
《持续交付》好评推荐
“如果你需要更频繁地部署软件,这本书就是为你准备的。应用书中的内容将帮助你降低风险、消除繁琐工作并增强信心。我会在我所有的当前项目中使用这里的原则和实践。”
—Kent Beck, Three Rivers Institute
“无论你的软件开发团队是否已经理解持续集成和源代码控制一样必不可少,这都是必读书籍。这本书的独特之处在于将整个开发和交付过程联系在一起,提供了哲学和原则,而不仅仅是技术和工具。作者让从测试自动化到自动化部署的主题对广大读者都易于理解。开发团队中的每个人,包括程序员、测试人员、系统管理员、数据库管理员和经理,都需要阅读这本书。”
—Lisa Crispin,《敏捷测试》合著者
“对于许多组织来说,持续交付不仅仅是一种部署方法,它对业务运营至关重要。这本书向你展示如何在你的环境中使持续交付成为有效的现实。”
—James Turnbull,《Puppet实战》作者
“一本清晰、精确、写得很好的书,让读者了解发布过程中的期望。作者对软件部署的期望和障碍进行了循序渐进的说明。这本书是任何软件工程师藏书的必备品。”
—Leyna Cotran, 加州大学欧文分校软件研究所
“Humble 和 Farley 阐述了使快速增长的Web应用成功的要素。持续部署和交付已经从有争议变为普遍,这本书对此进行了出色的介绍。它真正体现了开发和运维在多个层面的交叉,这些作者把握得非常准确。”
—John Allspaw, Etsy.com技术运营副总裁,《容量规划的艺术》和《Web运维》作者
“如果你从事构建和交付基于软件的服务业务,深入理解《持续交付》中如此清晰解释的概念将使你受益匪浅。但除了概念之外,Humble 和 Farley 还提供了一个出色的快速可靠交付变更的行动手册。”
—Damon Edwards, DTO Solutions总裁和dev2ops.org联合编辑
“我相信任何处理软件发布的人都能够拿起这本书,翻到任何章节并快速获得有价值的信息;或者从头到尾阅读这本书,并能够以适合其组织的方式简化他们的构建和部署流程。在我看来,这是构建、部署、测试和发布软件的必备手册。”
—Sarah Edrie, 哈佛商学院质量工程总监
“持续交付是任何现代软件团队在持续集成之后的合乎逻辑的下一步。这本书采用了持续向客户交付有价值软件这一公认雄心勃勃的目标,并通过一套清晰有效的原则和实践使其可实现。”
—Rob Sanheim, Relevance公司首席顾问
Jez Humble 和 David Farley 著
 Upper Saddle River, NJ •
Boston • Indianapolis • San Francisco New York • Toronto • Montreal •
London • Munich • Paris • Madrid Cape Town • Sydney • Tokyo • Singapore
• Mexico City
Upper Saddle River, NJ •
Boston • Indianapolis • San Francisco New York • Toronto • Montreal •
London • Munich • Paris • Madrid Cape Town • Sydney • Tokyo • Singapore
• Mexico City
制造商和销售商用于区分其产品的许多名称被声明为商标。当这些名称出现在本书中,且出版商知晓商标声明时,这些名称已用首字母大写或全部大写字母印刷。
作者和出版商在本书的准备过程中已尽力谨慎,但不做任何明示或暗示的保证,也不对错误或遗漏承担责任。对于因使用本书中包含的信息或程序而产生或引起的附带或间接损害,不承担任何责任。
当批量购买或特别销售本书时,出版商提供优惠折扣,其中可能包括电子版本和/或针对您的业务、培训目标、营销重点和品牌利益定制的封面和内容。有关更多信息,请联系:
美国企业和政府销售 (800) 382-3419 corpsales@pearsontechgroup.com
美国以外的销售请联系:
国际销售 international@pearson.com
访问我们的网站:informit.com/aw
国会图书馆出版物编目数据:
Humble, Jez.
持续交付:通过构建、测试和部署自动化实现可靠的软件发布 / Jez Humble, David Farley. p. cm.
包括参考文献和索引。
ISBN 978-0-321-60191-9 (精装 : alk. paper) 1. 计算机软件–开发。2. 计算机软件–可靠性。3. 计算机软件–测试。I. Farley, David, 1959-II. 书名。
QA76.76.D47H843 2010
005.1–dc22
版权所有 © 2011 Pearson Education, Inc.
保留所有权利。在美国印刷。本出版物受版权保护,在进行任何禁止的复制、存储在检索系统中或以任何形式或方式(电子、机械、影印、录制或类似方式)传输之前,必须获得出版商的许可。有关权限的信息,请写信至:
Pearson Education, Inc Rights and Contracts Department 501 Boylston Street, Suite 900 Boston, MA 02116 传真 (617) 671 3447
ISBN-13: 978-0-321-60191-9 ISBN-10: 0-321-60191-2 文本在美国印第安纳州克劳福兹维尔的RR Donnelley用再生纸印刷。
首次印刷 2010年8月
本书献给我的父亲,他一直给予我无条件的爱和支持。 —Jez
本书献给我的父亲,他总是为我指引正确的方向。 —Dave
前言
序言
致谢
关于作者
第一部分:基础
第1章:软件交付的问题
引言
一些常见的发布反模式
反模式:手动部署软件
反模式:仅在开发完成后才部署到类生产环境
反模式:生产环境的手动配置管理
我们能做得更好吗?
我们如何实现目标?
每次变更都应触发反馈过程
必须尽快收到反馈
交付团队必须接收反馈并据此采取行动
这个过程能扩展吗?
有哪些好处?
赋能团队
减少错误
降低压力
部署灵活性
熟能生巧
发布候选版本
每次检入都会产生一个潜在发布版本
软件交付原则
创建可重复、可靠的软件发布流程
几乎一切都自动化
将所有内容纳入版本控制
如果某事很痛苦,就更频繁地做它,并将痛苦提前
内建质量
完成意味着已发布
每个人都对交付过程负责
持续改进
总结
第2章:配置管理
引言
使用版本控制
将所有内容都纳入版本控制
定期检入主干
使用有意义的提交信息
管理依赖关系
管理外部库
管理组件
管理软件配置
配置与灵活性
配置类型
管理应用程序配置
跨应用程序管理配置
管理应用程序配置的原则
管理您的环境
管理环境的工具
管理变更过程
总结
第3章:持续集成
引言
实施持续集成
开始之前需要什么
基本的持续集成系统
持续集成的先决条件
定期检入
创建全面的自动化测试套件
保持构建和测试过程简短
管理您的开发工作空间
使用持续集成软件
基本操作
附加功能
基本实践
不要在构建失败时检入
在提交前始终在本地运行所有提交测试,或让您的CI服务器为您执行此操作
等待提交测试通过后再继续
永远不要在构建失败时下班回家
始终准备好恢复到先前的版本
在恢复前设定修复时间限制
不要注释掉失败的测试
对您的更改导致的所有故障负责
测试驱动开发
建议实践
极限编程(XP)开发实践
架构违规时使构建失败
测试缓慢时使构建失败
警告和代码风格违规时使构建失败
分布式团队
对流程的影响
集中式持续集成
技术问题
替代方法
分布式版本控制系统
总结
第4章:实施测试策略
引言
测试类型
支持开发过程的面向业务测试
支持开发过程的面向技术测试
评估项目的面向业务测试
评估项目的面向技术测试
测试替身(Test Doubles)
实际情况和策略
新项目
项目中期
遗留系统
集成测试
流程
管理缺陷积压
总结
第二部分:部署流水线
第5章:部署流水线剖析
引言
什么是部署流水线?
基本的部署流水线
部署流水线实践
只构建一次二进制文件
以相同方式部署到每个环境
对您的部署进行冒烟测试
部署到生产环境的副本
每次变更应立即通过流水线传播
如果流水线的任何部分失败,停止生产线
提交阶段
提交阶段最佳实践
自动化验收测试关卡
自动化验收测试最佳实践
后续测试阶段
手动测试
非功能性测试
准备发布
自动化部署和发布
回退变更
在成功的基础上构建
实施部署流水线
建模您的价值流并创建行走骨架
自动化构建和部署过程
自动化单元测试和代码分析
自动化验收测试
演进您的流水线
度量指标
总结
第6章:构建和部署脚本
引言
构建工具概览
Make
Ant
NAnt和MSBuild
Maven
Rake
Buildr
Psake
构建和部署脚本的原则与实践
为部署流水线中的每个阶段创建脚本
使用适当的技术部署您的应用程序
使用相同的脚本部署到每个环境
使用操作系统的打包工具
确保部署过程是幂等的
增量演进您的部署系统
面向JVM的应用程序项目结构
项目布局
部署脚本
在90年代末,我拜访了Kent Beck,当时他在瑞士为一家保险公司工作。他向我展示了他的项目,他那支高度自律的团队的一个有趣之处在于他们每天晚上都会将软件部署到生产环境。这种定期部署给他们带来了许多优势:编写的软件不会无用地等待部署,他们可以快速响应问题和机遇,快速的周转导致他们与业务客户和最终客户之间建立了更深入的关系。
在过去十年中,我在ThoughtWorks工作,我们项目的一个共同主题是缩短从想法到可用软件之间的周期时间。我看到很多项目案例,几乎所有项目都涉及坚定地缩短这个周期。虽然我们通常不会每天部署到生产环境,但现在看到团队进行双周发布已经很常见了。
Dave和Jez是这场巨变的一部分,他们积极参与了建立频繁、可靠交付文化的项目。他们和我们的同事已经将那些每年难以部署一次软件的组织带入了持续交付的世界,在这个世界里,发布变成了例行公事。
至少对于开发团队来说,这种方法的基础是持续集成(Continuous Integration, CI)。CI使整个开发团队保持同步,消除了集成问题导致的延迟。几年前,Paul Duvall在这个系列中写了一本关于CI的书。但CI只是第一步。成功集成到主线代码流中的软件仍然不是在生产环境中执行其工作的软件。Dave和Jez的书从CI继续讲述这个故事,描述如何构建将集成代码转变为生产软件的部署流水线。
这种交付思维长期以来一直是软件开发中被遗忘的角落,陷入开发团队和运维团队之间的空白地带。因此,本书中的技术基于将这些团队聚集在一起也就不足为奇了——这是新兴但不断增长的DevOps运动的先兆。这个过程还涉及测试人员,因为测试是确保无错误发布的关键要素。贯穿所有这些的是高度的自动化,因此可以快速且无错误地完成工作。
让所有这些运作起来需要付出努力,但好处是深远的。漫长、高强度的发布成为过去。软件的客户看到想法迅速转变为他们每天可以使用的工作代码。也许最重要的是,我们消除了软件开发中最大的压力源之一。没有人喜欢那些紧张的周末,试图在周一黎明之前完成系统升级发布。
在我看来,一本能向你展示如何频繁且无需通常压力地交付软件的书是必读的。为了你的团队,我希望你同意这一点。
昨天你的老板要求你向客户演示系统的强大新功能,但你无法展示任何内容。你的所有开发人员都在开发新功能的中途,现在没有人能运行应用程序。你有代码,它可以编译,持续集成服务器上的所有单元测试都通过了,但将新版本发布到可公开访问的UAT环境需要几天时间。在如此短的通知时间内期待演示是不是不合理?
你的生产环境中有一个严重的bug。它每天都在给你的业务造成损失。你知道修复方法是什么:在三层系统的所有三层中使用的库中改一行代码,以及对一个数据库表进行相应的更改。但上次你将软件的新版本发布到生产环境时,花了整个周末工作到凌晨3点,而且负责部署的人在那之后不久就因厌恶而辞职了。你知道下次发布将会超过周末,这意味着应用程序将在工作日期间停机一段时间。要是业务部门能理解我们的问题就好了。
这些问题虽然太常见了,但并不是软件开发过程不可避免的结果:它们表明出了问题。软件发布应该是一个快速、可重复的过程。如今,许多公司一天内发布多个版本。即使是具有复杂代码库的大型项目,这也是可能的。在本书中,我们将向你展示如何做到这一点。
Mary和Tom Poppendieck问道:“你的组织部署一个只涉及一行代码的更改需要多长时间?你是否在可重复、可靠的基础上做到这一点?”从决定需要进行更改到将其部署到生产环境的时间称为周期时间(cycle time),它是任何项目的重要指标。
在许多组织中,周期时间以周或月为单位来衡量,发布过程肯定不是可重复或可靠的。它是手动的,通常需要一个团队来将软件部署到测试或预发环境,更不用说部署到生产环境了。然而,我们遇到过同样复杂的项目,这些项目一开始是这样的,但在经过广泛的重新设计后,团队能够将关键修复的周期时间缩短到几小时甚至几分钟。这是可能的,因为创建了一个完全自动化、可重复、可靠的过程,用于将更改通过构建、部署、测试和发布过程的各个阶段。自动化是关键。它允许开发人员、测试人员和运维人员通过按下按钮来执行创建和部署软件所涉及的所有常见任务。
本书描述了如何通过缩短从想法到实现业务价值的路径(周期时间),使其更短、更安全,从而彻底改变软件交付。
软件在到达用户手中之前不会产生收入。这是显而易见的,但在大多数组织中,将软件发布到生产环境是一个手动密集、容易出错且风险高的过程。虽然以月为单位衡量的周期时间很常见,但许多公司的情况要糟糕得多:超过一年的发布周期并非闻所未闻。对于大公司来说,从有想法到发布实现它的代码之间的每一周延迟都可能代表数百万美元的机会成本,然而这些公司往往是周期时间最长的。
尽管如此,允许低风险交付软件的机制和流程尚未成为当今大多数软件开发项目的组成部分。
我们的目标是使软件从开发人员手中交付到生产环境成为一个可靠、可预测、可见且在很大程度上自动化的过程,具有充分理解、可量化的风险。使用我们在本书中描述的方法,可以在几分钟或几小时内从有想法到将实现它的工作代码交付到生产环境,同时提高交付软件的质量。
交付成功软件的大部分相关成本是在首次发布后产生的。这是支持、维护、添加新功能和修复缺陷的成本。对于通过迭代过程交付的软件来说尤其如此,其中首次发布包含为客户提供价值的最少功能。因此本书的标题为《持续交付》(Continuous Delivery),取自敏捷宣言的第一原则:“我们的最高优先级是通过早期和持续交付有价值的软件来满足客户”。这反映了现实:对于成功的软件,首次发布只是交付过程的开始。
我们在本书中描述的所有技术都减少了向用户交付软件新版本的时间和风险。它们通过增加反馈并改善负责交付的开发、测试和运维人员之间的协作来实现这一点。这些技术确保当你需要修改应用程序时,无论是修复bug还是交付新功能,从进行修改到将结果部署并投入使用的时间尽可能短,问题在容易修复的早期就被发现,并且相关风险被充分理解。
本书的主要目标之一是改善负责交付软件的人员之间的协作。特别是,我们考虑的是开发人员、测试人员、系统和数据库管理员以及管理人员。
我们涵盖的主题包括:从传统的配置管理、源代码控制、发布规划、审计、合规性和集成,到构建、测试和部署过程的自动化。我们还描述了诸如自动化验收测试、依赖管理、数据库迁移以及测试和生产环境的创建和管理等技术。
许多参与软件创建的人认为这些活动是编写代码的次要工作。然而,根据我们的经验,这些活动会占用大量时间和精力,并且对成功交付软件至关重要。当围绕这些活动的风险没有得到充分管理时,它们最终可能会花费大量资金,通常超过最初构建软件的成本。本书提供您需要的信息来理解这些风险,更重要的是,描述了缓解这些风险的策略。
这是一个雄心勃勃的目标,当然我们无法在一本书中详细涵盖所有这些主题。实际上,我们可能会疏远我们的每一个目标受众:开发人员,因为未能深入讨论架构、行为驱动开发和重构等主题;测试人员,因为没有花足够时间讨论探索性测试和测试管理策略;运维人员,因为没有充分关注容量规划、数据库迁移和生产监控。
然而,已经有书籍详细讨论了这些主题。我们认为文献中缺少的是一本讨论所有活动部分如何协同工作的书:配置管理、自动化测试、持续集成和部署、数据管理、环境管理和发布管理。精益软件开发运动教给我们的一点是,优化整体很重要。为了做到这一点,需要采用整体方法,将交付过程的每个部分以及参与其中的每个人联系在一起。只有当您能够控制每个变更从引入到发布的进展时,您才能开始优化和提高软件交付的质量和速度。
我们的目标是提出一种整体方法,以及这种方法所涉及的原则。我们将为您提供所需的信息,以决定如何在自己的项目中应用这些实践。我们不认为软件开发的任何方面都有”一刀切”的方法,更不用说像企业系统的配置管理和运营控制这样庞大的主题领域了。然而,我们在本书中描述的基本原理广泛适用于各种不同的软件项目——无论是大型、小型、高度技术性的项目,还是快速冲刺以实现早期价值的项目。
当您开始将这些原则付诸实践时,您将发现针对您特定情况需要更多细节的领域。本书末尾有参考书目,以及在线其他资源的指引,您可以在其中找到有关我们涵盖的每个主题的更多信息。
本书由三个部分组成。第一部分介绍持续交付背后的原则以及支持它所需的实践。第二部分描述了本书的核心范式——我们称之为部署流水线(deployment pipeline)的模式。第三部分更详细地介绍了支持部署流水线的生态系统——实现增量开发的技术;高级版本控制模式;基础设施、环境和数据管理;以及治理。
这些技术中的许多可能看起来只适用于大规模应用程序。虽然我们的大部分经验确实来自大型应用程序,但我们相信即使是最小的项目也能从这些技术的全面掌握中受益,原因很简单:项目会增长。您在启动小型项目时做出的决策将不可避免地影响其演进,通过以正确的方式开始,您将为自己(或后来者)节省后续过程中的大量痛苦。
本书作者拥有精益和迭代软件开发哲学的背景。这意味着我们的目标是快速迭代地向用户交付有价值的、可工作的软件,持续努力从交付过程中消除浪费。我们描述的许多原则和技术最初是在大型敏捷项目的背景下开发的。然而,我们在本书中介绍的技术具有普遍适用性。我们的大部分重点是通过更好的可见性和更快的反馈来改善协作。这将对每个项目产生积极影响,无论它是否使用迭代软件开发过程。
我们努力确保章节甚至章节内的部分都可以独立阅读。至少,我们希望您需要了解的任何内容以及对更多信息的引用都清晰地标示出来并且易于访问,以便您可以将本书用作参考。
我们应该提到,我们在处理所涵盖的主题时并不追求学术严谨性。市场上有很多更理论化的书籍,其中许多提供了有趣的阅读和见解。特别是,我们不会在标准上花费太多时间,而是专注于在软件项目中工作的每个人都会发现有用的经过实战检验的技能和技术,并清晰简单地解释它们,以便它们可以在现实世界中每天使用。在适当的情况下,我们将提供一些实战案例来说明这些技术,以帮助将它们置于背景中。
我们知道并非每个人都想从头到尾阅读这本书。我们在编写时考虑到了这一点,一旦你阅读完引言部分,就可以通过几种不同的方式来学习本书。这涉及一定程度的重复,但希望不会让那些决定从头到尾阅读的读者感到乏味。
本书由三个部分组成。第一部分,章节1到4,带你了解规律的、可重复的、低风险发布的基本原则以及支持这些原则的实践。第二部分,章节5到10,描述部署流水线(deployment pipeline)。从第11章开始,我们深入探讨支持持续交付的生态系统。
我们建议每个人都阅读第1章。我们相信那些刚接触软件发布流程的人,即使是经验丰富的开发人员,也会发现大量材料挑战他们对专业软件开发的理解。本书的其余部分可以在闲暇时翻阅—或者在紧急情况下查阅。
第一部分描述了理解部署流水线的前提条件。每一章都建立在前一章的基础上。
第1章,“软件交付的问题”,首先描述了我们在许多软件开发团队中看到的一些常见反模式(antipatterns),然后描述我们的目标以及如何实现它。最后,我们阐述了本书其余部分所基于的软件交付原则。
第2章,“配置管理”,阐述如何管理构建、部署、测试和发布应用程序所需的一切,从源代码和构建脚本到环境和应用程序配置。
第3章,“持续集成”,涵盖了针对应用程序的每次变更构建和运行自动化测试的实践,以便确保软件始终处于可工作状态。
第4章,“实施测试策略”,介绍了构成每个项目不可或缺部分的各种手动和自动化测试,并讨论如何决定哪种策略适合你的项目。
本书的第二部分详细介绍部署流水线,包括如何实现流水线中的各个阶段。
第5章,“部署流水线剖析”,讨论了构成本书核心的模式—一个从签入(check-in)到发布的每次变更的自动化流程。我们还讨论如何在团队和组织层面实施流水线。
第6章,“构建和部署脚本”,讨论可用于创建自动化构建和部署流程的脚本技术,以及使用它们的最佳实践。
第7章,“提交阶段”,涵盖流水线的第一阶段,这是一组应该在应用程序引入任何变更时立即触发的自动化流程。我们还讨论如何创建快速、有效的提交测试套件。
第8章,“自动化验收测试”,介绍从分析到实施的自动化验收测试。我们讨论为什么验收测试对持续交付至关重要,以及如何创建一个具有成本效益的验收测试套件来保护应用程序的重要功能。
第9章,“测试非功能性需求”,讨论非功能性需求,重点是容量测试。我们描述如何创建容量测试,以及如何建立容量测试环境。
第10章,“部署和发布应用程序”,涵盖自动化测试之后发生的事情:按钮式将候选版本(release candidates)推送到手动测试环境、UAT、预发布(staging),最后是发布,涉及诸如持续部署、回滚和零停机发布等重要主题。
本书的最后部分讨论支持部署流水线的横切实践和技术。
第11章,“管理基础设施和环境”,涵盖环境的自动化创建、管理和监控,包括虚拟化和云计算的使用。
第12章,“管理数据”,展示如何在应用程序的整个生命周期中创建和迁移测试数据和生产数据。
第13章,“管理组件和依赖项”,首先讨论如何在不使用分支的情况下使应用程序始终处于可发布状态。然后我们描述如何将应用程序组织为组件集合,以及如何管理构建和测试它们。
第14章,“高级版本控制”,概述了最流行的工具,并详细介绍了使用版本控制的各种模式。
第15章,“管理持续交付”,阐述了风险管理和合规性的方法,并提供了配置和发布管理的成熟度模型。在此过程中,我们讨论持续交付对业务的价值,以及以增量方式交付的迭代项目的生命周期。
我们没有完整地提供外部网站链接,而是将它们缩短并以此格式放入关键字:[bibNp0]。你可以通过两种方式访问链接。使用 bit.ly,这种情况下示例键的 URL 将是 http://bit.ly/bibNp0。或者,你可以使用我们安装在 http://continuousdelivery.com/go/ 的 URL 缩短服务,它使用相同的键——因此示例键的 URL 是 http://continuousdelivery.com/go/bibNp0。这样做的目的是,如果 bit.ly 因某种原因关闭,链接仍然可以保留。如果网页地址更改,我们将尽力保持 http://continuousdelivery.com/go/ 的缩短服务更新,所以如果 bit.ly 的链接无法使用,请尝试这个。
Martin Fowler 签名系列中的所有书籍封面上都有一座桥。我们最初计划使用铁桥(Iron Bridge)的照片,但它已经被该系列的另一本书选用。因此,我们选择了另一座英国桥梁:福斯铁路桥(Forth Railway Bridge),这里展示的是 Stewart Hardy 拍摄的精美照片。
福斯铁路桥是英国第一座使用钢材建造的桥梁,采用新的西门子-马丁平炉法(Siemens-Martin open-hearth process)制造,由苏格兰的两家钢厂和威尔士的一家钢厂供应。钢材以制成的管状桁架形式交付——这是英国桥梁首次使用批量生产的部件。与早期桥梁不同,设计师 John Fowler 爵士、Benjamin Baker 爵士和 Allan Stewart 对架设应力的发生率、降低未来维护成本的措施、风压以及温度应力对结构的影响进行了计算——就像我们在软件中制定的功能性和非功能性需求一样。他们还监督了桥梁的建造,以确保满足这些要求。
这座桥的建造涉及 4,600 多名工人,其中不幸约有一百人死亡,数百人致残。然而,最终成果是工业革命的奇迹之一:在 1890 年完工时,它是世界上最长的桥梁,到 21 世纪初,它仍然是世界第二长的悬臂桥。就像一个长期运行的软件项目一样,这座桥需要持续维护。这在设计时就已规划,桥梁的辅助工程不仅包括维护车间和场地,还包括在 Dalmeny 站的一个约 50 座房屋的铁路”社区”。这座桥的剩余使用寿命估计超过 100 年。
本书直接用 DocBook 编写。Dave 在 TextMate 中编辑文本,Jez 使用 Aquamacs Emacs。图表使用 OmniGraffle 创建。Dave 和 Jez 通常不在世界的同一地方,通过将所有内容提交到 Subversion 进行协作。我们还使用了持续集成(continuous integration),使用 CruiseControl.rb 服务器,每次我们其中一人提交更改时,它都会运行 dblatex 生成书籍的 PDF。
在本书付印前一个月,Dmitry Kirsanov 和 Alina Kirsanova 开始制作工作,通过他们的 Subversion 仓库、电子邮件和共享的 Google Docs 表格与作者协作协调。Dmitry 在 XEmacs 中对 DocBook 源代码进行文字编辑,Alina 完成了其他所有工作:使用自定义 XSLT 样式表和 XSL-FO 格式化程序排版页面,从源代码中作者的索引标签编译和编辑索引,以及对书籍进行最终校对。
许多人为本书做出了贡献。特别要感谢我们的审稿人:David Clack、Leyna Cotran、Lisa Crispin、Sarah Edrie、Damon Edwards、Martin Fowler、James Kovacs、Bob Maksimchuk、Elliotte Rusty Harold、Rob Sanheim 和 Chris Smith。我们还要特别感谢 Addison-Wesley 的编辑和制作团队:Chris Guzikowski、Raina Chrobak、Susan Zahn、Kristy Hart 和 Andy Beaster。Dmitry Kirsanov 和 Alina Kirsanova 在文字编辑、校对和使用他们的全自动系统排版方面做了出色的工作。
我们的许多同事在发展本书的思想方面发挥了重要作用,包括(排名不分先后)Chris Read、Sam Newman、Dan North、Dan Worthington-Bodart、Manish Kumar、Kraig Parkinson、Julian Simpson、Paul Julius、Marco Jansen、Jeffrey Fredrick、Ajey Gore、Chris Turner、Paul Hammant、Hu Kai、Qiao Yandong、Qiao Liang、Derek Yang、Julias Shaw、Deepthi、Mark Chang、Dante Briones、Li Guanglei、Erik Doernenburg、Kraig Parkinson、Ram Narayanan、Mark Rickmeier、Chris Stevenson、Jay Flowers、Jason Sankey、Daniel Ostermeier、Rolf Russell、Jon Tirsen、Timothy Reaves、Ben Wyeth、Tim Harding、Tim Brown、Pavan Kadambi Sudarshan、Stephen Foreshew、Yogi Kulkarni、David Rice、Chad Wathington、Jonny LeRoy 和 Chris Briesemeister。
Jez 要感谢他的妻子 Rani,她是他所能期望的最有爱心的伴侣,在他写作本书时脾气暴躁时为他加油打气。他还感谢他的女儿 Amrita,感谢她的咿呀学语、拥抱和灿烂的笑容。他还深深感谢 ThoughtWorks 的同事们,让它成为一个鼓舞人心的工作场所,并感谢 Cyndi Mitchell 和 Martin Fowler 对本书的支持。最后,向 Jeffrey Fredrick 和 Paul Julius 创建 CITCON 致敬,并感谢他在那里遇到的人们进行的许多精彩对话。
Dave 感谢他的妻子 Kate 以及孩子 Tom 和 Ben,感谢他们在这个项目以及许多其他项目中每一刻的坚定支持。他还要特别提到 ThoughtWorks,虽然不再是他的雇主,但该公司为在那里工作的人们提供了一个充满启迪和鼓励的环境,从而培育了一种寻找解决方案的创造性方法,其中许多方法都体现在本书的页面中。此外,他还要感谢他目前的雇主 LMAX,特别感谢 Martin Thompson,感谢他们的支持、信任以及在世界级高性能计算这一极具挑战性的技术环境中积极采用本书所述的技术。
Jez Humble 自从 11 岁时获得第一台 ZX Spectrum 以来,就对计算机和电子设备着迷,并花了数年时间用 6502 和 ARM 汇编语言以及 BASIC 在 Acorn 机器上进行黑客编程,直到他年龄足够大可以找到一份正式工作。他在 2000 年进入 IT 行业,正好赶上互联网泡沫破裂。从那时起,他担任过开发人员、系统管理员、培训师、顾问、经理和演讲者。他使用过各种平台和技术,为非营利组织、电信、金融服务和在线零售公司提供咨询。自 2004 年以来,他在北京、班加罗尔、伦敦和旧金山的 ThoughtWorks 和 ThoughtWorks Studios 工作。他拥有牛津大学物理学和哲学学士学位,以及伦敦大学东方与非洲研究学院民族音乐学硕士学位。他目前与妻子和女儿住在旧金山。
Dave Farley 从事计算机工作近 30 年,乐在其中。在此期间,他从事过大多数类型的软件工作——从固件、修改操作系统和设备驱动程序,到编写游戏和各种规模的商业应用程序。大约二十年前,他开始从事大规模分布式系统的工作,研究松耦合、基于消息的系统的开发——这是 SOA(面向服务架构)的先驱。他在英国和美国领导大小团队开发复杂软件方面拥有丰富的经验。Dave 是敏捷开发技术的早期采用者,从 1990 年代初开始在商业项目中采用迭代开发、持续集成和大量自动化测试。他在 ThoughtWorks 工作的四年半期间磨练了他的敏捷开发方法,在那里他担任技术负责人,负责一些最大、最具挑战性的项目。Dave 目前在伦敦多资产交易所(LMAX)工作,该组织正在构建世界上性能最高的金融交易所之一,他们依赖本书中描述的所有主要技术。
作为软件专业人员,我们面临的最重要问题是:如果有人想到一个好主意,我们如何尽快将其交付给用户?本书展示了如何解决这个问题。
我们专注于构建、部署、测试和发布过程,关于这些方面的文献相对较少。这并不是因为我们认为软件开发方法不重要;而是因为,如果不关注软件生命周期的其他方面——这些方面通常被视为整体问题的次要部分——就不可能实现可靠、快速、低风险的软件发布,从而高效地将我们的劳动成果交到用户手中。
软件开发方法有很多,但它们主要关注需求管理及其对开发工作的影响。有许多优秀的书籍详细介绍了软件设计、开发和测试的不同方法;但这些书籍也只涵盖了价值流(Value Stream)的一部分,而价值流才是为赞助我们工作的人员和组织交付价值的完整过程。
当需求被识别、解决方案被设计、开发和测试后会发生什么?如何将这些活动连接在一起并进行协调,以使流程尽可能高效和可靠?我们如何让开发人员、测试人员、构建和运维人员有效地协同工作?
本书描述了一种将软件从开发到发布的有效模式。我们描述了有助于实现这种模式的技术和最佳实践,并展示了这种方法如何与软件交付的其他方面相结合。

图 1.1 部署流水线
本书的核心模式是部署流水线(Deployment Pipeline)。部署流水线本质上是应用程序构建、部署、测试和发布过程的自动化实现。每个组织在实现其部署流水线时都会有所不同,这取决于他们发布软件的价值流,但支配它们的原则是不变的。图 1.1 给出了一个部署流水线的示例。
部署流水线的工作方式可以用一段话概括如下。对应用程序的配置、源代码、环境或数据所做的每一次更改,都会触发创建一个新的流水线实例。流水线的第一步是创建二进制文件和安装程序。流水线的其余部分会对这些二进制文件运行一系列测试,以证明它们可以发布。候选发布版本通过的每一项测试都会增强我们的信心,证明这个特定的二进制代码、配置信息、环境和数据的组合能够正常工作。如果候选发布版本通过了所有测试,它就可以被发布。
部署流水线的基础是持续集成流程,本质上是持续集成原则的逻辑延伸。
部署流水线的目标有三个方面。首先,它使构建、部署、测试和发布软件过程的每个部分对所有相关人员可见,从而促进协作。其次,它改善反馈,使问题能够在流程中尽早被识别并解决。最后,它使团队能够通过完全自动化的流程,随时将任何版本的软件部署和发布到任何环境。
软件发布日往往是紧张的一天。为什么会这样?对于大多数项目来说,是与流程相关的风险程度使得发布成为一个令人担忧的时刻。
在许多软件项目中,发布是一个需要大量手工操作的过程。托管软件的环境通常由运维或信息系统团队单独搭建。应用程序依赖的第三方软件会被安装。应用程序本身的软件制品会被复制到生产主机环境。配置信息通过Web服务器、应用服务器或其他第三方组件的管理控制台进行复制或创建。参考数据被复制,最后应用程序启动——如果是分布式或面向服务的应用程序,则需要逐个启动。
紧张的原因应该很清楚:这个过程中有很多可能出错的地方。如果任何一步没有完美执行,应用程序将无法正常运行。此时可能根本不清楚错误在哪里,或者哪一步出了问题。
本书的其余部分将讨论如何避免这些风险——如何减少发布日的压力,以及如何确保每次发布都具有可预测的可靠性。
在此之前,让我们明确我们试图避免的流程失败类型。以下是一些常见的反模式,它们会阻碍可靠的发布流程,但在我们的行业中却非常普遍,甚至已成为常态。
大多数有一定规模的现代应用程序部署起来都很复杂,涉及许多活动部件。许多组织以手动方式发布软件。我们的意思是,部署此类应用程序所需的步骤被视为独立且原子性的,每个步骤由个人或团队执行。这些步骤中必须做出判断,使它们容易出现人为错误。即使不是这种情况,这些步骤的顺序和时间上的差异也可能导致不同的结果。这些差异很少是好事。
这种反模式的迹象包括:
• 制作大量详细的文档,描述要执行的步骤以及步骤可能出错的方式
• 依赖手动测试来确认应用程序是否正常运行
• 在发布日频繁致电开发团队,以解释为什么部署出现问题
• 在发布过程中频繁修正发布流程
• 集群中的环境配置不同,例如应用服务器具有不同的连接池设置、文件系统具有不同的布局等
• 发布需要超过几分钟才能完成
• 发布结果不可预测,经常需要回滚或遇到意外问题
• 在发布日后的凌晨2点,睁着疲惫的眼睛坐在显示器前,试图找出如何使其正常工作
相反…
随着时间的推移,部署应该趋向于完全自动化。人类在将软件部署到开发、测试或生产环境时应该只需要执行两项任务:选择版本和环境,然后按下”部署”按钮。发布打包软件应该涉及一个创建安装程序的单一自动化流程。
在本书的过程中,我们大量讨论了自动化,我们知道有些人并不完全认同这个想法。让我们解释一下为什么我们将自动化部署视为不可或缺的目标。
• 当部署未完全自动化时,每次执行都会发生错误。唯一的问题是错误是否重要。即使有出色的部署测试,错误也可能难以追踪。
• 当部署流程未自动化时,它就不可重复或不可靠,导致在调试部署错误上浪费时间。
• 手动部署流程必须有文档记录。维护文档是一项复杂且耗时的任务,涉及多人协作,因此文档在任何给定时间通常都是不完整或过时的。一组自动化部署脚本可以作为文档,并且它始终是最新和完整的,否则部署将无法工作。
• 自动化部署促进协作,因为所有内容都在脚本中明确表达。文档必须对读者的知识水平做出假设,实际上通常是作为执行部署人员的备忘录编写的,这使得其他人难以理解。
• 上述观点的推论:手动部署依赖于部署专家。如果他或她在度假或离职,你就会陷入困境。
• 执行手动部署既枯燥又重复,却需要相当程度的专业知识。要求专家做枯燥、重复但技术要求高的任务,是我们能想到的最确定会导致人为错误的方式,仅次于睡眠不足或醉酒。自动化部署可以让你昂贵的、高技能的、工作过度的员工去从事更高价值的活动。
• 测试手动部署流程的唯一方法就是执行它。这通常既耗时又昂贵。自动化部署流程测试起来既便宜又简单。
• 我们听说过有人认为手动流程比自动化流程更易于审计。我们对这种说法完全困惑。对于手动流程,无法保证文档已被遵循。只有自动化流程才是完全可审计的。还有什么比可运行的部署脚本更易于审计的呢?
自动化部署流程必须被所有人使用,并且应该是部署软件的唯一方式。这种纪律确保部署脚本在需要时能够正常工作。我们在本书中描述的原则之一是使用相同的脚本部署到每个环境。如果你使用相同的脚本部署到每个环境,那么生产环境的部署路径在发布日之前已经被测试了数百甚至数千次。如果发布时出现任何问题,你可以确定这些是特定环境配置的问题,而不是脚本的问题。
我们确信,偶尔手动密集型发布会顺利进行。我们可能只是不幸地主要看到了糟糕的情况。然而,如果这不被认为是软件生产过程中可能容易出错的步骤,为什么会有如此多的仪式?为什么有这么多流程和文档?为什么要在周末召集团队?为什么要让人们待命以防出现问题?
在这种模式中,软件第一次部署到类生产环境(例如预发布环境)是在大部分开发工作完成之后——至少是开发团队定义的”完成”。
这种模式看起来有点像这样。
• 如果测试人员在此之前参与了这个过程,他们是在开发机器上测试系统的。
• 发布到预发布环境是运维人员第一次与新版本交互。在某些组织中,使用独立的运维团队将软件部署到预发布环境和生产环境。在这种情况下,运维人员第一次看到软件是在发布到生产环境的那天。
• 要么类生产环境成本高昂以至于对其访问受到严格控制,要么没有及时准备好,要么根本没人费心创建一个。
• 开发团队组装正确的安装程序、配置文件、数据库迁移脚本和部署文档,交给实际执行部署的人员——所有这些都没有在类似生产或预发布的环境中测试过。
• 开发团队和实际执行部署的人员之间几乎没有任何协作来创建这些材料。
当部署到预发布环境时,会组建一个团队来执行部署。有时这个团队具备所有必要的技能,但在非常大型的组织中,部署职责通常在几个组之间分配。数据库管理员(DBA)、中间件团队、Web团队和其他人都参与部署应用程序的最新版本。由于各个步骤从未在预发布环境中测试过,它们经常出错。文档遗漏了重要步骤。文档和脚本对目标环境的版本或配置做出了错误的假设,导致部署失败。部署团队不得不猜测开发团队的意图。
在部署到预发布环境时造成如此多问题的协作不良,通常通过临时电话、电子邮件和快速修复来弥补。一个非常有纪律的团队会将所有这些沟通纳入部署计划——但这个过程很少有效。随着压力增加,为了在分配给部署团队的时间内完成部署,开发团队和部署团队之间定义的协作流程会被破坏。
在执行部署的过程中,经常会发现关于生产环境的错误假设已经被固化到系统设计中。例如,我们参与部署的一个应用程序使用文件系统来缓存数据。这在开发人员工作站上运行良好,但在集群环境中效果不佳。解决这类问题可能需要很长时间,在这些问题解决之前,不能说应用程序已经部署完成。
一旦应用程序部署到预发布环境(staging),通常会发现新的bug。不幸的是,往往没有时间修复所有bug,因为截止日期即将到来,而且在项目的这个阶段,推迟发布日期是不可接受的。因此,最关键的bug会被匆忙修补,项目经理会保存一份已知缺陷清单,以便在下一个版本开始时降低优先级。
有时情况可能更糟。以下是一些可能加剧发布相关问题的因素:
• 开发新应用程序时,首次部署到预发布环境可能是最麻烦的。
• 发布周期越长,开发团队在部署发生之前做出错误假设的时间就越长,修复这些问题所需的时间也就越长。
• 在大型组织中,交付流程被划分到不同的团队,如开发、数据库管理员(DBA)、运维、测试等,这些孤岛之间的协调成本可能是巨大的,有时会使发布流程陷入工单地狱。在这种情况下,开发人员、测试人员和运维人员不断地互相提交工单(或发送电子邮件)以执行任何给定的部署——更糟糕的是,解决部署期间出现的问题。
• 开发环境和生产环境之间的差异越大,开发过程中必须做出的假设就越不切实际。这可能难以量化,但可以肯定的是,如果你在Windows机器上开发并部署到Solaris集群,你将会遇到一些意外。
• 如果你的应用程序由用户安装或包含由用户安装的组件,你可能无法完全控制他们的环境,特别是在企业环境之外。在这种情况下,需要进行大量额外的测试。
更好的做法是…
解决方案是将测试、部署和发布活动集成到开发过程中。使它们成为开发过程中正常且持续的一部分,这样当你准备将系统发布到生产环境时,几乎没有风险,因为你已经在越来越接近生产环境的一系列测试环境中多次演练过。确保参与软件交付流程的每个人,从构建和发布团队到测试人员再到开发人员,从项目开始就共同协作。
我们是测试狂热者,广泛使用持续集成(continuous integration)和持续部署(continuous deployment)作为测试软件和部署流程的手段,是我们所描述方法的基石。
许多组织通过运维团队来管理其生产环境的配置。如果需要进行更改,例如更改数据库连接设置或增加应用服务器上线程池中的线程数,则会在生产服务器上手动执行。如果记录了这样的更改,可能只是在变更管理数据库中的一个条目。
这种反模式的迹象包括:
• 尽管已经成功多次部署到预发布环境,但部署到生产环境时却失败了。
• 集群的不同成员表现不同——例如,一个节点承受的负载较小或处理请求所需的时间比另一个节点更长。
• 运维团队需要很长时间来为发布准备环境。
• 你无法回退到系统的早期配置,这可能包括操作系统、应用服务器、Web服务器、关系型数据库管理系统(RDBMS)或其他基础设施设置。
• 集群中的服务器无意中拥有不同版本的操作系统、第三方基础设施、库或补丁级别。
• 系统的配置是通过直接修改生产系统上的配置来执行的。
更好的做法是…
每个测试、预发布和生产环境的所有方面,特别是系统中任何第三方元素的配置,都应该通过自动化流程从版本控制中应用。
我们在本书中描述的一个关键实践是配置管理,其中一部分意味着能够重复创建应用程序使用的每一个基础设施组件。这意味着操作系统、补丁级别、操作系统配置、应用程序栈、其配置、基础设施配置等都应该被管理。你应该能够精确地重新创建生产环境,最好是以自动化方式。虚拟化可以帮助你开始实现这一点。
你应该确切地知道生产环境中有什么。这意味着对生产环境所做的每一项更改都应该被记录并可审计。部署经常失败是因为有人在上次部署时修补了生产环境,但没有记录这一更改。实际上,不应该可以手动更改测试、预发布和生产环境。更改这些环境的唯一方式应该是通过自动化流程。
应用程序通常依赖于其他应用程序。应该能够一目了然地看到每个软件的当前发布版本。
虽然发布可能令人兴奋,但也可能令人疲惫和沮丧。几乎每次发布都涉及最后一刻的更改,例如修复数据库登录详细信息或更新外部服务的URL。应该有一种方法来引入这样的更改,以便它们既被记录又被测试。同样,自动化是必不可少的。更改应该在版本控制中进行,然后通过自动化流程传播到生产环境。
如果部署出现问题,应该可以使用相同的自动化流程回滚到生产环境的先前版本。
当然可以,本书的目标就是描述如何做到这一点。我们描述的原则、实践和技术旨在让发布变得平淡无奇,即使在复杂的”企业”环境中也是如此。软件发布可以——也应该——是一个低风险、频繁、成本低、快速且可预测的过程。这些实践是在过去几年中发展起来的,我们已经看到它们在许多项目中产生了巨大的影响。本书中的所有实践都已在拥有分布式团队的大型企业项目以及小型开发团队中得到了验证。我们知道它们是有效的,我们也知道它们可以扩展到大型项目。
我们的一个客户过去每次发布都需要一个庞大的专门团队。该团队连续工作七天,包括整个周末,才能将应用程序部署到生产环境。他们的成功率很低,许多发布都会引入错误或在发布当天需要大量干预,而且通常还需要在随后几天打补丁和修复,以纠正发布引入的错误或配置新软件时的人为错误。
我们帮助他们实现了一个复杂的自动化构建、部署、测试和发布系统,并引入了支持该系统所需的开发实践和技术。我们见证的最后一次发布只用了七秒钟就将应用程序部署到了生产环境。除了发布实现的新行为突然可用之外,没有人注意到发生了什么。如果这个主要网站背后的系统部署因任何原因失败,我们可以在同样的时间内回滚这个变更。
我们的目标是描述如何使用部署流水线(deployment pipeline),结合高度自动化的测试和部署,以及全面的配置管理,来实现一键式软件发布。也就是说,一键式软件发布到任何部署目标——开发环境、测试环境或生产环境。
在此过程中,我们将描述这个模式本身以及您需要采用的技术才能使其发挥作用。我们将为您可能面临的一些问题提供不同解决方法的建议。我们发现,这种方法的优势远远超过了实现它的成本。
这一切都在任何项目团队的能力范围之内。它不需要僵化的流程、大量的文档或很多人员。在本章结束时,我们希望您能够理解这种方法背后的原则。
正如我们所说,作为软件专业人员,我们的目标是尽快向用户交付有用的、可工作的软件。
速度至关重要,因为不交付软件会带来机会成本。只有在软件发布后,您才能开始获得投资回报。因此,本书的两个首要目标之一就是找到减少周期时间的方法,即从决定进行变更(无论是错误修复还是功能开发)到用户可用的时间。
快速交付也很重要,因为它可以让您验证您的功能和错误修复是否真正有用。我们将应用程序创建背后的决策者称为客户(customer),他们对哪些功能和错误修复对用户有用做出假设。然而,在这些假设交到用户手中,用户通过选择使用软件来投票之前,它们仍然只是假设。因此,最小化周期时间以建立有效的反馈循环至关重要。
有用性的一个重要部分是质量。我们的软件应该适合其目的。质量不等于完美——正如伏尔泰所说,“完美是好的敌人”——但我们的目标应该始终是交付足够质量的软件,为用户带来价值。因此,虽然尽快交付软件很重要,但保持适当的质量水平是必不可少的。
所以,稍微细化我们的目标,我们希望找到以高效、快速和可靠的方式交付高质量、有价值软件的方法。
我们和我们的同行实践者发现,为了实现这些目标——低周期时间和高质量——我们需要频繁、自动化地发布软件。为什么呢?
• 自动化。如果构建、部署、测试和发布过程没有自动化,那么它就不可重复。每次执行时都会不同,因为软件、系统配置、环境和发布过程都在变化。由于步骤是手动的,所以容易出错,而且无法准确审查所做的操作。这意味着无法控制发布过程,因此无法确保高质量。发布软件经常是一门艺术;它应该是一门工程学科。
• 频繁。如果发布频繁,发布之间的增量将会很小。这显著降低了与发布相关的风险,并使回滚变得更容易。频繁发布也会带来更快的反馈——事实上,它们需要这样的反馈。本书的大部分内容集中在尽快获得对应用程序及其相关配置(包括其环境、部署过程和数据)的变更反馈上。
反馈对于频繁的自动化发布至关重要。反馈要有用,需要满足三个标准。
• 任何类型的变更都需要触发反馈过程。
• 反馈必须尽快交付。
• 交付团队必须接收反馈并采取行动。
让我们详细审视这三个标准,并考虑如何实现它们。
一个可运行的软件应用程序可以有效地分解为四个组件:可执行代码、配置、宿主环境和数据。如果其中任何一个发生变更,都可能导致应用程序行为的改变。因此,我们需要控制这四个组件,并确保对其中任何一个的变更都得到验证。
当源代码发生变更时,可执行代码也会随之改变。每次对源代码进行变更时,都必须构建并测试生成的二进制文件。为了控制这个过程,应该自动化构建和测试二进制文件。每次签入时构建和测试应用程序的做法被称为持续集成(continuous integration);我们将在第3章详细描述。
这个可执行代码应该是部署到每个环境中的相同可执行代码,无论是测试环境还是生产环境。如果您的系统使用编译型语言,您应该确保构建过程的二进制输出——可执行代码——在需要的地方被重用,而不是重新构建。
任何在不同环境之间变化的内容都应作为配置信息捕获。应用程序配置的任何变更,无论在哪个环境中,都应该进行测试。如果软件要由用户安装,则应在具有代表性的示例系统范围内测试可能的配置选项。配置管理将在第2章讨论。
如果应用程序要部署到的环境发生变更,则应该用环境的变更对整个系统进行测试。这包括操作系统配置的变更、支持应用程序的软件栈、网络配置以及任何基础设施和外部系统的变更。第11章处理基础设施和环境的管理,包括测试和生产环境的创建和维护的自动化。
最后,如果数据的结构发生变更,这种变更也必须经过测试。我们将在第12章讨论数据管理。
什么是反馈过程?它涉及尽可能以完全自动化的方式测试每次变更。测试会因系统而异,但通常至少包括以下检查。
• 创建可执行代码的过程必须成功。这验证了源代码的语法是否有效。
• 软件的单元测试必须通过。这检查您的应用程序代码是否按预期运行。
• 软件应满足某些质量标准,如测试覆盖率和其他特定技术的指标。
• 软件的功能验收测试必须通过。这检查您的应用程序是否符合其业务验收标准——是否交付了预期的业务价值。
• 软件的非功能性测试必须通过。这检查应用程序在容量、可用性、安全性等方面是否表现良好,以满足用户的需求。
• 软件必须经过探索性测试以及向客户和部分用户的演示。这通常在手动测试环境中完成。在这部分过程中,产品负责人可能会决定有缺失的功能,或者我们可能会发现需要修复的缺陷以及需要创建的自动化测试以防止回归。
运行这些测试的环境必须尽可能与生产环境相似,以验证对环境的任何变更是否影响了应用程序的工作能力。
快速反馈的关键是自动化。通过完全自动化的流程,您唯一的限制就是可以用于解决问题的硬件资源量。如果使用手动流程,您就依赖于人来完成工作。人需要更长时间,会引入错误,并且不可审计。此外,执行手动构建、测试和部署过程是枯燥且重复的——远非人的最佳用途。人是昂贵且宝贵的,他们应该专注于生产令用户愉悦的软件,然后尽快交付这些令人愉悦的功能——而不是枯燥、容易出错的任务,如回归测试、虚拟服务器配置和部署,这些最好由机器来完成。
然而,实施部署流水线需要大量资源,特别是一旦拥有了全面的自动化测试套件。它的一个关键目标是优化人力资源的使用:我们希望解放人们去做有趣的工作,将重复性工作留给机器。
我们可以将流水线提交阶段(图1.1)中的测试特征描述如下。
• 它们运行速度快。
• 它们尽可能全面——也就是说,它们覆盖了代码库的75%以上,这样当它们通过时,我们对应用程序工作正常有很好的信心。
• 如果其中任何一个失败,意味着我们的应用程序存在严重故障,在任何情况下都不应发布。这意味着检查UI元素颜色的测试不应包含在这组测试中。
• 它们尽可能与环境无关——也就是说,环境不必是生产环境的精确副本,这意味着它可以更简单、成本更低。
另一方面,后期阶段的测试具有以下一般特点:
• 运行速度较慢,因此适合并行化处理。
• 其中一些可能会失败,但在某些情况下我们仍可能选择发布应用程序(可能是候选版本中有一个关键修复导致性能低于预定义阈值——但我们可能仍决定发布)。
• 应在尽可能接近生产环境的环境中运行,因此除了测试的直接重点外,它们还测试部署流程和生产环境的任何变更。
这种测试流程的组织方式意味着,在第一组测试后,我们对软件有很高的信心,这些测试在最便宜的硬件上运行最快。如果这些测试失败,候选版本不会进入后续阶段。这确保了资源的最优使用。关于流水线的更多内容请参见第5章“部署流水线剖析”,以及后续的第7章、第8章和[第9章],它们分别描述了提交测试阶段、自动化验收测试和非功能性需求测试。
我们方法的基本原则之一是需要快速反馈。确保对变更的快速反馈要求我们关注软件开发过程——特别是如何使用版本控制以及如何组织代码。开发人员应该频繁地将变更提交到版本控制系统,并将代码拆分为独立的组件,以此作为管理大型或分布式团队的方法。在大多数情况下,应该避免分支。我们在[第13章]“管理组件和依赖项”中讨论增量交付和组件的使用,在[第14章]“高级版本控制”中讨论分支和合并。
所有参与软件交付过程的人员都参与反馈过程至关重要。这包括开发人员、测试人员、运维人员、数据库管理员、基础设施专家和管理人员。如果这些角色的人员不能每天一起工作(尽管我们建议团队应该是跨职能的),那么他们必须经常会面并努力改进软件交付过程。基于持续改进的流程对于快速交付高质量软件至关重要。迭代流程有助于为这类活动建立常规节奏——至少每次迭代举行一次回顾会议,每个人都讨论如何改进下一次迭代的交付过程。
能够对反馈做出反应也意味着广播信息。使用大型可视化仪表板(不一定是电子的)和其他通知机制对于确保反馈确实被反馈并最终进入某人的脑海至关重要。仪表板应该无处不在,每个团队室至少应该有一个。
最后,除非采取行动,否则反馈没有用。这需要纪律和计划。当需要做某事时,整个团队有责任停下手头的工作并决定行动方案。只有完成这一步,团队才应继续他们的工作。
我们听到的一个常见反对意见是,我们描述的流程过于理想化。这些批评者说,它可能在小团队中有效,但不可能在我庞大的分布式项目中工作!
多年来,我们在多个不同行业的许多大型项目中工作过。我们也很幸运能够与拥有丰富经验的同事一起工作。本书中描述的所有技术和原则都已在各种组织的实际项目中得到验证,无论大小,在各种情况下。在这些项目中一次又一次地遇到相同的问题,这驱使我们写这本书。
读者会注意到,本书的大部分内容受到精益运动的哲学和思想的启发。精益制造(lean manufacturing)的目标是确保快速交付高质量产品,专注于消除浪费和降低成本。精益制造在多个行业带来了巨大的成本和资源节约、更高质量的产品以及更快的上市时间。这一哲学也开始在软件开发领域成为主流,并为本书讨论的大部分内容提供了指导。精益的应用当然不局限于小型系统。它是在大型组织甚至整个经济体中创建和应用的。
这些理论和实践与大型团队的相关性与小型团队一样,我们的经验表明它们是有效的。但是,我们不要求您相信我们所说的。自己尝试并找出答案。保留有效的,丢弃无效的,并写下您的经验,以便其他人可以受益。
我们在前面部分描述的方法的主要好处是,它创建了一个可重复、可靠且可预测的发布流程,从而大大缩短了周期时间,从而快速将功能和错误修复交付给用户。仅成本节约就不仅值这本书的定价,而且值得投入时间来建立和维护这样一个发布系统。
除此之外还有许多其他好处,其中一些是我们事先预测到的,而另一些则更像是我们观察到它们时的惊喜。
部署流水线(deployment pipeline)的核心原则之一是它是一个拉取系统——它允许测试人员、运维人员或支持人员自助获取他们想要的应用程序版本并部署到他们选择的环境中。根据我们的经验,交付周期时间的一个主要影响因素是交付流程中的人员等待获得应用程序的”良好构建版本”。获取良好的构建版本通常需要发送无数的电子邮件、提交工单或其他低效的沟通方式。当交付团队分布在不同地点时,这就成为效率低下的主要来源。通过实施部署流水线,这个问题被彻底解决了——每个人都应该能够查看哪些构建版本可以部署到他们关心的环境中,并能够通过按下按钮来执行部署。
我们经常看到的结果是,随着团队不同成员进行各自的工作,在不同环境中会同时运行多个不同版本。能够轻松地将任何版本的软件部署到任何环境中有许多优势。
• 测试人员可以选择应用程序的旧版本来验证新版本中行为的变化。
• 支持人员可以将已发布的应用程序版本部署到环境中以重现缺陷。
• 运维人员可以选择已知的良好构建版本部署到生产环境,作为灾难恢复演练的一部分。
• 可以通过按下按钮来执行发布。
我们的部署工具为他们提供的灵活性改变了他们的工作方式——变得更好。总的来说,团队成员对自己的工作有了更多的控制权,因此他们的工作质量得到提高,应用程序的质量也随之提高。他们更有效地协作,减少了被动反应,工作效率更高,因为他们不再花那么多时间等待良好的构建版本推送给他们。
错误可能从各种地方渗入软件中。最初委托软件的人可能要求了错误的东西。捕获需求的分析师可能理解错误,开发人员可能编写有缺陷的代码。然而,我们这里讨论的错误是那些由于糟糕的配置管理而引入到生产环境中的错误。我们将在第2章中更详细地描述配置管理的含义。现在,想想那些必须完全正确才能使典型应用程序正常工作的东西——正确的代码版本,当然,但还有正确的数据库模式版本,负载均衡器的正确配置,用于查询价格的Web服务的正确URL,等等。当我们谈论配置管理时,我们指的是允许您识别和控制完整信息集的流程和机制,每一个比特和字节。
几年前,Dave在为一家知名零售商开发大规模销售点系统。那是我们开始思考自动化部署流程的早期阶段,所以虽然某些方面已经相当自动化,但其他方面还没有。生产环境中出现了一个非常严重的错误。在某些未知的、难以确定的情况组合下,我们的日志中突然出现了大量错误跟踪。我们无法在任何测试环境中重现这个问题。我们尝试了各种方法:在性能环境中进行负载测试,试图模拟看起来像生产环境中的病理情况——但我们就是无法重现问题。最后,经过比这里描述的更多的调查后,我们决定审查所有我们能想到的可能在两个系统之间不同的东西。我们最终发现,我们的应用程序依赖的一个二进制库(属于我们使用的应用服务器软件)在生产环境和测试环境中是不同的。我们更改了生产环境中二进制文件的版本,问题就消失了。
这个故事的重点不是我们不够勤奋,或不够谨慎,甚至也不是因为我们想到审查系统而很聪明。真正的重点是软件可能非常脆弱。这是一个相当大的系统,有数万个类、数千个库,以及许多与外部系统的集成点。然而,由于第三方二进制文件版本之间几个字节的差异,就将一个严重错误引入了生产环境。
在现代软件系统中,集体包含的许多千兆字节的信息中,没有任何一个人——或一组人——能够在没有机器辅助的情况下发现前面侧边栏示例中描述的规模的变化。与其等到问题发生,为什么不利用机器辅助首先防止它发生呢?
通过主动管理版本控制中可能改变的所有内容——例如配置文件、创建数据库及其模式的脚本、构建脚本、测试工具,甚至开发环境和操作系统配置——我们让计算机做它们擅长的事情:确保每一个比特和字节都在我们期望的位置,至少在我们的代码开始运行之前是这样。
我们参与的另一个项目拥有大量专用的测试环境。每个环境都运行着一个流行的 EJB 应用服务器。这个应用是以敏捷项目的方式开发的,具有良好的自动化测试覆盖率。本地构建管理得很好,因此开发人员可以相对容易地在本地快速运行代码以便进行开发。然而,这是在我们开始更加谨慎地自动化应用部署之前。每个测试环境都是手动配置的,使用的是应用服务器供应商提供的基于控制台的工具。尽管开发人员用于配置本地安装的配置文件副本保存在版本控制系统中,但每个测试环境的配置却没有。每个环境都与其他环境不同。它们的属性顺序不同,有些缺失,有些设置为不同的值,有些名称不同,有些具有其他环境没有的属性。没有两个测试环境是相同的,而且它们都与生产环境不同。要确定哪些属性是必需的、哪些是冗余的、哪些应该在环境之间通用、哪些应该是唯一的,这非常困难。因此,该项目雇用了一个由五人组成的团队来负责管理这些不同环境的配置。
根据我们的经验,这种对手动配置管理的依赖很常见。在我们合作过的许多组织中,无论是生产系统还是测试环境都是如此。有时,服务器 A 的连接池限制为 100 而服务器 B 的连接池设置为 120 可能并不重要。但在其他时候,这可能非常重要。
哪些配置差异重要、哪些不重要,这不是你想要在最繁忙的交易时段意外发现的事情。这类配置信息定义了代码运行的环境,并且经常实际上指定了通过代码的新路径。对此类配置信息的更改需要认真考虑,代码运行的环境需要像代码本身的行为一样被明确定义和控制。如果我们能访问你的数据库、应用服务器或 Web 服务器的配置,我们保证能让你的应用失败的速度比你给我们访问编译器和源代码更快。
当这些配置参数是手动定义和管理时,它们容易受到人类在重复性任务中犯错误倾向的影响。仅在错误的地方打一个错字就可能让应用停止运行。更糟糕的是,编程语言有语法检查,也许还有单元测试来验证没有错字。而对于配置信息,特别是直接输入到某个控制台的配置信息,很少有任何类型的检查。
将配置信息添加到版本控制系统这一简单行为就是一个巨大的进步。最简单的情况下,版本控制系统会提醒你无意中更改了配置。这至少消除了一个非常常见的错误来源。
一旦所有配置信息都存储在版本控制系统中,下一个显而易见的步骤就是消除中间人,让计算机来应用配置而不是手动输入。某些技术比其他技术更适合这样做,但如果你仔细考虑,即使是最难处理的第三方系统的配置,你(通常还有基础设施供应商)也会惊讶于能做到什么程度。我们将在第 4 章中详细讨论这一点,并在第 11 章中进行深入探讨。
在显而易见的好处中,最令人愉快的是减少了与发布相关的各方的压力。大多数曾经接触过接近发布日期的软件项目的人都知道,这些确实是压力很大的事件。根据我们的经验,这本身就可能成为问题的来源。我们见过理智、保守、注重质量的项目经理问他们的开发人员:“你就不能直接修改代码吗?”或者其他正常的数据库管理员在他们不了解的应用的数据库表中输入数据。在这两种情况下,以及许多其他类似的情况下,这些更改都是直接响应”让某些东西工作起来”的压力。
不要误解我们,我们也经历过这些。我们甚至不是说这总是错误的响应:如果你刚刚发布了一些导致组织流失资金的代码到生产环境,几乎任何能止血的方法都可能是合理的。
我们这里的观点不同。这两个快速修复新部署的生产系统的例子都不是由这种直接的商业需求驱动的,而是由按计划发布日期发布的更微妙的压力驱动的。这里的问题是发布到生产环境是重大事件。只要这是事实,它们就会伴随着大量的仪式和紧张。
想象一下,你即将进行的发布可以通过按下按钮来完成。想象一下它可以在几分钟甚至几秒钟内完成,如果最坏的情况发生,你可以在同样的几分钟或几秒钟内回退发布。想象一下你经常发布,因此当前生产环境中的内容与新发布之间的差异很小。如果这是真的,那么发布的风险将大大降低,你把职业生涯押在其成功上的不愉快感觉也会显著减少。
对于一小部分项目来说,这个理想可能无法实际实现。然而,在大多数项目中这确实是可以做到的,尽管需要付出一定的努力。减少压力的关键是拥有我们所描述的那种自动化部署流程,频繁地执行它,并在最坏情况发生时有良好的回滚能力。第一次进行自动化时会很痛苦——但它会变得越来越容易,而对项目和你自己的好处几乎是无法估量的。
在新环境中启动应用程序应该是一项简单的任务——理想情况下只需要准备好机器或虚拟镜像,并创建一些描述该环境独特属性的配置信息。然后你应该能够使用自动化部署流程来为新环境做好部署准备,并将选定版本的应用程序部署到该环境中。
我们最近参与的一个项目,因政府立法的意外变化而导致其商业案例失效。该项目旨在为一家新企业创建核心企业系统。该业务将分布在国际范围内,软件被设计为在大量异构的昂贵计算机上运行。当然,项目存在的理由突然消失的消息让每个人都有些沮丧。
不过对我们来说有一个小小的亮点。我们为之开发软件的组织进行了一次精简分析。“新系统的最小硬件占用是什么,我们如何限制资本成本?”他们问道。“嗯,它可以在这台笔记本电脑上运行,”我们回答。他们很惊讶,因为这是一个复杂的多用户系统。“你怎么知道它能工作?”他们思考后问道。“嗯,我们可以像这样运行所有验收测试……”,然后我们演示给他们看。“它需要承受什么样的负载?”我们问他们。他们告诉我们负载量,我们对性能测试的扩展参数做了一行修改并运行了测试。我们证明笔记本电脑太慢了,但差距并不大。一台配置合理的服务器就能满足他们的需求,当这台服务器可用时,只需几分钟就能让应用程序在上面运行起来。
这种部署灵活性不仅是我们在本书中描述的自动化部署技术的功能;应用程序本身也设计得相当好。然而,我们能够按需将软件部署到任何需要的地方,这给了我们和客户极大的信心,相信我们能够在任何时候管理任何发布。随着发布变得不那么令人担忧,考虑敏捷理念中在每次迭代结束时发布就变得更容易了。即使这对特定项目不合适,也意味着我们可以夺回自己的周末时间。
在我们参与的项目中,我们尝试为每个开发者或开发者对提供一个专用的开发环境。然而,即使在没有做到这一点的项目中,任何使用持续集成(Continuous Integration)或迭代、增量开发技术的团队都需要频繁部署应用程序。
最佳策略是无论部署目标是什么,都使用相同的部署方法。不应该有特殊的QA部署策略,或特殊的验收测试,或生产部署策略。这样,每次部署应用程序时,我们都在确认部署机制工作正常。本质上,最终的生产部署在每次软件部署到任何目标时都在被演练。
有一个特殊情况可以允许一些变化:开发环境。开发者需要构建二进制文件而不是使用在其他地方构建好的预制二进制文件是合理的,因此这个约束可以在这些部署中放宽。不过即使在开发者工作站上,我们也尽可能以相同的方式部署和管理。
什么是发布候选版本(Release Candidate)?对代码的更改可能可以发布,也可能不可以。如果你查看一个更改并问”我们应该发布这个更改吗?“那么答案只能是猜测。正是我们应用于该更改的构建、部署和测试流程验证了该更改是否可以发布。这个流程让我们对更改可以安全发布越来越有信心。我们采用那个小的更改——无论是新功能、错误修复,还是为实现某些性能变化而对系统进行的调整——并验证我们是否能够以高度的信心发布带有该更改的系统。为了进一步降低风险,我们希望在尽可能短的时间内完成这个验证。
虽然任何更改都可能产生可以发布给用户的制品(Artifact),但它们一开始并不是这样的。每个更改都必须评估其适用性。如果最终产品被发现没有缺陷,并且满足客户设定的验收标准,那么它就可以发布。
图1.2 发布候选版本的传统视图

大多数软件发布方法都是在流程末期才确定候选发布版本。当需要进行跟踪工作时,这样做有一定道理。在撰写本文时,维基百科关于开发阶段的条目将”候选发布版本”作为流程中的一个独立步骤([图1.2])。我们的看法略有不同。
传统的软件开发方法会推迟候选发布版本的确定,直到完成几个漫长且昂贵的步骤以确保软件具有足够的质量并在功能上完整。然而,在积极追求构建和部署自动化以及全面自动化测试的环境中,无需在项目末期花费时间和金钱进行漫长的手动密集型测试。在这个阶段,应用程序的质量通常已经显著提高,因此手动测试只是对功能完整性的确认。
实际上,根据我们的经验,将测试推迟到开发流程之后,是降低应用程序质量的可靠方法。缺陷最好在引入时就被发现和修复。当它们在后期被发现时,修复成本总是更高。开发人员已经忘记了引入缺陷时正在做什么,而且功能可能在此期间已经发生了变化。将测试留到最后通常意味着没有时间真正修复bug,或者只能修复其中的一小部分。因此,我们希望在最早的时机发现并修复它们,最好是在它们被提交到代码之前。
开发人员对代码库的每次更改都旨在以某种方式增加价值。提交到版本控制的每次更改都应该增强我们正在开发的系统。我们如何知道这是否属实?唯一的方法是通过运行软件来查看它是否实现了我们所期望的价值。大多数项目将流程的这一部分推迟到正在开发的功能的后期。这意味着据任何人所知,系统在测试或使用时被发现正常工作之前是处于故障状态的。如果在这个时候发现系统有问题,通常需要大量工作才能使系统正常运行。这个阶段通常被称为集成,往往是开发过程中最不可预测和最难管理的部分。由于它如此痛苦,团队会推迟它,不频繁地集成,这只会让情况变得更糟。
在软件开发中,当某件事很痛苦时,减少痛苦的方法是更频繁地做它,而不是更少。因此,我们不应该不频繁地集成,而应该频繁地集成;实际上,我们应该在系统的每次更改后都进行集成。这种持续集成(Continuous Integration)的实践将频繁集成的理念发挥到极致。这样做会在软件开发流程中创造范式转变。持续集成会在破坏系统或不满足客户验收标准的任何更改被引入系统时检测到它。然后团队会在问题发生时立即修复它(这是持续集成的第一条规则)。遵循这种实践时,软件始终处于工作状态。如果您的测试足够全面,并且您在足够类似生产环境的环境中运行测试,那么软件实际上始终处于可发布状态。
每次更改实际上都是一个候选发布版本。每次将更改提交到版本控制时,期望是它将通过所有测试,生成可工作的代码,并且可以发布到生产环境。这是起始假设。持续集成系统的工作是推翻这个假设,证明特定的候选发布版本不适合进入生产环境。
本书背后的理念来自作者多年来参与的大量项目。当我们开始综合我们的想法并将其记录在这些页面上时,我们注意到相同的原则反复出现。我们在此列举了它们。我们所说的某些内容需要解释或附加说明;但以下原则不需要。如果我们希望交付流程有效,这些是我们无法想象缺少的东西。
这个原则实际上是我们撰写本书的目标声明:发布软件应该很容易。之所以容易,是因为您之前已经测试了发布流程的每个部分数百次。它应该像按下按钮一样简单。可重复性和可靠性源于两个原则:几乎自动化一切,并将构建、部署、测试和发布应用程序所需的一切都保存在版本控制中。
部署软件最终涉及三件事:
• 配置和管理应用程序将运行的环境(硬件配置、软件、基础设施和外部服务)。
• 将应用程序的正确版本安装到其中。
• 配置您的应用程序,包括它所需的任何数据或状态。
应用程序的部署可以通过版本控制实现完全自动化的流程。应用程序配置也可以是完全自动化的过程,必要的脚本和状态保存在版本控制或数据库中。显然,硬件无法保存在版本控制中;但是,特别是随着廉价虚拟化技术和Puppet等工具的出现,配置过程也可以实现完全自动化。
本书的其余部分主要描述实现这一原则的策略。
有些事情是不可能自动化的。探索性测试依赖于经验丰富的测试人员。向用户社区代表演示工作软件无法由计算机执行。出于合规目的的审批按定义需要人工干预。然而,无法自动化的事情清单比许多人想象的要少得多。一般来说,你的构建过程应该自动化到需要具体人工指导或决策的程度。你的部署过程以及实际上你的整个软件发布过程也是如此。验收测试可以自动化。数据库升级和降级也可以自动化。甚至网络和防火墙配置也可以自动化。你应该尽可能地自动化一切。
作者可以诚实地说,他们还没有发现无法通过足够的工作和智慧实现自动化的构建或部署过程。
大多数开发团队不自动化他们的发布过程,因为这似乎是一项艰巨的任务。手动操作更容易。也许第一次执行流程中的某个步骤时确实如此,但到第十次执行该步骤时肯定不是这样,到第三或第四次时可能也不是这样。
自动化是部署流水线(deployment pipeline)的前提条件,因为只有通过自动化,我们才能保证人们只需按下按钮就能获得他们需要的东西。然而,你不需要一次自动化所有内容。你应该首先关注构建、部署、测试和发布过程中当前的瓶颈部分。你可以而且应该随着时间逐步自动化。
构建、部署、测试和发布应用程序所需的一切都应该保存在某种形式的版本存储中。这包括需求文档、测试脚本、自动化测试用例、网络配置脚本、部署脚本、数据库创建、升级、降级和初始化脚本、应用程序栈配置脚本、库、工具链、技术文档等等。所有这些东西都应该进行版本控制,并且任何给定构建的相关版本都应该是可识别的。也就是说,这些变更集应该有一个单一标识符,例如构建号或版本控制变更集号,引用每一部分。
新团队成员应该能够坐在新工作站前,检出项目的版本控制仓库,并运行单个命令来构建和部署应用程序到任何可访问的环境,包括本地开发工作站。
还应该能够看到各种应用程序的哪个构建部署到每个环境中,以及这些构建来自版本控制中的哪些版本。
这是我们列表中最通用的原则,或许最好描述为启发式方法(heuristic)。但它可能是我们在交付软件的背景下所知道的最有用的启发式方法,它为我们所说的一切提供了依据。集成通常是一个非常痛苦的过程。如果你的项目中确实如此,那么每次有人签入时就进行集成,并从项目开始时就这样做。如果测试是一个在发布前才发生的痛苦过程,不要在最后才做。相反,从项目开始就持续进行。
如果发布软件很痛苦,那就争取在每次有人签入通过所有自动化测试的更改时发布它。如果你无法在每次更改时发布给真实用户,那就在每次签入时发布到类生产环境。如果创建应用程序文档很痛苦,那就在开发新功能时就做,而不是留到最后。将功能的文档作为完成定义(definition of done)的一部分,并尽可能地自动化该过程。
根据你当前的专业水平,达到这个目标可能需要大量的努力,当然你仍然需要在此期间交付软件。设定中间目标,例如每几周进行一次内部发布,或者如果你已经在这样做,就每周一次。逐步努力接近理想状态——即使是小步前进也会带来巨大的好处。
极限编程(extreme programming)本质上是将这一启发式方法应用于软件开发过程的结果。本书中的大部分建议来自我们将相同原则应用于软件发布过程的经验。
这个原则和本节中我们提到的最后一个原则——持续改进——是从精益运动(lean movement)中借鉴的。“构建质量”是W. Edwards Deming的座右铭,他除了其他成就外,还是精益运动的先驱之一。越早发现缺陷,修复成本越低。如果缺陷从一开始就没有签入版本控制,那么修复成本最低。
我们在本书中描述的技术,如持续集成(continuous integration)、全面自动化测试和自动化部署,旨在尽早在交付过程中捕获缺陷(这是”将痛苦前移”原则的应用)。下一步是修复它们。如果每个人都忽视火警,那么火警就毫无用处。交付团队必须严格遵守一旦发现缺陷就立即修复的纪律。
“构建质量”还有两个推论。首先,测试不是一个阶段,当然也不是在开发阶段之后才开始的阶段。如果将测试留到最后,就为时已晚。将没有时间修复缺陷。其次,测试也不纯粹是、甚至不主要是测试人员的领域。交付团队中的每个人始终都对应用程序的质量负责。
你多久听到一次开发人员说某个故事或功能”完成了”?也许你听过项目经理问那个开发人员它是否”真正完成了”?“完成”是什么意思?实际上,只有当功能向用户交付价值时,它才算完成。这是持续部署实践背后的部分动机(见第10章,“部署和发布应用程序”)。
对于一些敏捷交付团队来说,“完成”意味着发布到生产环境。这是软件开发项目的理想状态。然而,使用这个标准来衡量完成并不总是切实可行的。软件系统的初始发布可能需要一段时间才能达到真正的外部用户从中获益的状态。因此,我们将退而求其次,选择次优方案,即一旦功能成功展示,也就是说,在类生产环境中向用户社区的代表演示并由其试用后,该功能就算”完成”了。
没有”80%完成”这回事。事情要么完成了,要么没有完成。可以估算某件事完成之前剩余的工作——但这些永远只是估算。使用估算来确定剩余工作总量会导致指责和相互推诿,因为那些引用百分比的人最终总会被证明是错误的。
这个原则有一个有趣的推论:让某件事完成不在一个人的能力范围内。需要交付团队中的许多人共同合作才能完成任何事情。这就是为什么每个人——测试人员、构建和运维人员、支持团队、开发人员——从一开始就一起工作如此重要。这也是为什么整个交付团队对交付负责——这个原则如此重要,以至于它有自己的专门章节…
理想情况下,组织内的每个人都与其目标保持一致,人们共同努力帮助彼此实现目标。最终,团队作为一个整体成功或失败,而不是作为个人。然而,在太多项目中,现实是开发人员将工作抛给测试人员。然后测试人员在发布时将工作抛给运维团队。当出现问题时,人们花在相互指责上的时间和修复缺陷的时间一样多,而这些缺陷不可避免地源于这种孤岛式(siloed)的方法。
如果你在一个小型组织或相对独立的部门工作,你可能完全控制发布软件所需的资源。如果是这样,太好了。如果不是,实现这一原则可能需要长期的艰苦工作,以打破隔离不同角色人员的孤岛之间的障碍。
首先,从新项目开始时就让所有参与交付过程的人聚在一起,并确保他们有机会定期频繁地沟通。一旦障碍被打破,这种沟通应该持续进行,但你可能需要逐步朝着这个目标前进。建立一个系统,让每个人都能一目了然地看到应用程序的状态、其健康状况、各种构建、它们通过了哪些测试,以及可以部署到的环境的状态。该系统还应该使人们能够执行他们完成工作所需的操作,例如部署到他们控制的环境。
这是DevOps运动的核心原则之一。DevOps运动专注于我们在本书中设定的同一目标:鼓励所有参与软件交付的人员之间进行更多协作,以便更快、更可靠地发布有价值的软件 [aNgvoV]。
值得强调的是,应用程序的首次发布只是其生命周期的第一阶段。所有应用程序都会演进,并且会有更多发布跟进。重要的是,你的交付过程也要随之演进。
整个团队应该定期聚集在一起,对交付过程进行回顾。这意味着团队应该反思哪些进展顺利、哪些进展不顺利,并讨论如何改进的想法。应该指定某人负责每个想法,并确保付诸实施。然后,下次团队聚集时,他们应该汇报发生了什么。这被称为戴明循环(Deming cycle):计划、执行、研究、行动。
组织中的每个人都参与这个过程至关重要。只允许在孤岛内部而不是跨孤岛进行反馈是灾难的根源:它导致以牺牲整体优化为代价的局部优化——最终导致相互指责。
传统上,软件发布一直是一个充满压力的时刻。同时,与代码创建和管理相关的规范相比,发布被视为一个未经验证的手动过程,依赖于临时的配置管理技术来处理系统配置的关键方面。在我们看来,与软件发布相关的压力及其手动、易出错的特性是相关因素。
通过采用自动化构建、测试和部署技术,我们获得了许多好处。我们能够验证变更,使流程在各种环境中可重复,并在很大程度上消除了错误进入生产环境的机会。我们能够部署变更,从而更快地带来业务收益,因为发布过程本身不再是障碍。实施自动化系统鼓励我们实施其他良好实践,如行为驱动开发和全面的配置管理。
我们还能够花更多的周末与家人和朋友在一起,以更少的压力生活,同时提高工作效率。这有什么不好的呢?生命太短暂,不应该把周末花在服务器机房部署应用程序上。
开发、测试和发布流程的自动化对发布软件的速度、质量和成本产生了深远影响。本书作者之一负责一个复杂的分布式系统。该系统发布到生产环境,包括大规模数据库中的数据迁移,根据特定发布相关的数据迁移规模,需要5到20分钟。迁移数据需要很长时间。我们所知的一个密切相关且可比的系统,同样的流程部分需要30天。
本书的其余部分将在我们提供的建议和推荐方面更加具体,但我们希望这一章能让您从两万英尺高空俯瞰本书的范围——一个理想但现实的视角。我们在这里提到的项目都是真实项目,虽然我们可能稍微掩饰了一些以保护当事人,但我们非常努力地不夸大任何技术细节或任何技术的价值。
配置管理是一个广泛使用的术语,通常作为版本控制的同义词。值得用我们自己的非正式定义为本章设定背景:
配置管理是指一个过程,通过该过程,与您的项目相关的所有工件及其之间的关系被存储、检索、唯一标识和修改。
您的配置管理策略将决定如何管理项目中发生的所有变更。因此,它记录了系统和应用程序的演变。它还将管理团队如何协作——这是任何配置管理策略的一个重要但有时被忽视的后果。
尽管版本控制系统是配置管理中最明显的工具,但决定使用版本控制系统(每个团队都应该使用,无论多小)只是制定配置管理策略的第一步。
最终,如果您有一个良好的配置管理策略,您应该能够对以下所有问题回答”是”:
• 我能否准确重现我的任何环境,包括操作系统版本、补丁级别、网络配置、软件栈、部署到其中的应用程序及其配置?
• 我能否轻松地对这些单个项目中的任何一个进行增量更改,并将更改部署到我的任何或所有环境?
• 我能否轻松地看到特定环境发生的每个更改,并追溯以准确了解更改是什么、谁进行了更改以及何时进行的?
• 我能否满足我所遵守的所有合规法规?
• 团队的每个成员是否容易获得他们需要的信息,并进行他们需要进行的更改?还是该策略妨碍了高效交付,导致周期时间增加和反馈减少?
最后一点很重要,因为我们经常遇到配置管理策略,它们解决了前四点,但在团队之间的协作方面设置了各种障碍。这是不必要的——只要足够小心,最后这个约束不需要与其他约束相矛盾。我们不会在本章告诉您如何回答所有这些问题,尽管我们在整本书中都会解决它们。在本章中,我们将问题分为三个部分:
做好管理应用程序构建、部署、测试和发布过程的先决条件。我们分两部分解决这个问题:将所有内容纳入版本控制和管理依赖关系。
管理应用程序的配置。
整个环境的配置管理——应用程序依赖的软件、硬件和基础设施;环境管理背后的原则,从操作系统到应用服务器、数据库和其他商业现成(COTS)软件。
版本控制系统,也称为源代码控制、源代码管理系统或修订控制系统,是一种保存文件多个版本的机制,因此当您修改文件时,您仍然可以访问以前的修订版本。它们也是参与软件交付的人员进行协作的机制。
最早流行的版本控制系统是一个名为 SCCS(Source Code Control System,源代码控制系统)的专有 UNIX 工具,可以追溯到 1970 年代。它后来被 RCS(Revision Control System,修订控制系统)取代,再后来是 CVS(Concurrent Versions System,并发版本系统)。这三个系统至今仍在使用,尽管市场份额越来越小。如今有大量更好的版本控制系统,包括开源和专有的,专为各种不同环境设计。特别是,我们相信在很少的情况下,开源工具——Subversion、Mercurial 或 Git——无法满足大多数团队的需求。我们将在第 14 章”高级版本控制”中花更多时间探讨版本控制系统及其使用模式,包括分支和合并。
本质上,版本控制系统的目标是双重的:首先,它保留并提供对存储在其中的每个文件的每个版本的访问。这类系统还提供了一种方法,可以将元数据(metadata)——即描述所存储数据的信息——附加到单个文件或文件集合。其次,它允许可能在空间和时间上分布的团队进行协作。
你为什么想这样做?有几个原因,但最终是为了能够回答这些问题:
• 什么构成了软件的特定版本?你如何重现生产环境中存在的软件二进制文件和配置的特定状态?
• 什么时候做了什么,由谁做的,出于什么原因?这不仅在出错时很有用,而且还讲述了你的应用程序的故事。
这些是版本控制的基础。大多数项目使用版本控制。如果你的项目还没有,请阅读接下来的几节,然后放下这本书并立即添加它。以下几节是我们关于如何最有效地使用版本控制的建议。
我们使用术语”版本控制”而不是”源代码控制”的一个原因是,版本控制不仅仅用于源代码。与创建软件相关的每一个工件都应该在版本控制之下。开发人员当然应该用它来管理源代码,还应该用于测试、数据库脚本、构建和部署脚本、文档、库和应用程序的配置文件、编译器和工具集等——这样团队的新成员可以从零开始工作。
同样重要的是存储重新创建应用程序运行的测试和生产环境所需的所有信息。这应该包括应用程序软件栈和构成环境的操作系统的配置信息、DNS 区域文件、防火墙配置等。至少,你需要重新创建应用程序二进制文件及其运行环境所需的所有内容。
目标是以受控的方式存储在项目生命周期中任何时候可能发生变化的所有内容。这使你能够恢复整个系统状态的精确快照,从开发环境到生产环境,在项目历史的任何时刻。甚至将开发团队的开发环境配置文件保存在版本控制中也很有帮助,因为这使团队中的每个人都可以轻松使用相同的设置。分析师应该存储需求文档。测试人员应该将他们的测试脚本和流程保存在版本控制中。项目经理应该在这里保存他们的发布计划、进度图表和风险日志。简而言之,团队的每个成员都应该将与项目相关的任何文档或文件存储在版本控制中。
多年前,其中一位作者在一个项目上工作,该项目由来自三个不同地点的三个不同团队开发。每个团队正在开发的子系统通过 IBM MQSeries 使用专有消息协议相互通信。这是在我们开始使用持续集成作为配置管理问题的防护措施之前。
我们对源代码的版本控制非常严格。我们在职业生涯的早期就学到了这一课。然而,我们的版本控制仅限于源代码。
当接近项目第一次发布,需要集成三个独立的子系统时,我们发现其中一个团队使用的是描述消息协议的功能规范的不同版本。实际上,他们实现的文档已经过时了六个月。自然,我们在试图解决由此引起的问题并保持项目进度时熬了很多夜。
如果我们只是将文档签入版本控制系统,我们就不会遇到这个问题,也不会有那些熬夜!如果我们使用了持续集成,项目会提前很多完成。
我们真的无法过分强调良好的配置管理有多重要。它使本书中的所有其他内容成为可能。如果你的项目没有将所有源工件放入版本控制,你将无法享受我们在本书中讨论的任何好处。我们讨论的所有减少软件周期时间和提高质量的实践,从持续集成和自动化测试到一键式部署,都依赖于将与项目相关的所有内容放在版本控制存储库中。
除了存储源代码和配置信息外,许多项目还在版本控制中存储应用服务器、编译器、虚拟机和工具链其他部分的二进制镜像。这非常有用,可以加快新环境的创建速度,更重要的是,确保基础配置被完全定义,从而确保其可靠性。只需从版本控制仓库中检出所需的所有内容,就能为开发、测试甚至生产环境提供稳定的平台。然后,你可以将整个环境(包括应用了配置基线的基础操作系统)存储为虚拟镜像,以获得更高级别的保障和部署简便性。
这种策略提供了最终的控制和有保障的行为。在如此严格的配置管理下,系统不可能在后续流程阶段添加错误。这种级别的配置管理确保,只要保持仓库完整,你就始终能够检索到软件的可用版本。即使与项目相关的编译器、编程语言或其他工具已经陷入被遗忘的深渊,这也能保护你。
我们不建议在版本控制中保存的一件事是应用程序编译的二进制输出。原因有几个。首先,它们体积大,而且与编译器不同,它们增长迅速(我们为每次编译并通过自动提交测试的检入创建新的二进制文件)。其次,如果你有自动化构建系统,你应该能够通过重新运行构建脚本从源代码轻松重新创建它们。请注意:我们不建议将重新编译作为构建过程的常规部分。但是,构建系统和源代码的组合应该是在紧急情况下重新创建应用程序实例所需的全部内容。最后,存储构建的二进制输出违背了为每个应用程序版本识别仓库单一版本的理念,因为同一版本可能有两次提交,一次用于源代码,另一次用于二进制文件。这可能看起来晦涩难懂,但在创建部署流水线时变得极其重要——这是本书的核心主题之一。
将每个文件的每个版本都放在版本控制中的一个推论是,它允许你主动删除你认为不需要的东西。有了版本控制,你可以用”可以!“来回答”我们应该删除这个文件吗?“这个问题,而且没有风险;如果你做了错误的决定,通过从早期配置集中检索文件就能轻松修复。
这种删除的自由本身就是大型配置集可维护性的重大进步。一致性和组织性是保持大型团队高效工作的关键。清理旧想法和实现的能力使团队能够自由尝试新事物并改进代码。
在使用版本控制时存在一个核心矛盾。一方面,为了获得版本控制的许多好处,例如能够回退到最近的已知良好版本的工件,频繁检入很重要。
另一方面,一旦你将更改检入版本控制,它们就变成公开的,立即对团队中的其他所有人可用。此外,如果你正在使用我们推荐的持续集成(continuous integration),你的更改不仅对团队中的其他开发人员可见;你刚刚创建了一个可能最终进入验收测试甚至生产环境的构建。
由于检入是一种发布形式,重要的是确保你的工作(无论是什么)已经为检入所暗示的公开程度做好准备。这尤其适用于开发人员,鉴于他们工作的性质,他们需要谨慎对待检入的影响。如果开发人员正在系统的复杂部分工作,他们不会希望在完成之前提交代码;他们希望确信代码处于良好状态,不会对系统的其他功能产生不利影响。
在某些团队中,这可能导致检入之间间隔数天甚至数周,这是有问题的。当你定期提交时,版本控制的好处会得到增强。特别是,除非每个人都频繁提交到主线(mainline),否则无法安全地重构应用程序——合并会变得太复杂。如果你频繁提交,你的更改对其他人可见并可以互动,你会得到清楚的指示表明你的更改没有破坏应用程序,并且合并总是小而可管理的。
有些人用来解决这个困境的一个解决方案是在版本控制系统中为新功能创建一个单独的分支。在某个时候,当更改被认为令人满意时,它们将被合并到主开发分支中。这有点像两阶段检入;实际上,一些版本控制系统自然地以这种方式工作。
然而,我们反对这种做法(除了三个例外,在第14章中讨论)。这是一个有争议的观点,尤其是对ClearCase等工具的用户而言。这种方法存在几个问题。
• 它与持续集成相悖,因为创建分支推迟了新功能的集成,并且只有在合并分支时才会发现集成问题。
• 如果多个开发人员创建分支,问题会呈指数级增长,合并过程可能变得极其复杂。
• 尽管有一些优秀的自动合并工具,但它们无法解决语义冲突,例如有人在一个分支中重命名了一个方法,而另一个人在另一个分支中添加了对该方法的新调用。
• 重构代码库变得非常困难,因为分支往往会涉及许多文件,这使得合并变得更加困难。
我们将在第14章”高级版本控制”中更详细地讨论分支和合并的复杂性。
更好的解决方案是增量开发新功能,并定期频繁地将它们提交到版本控制的主干 (trunk) 中。这使软件始终保持工作和集成状态。这意味着您的软件始终经过测试,因为每次签入时,持续集成 (CI) 服务器都会在主干上运行自动化测试。它减少了重构导致的大型合并冲突的可能性,确保集成问题在成本较低时立即被发现和修复,并产出更高质量的软件。我们将在第13章”管理组件和依赖”中更详细地讨论避免分支的技术。
为了确保签入时不会破坏应用程序,有两种实践很有用。一种是在签入之前运行提交测试套件。这是一组运行快速(少于十分钟)但相对全面的测试,用于验证您没有引入任何明显的回归问题。许多持续集成服务器都有一个称为预测试提交 (pretested commit) 的功能,允许您在签入之前在类生产环境中运行这些测试。
第二种是增量引入更改。我们建议您在完成每个单独的增量更改或重构后,将更改提交到版本控制系统。如果您正确使用此技术,您应该每天至少签入一次,通常是每天多次。如果您不习惯这样做,这可能听起来不现实,但我们向您保证,这会带来更高效的软件交付流程。
每个版本控制系统都有添加提交描述的功能。很容易忽略这些消息,许多人养成了这样做的坏习惯。编写描述性提交消息的最重要原因是,当构建失败时,您可以知道是谁破坏了构建以及原因。但这不是唯一的原因。我们的作者因没有使用足够描述性的提交消息而被困扰过好几次,最常见的是在紧迫的截止日期下尝试调试复杂问题时。通常的场景是这样的:
您发现一个 bug,它归因于一行相当晦涩的代码。
您使用版本控制系统查找是谁在什么时候添加了那行代码。
那个人正在休假或已经下班回家,并留下了一条提交消息说”修复了一个晦涩的 bug”。
您更改那行晦涩的代码以修复 bug。
其他东西出问题了。
您花了几个小时试图让应用程序重新工作。
在这些情况下,一条提交消息解释那个人提交更改时正在做什么,可以为您节省数小时的调试时间。这种情况发生得越多,您就越希望自己使用了良好的提交消息。写最短的提交消息没有奖励。一两句中长句概述您正在做什么,通常会在以后为您节省数倍的精力。
我们喜欢的一种风格是多段落提交消息,其中第一段是摘要,后续段落添加更多细节。第一段是在每行一个提交的显示中显示的内容——把它想象成报纸标题,给读者足够的信息来判断她是否有兴趣继续阅读。
您还应该包含项目管理工具中您正在处理的功能或 bug 的标识符链接。在我们工作过的许多团队中,系统管理员会锁定他们的版本控制系统,使得不包含此信息的提交会失败。
应用程序中最常见的外部依赖是它使用的第三方库,以及组织内其他团队正在开发的组件或模块之间的关系。库通常以二进制文件的形式部署,从不被应用程序的开发团队更改,并且很少更新。组件和模块通常由其他团队积极开发,并且变化相当频繁。
我们在第13章”管理组件和依赖”中花费了大量时间讨论依赖关系。然而,在这里,我们将触及依赖管理的一些关键问题,因为它影响配置管理。
外部库通常以二进制形式提供,除非您使用的是解释型语言。即使使用解释型语言,外部库通常也会通过包管理系统(如 Ruby Gems 或 Perl 模块)全局安装在您的系统上。
关于是否对库进行版本控制存在一些争论。例如,Maven 是一个 Java 构建工具,允许您指定应用程序依赖的 JAR 文件,并从互联网上的仓库(或本地缓存,如果您有的话)下载它们。
这并不总是理想的;新团队成员可能被迫”下载整个互联网”(或至少相当大的部分)才能开始项目工作。然而,这确实使版本控制检出变得更小。
我们建议您在本地保留外部库的副本(对于 Maven,您应该为组织创建一个仓库,其中包含批准使用的库版本)。如果您必须遵守合规法规,这一点至关重要,同时也能加快项目启动速度。这也意味着您始终有能力重现构建。此外,我们强调您的构建系统应该始终指定所使用外部库的确切版本。如果不这样做,就无法重现构建。未能绝对明确还会导致偶尔出现漫长的调试会话,追踪由于人员或构建系统使用不同版本库而导致的奇怪错误。
是否将外部库保存在版本控制中涉及一些权衡。这使得将软件版本与用于构建它们的库版本关联起来变得容易得多。然而,这会使版本控制仓库变大,检出时间更长。
除了最小的应用程序外,将应用程序拆分为组件是一个良好实践。这样做可以限制应用程序变更的范围,减少回归缺陷。它还鼓励重用,并在大型项目中实现更高效的开发流程。
通常,您会从单体构建开始,在一个步骤中为整个应用程序创建二进制文件或安装程序,通常同时运行单元测试。根据您使用的技术栈,单体构建通常是构建中小型应用程序最高效的方式。
然而,如果您的系统增长或您有多个项目依赖的组件,您可以考虑将组件构建拆分为单独的流水线。如果这样做,重要的是在流水线之间建立二进制依赖而不是源代码依赖。重新编译依赖项不仅效率较低;它还意味着您创建的制品可能与您已经测试过的制品不同。使用二进制依赖可能使追溯故障到导致它的源代码变更变得困难,但优秀的 CI 服务器会帮助您解决这个问题。
虽然现代 CI 服务器在管理依赖方面做得相当好,但它们通常以使在开发人员工作站上重现整个端到端构建过程变得更困难为代价。理想情况下,如果我的机器上检出了几个组件,应该相对简单地在其中一些组件中进行更改,然后运行单个命令,以正确的顺序重建必要的部分,创建适当的二进制文件,并运行相关测试。遗憾的是,这超出了大多数构建系统的能力,至少在没有构建工程师进行大量巧妙处理的情况下是这样,尽管像 Ivy 和 Maven 这样的工具以及 Gradle 和 Buildr 这样的脚本技术确实使生活比以前更容易。
关于管理组件和依赖的更多内容请参见第 13 章。
配置是构成应用程序的三个关键部分之一,另外两个是二进制文件和数据。配置信息可用于在构建时、部署时和运行时改变软件的行为。交付团队需要仔细考虑应该提供哪些配置选项,如何在应用程序的整个生命周期中管理它们,以及如何确保配置在组件、应用程序和技术之间得到一致管理。我们认为您应该像对待代码一样对待系统的配置:使其接受适当的管理和测试。
如果被问到,每个人都想要灵活的软件。为什么不呢?但灵活性通常是有代价的。
显然存在一个连续体:一端是单一用途的软件,它能很好地完成一项工作,但几乎没有修改其行为的能力。频谱的另一端是编程语言,您可以用它来编写游戏、应用服务器或库存控制系统——这就是灵活性!然而,大多数应用程序都不在这两个极端。相反,它们是为特定目的而设计的,但在该目的的范围内,通常会有一些可以修改其行为的方式。
实现灵活性的愿望可能导致常见的反模式”终极可配置性”,这在软件项目中经常被作为需求提出。这充其量是无益的,最坏的情况下,这一个需求就可能扼杀一个项目。
任何时候,当您改变应用程序的行为时,您就是在编程。您编程更改所使用的语言可能或多或少受到约束,但它仍然是编程。您打算为用户提供的可配置性越多,根据定义,您对系统配置施加的约束就越少,因此编程环境需要变得越复杂。
根据我们的经验,认为配置信息的更改风险比源代码更低是一个持久的误区。我们敢打赌,如果同时可以访问这两者,我们通过更改配置就能像更改源代码一样轻松地停止你的系统。如果我们更改源代码,有多种方式可以保护我们自己不犯错;编译器会排除无意义的内容,自动化测试应该能捕获大多数其他错误。另一方面,大多数配置信息是自由格式且未经测试的。在大多数系统中,没有任何机制能阻止我们将URI从”http://www.asciimation.co.nz/“更改为”this is not a valid URI”。大多数系统直到运行时才会捕获这样的更改——到那时,你的用户看到的不是《星球大战》的ASCII版本,而是一个令人讨厌的异常报告,因为URI类无法解析”this is not a valid URI”。
在通往高度可配置软件的道路上有许多重大陷阱,但最糟糕的可能是以下几点。
• 它经常导致分析瘫痪(analysis paralysis),问题看起来如此庞大且如此棘手,以至于团队把所有时间都花在思考如何解决它上,而没有时间真正解决任何问题。
• 系统变得如此复杂以至于难以配置,灵活性的许多好处都丧失了,配置所需的工作量与定制开发的成本相当。
我们曾经遇到过一个客户,他们花了三年时间与一个在其特定垂直市场的打包应用程序供应商合作。这个应用程序被设计得非常灵活,可以配置以满足客户的需求,尽管需要由配置专家来完成。
我们的客户担心该系统仍然远未准备好投入生产使用。我们的组织用Java从头开始实现了一个定制构建的等效系统,只用了八个月。
可配置软件并不总是看起来那样便宜的解决方案。几乎总是更好的做法是专注于以很少的配置交付高价值功能,然后在必要时再添加配置选项。
不要误解我们:配置本身并不邪恶。但它需要被仔细且一致地管理。现代计算机语言已经发展出各种特性和技术来帮助减少错误。在大多数情况下,这些保护机制对配置信息并不存在,而且往往甚至没有任何测试来验证你的软件在测试和生产环境中是否被正确配置。部署冒烟测试(deployment smoke tests),如第117页”冒烟测试你的部署”一节所述,是缓解这个问题的一种方法,应该始终使用。
配置信息可以在构建、部署、测试和发布过程的多个点注入到你的应用程序中,通常会在多个点包含配置。
• 你的构建脚本可以在构建时拉取配置并将其合并到二进制文件中。
• 你的打包软件可以在打包时注入配置,例如在创建assemblies、ears或gems时。
• 你的部署脚本或安装程序可以获取必要的信息或向用户询问,并在部署时作为安装过程的一部分将其传递给你的应用程序。
• 你的应用程序本身可以在启动时或运行时获取配置。
一般来说,我们认为在构建或打包时注入配置信息是不好的做法。这源于这样一个原则:你应该能够将相同的二进制文件部署到每个环境,这样你就可以确保发布的东西与测试的东西是相同的。由此推论,任何在部署之间发生变化的东西都需要作为配置捕获,而不是在应用程序编译或打包时烘焙进去。
J2EE规范的一个严重问题是配置必须与应用程序的其余部分一起打包在war或ear中。除非你使用另一种配置机制而不是规范提供的机制,否则这意味着如果存在任何配置差异,你必须为部署到的每个环境创建不同的war或ear文件。如果你陷入这种情况,你需要找到另一种方式在部署时或运行时配置你的应用程序。我们在下面提供了一些建议。
通常能够在部署时配置你的应用程序是很重要的,这样你就可以告诉它所依赖的服务(如数据库、消息服务器或外部系统)位于何处。例如,如果你的应用程序的运行时配置存储在数据库中,你可能希望在部署时将数据库的连接参数传递给应用程序,以便它在启动时可以检索它。
如果你控制生产环境,通常可以安排部署脚本获取此配置并将其提供给你的应用程序。对于打包软件的情况,默认配置通常是包的一部分,但需要有某种方式在部署时覆盖它以用于测试目的。
最后,您可能需要在启动时或运行时配置应用程序。启动时配置可以通过环境变量或启动系统的命令参数来提供。或者,您可以使用与运行时配置相同的机制:注册表设置、数据库、配置文件或外部配置服务(例如通过 SOAP 或 REST 风格的接口访问)。
无论您选择哪种机制,我们强烈建议,在实际可行的范围内,您应该尝试通过相同的机制为组织中的所有应用程序和环境提供所有配置信息。这并非总是可行,但如果可以做到,这意味着只有一个配置源需要更改、管理、版本控制和覆盖(如有必要)。在没有遵循这一实践的组织中,我们看到人们经常花费数小时在其环境中追踪某个特定设置的来源。
管理应用程序配置时需要考虑三个问题:
如何表示配置信息?
部署脚本如何访问它?
它在不同环境、应用程序和应用程序版本之间如何变化?
配置信息通常被建模为一组名称-值字符串。
有时在配置系统中使用类型并以层次结构组织它是有用的。包含按标题组织的名称-值字符串的 Windows 属性文件、Ruby 世界中流行的 YAML 文件以及 Java 属性文件都是相对简单的格式,在大多数情况下提供了足够的灵活性。复杂度的有用上限可能是将配置存储为 XML 文件。
存储应用程序配置有几个明显的选择:数据库、版本控制系统或目录或注册表。版本控制可能是最简单的——您只需签入配置文件,就可以免费获得配置随时间变化的历史记录。值得将应用程序的可用配置选项列表保存在与其源代码相同的仓库中。

