情感、理性以及我们与他们之间的鸿沟》 (纽约:企鹅出版社,2014年)。
图13显示了结果: 考虑到这些评级中的大量噪音,你可能会对愤怒和惩罚意图判断之间的极高相关性(.98)感到困惑,这为愤怒假说提供了支持。当你回想起相关性是在判断的平均值之间计算的时候,困惑就消失了。对于100个判断的平均值,噪音(判断的标准偏差)减少了10倍。当许多判断被聚合时,噪音不再是一个因素。参见第21章。
强度比率: S. S. Stevens,《心理物理学:感知、神经和社会前景导论》 (纽约:John Wiley & Sons出版社,1975年)。
“coherent arbitrariness”(连贯的任意性): Dan Ariely, George Loewenstein, and Drazen Prelec, ” ‘Coherent Arbitrariness’: Stable Demand Curves Without Stable Preferences,” Quarterly Journal of Economics 118, no. 1 (2003): 73–106.
将美元奖励转化为排名: 转化为排名会导致信息丢失,因为判断之间的距离没有被保留。假设只有三个案例,一名陪审员建议的损害赔偿金分别为1000万美元、200万美元和100万美元。显然,陪审员意图传达前两个案例之间的惩罚性差异大于第二和第三个案例之间的差异。然而,一旦转换为排名,差异将是相同的——仅仅是一个排名的差异。这个问题可以通过将判断转换为标准分数来解决。
感知过程: R. Blake and N. K. Logothetis, “Visual competition,” Nature Reviews Neuroscience 3 (2002) 13–21; M. A. Gernsbacher and M. E. Faust, “The Mechanism of Suppression: A Component of General Comprehension Skill,” Journal of Experimental Psychology: Learning, Memory, and Cognition 17 (March 1991): 245–262; and M. C. Stites and K. D. Federmeier, “Subsequent to Suppression: Downstream Comprehension Consequences of Noun/Verb Ambiguity in Natural Reading,” Journal of Experimental Psychology: Learning, Memory, and Cognition 41 (September 2015): 1497–1515.
比我们应该的更自信: D. A. Moore and D. Schatz, “The three faces of overconfidence,” Social and Personality Psychology Compass 11, no. 8 (2017), article e12331.
构建团队: P. J. Lamberson and Scott Page, “Optimal forecasting groups,” Management Science 58, no. 4 (2012): 805–10. 我们感谢Scott Page让我们注意到这个模式噪声来源。
早期扫描尝试: Allport和Odbert (1936)关于英语人格相关词汇的工作被引用在Oliver P. John and Sanjay Srivastava, “The Big-Five Trait Taxonomy: History, Measurement, and Theoretical Perspectives,” in Handbook of Personality: Theory and Research, 2nd ed., ed. L. Pervin and Oliver P. John (New York: Guilford, 1999).
被认为较高: Ian W. Eisenberg, Patrick G. Bissett, A. Zeynep Enkavi et al., “Uncovering the structure of self-regulation through data-driven ontology discovery,” Nature Communications 10 (2019): 2319.
当受到身体威胁时: Walter Mischel, “Toward an integrative science of the person,” Annual Review of Psychology 55 (2004): 1–22.
MSE如何分解: 虽然关于偏差和噪声的分解没有通用规则,但这个图表中的比例大致代表了我们审查过的一些实际或虚构的例子。具体而言,在这个图表中,偏差和噪声相等(就像GoodSell的销售预测一样)。水平噪声的平方占系统噪声平方的37%(就像惩罚性损害赔偿研究中的情况)。如图所示,场合噪声的平方约占模式噪声平方的35%。
专利局: 见引言中的参考文献。Mark A. Lemley and Bhaven Sampat, “Examiner Characteristics and Patent Office Outcomes,” Review of Economics and Statistics 94, no. 3 (2012): 817–827. 另见Iain Cockburn, Samuel Kortum, and Scott Stern, “Are All Patent Examiners Equal? The Impact of Examiner Characteristics,” working paper 8980, June 2002, www.nber.org/papers/w8980; and Michael D. Frakes and Melissa F. Wasserman, “Is the Time Allocated to Review Patent Applications Inducing Examiners to Grant Invalid Patents? Evidence from Microlevel Application Data,” Review of Economics and Statistics 99, no. 3 (July 2017): 550–563.
儿童保护服务: Joseph J. Doyle Jr., “Child Protection and Child Outcomes: Measuring the Effects of Foster Care,” American Economic Review 95, no. 5 (December 2007): 1583–1610.
庇护法官: Andrew I. Schoenholtz, Jaya Ramji-Nogales, and Philip G. Schrag, “Refugee Roulette: Disparities in Asylum Adjudication,” Stanford Law Review 60, no. 2 (2007).
约2.8年: 这个数值是根据第6章中提出的计算估算的,其中交互方差占总方差的23%。假设刑期呈正态分布,两个随机选择观察值之间的平均绝对差异是1.128个标准差。
普林斯顿的一组研究人员: J. E. Martinez, B. Labbree, S. Uddenberg, and A. Todorov, “Meaningful ‘noise’: Comparative judgments contain stable idiosyncratic contributions” (unpublished ms.).
保释法官研究: J. Kleinberg, H. Lakkaraju, J. Leskovec, J. Ludwig, and S. Mullainathan, “Human Decisions and Machine Predictions,” Quarterly Journal of Economics 133 (2018): 237–293.
应用模拟法官: 该模型为每位法官产生了141,833个案例的排序和一个超过该阈值就会批准保释的门槛。水平噪声反映了阈值的可变性,而模式噪声反映了案例排序的可变性。
稳定的模式噪声: Gregory Stoddard, Jens Ludwig, and Sendhil Mullainathan, e-mail exchanges with authors, June–July 2020.
Phil Rosenzweig有说服力地论证: Phil Rosenzweig. Left Brain, Right Stuff: How Leaders Make Winning Decisions (New York: PublicAffairs, 2014).
群体由更有能力的人组成: Albert E. Mannes et al., “The Wisdom of Select Crowds,” Journal of Personality and Social Psychology 107, no. 2 (2014): 276–299; Jason Dana et al., “The Composition of Optimally Wise Crowds,” Decision Analysis 12, no. 3 (2015): 130–143.
信心启发式: Briony D. Pulford, Andrew M. Colmna, Eike K. Buabang, and Eva M. Krockow, “The Persuasive Power of Knowledge: Testing the Confidence Heuristic,” Journal of Experimental Psychology: General 147, no. 10 (2018): 1431–1444.
它不仅与: Nathan R. Kuncel and Sarah A. Hezlett, “Fact and Fiction in Cognitive Ability Testing for Admissions and Hiring Decisions,” Current Directions in Psychological Science 19, no. 6 (2010): 339–345.
持续的误解: Kuncel and Hezlett, “Fact and Fiction.”
正如一篇综述所说: Frank L. Schmidt and John Hunter, “General Mental Ability in the World of Work: Occupational Attainment and Job Performance,” Journal of Personality and Social Psychology 86, no. 1 (2004): 162.
尽责性和坚毅: Angela L. Duckworth, David Weir, Eli Tsukayama, and David Kwok, “Who Does Well in Life? Conscientious Adults Excel in Both Objective and Subjective Success,” Frontiers in Psychology 3 (September 2012). For grit, see Angela L. Duckworth, Christopher Peterson, Michael D. Matthews, and Dennis Kelly, “Grit: Perseverance and Passion for Long-Term Goals,” Journal of Personality and Social Psychology 92, no. 6 (2007): 1087–1101.
流体智力: Richard E. Nisbett et al., “Intelligence: New Findings and Theoretical Developments,” American Psychologist 67, no. 2 (2012): 130–159.
“比大多数更大”: Schmidt and Hunter, “Occupational Attainment,” 162.
在0.50范围内: Kuncel and Hezlett, “Fact and Fiction.”
按照社会科学标准: 这些相关性来自元分析,对观察到的相关性进行了测量误差校正和范围限制校正。研究者对这些校正是否夸大了GMA的预测价值存在一些争议。然而,由于这些方法论争议也适用于其他预测因子,专家普遍认为GMA(连同工作样本测试;见第24章)是可获得的工作成功最佳预测因子。见Kuncel and Hezlett, “Fact and Fiction.”
几乎没有低于平均GMA的人: Schmidt and Hunter, “Occupational Attainment,” 162.
即使在前1%中: David Lubinski, “Exceptional Cognitive Ability: The Phenotype,” Behavior Genetics 39, no. 4 (2009): 350–358.
2013年一项专注于财富500强公司CEO的研究: Jonathan Wai, “Investigating America’s Elite: Cognitive Ability, Education, and Sex Differences,” Intelligence 41, no. 4 (2013): 203–211.
其他被提出的问题: Keela S. Thomson and Daniel M. Oppenheimer, “Investigating an Alternate Form of the Cognitive Reflection Test,” Judgment and Decision Making 11, no. 1 (2016): 99–113.
较低的CRT分数与: Gordon Pennycook et al., “Everyday Consequences of Analytic Thinking,” Current Directions in Psychological Science 24, no. 6 (2015): 425–432.
容易被明显不准确的”假新闻”欺骗: Gordon Pennycook and David G. Rand, “Lazy, Not Biased: Susceptibility to Partisan Fake News Is Better Explained by Lack of Reasoning than by Motivated Reasoning,” Cognition 188 (June 2018): 39–50.
人们使用智能手机的程度: Nathaniel Barr et al., “The Brain in Your Pocket: Evidence That Smartphones Are Used to Supplant Thinking,” Computers in Human Behavior 48 (2015): 473–480.
使用反思性思维的倾向: Niraj Patel, S. Glenn Baker, and Laura D. Scherer, “Evaluating the Cognitive Reflection Test as a Measure of Intuition/Reflection, Numeracy, and Insight Problem Solving, and the Implications for Understanding Real-World Judgments and Beliefs,” Journal of Experimental Psychology: General 148, no. 12 (2019): 2129–2153.
认知需求量表: John T. Cacioppo and Richard E. Petty, “The Need for Cognition,” Journal of Personality and Social Psychology 42, no. 1 (1982): 116–131.
较少受到已知认知偏见的影响: Stephen M. Smith and Irwin P. Levin, “Need for Cognition and Choice Framing Effects,” Journal of Behavioral Decision Making 9, no. 4 (1996): 283–290.
剧透警告: Judith E. Rosenbaum and Benjamin K. Johnson, “Who’s Afraid of Spoilers? Need for Cognition, Need for Affect, and Narrative Selection and Enjoyment,” Psychology of Popular Media Culture 5, no. 3 (2016): 273–289.
成人决策能力量表: Wandi Bruine De Bruin et al., “Individual Differences in Adult Decision-Making Competence,” Journal of Personality and Social Psychology 92, no. 5 (2007): 938–956.
Halpern批判性思维: Heather A. Butler, “Halpern Critical Thinking Assessment Predicts Real-World Outcomes of Critical Thinking,” Applied Cognitive Psychology 26, no. 5 (2012): 721–729.
可能预测预测能力: Uriel Haran, Ilana Ritov, and Barbara Mellers, “The Role of Actively Open-Minded Thinking in Information Acquisition, Accuracy, and Calibration,” Judgment and Decision Making 8, no. 3 (2013): 188–201.
“积极开放思维”: Haran, Ritov, and Mellers, “Role of Actively Open-Minded Thinking.”
一项可以教授的技能: J. Baron, “Why Teach Thinking? An Essay,” Applied Psychology: An International Review 42 (1993): 191–214; J. Baron, The Teaching of Thinking: Thinking and Deciding, 2nd ed. (New York: Cambridge University Press, 1994), 127–148.
他们的核心发现: 关于出色的综述,请参见 Jack B. Soll et al., “A User’s Guide to Debiasing,” in The Wiley Blackwell Handbook of Judgment and Decision Making, ed. Gideon Keren and George Wu, vol. 2 (New York: John Wiley & Sons, 2015), 684.
绿皮书: HM Treasury, The Green Book: Central Government Guidance on Appraisal and Evaluation (London: UK Crown, 2018), https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/685903/The_Green_Book.pdf.
nudges: Richard H. Thaler and Cass R. Sunstein, Nudge: Improving Decisions about Health, Wealth, and Happiness (New Haven, CT: Yale University Press, 2008).
boosting: Ralph Hertwig and Till Grüne-Yanoff, “Nudging and Boosting: Steering or Empowering Good Decisions,” Perspectives on Psychological Science 12, no. 6 (2017).
教育是有用的: Geoffrey T. Fong et al., “The Effects of Statistical Training on Thinking About Everyday Problems,” Cognitive Psychology 18, no. 3 (1986): 253–292.
同样过度自信: Willem A. Wagenaar and Gideon B. Keren, “Does the Expert Know? The Reliability of Predictions and Confidence Ratings of Experts,” Intelligent Decision Support in Process Environments (1986): 87–103.
减少了错误数量: Carey K. Morewedge et al., “Debiasing Decisions: Improved Decision Making with a Single Training Intervention,” Policy Insights from the Behavioral and Brain Sciences 2, no. 1 (2015): 129–140.
应用了这种学习: Anne-Laure Sellier et al., “Debiasing Training Transfers to Improve Decision Making in the Field,” Psychological Science 30, no. 9 (2019): 1371–1379.
偏见盲点: Emily Pronin et al., “The Bias Blind Spot: Perceptions of Bias in Self Versus Others,” Personality and Social Psychology Bulletin 28, no. 3 (2002): 369–381.
可能影响的偏见: Daniel Kahneman, Dan Lovallo, and Olivier Sibony, “Before You Make That Big Decision …,” Harvard Business Review 89, no. 6 (June 2011): 50–60.
检查清单有悠久的历史: Atul Gawande, Checklist Manifesto: How to Get Things Right (New York: Metropolitan Books, 2010).
一个简单的检查清单: Office of Information and Regulatory Affairs, “Agency Checklist: Regulatory Impact Analysis,” no date, www.whitehouse.gov/sites/whitehouse.gov/files/omb/inforeg/inforeg/regpol/RIA_Checklist.pdf.
我们已经包含: 这个检查清单部分改编自 Daniel Kahneman et al., “Before You Make That Big Decision,” Harvard Business Review.
促进其采用: 参见 Gawande, Checklist Manifesto.
“人为错误”: R. Stacey, “A Report on the Erroneous Fingerprint Individualisation in the Madrid Train Bombing Case,” Journal of Forensic Identification 54 (2004): 707–718.
FBI网站: Michael Specter, “Do Fingerprints Lie?,” The New Yorker, May 27, 2002. 强调为笔者所加。
正如Dror所说: I. E. Dror and R. Rosenthal, “Meta-analytically Quantifying the Reliability and Biasability of Forensic Experts,” Journal of Forensic Science 53 (2008): 900–903.
在第一项研究中: I. E. Dror, D. Charlton, and A. E. Péron, “Contextual Information Renders Experts Vulnerable to Making Erroneous Identifications,” Forensic Science International 156 (2006): 74–78.
在第二项研究中: I. E. Dror and D. Charlton, “Why Experts Make Errors,” Journal of Forensic Identification 56 (2006): 600–616.
“专业指纹检验员”: I. E. Dror and S. A. Cole, “The Vision in ‘Blind’ Justice: Expert Perception, Judgment, and Visual Cognition in Forensic Pattern Recognition,” Psychonomic Bulletin and Review 17 (2010): 161–167, 165. 另见 I. E. Dror, “A Hierarchy of Expert Performance (HEP),” Journal of Applied Research in Memory and Cognition (2016): 1–6.
在另一项独立研究中: I. E. Dror et al., “Cognitive Issues in Fingerprint Analysis: Inter- and Intra-Expert Consistency and the Effect of a ‘Target’ Comparison,” Forensic Science International 208 (2011): 10–17.
后来的一项独立研究: B. T. Ulery, R. A. Hicklin, M. A. Roberts, and J. A. Buscaglia, “Changes in Latent Fingerprint Examiners’ Markup Between Analysis and Comparison,” Forensic Science International 247 (2015): 54–61.
即使是DNA分析: I. E. Dror and G. Hampikian, “Subjectivity and Bias in Forensic DNA Mixture Interpretation,” Science and Justice 51 (2011): 204–208.
检验员经常收到: M. J. Saks, D. M. Risinger, R. Rosenthal, and W. C. Thompson, “Context Effects in Forensic Science: A Review and Application of the Science of Science to Crime Laboratory Practice in the United States,” Science Justice Journal of Forensic Science Society 43 (2003): 77–90.
验证检验员知道的: 总统科学技术顾问委员会(PCAST),《向总统报告:刑事法庭中的法医学:确保特征比较方法的科学有效性》(华盛顿特区:总统行政办公室,PCAST,2016年)。
后续对错误的调查: Stacey,“错误指纹”。
一位备受尊敬的独立专家: Dror和Cole,“’盲目’正义中的视觉”。
偏见级联: I. E. Dror,“法医专家中的偏见”,《科学》360 (2018):243。
有时会改变想法: Dror和Charlton,“专家为什么会出错”。
2012年的一项研究: B. T. Ulery,R. A. Hicklin,J. A. Buscaglia和M. A. Roberts,“潜在指纹检验员决定的重复性和再现性”,《公共科学图书馆综合》7 (2012)。
无罪项目: 无罪项目,“推翻涉及法医学误用的错误定罪”,《法医学误用》(2018):1–7,www.innocenceproject.org/causes/misapplication-forensic-science。另见S. M. Kassin,I. E. Dror,J. Kukucka和L. Butt,“法医确认偏见:问题、观点和建议解决方案”,《记忆与认知应用研究期刊》2 (2013):42–52。
深入审查: PCAST,《向总统报告》。
指纹大规模研究: B. T. Ulery,R. A. Hicklin,J. Buscaglia和M. A. Roberts,“法医潜在指纹决定的准确性和可靠性”,《美国国家科学院院刊》108 (2011):7733–7738。
“高得多”: (PCAST),《向总统报告》,第95页。原文强调。
在佛罗里达州进行的后续研究: Igor Pacheco,Brian Cerchiai和Stephanie Stoiloff,“迈阿密-戴德ACE-V流程可靠性研究:潜在指纹检验的准确性和精确度”,最终报告,迈阿密-戴德警察局法医服务局,2014年,www.ncjrs.gov/pdffiles1/nij/grants/248534.pdf。
“在大多数案例工作中”: B. T. Ulery,R. A. Hicklin,M. A. Roberts和J. A. Buscaglia,“与潜在指纹排除决定相关的因素”,《国际法医学》275 (2017):65–75。
假阳性识别要少得多: R. N. Haber和I. Haber,“指纹比较有效性和可靠性的实验结果:回顾和批判性分析”,《科学与正义》54 (2014):375–389。
“更容易产生偏见”: Dror,“专家表现的层次结构”,3。
“去迪士尼乐园找工作”: M. Leadbetter,致编辑的信,《指纹世界》33 (2007):231。
“实际上没有改变他们的判断”: L. Butt,“法医确认偏见:问题、观点和建议解决方案——法医检验员的评论”,《记忆与认知应用研究期刊》2 (2013):59–60。强调为后加。
即使是FBI: Stacey,“错误指纹”,713。强调为后加。
在对四百名的调查中: J. Kukucka,S. M. Kassin,P. A. Zapf和I. E. Dror,“认知偏见和盲目性:法医检验员全球调查”,《记忆与认知应用研究期刊》6 (2017)。
线性序列揭露: I. E. Dror等,致编辑的信:“情境管理工具箱:最小化法医决策中认知偏见的线性序列揭露(LSU)方法”,《法医学期刊》60 (2015):1111–1112。
官方机构: Jeffrey A. Frankel,“官方预算机构预测中的过度乐观及其影响”,工作论文17239,国家经济研究局,2011年12月,www.nber.org/papers/w17239。
倾向于过度自信: H. R. Arkes,“判断性预测中的过度自信”,载于《预测原理:研究者和实践者手册》,Jon Scott Armstrong编,第30卷,运筹学与管理科学国际系列(波士顿:施普林格出版社,2001年)。
持续的季度调查: Itzhak Ben-David,John Graham和Campell Harvey,“管理误校准”,《经济学季刊》128,第4期(2013年11月):1547–1584。
“不可靠性是一个来源”: T. R. Stewart,“提高判断性预测的可靠性”,载于《预测原理:研究者和实践者手册》,Jon Scott Armstrong编,第30卷,运筹学与管理科学国际系列(波士顿:施普林格出版社,2001年)(以下简称《预测原理》),82。
预测最高法院裁决: Theodore W. Ruger,Pauline T. Kim,Andrew D. Martin和Kevin M. Quinn,“最高法院预测项目:预测最高法院决策的法律和政治科学方法”,《哥伦比亚法律评论》104 (2004):1150–1209。
空气污染法规: Cass Sunstein,“极大极小”,《耶鲁监管期刊》(草稿;2020年5月3日),https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3476250。
许多例子: 关于众多例子,见Armstrong,《预测原理》。
平均多个预测: Jon Scott Armstrong,“结合预测”,载于《预测原理》,417–439。
优于大多数: T. R. Stewart, “Improving Reliability of Judgmental Forecasts,” in Principles of Forecasting, 95.
平均12.5%: Armstrong, “Combining Forecasts.”
精选群体: Albert E. Mannes et al., “The Wisdom of Select Crowds,” Journal of Personality and Social Psychology 107, no. 2 (2014): 276–299.
预测市场被发现表现很好: Justin Wolfers and Eric Zitzewitz, “Prediction Markets,” Journal of Economic Perspectives 18 (2004): 107–126.
使用预测市场: Cass R. Sunstein and Reid Hastie, Wiser: Getting Beyond Groupthink to Make Groups Smarter (Boston: Harvard Business Review Press, 2014).
德尔菲法: Gene Rowe and George Wright, “The Delphi Technique as a Forecasting Tool: Issues and Analysis,” International Journal of Forecasting 15 (1999): 353–375. See also Dan Bang and Chris D. Frith, “Making Better Decisions in Groups,” Royal Society Open Science 4, no. 8 (2017).
实施起来具有挑战性: R. Hastie, “Review Essay: Experimental Evidence on Group Accuracy,” in B. Grofman and G. Guillermo, eds., Information Pooling and Group Decision Making (Greenwich, CT: JAI Press, 1986), 129–157.
小型德尔菲法: Andrew H. Van De Ven and André L. Delbecq, “The Effectiveness of Nominal, Delphi, and Interacting Group Decision Making Processes,” Academy of Management Journal 17, no. 4 (2017).
“优于平均水平”: Superforecasting, 95.
“最强的预测因子”: Superforecasting, 231.
“尝试,失败,分析”: Superforecasting, 273.
一种复杂的统计技术: Ville A. Satopää, Marat Salikhov, Philip E. Tetlock, and Barb Mellers, “Bias, Information, Noise: The BIN Model of Forecasting,” February 19, 2020, 23, https://dx.doi.org/10.2139/ssrn.3540864.
“每当有干预措施”: Satopää et al., “Bias, Information, Noise,” 23.
“团队合作——不同于培训”: Satopää et al., 22.
” ’超级预测者’可能归功于”: Satopää et al., 24.
既独立又互补: Clintin P. Davis-Stober, David V. Budescu, Stephen B. Broomell, and Jason Dana. “The composition of optimally wise crowds.” Decision Analysis 12, no. 3 (2015): 130–143.
量化肌腱退化产生: Laura Horton et al., “Development and Assessment of Inter- and Intra-Rater Reliability of a Novel Ultrasound Tool for Scoring Tendon and Sheath Disease: A Pilot Study,” Ultrasound 24, no. 3 (2016): 134, www.ncbi.nlm.nih.gov/pmc/articles/PMC5105362.