请注意,存储配置的位置与应用程序访问配置的机制不同。您的应用程序可以通过本地文件系统上的文件访问其配置,或通过更特殊的机制(如 Web 或目录服务)或通过数据库访问;下一节将详细介绍。
通常重要的是将特定于应用程序每个测试和生产环境的实际配置信息保存在与源代码分离的仓库中。这些信息通常以不同于其他版本控制工件的速率变化。但是,如果采用这种方式,您必须小心跟踪哪些版本的配置信息与哪些版本的应用程序匹配。这种分离对于安全相关的配置元素(如密码和数字证书)尤其重要,对这些元素的访问应该受到限制。

如果运维人员发现您这样做,他们会用勺子挖出您的眼睛。不要给他们这个机会。如果必须将密码存储在大脑之外的某个地方,您可以尝试将它们以加密形式放在主目录中。
这种技术的一个严重变体是将应用程序某一层的密码存储在访问它的层的代码或文件系统中的某个位置。密码应该始终由执行部署的用户输入。有几种可接受的方法来处理多层系统的身份验证。您可以使用证书、目录服务或单点登录系统。
数据库、目录和注册表是存储配置的便利位置,因为它们可以远程访问。但是,请确保保留配置更改的历史记录,以便审计和回滚。要么使用自动处理此问题的系统,要么将版本控制视为配置的参考系统,并使用脚本在需要时将适当版本加载到数据库或目录中。
访问配置
管理配置最有效的方法是拥有一个中央服务,每个应用程序都可以通过它获取所需的配置。这对打包软件和内部企业应用程序以及托管在互联网上的软件即服务(SaaS)都同样适用。这些场景之间的主要区别在于何时注入配置信息——对于打包软件是在打包时,否则是在部署时或运行时。
应用程序访问其配置的最简单方法可能是通过文件系统。这具有跨平台和每种语言都支持的优势——尽管它可能不适合沙箱运行时(如小程序)。如果需要在集群上运行应用程序,还存在保持文件系统上配置同步的问题。
另一种替代方案是从集中式存储库(如 RDBMS、LDAP 或 Web 服务)获取配置。一个名为 ESCAPE [apvrEr] 的开源工具使得通过 RESTful 接口管理和访问配置信息变得简单。应用程序可以执行 HTTP GET 请求,在 URI 中包含应用程序名称和环境名称来获取其配置。当在部署时或运行时配置应用程序时,这种机制最有意义。你可以通过属性、命令行开关或环境变量将环境名称传递给部署脚本,然后脚本从配置服务获取相应的配置,并将其提供给应用程序,可能以文件系统上的文件形式。
无论配置信息存储的性质如何,我们建议你使用一个简单的外观类(Façade)将技术细节与应用程序隔离开来,提供
getThisProperty() getThatProperty()
风格的接口,这样你可以在测试中模拟它,并在需要时更改存储机制。
配置建模
每个配置设置都可以建模为一个元组(Tuple),因此应用程序的配置由一组元组组成。然而,可用元组的集合及其值通常取决于三个因素:
• 应用程序
• 应用程序的版本
• 运行环境(例如:开发、UAT、性能测试、预发布或生产)
例如,报表应用程序的 1.0 版本将拥有一组与 2.2 版本或投资组合管理应用程序 1.0 版本不同的元组。这些元组的值又会根据部署的环境而变化。例如,应用程序在 UAT 中使用的数据库服务器通常与生产环境中使用的不同,甚至可能在开发人员机器之间有所不同。这同样适用于打包软件或外部集成点——应用程序使用的更新服务在运行集成测试时与从客户端桌面访问时会有所不同。
无论你使用什么来表示和提供配置信息——源代码控制中的 XML 文件或 RESTful Web 服务——都应该能够处理这些不同的维度。以下是建模配置信息时要考虑的一些用例。
• 添加新环境(也许是新的开发人员工作站或容量测试环境)。在这种情况下,你需要能够为部署到这个新环境的应用程序指定一组新的值。
• 创建应用程序的新版本。通常,这会引入新的配置设置并删除一些旧的配置。你应该确保将这个新版本部署到生产环境时,它能获取新的设置,但如果必须回滚到旧版本,它将使用旧的设置。
• 将应用程序的新版本从一个环境提升到另一个环境。你应该确保任何新设置在新环境中可用,但为这个新环境设置了适当的值。
• 迁移数据库服务器。你应该能够非常简单地更新引用此数据库的每个配置设置,使其指向新的数据库。
• 使用虚拟化管理环境。你应该能够使用虚拟化管理工具创建特定环境的新实例,其中所有虚拟机都正确配置。你可能希望将此信息作为部署到该环境的应用程序特定版本的配置设置的一部分。
跨环境管理配置的一种方法是将预期的生产配置作为默认值,并在其他环境中适当覆盖此默认值(确保设置防火墙,以免生产系统被误操作)。这意味着任何特定环境的定制都减少到只需更改软件在该特定环境中工作所必需的那些配置属性。这简化了需要在何处配置什么的全貌。然而,这也取决于你的应用程序的生产配置是否具有特权——一些组织期望将生产配置保存在与其他环境分离的存储库中。
测试系统配置
与应用程序和构建脚本需要测试一样,配置设置也需要测试。测试配置有两个部分。
第一阶段是确保配置设置中对外部服务的引用是有效的。作为部署脚本的一部分,你应该确保配置使用的消息总线(Messaging Bus)确实在配置的地址上运行,并且应用程序在功能测试环境中期望使用的模拟订单履行服务(Mock Order Fulfillment Service)正在工作。至少,你可以 ping 所有外部服务。如果应用程序依赖的任何内容不可用,部署或安装脚本应该失败——这可以作为配置设置的绝佳冒烟测试(Smoke Test)。
第二阶段是在安装应用程序后实际运行一些冒烟测试,以确保它按预期运行。这应该只涉及几个测试,测试依赖于配置设置正确的功能。理想情况下,如果结果不符合预期,这些测试应该停止应用程序并使安装或部署过程失败。
管理配置的问题在中大型组织中尤其复杂,因为需要同时管理许多应用程序。通常在这类组织中,存在着配置选项晦涩难懂的遗留应用程序。最重要的任务之一是维护一个目录,记录每个应用程序的所有配置选项、它们的存储位置、生命周期以及修改方式。
如果可能,此类信息应该在构建过程中从每个应用程序的代码中自动生成。但如果无法实现,则应该将其收集到wiki或其他文档管理系统中。
在管理非完全用户安装的应用程序时,了解每个运行中应用程序的当前配置非常重要。目标是能够通过运维团队的生产监控系统查看每个应用程序的配置,该系统还应显示每个应用程序的哪个版本部署在哪个环境中。Nagios、OpenNMS和HP OpenView等工具都提供了记录此类信息的服务。或者,如果以自动化方式管理构建和部署过程,配置信息应始终通过该过程应用,因此应存储在版本控制或像Escape这样的工具中。
当应用程序相互依赖且必须协调部署时,实时访问这些信息尤为重要。无数时间浪费在一个应用程序的几个配置选项设置错误,从而导致整套服务瘫痪。这类问题极难诊断。
每个应用程序的配置管理都应该在项目启动阶段进行规划。考虑生态系统中其他应用程序如何管理配置,如果可能的话使用相同的方法。太多情况下,如何管理配置的决策是临时做出的,结果是每个应用程序将配置打包在不同位置,使用不同的机制访问。这使得确定环境配置变得不必要地困难。
像对待代码一样对待应用程序的配置。妥善管理并测试它。以下是创建应用程序配置系统时需要考虑的原则列表:
• 考虑在应用程序生命周期的哪个阶段注入特定配置项才有意义—是在打包发布候选版本的组装阶段,部署或安装时,启动时,还是运行时。与运维和支持团队沟通以了解他们的需求。
• 将应用程序的可用配置选项保存在与源代码相同的仓库中,但将具体值保存在其他地方。配置设置的生命周期与代码完全不同,而密码和其他敏感信息根本不应该检入版本控制。
• 配置应始终由自动化流程使用从配置仓库中获取的值来执行,这样您就可以随时识别每个环境中每个应用程序的配置。
• 您的配置系统应该能够根据应用程序、其版本以及部署的环境,为应用程序(包括其打包、安装和部署脚本)提供不同的值。任何人都应该能够轻松查看特定版本的应用程序在将要部署的所有环境中有哪些可用配置选项。
• 为配置选项使用清晰的命名约定。避免晦涩或隐晦的名称。试着想象有人在没有手册的情况下阅读配置文件—应该能够理解配置属性是什么。
• 确保配置信息是模块化和封装的,这样一处更改不会对其他看似无关的配置部分产生连锁影响。
• 使用DRY(不要重复自己)原则。定义配置元素时,让每个概念在配置信息集合中只有一个表示。
• 保持极简主义:使配置信息尽可能简单和专注。除非有需求或确实有意义,否则避免创建配置选项。
• 避免过度设计配置系统。保持尽可能简单。
• 确保有针对配置的测试,并在部署或安装时运行。检查应用程序依赖的服务是否可用,并使用冒烟测试(smoke test)来断言依赖配置设置的任何功能是否按预期工作。
没有应用程序是孤岛。每个应用程序都依赖于硬件、软件、基础设施和外部系统才能工作。在本书中,我们将其称为应用程序的环境。我们在第11章”管理基础设施和环境”中详细讨论了环境管理主题,但该主题在配置管理的背景下值得一些讨论,因此我们将在此介绍。
在管理应用程序运行环境时要牢记的原则是:环境配置与应用程序配置同样重要。例如,如果您的应用程序依赖于消息总线,总线必须正确配置,否则应用程序将无法工作。操作系统的配置也很重要。例如,您可能有一个依赖大量文件描述符的应用程序。如果操作系统默认的文件描述符数量限制较低,您的应用程序就无法工作。
管理配置信息最糟糕的方法是以临时方式处理。这意味着手动安装必需的软件并编辑相关配置文件。这是我们遇到的最常见策略。尽管看似简单,但这种策略在除最简单系统之外的所有系统中都会出现几个常见问题。最明显的陷阱是,如果新配置因任何原因无法工作,很难确定地返回到已知的良好状态,因为没有先前配置的记录。问题可以总结如下:
• 配置信息的集合非常庞大
• 一个小改动就可能破坏整个应用程序或严重降低其性能
• 一旦出现问题,找到并修复它需要不确定的时间,并且需要高级人员参与
• 极难精确复现手动配置的环境用于测试
• 难以维护这样的环境而不使不同节点的配置和行为发生偏离
在《The Visible Ops Handbook》(可见运维手册)中,作者将手动配置的环境称为”艺术品”。为了降低管理环境的成本和风险,必须将我们的环境转变为可重复创建且耗时可预测的批量生产对象。我们参与过太多项目,糟糕的配置管理意味着巨大的开支——仅为处理系统这一方面就要支付团队人员的费用。它还持续拖累开发流程的生产力,使测试环境、开发环境和生产环境的部署比必要的复杂和昂贵得多。
管理环境的关键是使其创建成为完全自动化的过程。创建新环境应该总是比修复旧环境更便宜。能够复现环境至关重要,原因如下:
• 消除了存在随机基础设施的问题,这些基础设施的配置只有已离职且无法联系的人才了解。当这些东西停止工作时,通常意味着严重的停机时间。这是一个巨大且不必要的风险。
• 修复一个环境可能需要许多小时。能够在可预测的时间内重建它以恢复到已知良好状态总是更好。
• 必须能够为测试目的创建生产环境的副本。在软件配置方面,测试环境应该是生产环境的精确复制品,这样可以及早发现配置问题。
您应该关注的环境配置信息类型包括:
• 环境中的各种操作系统,包括其版本、补丁级别和配置设置
• 支持应用程序所需安装在每个环境上的其他软件包,包括其版本和配置
• 应用程序工作所需的网络拓扑
• 应用程序依赖的任何外部服务,包括其版本和配置
• 其中存在的任何数据或其他状态(例如生产数据库)
我们发现有两个原则构成了有效配置管理策略的基础:将二进制文件与配置信息分开,并将所有配置信息集中在一个地方。将这些基本原则应用于系统的每个部分,将为创建新环境、升级系统部分以及在不使系统不可用的情况下推出新配置铺平道路,使其成为一个简单的自动化过程。
所有这些都需要考虑。虽然将操作系统签入版本控制显然不合理,但对其配置进行版本控制肯定是合理的。远程安装系统和环境管理工具(如Puppet和CfEngine)的组合使操作系统的集中管理和配置变得简单。第11章”管理基础设施和环境”详细介绍了这个主题。
对于大多数应用程序,将此原则应用于它们依赖的第三方软件堆栈更为重要。好的软件具有可以从命令行运行而无需任何用户干预的安装程序。它具有可以在版本控制中管理且不需要手动干预的配置。如果您的第三方软件依赖项不符合这些标准,您应该寻找替代方案——这些第三方软件选择标准非常重要,应该成为每个软件评估工作的核心。在评估第三方产品和服务时,首先要问以下问题:
• 我们能部署它吗?
• 我们能有效地对其配置进行版本控制吗?
• 它将如何融入我们的自动化部署策略?
如果这些问题中的任何一个答案是否定的,都有各种可能的应对方法——我们在[第11章]中会更详细地讨论它们。
处于正确部署状态的环境在配置管理(Configuration Management)术语中被称为基线(Baseline)。您的自动化环境配置系统应该能够建立或重新建立项目最近历史中存在过的任何给定基线。每当您更改应用程序宿主环境的任何方面时,都应该存储这个更改,创建基线的新版本,并将该版本的应用程序与新版本的基线关联起来。这样可以确保下次部署应用程序或创建新环境时,会包含这个更改。
本质上,您应该像对待代码一样对待您的环境——以增量方式更改它并将更改检入版本控制。每个更改都应该经过测试,以确保它不会破坏在新版本环境中运行的任何应用程序。
我们最近参与的两个项目突出展示了配置管理的有效使用与不太有效方法之间的差异。
在第一个项目中,我们决定替换项目所基于的消息传递基础设施。我们有非常有效的配置管理和良好的模块化设计。在替换基础设施之前,我们尝试升级到供应商向我们保证能解决大部分问题的最新版本。
我们的客户和供应商显然认为这次升级是件大事。他们已经为此计划了几个月,并担心对开发团队的破坏性影响。结果,我们团队的两名成员按照本节所述的方式准备了一个新的基线。我们在本地进行了测试,包括在试用版本上运行完整的验收测试包。我们的测试发现了许多问题。
我们修复了最明显的问题,但没有让所有验收测试都通过。然而,我们已经到达了一个可以确信修复应该是直接的点,而且我们的最坏情况是必须恢复到之前的基线镜像,所有这些都安全地存储在版本控制中。在获得开发团队其他成员的同意后,我们提交了我们的更改,这样整个团队就可以一起修复消息传递基础设施版本更改带来的错误。整个过程花了一天时间,包括运行所有自动化测试来验证我们的工作。在随后的迭代中,我们在手动测试期间仔细观察是否有更多错误,但一个也没有。我们的自动化测试覆盖率被证明是足够好的。
在第二个项目中,我们被要求对一个已经在生产环境中运行了几年的老旧遗留系统进行一些修复工作,该系统缓慢且容易出错。当我们到达时,它没有任何自动化测试,只有源代码级别的最基本配置管理。我们的任务之一是更新应用服务器的版本,因为系统运行的版本已经不再被供应商支持。对于处于这种状态的应用程序,没有支持的持续集成系统,也没有任何自动化测试,这个过程进行得还算顺利。然而,一个六人小团队花了两个月才完成更改、测试并部署到生产环境。
与软件项目一样,不可能进行直接比较。所涉及的技术完全不同,代码库也是如此。然而,两者都涉及升级核心中间件基础设施。一个花了六人团队两个月,另一个花了两个人半天时间。
Puppet和CfEngine是两个可以自动化方式管理操作系统配置的工具示例。使用这些工具,您可以声明式地定义诸如哪些用户应该有权访问您的服务器以及应该安装什么软件之类的内容。这些定义可以存储在您的版本控制系统中。在您的系统上运行的代理程序会定期拉取最新配置并更新操作系统和安装在其上的软件。有了这样的系统,就没有理由登录到服务器上进行修复:所有更改都可以通过版本控制系统启动,因此您拥有每个更改的完整记录——何时进行的以及由谁进行的。
虚拟化也可以提高环境管理过程的效率。您可以简单地复制环境中每个服务器的副本并将其存储为基线,而不是使用自动化过程从头创建新环境。然后创建新环境就变得微不足道了——只需点击一个按钮即可完成。虚拟化还有其他好处,例如能够整合硬件以及标准化您的硬件平台,即使您的应用程序需要异构环境。
我们在[第11章]“管理基础设施和环境”中更详细地讨论这些工具。
最后,能够管理对环境进行更改的过程至关重要。生产环境应该完全锁定。在不经过组织的变更管理流程的情况下,任何人都不可能对其进行更改。原因很简单:即使是微小的更改也可能破坏它。更改必须在进入生产环境之前进行测试,为此应该将其脚本化并检入版本控制。然后,一旦更改获得批准,就可以以自动化的方式将其推广到生产环境。
从这个意义上说,对环境的更改就像对软件的更改一样。它必须以与应用程序代码更改完全相同的方式经过构建、部署、测试和发布流程。
在这方面,测试环境应该与生产环境一样对待。审批流程通常会更简单——它应该掌握在管理测试环境的人员手中——但在所有其他方面,它们的配置管理是相同的。这至关重要,因为这意味着您正在测试用于管理生产环境的流程,而测试是在更频繁地部署到测试环境期间进行的。值得重申的是,测试环境在软件配置方面应该与生产环境非常相似——这样在部署到生产环境时就不会出现意外。这并不意味着测试环境必须是昂贵的生产环境的克隆;而是说它们应该通过相同的机制进行管理、部署和配置。
配置管理是本书中所有其他内容的基础。没有它,就不可能进行持续集成、发布管理和部署流水线。它还对交付团队内部的协作产生巨大的积极影响。正如我们希望已经说清楚的那样,这不仅仅是选择和实施工具的问题,尽管这很重要;至关重要的是,这也是将良好实践付诸实施的问题。
如果您的配置管理流程是健全的,您应该能够对以下问题回答”是”:
• 您能否从存储的版本控制资产中从头开始完全重新创建生产系统(不包括生产数据)?
• 您能否回退到应用程序的早期已知良好状态?
• 您能否确保生产、预发布和测试中部署的每个环境都以完全相同的方式设置?
如果不能,那么您的组织就面临风险。特别是,我们建议制定一个策略来存储基线并控制以下内容的更改:
• 应用程序的源代码、构建脚本、测试、文档、需求、数据库脚本、库和配置文件
• 开发、测试和运维工具链
• 开发、测试和生产中使用的所有环境
• 与应用程序关联的整个应用程序栈——包括二进制文件和配置
• 在整个应用程序生命周期(构建、部署、测试、运维)中,应用程序在其运行的每个环境中的配置
许多软件项目的一个极其奇怪但常见的特征是,在开发过程中的很长一段时间内,应用程序并不处于工作状态。事实上,大型团队开发的大多数软件在其开发时间中有相当大的一部分处于不可用状态。原因很容易理解:在应用程序完成之前,没有人有兴趣尝试运行整个应用程序。开发人员检入更改,甚至可能运行自动化单元测试,但没有人尝试实际启动应用程序并在类似生产的环境中使用它。
对于使用长期存在的分支或将验收测试推迟到最后的项目来说,这一点更是如此。许多此类项目在开发结束时安排冗长的集成阶段,以便让开发团队有时间合并分支并使应用程序正常工作,以便可以进行验收测试。更糟糕的是,一些项目发现,当他们进入这个阶段时,他们的软件不适合目的。这些集成期可能需要极长的时间,最糟糕的是,没有人能够预测需要多长时间。
另一方面,我们见过一些项目,它们最多只有几分钟处于应用程序无法使用最新更改的状态。区别在于使用持续集成。持续集成要求每次有人提交任何更改时,都要构建整个应用程序,并对其运行一套全面的自动化测试。至关重要的是,如果构建或测试过程失败,开发团队会停止正在做的任何事情,并立即修复问题。持续集成的目标是软件始终处于工作状态。
持续集成最早在 Kent Beck 的《解析极限编程》(Extreme Programming Explained) 一书中被提及(首次出版于 1999 年)。与其他极限编程实践一样,持续集成背后的理念是,如果定期集成代码库是好的,为什么不一直这样做呢?在集成的背景下,“一直”意味着每次有人向版本控制系统提交任何更改时。正如我们的一位同事 Mike Roberts 所说,“持续比你想象的更频繁” [aEu8Nu]。
持续集成代表了一种范式转变。没有持续集成时,你的软件在被证明可以工作之前一直是损坏的,这通常发生在测试或集成阶段。有了持续集成,你的软件在每次新变更时都被证明是可以工作的(假设有一套足够全面的自动化测试)——而且你能在软件出问题的那一刻就知道,并立即修复它。有效使用持续集成的团队能够比不使用的团队更快地交付软件,并且bug更少。bug在交付过程的早期就被发现,修复成本更低,从而显著节省了成本和时间。因此,我们认为持续集成是专业团队的一项基本实践,可能与使用版本控制一样重要。
本章其余部分描述了如何实施持续集成。我们将解释随着项目变得更加复杂时出现的常见问题的解决方法,列出支持持续集成的有效实践及其对设计和开发过程的影响。我们还将讨论更高级的主题,包括如何在分布式团队中进行持续集成。
持续集成在本书的配套书籍中有详细论述:Paul Duvall的《Continuous Integration》(持续集成)(Addison-Wesley, 2006)。如果你想要比我们在本章提供的更多细节,那就是你应该去的地方。
本章主要面向开发人员。然而,它也包含一些我们认为对想要更多了解持续集成实践的项目经理有用的信息。
持续集成的实践依赖于某些先决条件。我们将介绍这些先决条件,然后看看可用的工具。也许最重要的是,持续集成依赖于团队遵循一些基本实践,所以我们将花一些时间讨论这些。
在开始持续集成之前,你需要三样东西。
1. 版本控制
项目中的所有内容都必须签入单个版本控制仓库:代码、测试、数据库脚本、构建和部署脚本,以及创建、安装、运行和测试应用程序所需的任何其他内容。这可能听起来很明显,但令人惊讶的是,仍然有项目不使用任何形式的版本控制。有些人认为他们的项目不够大,不值得使用版本控制。我们不相信有小到可以不使用版本控制的项目。当我们在自己的计算机上为自己的需求编写代码时,我们仍然使用版本控制。现在存在几种简单、强大、轻量级且免费的版本控制系统。
我们在第32页的”使用版本控制”部分和第14章”高级版本控制”中更详细地描述了修订控制系统的选择和使用。
2. 自动化构建
你必须能够从命令行启动构建。你可以从一个命令行程序开始,该程序告诉你的IDE构建软件,然后运行测试,或者它可以是一组复杂的多阶段构建脚本相互调用。无论是什么机制,人或计算机都必须能够通过命令行以自动化方式运行你的构建、测试和部署过程。
如今,IDE和持续集成工具已经变得相当复杂,你通常可以在不接近命令行的情况下构建软件并运行测试。但是,我们认为你仍然应该有可以通过命令行运行的构建脚本,而不需要IDE。这可能看起来有争议,但有几个原因:
• 你需要能够从持续集成环境以自动化方式运行构建过程,以便在出现问题时可以进行审计。
• 你的构建脚本应该像代码库一样对待。它们应该被测试并不断重构,以便保持整洁和易于理解。使用IDE生成的构建过程是不可能做到这一点的。随着项目变得越来越复杂,这一点变得越来越重要。
• 它使理解、维护和调试构建变得更容易,并允许与运维人员更好地协作。
3. 团队的共识
持续集成是一种实践,而不是工具。它需要开发团队一定程度的承诺和纪律。你需要每个人频繁地将小的增量变更签入主线,并同意项目的最高优先级任务是修复任何破坏应用程序的变更。如果人们不采用使其工作所必需的纪律,你尝试持续集成将不会带来你希望的质量改进。
你不需要持续集成软件来进行持续集成——正如我们所说,它是一种实践,而不是工具。James Shore在一篇名为”Continuous Integration on a Dollar a Day”(一美元一天的持续集成)的文章[bAJpjp]中描述了开始持续集成的最简单方法,只使用一台闲置的开发机器、一只橡皮鸡和一个铃铛。这篇文章值得一读,因为它很好地展示了持续集成的基本要素,除了版本控制之外没有任何工具。
然而实际上,如今的持续集成工具安装和运行都非常简单。有几个开源选项可供选择,例如 Hudson 和久负盛名的 CruiseControl 家族(CruiseControl、CruiseControl.NET 和 CruiseControl.rb)。特别是 Hudson 和 CruiseControl.rb 的启动和运行极其简单。CruiseControl.rb 非常轻量级,任何具备一定 Ruby 知识的人都可以轻松扩展它。Hudson 拥有大量插件,可以与构建和部署生态系统中的几乎所有工具集成。
在撰写本文时,有两款商业持续集成服务器提供了面向小型团队的免费版本:ThoughtWorks Studios 的 Go 和 JetBrains 的 TeamCity。其他流行的商业持续集成服务器包括 Atlassian 的 Bamboo 和 Zutubi 的 Pulse。也可用于简单持续集成的高端发布管理和构建加速系统包括 UrbanCode 的 AntHillPro、ElectricCloud 的 ElectricCommander 和 IBM 的 BuildForge。市面上还有更多系统可供选择;完整列表请访问持续集成功能对比表 [bHOgH4]。
一旦安装了你选择的持续集成工具,在满足上述前提条件的情况下,只需几分钟即可开始使用,只需告诉工具在哪里找到源代码控制仓库、运行什么脚本来编译(如有必要)以及为应用程序运行自动化提交测试,以及如何在最新一组更改破坏软件时通知你。
第一次在持续集成工具上运行构建时,你可能会发现运行持续集成工具的机器缺少一堆软件和设置。这是一个独特的学习机会——记下你为使其正常工作所做的一切,并将其放在项目的 wiki 上。你应该花时间将系统依赖的任何软件或设置检入版本控制,并自动化配置新机器的过程。
下一步是让每个人都开始使用持续集成服务器。以下是一个简单的流程。
准备检入最新更改时:
检查构建是否已在运行。如果是,等待它完成。如果失败,需要与团队其他成员一起使构建通过,然后再检入。
构建完成且测试通过后,从版本控制仓库的此版本更新开发环境中的代码以获取任何更新。
在开发机器上运行构建脚本和测试,确保一切在你的计算机上仍然正常工作,或者使用持续集成工具的个人构建功能。
如果本地构建通过,将代码检入版本控制。
等待持续集成工具使用你的更改运行构建。
如果失败,停止手头工作并立即在开发机器上修复问题——转到步骤 3。
如果构建通过,庆祝并继续下一个任务。
如果团队中的每个人在每次提交任何更改时都遵循这些简单步骤,你就能知道软件在任何与持续集成机器配置相同的机器上始终可以工作。
持续集成本身不会修复你的构建过程。事实上,如果在项目中期才开始实施,可能会非常痛苦。要使持续集成有效,在开始之前需要具备以下实践。
要使持续集成正常工作,最重要的实践是频繁检入主干或主线。你应该每天至少检入几次代码。
定期检入带来许多其他好处。它使你的更改更小,因此不太可能破坏构建。这意味着当你犯错或走错路时,可以恢复到最近的已知良好版本。它帮助你更加自律地进行重构,坚持保持行为不变的小更改。它有助于确保修改大量文件的更改不太可能与其他人的工作冲突。它允许开发人员更具探索性,尝试想法并通过回退到最后提交的版本来放弃它们。它迫使你定期休息并伸展肌肉,帮助避免腕管综合征(carpal tunnel syndrome)或重复性劳损(RSI)。这也意味着如果发生灾难性事件(例如误删除某些内容),你不会丢失太多工作。
我们特意提到检入主干。许多项目使用版本控制中的分支来管理大型团队。但在使用分支时不可能真正进行持续集成,因为根据定义,如果你在分支上工作,你的代码就没有与其他开发人员的代码集成。使用长期分支的团队面临着与本章开头描述的完全相同的集成问题。除非在非常有限的情况下,否则我们不建议使用分支。关于这些问题的更详细讨论请参见第 14 章“高级版本控制”。
如果没有全面的自动化测试套件,构建通过只意味着应用程序可以编译和组装。虽然对某些团队来说这是一大进步,但必须具备一定程度的自动化测试才能提供应用程序实际运行的信心。自动化测试有多种类型,我们将在下一章详细讨论。然而,我们感兴趣的是从持续集成构建中运行三种测试:单元测试(unit tests)、组件测试(component tests)和验收测试(acceptance tests)。
单元测试用于测试应用程序中小部分代码的行为(例如一个方法、一个函数,或者它们之间的少量交互)。单元测试通常不需要启动整个应用程序就可以运行。它们不访问数据库(如果你的应用程序有数据库)、文件系统或网络。它们不需要应用程序在类生产环境中运行。单元测试应该运行得非常快——即使是大型应用程序,整个测试套件也应该能在十分钟内完成。
组件测试测试应用程序中多个组件的行为。与单元测试类似,它们并不总是需要启动整个应用程序。但是,它们可能会访问数据库、文件系统或其他系统(这些系统可能被打桩处理)。组件测试通常运行时间较长。
验收测试测试应用程序是否满足业务决定的验收标准,包括应用程序提供的功能及其特性,如容量、可用性、安全性等。验收测试最好以能够在类生产环境中针对整个应用程序运行的方式编写。验收测试可能需要很长时间运行——验收测试套件顺序运行超过一天的情况并不罕见。
这三组测试结合起来,应该能够提供极高的信心,确保任何引入的变更都没有破坏现有功能。
如果编译代码和运行单元测试花费的时间太长,你会遇到以下问题:
• 人们在签入代码前将不再进行完整构建和运行测试。你会开始遇到更多构建失败的情况。
• 持续集成过程将花费很长时间,以至于在你再次运行构建之前,已经发生了多次提交,因此你无法知道是哪次签入破坏了构建。
• 人们会减少签入频率,因为他们必须等待很长时间来编译软件和运行测试。
理想情况下,你在签入前和在CI服务器上运行的编译和测试过程应该只需要几分钟。我们认为十分钟是极限,五分钟更好,大约九十秒是理想的。对于习惯于小型项目的人来说,十分钟似乎很长。对于经历过长达一小时编译的老手来说,这似乎是非常短的时间。这大约是你可以用来泡杯茶、快速聊天、查看电子邮件或伸展肌肉的时间。
这个要求似乎与前一个要求——拥有全面的自动化测试集——相矛盾。但是你可以使用许多技术来缩短构建时间。首先要考虑的是让测试运行得更快。XUnit类型的工具,如JUnit和NUnit,在输出中提供了每个测试所花费时间的详细信息。找出运行缓慢的测试,看看是否有办法优化它们,或者用更少的处理获得同样的覆盖率和对代码的信心。这是你应该定期执行的实践。
但是,在某个时候你需要将测试过程分成多个阶段,如第5章”部署流水线剖析”中详细描述的那样。如何拆分它们?你的第一个行动应该是创建两个阶段。一个阶段应该编译软件,运行测试组成应用程序的各个类的单元测试套件,并创建可部署的二进制文件。这个阶段称为提交阶段。我们在第7章中详细介绍了构建的这个阶段。
第二阶段应该从第一阶段获取二进制文件并运行验收测试,以及集成测试,如果有的话还包括性能测试。现代CI服务器可以轻松地以这种方式创建分阶段构建,并发运行多个任务,并汇总结果,以便你可以一目了然地看到构建的状态。
提交阶段应该在签入前运行,并且应该在CI服务器上为每次签入运行。运行验收测试的阶段应该在签入测试套件通过后运行,但可以花费更长的时间。如果你发现第二次构建花费的时间超过半小时左右,你应该考虑在更大的多处理器机器上并行运行这个测试套件,或者建立一个构建网格。现代CI系统使这变得简单。将一个简单的冒烟测试套件纳入提交阶段通常很有用。这个冒烟测试应该执行一些简单的验收和集成测试,以确保最常用的功能没有被破坏——如果有问题则快速报告。
通常需要将验收测试按功能区域分组。这允许你在该区域进行更改后运行关注系统行为特定方面的测试集合。许多单元测试框架允许你以这种方式对测试进行分类。
你可能会达到这样一个阶段:你的项目需要被拆分成几个模块,每个模块在功能上都是独立的。这需要你仔细考虑如何在版本控制和CI服务器上组织这些子项目。我们将在第13章”管理组件和依赖项”中更详细地讨论这个问题。
对开发者的生产力和理智来说,仔细管理他们的开发环境至关重要。开发者在开始一项新工作时,应该始终从一个已知良好的起点开始。他们应该能够运行构建、执行自动化测试,并在自己控制的环境中部署应用程序。通常情况下,这应该是在他们自己的本地机器上。只有在特殊情况下,才应该使用共享环境进行开发。在本地开发环境中运行应用程序应该使用与持续集成和测试环境中相同的自动化流程,最终也与生产环境中使用的流程相同。
实现这一目标的第一个先决条件是仔细的配置管理,不仅仅是源代码,还包括测试数据、数据库脚本、构建脚本和部署脚本。所有这些都必须存储在版本控制中,并且这些内容的最新已知良好版本应该是编码开始时的起点。在这个语境中,“已知良好”意味着你正在使用的修订版本已经通过了持续集成服务器上的所有自动化测试。
第二步是对第三方依赖项、库和组件进行配置管理。至关重要的是,你拥有所有库或组件的正确版本,这意味着与你正在使用的源代码版本已知可以配合工作的相同版本。有开源工具可以帮助管理第三方依赖项,Maven和Ivy是最常见的。然而,在使用这些工具时,你需要小心确保它们配置正确,这样你就不会总是在本地工作副本中获得某些依赖项的最新可用版本。
对于大多数项目来说,它们所依赖的第三方库不会频繁更改,因此最简单的解决方案是将这些库与源代码一起提交到版本控制系统中。关于这些的更多信息请参见[第13章]“管理组件和依赖项”。
最后一步是确保自动化测试,包括冒烟测试(smoke tests),可以在开发者机器上运行。在大型系统上,这可能涉及配置中间件系统并运行内存数据库或单用户版本的数据库。这可能需要一定程度的努力,但使开发者能够在每次检入之前在开发者机器上对工作系统运行冒烟测试,可以极大地提高应用程序的质量。事实上,良好应用程序架构的一个标志是它允许应用程序在开发机器上轻松运行。
市场上有许多产品可以为你的自动化构建和测试流程提供基础设施。持续集成软件的最基本功能是轮询你的版本控制系统以查看是否发生了任何提交,如果有,则检出软件的最新版本,运行构建脚本来编译软件,运行测试,然后通知你结果。
本质上,持续集成服务器软件有两个组件。第一个是一个长期运行的进程,可以定期执行一个简单的工作流。第二个提供已运行进程结果的视图,通知你构建和测试运行的成功或失败,并提供对测试报告、安装程序等的访问。
通常的CI工作流会定期轮询你的版本控制系统。如果检测到任何更改,它将把项目的副本检出到服务器上的目录,或构建代理(build agent)上的目录。然后它将执行你指定的命令。通常,这些命令会构建你的应用程序并运行相关的自动化测试。
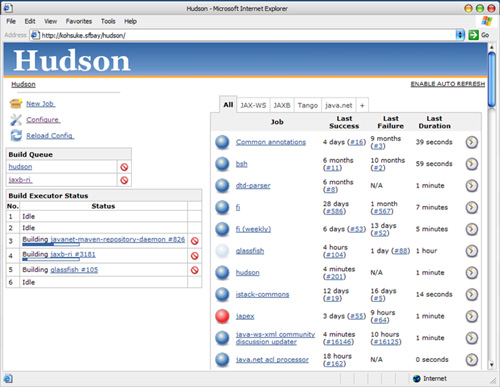
大多数CI服务器包含一个web服务器,向你显示已运行的构建列表([图3.1]),并允许你查看定义每个构建成功或失败的报告。这一系列构建指令应该以生成和存储结果产物(如二进制文件或安装包)而告终,以便测试人员和客户可以轻松下载软件的最新良好版本。大多数CI服务器可以通过web界面或简单脚本进行配置。
你可以使用CI包的工作流功能来做很多超出基本功能的其他事情。例如,你可以将最近构建的状态发送到外部设备。我们见过有人使用红色和绿色的熔岩灯来显示最后一次构建的状态,或者将状态发送到Nabaztag无线电子兔的CI系统。我们认识的一位在电子技术方面有一定技能的开发者,创建了一座华丽的闪光灯和警报器塔,它会爆发出行动来指示复杂项目上各种构建的进度。另一个技巧是使用文本转语音(text-to-speech)来读出破坏构建的人的名字。一些持续集成服务器可以显示构建状态,以及检入人员的头像——这可以显示在大屏幕上。
项目使用这些小工具的原因很简单:它们是让每个人一目了然地看到构建状态的绝佳方式。可见性是使用 CI 服务器最重要的好处之一。大多数 CI 服务器软件都附带一个小部件,你可以将其安装在开发机器上,在桌面的角落显示构建状态。这类工具对于分布式团队,或者至少不在同一房间工作的团队特别有用。
这种可见性的唯一缺点是,如果你的开发团队与客户紧密协作,就像大多数敏捷项目应该做的那样,构建失败——这是过程中很自然的一部分——可能会被视为应用程序质量有问题的标志。事实上,情况恰恰相反:每次构建失败,都表明发现了一个可能在生产环境中出现的问题。然而,这有时很难解释。经历过多次这种情况,包括在构建中断的时间比我们任何人希望的都长时与客户进行一些艰难的对话,我们只能建议你保持高可见性的构建监视器,并努力解释其真正的好处。当然,最好的答案是努力保持构建绿色。
你还可以让构建过程对源代码进行分析。团队通常会确定测试覆盖率、代码重复、遵守编码标准、圈复杂度(cyclomatic complexity)和其他健康指标,并在每次构建的摘要页面上显示结果。你还可以运行程序来生成对象模型或数据库模式的图表。这都是关于可见性的。
如今先进的 CI 服务器可以在构建网格中分配工作,管理协作组件集合的构建和依赖关系,直接报告到你的项目管理跟踪系统,以及做很多其他有用的事情。
在持续集成引入之前,许多开发团队使用每夜构建。这在微软是多年的常见做法。任何破坏构建的人都需要留下来监视后续构建,直到下一个人导致破坏。
许多项目仍然有每夜构建。这个想法是,当每个人下班回家时,批处理过程会在每晚编译和集成代码库。这是朝着正确方向迈出的一步,但当团队第二天早上到达时却发现代码没有编译,这并不是很有帮助。第二天他们进行新的更改——但无法验证系统是否集成,直到第二天晚上。所以构建会持续红色好几天——直到,你猜对了,集成时间再次到来。此外,当你有一个地理分散的团队从不同时区工作在一个共同的代码库时,这种策略就不太有用了。
下一个演进步骤是添加自动化测试。我们第一次尝试这个是很多年前。当时的测试是最基本的冒烟测试(smoke test),只是断言应用程序在编译后能够运行。这在当时是我们构建过程中的一大步,我们对自己非常满意。如今,即使是最基本的自动化构建,我们也期望更多。单元测试已经走了很长的路,即使是简单的单元测试套件也能为最终构建提供显著提高的信心水平。
下一个复杂度级别在一些项目中使用(尽管我们承认最近没有见过),是一个”滚动构建”过程,其中构建不是在夜间运行的计划批处理过程,而是持续运行。每次构建完成后,就从版本控制中收集最新版本,然后重新开始整个过程。Dave 在 1990 年代初期很好地使用了这个方法;它比夜间构建好得多。这种方法的问题是,特定的检入和构建之间没有直接联系。所以,虽然为开发人员提供了有用的反馈循环,但它没有提供足够的可追溯性来追溯到破坏构建的原因,无法真正扩展到更大的团队。
到目前为止,我们描述的大部分内容都与构建和部署的自动化有关。然而,这种自动化存在于人类过程的环境中。持续集成是一种实践,而不是工具,它依赖于纪律来使其有效。保持持续集成系统运行,特别是在处理大型和复杂的 CI 系统时,需要整个开发团队有相当程度的纪律。
我们 CI 系统的目标是确保我们的软件在本质上一直处于工作状态。为了确保这一点,以下是我们在团队中执行的实践。稍后我们将讨论可选但理想的实践,但这里列出的是持续集成工作所必需的。
持续集成的致命错误是在构建失败时仍然提交代码。如果构建失败,负责的开发人员应该等待并修复它。他们应该尽快找出失败的原因并进行修复。如果我们采用这个策略,我们将始终处于最佳位置来找出导致失败的原因并立即修复它。如果我们的同事提交了代码并导致构建失败,为了有最好的机会修复它,他们需要专注于这个问题。他们不希望我们提交更多的更改,触发新的构建,并让更多的问题使失败更加复杂。
当这条规则被打破时,修复构建不可避免地需要更长的时间。人们会习惯看到构建失败,很快你就会陷入构建一直处于失败状态的局面。这种情况会持续到团队中有人决定受够了,付出巨大的努力让构建变绿,然后整个过程重新开始。就在这项工作完成后,这是一个很好的时机,让大家聚在一起提醒他们,遵循这个原则将确保构建保持绿色状态,从而始终拥有可工作的软件。
正如我们已经确定的,一次提交会触发创建一个候选发布版本。这是一种发布形式。大多数人在以任何形式发布他们的工作之前都会检查他们的工作,提交代码也不例外。
我们希望提交足够轻量,这样我们可以很乐意每二十分钟左右定期提交一次,但也要足够正式,这样我们在提交之前会短暂地思考一下。在本地运行提交测试是提交前的合理性检查。这也是一种确保我们认为可以工作的东西确实可以工作的方法。
当开发人员完成工作并准备提交时,他们应该从版本控制系统更新来刷新本地项目副本。然后他们应该启动本地构建并运行提交测试。只有当这成功时,开发人员才准备好将更改提交到版本控制系统。
如果你以前没有遇到过这种方法,你可能会想知道为什么我们在提交前在本地运行提交测试,如果提交后第一件事就是代码将被编译并重新运行提交测试。这种方法有两个原因:
在你上次从版本控制更新后,其他人可能已经提交了代码,你的新更改和他们的更改组合可能会导致测试失败。如果你检出代码并在本地运行提交测试,你将在不破坏构建的情况下发现这个问题。
提交时常见的错误来源是忘记将一些新的文件添加到仓库中。如果你遵循这个过程,你的本地构建通过了,然后你的CI管理系统在提交阶段失败了,你就知道要么是因为在此期间有人提交了代码,要么是因为你忘记将刚刚处理的新类或配置文件添加到版本控制系统中。
遵循这个实践可以确保构建保持绿色状态。
许多现代CI服务器提供一个被称为预测试提交(pretested commit)、个人构建(personal build)或预检构建(preflight build)的功能。使用这个功能,你的CI服务器将获取你的本地更改并在CI网格上使用它们运行构建,而不是你自己提交。如果构建通过,CI服务器将为你提交更改。如果构建失败,它会让你知道出了什么问题。这是一个很好的方式来遵循这个实践,而不必等到提交测试通过后才开始处理下一个功能或错误修复。
在撰写本文时,CI服务器Pulse、TeamCity和ElectricCommander都提供此功能。这个实践最好与分布式版本控制系统结合使用,它允许你在本地存储提交而不将它们推送到中央服务器。这样,如果你的个人构建失败,通过创建补丁来搁置你的更改并回滚到你发送给CI服务器的代码版本就非常容易。
CI系统是团队的共享资源。当团队有效地使用CI,遵循我们的建议并频繁提交时,构建的任何失败对团队和整个项目来说都是一个小的绊脚石。
然而,构建失败是过程中正常和预期的一部分。我们的目标是尽快发现错误并消除它们,而不期望完美和零错误。
在提交时,进行提交的开发人员负责监控构建的进度。在他们的提交编译完成并通过提交测试之前,开发人员不应该开始任何新任务。他们不应该出去吃午饭或开始开会。他们应该足够关注构建,以便在提交阶段完成后几秒钟内知道其结果。
如果提交成功,开发人员才可以继续他们的下一个任务。如果失败,他们应该立即开始确定问题的性质并修复它—通过另一次提交或回滚到版本控制中的先前版本,也就是说,撤销他们的更改,直到他们了解如何使它们工作。
现在是周五下午5点30分。你的所有同事都走出了办公室,而你刚刚提交了你的变更。构建失败了。你有三个选择。你可以接受自己将会晚走的事实,并尝试修复它。你可以回滚你的变更,下周再尝试签入。或者你现在就离开,让构建保持失败状态。
如果你让构建保持失败状态,当你周一返回时,你对所做变更的记忆将不再清晰,理解问题并修复它将花费你更长的时间。如果你不是周一早上第一个回来修复构建的人,当团队其他成员到达时发现构建失败且他们的工作能力受到影响,你的名声将会很糟糕。如果你周末生病了,第二天无法上班,那么要么会接到几个电话询问你如何搞砸构建以及如何修复它,要么你的修订版本会被某位同事毫不客气地丢弃。不管怎样,你的名声都会很糟糕。
构建失败的影响,特别是在一天工作结束时留下失败构建的影响,如果你在一个分布式开发团队中工作,团队成员分布在不同时区,这种影响会被放大。在这种情况下,在构建失败时回家可能是疏远远程同事的最有效方式之一。
为了绝对明确,我们不建议你在工作时间之后加班修复构建。相反,我们建议你定期签入,并且足够早地签入以便有时间处理可能出现的问题。或者,将签入留到第二天;许多有经验的开发者特意不在下班前一小时内签入,而是留到第二天早上第一件事做。如果所有方法都失败了,只需从源代码控制中回滚你的变更,将其保留在本地工作副本中。一些版本控制系统,包括所有分布式系统,通过允许你在本地仓库中累积签入而不将其推送给其他用户,使这变得更容易。
你的作者曾经参与过一个我们认为在当时是世界上最大的敏捷项目。这是一个地理分布式项目,共享一个代码库。整个团队在项目生命周期的不同时期,同时在美国的旧金山和芝加哥、英国的伦敦以及印度的班加罗尔工作。在任何给定的24小时内,只有大约3个小时世界上某个地方没有人在处理代码。在剩余时间里,有源源不断的变更提交到版本控制系统,并有源源不断的新构建被触发。
如果印度团队破坏了构建并回家了,伦敦团队的一天工作可能会受到严重影响。同样,如果伦敦团队在构建失败时回家了,他们在美国的同事将在接下来的八小时里暗自咒骂。
严格的构建纪律至关重要,以至于我们有一名专职的构建管理员(build master),他不仅维护构建,有时还监督构建,确保破坏构建的人正在努力修复它。如果没有,构建工程师会回滚他们的签入。
如前所述,虽然我们努力保持勤勉,但我们都会犯错,所以我们预期每个人都会不时地破坏构建。在大型项目上,这通常是每天都会发生的事情,尽管预测试提交(pretested commits)会大大缓解这一问题。在这些情况下,修复通常是我们会立即识别并通过提交一个小的单行变更来修复的简单事情。然而,有时我们会犯更严重的错误,要么找不到问题所在,要么在签入失败后才意识到我们遗漏了刚做的变更的一些重要内容。
无论我们对失败的提交阶段有何反应,重要的是我们要快速让一切恢复正常。如果我们不能快速修复问题,无论出于什么原因,我们都应该回滚到修订控制中保存的之前的变更集,并在本地环境中修复问题。毕竟,我们首先需要修订控制系统的原因之一,就是允许我们精确地拥有这种回滚的自由。
飞行员被教导,每次着陆时都应该假设会出现问题,所以应该准备好中止着陆尝试并”复飞”进行另一次尝试。签入时使用同样的思维方式。假设你可能会破坏某些需要超过几分钟才能解决的东西,并知道如何回滚变更并返回到版本控制中已知良好的修订版本。你知道之前的修订版本是良好的,因为你不在构建失败时签入。
经验丰富的开发人员通常会执行这条规则,愉快地回退其他人中断了十分钟或更长时间的构建。
一旦你开始执行前面的规则,结果往往是开发人员为了签入他们的更改而注释掉失败的测试。这种冲动可以理解,但是错误的。当一直通过的测试开始失败时,可能很难找出原因。真的发现了回归问题吗?也许测试的某个假设不再有效,或者应用程序确实出于正当理由改变了被测试的功能。弄清楚适用哪种情况可能需要与很多人交谈并花费时间,但必须投入精力找出发生了什么,然后要么修复代码(如果发现了回归问题),要么修改测试(如果某个假设已经改变),要么删除它(如果被测试的功能不再存在)。
注释掉失败的测试应该始终是最后的手段,很少且不情愿地使用,除非你有足够的纪律立即修复它。偶尔注释掉一个测试等待一些需要安排的严肃开发工作或与客户的长期讨论是可以的。然而,这可能会让你走下坡路。我们见过一半测试都被注释掉的代码。建议跟踪被注释测试的数量,并将其显示在一个大的、可见的图表或屏幕上。如果被注释测试的数量超过某个阈值(也许是总数的2%),你甚至可以让构建失败。
如果你提交了一个更改,你编写的所有测试都通过了,但其他测试中断了,构建仍然是中断的。通常这意味着你在应用程序中引入了回归bug。因为是你做了更改,所以你有责任修复因你的更改而未通过的所有测试。在持续集成的背景下,这似乎很明显,但实际上在许多项目中并不是常见做法。
这种做法有几个含义。这意味着你需要访问任何可能因你的更改而中断的代码,以便在它中断时可以修复它。这意味着你不能让开发人员拥有只有他们才能处理的代码子集。为了有效地进行持续集成,每个人都需要访问整个代码库。如果出于某些原因,你被迫进入无法与整个团队共享代码访问权限的情况,你可以通过与拥有必要访问权限的人进行良好协作来管理。然而,这是次优选择,你应该努力消除这些限制。
拥有全面的测试套件对持续集成至关重要。虽然我们在下一章中详细讨论了自动化测试的策略,但值得强调的是,快速反馈(这是持续集成的核心成果)只有通过出色的单元测试覆盖率才能实现(出色的验收测试覆盖率也很重要,但这些测试运行时间更长)。根据我们的经验,获得出色单元测试覆盖率的唯一方法是通过测试驱动开发。虽然我们试图避免在本书中对敏捷开发实践持教条态度,但我们认为测试驱动开发对于实现持续交付的实践至关重要。
对于不熟悉测试驱动开发的人来说,其理念是在开发新功能或修复bug时,开发人员首先创建一个测试,该测试是对将要编写的代码的预期行为的可执行规范。这些测试不仅驱动应用程序的设计,还可以作为回归测试以及代码和应用程序预期行为的文档。
关于测试驱动开发的讨论超出了本书的范围。然而,值得注意的是,与所有此类实践一样,对测试驱动开发既要有纪律又要务实是很重要的。我们有两本书推荐进一步阅读这个主题:Steve Freeman和Nat Pryce的《测试驱动的面向对象软件开发》(Growing Object-Oriented Software, Guided by Tests),以及Gerard Meszaros的《xUnit测试模式:重构测试代码》(xUnit Test Patterns: Refactoring Test Code)。
以下实践不是必需的,但我们发现它们很有用,你至少应该考虑在项目中使用它们。
持续集成是Kent Beck书中描述的十二个核心XP实践之一,它与其他XP实践相辅相成。即使团队没有使用其他任何实践,持续集成也能带来巨大改变,但与其他实践结合使用会更加有效。特别是,除了我们在前一节中描述的测试驱动开发和共享代码所有权之外,你还应该将重构视为有效软件开发的基石。
重构意味着进行一系列小的、增量的更改来改进代码,而不改变应用程序的行为。CI和测试驱动开发通过确保你的更改不会改变应用程序的现有行为来支持重构。因此,团队可以自由地进行可能涉及大范围代码的更改,而不用担心会破坏应用程序。这种实践还支持频繁签入——开发人员在每次小的增量更改后就进行签入。
有时系统架构的某些方面很容易被开发人员忽略。我们使用过的一种技术是放置一些提交时测试来证明没有违反这些规则。
这种技术实际上只是一种战术性的方法,除了通过示例之外很难描述。
我们能回忆起的最佳示例来自一个作为分布式服务集合实现的项目。这是一个真正的分布式系统,因为它在客户端系统中执行重要的业务逻辑,在服务器端也执行真正的业务逻辑——这是因为真实的业务需求,而不仅仅是糟糕的编程。
我们的开发团队在开发环境中部署了客户端系统和服务器系统的所有代码。开发人员很容易从客户端向服务器或从服务器向客户端进行本地调用,而没有意识到如果他们真的想要这种行为,就必须进行远程调用。
我们将代码组织成代表分层策略的包来帮助部署。我们使用这些信息和一些开源软件来评估代码依赖关系,并使用grep搜索依赖工具的输出,查看包之间是否存在违反我们规则的依赖关系。
这防止了在功能测试时出现不必要的破坏,并帮助强化了系统架构——提醒开发人员注意两个系统之间进程边界的重要性。
这种技术可能看起来有点重量级,并不能替代开发团队对正在开发的系统架构的清晰理解。然而,当有重要的架构问题需要维护时——那些可能很难及早发现的问题——它会非常有用。
正如我们之前所说,CI在小的、频繁的提交下工作得最好。如果提交测试需要很长时间才能运行,由于等待构建和测试过程完成所花费的时间,可能会对团队的生产力产生严重的不利影响。这反过来会阻碍频繁签入,因此团队会开始积累签入,使每次签入变得更加复杂——更有可能出现合并冲突,更有可能引入错误,从而导致测试失败。所有这些都会进一步减慢一切。
为了让开发团队专注于保持测试快速的重要性,如果发现某个测试的运行时间超过某个指定时间,你可以使提交测试失败。上次我们使用这种方法时,对于任何运行时间超过两秒的测试,我们都会使构建失败。
我们倾向于喜欢小改变能产生更广泛影响的实践。这就是这样一种实践。如果开发人员编写的提交测试运行时间过长,当他们准备提交更改时构建就会失败。这鼓励他们仔细考虑使测试快速运行的策略。如果测试运行得很快,开发人员会更频繁地签入。如果开发人员更频繁地签入,合并问题的可能性就更小,即使出现问题也可能很小且易于解决,因此开发人员的生产力更高。
不过有一个警告:这种实践可能有点像双刃剑。你需要警惕创建不稳定的间歇性测试,如果你的CI环境由于某种原因处于异常负载下,这些测试就会失败。我们发现使用这种方法最有效的方式是作为让大型团队专注于特定问题的策略,而不是在每次构建中都采用。如果你的构建变慢了,你可以使用这种方法让团队在一段时间内专注于加快速度。
请注意:我们在这里讨论的是测试性能,而不是性能测试。容量测试在第9章”测试非功能性需求”中介绍。
编译器警告通常是有充分理由的。我们采用的一个颇为成功的策略(尽管开发团队常称其为”代码纳粹”)是在出现警告时使构建失败。这在某些情况下可能有点严苛,但作为一种强制执行良好实践的方式,它是有效的。
你可以根据需要强化这种技术,添加对特定或一般性编码疏漏的检查。我们已经成功使用了几个开源代码质量工具:
• Simian 是一个识别大多数流行语言(包括纯文本)重复代码的工具。
• JDepend 用于 Java,它的商业版 .NET 表亲 NDepend,能生成大量有用的(也有一些不太有用的)设计质量度量指标。
• CheckStyle 可以测试不良编码实践,如工具类中的公共构造函数、嵌套块和过长的代码行。它还能捕获常见的错误源和安全漏洞。它很容易扩展。FxCop 是其 .NET 表亲。
• FindBugs 是一个基于 Java 的系统,提供 CheckStyle 的替代方案,包括一套类似的验证规则。
如前所述,对某些项目来说,在任何警告出现时就让构建失败可能听起来太严苛了。我们用来逐步引入这一实践的一种方法是棘轮机制(ratcheting)。这意味着将警告或 TODO 的数量与上一次提交的数量进行比较。如果数量增加,我们就让构建失败。使用这种方法,你可以轻松强制执行一项策略:每次提交至少应将警告或 TODO 的数量减少一个。
在我们的一个项目中,我们将 CheckStyle 测试添加到提交测试集合中,结果我们都对它的过度唠叨感到有点厌烦。我们是一个经验丰富的开发团队,大家都认为忍受一段时间的唠叨是值得的,这能让我们养成良好习惯,为项目打下良好基础。
运行几周后,我们移除了 CheckStyle 测试。这加快了构建速度,也摆脱了唠叨。然后团队规模扩大了一些,几周后我们开始在代码中发现更多”代码坏味道”(smells),发现自己花在简单清理重构上的时间比以前多了。
最终我们意识到,尽管有代价,CheckStyle 帮助我们的团队掌控那些几乎微不足道的事情,而这些事情累积起来就是高质量代码和普通代码之间的差别。我们重新启用了 CheckStyle,不得不花时间纠正它提出的所有小问题,但这是值得的,至少对那个项目来说,我们学会了不再抱怨那种被唠叨的感觉。
在分布式团队中使用持续集成,从流程和技术角度来看,与其他环境基本相同。然而,团队成员不在同一个房间里工作(甚至可能在不同时区工作)这一事实确实会在其他一些方面产生影响。
从技术角度看最简单、从流程角度看最有效的方法是保留一个共享的版本控制系统和持续集成系统。如果你的项目使用后续章节描述的部署流水线(deployment pipelines),这些也应该简单地平等地提供给团队所有成员。
当我们说这种方法最有效时,应该强调它确实有效得多。值得努力实现这一理想状态;这里描述的所有其他方法都明显次于这种方法。
对于同一时区的分布式团队,持续集成基本相同。当然你不能使用物理签入令牌(check-in tokens)——尽管一些 CI 服务器支持虚拟令牌——而且稍微缺乏人情味,所以当你提醒某人修复构建时更容易冒犯对方。个人构建(personal builds)等功能变得更有用。但总体而言,流程是相同的。
对于不同时区的分布式团队,需要处理的问题更多。如果旧金山团队破坏了构建并下班回家,这对刚开始工作的北京团队来说可能是一个严重障碍。流程不会改变,但遵守流程的重要性被放大了。
在拥有分布式团队的大型项目中,VoIP(如 Skype)和即时消息等工具对于实现保持平稳运行所需的细粒度沟通至关重要。与开发相关的每个人——项目经理、分析师、开发人员、测试人员——都应该能够通过 IM 和 VoIP 访问并被访问到所有其他人。定期让人员来回飞行对于交付流程的顺畅运行至关重要,这样每个本地团队都能与其他团队的成员有个人接触。这对于在团队成员之间建立信任很重要——这往往是分布式团队中最先受损的东西。可以使用视频会议进行回顾会议、展示会、站会和其他定期会议。另一个很好的技巧是让每个开发团队使用屏幕录制软件录制一段简短视频,讲述他们当天所做的功能。
自然,这是一个比持续集成更广泛的话题。我们想表达的观点很简单:保持流程不变,但在应用时要更加自律。
一些更强大的持续集成服务器提供了集中管理的构建农场(build farms)和复杂的授权方案等功能,允许你为大型分布式团队提供集中式持续集成服务。这些系统使团队能够轻松自助获取持续集成服务,而无需获得自己的硬件。它们还允许运维团队整合服务器资源,控制持续集成和测试环境的配置以确保它们都保持一致并与生产环境相似,并强制执行良好实践,例如管理第三方库的配置和提供预装工具来收集代码覆盖率和质量的一致性指标。最后,它们允许跨项目收集和监控标准指标,为管理者和交付团队提供创建仪表板的能力,以在项目层面监控代码质量。
虚拟化也可以与集中式CI服务很好地配合使用,提供按下按钮就能从存储的基线镜像启动新虚拟机的能力。你可以使用虚拟化使配置新环境成为完全自动化的过程,交付团队可以自助完成。它还确保构建和部署始终在这些环境的一致基线版本上运行。这带来了一个好的效果,即消除了那些”艺术品”般的持续集成环境——它们经过数月积累了软件、库和配置设置,与测试和生产环境中的内容毫无关系。
集中式持续集成可以是一个双赢的局面。然而,为了实现这一点,开发团队必须能够以自动化的方式轻松自助获取新环境、配置、构建和部署,这一点至关重要。如果一个团队必须发送几封电子邮件并等待数天才能为他们的最新发布分支获得一个新的CI环境,他们将绕过这个流程,回到使用桌子下的备用机器来进行真正的持续集成——或者更糟的是,根本不做持续集成。
根据版本控制系统的选择,对于全球分布式团队来说,当团队之间存在缓慢链接时,共享版本控制系统以及构建和测试资源的访问可能会相当痛苦。
当持续集成运行良好时,整个团队会定期提交更改。这意味着与版本控制系统的交互往往保持在相当高的水平。尽管每次交互在交换的字节数方面通常相对较小,但由于提交和更新的频率,糟糕的通信会严重拖累生产力。值得投资在开发中心之间建立足够高带宽的通信。也值得考虑迁移到分布式版本控制系统,如Git或Mercurial,它们允许人们即使在没有连接到传统指定的”主”服务器时也能进行检入。
几年前,我们在一个项目中遇到过这个问题。到我们在印度的同事那里的通信基础设施如此缓慢且不可靠,以至于有些天他们根本无法检入,这会在之后的几天产生连锁反应。最终,我们对损失时间的成本进行了分析,发现升级通信的成本可以在几天内收回。在另一个项目中,根本不可能获得足够快速和可靠的连接。团队从使用集中式VCS的Subversion迁移到分布式VCS的Mercurial,生产力有了明显提升。
版本控制系统应该与托管运行自动化测试的构建基础设施相当接近,这是合理的。如果这些测试在每次检入后都运行,这意味着系统之间跨网络会有相当多的交互。
托管版本控制系统、持续集成系统以及部署流水线中各种测试环境的物理机器需要能够从每个开发站点平等访问。如果印度的版本控制系统因为磁盘已满而停止工作,印度办公室的所有人都已下班回家,而伦敦的开发团队无法访问系统,他们将处于相当不利的地位。应从每个位置提供对所有这些系统的系统管理员级别访问。确保每个站点的团队不仅有访问权限,而且具备管理其班次期间可能发生的任何问题的知识。
如果存在一些无法克服的问题,阻止你花费更多资金在开发中心之间建立更高带宽的通信,那么可以使用本地持续集成和测试系统,甚至在极端情况下使用本地版本控制系统。正如你所料,我们真的不建议采用这种方法。尽一切努力避免它;它在时间和精力方面成本高昂,而且效果远不如共享访问。
简单的部分是持续集成系统。完全可以拥有本地持续集成服务器和测试环境,甚至是功能完整的本地部署流水线(deployment pipeline)。当站点需要进行大量手动测试时,这可能很有价值。当然,这些环境需要仔细管理以确保跨区域的一致性。唯一需要注意的是,理想情况下,二进制文件或安装程序应该只构建一次,然后分发到所有需要它们的全球位置。然而,由于大多数安装程序的体积庞大,这通常不切实际。如果必须在本地构建二进制文件或安装程序,就更需要严格管理工具链(toolchain)的配置,以确保在各处创建完全相同的二进制文件。强制执行此操作的一种方法是使用md5或类似算法自动生成二进制文件的哈希值,并让CI服务器自动将它们与”主”二进制文件的哈希值进行比较,以确保没有差异。
在某些极端情况下,例如版本控制系统是远程的并通过慢速或不可靠的链接连接,在本地托管持续集成系统的价值会受到严重影响。我们在使用持续集成时经常提到的目标是能够在最早的时机发现问题。如果版本控制系统以任何方式分离,我们就会削弱这种能力。在被迫这样做的情况下,我们分离版本控制系统的目标必须是尽量减少从引入错误到我们能够发现它之间的时间。
主要有两种选择可以为分布式团队提供版本控制系统的本地访问:将应用程序划分为组件以及使用分布式或支持多主拓扑的版本控制系统。
在基于组件的方法中,版本控制仓库和团队都按组件或功能边界进行划分。第13章”管理组件和依赖关系”中更详细地讨论了这种方法。
我们看到的另一种技术是拥有团队本地仓库和构建系统,以及一个共享的全局主仓库。按功能分离的团队在整个工作日中提交到他们的本地仓库。每天在固定时间,通常是在另一个时区的分布式团队结束一天的工作后,本地团队的一名成员负责提交整个团队的所有更改,并承担合并大量更改的痛苦。显然,如果使用专门为此类任务设计的分布式版本控制系统,这会容易得多。然而,这个解决方案绝非理想,我们已经看到它因引入重大合并冲突而惨败。
总之,我们在本书中描述的所有技术都已在许多项目的分布式团队中得到充分验证。事实上,我们将CI的使用视为地理分布团队有效协作能力的两三个最重要因素之一。持续集成的持续性很重要;如果确实没有其他选择,有一些变通方法,但我们的建议是将钱花在通信带宽上——从中长期来看,这样更便宜。
分布式版本控制系统(DVCS)的兴起正在彻底改变团队协作的方式。开源项目曾经通过电子邮件发送补丁或在论坛上发布它们,而Git和Mercurial等工具使开发人员和团队之间来回拉取补丁以及分支和合并工作流变得非常容易。DVCS允许您轻松离线工作,在本地提交更改,并在将它们推送给其他用户之前进行变基(rebase)或搁置(shelve)。DVCS的核心特征是每个仓库都包含项目的完整历史记录,这意味着除了按约定外,没有任何仓库具有特权。因此,与集中式系统相比,DVCS具有额外的间接层:对本地工作副本的更改必须先检入本地仓库,然后才能推送到其他仓库,并且来自其他仓库的更新必须与本地仓库协调,然后才能更新工作副本。
DVCS提供了新的强大协作方式。例如,GitHub开创了开源项目协作的新模式。在传统模式中,提交者(committer)充当项目权威仓库的守门人,接受或拒绝贡献者的补丁。项目的分叉(fork)只在提交者之间存在不可调和的争论时才会发生这种极端情况。在GitHub模式中,这被颠倒了。贡献是通过首先分叉您希望贡献的项目仓库,进行更改,然后请求原始仓库的所有者拉取您的更改来完成的。在活跃的项目中,分叉网络迅速激增,每个分叉都有各种新功能集。偶尔这些分叉会出现分歧。这种模式比传统模式更具活力,在传统模式中,补丁被忽视,在邮件列表存档中无人问津。因此,GitHub上的开发速度往往更快,拥有更大的贡献者群体。
然而,这种模式挑战了持续集成实践的一个基本假设:存在一个单一的、权威的代码版本(通常称为主线或主干),所有变更都提交到这个版本。需要指出的是,你完全可以使用版本控制的主线模型,并使用分布式版本控制系统(DVCS)完美地进行持续集成。你只需指定一个仓库作为主仓库,让你的持续集成服务器在该仓库发生变更时触发构建,并让每个人都将变更推送到这个仓库以共享它们。这是一种完全合理的方法,我们在许多项目中都看到过成功的应用。它保留了分布式版本控制系统的许多优势,例如能够非常频繁地提交变更而不共享它们(就像保存游戏进度),这在探索新想法或执行一系列复杂重构时非常有用。然而,分布式版本控制系统的某些使用模式会阻碍持续集成。例如,GitHub模式违反了代码共享的主线/主干模型,因此无法实现真正的持续集成。
在GitHub中,每个用户的变更集存在于单独的仓库中,并且没有简单的方法来确定哪些用户的哪些变更集能够成功集成。你可以采用创建一个仓库来监视所有其他仓库的方法,并在检测到任何仓库发生变更时尝试将它们全部合并在一起。然而,这几乎总是会在合并阶段失败,更不用说运行自动化测试了。随着贡献者数量以及仓库数量的增长,问题会呈指数级恶化。没有人会关注持续集成服务器的反馈,因此持续集成作为传达应用程序当前是否正常工作(如果不正常,是谁和什么导致的)的方法就失效了。
图3.2 集成分支
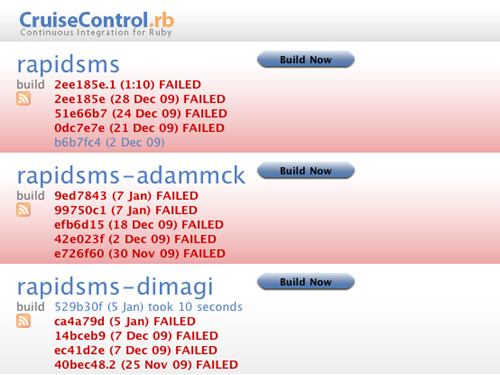
可以退回到一个更简单的模型,它能提供持续集成的部分好处。在这个模型中,你为每个仓库创建一个持续集成构建。每次发生变更时,你尝试从指定的主仓库合并并运行构建。图3.2展示了CruiseControl.rb为Rapidsms项目的主仓库以及它的两个分支构建。
为了创建这个系统,使用命令
git remote add core git://github.com/rapidsms/rapidsms.git
将指向主项目仓库的分支添加到CC.rb的每个Git仓库中。每次触发构建时,CC.rb尝试合并并运行构建:
git fetch core
git merge –no-commit core/master
[运行构建的命令]
构建完成后,CC.rb运行 git reset --hard
将本地仓库重置到它所指向的仓库的HEAD。这个系统并不提供真正的持续集成。然而,它确实能告诉分支的维护者——以及主仓库的维护者——他们的分支原则上是否可以与主仓库合并,以及合并结果是否会是应用程序的一个可工作版本。有趣的是,图3.2显示主仓库的构建当前是失败的,但Dimagi分支不仅成功地与它合并,而且还修复了失败的测试(并且可能添加了一些额外的功能)。
距离持续集成更远一步的是Martin Fowler所说的”混杂集成”(promiscuous integration) [bBjxbS]。在这个模型中,贡献者不仅在分支和中央仓库之间拉取变更,还在分支之间拉取变更。这种模式在使用GitHub的大型项目中很常见,当一些开发者在实际上是长期存在的特性分支上工作,并从其他从该特性分支派生的仓库拉取变更时。实际上,在这个模型中甚至不需要一个特权仓库。软件的特定发布版本可以来自任何分支,只要它通过了所有测试并被项目负责人接受。这种模式将分布式版本控制系统的可能性发挥到了逻辑上的极致。
这些持续集成的替代方案可以创建高质量、可工作的软件。然而,这只有在以下条件下才可能:
• 一个小型且经验丰富的提交者团队,他们管理拉取补丁、维护自动化测试并确保软件质量。
• 定期从分支拉取,以避免在分支上积累大量难以合并的库存。如果有严格的发布计划,这个条件尤其重要,因为人们的倾向是将合并留到发布前进行,此时会变得极其痛苦——这正是持续集成旨在解决的问题。
• 一组相对较小的核心开发者,可能由一个以相对较慢速度贡献的更大社区来补充。这使得合并变得可行。
这些条件适用于大多数开源项目以及一般的小型团队。然而,对于中型或大型全职开发者团队来说,这些条件很少能够满足。
总结:总体而言,分布式版本控制系统是一个巨大的进步,为协作提供了强大的工具,无论你是否在从事分布式项目。分布式版本控制系统可以作为传统持续集成系统的一部分非常有效,在这种系统中,有一个指定的中央仓库,每个人都定期(至少每天一次)向其推送变更。它们也可以用于其他不允许持续集成的模式,但这些模式仍可能是交付软件的有效模式。然而,我们建议不要在不满足上述正确条件时使用这些模式。第14章”高级版本控制”包含了对这些模式和其他模式以及它们有效的条件的完整讨论。
如果让你从本书中选择一个实践在开发团队中实施,我们建议你选择持续集成。我们一次又一次地看到它对软件开发团队的生产力产生了质的飞跃。
实施持续集成就是在团队中创造一种范式转变(paradigm shift)。没有持续集成时,你的应用处于损坏状态,直到你证明它是正常的。有了持续集成,你的应用的默认状态是可工作的,尽管信心水平取决于自动化测试覆盖率的程度。持续集成创建了一个紧密的反馈循环(feedback loop),让你在问题引入时就能发现它们,此时修复成本很低。
实施持续集成会迫使你遵循另外两个重要实践:良好的配置管理以及创建和维护自动化构建和测试流程。对某些团队来说,这似乎需要完成很多工作,但它们可以逐步实现。我们在前一章讨论了良好配置管理的步骤。关于构建自动化的更多内容在第6章”构建和部署脚本”中。我们在下一章更详细地介绍测试。
应该清楚的是,持续集成需要良好的团队纪律——但任何流程都需要这样。持续集成的不同之处在于,你有一个简单的指标来判断是否遵循了纪律:构建保持绿色。如果你发现构建是绿色的但缺乏足够的纪律,例如单元测试覆盖率低,你可以轻松地在持续集成系统中添加检查来强化更好的行为。
这让我们得出最后一点。一个成熟的持续集成系统是一个基础,你可以在此之上构建更多基础设施:
• 大型可视化显示屏,聚合来自构建系统的信息以提供高质量反馈
• 为测试团队提供报告和安装程序的参考系统
• 为项目经理提供应用质量数据的提供者
• 一个可以扩展到生产环境的系统,使用部署流水线(deployment pipeline),为测试人员和运维人员提供一键部署
太多项目仅依赖手工验收测试来验证软件是否符合其功能性和非功能性需求。即使存在自动化测试,它们通常也维护不善且过时,需要大量手工测试来补充。本章以及本书第二部分的相关章节旨在帮助你规划和实施有效的自动化测试系统。我们为常见场景中的自动化测试提供策略,并描述支持和启用自动化测试的实践。
戴明(W. Edwards Deming)的十四要点之一是:“停止依赖大规模检查来实现质量。改进流程并从一开始就把质量构建到产品中”。测试是一项跨职能活动,涉及整个团队,应该从项目开始就持续进行。构建质量意味着在多个层次(单元、组件和验收)编写自动化测试,并将它们作为部署流水线的一部分运行,该流水线在每次对应用程序、其配置或运行环境和软件栈进行更改时触发。手工测试也是构建质量的重要组成部分:展示、可用性测试和探索性测试需要在整个项目中持续进行。构建质量还意味着不断努力改进你的自动化测试策略。
在我们的理想项目中,测试人员从项目开始就与开发人员和用户协作编写自动化测试。这些测试在开发人员开始开发它们所测试的功能之前编写。这些测试共同构成了系统行为的可执行规范(executable specification),当它们通过时,就证明客户所需的功能已经完整且正确地实现了。自动化测试套件由持续集成系统在每次对应用进行更改时运行——这意味着该套件也充当回归测试集。
这些测试不仅测试系统的功能方面。容量、安全性和其他非功能性需求在早期就已确立,并编写自动化测试套件来强化它们。这些自动化测试确保任何危及这些需求实现的问题在修复成本低的早期就被发现。这些对系统非功能性行为的测试使开发人员能够基于经验证据进行重构和重新架构:“最近对搜索的更改导致应用性能下降——我们需要修改解决方案以确保满足容量需求。”
这个理想世界在早期采用适当纪律的项目中是完全可以实现的。如果你需要在已经运行一段时间的项目中实施它们,事情会稍微困难一些。达到高水平的自动化测试覆盖率需要时间和仔细规划,以确保在团队学习如何实施自动化测试的同时开发可以继续进行。遗留代码库(legacy codebase)肯定会从许多这些技术中受益,尽管可能需要很长时间才能达到从一开始就使用自动化测试构建的系统的质量水平。我们在本章后面讨论如何将这些技术应用于遗留系统。
测试策略的设计主要是一个识别和优先排序项目风险,并决定采取何种措施来缓解这些风险的过程。良好的测试策略会产生许多积极效果。测试建立了软件按预期工作的信心,这意味着更少的缺陷、降低的支持成本和更好的声誉。测试还为开发过程提供了约束,促进良好的开发实践。全面的自动化测试套件甚至提供了最完整和最新的应用程序文档形式,以可执行规范的形式,不仅说明系统应该如何工作,还说明它实际上是如何工作的。
最后,值得注意的是,我们在这里只能触及测试的表面。我们的目的是涵盖自动化测试的基础知识,为本书的其余部分提供足够的背景知识,并使您能够为项目实施合适的部署流水线。特别是,我们不会深入研究测试实现的技术细节,也不会详细涵盖探索性测试等主题。有关测试的更多详细信息,我们建议您查看本书的配套书籍之一:Lisa Crispin 和 Janet Gregory 的《敏捷测试》(Agile Testing)(Addison-Wesley,2009)。
图4.1 测试象限图,来自 Brian Marick,基于当时”流行”的想法
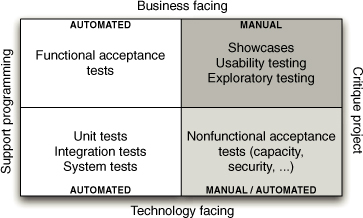
存在许多种测试。Brian Marick 提出了图4.1,该图被广泛用于建模您应该实施的各种类型的测试,以确保交付高质量的应用程序。
在此图中,他根据测试是面向业务还是面向技术,以及它们是支持开发过程还是用于评判项目来对测试进行分类。
此象限中的测试通常称为功能测试或验收测试。验收测试确保满足故事的验收标准。验收测试应该在故事开发开始之前编写,理想情况下是自动化的。验收测试与验收标准一样,可以测试正在构建的系统的各种属性,包括功能性、容量、可用性、安全性、可修改性、可用性等。涉及系统功能的验收测试称为功能验收测试——非功能验收测试属于图表的第四象限。有关功能测试和非功能测试之间有些模糊且经常被误解的区别的更多信息,请查看我们下面关于评判项目的面向技术的测试的内容。
验收测试在敏捷环境中至关重要,因为它们回答了以下问题:对于开发人员来说”我如何知道我完成了?“,对于用户来说”我得到了我想要的吗?“。当验收测试通过时,它们正在测试的任何需求或故事都可以被认为是完成的。因此,在理想世界中,客户或用户会编写验收测试,因为它们定义了每个需求的成功标准。现代自动化功能测试工具,如 Cucumber、JBehave、Concordion 和 Twist,旨在通过将测试脚本与实现分离,同时提供一种机制使它们保持同步变得简单,从而实现这一理想。通过这种方式,用户可以编写测试脚本,而开发人员和测试人员共同完成实现它们的代码。
一般来说,对于每个故事或需求,在用户将执行的操作方面,通过应用程序有一条规范路径。这被称为快乐路径(happy path)。这通常使用以下形式表达:“给定(Given)[测试开始时系统状态的几个重要特征],当(when)[用户执行某些操作集],那么(then)[系统新状态的几个重要特征]将产生。”这有时被称为测试的”给定-当-那么”模型。
然而,除了最简单的系统之外,任何用例都将允许初始状态、要执行的操作和应用程序最终状态的变化。有时,这些变化构成了不同的用例,然后被称为替代路径(alternate paths)。在其他情况下,它们应该导致错误条件,从而产生所谓的悲伤路径(sad paths)。对于这些变量的不同值,显然可以执行许多可能的测试。等价类划分分析和边界值分析将把这些可能性减少到一组较小的案例,这些案例将完全测试所讨论的需求。然而,即便如此,您仍需要使用直觉来选择最相关的案例。
验收测试应该在系统处于类生产模式时运行。手动验收测试通常通过将应用程序放在用户验收测试(UAT)(user acceptance testing)环境中来完成,该环境在配置和应用程序状态方面尽可能与生产环境相似——尽管它可能使用任何外部服务的模拟版本。测试人员使用应用程序的标准用户界面来执行测试。自动化验收测试同样应该在类生产环境中运行,测试工具以用户相同的方式与应用程序交互。
自动化验收测试
自动化验收测试具有许多有价值的属性:
• 它们使反馈循环更快——开发人员可以运行自动化测试来找出他们是否完成了特定需求,而无需去找测试人员。
• 它们减少了测试人员的工作量。
• 它们让测试人员能够专注于探索性测试和更高价值的活动,而不是枯燥重复的任务。
• 你的验收测试代表了一个强大的回归测试套件。在编写大型应用程序或在使用框架或多个模块的大型团队中工作时,这一点尤为重要,因为对应用程序某一部分的更改很可能会影响其他功能。
• 通过使用行为驱动开发(behavior-driven development)所倡导的人类可读的测试和测试套件名称,可以从测试中自动生成需求文档。事实上,Cucumber 和 Twist 等工具就是为了让分析师能够将需求编写为可执行的测试脚本而设计的。这种方法的好处是你的需求文档永远不会过时——它可以在每次构建时自动生成。
回归测试的问题尤为重要。回归测试在象限图上没有提到,因为它们是一个横切类别。回归测试代表了你的整个自动化测试集合。它们用于确保当你进行更改时不会破坏现有功能。它们还通过验证在重构完成时没有改变任何行为,使得轻松重构代码成为可能。在编写自动化验收测试时,你应该记住它们将成为回归测试套件的一部分。
然而,自动化验收测试的维护成本可能很高。如果做得不好,它们可能会给交付团队带来巨大成本。因此,有些人建议不要创建大型复杂的自动化测试套件。但是,通过遵循良好实践并使用适当的工具,可以大幅降低创建和维护自动化验收测试的成本,使其收益明显超过成本。我们将在第8章”自动化验收测试”中更详细地讨论这些技术。
重要的是要记住,并非所有事情都需要自动化。系统的许多方面确实更适合由人来测试。可用性、外观和感觉的一致性等都是难以在自动化测试中验证的。探索性测试也不可能自动完成——当然,测试人员在探索性测试中会使用自动化来完成诸如设置场景和创建测试数据之类的事情。在许多情况下,手动测试就足够了,或者确实可以优于自动化测试。一般来说,我们倾向于将自动化验收测试限制在对正常路径(happy path)行为的完整覆盖,以及对最重要的其他部分的有限覆盖。这是一种安全且高效的策略,前提是你已经拥有其他类型的全面自动化回归测试集。我们通常将全面定义为大于80%的代码覆盖率,尽管测试的质量非常重要,单靠覆盖率是一个糟糕的指标。这里的自动化测试覆盖率包括单元测试、组件测试和验收测试,每一种都应该覆盖应用程序的80%(我们不赞同这种天真的想法:你可以通过60%的单元测试覆盖率和20%的验收测试覆盖率来获得80%的覆盖率)。
作为自动化验收测试覆盖率的一个好的试金石,考虑以下场景。假设你替换掉系统的某个部分——比如持久化层——并用不同的实现替换它。你完成替换,运行自动化验收测试,测试通过了。你对系统真正正常工作有多大信心?一个好的自动化测试套件应该给你必要的信心来执行重构甚至重新架构你的应用程序,因为你知道如果测试通过,应用程序的行为确实没有受到影响。
与软件开发的其他所有方面一样,每个项目都是不同的,你需要监控在重复手动测试上花费了多少时间,以便决定何时将它们自动化。一个好的经验法则是,一旦你重复了同样的测试几次,并且当你确信不会在维护测试上花费大量时间时,就将其自动化。关于何时自动化的更多信息,请阅读 Brian Marick 的论文”何时应该自动化测试?“。
验收测试通常是端到端测试,运行在类似于生产环境的真实工作环境上。这意味着在理想情况下,它们应该直接针对应用程序的UI运行。
然而,大多数UI测试工具采用了一种天真的方法,使它们与UI紧密耦合,结果是当UI发生轻微变化时,测试就会失败。这会导致许多误报——测试失败不是因为应用程序行为有任何问题,而是因为某个复选框的名称被更改了。让测试与应用程序保持同步可能会消耗大量时间而不提供任何价值。你应该时不时地问自己一个好问题:“我的验收测试有多少次是因为真正的bug而失败的,又有多少次是因为需求变更而失败的?”
解决这个问题有几种方法。一种是在测试和UI之间添加一个抽象层,以减少UI变更时所需的工作量。另一种是针对位于UI下方的公共API运行验收测试——这个API也是UI用来实际执行操作的(不言而喻,UI中不应包含任何业务逻辑)。这并不能消除UI测试的必要性,但这意味着可以将UI测试减少到少量针对UI本身的检查,而不是业务逻辑。然后,大部分验收测试套件可以直接针对业务逻辑运行。
我们在第8章“自动化验收测试”中更详细地讨论了这个主题。
最重要的自动化测试是主要的正常路径测试。每个用户故事或需求至少应该有一个自动化的正常路径验收测试。开发人员应该单独使用这些测试作为冒烟测试,以快速反馈他们是否破坏了正在开发的某些功能。这些测试应该是自动化的首要目标。
当你有时间编写和自动化更多测试时,很难在替代正常路径和异常路径之间做出选择。如果你的应用程序相当稳定,那么替代路径应该是你的优先级,因为它们代表了所有用户定义的场景。如果你的应用程序有bug且经常崩溃,策略性地应用异常路径测试可以帮助你识别问题区域并修复它们,自动化可以确保应用程序保持稳定。
这些自动化测试完全由开发人员编写和维护。属于这一类的测试有三种:单元测试、组件测试和部署测试。单元测试以隔离的方式测试代码的特定部分。因此,它们通常依赖于使用测试替身模拟系统的其他部分(参见[第91页]“测试替身”部分)。单元测试不应该涉及调用数据库、使用文件系统、与外部系统通信,或者通常意义上的系统组件之间的交互。这使得它们可以非常快速地运行,因此你可以快速获得关于变更是否破坏了任何现有功能的反馈。这些测试还应该覆盖系统中几乎所有的代码路径(最低80%)。因此,它们构成了回归测试套件的关键部分。
然而,这种速度是以错过那些由应用程序各部分之间交互产生的bug为代价的。例如,对象(在面向对象编程中)或应用程序数据的生命周期非常不同是很常见的。只有通过测试应用程序的更大块,你才能发现由于数据或对象的生命周期管理不当而导致的bug。
组件测试测试更大的功能集群,以便它们可以捕获这样的问题。它们通常较慢,因为它们可能需要更复杂的设置并执行更多的I/O操作,与数据库、文件系统或其他系统通信。有时,组件测试被称为”集成测试”——但”集成测试”这个术语被过度使用,所以我们在本书中不会在这种情况下使用它。
部署测试在部署应用程序时执行。它们检查部署是否成功——换句话说,应用程序是否正确安装、正确配置、能够联系到它需要的任何服务,以及它是否正在响应。
这些手动测试验证应用程序实际上是否会向用户交付他们期望的价值。这不仅仅是验证应用程序是否满足规格的问题;还要检查规格是否正确。我们从未参与过或听说过一个项目能够提前完美地指定应用程序。不可避免地,当用户在实际生活中尝试应用程序时,他们会发现还有改进的空间。他们会破坏东西,因为他们设法执行了以前没有人尝试过的一系列操作。他们抱怨应用程序在帮助他们完成最常执行的任务方面可以做得更好。也许他们受到应用程序的启发,识别出能够为他们提供更多价值的新功能。软件开发是一个自然的迭代过程,依靠建立有效的反馈循环而蓬勃发展,如果我们以任何其他方式看待它,我们就是在自欺欺人。
面向业务、评估项目的测试的一种特别重要的形式是演示(showcase)。敏捷团队在每次迭代结束时向用户进行演示,以展示他们交付的新功能。在开发过程中,还应该尽可能频繁地向客户演示功能,以确保尽早发现任何误解或规格问题。进展顺利的演示既是福音也是诅咒——用户喜欢接触新东西并使用它。但他们总是有大量的改进建议。此时,客户和项目团队必须决定他们希望在多大程度上改变项目计划以纳入这些建议。无论结果如何,尽早获得反馈总比在项目结束时为时已晚要好得多。演示是任何项目的心跳:这是你第一次可以说一项工作真正完成并令那些支付账单的人满意。
探索式测试(Exploratory Testing)被James Bach描述为一种手工测试形式,在这种测试中”测试人员在执行测试时主动控制测试的设计,并利用测试过程中获得的信息来设计新的更好的测试。“[2] 探索式测试是一个富有创造性的学习过程,它不仅能发现缺陷,还能促进创建新的自动化测试集,并可能为应用程序提出新的需求。
可用性测试(Usability Testing)用于发现用户使用您的软件完成目标的难易程度。在开发过程中很容易过于接近问题本身,即使是负责应用程序规格说明的非技术人员也是如此。因此,可用性测试是验证您的应用程序是否真正能为用户交付价值的终极测试。可用性测试有多种不同方法,从情境调查到让用户坐在应用程序前完成常见任务并进行录像。可用性测试人员收集指标数据,记录用户完成任务所需的时间,观察人们是否按错按钮,记录他们找到正确文本框所需的时间,并让他们在结束时记录满意度。
最后,您可以通过Beta测试程序将应用程序提供给真实用户。实际上,许多网站似乎永远处于Beta状态。一些更具前瞻性的网站(例如NetFlix)会持续向选定用户发布新功能,用户甚至不会注意到。许多组织使用金丝雀发布(Canary Releasing)(参见第263页”金丝雀发布”部分),其中应用程序的几个略有不同的版本同时在生产环境中运行,并比较它们的有效性。这些组织收集关于新功能使用情况的统计数据,如果功能没有提供足够的价值就将其淘汰。这为功能采用提供了一种非常有效的演进式方法。
验收测试分为两类:功能测试和非功能测试。所谓非功能测试,是指系统除功能之外的所有质量特性,如容量、可用性、安全性等。正如我们上面提到的,功能测试和非功能测试之间的区别在某种程度上是虚假的,认为这些测试不是面向业务的想法也是如此。这似乎很明显,但许多项目并没有像对待其他需求一样对待非功能需求,或者(更糟糕的)根本不去验证它们。虽然用户很少花大量时间预先指定容量和安全特性,但如果他们的信用卡信息被盗或网站因容量问题而频繁宕机,他们肯定会非常不满。因此,许多人认为”非功能需求”是一个不好的名称,建议使用跨功能需求或系统特性等替代术语。尽管我们对这一观点表示同情,但在本书中我们将它们称为非功能特性,以便每个人都知道我们在谈论什么。无论您如何称呼它们,非功能验收标准都应该像功能验收标准一样作为应用程序需求的一部分来指定。
用于检查是否满足这些验收标准的测试,以及用于运行测试的工具,往往与用于验证符合功能验收标准的测试大不相同。这些测试通常需要大量资源,如特殊的运行环境和设置与实施所需的专业知识,并且通常需要很长时间才能运行(无论是否自动化)。因此,它们的实施往往会被推迟。即使它们完全自动化,它们的运行频率也往往较低,在部署流水线中的位置也比功能验收测试更靠后。
然而,情况正在发生变化。用于执行这些测试的工具正在成熟,用于开发它们的技术也变得更加主流。由于多次在发布前因性能问题而措手不及,我们建议您在任何项目开始时至少建立一些基本的非功能测试,无论项目多么简单或无关紧要。对于更复杂或关键任务项目,您应该考虑从项目开始就分配项目时间来研究和实施非功能测试。
自动化测试的一个关键部分涉及在运行时用模拟版本替换系统的一部分。这样,被测应用程序部分与应用程序其余部分的交互可以被严格限制,从而更容易确定其行为。此类模拟通常被称为Mock、Stub、Dummy等。我们将遵循Gerard Meszaros在其著作《xUnit测试模式》中使用的术语,如Martin Fowler所总结的那样[aobjRH]。Meszaros创造了通用术语”测试替身”,并进一步区分了各种类型的测试替身,如下所示:
• 虚拟对象(Dummy Objects)被传递但从未实际使用。它们通常只是用来填充参数列表。
• 伪对象(Fake Objects)实际上有可工作的实现,但通常采用某种捷径,使它们不适合生产环境。一个很好的例子是内存数据库。
• 桩对象(Stubs)为测试期间的调用提供预设答案,通常根本不响应测试中未编程的任何内容。
• 间谍(Spies)是存根的一种形式,它们还会根据调用方式记录一些信息。其中一种形式可能是电子邮件服务,它会记录发送了多少条消息。
• 模拟对象(Mocks)预先编程了期望值,这些期望值形成了它们预期接收的调用规范。如果收到意外的调用,它们可以抛出异常,并在验证期间进行检查以确保获得了所有预期的调用。
模拟对象是一种特别容易被滥用的测试替身形式。通过编写既无意义又脆弱的测试来误用模拟对象非常容易,仅仅用它们来断言某些代码工作的具体细节,而不是其与协作者的交互。这种用法很脆弱,因为如果实现发生变化,测试就会中断。研究模拟对象和存根之间的区别超出了本书的范围,但您可以在第8章“自动化验收测试”中找到更多细节。可能最全面阐述如何正确使用模拟对象的论文是”Mock Roles, Not Objects” [duZRWb]。Martin Fowler在他的文章”Mocks Aren’t Stubs” [dmXRSC]中也给出了一些指导。
以下是决定自动化测试的团队面临的一些典型场景。
新项目代表了实现我们在本书中描述的理想的机会。在这个阶段,变更成本较低,通过建立一些相对简单的基本规则和创建一些相对简单的测试基础设施,您可以为持续集成过程开个好头。在这种情况下,重要的是从一开始就编写自动化验收测试。为了做到这一点,您需要:
• 选择技术平台和测试工具。
• 建立简单的自动化构建。
• 制定遵循INVEST原则[ddVMFH]的用户故事(它们应该是独立的(Independent)、可协商的(Negotiable)、有价值的(Valuable)、可估算的(Estimable)、小型的(Small)和可测试的(Testable)),并附带验收标准。
然后您可以实施严格的流程:
• 客户、分析师和测试人员定义验收标准。
• 测试人员与开发人员合作,根据验收标准自动化验收测试。
• 开发人员编写代码以满足验收标准。
• 如果任何自动化测试失败(无论是单元测试、组件测试还是验收测试),开发人员都优先修复它们。
在项目开始时采用这个流程比在几次迭代后决定需要验收测试要简单得多。在这些后期阶段,您不仅需要尝试想出实施验收测试的方法,因为您的框架中还不存在对它们的支持—您还必须说服持怀疑态度的开发人员需要认真遵循这个流程。如果从项目开始就着手,让团队习惯自动化测试会更容易实现。
然而,团队中的每个人,包括客户和项目经理,都认同这些好处也是至关重要的。我们见过项目被取消,因为客户觉得在自动化验收测试上花费了太多时间。如果客户真的宁愿牺牲自动化验收测试套件的质量以便快速推向市场,他们有权做出这个决定—但应该明确说明后果。
最后,重要的是确保您的验收标准经过仔细编写,以便从用户的角度表达故事交付的业务价值。盲目地自动化编写不当的验收标准是导致验收测试套件无法维护的主要原因之一。对于您编写的每个验收标准,应该能够编写一个自动化验收测试来证明所描述的价值已交付给用户。这意味着测试人员应该从一开始就参与编写需求,确保在系统演进的整个过程中支持一致的、可维护的自动化验收测试套件。
遵循我们描述的流程会改变开发人员编写代码的方式。比较从一开始就使用自动化验收测试开发的代码库与验收测试作为事后考虑的代码库,我们几乎总是在前者中看到更好的封装、更清晰的意图、更清晰的关注点分离和更多的代码重用。这确实是一个良性循环:在正确的时间进行测试会产生更好的代码。
虽然从头开始一个项目总是令人愉快的,但现实是我们经常发现自己在一个资源匮乏的大型团队中工作,开发快速变化的代码库,承受着交付压力。
引入自动化测试的最佳方式是从应用程序最常见、最重要和最高价值的用例开始。这需要与您的客户进行对话,以清楚地确定真正的业务价值所在,然后用测试保护这些功能免受回归影响。基于这些对话,您应该自动化涵盖这些高价值场景的正常路径测试。
此外,最大化这些测试覆盖的操作数量也很有用。让它们覆盖比通常用故事级验收测试处理的场景稍微更广泛一些。尽可能填写更多字段并按下更多按钮以满足测试需求。这种方法为这些核心行为测试中正在测试的功能提供了一些广泛的覆盖,即使这些测试不会突出显示系统细节中的故障或变化。例如,你会知道系统的基本行为正在运行,但可能会错过某些验证未生效的事实。这还有一个额外的好处,就是让手动测试更高效一些,因为你不必测试每一个字段。你会确信通过自动化测试的构建能够正常运行并交付业务价值,即使它们的某些行为方面不如你所愿。
这种策略意味着,由于你只自动化了正常路径(happy path),你将不得不执行相应更多的手动测试以确保系统完全按预期工作。你应该会发现手动测试变化很快,因为它们将测试新的或新修改的功能。一旦你发现自己手动测试同一个功能超过几次,就检查一下该功能是否可能会改变。如果不会,就自动化这个测试。相反,如果你发现自己花费大量时间修复特定的测试,你可以假设被测试的功能正在变化。再次与客户和开发团队确认是否是这种情况。如果是,通常可以告诉你的自动化测试框架忽略该测试,记得在忽略注释中提供尽可能多的细节,这样你就知道何时让测试再次工作。如果你怀疑该测试不会再以目前的形式使用,就删除它——如果你错了,你总是可以从版本控制中检索它。
当你时间紧迫时,你将无法花费大量精力编写具有大量交互的复杂场景脚本。在这种情况下,最好使用各种测试数据集以确保覆盖率。清楚地指定测试的目标,找到满足这个目标的最简单的脚本,并在测试开始时用尽可能多的应用程序状态场景来补充它。我们在第12章”管理数据”中讨论自动化加载测试数据。
Michael Feathers 在他的书《修改代码的艺术》(Working Effectively with Legacy Code)中,挑衅性地将遗留系统定义为没有自动化测试的系统。这是一个有用且简单的定义(尽管有争议)。伴随这个简单的定义而来的是一个简单的经验法则:测试你修改的代码。
处理这样的系统时,第一个优先事项是创建一个自动化构建流程(如果不存在),然后围绕它创建一个自动化功能测试脚手架。如果有文档,或者更好的是有参与过遗留系统工作的团队成员,创建自动化测试套件会更容易。然而,情况往往并非如此。
通常,项目赞助人不愿意让开发团队花时间在对他们来说似乎是低价值的活动上——为已经投入生产的系统的行为创建测试:“这不是过去已经被QA团队测试过了吗?”因此,重要的是针对系统的高价值操作。向客户解释创建回归测试套件以保护系统这些功能的价值是很容易的。
重要的是与系统用户坐下来识别其高价值用途。使用前面章节中描述的相同技术,创建一组覆盖这些核心高价值功能的广泛自动化测试。你不应该在这上面花费太长时间,因为这是保护遗留功能的骨架。你稍后将为添加的新行为增量添加新测试。这些本质上是你遗留系统的冒烟测试(smoke tests)。
一旦这些冒烟测试就位,你就可以开始故事的开发。此时采用分层方法来处理自动化测试是有用的。第一层应该是非常简单且快速运行的测试,用于检测阻止你对正在处理的任何功能进行有用测试和开发的问题。第二层测试特定故事的关键功能。尽可能地,新行为应该以我们为新项目描述的相同方式进行开发和测试。应该为新特性创建带有验收标准的故事,并且应该强制要求用自动化测试来代表这些故事的完成。
这有时可能比听起来更难。设计为可测试的系统往往比那些不可测试的系统更模块化且更容易测试。然而,这不应该让你偏离目标。
这类遗留系统的一个特殊问题是代码通常不太模块化和结构良好。因此,代码某一部分的更改通常会对另一个区域的行为产生不利影响。在这种情况下,一个有用的策略是在测试完成时仔细验证应用程序的状态。如果你有时间,可以测试故事的替代路径。最后,你可以编写更多验收测试来检查异常条件或防范常见故障模式或不良副作用。
重要的是要记住,你应该只在能够带来价值的地方编写自动化测试。你可以将应用程序基本分为两个部分。一部分是实现应用程序功能的代码,另一部分是其下的支撑或框架代码。绝大多数回归错误是由修改框架代码引起的——因此,如果你只是为应用程序添加不需要更改框架和支撑代码的功能,那么编写全面的脚手架(scaffolding)几乎没有什么价值。
这个规则的例外情况是,当你的软件必须在多个不同环境中运行时。在这种情况下,自动化测试结合自动化部署到类生产环境会带来很大的价值,因为你只需将脚本指向要测试的环境,就可以节省大量手动测试的工作。
如果你的应用程序通过一系列不同的协议与各种外部系统交互,或者你的应用程序本身由一系列松耦合的模块组成,这些模块之间存在复杂的交互,那么集成测试就变得非常重要。集成测试和组件测试之间的界限是模糊的(不仅因为集成测试是一个有些过载的术语)。我们使用术语集成测试来指确保应用程序的每个独立部分与其所依赖的服务正确工作的测试。
集成测试的编写方式与编写普通验收测试的方式相同。通常,集成测试应该在两种上下文中运行:首先是被测系统针对其所依赖的真实外部系统运行,或者针对服务提供商控制的副本运行;其次是针对你作为代码库一部分创建的测试工具(test harness)运行。
必须确保不要访问真实的外部系统,除非你处于生产环境,或者你有某种方式告诉服务你正在发送用于测试目的的虚拟交易。有两种常见方法可以确保你能够安全地测试应用程序而不访问真实的外部系统,通常你需要同时使用这两种方法:
• 在测试环境中使用防火墙隔离对外部系统的访问,无论如何,在开发过程的早期你可能都想这样做。这也是测试应用程序在外部服务不可用时行为的有用技术。
• 在应用程序中设置一个配置选项,使其与外部系统的模拟版本通信。
在理想情况下,服务提供商会有一个副本测试服务,其行为与生产服务完全相同,只是在性能特征方面有所不同。你可以针对这个副本开发测试。然而,在现实世界中,你通常需要开发自己的测试工具。这种情况发生在:
• 外部系统正在开发中,但接口已提前定义(在这种情况下,要准备好接口可能会变化)。
• 外部系统已经开发完成,但你没有可用于测试的测试实例,或者测试系统太慢或有太多错误,无法作为常规自动化测试运行的服务。
• 测试系统存在,但响应不确定,因此使自动化测试的结果验证变得不可能(例如,股票市场数据源)。
• 外部系统采用另一个应用程序的形式,该应用程序难以安装或需要通过UI进行手动干预。
• 你需要为涉及外部服务的功能编写标准的自动化验收测试。这些测试几乎总是应该针对测试替身(test doubles)运行。
• 你的自动化持续集成系统施加的负载以及它所需的服务级别,超出了只能应对少数手动探索性交互的轻量级测试环境的承受能力。
测试工具可能相当复杂,特别是取决于它所替代的服务是否记住状态。如果外部系统记住状态,你的测试工具将根据你发送的请求表现出不同的行为。在这种情况下,你能编写的最有价值的测试是黑盒测试,其中你考虑外部系统可以给出的所有可能响应,并为每个响应编写一个测试。你的模拟外部系统需要某种方式来识别你的请求并发送回适当的响应,如果收到意外的请求则发送异常。