当病理学家评估核心: Laura C. Collins et al., “Diagnostic Agreement in the Evaluation of Image-guided Breast Core Needle Biopsies,” American Journal of Surgical Pathology 28 (2004): 126, https://journals.lww.com/ajsp/Abstract/2004/01000/Diagnostic_Agreement_in_the_Evaluation_of.15.aspx.
没有快速抗原检测结果: Julie L. Fierro et al., “Variability in the Diagnosis and Treatment of Group A Streptococcal Pharyngitis by Primary Care Pediatricians,” Infection Control and Hospital Epidemiology 35, no. S3 (2014): S79, www.jstor.org/stable/10.1086/677820.
你被认为患有糖尿病: Diabetes Tests, Centers for Disease Control and Prevention, https://www.cdc.gov/diabetes/basics/getting-tested.html (last accessed January 15, 2020).
在一些医院,第二: Joseph D. Kronz et al., “Mandatory Second Opinion Surgical Pathology at a Large Referral Hospital,” Cancer 86 (1999): 2426, https://onlinelibrary.wiley.com/doi/full/10.1002/(SICI)1097-0142(19991201)86:11%3C2426::AID-CNCR34%3E3.0.CO;2-3.
达特茅斯地图集项目致力于: Most of the material can be found online; a book-length outline is Dartmouth Medical School, The Quality of Medical Care in the United States: A Report on the Medicare Program; the Dartmouth Atlas of Health Care 1999 (American Hospital Publishers, 1999).
类似的结论在: See, for example, OECD, Geographic Variations in Health Care: What Do We Know and What Can Be Done to Improve Health System Performance? (Paris: OECD Publishing, 2014), 137–169; Michael P. Hurley et al., “Geographic Variation in Surgical Outcomes and Cost Between the United States and Japan,” American Journal of Managed Care 22 (2016): 600, www.ajmc.com/journals/issue/2016/2016-vol22-n9/geographic-variation-in-surgical-outcomes-and-cost-between-the-united-states-and-japan; and John Appleby, Veena Raleigh, Francesca Frosini, Gwyn Bevan, Haiyan Gao, and Tom Lyscom, Variations in Health Care: The Good, the Bad and the Inexplicable (London: The King’s Fund, 2011), www.kingsfund.org.uk/sites/default/files/Variations-in-health-care-good-bad-inexplicable-report-The-Kings-Fund-April-2011.pdf.
一项关于肺炎诊断的研究: David C. Chan Jr. et al., “Selection with Variation in Diagnostic Skill: Evidence from Radiologists,” National Bureau of Economic Research, NBER Working Paper No. 26467, November 2019, www.nber.org/papers/w26467.
[这里和其他地方一样,培训]: P. J. Robinson,“放射学的致命弱点:伦琴图像解释中的错误和变异”,《英国放射学杂志》70 (1997): 1085,www.ncbi.nlm.nih.gov/pubmed/9536897。一项相关研究是 Yusuke Tsugawa 等人,“美国医院老年患者的医生年龄和结局:观察性研究”,《BMJ》357 (2017),www.bmj.com/content/357/bmj.j1797,该研究发现医生的结局随着远离培训时间而变差。由此可见,发展经验(来自多年实践)与熟悉最新证据和指南之间存在权衡关系。研究发现,最佳结局来自住院医师培训后前几年的医生,因为他们对这些证据记忆犹新。
[例如,放射科医生称]: Robinson,“放射学的致命弱点”。
[kappa统计量]:与相关系数一样,kappa值可以是负数,尽管在实践中很少见。以下是对不同kappa统计量含义的一种表征:“轻微 (κ = 0.00 到 0.20),一般 (κ = 0.21 到 0.40),中等 (κ = 0.41 到 0.60),显著 (κ = 0.61 到 0.80),和几乎完美 (κ > 0.80)” (Ron Wald, Chaim M. Bell, Rosane Nisenbaum, Samuel Perrone, Orfeas Liangos, Andreas Laupacis, 和 Bertrand L. Jaber,“尿沉渣解释的观察者间可靠性”,《美国肾脏病学会临床杂志》4,第3期 [2009年3月]: 567–571,https://cjasn.asnjournals.org/content/4/3/567)。
[药物-药物相互作用]: Howard R. Strasberg 等人,“医生对药物-药物相互作用临床意义的评估者间一致性”,《AMIA年度研讨会论文集》(2013): 1325,www.ncbi.nlm.nih.gov/pmc/articles/PMC3900147。
[但肾脏病专家仅显示]: Wald 等人,“尿沉渣解释的观察者间可靠性”,https://cjasn.asnjournals.org/content/4/3/567。
[乳腺病变是否]: Juan P. Palazzo 等人,“乳腺增生性导管和小叶病变及原位癌:社区和学术病理学家对当前诊断标准的重现性”,《乳腺杂志》4 (2003): 230,www.ncbi.nlm.nih.gov/pubmed/21223441。
[乳腺增生性病变]: Rohit K. Jain 等人,“非典型导管增生:观察者间和观察者内变异性”,《现代病理学》24 (2011): 917,www.nature.com/articles/modpathol201166。
[脊柱狭窄程度]: Alex C. Speciale 等人,“磁共振成像评估腰椎管狭窄严重程度的观察者变异性及其与横截面椎管面积的关系”,《脊柱》27 (2002): 1082,www.ncbi.nlm.nih.gov/pubmed/12004176。
[心脏病是主要死因]: 疾病控制与预防中心,“心脏病事实”,2020年6月16日访问,www.cdc.gov/heartdisease/facts.htm。
[一项早期研究发现31%]: Timothy A. DeRouen 等人,“冠状动脉造影分析的变异性”,《循环》55 (1977): 324,www.ncbi.nlm.nih.gov/pubmed/832349。
[他们在诊断上严重分歧]: Olaf Buchweltz 等人,“轻微和轻度子宫内膜异位症诊断的观察者间变异性”,《欧洲妇产科与生殖生物学杂志》122 (2005): 213,www.ejog.org/article/S0301-2115(05)00059-X/pdf。
[TB诊断的显著变异性]: Jean-Pierre Zellweger 等人,“结核病放射学评估的观察者内部和总体一致性”,《国际结核病与肺病杂志》10 (2006): 1123,www.ncbi.nlm.nih.gov/pubmed/17044205。关于”一般”评估者间一致性,见 Yanina Balabanova 等人,“俄罗斯临床医生胸部X光片解释的变异性及对筛查项目的影响:观察性研究”,《BMJ》331 (2005): 379,www.bmj.com/content/331/7513/379.short。
[不同国家放射科医生之间]: Shinsaku Sakurada 等人,“两个亚洲国家间结核病胸部X光异常发现评估的评估者间一致性”,《BMC感染性疾病》12,文章31 (2012),https://bmcinfectdis.biomedcentral.com/articles/10.1186/1471-2334-12-31。
[审查的八位病理学家]: Evan R. Farmer 等人,“专家病理学家在黑色素瘤和黑色素细胞痣组织病理学诊断上的不一致”,《人类病理学》27 (1996): 528,www.ncbi.nlm.nih.gov/pubmed/8666360。
[肿瘤中心的另一项研究]: Alfred W. Kopf, M. Mintzis, 和 R. S. Bart,“恶性黑色素瘤的诊断准确性”,《皮肤病学档案》111 (1975): 1291,www.ncbi.nlm.nih.gov/pubmed/1190800。
[该研究的作者得出结论]: Maria Miller 和 A. Bernard Ackerman,“皮肤科医生诊断黑色素瘤的准确性如何?准确程度和影响”,《皮肤病学档案》128 (1992): 559,https://jamanetwork.com/journals/jamadermatology/fullarticle/554024。
类似地,假阳性率范围: Craig A. Beam et al., “Variability in the Interpretation of Screening Mammograms by US Radiologists,” Archives of Internal Medicine 156 (1996): 209, www.ncbi.nlm.nih.gov/pubmed/8546556.
放射科医生有时提供: P. J. Robinson et al., “Variation Between Experienced Observers in the Interpretation of Accident and Emergency Radiographs,” British Journal of Radiology 72 (1999): 323, www.birpublications.org/doi/pdf/10.1259/bjr.72.856.10474490.
血管造影中的阻塞程度: Katherine M. Detre et al., “Observer Agreement in Evaluating Coronary Angiograms,” Circulation 52 (1975): 979, www.ncbi.nlm.nih.gov/pubmed/1102142.
在涉及模糊标准的领域: Horton et al., “Inter- and Intra-Rater Reliability”; and Megan Banky et al., “Inter- and Intra-Rater Variability of Testing Velocity When Assessing Lower Limb Spasticity,” Journal of Rehabilitation Medicine 51 (2019), www.medicaljournals.se/jrm/content/abstract/10.2340/16501977-2496.
但另一项研究,不涉及: Esther Y. Hsiang et al., “Association of Primary Care Clinic Appointment Time with Clinician Ordering and Patient Completion of Breast and Colorectal Cancer Screening,” JAMA Network Open 51 (2019), https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2733171.
另一个关于角色作用的例证: Hengchen Dai et al., “The Impact of Time at Work and Time Off from Work on Rule Compliance: The Case of Hand Hygiene in Health Care,” Journal of Applied Psychology 100 (2015): 846, www.ncbi.nlm.nih.gov/pubmed/25365728.
重大贡献: Ali S. Raja, “The HEART Score Has Substantial Interrater Reliability,” NEJM J Watch, December 5, 2018, www.jwatch.org/na47998/2018/12/05/heart-score-has-substantial-interrater-reliability (reviewing Colin A. Gershon et al., “Inter-rater Reliability of the HEART Score,” Academic Emergency Medicine 26 [2019]: 552).
正如我们提到的,培训: Jean-Pierre Zellweger et al., “Intra-observer and Overall Agreement in the Radiological Assessment of Tuberculosis,” International Journal of Tuberculosis & Lung Disease 10 (2006): 1123, www.ncbi.nlm.nih.gov/pubmed/17044205; Ibrahim Abubakar et al., “Diagnostic Accuracy of Digital Chest Radiography for Pulmonary Tuberculosis in a UK Urban Population,” European Respiratory Journal 35 (2010): 689, https://erj.ersjournals.com/content/35/3/689.short.
多位医生的集体智慧聚合也是如此: Michael L. Barnett et al., “Comparative Accuracy of Diagnosis by Collective Intelligence of Multiple Physicians vs Individual Physicians,” JAMA Network Open 2 (2019): e19009, https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2726709; Kimberly H. Allison et al., “Understanding Diagnostic Variability in Breast Pathology: Lessons Learned from an Expert Consensus Review Panel,” Histopathology 65 (2014): 240, https://onlinelibrary.wiley.com/doi/abs/10.1111/his.12387.
这些方法中最好的已被发现: Babak Ehteshami Bejnordi et al., “Diagnostic Assessment of Deep Learning Algorithms for Detection of Lymph Node Metastases in Women with Breast Cancer,” JAMA 318 (2017): 2199, https://jamanetwork.com/journals/jama/fullarticle/2665774.
深度学习算法已经: Varun Gulshan et al., “Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs,” JAMA 316 (2016): 2402, https://jamanetwork.com/journals/jama/fullarticle/2588763.
AI现在的表现至少: Mary Beth Massat, “A Promising Future for AI in Breast Cancer Screening,” Applied Radiology 47 (2018): 22, www.appliedradiology.com/articles/a-promising-future-for-ai-in-breast-cancer-screening; Alejandro Rodriguez-Ruiz et al., “Stand-Alone Artificial Intelligence for Breast Cancer Detection in Mammography: Comparison with 101 Radiologists,” Journal of the National Cancer Institute 111 (2019): 916, https://academic.oup.com/jnci/advance-article-abstract/doi/10.1093/jnci/djy222/5307077.
表3: Apgar评分, Medline Plus, https://medlineplus.gov/ency/article/003402.htm (最后访问时间:2020年2月4日).
Apgar评分产生的噪声很少: L. R. Foster et al., “The Interrater Reliability of Apgar Scores at 1 and 5 Minutes,” Journal of Investigative Medicine 54, no. 1 (2006): 293, https://jim.bmj.com/content/54/1/S308.4.