至关重要的是,你的测试工具不仅要复制对服务调用的预期响应,还要复制意外响应。在《Release It!》一书中,Michael Nygard讨论了创建一个测试工具,该工具模拟你可以从出错的远程系统或基础设施问题中预期的各种恶意行为。这些行为可能是由于网络传输问题、网络协议问题、应用协议问题和应用逻辑问题引起的。例如包括诸如拒绝网络连接、接受连接然后断开、接受连接但从不回复、对请求响应极其缓慢、发送回异常大量的数据、回复垃圾信息、拒绝凭据、发送回异常,或者回复一个格式良好但根据应用程序状态无效的响应等病态现象。你的测试工具应该能够模拟这些条件中的每一种,也许可以通过监听几个不同的端口来实现,每个端口对应某种故障模式。
您应该针对尽可能多的异常情况进行测试,以确保应用程序能够处理它们。Nygard描述的其他模式,如断路器(Circuit Breaker)和隔离舱(Bulkheads),可以用来增强应用程序对生产环境中必然发生的意外事件的抵御能力。
自动化集成测试可以在系统部署到生产环境时作为冒烟测试重复使用。它们也可以用作监控生产系统的诊断工具。如果您在开发过程中识别出集成问题存在风险,而这几乎是不可避免的,那么开发自动化集成测试应该是一个优先事项。
将与集成相关的活动纳入发布计划至关重要。与外部服务集成是复杂的,需要时间和规划。每次需要与外部系统集成时,都会给项目增加风险:
• 测试服务是否可用,性能是否良好?
• 服务提供商是否有足够的资源来回答问题、修复缺陷和添加自定义功能?
• 我能否访问生产版本的系统来诊断容量或可用性问题?
• 使用我的应用程序开发技术是否可以轻松访问服务API,还是需要团队具备专业技能?
• 我们是否需要编写和维护自己的测试服务?
• 当外部服务表现不符合预期时,我的应用程序将如何运行?
此外,您还需要为构建和维护集成层及相关的运行时配置增加范围,以及所需的任何测试服务和测试策略(如容量测试)。
如果团队成员之间沟通不畅,验收测试的制作可能是一项昂贵甚至繁重的任务。许多项目依赖测试人员详细检查即将到来的需求,遍历所有可能的场景,并设计他们稍后将遵循的复杂测试脚本。这个过程的结果可能会发送给客户审批,之后再实施测试。
这个过程有几个环节可以非常简单地优化。我们发现最好的解决方案是在每次迭代开始时与所有利益相关者召开一次会议,或者如果不使用迭代,则在故事开始开发前一周左右。我们让客户、分析师和测试人员聚在一起,提出需要测试的最高优先级场景。Cucumber、JBehave、Concordion和Twist等工具允许您在文本编辑器中用自然语言编写验收标准,然后编写代码使这些测试可执行。对测试代码的重构也会更新测试规范。另一种方法是使用领域特定语言(DSL)进行测试。这允许在DSL中输入验收标准。至少,我们会要求客户当场编写涵盖这些场景快乐路径的最简单验收测试。稍后,在会议结束后,人们通常会添加更多数据集以提高测试覆盖率。
这些验收测试及其目标的简短描述,随后成为开发人员处理相关故事的起点。测试人员和开发人员应该在开始开发之前尽早聚在一起讨论验收测试。这使开发人员能够很好地了解故事并理解最重要的场景是什么。这减少了开发人员和测试人员之间的反馈周期,否则这种反馈循环可能会在故事开发结束时发生,并有助于减少遗漏的功能和缺陷数量。
故事结束时开发人员和测试人员之间的交接过程很容易成为瓶颈。在最坏的情况下,开发人员可以完成一个故事,开始另一个故事,然后在新故事进行到一半时被测试人员打断,因为测试人员在之前的故事(甚至是一段时间前完成的故事)上发现了缺陷。这是非常低效的。
开发人员和测试人员在整个故事开发过程中的密切协作对于顺利发布至关重要。每当开发人员完成某些功能时,他们应该叫来测试人员进行审查。测试人员应该接管开发人员的机器来进行测试。在此期间,开发人员可能会在相邻的终端或笔记本电脑上继续工作,也许修复一些未解决的回归缺陷。这样他们仍然有事可做(因为测试可能需要一些时间),但在测试人员需要讨论任何事情时仍然随时可用。
理想情况下,缺陷永远不应该被引入到您的应用程序中。如果您正在实践测试驱动开发和持续集成,并且拥有全面的自动化测试集,包括系统级别的验收测试以及单元和组件测试,开发人员应该能够在测试人员或用户发现缺陷之前捕获它们。然而,探索性测试、演示和用户不可避免地会在您的系统中发现缺陷。这些缺陷通常会进入缺陷待办事项。
关于什么是可接受的缺陷待办事项以及如何处理它,有几种不同的观点。James Shore主张零缺陷。实现这一目标的一种方法是确保每当发现缺陷时立即修复。当然,这要求您的团队结构能够让测试人员尽早发现缺陷,开发人员可以立即修复。然而,如果您已经有了缺陷待办事项,这将无济于事。
当存在大量积压的缺陷时,重要的是让问题对每个人都清晰可见,并让开发团队成员负责推动减少积压的过程。特别是,如果验收构建的状态总是显示为”通过”或”失败”是不够的,尤其是在总是失败的情况下。相反,应该显示通过的测试数量、失败的数量和被忽略的数量,并在显眼的地方展示这些数字随时间变化的图表。这样可以将团队的注意力集中在问题上。
决定继续处理积压缺陷的场景是有风险的。这是一个滑坡。过去许多开发团队和开发流程忽略了大量缺陷,将修复工作推迟到未来某个更方便的时间。几个月后,这几乎不可避免地导致一个庞大的缺陷列表,其中一些永远不会被修复,一些由于应用程序的功能已经改变而不再相关,一些对某些用户至关重要但在所有噪音中被遗忘了。
当没有验收测试或验收测试无效时,问题会更严重,因为功能是在未定期合并到主干的分支上开发的。在这种情况下,一旦代码集成并开始手动系统级测试,团队完全被缺陷淹没是非常常见的。测试人员、开发人员和管理层之间爆发争论,发布日期推迟,用户得到的是质量差的软件。这是一个通过遵循更好流程可以预防许多缺陷的案例。详见第14章”高级版本控制”。
另一种方法是将缺陷与功能同等对待。毕竟,处理缺陷需要时间和精力,会影响其他功能的开发,因此由客户决定特定缺陷相对于该功能的优先级。例如,在只有几个用户的管理界面中,一个罕见的、有已知解决方法的缺陷,可能不如为整个应用程序带来收入的新功能重要。至少,将缺陷分类为”关键”、“阻塞”、“中等”和”低”优先级是有意义的。更全面的方法可能会考虑缺陷发生的频率、对用户的影响以及是否有解决方法。
有了这种分类,缺陷可以像故事一样在待办事项中进行优先级排序,它们可以一起出现。除了立即消除关于某项工作是缺陷还是功能的争论外,这意味着你可以一目了然地看到还有多少工作要做,并相应地确定优先级。低优先级的缺陷会在待办事项中靠后,你可以像对待低优先级故事一样对待它们。通常情况下,客户宁愿不修复某些缺陷——因此将缺陷与功能一起放在待办事项中是管理它们的合理方式。
在许多项目中,测试被视为由专家执行的独立阶段。然而,只有当测试成为交付软件的每个人的责任,并从项目开始到整个生命周期都进行实践时,才可能产生高质量的软件。测试主要关注建立驱动开发、设计和发布的反馈循环。任何将测试推迟到项目末期的计划都是有问题的,因为它移除了产生更高质量、更高生产力以及最重要的项目完成度度量的反馈循环。
最短的反馈循环是通过在系统每次更改时运行的自动化测试集创建的。这些测试应该在所有层级运行——从单元测试到验收测试(功能性和非功能性)。自动化测试应该通过探索性测试和演示等手动测试来补充。本章旨在让你充分理解创建出色反馈所需的各种自动化和手动测试类型,以及如何在各种类型的项目中实施它们。
在”引言”部分第83页讨论的原则中,我们讨论了什么定义了”完成”。将测试纳入交付流程的每个部分对于完成工作至关重要。由于我们的测试方法定义了我们对”完成”的理解,测试结果是项目规划的基石。
测试与你对”完成”的定义从根本上相互关联,你的测试策略应该专注于能够逐个功能地交付这种理解,并确保测试贯穿整个流程。
对于大多数采用持续集成的项目来说,它在生产力和质量方面都是一个巨大的进步。它确保协作创建大型复杂系统的团队能够以比没有持续集成更高的信心和控制水平来完成工作。CI通过为我们提交的更改可能引入的任何问题提供快速反馈,确保我们作为团队创建的代码能够正常工作。它主要专注于断言代码成功编译并通过一组单元测试和验收测试。然而,CI还不够。
CI 主要关注开发团队。CI 系统的输出通常成为手动测试流程的输入,然后进入发布流程的其余部分。在发布软件过程中,大部分浪费来自软件在测试和运维阶段的流转。例如,常见的情况包括:
• 构建和运维团队等待文档或修复
• 测试人员等待软件的”良好”构建版本
• 开发团队在转向新功能数周后才收到 bug 报告
• 在开发过程接近尾声时才发现,应用程序的架构无法支持系统的非功能性需求
这导致软件无法部署,因为将其部署到类生产环境需要太长时间;并且错误百出,因为开发团队与测试和运维团队之间的反馈周期太长。
有多种渐进式改进软件交付方式的方法可以立即带来收益,例如教开发人员编写可投产的软件、在类生产系统上运行 CI,以及建立跨职能团队。然而,虽然这些实践肯定会改善情况,但它们仍然无法让你洞察交付过程中的瓶颈在哪里,或如何对其进行优化。
解决方案是采用更全面的端到端软件交付方法。我们已经解决了配置管理的更广泛问题,并自动化了构建、部署、测试和发布流程的大部分工作。我们已经做到这样的程度:部署我们的应用程序,甚至部署到生产环境,通常只需简单地点击一个按钮来选择我们希望部署的构建版本。这创建了一个强大的反馈循环:由于将应用程序部署到测试环境非常简单,你的团队可以快速获得关于代码和部署流程的反馈。由于部署流程(无论是部署到开发机器还是最终发布)是自动化的,它会被定期运行和测试,从而降低发布风险并将部署流程的知识传递给开发团队。
我们最终得到的是(用精益术语来说)一个拉动式系统(pull system)。测试团队只需按下按钮,就可以自己将构建版本部署到测试环境中。运维人员只需按下按钮,就可以将构建版本部署到预发布和生产环境中。开发人员可以看到哪些构建版本经过了发布流程中的哪些阶段,以及发现了哪些问题。管理者可以观察周期时间、吞吐量和代码质量等关键指标。因此,交付流程中的每个人都获得了两样东西:在需要时访问所需内容的能力,以及对发布流程的可见性,以改进反馈,从而识别、优化和消除瓶颈。这带来了一个不仅更快而且更安全的交付流程。
构建、部署、测试和发布流程的端到端自动化实施产生了一系列连锁效应,带来了一些意想不到的好处。其中一个结果是,在使用这些技术的许多项目过程中,我们发现我们构建的部署流水线系统之间有很多共同点。我们相信,通过我们识别出的抽象概念,一些通用模式到目前为止已经适用于我们尝试过的所有项目。这种理解使我们能够在项目开始时就非常快速地启动和运行相当复杂的构建、测试和部署系统。这些端到端的部署流水线系统意味着我们在交付项目中体验到了几年前难以想象的自由度和灵活性。我们确信,这种方法使我们能够以比其他方式显著更低的成本和风险创建、测试和部署更高质量的复杂系统。
这就是部署流水线的目的。
在抽象层面上,部署流水线是将软件从版本控制系统交付到用户手中的流程的自动化体现。对软件的每一次更改都会经历一个复杂的流程才能发布。该流程涉及构建软件,然后这些构建版本在多个测试和部署阶段中推进。这反过来需要许多人之间的协作,可能涉及多个团队。部署流水线对这个流程进行建模,它在持续集成和发布管理工具中的体现使你能够看到并控制每个更改从版本控制通过各种测试和部署集到向用户发布的过程。
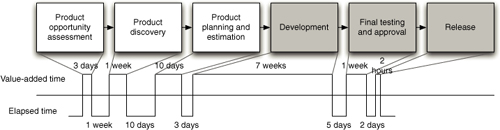
图5.1 产品的简单价值流图
因此,部署流水线建模的流程,即从签入到发布的软件交付流程,构成了将功能从客户或用户的想法交付到他们手中的流程的一部分。从概念到现金的整个流程可以建模为价值流图(value stream map)。图5.1显示了创建新产品的高层级价值流图。
这个价值流图讲述了一个故事。整个过程大约需要三个半月。其中大约两个半月是实际工作时间——在软件从概念到现金的各个阶段之间存在等待时间。例如,开发团队完成第一个版本的工作与测试过程开始之间有五天的等待时间。这可能是由于将应用程序部署到类生产环境所需的时间。顺便说一下,这个图表中故意没有明确说明该产品是否以迭代方式开发。在迭代过程中,你会期望看到开发过程本身包含几个迭代,其中包括测试和展示。从发现到发布的整个过程也会重复多次。
创建价值流图可以是一个低技术含量的过程。在 Mary 和 Tom Poppendieck 的经典著作《精益软件开发:敏捷工具包》中,他们这样描述:
带着铅笔和记事本,前往客户请求进入你组织的地方。你的目标是绘制一张平均客户请求从到达到完成的图表。与参与每个活动的人员一起工作,你勾画出满足请求所需的所有流程步骤,以及请求在每个步骤中花费的平均时间。在地图底部,绘制一条时间线,显示请求在增值活动中花费的时间以及在等待状态和非增值活动中花费的时间。
如果你有兴趣进行一些组织转型工作来改进流程,你需要更详细地描述谁负责流程的哪一部分、异常情况下会发生哪些子流程、谁批准交接、需要哪些资源、组织报告结构是什么等等。然而,这对于我们这里的讨论来说并不必要。有关更多详细信息,请参阅 Mary 和 Tom Poppendieck 的著作《实施精益软件开发:从概念到现金》。
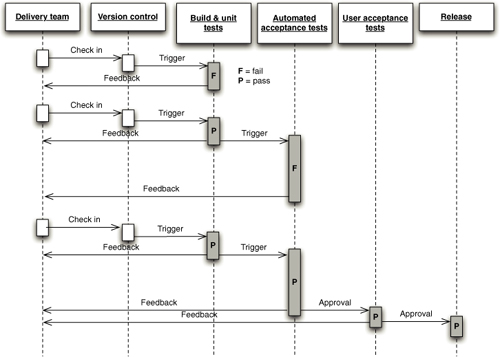
我们在本书中讨论的价值流部分是从开发到发布的部分。这些是图5.1中价值流中的阴影框。这部分价值流的一个关键区别是,构建在发布之前会多次通过它。实际上,理解部署流水线以及变更如何通过它的一种方法是将其可视化为序列图,如图5.2所示。
注意,流水线的输入是版本控制中的特定修订版本。每个变更都会创建一个构建,它将像某个神话英雄一样,通过一系列测试和挑战,以验证其作为生产版本的可行性。这个由一系列测试阶段组成的过程,每个阶段从不同角度评估构建,从每次提交到版本控制系统时开始,就像启动持续集成过程一样。
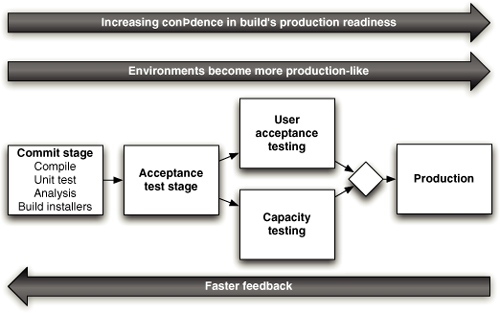
随着构建通过每个适用性测试,对它的信心会增加。因此,我们愿意在它上面花费的资源会增加,这意味着构建通过的环境逐渐变得更像生产环境。目标是尽早在流程中消除不合格的候选版本,并尽快向团队反馈失败的根本原因。为此,未能通过流程中某个阶段的构建通常不会被提升到下一个阶段。这些权衡如图5.3所示。
应用这种模式有一些重要的后果。首先,它有效地防止你将未经彻底测试且不适合其预期目的的构建发布到生产环境。避免了回归错误(regression bug),特别是在需要将紧急修复发布到生产环境时(此类修复与任何其他变更一样经过相同的流程)。根据我们的经验,新发布的软件由于系统组件与其环境之间的某些意外交互而崩溃也是极其常见的,例如由于新的网络拓扑或生产服务器配置的细微差异。部署流水线的规范缓解了这一问题。
其次,当部署和生产发布本身是自动化的时,它们是快速、可重复和可靠的。一旦流程自动化,执行发布通常会变得如此容易,以至于它们成为”正常”事件——这意味着,如果你选择,你可以更频繁地执行发布。当你能够回退到早期版本以及向前推进时,情况尤其如此。当这种能力可用时,发布基本上是没有风险的。最坏的情况是你发现引入了一个严重错误——此时你可以恢复到不包含该错误的早期版本,同时离线修复新版本(参见第10章”部署和发布应用程序”)。
要达到这种令人羡慕的状态,我们必须自动化一套测试,证明我们的候选版本适合其目的。我们还必须自动化部署到测试、预发布和生产环境,以消除这些手动密集型、容易出错的步骤。对于许多系统,还需要其他形式的测试以及发布过程中的其他阶段,但所有项目共有的子集如下:
• 提交阶段确保系统在技术层面正常工作。它能够编译、通过一套(主要是单元级别的)自动化测试,并运行代码分析。
• 自动化验收测试阶段确保系统在功能和非功能层面正常工作,即在行为上满足用户需求和客户规范。
• 手工测试阶段确保系统可用且满足需求,检测自动化测试未捕获的缺陷,并验证系统为用户提供价值。这些阶段通常包括探索性测试环境、集成环境和UAT(用户验收测试)。
• 发布阶段将系统交付给用户,可以是打包软件形式,也可以通过部署到生产环境或预发布环境(预发布环境是与生产环境完全相同的测试环境)。
我们将这些阶段以及建模软件交付流程可能需要的其他阶段称为部署流水线(deployment pipeline)。它有时也被称为持续集成流水线、构建流水线、部署生产线或实时构建。无论叫什么名称,本质上这都是一个自动化的软件交付流程。这并不意味着在整个发布过程中没有人工交互;相反,它确保容易出错和复杂的步骤在执行中是自动化、可靠和可重复的。事实上,人工交互反而增加了:能够通过按下按钮在开发的所有阶段部署系统,鼓励测试人员、分析师、开发人员和(最重要的)用户频繁使用。
图5.4 基础部署流水线
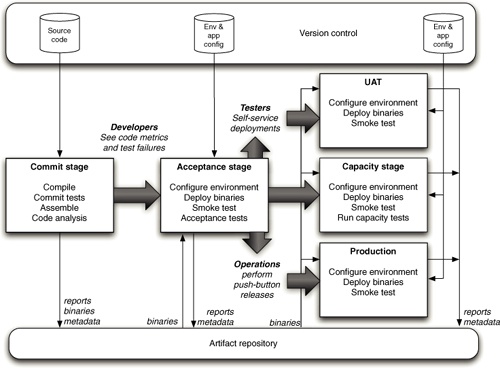
图5.4展示了一个典型的部署流水线,抓住了这种方法的精髓。当然,真实的流水线会反映你的项目实际的软件交付流程。
流程从开发人员将变更提交到版本控制系统开始。此时,持续集成管理系统响应提交,触发流水线的新实例。流水线的第一阶段(提交阶段)编译代码、运行单元测试、执行代码分析并创建安装程序。如果单元测试全部通过且代码符合标准,我们将可执行代码组装成二进制文件并存储在制品仓库中。现代CI服务器提供存储这类制品的功能,使用户和流水线后续阶段都能轻松访问。或者,也有很多工具如Nexus和Artifactory可以帮助你管理制品。作为流水线提交阶段的一部分,你可能还会运行其他任务,例如准备用于验收测试的测试数据库。现代CI服务器允许你在构建网格上并行执行这些任务。
第二阶段通常由运行时间较长的自动化验收测试组成。同样,你的CI服务器应该允许你将这些测试拆分成可以并行执行的测试套件,以提高速度并更快地提供反馈——通常在一两个小时内。该阶段将在流水线第一阶段成功完成后自动触发。
此时,流水线分支以支持将构建独立部署到各种环境——在本例中是UAT(用户验收测试)、容量测试和生产环境。通常,你不希望这些阶段在验收测试阶段成功完成后自动触发。相反,你希望测试人员或运维团队能够手动自助式地将构建部署到他们的环境中。为此,你需要一个执行部署的自动化脚本。测试人员应该能够看到可用的候选版本及其状态——每个构建通过了前两个阶段中的哪些、签入注释是什么,以及关于这些构建的任何其他注释。然后他们应该能够按下按钮,通过在相关环境中运行部署脚本来部署所选构建。
相同的原则适用于流水线的后续阶段,不同之处在于,通常你想要部署到的各种环境会有不同的用户组”拥有”这些环境,并有能力自助式部署到它们。例如,你的运维团队可能希望成为唯一能够批准生产部署的人。
图5.5 Go显示哪些变更通过了哪些阶段
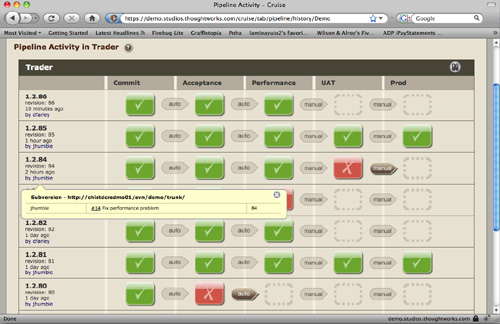
最后,重要的是要记住,所有这些的目的是尽快获得反馈。为了加快反馈周期,你需要能够看到哪个构建部署到哪个环境,以及每个构建通过了流水线的哪些阶段。图5.5是Go的截图,展示了这在实践中的样子。
注意,你可以在页面侧边看到每次签入,每次签入经过的流水线中的每个阶段,以及它是通过还是未通过该阶段。能够将特定的签入(因此也是构建)与它经过的流水线阶段关联起来至关重要。这意味着如果你在验收测试中(例如)发现问题,你可以立即找出哪些变更被签入版本控制导致验收测试失败。
很快,我们将更详细地介绍部署流水线的各个阶段。但在此之前,为了获得这种方法的好处,您应该遵循一些实践。
为了方便起见,我们将可执行代码的集合称为二进制文件,尽管如果您不需要编译代码,这些”二进制文件”可能只是源文件的集合。Jar文件、.NET程序集和.so文件都是二进制文件的例子。
许多构建系统使用版本控制系统中保存的源代码作为许多步骤的规范源。代码会在不同的上下文中重复编译:在提交过程中、在验收测试时、在容量测试时,以及通常为每个单独的部署目标编译一次。每次编译代码时,都有引入某些差异的风险。后续阶段安装的编译器版本可能与您用于提交测试的版本不同。您可能会意外获取到不同版本的第三方库。即使是编译器的配置也可能改变应用程序的行为。我们见过这些来源的每一个错误都进入了生产环境。
一个相关的反模式是在源代码级别而不是在二进制级别进行提升。有关此反模式的更多信息,请参阅第403页的”ClearCase和从源代码重建反模式”部分。
这种反模式违反了两个重要原则。第一个是保持部署流水线的高效性,以便团队尽快获得反馈。重新编译违反了这一原则,因为它需要时间,尤其是在大型系统中。第二个原则是始终建立在已知可靠的基础之上。部署到生产环境的二进制文件应该与通过验收测试过程的二进制文件完全相同——实际上,在许多流水线实现中,通过在创建二进制文件时存储其哈希值并在后续每个阶段验证二进制文件是否相同来检查这一点。
如果我们重新创建二进制文件,就有可能在创建二进制文件和发布之间引入某些变化,例如编译之间工具链的变化,导致我们发布的二进制文件与我们测试的不同。出于审计目的,必须确保在创建二进制文件和执行发布之间,没有恶意或错误地引入任何更改。一些组织坚持编译和组装,或者对于解释型语言的打包,必须在一个特殊环境中进行,该环境只能由高级人员访问。一旦我们创建了二进制文件,我们将重用它们,而不是在使用时重新创建它们。
因此,您应该只在构建的提交阶段构建一次二进制文件。这些二进制文件应该存储在某个文件系统上(不是版本控制中,因为它们是基线的衍生物,而不是其定义的一部分),以便在流水线的后续阶段轻松检索它们。大多数持续集成(CI)服务器会为您处理这个问题,并且还会执行关键任务,允许您追溯到用于创建它们的版本控制签入。不值得花费大量时间和精力来确保二进制文件被备份——应该可以通过从版本控制中的正确修订版本运行自动化构建过程来精确地重新创建它们。
如果您接受我们的建议,最初会感觉您有更多的工作要做。如果您的CI工具还没有为您做这件事,您将需要建立某种方式将二进制文件传播到部署流水线的后续阶段。一些流行开发环境附带的简单配置管理工具可能做的是错误的事情。一个值得注意的例子是项目模板,它直接生成包含代码和配置文件的程序集,例如ear和war文件,作为构建过程中的单个步骤。
这一原则的一个重要推论是,必须能够将这些二进制文件部署到每个环境。这迫使您分离代码(在不同环境之间保持不变)和配置(在不同环境之间有所不同)。这反过来会引导您正确管理配置,对构建更好结构的构建系统施加温和的压力。
我们认为创建旨在在单个环境中运行的二进制文件是一种非常糟糕的做法。这种方法虽然常见,但有几个严重的缺点,损害了系统的整体部署便利性、灵活性和可维护性。有些工具甚至鼓励这种方法。
当构建系统以这种方式组织时,它们通常会很快变得非常复杂,产生许多特殊情况的黑客手段来应对各种部署环境的差异和变化无常。在我们参与的一个项目中,构建系统非常复杂,需要一个由五人组成的全职团队来维护它。最终,我们通过重新组织构建并将特定于环境的配置与环境无关的二进制文件分离,使他们摆脱了这项不受欢迎的工作。
这样的构建系统使得本应简单的任务变得不必要地复杂,比如向集群添加新服务器。这反过来又迫使我们采用脆弱且昂贵的发布流程。如果你的构建创建的二进制文件只能在特定机器上运行,现在就开始计划如何重构它们!
这就自然引出了下一个实践。
使用相同的流程部署到每个环境至关重要——无论是开发人员或分析师的工作站、测试环境还是生产环境——以确保构建和部署流程得到有效测试。开发人员经常部署;测试人员和分析师部署的频率较低;通常,你向生产环境部署的频率会相当低。但这种部署频率与每个环境相关的风险成反比。你最不常部署的环境(生产环境)是最重要的。只有在你已经在许多环境上测试了数百次部署流程之后,你才能排除部署脚本作为错误来源。
每个环境在某些方面都是不同的。即使没有其他差异,它也会有唯一的IP地址,但通常还有其他差异:操作系统和中间件配置设置、数据库和外部服务的位置,以及需要在部署时设置的其他配置信息。这并不意味着你应该为每个环境使用不同的部署脚本。相反,将每个环境独有的设置分离开来。一种方法是使用属性文件来保存配置信息。你可以为每个环境准备单独的属性文件。这些文件应该签入版本控制,并通过查看本地服务器的主机名或(在多机器环境中)使用提供给部署脚本的环境变量来选择正确的文件。提供部署时配置的其他方法包括将其保存在目录服务(如LDAP或ActiveDirectory)中,或将其存储在数据库中并通过应用程序(如ESCAPE)访问它。关于管理软件配置的更多信息,请参见第39页的”管理软件配置”部分。
对每个应用程序使用相同的部署时配置机制非常重要。这在大公司或使用许多异构技术的地方尤其如此。通常,我们反对自上而下的命令——但我们见过太多组织,在这些组织中,要弄清楚对于给定环境中的给定应用程序,在部署时实际提供了什么配置是极其困难的。我们知道有些地方,你必须给不同大陆的不同团队发送电子邮件才能拼凑出这些信息。当你试图找出某个错误的根本原因时,这会成为效率的巨大障碍——当你将它引入价值流的延迟加在一起时,成本是非常高昂的。
应该可以查询单一来源(版本控制仓库、目录服务或数据库)来找到所有应用程序在所有环境中的配置设置。
如果你在一家公司工作,其中生产环境由不同于负责开发和测试环境的团队管理,那么两个团队都需要合作,以确保自动化部署流程在所有环境(包括开发环境)中有效工作。使用相同的脚本部署到生产环境和开发环境是防止”在我的机器上可以运行”综合症的绝佳方法。这也意味着当你进行发布时,你已经通过部署到所有其他环境测试了数百次部署流程。这是我们所知的降低软件发布风险的最佳方法之一。
我们假设你有一个自动化的应用程序部署流程——但当然,许多组织仍然手动部署。如果你有手动部署流程,你应该首先确保每个环境的流程都相同,然后开始一点一点地自动化它,目标是完全脚本化。最终,你应该只需要指定目标环境和应用程序版本就能启动成功的部署。自动化、标准化的部署流程将对你可重复且可靠地发布应用程序的能力产生巨大的积极影响,并确保流程被完整记录和审计。我们将在下一章详细介绍自动化部署。
这个原则实际上是你应该将变化的内容与不变的内容分离这一规则的另一个应用。如果你的部署脚本在不同环境中是不同的,你就无法知道你正在测试的东西在上线时是否真的有效。相反,如果你在所有地方使用相同的流程进行部署,当部署在特定环境中不起作用时,你可以将原因缩小到以下三种之一:
• 应用程序特定于环境的配置文件中的设置
• 基础设施或应用程序所依赖的某个服务的问题
• 环境的配置
确定这些问题中哪个是根本原因,是接下来两个实践的主题。
当你部署应用程序时,应该有一个自动化脚本来执行冒烟测试,以确保应用程序正常运行。这可以简单到启动应用程序并检查主屏幕是否显示预期内容。你的冒烟测试还应该检查应用程序依赖的任何服务是否正常运行——例如数据库、消息总线或外部服务。
冒烟测试,或称部署测试,可能是在你建立单元测试套件之后最重要的测试——实际上,它甚至可以说更重要。它让你确信应用程序确实在运行。如果它没有运行,你的冒烟测试应该能够提供一些基本诊断,说明应用程序是否因为它所依赖的某些服务未正常工作而宕机。
许多团队在上线时遇到的另一个主要问题是,他们的生产环境与测试和开发环境有很大不同。为了对上线能否真正成功建立足够的信心,你需要在与生产环境尽可能相似的环境中进行测试和持续集成。
理想情况下,如果你的生产环境比较简单,或者你有足够大的预算,你可以拥有生产环境的完全副本来运行手动和自动化测试。确保你的环境相同需要一定的纪律来应用良好的配置管理实践。你需要确保:
你可以使用磁盘镜像和虚拟化等实践,以及 Puppet 和 InstallShield 等工具,结合版本控制仓库来管理你的环境配置。我们会在第11章”管理基础设施和环境”中详细讨论这个问题。
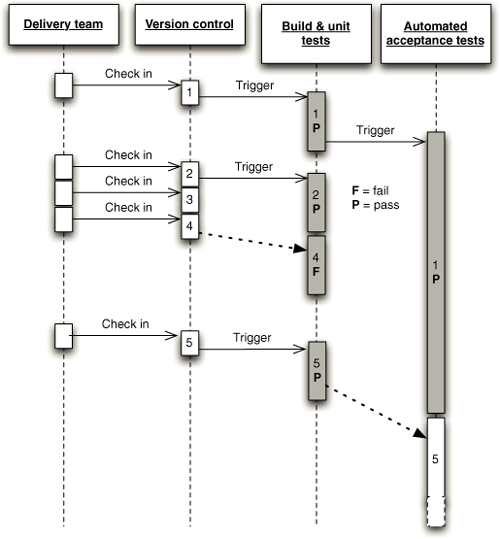
图 5.6 流水线中的阶段调度
在引入持续集成之前,许多项目按计划运行流程的各个部分——例如,构建可能每小时运行一次,验收测试每晚运行,容量测试在周末运行。部署流水线采用了不同的方法:第一阶段应该在每次检入时触发,每个阶段应该在成功完成后立即触发下一个阶段。当然,当开发人员(特别是在大型团队中)非常频繁地检入时,这并不总是可行的,因为流程中的阶段可能需要不少时间。图 5.6 显示了这个问题。
在这个例子中,有人向版本控制检入了一个变更,创建了版本1。这反过来触发了流水线的第一阶段(构建和单元测试)。这个阶段通过了,并触发了第二阶段:自动化验收测试。然后有人又检入了另一个变更,创建了版本2。这再次触发了构建和单元测试。然而,即使这些测试已经通过,它们也不能触发新的自动化验收测试实例,因为验收测试已经在运行中。与此同时,又快速连续发生了两次检入。然而,持续集成系统不应该尝试构建这两个——如果它遵循这个规则,而开发人员继续以相同的速度检入,构建就会越来越落后于开发人员当前正在做的事情。
相反,一旦构建和单元测试的一个实例完成,持续集成系统会检查是否有新的变更可用,如果有,就基于最新的可用集合进行构建——在这种情况下是版本4。假设这破坏了构建和单元测试阶段。构建系统不知道是提交3还是提交4导致阶段失败,但开发人员通常很容易自己弄清楚。一些持续集成系统允许你无序运行指定的版本,在这种情况下,开发人员可以从修订版3触发第一阶段,看看它是通过还是失败,从而确定是提交3还是提交4破坏了构建。无论哪种方式,开发团队检入版本5,修复了问题。
当验收测试最终完成时,持续集成系统的调度器注意到有新的变更可用,并针对版本5触发验收测试的新运行。
这种智能调度对于实现部署流水线至关重要。确保你的持续集成服务器支持这种调度工作流——许多都支持——并确保变更立即传播,这样你就不必按固定时间表运行阶段。
这只适用于完全自动化的阶段,例如包含自动化测试的阶段。流水线中执行部署到手动测试环境的后期阶段需要按需激活,我们将在本章后面的部分中描述。
正如我们在第56页”实施持续集成”一节中所说,实现本书目标——快速、可重复、可靠的发布——最重要的一步是让你的团队接受:每次他们将代码检入版本控制系统时,代码都将成功构建并通过每一项测试。这适用于整个部署流水线。如果部署到某个环境失败,整个团队都对这次失败负有责任。他们应该停下来并在做任何其他事情之前修复它。
每次检入代码都会创建一个新的部署流水线实例,如果第一阶段通过,就会生成一个发布候选版本。流水线第一阶段的目标是淘汰不适合生产的构建,并尽快向团队发出应用程序已损坏的信号。我们希望在明显有问题的应用程序版本上花费最少的时间和精力。因此,当开发人员向版本控制系统提交更改时,我们希望快速评估应用程序的最新版本。然后,签入代码的开发人员在继续下一个任务之前等待结果。
作为提交阶段的一部分,我们需要做几件事。通常,这些任务作为构建网格(大多数CI服务器提供的功能)上的一组作业运行,以便该阶段在合理的时间内完成。提交阶段理想情况下应少于5分钟运行完成,最多不超过10分钟。提交阶段通常包括以下步骤:
• 编译代码(如有必要)。
• 运行一组提交测试。
• 创建供后续阶段使用的二进制文件。
• 对代码进行分析以检查其健康状况。
• 准备工件,如测试数据库,供后续阶段使用。
第一步是编译源代码的最新版本,如果编译出错,则通知自上次成功检入以来提交更改的开发人员。如果这一步失败,我们可以立即使提交阶段失败,并将此流水线实例从进一步考虑中排除。
接下来,运行一组经过优化以非常快速执行的测试套件。我们将这组测试称为提交阶段测试,而不是单元测试,因为尽管其中绝大多数确实是单元测试,但在此阶段包含少量其他类型的测试是有用的,以便在提交阶段通过时获得更高程度的信心,确信应用程序确实在正常工作。这些测试与开发人员在检入代码之前运行的测试相同(或者,如果他们有条件这样做,可以通过构建网格上的预测试提交)。
首先运行所有单元测试来设计提交测试套件。随后,当你了解到在验收测试运行和流水线后续阶段中哪些类型的失败更常见时,你应该向提交测试套件添加特定测试,以尝试尽早发现它们。这是一个持续的流程优化过程,如果你要避免在后续流水线阶段查找和修复错误的更高成本,这一点很重要。
确认代码能够编译并通过测试固然很好,但这并不能告诉你太多关于应用程序非功能特性的信息。测试容量等非功能特性可能很困难,但你可以运行分析工具,为你提供有关代码库特性的反馈,如测试覆盖率、可维护性和安全漏洞。如果你的代码未能达到这些指标的预设阈值,应该像测试失败一样使提交阶段失败。有用的指标包括:
• 测试覆盖率(如果你的提交测试仅覆盖代码库的5%,那么它们几乎毫无用处)
• 重复代码量
• 圈复杂度(Cyclomatic complexity)
• 传入耦合和传出耦合(Afferent and efferent coupling)
• 警告数量
• 代码风格
提交阶段的最后一步,在成功执行到此为止的所有步骤之后,是创建代码的可部署程序集,准备部署到任何后续环境。这一步也必须成功,提交阶段才能被视为整体成功。将可执行代码的创建作为成功标准本身,是确保我们的构建过程本身也处于持续集成系统的持续评估和审查之下的简单方法。
第3章”持续集成”中描述的大多数实践都适用于提交阶段。开发人员需要等到部署流水线的提交阶段成功。如果失败,他们应该快速修复问题,或者从版本控制中回退他们的更改。在理想的世界中——一个拥有无限处理器能力和无限网络带宽的世界——我们希望开发人员等待所有测试通过,甚至包括手动测试,以便他们可以立即修复任何问题。实际上,这是不切实际的,因为部署流水线的后续阶段(自动化验收测试、容量测试和手动验收测试)都是耗时的活动。这就是将测试流程流水线化的原因——重要的是尽快获得反馈,因为此时修复问题成本较低,但不能以牺牲在更全面的反馈可用时获取它为代价。
当我们第一次使用这个想法时,我们将其命名为流水线(pipeline),不是因为它像液体流经管道;相反,对于我们当中的硬核极客来说,它让我们想起了处理器”流水线化”指令执行以实现一定程度并行性的方式。处理器芯片可以并行执行指令。但是如何将一串本应串行执行的机器指令分解成有意义的并行流呢?处理器的做法非常巧妙且相当复杂,但本质上它们经常会在某些点上有效地”猜测”一个独立执行流水线中的操作结果,并基于这个猜测开始执行。如果后来发现猜测是错误的,基于它的执行流的结果就会被简单地丢弃。虽然没有收益——但也没有损失。然而,如果猜测是正确的,处理器就在单一执行流所需的时间内完成了两倍的工作——因此在那段时间里,它的运行速度是原来的两倍。
我们的部署流水线(deployment pipeline)概念以同样的方式工作。我们设计提交阶段(commit stage)以便它能够捕获大多数问题,同时运行非常快速。因此,我们”猜测”后续所有测试阶段都会通过,于是我们继续开发新功能,为下一次提交和下一个发布候选版本的启动做准备。与此同时,我们的流水线乐观地基于我们对成功的假设工作,与我们开发新功能并行进行。
通过提交阶段是发布候选版本旅程中的一个重要里程碑。它是我们流程中的一道关卡,一旦通过,就释放开发人员去处理下一个任务。然而,他们仍有责任监控后续阶段的进展。即使这些破坏发生在流水线的后期阶段,修复失败的构建仍然是开发团队的首要任务。我们在赌成功——但如果赌注失败,我们已经准备好偿还技术债务。
如果你只在开发过程中实施提交阶段,通常这代表着团队输出的可靠性和质量向前迈出的巨大一步。然而,完成我们认为的最小部署流水线还需要几个额外的阶段。
全面的提交测试套件对许多类型的错误来说是一个出色的试金石,但它无法捕获很多问题。单元测试构成了提交测试的绝大部分,它们与底层API如此紧密耦合,以至于开发人员往往很难避免陷入证明解决方案以特定方式工作的陷阱,而不是断言它解决了特定的问题。
我们曾在一个拥有约80名开发人员的大型项目上工作。该系统使用持续集成作为开发过程的核心进行开发。作为一个团队,我们的构建纪律相当好;对于这样规模的团队来说,我们需要这样。
有一天,我们将通过了单元测试的最新构建部署到测试环境中。这是一个漫长但受控的部署方法,由我们的环境专家执行。然而,系统似乎无法工作。我们花了很多时间试图找出环境配置的问题,但找不到问题所在。然后我们的一位资深开发人员在他的开发机器上尝试了这个应用程序。它在那里也不工作。
他逐步回退到越来越早的版本,直到发现系统实际上在三周前就已经停止工作了。一个微小而隐蔽的bug阻止了系统正确启动。
这个项目有良好的单元测试覆盖率,所有模块的平均覆盖率约为90%。尽管如此,80名通常只运行测试而不运行应用程序本身的开发人员在三周内都没有发现这个问题。
我们修复了这个bug,并在持续集成过程中引入了几个简单的自动化冒烟测试(smoke tests),证明应用程序能够运行并执行其最基本的功能。
我们从这个以及这个大型复杂项目的许多其他经验中学到了很多教训。但最根本的一个是,单元测试只能从开发人员的角度测试问题的解决方案。它们在证明应用程序从用户角度做了它应该做的事情方面能力有限。如果我们想确保应用程序为用户提供我们希望它提供的价值,我们需要另一种形式的测试。我们的开发人员本可以通过更频繁地运行应用程序并与之交互来实现这一点。这本可以解决我们上面描述的具体问题,但对于一个大型复杂的应用程序来说,这不是一个非常有效的方法。
这个故事还指出了我们当时使用的开发过程中的另一个常见失败点。我们的第一个假设是部署出了问题——我们在将系统部署到测试环境时以某种方式配置错误了。这是一个合理的假设,因为这类故障相当常见。部署应用程序是一个复杂的、手工密集的过程,相当容易出错。
尽管我们已经建立了一个复杂、管理良好、规范严格的持续集成(Continuous Integration)流程,但我们仍然无法确信能够识别真正的功能问题。我们也无法确定,当需要部署系统时,不会引入更多的错误。此外,由于部署耗时太长,每次部署时流程往往都会发生变化。这意味着每次部署尝试都是一次新的实验——一个手动的、容易出错的过程。这造成了恶性循环,导致发布风险极高。
针对每次代码提交运行的提交测试为我们提供了关于最新构建问题和应用程序小范围bug的及时反馈。但如果不在类生产环境中运行验收测试(Acceptance Tests),我们就无法知道应用程序是否满足客户的规格要求,也不知道它能否在真实世界中成功部署和运行。如果我们想要获得这些方面的及时反馈,就必须扩展持续集成流程的范围,也对系统的这些方面进行测试和演练。
自动化验收测试阶段在部署流水线中的作用,与提交阶段和单元测试的关系类似。在验收测试阶段运行的大部分测试都是功能验收测试,但并非全部。
验收测试阶段的目标是确认系统交付了客户期望的价值,并且满足验收标准。验收测试阶段还充当回归测试套件,验证新的变更没有在现有功能中引入bug。正如我们在第8章”自动化验收测试”中所述,创建和维护自动化验收测试的过程不是由独立团队完成的,而是融入开发流程的核心,由跨职能交付团队执行。开发人员、测试人员和客户共同创建这些测试,将其作为正常开发流程的一部分,与单元测试和代码一起编写。
关键是,开发团队必须立即响应正常开发过程中出现的验收测试失败。他们必须判断失败是由于引入了回归、应用程序行为的有意变更,还是测试本身的问题。然后采取适当措施,让自动化验收测试套件重新通过。
自动化验收测试关卡是发布候选版本生命周期中的第二个重要里程碑。部署流水线只允许后续阶段(如手动请求的部署)访问成功通过自动化验收测试的构建。虽然可以尝试绕过这个系统,但这非常耗时且代价高昂,不如把精力用在修复部署流水线发现的问题上,并以它支持的可控、可重复的方式进行部署。部署流水线让做正确的事比做错误的事更容易,所以团队会做正确的事。
因此,不满足所有验收标准的发布候选版本永远不会发布给用户。
重要的是要考虑应用程序在生产环境中会遇到的环境。如果你只需要部署到一个由你控制的生产环境,那你很幸运。只需在该环境的副本上运行验收测试即可。如果生产环境复杂或成本高昂,你可以使用它的缩小版本,例如使用几台中间件服务器,而生产环境中可能有很多台。如果你的应用程序依赖外部服务,可以为依赖的外部基础设施使用测试替身(Test Doubles)。我们在第8章”自动化验收测试”中会详细介绍这些方法。
如果你必须针对多种不同环境,例如开发需要安装在用户计算机上的软件,你需要在一系列可能的目标环境上运行验收测试。这可以通过构建网格(Build Grid)轻松实现。为每个目标测试环境至少设置一个测试环境,并在所有环境上并行运行验收测试。
在许多进行自动化功能测试的组织中,一个常见做法是设立专门的团队来生产和维护测试套件。正如第4章”实现测试策略”中详细描述的,这是个坏主意。最大的问题是开发人员不觉得自己拥有验收测试。结果,他们往往不关注部署流水线这个阶段的失败,导致它长时间处于失败状态。在没有开发人员参与的情况下编写的验收测试也往往与UI紧密耦合,因此脆弱且结构不良,因为测试人员对UI的底层设计没有洞察力,也缺乏创建抽象层或针对公共API运行验收测试的技能。
现实是整个团队拥有验收测试,就像整个团队拥有流水线的每个阶段一样。如果验收测试失败,整个团队应该停下来立即修复。
这一实践的一个重要推论是,开发人员必须能够在开发环境中运行自动化验收测试。当开发人员发现验收测试失败时,应该能够轻松地在自己的机器上修复它,并通过在本地运行该验收测试来验证修复。最常见的障碍是所使用的测试软件许可证不足,以及应用程序架构阻止系统部署到开发环境,从而无法针对它运行验收测试。如果你的自动化验收测试策略要在长期内取得成功,就需要消除这些障碍。
验收测试很容易与应用程序中的特定解决方案过度耦合,而不是断言系统的业务价值。当这种情况发生时,会花费越来越多的时间来维护验收测试,因为系统行为的微小变化会使测试失效。验收测试应该用业务语言(Eric Evans 称之为”通用语言”)来表达,而不是用应用程序的技术语言。我们的意思是,虽然用团队开发时使用的编程语言编写验收测试是可以的,但抽象应该在业务行为层面工作——“下订单”而不是”点击订单按钮”,“确认资金转账”而不是”检查 fund_table 有结果”,等等。
虽然验收测试非常有价值,但创建和维护它们的成本也可能很高。因此必须记住,自动化验收测试也是回归测试。不要遵循天真的流程,盲目地将验收标准自动化。
我们在几个项目中发现,由于遵循了上述一些不良实践,自动化功能测试没有提供足够的价值。它们的维护成本太高,因此停止了自动化功能测试。如果测试的成本高于它们节省的工作量,这是正确的决定,但改变测试创建和维护的管理方式可以显著减少投入的工作量,并显著改变成本效益方程。正确进行验收测试是第8章”自动化验收测试”的主要主题。
验收测试阶段是候选发布版本生命周期中的一个重要里程碑。一旦完成这个阶段,成功的候选发布版本就从主要属于开发团队的领域转变为更广泛关注和使用的东西。
对于最简单的部署流水线,通过验收测试的构建就可以发布给用户,至少就系统的自动化测试而言是这样。如果候选版本在这个阶段失败,那么根据定义它就不适合发布。
候选发布版本到这一点的进展是自动的,成功的候选版本会自动晋升到下一阶段。如果你以增量方式交付软件,可以自动部署到生产环境,正如 Timothy Fitz 的博客文章”持续部署”中所述。但对于许多系统来说,即使有全面的自动化测试集,在发布之前也需要某种形式的手动测试。许多项目有用于测试与其他系统集成的环境、用于测试容量的环境、探索性测试环境,以及预发布和生产环境。这些环境中的每一个都可以或多或少地类似生产环境,并有自己独特的配置。
部署流水线也负责部署到测试环境。AntHill Pro 和 Go 等发布管理系统提供了查看当前部署到每个环境的内容以及按钮式部署到该环境的能力。当然在幕后,这些只是运行你编写的部署脚本来执行部署。也可以基于 Hudson 或 CruiseControl 系列等开源工具构建自己的系统,尽管商业工具提供了开箱即用的可视化、报告和细粒度的部署授权。如果创建自己的系统,关键要求是能够看到已通过验收测试阶段的候选发布版本列表,有一个按钮可以将你选择的版本部署到你选择的环境中,查看每个环境中当前部署的候选发布版本以及它来自版本控制中的哪个版本。图5.7展示了一个执行这些功能的自制系统。
到这些环境的部署可以按顺序执行,每个都依赖于前一个的成功结果,因此只有在部署到 UAT 和预发布环境后才能部署到生产环境。它们也可以并行进行,或作为手动选择的可选阶段提供。
至关重要的是,部署流水线允许测试人员按需将任何构建部署到他们的测试环境中。这取代了”每夜构建(nightly build)“的概念。在部署流水线中,测试人员不再被动接收基于任意修订版本的构建(即每个人下班前提交的最后一次变更),而是可以查看哪些构建通过了自动化测试、对应用程序做了哪些变更,并选择他们想要的构建。如果构建在某些方面不令人满意——也许它没有包含正确的变更,或包含了某些使其不适合测试的缺陷——测试人员可以重新部署任何其他构建。
在迭代过程中,验收测试之后总是会进行一些手工测试,包括探索性测试、可用性测试和演示展示。在此之前,开发人员可能已经向分析师和测试人员演示了应用程序的功能,但这两个角色都不会在尚未通过自动化验收测试的构建上浪费时间。测试人员在这个过程中的角色不应该是对系统进行回归测试,而是首先通过手动验证验收标准来确保验收测试真正验证了系统的行为。
之后,测试人员专注于人类擅长但自动化测试不擅长的测试类型。他们进行探索性测试,执行应用程序可用性的用户测试,检查各种平台上的外观和体验,并执行病理性的最坏情况测试。自动化验收测试释放了测试人员的时间,使他们能够专注于这些高价值活动,而不是成为人工测试脚本执行机器。
每个系统都有许多非功能性需求。例如,几乎每个系统都有某种容量和安全性方面的需求,或必须遵守的服务级别协议。运行自动化测试来衡量系统对这些需求的遵守程度通常是有意义的。有关如何实现这一点的更多详细信息,请参见第9章”测试非功能性需求”。对于其他系统,非功能性需求的测试不需要持续进行。在我们的经验中,即使如此,在流水线中为运行这些自动化测试创建一个阶段仍然是有价值的。
容量测试阶段的结果是形成一个门控还是仅仅为人工决策提供信息,这是决定部署流水线组织方式的标准之一。对于高性能应用程序,在候选版本成功通过验收测试阶段后,将容量测试作为完全自动化的结果运行是有意义的。如果候选版本未通过容量测试,通常不会被视为可部署。
然而,对于许多应用程序来说,对可接受内容的判断比这更主观。在容量测试阶段结束时呈现结果,并允许人来决定候选版本是否应该被提升,这样做更有意义。
每次生产系统的发布都与业务风险相关。在最好的情况下,如果在发布时出现严重问题,可能会延迟引入有价值的新功能。在最坏的情况下,如果没有合理的回退计划,可能会使企业失去关键任务资源,因为它们必须作为新系统发布的一部分而退役。
当我们将发布步骤视为部署流水线的自然结果时,这些问题的缓解措施非常简单。从根本上说,我们希望:
• 制定一个由所有参与软件交付的人员共同创建和维护的发布计划,包括开发人员和测试人员,以及运维、基础设施和支持人员
• 通过尽可能多地自动化流程来最小化人为错误的影响,从最容易出错的阶段开始
• 在类生产环境中经常排练该过程,以便调试流程和支持它的技术
• 如果事情没有按计划进行,能够回退发布
• 制定在升级和回滚过程中迁移配置和生产数据的策略
我们的目标是完全自动化的发布过程。发布应该像选择要发布的应用程序版本并按下按钮一样简单。回退也应该同样简单。关于这些主题的更多信息请参见第10章”部署和发布应用程序”。
我们对代码执行环境的控制越少,出现意外行为的可能性就越大。因此,每当我们发布软件系统时,我们希望控制部署的每一个比特。有两个因素可能会影响这一理想。第一个是对于许多应用程序,您根本无法完全控制所创建软件的运行环境。对于由用户安装的产品和应用程序,如游戏或办公应用程序,尤其如此。这个问题通常通过选择目标环境的代表性样本并在每个样本环境上并行运行自动化验收测试套件来缓解。然后,您可以挖掘生成的数据,找出哪些测试在哪些平台上失败。
第二个限制是,建立这种控制程度的成本通常被认为超过了收益。然而,通常情况恰恰相反:生产环境的大多数问题都是由于控制不足造成的。正如我们在第11章中描述的那样,生产环境应该完全锁定——对它们的更改只能通过自动化流程进行。这不仅包括应用程序的部署,还包括对其配置、软件栈、网络拓扑和状态的更改。只有通过这种方式,才能可靠地审计它们、诊断问题,并在可预测的时间内修复它们。随着系统复杂性的增加,不同类型服务器的数量也会增加,所需的性能水平越高,这种控制级别就变得越重要。
管理生产环境的流程应该用于其他测试环境,如预发布(staging)、集成等。通过这种方式,您可以使用自动化变更管理系统在手动测试环境中创建完美调优的配置。这些配置可以调整到完美,也许可以使用容量测试的反馈来评估您所做的配置更改。当您对结果满意时,可以以可预测、可靠的方式将其复制到需要该配置的每台服务器,包括生产环境。环境的所有方面都应该以这种方式管理,包括中间件(数据库、Web服务器、消息代理和应用服务器)。每个都可以进行调优和调整,将最优设置添加到您的配置基线中。
通过使用环境的自动化配置和管理、良好的配置管理实践以及(如果适用)虚拟化,可以显著降低自动化环境配置和维护的成本。
一旦正确管理了环境的配置,就可以部署应用程序。具体细节会因系统中采用的技术而大相径庭,但步骤总是非常相似的。我们在第6章”构建和部署脚本”中讨论的构建和部署脚本的创建方法,以及我们监控流程的方式中,都利用了这种相似性。
通过自动化部署和发布,交付过程变得民主化了。开发人员、测试人员和运维团队不再需要依赖工单系统和电子邮件线程来部署构建,以便收集关于系统生产就绪性的反馈。测试人员可以决定他们想在测试环境中使用哪个版本的系统,而不需要自己成为技术专家,也不需要依赖这种专业知识来进行部署。由于部署很简单,他们可以更频繁地更改被测试的构建,也许在发现特别有趣的bug时返回到系统的早期版本,将其行为与最新版本的行为进行比较。销售人员可以访问具有能够促成客户交易的杀手级功能的最新版本应用程序。还有更微妙的变化。根据我们的经验,人们开始稍微放松一些。他们认为整个项目的风险更小——主要是因为它确实风险更小。
风险降低的一个重要原因是发布过程本身被演练、测试和完善的程度。由于您使用相同的流程将系统部署到每个环境并发布它,因此部署过程会被非常频繁地测试——也许每天多次。在您第五十次或第一百次毫无问题地部署复杂系统后,您不再将其视为一件大事。我们的目标是尽快达到这个阶段。如果我们想对发布过程和技术完全有信心,我们必须定期使用它并证明它是好的,就像我们系统的任何其他方面一样。应该能够以最小的时间和形式通过部署流水线将单个更改部署到生产环境。发布过程应该被持续评估和改进,尽可能在引入问题的时间点附近识别任何问题。
许多企业需要每天多次发布软件新版本的能力。即使是产品公司也经常需要快速向用户提供软件的新版本,以防发现严重缺陷或安全漏洞。本书中的部署流水线和相关实践使安全可靠地做到这一点成为可能。尽管许多敏捷开发过程依赖于频繁发布到生产环境——这是我们在适用时强烈推荐的过程——但这样做并不总是有意义。有时我们必须做大量工作才能发布一组对用户整体有意义的功能,特别是在产品开发领域。然而,即使您不需要每天多次发布软件,实施部署流水线的过程仍然会对您组织快速可靠地交付软件的能力产生巨大的积极影响。
发布日传统上令人恐惧有两个原因。第一个是担心引入问题,因为在执行软件发布的手动步骤时,某人可能会犯下难以察觉的错误,或者发布说明中存在错误。第二个恐惧是,如果发布失败——无论是因为发布流程中的问题还是软件新版本中的缺陷——你都已经陷入困境。无论哪种情况,唯一的希望就是你能足够聪明地快速解决问题。
第一个问题我们通过每天多次演练发布来缓解,证明我们的自动化部署系统是有效的。第二个恐惧通过提供回退策略来缓解。在最坏的情况下,你可以回到开始发布之前的状态,这样你就有时间评估问题并找到合理的解决方案。
一般来说,最佳的回退策略是在发布新版本时保留应用程序的先前版本——并在之后保留一段时间。这是我们在第10章”部署和发布应用程序”中讨论的一些部署模式的基础。在一个非常简单的应用程序中,这可以通过为每个发布创建一个目录并使用符号链接指向当前版本来实现(忽略数据和配置迁移)。通常,与部署和回滚相关的最复杂问题是迁移生产数据。这在第12章”管理数据”中有详细讨论。
次佳选择是从头重新部署应用程序的先前良好版本。为此,你应该能够点击按钮来发布已通过所有测试阶段的任何版本的应用程序,就像对部署流水线控制下的其他环境一样。这种理想状态对于某些系统是完全可以实现的,即使是对于具有大量关联数据的系统。然而,对于某些系统,即使是单个变更,提供完整的、版本中立的回退的成本在时间上(如果不是金钱上)也可能过高。尽管如此,这个理想很有用,因为它设定了每个项目都应该努力实现的目标。即使在某些方面略有不足,越接近这个理想状态,部署就越容易。
绝对不应该为回退和部署使用不同的流程,也不要执行增量部署或回滚。这些流程很少被测试,因此不可靠。它们也不会从已知良好的基线开始,因此会很脆弱。始终通过保留应用程序的旧版本部署或完全重新部署先前已知良好的版本来回滚。
当发布候选版本可以部署到生产环境时,我们将确信关于它的以下断言是真实的:
• 代码可以编译。
• 代码按照开发人员的预期工作,因为它通过了单元测试。
• 系统按照分析师或用户的预期工作,因为它通过了所有验收测试。
• 基础设施和基准环境的配置得到适当管理,因为应用程序已在生产环境的模拟环境中测试过。
• 代码具备所有正确的组件,因为它是可部署的。
• 部署系统是有效的,因为至少这个发布候选版本在开发环境中使用过一次,在验收测试阶段使用过一次,在候选版本被提升到这个阶段之前在测试环境中使用过一次。
• 版本控制系统保存了我们部署所需的一切,无需人工干预,因为我们已经多次部署了系统。
这种”建立在成功之上”的方法,结合我们尽可能快地使流程或其任何部分失败的理念,在每个层面都有效。
无论你是从头开始一个新项目,还是试图为现有系统创建自动化流水线,通常都应该采用增量方法来实现部署流水线。在本节中,我们将制定一个从零到完整流水线的策略。一般来说,步骤如下:
建模你的价值流并创建一个行走骨架(walking skeleton)。
自动化构建和部署流程。
自动化单元测试和代码分析。
自动化验收测试。
自动化发布。
如本章开头所述,第一步是绘制从签入到发布的价值流部分。如果你的项目已经在运行,你可以用铅笔和纸在大约半小时内完成。去与参与此流程的每个人交谈,并写下这些步骤。包括对经过时间和增值时间的最佳估计。如果你正在开展一个新项目,你将不得不提出一个合适的价值流。一种方法是查看同一组织内具有与你类似特征的另一个项目。或者,你可以从最基本的开始:一个提交阶段来构建你的应用程序并运行基本指标和单元测试,一个阶段来运行验收测试,以及第三个阶段将你的应用程序部署到类生产环境,以便你可以演示它。
一旦你有了价值流图,你就可以在持续集成和发布管理工具中对流程进行建模。如果你的工具不允许直接对价值流建模,你可以通过项目之间的依赖关系来模拟它。这些项目最初什么都不做——它们只是占位符,你可以依次触发它们。以我们的”最低限度”示例为例,每当有人提交到版本控制时,就应该运行提交阶段。运行验收测试的阶段应该在提交阶段通过时自动触发,使用提交阶段中创建的相同二进制文件。任何将二进制文件部署到类生产环境以进行手动测试或发布的阶段都应该要求你按下按钮来选择要部署的版本,这个功能通常需要授权。
然后你可以让这些占位符真正发挥作用。如果你的项目已经进行了一段时间,这意味着插入现有的构建、测试和部署脚本。如果没有,你的目标是创建一个”行走的骨架”(walking skeleton) [bEUuac],这意味着做尽可能少的工作来建立所有关键元素。首先,让提交阶段运行起来。如果你还没有任何代码或单元测试,只需创建最简单的”Hello world”示例,或者对于Web应用程序,创建一个HTML页面,并放置一个断言为true的单元测试。然后你可以进行部署——也许在IIS上设置一个虚拟目录并将你的网页放入其中。最后,你可以进行验收测试——你需要在部署之后进行此操作,因为你需要部署应用程序才能对其运行验收测试。你的验收测试可以启动WebDriver或Sahi,并验证网页包含文本”Hello world”。
对于新项目,所有这些都应该在开发工作开始之前完成——如果你使用迭代开发过程,作为迭代零(iteration zero)的一部分。你的组织的系统管理员或运维人员应该参与设置类生产环境以运行演示,并开发将应用程序部署到该环境的脚本。在接下来的章节中,有关于如何创建行走的骨架并随着项目的发展而开发它的更多细节。
实现流水线的第一步是自动化构建和部署过程。构建过程将源代码作为输入并产生二进制文件作为输出。“二进制文件”是一个故意模糊的词,因为你的构建过程产生的内容将取决于你使用的技术。二进制文件的关键特征是你应该能够将它们复制到新机器上,并且在适当配置的环境和该环境中应用程序的正确配置下,启动你的应用程序——而不依赖于该机器上安装的任何开发工具链。
构建过程应该在每次有人提交时由持续集成服务器软件执行。使用第56页”实施持续集成”部分列出的众多工具之一。你的CI服务器应该配置为监视你的版本控制系统,每次对其进行更改时检出或更新源代码,运行自动化构建过程,并将二进制文件存储在文件系统上,整个团队可以通过CI服务器的用户界面访问它们。
一旦你有了持续构建过程并运行起来,下一步是自动化部署。首先,你需要获得一台机器来部署你的应用程序。对于新项目,这可以是你的持续集成服务器所在的机器。对于更成熟的项目,你可能需要找到几台机器。根据你的组织的惯例,这个环境可以称为预发布(staging)或用户验收测试(UAT)环境。无论哪种方式,这个环境都应该在某种程度上像生产环境,如第10章”部署和发布应用程序”中所述,其配置和维护应该是一个完全自动化的过程,如第11章”管理基础设施和环境”中所述。
第6章”构建和部署脚本”中讨论了几种常见的部署自动化方法。部署可能首先涉及打包你的应用程序,如果应用程序的不同部分需要安装在不同的机器上,可能会打包成几个单独的包。接下来,安装和配置应用程序的过程应该自动化。最后,你应该编写某种形式的自动化部署测试来验证应用程序已成功部署。重要的是部署过程是可靠的,因为它也被用作自动化验收测试的先决条件。
一旦你的应用程序的部署过程自动化,下一步是能够按按钮部署到你的UAT环境。配置你的CI服务器,以便你可以选择应用程序的任何构建并点击按钮触发一个过程,该过程获取该构建产生的二进制文件,运行部署构建的脚本,并运行部署测试。确保在开发构建和部署系统时使用我们描述的原则,例如只构建一次二进制文件并将配置与二进制文件分离,以便相同的二进制文件可以在每个环境中使用。这将确保你的项目的配置管理建立在坚实的基础上。
除了用户安装的软件外,发布过程应该与你用于部署到测试环境的过程相同。唯一的技术差异应该在于环境的配置。
开发部署流水线的下一步是实现完整的提交阶段。这意味着在每次签入时运行单元测试、代码分析,以及最终的一系列验收测试和集成测试。运行单元测试不需要任何复杂的设置,因为根据定义,单元测试不依赖于应用程序的运行状态。相反,它们可以通过众多xUnit风格的框架针对二进制文件运行。
由于单元测试不会访问文件系统或数据库(否则它们就是组件测试了),因此运行速度应该很快。这就是为什么你应该在构建应用程序后立即开始运行单元测试。然后,你还可以对应用程序运行静态分析工具,以报告有用的诊断数据,如编码风格、代码覆盖率、圈复杂度(cyclomatic complexity)、耦合度等。
随着应用程序变得更加复杂,你需要编写大量的单元测试以及一组组件测试。这些都应该放入提交阶段。一旦提交阶段超过5分钟,就有必要将其拆分为并行运行的测试套件。为了做到这一点,你需要准备几台机器(或一台具有充足RAM和多个CPU的机器),并使用支持分配工作并并行运行的CI服务器。
流水线的验收测试阶段可以重用你用于部署到测试环境的脚本。唯一的区别是,在冒烟测试运行之后,需要启动验收测试框架,并且应该在测试运行结束时收集它生成的报告以供分析。存储应用程序创建的日志也是有意义的。如果你的应用程序有GUI,你还可以使用Vnc2swf之类的工具在验收测试运行时创建屏幕录像,以帮助你调试问题。
验收测试分为两种类型:功能性和非功能性。从项目早期就开始测试非功能性参数(如容量和扩展特性)至关重要,这样你就能了解应用程序是否会满足其非功能性需求。在设置和部署方面,这个阶段的工作方式可以与功能验收测试阶段完全相同。然而,测试内容当然会有所不同(参见第9章”测试非功能性需求”,了解有关创建此类测试的更多信息)。刚开始时,完全可以将验收测试和性能测试作为单个阶段的一部分连续运行。然后,你可以将它们分开,以便能够轻松区分哪组测试失败了。一套良好的自动化验收测试将帮助你追踪间歇性和难以重现的问题,如竞态条件(race conditions)、死锁(deadlocks)和资源争用(resource contention),这些问题在应用程序发布后将更难发现和调试。
你在流水线的验收测试和提交测试阶段创建的各种测试当然将由你的测试策略决定(参见第4章”实施测试策略”)。然而,你应该尝试在项目早期就自动化至少一到两个你需要运行的每种类型的测试,并将它们整合到部署流水线中。这样,你就拥有了一个框架,可以随着项目的发展轻松添加测试。
我们上面描述的步骤几乎存在于我们见过的每个价值流(因此也包括流水线)中。它们通常是自动化的首要目标。随着项目变得更加复杂,你的价值流也会演进。流水线还有两种常见的潜在扩展:组件和分支。大型应用程序最好构建为一组组装在一起的组件。在这样的项目中,为每个组件设置一个小型流水线可能是有意义的,然后有一个流水线将所有组件组装起来,并让整个应用程序经过验收测试、非功能性测试,然后部署到测试、预发布和生产环境。这个主题在第13章”管理组件和依赖关系”中有详细讨论。管理分支在第14章”高级版本控制”中讨论。
流水线的实现在不同项目之间会有很大差异,但任务本身对大多数项目来说是一致的。将它们作为模式使用可以加快任何项目的构建和部署过程的创建。然而,归根结底,流水线的意义在于为构建、部署、测试和发布应用程序的过程建立模型。然后,流水线确保每个变更都能以尽可能自动化的方式独立通过这个过程。
当你实现流水线时,你会发现与相关人员的对话以及你实现的效率提升反过来会影响你的流程。因此,记住三件事很重要。
首先,整个流水线不需要一次性实现。它应该增量实现。如果你的流程中有某个部分目前是手动的,请在工作流中为其创建一个占位符。确保你的实现记录了这个手动流程何时开始和何时完成。这样你就可以看到每个手动流程花费了多少时间,从而估计它在多大程度上是一个瓶颈。
其次,你的流水线是关于构建、部署、测试和发布应用程序过程效率的丰富数据源。你创建的部署流水线实现应该记录每次进程的开始和结束时间,以及通过每个阶段的确切变更内容。这些数据反过来让你能够测量从提交变更到部署到生产环境的周期时间(cycle time),以及在流程每个阶段花费的时间(市场上的一些商业工具会为你完成这项工作)。因此,你可以准确地看到流程的瓶颈在哪里,并按优先级解决它们。
最后,你的部署流水线是一个活的系统。当你持续改进交付流程时,你应该继续维护你的部署流水线,以改进和重构它的方式就像你改进使用它来交付的应用程序一样。
反馈是任何软件交付流程的核心。改进反馈的最佳方法是缩短反馈周期并使结果可见。你应该持续测量并以某种难以忽视的方式广播测量结果,比如在墙上非常显眼的海报上,或者在专门用于显示醒目、大号结果的计算机显示器上。这样的设备被称为信息辐射器(information radiator)。
然而,重要的问题是:你应该测量什么?你选择测量的内容将对团队的行为产生巨大影响(这被称为霍桑效应,Hawthorne effect)。测量代码行数,开发人员就会编写许多短代码行。测量修复的缺陷数量,测试人员就会记录那些本可以通过与开发人员快速讨论就能修复的bug。
根据精益哲学(lean philosophy),必须进行全局优化,而不是局部优化。如果你花费大量时间消除一个实际上并不是制约交付流程的瓶颈,你不会对交付流程产生任何影响。因此,拥有一个可用于确定整个交付流程是否存在问题的全局指标非常重要。
对于软件交付流程,最重要的全局指标是周期时间。这是从决定需要实现一个功能到将该功能发布给用户之间的时间。正如Mary Poppendieck所问:“你的组织部署一个只涉及一行代码的变更需要多长时间?你是否在可重复、可靠的基础上做到这一点?”这个指标很难测量,因为它涵盖了软件交付流程的许多部分——从分析、开发到发布。然而,它比任何其他指标都更能说明你的流程状况。
许多项目错误地选择其他度量作为主要指标。关注软件质量的项目通常选择测量缺陷数量。然而,这是一个次要度量。如果使用这个度量的团队发现了一个缺陷,但需要六个月才能发布修复程序,那么知道缺陷的存在并不是很有用。专注于缩短周期时间会鼓励提高质量的实践,比如使用在每次提交后运行的全面自动化测试套件。
部署流水线的正确实现应该能够简单地计算从提交到发布这部分价值流对应的周期时间。它还应该让你看到从提交到流程每个阶段的前置时间(lead time),这样你就能发现瓶颈。
一旦你知道应用程序的周期时间,就可以找出如何最好地缩短它。你可以使用约束理论(Theory of Constraints)来做到这一点,应用以下流程:
识别系统的限制性约束。这是构建、测试、部署和发布流程中的瓶颈部分。随便举个例子,可能是手动测试流程。
利用约束。这意味着你应该最大化该流程部分的吞吐量。在我们的例子(手动测试)中,你要确保始终有一个等待手动测试的故事缓冲区,并确保参与手动测试的资源不会被用于其他任何事情。
使所有其他流程服从约束。这意味着其他资源不会以100%的效率工作——例如,如果你的开发人员全力开发故事,等待测试的故事积压会持续增长。相反,让你的开发人员刚好努力工作到保持积压恒定,并将其余时间用于编写自动化测试来捕获bug,这样就可以减少手动测试所需的时间。
提升约束。如果你的周期时间仍然太长(换句话说,步骤2和3还不够有效),你需要增加可用资源——雇用更多测试人员,或者在自动化测试上投入更多精力。
冲洗并重复。找到系统的下一个约束并返回步骤1。
虽然周期时间是软件交付中最重要的指标,但还有许多其他诊断指标可以警告你存在问题。这些包括:
• 自动化测试覆盖率
• 代码库属性,如重复量、圈复杂度(cyclomatic complexity)、传出和传入耦合(efferent and afferent coupling)、样式问题等
• 缺陷数量
• 速率(velocity),即团队交付经过工作、测试、可用代码的速率
• 每天提交到版本控制系统的次数
• 每天构建的次数
• 每天构建失败的次数
• 构建持续时间,包括自动化测试
值得考虑的是如何呈现这些指标。上述报告会产生大量数据,而解读这些数据是一门艺术。例如,项目经理可能希望看到这些数据被分析并汇总成一个”健康度”指标,以红绿灯的形式显示红色、黄色或绿色。团队的技术负责人则需要更详细的信息,但即使是他们也不想翻阅大量报告。我们的同事Julias Shaw创建了一个名为Panopticode的项目,它针对Java代码运行一系列此类报告,并生成丰富、密集的可视化图表(如图5.8),让你一眼就能看出代码库是否存在问题以及问题所在。关键是创建能够汇总数据并以某种形式呈现的可视化图表,使人脑能够最有效地利用其无与伦比的模式匹配能力来识别流程或代码库中的问题。
每个团队的持续集成服务器应该在每次签入时生成这些报告和可视化图表,并将报告存储在制品仓库中。然后应该将结果整理到数据库中,并跟踪每个团队的情况。这些结果应该发布在内部网站上——为每个项目创建一个页面。最后,将它们汇总在一起,以便可以监控开发计划中所有项目的情况,甚至是整个组织的情况。
部署流水线的目的是让参与软件交付的每个人都能看到从签入到发布的构建进度。应该能够看到哪些变更破坏了应用程序,哪些变更产生了适合手动测试或发布的候选版本。你的实现应该能够一键部署到手动测试环境,并查看哪些候选版本在这些环境中。选择发布应用程序的特定版本也应该是一项一键式任务,可以在完全了解所部署的候选版本已成功通过整个流水线的情况下执行,因此已经在类生产环境中对其进行了一系列自动化和手动测试。
一旦实现了部署流水线,发布流程中的低效问题就会变得显而易见。可以从运行中的部署流水线中获得各种有用的信息,例如候选版本通过各个手动测试阶段需要多长时间、从签入到发布的平均周期时间,以及在流程的哪个阶段发现了多少缺陷。有了这些信息,你就可以优化构建和发布软件的流程。
实现部署流水线没有放之四海而皆准的解决方案。关键是创建一个记录系统,管理从签入到发布的每个变更,提供你需要的信息,以便尽早在流程中发现问题。拥有部署流水线的实现后,可以用来找出流程中的低效之处,从而加快反馈周期并使其更强大,也许可以通过添加更多自动化验收测试并更积极地并行化它们,或者使测试环境更接近生产环境,或者实施更好的配置管理流程。
反过来,部署流水线依赖于一些基础条件:良好的配置管理、用于构建和部署应用程序的自动化脚本,以及证明应用程序将为用户提供价值的自动化测试。它还需要纪律性,例如确保只有通过自动化构建、测试和部署系统的变更才能发布。我们在第15章”管理持续交付”中讨论了这些先决条件和必要的纪律,其中包括持续集成、测试、数据管理等方面的成熟度模型。
本书的后续章节将更详细地探讨实现部署流水线,探讨一些可能出现的常见问题,并讨论可以在此处描述的完整生命周期部署流水线的背景下采用的技术。
在非常简单的项目中,可以使用IDE(集成开发环境)的功能来完成软件的构建和测试。然而,这实际上只适用于最琐碎的任务。一旦项目扩展到不止一个人、跨越几天以上,或者输出的不止一个可执行文件,就需要更多的控制,否则会变得复杂和难以管理。在大型或分布式团队(包括开源项目)上工作时,编写构建、测试和打包应用程序的脚本也至关重要,否则可能需要几天时间才能让新团队成员启动并运行。
第一步实际上非常简单:几乎所有现代平台都有从命令行运行构建的方法。Rails项目可以运行默认的Rake任务;.NET项目可以使用MsBuild;Java项目(如果设置正确)可以使用Ant、Maven、Buildr或Gradle;而使用SCons,启动一个简单的C/C++项目不需要太多工作。这使得开始持续集成变得简单明了——只需让你的CI服务器运行此命令来创建二进制文件。在许多平台上运行测试也是一个相对简单的过程,只要你使用的是比较流行的测试框架之一。Rails用户和使用Maven或Buildr的Java项目只需运行相关命令即可。.NET和C/C++用户需要进行一些复制粘贴才能让程序运行起来。然而,一旦你的项目变得更加复杂——你有多个组件,或有不寻常的打包需求——你就需要卷起袖子深入研究构建脚本了。
自动化部署引入了更多的复杂性。将软件部署到测试和生产环境中很少像将单个二进制文件放入生产环境然后满意地坐下来那样简单。在大多数情况下,它需要一系列步骤,例如配置应用程序、初始化数据、配置基础设施、操作系统和中间件、设置模拟外部系统等等。随着项目变得更加复杂,这些步骤变得更多、更长,并且(如果它们没有自动化)更容易出错。
除了最简单的情况外,使用通用构建工具执行部署都是在自找麻烦。可用的部署机制将仅限于支持你的目标环境和中间件的那些。更重要的是,如何进行自动化部署的决策应该由开发人员和运维人员共同做出,因为他们都需要熟悉这项技术。
本章旨在为你概述所有构建和部署工具的共同原则,帮助你入门的信息,一些技巧和窍门,以及更多信息的指引。我们在本章中不涉及通过脚本管理环境;这将在第11章”管理基础设施和环境”中介绍。本章中我们也不提供代码示例和工具的详细描述,因为这些很快就会过时。你可以在本书的网站上找到关于可用工具的更多详细信息以及示例脚本。
构建和部署系统必须是有生命力的,能够持续不仅在初始开发项目期间,而且在其作为可维护软件系统在生产中的整个生命周期内。因此,它们必须经过精心设计和维护——以与对待其余源代码相同的方式对待——并定期运行,以便我们知道当我们准备使用它们时它们是有效的。
图6.1 一个简单的构建依赖网络
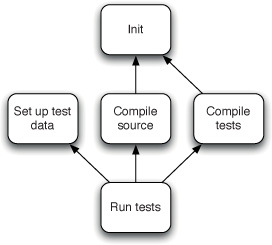
自动化构建工具已经成为软件开发的一部分很长时间了。许多人会记得Make及其众多变体,它们是多年来使用的标准构建工具。所有构建工具都有一个共同的核心:它们允许你建模一个依赖网络。当你运行工具时,它将计算如何通过按正确顺序执行任务来达到你指定的目标,每个目标所依赖的任务只运行一次。例如,假设你想运行测试。为了做到这一点,需要编译你的代码和测试,并设置测试数据。编译任何东西都需要初始化环境。图6.1显示了一个示例依赖网络。
你的构建工具将计算出它需要执行依赖网络中的每个任务。它可以从init或设置测试数据开始,因为这些任务是独立的。一旦完成init,它就可以编译源代码或测试——但它必须两者都做,并且在运行测试之前设置测试数据。即使多个目标依赖于init,它也只会执行一次。
值得注意的一个小点是,任务有两个基本特征:它所做的事情和它所依赖的其他事情。这两个特征在每个构建工具中都有建模。
然而,构建工具存在一个不同之处:它们是面向任务的还是面向产品的。面向任务的构建工具(例如Ant、NAnt和MsBuild)根据一组任务来描述依赖网络。面向产品的工具,如Make,根据它们生成的产品(如可执行文件)来描述事物。
这种区别乍一看似乎有些学术化,但为了理解如何优化构建并确保构建过程的正确性,这一点很重要。例如,构建工具必须确保对于给定的目标,每个前置条件必须恰好执行一次。如果遗漏了前置条件,构建过程的结果将是错误的。如果前置条件执行了多次,最好的情况是构建将花费更长时间(如果前置条件是幂等的),最坏的情况是构建过程的结果再次是错误的。
通常,构建工具将遍历整个网络,调用(但不一定执行)每个任务。因此,在我们的示例中,我们假设的构建工具可能会依次调用设置测试数据、Init、编译源代码、Init、编译测试,然后是运行测试任务。在面向任务的工具中,每个任务都会知道它是否已经作为构建的一部分执行过。因此,即使Init任务被调用两次,它也只会执行一次。
然而,在面向产品的工具中,世界被建模为一组文件。例如,在我们的示例中,编译源代码和编译测试目标都会生成一个包含所有编译代码的单个文件——我们称它们为 source.so 和 tests.so。运行测试目标则会生成一个名为 testreports.zip 的文件。面向产品的构建系统会确保在编译源代码和编译测试之后调用运行测试,但运行测试目标只有在任一 .so 文件的时间戳晚于 testreports.zip 的时间戳时才会真正执行。
因此,面向产品的构建工具以每个任务生成的文件的时间戳形式保存其状态(SCons 使用 MD5 签名)。这在编译 C 或 C++ 时非常有用,因为 Make 会确保只编译自上次构建以来发生更改的源代码文件。这个功能称为增量构建(incremental build),在大型项目中可以比完全构建节省数小时时间。C/C++ 中的编译需要相对较长的时间,因为编译器必须做大量工作来优化代码。而在虚拟机上运行的语言中,编译器只是创建字节码,虚拟机的即时(JIT)编译器在运行时进行优化。
相比之下,面向任务的构建工具在构建之间不保留任何状态。这使得它们功能较弱,完全不适合编译 C++。但是,它们对于 C# 等语言工作良好,因为这些语言的编译器内置了执行增量构建的逻辑。最后值得注意的是,Rake 既可以作为面向产品的工具,也可以作为面向任务的工具。有关依赖网络的更多信息,请参阅 Martin Fowler 的《领域特定语言》(Domain-Specific Languages)[8ZKox1]。
现在我们将简要概述当前的构建工具。同样,你可以在本书网站[dzMeNE]找到使用这些技术的构建脚本示例和进一步的参考资料。
Make 及其变体在系统开发领域仍然很强大。它是一个强大的面向产品的构建工具,能够跟踪构建中的依赖关系,并且只构建受特定更改影响的组件。当编译时间是开发周期中的重要成本时,这对于优化开发团队的性能至关重要。
不幸的是,Make 有许多缺点。随着应用程序变得更加复杂,组件之间的依赖关系数量增加,Make 中内置规则的复杂性意味着它们变得难以调试。
为了驯服这种复杂性,大型代码库团队采用的常见约定是为每个目录创建一个 Makefile,并有一个顶级 Makefile 递归运行每个子目录中的 Makefile。这意味着构建信息和过程可能分散在许多文件中。当有人提交对构建的更改时,很难弄清楚具体发生了什么变化以及它将如何影响最终的交付物。
Makefile 还容易出现一类非常难以发现的错误,因为在某些情况下空白字符可能很重要。例如,在命令脚本中,要传递给 shell 的命令必须以制表符开头。如果使用空格,脚本将无法工作。
Make 的另一个缺点是它依赖 shell 来实际执行任何操作。因此,Makefile 是特定于操作系统的(实际上,围绕 Make 的工具链已经做了大量工作,以使构建能够跨各种 UNIX 版本工作)。由于 Makefile 是一种外部 DSL,不提供对核心系统的扩展(除了定义新规则),因此任何扩展都必须在无法访问 Make 内部数据结构的情况下重新发明常见解决方案。
这些问题,加上 Make 应用程序根基的声明式编程模型对大多数开发者来说并不熟悉(他们通常更习惯命令式编程),意味着 Make 很少被用作新开发商业应用程序的主要构建工具。
“这是我对软件不满意的日子之一。有时让我惊讶的是,有多少这样的日子涉及 Make。”——Mark Dominus,“Suffering from ‘make install’”[dyGIMy]。
如今,许多 C/C++ 开发者更喜欢使用 SCons 而不是 Make。SCons 本身及其构建文件都是用 Python 编写的。这使它成为比 Make 更强大、更可移植的工具。它包括许多有用的功能,例如开箱即用地支持 Windows 和并行化构建。
随着 Java 的出现,开发者开始进行更多跨平台开发。Make 固有的局限性变得更加痛苦。作为回应,Java 社区尝试了几种解决方案,最初将 Make 本身移植到 Java。与此同时,XML 作为构建结构化文档的便捷方式开始流行。这两种方法融合在一起,产生了 Apache Ant 构建工具。
Ant 是完全跨平台的,包含一组用 Java 编写的任务来执行常见操作,如编译和文件系统操作。Ant 可以轻松地用 Java 编写的新任务进行扩展。Ant 迅速成为 Java 项目的事实标准构建工具。现在它得到了 IDE 和其他工具的广泛支持。
Ant 是一个面向任务的构建工具。Ant 的运行时组件是用 Java 编写的,但 Ant 脚本是用 XML 编写的外部 DSL。这种组合赋予 Ant 强大的跨平台能力。它也是一个极其灵活和强大的系统,几乎为你想做的任何事情都提供了 Ant 任务。
然而,Ant 存在几个缺点:
• 你需要用 XML 编写构建脚本,这既不简洁也不便于人类阅读。
• Ant 的领域模型很薄弱。除了任务(task)之外没有真正的领域概念,这意味着你必须花费大量时间编写样板代码来完成编译、创建 JAR 包、运行测试等工作。
• Ant 是一种声明式语言,而不是命令式语言。然而,它有足够多的命令式风格标签(如令人畏惧的 <antcall>),允许用户混用两种风格,从而造成混乱和困惑。
• 你无法轻松地查询 Ant 任务的信息,比如”运行了多少个测试?“和”它们花了多长时间?“你只能让工具将这些信息打印到命令行以便解析,或者通过编写自定义 Java 代码来插桩(instrument) Ant 的内部机制。
• 虽然 Ant 通过 import 和 macrodef 任务支持复用,但新手用户对这些功能理解不足。
由于这些限制,Ant 文件往往冗长且结构不良——Ant 文件长达数千行并不罕见。在处理 Ant 文件时,Julian Simpson 在《The ThoughtWorks Anthology》中的文章”重构 Ant 构建文件”是一个宝贵的资源。
当微软首次推出 .NET 框架时,它与 Java 语言和环境有许多共同特性。在这个新平台上工作的 Java 开发人员迅速移植了一些他们喜爱的开源 Java 工具。因此,我们有了 NUnit 和 NMock 来代替 JUnit 和 JMock——而且可以预见的是,还有 NAnt。NAnt 本质上使用与 Ant 相同的语法,只有少数差异。
微软后来推出了自己对 NAnt 的小幅改进版本,称为 MSBuild。它是 Ant 和 NAnt 的直接后代,任何使用过这些工具的人都会觉得熟悉。然而,它与 Visual Studio 的集成更紧密,能够理解如何构建 Visual Studio 解决方案和项目以及如何管理依赖(因此,NAnt 脚本经常调用 MSBuild 来进行编译)。虽然一些用户抱怨 MSBuild 提供的灵活性不如 NAnt,但它更新更频繁且作为 .NET 框架的一部分发布,这使 NAnt 成为了小众工具。
它们都受到上述 Ant 的许多限制的困扰。
有一段时间,Ant 在 Java 社区无处不在——但创新并未止步于此。Maven 试图通过拥有更复杂的领域来消除 Ant 文件中的大量样板代码,该领域对 Java 项目的布局方式做出了许多假设。这种约定优于配置(convention over configuration)的原则意味着,只要你的项目符合 Maven 规定的结构,它就能用一个命令执行几乎所有你能想象的构建、部署、测试和发布任务,而无需编写超过几行 XML。这包括为你的项目创建一个网站,默认托管应用程序的 Javadoc。
Maven 的另一个重要特性是支持自动管理 Java 库和项目间的依赖,这是大型 Java 项目中的痛点之一。Maven 还支持一个复杂但严格的软件分区方案,允许你将复杂的解决方案分解为更小的组件。
Maven 的问题有三个方面。首先,如果你的项目不符合 Maven 对结构和生命周期的假设,让 Maven 按你的意愿工作可能会极其困难(甚至不可能)。在一些团队中,这被认为是一个特性——它迫使开发团队按照 Maven 的规定来组织项目。对于缺乏经验的开发团队或有大量项目的情况,这可能是件好事。但如果你想做稍微偏离常规的事情(比如在执行测试前加载一些自定义测试数据),你将不得不破坏 Maven 的生命周期和领域模型——这是一个极其痛苦且难以维护的做法,但往往不可避免。Ant 比 Maven 灵活得多。
Maven 的第二个问题是它也使用用 XML 编写的外部 DSL,这意味着为了扩展它,你需要编写代码。虽然编写 Maven 插件并不过分复杂,但这不是你能在几分钟内完成的事情;你需要了解 Mojo、插件描述符(plugin descriptor)以及你阅读本文时 Maven 正在使用的任何控制反转(inversion-of-control)框架。幸运的是,Maven 几乎为你在普通 Java 项目中想做的所有事情都提供了插件。
Maven 的第三个问题是,在默认配置下,它会自动更新。Maven 的核心非常小,为了使自己功能完整,它会从互联网下载自己的插件。Maven 每次运行时都会尝试升级自己,由于插件的升级或降级,它可能会出现不可预测的故障。也许更严重的是,这意味着你无法重现构建。一个相关的问题是 Maven 的库和依赖管理功能允许跨项目使用组件的快照(snapshot),这再次使得重现特定构建变得困难,如果它使用了快照依赖的话。
对于某些团队来说,Maven 的约束可能过于严格,或者重构构建以匹配 Maven 的假设需要付出太多努力。因此,他们坚持使用 Ant。最近,一个名为 Ivy 的工具被创建出来,它允许你管理库和组件间的依赖而无需使用 Maven。这使得如果你因某种原因必须使用 Ant,也能获得 Maven 的一些好处。
请注意,虽然 Ivy 和 Maven 在管理组件之间的依赖关系方面表现出色,但它们管理外部依赖的默认机制——从 Maven 社区维护的互联网存档库中下载——并不总是最佳选择。首先,有一个众所周知的问题:第一次启动构建时,会导致等待 Maven 下载半个互联网的内容。更麻烦的是,除非你对每个依赖使用的版本非常严格,否则很容易出现菱形依赖问题,以及因为 Maven 在你不知情的情况下更改了某个库的版本而导致的故障。
关于管理库和组件之间依赖关系的更多信息,请参阅第 13 章”管理组件和依赖”。
Ant 及其同类工具是用于构建软件的外部领域特定语言(DSL)。然而,它们选择用 XML 来表示这些语言,使得它们难以创建、阅读、维护和扩展。Ruby 的主流构建工具 Rake 诞生于一个实验,目的是看看是否可以通过在 Ruby 中创建内部 DSL 来轻松复制 Make 的功能。答案是”可以”,于是 Rake 诞生了。Rake 是一个类似于 Make 的面向产物的工具,但它也可以用作面向任务的工具。
与 Make 一样,Rake 除了任务和依赖关系之外不理解任何东西。然而,由于 Rake 脚本是纯 Ruby 代码,你可以使用 Ruby 的 API 来执行任何你想要的任务。因此,在 Rake 中创建强大的、平台无关的构建文件非常简单:你可以使用通用编程语言的全部原生能力。
当然,使用通用语言意味着在正常开发中可用的所有工具在维护构建脚本时也都可用。你可以重构和模块化你的构建,并且可以使用常规的开发环境。使用标准 Ruby 调试器调试 Rake 非常简单。如果在执行 Rake 构建脚本时遇到错误,你会得到一个堆栈跟踪来帮助你理解出了什么问题。实际上,由于 Ruby 中的类可以扩展,你可以从构建脚本内部向 Rake 的类添加方法以进行调试。Martin Fowler 的 bliki 条目”使用 Rake 构建语言”中描述了这个以及许多其他有用的 Rake 技术。
Rake 由 Ruby 程序员开发并广泛用于 Ruby 项目,这并不意味着它不能用于使用其他技术的项目(例如,Albacore 项目提供了一组用于构建 .NET 系统的 Rake 任务)。Rake 是一个通用的构建脚本工具。当然,你的开发团队需要具备(或获得)一些 Ruby 的基本编程技能,但对于 Ant 或 NAnt 你也可以这么说。
Rake 有两个普遍的缺点:首先,你必须确保在你的平台上有一个可用的运行时(JRuby 正在迅速成为最便携和可靠的平台);其次,你必须与 RubyGems 交互。
Rake 的简洁性和强大功能提供了一个令人信服的理由,即构建脚本应该用真正的编程语言编写。新一代构建工具,如 Buildr、Gradle 和 Gantt,都采用了这种方法。它们都具有用于构建软件的内部 DSL。然而,它们试图让依赖管理和多项目构建的更复杂挑战同样简单。我们将更详细地讨论 Buildr,因为这是我们最熟悉的工具。
Buildr 构建在 Rake 之上,所以你在 Rake 中可以做的所有事情在 Buildr 中也可以继续做。然而,Buildr 也是 Maven 的替代品——它使用与 Maven 相同的约定,包括文件系统布局、工件规范和仓库。它还允许你在零配置的情况下使用 Ant 任务(包括任何自定义任务)。它利用 Rake 的面向产物框架来执行增量构建。令人惊讶的是,它也比 Maven 更快。然而,与 Maven 不同,自定义任务和创建自己的新任务极其简单。
如果你正在启动一个新的 Java 项目,或者正在寻找 Ant 或 Maven 的替代品,我们强烈建议你考虑 Buildr,如果你更喜欢 Groovy 中的 DSL,也可以考虑 Gradle。
Windows 用户也不会错过新一波的内部 DSL 构建工具。Psake 发音为”清酒”,是一个用 PowerShell 编写的内部 DSL,它提供了面向任务的依赖网络。
在本节中,我们将阐述构建和部署脚本的一些通用原则和实践,这些原则和实践应该适用于你使用的任何技术。
我们是领域驱动设计(DDD)的忠实粉丝,并在创建的任何软件设计中应用这些技术。在设计构建脚本时也不例外。这也许是一种有点浮夸的说法,即我们希望构建脚本的结构能够清晰地表示它们正在实现的过程。采用这种方法可以确保我们的脚本具有明确定义的结构,帮助我们在维护期间保持它们的整洁,并最大限度地减少构建和部署系统组件之间的依赖关系。幸运的是,部署流水线(Deployment Pipeline)为划分构建脚本之间的职责提供了出色的组织原则。
当您首次开始项目时,使用一个包含部署流水线执行过程中所有操作的单一脚本是合理的,其中包含尚未自动化步骤的虚拟目标。然而,一旦脚本变得足够长,您可以将其拆分为流水线中每个阶段的独立脚本。因此,您将拥有一个提交脚本,其中包含编译应用程序、打包、运行提交测试套件以及执行代码静态分析所需的所有目标。然后您需要一个功能验收测试脚本,它调用部署工具将应用程序部署到适当的环境,然后准备数据,最后运行验收测试。您还可以创建一个脚本来运行任何非功能性测试,如压力测试或安全测试。
确保将所有脚本保存在版本控制仓库中,最好与源代码位于同一仓库。开发人员和运维人员能够在构建和部署脚本上协作至关重要,将它们保存在同一仓库中正是实现这一点的关键。
在典型的部署流水线中,成功的提交阶段之后的大多数阶段,如自动化验收测试阶段和用户验收测试阶段,都依赖于将应用程序部署到类生产环境。自动化这一部署同样至关重要。然而,在自动化部署时应该使用合适的工具,而不是通用脚本语言(除非部署过程极其简单)。几乎每个常见的中间件都有配置和部署工具,因此您应该使用这些工具。例如,如果您使用WebSphere Application Server,则需要使用Wsadmin工具来配置容器并部署应用程序。
最重要的是,应用程序部署将由开发人员(至少在他们的本地机器上)以及测试人员和运维人员完成。因此,如何部署应用程序的决策需要所有这些人员参与。这也需要在项目开始时就进行。
在一家大型电信公司的一个项目中,开发人员创建了一个基于Ant的系统来在本地部署他们的应用程序。然而,当需要将应用程序部署到类生产的UAT环境时,开发人员的部署脚本不仅完全失败,而且管理该环境的运维团队拒绝使用它,因为他们没有Ant方面的专业知识。
部分出于这个原因,组建了一个构建团队来创建统一的流程以部署到每个环境。该团队必须与运维人员和开发人员密切合作,创建一个双方都能接受的系统,并提出了一套Bash脚本(统称为Conan the Deployer),用于执行诸如远程连接到应用服务器节点以及重新配置Apache和WebLogic等操作。
运维团队乐意使用Conan部署到生产环境有两个主要原因。首先,他们参与了它的创建。其次,他们看到该脚本在整个流水线中用于部署到每个测试环境,因此开始信任它。
部署脚本应该涵盖升级应用程序和从头安装的情况。这意味着,例如,它应该在部署之前关闭先前运行的应用程序版本,并且应该能够从头创建任何数据库以及升级现有数据库。
如第113页”部署流水线实践”部分所述,使用相同的流程部署到应用程序运行的每个环境至关重要,以确保构建和部署过程得到有效测试。这意味着使用相同的脚本部署到每个环境,并将环境之间的差异(如服务URI和IP地址)表示为单独管理的配置信息。将配置信息从脚本中分离出来并存储在版本控制中,为部署脚本提供某种机制来检索它,如第2章”配置管理”中所述。
构建和部署脚本在开发人员的机器上以及类生产环境中都能正常工作至关重要,并且开发人员应使用它们执行所有构建和部署活动。很容易出现一个只有开发人员使用的并行构建系统——但这会削弱保持构建和部署脚本灵活、良好分解和充分测试的关键驱动力之一。如果您的应用程序依赖于内部开发的其他组件,您需要确保能够轻松获取正确的版本——即已知可以可靠地协同工作的版本——到开发人员的机器上。这是Maven和Ivy等工具非常有用的领域之一。
如果你的应用程序在部署架构方面很复杂,你将不得不做一些简化才能使其在开发人员机器上运行。这可能涉及大量工作,例如在部署时能够用内存数据库替换 Oracle 集群。然而,这些努力肯定会得到回报。当开发人员必须依赖共享资源才能运行应用程序时,运行的频率必然会大大降低,反馈循环也会变慢。这反过来会导致更多缺陷和更慢的开发速度。问题不是”我们如何证明成本的合理性?“而是”我们如何证明不投资于让应用程序在本地运行的合理性?”
在本书中,我们使用”二进制文件”一词作为一个总称,指代作为应用程序部署过程的一部分放置到目标环境中的对象。大多数时候,这是由构建过程创建的一堆文件、应用程序所需的任何库,以及可能已签入版本控制的另一组静态文件。
然而,部署一堆需要分布在整个文件系统中的文件是非常低效的,并且使维护——以升级、回滚和卸载的形式——变得极其痛苦。这就是发明打包系统的原因。如果你的目标是单个操作系统或一小组相关操作系统,我们强烈建议使用该操作系统的打包技术来捆绑所有需要部署的内容。例如,Debian 和 Ubuntu 都使用 Debian 包系统;RedHat、SuSE 和许多其他 Linux 版本使用 RedHat 包系统;Windows 用户可以使用 Microsoft Installer 系统,等等。所有这些打包系统都相对简单易用,并且有很好的工具支持。
每当你的部署涉及在文件系统中散布文件或向注册表添加键时,使用打包系统来完成。这有很多优势。它不仅使维护应用程序变得非常简单,而且你还可以将部署过程附加到环境管理工具上,如 Puppet、CfEngine 和 Marimba;只需将你的包上传到组织存储库,并让这些工具安装你的包的正确版本——就像让它们安装正确版本的 Apache 一样。如果你需要在不同的机器上安装不同的东西(也许你使用的是 n 层架构),你可以为每一层或每种类型的机器创建一个包。打包你的二进制文件应该是部署流水线的自动化部分。
当然,并非所有部署都可以通过这种方式管理。例如,商业中间件服务器通常需要特殊工具来执行部署。在这种情况下,需要采用混合方法。使用包来放置不需要特殊工具的任何内容,然后使用专用工具来执行剩余的部署。
你也可以使用特定平台的打包系统,如 Ruby Gems、Python Eggs、Perl 的 CPAN 等来分发你的应用程序。然而,在创建用于部署的包时,我们倾向于首选操作系统打包系统。如果你要为该平台分发库,特定平台的工具可以很好地工作,但它们是由开发人员设计的,也是为开发人员服务的,而不是系统管理员。大多数系统管理员不喜欢这些工具,因为它们增加了另一层需要处理的管理层,而这一层并不总是与操作系统的包管理系统很好地协作。如果你要跨多个操作系统部署纯 Rails 应用程序,那么一定要使用 RubyGems 来打包它。但在可能的情况下,坚持使用操作系统的标准包管理工具链。[5]
无论部署过程在开始部署时发现目标环境处于什么状态,它都应该始终将目标环境保持在相同的(正确的)状态。
实现这一点的最简单方法是从一个已知良好的基线环境开始,该环境通过自动化或虚拟化进行配置。此环境应包括所有适当的中间件和应用程序工作所需的任何其他内容。然后,你的部署过程可以获取你指定的应用程序版本,并使用适当的中间件部署工具将其部署到此环境。
如果你的配置管理程序不够好以实现这一点,下一个最佳步骤是验证部署过程对环境所做的假设,如果不满足这些假设,则使部署失败。例如,你可以验证是否已安装、正在运行适当的中间件,并且版本正确。无论如何,你还应该验证应用程序所依赖的任何服务是否正在运行且版本正确。
如果你的应用程序作为单个整体进行测试、构建和集成,那么将其作为单个整体进行部署通常是有意义的。这意味着每次部署时,你都应该从头开始部署所有内容,基于从版本控制中的单个修订版派生的二进制文件。这包括多层系统,例如,应用层和表示层同时开发。当你部署一层时,你应该部署所有层。
许多组织坚持认为应该只部署那些已更改的产物,以最大限度地减少变更。但是,确定哪些内容发生了变化的过程可能比从头开始部署更复杂且更容易出错。这种方式也更难测试;当然,不可能测试这种过程的每一种可能排列组合,因此你没有考虑到的病态情况将会是在发布期间发生的那一种,导致你的系统处于未定义状态。
这条规则有几个例外。首先,对于集群系统,同时重新部署整个集群并不总是有意义的;更多细节请参见第263页的”金丝雀发布(Canary Releasing)“部分。
其次,如果你的应用程序是组件化的,并且组件来自多个源代码仓库,你需要从版本控制仓库中部署由修订版本元组(x, y, z,…)创建的二进制文件。在这种情况下,如果你知道只有一个组件发生了变化,并且如果你已经测试了即将在生产环境中使用的组件版本组合,那么你可以只部署正在变化的组件。这里的关键区别在于,从之前状态升级到新状态的过程已经经过测试。同样的原则也适用于构成面向服务架构的各个服务。
最后,另一种方法是使用本身具有幂等性(idempotent)的部署工具。例如,在较低层面,Rsync将确保一个系统上的目标目录与另一个系统上的源目录完全相同,无论目标目录中的文件处于什么状态,使用强大的算法仅通过网络传输目标目录和源目录之间的差异。执行目录更新的版本控制也能达到类似的结果。Puppet在第11章”管理基础设施和环境”中有详细描述,它会分析目标环境的配置,并仅进行必要的更改以使其与环境期望状态的声明性规范保持同步。BMC、HP和IBM生产了大量商业应用程序来管理部署和发布。
每个人都能看到全自动部署流程的吸引力:“一键发布你的软件。”当你看到一个以这种方式部署的大型企业系统时,它看起来像魔法一样。魔法的问题在于,从外部看它可能令人望而生畏。事实上,如果你检查我们的某个部署系统,它只不过是一系列非常简单的增量步骤的集合,随着时间的推移创建了一个复杂的系统。
我们这里的观点是,你不必完成所有步骤才能从工作中获得价值。当你第一次编写脚本在本地开发环境中部署应用程序并与团队共享时,你已经节省了各个开发人员的大量工作。
首先让运维团队与开发人员合作,自动化将应用程序部署到测试环境中。确保运维人员对用于部署的工具感到满意。确保开发人员可以使用相同的过程在他们的开发环境中部署和运行应用程序。然后,继续优化这些脚本,以便它们可以在验收测试环境中用于部署和运行应用程序,从而可以运行测试。然后,沿着部署流水线进一步推进,确保运维团队可以使用相同的工具将应用程序部署到预发布和生产环境。
尽管本书力求尽可能避免特定于技术,但我们认为值得花一节来描述如何布局针对JVM的项目。这是因为,虽然有有用的约定,但它们在Maven世界之外并未强制执行。6然而,如果开发人员遵循标准布局,会让生活变得更轻松。应该可以将此处提供的信息抽象到其他技术,而无需付出太多额外努力。特别是,.NET项目可以有效地使用完全相同的布局,当然要用反斜杠替换正斜杠。7
我们将展示Maven假定的项目布局,称为Maven标准目录布局(Maven Standard Directory Layout)。即使你不使用(甚至不喜欢)Maven,它最重要的贡献之一就是引入了项目布局的标准约定。
典型的源代码布局将如下所示:

如果你使用Maven子项目,它们每个都放在项目根目录下的一个目录中,子目录也遵循Maven标准目录布局。请注意,lib目录不是Maven的一部分——Maven将自动下载依赖项并将它们存储在其管理的本地仓库中。但是,如果你不使用Maven,将库作为源代码的一部分检入是有意义的。
管理源代码
始终遵循标准的 Java 实践,将文件保存在以其所属包命名的目录中,每个文件包含一个类。Java 编译器和所有现代开发环境都会强制执行这个约定,但我们仍然会发现有人违反它的情况。如果你不遵循这个以及该语言的其他约定,可能会导致难以发现的 bug,但更重要的是它会使项目维护变得更困难,并且编译器会发出警告。出于同样的原因,务必遵循 Java 命名约定,包名使用 PascalCase,类名使用 camelCase。使用开源工具如 CheckStyle 或 FindBugs 在提交阶段的代码分析步骤中强制执行这些命名约定。有关命名约定的更多信息,请参阅 Sun 的文档”Java 编程语言代码约定”。
任何生成的配置或元数据(例如由注解或 XDoclet 生成)不应放在 src 目录中。而应将它们放在 target 目录中,这样当你运行清理构建时可以删除它们,并且避免它们被误提交到版本控制中。
所有测试源代码放入 test/[language] 目录。单元测试应存储在与代码包层次结构相对应的镜像结构中——即给定类的测试应与该类位于同一包中。
其他类型的测试,如验收测试、组件测试等,可以保存在单独的包集合中,例如 com.mycompany.myproject.acceptance.ui, com.mycompany.myproject.acceptance.api, com.mycompany.myproject.integration。然而,通常将它们保存在与其余测试相同的目录下。在构建脚本中,你可以使用基于包名的过滤来确保它们单独执行。有些人更喜欢在 test 下为不同类型的测试创建单独的目录——但这是个人偏好问题,因为 IDE 和构建工具完全能够处理这两种布局。
当 Maven 构建项目时,它会将所有内容放入项目根目录下名为 target 的目录中。这包括生成的代码、元数据文件(如 Hibernate 映射文件)等。将这些内容放入单独的目录可以轻松清理上次构建的产物,因为你只需删除该目录即可。你不应该将此目录中的任何内容提交到版本控制;如果你确实决定检入任何二进制产物,请将它们复制到仓库中的另一个目录。版本控制系统应忽略 target 目录。Maven 按以下方式在此目录中创建文件:
如果你没有使用 Maven,可以在 target 下使用名为 reports 的目录来存储测试报告。
构建过程最终应以 JAR、WAR 和 EAR 的形式生成二进制文件。这些文件放入 target 目录,由构建系统存储到制品仓库中。首先,每个项目应创建一个 JAR。然而,随着项目的增长,你可以为不同的组件创建不同的 JAR(有关组件的更多信息,请查看第 13 章”管理组件和依赖”)。例如,你可以为代表完整组件或服务的系统功能块创建 JAR。
无论采用什么策略,请记住创建多个 JAR 的目的有两个:首先,简化应用程序的部署;其次,使构建过程更高效并最小化依赖图的复杂性。这些考虑因素应指导你如何打包应用程序。
另一个替代方案是,不是将所有代码存储为一个项目并创建多个 JAR,而是为每个组件或子项目创建单独的项目。一旦项目达到一定规模,从长远来看这可能更易于维护,尽管在某些 IDE 中这也可能妨碍代码库的导航性。这个选择实际上取决于你的开发环境以及不同组件中代码之间的耦合程度。在构建过程中创建单独的步骤来从组成应用程序的各个 JAR 中组装应用程序,可以帮助保持灵活性,以便改变你做出的打包决策。
你有几个选项来管理库。一个是完全将库管理委托给像 Maven 或 Ivy 这样的工具。在这种情况下,你不需要将任何库检入版本控制——只需在项目规范中声明所需的依赖项即可。另一个极端是,你可以将项目构建、测试或运行系统所需的所有库检入源代码控制,在这种情况下,通常将它们放入项目根目录下名为 lib 的目录中。我们喜欢根据这些库是在构建时、测试时还是运行时需要,将它们分别放入不同的目录。
关于构建时依赖项(如 Ant 本身)的存储范围存在一些争论。我们认为这在很大程度上取决于项目的规模和持续时间。一方面,像编译器或 Ant 版本这样的工具可能用于构建许多不同的项目,因此将它们存储在每个项目中会造成浪费。但这里有一个权衡:随着项目的增长,维护依赖项成为越来越大的问题。一个简单的解决方案是将大多数依赖项存储在版本控制系统中的单独项目中。
一个更复杂的方法是在组织内创建一个仓库来存储所有项目所需的所有库。Ivy和Maven都支持自定义仓库。在合规性很重要的组织中,这可以作为一种使经过适当批准的库可用的方式。这些方法在第13章”管理组件和依赖项”中有更详细的讨论。
您需要确保应用程序依赖的任何库都与应用程序的二进制文件一起打包,作为部署管道的一部分,如第154页”使用操作系统的打包工具”一节所述。Ivy和Maven不应该出现在生产环境中。
环境管理的核心原则之一是,对测试和生产环境的更改只能通过自动化流程进行。这意味着您不应该远程登录到此类系统来执行部署;它们应该完全通过脚本完成。有三种方法可以执行脚本化部署。首先,如果您的系统将在单个服务器上运行,您可以编写一个脚本来完成该服务器本地需要完成的所有工作。
但是,大多数时候部署需要一定程度的编排(orchestration)——即在不同的计算机上运行脚本以执行部署。在这种情况下,您需要有一组部署脚本——每个独立的部署流程部分对应一个脚本——并在所有必要的服务器上运行它们。这并不意味着每个服务器一个脚本——例如,可能有一个脚本用于升级数据库,一个脚本用于将新的二进制文件部署到每个应用程序服务器,第三个脚本用于升级应用程序依赖的服务。
您有三个选项可以部署到远程机器。第一个是编写一个脚本,登录到每个服务器并运行适当的命令。第二个是编写一个在本地运行的脚本,并让代理(agent)在每个远程机器上运行该脚本。第三个选项是使用平台适当的打包技术打包应用程序,并让基础设施管理或部署工具推送新版本,运行任何必要的工具来初始化中间件。第三个选项是最强大的,原因如下:
• 像ControlTier和BMC BladeLogic这样的部署工具,以及像Marionette Collective、CfEngine和Puppet这样的基础设施管理工具,都是声明式(declarative)和幂等(idempotent)的,确保即使某些服务器在计划部署时处于关闭状态,或者如果您向环境中添加新机器或虚拟机,也能在所有必要的服务器上安装正确版本的软件包。有关这些工具的更多信息,请参阅第11章”管理基础设施和环境”。
• 您可以使用同一组工具来管理应用程序部署和管理基础设施。由于负责这两件事的是同一批人——运维团队——而且这两者密切相关,因此使用单一工具来实现这两个目的是有意义的。
如果这个选项不可行,具有代理模型的持续集成服务器(也就是说,几乎所有的CI服务器)可以很容易地采用第二个选项。这种方法有几个好处:
• 您需要做的工作更少:只需编写脚本,就好像它们在本地执行一样,将它们检入版本控制,并让CI服务器在指定的远程机器上运行它们。
• CI服务器提供了管理作业的所有基础设施,例如在失败时重新运行作业、显示控制台输出,以及提供一个仪表板,您可以在其中查看部署状态以及当前部署到每个环境的应用程序版本。
• 根据您的安全要求,让服务器上的CI代理调用CI服务器以获取它们需要的所有内容可能是有意义的,而不允许脚本远程访问测试和生产环境。
最后,如果由于某种原因您无法使用上述任何工具,您可以编写自己的部署脚本。如果您的远程机器是UNIX,您可以使用普通的Scp或Rsync来复制二进制文件和数据,并使用Ssh来执行相关命令以执行部署。如果您使用的是Windows,您也有选择:PsExec和PowerShell。还有更高级的工具,如Fabric、Func和Capistrano,它们为您处理细节,使编写自己的部署脚本变得非常简单。
然而,无论是使用CI系统还是编写自己的部署脚本都无法处理错误情况,例如部分完成的部署,或者将新节点添加到集群并需要配置和部署的情况。因此,使用适当的部署工具是更好的选择。
该领域可用的工具在不断发展。本书网站[dzMeNE]上有使用其中一些工具的示例,以及关于新工具的更新。
如果说我们的交付方法,特别是复杂系统的构建和部署方法有一个基本核心,那就是您应该始终努力在已知良好的基础上构建。我们不会费心测试无法编译的更改,不会费心对未通过提交测试的更改进行验收测试,等等。
图6.2 分层部署软件
这一点在将发布候选版本部署到类生产环境时更加重要。在我们将二进制交付物复制到文件系统的正确位置之前,我们需要确认环境已经准备就绪。为此,我们倾向于将部署视为一系列层的叠加,如图6.2所示。
最底层是操作系统。接下来是中间件和应用程序依赖的其他软件。这两层就位后,需要应用特定配置来为部署应用程序做准备。只有在完成这些配置后,才能部署我们的软件——可部署的二进制文件、服务或守护进程,以及它们相关的配置。
如果部署不当,每一层都可能导致应用程序无法正常运行。这意味着应该在应用每一层时进行测试,以便在出现问题时快速使环境配置过程失败。测试应该清楚地指出问题所在。
这些测试不需要详尽无遗。它们只需要捕获常见故障或可能造成重大损失的潜在故障。它们应该是非常简单的”冒烟测试”,用于断言关键资源的存在或不存在。目标是为刚刚部署的层正常工作提供一定程度的保证。
图6.3 部署测试层
您编写的基础设施冒烟测试对于任何给定系统都是独特的。但测试的目的是一致的:证明环境配置符合我们的预期。有关基础设施监控的更多信息,请参阅第317页的”监控基础设施和应用程序”部分。为了让您了解我们的想法,以下是我们过去发现有用的一些测试示例:
• 确认我们可以从数据库中检索记录。
• 确认我们可以访问网站。
• 断言我们的消息代理(message broker)已注册正确的消息集。
• 通过防火墙发送多个”ping”以证明它允许我们的流量通过,并在服务器之间提供轮询负载分配(round-robin load distribution)。
我们正在将一个.NET项目部署到一组服务器上。与许多其他.NET环境一样,存在多个物理分离的层级。在这个系统中,Web服务被部署到两台服务器:一台数据库服务器和一台应用服务器。每个Web服务在其他层级的配置文件中都有自己的端口和URI。诊断通信问题非常痛苦,需要在通信通道两端的机器上翻查服务器日志才能找出问题所在。
我们编写了一个简单的Ruby脚本,解析config.xml文件并依次尝试连接每个URI。然后在控制台打印结果,如下所示:

这使得诊断连接问题变得非常简单。
在本节中,我们将列出一些用于解决常见构建和部署问题的解决方案和策略。
构建中最常见的错误是默认使用绝对路径。这会在特定机器的配置与构建过程之间创建紧密依赖,使其他服务器难以配置和维护。例如,这使得在一台机器上拥有同一项目的两个检出(check-out)变得不可能——而这种做法在许多不同情况下都非常有用,从比较调试到并行测试。
默认应该对所有内容使用相对路径。这样,构建的每个实例都是完全自包含的,提交到版本控制系统的镜像会自动确保所有内容都在正确的位置并按预期工作。
有时很难避免使用绝对路径。尽量发挥创造力,尽可能避免。如果不得不使用绝对路径,请确保它们是构建中的特殊情况,而不是常规做法。确保将它们保存在属性文件或其他独立于构建系统的配置机制中。在某些情况下可能确实需要使用绝对路径。第一种是必须与依赖硬编码路径的第三方库集成。尽可能隔离系统的这些部分,不要让它们影响构建的其余部分。
即使在部署应用程序时,也可以避免使用绝对路径。每个操作系统和应用程序栈都有安装软件的约定,例如UNIX的文件系统层次标准(Filesystem Hierarchy Standard, FHS)。使用系统的打包工具来执行这些约定。如果必须安装到某个非标准位置,请通过配置系统中的选项来实现。尽量通过使系统中的所有路径相对于一个或多个明确定义的根路径——部署根路径、配置根路径等——来最小化这些情况,并仅覆盖这些根路径。
有关在部署时配置应用程序的更多信息,请参阅第2章”配置管理”。
令人惊讶的是,有多少人通过手动方式或 GUI 驱动的工具来部署他们的软件。对于许多组织来说,所谓的”构建脚本”其实是一份打印出来的文档,上面列着一系列指令,比如:

这种部署方式既繁琐又容易出错。文档总是错误的或过时的,因此需要在预生产环境中进行大量演练。每次部署都是独特的——一个 bug 修复或系统的小改动可能只需要重新部署系统的一两个部分。因此,每次发布都必须修订部署流程。之前部署的知识和产物无法重用。每次部署实际上都是对执行者的记忆力和系统理解力的考验,从根本上说容易出错。
那么,什么时候应该考虑自动化一个流程呢?最简单的答案是,“当你第二次做它的时候。”第三次做同样的事情时,就应该使用自动化流程来完成。这种细粒度的增量方法会快速创建一个系统,用于自动化开发、构建、测试和部署流程中的重复部分。
能够从任何给定的二进制文件确定使用了版本控制中的哪个修订版本来生成它,这一点至关重要。如果你的生产环境出现问题,能够准确找出那台机器上每个组件的确切版本以及它们的来源,可能会成为救命稻草(Bob Aiello 在他的书《配置管理最佳实践》中讲述了一个很棒的故事)。
有多种方法可以做到这一点。在 .NET 中,你可以在程序集中包含版本元数据——确保你的构建脚本始终这样做,并包含版本控制修订标识符。JAR 文件也可以在其清单中包含元数据,因此你可以在这里做类似的事情。如果你使用的技术不支持将元数据构建到包中,你可以反过来做:对构建过程生成的每个二进制文件及其名称和来源的修订标识符进行 MD5 哈希,并将它们存储在数据库中。这样你就可以对任何二进制文件进行 MD5 运算,并准确确定它是什么以及来自哪里。
有时候,在构建过程中将二进制文件或报告检入版本控制似乎是个好主意。然而,一般来说,你应该抵制这种做法。这在多个方面都是个坏主意。
首先,修订控制标识符最重要的功能之一是能够追踪特定检入集发生了什么。通常你会将修订控制 ID 与构建标签关联起来,并使用它来追踪一组变更在不同环境中的传递过程,直到进入生产环境。如果你在构建时检入二进制文件和报告,这意味着对应于某个版本控制修订标识符的二进制文件将有它们自己的不同修订标识符——这会造成混乱。
相反,应该将二进制文件和报告放到共享文件系统上。如果你丢失了它们或需要重新创建它们,最佳实践是获取源代码并再次创建它们。如果你无法从源代码可靠地重新创建二进制文件,这意味着你的配置管理还不够完善,需要改进。
一般的经验法则是不要将构建、测试和部署周期中创建的任何内容检入源代码控制。相反,将这些产物视为元数据,与触发构建的修订标识符关联起来。大多数现代 CI 和发布管理服务器都有产物仓库和元数据管理系统可以帮助你做到这一点,或者你可以使用 Maven、Ivy 或 Nexus 等工具。
在某些构建系统中,默认行为是当任务失败时构建立即失败。例如,如果你有一个”test”目标,并且该目标中指定的测试失败了,那么整个构建会在目标运行后立即失败。这几乎总是一件坏事——相反,应该记录活动失败的事实,并继续执行构建流程的其余部分。然后,在流程结束时,查看是否有任何单独的任务失败,如果有,则以失败代码退出。
出现这个问题是因为在许多项目中,拥有多个测试目标是有意义的。例如,在提交测试套件中可能有一组单元测试、几个集成测试和少量验收冒烟测试。如果单元测试首先运行并使构建失败,那么我们直到下次检入时才会知道集成测试是否会通过。这是更多的时间浪费。
更好的做法是让失败设置一个标志,但在生成更有用的报告或运行更完整的测试集之后再使构建失败。例如,在 NAnt 和 Ant 中,可以在测试任务上使用 failure-property 属性来实现这一点。
交互设计师经常约束界面以防止不希望的用户输入。同样,你可以约束你的应用,使它们在发现自己处于不熟悉的情况时无法工作。例如,你可以让部署脚本在部署任何东西之前检查它们是否在正确的机器上运行。这对于测试和生产配置尤其重要。
几乎所有系统都有一个定期运行的”批处理”部分。在会计系统中,有些组件只在每月、每季度或每年运行一次。在这种情况下,请确保部署的版本在安装时验证其配置。你不会想在明年1月1日凌晨3点调试今天的安装问题。
.NET 有其自身的特殊性——以下是一些你应该注意的事项。
.NET 中的解决方案和项目文件包含对它们实际将要构建的文件的引用。如果文件未被引用,它就不会被构建。这意味着文件可能从解决方案中删除但仍然存在于文件系统中。这可能导致难以诊断的问题,因为在某个地方,某人会查看这个文件并想知道它是干什么用的。通过删除这些文件来保持项目整洁非常重要。一个简单的方法是在所有解决方案中打开显示隐藏文件功能,然后留意没有图标的文件。当你看到这样的文件时,从源代码控制系统中删除它。
理想情况下,当你从解决方案中删除文件时应该自动执行此操作,但遗憾的是,大多数与 Visual Studio 集成的源代码控制集成工具都不会这样做。在等待工具供应商实现此功能的同时,关注这个问题非常重要。
注意 bin 和 obj 目录。确保你的清理操作删除解决方案中的所有 bin 和 obj 目录。确保这一点的一种方法是让你的”清理”调用 Devenv 的 clean solution 命令。
我们在相当广泛的意义上使用”脚本”这个术语。一般来说,我们指的是帮助我们构建、测试、部署和发布软件的所有自动化。当你从部署流水线的末端看待那一大堆脚本时,它看起来复杂得令人生畏。然而,构建或部署脚本中的每个任务都很简单,过程本身也不复杂。我们强烈建议使用构建和部署过程作为脚本集合的指南。逐步增强你的自动化构建和部署能力,通过迭代识别并自动化最痛苦的步骤来完成部署流水线。始终牢记最终目标——即在开发、测试和生产之间共享相同的部署机制的目标,但在创建工具的早期不要过于纠结这个想法。但是,一定要让运维和开发人员都参与这些机制的创建。
如今,存在各种各样的技术来编写构建、测试和部署过程的脚本。即使是 Windows,在自动化方面传统上处于弱势地位,随着 PowerShell 以及 IIS 和 Microsoft 技术栈其余部分的脚本接口的出现,也拥有了一些令人羡慕的工具。我们在本章中重点介绍了最流行的工具,并提供了有关这些工具和其他资源的更多信息的指引。显然,在像这样的通用书籍中,我们只能触及这个主题的表面。如果我们让你对构建脚本的基础和向你开放的各种可能性有了扎实的理解——更重要的是,激励你前进并实现自动化——那么我们就达到了目标。
最后,值得重申的是,脚本是系统的一等组成部分。它们应该在系统的整个生命周期中存在。它们应该被版本控制、维护、测试和重构,并且是你用来部署软件的唯一机制。许多团队将构建系统视为事后的想法;根据我们的经验,构建和部署系统在设计方面几乎总是次要的。因此,这种维护不善的系统往往成为合理、可重复的发布过程的障碍,而不是其基础。交付团队应该花时间和精力来正确编写构建和部署脚本。这不是团队中的实习生练手的任务。花一些时间,考虑你想要实现的目标,并设计你的构建和部署过程来实现这些目标。
提交阶段始于项目状态的变化——即对版本控制系统的提交。它以失败报告或(如果成功)二进制工件和可部署程序集的集合结束,这些内容将用于后续的测试和发布阶段,以及应用程序状态的报告。理想情况下,提交阶段应该在不到五分钟内完成,当然不超过十分钟。
提交阶段在多个方面代表了进入部署流水线的入口。它不仅是创建新候选发布版本的点;也是许多团队开始实施部署流水线时的起点。当团队实施持续集成实践时,它在此过程中创建了一个提交阶段。
这是至关重要的第一步。使用提交阶段可以确保你的项目最大限度地减少在代码级集成上花费的时间。它推动良好的设计实践,并对代码质量——以及交付速度——产生显著影响。
提交阶段也是你应该开始构建部署流水线的点。
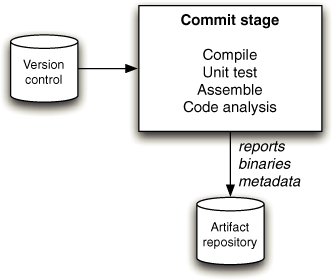
我们在之前的章节”持续集成”和”部署流水线剖析”中已经简要描述了提交阶段。在本章中,我们将详细介绍如何创建有效的提交阶段和高效的提交测试,以扩展之前的内容。这主要面向开发人员,因为他们是提交阶段反馈的主要使用者。提交阶段如图7.1所示。
简要回顾一下,提交阶段的工作流程如下。有人将更改提交到版本控制的主线(trunk)。你的持续集成服务器检测到更改,检出源代码,并执行一系列任务,包括:
• 编译(如有必要)并针对集成后的源代码运行提交测试
• 创建可以部署到任何环境的二进制文件(如果你使用编译型语言,这将包括编译和组装)
• 执行必要的分析以检查代码库的健康状况
• 创建其他将在部署流水线后续阶段使用的产物(如数据库迁移脚本或测试数据)
这些任务由构建脚本编排,并由持续集成服务器运行。你可以在第6章”构建和部署脚本”中了解更多关于构建脚本的内容。二进制文件(如果阶段成功)和报告随后存储到中央产物仓库,供交付团队和流水线后续阶段使用。
对于开发人员来说,提交阶段是开发过程中最重要的反馈循环。它为开发人员引入系统的最常见错误提供快速反馈。提交阶段的结果代表了每个发布候选版本生命周期中的重要事件。这个阶段的成功是进入部署流水线的唯一途径,从而启动软件交付过程。
如果部署流水线的目标之一是淘汰不适合进入生产环境的构建,那么提交阶段就是门口的保安。它的目的是确保任何不合格的构建在造成任何麻烦之前被拒绝。提交阶段的主要目标是创建可部署的产物,或者快速失败并通知团队失败的原因。
以下是一些有效提交阶段的原则和实践。
提交测试中的失败通常可归因于以下三种原因之一。要么代码中引入了语法错误,在编译型语言中被编译捕获;要么应用程序中引入了语义错误,导致一个或多个测试失败;要么应用程序或其环境(包括操作系统)的配置存在问题。无论是什么问题,在失败的情况下,提交阶段应该在提交测试完成后立即通知开发人员,并提供失败原因的简明摘要,例如失败测试列表、编译错误或任何其他错误条件。开发人员还应该能够轻松访问提交阶段运行的控制台输出,这些输出可能分布在多个机器上。
如果错误在引入点附近尽早被检测到,修复起来最容易。这不仅是因为这些错误在引入者的记忆中还很新鲜,而且发现错误原因的机制也更简单。如果开发人员进行的更改导致测试失败,而失败原因不是立即显而易见的,自然的做法是查看自上次系统正常工作以来的所有更改,以缩小搜索范围。
如果该开发人员一直遵循我们的建议并频繁提交更改,那么每次更改的范围都会很小。如果部署流水线能够快速识别失败,理想情况下在提交阶段,那么更改范围仅限于开发人员个人所做的更改。这意味着修复提交阶段发现的问题比在流水线后续阶段发现的问题要简单得多,因为后续阶段可能正在测试批量打包在一起的大量更改。
因此,为了使我们的部署流水线高效,我们需要尽早捕获错误。在大多数项目中,我们实际上在提交阶段之前就开始了这个过程,通过最大化利用现代开发环境——努力在开发环境中突出显示编译时警告(如果适用)或语法错误时立即修复它们。许多现代持续集成服务器还提供称为预测试提交(pretested commit)或预检构建(preflight build)的功能,在更改签入之前针对更改运行提交阶段。如果你没有这个功能,你必须在提交之前在本地编译并运行提交测试。
提交阶段是将我们对质量的关注扩展到单个开发人员范围之外的第一个正式步骤。提交阶段发生的第一件事是提交者的更改与主线集成,然后对集成后的应用程序执行一种自动化的”校对”。如果我们要坚持尽早识别错误的目标,我们需要专注于快速失败,因此我们需要提交阶段捕获开发人员可能引入应用程序的大多数错误。
持续集成早期采用中的一个常见错误是将”快速失败”(fail fast)的原则理解得过于字面化,在发现错误时立即使构建失败。这种做法接近正确,但优化过度了。我们通常将提交阶段划分为一系列任务(具体任务取决于项目),比如编译、运行单元测试等等。我们只在错误阻止阶段其余部分运行时才停止提交阶段——例如编译错误。否则,我们会将提交阶段运行到结束,并呈现所有错误和失败的汇总报告,以便一次性修复它们。
传统上,提交阶段被设计为在上述某种情况下失败:编译失败、测试中断或存在环境问题。否则,提交阶段成功,报告一切正常。但如果测试通过是因为只有少量测试呢?如果代码质量很差呢?如果编译成功但有数百个警告,我们应该满意吗?绿色的提交阶段很容易是假阳性,暗示应用程序的质量可以接受,而实际上并非如此。
有充分理由认为我们对提交阶段施加的二元约束——要么成功要么失败——太局限了。应该可以提供更丰富的信息,例如在提交阶段运行完成后提供一组代表代码覆盖率和其他指标的图表。这些信息可以通过一系列阈值汇总为交通灯显示(红、黄、绿)或滑动刻度。例如,如果单元测试覆盖率降到60%以下,我们可以使提交阶段失败,如果降到80%以下,可以让它通过但状态为黄色而不是绿色。
我们在实际中还没有看到如此复杂的做法。然而,我们编写过提交阶段脚本,当警告数量增加或未能减少时使其失败(我们称这种做法为”棘轮效应”(ratcheting)),如第73页”因警告和代码风格违规而使构建失败”部分所述。如果重复代码量增加超过某个预设限制,或出现其他代码质量违规,让脚本使提交阶段失败是完全可以接受的。
但请记住,如果提交阶段失败,规则是交付团队必须立即停止正在做的任何事情并修复它。不要因为整个团队未达成一致的原因而使提交测试失败,否则人们会不再认真对待失败,持续集成将会崩溃。但是,要持续审查应用程序的质量,并在适当的情况下考虑通过提交阶段强制执行质量指标。
提交阶段将包括构建脚本和运行单元测试、静态分析工具等的脚本。这些脚本需要仔细维护,并以与对待应用程序任何其他部分相同的尊重程度来对待。像任何其他软件系统一样,当构建脚本设计和维护不良时,保持它们正常工作所需的工作量似乎会以指数方式增长。这会产生双重打击效果。糟糕的构建系统不仅会将宝贵且昂贵的开发工作从创建应用程序业务行为这一重要工作中抽离出来;它还会减慢仍在尝试实现该业务行为的任何人的速度。我们看到过几个项目在构建问题的重压下几乎陷入停滞。
随着提交阶段脚本的演进,要不断努力提高其质量、设计和性能。高效、快速、可靠的提交阶段是任何开发团队生产力的关键推动因素,因此在时间和思考上的小投资来使其运行良好几乎总能很快得到回报。保持提交构建的快速并确保各种失败都能被及早发现需要创造力,例如仔细选择和设计测试用例。被视为应用程序代码次要的脚本会迅速变得不可理解和维护。到目前为止我们的记录是继承了一个项目,其Ant脚本重达10,000行XML。不用说,这个项目需要一整个团队专门保持构建正常运行——完全是资源浪费。
确保你的脚本是模块化的,如第6章”构建和部署脚本”中所述。结构化它们以保持常用任务(一直使用但很少更改)与经常更改的任务(例如向代码库添加新模块)分离。将运行部署管道不同阶段的代码分离到单独的脚本中。最重要的是,避免特定于环境的脚本:将特定于环境的配置与构建脚本本身分离。
在某些组织中,有专家团队擅长创建有效的模块化构建管道和管理它们运行的环境。我们两人都曾担任过这个角色。然而,如果到了只有这些专家才能维护CI系统的地步,我们认为这是一种失败。
交付团队对提交阶段(实际上是管道基础设施的其余部分)拥有所有权感至关重要。它与他们的工作和生产力密切相关。如果你在开发人员和他们快速有效地进行更改的能力之间设置任何障碍,你将减慢他们的进度并为以后埋下麻烦。
像添加新库、配置文件等日常变更,应该由开发人员和运维人员根据需要共同完成。这类活动不应该由构建专家来做,除非在项目早期阶段,团队正在建立构建体系时可能需要。
专家的专业知识不应被低估,但他们的目标应该是建立良好的结构、模式和技术应用,并将知识传递给交付团队。一旦这些基本规则建立起来,他们的专业知识应该只在重大结构变化时才需要,而不是日常的构建维护。
对于非常大的项目,有时确实有足够的工作让环境或构建专家全职忙碌,但根据我们的经验,这最好被视为解决棘手问题的临时措施,并通过开发人员与专家合作将所获知识传播到整个交付团队。
开发人员和运维人员必须对构建系统的维护感到熟悉并负有责任。
在20到30人的小型和集中办公团队中,自组织可以运作得很好。如果构建出现问题,在这种规模的团队中通常很容易找到责任人,如果他们没在处理就提醒他们,如果他们正在处理就提供帮助。
在更大或更分散的团队中,这并不总是容易的。在这种情况下,设置一个”构建负责人”(build master)角色会很有用。他们的工作是监督和指导构建的维护,同时鼓励和执行构建纪律。如果构建出现问题,构建负责人会注意到,并温和地——或者如果已经过了一段时间就不那么温和地——提醒责任人有责任快速修复构建或回退他们的更改。
另一个我们发现这个角色有用的情况是,在刚开始使用持续集成的团队中。在这样的团队中,构建纪律还没有根深蒂固,所以需要提醒来保持正轨。
构建负责人不应该是一个永久角色。团队成员应该轮流担任,也许每周轮换一次。让每个人时不时地尝试这个角色是很好的纪律——也是重要的学习经历。无论如何,想要全职做这件事的人少之又少。
提交阶段(commit stage),像部署流水线中的每个阶段一样,都有输入和输出。输入是源代码,输出是二进制文件和报告。生成的报告包括测试结果,这对于在测试失败时找出问题所在至关重要,以及代码库的分析报告。分析报告可以包括测试覆盖率、圈复杂度(cyclomatic complexity)、复制粘贴分析、传入和传出耦合(afferent and efferent coupling),以及其他有助于确定代码库健康状况的有用指标。提交阶段生成的二进制文件与将在整个流水线中重用并可能发布给用户的文件完全相同。
提交阶段的输出,即报告和二进制文件,需要存储在某个地方,以便在流水线的后续阶段重用,并让团队能够获取它们。显而易见的地方似乎是版本控制系统。但有几个原因说明这样做是不对的,除了可能很快耗尽磁盘空间这个附带事实,以及某些版本控制系统不支持这种行为。
• 制品仓库(artifact repository)是一种特殊的版本控制系统,它只需要保留某些版本。一旦发布候选在部署流水线的某个阶段失败,我们就不再对它感兴趣了。因此,如果我们愿意,可以从制品仓库中清除二进制文件和报告。
• 能够从发布的软件追溯到用于创建它的版本控制中的修订版本是至关重要的。为了做到这一点,流水线的实例应该与触发它的版本控制系统中的修订版本相关联。在流水线过程中向源代码控制中检入任何内容,会通过引入与流水线关联的更多修订版本使这个过程变得更加复杂。
• 良好配置管理策略的验收标准之一是二进制文件创建过程应该是可重复的。也就是说,如果我删除二进制文件,然后从最初触发它的相同修订版本重新运行提交阶段,我应该得到完全相同的二进制文件。二进制文件在配置管理世界中是二等公民,尽管值得在永久存储中保留二进制文件的哈希值,以验证可以重新创建完全相同的东西,并从生产环境审计回提交阶段。
大多数现代持续集成服务器都提供制品仓库(artifact repository),包括允许在一定时间后清除不需要的制品的设置。它们通常提供一种机制来声明式地指定你想要在运行任何作业后存储在仓库中的制品,并提供一个Web界面让你的团队访问报告和二进制文件。或者,你可以使用专用的制品仓库,如Nexus或其他Maven风格的仓库管理器来处理二进制文件(这些通常不适合存储报告)。仓库管理器使得从开发机器访问二进制文件变得更加容易,而无需与CI服务器集成。
如果你想要的话,创建自己的制品仓库非常简单。我们在第13章”管理组件和依赖”中更详细地描述了制品仓库背后的原则。
图7.2 制品仓库的作用
图7.2展示了典型安装中使用制品仓库的示意图。它是一个关键资源,存储每个发布候选版本的二进制文件、报告和元数据。
以下详细说明了成功进入生产环境的发布候选版本的正常路径中的每个步骤。这些数字对应图7.2中显示的编号步骤。
交付团队中的某人提交了一个变更。
你的持续集成服务器运行提交阶段。
成功完成后,二进制文件以及任何报告和元数据都保存到制品仓库中。
然后你的CI服务器检索由提交阶段创建的二进制文件,并部署到类生产环境的测试环境中。
你的持续集成服务器然后运行验收测试(acceptance tests),重用由提交阶段创建的二进制文件。
成功完成后,发布候选版本被标记为已通过验收测试。
测试人员可以获取所有已通过验收测试的构建列表,并可以按下按钮运行自动化流程将它们部署到手动测试环境中。
测试人员执行手动测试。
手动测试成功结束后,测试人员更新发布候选版本的状态以表明它已通过手动测试。
你的CI服务器从制品仓库中检索已通过验收测试或手动测试(取决于流水线配置)的最新候选版本,并将应用程序部署到生产测试环境。
针对发布候选版本运行容量测试。
如果成功,候选版本的状态更新为”已通过容量测试”。
这个模式会根据流水线所需的阶段数重复进行。
一旦RC通过了所有相关阶段,它就”准备发布”了,任何具有适当授权的人都可以发布它,通常需要QA和运维人员的签字批准组合。
在发布过程结束时,RC被标记为”已发布”。
为简单起见,我们将此描述为一个顺序过程。对于早期阶段来说这是正确的:它们应该按顺序执行。但是,根据项目的不同,以非顺序方式运行一些验收阶段之后的步骤可能是有意义的。例如,手动测试和容量测试都可以由验收测试的成功完成触发。或者,测试团队可以选择将不同的发布候选版本部署到他们的环境中。
有一些重要的原则和实践管理着提交测试套件的设计。你的提交测试的绝大部分应该由单元测试组成,这也是我们在本节中关注的重点。单元测试最重要的特性是它们应该执行得非常快。有时如果套件不够快,我们就会使构建失败。第二个重要特性是它们应该覆盖代码库的很大比例(大约80%是一个好的经验法则),让你有充分的信心,当它们通过时,应用程序很可能是正常工作的。当然,每个单元测试只测试应用程序的一小部分而不启动它——所以,根据定义,单元测试套件不能给你完全的信心,认为你的应用程序正常工作;这就是部署流水线其余部分的作用。
图7.3 测试自动化金字塔(Cohn, 2009, 第15章)
Mike Cohn有一个很好的方式来可视化你应该如何构建自动化测试套件。在他的测试自动化金字塔中,如图7.3所示,单元测试构成了测试的绝大部分。但由于它们执行得如此之快,单元测试套件仍应该在几分钟内完成。尽管验收测试较少(这些进一步细分为服务测试和UI测试),但它们通常需要更长的执行时间,因为它们针对完整运行的系统运行。所有级别对于确保应用程序正常工作并提供预期的业务价值都是必不可少的。这个测试金字塔涵盖了第84页”测试类型”部分所示的测试象限图的左侧(“支持编程”)。
设计能够快速运行的提交测试并不总是简单的。我们将在接下来的几段中描述几种策略。不过,它们大多数都是为了实现一个目标的技术:最小化任何给定测试的范围,并使其尽可能专注于仅测试系统的一个方面。特别是,运行单元测试不应该涉及文件系统、数据库、库、框架或外部系统。对环境这些部分的任何调用都应该用测试替身(test double)替换,例如模拟对象(mock)和存根(stub)(测试替身的类型在[第91页]的”测试替身”部分中定义)。关于单元测试和测试驱动开发已有大量文献,因此我们在这里只是浅尝辄止。请查看参考书目以了解更多相关主题。
用户界面从定义上来说是用户最容易发现缺陷的地方。因此,人们自然倾向于将测试工作集中在用户界面上,有时甚至以牺牲其他类型的测试为代价。
但是,对于提交测试而言,我们建议您根本不要通过用户界面进行测试。用户界面测试的困难是双重的。首先,它往往涉及被测软件的许多组件或层次。这是有问题的,因为在执行测试本身之前,需要花费精力和时间来准备好所有部分。其次,用户界面是为了在人类时间尺度上工作而设计的,与计算机时间尺度相比,这是非常缓慢的。
如果您的项目或技术选择允许您避免这两个问题,也许值得创建通过用户界面操作的单元级测试,但根据我们的经验,用户界面测试通常是有问题的,通常最好在部署流水线的验收测试阶段处理。
我们将在验收测试章节中更详细地讨论用户界面测试的方法。
依赖注入(dependency injection),或称控制反转(inversion of control),是一种设计模式,它描述了对象之间的关系应该如何从对象外部而不是从内部建立。显然,此建议仅适用于使用面向对象语言的情况。
如果我创建一个 Car 类,我可以将其设计为每当创建新的
Car 时它就创建自己的
Engine。或者,我可以选择将 Car
设计为在创建它时强制我为它提供一个 Engine。
后者就是依赖注入。这更灵活,因为现在我可以使用不同类型的
Engine 创建 Car,而无需更改 Car
的代码。我甚至可以在测试 Car 时使用一个特殊的
TestEngine 来创建我的 Car,它只是假装是一个
Engine。
这种技术不仅是通向灵活、模块化软件的好方法,而且还使将测试范围限制为只测试您想要测试的类变得非常容易,而不包括它们所有的依赖包袱。
刚接触自动化测试的人通常会编写与代码中某一层交互的测试,将结果存储在数据库中,然后确认结果已被存储。虽然这种方法易于理解,但在其他所有方面都不是一种非常有效的方法。
首先,它产生的测试运行速度要慢得多。当您想要重复测试或连续运行几个类似的测试时,测试的有状态性可能成为障碍。基础设施设置的复杂性使整个测试方法更加复杂,难以建立和管理。最后,如果无法简单地从测试中消除数据库,这意味着代码中的分层和关注点分离较差。这是可测试性和持续集成对您和您的团队施加微妙压力以开发更好代码的另一个领域。
构成提交测试主体的单元测试永远不应该依赖于数据库。要实现这一点,您应该能够将被测代码与其存储分离。这需要代码中良好的分层,以及使用依赖注入等技术,或者甚至作为最后的手段使用内存数据库。
但是,您还应该在提交测试中包含一两个非常简单的冒烟测试(smoke test)。这些应该是来自验收测试套件的端到端测试,用于测试高价值、常用的功能,并证明您的应用程序确实可以运行。
单个测试用例范围内的异步行为使系统难以测试。最简单的方法是通过拆分测试来避免异步,使一个测试运行到异步中断点,然后另一个单独的测试开始。
例如,如果您的系统发布一条消息然后对其采取行动,请使用您自己的接口包装原始消息发送技术。然后,您可以在一个测试用例中确认按预期进行了调用,可能使用实现消息接口的简单存根或使用下一节中描述的模拟。您可以添加第二个测试来验证消息处理程序的行为,只需调用通常由消息基础设施调用的点即可。但是,有时根据您的架构,如果不做大量工作,这是不可能的。
我们建议您非常努力地消除提交阶段测试中的异步性。依赖基础设施的测试,例如消息传递(即使是内存中的),应算作组件测试,而非单元测试。更复杂、运行更慢的组件测试应该是验收测试阶段的一部分,而不是提交阶段。
理想的单元测试应专注于少量紧密相关的代码组件,通常是单个类或几个紧密相关的类。
然而,在一个设计良好的系统中,每个类的规模相对较小,并通过与其他类的交互来实现其目标。这是良好封装的核心——每个类对其他类隐藏它如何实现其目标的秘密。
问题在于,在这样一个设计良好的模块化系统中,测试处于关系网络中间的对象可能需要在所有周围类中进行冗长的设置。解决方案是伪造与类的依赖项的交互。
对这类依赖项的代码进行桩化(stubbing)有着悠久而光荣的传统。我们已经描述了依赖注入的使用,并在建议使用 TestEngine 代替 Engine 时提供了一个简单的桩化示例。
桩化是用提供固定响应的模拟版本替换系统的一部分。桩不会响应任何编程之外的内容。这是一种强大而灵活的方法,在每个层级都很有用——从桩化被测代码依赖的单个简单类,到桩化整个系统。
Dave 曾在一个交易系统上工作,该系统需要通过消息队列以相当复杂的方式与另一个团队正在开发的系统交互。这种对话相当丰富,包含一系列消息,这些消息在很大程度上驱动了交易的生命周期,并使两个系统之间保持同步。如果没有这个外部系统,我们的系统就无法拥有交易的完整生命周期,因此很难创建有意义的端到端验收测试。
我们实现了一个相当复杂的桩来模拟实际系统的操作。这给我们带来了很多好处。它使我们能够在测试目的上填补系统生命周期中的空白。它还具有允许我们模拟在实际系统中难以设置的困难边界情况的优势。最后,它打破了我们对另一个系统中正在进行的并行开发的依赖。
我们不必维护一个复杂的分布式系统网络相互通信,而是可以选择何时与真实系统交互,何时处理更简单的桩。我们通过配置管理桩的部署,因此我们可以根据环境变化来确定是与真实系统交互还是与桩交互。
我们倾向于广泛地将桩化用于大规模组件和子系统,但在编程语言级别的组件中较少使用;在这个层级,我们通常更喜欢模拟(mocking)。
模拟是一种较新的技术。它源于对桩的喜爱,以及希望广泛使用它们而不产生编写大量桩代码的工作量。如果我们不必编写繁琐的代码来桩化正在测试的类的所有依赖项,而只需让计算机自动为我们构建一些桩,那不是很好吗?
模拟本质上就是这样。有几个模拟工具集,例如 Mockito、Rhino、EasyMock、JMock、NMock、Mocha 等。模拟允许您有效地说:“为我构建一个可以假装是 X 类型的类的对象。”
至关重要的是,它进一步允许您在几个简单的断言中指定您期望从正在测试的代码中获得的行为。这是模拟和桩化之间的本质区别——对于桩,我们不关心桩是如何被调用的;对于模拟,我们可以验证我们的代码是否以我们期望的方式与模拟进行了交互。
让我们回到 Car 示例,并并排考虑这两种方法。为了我们的示例,考虑一个需求:当我们调用 Car.drive 时,我们期望依次调用 Engine.start 和 Engine.accelerate。
正如我们已经描述的,在两种情况下,我们都将使用依赖注入将 Engine 与 Car 关联起来。我们的简单类可能如下所示:

如果我们使用桩化,我们将创建一个桩实现,一个 TestEngine,它将记录 Engine.start 和 Engine.accelerate 都被调用的事实。由于我们要求首先调用 Engine.start,如果先调用 Engine.accelerate,我们可能应该在桩中抛出异常,或者以某种方式记录错误。
我们的测试现在将包括创建一个新的 Car,将 TestEngine 传递到其构造函数中,调用 Car.drive 方法,并确认 Engine.start 和 Engine.accelerate 依次被调用。

使用模拟工具的等效测试更像这样:我们通过调用模拟类来创建一个模拟 Engine,传递对定义 Engine 接口的接口或类的引用。
我们声明了两个期望,按照正确的顺序指定我们期望 Engine.start 和 Engine.accelerate 被调用。最后,我们要求模拟系统验证我们期望发生的事情是否实际发生了。

这里的示例基于一个名为 JMock 的开源模拟系统,但其他系统类似。在这种情况下,最后的验证步骤在每个测试方法结束时隐式完成。
模拟(mocking)的好处显而易见。代码量大大减少,即使在这个过于简化的示例中也是如此。在实际使用中,模拟可以节省大量工作。模拟也是将第三方代码从测试范围中隔离出来的好方法。你可以模拟第三方代码的任何接口,从而将实际代码从测试范围中排除——当这些交互使用昂贵的远程通信或重量级基础设施时,这是一个很好的做法。
最后,与组装所有依赖项及其相关状态相比,使用模拟的测试通常非常快。模拟是一种具有许多优点的技术:我们强烈向你推荐。
理想情况下,你的单元测试应该专注于断言系统的行为。一个常见问题,特别是对于有效测试设计的新手来说,是测试周围状态的累积。这个问题实际上是双重的。首先,很容易设想几乎任何形式的测试,你向系统的某个组件输入一些值并获得一些返回结果。你通过组织相关的数据结构来编写测试,以便能够以正确的形式提交输入,并将结果与期望的输出进行比较。事实上,几乎所有测试在不同程度上都是这种形式。问题是,如果不小心,系统及其相关测试会变得越来越复杂。
为了支持你的测试而构建复杂、难以理解和难以维护的数据结构是很容易陷入的陷阱。理想的测试是快速且易于设置的,甚至更快、更容易清理。良好重构的代码往往具有简洁的测试。如果你的测试看起来笨重而复杂,这反映了你系统的设计。
不过,这是一个难以解决的问题。我们的建议是努力最小化测试中对状态的依赖。你永远无法现实地消除它,但持续关注运行测试所需构建的环境复杂性是明智的。随着测试变得越来越复杂,它很可能在发出需要审视代码结构的信号。
时间在自动化测试中可能因多种原因成为问题。也许你的系统需要在晚上 8 点触发一个日终处理。也许它需要等待 500 毫秒后才能进行下一步。也许它需要在闰年的 2 月 29 日做一些不同的事情。
所有这些情况都可能难以处理,如果你试图将它们绑定到实际的系统时钟,对你的单元测试策略来说可能是灾难性的。
我们对任何基于时间的行为的策略是将我们对时间信息的需求抽象到一个由我们控制的单独类中。我们通常使用依赖注入(dependency injection)来注入我们对所使用的系统级时间行为的包装器。
这样,我们可以存根(stub)或模拟我们的 Clock 类的行为,或者我们选择的任何合适的抽象。如果我们在测试范围内决定现在是闰年或 500 毫秒之后,这完全在我们的控制之下。
对于快速构建来说,这对于任何需要延迟或等待的行为最为重要。构建你的代码,使测试运行期间的所有延迟都为零,以保持良好的测试性能。如果你的单元测试需要真实的延迟,也许值得重新考虑你的代码和测试设计以避免它。
这已经深深植根于我们自己的开发中,如果我们编写任何几乎在任何方面需要时间的代码,我们期望需要抽象对系统时间服务的访问,而不是在业务逻辑中直接调用它们。
开发人员总是会争取最快的提交周期。但实际上,这种需求必须与提交阶段识别你可能引入的最常见错误的能力相平衡。这是一个只能通过试错来进行的优化过程。有时,接受较慢的提交阶段比花太多时间优化测试速度或减少它们捕获的错误比例要好。
我们通常的目标是将提交阶段保持在 10 分钟以内。就我们而言,这几乎是上限。它比理想状态长,理想状态是 5 分钟以内。从事大型项目的开发人员可能会认为 10 分钟的目标低得无法实现。其他开发团队会认为这种妥协太过分了,因为他们知道最高效的提交阶段要快得多。不过,根据我们对许多项目的观察,我们认为这个数字是一个有用的指导。当突破这个限制时,开发人员会开始做两件事,这两件事都对开发过程产生极其糟糕的影响:他们开始减少提交频率,并且如果提交阶段运行时间显著超过 10 分钟,他们会停止关心提交测试套件是否通过。
有两个技巧可以让你的提交测试套件运行得更快。首先,将它拆分成独立的套件,在多台机器上并行运行。现代CI服务器具有”构建网格”功能,使这一操作变得极其简单。请记住,计算能力是便宜的,而人力是昂贵的。及时获得反馈比几台服务器的成本更有价值。你可以使用的第二个技巧是,作为构建优化过程的一部分,将那些运行时间长且不经常失败的测试推送到验收测试阶段。但是请注意,这会导致等待更长时间才能获得关于一组变更是否破坏这些测试的反馈。
提交阶段应该专注于一件事:尽可能快地检测系统变更可能引入的最常见故障,并通知开发人员以便他们能够快速修复问题。提交阶段提供的反馈价值如此之大,以至于投资保持其高效运行非常重要,最重要的是保持快速。
应用程序的代码或配置发生任何变更时,都应该运行部署流水线的提交阶段。因此,开发团队的每个成员每天都会多次执行它。开发人员的自然倾向是,如果构建性能低于可接受的标准就会抱怨:让它增长到超过五分钟,抱怨就会开始。重要的是倾听这些反馈,并尽一切可能保持这个阶段的快速,同时关注真正的价值——即快速失败,从而提供关于错误的反馈,否则这些错误在以后修复的成本会高得多。
因此,建立提交阶段——一个自动化流程,在每次变更时启动,构建二进制文件,运行自动化测试并生成指标——是你在采用持续集成实践过程中可以做的最低限度工作。提交阶段为交付流程的质量和可靠性提供了巨大的进步——假设你遵循持续集成中涉及的其他实践,例如定期检入并在发现缺陷后立即修复。虽然它只是部署流水线的起点,但它可能提供了最大的投资回报:一种范式转变,即确切知道引入破坏应用程序的变更的时刻,并能够立即使其恢复正常工作。
图8.1 验收测试阶段
在本章中,我们将更详细地探讨自动化验收测试及其在部署流水线中的位置。验收测试是部署流水线中的关键阶段:它们将交付团队带到基本持续集成之外。一旦有了自动化验收测试,你就是在测试应用程序的业务验收标准,也就是验证它是否为用户提供了有价值的功能。验收测试通常针对通过提交测试的每个版本的软件运行。部署流水线的验收测试阶段的工作流程如图8.1所示。
我们首先讨论验收测试在交付过程中的重要性。然后深入讨论如何编写有效的验收测试以及如何维护高效的验收测试套件。最后,我们涵盖管理验收测试阶段本身的原则和实践。但在所有这些之前,我们应该说明我们所说的验收测试是什么意思。验收测试与功能测试或单元测试的区别是什么?
单个验收测试旨在验证某个故事或需求的验收标准是否已得到满足。验收标准有许多不同的类型;首先,它们可以是功能性的或非功能性的。非功能性验收标准包括容量、性能、可修改性、可用性、安全性、易用性等内容。这里的关键点是,当与特定故事或需求相关的验收测试通过时,它们证明了其验收标准已得到满足,因此它既是完整的又是可工作的。
整个验收测试套件既验证应用程序是否提供了客户期望的业务价值,又防止破坏应用程序现有功能的回归或缺陷。
关注验收测试作为展示应用程序满足每个需求的验收标准的手段还有一个额外的好处。它使交付过程中涉及的每个人——客户、测试人员、开发人员、分析师、运维人员和项目经理——思考每个需求的成功意味着什么。我们将在第195页的”作为可执行规范的验收标准”一节中更详细地介绍这一点。
如果你有测试驱动设计的背景,你可能会疑惑为什么这些测试与单元测试不同。区别在于验收测试(acceptance tests)是面向业务的,而不是面向开发者的。它们在类生产环境中针对应用程序的运行版本一次测试完整的用户故事(stories)。单元测试是任何自动化测试策略的重要组成部分,但它们通常无法提供足够高的信心来确保应用程序可以发布。验收测试的目标是证明我们的应用程序确实做到了客户想要的,而不仅仅是按照程序员认为应该工作的方式运行。单元测试有时也会关注这一点,但并非总是如此。单元测试的目的是证明应用程序的单个部分按照程序员的意图工作;这与断言用户获得了他们需要的东西完全不同。
围绕自动化验收测试一直存在大量争议。项目经理和客户经常认为创建和维护这些测试成本太高——事实上,如果做得不好,确实如此。许多开发者认为通过测试驱动开发创建的单元测试套件足以防止回归问题(regressions)。我们的经验是,正确创建和维护的自动化验收测试套件的成本远低于频繁进行手工验收和回归测试的成本,或者发布低质量软件的代价。我们还发现,自动化验收测试能够捕获到严重的问题,而这些问题是单元测试或组件测试套件无论多么全面都无法捕获的。
首先,值得指出手工验收测试的成本。为了防止缺陷被发布,每次发布应用程序时都需要进行验收测试。我们知道有一个组织每次发布需要花费300万美元进行手工验收测试。这严重制约了他们频繁发布软件的能力。任何有价值的手工测试工作,当对具有一定复杂度的应用程序进行测试时,都会非常昂贵。
此外,为了发挥捕获回归缺陷的作用,这类测试需要在开发完成和发布临近时作为一个阶段来执行。因此,手工测试通常发生在项目团队承受巨大压力要将软件推出的时期。结果是,通常没有计划足够的时间来修复手工验收测试中发现的缺陷。最后,当发现需要复杂修复的缺陷时,很有可能会给应用程序引入更多的回归问题。
敏捷社区中一些人倡导的方法是几乎完全放弃自动化验收测试,编写全面的单元测试和组件测试套件。这些测试结合其他XP实践,如结对编程(pair programming)、重构(refactoring),以及客户、分析师和测试人员共同进行的仔细分析和探索性测试(exploratory testing),被一些人认为是优于自动化验收测试成本的替代方案。
这个论点存在几个缺陷。首先,没有其他类型的测试能够证明应用程序在接近生产环境的运行状态下,能够提供用户期望的业务价值。单元测试和组件测试不测试用户场景,因此无法发现用户在与应用程序交互过程中使应用程序经历一系列状态时出现的那类缺陷。验收测试正是为此而设计的。它们还擅长捕获线程问题、事件驱动应用程序中的涌现行为(emergent behavior),以及由架构错误或环境和配置问题导致的其他类别的bug。这类缺陷很难通过手工测试发现,更不用说单元测试或组件测试了。
验收测试还能在你对应用程序进行大规模更改时保护你的应用程序。在这种情况下,单元测试和组件测试通常必须随着你的领域模型进行根本性的修改,这限制了它们作为应用程序功能保护者的能力。只有验收测试能够证明你的应用程序在这个过程结束后仍然正常工作。
最后,选择放弃自动化验收测试的团队会给测试人员带来更大的负担,测试人员必须花更多时间在枯燥和重复的回归测试上。我们认识的测试人员并不赞成这种方法。虽然开发者可以承担部分负担,但许多编写单元测试和组件测试的开发者在发现自己工作中的缺陷方面,效率远不如测试人员。根据我们的经验,有测试人员参与编写的自动化验收测试在发现用户场景中的缺陷方面,比开发者编写的测试要好得多。
人们不喜欢自动化验收测试的真正原因是它被认为成本太高。然而,将验收测试自动化的成本降低到远低于其变得高效和具有成本效益的水平是可能的。当自动化验收测试针对每个通过提交测试(commit tests)的构建运行时,对软件交付过程的影响是巨大的。首先,由于反馈循环更短,缺陷会更早被发现,此时修复成本更低。其次,由于测试人员、开发者和客户需要密切合作来创建良好的自动化验收测试套件,他们之间会有更好的协作,每个人都专注于应用程序应该交付的业务价值。
采用基于验收测试的有效策略还会带来其他积极的副作用:验收测试在结构良好的应用程序中效果最好,这些应用程序需要有适当的结构,具备薄UI层,并经过精心设计,能够在开发机器和生产环境中运行。
我们将创建和维护有效的自动化验收测试的问题分为四个部分:创建验收测试;创建应用程序驱动层;实现验收测试;以及维护验收测试套件。在详细介绍之前,我们将简要介绍我们的方法。
编写可维护的验收测试首先需要对分析过程给予仔细关注。验收测试源自验收标准,因此应用程序的验收标准必须考虑到自动化,并且必须遵循INVEST原则,特别要关注对最终用户有价值和可测试性。这是自动化验收测试对整个开发过程施加的另一个微妙但重要的压力:对更好需求的压力。对编写不当的验收标准进行自动化,如果这些标准没有解释要开发的功能对用户的价值,是导致验收测试套件质量差且难以维护的主要原因。
图8.2 验收测试中的层次
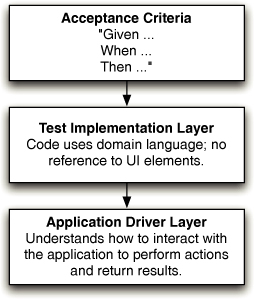
一旦有了一组描述要交付给用户的价值的验收标准,下一步就是将它们自动化。自动化验收测试应该始终分层,如图8.2所示。
验收测试的第一层是验收标准。Cucumber、JBehave、Concordion、Twist和FitNesse等工具允许你直接在测试中放入验收标准,并将它们与底层实现链接起来。但是,如本章后面所述,你也可以采用在xUnit测试名称中编码验收标准的方法。然后,你可以直接从xUnit测试框架运行验收测试。
至关重要的是,你的测试实现使用你的领域语言(domain language),并且不包含如何与应用程序交互的细节。直接引用应用程序API或UI的测试实现很脆弱,即使UI的微小更改也会立即破坏所有引用已更改UI元素的测试。当单个UI元素更改时,看到这类验收测试套件的大片区域崩溃并不罕见。
不幸的是,这种反模式(antipattern)非常常见。大多数测试都是在详细执行层面编写的:“戳这个,戳那个,在这里查看结果。”这类测试通常是录制回放式测试自动化产品的输出,这是自动化验收测试被认为成本高昂的主要原因之一。使用此类工具创建的任何验收测试套件都与UI紧密耦合,因此极其脆弱。
大多数UI测试系统提供的操作允许你将数据放入字段、点击按钮以及从页面的指定区域读取结果。这种详细程度最终是必要的,但它与测试用例的意义——真正的价值——相去甚远。任何给定验收测试用例旨在断言的行为,不可避免地处于非常不同的抽象层次。我们真正想知道的是诸如”如果我下订单,它是否被接受?“或”如果我超过信用额度,我是否得到正确的通知?“这样的问题的答案。
测试实现应该调用我们称之为应用程序驱动层的下层,以实际与被测系统交互。应用程序驱动层有一个知道如何执行操作和返回结果的API。如果你的测试针对应用程序的公共API运行,则应用程序驱动层知道此API的详细信息并调用其正确部分。如果你的测试针对GUI运行,则此层将包含窗口驱动程序(window driver)。在结构良好的窗口驱动程序中,给定的GUI元素只会被引用几次,这意味着如果它被更改,只需要更新对它的这些引用。
长期维护验收测试需要纪律。必须仔细注意保持测试实现的高效和良好的结构,特别是在管理状态、处理超时和使用测试替身(test doubles)方面。随着新验收标准的添加,必须重构验收测试套件以确保它们保持一致性。
编写验收测试时的一个重要关注点是是否直接针对应用程序的GUI运行测试。由于我们的验收测试旨在模拟用户与系统的交互,理想情况下,如果系统有用户界面,我们应该通过系统的用户界面进行工作。如果我们不通过用户界面测试,就不是在测试用户在实际交互中将调用的相同代码路径。然而,直接针对GUI测试存在几个问题:其快速变化率、场景设置的复杂性、测试结果的访问以及不可测试的GUI技术。
在应用程序开发过程中,用户界面通常变化频繁。如果验收测试与UI耦合,UI的微小更改很容易破坏验收测试套件。这不仅限于应用程序开发期间;由于可用性改进、拼写更正等原因,在系统的用户测试期间也可能发生这种情况。
其次,如果UI是进入系统的唯一途径,场景设置可能会很复杂。设置测试用例可能需要多次交互才能使系统进入准备就绪的状态。测试结束时,结果可能无法通过UI直观显示,因为UI可能无法提供验证测试结果所需的信息。
最后,某些UI技术,尤其是较新的技术,很难自动化测试。重要的是要检查您选择的UI技术是否可以通过自动化框架驱动。
有一种替代方案可以绕过GUI进行测试。如果您的应用程序设计良好,GUI层代表一组定义明确的纯显示代码,不包含任何自己的业务逻辑。在这种情况下,绕过它并针对其下面的代码层编写测试的相关风险可能相对较小。为可测试性而设计的应用程序将具有一个API,GUI和测试工具都可以通过它来驱动应用程序。直接针对业务层运行测试是一种合理的策略,如果您的应用程序可以支持,我们建议采用这种方法。这只需要开发团队保持足够的纪律,使表示层专注于像素绘制,而不涉及业务或应用程序逻辑领域。
如果您的应用程序不是这样设计的,您就必须直接针对UI进行测试。我们将在本章后面讨论管理这种情况的策略,主要策略是窗口驱动模式(window driver pattern)。
在本节中,我们将讨论如何创建自动化验收测试。我们将从分析师、测试人员和客户共同识别验收标准开始,然后讨论如何以可自动化的形式表示验收标准。
您的开发流程应该根据具体项目的需求进行调整,但一般来说,我们建议大多数有一定规模的项目都应该有一名业务分析师作为每个团队的一部分。业务分析师的主要角色是代表系统的客户和用户。他们与客户合作识别和优先排序需求。他们与开发人员合作,确保他们从用户角度充分理解应用程序。他们指导开发人员,确保用户故事(story)交付预期的业务价值。他们与测试人员合作,确保正确指定验收标准,并确保开发的功能满足这些验收标准并交付预期价值。
测试人员在任何项目中都是必不可少的。他们的最终角色是确保交付团队中的每个人(包括客户)都了解正在开发的软件的当前质量和生产就绪程度。他们通过以下方式实现这一目标:与客户和分析师合作定义用户故事或需求的验收标准,与开发人员合作编写自动化验收测试,以及执行手动测试活动,如探索性测试、手动验收测试和演示。
并非每个团队都有100%时间执行这些角色的独立个人。有时,开发人员充当分析师,或者分析师充当测试人员。理想情况下,客户与团队坐在一起执行分析师角色。重要的是这些角色应该始终存在于团队中。
总的来说,在本书中我们一直试图避免对您使用的开发流程做任何预设。我们相信我们描述的模式对任何交付团队都有益,无论他们使用什么流程。然而,我们认为迭代开发流程对于创建高质量软件至关重要。因此,我们希望您能原谅我们在这里给出更多关于迭代开发流程的细节,因为这有助于明确分析师、测试人员和开发人员的角色。
在迭代交付方法中,分析师大部分时间都在定义验收标准。这些标准是团队判断特定需求是否得到满足的依据。最初,分析师将与测试人员和客户密切合作定义验收标准。鼓励分析师和测试人员在此阶段合作有助于双方,使流程更有效。分析师受益,因为测试人员可以根据经验提供什么样的事情可以且应该有效地测量以定义用户故事何时完成。测试人员受益,因为在测试这些需求成为他们的主要关注点之前,他们就能了解需求的性质。
一旦定义了验收标准,就在需求即将实施之前,分析师和测试人员与将要进行实施的开发人员坐在一起,如果可能的话还有客户。分析师描述需求及其所在的业务背景,并详细说明验收标准。然后测试人员与开发人员合作,商定一组自动化验收测试,以证明验收标准已得到满足。
这些简短的启动会议是将迭代交付过程紧密联系在一起的重要组成部分,确保需求实现的各方都对该需求以及他们在交付中的角色有良好的理解。这种方法防止分析师创建实施或测试成本高昂的”象牙塔”需求。它防止测试人员提出实际上不是缺陷而是对系统误解的缺陷。它防止开发人员实现与任何人真正想要的内容几乎没有关系的东西。
在需求实现过程中,如果开发人员发现他们理解不够充分的领域,或者发现了问题或解决需求所提出问题的更有效方法,他们会咨询分析师。这种交互性是迭代交付过程的核心,部署流水线提供的能力极大地促进了这一点,使我们能够在需要时在选择的环境中运行应用程序。
当开发人员认为他们已经完成了工作——这意味着所有相关的单元测试和组件测试都通过了,并且所有验收测试都已实现并显示系统已满足需求——他们将向分析师、测试人员和客户演示。这次审查让分析师和客户看到需求的工作解决方案,并让他们有机会确认它确实按预期满足了需求。通常在这次审查中会发现一些小问题,这些问题会立即得到解决。有时,这样的审查会引发关于替代方案或变更影响的讨论。这是团队测试他们对系统演进方向共同理解的好机会。
一旦分析师和客户满意需求已得到满足,它就会转交给测试人员进行测试。
随着自动化测试在使用迭代过程的项目交付中变得越来越核心,许多从业者已经意识到自动化测试不仅仅是关于测试。相反,验收测试是正在开发的软件行为的可执行规范。这是一个重要的认识,催生了一种新的自动化测试方法,称为行为驱动开发(behavior-driven development)。行为驱动开发的核心思想之一是,你的验收标准应该以客户对应用程序行为的期望形式编写。然后应该可以采用这样编写的验收标准,并直接针对应用程序执行它们,以验证应用程序是否符合其规范。
这种方法有一些显著的优势。大多数规范在应用程序演进时开始过时。但可执行规范不可能出现这种情况:如果它们没有准确地指定应用程序的功能,它们在运行时会引发相应的异常。当针对不符合其规范的应用程序版本运行时,流水线的验收测试阶段将失败,因此该版本将无法用于部署或发布。
验收测试是面向业务的,这意味着它们应该验证你的应用程序为其用户提供价值。分析师为用户故事定义验收标准——必须满足这些标准才能认为故事完成。Chris Matts和Dan North提出了一种用于编写验收标准的领域特定语言(domain-specific language),其形式如下:
Given 某些初始上下文,
When 发生某个事件,
Then 会有某些结果。
就你的应用程序而言,“given”代表测试用例开始时应用程序的状态。“when”子句描述用户与应用程序之间的交互。“then”子句描述交互完成后应用程序的状态。测试用例的工作是使应用程序进入”given”子句中描述的状态,执行”when”子句中描述的操作,并验证应用程序的状态是否如”then”子句中描述的那样。
例如,考虑一个金融交易应用程序。我们可以按以下格式编写验收标准:

像Cucumber、JBehave、Concordion、Twist和FitNesse这样的工具允许你将这样的验收标准编写为纯文本,并使它们与实际应用程序保持同步。例如,在Cucumber中,你可以将上述验收标准保存在名为features/placing_an_order.feature的文件中。该文件代表图8.2中的验收标准。然后你将创建一个Ruby文件,列出此场景所需的步骤,保存为features/step_definitions/placing_an_order_steps.rb。该文件代表图8.2中的测试实现层。

为了支持这个测试和其他测试,你需要在application_driver目录中创建AdminApi和TradingUi类。这些类构成图8.2中应用程序驱动层的一部分。如果你的应用程序是基于Web的,它们可能会调用Selenium、Sahi或WebDriver;如果是富客户端.NET应用程序,则调用White;或者如果你的应用程序有REST API,则使用HTTP POST或GET。在命令行上运行cucumber会产生以下输出:
这种创建可执行规范的方法是行为驱动设计的本质。总结一下,这个过程是:
应用程序驱动层是理解如何与您的应用程序(被测系统)交互的层。应用程序驱动层的API以领域语言表达,实际上可以被视为一种领域特定语言。
领域特定语言(DSL, Domain-Specific Language)是一种针对特定问题域的计算机编程语言。它与通用编程语言的不同之处在于,它无法解决许多类别的问题,因为它被设计为仅在其特定问题领域内工作。
DSL可以分为两种类型:内部DSL和外部DSL。外部领域特定语言需要在执行其中的指令之前进行显式解析。前一节Cucumber示例中形成顶层的验收标准脚本展示了外部DSL。其他例子包括Ant和Maven的XML构建脚本。外部DSL不需要是图灵完备的。
内部DSL是直接用代码表达的。下面的Java示例是一个内部DSL。Rake是另一个例子。一般来说,内部DSL更强大,因为您可以使用底层语言的全部功能,但根据底层语言的语法,它们的可读性可能较差。
在可执行规范领域有一些非常有趣的工作正在进行,它与现代计算中的其他几个主题交叉:意图编程和领域特定语言。您可以开始将测试套件,或者说可执行规范,视为定义应用程序的意图。您陈述该意图的方式可以被视为一种领域特定语言,其中领域是应用程序规范。
有了设计良好的应用程序驱动层,就可以完全省去验收标准层,在测试的实现中直接表达验收标准。以下是我们在上面用Cucumber编写的同一个验收测试,表达为一个简单的JUnit测试。这个例子是从Dave当前项目中稍作改编的。
此测试创建一个新用户,成功注册他们并确保他们有足够的资金进行交易。它还为他们创建一个新的交易工具。这两个活动本身都是复杂的交互,但DSL将它们抽象到使初始化此测试的任务简化为几行代码的程度。以这种方式编写的测试的关键特征是它们将测试从实现细节中抽象出来。
这些测试的一个关键特征是使用别名来表示关键值。在上面的示例中,我们创建了一个名为bond的工具和一个名为Dave的系统用户。应用程序驱动层在幕后所做的是创建真实的工具和用户,每个都有自己由应用程序生成的唯一标识符。应用程序驱动层将在内部为这些值设置别名,以便我们始终可以引用Dave或bond,即使真实用户可能被称为类似testUser11778264441的名称。该值是随机的,每次运行测试时都会改变,因为每次都会创建一个新用户。
这有两个好处。首先,它使验收测试完全独立于彼此。因此,您可以轻松地并行运行验收测试,而不必担心它们会相互干扰数据。其次,它允许您使用几个简单的高级命令创建测试数据,使您无需为测试集合维护复杂的种子数据。
在上面显示的DSL样式中,每个操作(placeOrder、confirmOrderSuccess等)都用多个字符串参数定义。有些参数是必需的,但大多数是可选的,具有简单的默认值。例如,登录操作允许我们除了为用户指定别名外,还可以指定特定的密码和产品代码。如果我们的测试不关心这些细节,DSL将提供有效的默认值。
为了让您了解这里进行的默认设置级别,我们的createUser指令的完整参数集是:
• name(必需)
• password(默认为 password)
• productType(默认为 DEMO)
• balance(默认为 15000.00)
• currency(默认为 USD)
• fxRate(默认为 1)
• firstName(默认为 Firstname)
• lastName(默认为 Surname)
• emailAddress(默认为
test@somemail.com)
• homeTelephone(默认为 02012345678)
• securityQuestion1(默认为
Favourite Colour?)
• securityAnswer1(默认为 Blue)
设计良好的应用驱动层带来的一个结果是提高了测试的可靠性。本例所取自的系统实际上是高度异步的,这意味着我们的测试在进入下一步之前通常需要等待结果。这可能导致间歇性或脆弱的测试,对时序的细微变化非常敏感。由于使用DSL隐含了高度的重用,复杂的交互和操作可以编写一次并在多个测试中使用。如果在验收测试套件中运行测试时出现间歇性问题,这些问题会在单一位置得到修复,从而确保未来重用这些功能的测试同样可靠。
我们以非常简单的方式开始构建应用驱动层——建立几个案例并构建一些简单的测试。从那时起,团队基于需求工作,每当发现某个特定测试需要的功能缺失时,就向该层添加内容。在相对较短的时间内,应用驱动层及其API所代表的DSL往往会变得相当广泛。
比较上面JUnit中的验收测试示例与前一节中Cucumber表达的测试是很有启发的。这两种方法都可以很好地工作,各有优缺点。这两种方法都代表了对传统验收测试方法的重大改进。Jez在他当前的项目中使用Cucumber风格的方法(尽管使用的是Twist而不是Cucumber),而Dave直接使用JUnit(如上面的示例)。
外部DSL方法的好处是你可以往返你的验收标准。你的验收标准——以及你的故事——本身就是你的可执行规范,而不是在跟踪工具中有验收标准,然后在xUnit测试套件中重新表达它们。然而,虽然现代工具减少了编写可执行验收标准并使其与验收测试实现保持同步的开销,但不可避免地会有一些开销。
如果你的分析师和客户有足够的技术能力使用内部DSL编写的xUnit测试,那么使用直接的xUnit方法效果很好。它需要的工具不那么复杂,并且你可以使用常规开发环境中内置的自动完成功能。你还可以从测试中直接访问DSL,而不必经过一个间接层——上面描述的别名方法的所有功能都触手可及。然而,虽然你可以使用AgileDox等工具将类名和方法名转换为列出功能(“下订单”,如上例所示)和场景(“用户订单应正确扣除账户余额”)的纯文本文档,但更难将实际测试转换为一组纯文本步骤。此外,转换是单向的——你必须在测试中进行更改,而不是在验收标准中。
本章中的示例旨在清楚地说明将验收测试分为三层:可执行验收标准、测试实现和应用驱动层。应用驱动层是唯一理解如何与应用交互的层——其他两层只使用业务的领域语言(domain language)。如果你的应用有GUI,并且你决定验收测试应该针对GUI运行,那么应用驱动层将理解如何与之交互。应用驱动层中与GUI交互的部分称为窗口驱动。
窗口驱动模式旨在通过提供一个抽象层来降低验收测试和被测系统GUI之间的耦合,从而使针对GUI运行的测试不那么脆弱。因此,它有助于隔离我们的测试免受系统GUI变化的影响。本质上,我们编写一个抽象层,该层对我们的测试来说假装是用户界面。所有测试仅通过该层与真实UI交互。因此,如果对GUI进行了更改,我们可以对窗口驱动进行相应的更改,这样窗口驱动的接口以及测试保持不变。
FitNesse开源测试工具采用了非常相似的方法,允许创建Fit fixtures作为你需要测试的任何东西的”驱动”。这是一个在此上下文中大放异彩的优秀工具。
图8.3 验收测试中窗口驱动模式的使用
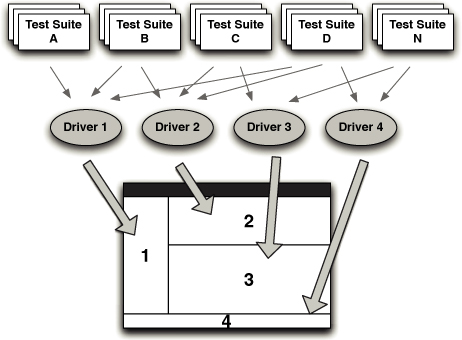
在实现窗口驱动模式时,你应该为GUI的每个部分编写相当于设备驱动程序的代码。验收测试代码只通过适当的窗口驱动与GUI交互。窗口驱动提供了一个抽象层,它构成应用程序驱动层的一部分,将你的测试代码与UI的具体细节变化隔离开来。当UI发生变化时,你只需修改窗口驱动中的代码,所有依赖它的测试就都修复了。窗口驱动模式如图8.3所示。
应用程序驱动和窗口驱动之间的区别在于:窗口驱动负责理解如何与GUI交互。如果你为应用程序提供了新的GUI——例如,在Web界面之外增加一个富客户端——你只需创建一个新的窗口驱动并将其插入应用程序驱动即可。
在一个非常大的项目中,我们选择使用开源GUI测试脚本工具。在第一个版本的开发过程中,我们几乎能够跟上开发进度:我们的自动化验收测试套件正在运行,尽管在软件版本上滞后一两周。
在第二个版本中,我们的验收测试套件落后的速度越来越快。到该版本结束时,它已经落后到第一个版本的测试一个都无法运行——一个都没有!
我们在第三个版本中实现了窗口驱动模式,并改变了测试创建和维护过程的某些方面,最显著的是让开发人员负责测试维护。到该版本结束时,我们有了一个可工作的部署流水线(deployment pipeline),其中包括在每次成功提交后立即运行自动化测试。
以下是一个没有使用本章所述任何分层的验收测试示例:

以下是重构为两层的相同示例:测试实现和窗口驱动。本例中的AccountPanelDriver就是窗口驱动。这是分解测试的一个良好开端。

我们可以看到测试的语义与底层UI交互细节之间有了更清晰的分离。如果考虑支撑这个测试的代码——窗口驱动中的代码——这个测试的整体代码量更多了,但抽象级别更高。我们将能够在许多与该页面交互的不同测试中重用窗口驱动,并在使用过程中不断增强它。
如果为了我们的示例,业务决定用触摸屏上的基于手势的用户界面来替代基于Web的用户界面,认为这样产品会更有效,那么这个测试的基本结构将保持不变。我们可以创建一个新的窗口驱动来与基于手势的UI交互,而不是与老旧的Web页面交互,在应用程序驱动层中用它替换原始驱动,测试将继续工作。
实现验收测试不仅仅是分层。验收测试涉及将应用程序置于特定状态、对其执行多个操作并验证结果。验收测试必须编写为能够处理异步和超时,以避免不稳定性(flakiness)。测试数据必须谨慎管理。通常需要测试替身(test doubles)来模拟与外部系统的任何集成。这些主题是本节的内容。
在前面的章节中,我们讨论了有状态单元测试的问题,并建议尽量减少测试对状态的依赖。这对于验收测试来说是一个更加复杂的问题。验收测试旨在模拟用户与系统的交互,以此来测试系统并证明它满足业务需求。当用户与你的系统交互时,他们会积累并依赖系统管理的信息。没有这样的状态,你的验收测试就毫无意义。但是建立一个已知良好的初始状态——任何真正测试的前提条件——然后构建一个依赖该状态的测试可能会很困难。
当我们谈论有状态测试时,我们使用的是一种简写。我们使用”有状态”这个术语想要表达的是,为了测试应用程序的某些行为,测试依赖于应用程序处于特定的初始状态(行为驱动开发(behavior-driven development)的”给定”子句)。也许应用程序需要一个具有特定权限的账户,或者需要对特定的库存项集合进行操作。无论需要什么初始状态,让应用程序准备好展示被测行为通常是编写测试中最困难的部分。
虽然我们无法现实地从任何测试(更不用说验收测试)中消除状态,但重要的是要专注于最小化测试对复杂状态的依赖。
首先,避免获取生产数据转储来填充验收测试的测试数据库(尽管这偶尔对容量测试有用)。相反,应该维护一个可控的、最小化的数据集。测试的一个关键方面是建立一个已知良好的起点。如果你试图在测试环境中跟踪生产系统的状态——我们在许多不同组织中见过很多次这种做法——你会花更多时间试图让数据集工作,而不是进行测试。毕竟,测试的重点应该是系统的行为,而不是数据。
维护允许你探索系统行为的最小连贯数据集。当然,这个最小起始状态应该表示为一组脚本,存储在你的版本控制系统中,可以在验收测试运行开始时应用。理想情况下,如我们在第12章”管理数据”中描述的,测试应该使用应用程序的公共API将其置于正确状态以开始测试。这比直接将数据运行到应用程序数据库中更不脆弱。
理想的测试应该是原子性的。拥有原子性测试意味着它们执行的顺序无关紧要,消除了难以追踪的bug的主要原因。这也意味着测试可以并行运行,这对于在你拥有任何规模的应用程序时获得快速反馈至关重要。
原子性测试创建执行所需的一切,然后清理自己,除了通过或失败的记录外不留下任何痕迹。在验收测试中这可能很难实现,但并非不可能。我们在处理事务系统(特别是关系数据库)的组件测试时经常使用的一种技术是在测试开始时建立一个事务,然后在测试结束时回滚它。这样数据库就保持在测试运行之前的相同状态。不幸的是,如果你采纳我们的另一条建议,即将验收测试视为端到端测试,这种方法通常不可用。
验收测试最有效的方法是使用应用程序的功能来隔离测试范围。例如,如果你的软件支持拥有独立账户的多个用户,使用应用程序的功能在每次测试开始时创建一个新账户,如前一节中的示例所示。在应用程序驱动层中创建一些简单的测试基础设施,使新账户的创建变得非常简单。现在当你的测试运行时,属于与测试关联的账户的任何活动和结果状态都独立于其他账户中发生的活动。这种方法不仅确保你的测试是隔离的,而且还测试了这种隔离,特别是当你并行运行验收测试时。这种有效的方法只有在应用程序不寻常到没有自然方式隔离案例时才会有问题。
然而,有时在测试用例之间共享状态别无选择。在这些情况下,测试必须非常仔细地设计。像这样的测试往往很脆弱,因为它们不是在起点已知的环境中运行。简单地说,如果你编写一个测试向数据库写入四条记录,然后在下一步检索第三条,你最好确定在测试开始之前没有其他人添加任何行,否则你会选择错误的记录。你还应该小心,不要在运行之间没有执行拆卸过程的情况下重复运行测试。这些是维护和保持运行的讨厌测试。遗憾的是,它们有时很难避免,但值得努力尽可能避免它们。仔细思考如何以不同方式设计测试,使其不会留下任何状态。
当你到达最后的手段并发现必须创建起始状态无法保证且无法清理的测试时,我们建议你专注于使这些测试非常防御性。验证测试开始时的状态是否符合你的预期,如果有任何异常立即失败测试。用前置条件断言保护你的测试,确保系统准备好运行你的测试。使这些测试以相对而非绝对方式工作;例如,不要编写一个向集合添加三个对象然后确认其中只有三个对象的测试,而是获取初始计数并断言有 x + 3 个。
最直接的测试,因此应该成为所有验收测试模型的测试,是那些证明系统需求而不需要对其进行任何特权访问的测试。自动化测试的新手认识到,要使他们的代码可测试,他们必须修改其设计方法,这是真的。但通常,他们期望需要为代码提供许多秘密后门以允许确认结果,这是不真实的。正如我们在其他地方描述的,自动化测试确实会对你施加压力,使你的代码更加模块化和更好地封装,但如果你为了使其可测试而打破封装,你通常会错过实现相同目标的更好方法。
在大多数情况下,你应该对创建一段仅用于验证应用程序行为的代码持高度怀疑态度。要努力避免这种特权访问,在妥协之前要深思熟虑,对自己采取强硬立场——在你绝对确定找不到更好的方法之前,不要屈服于简单的选择。
然而,有时灵感匮乏,你不得不提供某种后门。这些可能是允许你修改系统某部分行为的调用,也许是返回某些关键结果,或者将系统的那部分切换到特定的测试模式。如果你真的别无选择,这种方法是可行的。然而,我们建议你只对系统外部的组件这样做,用可控的桩(stub)或其他测试替身(test double)替换负责与外部组件交互的代码。我们建议你永远不要向将部署到生产环境的远程系统组件添加仅用于测试的接口。
我们遇到的这个问题最明显的例子是,当我们在测试中碰到进程边界时。我们想编写一个验收测试,涉及与一个服务通信,该服务代表通往另一个系统的网关,这个系统不在我们的测试范围内。然而,我们需要确保我们的系统在此之前能正常工作。我们还需要确保我们的系统能够适当地响应该通信的任何问题。
我们已经有一个桩来代表外部系统,我们的服务与之交互。最后,我们实现了一个”下次调用时做什么”的方法,我们的测试可以使用它将桩切换到等待模式,触发后按我们定义的方式响应下一次调用。
作为特殊接口的替代方案,你可以提供对”魔法”数据值做出反应的测试时组件。同样,这种策略有效,但应该保留给不会作为生产系统一部分部署的组件。这对测试替身来说是一种有用的策略。
这两种策略都倾向于导致高维护成本的测试,经常需要调整。真正的解决方案是尽可能避免这些妥协,依靠系统本身的实际行为来验证任何测试的成功完成。只有在用尽其他选择时才使用这些策略。
测试异步系统会带来一系列问题。对于单元测试,你应该避免测试范围内的任何异步,或者跨测试边界的异步。后者可能导致难以发现的间歇性测试失败。对于验收测试,根据应用程序的性质,异步可能无法避免。这个问题不仅出现在显式异步系统中,也出现在使用线程或事务的任何系统中。在这样的系统中,你的调用可能需要等待另一个线程或事务完成。
这里的问题归结为:测试失败了,还是我们只是在等待结果到达?我们发现最有效的策略是构建将测试本身与这个问题隔离开来的测试夹具(fixture)。诀窍是,就测试本身而言,让体现测试的事件序列看起来是同步的。这是通过将异步隔离在同步调用后面来实现的。
想象一下,我们正在构建一个收集文件并存储它们的系统。我们的系统将有一个收件箱,即文件系统上的一个位置,它将定期轮询。当它在那里找到一个文件时,会安全地存储它,然后给某人发送一封电子邮件,说有新文件到达。
当我们编写在提交时运行的单元测试时,可以孤立地测试系统的每个组件,使用测试替身断言每个组件在这个小对象集群中与其邻居适当地交互。这样的测试实际上不会接触文件系统,而是使用测试替身来模拟文件系统。如果我们在测试过程中遇到时间概念——由于轮询我们会遇到——我们会伪造时钟,或者只是强制轮询为”现在”。
对于我们的验收测试,我们需要了解更多。我们需要知道我们的部署是否有效,我们是否能够配置轮询机制,我们的电子邮件服务器是否正确配置,以及我们所有的代码是否无缝协作。
这里我们的测试有两个问题:系统在检查是否有新文件到达之前等待的轮询间隔,以及电子邮件到达所需的时间。
我们理想测试的大纲(使用C#语法)看起来像这样:
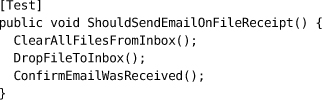
然而,如果我们天真地编写这个测试的代码,只是在测试中到达那一行时检查我们是否收到了预期的电子邮件,我们的测试几乎肯定会超过应用程序的速度。当我们检查邮件到达时,电子邮件还没有被接收。我们的测试会失败,尽管实际上只是测试到达断言的速度比应用程序传递电子邮件的速度更快。
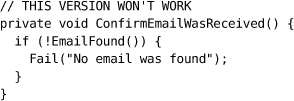
相反,我们的测试必须暂停,让应用程序有机会赶上来,然后再决定失败。

如果我们将DELAY_PERIOD设置得足够长,这将作为一个有效的测试工作。
这种方法的缺点是这些 DELAY_PERIOD 会迅速累加。我们曾经通过从这种策略改为更加精细的方法,将验收测试时间从2小时减少到40分钟。
新策略主要基于两个想法。一个是轮询结果,另一个是监控中间事件作为测试的关卡。我们实现了一些重试机制,而不是简单地等待超时前最长的可接受时间。

在这个例子中,我们保留了一个小的暂停,否则我们会浪费宝贵的CPU周期来检查本可以用于处理传入邮件的邮件。但即使有这个 SMALL_PAUSE,这个测试也比前面的版本高效得多,前提是 SMALL_PAUSE 与 DELAY_PERIOD 相比要小(通常小两个或更多数量级)。
最后的改进更具机会主义性质,并且在很大程度上取决于应用程序的性质。我们发现在大量使用异步的系统中,通常还有其他事情可以提供帮助。在我们的例子中,假设我们有一个处理传入邮件的服务。当邮件到达时,它会生成一个相应的事件。如果我们等待该事件而不是轮询邮件的到达,我们的测试会变得更快(尽管更复杂)。
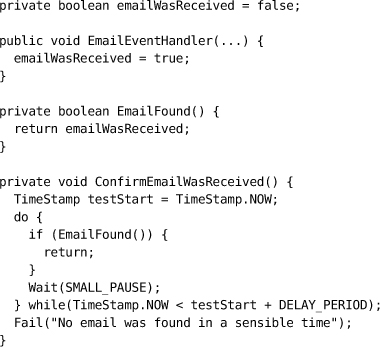
对于 ConfirmEmailWasRecived 的任何客户端来说,确认步骤看起来是同步的,适用于我们在这里展示的所有版本。这使得使用它的高级测试编写起来更简单,特别是如果测试中有遵循此检查的操作。这类代码应该存在于应用程序驱动程序层中,以便可以被许多不同的测试用例重用。它的相对复杂性是值得努力的,因为它可以被调整为高效且完全可靠,使所有依赖于它的测试也调整良好且可靠。
验收测试依赖于在类生产环境中执行自动化测试的能力。然而,这种测试环境的一个重要属性是它能够成功支持自动化测试。自动化验收测试与用户验收测试不同。其中一个区别是自动化验收测试不应该在包含与所有外部系统集成的环境中运行。相反,你的验收测试应该专注于提供一个可控的环境,在其中可以运行被测系统。这里的”可控”意味着你能够为我们的测试创建正确的初始状态。与真实外部系统集成会削弱我们做到这一点的能力。
你应该努力在验收测试期间最小化外部依赖的影响。然而,我们的目标是尽早发现问题,为了实现这一点,我们的目标是持续集成我们的系统。显然这里存在矛盾。与外部系统的集成可能很难正确实现,并且是常见的问题来源。这意味着仔细有效地测试这些集成点很重要。问题是,如果你将外部系统本身包含在验收测试范围内,你对系统及其起始状态的控制就会减少。此外,自动化测试的强度可能会在项目生命周期的早期对这些外部系统造成显著且意外的负载,这比负责这些系统的人员预期的要早得多。
图8.4 外部系统的测试替身
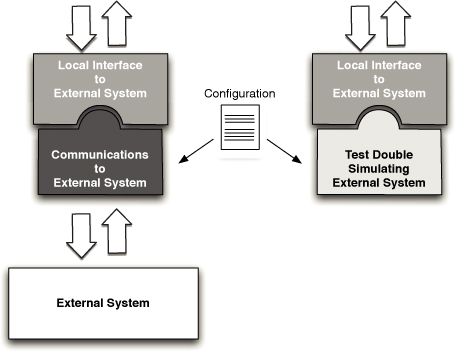
这种平衡通常会导致团队作为其测试策略的一部分建立某种妥协。与开发过程的任何其他方面一样,很少有”正确”的答案,项目会有所不同。我们的策略是双管齐下的:我们通常创建测试替身来代表与我们系统交互的所有外部系统的连接,如图8.4所示。我们还围绕每个集成点构建小型测试套件,旨在在确实与这些外部系统有真实连接的环境中运行。
除了为我们提供建立已知起点作为测试基础的能力外,创建测试替身来代替外部系统还有另一个优势:它为我们在应用程序中提供了额外的控制点,我们可以在其中控制行为、模拟通信故障、模拟错误响应或负载下的响应等等——所有这些都完全在我们的控制之下。
良好的设计原则应该引导你最小化外部系统与你正在开发的系统之间的耦合。我们通常的目标是让系统的一个组件代表与外部系统的所有交互——也就是说,每个外部系统一个组件(网关或适配器)。该组件将通信及其相关的任何问题集中到一个地方,并将该通信的技术细节与系统的其余部分隔离开来。它还允许你实现模式来提高应用程序的稳定性,例如 Release It![6] 中描述的断路器模式(Circuit Breaker Pattern)。
这个组件代表与外部系统的接口。无论暴露的接口是属于外部系统本身还是属于你的代码库,这个接口代表了你需要证明其有效性的契约。这个接口需要从两个角度得到验证:你的系统与它的交互方式,以及作为与外部系统通信的真实接入点。桩(Stub)允许你断言你的系统与远程系统正确交互。集成测试(我们接下来会描述)允许你断言外部系统在你的交互中按预期行为运行。从这个意义上说,测试替身(Test Doubles)和交互测试共同协作,消除了出错的可能性。
测试外部集成点
与外部系统的集成点是导致问题的常见来源,原因有很多。你的团队正在开发的代码可能会改变与成功通信相关的某些内容。你的系统和外部系统之间共享的数据结构的变化,或消息交换频率的变化,或寻址机制配置的变化——几乎任何类型的差异都可能成为问题。通信另一端的代码也可能发生变化。
我们编写用于断言这些集成点行为的测试应该聚焦于可能出现的问题,这些问题在很大程度上取决于集成的性质以及外部系统在其生命周期中的位置。如果外部系统已经成熟并在生产环境中运行,问题会与它处于活跃开发阶段时你将面临的问题不同。这些因素将在一定程度上决定我们在何处和何时运行这些测试。
如果外部系统正在活跃开发中,两个系统之间的接口性质很可能会发生变化。模式(Schema)、契约等可能会改变,或者更微妙的是,你们交换的信息内容的方式可能会改变。这种场景需要定期进行仔细测试,以识别两个团队产生分歧的点。根据我们的经验,大多数集成中通常有几个明显的场景需要模拟。我们建议你用少量测试覆盖这些明显的场景。这个策略会遗漏一些问题。我们的方法是在发现问题时,通过编写测试来捕获每个案例来解决这些问题。随着时间的推移,我们为每个集成点构建了一个小型测试套件,能够非常快速地捕获大多数问题。这个策略并不完美,但在这种场景中试图获得完美的覆盖率通常非常困难,而且努力与回报的比例会很快递减。
测试应该始终限定在覆盖你的系统与外部系统的特定交互上。它们不应该旨在完全测试外部系统接口。同样,这基于收益递减法则:如果你不关心某个特定字段的存在或缺失,就不要测试它。此外,遵循我们在第96页”集成测试”部分提供的指南。
正如我们所说,何时运行集成测试的时机无法固定。它因项目而异,也因集成点而异。偶尔,集成点可以合理地与验收测试同时运行,但更多时候情况并非如此。仔细考虑你将对外部系统提出的要求。记住你的测试每天会运行多次。如果与外部系统的每次交互测试都导致真实的交互,你的自动化测试可能会在外部系统上产生类似生产环境的负载。这可能并不总是受欢迎,特别是如果你的外部系统提供方自己不做太多自动化测试的话。
缓解这一问题的一个策略是实现你的测试套件,使其不是每次验收测试运行时都运行,而是可能每天一次或每周一次。例如,你可以将这些测试作为部署流水线中的单独阶段运行,或作为容量测试阶段的一部分运行。
一旦你有了验收测试套件,它们就需要作为部署流水线的一部分运行。规则是验收测试套件应该针对通过提交测试的每个构建运行。以下是一些适用于运行验收测试的实践。
未通过验收测试的构建将无法部署。在部署流水线模式中,只有通过此阶段的候选发布版本才能部署到后续阶段。后续流水线阶段通常被视为人工判断的问题:如果候选发布版本未能通过容量测试,在大多数项目中,会有人决定这个失败是否重要到足以在那里结束候选版本的旅程,还是允许它在性能问题存在的情况下继续进行。验收测试不允许这种模糊的结果。通过意味着候选发布版本可以继续进行,失败意味着它永远不能。
由于这条严格的界线,验收测试关卡是一个极其重要的门槛,如果您希望开发过程顺利进行,就必须认真对待它。保持复杂的验收测试运行将占用开发团队的时间。然而,这种成本是一种投资形式,根据我们的经验,它会在降低维护成本、提供保护以便您对应用程序进行大范围更改以及显著提高质量方面获得数倍回报。这遵循了我们在流程中提前暴露痛点的一般原则。我们从经验中知道,如果没有出色的自动化验收测试覆盖,会发生三种情况之一:要么在您认为已经完成时,在流程末尾花费大量时间来查找和修复缺陷;要么在手动验收和回归测试上花费大量时间和金钱;要么最终发布质量低劣的软件。
自动化UI测试的一个常见问题是准确理解测试为什么失败。由于这些测试必然是非常高层次的,因此存在许多潜在的故障点。有时这些可能根本与项目无关。在其他时候,可能在测试套件的早期,在不同的窗口或对话框中发生故障,导致后来出现问题。通常,找出问题所在的唯一方法是重新运行测试并在其进行过程中观察它。
在一个项目中,我们找到了一种让这变得更容易的方法。在测试开始之前,我们会使用一个名为Vnc2swf的开源工具在测试机器上启动屏幕捕获录制。测试完成后,如果出现故障,我们会将视频发布为制品(artifact)。只有在创建此视频后,我们才会使构建失败。这样调试验收测试就变得非常简单。
有一次我们发现有人登录到机器上并查看了任务管理器,可能是为了检查内存使用情况或性能。他们让窗口保持打开状态,由于它是一个模态窗口,它遮挡了应用程序窗口。因此UI测试无法点击某些按钮。构建页面报告的错误是”找不到按钮’X’“—但视频揭示了真正的原因。
很难列举使项目值得进行如此投资于自动化验收测试的原因。对于我们通常参与的项目类型,我们的默认做法是自动化验收测试和部署流水线的实现通常是一个合理的起点。对于持续时间极短且团队规模小的项目,可能只有四个或更少的开发人员,这可能有些过度—您可以改为将一些端到端测试作为单阶段CI流程的一部分运行。但对于任何比这更大的项目,自动化验收测试为开发人员提供的对业务价值的关注是如此宝贵,以至于它值得付出成本。值得重复的是,大型项目都是从小型项目开始的,而当项目变大时,如果不付出艰巨的努力,通常为时已晚,无法补充一套全面的自动化验收测试。
我们建议,对于您的所有项目,应该默认使用由交付团队创建、拥有和维护的自动化验收测试。
由于运行有效的验收测试套件所需的时间,在部署流水线的后期运行它们通常是有意义的。问题在于,如果开发人员不像等待提交测试那样坐在那里等待测试通过,他们通常会忽略验收测试失败。
这种低效率是我们接受的权衡,以换取一个部署流水线,它允许我们在提交测试关卡非常快速地捕获大多数故障,同时也保持对应用程序的良好自动化测试覆盖。让我们快速解决这个反模式(antipattern):归根结底,这是一个纪律问题,整个交付团队负责保持验收测试通过。
当验收测试失败时,团队需要停下来并立即分类问题。这是一个脆弱的测试、配置不当的环境、由于应用程序更改而不再有效的假设,还是真正的故障?然后需要有人立即采取行动使测试再次通过。
有一段时间,我们使用了相当传统的模型,即验收测试是测试团队的责任。这种策略证明非常麻烦,特别是在大型项目上。测试团队总是处于开发链的末端,因此我们的验收测试在其生命周期的大部分时间都处于失败状态。
我们的开发团队会一直工作,进行的更改会破坏大量验收测试,而没有意识到他们更改的影响。测试团队会在流程中相对较晚才发现更改,即在它已经被开发并签入之后。由于测试团队有太多自动化测试需要修复,需要一些时间才能着手修复最近的破坏,这意味着开发人员通常已经转移到其他任务上,因此没有处于修复问题的理想位置。测试团队很快就被需要修复的测试淹没了,同时还要为开发人员正在实现的新需求实现新测试。
这不是一个简单的问题。验收测试通常很复杂。确定验收测试失败的根本原因往往需要时间。正是这种情况促使我们尝试第一个流水线构建。我们希望缩短从代码变更暴露问题到有人知道验收测试存在问题之间的时间。
我们改变了自动化验收测试的所有权。测试团队不再负责开发和维护这些测试,而是由整个交付团队(包括开发人员和测试人员)共同负责。这带来了许多积极的好处:它使开发人员专注于实现需求的验收标准。由于他们需要负责跟踪验收测试构建,这让他们更快地意识到自己所做变更的影响。这也意味着,现在开发人员以验收测试的角度思考问题,他们通常能更成功地预测新变更可能影响验收测试套件的哪些区域,从而更好地定位工作重点。
为了保持验收测试正常运行,并让开发人员保持对应用程序行为的关注,重要的是验收测试应由整个交付团队拥有和维护,而不是由单独的测试团队负责。
如果让验收测试腐化会发生什么?当接近发布时间时,你试图让验收测试通过,以便对软件质量有信心。在检查验收测试时,你会发现很难区分以下几种失败情况:验收标准已变更导致的失败、代码重构且测试之前与实现过度耦合导致的失败,或者应用程序行为现在确实错误导致的失败。在这种情况下,由于没有足够的时间进行必要的代码考古来找出失败原因,测试通常最终会被删除或忽略。你最终会陷入持续集成本应解决的同样困境——在最后阶段匆忙让一切正常运行,但不知道需要多长时间,而且对代码的实际状态缺乏清晰认识。
尽快修复验收测试故障至关重要,否则测试套件将无法提供真正的价值。最重要的步骤是让故障可见。我们尝试过各种方法,例如让构建负责人(build master)追踪最可能导致故障的变更人员、向可能的责任人发送邮件,甚至站起来大喊”谁在修复验收测试构建?“(这个方法效果不错)。我们发现最有效的方法是通过一些小技巧,例如熔岩灯、大型构建监视器,或第63页”花哨功能”部分描述的其他技术。以下是一些保持测试良好状态的方法。
确定特定验收测试失败的原因并不像单元测试那样简单。单元测试会由单个开发人员或开发人员配对的单次提交触发。如果你提交了代码,而之前正常的构建失败了,那么毫无疑问是你导致的故障。
然而,由于两次验收测试运行之间可能有多次提交,构建被破坏的机会就更多。设计构建流水线时,能够追踪哪些变更与每次验收测试运行相关联是很有价值的步骤。一些现代持续集成系统可以轻松追踪流水线构建的整个生命周期,从而相对直接地解决这个问题。
在我们实施复杂构建流水线的第一个项目中,我们编写了一些简单的脚本,作为多阶段CruiseControl构建过程的一部分运行。这些脚本会整理自上次成功验收测试运行以来的所有提交,识别所有提交标签以及所有做出提交的开发人员,这样我们就可以向所有做出尚未经过验收测试运行验证的提交的人发送邮件。这在这个非常大的团队中运作得相当好,但我们仍然需要有人担任构建负责人的角色来执行纪律并确保故障得到处理。
如前所述,一个好的验收测试专注于证明特定故事或需求的特定验收标准已得到满足。最好的验收测试是原子性的——即它们创建自己的起始条件并在结束时清理。这些理想的测试最小化对状态的依赖,仅通过公开可访问的渠道测试应用程序,不使用后门访问。然而,有些类型的测试不符合这个标准,但在验收测试阶段运行仍然非常有价值。
当我们运行验收测试时,我们将测试环境设计得尽可能接近预期的生产环境。如果成本不高,它们应该完全相同。否则使用虚拟化技术尽可能模拟你的生产环境。操作系统和你使用的任何中间件都应该与生产环境完全相同,而且我们在开发环境中可能模拟或忽略的重要进程边界在这里一定会被体现出来。
这意味着除了测试我们的验收标准是否已经满足之外,这也是我们确认自动化部署到类生产环境成功运行以及部署策略有效的最早机会。我们经常选择运行一小部分新的冒烟测试,旨在断言我们的环境配置符合预期,并且系统各个组件之间的通信通道已正确就位并按预期工作。我们有时将这些称为基础设施测试或环境测试,但它们实际上是部署测试,旨在证明部署已经成功,并为执行更偏功能性的验收测试建立一个已知良好的起点。
像往常一样,我们的目标是快速失败。我们希望验收测试构建在将要失败时尽快失败。因此,我们经常将部署测试作为一个特殊的测试套件来对待。如果它们失败,我们会立即使整个验收测试阶段失败,而不会等待通常冗长的验收测试套件完成运行。这在测试异步系统时尤其重要,因为如果你的基础设施没有正确设置,你的测试将在每个点都执行到它们的最大超时时间。我们一个项目中的这种失败模式曾经导致等待超过30小时才完全失败的验收测试运行——而在正常情况下这个测试运行大约90分钟就能完成。
这个优先级高、快速失败的测试集合也是放置任何间歇性测试或经常捕获常见问题的测试的便利位置。正如我们之前所说,你应该找到能够捕获常见失败模式的提交级测试,但有时这种策略可以作为一个中间步骤,在你思考如何捕获一个常见但难以测试的问题时使用。
在我们的一个项目中,我们使用基于JUnit的验收测试。我们对哪些测试套件何时运行的唯一便捷控制是套件的名称——它们按字母顺序排序。我们组建了一组环境测试,并将它们称为”土豚点名测试”,以确保它们在任何其他套件之前运行。
在你开始依赖你的土豚之前,永远记得给它们点名。
由于我们的自动化验收测试是为了断言我们的系统向用户交付了预期的价值,它们的性能并不是我们的首要关注点。首先创建部署流水线(Deployment Pipeline)的原因之一就是验收测试通常需要太长时间才能运行完成,无法在提交周期中等待它们的结果。有些人在哲学上反对这种观点,认为性能不佳的验收测试套件是维护不善的验收测试套件的症状。让我们明确一点:我们认为持续维护你的验收测试套件以保持其良好的结构和连贯性很重要,但最终拥有一个全面的自动化测试套件比拥有一个能在十分钟内运行完成的测试套件更重要。
验收测试必须断言系统的行为。它们必须尽可能从外部用户的视角来做到这一点,而不仅仅是通过测试系统内部某个隐藏层的行为。即使对于相对简单的系统,这也自动意味着性能损失。系统及其所有适当的基础设施必须被部署、配置、启动和停止,这甚至还没考虑运行单个测试所需的时间。
然而,一旦你开始走上实施部署流水线的道路,快速失败系统和快速反馈循环就开始显示其价值。从引入问题的时刻到发现问题的时刻之间的时间越长,找到问题根源并修复它就越困难。通常,验收测试套件需要几个小时才能完成,而不是几分钟。这肯定是一个可行的状态;许多项目在多小时的验收测试阶段下工作得很好。但你可以更高效。你可以应用一系列技术来缩短从验收测试阶段获得结果所需的时间,从而提高团队的整体效率。
显而易见的第一步是通过保留一个最慢测试的列表来寻找快速获胜的机会,并定期在它们身上花一点时间来找到使它们更高效的方法。这正是我们建议用于管理单元测试的相同策略。
这种方法的进一步提升是寻找通用模式,特别是在测试设置中。一般来说,就其本质而言,验收测试(acceptance tests)比单元测试(unit tests)更具有状态性。由于我们建议您对验收测试采用端到端方法并最小化共享状态,这意味着每个验收测试都应该设置自己的初始条件。通常,此类测试设置中的特定步骤在许多测试中是相同的,因此值得花一些额外时间来确保这些步骤是高效的。如果可以使用公共API而不是通过UI执行此类设置,那是理想的选择。有时,使用”种子数据”预填充应用程序或使用某个后门向应用程序填充测试数据是一种有效的方法,但您应该对这种后门保持一定程度的怀疑态度,因为这些测试数据很容易与应用程序正常操作创建的数据不完全相同,这会使后续测试的正确性失效。
无论采用何种机制,重构测试以确保它们为通用任务执行的代码通过创建测试辅助类保持一致,是提高测试性能和可靠性的重要步骤。
我们在前面的章节中已经描述了一些在提交阶段测试中实现测试适当初始状态的技术。这些技术可以适用于验收测试,但验收测试的黑盒性质排除了一些选项。
解决此问题的直接方法是在测试开始时创建应用程序的标准空白实例,并在测试结束时丢弃它。然后测试完全负责使用其所需的任何初始数据填充此实例。这种方法简单且非常可靠,具有一个宝贵的特性,即每个测试都从一个已知的、完全可重现的起点开始。不幸的是,对于我们创建的大多数系统来说,这种方法也非常慢,因为对于除最简单的软件系统之外的任何系统,清除任何状态并首先启动应用程序都需要大量时间。
因此有必要做出妥协。我们需要选择哪些资源将在测试之间共享,哪些将在单个测试的上下文中管理。通常,对于大多数基于服务器的应用程序,可以从共享被测系统本身的一个实例开始。在验收测试运行开始时创建被测系统的干净运行实例,针对该实例运行所有验收测试,并在结束时关闭它。根据被测系统的性质,有时还可以优化其他耗时的资源,以使整个验收测试套件运行得更快。
在Dave当前的项目中,他使用出色的开源Selenium工具来测试Web应用程序。他使用Selenium远程控制,并使用本章前面描述的DSL技术将验收测试编写为JUnit测试,DSL位于窗口驱动程序层之上。最初,这些窗口驱动程序会根据需要启动和停止Selenium实例和测试浏览器。这很方便、健壮且可靠,但速度很慢。
Dave可以修改他的代码,以在测试之间共享Selenium和浏览器的运行实例。这会使代码稍微复杂一些,并可能在会话状态方面产生一些复杂性,但最终可能是加速三小时验收测试构建的一个选项。
相反,Dave最终选择了不同的策略:并行化验收测试并在计算网格上运行它。后来,他优化了每个测试客户端以运行自己的Selenium实例,如下一节所述。
当验收测试的隔离性良好时,就会出现另一种加速的可能性:并行运行测试。对于多用户的基于服务器的系统,这是一个明显的步骤。如果您可以划分测试,使它们之间没有交互风险,那么针对系统的单个实例并行运行测试将显著减少整个验收测试阶段的持续时间。
对于非多用户的系统,对于本身成本高昂的测试,或者对于需要模拟许多并发用户的测试,使用计算网格(compute grids)具有巨大的优势。当与虚拟服务器的使用相结合时,这种方法变得极其灵活和可扩展。在极限情况下,您可以为每个测试分配自己的主机,因此验收测试套件只需要花费最慢测试的时间。
在实践中,更受约束的分配策略通常更合理。这一优势并没有被该领域的一些供应商忽视。大多数现代CI服务器都提供管理测试服务器网格的功能,正是为了这个目的。如果您使用Selenium,另一个选择是使用开源的Selenium Grid,它允许使用为Selenium远程控制编写的未修改的验收测试在计算网格上并行执行。
Dave的一个项目随着时间推移,其验收测试环境的复杂度不断提升。我们最初使用基于Java的验收测试,用JUnit编写,通过Selenium Remoting与web应用交互。这种方式效果很好,但随着测试用例的增加,验收测试套件的运行时间不断延长。
我们首先采用常规的优化方法,识别并重构验收测试中的通用模式。最终我们得到了一些非常实用的辅助类,这些类抽象并简化了大部分测试设置工作。这在一定程度上提升了性能,但更重要的是提高了测试的可靠性——我们的应用具有高度异步性,难以测试。
我们的应用有一个公共API,以及几个不同的web应用,它们通过API与后端系统交互。因此我们做的下一个优化是将API测试分离出来,在基于UI的测试之前运行。如果API验收测试套件(运行速度远快于UI测试)失败,我们就立即终止验收测试。这让我们能更快地发现失败,提升了快速捕获并修复错误的能力。
尽管如此,随着测试的增加,验收测试时间仍在攀升。
我们的下一步是对测试进行粗粒度的并行运行。我们将测试分成几批,为了简单起见,按字母顺序组织分组。然后我们在开发环境的不同虚拟机上运行这两批测试,每批测试都有自己的应用实例。此时我们已经在开发环境中大量使用虚拟化技术,所有服务器(包括开发和生产环境)都是虚拟的。
这一举措将验收测试时间缩短了一半,而且我们可以轻松扩展这种方法,配置开销很小。这种方法的明显优势是,相比完全并行运行,它对测试隔离的要求更低。每个部分验收测试套件可以有自己独立的应用实例;在每个套件的范围内,测试像以前一样串行运行。这种优势的代价是需要额外的主机(虚拟或物理),主机数量与部分验收测试套件的数量相同。
图8.5 使用计算网格进行验收测试的具体示例
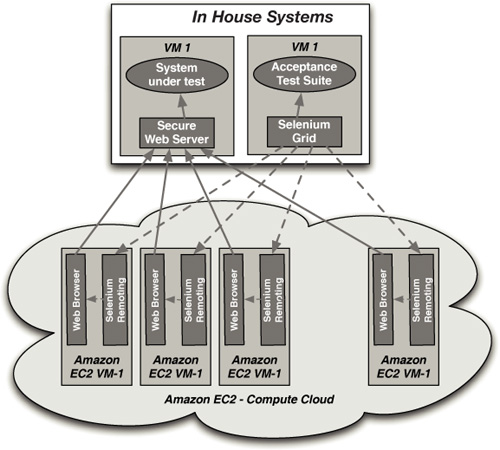
然而,在这一点上我们决定稍微改变策略。我们转向使用Amazon EC2计算云,以便轻松获得更广泛的可扩展性。图8.5展示了测试虚拟机的逻辑组织图。一组VM托管在内部;另一组运行模拟客户端与被测系统交互,分布在Amazon EC2云中。
使用验收测试是提升开发流程有效性的重要补充。它将交付团队所有成员的注意力集中在真正重要的事情上:用户需要从系统获得的行为。
自动化验收测试通常比单元测试更复杂。它们需要更多时间来维护,而且由于从修复失败到验收测试套件通过之间存在固有的延迟,它们处于失败状态的时间可能比单元测试更长。然而,当它们被用作从用户角度保证系统行为的手段时,它们为防止任何复杂应用在生命周期中出现的回归问题提供了宝贵的防御。
由于几乎不可能以任何有意义的方式对一个软件项目与另一个进行衡量,这使我们很难提供数据来支持我们的断言——使用自动化验收测试会带来数倍的回报。我们只能向你保证,尽管我们在许多项目中保持验收测试运行是一项艰苦的工作,并使我们面临一些复杂的问题,但我们从未后悔使用它们。实际上,它们经常通过提供安全地更改系统大部分的能力来拯救我们。我们仍然坚信,这种测试在开发团队中鼓励的关注点是成功交付软件的强大要素。我们建议你尝试采用本章描述的对验收测试的关注,亲自看看它是否值得。
采用拒绝任何无法通过验收测试门槛的发布候选版本的纪律,在我们看来是交付团队输出质量向前迈出的又一重要步骤。
我们在软件行业的经验是,手工测试是常态,通常代表团队采用的唯一测试形式。我们发现手工测试既昂贵得令人望而却步,又很少能单独确保高质量的结果。当然,手工测试有其用武之地:探索性测试、可用性测试、用户验收测试、演示展示。但人类根本不具备在手工回归测试所要求的那种单调、重复但复杂的任务中有效工作的能力——至少不会感到痛苦。低质量的软件是这种低质量流程不可避免的结果。
近年来,对单元测试的日益关注帮助一些团队提升了水平。相比仅依赖手工测试,这是一个重大进步,但根据我们的经验,它仍然可能导致代码无法满足用户的需求。单元测试不以业务为中心。我们相信,采用由验收标准驱动的测试代表了进一步的进步,因为它:
• 增强了软件符合目的的信心
• 提供针对系统大规模变更的保护
• 通过全面的自动化回归测试显著提高质量
• 在出现缺陷时提供快速可靠的反馈,以便立即修复
• 解放测试人员,让他们能够设计测试策略、开发可执行规范,并进行探索性测试和可用性测试
• 缩短周期时间并实现持续部署
我们已经描述了在实现部署流水线过程中自动化测试应用程序的各个方面。然而,到目前为止,我们的重点主要集中在测试那些通常被描述为功能性需求的应用程序行为。在本章中,我们将描述测试非功能性需求的方法,特别关注容量、吞吐量和性能的测试。
首先,让我们澄清一些术语上的混淆。我们将使用与Michael Nygard相同的术语。[^1] 简而言之,性能是衡量处理单个事务所需时间的指标,可以单独衡量,也可以在负载下衡量。吞吐量是系统在给定时间段内可以处理的事务数量。它总是受到系统中某个瓶颈的限制。对于给定的工作负载,系统能够维持的最大吞吐量,同时为每个单独请求保持可接受的响应时间,就是它的容量。客户通常对吞吐量或容量感兴趣。在实际中,“性能”常被用作一个泛指术语;我们将在本章中更加谨慎地使用这些术语。
非功能性需求(NFRs)很重要,因为它们对软件项目构成了重大的交付风险。即使你清楚非功能性需求是什么,也很难恰到好处地完成足够的工作来确保满足这些需求。许多系统失败是因为它们无法应对施加的负载、不够安全、运行太慢,或者最常见的,由于代码质量差而变得无法维护。一些项目失败是因为它们走向了另一个极端,过度担心非功能性需求,导致开发过程太慢,或者系统变得过于复杂和过度设计,没有人能弄清楚如何高效或恰当地开发。
因此,在许多方面,将需求划分为功能性和非功能性是人为的。诸如可用性、容量、安全性和可维护性等非功能性需求与功能性需求同样重要和有价值,它们对系统的运行至关重要。这个名称具有误导性——已经有人建议使用跨功能需求和系统特性等替代术语——根据我们的经验,处理它们的常见方式很少能很好地工作。项目的利益相关者应该能够优先决定是实现允许系统接受信用卡支付的功能,还是实现允许1000个并发用户访问的功能。其中一个对业务的价值可能确实大于另一个。
在项目开始时识别哪些非功能性需求是重要的,这一点至关重要。然后,团队需要找到一种方法来衡量它们,并将对它们的定期测试纳入交付计划,以及在适当的情况下纳入部署流水线。本章开始时讨论非功能性需求的分析。然后讨论如何开发应用程序以满足其容量需求。接下来,介绍如何衡量容量以及如何创建进行测量的环境。最后,讨论从自动化验收测试套件创建容量测试的策略,以及将非功能性测试纳入部署流水线的方法。
从某种意义上说,非功能性需求(NFRs)与其他需求相同:它们可以具有真正的业务价值。从另一种意义上说,它们是不同的,因为它们往往跨越其他需求的边界。许多非功能性需求的跨领域特性使得它们在分析和实现方面都难以处理。
将系统的非功能性需求与功能性需求区别对待的困难在于,这使得它们很容易从项目计划中被删除,或者对它们的分析关注不足。这可能是灾难性的,因为非功能性需求是项目风险的频繁来源。在交付过程的后期才发现应用程序由于根本性的安全漏洞或极差的性能而不适合使用,这种情况太常见了——并且可能导致项目延迟甚至被取消。
在实现方面,非功能性需求很复杂,因为它们通常对系统架构有非常强的影响。例如,任何需要高性能的系统都不应该涉及请求遍历多个层级。由于系统架构在交付过程的后期很难改变,因此在项目开始时就考虑非功能性需求至关重要。这意味着需要预先进行足够的分析,以便对系统选择什么架构做出明智的决定。
此外,非功能性需求往往会以不利的方式相互影响:非常安全的系统通常会在易用性上做出妥协;非常灵活的系统通常会在性能上做出妥协,等等。我们的观点是,虽然在理想世界中,每个人都希望他们的系统高度安全、高性能、大规模灵活、极其可扩展、易于使用、易于支持、简单开发和维护,但实际上这些特性中的每一个都是有代价的。每个架构都涉及非功能性需求之间的某些权衡——因此软件工程研究所开发了架构权衡分析方法(ATAM),旨在通过对非功能性需求(称为”质量属性”)的全面分析来帮助团队确定合适的架构。
总之,在项目开始时,参与交付的每个人——开发人员、运维人员、测试人员和客户——需要仔细考虑应用程序的非功能性需求及其可能对系统架构、项目进度、测试策略和总体成本产生的影响。
对于正在进行的项目,如果我们预计不需要付出大量额外努力来满足非功能性需求,我们有时会将其作为功能性故事的常规验收标准来捕获。但这通常是一种笨拙且低效的管理方式。相反,创建针对非功能性需求的特定故事集或任务集通常更有意义,尤其是在项目初期。由于我们的目标是尽量减少处理横切关注点的程度,因此需要混合使用这两种方法——创建特定任务来管理非功能性需求,同时向其他需求添加非功能性验收标准。
例如,管理可审计性等非功能性需求的一种方法是说”所有与系统的重要交互都应该被审计”,并可能创建一个策略,向涉及需要审计的交互的故事添加相关验收标准。另一种方法是从审计员的角度捕获需求。该角色的用户希望看到什么?我们只需描述审计员对他们想看到的每个报告的需求。这样,审计不再是横切的非功能性需求;相反,我们将其与其他需求同等对待,以便可以对其进行测试并与其他需求同等优先级排序。
容量等特性也是如此。定量地将系统的期望定义为故事是有意义的,并以足够的细节进行规范,以便进行成本效益分析,从而相应地确定优先级。根据我们的经验,这也往往会使需求管理更加高效,从而使用户和客户更加满意。这种策略对于大多数常见类别的非功能性需求都很有效:安全性、可审计性、可配置性等。
在分析非功能性需求时,提供合理的细节水平至关重要。仅仅说响应时间的需求是”尽可能快”是不够的。“尽可能快”对可以合理应用的工作量或预算没有设置上限。“尽可能快”是指仔细考虑如何缓存和缓存什么内容,还是意味着制造自己的CPU,就像苹果为iPad所做的那样?所有需求,无论是否为功能性需求,都必须分配一个价值,以便可以对其进行估算和优先级排序。这种方法迫使团队思考开发预算最好花在哪里。
许多项目面临应用程序验收标准理解不清的问题。他们会有看似定义明确的陈述,如”所有用户交互的响应时间将少于两秒”或”系统将每小时处理80,000个事务”。这样的定义对我们来说过于笼统。关于”应用程序性能”的模糊讨论通常被用作描述性能需求、可用性需求和许多其他需求的简写方式。如果我们声明应用程序应该在两秒内响应,这是否意味着在所有情况下?如果我们的一个数据中心发生故障,我们是否仍需要满足两秒的阈值?该阈值是否仍然适用于很少使用的交互,还是仅适用于常见的交互?当我们说两秒时,是指交互成功完成的两秒,还是仅仅是用户收到某种反馈之前的两秒?如果出现问题,我们是否需要在两秒内以错误消息响应,还是仅针对成功情况?两秒的需求是在系统承受压力、处理峰值负载时满足,还是平均响应时间?
性能需求的另一个常见误用是作为描述系统可用性的懒惰方式。许多人说”两秒内响应”时,真正的意思是”我不想在没有任何反馈的情况下在电脑前坐太久”。当可用性问题被识别为这样的问题时,最好处理它们,而不是伪装成性能需求。
分析不当的非功能性需求的问题在于,它们往往会限制思维,并经常导致过度设计和不当优化。花费过多时间编写”高性能”代码太容易了。程序员在预测应用程序性能瓶颈在哪里方面相当薄弱。他们倾向于使代码不必要地复杂,从而维护成本高昂,以实现可疑的性能提升。值得完整引用Donald Knuth的著名格言:
我们应该忘记那些小的效率问题,大约97%的时间:过早优化是万恶之源。然而,我们不应该错过那关键的3%的机会。一个优秀的程序员不会被这样的推理所麻痹而自满,他会明智地仔细审视关键代码;但只有在识别出那些代码之后才这样做。
关键的短语是最后一句。在找到解决方案之前,必须先识别问题的来源。在此之前,我们需要知道我们是否真的存在问题。容量测试阶段的目的是告诉我们是否有问题,以便我们能够继续修复它。不要猜测;要测量。
我们的一个项目涉及”增强”一个遗留系统。这个系统是为相对较小的用户群编写的,由于性能太差,实际使用者更少。对于一组交互操作,需要显示一个来自消息队列的错误消息。错误从队列中提取并放入内存中的列表。这个列表在单独的线程中异步轮询,然后转发到另一个模块,在那里被放入第二个列表,然后再次轮询。这个模式重复了七次,最后消息才在用户界面中显示。
你可能会认为这是糟糕的设计——确实如此。但设计背后的意图是为了避免性能瓶颈。异步轮询模式旨在处理负载激增而不影响应用程序的整体容量。显然,重复七次是过度的,但从理论上讲,如果负载变重,这并不是保护应用程序的糟糕策略。真正的问题是,这是一个针对不存在问题的复杂解决方案。这种情况根本没有出现,因为消息队列从未被错误淹没。即使被淹没,也不能压垮应用程序,除非应用程序过于频繁地请求信息。有人发明了七个手工制作的队列,放在一个商业消息队列前面。
这种几乎偏执的容量关注是导致过度复杂——因此糟糕——代码的常见原因。设计高容量系统是困难的,但如果在开发过程的错误时间点担心容量问题,会使其变得更加困难。
过早和过度关注优化应用程序容量是低效的、昂贵的,并且很少能交付高性能系统。在最极端的情况下,它可能导致项目根本无法交付。
事实上,为高容量系统编写的代码,必然比为普通系统编写的代码更简单。复杂性会增加延迟,但大多数程序员发现这很难理解,更不用说采取行动了。本书并不是讨论高性能系统设计的专著,但这里概述了我们使用的方法——在此提出是为了将容量测试放入交付过程的上下文中。
在任何系统的设计中,瓶颈都会存在,系统性能在那里受到限制。有时,这些瓶颈很容易预测,但更多时候不是。在项目启动时,明智的做法是识别容量问题最常见的原因,并努力避免遇到它们。大多数现代系统做的最昂贵的事情是跨网络通信或在磁盘上存储数据。跨进程和网络边界的通信在性能方面非常昂贵,并影响应用程序稳定性,因此应该最小化这种通信。
编写高容量软件比其他类型的系统需要更多的纪律,以及对支持应用程序的底层硬件和软件如何工作的一定程度的机械同情(mechanical sympathy)。高性能需要额外的成本,必须理解这些额外成本,并权衡增加性能带来的业务价值。对容量的关注往往迎合了技术人员的心态。它可能会激发我们最糟糕的一面,成为过度工程化解决方案和项目成本膨胀的最可能原因。将系统容量特性的决策权交给业务发起人是极其重要的。我们想重申一个事实,高性能软件实际上更简单,而不是更复杂。问题在于,为问题找到简单的解决方案可能需要额外的工作。
需要取得平衡。构建高容量系统很棘手,天真地假设以后能够修复所有问题也不是成功的好策略。一旦在定义架构级别处理了应用程序最初的、可能比较广泛的性能问题,以最小化跨进程边界交互,除非它们在修复一个明确识别和可测量的问题,否则在开发过程中应该避免更详细的”优化”。这就是经验的作用。为了成功,你必须避免两个极端:一端是假设以后能够修复所有容量问题;另一端是出于对未来容量问题的恐惧而编写防御性的、过度复杂的代码。
我们的策略是以以下方式解决容量问题:
为您的应用程序决定一个架构。特别注意进程和网络边界以及一般的I/O。
理解并使用影响系统稳定性和容量的模式,避免反模式(antipattern)。Michael Nygard的优秀著作《Release It!》详细描述了这些内容。
让团队在选定的架构边界内工作,但除了在适当的地方应用模式外,不要被优化容量的诱惑所吸引。鼓励代码清晰简洁,而不是追求深奥难懂。除非有明确的测试证明其价值,否则永远不要为了容量而牺牲可读性。
注意选择的数据结构和算法,确保它们的特性适合你的应用程序。例如,如果需要 O(1) 性能,就不要使用 O(n) 算法。
对线程要极其小心。Dave 目前的项目是他工作过的性能最高的系统——他的交易系统每秒可以处理数万笔交易——实现这一目标的关键方法之一就是保持应用程序核心为单线程。正如 Nygard 所说,“阻塞线程反模式是大多数故障的直接原因…导致连锁反应和级联故障。”
建立自动化测试来断言期望的容量水平。当这些测试失败时,将它们用作解决问题的指南。
使用性能分析工具作为修复测试识别出的问题的集中尝试,而不是作为一般的”尽可能快”策略。
尽可能使用真实世界的容量度量。你的生产系统是你唯一真正的度量来源。使用它并理解它告诉你什么。特别注意系统的用户数量、他们的行为模式以及生产数据集的大小。
度量容量涉及调查应用程序的广泛特征。以下是可以执行的一些度量类型:
• 可扩展性测试(Scalability testing)。当我们增加更多服务器、服务或线程时,单个请求的响应时间和可能的并发用户数量如何变化?
• 持久性测试(Longevity testing)。这涉及长时间运行系统,以查看性能在长期运行期间是否会发生变化。这种类型的测试可以捕获内存泄漏或稳定性问题。
• 吞吐量测试(Throughput testing)。系统每秒可以处理多少事务、消息或页面点击量?
• 负载测试(Load testing)。当应用程序的负载增加到类似生产的比例甚至更高时,容量会发生什么变化?这也许是最常见的容量测试类型。
所有这些都代表了对系统行为的有趣且有效的度量,但可能需要不同的方法。前两种测试类型与其他两种测试根本不同,因为它们暗示相对度量:当我们改变系统属性时,系统的性能特征如何变化?然而,第二组测试仅作为绝对度量才有用。
在我们看来,容量测试的一个重要方面是能够为给定应用程序模拟真实的使用场景。这种方法的替代方案是对系统中的特定技术交互进行基准测试:“数据库每秒可以存储多少事务?”、“消息队列每秒可以传递多少消息?”等等。虽然在项目中有时这样的基准度量可能有价值,但与更侧重于业务的问题相比,它们是学术性的,比如”在常规使用模式下,我每秒可以处理多少笔销售?“或”在峰值负载时,我预测的用户群能否有效使用系统?”
集中的、基准式的容量测试对于防范代码中的特定问题和优化特定区域的代码非常有用。有时,它们可以通过提供信息来帮助技术选择过程。然而,它们只构成了整体图景的一部分。如果性能或吞吐量是应用程序的重要问题,那么我们需要一些测试来断言系统满足其业务需求的能力,而不是我们作为技术人员对特定组件吞吐量应该是什么的猜测。
因此,我们认为将基于场景的测试纳入我们的容量测试策略至关重要。我们将系统使用的特定场景表示为测试,并根据我们对其在真实世界中必须实现的业务预测来评估它。我们在第238页的”自动化容量测试”部分更详细地描述了这一点。
然而,在现实世界中,大多数现代系统——至少是我们通常工作的类型——不是一次只做一件事。虽然销售系统的重点是处理销售,但它也在更新库存位置、处理服务订单、记录考勤表、支持店内审计等。如果我们的容量测试不测试这些复杂的交互组合,那么它们将无法防范许多类别的问题。这意味着我们的每个基于场景的测试都应该能够与涉及其他交互的其他容量测试一起运行。为了最有效,容量测试应该可以组合成更大规模的测试套件,这些套件将并行运行。
正如 Nygard 所说,计算出应用多少负载以及什么样的负载,并处理诸如未经授权的索引服务抓取你的系统等替代路径场景,“既是艺术也是科学。不可能复制真实的生产流量,所以你使用流量分析、经验和直觉来实现尽可能接近现实的模拟。”
我们所见过的大部分容量测试实际上更多是测量而非真正的测试。成功或失败通常由人工分析收集到的测量数据来决定。相比容量测试策略,容量测量策略的缺点在于分析结果可能需要很长时间。然而,如果容量测试系统能够生成测量数据,不仅能给出成功或失败的二元结果,还能提供洞察事件发生的过程,这对任何容量测试系统来说都是一个非常有用的特性。在容量测试的场景中,一张图表真的胜过千言万语——趋势对于决策的重要性不亚于绝对值。因此,我们总是将图表作为容量测试的一部分来创建,并确保可以从部署流水线仪表板轻松访问它们。
然而,如果我们将容量环境同时用于测试和测量,那么对于运行的每个测试,我们都需要定义什么叫做通过。设置容量测试的通过标准很棘手。一方面,如果你把标准设得太高,让应用程序只有在一切条件都很理想时才能勉强通过,你很可能会遇到经常性的间歇性测试失败。当网络被其他任务占用时,或者当容量测试环境同时处理另一个任务时,测试可能会失败。
相反,如果你的测试断言应用程序必须处理每秒100个事务(tps),而实际上它能处理200个,那么你的测试不会发现引入的变更几乎将吞吐量减半了。这意味着你会将一个潜在的困难问题推迟到某个不可预测的未来时间,早已忘记了有问题的变更的细节。一段时间后,你可能会做出一个本来无害的变更,出于正当理由降低了容量,即使减少只有几个百分点,测试也会失败。
这里有两种策略可以采用。首先,追求稳定、可重现的结果。在实际可行的范围内,将容量测试环境与其他影响因素隔离开来,并专门用于测量容量的任务。这可以最大限度地减少其他非测试相关任务的影响,从而使结果更加一致。容量测试是虚拟化不适用的少数情况之一(除非你的生产环境是虚拟的),因为虚拟化会引入性能开销。接下来,通过在测试以最低可接受水平通过后逐步提高通过阈值来调整每个测试的通过阈值。这为你提供了针对假阳性场景的保护。如果在提交后测试开始失败,并且阈值设置远高于你的要求,那么如果容量降低是出于一个充分理解且可接受的原因,你总是可以决定简单地降低阈值,但测试将保留其作为防止无意中损害容量的变更的价值。
让我们以一个用于处理文档的虚构系统为例。该系统需要每天接收100,000个文档。每个文档将在三天内通过一系列五个验证步骤。出于我们示例的目的,让我们假设此应用程序将在单个时区运行,并且由于其性质,会在营业时间内达到峰值负载。
从文档开始,我们可以假设如果负载分布相当均匀,我们需要在每个工作日的8小时内处理大约100,000个文档。也就是每小时12,500个文档。如果我们主要关注应用程序的吞吐量,我们实际上不需要运行整整一天,甚至一整个小时——我们会将长期测试作为单独的练习来处理。每小时12,500个文档略低于每分钟210个文档或每秒3.5个文档。我们可以运行测试30秒,如果我们能接收105个文档,就可以相当确信一切正常。
嗯,差不多。在现实世界中,当所有这些文档被接收时,系统中还有其他工作在进行。如果我们想要一个能代表现实的测试,我们需要模拟系统在接收文档时承受的其他负载。每个文档将运行三天,每个都要经历五步验证过程。因此,在任何给定的一天,除了系统应对接收文档所施加的负载之外,我们还必须添加一个代表这些验证的负载。在任何给定的一天,我们将处理两天前的5/3验证、一天前的5/3验证和今天的5/3验证。因此平均而言,对于系统接收的每个文档,我们必须在同一时间模拟五个验证步骤中的每一个。
因此,我们30秒测试的通过标准现在看起来像是:“在30秒内接收105个文档并执行每个验证步骤105次。”
这个例子基于我们在一个真实项目中执行的测试——对于该项目,这种推算是准确的。然而,重要的是要记住,许多系统具有更加尖峰的负载曲线,负载变化很大,因此代表性测试的任何计算都应基于峰值负载的估计。
为了使我们的测试成为真正的测试,而不是性能测量,每个测试都必须体现一个特定的场景,并且必须针对一个阈值进行评估,超过该阈值测试被认为是通过的。
对系统容量进行绝对测量时,理想情况下应该在尽可能复制生产环境的环境中进行,因为系统最终将在生产环境中运行。
虽然从配置不同的环境中也能学到有用的信息,但除非基于实际测量,否则从测试环境容量推断生产环境容量都是高度推测性的。高性能计算机系统的行为是一个专业且复杂的领域。配置变更往往对容量特性产生非线性影响。简单的改变,比如调整允许的UI会话数与应用服务器连接数和数据库连接数的比例,就能使系统的整体吞吐量(throughput)提高一个数量级(所以这些是需要调整的重要变量)。
如果容量或性能对你的应用来说是个严重问题,就应该投资为系统的核心部分创建一个生产环境的克隆。使用相同的硬件和软件规格,并遵循我们关于如何管理配置的建议,确保每个环境使用相同的配置,包括网络、中间件(middleware)和操作系统配置。在大多数情况下,如果你正在构建一个高容量系统,除此之外的任何策略都是妥协,会带来额外的风险——当系统在生产环境中运行,连接到真实的外部系统,面对真实负载和生产规模的数据集时,你的应用可能无法满足容量需求。
我们的一个同事团队为一家知名的网络公司做项目。这是一家历史悠久的公司,积累了足够多的历史遗留问题。我们的团队为这个客户构建了一个全新的系统,但客户试图通过使用非常老旧的生产硬件作为性能测试环境来节省成本。
客户对系统容量的担忧是合理的,花了大量时间和金钱试图让开发团队关注容量问题。在多次对话中,我们的团队指出测试环境中的硬件太老旧,这本身就对应用感知到的容量不足造成了重大影响。
在一次特别糟糕的测试结果后,团队做了一些对比,证明容量测试环境的性能甚至比不上一个iPod集群。在展示这些发现后,客户购买了一些更新的测试硬件。
在现实世界中,在完全复制生产环境中进行容量测试的理想情况并不总是可行的。有时甚至是不合理的,比如项目规模足够小,或者应用的性能问题不足以证明复制生产硬件的费用是合理的。
对于另一个极端的项目,复制生产环境同样不合适。大型软件即服务(SaaS)提供商通常在生产环境中运行数百或数千台服务器,因此完全复制其生产环境不仅硬件成本高昂,维护开销也难以承受。即使他们做到了,生成负载来压测这样的环境以及准备具有代表性的数据集也将是一项巨大的工程。在这种情况下,容量测试可以作为金丝雀发布(canary release)策略的一部分来执行(更多内容请参见第263页的”金丝雀发布”部分)。新变更改变应用容量的风险可以通过更频繁的发布来缓解。
不过,大多数项目介于这两个极端之间,这些项目应该尝试在尽可能接近生产环境的环境中运行容量测试。即使项目太小,不值得复制生产环境的费用,你也应该记住,虽然在较低规格硬件上进行容量测试会突出任何严重的容量问题,但它无法证明应用能够完全达到其目标。这是项目必须评估的风险——但不要在计算中过于天真。
不要自欺欺人地指望你的应用会随着硬件的某个特定参数线性扩展。例如,如果测试处理器的时钟频率是生产服务器的一半,就天真地假设应用在生产环境中会快两倍。这不仅假设你的应用是CPU密集型(CPU-bound)的,还假设随着CPU速度增加,它仍然是瓶颈。复杂系统很少以这种线性方式运行,即使它们被设计成这样。
如果你别无选择,尽可能尝试进行多次扩展性运行,以基准测试(benchmark)测试环境和生产环境之间的差异。
在我们的一个项目中,客户不愿意花钱购买两套生产标准的硬件,而是提供了性能明显较弱的机器来托管我们的容量测试。幸运的是,我们设法说服他们,如果能将升级后的生产服务器的投入使用推迟一周,我们就能更好地缓解我们告诉他们的容量风险。在那一周里,我们拼命运行容量测试并收集了大量数据。然后,我们在性能较低的容量测试环境中精确地重新运行了相同的测试,并建立了一系列比例因子(scaling factors),用于推断未来的容量测试结果。
这是一个不错的案例,但实际上,当我们的系统投入生产时,仍然发现了几个意外的容量问题,如果我们有生产标准的硬件,这些问题本可以被发现。对于这个特定项目来说,不为容量测试复制生产环境是一种虚假的节约,因为我们正在构建一个高性能系统,而我们发现的问题在我们低规格容量测试环境中根本无法施加的负载下才会显现。这些后续问题的修复成本很高。
图 9.1 生产服务器集群示例
图 9.2 容量测试环境示例
在应用程序将部署到服务器集群的生产环境中时,有一个明显的策略可以限制测试环境成本并提供合理准确的性能测量,如图 9.1 所示。复制服务器的一个切片,如图 9.2 所示,而不是整个集群。
例如,如果您的应用程序部署到四台 Web 服务器、八台应用服务器和四台数据库服务器,那么在性能测试环境中各配置一台 Web 服务器和数据库服务器,以及两台应用服务器。这将为您提供单个分支的相当准确的性能测量,并且可能会揭露当两台或更多服务器竞争另一层资源(如数据库连接)时出现的一些问题。
推断容量是一种启发式方法(heuristic),在如何最佳实践以及是否成功方面,不同项目之间会有很大差异。我们只能建议您以健康的怀疑态度对待关于推断结果的假设。
在过去的项目中,我们错误地将容量测试视为一项完全独立的工作:交付过程中的一个独立阶段。这种方法是对开发和运行这些测试成本的反应。暂且不考虑成本,当容量是项目的特定问题时,了解您引入了影响系统容量的变更,与了解您引入了功能问题同样重要。您需要在引入相应变更后尽快了解容量下降,以便快速高效地修复它。这就需要将容量测试作为一个阶段添加到部署流水线(deployment pipeline)中。
如果我们要将容量测试添加到流水线中,应该创建一个自动化容量测试套件,并针对通过提交阶段和(可选的)验收测试阶段的系统每次变更运行。这可能很困难,因为与其他类型的验收测试相比,容量测试可能更加脆弱和复杂,软件的微小变更就容易使其失效—不是那种指示容量问题的有用失效,而是由于容量测试交互的接口发生变化而导致的失效。
容量测试应该:
• 测试特定的真实场景,这样我们就不会因为过于抽象的测试而遗漏真实使用中的重要缺陷
• 具有预定义的成功阈值,以便我们能够判断测试是否通过
• 持续时间短,以便容量测试可以在合理的时间内完成
• 在面对变更时保持稳健,避免为了跟上应用程序的变更而不断返工
• 可组合成更大规模的复杂场景,以便我们能够模拟真实的使用模式
• 可重复,能够顺序和并行运行,以便我们既可以构建测试套件来施加负载,又可以运行长期测试
以不会因过度工程化的测试而阻碍开发进度的方式实现所有这些目标并不容易。一个好的策略是采用一些现有的验收测试并将其改编为容量测试。如果您的验收测试是有效的,它们将代表与系统交互的真实场景,并且在应用程序发生变更时保持稳健。它们缺少的属性是:能够扩展以便对应用程序施加严重负载的能力,以及成功的度量规范。
在大多数其他方面,我们在前几章关于编写和管理有效验收测试的建议意味着它们在很大程度上已经满足了上述关于良好容量测试的大部分标准。我们的目标有两个:创建一个真实的类生产环境负载,以及选择和实施代表真实但病态的现实负载情况的场景。最后一点至关重要:我们不仅仅测试验收测试中的正常路径,容量测试也是如此。例如,Nygard建议了一种测试系统扩展性的有用技术:“识别出你最昂贵的事务是什么,然后将这些事务的比例翻倍或翻三倍。”
如果你能记录这些测试与系统执行的交互,将它们复制很多次,然后重放这些副本,你就可以对被测系统施加各种负载,从而测试各种场景。
我们已经看到这个通用策略在几个项目中发挥作用,每个项目使用非常不同的技术,每个项目都有非常不同的容量测试需求。测试信息本身如何记录、如何扩展以及如何重放的细节在项目之间差异很大。一致的是记录功能验收测试输出、后处理以扩展请求、为每个测试添加成功标准,然后重放测试以对系统施加非常高的交互量的基本原理。
要做出的第一个战略决策是应用程序中的哪个点应该进行记录和后续回放。我们的目标是尽可能接近地模拟系统的真实使用;然而,这是有成本的。对于某些系统,只需记录通过用户界面执行的交互并回放它们就足够了。但是,如果你正在开发一个供数万或更多用户使用的系统,不要尝试通过UI交互来对系统施加负载。要使这成为真实的模拟,你需要数千台客户端机器专门用于向系统注入负载的任务。有时必须做出妥协。
使用现代面向服务架构(service-oriented architectures)构建的系统,或使用异步通信作为主要输入的系统,特别适合我们的一个常见策略:记录和回放。
图9.3 容量测试的潜在注入点
根据系统行为和基本架构的许多变量,选择归结为在几个点记录和回放(图9.3):
通过用户界面。
通过服务或公共API——例如,直接向Web服务器发出HTTP请求。
通过较低级别的API——例如,直接调用服务层或数据库。
记录并随后回放与系统交互的最明显点是通过用户界面。这是大多数商业负载测试产品运行的点。这些工具提供通过用户界面编写脚本或直接记录交互的能力,然后复制和扩展这些测试交互,以便测试可以为每个测试用例模拟数百或数千次交互。
正如我们已经提到的,对于大容量系统,尽管完全运行系统具有显著优势,但这并不总是一种实用的方法。这种方法还有另一个重大缺点:在分布式架构中,服务器托管重要的业务逻辑——因此容量问题更可能集中在这里——可能无法对系统施加足够的负载来适当地测试它。当客户端要么过于复杂,拥有自己的重要逻辑,要么过于轻量,例如集中式服务的轻量级UI时,这种系统可能出现这种情况。在这些情况下,真正的衡量标准是客户端与服务器的比率。
对于某些系统,基于UI的测试是正确的做法,但实际上,它仅对处理中等容量的系统是合适的策略。即使如此,管理和维护以UI为中心的测试的成本也可能非常高。
基于UI的测试存在一个根本问题。任何设计良好的系统都将包含专注于不同关注点的组件。在大多数应用程序中,UI的作用是顾名思义,提供一个适合系统用户与之交互的界面。这个界面通常采用一组广泛的交互,并将它们浓缩为与系统其他组件更有针对性的交互:例如,一系列文本输入、列表选择、按钮点击等通常会导致传递给另一个组件的单个事件。第二个组件将具有更稳定的API(应用程序编程接口),因此针对该API编写的测试将比针对GUI编写的测试更不脆弱。
在分布式应用程序的容量测试中,我们是否关注UI客户端的性能取决于系统的特性。对于简单、轻量级的基于Web的客户端,我们通常不太关心客户端本身的性能,而更关注通信服务器端的集中式资源性能。如果我们的验收测试是为了测试UI并确保通过它的交互能够以功能正确的方式运行,那么在应用程序的后面节点记录以用于容量测试可能是更有效的选择。然而,相反地,一些容量问题只在客户端和服务器之间的交互中表现出来,特别是在厚客户端的情况下。
对于具有复杂客户端应用程序和集中式基于服务器组件的分布式系统,通常有必要分离出容量测试,如我们之前所述,找到一个中间记录和注入点来测试服务器,并定义独立的UI客户端测试,其中UI针对后端系统的桩(stub)版本运行。我们认识到这个建议与我们之前关于使用端到端”整体系统”测试进行容量测试的建议相悖,但我们认为在容量测试分布式系统时,UI是一个特殊情况,最好作为特例处理。在这种情况下,比其他情况更取决于被测系统的特性。
总而言之,尽管通过UI进行容量测试是最常见的方法,当然这也体现在现成的容量测试产品中,但我们通常更倾向于避免通过UI进行容量测试。例外情况是当需要证明UI本身,或者客户端和服务器之间的交互不是性能瓶颈时。
这种策略可用于提供除图形用户界面之外的公共API的应用程序,如Web服务、消息队列或其他事件驱动的通信机制。这可以是记录交互的理想点,允许您回避客户端扩展问题、管理数百或数千个客户端进程的复杂性,以及通过用户界面与系统交互的相对脆弱性。面向服务的架构(SOA)特别适合这种方法。
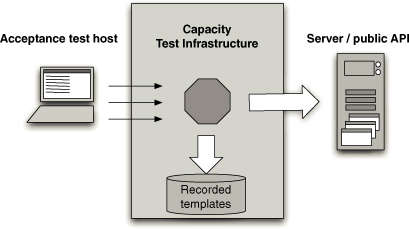
[图9.4]显示了容量测试记录器组件在交互发生时进行记录的示意图。
我们首先记录交互的目标是实现一种与系统交互的模板,这种模板体现了验收测试。这些交互模板将在稍后用于为后续的容量测试运行生成容量测试数据。
我们的理想做法是对验收测试或代表容量测试场景的子集执行特殊运行。在这次特殊运行期间,我们将通过注入一段额外的代码来以某种方式对代码进行插桩(instrument),该代码将记录交互,将它们保存到磁盘,并将它们转发到系统本身。从系统其余部分的角度来看,所发生的交互没有区别—记录是透明的:我们只是将所有输入和输出的副本转移到磁盘。
[图9.5]显示了这个过程的一个简单示例的示意图。在此示例中,一些值被标记为将来替换,而一些值保持不变,因为它们不影响测试的含义。显然,可以根据需要在消息中进行尽可能多或尽可能少的标记。然而,总体而言,我们倾向于较少而不是较多的替换;我们应该旨在尽可能少地替换。这将限制测试和测试数据之间的耦合,从而使我们的测试更加灵活且不易出错。
一旦记录了交互模板,我们将创建与之配套的测试数据。生成此数据以补充交互模板,每组测试数据在与适当的模板组合时,代表与被测系统的有效交互实例。[图9.6]显示了表示流程中此步骤的示意图。
除了模板的记录内容之外,我们还为模板所代表的测试添加成功标准。我们还没有足够的经验以这种方式进行测试,无法推荐它是最好且唯一的方法;到目前为止,我们只在一个项目上尝试过,但对于那个项目,这非常成功,帮助我们创建了一个非常简单但非常强大的容量测试系统。一旦建立,这个系统只需要很少的工作就能记录新测试,并且不需要任何工作就能准备和执行容量测试运行。
最后,当需要执行容量测试时,单独的测试实例在同一点被反馈到系统中。
交互模板和测试数据也可用作开源性能测试工具的输入,例如Apache的JMeter、Marathon或Bench。也可以编写一个简单的测试工具来以这种方式管理和运行测试。构建自己的容量测试工具既不像听起来那么愚蠢,也不像听起来那么困难;它允许容量测试工具被定制以精确测量项目所需的内容。
对于本节中提出的建议,我们有一个注意事项。对于容量和性能要求极高的系统,整个系统中性能最高的部分必然是测试,而不是生产代码。测试必须运行得足够快,以施加负载并确认结果。现代硬件速度如此之快,以至于我们讨论的性能水平是极不寻常的,但如果你需要精确到计算时钟周期并调整编译器生成的机器代码,交互模板的成本就太高了。至少,我们还没有找到一种方法让它们足够高效来测试应用程序。
对于超高性能系统中的容量测试,编写容量测试的复杂性往往超过编写足够快的代码来通过测试的复杂性。因此,断言测试能够以必要的速率进行测试并确认通过是至关重要的。每当你编写容量测试时,重要的是首先实现一个简单的无操作(no-op)桩,用于测试应用程序、接口或技术,这样你就可以证明你的测试能够以所需的速度运行,并在另一端不做任何工作时正确断言通过。
这听起来可能有些过度,但我们向你保证,我们见过许多容量测试断言应用程序失败,而实际上是测试本身无法跟上。在撰写本文时,Dave正在一个超高性能计算环境中工作。在那个项目中,我们在所有级别运行一系列容量和性能测试。正如你所期望的,这些测试作为部署流水线的一部分运行,其中大多数测试都有一个基准运行,首先针对测试桩执行每个测试,在我们信任其结果之前断言测试本身是有效的。这些基准运行的结果与我们的其他容量测试结果一起报告,因此我们可以清楚地知道任何失败发生在哪里。
大多数应用程序需要满足某些最低容量阈值。大多数现代商业应用程序将服务于许多并发用户,因此需要扩展以满足其峰值需求配置,同时提供可接受的性能。在开发过程中,我们需要的是能够断言我们的应用程序将达到客户要求的容量。
虽然与容量相关的非功能性需求是项目开发的重要方面,但重要的是要用某种可量化的度量来指定”足够好”的含义。这些度量应该通过某种自动化测试来评估,这些测试作为部署流水线的一部分运行。这意味着通过提交测试和验收测试的每个变更都应该对其运行自动化容量测试。因此,可以确定引入显著影响应用程序容量的变更的时刻。
通过自动化容量测试,其成功标准清晰地界定了最佳点,确保满足容量要求。通过这种方式,我们可以防止对容量问题的过度工程化解决方案。我们始终遵循这样的原则:我们将做最少量的工作来实现我们的目标,正如YAGNI(“You Ain’t ’Gonna Need It”,你不会需要它)原则所暗示的那样。YAGNI提醒我们,任何我们防御性添加的行为都可能是浪费精力。应用Knuth的格言,优化应该推迟到明确需要它们的时候,推迟到最后负责任的时刻,并基于运行时应用程序性能分析进行针对性优化,以便按重要性降序攻克瓶颈。
一如既往,我们进行任何测试的目标是在引入破坏我们假设的变更后尽快失败。通过这种方式,可以轻松识别并快速修复变更。然而,容量测试通常相对复杂,可能需要很长时间才能运行。
如果你足够幸运,能够在几秒钟内证明你的应用程序满足其性能目标,请将你的容量测试添加到提交测试阶段,这样你就可以立即获得有关任何问题的反馈。但是,在这种情况下要注意任何依赖运行时优化编译器的技术。.NET和Java中的运行时优化需要多次迭代才能稳定,只有在几分钟的”预热”之后才能收集到合理的结果。
类似的策略可用于保护已知的性能热点,防止它们随着代码开发而变得更糟。当识别出这样的热点时,创建一个”保护测试”,作为提交测试周期的一部分快速运行。这样的测试充当一种性能冒烟测试——它们不会告诉你你的应用程序满足其所有性能标准,但它们可能会突出错误方向的趋势,让你在它们成为问题之前解决它们。但是,请注意,不要使用这种策略引入间歇性失败的不可信测试。
然而,大多数容量测试不适合作为部署流水线的提交阶段的候选。它们通常需要太长时间并且需要太多资源才能运行。如果容量测试保持相当简单并且不需要太长时间运行,将容量测试添加到验收阶段是可行的。但总的来说,我们不建议将容量测试添加到部署流水线的验收测试阶段。有几个原因:
• 要真正有效,容量测试需要在专门的环境中运行。如果最新候选版本未能通过容量要求的真正原因是其他自动化测试同时在相同环境上运行,那么试图找出原因可能会付出相当大的代价。某些CI系统允许您为测试指定目标环境。您可以使用此功能来划分容量测试,并使其与验收测试并行运行。
• 某些类型的容量测试可能需要很长时间才能运行,导致在获得验收测试结果之前出现难以接受的延迟。
• 验收测试之后的许多活动可以与容量测试并行进行,例如演示最新的工作软件、手动测试、集成测试等。将这些活动建立在容量测试成功运行的基础上是不必要的,对于许多项目来说也是低效的。
• 对于某些项目,不需要像验收测试那样频繁地运行容量测试。
一般来说,除了我们描述的性能冒烟测试(smoke tests)之外,我们更倾向于将自动化容量测试作为部署流水线中完全独立的阶段添加。
容量阶段在流水线中的处理方式因项目而异。对于某些项目,将其以类似于验收测试阶段的方式处理是合理的——作为一个完全自动化的部署关卡。也就是说,除非容量测试阶段的所有测试都通过,否则您无法在没有手动覆盖的情况下部署应用程序。这最适合那些高性能或大规模的应用程序,如果它们不满足明确的容量阈值,就根本无法达到预期目的。这是最严格的容量测试模型,表面上看似乎对大多数项目来说是最优的。然而,情况并非总是如此。
如果存在吞吐量或延迟的实际问题,或者某些信息仅在特定时间窗口内相关或准确,自动化测试可以非常有效地作为可执行规范来断言需求得到满足。
图9.7 部署流水线的容量测试阶段
在高层次上,部署流水线中的验收测试阶段是所有后续测试阶段(包括容量测试)的模板,如图9.7所示。对于容量测试和其他测试一样,该阶段从准备部署开始,然后部署,接着验证环境和应用程序是否正确配置和部署。只有在此之后才会运行容量测试。
容量测试系统通常是最接近您预期生产系统的环境。因此,它是一个非常宝贵的资源。此外,如果您遵循我们的建议,将容量测试设计为一系列可组合的、基于场景的测试,那么您实际拥有的是一个复杂的生产系统模拟。
这是一个宝贵的资源,原因有很多。我们已经讨论过为什么基于场景的容量测试很重要,但鉴于更常见的方法是对特定的、技术重点的交互进行基准测试,值得重申一下。基于场景的测试提供了与系统真实交互的模拟。通过将这些场景的集合组织成复杂的组合,您可以在类生产系统中有效地进行实验,并使用任意多的诊断工具。
我们使用此功能帮助我们执行各种活动:
• 重现复杂的生产缺陷
• 检测和调试内存泄漏
• 长期运行测试(longevity testing)
• 评估垃圾回收(garbage collection)的影响
• 调优垃圾回收
• 调优应用程序配置参数
• 调优第三方应用程序配置,例如操作系统、应用服务器和数据库配置
• 模拟病理性的、最坏情况的场景
• 评估复杂问题的不同解决方案
• 模拟集成失败
• 通过一系列不同硬件配置的运行来衡量应用程序的可扩展性
• 对与外部系统的通信进行负载测试,即使我们的容量测试最初是针对桩接口(stubbed interfaces)运行的
• 演练复杂部署的回滚
• 选择性地使应用程序的某些部分失效,以评估服务的优雅降级(graceful degradation)
• 在临时可用的生产硬件上执行真实世界的容量基准测试,以便我们可以为长期的、较低规格的容量测试环境计算更准确的扩展因子
这不是一个完整的列表,但这些场景中的每一个都来自真实项目。
从根本上说,您的容量测试系统是一个实验资源,您可以在其中有效地加快或减慢时间以满足您的需求。您可以使用它来设计和执行各种实验,以帮助诊断问题,或预测问题并制定应对策略。
设计系统以满足其非功能性需求(nonfunctional requirements, NFRs)是一个复杂的主题。许多非功能性需求的横切特性(crosscutting nature)意味着很难管理它们对任何给定项目构成的风险。这反过来又会导致两种令人困扰的行为:从项目开始就没有给予足够的关注,或者在另一个极端,进行防御性架构(defensive architecture)和过度工程(over-engineering)。
软件发布到生产环境与部署到测试环境之间存在差异——尤其是执行发布的人员血液中的肾上腺素水平。然而,从技术角度来看,这些差异应该被封装在一组配置文件中。当部署到生产环境时,应该遵循与其他部署相同的流程。启动你的自动化部署系统,给它指定要部署的软件版本和目标环境名称,然后执行。这个相同的流程也应该用于所有后续的部署和发布。
由于两者使用相同的流程,本章同时讨论软件的部署和发布。我们将描述如何创建和遵循软件发布策略,包括部署到测试环境。部署和发布之间的主要区别在于回滚能力,我们在本章中详细讨论这个问题。我们还介绍了两种极其强大的技术,可用于在最大型的生产系统上执行零停机时间的发布和回滚:蓝绿部署(blue-green deployments)和金丝雀发布(canary releasing)。
所有这些流程——部署到测试和生产环境以及回滚——都需要成为部署流水线(deployment pipeline)实现的一部分。应该能够看到可部署到每个环境的构建列表,并通过按下按钮或点击鼠标选择要部署的版本和部署目标环境来运行自动化部署流程。实际上,这应该是对这些环境进行任何类型更改的唯一方式——包括操作系统和第三方软件的配置。因此可以准确地看到应用程序的哪些版本在哪些环境中、谁授权了部署,以及自上次部署以来对应用程序做了哪些更改。
本章重点关注将应用软件部署到多用户共享环境的问题,尽管相同的原则也适用于用户安装的软件。特别是,我们讨论发布产品并确保客户端安装软件的持续交付(continuous delivery)。
创建发布策略最重要的部分是让应用程序的利益相关者(stakeholders)在项目规划过程中会面。他们讨论的重点应该是就应用程序在整个生命周期中的部署和维护达成共识。然后将这种共识记录为发布策略。该文档将在应用程序的整个生命周期中由利益相关者更新和维护。
在项目开始时创建发布策略的第一个版本时,应考虑包含以下内容:
• 负责部署到各个环境以及负责发布的相关方
• 资产和配置管理策略
• 用于部署的技术描述。这应该由运维团队和开发团队共同商定
• 实施部署流水线的计划
• 列出可用于验收测试、容量测试、集成测试和用户验收测试的环境,以及构建版本在这些环境中流转的流程。
• 描述部署到测试环境和生产环境时需要遵循的流程,例如需要提交的变更请求以及需要获得的审批。
• 应用程序监控要求,包括应用程序应使用的任何 API 或服务,以便向运维团队通知其状态。
• 讨论如何管理应用程序的部署时配置和运行时配置的方法,以及这与自动化部署流程的关系。
• 描述与任何外部系统的集成。在发布过程中,它们在什么阶段以及如何进行测试?运维人员在出现问题时如何与供应商沟通?
• 日志记录详情,以便运维人员能够确定应用程序的状态并识别任何错误情况。
• 灾难恢复计划,以便在发生灾难后可以恢复应用程序的状态。
• 软件的服务级别协议(SLA),这将决定应用程序是否需要故障转移和其他高可用性策略等技术。
• 生产环境的规模和容量规划:实际运行的应用程序会产生多少数据?需要多少日志文件或数据库?需要多少带宽和磁盘空间?客户端期望的延迟是多少?
• 归档策略,以便不再需要的生产数据可以保留用于审计或支持目的。
• 首次部署到生产环境的工作方式。
• 如何处理缺陷修复和为生产环境应用补丁。
• 如何处理生产环境的升级,包括数据迁移。
• 如何管理应用程序支持。
制定发布策略的过程本身就很有用:它通常会成为软件开发以及硬件环境的设计、配置和调试的功能性和非功能性需求的来源。这些需求应该被认定为需求,并在发现时添加到开发计划中。
当然,制定策略只是开始;随着项目的推进,它会不断增补和变更。
发布策略的一个重要组成部分是发布计划,它描述了如何执行发布。
首次发布通常是风险最高的一次;它需要仔细规划。此规划的结果可能是自动化脚本、文档或可靠且可重复地将应用程序部署到生产环境所需的其他程序。除了发布策略中的内容外,它还应包括:
• 首次部署应用程序所需的步骤
• 如何在部署过程中对应用程序及其使用的任何服务进行冒烟测试
• 部署出现问题时回退部署所需的步骤
• 备份和恢复应用程序状态所需的步骤
• 在不破坏应用程序状态的情况下升级应用程序所需的步骤
• 应用程序失败时重启或重新部署应用程序的步骤
• 日志的位置以及对其包含信息的描述
• 监控应用程序的方法
• 执行发布过程中必要的任何数据迁移的步骤
• 以往部署中出现的问题及其解决方案的问题日志
有时还需要考虑其他因素。例如,如果新软件要取代遗留系统,则应记录将用户转移到新系统和停用旧系统的步骤,不要忘记在出现问题时的回滚流程。
同样,此计划需要随着项目的推进和新见解的获得而维护。
上面列出的策略和计划相当通用。对于所有项目都值得考虑,即使经过一些考虑后,您决定只使用其中的几个部分。
有一类软件项目必须考虑其他问题,那就是作为商业产品发布的软件。如果项目的输出是软件产品,以下是应该考虑的额外交付成果列表:
• 定价模型
• 许可策略
• 围绕使用的第三方技术的版权问题
• 打包
• 营销材料——印刷品、基于网络的内容、播客、博客、新闻稿、会议等
• 产品文档
• 安装程序
• 准备销售和支持团队
以可靠、一致的方式部署任何应用程序的关键是持续练习:使用相同的流程部署到每个环境,包括生产环境。自动化部署应该从首次部署到测试环境时就开始。不要手动将软件的各个部分组装到位,而是编写一个简单的脚本来完成这项工作。
任何应用程序的第一次部署都应该在第一次迭代中进行,此时你向客户展示第一批故事或需求。在第一次迭代中选择一两个优先级高但非常简单的故事或需求来交付(假设你的迭代周期是一到两周,并且你有一个小团队——如果这些条件不适用,你应该选择更多)。利用这次展示作为理由,使应用程序可以部署到类生产环境的展示环境(UAT)。在我们看来,项目第一次迭代的主要目标之一是让部署流水线的早期阶段运行起来,并能够在结束时部署和演示某些东西,无论多么小。这是我们推荐优先考虑技术价值而非业务价值的极少数情况之一。你可以将这种策略看作是启动你的开发过程。
在这个启动迭代结束时,你应该具备以下条件:
• 部署流水线的提交阶段
• 一个可以部署到的类生产环境
• 一个自动化流程,将提交阶段创建的二进制文件部署到环境中
• 一个简单的冒烟测试,验证部署是否成功以及应用程序是否正在运行
对于一个只开发了几天的应用程序来说,这应该不会太麻烦。这里的棘手之处在于确定环境应该有多接近生产环境。你的部署目标不需要是最终生产环境的克隆,但生产环境的某些方面比其他方面更重要。
一个好问题是:“生产环境与我的开发环境有多大不同?”如果生产环境运行在不同的操作系统上,你应该为UAT环境使用将在生产中使用的相同操作系统。如果你的生产环境是一个集群,你应该为暂存环境构建一个小型的有限集群。如果你的生产环境是一个具有许多不同节点的分布式环境,请确保你的类生产测试环境至少有一个单独的进程来代表每一类进程边界。
虚拟化和鸡计数法(0, 1, 多)是你的好朋友。虚拟化使得创建一个代表生产环境重要方面的环境变得容易,同时能够在单个物理机器上运行。鸡计数法意味着如果你的生产站点有250台Web服务器,2台应该足以代表重要的进程边界。随着开发的进展,你可以变得更复杂。
一般来说,类生产环境具有以下特征:
• 它应该运行与生产系统相同的操作系统
• 它应该安装与生产系统相同的软件——特别是,不应该在其上安装任何开发工具链(如编译器或IDE)
• 在合理范围内,这个环境应该以与生产环境相同的方式管理,使用第11章”管理基础设施和环境”中描述的技术
• 在客户端安装软件的情况下,你的UAT环境应该能够代表你的客户的硬件统计数据,或者至少是其他人的真实世界统计数据
随着你的应用程序增长并变得更加复杂,你的部署流水线实现也会如此。由于你的部署流水线应该对你的测试和发布流程进行建模,你首先需要弄清楚这个流程是什么。虽然这通常用在环境之间推进构建来表达,但我们关心的细节更多。特别重要的是捕获:
• 一个构建为了被发布必须经过哪些阶段(例如,集成测试、QA验收测试、用户验收测试、暂存、生产)
• 需要哪些关卡或审批
• 对于每个关卡,谁有权批准构建通过该关卡
图10.1 测试和发布流程图示例
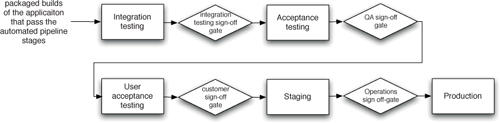
在这个练习结束时,你可能会得到一个类似图10.1的图表。当然,你的流程可能比这更复杂或更简单。创建这样的图表实际上是为你的发布流程创建价值流图的第一步。我们在第5章”部署流水线剖析”中讨论了价值流图作为优化发布流程的一种方式。
一旦你创建了这个图表,你就可以在用于管理部署的工具中为发布流程的每个部分创建占位符。Go和AntHill Pro都允许你开箱即用地做到这一点,大多数持续集成工具也可以通过一些工作来建模和管理这个流程。完成后,负责审批的人员应该能够使用你的工具批准特定构建在发布流程中通过关卡。
管理部署流水线的工具必须提供的另一个关键功能是:对于每个阶段,能够查看哪些构建已通过流水线中所有前置阶段的测试,因此可以进入下一阶段。然后应该能够选择其中一个构建,按下按钮即可完成部署。这个过程称为晋升(promotion)。按下按钮即可晋升构建,这使得部署流水线成为一个拉式系统,让参与交付过程的每个人都能够管理自己的工作。分析师和测试人员可以自助部署用于探索性测试、演示或可用性测试。运维人员可以按下按钮将任何版本部署到预发布环境或生产环境。
自动化部署机制使晋升变成了一件简单的事情:选择所需的候选版本,等待它部署到正确的环境即可。这种自动化部署机制应该可以被任何需要部署应用的人使用。它不应该要求使用者具备任何关于部署技术细节的知识或理解。为此,在部署系统认为系统已准备就绪后运行自动化冒烟测试(smoke tests)非常有帮助。这样,我们可以向请求部署的人——无论是分析师、测试人员还是运维人员——保证系统已准备就绪并按预期工作,或者在出现问题时更容易诊断原因。
我们参与的一个项目是为一家初创公司工作。这是在一个全新业务领域的绿地开发。能够向潜在客户、合作伙伴和投资者展示他们将要获得什么,这一点极其重要。在项目的早期阶段,这些任务通过模型、幻灯片和简单原型来完成。
但很快,应用程序就超越了原型,因此我们开始使用手动测试环境之一进行这类演示,通常是在很短的通知时间内。我们的部署流水线很完善,因此我们可以确信任何通过验收测试关卡的构建都适合用于演示。我们也可以确信能够非常轻松快速地部署任何候选版本。
我们的业务分析师可以控制向测试环境的部署。他们可以选择要展示的候选版本,并与测试团队协调使用哪个测试环境,而不会干扰测试。
测试和发布流程中的每个阶段基本上涉及相同的工作流程:测试应用程序的特定版本,根据一组验收标准确定其是否适合发布。为了执行这些测试,需要将所选的应用程序构建部署到一个环境中。如果你的应用是需要手动测试的用户安装软件,这个环境可能是测试人员的台式机。对于嵌入式软件,这可能需要一个专门的、独立的硬件环境。对于托管软件服务,它可能是一组类似生产环境的机器。或者可能是这些情况的组合。
在任何这些情况下,流程中任何测试阶段的工作流程都是相似的。
执行测试的人员或团队应该有办法选择要部署到测试环境的应用程序版本。此列表将包括已通过部署流水线所有前置阶段的所有应用程序版本。选择特定构建应该会导致以下步骤(直到实际测试)自动执行。
准备环境和相关基础设施(包括中间件),使其处于干净状态,准备好部署应用程序。这应该以完全自动化的方式完成,如第11章”管理基础设施和环境”中所述。
部署应用程序的二进制文件。这些二进制文件应该始终从制品仓库获取,绝不要为每次部署从头构建。
配置应用程序。配置信息应该在所有应用程序中以一致的方式管理,并在部署时或运行时应用,使用像Escape [apvrEr]这样的工具。关于这个主题的更多信息,请参阅第2章”配置管理”。
准备或迁移应用程序管理的任何数据,如第12章”管理数据”中所述。
对部署进行冒烟测试。
执行测试(可能是手动或自动化)。
如果此版本的应用程序通过测试,批准其晋升到下一个环境。
如果此版本的应用程序未通过测试,记录原因。
不仅仅是二进制文件需要晋升。环境和应用程序的配置也需要同时晋升。更复杂的是,你不想晋升所有配置。例如,你需要确保任何新的配置设置都被晋升,但你不希望将指向SIT数据库或外部服务测试替身的设置晋升到生产环境。管理与应用程序相关的某些配置部分的晋升——而不是那些与环境相关的配置——是一个复杂的问题。
一种解决这个问题的方法是让你的冒烟测试验证你是否指向了正确的对象。例如,你可以让一个测试替身服务返回它期望通信的环境字符串,并让冒烟测试检查你的应用程序从外部服务获取的字符串是否与它所部署的环境匹配。对于中间件配置(如线程池)的情况,你可以使用 Nagios 等工具来监控这些设置。你还可以编写基础设施测试来检查任何关键设置,并将它们报告给你的监控软件。“行为驱动监控”部分(第 323 页)提供了更多细节。
在面向服务架构和组件化应用程序的情况下,组成应用程序的所有服务或组件需要一起晋级(promote)。正如我们在上一节中讨论的,通常是在系统集成测试环境中找到应用程序服务和组件的良好版本组合。你的部署系统需要强制将这个组合作为一个整体进行晋级,以避免有人部署了某个服务的错误版本,导致应用程序失败——或者更糟的是,引入一个间歇性且难以追踪的缺陷。
环境通常在多个应用程序之间共享。这可能会以两种方式造成复杂性。首先,这意味着在为应用程序的新部署准备环境时,你必须格外小心,以免干扰该环境中其他任何应用程序的运行。这通常意味着确保对操作系统或任何中间件配置的更改不会导致其他应用程序出现故障。如果生产环境在相同的应用程序之间共享,那么这项工作就有了实用目的:确保所选应用程序版本之间没有冲突。如果这被证明是一项复杂的工作,你可能会考虑使用某种形式的虚拟化技术将应用程序彼此隔离。
其次,共享环境的应用程序可能相互依赖。这在使用面向服务架构时很常见。在这种情况下,集成测试(也称为系统集成测试,或 SIT)环境是应用程序首次相互通信而不是与某种测试替身通信的时刻。因此,SIT 环境中的大部分工作涉及部署每个应用程序的新版本,直到它们都能协作。在这种情况下,冒烟测试套件通常是针对整个应用程序运行的完整验收测试集。
在让你的应用程序面对毫无防备的用户之前,你应该在一个非常类似于生产环境的预发布(staging)环境中执行一些最终测试。如果你设法获得了一个接近生产环境的容量测试环境,有时跳过预发布步骤可能是合理的:你可以将容量测试环境同时用于容量测试和预发布。但是,对于简单系统以外的任何系统,我们通常不建议这样做。如果你的应用程序包括与外部系统的任何集成,预发布是你最终确认每个系统预期生产版本之间所有集成方面都能正常工作的时刻。
你应该从项目开始时就着手搭建你的预发布环境。如果你有生产环境的硬件并且它没有被用于其他任何用途,在执行第一次发布之前将其用作预发布环境。以下是从项目开始时就需要规划的一些事项:
• 确保你的生产、容量测试和预发布环境已配置就绪。特别是在全新项目中,在发布前一段时间准备好你的生产环境,并将其部署作为流水线的一部分。
• 拥有一个自动化过程来配置你的环境,包括网络、外部服务和基础设施。
• 确保部署过程经过充分的冒烟测试。
• 测量你的应用程序的预热(warm-up)时间。如果你的应用程序使用缓存,这一点尤其适用。将此纳入你的部署计划。
• 测试与外部系统的集成。你不希望应用程序的发布是你首次针对真实外部系统运行的时刻。
• 如果可能,在发布之前就将你的应用程序部署到生产环境。如果”发布”可以简单到重新配置某个路由器,将流量从一个临时页面引导到你的生产环境,那就更好了。这种技术称为蓝绿部署(blue-green deployment),将在本章稍后描述。
• 如果可能,在向所有人推出之前,尝试将你的系统推出给一小部分用户。这种技术称为金丝雀发布(canary releasing),也将在本章稍后描述。
• 将通过验收测试的每个变更部署到你的预发布环境(尽管不一定部署到生产环境)。
当部署出现问题时,能够回滚部署是至关重要的。在运行的生产环境中调试问题几乎肯定会导致深夜加班、产生不幸后果的错误以及愤怒的用户。当事情出错时,你需要有一种方法来恢复服务给用户,这样你就可以在正常工作时间内从容地调试故障。我们将在这里讨论几种执行回滚的方法。更高级的技术——蓝绿部署和金丝雀发布——也可以用于执行零停机发布和回滚。
在开始之前,有两个重要的约束条件。第一个是你的数据。如果你的发布过程对数据进行了更改,回滚就会变得困难。另一个约束是你集成的其他系统。涉及多个系统的发布(称为编排发布(orchestrated releases)),回滚过程也会变得更加复杂。
在创建回滚发布的计划时,你应该遵循两个一般原则。第一个是确保在发布之前备份生产系统的状态,包括数据库和文件系统中保存的状态。第二个是练习你的回滚计划,包括在每次发布之前从备份恢复或将数据库迁移回去,以确保它能正常工作。
这通常是最简单的回滚方式。如果你有一个自动化的应用程序部署流程,回到良好状态的最简单方法是从头开始重新部署先前的良好版本。这还将包括重新配置它运行的环境,使其配置与之前完全相同。这就是能够从头开始重建环境如此重要的原因之一。
为什么要从头开始创建环境并进行部署?有几个充分的理由:
• 如果你没有自动化的回滚流程但有自动化的部署流程,那么重新部署上一个版本是一个固定时间的操作,风险较低(因为出错的可能性更小)。
• 这是你(希望)之前测试过数百次的相同流程。回滚的执行频率要低得多,因此更有可能包含错误。
我们想不出任何这种方法不起作用的情况。但是,有一些缺点:
• 尽管重新部署旧版本所需的时间是固定的,但它不为零。因此会导致停机时间。
• 这使得调试出错原因变得更加困难。重新部署旧版本通常会覆盖新版本,从而失去了找出发生了什么的机会。如果你的生产环境是虚拟的,这可以得到缓解,我们稍后会描述。对于相对简单的应用程序,通常很容易通过将每个版本部署到新目录并使用符号链接指向当前版本来保留旧版本。
• 如果你从部署最新版本之前进行的数据库备份恢复,你将丢失部署后创建的任何数据。如果你快速回滚,这可能不是什么大问题,但在某些情况下这是不可接受的。
零停机发布,也称为热部署(hot deployment),是指将用户从一个版本切换到另一个版本的实际过程几乎瞬间发生。至关重要的是,如果出现问题,也必须能够几乎瞬间将用户回退到先前的版本。
零停机发布的关键是解耦发布过程的各个部分,使它们能够尽可能独立地进行。特别是,应该能够在升级应用程序之前,先部署应用程序所依赖的共享资源(如数据库、服务和静态资源)的新版本。
对于静态资源和基于Web的服务,这相对容易。你只需在URI中包含资源或服务的版本,就可以同时拥有它们的多个版本。例如,Amazon Web Services有一个基于日期的版本控制系统,EC2 API的最新版本(在撰写本文时)可在 http://ec2.amazonaws.com/doc/2009-11-30/AmazonEC2.wsdl 获得。当然,他们也会在旧的URI上保持API的早期版本正常工作。对于资源,当你推出网站的新版本时,你将静态资源(如图像、Javascript、HTML和CSS)放到一个新目录中——例如,你可以将应用程序2.6.5版本的图像放在 /static/2.6.5/images 下。
数据库的情况要困难一些。第12章”管理数据”中有专门介绍在零停机场景中管理数据库的部分。
这是我们所知的最强大的发布管理技术之一。其思想是拥有两个相同的生产环境版本,我们称之为蓝色和绿色。
在[图 10.2]的示例中,系统用户被路由到绿色环境,这是当前指定的生产环境。我们想发布应用程序的新版本。因此我们将其部署到蓝色环境,并让应用程序预热(你可以根据需要进行多次预热)。这不会以任何方式影响绿色环境的运行。我们可以对蓝色环境运行冒烟测试(smoke tests)以检查其是否正常工作。当我们准备好时,切换到新版本就像更改路由器配置以指向蓝色环境而不是绿色环境一样简单。蓝色环境因此成为生产环境。这种切换通常可以在不到一秒的时间内完成。
如果出现问题,我们只需将路由器切换回绿色环境即可。然后我们可以在蓝色环境上调试出了什么问题。
可以看出,这种方法比重新部署方法产生了几项改进。但是,在使用蓝绿部署管理数据库时需要一些注意。通常不可能直接从绿色数据库切换到蓝色数据库,因为如果存在模式(schema)变更,将数据从一个版本迁移到下一个版本需要时间。
解决这个问题的一种方法是在切换前不久将应用程序置于只读模式。然后你可以复制绿色数据库,将其恢复到蓝色数据库,执行迁移,然后切换到蓝色系统。如果一切正常,你可以将应用程序恢复到读写模式。如果出现问题,你可以简单地切换回绿色数据库。如果这发生在应用程序恢复到读写模式之前,则不需要做任何其他事情。如果你的应用程序已将你想保留的数据写入新数据库,你需要找到一种方法来获取新记录并将它们迁移回绿色数据库,然后再次尝试发布。或者,你可以找到一种方法将新版本应用程序的事务同时发送到新旧数据库。
另一种方法是设计你的应用程序,使你可以独立于升级过程迁移数据库,我们将在[第 12 章]“管理数据”中详细描述。
如果你只能负担得起单个生产环境,你仍然可以使用蓝绿部署。只需在同一环境上并行运行应用程序的两个副本。每个副本都有自己的资源—自己的端口、自己的文件系统根目录等等—因此它们可以同时运行而不会相互干扰。你可以独立部署到每个环境。另一种方法是使用虚拟化,尽管你应该首先测试虚拟化对应用程序容量的影响。
如果你有足够的预算,你的蓝色和绿色环境可以是彼此完全独立的副本。这需要更少的配置,但当然更昂贵。这种方法的一个变体,称为影子域发布、影子环境发布或双活发布,是将你的预发布(staging)和生产环境用作蓝绿环境。将应用程序的新版本部署到预发布环境,然后将用户从生产环境切换到预发布环境以使应用程序的新版本上线。此时,预发布环境成为生产环境,生产环境成为预发布环境。
我们曾与一个非常大的组织合作,他们有五个并行的生产环境。他们使用这种技术,但也保持多个版本的生产系统并行运行,允许他们以不同的速度迁移业务的不同区域。这种方法也具有下面描述的金丝雀发布(canary releasing)的一些特征。
通常可以安全地假设你在生产环境中一次只有一个版本的软件。这使得管理错误修复以及基础设施更加容易。但是,这也给测试软件带来了障碍。即使有可靠和全面的测试策略,缺陷仍会在生产环境中出现。即使有较低的周期时间,开发团队仍然可以从对新功能的更快反馈中受益,以及他们可以做些什么来使他们的软件更有价值。
此外,如果你有一个非常大的生产环境,就不可能创建一个有意义的容量测试环境(除非你的应用程序架构采用端到端共享)。你如何确保应用程序的新版本不会表现不佳?
图 10.3 金丝雀发布
金丝雀发布旨在解决这些挑战。如[图 10.3]所示,金丝雀发布涉及将应用程序的新版本推出到生产服务器的子集以获得快速反馈。就像煤矿中的金丝雀一样,这可以快速发现新版本的任何问题,而不会影响大多数用户。这是降低发布新版本风险的好方法。
与蓝绿部署类似,你需要先将应用程序的新版本部署到一组不会路由用户流量的服务器上。然后你可以对新版本进行冒烟测试,如果需要的话,还可以进行容量测试。最后,你可以开始将选定的用户路由到新版本的应用程序。一些公司会选择”高级用户”首先访问新版本的应用程序。你甚至可以同时在生产环境中运行应用程序的多个版本,根据需要将不同的用户组路由到不同的版本。
金丝雀发布有以下几个好处:
它使回滚变得容易:只需停止将用户路由到有问题的版本,你就可以从容地调查日志。
你可以通过将一些用户路由到新版本、一些用户路由到旧版本来进行A/B测试。一些公司会衡量新功能的使用情况,如果使用的人不够多就会放弃这些功能。其他公司会衡量新版本实际产生的收入,如果新版本的收入较低就会回滚。如果你的软件生成搜索结果,你可能会比较真实用户在新版本和旧版本中获得的结果质量。你不需要将大量用户路由到新版本来进行A/B测试;有代表性的样本就足够了。
你可以通过逐步增加负载来检查应用程序是否满足容量要求,慢慢地将越来越多的用户路由到应用程序,并测量应用程序的响应时间和诸如CPU使用率、I/O和内存使用率等指标,同时监视日志中的异常。如果你的生产环境太大而无法创建一个真实的类生产容量测试环境,这是一种相对低风险的容量测试方法。
这个主题也有一些变体。金丝雀发布并不是进行A/B测试的唯一方法——你可以在应用程序中使用开关将不同的用户路由到不同的行为。或者,你可以使用运行时配置设置来改变行为。然而,这些替代方案并不能提供金丝雀发布的其他好处。
不过,金丝雀发布并不适合所有人。当用户在自己的计算机上安装了你的软件时,使用它会更困难。这个问题有一个解决方案(在网格计算中使用的方案)——使你的客户端软件或桌面应用程序能够自动更新到你服务器上托管的已知良好版本。
金丝雀发布对数据库升级施加了进一步的约束(这也适用于其他共享资源,如共享会话缓存或外部服务):任何共享资源都需要与你想在生产环境中运行的所有版本的应用程序兼容。另一种方法是使用无共享架构(shared-nothing architecture),其中每个节点都是真正独立于其他节点的,没有共享数据库或服务,或者两种方法的某种混合。
金丝雀发布可能听起来有点理论化,但我们向你保证,它出现在这里只是因为我们在实际项目中见过它的使用(远早于Google、NetFlix和IMVU提出这个想法)。在一个交付高容量销售点系统的项目中,我们出于上述所有原因使用了这一策略。我们的应用程序是一个高度分布式的富客户端系统。有数万个客户端。当需要将更改部署到客户端系统时,有时我们根本没有足够的网络带宽在所有商店关闭期间将所有更改推送到所有客户端。相反,我们会在几天甚至几周的时间内逐步推出新版本的系统。
这意味着不同的商店集合将运行不同版本的客户端系统,与不同版本的服务器端系统通信,但都共享一个通用的底层数据库。
使用我们系统的商店被划分为几个不同的品牌。我们的增量推出策略意味着不同的商店组可以决定何时承担更新系统的风险。如果一个版本具有对其运营至关重要的新功能,他们会急于尽早采用,但如果它主要关注与其兄弟商店组更相关的功能,他们可以推迟该版本,直到它在其他地方得到验证。
最后,重要的是尽可能少地在生产环境中保留应用程序的版本——尽量将其限制在两个。支持多个版本是痛苦的,因此将金丝雀的数量保持在最低限度。
在每个系统中,都会有一个时刻发现关键缺陷并必须尽快修复。在这种情况下,要记住的最重要的事情是:在任何情况下都不要破坏你的流程。紧急修复必须经历与任何其他变更相同的构建、部署、测试和发布流程。我们为什么这么说?因为我们见过太多次通过直接登录生产环境并进行不受控制的更改来进行修复的情况。
这会带来两个不幸的后果。第一个是变更没有得到适当的测试,这可能导致回归问题,补丁无法修复问题,甚至可能使问题恶化。其次,变更通常没有被记录(即使被记录了,为了修复第一次变更引入的问题而进行的第二次和第三次变更也没有被记录)。因此,环境最终处于未知状态,无法重现,并以无法管理的方式破坏后续的部署。
这个故事的寓意是:让每一个紧急修复都通过你的标准部署流水线。这只是保持低周期时间的又一个理由。
有时候,通过紧急修复来修复缺陷实际上并不值得。你应该始终考虑缺陷影响了多少人、发生的频率如何,以及缺陷对用户的影响严重程度。如果缺陷影响的人很少,发生频率低,且影响较小,那么如果部署新版本的相关风险相对较高,立即修复可能就没有意义。当然,这也是一个很好的理由,通过有效的配置管理和自动化部署流程来降低与部署相关的风险。
紧急修复的另一个替代方案是回滚到之前已知的良好版本,如前所述。
以下是处理生产环境中的缺陷时需要考虑的一些因素:
• 永远不要在深夜进行,并且始终与其他人配对工作。
• 确保你已经测试了紧急修复流程。
• 只有在极端情况下才绕过对应用程序进行变更的常规流程。
• 确保你已经使用预发布环境测试了紧急修复。
• 有时候回滚到之前的版本比部署修复更好。进行一些分析以确定最佳解决方案。考虑如果丢失数据或面临集成或编排问题会发生什么。
遵循极限编程(Extreme Programming)的座右铭——如果它很痛苦,就更频繁地做它——逻辑上的极端做法是将通过自动化测试的每个变更都部署到生产环境。这种技术被称为持续部署(continuous deployment),这个术语由Timothy Fitz [aJA8lN]推广。当然,这不仅仅是持续部署(我可以随意持续部署到UAT:没什么大不了的)。关键点在于这是持续部署到生产环境。
这个想法很简单:我使用我的流水线,并将最后一步——部署到生产环境——自动化。这样,如果一次签入通过了所有自动化测试,它就会直接部署到生产环境。为了避免造成破坏,你的自动化测试必须非常出色——应该有自动化单元测试、组件测试和验收测试(功能性和非功能性)覆盖你的整个应用程序。你必须先编写所有测试——包括验收测试——这样只有当一个故事(story)完成时,签入才会通过验收测试。
持续部署可以与金丝雀发布(canary releasing)结合使用,通过使用自动化流程,首先将新版本推出给一小部分用户,一旦确定(可能作为手动步骤)新版本没有问题,就将其推出给所有用户。良好的金丝雀发布系统提供的额外保障使持续部署成为一个风险更低的提案。
持续部署并不适合所有人。有时候,你不想立即将新功能发布到生产环境。在有合规性约束的公司中,部署到生产环境需要批准。产品公司通常必须支持他们发布的每个版本。然而,它确实有潜力在许多地方发挥作用。
对持续部署的直觉反对意见是它风险太大。但是,正如我们之前所说,更频繁的发布导致发布任何特定版本的风险更低。这是真的,因为版本之间的变更量减少了。所以,如果你发布每个变更,风险量就仅限于那一个变更本身固有的风险。持续部署是降低任何特定发布风险的好方法。
也许最重要的是,持续部署迫使你做正确的事(正如Fitz在他的博客文章中指出的那样)。如果不自动化整个构建、部署、测试和发布流程,你就无法做到。如果没有一套全面、可靠的自动化测试,你就无法做到。如果不编写针对类生产环境运行的系统测试,你就无法做到。这就是为什么,即使你实际上无法发布通过所有测试的每一组变更,你也应该致力于创建一个让你在选择时可以这样做的流程。
你的作者们非常高兴看到持续部署文章在软件开发社区引起如此大的轰动。它强化了我们多年来一直在说的关于发布流程的观点。部署流水线的核心是创建一个可重复、可靠、自动化的系统,以尽可能快的速度将变更投入生产。它是关于使用最高质量的流程创建最高质量的软件,同时大幅降低发布流程的风险。持续部署将这种方法推向其逻辑结论。它应该被认真对待,因为它代表了软件交付方式的范式转变。即使你有充分的理由不发布每一个变更——而这样的理由比你想象的要少——你也应该表现得好像你将要这样做。
向您控制的生产环境发布应用程序的新版本是一回事。向用户自己机器上安装的软件发布新版本——客户端安装软件——则是另一回事。需要考虑以下几个问题:
• 管理升级体验
• 迁移二进制文件、数据和配置
• 测试升级过程
• 从用户处获取崩溃报告
客户端安装软件的一个严重问题是管理随时间推移而出现在外部的大量软件版本。这可能会造成支持噩梦:为了调试任何问题,你必须将源代码恢复到正确的版本,并回想起应用程序在那个时间点的特性,以及任何已知问题。理想情况下,你希望每个人都使用同一版本的软件:最新的稳定版本。为了实现这一点,必须使升级体验尽可能无痛。
客户端可以通过以下几种方式处理升级过程:
让软件检查新版本并提示用户下载和升级到最新版本。这是最容易实现的,但使用起来最痛苦。没有人想看下载进度条。
在后台下载并提示安装。在这种模式下,软件在运行时定期检查更新并静默下载。下载成功后,持续提示用户升级到最新版本。
在后台下载并在下次重启应用程序时静默升级。应用程序也可能提示你如果想升级现在就重启(如Firefox所做的)。
如果你想保守一些,选项1和2可能看起来更有吸引力。然而,在几乎所有情况下,它们都是错误的选择。作为应用程序开发者,你想给用户选项。然而,在升级的情况下,用户不理解为什么他们可能想延迟升级。这迫使他们思考升级,却没有提供任何信息来帮助他们做出决定。因此,理性的选择通常是不升级,仅仅因为任何升级都可能破坏应用程序。
事实上,开发团队的脑海中也在进行完全相同的思考过程。升级过程可能会破坏应用程序,开发团队这样想,所以我们应该给用户一个选择。但是,如果升级过程确实不可靠,用户当然永远不升级是正确的。如果升级过程不是不可靠的,那么提供选择就没有意义:升级应该自动进行。所以事实上,给用户选择只是告诉他们开发者对升级过程没有信心。
正确的解决方案是使升级过程万无一失——并静默升级。特别是,如果升级过程失败,应用程序应该自动恢复到以前的版本并向开发团队报告失败。然后他们可以修复问题并推出一个(希望)能正确升级的新版本。所有这些都可以在用户甚至不需要知道任何事情的情况下发生。提示用户的唯一好理由是需要采取一些纠正措施。
当然,有一些原因可能导致你不希望软件静默升级。也许你不希望它回传数据,或者你是企业网络运维团队的一员,该团队只允许在新版本应用程序与其他已批准的应用程序进行详尽测试以确保稳定的桌面环境后才能部署。这些都是合理的用例,可以通过配置选项来关闭自动升级。
为了提供万无一失的升级体验,你需要处理迁移二进制文件、数据和配置。在每种情况下,升级过程都应该保留旧版本的副本,直到它绝对确定升级成功。如果升级失败,它应该静默恢复旧的二进制文件、数据和配置。一个简单的方法是在安装目录内有一个包含所有这些内容的当前版本的目录,并创建一个包含新版本的新目录。然后,切换版本只是重命名目录或将对当前版本目录的引用放在某处(在UNIX系统上,通常使用符号链接来实现)。
你的应用程序应该能够从任何版本升级到任何其他版本。为了做到这一点,你需要对数据存储和配置文件进行版本控制。每次更改数据存储或配置的架构时,都需要创建一个脚本来将它们从一个版本向前滚动到下一个版本,如果你想支持降级,还需要一个脚本从新版本回滚到旧版本。然后,当升级脚本运行时,它确定数据存储和配置的当前版本,并应用相关脚本将它们迁移到最新版本。这种技术在第12章”管理数据”中有更详细的描述。
你应该将升级过程作为部署流水线的一部分进行测试。你可以在流水线中专门设置一个阶段,从友好用户那里获取一系列具有真实数据和配置的初始状态,并运行升级到最新版本。这应该在代表性的目标机器选择上自动完成。
最后,客户端安装的软件必须能够向开发团队报告崩溃信息。在他关于客户端软件持续部署的博客文章中 [amYycv],Timothy Fitz 描述了客户端软件遇到的各种恶劣事件:“硬件损坏、内存不足、外语操作系统、随机 DLL、其他进程将代码注入到你的程序中、驱动程序争夺崩溃事件的优先处理权,以及其他越来越深奥和不可预测的集成问题。”
这使得崩溃报告框架变得至关重要。Google 已经开源了其用于 Windows 上 C++ 的框架 [b84QtM],如果需要可以从 .NET 内部调用。关于如何做好崩溃报告以及报告哪些指标有用的讨论取决于你使用的技术栈,超出了本书的范围。Fitz 的博客文章提供了一些有用的讨论作为起点。
部署团队经常被要求部署他们没有参与开发的系统。他们拿到一张 CD 和一叠复印的文件,上面有模糊的指令,比如”安装 SQL Server”。
这种情况是运维和开发团队之间关系不良的症状,可以肯定的是,当真正部署到生产环境时,流程将是痛苦和漫长的,伴随着许多相互指责和急躁情绪。
开发人员在开始项目时应该做的第一件事是非正式地找到运维人员,让他们参与到开发过程中。这样,运维人员从一开始就参与了软件开发,双方在发布之前很早就知道并多次练习过确切将要发生的事情,因此发布将会像新生儿的屁股一样顺滑。
我们想在非常紧迫的时间表下部署一个系统。在运维和开发团队的会议上,运维团队对进度表提出了强烈的反对。会议结束后,一些技术人员留下来聊天,并交换了电话号码。在接下来的几周里,他们继续沟通,一个月后系统被部署到生产服务器并面向一小群用户。
部署团队的一名成员与开发团队一起创建部署脚本,同时在 wiki 上编写安装文档。这意味着在部署时没有意外情况。在讨论和安排许多系统部署的运维团队会议上,这个系统几乎没有被讨论,因为运维团队对他们部署它的能力和软件本身的质量充满信心。
如果你的部署流程没有完全自动化,包括环境的配置,记录自动化部署流程复制或创建的所有文件是很重要的。这样,调试出现的任何问题就很容易——你确切地知道在哪里查找配置信息、日志和二进制文件。
同样,保存环境中每一件硬件的清单、在部署期间接触过的部分以及实际部署的日志也很重要。
当你进行部署时,确保保留上一个版本的副本。然后,确保在部署新版本之前清除旧文件。如果旧部署的一个杂散文件仍然留在新部署的版本中,可能会导致难以追踪的错误。最坏的情况下,如果例如旧的管理界面页面还留在原地,可能会导致数据损坏。
在 UNIX 世界中,一个好的做法是将应用程序的每个版本部署到一个新目录中,并使用指向当前版本的符号链接。部署和回滚版本只需将符号链接更改为指向先前版本即可。网络版本是将不同版本放在不同服务器上或同一服务器上的不同端口范围。使用反向代理在它们之间切换,正如我们在第261页的”蓝绿部署”部分所描述的。
“构建和部署专家”是一种反模式(antipattern)。团队的每个成员都应该知道如何部署,团队的每个成员都应该知道如何维护部署脚本。这可以通过确保每次构建软件时(即使在开发人员的机器上)都使用真实的部署脚本来实现。
部署脚本损坏应该导致构建失败。
在服务器应用程序中使用GUI曾经很常见。这在PowerBuilder和Visual Basic应用程序中尤其常见。这些应用程序通常还存在我们提到的其他问题,例如配置无法脚本化、应用程序对安装位置敏感等。但主要问题是,要使应用程序正常工作,机器必须有用户登录并显示UI界面。这意味着重启(无论是意外还是由于升级)会使用户退出登录,服务器将停止运行。然后支持工程师必须登录到机器并手动启动服务器。
在一个客户那里,有一个PowerBuilder应用程序处理一家大型商品经纪商的所有传入交易。该应用程序有GUI界面,必须每天手动启动。它还是一个单线程应用程序,如果在处理交易时发生错误,应用程序会弹出一个对话框,上面写着”错误。继续?“和一个”确定”按钮。
当这个对话框出现在屏幕上时,所有交易处理都会停止。需要交易员打来沮丧的电话,支持人员才会去查看机器,并按下”确定”按钮让处理继续。有一次,有人编写了另一个VB应用程序,其作用是监视该对话框并以编程方式单击”确定”按钮。
很久之后,当系统的其他部分得到改进时,我们发现了另一个特点。在某个阶段,该应用程序被部署在旧版本的Windows 3.x上,该系统无法可靠地关闭保存的文件。应用程序通过为每笔交易加入硬编码的五秒暂停来解决这个问题。加上单线程约束,这意味着如果同时有大量交易进入,系统将需要很长时间来处理所有交易。沮丧情绪会上升,交易员会重新将交易输入系统,导致重复条目并降低系统的可靠性。
这是在2003年。不要低估你的应用程序会被使用多长时间。
不要在预定时间开启你的eBay杀手级网站。当网站正式”上线”时,它应该已经运行了一段时间,足够让应用服务器和数据库填充缓存、建立所有连接并”预热”。
对于网站,这可以通过金丝雀发布(canary releasing)来实现。你的新服务器和新版本可以从处理一小部分请求开始,然后,当环境稳定并得到验证后,你可以将更多负载切换到新系统。
许多应用程序都有内部缓存,在部署时会急切地填充。在缓存填充完成之前,应用程序通常响应时间较差,甚至可能失败。如果你的应用程序表现如此,请确保在部署计划中记录下来,包括填充缓存所需的时间(当然你会在类生产环境中测试过)。
部署脚本应包含测试以确保部署成功。这些测试应作为部署本身的一部分运行。它们不应该是全面的单元测试,而是简单的冒烟测试,确保部署的单元正常工作。
理想情况下,系统应在初始化时执行这些检查,如果遇到错误,应无法启动。
生产环境中的大多数停机时间是由不受控制的更改引起的。生产环境应完全锁定,只有你的部署流水线可以对其进行更改。这包括从环境配置到部署在其上的应用程序及其数据的所有内容。许多组织都有严格的访问管理流程。我们见过的用于管理生产访问的方案包括通过审批流程创建的有限生命周期密码,以及需要从RSA令牌输入代码的两阶段认证系统。在一个组织中,对生产的更改只能从锁定房间内的终端授权,并有闭路电视摄像头监控屏幕。
这些授权流程应融入你的部署流水线。这样做会给你带来相当大的好处:这意味着你有一个记录生产中每次更改的系统。没有比准确记录对生产进行了哪些更改、何时进行以及由谁授权更好的审计跟踪了。部署流水线恰好提供了这样的功能。
部署流水线的后期阶段都与部署到测试和生产环境有关。这些阶段与流水线的前期阶段不同,因为后期阶段没有运行自动化测试。这意味着这些阶段不会通过或失败。但它们仍然构成流水线的组成部分。你的实现应该使得只需按一个按钮(在具有正确凭据的情况下),就可以将通过自动化测试的应用程序的任何版本部署到任何环境中。团队中的每个人都应该能够准确看到在哪里部署了什么,以及该版本包含哪些更改。
降低发布风险的最佳方法当然是对发布进行演练。应用程序发布到各种测试环境的频率越高越好。具体来说,应用程序首次发布到新测试环境的频率越高,流程就越可靠,在生产发布中遇到问题的可能性就越低。自动化部署系统应该能够从头开始配置新环境,以及更新已存在的环境。
然而,对于任何规模和复杂度的系统,首次发布到生产环境总是一个重大时刻。至关重要的是,必须充分考虑和规划这个过程,使其尽可能简单明了。无论团队有多敏捷,发布策略都是软件项目中那些做出决策的最后责任时刻不是发布前几天,甚至不是几个迭代的方面之一。这应该是规划的一部分,至少在某种程度上,从项目早期就应该影响开发决策。发布策略将会并且应该随着时间演进,随着首次发布时间的临近变得更加准确和详细。
发布规划最关键的部分是召集组织中参与交付的各个部门的代表:构建、基础设施和运维团队、开发团队、测试人员、数据库管理员和支持人员。这些人应该在整个项目生命周期中持续会面,并不断努力提高交付流程的效率。
正如我们在第1章中描述的,部署软件有三个步骤:
• 创建和管理运行应用程序的基础设施(硬件、网络、中间件和外部服务)
• 将正确版本的应用程序安装到其中
• 配置应用程序,包括它所需的任何数据或状态
本章讨论这些步骤中的第一步。由于我们的目标是所有测试环境(包括持续集成环境)都应该像生产环境一样,特别是在管理方式上,因此本章也将延伸涵盖测试环境的管理。
让我们从定义在此上下文中环境的含义开始。环境是应用程序运行所需的所有资源及其配置。以下属性描述了环境:
• 构成环境的服务器硬件配置(如CPU的数量和类型、内存容量、磁盘、网卡等)以及连接它们的网络基础设施
• 支持将在其中运行的应用程序所需的操作系统和中间件(如消息系统、应用服务器和Web服务器、数据库服务器)的配置
通用术语基础设施代表组织中的所有环境,以及支持它们的服务,如DNS服务器、防火墙、路由器、版本控制仓库、存储、监控应用程序、邮件服务器等。实际上,应用程序环境与组织其余基础设施之间的边界可能从非常明确(例如嵌入式软件的情况)到极其模糊(在面向服务架构的情况下,许多基础设施是共享的并被应用程序依赖)。
为部署准备环境并在部署后管理它们的过程是本章的主要焦点。然而,使这一切成为可能的是一种管理所有基础设施的整体方法,基于以下原则:1
• 基础设施的期望状态应该通过版本控制的配置来指定。
• 基础设施应该是自治的(autonomic)——也就是说,它应该自动纠正到期望状态。
• 你应该始终通过监测和监控了解基础设施的实际状态。
虽然基础设施应该是自治的,但同样重要的是它应该易于重建,这样在硬件故障等情况下,你可以快速重新建立一个已知良好的新配置。这意味着基础设施配置也应该是一个自动化过程。自动化配置和自治维护的结合确保了基础设施可以在故障发生时在可预测的时间内重建。
在部署到任何类生产环境时,有几件事需要仔细管理以降低风险:
• 测试和生产环境的操作系统及其配置
• 中间件软件栈及其配置,包括应用服务器、消息系统和数据库
• 基础设施软件,如版本控制仓库、目录服务和监控系统
• 外部集成点,如外部系统和服务
• 网络基础设施,包括路由器、防火墙、交换机、DNS、DHCP等
• 应用程序开发团队与基础设施管理团队之间的关系
我们将从列表的最后一项开始。在这个技术性的列举中,这一项似乎有些不合时宜。然而,如果这两个团队紧密合作解决问题,其他一切都会变得容易得多。他们应该从项目一开始就在环境管理和部署的所有方面进行协作。
对协作的关注是DevOps运动的核心原则之一,该运动旨在将敏捷方法引入系统管理和IT运维领域。该运动的另一个核心原则是敏捷技术可以有效地应用于基础设施管理。本章讨论的许多技术,如自主基础设施(autonomic infrastructure)和行为驱动监控(behavior-driven monitoring),都是由参与创立这一运动的人开发的。
在阅读本章时,请记住一个指导原则:测试环境应该与生产环境相似。这意味着它们在上面列出的大多数技术方面应该是相似的(尽管不一定完全相同)。目标是尽早发现环境问题,并在进入生产环境之前预演部署和配置等关键活动,从而降低发布风险。测试环境应该足够相似以实现这一目标。至关重要的是,管理它们的技术应该是相同的。
这种方法可能需要大量工作且成本较高,但有一些工具和技术可以提供帮助,例如虚拟化和自动化数据中心管理系统。这种方法的好处非常大,能够在开发过程的早期发现那些晦涩难以重现的配置和集成问题,你的努力将会得到数倍的回报。
最后,尽管本章假设你的应用程序的生产环境由运维团队控制,但对于软件产品来说,原则和问题是相同的。例如,尽管软件产品不一定有人定期备份其数据,但数据恢复对任何用户来说都是一个重要的关注点。这同样适用于其他非功能性需求,如可恢复性、可支持性和可审计性。
大多数项目失败是由于人的问题而不是技术问题,这是不言而喻的。在将代码部署到测试和生产环境时,这一点尤为真实。几乎所有中大型公司都将开发和基础设施管理(或通常所说的运维)活动分成不同的小组或部门。这两组利益相关者之间的关系往往不太融洽。这是因为开发团队被激励尽快交付软件,而运维团队的目标是稳定性。
最重要的是要记住,所有利益相关者都有一个共同目标:使有价值软件的发布成为一项低风险活动。根据我们的经验,实现这一目标的最佳方法是尽可能频繁地发布(因此称为持续交付)。这确保了发布之间的变化尽可能少。如果你在一个发布需要几天时间,伴随着不眠之夜和长时间工作的组织中工作,你无疑会对这个想法感到恐惧。我们的回应是,发布可以而且应该是一项可以在几分钟内完成的活动。这可能看起来不现实。然而,我们在大公司的许多大型项目中看到,发布已经从由甘特图驱动的睡眠剥夺实验变成了每天进行数次、在几分钟内完成的低风险活动。
在小型组织中,开发团队通常负责运维。然而,在大多数中大型组织中,这些是独立的小组。每个小组都有自己的汇报线:有运维主管和软件开发主管。每次生产发布时,这些团队及其管理者都会努力确保出现的任何问题不是他们的错。这显然是小组之间紧张关系的潜在原因。每个小组都想最小化部署风险,但每个小组都有自己的方法。
运维团队通过关键的服务质量指标来衡量其有效性,例如平均故障间隔时间(MTBF)和平均故障修复时间(MTTR)。运维团队通常需要满足服务级别协议(SLA)。任何变更,包括流程变更,只要影响运维团队满足这些目标和其他目标(如符合法律法规)的能力,就代表着风险。在此背景下,以下是运维团队最重要的一些高层次关注点。
运维管理者希望确保对他们控制的任何环境的任何变更都被记录和审计,这样,如果出现问题,他们可以找到导致问题的相关变更。
运维管理者关注其跟踪变更能力还有其他原因,例如,符合萨班斯-奥克斯利法案(Sarbanes-Oxley)(旨在鼓励良好企业审计和责任的美国立法),以及确保环境保持一致的愿望。但主要是为了让他们能够找出在环境的最后已知良好状态和任何故障之间发生了什么。
组织实施的最重要流程之一是变更管理流程(Change Management Process),用于管理对任何受控环境的每一项变更——运维团队通常会同时控制生产环境和类生产测试环境。这通常意味着,任何人想对任何测试或生产环境进行变更时,都必须提交变更请求。许多类型的低风险配置变更可以由运维团队自行完成(在ITIL中,这些被称为”标准”变更)。
然而,部署应用程序的新版本通常属于”常规”变更,需要变更管理经理(Change Manager)在变更咨询委员会(CAB, Change Advisory Board)的建议下批准。变更请求需要包含变更的风险和影响的详细信息,以及变更失败时的补救措施。请求应在开始新版本部署工作之前提交,而不是在业务期望上线前几个小时才提交。第一次经历这个流程时,预计会被问很多问题。
软件开发团队成员有责任熟悉运维团队实施的任何此类系统和流程,并遵守它们。识别发布软件需要遵循的程序应该是开发团队发布计划的一部分。
运维管理人员会部署系统来监控他们的基础设施和运行的应用程序,并希望在他们管理的任何系统发生异常情况时收到警报,以便能够最大限度地减少停机时间。
每个运维团队都有某种方式监控他们的生产环境。他们可能使用OpenNMS,或者Nagios或HP Operations Manager等替代方案。也许他们创建了自己的定制监控系统。无论他们使用哪个系统,他们都希望你的应用程序能够接入该系统,以便在发生任何错误情况时立即知晓,并知道在哪里查找更多细节以确定出了什么问题。
在项目开始时就了解运维团队期望如何监控你的应用程序,并将其纳入发布计划,这一点非常重要。他们想监控什么?他们期望你的日志在哪里?你的应用程序应该使用什么钩子来通知运维人员故障?
例如,缺乏经验的开发人员最常犯的编码错误之一是吞噬错误。与运维团队的快速沟通应该能让你认识到,将每个错误情况记录到一个众所周知的单一位置,并标注适当的严重性级别是必要的,这样他们才能准确知道问题所在。由此推论,如果你的应用程序因某种原因失败,运维人员应该能够轻松地重启或重新部署它。
同样,确定运维团队的监控需求并将其纳入发布计划是开发团队的责任。解决这些需求的最佳方法是像对待任何其他需求一样对待它们。从运维人员的角度积极考虑应用程序的使用——他们是重要的用户群体。在首次发布临近时,你需要在发布计划中更新重启和重新部署应用程序的程序。
首次发布只是任何应用程序生命周期的开始。应用程序的每个新版本都会有不同的表现,包括产生的错误类型和日志消息,以及可能的监控方式。它也可能以新的方式失败。当你发布应用程序的新版本时,让运维人员了解情况非常重要,这样他们才能为这些变更做好准备。
运维管理人员将参与创建、实施、测试和维护组织的IT服务连续性计划(IT Service Continuity Plan)。运维团队管理的每项服务都有一个恢复点目标(RPO, Recovery Point Objective)——衡量灾难发生前可接受数据丢失的时间长度,以及一个恢复时间目标(RTO, Recovery Time Objective)——恢复服务前允许的最长时间。
RPO决定了数据备份和恢复策略,因为数据备份频率必须足够高才能实现RPO。当然,没有应用程序操作数据以及数据所在的环境和基础设施,数据是没有用的,因此你需要能够重新部署应用程序的正确版本及其环境和基础设施。这反过来意味着,所有这些内容都必须经过仔细的配置管理,以便运维团队能够重现它们。
为了满足业务期望的RTO,可能需要在第二个位置建立生产环境和基础设施的副本,以便在主系统故障时使用。应用程序应该能够应对这种情况。对于高可用性应用程序,这意味着在应用程序运行时复制数据和配置。
一个相关的需求是归档:应用程序在生产环境中生成的数据量可能很快变得非常大。应该有一些简单的方法来归档生产数据,以便在不占满磁盘或降低应用程序速度的情况下,将其保留用于审计或支持目的。
作为业务连续性测试的一部分,你应该测试过应用程序数据的备份、恢复和归档,以及检索和部署应用程序任何给定版本的操作,并向运维团队提供执行每项活动的流程,作为发布计划的一部分。
运维经理希望使用他们团队熟悉的技术来对环境进行变更,这样他们才能拥有并维护自己的环境。
运维团队通常精通 Bash 或 PowerShell,但不太可能是 Java 或 C# 专家。然而,几乎可以肯定的是,他们希望审查对环境和基础设施配置所做的变更。如果运维团队无法理解部署过程,因为它使用了他们不熟悉的技术和语言,那么进行变更的风险必然会增加。运维团队可能会否决他们没有维护技能的部署系统。
开发团队和运维团队应该在每个项目开始时坐下来,决定如何执行应用程序的部署。可能需要运维团队或软件开发团队学习商定的技术——也许是像 Perl、Ruby 或 Python 这样的脚本语言,或者像 Debian 打包系统或 WiX 这样的打包技术。
两个团队都理解部署系统很重要,因为必须使用相同的流程将变更部署到每个环境——开发、持续集成、测试和生产环境——而开发人员最初将负责创建它们。在某个时候,它们将被移交给运维团队,运维团队将负责维护它们,这意味着他们应该从一开始就参与编写。用于部署和对环境及基础设施进行其他变更的技术应该成为发布计划的一部分。
部署系统构成应用程序的一个组成部分——它应该像应用程序的其余部分一样被测试和重构,并保存在版本控制中。如果不是这样(我们看到许多项目都不是这样),结果总是一组测试不足、脆弱且理解不清的脚本,使变更管理变得有风险和痛苦。
除了干系人管理之外,本章的其他所有内容都可以广泛地视为配置管理的一个分支。然而,在测试和生产环境中实施完整的配置管理并非易事,这解释了我们为这个主题投入的大量篇幅。即便如此,我们也只会涵盖环境和基础设施管理的高层原则。
图 11.1 服务器类型及其配置
在任何环境中都有许多不同类别的配置信息在起作用,所有这些都应该以自动化的方式进行配置和管理。图 11.1 显示了一些服务器类型的示例,按抽象级别划分。
如果您完全控制正在创建的系统的技术选择,您应该在采购和启动过程中询问,自动化硬件和软件基础设施本身的部署和配置有多容易。拥有可以以自动化方式配置和部署的底层技术,是自动化系统集成、测试和部署流程的必要条件。
即使您无法控制基础设施的选择,如果您打算完全自动化构建、集成、测试和部署,也必须解决以下每个问题:
• 我们将如何配置基础设施?
• 我们将如何部署和配置构成基础设施一部分的各种软件?
• 基础设施配置完成后,我们如何管理它?
现代操作系统有数千种方式可以使一个安装与另一个安装不同:不同的设备驱动程序、不同的系统配置设置,以及大量会影响软件运行方式的参数。有些软件系统比其他系统更能容忍这个级别的差异。大多数商业现货软件(COTS)预期在各种软件和硬件配置中运行,因此不应该太在意这个级别的差异——尽管您应该始终在采购或升级过程中检查 COTS 的系统要求。然而,高性能的 Web 应用程序可能对即使是微小的变化也很敏感,例如数据包大小或文件系统配置的变化。
对于大多数在服务器上运行的多用户应用程序来说,简单地接受操作系统和中间件的默认设置是不合适的。操作系统需要配置访问控制、防火墙和其他加固措施(例如禁用非必要服务)。数据库需要配置并设置具有正确权限的用户,应用服务器需要部署组件,消息代理需要定义消息并注册订阅,等等。
与交付流程的其他方面一样,您应该将创建和维护基础设施所需的所有内容保存在版本控制下。至少,这意味着:
• 操作系统安装定义(例如 Debian Preseed、RedHat Kickstart 和 Solaris Jumpstart 使用的定义)
• 数据中心自动化工具(如 Puppet 或 CfEngine)的配置
版本控制中的这些文件与源代码一样,作为部署流水线的输入。在基础设施变更的情况下,部署流水线的工作有三个方面。首先,它应该在推送到生产环境之前验证所有应用程序是否能够与任何基础设施变更正常工作,确保每个受影响的应用程序的功能和非功能测试都能通过新版本的基础设施。其次,它应该用于将变更推送到运维管理的测试和生产环境。最后,流水线应该执行部署测试以确保新的基础设施配置已成功部署。
回顾图11.1,值得注意的是,用于部署和配置应用程序、服务和组件的脚本和工具通常与用于配置和管理其余基础设施的脚本和工具是不同的。有时,为部署应用程序创建的流程也会执行部署和配置中间件的任务。这些部署流程通常由负责相关应用程序的开发团队创建,但它们当然隐式依赖于其余基础设施已就位并处于正确状态。
处理基础设施时的一个重要考虑因素是共享程度。如果某个基础设施配置仅与特定应用程序相关,那么它应该是该应用程序部署流水线的一部分,并且没有自己独立的生命周期。但是,如果某些基础设施在应用程序之间共享,那么你就面临管理应用程序与它们所依赖的基础设施版本之间依赖关系的问题。这意味着需要记录每个版本的应用程序需要哪个版本的基础设施才能正常工作。然后你需要建立一个单独的流水线来推送基础设施变更,确保影响多个应用程序的变更以遵守依赖规则的方式通过交付流程。
如果你的组织规模小或刚成立,你有机会为所有基础设施的配置管理设计一个策略。如果你有一个现有系统没有得到良好控制,你需要找出如何控制它。这包括三个部分:
虽然我们通常不赞成锁定事物和建立审批流程,但在涉及生产基础设施时这是必不可少的。作为推论,由于我们认为你应该以对待生产环境的方式对待测试环境,同样的流程应该适用于两者。
锁定生产环境以防止未经授权的访问不仅来自组织外部的人,也来自内部的人——甚至运维人员,这一点至关重要。否则,当出现问题时,登录到相关环境并四处探查以解决问题(这个过程有时被礼貌地称为”问题解决启发式方法”)就太诱人了。这几乎总是一个糟糕的主意,原因有二。首先,它通常会导致服务中断(人们倾向于随机尝试重启或应用服务包)。其次,如果以后出现问题,没有记录谁在何时做了什么,这意味着无法找出你所面临的任何问题的原因。在这种情况下,你不如从头开始重新创建环境,使其处于已知状态。
如果你的基础设施无法通过自动化流程从头开始重新创建,首先要做的是实施访问控制,使任何对基础设施的变更都必须经过审批流程。《Visible Ops手册》称之为”稳定患者”。这无疑会引起很多烦恼,但这是下一步的先决条件:创建一个管理基础设施的自动化流程。如果不关闭访问,运维人员最终会把所有时间都花在救火上,因为计划外的变更总是会破坏事物。设定何时完成工作的期望并实施访问控制的一个好方法是创建维护窗口。
对生产和测试环境进行变更的请求应该经过变更管理流程。这不需要官僚化:正如《Visible Ops手册》中指出的,许多在MTBF(平均故障间隔时间)和MTTR(平均修复时间)方面表现最好的组织”每周进行1000-1500次变更,变更成功率超过99%“。
然而,对测试环境的变更批准当然应该比生产变更的批准更容易获得。通常,对生产环境的变更必须得到部门负责人或CTO的批准(取决于组织的规模及其监管环境)。然而,大多数CTO如果被要求批准对UAT环境的变更会感到不满。重要的是,你对测试环境经过的流程与对生产环境的流程相同。
当然,有时候对基础设施进行变更是必要的。一个有效的变更管理流程应具备以下几个关键特征:
• 每一个变更,无论是更新防火墙规则还是部署旗舰服务的新版本,都应遵循相同的变更管理流程。
• 该流程应通过单一的工单系统进行管理,所有人都能登录使用,并能生成有用的指标,如每个变更的平均周期时间。
• 所做的具体变更应被记录下来,以便日后轻松审计。
• 应能够查看每个环境的变更历史记录,包括部署历史。
• 你想进行的变更应首先在类生产环境的测试环境中进行测试,并运行自动化测试以确保不会破坏任何使用该环境的应用程序。
• 变更应提交到版本控制系统,然后通过自动化流程部署基础设施变更。
• 应有测试来验证变更是否生效。
创建从版本控制系统自动部署基础设施变更的流程是良好变更管理的核心。最有效的方法是要求通过中央系统对环境进行所有变更。使用测试环境制定你想要进行的变更,在全新的类生产环境的预发布环境中测试,将其纳入配置管理以便未来重建时包含该变更,获得批准后由自动化系统推出变更。许多组织已经构建了自己的解决方案,但如果你还没有,可以使用数据中心自动化工具,如 Puppet、CfEngine、BladeLogic、Tivoli 或 HP Operations Center。
强制执行可审计性的最佳方法是通过自动化脚本执行所有变更,这些脚本可以在日后需要查明具体操作时被引用。通常,出于这个原因我们更倾向于自动化而非文档。书面文档永远无法保证记录的变更被正确执行,而某人声称所做的和实际所做的之间的差异足以导致可能需要数小时或数天才能追踪到的问题。
在小型甚至中型运维中,服务器配置和供应管理常常被忽视,原因很简单——这看起来很复杂。几乎每个人启动和运行服务器的最初经验都来自于插入安装介质,放入计算机,进行交互式安装,然后进行不受控制的配置管理过程。然而,这很快会导致服务器成为”艺术品”,进而导致服务器之间行为不一致,以及在发生故障时无法轻松重建系统。此外,配置新服务器是一个手动、重复、资源密集且容易出错的过程——这正是可以通过自动化解决的问题类型。
图 11.2 服务器的自动化配置和供应
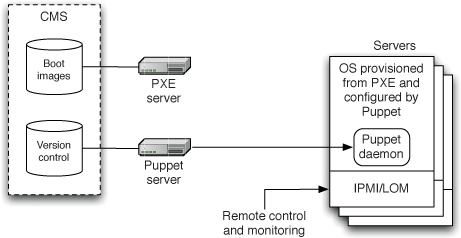
从高层次来看,配置服务器——无论是用于测试还是生产环境——始于将新机器放入数据中心并接线。完成后,其生命周期的几乎每个部分,包括首次开机,都可以通过完全自动化的方式远程完成。你可以使用带外管理系统(out-of-band management)如 IPMI 或 LOM 来打开机器,通过 PXE(如下所述)网络启动安装基础操作系统,其中应包含数据中心管理工具的代理。然后数据中心管理工具(下图中的 Puppet)从此管理该机器的配置。这个完全自动化的流程如图 11.2 所示。
创建操作系统基线有几种方法:
• 完全手动流程
• 自动化远程安装
• 虚拟化
我们不会考虑完全手动流程,只需注意它不是可靠可重复的,因此无法扩展。然而,开发团队通常是这样管理他们的环境的。开发人员工作站甚至开发团队管理的持续集成环境往往是长期积累了大量冗余内容的”艺术品”。这些环境与应用程序实际运行的环境毫无关系。这本身可能是效率低下的巨大来源。实际上,这些系统应该以管理测试和生产环境的相同方式进行管理。
作为创建操作系统基线和管理环境方式的虚拟化将在后面的”虚拟化”章节(第 303 页)中讨论。
自动化远程安装是接收新物理机器并使其运行的最佳选择(即使你计划稍后将其用作虚拟主机)。最好的起点是 PXE(Preboot eXecution Environment,预启动执行环境)或 Windows Deployment Services。
PXE 是一个通过以太网启动系统的标准。当你在 BIOS 中选择通过网络启动时,底层发生的就是 PXE。该协议使用修改版的 DHCP 来查找提供启动镜像的服务器。当用户选择要启动的镜像后,客户端通过 TFTP 将相应的镜像加载到 RAM 中。标准的 Internet Services Consortium DHCP 服务器 dhcpd,随所有 Linux 发行版一起提供,可以配置为提供 PXE 服务,然后你需要配置一个 TFTP 服务器来提供实际的镜像。如果你使用 RedHat,一个名为 Cobbler 的应用程序将通过 PXE 提供一系列 Linux 操作系统镜像。它还可以让你(如果你运行的是 RedHat 系统)使用所选的操作系统镜像创建新的虚拟机。Hudson 还有一个提供 PXE 服务的插件。BMC 的 BladeLogic 包含一个 PXE 服务器。
几乎所有常见的 UNIX 版本都提供适合 PXE 的镜像。当然你也可以创建自己的自定义镜像——RedHat 和 Debian 的包管理系统都允许你将已安装系统的状态保存到一个文件中,然后可以用来初始化其他系统。
一旦配置好基础系统,你就需要对其进行配置。一种方法是使用操作系统的无人值守安装过程:RedHat 的 Kickstart、Debian 的 Preseed 或 Solaris 的 Jumpstart。这些可以用于执行安装后活动,例如安装操作系统补丁和决定运行哪些守护进程(daemon)。安装后的下一步是在系统上安装基础设施管理系统的代理(agent),然后让这些工具从此管理操作系统的配置。
Windows 中 PXE 的类似物称为 Windows Deployment Services——实际上,它底层使用的就是 PXE。WDS 包含在 Windows Server 2008 企业版中,也可以安装在 Windows Server 2003 上。它可以用于启动从 Windows 2000 及以后的 Windows 版本(不包括 ME)——尽管从 Vista 开始,流程已经大大简化。要使用 WDS,你需要一个 ActiveDirectory 域、一个 DHCP 服务器和一个 DNS 服务器。然后你可以安装(如果需要)并启用 WDS。要在 WDS 中设置一个用于启动的配置文件,你需要两样东西:一个启动镜像和一个安装镜像。启动镜像是 PXE 加载到 RAM 中的内容——在 Windows 的情况下,这是一个名为 WinPE(Windows 预安装环境)的软件,这是你启动 Vista(或更高版本)安装 DVD 时运行的程序。安装镜像是启动镜像加载到你的机器上的实际完整安装镜像。从 Vista 开始,这两个镜像都可以在安装 DVD 的 Sources 目录中找到,分别是 BOOT.WIM 和 INSTALL.WIM。有了这两个文件,WDS 将完成所有必要的配置,使它们可以通过网络启动。
你还可以为 WDS 创建自己的自定义安装镜像。最简单的方法是使用 Microsoft Hyper-V,如 Ben Armstrong [9EQDL4] 所述。只需基于你想要创建镜像的操作系统启动一个虚拟机。按照你想要的方式配置它,在上面运行 Sysprep,然后使用 ImageX 将驱动器镜像转换为可以在 WDS 中注册的 WIM 文件。
一旦安装了操作系统,你需要确保其配置不会以不受控制的方式更改。这意味着首先要确保除了运维团队之外没有人能够登录系统,其次要确保任何更改都使用自动化系统执行。这包括应用操作系统服务包、升级、安装新软件、更改设置或执行部署。
配置管理流程的目标是确保配置管理是声明式(declarative)和幂等(idempotent)的——这意味着你配置基础设施的期望状态,然后由系统确保应用此配置,这样无论基础设施的初始状态如何,最终结果都是相同的,即使重新应用相同的配置也是如此。这在 Windows 和 UNIX 世界中都是可能的。
一旦这个系统就位,就可以从一个集中的、版本控制的配置管理系统管理基础设施中的所有测试和生产环境。然后你可以获得以下好处:
• 你可以确保所有环境的一致性。
• 你可以轻松配置与现有环境配置匹配的新环境,例如创建与生产环境匹配的预发布(staging)环境。
• 如果你的某台服务器出现硬件故障,你可以放入一台新服务器,并使用完全自动化的流程将其配置成与旧服务器相同的方式。
在我们的一个项目中,生产环境的部署神秘地失败了。部署脚本只是挂起。我们将问题追踪到生产服务器上的登录 shell 设置为 sh,而预发布服务器上设置为 bash。这意味着当我们试图在生产环境上分离一个进程时,我们无法做到。这是一个简单的问题,但只有一个灵感的猜测才阻止了我们回滚部署。这种微妙的差异可能比这更难发现;全面的配置管理至关重要。
在 Windows 平台上,微软除了提供 Windows Deployment Services 之外,还提供了一个用于管理微软基础设施的解决方案:System Center Configuration Manager。SCCM 使用 ActiveDirectory 和 Windows Software Update Services 来管理操作系统配置,包括组织中每台机器的更新和设置。你也可以使用 SCCM 部署应用程序。SCCM 还能与微软的虚拟化技术通信,允许你用管理物理服务器的方式来管理虚拟服务器。访问控制通过 Group Policy 来管理,它与 ActiveDirectory 集成,并内置于 Windows 2000 之后的所有微软服务器中。
回到 UNIX 世界,LDAP 与常规的 UNIX 访问控制配合使用,来控制谁可以在哪些机器上做什么。有许多解决方案用于持续管理操作系统配置,包括安装哪些软件和更新。最流行的可能是 CfEngine、Puppet 和 Chef,但也存在其他几个类似的工具,如 Bcfg2 和 LCFG。在撰写本文时,唯一支持 Windows 的此类工具是 WPKG,它不支持 UNIX 平台。不过,Puppet 和 Chef 都在进行添加 Windows 支持的工作。另外值得一提的是出色的 Marionette Collective(简称 mcollective),这是一个使用消息总线来查询和管理大量服务器的工具。它有插件可以远程控制其他服务,并且可以与 Puppet 和 Facter 通信。
另一种选择是,正如你所预期的,有强大而昂贵的商业工具来管理你的服务器基础设施。除了微软,主要的厂商包括 BMC 的 BladeLogic 套件、IBM 的 Tivoli,以及 HP 的 Operations Center 套件。
所有这些工具——无论是开源的还是商业的——都以类似的方式运作。你指定希望机器达到的状态,工具确保你的基础设施处于指定的状态。这是通过在每台机器上运行代理(agent)来实现的,代理获取配置并修改其他机器的状态以匹配它,执行诸如安装软件和进行配置更改等任务。这类系统的关键特性是它们实现幂等性(idempotence)——也就是说,无论代理发现机器处于什么状态,无论代理应用配置多少次,机器最终都会达到期望的最终状态。简而言之,你只需指定期望的最终状态,启动工具,它就会持续进行适当的调整。这实现了使你的基础设施自主化(autonomic)的更高目标——换句话说,就是自我修复。
你应该能够获取一组原始的服务器,并从头开始将所有东西部署到它们上面。实际上,将自动化或虚拟化引入你的构建、部署、测试和发布策略的一个好方法是,将其作为环境配置流程的一个测试。一个值得提出并测试的好问题是:如果我的生产环境发生灾难性故障,配置一个新的生产环境副本需要多长时间?
对于大多数开源工具,你的环境配置信息以一系列文本文件的形式存储,可以保存在版本控制中。这反过来意味着你的基础设施配置是自文档化的——你只需查看版本控制就能看到其当前的预期状态。商业工具通常包含数据库来管理配置信息,并提供可视化界面来编辑它。
我们将更详细地介绍 Puppet,因为它是目前最流行的开源系统之一(与 CfEngine 和 Chef 并列)。其他工具的基本原理是相同的。Puppet 通过一种声明式的、外部的领域特定语言(DSL)来管理配置,该语言专门用于配置信息。这允许进行复杂的企业级配置,将通用模式提取为可共享的模块。因此你可以避免重复配置信息。
Puppet 配置由一个中央主服务器管理。该服务器运行 Puppet 主守护进程(puppetmasterd),它有一个受其控制的机器列表。每台受控机器运行 Puppet 代理(puppetd)。它与服务器通信,以确保 Puppet 控制下的服务器与配置的最新版本同步。
Matthias Marschall 描述了如何使用测试驱动的方法对你的环境进行变更。思路是这样的:
在你的监控系统中,编写一个服务来监控你要解决的问题,并确保该服务在你的仪表板上显示红色。
实施配置变更,让 Puppet 将其推送到你的测试系统。
一旦该服务在你的仪表板上显示绿色,就让 Puppet 将变更推送到生产环境。
当配置发生变化时,Puppetmaster 会将该变化传播到所有需要更新的客户端,安装和配置新软件,并在必要时重启服务器。配置是声明式的,描述了每台服务器的期望最终状态。这意味着它们可以从任何起始状态进行配置,包括虚拟机的全新副本或新配置的机器。
这种方法的强大之处从一个例子中就能看出来。
Ajey 正在为一家全球 IT 咨询公司维护大量服务器。这些服务器分布在班加罗尔、北京、悉尼、芝加哥和伦敦的机房中。
他登录变更管理工单系统,看到某个项目团队提交了一个新的 UAT 环境请求。他们即将进入最新版本的 UAT 流程,并将继续在主干上开发新功能。新环境需要三台机器,Ajey 很快找到了三台符合规格要求的服务器。由于该项目已经有一个测试环境,他可以直接重用该环境的定义。
他在 Puppet master 的定义中添加了三行,并将文件检入源代码控制系统。Puppet master 捕获到变更并配置这些机器,完成后会向 Ajey 发送邮件。Ajey 关闭工单,并在评论中添加机器名称和 IP 地址。工单系统向团队发送邮件,告知他们环境已经准备就绪。
让我们以安装 Postfix 为例来说明如何使用 Puppet。我们将编写一个模块来定义如何在邮件服务器上配置 Postfix。模块由清单(manifest)以及可选的模板和其他文件组成。我们将创建一个名为 postfix 的新模块来存放新清单,该清单定义了 Postfix 的安装方式。这意味着要在模块根目录(/etc/puppet/modules)下创建一个名为 postfix/manifests 的目录,并在那里创建一个名为 init.pp 的清单文件:
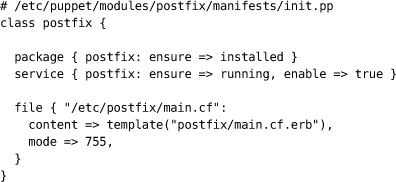
该文件定义了一个描述如何安装 Postfix 的类。package 语句确保安装 postfix 软件包。Puppet 可以与所有流行的打包系统通信,包括 Yum、Aptitude、RPM、Dpkg、Sun 的包管理器、Ruby Gems,以及 BSD 和 Darwin ports。service 语句确保 Postfix 服务已启用并正在运行。file 语句在服务器上创建 /etc/postfix/main.cf 文件,内容来自一个 erb 模板。erb 模板从 Puppetmaster 文件系统上的 /etc/puppet/modules/[module name]/templates 获取,因此你需要在 /etc/puppet/modules/postfix/templates 中创建 main.cf.erb 文件。
哪些清单应用于哪些主机是在 Puppet 的主 site.pp 文件中定义的:
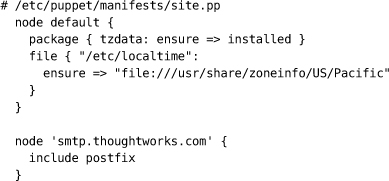
在这个文件中,我们告诉 Puppet 将 Postfix 清单应用于主机 smtp.thoughtworks.com。还有一个默认节点的定义,它会应用于每台安装了 Puppet 的服务器。我们使用这个目标来确保所有服务器都设置为太平洋时区(这个语法创建一个符号链接)。
这里有一个更高级的例子。在许多组织中,将应用程序打包并存储在组织的包服务器上是有意义的。但是,你不想手动配置每台服务器来访问组织的包服务器。在这个例子中,我们让 Puppet 告诉服务器我们自定义 Apt 仓库的位置,将正确的 Apt GPG 密钥添加到这些服务器上,并添加一个 crontab 条目在每天午夜运行 Apt 更新。