评估和评分相对: Warren J. McIsaac et al., “Empirical Validation of Guidelines for the Management of Pharyngitis in Children and Adults,” JAMA 291 (2004): 1587, www.ncbi.nlm.nih.gov/pubmed/15069046.
一项研究发现BI-RADS: Emilie A. Ooms et al., “Mammography: Interobserver Variability in Breast Density Assessment,” Breast 16 (2007): 568, www.sciencedirect.com/science/article/abs/pii/S0960977607000793.
在病理学中,已有研究显示: Frances P. O’Malley et al., “Interobserver Reproducibility in the Diagnosis of Flat Epithelial Atypia of the Breast,” Modern Pathology 19 (2006): 172, www.nature.com/articles/3800514.
因此,噪声降低: 参见 Ahmed Aboraya et al., “The Reliability of Psychiatric Diagnosis Revisited,” Psychiatry (Edgmont) 3 (2006): 41, www.ncbi.nlm.nih.gov/pmc/articles/PMC2990547. 综述参见 N. Kreitman, “The Reliability of Psychiatric Diagnosis,” Journal of Mental Science 107 (1961): 876–886, www.cambridge.org/core/journals/journal-of-mental-science/article/reliability-of-psychiatric-diagnosis/92832FFA170F4FF41189428C6A3E6394.
1964年一项涉及91名患者的研究: Aboraya et al., “Reliability of Psychiatric Diagnosis Revisited,” 43.
但在初步努力: C. H. Ward et al., “The Psychiatric Nomenclature: Reasons for Diagnostic Disagreement,” Archives of General Psychiatry 7 (1962): 198.
虽然”有发展训练背景的临床医生”: Aboraya et al., “Reliability of Psychiatric Diagnosis Revisited.”
DSM-III导致了显著的: Samuel M. Lieblich, David J. Castle, Christos Pantelis, Malcolm Hopwood, Allan Hunter Young, and Ian P. Everall, “High Heterogeneity and Low Reliability in the Diagnosis of Major Depression Will Impair the Development of New Drugs,” British Journal of Psychiatry Open 1 (2015): e5–e7, www.ncbi.nlm.nih.gov/pmc/articles/PMC5000492/pdf/bjporcpsych_1_2_e5.pdf.
但手册还远未: Lieblich et al., “High Heterogeneity.”
即使在2000年的重大修订之后: 参见 Elie Cheniaux et al., “The Diagnoses of Schizophrenia, Schizoaffective Disorder, Bipolar Disorder and Unipolar Depression: Interrater Reliability and Congruence Between DSM-IV and ICD-10,” Psychopathology 42 (2009): 296–298, 特别是293页; 以及 Michael Chmielewski et al., “Method Matters: Understanding Diagnostic Reliability in DSM-IV and DSM-5,” Journal of Abnormal Psychology 124 (2015): 764, 768–769.
“提高精神病诊断的可靠性”: Aboraya et al., “Reliability of Psychiatric Diagnosis Revisited,” 47.
一个严重风险: Aboraya et al., 47.
手册的另一个版本: 参见 Chmielewski et al., “Method Matters.”
美国精神病学协会: 例如参见 Helena Chmura Kraemer et al., “DSM-5: How Reliable Is Reliable Enough?,” American Journal of Psychiatry 169 (2012): 13–15.
精神科医生仍然表现出: Lieblich et al., “High Heterogeneity.”
“精神科医生很难”: Lieblich et al., “High Heterogeneity,” e-5.
DSM-5的实地试验发现: Lieblich et al., e-5.
根据一些实地试验: Lieblich et al., e-6.
可靠性有限的主要原因: Aboraya et al., “Reliability of Psychiatric Diagnosis Revisited,” 47.
这些包括(1)澄清: Aboraya et al.
用一位观察者的话说: Aboraya et al.
医学专业需要更多: 一些有价值的警示性说明可参见 Christopher Worsham and Anupam B. Jena, “The Art of Evidence-Based Medicine,” Harvard Business Review, January 30, 2019, https://hbr.org/2019/01/the-art-of-evidence-based-medicine.
一个报纸标题: Jena McGregor, “Study Finds That Basically Every Single Person Hates Performance Reviews,” Washington Post, January 27, 2014.
基于判断的普遍性: 许多组织正在经历的数字化转型可能在这里创造新的可能性。理论上,公司现在可以收集大量关于每个员工绩效的细粒度实时信息。这些数据可能使某些职位的完全算法化绩效评估成为可能。然而,我们这里关注的是那些无法完全从绩效测量中消除判断的职位。参见 E. D. Pulakos, R. Mueller-Hanson, and S. Arad, “The Evolution of Performance Management: Searching for Value,” Annual Review of Organizational Psychology and Organizational Behavior 6 (2018): 249–271.
大多数研究者发现: S. E. Scullen, M. K. Mount, and M. Goff, “Understanding the Latent Structure of Job Performance Ratings,” Journal of Applied Psychology 85 (2000): 956–970.
其余70%到80%的方差: 在一些研究中,一个小的组成部分——总方差的10%——是研究者所称的评价者视角,或层级效应,这里的层级是指组织中的层级,而不是我们定义的层级噪声。评价者视角反映了在评价同一个人时,老板与同事之间、同事与下属之间存在系统性差异。从360度评价系统结果的宽容解释来看,人们可以认为这不是噪声。如果组织中不同层级的人系统性地看到同一个人绩效的不同方面,他们对此人的判断应该系统性地不同,他们的评价应该反映这一点。
多项研究: Scullen, Mount, and Goff, “Latent Structure”; C. Viswesvaran, D. S. Ones, and F. L. Schmidt, “Comparative Analysis of the Reliability of Job Performance Ratings,” Journal of Applied Psychology 81 (1996): 557–574. G. J. Greguras and C. Robie, “A New Look at Within-Source Interrater Reliability of 360-Degree Feedback Ratings,” Journal of Applied Psychology 83 (1998): 960–968; G. J. Greguras, C. Robie, D. J. Schleicher, and M. A. Goff, “A Field Study of the Effects of Rating Purpose on the Quality of Multisource Ratings,” Personnel Psychology 56 (2003): 1–21; C. Viswesvaran, F. L. Schmidt, and D. S. Ones, “Is There a General Factor in Ratings of Job Performance? A Meta-Analytic Framework for Disentangling Substantive and Error Influences,” Journal of Applied Psychology 90 (2005): 108–131; and B. Hoffman, C. E. Lance, B. Bynum, and W. A. Gentry, “Rater Source Effects Are Alive and Well After All,” Personnel Psychology 63 (2010): 119–151.
“工作绩效之间的关系”: K. R. Murphy, “Explaining the Weak Relationship Between Job Performance and Ratings of Job Performance,” Industrial and Organizational Psychology 1 (2008): 148–160, especially 151.
员工的真实绩效: 在讨论噪音来源时,我们忽略了可能因为对某些员工或某类员工的系统性偏见而产生的个案偏差。我们找到的关于绩效评级变异性的研究中,没有一项将评级与外部评估的”真实”绩效进行比较。
“策略性”评价人员: E. D. Pulakos and R. S. O’Leary, “Why Is Performance Management Broken?,” Industrial and Organizational Psychology 4 (2011): 146–164; M. M. Harris, “Rater Motivation in the Performance Appraisal Context: A Theoretical Framework,” Journal of Management 20 (1994): 737–756; and K. R. Murphy and J. N. Cleveland, Understanding Performance Appraisal: Social, Organizational, and Goal-Based Perspectives (Thousand Oaks, CA: Sage, 1995).
纯发展性的: Greguras et al., “Field Study.”
预测客观可测量的: P. W. Atkins and R. E. Wood, “Self-Versus Others’ Ratings as Predictors of Assessment Center Ratings: Validation Evidence for 360-Degree Feedback Programs,” Personnel Psychology (2002).
过度设计的问卷: Atkins and Wood, “Self-Versus Others’ Ratings.”
98%: Olson and Davis, cited in Peter G. Dominick, “Forced Ranking: Pros, Cons and Practices,” in Performance Management: Putting Research into Action, ed. James W. Smither and Manuel London (San Francisco: Jossey-Bass, 2009), 411–443.
强制排名: Dominick, “Forced Ranking.”
在绩效评级中应用: Barry R. Nathan and Ralph A. Alexander, “A Comparison of Criteria for Test Validation: A Meta-Analytic Investigation,” Personnel Psychology 41, no. 3 (1988): 517–535.
图17: 改编自 Richard D. Goffin and James M. Olson, “Is It All Relative? Comparative Judgments and the Possible Improvement of Self-Ratings and Ratings of Others,” Perspectives on Psychological Science 6, no. 1 (2011): 48–60.
德勤: M. Buckingham and A. Goodall, “Reinventing Performance Management,” Harvard Business Review, April 1, 2015, 1–16, doi:ISSN: 0017-8012.
一项研究: Corporate Leadership Council, cited in S. Adler et al., “Getting Rid of Performance Ratings: Genius or Folly? A Debate,” Industrial and Organizational Psychology 9 (2016): 219–252.
“无论如何”: Pulakos, Mueller-Hanson, and Arad, “Evolution of Performance Management,” 250.
“绩效管理革命”: A. Tavis and P. Cappelli, “The Performance Management Revolution,” Harvard Business Review, October 2016, 1–17.
证据表明: Frank J. Landy and James L. Farr, “Performance Rating,” Psychological Bulletin 87, no. 1 (1980): 72–107.
他们练习评估绩效: D. J. Woehr and A. I. Huffcutt, “Rater Training for Performance Appraisal: A Quantitative Review,” Journal of Occupational and Organizational Psychology 67 (1994): 189–205; S. G. Roch, D. J. Woehr, V. Mishra, and U. Kieszczynska, “Rater Training Revisited: An Updated Meta-Analytic Review of Frame-of-Reference Training,” Journal of Occupational and Organizational Psychology 85 (2012): 370–395; and M. H. Tsai, S. Wee, and B. Koh, “Restructured Frame-of-Reference Training Improves Rating Accuracy,” Journal of Organizational Behavior (2019): 1–18, doi:10.1002/job.2368.
图18: 左侧面板改编自 Richard Goffin and James M. Olson, “Is It All Relative? Comparative Judgments and the Possible Improvement of Self-Ratings and Ratings of Others,” Perspectives on Psychological Science 6, no. 1 (2011): 48–60.
大多数研究: Roch et al., “Rater Training Revisited.”
“明星人才”: Ernest O’Boyle and Herman Aguinis, “The Best and the Rest: Revisiting the Norm of Normality of Individual Performance,” Personnel Psychology 65, no. 1 (2012): 79–119; and Herman Aguinis and Ernest O’Boyle, “Star Performers in Twenty-First Century Organizations,” Personnel Psychology 67, no. 2 (2014): 313–350.
“这很少见”: A. I. Huffcutt and S. S. Culbertson, “Interviews,” in S. Zedeck, ed., APA Handbook of Industrial and Organizational Psychology (Washington, DC: American Psychological Association, 2010), 185–203.
在某种程度上依赖他们的直觉判断: N. R. Kuncel, D. M. Klieger, and D. S. Ones, “In Hiring, Algorithms Beat Instinct,” Harvard Business Review 92, no. 5 (2014): 32.
“最高问题”: R. E. Ployhart, N. Schmitt, and N. T. Tippins, “Solving the Supreme Problem: 100 Years of Selection and Recruitment at the Journal of Applied Psychology,” Journal of Applied Psychology 102 (2017): 291–304.
其他研究报告: M. McDaniel, D. Whetzel, F. L. Schmidt, and S. Maurer, “Meta Analysis of the Validity of Employment Interviews,” Journal of Applied Psychology 79 (1994): 599–616; A. Huffcutt and W. Arthur, “Hunter and Hunter (1984) Revisited: Interview Validity for Entry-Level Jobs,” Journal of Applied Psychology 79 (1994): 2; F. L. Schmidt and J. E. Hunter, “The Validity and Utility of Selection Methods in Personnel Psychology: Practical and Theoretical Implications of 85 Years of Research Findings,” Psychology Bulletin 124 (1998): 262–274; and F. L. Schmidt and R. D. Zimmerman, “A Counterintuitive Hypothesis About Employment Interview Validity and Some Supporting Evidence,” Journal of Applied Psychology 89 (2004): 553–561. 注意,当考虑某些研究子集时,效度会更高,特别是如果研究使用专门为此目的创建的绩效评级,而不是现有的管理评级。
客观无知: S. Highhouse, “Stubborn Reliance on Intuition and Subjectivity in Employee Selection,” Industrial and Organizational Psychology 1 (2008): 333–342; D. A. Moore, “How to Improve the Accuracy and Reduce the Cost of Personnel Selection,” California Management Review 60 (2017): 8–17.
文化上与他们相似: L. A. Rivera, “Hiring as Cultural Matching: The Case of Elite Professional Service Firms,” American Sociology Review 77 (2012): 999–1022.
相关性的测量: Schmidt and Zimmerman, “Counterintuitive Hypothesis”; Timothy A. Judge, Chad A. Higgins, and Daniel M. Cable, “The Employment Interview: A Review of Recent Research and Recommendations for Future Research,” Human Resource Management Review 10 (2000): 383–406; and A. I. Huffcutt, S. S. Culbertson, and W. S. Weyhrauch, “Employment Interview Reliability: New Meta-Analytic Estimates by Structure and Format,” International Journal of Selection and Assessment 21 (2013): 264–276.
很重要—非常重要: M. R. Barrick et al., “Candidate Characteristics Driving Initial Impressions During Rapport Building: Implications for Employment Interview Validity,” Journal of Occupational and Organizational Psychology 85 (2012): 330–352; M. R. Barrick, B. W. Swider, and G. L. Stewart, “Initial Evaluations in the Interview: Relationships with Subsequent Interviewer Evaluations and Employment Offers,” Journal of Applied Psychology 95 (2010): 1163.
握手的质量: G. L. Stewart, S. L. Dustin, M. R. Barrick, and T. C. Darnold, “Exploring the Handshake in Employment Interviews,” Journal of Applied Psychology 93 (2008): 1139–1146.
积极的第一印象: T. W. Dougherty, D. B. Turban, and J. C. Callender, “Confirming First Impressions in the Employment Interview: A Field Study of Interviewer Behavior,” Journal of Applied Psychology 79 (1994): 659–665.
在一项引人注目的实验中: J. Dana, R. Dawes, and N. Peterson, “Belief in the Unstructured Interview: The Persistence of an Illusion,” Judgment and Decision Making 8 (2013): 512–520.
人力资源专业人士偏爱: Nathan R. Kuncel et al., “Mechanical versus Clinical Data Combination in Selection and Admissions Decisions: A Meta-Analysis,” Journal of Applied Psychology 98, no. 6 (2013): 1060–1072.
“零关系”: Laszlo Bock, interview with Adam Bryant, The New York Times, June 19, 2013. See also Laszlo Bock, Work Rules!: Insights from Inside Google That Will Transform How You Live and Lead (New York: Hachette, 2015).
一位著名的猎头: C. Fernández-Aráoz, “Hiring Without Firing,” Harvard Business Review, July 1, 1999.
结构化行为面试: 关于结构化面试的易懂指南,请参见 Michael A. Campion, David K. Palmer, and James E. Campion, “Structuring Employment Interviews to Improve Reliability, Validity and Users’ Reactions,” Current Directions in Psychological Science 7, no. 3 (1998): 77–82.
必须包含才能符合条件: J. Levashina, C. J. Hartwell, F. P. Morgeson, and M. A. Campion, “The Structured Employment Interview: Narrative and Quantitative Review of the Research Literature,” Personnel Psychology 67 (2014): 241–293.
结构化面试的预测性要强得多: McDaniel et al., “Meta Analysis”; Huffcutt and Arthur, “Hunter and Hunter (1984) Revisited”; Schmidt and Hunter, “Validity and Utility”; and Schmidt and Zimmerman, “Counterintuitive Hypothesis.”
工作样本测试: Schmidt and Hunter, “Validity and Utility.”
以色列军队: Kahneman, Thinking, Fast and Slow, 229.
实用建议: Kuncel, Klieger, and Ones, “Algorithms Beat Instinct.” See also Campion, Palmer, and Campion, “Structuring Employment Interviews.”
“幻觉的持续存在”: Dana, Dawes, and Peterson, “Belief in the Unstructured Interview.”
中介评估协议: Daniel Kahneman, Dan Lovallo, and Olivier Sibony, “A Structured Approach to Strategic Decisions: Reducing Errors in Judgment Requires a Disciplined Process,” MIT Sloan Management Review 60 (2019): 67–73.
estimate-talk-estimate: Andrew H. Van De Ven 和 André Delbecq,“名义、德尔菲和交互式群体决策过程的有效性”,《管理学院期刊》第17卷,第4期(1974年):605-621页。另见第21章。
在他们看来: Kate Stith 和 José A. Cabranes,《对判决的恐惧:联邦法院的量刑指导原则》(芝加哥:芝加哥大学出版社,1998年),第177页。
首先,这样的努力可能: Albert O. Hirschman,《反动的修辞:反常、徒劳、危险》(马萨诸塞州剑桥:贝尔纳普出版社,1991年)。
引用瓦茨拉夫·哈维尔的话,他们: Stith 和 Cabranes,《对判决的恐惧》。
“三振出局”: 例如,参见斯坦福大学法学院的《三振基础知识》,https://law.stanford.edu/stanford-justice-advocacy-project/three-strikes-basics/。
“伍德森诉北卡罗来纳州案”: 428 U.S. 280 (1976)。
可能嵌入偏见: Cathy O’Neil,《数学毁灭武器:大数据如何加剧不平等并威胁民主》(纽约:皇冠出版社,2016年)。
“潜在偏见”: Will Knight,“有偏见的算法无处不在,似乎没有人关心”,《MIT技术评论》,2017年7月12日。
ProPublica: Jeff Larson、Surya Mattu、Lauren Kirchner 和 Julia Angwin,“我们如何分析COMPAS累犯算法”,《ProPublica》,2016年5月23日,www.propublica.org/article/how-we-analyzed-the-compas-recidivism-algorithm。这个例子中的偏见指控存在争议,偏见的不同定义可能导致相反的结论。关于这个案例的观点以及算法偏见定义和测量的更广泛讨论,请参见后面的注释”如何准确测试”。
“预测性警务”: Aaron Shapiro,“改革预测性警务”,《自然》第541卷,第7638期(2017年):458-460页。
确实,在这方面,算法: 尽管这一担忧在基于AI模型的背景下重新浮现,但它并不是AI特有的。早在1972年,Paul Slovic就注意到,建模直觉会保持和强化,甚至可能放大现有的认知偏见。Paul Slovic,“人类判断的心理学研究:对投资决策的启示”,《金融期刊》第27期(1972年):779页。
如何准确测试: 关于COMPAS累犯预测算法争议背景下这一辩论的介绍,请参见 Larson 等人,“COMPAS累犯算法”;William Dieterich 等人,“COMPAS风险量表:展示准确性、公平性和预测平等”,Northpointe公司,2016年7月8日,http://go.volarisgroup.com/rs/430-MBX-989/images/ProPublica_Commentary_Final_070616.pdf;Julia Dressel 和 Hany Farid,“预测累犯的准确性、公平性和局限性”,《科学进展》第4卷,第1期(2018年):1-6页;Sam Corbett-Davies 等人,“一个用于保释和量刑决定的计算机程序被贴上了歧视黑人的标签。实际上并没有那么明确”,《华盛顿邮报》,2016年10月17日,www.washingtonpost.com/news/monkey-cage/wp/2016/10/17/can-an-algorithm-be-racist-our-analysis-is-more-cautious-than-propublicas;Alexandra Chouldechova,“不同影响的公平预测:累犯预测工具偏见研究”,《大数据》第153期(2017年):5页;以及 Jon Kleinberg、Sendhil Mullainathan 和 Manish Raghavan,“风险评分公平确定中的固有权衡”,莱布尼茨国际信息学会议录,2017年1月。
他们可能知道自己的: Tom R. Tyler,《人们为什么遵守法律》,第2版(康涅狄格州纽黑文:耶鲁大学出版社,2020年)。
美国一个著名的令人困惑的决定:克利夫兰教育委员会诉拉弗勒案,414 U.S. 632 (1974)。
当时有影响力的评论家: Laurence H. Tribe,“结构性正当程序”,《哈佛公民权利-公民自由法律评论》第10卷,第2期(1975年春季):269页。
回想起强烈的负面: Stith 和 Cabranes,《对判决的恐惧》,第177页。
在一系列充满活力的: 例如,参见 Philip K. Howard,《常识之死:法律如何窒息美国》(纽约:兰登书屋,1995年);以及 Philip K. Howard,《尝试常识:替代左右两派失败的意识形态》(纽约:W. W. Norton & Company,2019年)。
Facebook 2020年社区标准 12. 仇恨言论,Facebook:社区标准,www.facebook.com/communitystandards/hate_speech。