主 apt 类首先检查应用清单的节点是否运行 Debian。这是使用客户端事实(fact)的一个例子—变量 $operatingsystem 是基于 Puppet 对客户端了解的几个自动预定义变量之一。在命令行运行 facter 可以列出 Puppet 已知的所有事实。然后我们将文件 custom-repository 从 Puppet 的内部文件服务器复制到服务器上的正确位置,并在 root 的 crontab 中添加一个条目,每晚运行 apt-get update。crontab 操作是幂等的(idempotent)—也就是说,如果条目已存在,不会重新创建。apt::key 定义从 Puppet 的文件服务器复制 GPG 密钥,并对其运行 apt-key add 命令。我们通过告诉命令在 Apt 已经知道该密钥时不要运行来确保幂等性(这是 unless 行)。
你需要确保定义自定义 Apt 仓库的文件 custom-repository 和包含其 GPG 密钥的文件 custom-repository-gpgkey 放置在 Puppet master 服务器的 /etc/puppet/modules/apt/files 目录中。然后,按如下方式包含定义,替换为正确的密钥 ID:
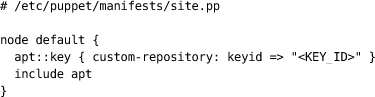
请注意,Puppet 设计为与版本控制配合使用:/etc/puppet 下的所有内容都应该保存在版本控制系统中,并且只能通过版本控制进行更改。
一旦操作系统的配置得到妥善管理,你需要考虑其上运行的中间件的管理。中间件—无论是 Web 服务器、消息系统还是商业现成软件(COTS, Commercial Off-The-Shelf)—都可以分解为三个部分:二进制文件、配置和数据。这三者有不同的生命周期,因此独立处理它们很重要。
数据库模式、Web 服务器配置文件、应用服务器配置信息、消息队列配置,以及系统运行所需更改的其他各个方面都应该纳入版本控制。
对于大多数系统来说,操作系统和中间件之间的区别是相当模糊的。例如,如果你使用基于 Linux 的开源技术栈,几乎所有中间件都可以像管理操作系统一样进行管理,使用 Puppet 或其他类似工具。在这种情况下,你不需要做任何特殊的事情来管理中间件。只需遵循与前一节中 Postfix 示例相同的模式来管理其余的中间件:告诉 Puppet 确保安装正确的软件包,并从 Puppet 主服务器上的模板更新配置,这些模板已签入版本控制。添加新网站和新组件等操作也可以通过这种方式进行管理。在 Microsoft 环境中,你可以使用 System Center Configuration Manager,或者像 BladeLogic 或 Operations Center 这样的商业工具。
如果你的中间件不是标准操作系统安装的一部分,次优的做法是使用操作系统的包管理系统将其打包,并放在组织的内部包服务器上。然后你可以使用选择的服务器管理系统以相同的模式管理这个中间件。
然而,有些中间件不适合这种处理方式——通常是那些在设计时没有考虑脚本化和静默安装的中间件。我们将在下一节中解决这种情况。
我们参与过的一个大型项目有许多不同的测试和生产环境。我们的应用程序由一个知名的商业 Java 应用服务器托管。每个服务器都是使用应用服务器提供的管理控制台手动配置的。每个都不相同。
我们有一个专门的团队来维护这些配置。当我们需要将应用程序部署到新环境时,需要进行规划以确保硬件就绪、配置操作系统、部署应用服务器、配置它、部署应用程序,然后手动测试以确认其工作正常。整个过程对于一个新环境需要几天时间,而仅部署新版本的软件就至少需要一天。
我们尝试在文档中详细说明手动步骤,花费大量精力来捕获和记录理想的配置,但仍然存在细微差异。我们经常在一个环境中遇到无法在另一个环境中重现的错误。在某些情况下,我们仍然不知道为什么。
为了解决这个问题,我们将应用服务器的安装目录放入源代码控制中。然后我们编写了一个脚本,从源代码控制中检出它,并远程复制到我们选择的环境中的正确位置。
我们还记录了它存储配置的位置。我们在一个单独的版本控制仓库中为每个需要部署的环境创建了一个目录。在每个环境的目录中,我们放置了与该环境相关的应用服务器配置文件。
我们的自动化部署流程运行脚本部署应用服务器的二进制文件,检出与我们要部署的环境相关的配置文件,并将其复制到文件系统上的相关位置。事实证明,这个过程作为设置应用服务器部署的方法是稳健、可靠和可重复的。
我们在前面侧边栏中描述的项目是几年前完成的。如果我们现在开始这个项目,我们会在一开始就更加小心地管理与各种测试和生产环境相关的配置信息。我们还会在项目早期进行必要的工作,尽可能消除这个过程中的手动步骤,为每个人节省大量工作。
与中间件相关的配置信息与用你喜欢的编程语言编写的程序一样,都是系统的一部分。许多现代中间件支持脚本化的配置方法:XML 配置很常见,有些还提供适合脚本化的简单命令行工具。学习并利用这些功能。像对系统中所有其他代码进行版本控制一样,对这些文件进行版本控制。
如果你有选择,请选择具有这些功能的中间件。根据我们的经验,这些功能比最炫的管理工具甚至最新级别的标准合规性都要重要得多。
遗憾的是,仍然有许多(通常很昂贵的)中间件产品,虽然旨在提供”企业级服务”,但在部署和配置管理的便捷性方面却不尽如人意。根据我们的经验,项目的成功往往取决于其能否干净可靠地部署。
在我们看来,除非技术能够以自动化方式进行部署和配置,否则不能被视为真正的企业就绪(enterprise-ready)。如果你无法将重要的配置信息保存在版本化存储中,从而以受控的方式管理变更,那么该技术将成为交付高质量结果的障碍。我们过去多次因此而吃过苦头。
当凌晨两点,你需要将一个关键的错误修复发送到生产环境时,在基于 GUI 的配置工具中输入数据时很容易出错。正是在这样的时候,自动化部署程序会拯救你。
通常,开源系统和组件在可脚本化配置方面处于领先地位。因此,针对基础设施问题的开源解决方案通常易于管理和集成。令人失望的是,软件行业的某些部分采取了不同的观点。我们经常被要求参与一些项目,而在这些项目中我们没有自由选择权。那么,当在你精心设计的模块化、可配置、版本化、自动化的构建和部署流程中遇到一个庞大的单体系统时,应该采用什么策略呢?
在寻找低成本、低能耗解决方案时,显而易见的起点是绝对确定所讨论的产品没有一个宣传不足的自动化配置选项。仔细阅读文档,专门寻找此类选项,在网上搜索建议,与产品的支持代表交谈,查看论坛或群组。简而言之,在转向下面描述的其他策略之前,确保没有更好的选择。
奇怪的是,我们发现产品支持途径的帮助出乎意料地小。毕竟,我们要求的只是能够对我们在其产品中投入的工作进行版本控制。我们从一家大型供应商那里得到的最喜欢的回复是:“哦,是的,我们将在下下个版本中将我们自己的版本控制构建到系统中。”即使他们真的这样做了,即使在一两年后拥有该功能可以对我们当时正在进行的项目产生任何影响,集成到一个粗糙的专有版本控制系统也无法帮助我们管理一致的配置集。
如果你确定中间件不支持任何形式的自动化配置,下一步是看看能否通过在其背后对其存储进行版本控制来作弊。如今,许多产品使用XML文件来存储其配置信息。这些文件与现代版本控制系统配合得非常好,几乎没有问题。如果第三方系统将其状态存储在二进制文件中,请考虑对这些二进制文件进行修订控制。随着开发的进展,它们通常会频繁更改。
在大多数情况下,当使用任何类型的平面文件向产品提供配置信息时,你将面临的主要问题是产品如何以及何时读取相关的配置信息。在少数自动化友好的情况下,只需将文件的新版本复制到正确位置即可。如果这样做有效,你可以更进一步,将产品的二进制文件与其配置分离。在这种情况下,有必要对安装过程进行逆向工程,并且基本上编写你自己的安装程序。你需要查看应用程序将其二进制文件和库安装在何处。
然后你有两个选择。最简单的选择是将相关的二进制文件与将它们安装到相关环境的脚本一起存储在版本控制中。选项二是真正着手编写你自己的安装程序(或者如果你使用的是基于RedHat的Linux发行版,则创建RPM等包)。创建RPM(或其他安装程序)并不那么困难,根据你的情况,这可能非常值得。然后,你可以使用安装程序将产品部署到新环境,并从版本控制应用配置。
一些产品使用数据库来存储其配置信息。这些产品通常具有复杂的管理控制台,隐藏了它们存储的信息的复杂性。这些产品给自动化环境管理带来了特殊的困难。你基本上必须将数据库视为一个blob(二进制大对象)。但是,你的供应商至少应该提供备份和恢复数据库的说明。如果是这样,你肯定应该创建一个自动化流程来执行此操作。然后可能可以进行备份,弄清楚如何操作其数据,然后使用你的更改将其恢复回去。
我们在这里讨论的许多产品都以一种或另一种形式支持编程接口。有些可能允许你充分配置系统以满足你的需求。一种策略是为你正在使用的系统定义你自己的简单配置文件。创建自定义构建任务来解释这些脚本并使用API来配置系统。这种”发明你自己的”配置文件的策略将配置管理重新掌握在你手中—允许你对配置文件进行版本控制并自动化其使用。微软的IIS是我们过去使用这种方法的一个系统,使用其XML metabase(元数据库)。但是,较新版本的IIS允许通过PowerShell进行脚本编写。
从理论上讲,你可以尝试一些其他方法—例如,创建你自己的版本控制友好的配置信息,并编写代码通过任何可能的方式将其映射到产品的本地配置中,例如通过管理控制台回放用户交互或对数据库结构进行逆向工程。实际上,我们还没有达到这一点。我们有几次接近了,但通常会找到允许我们做我们需要做的事情的API。
虽然可以对基础设施产品的二进制文件格式甚至数据库模式进行逆向工程,但你应该检查这样做是否会违反许可协议条款。如果你发现自己处于这种极端情况,值得询问供应商是否可以提供帮助,也许可以提出分享你开发的任何技术,作为回报为他们提供一些好处。一些供应商(特别是规模较小的供应商)在这类事情上相当开明,所以值得一试。然而,由于支持此类解决方案的难度,许多供应商不会感兴趣。如果是这样,此时我们强烈建议采用更易处理的替代技术。
许多组织对更换他们使用的软件平台持谨慎态度,因为他们已经在上面投入了大量资金。然而,这种论点被称为沉没成本谬误(sunk cost fallacy),它没有考虑到迁移到更优秀技术所带来的机会成本损失。试着让足够高层的人员或友好的审计师理解你正在遭受的效率损失所带来的财务影响,并让他们投资于更优秀的替代方案。在我们的一个项目中,我们保留了一个”痛苦登记簿”,记录因低效技术而损失的时间,一个月后就轻松证明了在减慢交付速度的技术上挣扎的成本。
基础设施服务(如路由器、DNS和目录服务)出现问题,导致在部署流水线中完美运行的软件在生产环境中崩溃,这种情况极为常见。Michael Nygard为InfoQ撰写了一篇文章,讲述了一个系统每天在同一时间神秘死亡的故事。问题原来是防火墙会在一小时后丢弃不活跃的TCP连接。由于系统在夜间空闲,当早晨开始活动时,来自池化数据库连接的TCP数据包会被防火墙静默丢弃。
这样的问题会发生在你身上,当它们发生时,会令人抓狂地难以诊断。尽管网络有着悠久的历史,但很少有人真正理解整个TCP/IP协议栈的来龙去脉(以及某些基础设施,如防火墙,如何打破规则),特别是当几种不同的实现在同一网络上共存时。这是生产环境中的常见情况。
我们有几条建议给你。
• 网络基础设施配置的每个部分,从DNS区域文件到DHCP,到防火墙和路由器配置,再到SMTP和应用程序依赖的其他服务,都应该进行版本控制。使用像Puppet这样的工具从版本控制推送配置到你的系统,使它们具有自主性,并且你知道除了通过更改版本控制中的配置文件之外,没有其他方式引入更改。
• 安装一个好的网络监控系统,如Nagios、OpenNMS、HP Operations Manager或它们的同类产品。确保你知道网络连接何时中断,并监控应用程序使用的每条路由上的每个端口。监控在第317页的”监控基础设施和应用程序”部分有更详细的讨论。
•
日志是你的朋友。每当网络连接超时或发现意外关闭时,你的应用程序应该以WARNING级别记录日志。每次关闭连接时,你应该以INFO级别记录日志,或者如果日志过于冗长,则使用DEBUG级别。每次打开连接时,你应该以DEBUG级别记录日志,包括尽可能多的关于连接端点的信息。
• 确保你的冒烟测试在部署时检查所有连接,以发现任何路由或连接问题。
• 使你的集成测试环境的网络拓扑尽可能与生产环境相似,包括使用相同的硬件设备,它们之间使用相同的物理连接(细化到使用完全相同的插槽和相同型号的电缆)。这样构建的环境可以在硬件故障发生时充当备份环境。实际上,许多企业有一个称为预发布(staging)的环境,它具有双重目的:既精确复制生产环境以便测试生产部署,又充当故障转移。蓝绿部署模式(在第261页的”蓝绿部署”部分描述)允许你即使只有一个物理环境也能做到这一点。
最后,当确实出现问题时,要准备好取证工具。Wireshark和Tcpdump都是非常有用的工具,可以轻松查看飞过的数据包,并过滤它们,以便你可以准确定位你正在寻找的数据包。UNIX工具Lsof及其Windows版本Handle和TCPView(Sysinternals套件的一部分)也非常方便,可以查看机器上打开的文件和套接字。
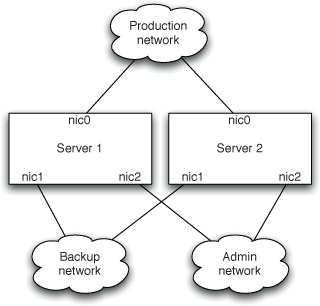
生产系统强化的一个重要部分是为不同类型的流量使用多个隔离网络,并结合多宿主服务器。多宿主服务器具有多个网络接口,每个接口与不同的网络通信。至少,你可能有一个用于监控和管理生产服务器的网络,一个用于运行备份的网络,以及一个用于生产数据进出服务器的网络。这样的拓扑如图11.3所示。
由于安全原因,管理网络与生产网络物理隔离。通常,用于控制和监控生产服务器的任何服务(如ssh或SNMP)都会被配置为仅绑定到nic2,因此无法从生产网络访问这些服务。备份网络与生产网络物理隔离,这样在备份期间移动的大量数据就不会影响性能或管理网络。高可用性和高性能系统有时会使用多个NIC来处理生产数据,用于故障转移或专用服务——例如,您可能为组织的消息总线或数据库配置单独的专用网络。
首先,重要的是确保在多宿主机器上运行的每个服务和应用程序仅绑定到相关的NIC。特别是,应用程序开发人员需要在部署时使其应用程序监听的IP地址可配置。
其次,多宿主网络配置的所有配置(包括路由)都应该集中管理和监控。很容易犯错误导致需要访问数据中心——比如Jez在职业生涯早期曾关闭了生产机器上的管理NIC,忘记了他是通过ssh连接而不是在物理tty上。正如Nygard指出的那样,也可能犯更严重的路由错误,例如允许流量从多宿主机器上的一个NIC通过到另一个NIC,这可能会造成安全漏洞,比如暴露客户数据。
我们已经讨论了当环境因服务器是艺术品而不同时出现的问题。虚拟化提供了一种方法来放大本章已经描述的自动化服务器和环境配置技术的好处。
一般来说,虚拟化是一种在一个或多个计算机资源之上添加抽象层的技术。然而,在本章中我们主要关注平台虚拟化。
平台虚拟化是指模拟整个计算机系统,以便在单台物理机器上同时运行多个操作系统实例。在这种配置中,有一个虚拟机监视器(VMM)或hypervisor(虚拟机管理程序),它完全控制物理机器的硬件资源。客户操作系统运行在虚拟机上,由VMM管理。环境虚拟化涉及模拟一个或多个虚拟机以及它们之间的网络连接。
虚拟化最初由IBM在20世纪60年代开发,作为创建多任务分时操作系统的替代方案。虚拟化技术的主要应用是服务器整合。确实有一段时间IBM避免向客户推荐其VM系列,因为这会导致硬件销售下降。然而,这项强大技术还有许多其他应用。它可以用于各种情况,例如在现代硬件上模拟历史计算机系统(复古游戏社区的常见做法),或作为支持灾难恢复的机制,或作为配置管理系统的一部分来支持软件部署。
这里我们将描述使用环境虚拟化来帮助提供受控的、完全可重复的部署和发布过程。虚拟化可以通过多种方式帮助减少部署软件所需的时间以及与之相关的风险。在部署中使用虚拟机对于在系统的广度和深度上实现有效的配置管理有巨大帮助。
特别是,虚拟化提供以下好处:
• 快速响应不断变化的需求。需要一个新的测试环境?新的虚拟机可以在几秒钟内免费配置,而获得新的物理环境需要几天或几周时间。显然,您不能在单个主机上运行无限数量的虚拟机——但在某些情况下,使用虚拟化可以将购买新硬件的需求与其运行的环境的生命周期解耦。
• 整合。当组织相对不成熟时,每个团队通常会在办公桌下的物理机器上拥有自己的CI服务器和测试环境。虚拟化使整合CI和测试基础设施变得容易,从而可以作为服务提供给交付团队。在硬件使用方面也更高效。
• 标准化硬件。应用程序的组件和子系统之间的功能差异不再迫使您维护不同的硬件配置,每个配置都有自己的规格。虚拟化允许您为物理环境标准化单一硬件配置,但虚拟地运行各种异构环境和平台。
• 更易于维护的基线。您可以维护一个基线镜像库——操作系统加应用程序栈——甚至是环境,只需点击按钮即可将它们推送到集群。
在应用于部署流水线时,最有用的是维护和配置新环境的简单性。
• 虚拟化提供了一种简单的机制来为系统运行环境创建基准线(baseline)。你可以将托管应用程序的环境创建并调优为虚拟服务器,一旦对结果满意,就可以保存镜像和配置,然后继续创建任意数量的副本,确保得到的是原始环境的忠实克隆。
• 由于构建主机的服务器镜像存储在库中,并且可以与应用程序的特定构建版本关联,因此可以轻松将任何环境恢复到以前的状态——不仅是应用程序,还包括你部署的软件的各个方面。
• 使用虚拟服务器作为主机环境基准线,可以轻松创建生产环境的副本(即使生产环境包含多台服务器),并将其复制用于测试目的。现代虚拟化软件提供了相当大的灵活性,允许通过编程方式控制系统的某些方面,如网络拓扑。
• 这是实现应用程序任意构建版本真正一键式部署的最后一块拼图。如果你需要一个新环境来向潜在客户演示最新功能,可以在早上创建新环境,在午餐时间进行演示,然后在下午将其删除。
虚拟化还提高了我们测试功能性和非功能性需求的能力。
• VMM(虚拟机监视器)提供了对系统功能的编程控制,例如网络连接。这使得非功能性需求(如可用性)的测试变得更加容易,并且能够实现自动化。例如,通过编程方式断开一个或多个节点的连接并观察对系统的影响,可以相对简单地测试服务器集群的行为。
• 虚拟化还提供了显著加快长时间运行测试的能力。你可以在虚拟机构建网格上并行运行测试,而不是在单个机器上运行。我们在项目中经常这样做。在我们的一个大型项目中,它将运行测试的时间从13小时缩短到45分钟。
VMM最重要的特性之一是虚拟机镜像是单个文件。这样的文件称为磁盘镜像(disk image)。磁盘镜像的有用之处在于你可以复制它们并对其进行版本控制(可能不是在版本控制系统中,除非你的VCS能够处理大量非常大的二进制文件)。然后你可以将它们用作模板或基准线(在配置管理术语中)。一些VMM将模板视为与磁盘镜像不同的东西,但最终它们是相同的。许多VMM甚至允许你从运行中的虚拟机创建模板。然后你可以在几秒钟内从这些模板创建任意数量的运行实例。
一些VMM供应商提供的另一个有用工具是对物理机进行快照并将其转换为磁盘镜像。这非常有用,因为这意味着你可以复制生产环境中的机器,将它们保存为模板,并启动生产环境的副本来进行持续集成和测试。
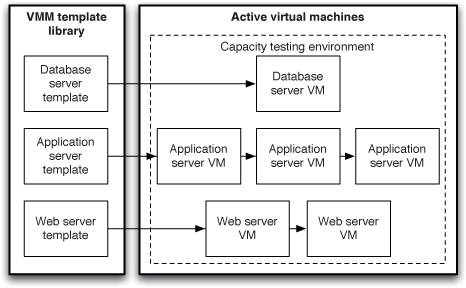
在本章前面,我们讨论了如何使用完全自动化的流程来配置新环境。如果你有虚拟化基础设施,可以创建如此配置的服务器的磁盘镜像,并将其用作使用相同配置的每台服务器的模板。或者,你可以使用rPath的rBuilder等工具来为你创建和管理基准线。一旦你拥有环境中所需的每种类型机器的模板,就可以根据需要使用VMM软件从模板启动新环境。图11.4演示了这一点。
这些模板构成了基准线,即环境的已知良好版本,在此基础上可以进行其余的配置和部署。我们可以轻松满足这样的需求:配置新环境应该比调试和修复由于不受控制的更改而处于未知状态的环境更快——你只需停用有缺陷的虚拟机,并从基准线模板启动一个新的虚拟机。
现在可以以增量方式实现环境配置的自动化流程。你可以从已知良好的基准线镜像开始配置过程,而不是总是从头开始,该镜像可能只安装了基本操作系统。你仍然应该在每个模板上为数据中心自动化工具(下面图11.5中的Puppet)安装一个代理,以便你的虚拟机是自治的,并且可以在整个系统中一致地推出更改。
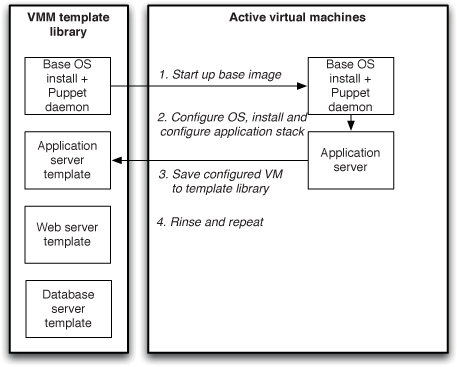
然后你可以运行自动化流程来配置操作系统,并安装和配置应用程序所需的任何软件。再次,在此时,将环境中每种类型的机器的副本保存为基准线。此工作流程如图11.5所述。
虚拟化还使本章前面讨论的另外两种棘手场景变得更容易管理:处理以不受控制的方式演变的环境,以及处理技术栈中无法以自动化方式管理的软件。
每个组织都会遇到这样的问题:环境经过未记录或记录不完善的手动变更而演变,包括遗留系统。如果这些”艺术品”出现故障,调试它们极其困难,而且几乎不可能为测试目的制作副本。如果设置和管理这些系统的人离职或休假,一旦出现问题,你就会陷入困境。对这些系统进行变更也非常危险。
虚拟化提供了一种降低这种风险的方法。使用虚拟化软件对组成环境的运行机器进行快照,并将它们转换为虚拟机。然后你可以轻松创建环境副本用于测试目的。
这种技术提供了一种宝贵的方法,可以从手动管理环境逐步过渡到自动化方法。与其从头开始自动化配置过程,不如基于当前已知良好的系统创建模板。同样,你可以用虚拟环境替换真实环境,以确认模板是良好的。
最后,虚拟化提供了一种处理应用程序依赖的、无法以自动化方式安装或配置的软件的方法,包括商用现成软件(COTS)。只需在虚拟机上手动安装和配置软件,然后从中创建模板。这可以作为基线(baseline),你可以根据需要进行复制。
如果以这种方式管理环境,跟踪基线版本至关重要。每次对基线进行变更时,都需要将其存储为新版本,正如我们之前所说,需要针对最新的候选发布版本重新运行基于该基线的所有流水线阶段。你还需要能够将特定基线版本的使用与已知可在其上运行的应用程序版本相关联,这适用于每个环境,这就引出了下一节。
图 11.6 一个简单的流水线