《纽约客》: Andrew Marantz,“为什么Facebook无法自我修复”,《纽约客》,2020年10月12日。
嘈杂的判断: 官僚正义:Jerry L. Mashaw,《官僚正义》(康涅狄格州纽黑文:耶鲁大学出版社,1983年)。
恰恰相反的情况在很大程度上获得了: David M. Trubek,“马克斯·韦伯论法律和资本主义的兴起”,《威斯康星法律评论》第720期(1972年):733页,注22(引用马克斯·韦伯,《中国的宗教》[1951年],149页)。
此索引中的页码与本书印刷版相关;它们与您的电子书页码不匹配。您可以使用电子书阅读器的搜索工具来查找特定单词或段落。
A
Aboraya, Ahmed, 284
缺乏共识 参见 分歧
绝对判断的局限性, 183–184
绝对评级, 绩效评估, 292–296
准确性
作为判断的目标, 40, 371
自然变异性, 40–41
积极开放的思维, 234, 267, 370
成人决策能力量表, 233
情感启发式, 170
聚合
决策卫生, 373–374
预测, 260, 271–272
平均法, 261
德尔菲方法, 262
估计-讨论-估计法, 262
预测市场, 261–262
求职面试, 307–308
绩效评估, 291–292
AI (artificial intelligence), 143. 另见 机器学习模型
航空业
国际象棋程序, 332
规则vs标准, 355
算法. 另见 机器学习模型; 基于规则的方法
算法厌恶, 135
算法偏见, 334
定义, 128–133
预测性警务, 335–336
Amazon Mechanical Turk, 214
锚定效应, 170–171, 183, 195–197
Apgar, Virginia, 280–281
Apgar评分, 280–282, 351, 372
任意残酷, 刑事判决, 14–15, 53
算术平均 参见 平均法
Armstrong, J. Scott, 260
artificial intelligence (AI), 143. 另见 机器学习模型
假设模型, 预测性判断, 118
庇护决定
结论偏见, 174
无关信息的影响, 17
水平噪声和, 213
噪声, 6–7
案件顺序和, 90–91
Austin, William, 16
可得性启发式, 167
平均法, 66, 373
辩证自举法, 84–85
预测, 261
平均刑期, 71
均方误差, 59–61
精选群体策略, 261
直接平均法, 261
群体智慧效应, 83–84, 223
B
保释决定
简约模型, 127–128
机器学习模型, 130, 143
噪声, 7
Baron, Jonathan, 234
基准率信息, 166
行为规制, 350–360
行为锚定评级量表, 绩效评估, 297–298
Bentham, Jeremy, 88
Bertillon, Alphonse, 246
人际噪声, 47, 173, 276, 279
偏见. 另见 心理偏见
偏见级联, 252
偏见检查清单, 242–243
偏见观察检查清单, 387–389
词汇的广泛使用, 163–164
认知偏见, 90, 239–240, 256
结论偏见, 168–171, 174
确认偏见, 169, 172
对误差的贡献, 55–56, 62–66
刑事判决, 15, 19
去偏见化, 222, 236–244, 370, 387–389
定义, 3–4, 163–164
期望偏见, 169
诊断, 162–164
与噪声的等式, 58
误差和, 362–363
过度一致性, 171–173, 174
法医确认偏见, 249–253, 255–256
招聘决定, 303
圈数练习, 40
测量, 363–364
噪声减少和, 334–337
噪声vs偏见, 4–6, 8, 53
总体误差方程, 62–66
过度自信, 140–142, 144–145, 239–240, 259–260
计划谬误, 162
减少, 58, 64
规则vs标准, 353, 360
射击靶场比喻, 3–5
统计偏见, 161–162, 173
现状偏见, 240
替代偏见, 164–168, 173–174
偏见、信息和噪声(BIN)预测模型, 269
偏见盲点, 240
人格五因素模型, 117, 207
BIN (偏见、信息和噪声)预测模型, 269
BI-RADS (乳腺影像报告和数据系统), 283
Bock, Laszlo, 307
促进, 238–239
大脑功能变异性, 92–93
乳腺癌诊断变异性, 276, 278
乳腺影像报告和数据系统(BI-RADS), 283
Breyer, Stephen, 18
Brier, Glenn W., 264
Brier评分, 264–265
断腿原则
机器学习模型, 129
简单模型, 129
废话接受性, 87–88
官僚主义正义, 356
C
Cabranes, José, 20, 326
菜单上的卡路里标注, 172
案例量表
定义, 374
中介评估协议, 322
绩效评估, 297–298
个案判断, 339–348
创造力, 346
威慑, 346
系统博弈, 344–345
道德价值观和, 341–344
士气, 347
概述, 339–340
风险厌恶, 346
因果思维, 153–154, 157–158, 219
因果关系vs相关关系, 152–153
Centor, Robert, 282
Centor评分, 282–283
谷神星, 61–62
儿童保护和监护决定, 6, 360
保险理赔员, 24–27
客户, 噪声审计, 380
临床判断 参见 判断
临床vs统计预测 (Meehl), 114
临床vs机械辩论, 114–116, 134, 142–144
“云朵让书呆子看起来很棒” (Simonsohn), 90
认知偏见
指纹分析, 256
赌徒谬误, 90
过度自信, 239–240
预测, 259–260
客观无知和, 140–142, 144–145
认知反思测试(CRT), 232
认知风格, 尊重专家, 232–235
连贯任意性, 195–197
COMPAS算法, 335
全面连贯性, 202
结论偏见, 168–171
情感启发式, 170
锚定效应, 170–171
确认偏见, 169
期望偏见, 169
噪声, 174
信心, 尊重专家, 228
确认偏见, 169, 172
宪法, 352
修正预测, 391–395
保守性质, 394–395
直觉和, 392–393
匹配预测vs修正预测, 391–392
异常值, 395
量化可用数据的诊断价值, 393–394
回归均值, 392
采取外部视角, 393
纠正性(事后)去偏见化, 237
相关性
因果关系vs相关性, 152–153
交叉验证相关性, 125–126
面试-绩效相关性, 138–139, 302
Corrigan, Bernard, 124–125
反事实思维, 37–38
Cowgill, Bo, 132
创造力, 328, 346–348
刑事判决
任意残酷, 14–15, 53
偏见, 15, 19
死刑, 333
评价性判断, 51
影响法官决定的外部因素, 16–17
特殊命令, 15
法官间差异, 14–18, 20–21
法官-案件, 76
司法裁量权, 13–14
水平误差, 73–74
水平噪声, 74
强制死刑, 333
平均刑期, 71–72
噪声审计, 8, 69–76
模式误差, 75, 203
模式噪声, 74–77
量刑指导原则, 18–21
建议性, 20–21
强制性, 18–20
《1984年判刑改革法案》,18
三振出局政策,332,356
美国量刑委员会,18,19
天气与,89–90
Woodson诉北卡罗来纳州案,333
交叉验证相关性,125–126
内在群体,84–85
CRT(认知反思测试),232
晶体智力,229
库里,斯蒂芬,79
D
达特茅斯地图集项目,275
道斯,罗宾,124–126
死刑,333
去偏差,370
偏差盲点,240
决策观察者,222,240–243,370,387–389
事前,237–240
助推,238–239
轻推,237–238
事后,237
局限性,239–240
概述,236–237
另见中介评估协议;降噪
错误成本,357–359
去偏差与,243–244
预测,271–272
线性序列解蔽,256–257
概述,9
原则,370–374
聚合,373–374
分而治之原则,372
判断准确性目标,371
外部视角原则,371–372
相对判断,374
信息排序,256–258,373
单一决策,374
结构化复杂判断,307
另见群体动态与决策制定
决策成本,357–359
评价性判断与,67–68
不混合价值观和事实,67
重复性决策,34–36
单一决策,34–38,374
决策观察者,222,240–243,370,387–389
决策制定研究,383。另见噪音审计
分解见中介评估协议
延迟整体判断,309–310
德尔菲法,预测,262
无知否认,144–146
义务论伦理学,88
期望偏差,169
威慑
刑事判决与,74
风险厌恶与,346
发展性评估,绩效评估,290,297
《精神疾病诊断与统计手册》第3版(DSM-III)指导原则,284
《精神疾病诊断与统计手册》第4版(DSM-IV)指导原则,284
《精神疾病诊断与统计手册》第5版(DSM-5)指导原则,285
乳腺癌,276,278
子宫内膜异位症,277
心脏病,277
黑色素瘤,278
病理学,278
放射学,275–277
结核病,278
辩证自举法,84–85
残疾矩阵,355–356
多样性与,20–21
有界分歧预期,44,52,362
评判者间差异,14–18,20–21
医疗决策,273–279
另见偏差
算法与,334–336
刑事判决中的,14–15,53,71,132
缺乏共识与,20–21
不必要的变异性对比,27–29
分而治之原则,决策卫生,372
DNA分析,7
金钱奖励,194–197
德雷福斯,阿尔弗雷德,247
德罗尔,伊蒂尔,248–252
E
教育,用于克服偏差,238–239
雇佣面试见工作面试
子宫内膜异位症,诊断变异性,277
等权重模型(不当线性模型),124–127
另见偏差;噪音
错误成本,357–359
法医科学与,245–246,253–255
圈数练习,40
最小二乘法,59–62
均方误差,59–66,68,363–364
降噪与,331–334
噪音在错误中的作用,40–41
可验证判断评分,48–49
单次测量误差,62
评价性判断,67
总体误差,62–66
估计-讨论-估计法
预测,262
中介评估协议,319,323
决策制定与,67–68
错误方程,67
有界分歧预期,52
多选项和权衡,51
噪音在其中的作用,52–53
预测性对比,52
事前去偏差,237–240
助推,238–239
轻推,237–238
过度一致性,171–173
定义,372
噪音和偏差,174
有界分歧预期,44,52,362
《专家政治判断》(Tetlock),140
另见刑事判决
评判者间差异,14–18,20–21
噪音审计,380–381
尊重专家,226–235
积极开放思维,234
认知风格,232–235
自信,228
经验,228
智力,228–232
概述,226–227
专业教条,227–228
超级预测者,142,225–226,265–267
F
社区标准,353–354
实施标准,354
疲劳,作为偶然噪音来源,89
福尔兹,亨利,246
判断恐惧,326
ACE-V过程,247–248,251
认知偏差,256
排除决定,248
样本指纹,247
假阳性,253–254
法医确认偏差,249–253,255–256,258
识别决定,248
潜伏指纹,247
噪音审计,248–252
噪音在其中的作用,7
偶然噪音,248–249
概述,246–248
流体智力,229
人行天桥问题,88–89
强制排名系统,292,294–296
另见绩效预测
积极开放思维,267
聚合,271–272
平均法,261
德尔菲法,262
估计-讨论-估计,262
预测市场,261–262
人际噪音,260
预测中的偏差,267–270
BIN模型,269
决策卫生,271–272
多样性对比不必要的变异性,28
良好判断项目,262–266
改进预测,260–262
预测中的噪音,6,267–270
偶然噪音,260
过度自信,259–260
概述,259–260
永续测试版,266–267
心理偏差,270
选择,261,268,270–272
短期对比长期,141–142
统计偏差,270
超级预测者,142,225–226,265–267
团队合作,268,270
训练,268,269–270
法医确认偏差,249–253,255–256
错误与,245–246,253–255
指纹分析
认知偏差,256
法医确认偏差,249–253,255–256
偶然噪音,248–249
概述,246–248
噪音在其中的作用,7
信息排序,256–258
福加斯,约瑟夫,86–87
脆弱家庭与儿童福利研究,149–152
参考框架训练,绩效评估,297–298
Frankel, Marvin, 14–15, 21, 51, 53, 70–71, 134, 325
Frankfurt, Harry, 87
罚球,变异性,79–80
节俭模型(简单规则),127–128
基本归因错误,218
G
Galton, Francis, 83, 246–247
Gambardi问题,44–49, 163, 166–167, 177, 183, 266–267
赌徒谬误,90
游戏系统,344–345
Gates, Bill, 231
Gauss, Carl Friedrich, 59–62
高斯(正态)分布,56
GMA(一般心理能力),229–231
Goldberg, Lewis, 117–122
好判断项目,262–266
GoodSell噪声减少示例,56–59, 64–66
Google,面试实践
聚合,307
后门参考,309
构建复杂判断
延迟整体判断,309–310
独立评估,308
中介评估协议,307–308
《绿皮书》,237
群体动力学和决策制定,94–106
群体极化,103–106
信息级联,100–102, 106
音乐下载研究,95–97
政治立场,97–98
公投提案,97
流行度的自我强化性质,95–98
社会影响,96, 103
网站评论,98
群体智慧效应
独立性和,98–99
场合噪声,83–85
群体极化,103–106
指导原则 参见 规则与标准
易受骗性,情绪和,87–88
直觉感受 参见 判断完成的内部信号
H
光环效应,172, 291, 293–294
Halpern批判性思维评估,233
Haran, Uriel, 234
Havel, Václav, 332
心脏病,诊断变异性,277
Hertwig, Ralph, 84–85
Herzog, Stefan, 84–85
启发式和偏差方法
情感启发式,170
锚定效应,170–171
可得性启发式,167
结论偏差,168–171, 174
定义,161
过度一致性,171–173, 174
启发式和偏差程序,161
相似性与概率,164–168
替代偏差,164–168, 173–174
层级分类,184
后见之明,155–156, 218
招聘 参见 工作面试
Hirschman, Albert, 331
Hoffman, Paul, 117
Howard, Philip, 348
人权第一组织(人权律师委员会),14
I
无知 参见 客观无知
一致性错觉,29–33, 202
有效性错觉,115–116, 180
不完美信息,138
不当线性模型(等权重模型),124–127
失能,刑事判决和,74
独立评估,308, 317–318, 373
个性化处理 参见 个案判断
非正式操作,46
信息级联,100–102, 106
无罪项目,253
保险行业,8
理赔员,24–27
一致性错觉,29–33
朴素现实主义,31
噪声审计,24–27
概述,23–24
系统噪声,27–29
承保商,24–27
不需要的变异性,27–29
智力
晶体智力,229
流体智力,229
尊重专家,228–232
强度量表
标签与比较,184–186
绝对判断的局限性,183–184
匹配强度,178–179
判断完成的内部信号,48–49
客观无知和,137–138, 144–146
预测性判断,367
评分者间信度,47, 173, 276, 279
面试指南,精神病学,285
面试-表现相关性,138–139, 302。另见 工作面试
直觉,392–393。另见 判断完成的内部信号
J
工作面试
聚合,307–308
危险性,301–302
Google的面试实践,307
信息级联,100–102
噪声,7, 302–304
噪声减少,300–311
概述,300–301
错觉的持续,311
面试官心理学,304–306
结构化行为面试,308–309
结构化判断,306–311
延迟整体判断,309–310
独立评估,308
中介评估协议,307–308
工作样本测试,309
Jobs, Steve, 231
《应用心理学杂志》,301
法官-案件交互,76
法官。另见 刑事判决
法官间差异,14–18, 20–21
噪声审计,380–381
尊重专家,226–235
积极开放思维,234
认知风格,232–235
信心,228
经验,228
智力,228–232
概述,226–227
专业原则,227–228
超级预测者,142, 225–226, 265–267
判断。另见 刑事判决;评价性判断;预测性判断
比较判断,184–186
与结果比较,49–51
判断信心,202–203
定义,39–40, 112
评估过程,49–51
有界分歧的期望,44, 362
Gambardi任务,44–49
目标,39–40
一致性错觉,29–33
法官间差异,14–18, 20–21
判断完成的内部信号,48–49, 137–138, 144–146, 367
判断决定,362
司法自由裁量权,13–14
绝对判断的局限性,183–186
彩票,24–27
判断事项,43–44
测量类比,39–41
机械预测与,114–116
医疗决策,143–144
不可验证的,49–51, 362
意见和品味与,43–44
专业判断,362
复杂判断过程的步骤,45–46
系统噪声,21
思考与,361
不需要的变异性,27–29
可验证的,47–51, 362
人内与人间信度,47
判断决定,362
陪审团审议,103–105, 187–198
比较愤怒、惩罚意图和损害赔偿,192–194
金钱裁决,194–197
Joan Glover诉一般援助案例,187–191, 193–197
愤怒假说,190–193
惩罚性损害赔偿,190–194
陪审团无效化,356
K
Kadi正义,359
Kahana, Michael, 91–92
Kahneman, Daniel, 189
Kant, Immanuel, 88
kappa统计量,276
Kasdan, Lawrence, 168–169
Kennedy, Edward M., 17–18
Keynes, John Maynard, 264
Kuncel, Nathan, 32, 121–122
L
LaFleur, Jo Carol, 342
单圈时间练习,40
人权律师委员会(人权第一组织),14
最小二乘法,59–62
水平错误,73–74
水平噪声,74, 78, 193
刑事判决,332
定义,365–366
测量,212–217
绩效评估,294
Lewis, Michael,134
Lieblich, Samuel,284
生活轨迹
因果思维,153–154,157
相关性 vs. 因果关系,152–153
脆弱家庭与儿童福祉研究,149–152
后见之明,155–156
概述,148–149
统计思维,153–154,157
理解,152–153,154–156
线性回归模型 参见 简单模型
线性顺序揭示,256–257
贷款审批,90
抽签
刑事判决,72,76
罚球,79–80
保险业,24–27
场合噪音作为第二次抽签的产物,80–81,206
系统噪音作为第一次抽签的产物,81,206
Lucas, George,168–170
机器学习模型
算法
算法厌恶,135
算法偏见,334
定义,128–133
预测性警务,335–336
保释决定,130–133,143
断腿原则,129
公平性,132–133
生活轨迹,150
医疗决策,144,280
预测性判断,128–133
Macy, Michael,97
《神奇数字七》(Miller),183
MAP 参见 中介评估协议
Mapco收购Roadco案例
决定方法,312–315
决策会议,318–321
估计-讨论-估计方法,319,323
独立评估,317–318
外部观点,316–317
信息排序,315–316
透明度,318
Mashaw, Jerry,356
匹配,176–186
Bill,爵士乐演奏会计师例子,176–177
一致性与,176–178
定义,176
Julie的GPA例子,179–183
匹配强度,178–179
匹配预测
偏见,179–183
纠正预测 vs.,391–392
定义,391
噪音,183–186
Mayfield, Brandon,245–246,251
McLanahan, Sara,148–149
平均绝对差,72–73
均方误差(MSE),59–66,68,211,363–364
测量
定义,39
判断与,39–41
机械预测。另见 基于规则的方法
临床判断 vs.,114–116
定义,113
简单模型,113,117–122,129,150
中位数,60
中介评估协议(MAP),312–321
基础率,316
定义,372
工作面试,307–308
主要步骤,323
Mapco收购Roadco案例
决定方法,312–315
决策会议,318–321
估计-讨论-估计方法,319,323
独立评估,317–318
外部观点,316–317
信息排序,315–316
透明度,318
重复决策,321–322
参考类别,316
医疗决策,273–286
人际噪音,276,279
临床判断,143–144
心脏病发作诊断,143–144
诊断变异性,80
乳腺癌,276,278
子宫内膜异位症,277
心脏病,277
黑色素瘤,278
病理学和放射学,275–279
结核病,278
疲劳和阿片类药物处方,89
kappa统计量,276
机器学习模型,144
噪音,6
噪音减少,274–275,279–283
算法,280
Apgar评分,280–282
BI-RADS,283
Centor评分,282–283
场合噪音,278–279
精神病学,283–286
第二意见,274
白大褂综合征,273–274
Meehl, Paul,114–116,134
黑色素瘤,诊断变异性,278
Mellers, Barbara,142,234,262–266,268–270
记忆表现,91–92
《威尼斯商人》(Shakespeare),340
无意识一致性,122
迷你德尔菲法
预测,262
中介评估协议,319,323
法官模型,118–122
《点球成金》(Lewis),134
情绪和情绪操控,86–89,173
Moore, Don,262–266
道德价值观,341–344
士气,9,292,347
Morewedge, Carey,238
MSE(均方误差),59–66,68,211,363–364
Muchnik, Lev,98–99
Mullainathan, Sendhil,130–131,143–144
多元回归技术,113
音乐下载研究,95–97
朴素现实主义,31
Nash, Steve,79
美国国家篮球协会,79
谈判
锚定与,171
情绪与,87
噪音。另见 场合噪音;系统噪音
偏见 vs.,4–6,8,53
组成部分,210
结论偏见与,174
对错误的贡献,55–56,62–66
定义,3–5
效应,364–365
与偏见相等,58
过度一致性,174
总体讨论,6–10
识别的重要性,5
工作面试,302–304
圈数练习,40
水平噪音,74,78,193
匹配,183–186
测量,53–54,363–364
模糊性,369
最优噪音,9
总体错误方程,62–66
模式噪音,74–77,193,203–204
预测性判断,8
响应量表,192–194
射击场比喻,3–5,53
替代偏见,173–174
类型,365–367
噪音审计,53,379–385
实施,383–384
分析和结论,384–385
资产管理公司,28–29
客户,380
刑事判决,15–17,19–20,69–76
定义,364
指纹分析,248–252
功能,370
GoodSell噪音减少案例,56–59,64–66
保险,25–27
法官,380–381
启动前会议,382–383
项目经理,381
项目团队,380
模拟,381–382
标准差,57–58
噪音减少。另见 决策卫生
积极开放思维,370
成本,329–337
偏见,334–337
易出错,331–334
概述,329–331
去偏见,222,236–244,370,387–389
预测,260–262
GoodSell噪音减少案例,64–66
工作面试,300–311
聚合,307–308
危险,301–302
延迟整体判断,309–310
独立评估,308
中介评估协议,307–308
噪音,302–304
概述,300–301
面试官心理学,304–306
结构化行为面试,308–309
构建复杂判断,306–311
工作样本测试,309
医疗决策,274–275,279–283
算法,280
Apgar评分,280–282
BI-RADS,283
Centor评分,282–283
噪音审计,370
反对意见,327–328
总体错误方程,63–66
绩效评估
聚合,291–292
行为锚定评级量表,297–298
案例量表,297–298
强制排名系统,292,294–296
参考框架培训,297–298
排名,294
结构化,293–294
360度评价系统,291–292
通过规则和指导原则,21
非回归性错误,182
非验证性判断,49–51,362
正态(高斯)分布,56
推助,事前去偏,237–238
数字量表,46
O
奥巴马,巴拉克,35
Obermeyer, Ziad,143–144
客观无知
临床与机械辩论,142–144
否认无知,144–146
不完美信息,138
判断完成的内在信号,137–138,144–146
难以处理的不确定性,139–140
过度自信,140–142,144–145
绩效预测和,138
政治评论家,140–142
预测性判断,367
短期与长期预测,141–142
场合噪音,8,77–78,366–367
内在群体,84–85
辩证启发法,84–85
指纹分析,248–249
罚球示例,79–80
内在原因,91–93
测量,81–82,212–217
医疗决策,278–279
案例顺序作为来源,90
模式噪音和,203–204
作为第二次抽奖的产物,80–81,206
相对于系统噪音的大小,90–91
来源,86–90
替换偏见,173
群体智慧效应,83–85,98–99,223
OMB通告A-4文件,242
《论胡说》(Frankfurt),87–88
奥尼尔,沙奎尔,79
奥尼尔,凯西,334–335
最优噪音
个案判断,339–348
创造力,346
威慑,346
玩弄系统,344–345
道德价值观和,341–344
士气,347
概述,339–340
风险厌恶,346
噪音减少的成本,329–337
偏见,334–337
错误水平,331–334
概述,329–331
概述,325–328
规则与标准,350–360
航空业,355
偏见,353,360
官僚正义,356
决策成本,357–359
错误成本,357–359
残疾矩阵,355–356
消除噪音,359–360
无知和,352–353
陪审团拒判,356
卡迪正义,359
概述,350–351
社会和政治分歧,352
社交媒体,353–354
案例顺序,作为场合噪音的来源,90
异常值,395
外部视角,153–154,157,219–220,369
修正预测,393
决策卫生,371–372
错误预防和,167
中介评估协议,316–317
过度自信,239–240
预测,259–260
客观无知和,140–142,144–145
P
Pashler, Harold,83–85
专利授权,7,213
病理学,诊断变异性,275–279
模式错误,75,205–206,212
定义,203
暂时和永久因素,203
暂时错误和,203
模式噪音,74–77,193,206,209,366
法官与案件的交互作用,76
测量,212–217
场合噪音和,203–204
精神病学,284
来源,204–205
稳定模式噪音,203–204
模式
一致性错觉,202
朱莉的GPA示例,200–206
多重、冲突线索,200–202
个性类比,207–208
稳定模式噪音,203–204,206
PCAST(总统科学技术顾问委员会),253–254
Pennycook, Gordon,87
一致性百分比(PC)
定义,108
面试-绩效相关性,139,302
绩效评估,287–299
绝对评级,292–296
发展性评价,290,297
光环效应,291,293–294
噪音,7
噪音减少,291
聚合,291–292
行为锚定评级量表,297–298
案例量表,297–298
强制排名系统,292,294–296
参考框架培训,297–298
排名,294
结构化,293–294
360度评价系统,291–292
质疑价值,298–299
相对评级,292–296
系统噪音,289–290
绩效预测
临床判断,112,114–116
机械预测,113–116
多元回归技术,113
客观无知和,138
概述,111–112
随机线性模型,121–122
简单模型,113,117–122
标准统计方法,112–113
永久测试版,预测,266–267
个性类比,207–209
Big Five模型,207
情境与个性的结合,207–208
人事决策。另见工作面试;绩效评估
信息瀑布,100–102
噪音,7
规划谬误,162
政治立场,97–98
政治评论家,140–142
预测市场,261–262
预测性判断,8。另见绩效预测
拟合模型,118
偏见,162
定义,362
评价性与,52
有效性错觉,115–116
判断完成的内在信号,367
法官模型,118–122
噪音,52
非验证性,47–48,362
客观无知,367
绩效预测
临床判断,112
机械预测,113–116
多元回归技术,113
概述,111–112
简单模型,113
标准统计方法,112–113
心理偏见,367–368
基于规则的方法,123–135
节俭模型,127–128
不当线性模型,124–127
机器学习模型,128–133
概述,123–124
优于人类判断,133–135
可验证的,362
预测性警务,335–336
预判断 见 结论偏见
启动前会议,噪音审计,382–383
总统科学技术顾问委员会(PCAST),253–254
预防性去偏,237–240
促进,238–239
推助,237–238
Price, Mark,79
《预测原理》(Armstrong),260
概率思维,38
专业原则,尊重专家,227–228
专业判断,362。另见尊重专家
项目经理,噪音审计,381
项目团队,噪音审计,380
ProPublica,335
精神病学
DSM-5指导原则,285
DSM-III指导原则,284
DSM-IV指导原则,284
面试指南,285
噪音,6
模式噪音,284
心理偏见
因果思维和,218–219
结论偏见,168–171,174
诊断,162–164
过度连贯,171–173,174
预测,270
基本归因错误,218
后见之明,218
规划谬误,162
预测性判断,367–368
范围不敏感性,163
统计偏见和,161–162
替代偏见, 164–168, 173–174
勾股定理, 62–63
种族歧视, 71, 132, 337. 另见 偏见
放射学, 诊断变异性, 275–279
Ramji-Nogales, Jaya, 90–91
随机线性模型, 性能预测, 121–122
排名, 性能评估, 292, 294–296
比例量表, 195
招聘面试 见 工作面试
定义, 34
单一决策 vs., 35–36
公投提案, 97
回归均值, 182, 392
行为规制, 350–360
康复, 刑事判决和, 74
相对判断, 374
相对评级, 292–296
积极开放思维, 234
认知风格, 232–235
信心, 228
经验, 228
智力, 228–232
概述, 226–227
专业准则, 227–228
响应量表, 189
模糊性, 189, 199
比较愤怒、惩罚意图和损害赔偿, 192–194
金额奖励, 194–197
噪音, 192–194
愤怒假说, 190–193
惩罚性损害赔偿, 190–194
比例量表, 195–196
绝地归来 (电影), 168–169
反动的修辞 (Hirschman), 331
风险规避, 346
Ritov, Ilana, 234
Rosenzweig, Phil, 219
节俭模型, 127–128
不当线性模型, 124–127
机器学习模型, 128–133
概述, 123–124
优于人类判断, 133–135
航空业, 355
偏见, 353, 360
官僚正义, 356
决策成本, 357–359
错误成本, 357–359
残疾矩阵, 355–356
消除噪音, 359–360
无知和, 352–353
陪审团推翻判决(jury nullification), 356
Kadi正义, 359
概述, 350–351
社会和政治分歧, 352
社交媒体, 353–354
Salganik, Matthew, 95–97, 148–149
Salikhov, Marat, 269–270
Satopää, Ville, 268–270
明天多储蓄计划, 237
Schkade, David, 189
范围不敏感性, 163
第二意见, 医疗决策, 274
选择群体策略, 预测, 261
选择, 预测, 260, 261, 268, 270–272
选择性注意和回忆, 46
人气的自我强化性质, 95–98
Sellier, Anne-Laure, 239
1984年判决改革法案, 18
决策卫生, 373
法医科学, 256–258
中介评估协议, 315–316
共同规范, 尊重专家, 227–228
“共同愤怒和不稳定奖励” (Kahneman, Sunstein, Schkade), 194
射击场比喻, 3–5, 53, 162–163
Simonsohn, Uri, 90
简单模型, 113, 117–122
断腿原则, 129
人生轨迹, 150
简单规则 (节俭模型), 127–128
模拟, 噪音审计, 381–382
反事实思维, 37–38
决策卫生和, 374
噪音在其中, 36–38
噪音减少, 38
概述, 34–35
反复决策 vs., 35–36
COVID-19危机响应, 37–38
埃博拉威胁响应, 34–35, 36
Slovic, Paul, 170
社会影响, 96, 103
社交媒体, 353–354
稳定模式噪音, 206, 212–217, 366
标准差, 41, 57, 72
标准统计方法, 性能预测, 112–113
标准 见 规则 vs. 标准
统计偏见, 173
定义, 161
预测, 270
心理偏见和, 161–162
统计思维 见 外部视角
现状偏见, 240
Stevens, S. S., 195–197
Stith, Kate, 20, 326
压力, 作为场合噪音来源, 89
结构化行为面试, 308–309
延迟整体判断, 309–310
独立评估, 308
中介评估协议, 307–308
性能评估, 293–294
比尔, 爱好爵士乐的会计师例子, 164–166
噪音, 173–174
用简单判断替代困难判断, 167–168, 181–182
用一个问题替代另一个问题, 164–167
Sunstein, Cass R., 189
超级预测者, 142, 225–226, 265–267
替代解释的抑制, 202
结论偏见, 169
定义, 161
匹配, 184
匹配预测, 180, 182
结论偏见, 169
匹配预测, 182
组成部分, 78
分解为系统和模式噪音, 76
定义, 78, 363
不一致性, 53
陪审团审议, 193
水平噪音, 74, 78, 193
刑事判决, 332
定义, 365–366
测量, 212–217
性能评估, 294
保险公司噪音审计, 25–27
场合噪音, 366–367
模式噪音, 74–77, 193, 206, 209, 366
法官与案件交互, 76
测量, 212–217
场合噪音和, 203–204
精神病学, 284
来源, 204–205
稳定模式噪音, 203–204
性能评估, 289–290
作为第一次抽奖的产物, 206
稳定模式噪音, 366
不需要的变异性, 27–29
TB (结核病), 诊断变异性, 278
团队合作, 预测, 268, 270
测试-重测信度, 82
Tetlock, Philip, 140–142, 262–266, 268–270
思考, 快与慢 (Kahneman), 161, 309
360度评级系统, 性能评估, 291–292
三振出局政策, 332, 356
Todorov, Alexander, 214
预测, 268, 269–270
参考框架训练, 297–298
尊重专家, 227–228
透明度, 中介评估协议, 318
结核病 (TB), 诊断变异性, 278
不确定性, 139–140
后见之明和, 155–156
预测和, 152–153
承保商, 保险, 24–27, 31–32
《世界人权宣言》, 352, 359–360
美国判决委员会, 18, 19
功利主义计算, 88
正常谷, 154–158, 217
可验证判断, 47–51, 362
评估, 50–51
评分, 48–49
Vul, Edward, 83–85
Wainer, Howard, 126
数学毁灭武器 (O’Neil), 334–335
天气, 作为场合噪音来源, 89–90
Weber, Max, 359
网站评论, 98
Welch, Jack, 292
白大褂综合征, 273–274
Williams, Thomas, 16
葡萄酒竞赛, 80
群体智慧效应,225
预测,223,261,271
独立性与,98–99
场合噪音,83–85
个体内信度,47
Woodson v. North Carolina, 333
Work Rules! (Bock),307
工作样本测试,工作面试,309
Y
Yang, Crystal,20
Yu, Martin,121–122
Z
Zuckerberg, Mark,231
我们要感谢许多人。Linnea Gandhi担任我们的参谋长,提供实质性指导和帮助,保持我们的组织性,让我们微笑和欢笑,基本上主持着整个工作。除此之外,她对手稿提出了许多宝贵的建议。没有她我们无法完成这项工作。Dan Lovallo发挥了重要作用,共同撰写了催生本书的文章之一。我们的代理人John Brockman在每个阶段都表现出热情、希望、敏锐和智慧。我们对他深表感谢。我们的主编和指导Tracy Behar在大大小小的方面都让这本书变得更好。Arabella Pike和Ian Straus也提供了出色的编辑建议。
特别感谢Oren Bar-Gill、Maya Bar-Hillel、Max Bazerman、Tom Blaser、David Budescu、Jeremy Clifton、Anselm Dannecker、Vera Delaney、Itiel Dror、Angela Duckworth、Annie Duke、Dan Gilbert、Adam Grant、Anupam Jena、Louis Kaplow、Gary Klein、Jon Kleinberg、Nathan Kuncel、Kelly Leonard、Daniel Levin、Sara McLanahan、Barbara Mellers、Josh Miller、Sendhil Mullainathan、Scott Page、Eric Posner、Lucia Reisch、Matthew Salganik、Ville Satopää、Eldar Shafir、Tali Sharot、Philip Tetlock、Richard Thaler、Barbara Tversky、Peter Ubel、Duncan Watts、Caroline Webb和Crystal Yang,他们阅读并评论了章节草稿,在某些情况下还评论了全文草稿。我们感谢他们的慷慨和帮助。
我们很幸运受益于许多伟大研究者的建议。Julian Parris在许多统计问题上提供了宝贵的帮助。没有Sendhil Mullainathan、Jon Kleinberg、Jens Ludwig、Gregory Stoddard和Hye Chang,我们关于机器学习成就的章节就不可能完成。我们对判断一致性的讨论很大程度上归功于Alex Todorov和他的普林斯顿同事Joel Martinez、Brandon Labbree和Stefan Uddenberg,以及Scott Highhouse和Alison Broadfoot。这些了不起的研究团队不仅慷慨地分享了他们的见解,还友善地为我们进行了特殊分析。当然,任何误解或错误都是我们的责任。此外,我们感谢Laszlo Bock、Bo Cowgill、Jason Dana、Dan Goldstein、Harold Goldstein、Brian Hoffman、Alan Krueger、Michael Mauboussin、Emily Putnam-Horstein、Charles Scherbaum、AnneLaure Sellier和Yuichi Shoda分享他们的专业知识。
我们还要感谢多年来的一支真正的研究者大军,包括Shreya Bhardwaj、Josie Fisher、Rohit Goyal、Nicole Grabel、Andrew Heinrich、Meghann Johnson、Sophie Mehta、Eli Nachmany、William Ryan、Evelyn Shu、Matt Summers和Noam Ziv-Crispel。这里的许多讨论涉及我们缺乏专业知识的实质性领域,由于他们的出色工作,这本书比原本情况下的偏见和噪音都更少。
最后,作为一个三作者、两大洲的团队进行合作在最好的时候都具有挑战性,而2020年并不是最好的时候。没有Dropbox和Zoom的技术魔力,我们不可能完成这本书。我们感谢这些伟大产品背后的人们。
DANIEL KAHNEMAN是国际畅销书《思考,快与慢》的作者。他获得了2002年诺贝尔经济学奖和2013年国家自由勋章。Kahneman是普林斯顿大学Eugene Higgins心理学教授和普林斯顿公共与国际事务学院公共事务教授。他获得了众多奖项,其中包括美国心理学协会颁发的心理学杰出终身贡献奖。
OLIVIER SIBONY是巴黎高等商学院战略与商业政策教授。此前,他在麦肯锡公司巴黎和纽约办公室工作了二十五年,担任高级合伙人。Sibony关于改善战略决策质量的研究已在许多出版物中刊登,包括《哈佛商业评论》和《MIT斯隆管理评论》。他是《你即将犯一个可怕的错误!》的作者。@SibOliv
CASS R. SUNSTEIN是《纽约时报》畅销书《星球大战的世界》和《助推》(与Richard H. Thaler合著)等书的作者。他是哈佛大学Robert Walmsley大学教授,是行为经济学与公共政策项目的创始人和主任。从2009年到2012年,他担任白宫信息和监管事务办公室主任,从2013年到2014年,他在奥巴马总统的情报和通信技术审查小组任职。@Cass Sunstein
《思考,快与慢》
《你即将犯一个可怕的错误!:偏见如何扭曲决策——以及你可以做什么来对抗它们》
《信息过载:理解你不想知道的事情》
《助推:改善健康、财富和幸福的决策》(与Richard H. Thaler合著)

澳大利亚
HarperCollins Publishers Australia Pty. Ltd.
Level 13, 201 Elizabeth Street
Sydney, NSW 2000, Australia
加拿大
HarperCollins Canada
Bay Adelaide Centre, East Tower
22 Adelaide Street West, 41st Floor
Toronto, Ontario M5H 4E3, Canada
印度
HarperCollins India
A 75, Sector 57
Noida, Uttar Pradesh 201 301, India
新西兰
HarperCollins Publishers New Zealand
Unit D1, 63 Apollo Drive
Rosedale 0632
Auckland, New Zealand
英国
HarperCollins Publishers Ltd.
1 London Bridge Street
London SE1 9GF, UK
美国
HarperCollins Publishers Inc.
195 Broadway
New York, NY 10007