部署流水线(deployment pipeline)的目的是将你对应用程序所做的每个变更都经过自动化构建、部署和测试过程,以验证其是否适合发布。图 11.6 显示了一个简单的流水线。
在虚拟化环境中使用流水线方法时,有一些值得重新审视的特性。
• 流水线的每个实例都与触发它的版本控制中的变更相关联。
• 提交阶段之后的流水线的每个阶段都应该在类生产环境中运行。
• 在每个环境中都应该使用完全相同的部署过程和完全相同的二进制文件——环境之间的差异应该作为配置信息来捕获。
可以看出,流水线中测试的不仅仅是应用程序。实际上,当流水线中出现测试失败时,首先要做的是分类(triage)以确定失败原因。五个最可能的失败原因是:
• 应用程序代码中的错误
• 测试中的错误或无效期望
• 应用程序配置问题
• 部署过程问题
• 环境问题
因此,环境配置代表了配置空间中的自由度之一。由此可见,应用程序的已知良好版本不仅与版本控制系统中作为二进制代码、自动化测试、部署脚本和配置源的修订号相关联。应用程序的已知良好版本还与流水线实例运行时的环境配置相关联。即使它在多个环境中运行,它们都应该具有完全相同的类生产配置。
在发布到生产环境时,你应该使用与运行所有测试时完全相同的环境。所有这些的推论是,对环境配置的变更应该像任何其他变更(对源代码、测试、脚本等的变更)一样触发新的流水线实例。你的构建和发布管理系统应该能够记住用于运行流水线的虚拟机模板集,并能够在部署到生产环境时从该模板集精确启动。
图 11.7 变更通过部署流水线
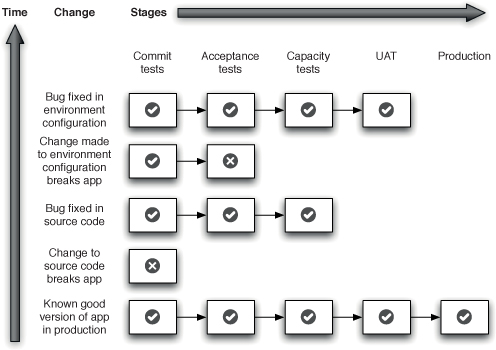
在这个例子中,你可以看到变更触发了新的候选发布版本,以及候选发布版本在部署流水线中的进展。首先,对源代码进行变更;也许开发人员提交了错误修复或新功能的部分实现。变更破坏了应用程序;提交阶段的测试失败,通知开发人员存在缺陷。开发人员修复缺陷并再次提交。这触发了新的构建,通过了自动化测试(提交阶段、验收测试阶段、容量测试阶段)。接下来,运维人员希望测试生产环境中某个软件的升级。她使用升级后的软件创建了新的虚拟机模板。这触发了新的流水线实例,验收测试失败。我们的运维人员与开发人员合作找到问题源(可能是某些配置设置)并修复它。这次,应用程序可以在新环境中工作,通过了所有自动化和手动测试。应用程序连同测试所用的环境基线已准备好部署到生产环境。
当然,当应用程序部署到 UAT 和生产环境时,它使用的 VM 模板与运行验收测试和容量测试时使用的完全相同。这验证了该应用程序版本在这个精确配置的环境中具有可接受的容量且没有缺陷。希望这个例子能够展示使用虚拟化的强大之处。
然而,通过复制虚拟基线并创建新基线来对暂存和生产环境进行每次更改并不是一个好主意。如果这样做,不仅会很快耗尽磁盘空间,还会失去通过声明式、版本控制配置管理的自治基础设施的优势。最好保持一个相对稳定的 VM 基线镜像——一个包含最新服务包、任何中间件或其他软件依赖项以及数据中心管理工具代理的基本操作系统镜像。然后,使用该工具完成配置过程,并将基线调整到所需的精确配置。
在用户安装软件的情况下,情况有所不同,特别是在企业环境之外。在这种情况下,你通常无法控制生产环境,因为它是用户的计算机。在这种情况下,在各种”类生产”环境中测试你的软件变得很重要。例如,桌面应用程序通常必须是多平台的,在 Linux、Mac OS 和 Windows 上运行,通常还要在这些平台的多个不同版本和配置上运行。
虚拟化为处理多平台测试提供了一种出色的方法。只需创建包含应用程序目标的每个潜在环境示例的虚拟机,并从中创建 VM 模板。然后在所有这些环境上并行运行流水线中的所有阶段(验收、容量、UAT)。现代持续集成工具使这种方法变得简单。
你可以使用相同的技术来并行化测试,以缩短昂贵的验收测试和容量测试的关键反馈周期。假设你的测试都是独立的(参见第 218 页”验收测试性能”部分中的建议),你可以在多个虚拟机上并行运行它们(当然你也可以将它们作为单独的线程并行运行,但这种方法的扩展性是有限的)。这种为构建创建专用计算网格的方法可以大大加快运行自动化测试的速度。最终,你的测试性能仅受运行最慢的单个测试用例所需的时间和硬件预算规模的限制。同样,现代 CI 工具和像 Selenium Grid 这样的软件使这变得非常简单。
现代虚拟化工具具有强大的网络配置功能,可以轻松设置私有虚拟网络。使用这些工具,可以通过复制生产环境中使用的精确网络拓扑(包括 IP 和 MAC 地址)来使你的虚拟环境更加类似于生产环境。我们已经看到这种技术被用于创建大型复杂环境的多个版本。在一个项目中,生产环境有五台服务器:一台 Web 服务器、一台应用服务器、一台数据库服务器、一台运行 Microsoft BizTalk 的服务器和一台托管遗留应用程序的服务器。
图 11.8 使用虚拟网络
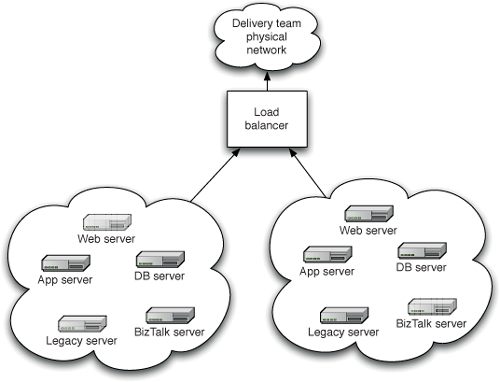
交付团队创建了每台服务器的基线模板,并使用其虚拟化工具创建了该环境的多个副本,用于同时进行 UAT、容量测试和运行自动化测试。设置如图 11.8 所示。
每个环境都通过虚拟 LAN 连接到外部世界。可以使用虚拟化 API 以编程方式模拟应用服务器和数据库服务器之间的连接断开,作为自动化非功能测试的一部分。不用说,没有虚拟化的话,做这种事情要困难几个数量级。
云计算是一个古老的概念,但近年来它已经变得无处不在。在云计算中,信息存储在互联网上,并通过同样在互联网上可用的软件服务进行访问和操作。云计算的定义特征是你使用的计算资源(如 CPU、内存、存储等)可以根据你的需求扩展和收缩,并且你只需为使用的部分付费。云计算既可以指软件服务本身,也可以指它们运行的硬件和软件环境。
与云计算通常联系在一起的一个概念是效用计算(utility computing)。这个理念是指计算资源(如CPU、内存、存储和带宽等资源)作为一种计量服务提供,就像天然气或电力供应到你家中一样。这个概念最早由John McCarthy在1961年提出,但计算基础设施花了几十年时间才足够成熟,使得基于云的服务能够可靠地提供给大量用户。HP、Sun和Intel已经提供云解决方案有一段时间了,但直到2006年8月亚马逊推出EC2服务后,云计算才真正腾飞。亚马逊网络服务受欢迎的一个简单原因是亚马逊已经在内部使用它们一段时间了——这意味着他们已经知道这项服务是有用的。从那时起,云计算生态系统呈现爆炸式增长,大量供应商提供云服务和帮助管理这些服务的工具。
效用计算的主要优势是它不需要基础设施的资本投资。许多初创公司开始使用Amazon Web Services(AWS)来托管他们的服务,因为这不需要最低合同期或预付款。因此,初创公司能够将AWS费用计入信用卡,并在从用户那里收到服务费用后再支付。效用计算对大型企业也很有吸引力,因为它在资产负债表上显示为经常性成本而不是资本支出。由于成本相对较低,采购不需要高级管理层的批准。它还允许你极其简单地管理扩展——假设你的软件已经能够在一组机器上运行,启动一个新的机器(或者说1000台)只需一个API调用即可。你可以从单个机器开始,如果你的新想法不是非常成功,你的损失也很低。
因此云计算鼓励了创业精神。在大多数组织中,采用计算云的主要障碍之一是对将公司的信息资产交给第三方以及这一举措的安全影响感到紧张。然而,随着Eucalyptus等技术的出现,在内部运行自己的计算云已经成为可能。
通常会区分云计算的三个类别:云中的应用程序、云中的平台和云中的基础设施。云中的应用程序是像WordPress、SalesForce、Gmail和Wikipedia这样的服务——托管在云基础设施上的传统基于网络的服务。SETI@Home可能是云中应用程序最早的主流例子。
在可配置性的最高层级是云中的基础设施,如Amazon Web Services(AWS)。AWS提供许多基础设施服务,包括消息队列、静态内容托管、流视频托管、负载均衡和存储,此外还有其著名的名为EC2的效用虚拟机托管服务。通过这些产品,你几乎可以完全控制系统,但你也必须做大部分工作来将所有内容整合在一起。
许多项目在其生产系统中使用AWS。假设你的软件架构合理,理想情况是无共享架构(shared-nothing architecture),那么在基础设施方面扩展你的应用程序就相当简单。有许多服务提供商可以帮助你简化资源管理,还有大量基于AWS构建的专业服务和应用程序。然而,你使用这些服务越多,就越会被锁定在他们的专有架构中。
即使你不在生产基础设施中使用AWS,它仍然可以成为你软件交付过程中极其有用的工具。EC2使得按需启动新的测试环境变得容易。其他用途包括并行运行测试以加快速度、容量测试以及多平台验收测试,如本章前面所述。
人们迁移到云基础设施时提出的两个重要问题是:安全性和服务水平。
安全性通常是中大型公司提到的第一个阻碍因素。当你的生产基础设施掌握在别人手中时,有什么能阻止人们破坏你的服务或窃取你的数据?云计算提供商意识到这个问题,并建立了各种机制来解决它们,如高度可配置的防火墙和连接到你组织VPN的私有网络。最终,云服务在安全性上没有根本理由比你自己拥有的基础设施上托管的公共可访问服务更不安全,尽管云基础设施的风险是不同的,你需要为基于云的部署做好规划。
合规性经常被提及为使用云计算的约束条件。然而,问题通常不在于法规禁止使用云计算,而在于法规尚未跟上云计算的发展步伐。由于许多法规忽略了云计算,这些法规对云托管服务的影响有时没有得到充分理解,或需要进行解释。通过仔细的规划和风险管理,通常可以调和两者。医疗保健公司TC3对其数据进行加密,从而能够在AWS上托管其服务,并因此能够保持HIPAA合规性。一些云供应商提供一定程度的PCI DSS合规性,还有一些提供符合PCI标准的支付服务,这样您就不必处理信用卡支付。即使是需要1级合规性的大型组织也可以使用混合方法,将支付系统托管在内部,而将系统的其余部分托管在云中。
当您的整个基础设施都外包时,服务级别尤为重要。与安全性一样,您需要进行一些研究以确保您的供应商能够满足您的要求。在性能方面尤其如此。亚马逊根据您的需求提供不同性能级别的服务——但即使是他们提供的最高级别也无法与高性能服务器相媲美。如果您需要运行具有大型数据集和高负载的RDBMS,您可能不希望将其放在虚拟化环境中。
云平台的示例包括Google App Engine和Force.com等服务,服务提供商为您提供标准化的应用程序栈。作为使用其栈的回报,他们负责处理应用程序和基础设施的扩展等事务。本质上,您牺牲了灵活性,以便提供商可以轻松处理容量和可用性等非功能性需求。云平台的优势如下:
• 在成本结构和配置灵活性方面,您可以获得与云基础设施相同的所有好处。
• 服务提供商将负责处理可扩展性、可用性和(在某种程度上)安全性等非功能性需求。
• 您部署到完全标准化的栈,这意味着无需担心配置或维护测试、预发布或生产环境,也无需处理虚拟机镜像。
最后一点尤其具有革命性。我们在本书中花了大量篇幅讨论如何自动化您的部署、测试和发布过程,以及如何设置和管理您的测试和部署环境。使用云平台几乎完全免除了许多这些考虑。通常,您只需运行一个命令即可将应用程序部署到互联网。您可以在几分钟内从零开始到发布应用程序,而按钮式部署几乎不需要您进行任何投资。
云平台的本质意味着您的应用程序总会受到相当严格的约束。这正是这些服务能够提供简单部署和高可扩展性及性能的原因。例如,Google App Engine仅提供BigTable的实现,而不是标准的RDBMS。您不能启动新线程、调用SMTP服务器等。
云平台也存在可能使云基础设施不适用的相同问题。特别值得指出的是,对于云平台,关于可移植性和供应商锁定的担忧要严重得多。
尽管如此,我们预计对于许多应用程序,这种类型的云计算将是一大进步。事实上,我们预计这些类型服务的可用性将改变人们构建应用程序的方式。
当然,您可以混合和匹配不同的服务来实现您的系统。例如,您可能将静态内容和流媒体视频托管在AWS上,将应用程序托管在Google App Engine上,并在自己的基础设施上运行专有服务。
为了实现这一点,应用程序必须设计为能够在这些类型的异构环境中工作。这种部署需要您实现松耦合架构。异构解决方案在成本和满足非功能性需求方面的价值为松耦合架构提供了令人信服的商业案例。实际设计一个有效的架构是困难的,超出了本书的范围。
云计算处于其演进的相对早期阶段。在我们看来,这不仅仅是最新的被过度炒作的必备技术——它是一个真正的进步,在未来几年将变得越来越重要。
云计算不一定要涉及时髦的新技术。我们知道有几个组织使用台式计算机上的空闲容量在台式机很少使用的时间执行系统功能。
我们合作过的一家银行通过使用下班回家的员工的台式计算机的容量来执行夜间批处理操作,将计算机硬件的资本成本减半。以前执行这些夜间计算所需的硬件不再需要,当计算被分解为可以分配给云的离散块时,计算运行得更快。
这是一个大型跨国组织,因此在一天中的任何时刻,总有成千上万在地球另一端睡觉的人,但他们的计算机正忙于向云贡献相对较小的计算能力。总的来说,云在任何给定时间的计算能力都是巨大的;所需要的只是将问题分解成足够小的块,以便分配给云中的离散元素。
尽管我们相信云计算将继续增长,但值得注意的是,并非所有人都对亚马逊、IBM或微软等公司向我们推销的云计算的巨大潜力感到欣喜若狂。
Larry Ellison曾评论说:“云计算有趣的地方在于,我们重新定义了云计算,将我们已经在做的所有事情都包括进来……我不明白除了改变一些广告的措辞之外,我们在云计算方面会做什么不同的事情。”(华尔街日报,2008年9月26日)。他找到了一个不太可能的盟友Richard Stallman,后者的批评更为尖锐:“这是愚蠢的。这比愚蠢更糟糕:这是一场营销炒作活动。有人说这是不可避免的—每当你听到有人这么说时,很可能是一群企业在推动使其成为现实。”(卫报,2008年9月29日)。
首先,“云”当然不是互联网—互联网是一个从底层设计就具有开放架构的系统,旨在实现互操作性和弹性。每个供应商提供不同的服务,你在某种程度上被绑定在你选择的平台上。曾经有一段时间,点对点服务似乎是构建大型、分布式、可扩展系统最有可能的范式。然而,点对点的愿景尚未实现,也许是因为供应商很难从点对点服务中赚钱,而云计算仍然非常遵循效用计算(utility computing)模型,其收入特征是众所周知的。本质上,这意味着你的应用程序和数据最终受制于供应商。这相对于你当前的基础设施可能是改进,也可能不是。
目前,即使是效用计算服务使用的基本虚拟化平台也没有通用标准。在API层面实现标准化的可能性似乎更小。Eucalyptus项目创建了AWS的API的部分实现,以允许人们创建私有云,但Azure或Google AppEngine提供的API将更难重新实现。这使得应用程序难以移植。云中的供应商锁定(vendor lock-in)和其他地方一样,甚至更严重。
最后,根据你的应用程序,经济因素可能会使使用云计算变得不合理。预测迁移到效用计算与拥有自己基础设施的成本和节省,并运行概念验证来验证你的假设。考虑诸如两种模型的盈亏平衡点等因素,同时考虑折旧、维护、灾难恢复、支持以及不花费资本账户的好处。云计算是否适合你,既取决于你的业务模式和组织约束,也取决于技术考虑。
关于云计算的利弊有详细讨论,包括一些有趣的经济建模,参见Armbrust等人的论文,“云端之上:伯克利对云计算的看法”[bTAJ0B]。
深入了解生产环境中发生的事情至关重要,原因有三个。首先,如果企业拥有实时业务情报,例如他们产生了多少收入以及这些收入来自哪里,他们可以更快地获得关于其战略的反馈。其次,当出现问题时,运维团队需要立即得到通知,并拥有必要的工具来追踪事件的根本原因并修复它。最后,历史数据对于规划至关重要。如果你没有关于当出现意外需求高峰或添加新服务器时系统如何表现的详细数据,就不可能规划基础设施的演进以满足业务需求。
在制定监控策略时需要考虑四个方面:
• 对应用程序和基础设施进行仪表化(instrumenting),以便收集所需数据
• 存储数据,以便轻松检索进行分析
• 创建仪表板(dashboard),汇总数据并以适合运维和业务的格式呈现
• 设置通知,以便人们可以了解他们关心的事件
首先,重要的是决定要收集什么数据。监控数据可以来自以下来源:
• 你的硬件,通过带外管理(out-of-band management)(也称为熄灯管理(lights-out management)或LOM)。几乎所有现代服务器硬件都实现了智能平台管理接口(Intelligent Platform Management Interface,IPMI),它允许你监控电压、温度、系统风扇速度、外围设备健康状况等,并执行诸如电源循环或点亮前面板上的识别灯等操作,即使机器已关闭电源。
• 您基础设施服务器上的操作系统。所有操作系统都提供接口来获取性能信息,如内存使用量、交换空间使用量、磁盘空间、I/O带宽(每个磁盘和网卡)、CPU使用率等。监控进程表以了解每个进程消耗的资源也很有用。在UNIX上,Collectd是收集这些数据的标准方式。在Windows上,则使用称为性能计数器的系统来完成,其他性能数据提供者也可以使用该系统。
• 您的中间件。它可以提供关于资源使用情况的信息,如内存、数据库连接池和线程池,以及连接数量、响应时间等信息。
• 您的应用程序。应用程序应该编写成具有监控钩子,以便监控运维团队和业务用户都关心的事项,如业务事务数量、价值、转化率等。应用程序还应便于分析用户人口统计和行为。它们应记录所依赖的外部系统的连接状态。最后,它们应该能够报告自己的版本号以及内部组件的版本(如适用)。
收集数据有多种方式。首先,有许多工具——包括商业和开源工具——可以收集整个数据中心的上述所有信息,存储数据,生成报告、图表和仪表板,并提供通知机制。领先的开源工具包括Nagios、OpenNMS、Flapjack和Zenoss,当然还有更多[dcgsxa]。领先的商业产品提供商是IBM的Tivoli、HP的Operations Manager、BMC和CA。Splunk是该领域相对较新的商业产品。
近年来IT运维领域最强大的工具之一是Splunk。Splunk会索引整个数据中心的日志文件和其他包含时间戳的文本数据(上述大多数数据源都可以配置为提供这些数据)。然后您可以执行实时搜索,定位异常事件并对正在发生的问题进行根本原因分析。Splunk甚至可以用作运维仪表板,并可配置为发送通知。
在底层,这些产品使用各种开放技术进行监控。主要包括SNMP、其后继者CIM以及JMX(用于Java系统)。
图11.9 SNMP架构
SNMP是最悠久且最普遍的监控标准。SNMP有三个主要组件:被管理设备(managed devices),即服务器、交换机、防火墙等物理系统;代理(agents),与您想通过SNMP监控和管理的各个应用程序或设备通信;以及网络管理系统(network management system),用于监控和控制被管理设备。网络管理系统和代理通过SNMP网络协议通信,这是一个位于标准TCP/IP协议栈之上的应用层协议。SNMP的架构如图11.9所示。
在SNMP中,一切都是变量。您通过观察变量来监控系统,通过设置变量来控制系统。对于任何给定类型的SNMP代理,哪些变量可用、它们的描述、类型以及是否可写或只读,都在MIB(管理信息库,Management Information Base)中描述,这是一种可扩展的数据库格式。每个供应商为其提供SNMP代理的系统定义MIB,IANA维护一个中央注册表[aMiYLA]。几乎每个操作系统、大多数常见中间件(例如Apache、WebLogic和Oracle)以及许多设备都内置了SNMP。当然,您也可以为自己的应用程序创建SNMP代理和MIB,尽管这是一项重大任务,需要开发和运维团队的密切协作。
日志记录也必须成为监控策略的核心部分。操作系统和中间件生成的日志对于了解用户行为和追踪问题源头都非常有用。
您的应用程序也需要生成高质量的日志。特别是要注意日志级别。大多数日志系统有多个级别,如DEBUG、INFO、WARNING、ERROR和FATAL。默认情况下,您的应用程序应该只显示WARNING、ERROR和FATAL级别的消息,但应该可以在运行时或部署时配置为在需要调试时显示其他级别。由于日志只对运维团队可用,因此在日志消息中打印底层异常是可以接受的。这可以大大帮助调试过程。
请记住,运维团队是日志文件的主要使用者。开发人员花时间与支持团队一起解决用户报告的问题,或与运维团队一起解决生产环境中的问题,是很有益的。开发人员会很快了解到,可恢复的应用程序错误(如用户无法登录)不应该超过DEBUG级别,而应用程序依赖的外部系统超时应该在ERROR或FATAL级别(取决于应用程序在没有外部服务的情况下是否仍能处理事务)。
日志记录是审计能力的一部分,应该被视为一级需求集,与其他非功能性需求具有同等地位。与运维团队沟通,了解他们的需求,并从一开始就将这些需求纳入构建。特别要考虑日志的全面性和人类可读性之间的权衡。人类必须能够轻松地浏览日志文件或使用 grep 获取所需数据——这意味着每个条目应使用单行表格或基于列的格式,一目了然地显示时间戳、日志级别、应用程序中的错误来源以及错误代码和描述。
图 11.10 Nagios 截图
与开发团队的持续集成一样,运维团队拥有一个大型可视化显示屏至关重要,他们可以从高层次查看是否有任何事件发生。然后,当出现问题时,他们需要能够深入细节以找出问题所在。所有开源和商业工具都提供此类功能,包括查看历史趋势和进行某种报告的能力。图 11.10 显示了 Nagios 的截图。了解每个应用程序的哪个版本在哪个环境中也非常有用,这需要一些额外的仪表化和集成工作。
可能有数千件事情需要监控,因此必须提前规划,以免运维仪表板淹没在噪音中。列出按概率和影响分类的风险清单。你的清单可能包括通用风险,例如磁盘空间不足或未经授权访问环境,以及特定于业务的风险,例如无法完成的事务。然后需要确定实际监控什么以及如何显示这些信息。
在数据聚合方面,红-黄-绿交通灯聚合被广泛理解和使用。首先,需要确定要聚合到哪些实体。可以为环境、应用程序或业务功能创建交通灯。不同的实体适合不同的目标受众。完成此操作后,需要为交通灯设置阈值。Nygard 提供了以下指南(Nygard, 2007, p. 273)。
绿色 表示以下所有条件均为真:
• 所有预期事件都已发生。
• 没有发生异常事件。
• 所有指标都是标称值(在此时间段的两个标准差内)。
• 所有状态完全正常运行。
黄色 表示以下至少一个条件为真:
• 预期事件尚未发生。
• 至少发生了一个中等严重性的异常事件。
• 一个或多个参数高于或低于标称值。
• 非关键状态未完全正常运行(例如,断路器切断了非关键功能)。
红色 表示以下至少一个条件为真:
• 必需事件尚未发生。
• 至少发生了一个高严重性的异常事件。
• 一个或多个参数远高于或低于标称值。
• 关键状态未完全正常运行(例如,“接受请求”为 false,但应该为 true)。
与开发人员通过编写自动化测试来验证应用程序行为进行行为驱动开发的方式相同,运维人员可以编写自动化测试来验证基础设施的行为。可以从编写测试开始,验证其失败,然后定义 Puppet 清单(或你选择的配置管理工具)将基础设施置于预期状态。然后运行测试以验证配置是否正常工作以及基础设施是否按预期运行。
提出这个想法的 Martin Englund 使用 Cucumber 编写测试。以下是他博客文章中的一个示例 [cs9LsY]:

Lindsay Holmwood 编写了一个名为 Cucumber-Nagios [anKH1W] 的程序,它允许你编写输出 Nagios 插件预期格式的 Cucumber 测试,因此可以在 Cucumber 中编写 BDD 风格的测试并在 Nagios 中监控结果。
还可以使用此范式将应用程序的冒烟测试插入监控应用程序。只需选择应用程序的一些冒烟测试,并使用 Cucumber-Nagios 将它们插入 Nagios,就可以验证的不仅是 Web 服务器是否运行,还可以验证应用程序是否按预期工作。
读完本章后,如果你觉得我们做得太过了,我们可以理解——我们真的在建议你的基础设施应该完全自主吗?我们真的认为你应该尝试颠覆昂贵企业软件提供的管理工具的使用吗?实际上,是的;我们在我们认为合理的限度内建议这些做法。
如前所述,你需要对基础设施进行配置管理的程度取决于其性质。简单的命令行工具可能对运行环境几乎没有期望,而一级网站则需要考虑所有这些事项甚至更多。根据我们的经验,大多数企业应用程序应该比现在更认真地考虑配置管理,而他们未能做到这一点会导致许多延迟、开发效率损失以及持续的所有权成本增加。
我们在本章中提出的建议和描述的策略确实为您必须创建的部署系统增加了复杂性。它们可能会促使您想出创造性的变通方法,来应对第三方产品在配置管理方面支持不足的问题。但是,如果您正在创建一个具有众多配置点的大型复杂系统,并且可能依赖于多种技术,那么这种方法可以拯救您的项目。
如果成本低廉且容易实现,我们都会希望拥有自治基础设施(Autonomic Infrastructure),使创建生产环境的副本变得简单直接。这个事实非常明显,几乎不值得陈述。然而,如果我们在免费的情况下都愿意接受它,那么我们反对随时完美复现任何环境的能力的唯一理由就是成本。因此,在成本范围内,在免费和过于昂贵之间的某个点,存在一个值得承担的成本。
我们相信,使用本章描述的技术,以及部署流水线这一更广泛的战略选择,您可以在一定程度上管理这些成本。虽然无疑会为创建版本控制、构建和部署系统增加一些成本,但这些成本远远低于手动环境管理的成本,不仅在应用程序的整个生命周期中如此,甚至在初始开发阶段也是如此。
如果您正在评估用于企业系统的第三方产品,确保它们适合您的自动化配置管理策略应该在您的优先级列表中排名非常靠前。哦,如果这些产品的供应商在这方面有所欠缺,请帮我们一个忙,给他们施加压力。太多的供应商在支持严肃的配置管理方面草率且不够用心。
最后,确保从项目一开始就制定基础设施管理策略,并在该阶段让开发和运维团队的利益相关者参与进来。
数据及其管理和组织给测试和部署流程带来了一系列特殊问题,主要有两个原因。首先是通常涉及的信息量之大。用于编码应用程序行为的字节——其源代码和配置信息——通常远远少于记录其状态的数据量。其次是应用程序数据的生命周期与系统其他部分不同。应用程序数据需要被保存——事实上,数据通常比用于创建和访问它的应用程序存在的时间更长。至关重要的是,在系统的新部署或回滚期间,数据需要被保存和迁移。
在大多数情况下,当我们部署新代码时,我们可以删除以前的版本并完全用新副本替换它。通过这种方式,我们可以确定我们的起始位置。虽然这个选项在少数有限的情况下适用于数据,但对于大多数真实世界的系统来说,这种方法是不可能的。一旦系统发布到生产环境,与之相关的数据就会增长,并且它本身就具有重大价值。事实上,可以说它是系统中最有价值的部分。当我们需要修改结构或内容时,这就带来了问题。
随着系统的增长和演变,这样的修改不可避免,因此我们必须建立机制,允许在最小化中断和最大化应用程序及部署流程可靠性的情况下完成更改。关键在于自动化数据库迁移过程。现在存在许多工具使数据迁移的自动化相对简单,因此可以将其作为自动化部署流程的一部分进行脚本化。这些工具还允许您对数据库进行版本控制,并将其从任何版本迁移到任何其他版本。这产生了解耦开发流程和部署流程的积极效果——您可以为每个所需的数据库更改创建迁移,即使您不独立部署每个模式(Schema)更改。这也意味着您的数据库管理员(DBA)不需要一个庞大的前期计划——他们可以随着应用程序的发展逐步工作。
本章涵盖的另一个重要领域是测试数据的管理。在执行验收测试或容量测试(有时甚至是单元测试)时,许多团队的默认选项是获取生产数据的转储。由于许多原因(尤其是数据集的大小),这是有问题的,我们在这里提供替代策略。
本章其余部分的一个警告:绝大多数应用程序依赖关系数据库技术来管理其数据。这不是存储数据的唯一方式,当然也不是所有用途的最佳选择,正如NoSQL运动的兴起所证明的那样。我们在本章中提供的建议与任何数据存储系统都相关,但当我们讨论细节时,我们将讨论RDBMS系统,因为它们仍然代表应用程序存储系统的绝大多数。
与系统中的任何其他变更一样,在构建、部署、测试和发布过程中使用的所有数据库变更都应该通过自动化流程进行管理。这意味着数据库初始化和所有迁移都需要以脚本形式捕获并签入版本控制。应该能够使用这些脚本来管理交付过程中使用的每个数据库,无论是为开发代码的开发人员创建新的本地数据库,为测试人员升级系统集成测试(SIT)环境,还是作为发布过程的一部分迁移生产数据库。
当然,数据库的架构(schema)会随着应用程序一起演进。这带来了一个问题,因为数据库必须具有正确的架构才能与特定版本的应用程序配合工作。例如,在部署到预发布环境时,必须能够将预发布数据库迁移到正确的架构,以便与正在部署的应用程序版本配合工作。如第327页”增量变更”一节所述,对脚本的精心管理使这成为可能。
最后,数据库脚本也应该作为持续集成过程的一部分使用。虽然根据定义,单元测试不应该需要数据库才能运行,但针对使用数据库的应用程序运行的任何有意义的验收测试都需要正确初始化数据库。因此,验收测试设置过程的一部分应该是创建具有正确架构的数据库以便与最新版本的应用程序配合工作,并加载运行验收测试所需的任何测试数据。类似的过程可以用于部署流水线的后续阶段。
我们交付方法的一个极其重要的方面是能够以自动化方式重现环境以及在其中运行的应用程序。没有这种能力,我们无法确定系统将按照我们预期的方式运行。
数据库部署的这个方面是最容易做到正确并在应用程序通过开发过程发生变更时保持的。几乎每个数据管理系统都支持从自动化脚本初始化数据存储的能力,包括架构和用户凭证。因此,创建和维护数据库初始化脚本是一个简单的起点。你的脚本应该首先创建数据库的结构、数据库实例、架构等,然后用应用程序启动所需的任何参考数据填充数据库中的表。
这个脚本以及所有其他涉及维护数据库的脚本当然应该与代码一起存储在版本控制中。
对于一些简单的项目,这就足够了。对于运营数据集在某种程度上是临时的项目,或者数据集是预定义的项目,例如在运行时将数据库用作只读资源的系统,简单地擦除以前的版本并用从版本化存储重新创建的全新副本替换它是一个简单而有效的策略。如果可以做到这一点,就这样做!
因此,从头开始部署数据库的过程最简单的情况如下:
• 擦除之前存在的内容。
• 创建数据库结构、数据库实例、架构等。
• 向数据库加载数据。
大多数项目以比这更复杂的方式使用数据库。我们需要考虑更复杂但更常见的情况,即在使用一段时间后进行变更。在这种情况下,存在必须作为部署过程的一部分进行迁移的现有数据。
持续集成要求我们能够在对应用程序进行的每次变更后保持应用程序正常工作。这包括对数据结构或内容的变更。持续交付要求我们必须能够将应用程序的任何成功的候选发布版本(包括对数据库的变更)部署到生产环境(对于包含数据库的用户安装软件也是如此)。除了最简单的系统之外,这意味着必须在保留其中包含的有价值数据的同时更新运营数据库。最后,由于在部署期间必须保留数据库中的数据这一约束,如果部署出现问题,我们需要有回滚策略。
以自动化方式迁移数据的最有效机制是对数据库进行版本控制。只需在数据库中创建一个包含其版本号的表。然后,每次对数据库进行变更时,都需要创建两个脚本:一个将数据库从版本 x 升级到版本 x + 1(前滚脚本),另一个将其从版本 x + 1 回退到版本 x (回滚脚本)。你还需要为应用程序设置一个配置项,指定它设计要使用的数据库版本(这可以作为常量保存在版本控制中,并在每次需要数据库变更时更新)。
在部署时,你可以使用一个工具来查看当前部署的数据库版本和应用程序版本所需的数据库版本。该工具会计算出需要运行哪些脚本来将数据库从当前版本迁移到所需版本,并按顺序在数据库上运行它们。对于前滚(roll forward),它将应用正确的前滚脚本组合,从最旧到最新;对于回滚(roll back),它将以相反的顺序应用相关的回滚脚本。如果你使用Ruby on Rails,这种技术已经内置,以ActiveRecord migrations的形式存在。如果你使用Java或.NET,我们的一些同事开发了一个名为DbDeploy(.NET版本是DbDeploy.NET)的简单开源应用程序来为你管理这个过程。还有其他几个类似的解决方案,包括Tarantino、Microsoft的DbDiff和IBatis的Dbmigrate。
这是一个简单的例子。当你开始编写应用程序时,你编写第一个SQL文件,1_create_initial_tables.sql:

在代码的后续版本中,你发现需要在表中添加客户的出生日期。因此你创建另一个脚本2_add_customer_date_of_birth.sql,描述如何添加此更改以及如何回滚:

文件中--//@UNDO注释之前的部分表示如何从数据库版本1前滚到版本2。注释之后的部分表示如何从版本2回滚到版本1。这个语法是DbDeploy和DbDeploy.NET使用的语法。
如果你的前滚脚本向数据库添加新结构,编写回滚脚本并不太难。你的回滚脚本可以简单地删除它们,记得先删除任何引用约束。通常也可以为更改现有结构的变更创建相应的回滚脚本。但是,在某些情况下需要删除数据。在这种情况下,仍然可以使你的前滚脚本是非破坏性的。让你的脚本创建一个临时表,将要销毁的数据在从主表删除之前复制到其中。在执行此操作时,还必须复制表的主键,以便数据可以被复制回去,并且引用约束可以通过回滚脚本重新建立。
有时在数据库前后切换的程度上存在实际限制。根据我们的经验,导致困难的最常见问题是更改数据库模式(schema)。如果这些更改是增量的,即它们创建新关系,那么你大多没问题—除非你做了诸如添加现有数据违反的约束,或添加没有默认值的新对象。如果模式更改是减量的,问题就会出现,因为一旦你失去了一条记录如何与另一条记录相关的信息,就更难重新构建该关系。
管理数据库变更的技术实现了两个目标:首先,它允许你持续部署应用程序,而不必担心要部署到的环境中数据库的当前状态。你的部署脚本只需将数据库回滚或前滚到你的应用程序期望的版本。
然而,它还允许你在某种程度上将数据库的更改与应用程序的更改解耦。你的DBA可以编写脚本来迁移数据库并将它们检入版本控制,而不必担心它们可能会破坏你的应用程序。为了实现这一点,你的DBA只需确保它们是迁移到更新版本数据库的一部分,直到编写代码使用它并且开发人员将所需的数据库版本设置为更新版本时才会实际运行。
我们推荐Scott Ambler和Pramod Sadalage的优秀著作《重构数据库》(Refactoring Databases),以及配套的迷你书《持续数据库集成秘诀》(Recipes for Continuous Database Integration),以获取有关管理数据库增量更改的更多详细信息。
在许多组织中,通过单个数据库集成所有应用程序是很常见的。我们不推荐这种做法;最好让应用程序直接相互通信,并在必要时分解出通用服务(例如,在面向服务的架构中)。但是,在某些情况下,通过数据库进行集成是有意义的,或者更改应用程序架构的工作量太大。
在这种情况下,对数据库进行更改可能会对使用该数据库的其他应用程序产生连锁反应。首先,在协调环境中测试此类更改很重要—换句话说,在数据库相当接近生产环境,并且托管使用它的其他应用程序版本的环境中。这样的环境通常被称为系统集成测试(SIT)环境,或者称为预发布(staging)环境。通过这种方式,假设针对使用数据库的其他应用程序频繁运行测试,你很快就会发现是否影响了另一个应用程序。
在考虑 Ward Cunningham 的”技术债务(technical debt)“概念如何应用于数据库设计时,这是值得思考的。任何设计决策都有不可避免的成本。有些成本是显而易见的,例如开发一个功能所需的时间。有些成本则不那么明显,例如未来维护代码的成本。当为了加快系统交付而做出较差的设计选择时,成本通常以系统中的错误数量来支付。这不可避免地影响设计质量,更重要的是,影响系统的维护成本。因此,债务的类比是恰当的。
如果我们做出次优的设计选择,实际上就是在向未来借款。与任何债务一样,需要支付利息。对于技术债务,利息以维护的形式支付。与财务债务完全相同,那些累积了大量技术债务的项目将达到这样一个点:它们只是在支付利息,而永远无法偿还原始贷款。这样的项目处于持续维护状态,只是为了保持它们的运行,但不会获得任何可以提高其为所有者带来价值的新功能。
一般来说,敏捷开发方法的一个公理是,你应该尝试通过在每次变更后重构设计来优化设计,以最小化技术债务。实际上,这是一种权衡;有时,向未来借款是有用的。重要的是要跟上还款进度。我们的经验是,大多数项目往往会非常快速地累积技术债务,而偿还速度非常缓慢,因此最好谨慎行事,在每次变更后进行重构。当达到这样一个点,认为承担一些技术债务对于实现某些短期目标是值得的时候,重要的是首先制定一个还款计划。
技术债务在管理数据时是一个重要考虑因素,因为数据库经常被用作系统中的集成点(这不是推荐的架构模式,但却是常见的)。因此,数据库经常代表一个设计变更可能产生广泛影响的点。
在这样的环境中,保留一个注册表来记录哪些应用程序使用哪些数据库对象也是有用的,这样你就知道哪些变更会影响哪些其他应用程序。
我们看到使用的一种方法是通过对代码库进行静态分析,自动生成每个应用程序接触的数据库对象列表。这个列表作为每个应用程序构建过程的一部分生成,结果对所有其他人都可用,因此很容易弄清楚你是否会影响其他人的应用程序。
最后,你需要确保与维护其他应用程序的团队合作,就可以进行哪些变更达成一致。管理增量变更的一种方法是使应用程序能够与数据库的多个版本协同工作,以便数据库可以独立于依赖它的应用程序进行迁移。这种技术对于零停机发布也很有用,我们将在下一节中更详细地描述。
一旦你为应用程序的每个版本都准备好了前滚和回滚脚本(如上一节所述),在部署时使用像 DbDeploy 这样的应用程序将现有数据库迁移到你正在部署的应用程序版本所需的正确版本就相对容易了。
然而,有一种特殊情况:部署到生产环境。有两个常见的需求会对生产环境部署施加额外约束:能够在不丢失升级后执行的事务的情况下回滚,以及根据严格的 SLA 保持应用程序可用的必要性,称为热部署或零停机发布。
在回滚的情况下,你的回滚脚本(如上一节所述)通常可以设计为保留升级后发生的任何事务。特别是,如果你的回滚脚本满足以下标准,应该不会有问题:
• 它们涉及不会丢失任何数据的模式更改(例如规范化或反规范化,或在表之间移动列)。在这种情况下,你只需运行回滚脚本。
• 它们删除了一些只有新系统理解的数据,但如果这些数据丢失并不重要。在这种情况下,同样,只需运行回滚脚本。
然而,在某些情况下,仅仅运行回滚脚本是不可能的。
• 回滚涉及从临时表中添加回数据。在这种情况下,自升级以来添加的新记录可能会违反完整性约束。
• 回滚涉及删除新事务中系统无法接受丢失的数据。
在这种情况下,有几种解决方案可用于回滚到应用程序的先前版本。
一种解决方案是缓存你不想丢失的事务,并提供一种重放它们的方法。当你将数据库和应用程序升级到新版本时,确保为每个进入新系统的事务创建一个副本。这可以通过记录来自用户界面的事件、拦截在系统组件之间传递的更粗粒度的消息(如果你的应用程序使用事件驱动范式则相对容易),或者从事务日志中实际复制发生的每个数据库事务来完成。一旦应用程序成功重新部署,这些事件就可以被回放。当然,这种方法需要仔细设计和测试才能工作,但如果你真的需要确保在回滚事件中不会丢失数据,这可能是一个可以接受的权衡。
第二种解决方案可以在使用蓝绿部署时采用(参见第10章”部署和发布应用程序”)。简单回顾一下,在蓝绿部署中,应用程序的旧版本和新版本并行运行,一个在蓝色环境中,另一个在绿色环境中。“发布”只是意味着将用户请求从旧版本切换到新版本,而”回滚”则意味着将它们切换回旧版本。
在蓝绿部署中,需要在发布时安排生产数据库(假设它是蓝色数据库)的备份。如果你的数据库不允许热备份,或者存在其他阻止这样做的约束,你需要将应用程序置于只读模式以便执行备份。然后将此备份恢复到绿色数据库,并对其执行迁移。作为发布过程的一部分,用户随后被切换到绿色环境。
如果需要执行回滚,只需将用户切换回蓝色环境即可。然后可以从绿色环境的数据库中恢复新事务,要么在尝试另一次升级之前重新应用到蓝色数据库,要么在再次执行升级后重新应用。
有些系统的数据量太大,以至于在不引起不可接受的停机时间的情况下,根本无法进行这样的备份和恢复操作。在这种情况下,这种方法无法使用——虽然蓝绿环境仍然可行,但它们在发布时切换运行的数据库,而不是拥有自己的独立数据库。
然而,还有第三种方法可用于管理热部署。就是将数据库迁移过程与应用程序部署过程解耦,并独立执行它们,如图12.1所示。这个解决方案也适用于管理编排的变更,以及第10章”部署和发布应用程序”中描述的蓝绿部署和金丝雀发布模式。
如果你频繁发布,你不需要为应用程序的每次发布都迁移数据库。当你确实需要迁移数据库时,不是让应用程序只能与新版本的数据库一起工作,而是必须确保它能与新版本和当前版本的数据库一起工作。在该图中,应用程序的版本241被设计为可以与当前部署的数据库版本14以及新版本15一起工作。
你部署这个过渡版本的应用程序,让它针对当前版本的数据库工作。当你确信应用程序的新版本是稳定的并且不需要回滚时,你可以将数据库升级到新版本(图中的版本15)。当然,在这样做之前你需要备份它。然后,当下一个要部署的应用程序版本准备好时(图中的版本248),你可以部署它而无需迁移数据库。这个版本的应用程序只需要与版本15的数据库一起工作。
这种方法在将数据库恢复到早期版本很困难的情况下也很有用。我们曾在新版本的数据库进行了一些重大更改(包括导致信息丢失的数据库模式更改)的情况下使用过这种方法。因此,升级会损害我们在出现问题时恢复到早期版本软件的能力。我们部署了应用程序的新版本,由于具有向后兼容性,它可以针对旧版本的数据库模式运行,而无需部署新的数据库更改。然后我们可以观察新版本的行为,确认它没有引入任何需要恢复到以前版本的问题。最后,一旦我们有信心,我们也部署了数据库更改。
向前兼容性也不是一个通用的解决方案,尽管对于常规的普通更改,它是一个有用的策略。在这种情况下,向前兼容性(Forward Compatibility)是指应用程序的早期版本能够针对后期版本的数据库模式工作的能力。自然,如果新模式中有额外的字段或表,这些将被未设计为与它们一起工作的应用程序版本所忽略。尽管如此,两个版本共有的数据库模式部分保持不变。
最好将此作为大多数更改的默认方法。也就是说,大多数更改应该是增量的,向我们的数据库添加新表或列,但在可能的情况下不更改现有结构。
另一种管理数据库变更和重构的方法是使用抽象层,以存储过程和视图的形式实现 [cVVuV0]。如果应用程序通过这样的抽象层访问数据库,就可以在保持视图和存储过程提供给应用程序的接口不变的情况下,对底层数据库对象进行更改。这是”通过抽象分支”的一个例子,在[第349页]的”通过抽象分支”部分有描述。
测试数据对所有测试都很重要,无论是手动测试还是自动化测试。什么样的数据能让我们模拟与系统的常见交互?什么样的数据代表边界情况,能证明我们的应用程序对异常输入也能正常工作?什么样的数据会迫使应用程序进入错误状态,以便我们评估它在这些情况下的响应?这些问题在我们测试系统的每个层级都相关,但对于依赖测试数据存储在数据库中某处的测试来说,会带来一系列特殊问题。
本节我们将重点关注两个问题。首先是测试性能。我们希望确保测试运行得尽可能快。对于单元测试,这意味着要么根本不针对数据库运行,要么针对内存数据库运行。对于其他类型的测试,这意味着要仔细管理测试数据,除了在少数有限的情况下,绝对不要使用生产数据库的转储。
第二个问题是测试隔离。理想的测试在一个定义明确的环境中运行,其输入是可控的,这样我们就能轻松评估其输出。而数据库是一个持久的信息存储,允许变更在测试调用之间持续存在——除非你明确采取措施来防止。这可能会使起始条件不明确,特别是当你可能无法直接控制测试的执行顺序时,这通常是常见情况。
单元测试不应该针对真实数据库运行,这一点很重要。通常单元测试会注入测试替身来代替与数据库交互的服务。但是,如果这不可行(例如,如果你想测试这些服务),还有另外两种策略可以应用。
图12.2 抽象数据库访问
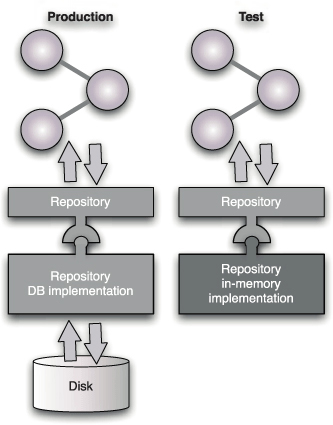
一种是用测试替身替换你的数据库访问代码。将访问数据库的代码封装在应用程序中是一个好的实践。实现这一目标的一个常用模式是仓储模式(Repository Pattern) [blIgdc]。在这个模式中,你在数据访问代码之上创建一个抽象层,将应用程序与所使用的数据库解耦(这实际上是[第13章]“管理组件和依赖关系”中描述的通过抽象分支模式的应用)。完成这个操作后,你就可以用测试替身替换数据访问代码。这种方法如[图12.2]所示。
这个策略不仅提供了一种支持测试的机制,正如我们所描述的,而且还鼓励将关注点放在系统的业务行为上,而不是数据存储需求上。它还倾向于确保所有数据访问代码保持在一起,从而使维护代码库更容易。这种组合优势通常超过维护单独抽象层的相对较小成本。
如果没有使用这种方法,仍然可以模拟数据库。有几个开源项目提供内存关系数据库(可以看看H2、SqlLite或JavaDB)。通过使应用程序交互的数据库实例可配置,你可以组织单元测试针对内存数据库运行。然后验收测试可以针对更常用的基于磁盘的数据库运行。同样,这种方法也有一些附加好处:它鼓励以稍微更解耦的方式编写代码,至少在能够针对两种不同数据库实现工作的程度上是如此。这反过来又确保了未来的更改——升级到更新版本,甚至可能更换到不同的RDBMS供应商——会更容易实现。
对于测试数据,重要的是测试套件中的每个单独测试都有一些可以依赖的状态。在编写验收标准的”给定、当、然后”格式中,测试开始时的初始状态是”给定”。只有当起始状态已知时,你才能将其与测试完成后的状态进行比较,从而验证所测试的行为。
对于单个测试来说这很简单,但对于测试套件来说需要一些思考才能实现,特别是对于依赖数据库的测试。
大体上,有三种管理测试状态的方法。
• 测试隔离: 组织测试,使每个测试的数据仅对该测试可见。
• 自适应测试: 每个测试被设计为评估其数据环境,并调整其行为以适应它看到的数据。
• 测试排序: 测试被设计为以已知顺序运行,每个测试的输入依赖于其前置测试的输出。
通常,我们强烈推荐第一种方法。将测试彼此隔离使它们更灵活,而且重要的是,能够并行运行以优化测试套件性能。
这两种方法都是可能的,但根据我们的经验,它们都不能很好地扩展。随着测试套件变得越来越大,它所体现的交互变得越来越复杂,这两种策略往往会导致非常难以检测和纠正的故障。测试之间的交互变得越来越模糊,维护一个可工作的测试套件的成本开始增长。
测试隔离是一种确保每个独立测试都是原子性的策略。也就是说,它不应该依赖其他测试的结果来建立其状态,其他测试也不应该以任何方式影响其成功或失败。对于提交测试来说,即使是那些测试数据库中数据持久性的测试,这种隔离级别也相对容易实现。
最简单的方法是确保在测试结束时,始终将数据库中的数据返回到测试运行之前的状态。你可以手动执行此操作,但最简单的方法是依赖大多数关系数据库管理系统的事务特性。
对于与数据库相关的测试,我们在测试开始时创建一个事务,在该事务中执行所有需要的操作和与数据库的交互,在测试结束时(无论通过与否),我们回滚该事务。这利用了数据库系统的事务隔离属性来确保其他测试或数据库用户不会看到测试所做的更改。
测试隔离的第二种方法是对数据执行某种功能分区。这对于提交测试和验收测试都是有效的策略。对于需要修改系统状态作为结果的测试,让你在测试中创建的主要实体遵循某种特定于测试的命名约定,这样每个测试将只查找和看到专门为它创建的数据。我们在第204页的”验收测试中的状态”部分更详细地描述了这种方法。
通过分区数据找到合适的测试隔离级别有多容易,在很大程度上取决于问题域。如果你的领域合适,这是保持测试相互独立的一个优秀且简单的策略。
无论选择哪种策略,在测试运行之前为测试建立一个已知良好的起始位置,并在测试结束时重新建立它,对于避免跨测试依赖关系至关重要。
对于隔离良好的测试,通常需要一个设置阶段来用相关的测试数据填充数据库。这可能涉及创建一个新事务,该事务将在测试结束时回滚,或者只是写入一些特定于测试的信息记录。
自适应测试将在启动时评估数据环境以建立已知的起始位置。
人们经常倾向于创建一个测试将遵循的连贯”故事”。这种方法的目的是使创建的数据保持连贯,从而最小化测试用例的设置和清理。这应该意味着每个测试本身都更简单一些,因为它不再负责管理自己的测试数据。这也意味着测试套件作为一个整体将运行得更快,因为它不会花费大量时间创建和销毁测试数据。
有时这种方法很诱人,但在我们看来,这是一个应该抵制的诱惑。这种策略的问题在于,在努力创建连贯故事的过程中,我们将测试紧密耦合在一起。这种紧密耦合有几个重要的缺点。随着测试套件规模的增长,测试变得更难设计。当一个测试失败时,它可能对依赖其输出的后续测试产生级联效应,使它们也失败。业务场景或技术实现的变化可能导致测试套件的痛苦返工。
但更根本的是,这种顺序有序的视图并不真正代表测试的现实。在大多数情况下,即使应用程序具有明确的步骤序列,在每个步骤中我们都想探索成功时会发生什么、失败时会发生什么、边界条件下会发生什么,等等。我们应该在非常相似的启动条件下运行一系列不同的测试。一旦我们转向支持这种视图,我们必然需要建立和重新建立测试数据环境,所以我们又回到了创建自适应测试或将测试彼此隔离的领域。
创建和管理用于自动化测试的数据可能是一项重大开销。让我们退一步。我们测试的重点是什么?
我们测试应用程序以断言它具有我们期望的各种行为特征。我们运行单元测试以保护自己免受无意中进行破坏应用程序的更改的影响。我们运行验收测试以断言应用程序向用户提供了预期的价值。我们执行容量测试以断言应用程序满足我们的容量要求。也许我们运行一套集成测试来确认我们的应用程序与它所依赖的服务正确通信。
在部署流水线的每个测试阶段,我们需要什么测试数据,我们应该如何管理它?
提交测试是部署流水线的第一阶段。提交测试快速运行对整个流程至关重要。提交阶段是开发人员等待测试通过后才能继续工作的节点。这个阶段每增加30秒都是昂贵的。
除了提交阶段测试的直接性能外,提交测试是防止系统意外变更的主要防线。这些测试与实现细节联系越紧密,它们在执行该角色时就越差。问题在于,当你需要重构系统某个方面的实现时,你希望测试能够保护你。如果测试与实现细节联系过于紧密,你会发现实现中的小改动会导致周围测试的更大改动。测试如果与实现细节耦合过紧,不仅无法保护系统行为从而促进必要的变更,反而会阻碍变更。如果你被迫为相对较小的实现改动而对测试进行大量修改,那么测试就没有有效地履行其作为行为可执行规范的角色。
这在关于数据和数据库的章节中可能听起来有些抽象,但测试中的紧耦合通常是过度复杂的测试数据造成的。
这是持续集成(Continuous Integration)过程带来一些看似无关的积极行为的关键点之一。好的提交测试避免复杂的数据设置。如果你发现自己在为特定测试建立数据时很费力,这肯定表明你的设计需要更好地分解。你需要将设计拆分为更多组件并独立测试每个组件,使用测试替身(Test Double)来模拟依赖关系,如第180页”使用测试替身”一节所述。
最有效的测试实际上不是真正的数据驱动;它们使用最少的测试数据来断言被测单元表现出预期的行为。那些确实需要更复杂数据来演示期望行为的测试应该谨慎创建数据,并尽可能重用测试辅助工具或夹具(Fixture)来创建数据,这样系统支持的数据结构设计的变更就不会对系统的可测试性造成灾难性打击。
在我们的项目中,我们通常会隔离创建这些常用数据结构测试实例的代码,并在许多不同的测试用例之间共享它们。我们可能有一个CustomerHelper或CustomerFixture类来简化为测试创建Customer对象的过程,这样它们就以一致的方式创建,每个Customer都有一组标准的默认值。然后每个测试可以定制数据以满足其需求,但它从一个已知的、一致的状态开始。
从根本上说,我们的目标是将每个测试特定的数据最小化为直接影响测试试图建立的行为的数据。这应该成为你编写的每个测试的目标。
验收测试与提交测试不同,它们是系统测试。这意味着它们的测试数据必然更加复杂,如果你想避免测试变得难以控制,就需要更仔细地管理。同样,目标是尽可能减少我们的测试对大型复杂数据结构的依赖。这种方法从根本上与提交阶段测试相同:我们的目标是在创建测试用例时实现重用,并最小化每个测试对测试数据的依赖。我们应该只创建足够的数据来测试系统的预期行为。
在考虑如何为验收测试设置应用程序状态时,区分三种数据类型很有帮助。
测试特定数据: 这是驱动被测行为的数据。它代表被测用例的具体内容。
测试参考数据: 通常有第二类数据与测试相关,但实际上对被测行为影响不大。它需要存在,但它是配角,不是主角。
应用程序参考数据: 通常,有些数据与被测行为无关,但需要存在才能让应用程序启动。
测试特定数据应该是唯一的,并使用测试隔离策略来确保测试在一个定义良好的环境中开始,不受其他测试副作用的影响。
测试参考数据可以通过使用预填充的种子数据来管理,这些数据在各种测试中重用以建立测试运行的一般环境,但不受测试操作的影响。
应用程序参考数据可以是任何值,甚至可以是空值,只要所选的值继续对测试结果没有影响。
应用程序参考数据以及测试参考数据(如果适用)—即应用程序启动所需的任何内容—可以以数据库转储的形式保存。当然,你必须对这些进行版本控制,并确保它们作为应用程序设置的一部分进行迁移。这是测试自动化数据库迁移策略的有效方法。
这种分类并不严格。在特定测试的上下文中,数据类别之间的界限往往有些模糊。然而,我们发现它是一个有用的工具,可以帮助我们专注于需要主动管理以确保测试可靠的数据,而不是那些只需要存在的数据。
从根本上说,让测试过度依赖代表整个应用程序的”完整”数据是一个错误。重要的是能够在一定程度的隔离下考虑每个测试,否则整个测试套件会变得过于脆弱,并且会随着数据的每一个小变化而不断失败。
然而,与提交测试不同,我们不建议使用应用程序代码或数据库转储来将应用程序置于测试所需的正确初始状态。相反,为了保持测试的系统级特性,我们建议使用应用程序的API将其置于正确状态。
这样做有几个优点:
• 使用应用程序代码或任何其他绕过应用程序业务逻辑的机制,可能会使系统处于不一致的状态。使用应用程序的API可以确保应用程序在验收测试期间永远不会处于不一致状态。
• 数据库或应用程序本身的重构对验收测试没有影响,因为根据定义,重构不会改变应用程序公共API的行为。这将使您的验收测试显著降低脆弱性。
• 您的验收测试也将作为应用程序API的测试。
考虑测试一个金融交易应用程序。如果某个特定测试侧重于确认在进行交易时用户的持仓位置被正确更新,那么起始持仓和结束持仓对该测试至关重要。
对于在具有实时数据库的环境中运行的一套有状态验收测试,这可能意味着该测试需要一个具有已知起始持仓的新用户账户。我们认为账户及其持仓是特定于测试的数据,因此对于验收测试而言,我们可以注册一个新账户并为其提供一些资金以允许交易,作为测试用例设置的一部分。
在测试过程中用于建立预期持仓的金融工具是测试的重要组成部分,但可以被视为测试参考数据,因为拥有一组被连续测试重用的工具不会影响我们”持仓测试”的结果。这些数据很可能是预填充的测试参考数据。
最后,建立新账户所需的选项详细信息与持仓测试无关,除非它们直接影响起始持仓或以某种方式影响用户持仓的计算。因此对于这些应用程序参考数据项,任何默认值都可以。
容量测试在大多数应用程序所需的数据规模方面存在问题。这个问题体现在两个方面:为测试提供足够量的输入数据的能力,以及提供合适的参考数据来同时支持许多测试用例。
如第9章”测试非功能性需求”所述,我们将容量测试主要视为重新运行验收测试的练习,但同时针对许多用例。如果您的应用程序支持下订单的概念,我们希望在进行容量测试时同时下许多订单。
我们的偏好是使用交互模板等机制自动生成这些大量的数据,包括输入和参考数据,详细信息请参见第241页的”使用记录的交互模板”部分。
这种方法实际上允许我们放大我们创建和管理的数据来支持我们的验收测试。我们倾向于尽可能广泛地应用这种数据重用策略,我们的理由是,我们作为验收测试套件的一部分编码的交互以及与这些交互相关的数据,主要是系统行为的可执行规范。如果我们的验收测试在这个角色上是有效的,它们就会捕获我们的应用程序支持的重要交互。如果它们没有编码我们想要作为容量测试的一部分测量的系统的重要行为,那就有问题了。
此外,如果我们有机制和流程来使这些测试随着应用程序的演进而保持运行,为什么在进行容量测试或任何其他验收后测试阶段时要放弃所有这些并重新开始呢?
因此,我们的策略是依靠我们的验收测试作为我们关注的系统交互的记录,然后将该记录用作后续测试阶段的起点。
对于容量测试,我们使用的工具会获取与选定验收测试相关的数据,并将其扩展到许多不同的”用例”,以便我们可以基于该测试对系统应用许多交互。
这种测试数据生成方法使我们能够将容量测试数据管理工作集中在对每个单独交互来说必然是唯一的数据核心上。
至少在设计理念层面,如果不是具体的技术方法,我们对所有验收后自动化测试阶段都应用相同的方法。我们的目标是将作为”行为规范”的自动化验收测试重用为任何非纯功能性测试的起点。
在创建 Web 应用程序时,我们使用验收测试套件不仅派生出容量测试,还派生出兼容性测试。对于兼容性测试,我们会针对所有主流 Web 浏览器重新运行整个验收测试套件。这不是详尽的测试——它无法告诉我们任何关于可用性的信息——但如果我们做出的更改在某个浏览器中完全破坏了用户界面,它确实会向我们发出警报。由于我们复用了部署机制和验收测试套件,并且使用虚拟机来托管测试,我们执行兼容性测试的能力几乎是免费的——除了运行测试所需的一些 CPU 时间和磁盘空间成本。
对于手动测试阶段,如探索性测试或用户验收测试环境,有几种测试数据处理方法。一种是运行最小的测试和应用程序参考数据集,使应用程序能够在空的初始状态下启动。然后测试人员可以试验用户初次开始使用应用程序时出现的场景。另一种方法是加载更大的数据集,以便测试人员可以执行假设应用程序已使用一段时间的场景。拥有大型数据集对于执行集成测试也很有用。
虽然可以为这些场景获取生产数据库的转储,但在大多数情况下我们不建议这样做。这主要是因为数据集太大而难以管理。迁移生产数据集有时可能需要数小时。尽管如此,在某些情况下使用生产数据转储进行测试很重要——例如,在测试生产数据库的迁移时,或者确定在什么时候需要归档生产数据以免过度拖慢应用程序时。
相反,我们建议创建用于手动测试的定制数据集,该数据集基于生产数据的子集,或基于运行一组自动化验收或容量测试后获取的数据库转储。你甚至可以定制容量测试框架,以生成一个数据库,该数据库代表一组用户持续使用后应用程序的真实状态。然后可以存储此数据集并将其作为部署到手动测试环境的一部分重复使用。当然,它需要作为此部署过程的一部分进行迁移。有时测试人员会保留多个数据库转储,作为各种测试的起点。
这些数据集,包括启动应用程序所需的最小数据集,也应该被开发人员在他们的环境中使用。开发人员绝对不应该在其环境中使用生产数据集。
由于其生命周期,数据管理带来的一系列问题不同于我们在部署流水线(deployment pipeline)背景下讨论的问题。然而,管理数据的基本原则是相同的。关键是确保有一个完全自动化的过程来创建和迁移数据库。此过程作为部署过程的一部分使用,确保其可重复和可靠。无论是将应用程序部署到带有最小数据集的开发或验收测试环境,还是作为生产部署的一部分迁移生产数据集,都应使用相同的过程。
即使有自动化的数据库迁移过程,仔细管理用于测试目的的数据仍然很重要。虽然生产数据库的转储可能是一个诱人的起点,但它通常太大而无法发挥作用。相反,让你的测试创建它们需要的状态,并确保它们以这样一种方式做到这一点:你的每个测试都独立于其他测试。即使对于手动测试,生产数据库转储是最佳起点的情况也很少。测试人员应该为自己的目的创建和管理更小的数据集。
以下是本章中一些更重要的原则和实践:
• 对数据库进行版本控制,并使用 DbDeploy 等工具自动管理迁移。
• 努力保持模式更改的前向和后向兼容性,以便你可以将数据部署和迁移问题与应用程序部署问题分开。
• 确保测试作为设置过程的一部分创建它们依赖的数据,并对数据进行分区以确保它不会影响可能同时运行的其他测试。
• 仅对应用程序启动所需的数据以及可能的一些非常通用的参考数据保留测试之间的设置共享。
• 尽可能尝试使用应用程序的公共 API 为测试设置正确的状态。
• 在大多数情况下,不要使用生产数据集的转储进行测试。通过仔细选择生产数据的较小子集,或从验收或容量测试运行中创建自定义数据集。
当然,这些原则需要适应你的情况。然而,如果将它们用作默认方法,它们将帮助任何软件项目最小化自动化测试和生产环境中与数据管理相关的最常见问题和事项的影响。
持续交付提供了每天多次发布软件新的可工作版本的能力。这意味着你必须始终保持应用程序处于可发布状态。但是,如果你正在进行大规模重构或添加复杂的新功能怎么办?在版本控制中使用分支似乎是解决这个问题的方案。然而,我们强烈认为这是错误的答案。本章介绍如何在持续变更的情况下,始终保持应用程序可发布。其中一个关键技术是大型应用程序的组件化,因此我们将详细讨论组件化,包括构建和管理包含多个组件的大型项目。
什么是组件?这在软件中是一个严重重载的术语,所以我们将尽可能清楚地说明我们的意思。当我们谈论组件时,我们指的是应用程序内相当大规模的代码结构,具有明确定义的API,可以潜在地被另一个实现替换。基于组件的软件系统的特点是代码库被划分为离散的部分,这些部分通过与其他组件的明确定义的、有限的交互来提供行为。
基于组件的系统的对立面是单体系统(monolithic system),在负责不同任务的元素之间没有清晰的边界或关注点分离。单体系统通常具有较差的封装性,逻辑上独立的结构之间的紧耦合违反了迪米特法则(Law of Demeter)。语言和技术并不重要——这与Visual Basic或Java中的GUI小部件无关。有些人将组件称为”模块”。在Windows中,组件通常打包为DLL。在UNIX中,它可能打包为SO文件。在Java世界中,它可能是一个JAR文件。
采用基于组件的设计通常被描述为鼓励重用和良好的架构特性,如松耦合。这是正确的,但它还有另一个重要的好处:它是大型开发团队协作的最有效方式之一。在本章中,我们还将介绍如何为基于组件的应用程序创建和管理构建系统。
如果你在一个小项目上工作,在阅读下一节之后(无论项目规模如何你都应该阅读),你可能会考虑跳过本章。许多项目使用单个版本控制仓库和简单的部署流水线就可以了。然而,许多项目已经演变成难以维护的代码泥潭,因为没有人在成本较低时做出创建离散组件的决定。小项目变成大项目的临界点是流动的,会悄悄地出现。一旦项目超过某个阈值,以这种方式更改代码就会非常昂贵。很少有项目负责人有勇气要求他们的团队停止开发足够长的时间,将大型应用程序重新架构为组件。如何创建和管理组件是我们将在本章中探讨的主题。
本章的内容依赖于对部署流水线的良好理解。如果你需要复习,请参阅第5章”部署流水线剖析”。在本章中,我们还将描述组件如何与分支交互。到本章结束时,我们将涵盖构建系统中的所有三个自由度:部署流水线、分支和组件。
在大型系统上工作时,同时使用这三个维度并不罕见。在这样的系统中,组件形成一系列依赖关系,这些依赖关系又依赖于外部库。每个组件可能有多个发布分支。找到这些组件的合适版本,将它们组装成一个甚至可以编译的系统是一个极其困难的过程,可能类似于打地鼠游戏——我们听说有些项目需要几个月的时间。只有完成这一步,你才能开始让系统通过部署流水线。
从本质上讲,这就是持续集成旨在解决的基本问题。像往常一样,我们提出的解决方案依赖于我们希望你现在已经熟悉的最佳实践。
持续集成旨在为你提供高度的信心,确保你的应用程序在功能层面正常工作。部署流水线作为持续集成的扩展,旨在确保你的软件始终可发布。但这两种实践都依赖于团队在主线上进行开发。
在开发过程中,团队不断添加功能,有时需要进行重大的架构更改。在这些活动期间,应用程序是不可发布的,尽管它仍然会通过持续集成的提交阶段。通常,在发布之前,团队会停止开发新功能并进入稳定阶段,在此期间只进行错误修复。当应用程序发布时,在版本控制中创建一个发布分支,新的开发在主干上重新开始。然而,这个过程通常导致发布之间间隔数周或数月。持续交付的目标是让应用程序始终处于可发布状态。我们如何实现这一目标?
一种方法是在版本控制中创建分支,在工作完成时合并,以便主线始终保持可发布状态。我们在下一章”高级版本控制”中会详细探讨这种方法。然而,我们认为这种方法并非最优,因为如果工作在分支上进行,应用程序就没有被持续集成。相反,我们主张每个人都在主线上提交。如何才能让每个人都在主线上工作,同时始终保持应用程序处于可发布状态?
在面对变更时保持应用程序可发布状态,需要采用四种策略:
• 隐藏新功能直到完成。
• 将所有变更作为一系列小变更增量进行,每个变更都是可发布的。
• 使用抽象分支对代码库进行大规模变更。
• 使用组件解耦应用程序中变更速度不同的部分。
我们将在这里讨论前三种策略。这三种策略应该足以应对小型项目。在大型项目中,你需要考虑使用组件,我们将在本章其余部分介绍。
应用程序持续部署的一个常见问题是,一个功能或一组功能可能需要很长时间才能开发完成。如果增量发布一组功能没有意义,通常会倾向于在版本控制的分支上开始新开发,并在功能准备好时集成,以免中断系统其余部分的工作,否则可能会阻止其发布。
一种解决方案是添加新功能,但使用户无法访问它们。例如,考虑一个提供旅行服务的网站。运营该网站的公司想要提供一项新服务:酒店预订。为此,将这项新服务作为一个独立组件开始工作,通过独立的URI根路径 /hotel 访问。如果需要,这个组件仍然可以与系统的其余部分一起部署——只要不允许访问其入口点(这可以通过Web服务器软件中的配置设置来实现)。
在Jez的一个项目中,开发人员使用这种方法开始开发新的UI。在开发期间,新UI放置在URI /new/ 下,没有任何链接指向它。当我们开始使用新UI的部分内容时,我们从现有导航链接到它们。这使我们能够以增量方式替换整个UI,同时保持应用程序始终正常工作。两个UI共享样式表,因此它们看起来相同,尽管它们使用完全不同的技术实现;除非查看URI,否则用户不知道哪个页面使用了哪种技术。
确保半完成组件可以交付但用户无法访问的另一种方法是通过配置设置来打开和关闭对它们的访问。例如,在富客户端应用程序中,你可能有两个菜单——一个包含新功能,一个不包含。你可以使用配置设置在两个菜单之间切换。这可以通过命令行选项或其他部署时或运行时配置来实现(有关配置软件的更多信息,请参见第2章”配置管理”)。通过运行时配置打开和关闭功能(或将它们替换为其他实现)的能力在运行自动化测试时也非常有用。
即使是大型组织也以这种方式开发软件。我们同事工作过的一个世界领先的搜索引擎公司不得不修补Linux内核,以便它能够接受大量的命令行参数来打开和关闭软件中的各种功能。这是一个极端的例子,我们不建议保留太多选项——一旦它们完成使命,应该仔细清理掉。可以在代码库中标记配置选项,并使用静态分析作为提交阶段的一部分,为此目的提供可用配置选项列表。
将半完成的功能与应用程序的其余部分一起交付是一个好的实践,因为这意味着你始终在集成和测试整个系统在任何时间点的状态。这使得规划和交付整个应用程序变得更加容易,因为这意味着不需要在项目计划中引入依赖关系和集成阶段。它确保正在开发的新组件从一开始就可以与软件的其余部分一起部署。它还意味着你始终在测试整个应用程序,包括新组件所需的任何新服务或修改后的服务,以防止回归。
以这种方式编写软件需要一定的规划、仔细的架构和严格的开发。然而,即使在添加主要功能集时也能发布软件新版本的好处通常非常值得付出额外的努力。这种方法也优于使用版本控制分支进行新功能开发。
上述故事——将应用程序逐步迁移到全新UI——只是一般策略的一个特定示例:以增量方式进行所有更改。在进行大规模更改时,通常很容易受到诱惑去分支源代码并在分支上进行更改。理论上认为,如果开发人员可以进行破坏应用程序的大规模高层次更改,然后再将所有内容重新连接起来,他们就可以更快地推进工作。然而,在实践中,将所有内容连接起来最终才是最困难的部分。如果其他团队同时在工作,最后的合并可能会很困难——而且更改越大,合并就越困难。表面上分支的理由越充分,你就越不应该分支。
即使将大规模更改转化为一系列小的增量更改在执行时是艰苦的工作,但这意味着你在过程中解决了保持应用程序运行的问题,避免了最后的痛苦。这也意味着如果需要的话你可以随时停止,避免陷入完成一半大更改后不得不放弃的沉没成本。
分析在能够将大规模更改作为一系列小更改方面发挥着重要作用。在许多方面,这个思考过程与将需求分解为更小任务所使用的思考过程是相同的。然后你要做的是将任务转化为一组更小的增量更改。这种额外的分析通常可以减少错误并使更改更有针对性——当然,如果你以增量方式进行更改,你可以边做边评估,并决定如何(以及是否)继续推进。
然而,有时有些更改很难以增量方式进行。此时,你应该考虑抽象分支(branch by abstraction)。
这种模式是当你需要对应用程序进行大规模更改时分支的替代方案。它不是分支,而是在需要更改的部分之上创建一个抽象层。然后与现有实现并行创建新实现,当新实现完成后,移除原始实现和(可选的)抽象层。
创建抽象层通常很困难。例如,在Windows桌面VB应用程序中,应用程序的所有逻辑都包含在事件处理程序中是很常见的。为这样的应用程序创建抽象层涉及为逻辑构建面向对象设计,并通过将现有代码从事件处理程序重构到一组VB(或者可能是C#)类中来实现它。然后新UI(可能是web UI)将重用新逻辑。请注意,不需要为逻辑实现创建接口——只有当你想对逻辑执行抽象分支时才需要这样做。
一个在最后不会移除抽象层的例子是,当你希望系统用户能够选择他们的实现时。在这种情况下,你本质上是在设计一个插件API。Eclipse中使用的OSGi等工具可以为使用Java的团队简化这个过程。根据我们的经验,最好不要在项目开始时预先创建插件API。相反,先创建你的第一个实现,然后是第二个,并从这些实现中提取出API。随着你添加更多实现和这些实现中使用的更多功能,你会发现你的API变化相当快。如果你计划公开公开它以允许其他人开发插件,你会希望等待它稳定下来。
尽管这种模式被我们的同事Paul Hammant命名为”抽象分支”,但它实际上是使用分支对应用程序进行大规模更改的替代方案。当应用程序的某些部分需要无法作为一系列小增量步骤实现的更改时,请执行以下操作:
在需要更改的系统部分之上创建抽象。
重构系统的其余部分以使用抽象层。
创建新实现,在完成之前它不属于生产代码路径。
更新抽象层以委托给新实现。
移除旧实现。
如果抽象层不再适用,则移除它。
抽象分支是使用分支或一步实现复杂更改的替代方案。它允许团队在持续集成中继续开发应用程序,同时也可以替换其大部分内容,所有这些都在主线上进行。如果代码库的某些部分需要更改,你首先找到这部分的入口点——一个接缝(seam)——并放入一个委托给当前实现的抽象层。然后在新实现旁边开发新实现。使用哪个实现由配置选项决定,该选项可以在部署时甚至运行时修改。
你可以在非常高的层次上进行抽象分支,例如替换整个持久层。你也可以在非常低的层次上进行——例如使用策略模式(strategy pattern)将一个类替换为另一个类。依赖注入(dependency injection)是另一种实现抽象分支的机制。诀窍在于找到或创建允许你插入抽象层的接缝。
这也是一个优秀的模式,可作为将使用大泥球”模式”的单体代码库转变为更模块化、结构更良好形式的策略的一部分。选取代码库中您想要作为组件分离出来或重写的部分。只要您能管理这部分代码库的入口点,可能使用外观模式,您就可以将混乱局部化,并使用抽象分支来保持应用程序使用旧代码运行,同时创建相同功能的新的模块化版本。这种策略有时被称为”扫到地毯下”或”波将金村”。
抽象分支最困难的两个部分是隔离相关代码库部分的入口点,以及管理需要对正在开发的功能进行的任何更改,可能作为bug修复的一部分。然而,这些问题比分支管理要容易得多。尽管如此,有时在代码库中找到一个好的接合点实在太难了,分支是唯一的解决方案。使用分支将代码库调整到可以执行抽象分支的状态。
对应用程序进行大规模更改,无论是通过抽象分支还是任何其他技术,都能从全面的自动化验收测试套件中获得巨大收益。当应用程序的大块内容被更改时,单元测试和组件测试的粒度不够粗,无法保护您的业务功能。
当一个软件为了构建或运行而依赖于另一个软件时,就会产生依赖关系。在除了最简单的应用程序之外的任何应用程序中,都会存在一些依赖关系。大多数软件应用程序至少依赖于它们的宿主操作环境。Java应用程序依赖于提供Java SE API实现的JVM,.NET应用程序依赖于CLR,Rails应用程序依赖于Ruby和Rails框架,C应用程序依赖于C标准库,等等。
在本章中有两个特别有用的区分:组件与库之间的区分,以及构建时依赖与运行时依赖之间的区分。
我们这样区分组件和库:库是指您的团队无法控制的软件包,除了选择使用哪个。库通常很少更新。相比之下,组件是您的应用程序依赖的软件片段,但也是由您的团队或组织中的其他团队开发的。组件通常频繁更新。这种区分很重要,因为在设计构建过程时,处理组件时要考虑的事情比库更多。例如,您是在单个步骤中编译整个应用程序,还是在每个组件发生变化时独立编译?如何管理组件之间的依赖关系,避免循环依赖?
构建时依赖与运行时依赖之间的区分如下:构建时依赖必须在应用程序编译和链接(如有必要)时存在;运行时依赖必须在应用程序运行并执行其常规功能时存在。这种区分很重要,原因有几个。首先,在部署流水线中,您将使用许多与应用程序的部署副本无关的不同软件,例如单元测试框架、验收测试框架、构建脚本框架等。其次,应用程序在运行时使用的库版本可能与构建时使用的版本不同。当然,在C和C++中,您的构建时依赖只是头文件,而在运行时您需要以动态链接库(DLL)或共享库(SO)形式存在的二进制文件。但您也可以在其他编译语言中做类似的事情,例如针对仅包含系统接口的JAR进行构建,并针对包含完整实现的JAR运行(例如,使用J2EE应用服务器时)。这些考虑因素也需要在构建系统中考虑。
管理依赖关系可能很困难。我们将从运行时库的最常见依赖问题概述开始。
依赖管理最著名的问题可能被称为”依赖地狱”,有时俗称”DLL地狱”。当应用程序依赖于某个特定版本的东西,但部署时使用了不同的版本,或者根本没有时,就会出现依赖地狱。
DLL地狱在早期版本的Microsoft Windows中是一个非常常见的问题。所有共享库以DLL形式存储在系统目录(windows)中,没有任何版本控制——新版本会简单地覆盖旧版本。除此之外,在Windows XP之前的版本中,COM类表是单例,因此需要特定COM对象的应用程序会被赋予首先加载的任何版本。所有这些意味着不同的应用程序不可能依赖于DLL的不同版本,甚至无法知道在运行时会得到哪个版本。
.NET框架的引入通过引入程序集(assembly)的概念解决了DLL地狱问题。经过加密签名的程序集可以被赋予版本号,从而允许区分同一库的不同版本,Windows将它们存储在全局程序集缓存(称为”GAC”)中,即使它们具有相同的文件名,GAC也可以区分库的不同版本。现在你可以为应用程序提供多个不同版本的库。使用GAC的优势在于,如果需要推送关键错误修复或安全修复,你可以一次性更新所有使用受影响DLL的应用程序。尽管如此,.NET也支持DLL的”xcopy部署”,即将它们保存在与应用程序相同的目录中,而不是GAC中。
Linux通过使用简单的命名约定来避免依赖地狱:它在全局库目录(/usr/lib)中的每个.so文件后附加一个整数,并使用软链接来确定规范的系统范围版本。管理员可以轻松更改应用程序要使用的版本。如果应用程序依赖于特定版本,它会请求具有相应版本号的文件。当然,拥有库的规范系统范围版本意味着要确保每个已安装的应用程序都能使用该版本。这个问题有两个答案:从源代码编译每个应用程序(Gentoo采用的方法),或对每个应用程序的二进制文件进行复杂的回归测试(大多数Linux发行版创建者首选)。这确实意味着,如果没有复杂的依赖管理工具,你就不能随意安装依赖于系统库新版本的应用程序的新二进制发行版。幸运的是,Debian软件包管理系统就是这样一个工具——可能是现存最出色的依赖管理工具,这也是Debian成为如此稳固的平台以及Ubuntu能够每年发布两次稳定版本的主要原因。
操作系统范围依赖问题的一个简单答案是明智地应用静态编译。这意味着在编译时将对应用程序最关键的依赖项聚合到单个程序集中,从而减少运行时依赖。然而,虽然这使部署更简单,但也有一些缺点。除了创建大型二进制文件外,它还将由此创建的二进制文件与特定版本的操作系统紧密耦合,并且无法通过操作系统更新来修复错误或安全漏洞。因此通常不建议使用静态编译。
对于动态语言,等效的方法是将应用程序依赖的任何框架或库与其一起发布。Rails采用这种方法,允许整个Rails框架与使用它的应用程序一起发布。这意味着你可以同时运行多个Rails应用程序,每个应用程序使用框架的不同版本。
由于类加载器的设计,Java面临着特别严重的运行时依赖问题。原始设计阻止了同一JVM中可用类的多个版本。这一限制已通过OSGi框架得到克服,该框架提供了多版本类加载以及热部署和自动更新功能。如果不使用OSGi,限制仍然存在,这意味着必须在构建时仔细管理依赖项。一个常见但令人不快的场景是应用程序依赖于两个库(在这种情况下是JAR),每个库都依赖于同一个底层库(例如日志库)但版本不同。应用程序可能会编译,但几乎肯定会在运行时失败,要么出现ClassNotFound异常(如果所需的方法或类不存在),要么出现微妙的错误。这个问题被称为钻石依赖问题。
我们将在本章后面讨论钻石依赖问题的解决方案以及另一个病态案例——循环依赖。
在软件项目中管理库有两种合理的方法。一种是将它们签入版本控制。另一种是声明它们并使用Maven或Ivy等工具从Internet仓库或(最好是)组织自己的制品仓库下载库。你需要强制执行的关键约束是构建是可重复的——也就是说,如果我从版本控制中检出项目并运行自动化构建,我可以保证得到与项目中其他人完全相同的二进制文件,并且三个月后当我需要调试用户报告的运行旧版本软件的问题时,我可以创建完全相同的二进制文件。
将库签入版本控制是最简单的解决方案,对于小型项目来说效果很好。传统上,在项目根目录中创建一个lib目录来放置库。我们建议添加三个子目录:build、test和run——分别用于构建时、测试时和运行时依赖项。我们还建议对库使用包含版本号的命名约定。因此不要只将nunit.dll签入lib目录——而是签入nunit-2.5.5.dll。这样,你就确切地知道使用的是哪个版本,并且很容易确定是否使用了所有最新最好的版本。这种方法的好处是构建应用程序所需的一切都在版本控制中——一旦你有了项目仓库的本地检出,你就知道可以重复构建与其他人相同的包。
将整个工具链纳入版本控制是个好主意,因为这代表了项目的构建时依赖。但是,你应该将它检入到与项目其余部分不同的仓库中,因为工具链仓库很容易变得非常庞大。你应该防止项目仓库变得过大,导致执行常见仓库操作(如查看本地更改和向中央仓库提交小更改)需要超过几秒钟的时间。另一个替代方案是将工具链保存在共享的网络存储上。
将库文件纳入版本控制存在几个问题。首先,随着时间推移,你检入的库仓库可能会变得庞大而混乱,可能很难知道应用程序仍在使用哪些库。如果你的项目必须与同一平台上的其他项目一起运行,就会出现另一个问题。一些平台可以处理项目使用同一库的多个版本,而其他平台(例如没有OSGi的JVM或Ruby Gems)不允许使用同一库的多个版本。在这种情况下,你需要小心使用与其他项目相同的库版本。手动管理跨项目的传递依赖很快就会变得痛苦。
Maven和Ivy提供了自动化的依赖管理方法,允许你在项目配置中准确声明所需库的版本。这些工具会下载所需库的适当版本,传递性地解析对其他项目的依赖(如果适用),并确保项目依赖图中没有不一致之处,例如两个组件需要某个公共库的互不兼容的版本。这些工具会在本地机器上缓存项目所需的库,因此尽管首次在新机器上运行项目时构建可能需要很长时间,但后续构建的速度与将库检入版本控制时一样快。Maven的问题在于,为了实现可重复构建,你必须将其配置为使用特定版本的插件,并确保为每个项目依赖指定确切的版本。本章稍后将详细介绍使用Maven进行依赖管理。
使用依赖管理工具时的另一个重要实践是管理自己的制品仓库(artifact repository)。开源制品仓库包括Artifactory和Nexus。这有助于确保构建的可重复性,并通过控制组织内项目可用的每个库的版本来防止依赖地狱(dependency hell)。这种做法还可以更容易地审计库,防止违反法律约束,例如在BSD许可的软件中使用GPL许可的库。
如果Maven和Ivy不合适,也可以通过使用简单的属性文件来构建自己的声明式依赖管理系统,该文件指定项目依赖的库及这些库的版本。然后可以编写脚本从组织的制品仓库下载这些库的正确版本—制品仓库可以简单到由简单的Web服务提供的备份文件系统。当然,如果需要处理更复杂的问题(如解析传递依赖),则需要更强大的解决方案。
几乎所有现代软件系统都由一组组件构成。这些组件可能是DLL、JAR文件、OSGi捆绑包、Perl模块或其他形式。组件在软件行业有着相对悠久的历史。然而,弄清楚如何将它们组装成可部署的制品,以及如何实现考虑到组件之间交互的部署流水线,是一项非常复杂的任务。这种复杂性的结果通常表现为构建需要花费数小时才能组装出可部署、可测试的应用程序。
大多数应用程序最初是单个组件。有些以两三个组件开始(例如客户端-服务器应用程序)。那么为什么要将代码库拆分为组件,以及应该如何管理它们之间的关系?除非这些关系得到有效管理,否则会影响将它们用作持续集成系统一部分的能力。
软件中”组件”的概念是大多数人看到时都能识别的,但有许多不同的、往往模糊的定义。我们在引言中已经粗略定义了本章中”组件”的含义,但组件还有一些大多数人都会同意的其他属性。一个相当没有争议的描述可能如下:“组件是可重用的、可替换为实现相同API的其他组件、可独立部署的,并封装了系统的某些一致的行为和职责集合。”
显然,单个类原则上可以具有这些特征—但通常情况并非如此。组件必须可独立部署的要求意味着类通常不符合条件。没有什么能阻止我们打包单个类以便部署,但在大多数情况下,与打包相关的开销在这个细节级别上没有意义。此外,类通常以集群方式工作,小组类紧密协作以提供有用的行为,相对而言,它们与紧密的协作者之间的耦合更紧密。
由此我们可以假定,对于什么构成一个组件存在某个下限。组件应该具有一定的复杂度才能被视为应用程序的独立部分。那么上限呢?我们将系统划分为组件的目的是提高团队效率。组件使软件开发过程更高效的原因有几个:
它们将问题划分为更小、更具表达力的块。
组件通常代表系统不同部分变化速率的差异,并且具有不同的生命周期。
它们鼓励我们设计和维护具有清晰职责界限的软件,从而限制变更的影响,使理解和修改代码库变得更容易。
它们可以为优化我们的构建和部署流程提供额外的自由度。
大多数组件的一个重要特征是它们以某种形式公开 API。这个 API 的技术基础可以以不同方式提供:动态链接、静态链接、Web 服务、文件交换、消息交换等等。API 的性质可能不同,但重要的是它代表了与外部协作者的信息交换——因此,至关重要的是,该组件与这些协作者的耦合程度。即使组件的接口是文件格式或消息模式,它仍然代表信息耦合,反过来需要考虑组件之间的依赖关系。
当组件被分离并在构建和部署过程中作为独立单元处理时,正是组件之间在接口和行为方面的耦合程度增加了复杂性。
以下是从代码库中分离组件的一些充分理由:
代码库的某部分需要独立部署(例如,服务器或富客户端)。
你想将单体代码库转变为核心和一组插件,也许是为了用替代实现替换系统的某部分,或提供用户可扩展性。
组件提供到另一个系统的接口(例如提供 API 的框架或服务)。
编译和链接代码花费太长时间。
在开发环境中打开项目花费太长时间。
你的代码库太大,无法由单个团队完成。
尽管此列表中的后三项听起来可能相当主观,但它们是提取组件的完全有效的理由。最后一点尤其关键。团队在由大约十个人组成、对代码库的特定部分了如指掌时效果最好,无论是功能组件还是其他边界。如果需要超过十个人以你需要的速度开发,一个非常有效的方法是将系统划分为松耦合的组件,并同时划分团队。
我们不建议让团队负责单个组件。这是因为在大多数情况下,需求并不按组件边界划分。根据我们的经验,由成员端到端开发功能的跨职能团队要有效得多。尽管每个组件一个团队可能看起来更有效率,但事实并非如此。
首先,通常很难单独为单个组件编写和测试需求,因为通常实现一项功能会涉及多个组件。如果按组件分组团队,因此需要两个或更多团队协作才能完成一个功能,这会自动增加大量且不必要的沟通成本。此外,以组件为中心的团队中的人往往会形成孤岛并进行局部优化,失去判断什么对整个项目最有利的能力。
更好的做法是拆分团队,让每个团队承担一个故事流(也许都有共同主题),并触及他们完成工作所需的任何组件。拥有实现业务级功能授权以及改变所需任何组件的自由的团队要高效得多。按功能区域而非组件组织团队,确保每个人都有权改变代码库的任何部分,定期在团队之间轮换人员,并确保团队之间有良好的沟通。
这种方法还有一个好处,就是让所有组件协同工作是每个人的责任,而不仅仅是集成团队的责任。每个组件一个团队的更严重危险之一是,整个应用程序直到项目结束才能工作,因为没有人有动力集成组件。
上面列表中的第四和第五个理由通常是设计不良、模块化不足的症状。遵循”不要重复自己”(DRY)原则、由遵守得墨忒耳定律(Law of Demeter)的良好封装对象组成的设计良好的代码库,通常更高效、更容易处理,并且在需要时更容易拆分为组件。然而,缓慢的构建过程也可能由过度激进的组件化引起。这在 .NET 世界中似乎特别普遍,一些人喜欢在解决方案中创建大量项目,却没有充分的理由。这样做不可避免地导致编译速度慢如蜗牛。
没有关于如何将应用程序组织为组件集合的硬性规定,除了上面讨论的良好设计的考虑因素之外。然而,有两种常见的失败模式:“到处都是组件”和”一个组件统治所有”。经验表明,这两个极端都不合适,但判断边界在哪里仍然是开发人员和架构师的判断问题,无论他们有多少经验。这是使软件设计成为一门艺术、工艺和社会科学,同时也是一门工程学科的诸多因素之一。
Sun在推出J2EE框架时普及了N层架构的概念。Microsoft继续将其作为.NET框架的最佳实践呈现。Ruby on Rails可以说是在鼓励类似的架构方法,当然同时使入门变得更简单,并对系统施加更多约束。N层架构通常代表了解决某些问题的良好方法,但不一定适用于所有问题。
在我们看来,N层架构经常被用作防御性设计的一种形式。它可以帮助防止大型且缺乏经验的团队创建紧密耦合的泥球。它也具有易于理解的容量和可扩展性特征。然而,它通常不是许多问题的最优解决方案(当然,这对所有技术和模式都是如此)。特别值得注意的是,在物理上分离的环境中运行多个层将导致响应任何特定请求时的高延迟。这反过来又经常导致引入复杂的缓存策略,这些策略难以维护和调试。在高性能环境中,事件驱动或分布式Actor模型架构可以提供更优越的性能。
我们遇到的一个大型项目的架构师曾强制要求架构中必须有七层。很多时候,其中一层或多层是冗余的。然而,仍然必须引入必需的类,并且必须记录对每个方法的每次调用。不用说,由于大量无意义的日志条目,应用程序很难调试。由于大量冗余代码,它难以理解,由于层之间的依赖关系,它难以修改。
使用组件并不强制使用N层架构。它意味着通过找到合理的抽象来将逻辑分离到封装的模块中,以促进这种分离。分层可能很有用——甚至N层分层——但它不是基于组件的开发的同义词。
在另一个极端,如果组件不会自动意味着分层,那么分层也不应该自动定义组件。如果你使用分层架构,不要为每一层创建一个组件。你几乎总是应该在一个层内有多个组件,实际上可能有被多个层使用的组件。基于组件的设计与分层是正交的。
最后,值得注意康威定律(Conway’s Law),该定律指出”设计系统的组织……被约束去产生这些设计,这些设计是这些组织的沟通结构的副本。“例如,开发人员仅通过电子邮件进行沟通的开源项目往往非常模块化,接口很少。由一个小型的、集中办公的团队开发的产品往往是紧密耦合且不模块化的。要小心如何设置你的开发团队——它会影响应用程序的架构。
如果你的代码库已经很大且是单体式的,开始将其分解为组件的一种方法是使用本章前面描述的抽象分支(branching by abstraction)。
即使你的应用程序由多个组件组成,也并不意味着你需要为每个组件都有一个独立的构建。实际上,最简单的方法,也是一种可以扩展到令人惊讶程度的方法,是为整个应用程序使用单个流水线。每次提交更改时,所有内容都会被构建和测试。在大多数情况下,我们建议将系统作为单个实体进行构建,直到获得反馈的过程变得太慢。正如我们所说,如果你遵循本书中的建议,你可能会发现可以用这种方式构建令人惊讶的大型和复杂系统。这种方法的优点是很容易追踪哪一行代码破坏了构建。
然而,实际上有许多情况受益于将系统拆分为几个不同的流水线。以下是一些适合使用独立流水线的情况示例:
• 应用程序中具有不同生命周期的部分(也许你构建自己版本的OS内核作为应用程序的一部分,但你只需要每几周做一次)。
• 由不同(可能是分布式的)团队处理的应用程序在功能上独立的区域可能具有特定于这些团队的组件。
• 使用不同技术或构建过程的组件。
• 被多个其他项目使用的共享组件。
• 相对稳定且不经常变化的组件。
• 构建应用程序需要太长时间,为每个组件创建构建会更快(但要注意,这一点成立的时机比大多数人认为的要晚得多)。
从构建和部署流程的角度来看,重要的一点是基于组件的构建总是会带来一些额外的管理开销。为了将单个构建拆分为多个,你需要为每个组件创建一个构建系统。这意味着每个独立的部署管道都需要一个新的目录结构和构建文件,每个都应该遵循与整个系统相同的模式。这意味着每个构建的目录结构应该包括单元测试、验收测试、它所依赖的库、构建脚本、配置信息,以及你通常会放入项目版本控制中的任何其他内容。每个组件或组件集的构建都应该有自己的管道来证明它适合发布。这个管道将执行以下步骤:
• 编译代码(如果需要)。
• 组装一个或多个可以部署到任何环境的二进制文件。
• 运行单元测试。
• 运行验收测试。
• 在适当的情况下支持手动测试。
这个流程与整个系统一样,确保你能够尽早获得反馈,验证每次变更的可行性。
一旦二进制文件通过了它们自己的小型发布流程,它们就可以被提升到集成构建中(下一节将详细介绍)。你需要将二进制文件发布到制品仓库(artifact repository),同时附带一些元数据来标识用于创建二进制文件的源代码版本。现代CI服务器应该能够为你完成这项工作,尽管如果你想自己做,可以简单地将二进制文件存储在以生成它的管道标签命名的目录中。另一个替代方案是使用Artifactory、Nexus或其他制品仓库软件。
请注意,我们明确表示你不应该为每个DLL或JAR创建一个管道。这就是为什么我们在上文中反复小心地说”组件或组件集”。一个组件可能包含多个二进制文件。通常,指导原则应该是尽量减少你运行的构建数量。一个比两个好,两个比三个好,依此类推。在转向并行管道方法之前,应该尽可能长时间地持续优化构建并提高其效率。
图13.1 集成管道
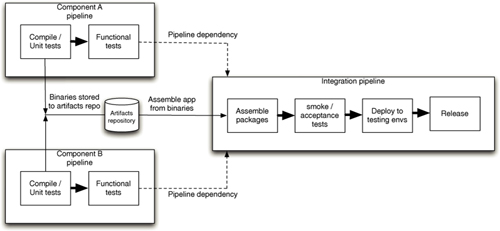
集成管道以组成你的系统的每个组件的二进制输出作为起点。集成管道的第一阶段应该通过组合适当的二进制文件集合来创建适合部署的包。第二阶段应该将生成的应用程序部署到类生产环境中,并对其运行冒烟测试(smoke tests),以便尽早发现任何基本的集成问题。如果这个阶段成功,那么管道应该进入常规的验收测试阶段,以通常的方式运行整个应用程序的验收测试。然后是适合该应用程序的正常阶段序列,如图13.1所示。
在创建集成管道时,需要记住部署管道的两个一般原则:快速反馈的需求和为所有相关方提供构建状态可见性的需求。反馈可能会被长管道或管道链所影响。如果你发现自己处于这种情况并且有足够的硬件,一个解决方案是在创建二进制文件并通过单元测试后立即触发下游管道。
在可见性方面,如果集成管道的任何阶段失败,应该能够准确地看到失败的原因。这意味着能够从集成构建追溯到为其贡献的每个组件的版本是关键。如果要能够发现导致故障的源代码变更,维护这些关系至关重要。现代CI工具应该能够为你完成这项工作,所以如果你的工具做不到,找一个能做到的。追踪集成管道失败的原因不应该超过几秒钟。
同样,并非每个独立组件的”绿色”构建在与组成整个应用程序的其他组件结合时实际上都是好的。因此,从事组件工作的团队应该能够看到他们组件的哪些版本实际上最终进入了绿色的集成管道(因此可以被认为适合集成)。只有这些版本的组件实际上才是真正”绿色”的。集成管道形成了每个独立组件管道的延伸。因此,双向的可见性都很重要。
如果在集成管道的一次运行和下一次运行之间有多个组件发生变化,它很可能会在大部分时间里处于失败状态。这是有问题的,因为它使得找出哪个变更破坏了你的应用程序变得更加困难,因为自上一个好版本的应用程序以来会有很多变更。
有几种不同的技术可以解决这个问题,我们将在本章的其余部分探讨。最简单的方法是构建组件的良好版本的每一种可能组合。如果你的组件不经常变化,或者你的构建网格(build grid)有足够的计算能力,你可以这样做。这是最好的方法,因为它不涉及任何人工干预或复杂的算法,而且计算能力最终比人工取证要便宜。所以如果可以,就这样做。
下一个最佳方法是尽可能多地构建应用程序的各个版本。你可以使用一个相对简单的调度算法来实现这一点,该算法获取每个组件的最新版本,并尽可能频繁地组装你的应用程序。如果这个操作足够快,你可以对应用程序的每个版本运行简短的冒烟测试套件。如果冒烟测试需要较长时间才能运行完成,那么它们可能最终只能对应用程序的每第三个版本运行测试。
然后你可以通过某种手动方式选择一组给定版本的组件,并说”组装这些组件,并使用它们创建我的集成流水线(integration pipeline)的一个实例”,这可以通过一些持续集成(CI)工具来实现。
对依赖项进行版本控制至关重要,包括库和组件。如果不对依赖项进行版本控制,你将无法重现构建。这意味着,当你的应用程序因依赖项的更改而中断时,你将无法回溯并找到导致中断的更改,也无法找到库的最后一个”良好”版本。
在上一节中,我们讨论了一组组件,每个组件都有自己的流水线,这些流水线汇入一个集成流水线,该流水线组装应用程序并对最终应用程序运行自动化和手动测试。然而,事情通常并不那么简单:组件之间可能存在依赖关系,包括第三方库。如果你绘制组件之间依赖关系的图表,它应该是一个有向无环图(DAG)。如果情况并非如此(特别是如果你的图中存在循环),那么你就遇到了病态的依赖问题,我们将很快解决这个问题。
图13.2 依赖图
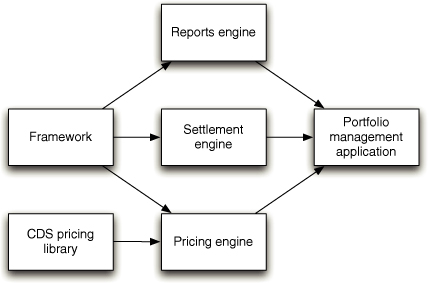
首先,重要的是考虑如何构建依赖关系图。考虑图13.2中显示的一组组件。
投资组合管理应用程序依赖于定价引擎、结算引擎和报告引擎。这些引擎又都依赖于一个框架。定价引擎依赖于由第三方(现在陷入困境)提供的信用违约互换(CDS)库。一般来说,我们将图表中更靠左的组件称为”上游”依赖项,将更靠右的组件称为”下游”依赖项。因此,定价引擎有两个上游依赖项,即CDS定价库和框架,以及一个下游依赖项,即投资组合管理应用程序。
每个组件都应该有自己的流水线,由该组件源代码的更改或任何上游依赖项的更改触发。下游依赖项将在该组件通过所有自动化测试后触发。在构建这个组件图时,需要考虑几种可能的场景。
对投资组合管理应用程序进行更改。在这种情况下,只需要重新构建投资组合管理应用程序。
对报告引擎进行更改。在这种情况下,必须重新构建报告引擎并通过所有自动化测试。然后需要使用新版本的报告引擎和当前版本的定价和结算引擎重新构建投资组合管理应用程序。
对CDS定价库进行更改。CDS定价库是第三方二进制依赖项。因此,如果正在使用的CDS版本更新,则需要针对新版本和当前版本的框架重新构建定价引擎。这反过来应该触发投资组合管理应用程序的重新构建。
对框架进行更改。如果对框架进行了成功的更改,意味着框架流水线通过了测试,则应该重新构建其直接下游依赖项:报告引擎、定价引擎和结算引擎。如果这三个依赖项都通过了,那么应该使用所有三个上游依赖项的新版本重新构建投资组合管理应用程序。如果三个中间组件构建中的任何一个失败,则不应重新构建投资组合管理应用程序,并且应将框架组件视为已损坏。应该修复框架,使其所有三个下游依赖项都能通过测试,这反过来应该导致投资组合管理应用程序通过。
从这个例子中可以得出一个重要的观察结果。在考虑场景4时,投资组合管理应用程序的上游依赖项之间似乎需要某种”与”关系。然而,事实并非如此——如果对报告引擎的源代码进行更改,无论定价引擎或结算引擎是否重新构建,都应该触发投资组合管理应用程序的重新构建。此外,考虑以下场景。
对这些场景最重要的约束是,投资组合管理应用程序应该只针对框架的一个版本进行构建。我们特别不希望出现这样的情况:(比如)定价引擎针对框架的某个版本构建,而结算引擎针对另一个版本构建。这就是经典的”菱形依赖”问题——这是我们在本章前面讨论的运行时”依赖地狱”问题的构建时类比。
图13.3 组件流水线
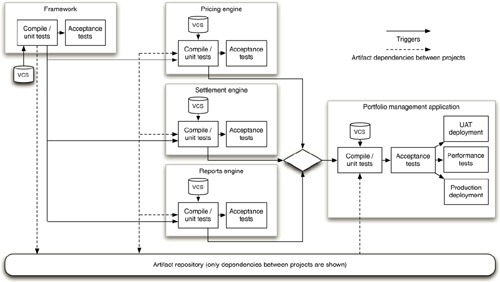
那么,我们如何基于上述项目结构构建部署流水线呢?流水线的关键要素是,团队必须尽快获得任何故障的反馈,并且我们应该遵守上述构建依赖的规则。我们的方法如图13.3所示。
有几个重要特性需要指出。首先,为了提高反馈速度,一旦每个项目流水线的提交阶段完成,就会触发依赖项目。你不需要等待验收测试通过——只需要创建下游项目所依赖的二进制文件。然后将这些文件存储在你的制品仓库中。当然,验收测试和各个部署阶段将重用这些二进制文件(为了防止混乱,图中未显示这一点)。
除了部署到手动测试和生产环境(通常需要手动授权)之外,所有触发器都是自动的。这些自动触发器确保每次对(例如)框架进行更改时,都会触发定价引擎、结算引擎和报告引擎的构建。如果这三个都使用新版本的框架成功构建,投资组合管理应用程序将使用所有上游组件的新版本重新构建。
图13.4 可视化上游依赖
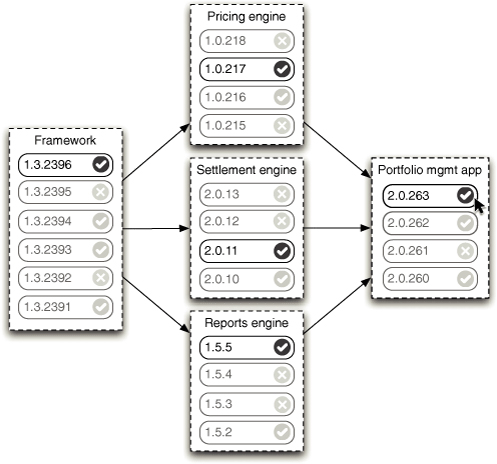
团队能够追踪构成应用程序特定构建的组件来源至关重要。一个好的CI工具不仅能做到这一点,还能显示哪些版本的组件成功集成在一起。例如在图13.4中,你可以看到投资组合管理应用程序的2.0.63版本是使用定价引擎的1.0.217版本、结算引擎的2.0.11版本、报告引擎的1.5.5版本和框架的1.3.2396版本构建的。
图13.5 可视化下游依赖
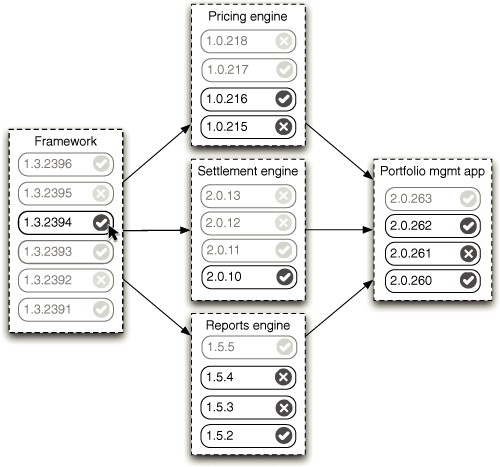
图13.5显示了使用所选框架版本(1.3.2394)构建的所有下游组件。
你的CI工具还应确保在整个流水线中使用一致的组件版本。它应该防止依赖地狱,并确保影响多个组件的版本控制更改只在流水线中传播一次。
我们在本章开头关于增量开发的所有建议也适用于组件。以不会破坏依赖关系的增量方式进行更改。当你添加新功能时,在变更的组件中为其提供新的API入口点。如果你想弃用旧功能,可以使用静态分析作为流水线的一部分来检测谁在使用旧API。如果你的任何更改意外破坏了任何依赖关系,流水线应该迅速告诉你。
图13.6 组件分支
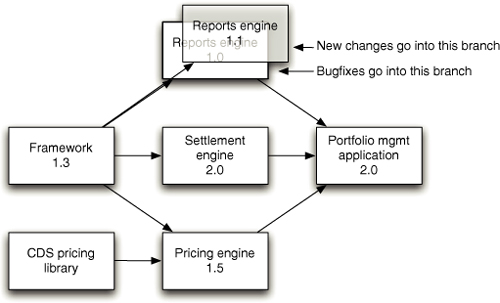
如果你确实需要对组件进行影响深远的更改,可以创建它的新版本。在图13.6中,我们假设负责报告引擎的团队需要创建一个会破坏某些API的新版本。为此,他们为1.0版本创建了一个分支,并在主线上开始1.1的开发。
报告引擎团队将继续在主线上添加新功能。同时,报告引擎的下游用户可以继续使用从1.0分支创建的二进制文件。如果他们需要错误修复,可以将其签入1.0分支并合并到主干。一旦下游用户准备好使用新版本,他们就可以切换。需要明确的是,这里描述的”按版本分支”模式仍然存在延迟集成的相同缺点,因此在持续集成方面是次优选择。但是,组件是(或至少应该是)松耦合的这一事实意味着以后痛苦集成的风险更可控。因此,这是管理组件更复杂变更的非常有用的策略。
上面讨论的所有示例都假设我们在上游依赖发生任何更改时触发新构建。这是正确的做法,但在许多团队中并非常态——相反,他们倾向于只在代码库稳定时更新依赖关系,可能在集成时或开发达到某个其他里程碑时。这种行为强调稳定性,但代价是可能花费大量时间进行集成的潜在风险。
可以看出,在涉及依赖关系的开发过程中存在一种张力。一方面,最好跟上上游依赖的最新版本,以确保您拥有最新的特性和错误修复。另一方面,集成每个依赖的最新版本可能会有成本,因为您可能会花费所有时间来修复这些新版本引起的破坏。大多数团队会妥协,在每次发布后刷新所有依赖,此时更新的风险较低。
决定多久更新一次依赖时的一个关键考虑因素是您对这些依赖的新版本有多信任。如果您有几个组件依赖于同样由您团队开发的组件,您通常可以非常快速和简单地修复由 API 变更引起的破坏,因此频繁集成是最好的。如果组件足够小,最好为整个应用程序进行单一构建,这样可以提供最快的反馈。
如果上游依赖由您组织内的另一个团队开发,这些组件最好在它们自己的流水线中独立构建。然后您可以决定是否每次更改时都采用这些上游组件的最新版本,或者坚持使用特定版本。这个决定基于它们更改的频率,以及负责它们的团队响应问题的速度。
您对组件变更的控制、可见性和影响力越少,对它的信任度越低,在接受新版本时就应该越保守。例如,如果没有明显的需要,不要盲目接受第三方库的更新。如果这些更改没有修复您遇到的问题,就不要更新,除非您正在使用的版本不再受支持。
在大多数情况下,团队在集成依赖的新版本方面采用更持续的方式效果最好。当然,持续更新所有依赖在集成所花费的资源(包括硬件和构建)以及修复错误和集成组件”未完成”版本的问题方面成本更高。
您需要在快速获得应用程序是否能够集成的反馈和过度活跃的构建之间取得平衡,后者会不断向您发送您不关心的破坏信息。一个潜在的解决方案是”谨慎乐观”,如 Alex Chaffee 在一篇论文中所描述的。
Chaffee 的提议是在依赖图中引入一种新的状态,即特定的上游依赖是”静态(static)“、”保护(guarded)“还是”流动(fluid)“。静态上游依赖的变更不会触发新的构建。流动上游依赖的变更总是触发新的构建。如果”流动”上游依赖的变更触发了构建但构建失败,该上游依赖会被标记为”保护”,组件会被固定到上游依赖的已知良好版本。“保护”的上游依赖的行为类似于静态依赖,它不接受新的变更,但它提醒开发团队存在需要解决的上游依赖问题。
实际上,我们明确表达了我们的偏好,即我们不希望从哪些依赖持续接受更新。我们还确保应用程序始终是”绿色”的,我们的构建系统会自动回退由于上游依赖的不良新版本导致的任何破坏。
图 13.7 谨慎乐观触发
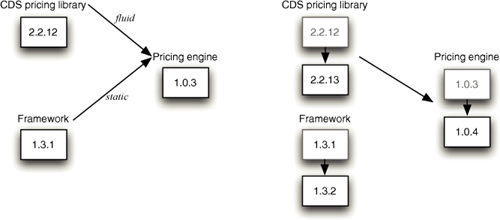
让我们看依赖图的一部分,如图 13.7 所示。我们将 CDS 定价库和定价引擎之间的依赖分配一个流动触发器,将框架和定价引擎之间的依赖分配一个静态触发器。
考虑 CDS 定价库和框架都更新的情况。新版本的框架会被忽略,因为定价引擎和框架之间的触发器是静态的。然而,CDS 定价库的新版本会触发定价引擎的新构建,因为其触发器设置为流动。如果定价引擎的这次新构建失败,触发器将被设置为保护,CDS 定价库的进一步变更将不会触发新的构建。如果构建通过,触发器保持流动。
然而,谨慎乐观可能导致复杂的行为。让我们将框架和定价引擎之间的触发器设置为流动,就像 CDS 定价库一样。在 CDS 定价库和框架都更新的情况下,定价引擎将进行一次新构建。如果定价引擎破坏,您不知道是什么破坏了构建,是 CDS 定价库的新版本还是框架的新版本。您必须尝试找出是哪个,与此同时,您的两个触发器都将变为保护状态。
Chaffee 提到了一种称为”知情悲观(informed pessimism)“的策略,作为任何依赖跟踪算法实现的起点。在这个策略中,每个触发器都设置为”静态”,但当上游依赖的新版本可用时,负责下游依赖的开发人员会收到通知。
Apache Gump 可以说是 Java 世界中第一个依赖管理工具。它诞生于 Apache Java 项目的早期,当时所有不同的工具(Xerces、Xalan、Ant、Avalon、Cocoon 等)都依赖于彼此的特定版本。开发这些工具的开发者需要一种方法来选择使用这些依赖的哪些版本,以便他们能够获得一个良好的应用程序版本,并通过操作 classpath 来实现这一点。Gump 被创建来自动化生成脚本以控制构建时使用的 classpath,使开发者可以尝试不同版本的依赖来找到一个良好的构建。它为这些项目的构建稳定性做出了重大贡献,尽管它要求你花费大量时间参数化你的构建。你可以在 [9CpgMi] 阅读更多关于 Gump 的历史——这是一篇简短而有趣的文章。
Gump 在 Java 项目中使用的许多组件成为标准 Java API 的一部分时变得过时了,而其他组件如 Ant 和 Commons 组件也变得向后兼容,所以在大多数情况下你不需要安装多个版本。这本身教给我们一个宝贵的教训:保持依赖图浅层化,并尽最大努力确保向后兼容——正如我们在本节中描述的,在构建时对组件图进行积极的回归测试将帮助你实现这一点。
最棘手的依赖问题可能是循环依赖。当依赖图包含循环时就会出现这种情况。最简单的例子是你有一个组件 A,它依赖于另一个组件 B。不幸的是,组件 B 反过来又依赖于组件 A。
这似乎会导致一个致命的引导问题。要构建组件 A,我需要构建组件 B,但要构建组件 B,我需要组件 A,如此循环往复。
图 13.8 循环依赖构建阶梯
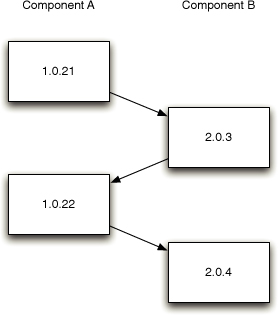
令人惊讶的是,我们见过构建系统中存在循环依赖的成功项目。你可能会质疑我们在这种情况下对”成功”的定义,但生产环境中有可运行的代码,这对我们来说已经足够了。关键点是你永远不会在项目开始时就有循环依赖——它们往往会在后期悄然出现。只要有一个可用于构建组件 B 的组件 A 版本,就可以(虽然不推荐)解决这个问题。然后你可以使用新版本的 B 来构建新版本的 A。这会产生一种”构建阶梯”,如图 13.8 所示。
在运行时,只要组件 A 和 B 同时可用,就没有问题。
正如我们所说,我们不推荐使用循环依赖。但如果你遇到一个难以避免的循环依赖,那么上述策略是可行的。没有构建系统能够开箱即用地支持这种配置,所以你必须修改工具链来支持它。你还必须谨慎处理构建各部分的交互:如果每个组件自动触发其依赖项的构建,这两个组件将因循环而永远构建下去。始终尝试消除循环依赖;但如果你发现自己在有循环依赖的代码库中工作,不要绝望——你可以使用构建阶梯作为临时解决方案,直到你能够消除这个问题。
我们已经花了相当多的时间讨论如何在分成组件的软件中组织构建。我们描述了如何为每个组件创建流水线(pipeline),当组件发生变化时触发下游组件流水线的策略,以及如何对组件进行分支。然而,我们还没有讨论如何在基于组件的构建中管理二进制文件。这很重要,因为在大多数情况下,组件应该对彼此有二进制依赖而不是源代码级依赖。接下来几页将讨论这个话题。
首先,我们将讨论制品仓库(artifact repository)工作原理背后的一般原则。然后我们将描述如何仅使用文件系统来管理二进制文件。在下一节中,我们将描述使用 Maven 来管理依赖。
你不必自己开发制品仓库。市场上有几种产品,包括开源项目 Artifactory 和 Nexus。一些工具,如 AntHill Pro 和 Go,包含了它们自己的制品仓库。
制品仓库最重要的属性是它不应该包含任何无法重现的内容。你应该能够删除你的制品仓库而不用担心无法重新获得任何有价值的东西。为了实现这一点,你的版本控制系统需要包含重新创建任何给定二进制文件所需的所有内容,包括自动化构建脚本。
需要删除制品的原因是它们很大(如果现在还不大,将来也会变大)。最终你需要删除它们以释放空间。因此,我们不建议将制品检入版本控制。如果你可以重新创建它们,你也不需要这样做。当然,值得保留那些已通过所有测试并因此成为发布候选的制品。任何已发布的制品也值得保留,以防你需要回滚到早期版本,或支持使用软件旧版本的人。
无论你保存构件本身多长时间,你都应该始终保存每个构件的哈希值,以便验证任何给定二进制文件的来源。这对于审计目的很重要——例如,如果你不确定特定环境中部署的是哪个应用程序。应该能够获取任何给定二进制文件的MD5值,并使用它来找出用于创建它的源代码控制中的确切修订版本。你可以使用构建系统来存储这些数据(一些CI服务器会为你做这件事),或者使用版本控制系统。无论哪种方式,管理哈希值都是配置管理策略的重要组成部分。
最简单的构件仓库是磁盘上的目录结构。通常,这个目录结构会在RAID或SAN上,因为虽然构件应该是可丢弃的,但应该由你来决定何时可以删除它们,而不是由某个行为异常的硬件来决定。
这种目录结构最重要的约束是,它应该能让你将二进制文件与用于创建它的源代码控制版本关联起来。通常,你的构建系统会为它运行的每个构建生成一个标签,通常是一个序列号。这个标签应该简短,以便能够轻松地传达给他人。它可以包含用于创建它的版本控制中的修订版本标识符(假设你没有使用像Git或Mercurial这样使用哈希作为标识符的工具)。然后,这个标签可以包含在二进制文件的清单中(例如JAR或.NET程序集的情况)。
为每个流水线创建一个目录,在其中为每个构建编号创建一个目录。然后可以将构建的所有构件存储在该目录中。
下一个小的改进是添加一个简单的索引文件,允许你将状态与每个构建关联起来,这样你就可以记录每个变更在部署流水线中的进展状态。
如果你不想为构件仓库使用共享驱动器,可以添加一个Web服务来存储和检索构件。但是,如果你已经到了这一步,应该考虑使用市场上众多免费或商业产品中的一个。
你的部署流水线实现需要做两件事:将构建过程生成的构件存储到构件仓库中,然后检索它们供以后使用。
考虑一个具有以下阶段的流水线:编译、单元测试、验收测试、手动验收测试和生产。
• 编译阶段将创建需要放入构件仓库的二进制文件。
• 单元测试和验收测试阶段将检索这些二进制文件,对它们运行单元测试,并将单元测试生成的报告存储在构件仓库中,以便开发人员可以查看结果。
• 用户验收测试阶段将获取二进制文件并将它们部署到UAT环境进行手动测试。
• 发布阶段将获取二进制文件并将它们发布给用户或部署到生产环境。
随着候选版本在流水线中的推进,每个阶段的成功或失败都会记录在索引中。后续流水线阶段可以依赖于此文件中的状态,因此只有通过验收测试的二进制文件才能用于手动测试和后续阶段。
有几种选项可以将构件存入和取出构件仓库。你可以将它们存储在一个共享文件系统中,该文件系统可以从你需要构建或部署的每个环境访问。然后,你的部署脚本可以引用此文件系统的路径。或者,你可以使用像Nexus或Artifactory这样的解决方案。
Maven是一个用于Java项目的可扩展构建管理工具。特别是,它提供了一个复杂的依赖管理机制。即使你不喜欢Maven的其他部分,也可以独立使用其强大的依赖管理功能。或者,你可以使用Ivy,它只解决依赖管理问题,而不涉及Maven构建管理工具链的其余部分。如果你不使用Java,可以跳过本节,除非你对Maven如何解决依赖管理问题感兴趣。
如前所述,项目有两种依赖:对外部库的依赖(我们在第354页的”管理库”部分讨论过),以及应用程序组件之间的依赖。Maven提供了一种抽象,让你能够以大致相同的方式处理它们。所有Maven领域对象,如项目、依赖和插件,都由一组坐标标识:groupId、artifactId和version,它们一起必须唯一标识一个对象(这些轴有时被称为GAV),以及packaging。这些通常以以下格式编写,这也是你在Buildr中声明它们的方式:groupId:artifactId:packaging:version。例如,如果你的项目依赖于Commons
Collections
3.2,你会这样描述该依赖:commons-collections:commons-collections:jar:3.2。
Maven 社区维护着一个镜像仓库,其中包含大量常见的开源库及其相关元数据(包括传递依赖)。这些仓库包含了几乎任何项目中可能需要的每一个开源库。你可以在网页浏览器中访问 http://repo1.maven.org/maven2 浏览此仓库。在 Maven 仓库中声明对某个库的依赖,将会在你构建项目时让 Maven 自动下载它。
你可以使用名为 pom.xml 的文件在 Maven 中声明一个项目,如下所示:

在项目构建时,这将会获取 JUnit 的 3.8.1 版本和 Commons Collections 的
3.2 版本到你本地的 Maven 工件仓库
~/.m2/repository/<groupId>/<artifactId>/<version>/。本地
Maven 工件仓库有两个用途:它是你项目依赖的缓存,同时也是 Maven
存储你的项目所创建的工件的地方(稍后详述)。注意你还可以指定依赖的作用域:test
表示该依赖仅在测试编译和组装期间可用。其他有效的作用域包括
runtime(用于编译时不需要但运行时需要的依赖)、provided(用于编译时需要但运行时会被提供的库)和
compile(默认值,用于编译时和运行时都需要的依赖)。
你还可以指定版本范围,例如 [1.0,2.0) 将会给你 1.x
系列的任何版本。圆括号表示排他量词,方括号表示包含量词。你可以省略左侧或右侧——所以
[2.0,) 表示高于 2.0 的任何版本。然而,即使你想给 Maven
一些选择版本的自由度,最好还是指定一个上界,以避免你的项目获取可能破坏应用程序的新主要版本。
这个项目还会创建自己的工件:一个 JAR 文件,它将被存储在本地仓库中 pom
指定的坐标位置。在上面的示例中,运行 mvn install
将会在你本地的 Maven
工件仓库中创建以下目录:~/.m2/repository/com/continuousdelivery/parent/1.0.0/。由于我们选择了
JAR 打包类型,Maven 会将你的代码打包成名为 parent-1.0.0.jar 的 JAR
并安装到这个目录中。我们在本地运行的任何其他项目现在都可以通过指定其坐标作为依赖来访问这个
JAR。Maven 还会将你项目 pom
的修改版本安装到同一目录中,其中包含有关其依赖的信息,以便 Maven
能够正确处理传递依赖。
通常你不会希望每次运行 mvn install
时都覆盖你的工件。为此,Maven
提供了快照构建(snapshot)的概念。只需在版本号后附加
-SNAPSHOT(所以在上面的示例中,它将是
1.0.0-SNAPSHOT)。然后,当你运行 mvn install
时,Maven 会创建一个格式为 version-yyyymmdd-hhmmss-n
的目录,而不是带版本号的目录。使用你的快照的项目可以只指定
1.0.0-SNAPSHOT,而不是完整的时间戳,并将获得本地仓库拥有的最新版本。
然而,你应该谨慎使用快照,因为它可能使重现构建变得更困难。更好的做法是让你的 CI 服务器为每个依赖生成规范版本,使用构建标签作为工件版本号的一部分,并将这些存储在你组织的中央工件仓库中。然后你可以在 pom 文件中使用 Maven 的版本量词来指定可接受版本的范围。如果你确实需要在本地机器上做一些探索性工作,你可以随时编辑你的 pom 定义来临时启用快照。
我们在本节中只是浅尝了 Maven 的皮毛。特别是,我们还没有讨论管理你自己的 Maven 仓库(如果你想在组织内管理依赖,这很重要),或者多模块项目(这是 Maven 创建组件化构建的方式)。虽然这些是重要的主题,但它们超出了我们在本章中可以合理涵盖的范围。如果你对更高级的 Maven 技巧感兴趣,我们建议你参考由 Sonatype 编写、O’Reilly 出版的优秀著作《Maven: The Definitive Guide》。同时,我们确实想介绍一些可以在 Maven 中进行的基本依赖重构。
假设你有一组被多个项目使用的依赖。如果你只想定义一次要使用的工件版本,你可以通过定义一个父项目来实现,该父项目包含每个工件要使用的版本。只需采用上面提供的
POM 定义,并在 <dependencies> 块周围包裹
<dependencyManagement>。然后你可以定义一个子项目,如下所示:

这将使用父项目中定义的这些依赖的版本——注意 junit 和
commons-collections 引用没有指定版本号。
你还可以重构你的 Maven 构建以消除常见依赖的重复。一个 Maven
项目可以创建一个 pom 作为其最终产品,而不是创建
JAR,然后由其他项目引用。在第一个代码清单中(artifactId 为
parent),你可以将 <packaging> 的值改为
pom 而不是
jar。然后你可以在任何想要使用相同依赖的项目中声明对这个 pom
的依赖:

Maven的一个非常有用的功能是,它可以分析项目的依赖关系,并告诉你未声明的依赖和未使用的已声明依赖。只需使用
mvn dependency:analyze
来运行此报告。关于使用Maven管理依赖的更多信息,请参阅:[cxy9dm]。
在本章中,我们讨论了确保团队尽可能高效开发的技术,同时保持应用程序始终处于可发布状态。一如既往,其原则是确保团队能够快速获得关于其变更对应用程序生产就绪性影响的反馈。实现这一目标的一个策略是确保每个变更都被分解为小的、增量的步骤,并提交到主线。另一个策略是将应用程序分解为组件。
将应用程序划分为一组松耦合、良好封装、协作的组件不仅是良好的设计。它还能在大型系统工作时实现更高效的协作和更快的反馈。在应用程序变得足够大之前,不需要单独构建组件——最简单的方法是使用单一的流水线,在第一阶段一次性构建整个应用程序。如果你专注于高效的提交构建和快速的单元测试,并为验收测试实施构建网格(build grids),你的项目可以增长到比你想象的更大规模。一个最多20人的团队全职工作几年,不需要创建多个构建流水线,当然他们仍然应该将应用程序分离为组件。
然而,一旦超过这些限制,组件的使用、基于依赖的构建流水线和有效的制品管理是实现高效交付和快速反馈的关键。本章描述的方法的优点在于,它建立在已经有益的基于组件的设计实践之上。这种方法避免了使用复杂的分支策略,这通常会导致集成应用程序时出现严重问题。然而,它确实依赖于一个设计良好的应用程序,该应用程序适合组件化构建。不幸的是,我们见过太多无法以这种方式轻松组件化的大型应用程序。很难将这样的应用程序调整到可以轻松修改和集成的状态。因此,请确保你有效地使用技术工具链来编写代码,一旦代码变得足够大,就可以作为一组独立的组件进行构建。
版本控制系统,也称为源代码控制和修订控制系统,旨在允许组织维护对其应用程序所做的每个更改的完整历史记录,包括源代码、文档、数据库定义、构建脚本、测试等。然而,它们还有另一个重要目的:它们使团队能够在应用程序的不同部分上协同工作,同时维护一个记录系统——应用程序的权威代码库。
一旦你的团队发展到超过几个开发人员,让许多人在同一个版本控制仓库上全职工作就会变得困难。人们会错误地破坏彼此的功能,通常会互相干扰。因此,本章的目的是研究团队如何有效地使用版本控制。
我们将从一些历史开始,然后直接深入版本控制中最具争议的话题:分支和合并。然后我们将讨论一些避免传统工具某些问题的现代范式:基于流的修订控制和分布式修订控制。最后,我们将介绍一组使用分支的模式——或者在某些情况下,避免使用分支的模式。
我们将在本章中花费大量时间讨论分支和合并。因此,让我们花点时间思考它如何融入我们花了大量时间讨论的部署流水线。部署流水线是一种以受控方式将代码从签入移至生产的范式。然而,它只是你在大型软件系统中可以使用的三个自由度之一。本章和上一章讨论了另外两个维度:分支和依赖。
分支代码有三个充分的理由。首先,可以为发布应用程序的新版本创建分支。这允许开发人员继续开发新功能而不影响稳定的公开发布版本。当发现错误时,首先在相关的公开发布分支中修复它们,然后将更改应用到主线。发布分支永远不会合并回主线。其次,当你需要尝试新功能或重构时;尝试分支会被丢弃,永远不会合并。最后,当你需要对应用程序进行大规模更改时,创建一个短期分支是可以接受的,这种更改无法通过上一章描述的任何方法实现——如果你的代码库结构良好,这是一种极其罕见的情况。此分支的唯一目的是使代码库达到可以通过增量方式或通过抽象分支进行进一步更改的状态。
所有版本控制系统的鼻祖是SCCS,由Marc J. Rochkind于1972年在贝尔实验室编写。从它演化出了大多数仍在使用的经典开源版本控制系统:RCS、CVS和Subversion。[1] 当然,市场上也有许多商业工具,每个都有自己的方法来帮助软件开发人员管理协作。其中最流行的包括Perforce、StarTeam、ClearCase、AccuRev和Microsoft Team Foundation System。
版本控制系统的演进并未放缓,目前有一个有趣的趋势是向分布式版本控制系统发展。DVCS(分布式版本控制系统)的创建是为了支持大型开源团队的工作模式,例如Linux内核开发团队。我们将在后面的章节中探讨分布式版本控制系统。[2]
由于SCCS和RCS如今很少使用,我们在此不做讨论;狂热的版本控制系统爱好者可以在线找到大量信息。
CVS代表Concurrent Versions System(并发版本系统)。这里的”并发”是指多个开发人员可以同时在同一个仓库上工作。CVS是一个在RCS之上实现的开源包装器,[3] 它提供了额外的功能,如客户端-服务器架构以及更强大的分支和标签功能。最初由Dick Grune于1984-1985年编写,并于1986年作为一组shell脚本公开发布,1988年由Brian Berliner移植到C语言。多年来,CVS一直是世界上最知名和最流行的版本控制系统,主要是因为它是唯一的免费VCS。
CVS为版本控制和软件开发过程带来了许多创新。其中最重要的可能是CVS的默认行为不锁定文件(因此称为”并发”)——事实上,这是CVS开发的主要动机。
尽管有其创新,CVS存在许多问题,其中一些是由于它从RCS继承了按文件跟踪变更的系统。
• CVS中的分支涉及将每个文件复制到仓库的新副本中。如果你有一个大型仓库,这可能需要很长时间并占用大量磁盘空间。
• 由于分支是副本,从一个分支合并到另一个分支可能会给你带来大量虚假冲突,并且不会自动将新添加的文件从一个分支合并到另一个分支。虽然有变通方法,但它们耗时、容易出错,而且总体上非常令人不快。
• CVS中的标签涉及触及仓库中的每个文件——在大型仓库中这是另一个耗时的过程。
• 对CVS的提交不是原子性的。这意味着如果你的提交过程被中断,你的仓库将处于中间状态。同样,如果两个人同时尝试提交,来自两个来源的更改可能会交错。这使得很难看清谁改变了什么,或者回滚一组更改。
• 重命名文件不是一等操作:你必须删除旧文件并添加新文件,在此过程中会丢失修订历史。
• 设置和维护仓库是一项艰巨的工作。
• 二进制文件在CVS中只是二进制大对象。它不会尝试管理对二进制文件的更改,因此磁盘使用效率低下。
Subversion (SVN)被设计为”更好的CVS”。它修复了CVS的许多问题,通常可以在任何情况下用作CVS的优秀替代品。它的设计目的是让CVS用户感到熟悉,并保留了基本相同的命令结构。这种熟悉性帮助Subversion在应用软件开发中迅速取代了CVS。
SVN的许多优点源于放弃了SCCS、RCS及其衍生物共有的格式。在SCCS和RCS中,文件是版本控制的单位:仓库中的每个签入文件都有一个对应的文件。在SVN中,版本控制的单位是修订版本,它包含对一组目录中文件的一组更改。[4] 你可以把每个修订版本想象成包含了当时仓库中所有文件的快照。除了描述对文件的更改外,增量还可以包含复制和删除文件的指令。在SVN中,每次提交都会原子性地应用所有更改并创建一个新的修订版本。
Subversion提供了一个称为”externals”的功能,允许你将远程仓库挂载到你仓库中的指定目录。如果你的代码依赖于某些其他代码库,这个功能非常有用。Git提供了一个类似的功能,称为”submodules”(子模块)。这提供了一种简单且低成本的方法来管理系统中组件之间的依赖关系,同时仍然为每个组件维护一个仓库。你还可以使用这种方法将源代码和任何大型二进制文件(编译器、工具链的其他部分、外部依赖项)分离到单独的仓库中,同时仍然使用户能够看到它们之间的链接。
Subversion仓库模型最重要的特征之一是修订版本号全局应用于仓库而不是单个文件。你不能再谈论单个文件从修订版本1移动到修订版本2。相反,你会想知道当仓库从修订版本1更改到修订版本2时,某个特定文件发生了什么。Subversion以处理文件的相同方式处理目录、文件属性和元数据,这意味着对这些对象的更改可以像对文件的更改一样进行版本控制。
Subversion 中的分支和标签功能也有了很大改进。Subversion
没有逐个更新每个文件,而是利用了写时复制仓库的速度和简洁性。按照惯例,每个
Subversion 仓库中都有三个子目录:trunk、tags 和
branches。要创建分支,只需在 branches
目录下创建一个以分支名称命名的目录,然后将要分支的版本的
trunk 内容复制到刚创建的新分支目录中。
这样创建的分支只是指向 trunk 所指向的同一组对象的指针——直到分支和
trunk 开始分离。因此,在 Subversion
中创建分支几乎是一个常数时间操作。标签的处理方式完全相同,只是它们存储在名为
tags 的目录下。Subversion
不区分标签和分支,因此差异只是一种约定。如果需要,可以在 Subversion
中将标记的版本视为分支。
Subversion 还通过保留每个文件上次从中央仓库检出时的本地副本来改进 CVS。这意味着许多操作(例如检查工作副本中的更改)可以在本地执行,使其比 CVS 快得多。即使中央仓库不可用时也可以执行这些操作,这使得在断开网络连接时可以继续工作。
然而,客户端-服务器模型仍然使某些事情变得困难:
• 只能在在线时提交更改。这听起来可能很明显,但分布式版本控制系统的主要优势之一在于,签入(check in)是一个独立于将更改发送到另一个仓库的操作。
• SVN 用于跟踪本地客户端更改的数据存储在仓库中每个文件夹的 .svn 目录中。可以将本地系统上的不同目录更新到不同的版本,甚至不同的标签或分支。虽然这在某些情况下可能是需要的,但在某些情况下可能会导致混淆甚至错误。
• 虽然服务器操作是原子的,但客户端操作不是。如果客户端更新被中断,工作副本可能会处于不一致的状态。通常这很容易修复,但在某些情况下需要删除整个子树并重新检出。
• 版本号在给定仓库中是唯一的,但在不同仓库之间不是全局唯一的。这意味着,例如,如果出于某种原因将仓库分解为较小的仓库,新仓库中的版本号将与旧版本号没有任何关系。虽然这听起来可能是小事,但这意味着 SVN 仓库无法支持分布式版本控制系统的某些功能。
Subversion 无疑代表了对 CVS 的巨大进步。较新版本的 Subversion 具有合并跟踪(merge tracking)等功能,使其在功能丰富性方面接近 Perforce 等商业工具,尽管在性能和可扩展性方面还有差距。然而,与 Git 和 Mercurial 等新一代分布式版本控制系统相比,它开始显示出其最初灵感”成为更好的 CVS”所带来的局限性。正如 Linus Torvalds 著名的说法:“没有办法正确地实现 CVS”。
尽管如此,如果您对集中式版本控制系统的局限性感到满意,Subversion 可能对您来说已经足够了。
软件工具的世界发展迅速,因此本节的内容可能会过时。请访问 http://continuousdelivery.com 获取最新信息。在撰写本文时,我们能够全心全意推荐的商业版本控制系统只有:
• Perforce。卓越的性能、可扩展性和出色的工具支持。Perforce 在一些真正庞大的软件开发组织中使用。
• AccuRev。提供类似 ClearCase 的基于流的开发能力,而没有与 ClearCase 相关的繁重管理开销和糟糕性能。
• BitKeeper。第一个真正的分布式版本控制系统,也是唯一的商业化系统。
如果您使用 Visual Studio,Microsoft 的 Team Foundation Server (TFS) 可能是您的默认选择——其紧密集成可能是其唯一的优势。除此之外,没有充分的理由使用其源代码控制产品,因为它本质上是 Perforce 的劣质仿品。Subversion 完胜 TFS。我们强烈建议您尽可能避免使用 ClearCase、StarTeam 和 PVCS。任何仍在使用 Visual SourceSafe 的人都应该立即迁移到不会在如此多情况下损坏数据库的工具(这在版本控制系统中是大忌)。对于简单的迁移路径,我们建议使用 SourceGear 的优秀产品 Vault(TFS 也提供简单的迁移路径,但我们不推荐)。
如果您的版本控制系统支持乐观锁定(optimistic locking),即在本地工作副本中编辑文件不会阻止其他人在他们的副本中编辑它,您应该使用它。悲观锁定(pessimistic locking)要求您必须获得文件的排他锁才能编辑它,这似乎是防止合并冲突的好方法。然而,在实践中它会降低开发过程的效率,特别是在较大的团队中。
悲观锁方式的版本控制系统以所有权为基础运作。悲观锁策略确保任何时候只有一个人可以操作任何给定的对象。如果 Tom 试图获取组件 A 的锁,而 Amrita 已经从版本控制中检出了它,他将被拒绝。如果他试图在未获取锁的情况下提交更改,操作将失败。
乐观锁系统的工作方式完全不同。它们不控制访问权限,而是基于这样的假设:大多数时候人们不会同时操作相同的内容,因此允许系统的所有用户自由访问其控制下的所有对象。这些系统跟踪其控制对象的变更,在需要提交变更时,使用算法来合并这些变更。通常合并是完全自动的,但如果版本控制系统检测到无法自动合并的变更,它会突出显示该变更并向提交者请求帮助。
乐观锁系统的工作方式通常取决于它们管理的内容性质。对于二进制文件,它们倾向于忽略增量变化,只采用最后提交的更改。然而,它们的优势在于处理源代码的方式。对于此类对象,乐观锁系统通常假设文件中的单行是合理的变更单位。因此,如果 Ben 在组件 A 上工作并修改了第 5 行,同时 Tom 也在组件 A 上工作并修改了第 6 行,当两人都提交后,版本控制系统将保留 Ben 的第 5 行和 Tom 的第 6 行。如果两人都决定修改第 7 行,并且 Tom 先检入,Ben 在提交时将被版本控制系统提示解决合并冲突。他将被要求保留 Tom 的更改、保留自己的更改,或手动编辑它们以保留两者的重要部分。
对于习惯使用悲观锁版本控制系统的人来说,乐观锁系统有时看起来过于乐观。“它们怎么可能正常工作?”实际上,它们运作得出奇地好,在许多方面明显优于悲观锁。
我们听到悲观锁系统的用户表达过担忧,认为乐观锁系统的用户会把所有时间都花在解决合并冲突上,或者自动合并会导致代码无法执行甚至无法编译。这些担忧在实践中根本不会发生。合并冲突确实会发生——在大型团队中相当频繁——但通常几乎所有冲突都能在几秒钟而非几分钟内解决。只有在忽略我们之前的建议、没有足够频繁地提交更改时,才会花费更长时间。
悲观锁唯一合理的使用场景是二进制文件,如图片和文档。在这种情况下,无法有意义地合并结果,因此悲观锁是一种合理的方法。Subversion 允许按需锁定文件,并且可以对此类文件应用 svn:needs-lock 属性来强制执行悲观锁。
悲观系统通常强制开发团队按组件分配行为,以避免因等待访问相同代码而造成的长时间延迟。创造力的流动——开发过程中自然且必不可少的部分——经常因需要检出开发人员未意识到会需要的文件而被打断。它们还使得在不影响许多其他用户的情况下,几乎不可能进行影响大量文件的更改。在大型团队从主线工作时,在启用悲观锁的情况下,团队几乎不可能进行重构。
乐观锁对开发过程的限制更少。版本控制系统不会对你施加任何策略。总体而言,它在使用中感觉明显更少侵入性、更轻量级,同时不会失去任何灵活性或可靠性,并且在可扩展性方面有很大提升,特别是对于大型分布式团队。如果你的版本控制系统有这个选项,请选择乐观锁。如果没有,考虑迁移到支持乐观锁的版本控制系统。
在代码库中创建分支(branches)或流(streams)的能力是每个版本控制系统的一级特性。此操作在版本控制系统内创建所选基线的副本。然后可以像操作原始版本一样(但独立于原始版本)操作此副本,允许两者发生分歧。分支的主要目的是促进并行开发:能够同时处理两个或多个工作流,而不相互影响。例如,在发布时进行分支是常见做法,允许在主线上继续开发,同时在发布分支中修复 bug。团队可能选择对代码进行分支的原因还有其他几个。
• 物理分支(Physical): 系统物理配置的分支——为文件、组件和子系统创建分支。
• 功能分支(Functional): 系统功能配置的分支——为特性、逻辑变更、bug 修复和增强功能,以及其他重要的可交付功能单元(例如补丁、发布版本和产品)创建分支。
• 环境分支(Environmental): 系统运行环境的分支——为构建和运行时平台的各个方面(编译器、窗口系统、库、硬件、操作系统等)和/或整个平台创建分支。
• 组织型:团队工作任务的分支——为活动/任务、子项目、角色和团队创建分支。
• 流程型:团队工作行为的分支——创建分支以支持各种策略、流程和状态。
这些类别并不相互排斥,但它们揭示了人们创建分支的原因。当然,你可以同时在多个维度上创建分支;如果这些分支永远不需要相互交互,这样做是可以的。然而,这通常不是实际情况——我们通常需要将一组变更从一个分支复制到另一个分支,这个过程称为合并(merging)。
在讨论合并之前,值得思考一下分支带来的问题。在大多数分支的情况下,你的整个代码库会在每个分支中独立演化——包括测试用例、配置、数据库脚本等等。首先,这突显了将所有内容都纳入版本控制的必要性。在开始对代码库进行分支之前,请确保你已经准备好——确保构建软件所需的一切都在版本控制中。
到目前为止,最常见的分支原因是功能性的。然而,为发布创建分支只是开始。我们合作过的一家大型网络基础设施供应商为其产品的每个主要客户都创建了分支。他们还为每个错误修复和新功能创建了子分支。他们软件的版本号是 w.x.y.z 格式,其中 w 是主版本号,x 是发布版本,y 是客户标识符,z 是构建号。我们被请来是因为他们需要12到24个月才能完成一次主版本发布。我们发现的第一个问题是,他们的测试与代码位于不同的版本控制仓库中。因此,他们很难确定哪些测试适用于哪个构建。这反过来又阻止了他们向代码库添加更多测试。
分支和流可能看起来是解决大型团队软件开发过程中许多问题的好方法。然而,合并分支的需求意味着在分支之前必须仔细思考,并确保有一个合理的流程来支持它。特别是,你需要为每个分支定义一个策略,描述其在交付流程中的角色,并规定谁可以在什么情况下检入代码。例如,一个小团队可能有一个所有开发人员都可以检入的主线,以及一个只有测试团队能够批准变更的发布分支。然后测试团队将负责将错误修复合并到发布分支。
在更大且监管更严格的组织中,每个组件或产品可能都有一个开发人员检入的主线,以及集成分支、发布分支和维护分支,只有运维人员被授权对这些分支进行变更。将变更引入这些分支可能需要创建变更请求,并让代码通过一系列测试(手动或自动)。将定义一个晋升流程,例如,变更必须从主线进入集成分支,然后才能晋升到发布分支。Berczuk (2003)的第117-127页更详细地讨论了代码线策略。
分支就像量子力学多世界诠释中假设的无限宇宙。每个宇宙都是完全独立的,在幸福的无知中存在着。然而,在现实生活中,除非你是为发布或探索性开发(spikes)而分支,否则你会遇到需要将一个分支中的变更应用到另一个分支的情况。这样做可能非常耗时,尽管市场上几乎所有版本控制系统都有一些功能来简化这个过程,而分布式版本控制系统使得合并无冲突的分支相对简单。
真正的问题出现在你想要合并的两个分支中做出了两个不同且冲突的变更时。当变更直接重叠时,你的版本控制系统会检测到它们并发出警告。然而,你的冲突可能只是意图上的差异,被版本控制系统忽略并”自动合并”。当合并之间间隔很长时间时,合并冲突通常是功能实现冲突的症状,导致需要重写大量代码以协调两个分支中发生的变更。在不知道代码作者意图的情况下,不可能合并这些变更——因此需要进行对话,可能是在最初编写被合并的代码几周之后。
未被版本控制系统捕获的语义冲突(semantic conflicts)可能是最有害的。例如,如果Kate在她的一个变更中执行了重命名类的重构,而Dave在他的一个变更中引入了对该类的新引用,他们的合并会正常工作。在静态类型语言中,当有人尝试编译代码时会发现这个问题。在动态语言中,直到运行时才会发现。通过合并可能会引入更微妙的语义冲突,如果没有全面的自动化测试体系,你甚至可能直到出现缺陷时才能捕获它们。
在合并分支之前等待的时间越长,在分支上工作的人越多,合并就会越痛苦。有一些方法可以最小化这种痛苦:
• 你可以创建更多分支来减少对特定分支的修改数量。例如,你可以在每次开始开发新特性时创建一个分支;这是”早期分支”的一个例子。然而,这意味着需要花更多精力来跟踪所有分支,而且你只是推迟了必须进行更多合并的痛苦。
• 你可以谨慎地创建分支,比如每个版本创建一个分支。这是”延迟分支”的一个例子。为了减少合并的痛苦,你可以频繁合并,这意味着合并会变得不那么痛苦。然而,你必须记得定期进行合并——例如每天一次。
事实上,有许多可能的分支模式,每种都有自己的策略、优点和缺点。我们将在本章后面探讨一些可能的分支风格。
细心的读者会注意到,使用分支与持续集成之间存在矛盾。如果团队的不同成员在独立的分支或流上工作,那么从定义上讲,他们就没有在持续集成。或许使持续集成成为可能的最重要实践是每个人每天至少向主线签入一次。所以如果你每天将分支合并到(而不仅仅是从)主线,那就没问题。如果你没有这样做,你就没有在做持续集成。实际上,有一种观点认为,任何在分支上的工作,从精益的角度来看,都是浪费——没有被拉入最终产品的库存。
图 14.1 分支控制不当的典型示例
持续集成基本上被忽视和人们随意分支的情况并不少见,这导致了一个涉及许多分支的发布过程。我们的同事 Paul Hammant 提供了图 14.1 中他参与的一个项目的例子。
在这个例子中,为作为应用程序开发工作计划的一部分而进行的各种项目创建了分支。合并回主干(或称为”集成分支”)的频率相当不规律,当合并发生时,往往会破坏它。结果,主干在很长一段时间内保持损坏状态,直到发布前的项目”集成阶段”。
不幸的是,这种相当典型的策略的问题在于,分支往往在很长时间内保持不可部署状态。此外,通常情况下分支之间存在软依赖关系。在给定的例子中,每个分支都需要从集成分支获取错误修复,并且每个分支都从性能调优分支获取性能修复。应用程序自定义版本的分支是一个进行中的工作,在很长一段时间内无法部署。
跟踪分支、确定合并什么和何时合并,然后实际执行这些合并会消耗大量资源,即使使用 Perforce 或 Subversion 等工具提供的合并点跟踪功能也是如此。即使完成这些之后,团队仍然需要将代码库变为可部署状态——这正是持续集成应该解决的问题。
图 14.2 发布分支策略
一个更易管理的分支策略——我们强烈推荐,也可以说是行业标准——是仅在发布时创建长期分支,如图 14.2 所示。
在这个模型中,新工作始终提交到主干。只有当必须对发布分支进行修复时才执行合并,然后从发布分支合并到主线。关键的错误修复也可能从主线合并到发布分支。这个模型更好,因为代码始终准备好发布,因此发布更容易。分支更少,所以合并和跟踪分支的工作量大大减少。
你可能担心不分支会妨碍你在不影响其他人的情况下创建新特性的能力。如何在不创建新分支来隔离工作的情况下进行大规模重构?我们在上一章的”保持应用程序可发布”一节(第 346 页)中详细讨论了这一点。
渐进式方法确实需要更多的纪律和谨慎——实际上也需要更多创造力——而不是创建一个分支然后一头扎进重新架构和开发新功能。但它显著降低了你的更改破坏应用程序的风险,并将为你和你的团队节省大量的合并、修复破坏和使应用程序进入可部署状态的时间。这类活动往往很难计划、管理和跟踪,最终使其成本远高于在主线上开发这种更有纪律的实践。
如果你在中型或大型团队工作,此时你可能会怀疑地摇头。在大型项目上不分支怎么可能工作?如果 200 人每天都在签入,那就是 200 次合并和 200 次构建。没人能完成任何工作——他们会把所有时间都花在合并上!
在实践中,即使每个人都在一个巨大的代码库中工作,大型团队也可以正常运作。200 次合并是可以的,前提是每个人都在代码的不同区域工作,并且每次更改都很小。在这么大的项目中,如果多个开发人员经常接触相同的代码部分,那表明代码库结构不良,封装不足且耦合度高。
如果合并被推迟到发布结束时才进行,情况会糟糕得多。到那时,几乎可以肯定每个分支都会与其他分支存在合并冲突。我们见过一些项目,其集成阶段一开始就要花费数周时间来解决合并冲突,并使应用程序达到可以运行的状态。只有到那时,项目的测试阶段才能真正启动。
对于中型和大型团队来说,正确的解决方案是将应用程序拆分为组件,并确保组件之间的松耦合。这些是设计良好的系统的特性。采用这种增量合并方法(即应用程序始终在主线上保持可工作状态)的结果是,它会施加一种温和而微妙的压力,促使你改进软件的设计。将组件集成到一个可工作的应用程序中,本身就是一个复杂而有趣的问题,我们在上一章中探讨了这个问题。然而,这是解决大型应用程序开发问题的一种无限优越的方式。
值得再次强调:你永远不应该使用长期存在、不频繁合并的分支作为管理大型项目复杂性的首选方式。这样做会在你尝试部署或发布应用程序时埋下隐患。你的集成过程将是一项风险极高的工作,不可预测,会耗费你大量的时间和金钱。任何版本控制系统供应商告诉你只需使用他们的合并工具就能解决问题,这根本就是在回避事实真相。
在过去几年中,分布式版本控制系统(DVCS)变得越来越流行。目前存在几个强大的开源DVCS,如Git和Mercurial。在本节中,我们将探讨DVCS的特别之处以及如何使用它们。
DVCS背后的基本设计原则是,每个用户在自己的计算机上保存一个独立的、一流的代码库。不需要特权的”主”代码库,尽管大多数团队会按照惯例指定一个(否则无法进行持续集成)。从这个设计原则出发,产生了许多有趣的特性。
• 你可以在几秒钟内开始使用DVCS——只需安装它,然后将更改提交到本地代码库。
• 你可以单独从其他用户那里拉取更新,而不需要他们将更改检入中央代码库。
• 你可以将更新推送给选定的一组用户,而不会强制每个人都接受这些更新。
• 补丁可以有效地在用户网络中传播,使得批准或拒绝单个补丁变得更加容易(这种做法称为挑选)。
• 你可以在离线工作时将更改检入源代码控制。
• 你可以定期将未完成的功能提交到本地代码库以设置检查点,而不会影响其他用户。
• 你可以在将更改发送给其他人之前,轻松修改、重新排序或批量处理本地提交(这称为变基)。
• 在本地代码库中尝试想法很容易,无需在中央代码库中创建分支。
• 由于能够在本地批量检入,中央代码库不会被频繁访问,使得DVCS具有更好的可扩展性。
• 本地代理代码库易于建立和同步,使得提供高可用性变得容易。
• 由于完整代码库有多个副本,DVCS具有更强的容错能力,尽管主代码库仍应进行备份。
图14.3 DVCS代码库中的开发线

如果你认为使用DVCS听起来很像每个人都拥有自己的SCCS或RCS,你是对的。分布式版本控制系统与前面部分方法的不同之处在于它们处理多用户或并发的方式。它不是使用带有版本控制系统的中央服务器来确保多人可以同时在代码库的同一分支上工作,而是采取相反的方法:每个本地代码库实际上都是一个独立的分支,没有”主线”(图14.3)。
DVCS设计中的大部分工作都花在使用户之间轻松共享更改上。正如Ubuntu母公司Canonical的创始人Mark Shuttleworth所指出的:“分布式版本控制的美妙之处在于自发团队的形成,当人们对某个缺陷或功能有共同兴趣时,他们开始工作,通过发布分支并相互合并来在彼此之间传递工作。当分支和合并的成本降低时,这些团队更容易形成,将这一点推向极致表明,在开发者的合并体验上进行投资是非常值得的。”
随着GitHub、BitBucket和Google Code的出现,这种现象尤为明显。使用这些网站,开发者可以轻松复制现有项目的代码库,进行更改,然后将他们的更改轻松提供给可能对此感兴趣的其他用户。如果原始项目的维护者喜欢这些更改,他们可以看到这些更改并将其拉回到他们项目的主代码库中。
这代表了协作方式的范式转变(paradigm shift)。现在人们可以发布自己的版本供他人试验,而不必将补丁提交给项目所有者以提交回项目仓库。这使得项目演进更快、试验更多、功能和缺陷修复的交付更快。如果有人做了巧妙的事情,其他人可以而且会使用它。这意味着提交权限不再是人们创建新功能或修复缺陷的瓶颈。
多年来,Linux内核的开发没有使用源代码控制。Linus Torvalds在自己的机器上开发,并以tarball形式提供源代码,这些源代码迅速复制到全球大量系统上。所有更改都以补丁形式发送给他,他可以轻松应用和撤销。因此,他不需要源代码控制——既不需要备份源代码,也不需要允许多个用户同时在仓库上工作。
然而,在1999年12月,Linux PowerPC项目开始使用BitKeeper,这是一个于1998年推出的专有分布式版本控制系统。Linus开始考虑采用BitKeeper来维护内核。在接下来的几年里,一些内核部分的维护者开始使用它。最终,在2002年2月,Linus采用了BitKeeper,将其描述为”最适合这项工作的工具”,尽管它不是开源产品。
BitKeeper是第一个广泛使用的分布式版本控制系统,它构建在SCCS之上。实际上,BitKeeper仓库只是一组SCCS文件。遵循分布式版本控制系统的理念,每个用户的SCCS仓库本身就是一个一流的仓库。BitKeeper是SCCS之上的一层,允许用户将delta(针对特定修订版的更改)视为一流的领域对象。
在BitKeeper之后,许多开源DVCS项目开始启动。第一个是Arch,由Tom Lord于2001年创建。Arch不再维护,已被Bazaar取代。今天有许多竞争的开源DVCS。其中最流行和功能最丰富的是Git(由Linus Torvalds创建以维护Linux内核,并被许多其他项目使用)、Mercurial(被Mozilla基金会、OpenSolaris和OpenJDK使用)和Bazaar(被Ubuntu使用)。其他正在积极开发的开源DVCS包括Darcs和Monotone。
在撰写本文时,商业组织采用DVCS的速度较慢。除了普遍的保守主义之外,公司使用DVCS还有三个明显的反对理由。
• 与仅在用户计算机上存储单一版本仓库的集中式版本控制系统不同,任何复制DVCS本地仓库的人都拥有其完整历史记录。
• 在DVCS领域,审计和工作流是更难把握的概念。集中式版本控制系统要求用户将所有更改检入中央仓库。DVCS允许用户相互发送更改,甚至在本地仓库中更改历史记录,而这些更改不会在中央系统中被跟踪。
• Git实际上允许你更改历史记录。这在受监管制度约束的企业环境中可能是一条红线,这些企业必须定期备份其仓库以保留发生的所有事情的记录。
实际上,在许多情况下,这些考虑因素不应成为企业采用的障碍。虽然理论上用户可以避免检入指定的中央仓库,但这样做意义不大,因为在有持续集成系统的情况下,不推送更改就不可能基于你的代码进行构建。在不进行集中检入的情况下将更改推送给同事通常得不偿失——当然,除非在你需要时这样做,此时拥有DVCS非常有用。一旦指定了中央仓库,集中式版本控制系统的所有属性都是可用的。
要记住的是,使用DVCS,开发人员和管理员可以轻松实现许多工作流。相反,集中式VCS只能通过添加颠覆底层(集中式)模型的复杂功能来支持非集中式模型(如分布式团队、共享工作空间的能力和审批工作流)。
分布式和集中式版本控制系统之间的主要区别在于,当你提交时,你是提交到仓库的本地副本——实际上是提交到你自己的分支。为了与他人共享你的更改,你需要执行额外的步骤。为此,DVCS有两个新操作:从远程仓库拉取更改和向其推送更改。
例如,这是Subversion上的典型工作流:
svn up——获取最新修订版。
编写一些代码。
svn up——将我的更改与中央仓库的任何新更新合并,并修复任何冲突。
在本地运行提交构建。
svn ci——将我的更改(包括我的合并)检入版本控制。
在分布式版本控制系统中,工作流如下所示:
hg pull——从远程仓库获取最新更新到你的本地仓库。
hg co—从本地仓库更新你的本地工作副本。
编写代码。
hg ci—将更改保存到本地仓库。
hg pull—从远程仓库获取任何新的更新。
hg merge—这将用合并结果更新你的本地工作副本,但不会检入合并。
在本地运行提交构建。
hg ci—这会将合并检入到本地仓库。
hg push—将更新推送到远程仓库。
我们在这里使用 Mercurial 作为示例,因为其命令语法与 Subversion 类似,但这些原则与其他 DCVS 完全相同。
图 14.4 DVCS 工作流程(图表由 Chris Turner 绘制)
看起来有点像[图 14.4](每个方框代表一个修订版本,箭头指示修订版本的父版本)。
合并过程比 Subversion 的等效过程稍微安全一些,因为有第 4 步。这个额外的检入步骤确保即使合并出现问题,你也可以回退到合并之前的状态并重试。这也意味着你记录了一个仅代表合并的变更,这样你就可以准确地看到合并做了什么,并且(假设你尚未推送更改)如果稍后认为合并不好,可以撤销它。
在执行第 9 步将更改发送到持续集成构建之前,你可以根据需要多次重复步骤 1-8。你甚至可以使用 Mercurial 和 Git 中可用的一个强大功能,称为变基(rebasing)。这使你可以更改本地仓库的历史记录,例如,你可以将所有更改合并为一次提交。这样,你可以继续检入以保存更改、合并其他人所做的更改,当然还可以在本地运行提交套件,而不会影响其他用户。当你正在开发的功能完成时,你可以进行变基并将所有更改作为单个提交发送到主仓库。
至于持续集成,它在 DVCS 中的工作方式与在集中式版本控制系统中完全相同。你仍然可以拥有一个中央仓库,并且它仍然会触发你的部署流水线实现。但是,DVCS 为你提供了尝试其他几种可能的工作流程的选项(如果你愿意)。我们在[第 79 页]的”分布式版本控制系统”部分详细讨论这些内容。

在将本地仓库的更改提交到馈送部署流水线的中央仓库之前,你的更改并未集成。频繁提交更改是持续集成的基本实践。为了进行集成,你必须每天至少一次将更改推送到中央仓库,理想情况下应该更频繁。因此,如果使用不当,DVCS 的某些优势可能会损害 CI 的有效性。
IBM 的 ClearCase 不仅是大型组织中最流行的版本控制系统之一;它还在版本控制系统中引入了一种新的范式:流(streams)。在本节中,我们将讨论流的工作原理以及如何使用基于流的系统进行持续集成。
基于流的版本控制系统,如 ClearCase 和 AccuRev,旨在通过使一次性将变更集应用于多个分支成为可能来改善合并问题。在流范式中,分支被更强大的流概念所取代,流的关键区别在于它们可以相互继承。因此,如果你对给定的流应用更改,其所有后代流都将继承这些更改。
考虑一下这种范式如何帮助处理两种常见情况:将错误修复应用于应用程序的多个版本,以及向代码库添加第三方库的新版本。
第一种情况在你的发布版本有长期存在的分支时很常见。假设你需要对某个发布分支进行错误修复。你如何同时将该错误修复应用到代码的所有其他分支?在没有基于流的工具的情况下,答案是手动合并。这是一个枯燥且容易出错的过程,尤其是当你有多个不同的分支需要应用更改时。使用基于流的版本控制,你只需将分支中的更改提升到所有需要更改的分支的共同祖先。这些分支的使用者随后可以更新以获取这些更改,并创建包含修复的新构建。
管理第三方库或共享代码时也适用同样的考虑。假设你想将图像处理库更新到新版本。每个组件都需要更新以依赖于相同的版本。使用基于流的 VCS,你可以将新版本检入到所有需要更新的流的祖先,所有从它继承的流都会获取它。
你可以将基于流的版本控制系统想象成类似于联合文件系统(union filesystem),但文件系统形成树结构(连通有向无环图)。因此,每个仓库都有一个根流,所有其他流都从它继承。你可以基于任何现有流创建新流。
图 14.5 基于流的开发
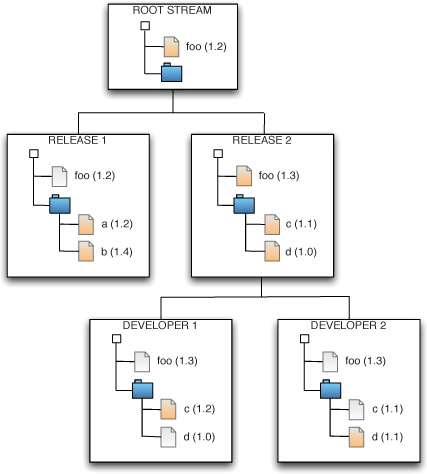
在[图14.5]的示例中,根流包含一个文件foo,版本为1.2,以及一个空目录。发布1和发布2流都从根流继承。在发布1流中,可以找到根流中的文件,以及两个新文件:a和b。在发布2流中,存在两个不同的文件:c和d。foo已被修改,现在是版本1.3。
两个开发人员在他们的工作区中处理发布2流。开发人员1正在修改文件c,开发人员2正在修改文件d。当开发人员1提交她的更改时,所有在发布2流上工作的人都会看到这些更改。如果文件c是发布1所需的错误修复,开发人员1可以将文件c提升到根流,这样从所有流都可以看到它。
因此,对一个流的更改不会影响任何其他流,除非这些更改被提升。一旦提升,它们将对从原始流继承的每个其他流可见。重要的是要记住,以这种方式提升更改不会改变历史。相反,它就像在流的现有内容之上添加一个包含新更改的覆盖层。
在基于流的系统中,鼓励开发人员在自己的工作区中开发。这样,开发人员可以执行重构,尝试解决方案,并开发功能,而不会影响其他用户。当他们准备好时,可以提升他们的更改以使其他人可以使用。
例如,你可能正在为特定功能创建的流上工作。当功能完成时,你可以将该流中的所有更改提升到团队流,该流可以持续集成。当测试人员想要测试已完成的功能时,他们可以拥有自己的流,所有准备进行手动测试的功能都可以提升到该流。通过测试的功能随后可以提升到发布流。
因此,中大型团队可以同时处理多个功能而不会相互影响,测试人员和项目经理可以挑选他们想要的功能。与大多数团队在发布时面临的困境相比,这是一个真正的改进。通常,创建发布涉及分支整个代码库然后稳定分支——但当然,当你分支时,没有简单的方法来挑选你想要的部分(有关此问题及其解决方法的更多详细信息,请参阅第409页的”为发布创建分支”部分)。
当然,在现实生活中事情从来都不是那么简单。功能之间从来都不是真正独立的,特别是如果你的团队像应该做的那样大力重构,当你在流之间提升大量代码时,合并问题会频繁发生。因此,由于以下原因导致集成问题很常见也就不足为奇了:
• 复杂的合并,因为不同的团队以不同的方式更改共享代码。
• 依赖管理问题,当新功能依赖于尚未提升的其他功能中引入的代码时。
• 集成问题,因为集成和回归测试在发布流上中断,因为代码处于新配置中。
当你有更多团队或更多层时,这些问题会变得更糟。这种效果通常是成倍增加的,因为对拥有更多团队的常见反应是创建更多层。目的是隔离团队之间的相互影响。一家大公司报告称有五层流:团队层、领域层、架构层、系统层,最后是生产层。每个更改都必须经过每一层才能到达生产环境。不用说,他们在发布方面面临重大问题,因为这些问题在每次提升时都会定期发生。
流开发模型的问题之一是提升是在源代码级别而不是二进制级别完成的。因此,每次将更改提升到更高的流时,都必须签出源代码并重建二进制文件。在许多ClearCase商店中,运维团队坚持只部署基于从发布分支签出的源代码从头重建的二进制文件是正常的。除此之外,这还会导致大量浪费。
此外,它违反了我们的一个关键原则——你发布的二进制文件应该是经过部署流水线其余部分的相同二进制文件,这样你才能确保发布的是你测试过的内容。除了没有人测试来自发布流的二进制文件这一事实外,构建过程中也可能引入差异,可能是运维团队使用不同的次要版本编译器或不同版本的某些依赖项。这些差异可能导致生产中的错误,需要数天才能追踪。
重要的是要记住,不每天多次提交到共享主线会妨碍持续集成的实践。有一些方法可以管理这个问题,但它们需要很强的纪律性——而且仍然无法完全解决中型和大型团队所面临的困境。经验法则是尽可能频繁地提升(promote),并在开发人员之间共享的流(stream)上尽可能频繁地运行尽可能多的自动化测试。在这方面,这种模式类似于本章后面描述的按团队分支。
不过,也不全是坏消息。Linux 内核开发团队使用的流程与上述描述非常相似,但每个分支都有一个所有者,其职责是保持该流的稳定性,当然”发布流”由 Linus Torvalds 维护,他对拉取到自己流中的内容非常挑剔。Linux 内核团队的工作方式是,存在一个分层的流结构,Linus 的流位于顶层,变更由流所有者拉取(pull),而不是向上推送(push)给他们。这与大多数组织中存在的结构完全相反,在那些组织中,运维或构建团队不幸地承担着试图合并所有内容的职责。
最后,关于这种开发风格的一点说明:你不需要显式支持流的工具来实现这一点。实际上,Linux 内核开发团队使用 Git 来管理他们的代码,像 Git 和 Mercurial 这样的新一代分布式版本控制系统足够灵活,可以处理这种流程——尽管没有像 AccuRev 这样的产品提供的一些精美的图形化工具。
ClearCase 有一个称为”动态视图”的特性。当文件从开发人员的流所继承的流中合并进来时,它会立即更新每个开发人员的视图。这意味着开发人员会立即自动获取对其流的任何更改。在更传统的静态视图中,开发人员在决定更新之前不会看到更改。
动态视图是在更改提交的那一刻就获取更改的好方法,这有助于消除合并冲突并简化集成——假设开发人员频繁且定期地签入。然而,在技术层面和实际变更管理层面都存在问题。在技术层面,这个特性非常慢:根据我们的经验,它显著降低了对开发人员文件系统的访问速度。由于大多数开发人员经常执行文件系统密集型任务(如编译),这种成本是不可接受的。更实际的是,如果你正在进行某项工作而被强制进行合并,它可能会打断你的思路并混淆你对问题的理解。
基于流的开发所宣称的好处之一是让开发人员更容易在自己的私有流上工作,并承诺稍后合并会更容易。从我们的角度来看,这种方法存在一个根本缺陷:当定期提升变更时(即每天多次)一切都很好,但如此频繁地提升往往会限制这种方法最初的好处。如果你频繁提升,更简单的解决方案会同样好或更好。如果你不频繁提升,你的团队在发布时更有可能遇到问题。他们将花费不确定的时间来让一切就绪,拼凑每个人都认为正在工作的功能,并修复由复杂合并引入的错误。这正是持续集成应该解决的问题。
像 ClearCase 这样的工具确实具有强大的合并能力。然而,ClearCase 也有一个完全基于服务器的模型,从合并到标记再到删除文件的所有操作都需要大量的服务器活动。实际上,在 ClearCase 中将变更提升到父流需要提交者解决在同级流上发生的任何错误合并。
我们使用 ClearCase 的经验,以及我们同事的经验都表明,对于任何规模的仓库,你期望很简单的操作——比如签入、删除文件,以及(尤其是)标记——都需要花费过长的时间。如果你想定期签入,仅这一点就会给使用这些工具的开发增加非常显著的成本。实际上,与具有原子提交的 Accurev 不同,ClearCase 需要标记才能回滚到仓库的已知版本。如果你有一个经验丰富、才华横溢的 ClearCase 管理员团队帮忙,你的开发流程可能是可管理的。我们恐怕我们的经验一直都很糟糕。因此,我们经常采用的方法是在开发团队内使用像 Subversion 这样的工具,并定期进行单向自动合并到 ClearCase,作为让每个人都满意的方式。
基于流的版本控制系统最重要的特性——提升变更集的能力——在涉及持续集成时也会带来一些问题。考虑一个具有多个流用于各种点发布的应用程序。如果一个错误修复被提升到所有这些流的祖先流,它将触发每个后代流的新构建。这可能会很快耗尽你的构建系统的全部容量。在一个在任何给定时间有多个活跃流的团队中,如果定期提升,构建将在每个流上持续运行。
处理这个问题有两种选择:在构建硬件或虚拟资源上花费大量资金,或者改变触发构建的方式。一个有用的策略是仅在与部署流水线关联的流发生更改时触发构建,而不是在更改被提升到其祖先流时触发。当然,这样创建的发布候选版本仍应获取流的最新版本,包括任何提升到其祖先流的更改。手动触发的构建也会导致这些更改被包含在发布候选版本中,基础设施团队需要确保在适当的时候触发手动构建,以确保在必要时创建相关的发布候选版本。
在本节和后续章节中,我们将研究各种分支和合并模式、它们的优缺点,以及适用的情况。我们将从在主线上开发开始,因为这种开发方法经常被忽视。实际上,它是一种极其有效的开发方式,也是唯一能够实现持续集成的方法。
在这种模式中,开发人员几乎总是提交到主线。分支很少使用。在主线上开发的好处包括:
• 确保所有代码持续集成
• 确保开发人员立即获取彼此的更改
• 避免项目结束时的”合并地狱”和”集成地狱”
在这种模式中,正常开发时,开发人员在主线上工作,每天至少提交一次代码。当需要进行复杂更改时,无论是开发新功能、重构系统的一部分、进行影响深远的性能改进,还是重新架构系统的各层,默认情况下都不使用分支。相反,更改被规划并实施为一系列小的增量步骤,保持测试通过,因此不会破坏现有功能。这在第346页的”保持应用程序可发布”章节中有详细描述。
主线开发并不排斥分支。相反,它意味着”所有正在进行的开发活动最终都会在某个时间点汇聚到单一代码线上”(Berczuk,2003,第54页)。然而,分支只应在不需要合并回主线时创建,例如在执行发布或尝试性更改时。Berczuk(同上)引用了Wingerd和Seiward关于主线开发优势的观点:“90%的配置管理’流程’是在强制执行代码线提升,以弥补缺少主线的不足”(Wingerd,1998)。
主线开发的一个后果是,并非每次提交到主线的代码都是可发布的。如果你习惯于为功能开发创建分支或使用基于流的开发方式将更改通过多个级别提升到发布流,这似乎是对主线开发实践的致命反驳。如果你将每个更改都提交到主线,如何管理在多个发布上工作的大型开发团队?答案是良好的软件组件化、增量开发和功能隐藏。这需要在架构和开发上更加小心,但避免不可预测的漫长集成阶段(需要合并多个流的工作以创建可行的发布分支)所带来的好处远远超过这些努力。
部署流水线的目标之一是允许大型团队频繁提交到主线,这可能导致临时的不稳定性,同时仍然允许你交付稳定可靠的发布版本。从这个意义上说,部署流水线与源代码提升模型是对立的。部署流水线的主要优势在于,你可以快速获得关于每个更改对完全集成的应用程序影响的反馈——这在源代码提升模型中是不可能的。这种反馈的价值在于,你可以随时确切地知道应用程序的状态——你不必等到集成阶段才发现你的应用程序需要额外几周或几个月的工作才能发布。
在你想对代码库进行复杂更改的情况下,创建一个分支来进行更改以免打断其他开发人员的工作似乎是最简单的做法。然而,实际上,这种方法会导致多个长期存在的分支,这些分支与主线产生严重分歧。在发布时合并分支几乎总是一个复杂的过程,需要不可预测的时间。每次新的合并都会破坏现有功能的不同部分,随后需要进行稳定主线的过程,然后才能进行下一次合并。
结果是,发布所需的时间比计划的长得多,范围更小,质量也低于预期。在这种模型中,重构更加困难,除非你的代码库是松耦合的并且遵守迪米特法则(Law of Demeter),这意味着技术债务(technical debt)的偿还也非常缓慢。这会迅速导致无法维护的代码库,使添加新功能、修复错误和重构变得更加困难。
简而言之,你会面临持续集成应该解决的所有问题。创建长期存在的分支从根本上与成功的持续集成策略相对立。
我们的提议不是技术解决方案,而是一种实践:始终提交到主干(trunk),并且每天至少提交一次。如果这似乎与对代码进行深远的更改不兼容,那么我们谦虚地认为,也许你还没有足够努力地尝试。根据我们的经验,尽管有时候将功能实现为一系列小的、增量的步骤以保持代码处于工作状态可能需要更长的时间,但好处是巨大的。拥有始终工作的代码是基础性的——我们怎么强调这种实践在实现有价值的、可工作软件的持续交付中的重要性都不为过。
有些时候这种方法不会奏效,但这些情况确实非常罕见,即使在那时也有策略可以减轻影响(参见第346页的”保持你的应用程序可发布”部分)。然而,即使在那时,最好还是避免首先需要这样做。通过定期检入主线的增量更改从A移动到B几乎总是正确的做法,所以总是把它放在你的选项列表的顶部。
在一个非常大的开发项目中,我们被迫维护一系列并行分支。在某个阶段,我们在生产环境中有一个发布版本,它有一些错误(发布版本1)。由于这些错误在生产环境中,修复它们至关重要,所以我们有一个专门负责这项任务的小团队。我们有第二个处于活跃开发中的分支,有一百多人在上面工作(发布版本2)。这个分支计划即将发布,但存在一系列相当严重的结构性问题,我们知道必须为项目的未来健康解决这些问题。为了为更稳定的未来版本做好准备,我们有另一个小团队在进行相当基础的代码重构(发布版本3)。
发布版本1和2在整体结构上有很大程度的共享。发布版本3一旦开始开发就迅速分化:由于其他两个发布版本中积累的技术债务(technical debt),它必须这样做。发布版本3的功能是偿还这些技术债务中最昂贵的部分。
很快就清楚了,我们必须在合并更改的方法上保持极度的纪律。发布版本1中所做的更改范围不如其他版本中所做的更改广泛,但它们是至关重要的生产错误修复。如果不仔细管理,发布版本2开发团队所做的大量更改将是压倒性的,而发布版本3中的更改对项目的长期成功至关重要。
我们建立了几件帮助我们的事情:
一个清晰描述的合并策略
为这些相对长期存在的分支中的每一个设置单独的持续集成服务器
一个小型的、专门的合并团队来管理这个过程,并在大多数情况下执行合并操作
图14.6 一致合并策略的设计和采用
[图14.6]展示了我们在这个项目中采用的策略图。这不是每个项目的正确策略,但对我们来说是正确的。发布版本1在生产环境中,只对这个代码分支进行关键更改,因为另一个发布版本即将到来。对发布版本1的任何更改都很重要;它尽可能快地在那里进行,并且如果有必要,通过发布流程将”修复”投入生产。所有发布版本1的更改随后按照它们在发布版本1中的顺序应用到发布版本2。
发布版本2处于非常活跃的开发中。所有更改,无论是从发布版本1发起的还是直接在发布版本2中进行的,随后都应用到发布版本3。同样,这些更改按顺序进行。
合并团队全职工作以在三个发布分支之间移动更改,使用版本控制系统来维护更改的顺序。他们使用我们能找到的最好的代码合并工具,但由于发布版本1和2之间的广泛功能更改,以及发布版本2和3之间的广泛结构更改,合并往往是不够的。在许多情况下,早期版本中的错误修复在新的发布版本3中消失了,因为我们正在改进。在其他情况下,它们必须从头重写,因为虽然问题以某种形式仍然存在,但实现现在完全不同了。
这是困难的、令人沮丧的工作,团队在这方面变得非常擅长。我们在团队中轮换人员,但核心开发人员决定坚持到底,因为他们理解这项工作有多重要。在高峰期,合并团队是四个人全职工作了几个月。
分支并不总是如此昂贵,但它总是伴随着一些成本。如果我们再来一次,我们会选择不同的策略,例如通过抽象分支(branching by abstraction)来允许重构在主线上继续工作的同时进行。
唯一总是可以接受创建分支的情况是在发布之前不久。一旦创建了分支,就从分支上的代码进行发布的测试和验证,而新的开发在主线上进行。
为发布创建分支取代了代码冻结(code freeze)的恶劣做法,在代码冻结中,提交到版本控制完全关闭数天甚至数周。通过创建发布分支,开发人员可以继续检入主线,而对发布分支的更改仅针对关键错误修复。按发布分支如图14.2所示。
在这个模式中:
• 功能总是在主线上开发。
• 当你的代码对于特定版本已经功能完成,并且你想要开始进行新功能开发时,就创建一个分支。
• 只有关键缺陷的修复才被提交到分支上,并且它们会立即合并到主线。
• 当你执行实际发布时,这个分支可选择性地打标签(如果你的版本控制系统仅按文件级别管理变更,如CVS、StarTeam或ClearCase,则此步骤是强制性的)。
促使为发布创建分支的场景如下。开发团队需要开始进行新功能开发,而当前版本正在测试并准备部署,测试团队希望能够为当前版本修复缺陷,而不影响正在进行的新功能开发。在这种场景下,将新功能开发工作与分支上的缺陷修复在逻辑上分离是合理的。重要的是要记住,缺陷修复最终必须合并回主干;通常,在缺陷修复提交到分支后立即执行此操作是明智的。
在产品开发中,需要维护版本来解决在下一个版本准备好之前必须修复的问题。例如,安全问题需要在小版本中修复。有时功能和缺陷修复之间的界限难以区分,导致分支上的开发相当复杂。仍在使用早期软件版本的付费客户可能不愿意(或无法)升级到最新版本,需要在旧分支上实现某些功能。团队应该始终尽可能减少这种情况。
这种分支方式在大型项目上效果不太好,因为大型团队或多个团队很难同时完成一个版本的工作。在这种情况下,理想的方法是拥有组件化架构,为每个组件设置发布分支,这样团队可以为他们的组件创建分支并继续新工作,而其他团队正在完成他们的组件。如果这不可行,请查看本章后面的按团队分支模式,看看应用该模式是否更合理。如果你需要能够精选(cherry-pick)功能,请查看下一个模式——按功能分支。
在为发布创建分支时,重要的是不要在发布分支上创建更多分支。后续版本的分支应该始终从主线创建,而不是从现有的发布分支创建。在现有分支上创建分支会产生”阶梯”结构(Berczuk, 2003, p. 150),这使得难以找出版本之间的公共代码。
一旦你达到一定的发布频率,大约每周一次左右,为发布创建分支就不再有意义了。在这种场景下,简单地发布软件的新版本比在发布分支上打补丁更便宜、更容易。相反,你的部署流水线会记录执行了哪些发布、何时执行以及它们来自版本控制中的哪个修订版本。
这种模式旨在使大型团队更容易同时进行功能开发,同时保持主线处于可发布状态。每个故事或功能都在单独的分支上开发。只有在测试人员接受故事之后,才将其合并到主线,以确保主线始终可发布。
这种模式通常是出于保持主干始终可发布的愿望,因此在分支上完成所有开发,这样就不会干扰其他开发人员或团队。许多开发人员不喜欢在完全完成之前公开暴露他们的工作。此外,如果每次提交代表一个完整的功能或完整的缺陷修复,会使版本控制历史在语义上更加丰富。
要使这种模式有效运作,更不用说运作良好,需要满足一些先决条件。
• 主线的任何变更都必须每天合并到每个分支上。
• 分支必须是短期的,理想情况下少于几天,绝不超过一个迭代周期。
• 任何时候存在的活动分支数量必须限制为正在进行的故事数量。除非代表他们上一个故事的分支已合并回主线,否则任何人都不应开始新分支。
• 考虑让测试人员在故事合并之前接受它们。只允许开发人员在故事被接受后合并到主干。
• 重构必须立即合并以最小化合并冲突。这个约束很重要但可能会很痛苦,并进一步限制了这种模式的实用性。
• 技术负责人的部分职责是负责保持主干可发布。技术负责人应该审查所有合并,可能以补丁形式。技术负责人有权拒绝可能破坏主干的补丁。
拥有许多长期存在的分支是不好的,因为合并会带来组合问题。如果你有四个分支,每个分支只会从主线合并,而不会彼此合并。所有四个分支都在分歧。在紧密耦合的代码库中,只需要两个分支进行重构,当其中一个合并时,就会让整个团队陷入停滞。值得重申的是,分支从根本上与持续集成(continuous integration)相悖。即使你在每个分支上执行持续集成,也无法真正解决集成的问题,因为你实际上并没有集成你的分支。最接近真正持续集成的做法是让你的CI系统将每个分支合并到一个假设的”主干”中,该主干代表如果每个人都合并后主干的样子,并对其运行所有自动化测试。这是我们在分布式版本控制系统的上下文中在第79页描述的实践。当然,这样的合并很可能在大多数时候都会失败,这很好地说明了这个问题。
按特性分支(Branch by feature)经常在”特性团队”模式[cfyl02]的文献中以及一些看板开发流程的倡导者中被提及。然而,你可以在不为每个特性创建分支的情况下进行看板开发和特性团队,并且效果很好(甚至比使用按特性分支更好)。这些模式是完全正交的。
我们对按特性分支的批评不应被解读为对特性团队或看板开发流程的攻击——我们已经看到这两种开发流程都非常有效地运作。
分布式版本控制系统(DVCS)正是为这种模式设计的,它使得向主干合并或从主干合并以及针对头部创建补丁变得极其容易。使用GitHub的开源项目(例如)可以通过让用户轻松地分支仓库来添加特性,然后使该分支可供提交者拉取,从而在开发速度上获得巨大提升。然而,开源项目有一些关键属性使其特别适合这种模式。
• 虽然许多人可以为它们做出贡献,但它们由相对较小的经验丰富的开发人员团队管理,这些人拥有接受或拒绝补丁的最终权力。
• 发布日期相对灵活,允许开源项目的提交者在拒绝次优补丁方面有很大的自由度。虽然这也可能适用于商业产品,但这不是常态。
因此,在开源世界中,这种模式可以非常有效。它也可以适用于核心开发团队规模小且经验丰富的商业项目。它可以在更大的项目中发挥作用,但只有在以下条件适用的情况下:代码库是模块化的且重构良好;交付团队分为几个小团队,每个团队都有经验丰富的领导者;整个团队致力于频繁地签入并与主线集成;交付团队不会受到可能导致次优决策的过度发布压力。
我们对推荐这种模式持谨慎态度,因为它与商业软件开发中最常见的反模式之一密切相关。在这个邪恶但极其常见的镜像宇宙中,开发人员通过分支来创建特性。这个分支会长时间保持隔离。与此同时,其他开发人员正在创建其他分支。当接近发布时间时,所有分支都会合并到主干中。
此时,还有几周时间,整个测试团队基本上一直在主干上发现零星的bug而无所事事,突然有整个发布版本的集成和系统级bug要发现,以及所有特性级别的bug,这些bug尚未被发现,因为没有人在分支集成之前让测试人员正确检查它们。测试人员也可以不用费心,因为开发团队在发布日期之前没有时间修复许多bug。管理层、测试人员和开发团队将花费一到四周的时间疯狂地重新确定优先级并努力在将整个混乱局面转交给运维团队之前修复关键bug,让运维团队想办法将其投入生产或以其他方式提供给用户——用户对收到的这团乱麻并不满意。
这种力量非常强大,需要一个极其自律的团队才能避免这个问题。使用这种模式来推迟确保应用程序处于可发布状态的痛苦实在太容易了。我们甚至看到小型的、经验丰富的、忍者级别的敏捷团队也搞砸了这种模式,所以我们其他人几乎没有希望。你应该始终从”在主线上开发”模式开始,然后,如果你想尝试按特性分支,请严格按照上述规则进行。Martin Fowler写了一篇文章,生动地展示了按特性分支的风险[bBjxbS],特别是它与持续集成之间的不稳定关系。关于在持续集成中使用DVCS的更多信息,请参见第79页的”分布式版本控制系统”部分。
总的来说,你需要相当确定这种模式的收益超过了其相当大的开销,并且在发布时不会导致崩溃。你还应该考虑其他模式,例如使用组件而非分支来管理规模扩展的抽象分支(branch by abstraction),或者只是应用扎实的工程纪律,使每个变更都小而渐进,并定期检入主线。所有这些实践在上一章中都有详细描述。
值得强调的是,按特性分支(branching by feature)实际上是持续集成的对立面,我们关于如何使其工作的所有建议只是为了确保在合并时痛苦不会太可怕。首先避免痛苦要简单得多。当然,就像软件开发中的所有”规则”一样,也有例外情况可能有意义,例如开源项目或使用分布式版本控制系统的小型经验丰富的开发团队。但是,请注意,当你采用这种模式时,你是在”拿着剪刀奔跑”。
这种模式试图解决让大型开发团队在多个工作流上工作,同时仍然维护一个始终可以发布的主线的问题。与按特性分支一样,这种模式的主要目的是确保主干始终可发布。为每个团队创建一个分支,只有当分支稳定时才合并到主干。对任何给定分支的每次合并都应立即拉入其他每个分支。
图14.7 按团队分支
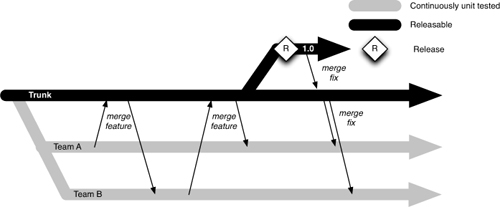
以下是按团队分支的工作流程:
创建小团队,每个团队在自己的分支上工作。
一旦完成特性/用户故事,该分支就会稳定并合并到主干。
主干上的任何变更每天都会合并到每个分支。
单元测试和验收测试在分支上的每次检入时运行。
所有测试,包括集成测试,在每次分支合并到主干时都会在主干上运行。
当你让开发人员直接检入主干时,很难确保你可以按照迭代开发方法的要求定期发布你的工作。如果你有多个团队在处理用户故事,主干几乎总是包含半完成的工作,这会阻止应用程序按原样发布,除非你严格遵守第346页”保持应用程序可发布”部分中的规则。在这种模式中,开发人员只检入到他们团队的分支。只有当正在处理的所有特性都完成时,此分支才会合并到主干。
当你有几个小型、相对独立的团队在系统的功能独立区域上工作时,这种模式会奏效。至关重要的是,每个分支都需要有一个负责定义和维护其策略的所有者,包括管理谁检入到该分支。如果你想检入到一个分支,你必须找到一个你的检入不会违反其策略的分支。否则,你必须创建一个新分支。
这种模式旨在将主干维护在可发布状态。然而,这种模式中的每个分支都面临完全相同的问题—只有当它”稳定”时才能合并到主干。实际策略认为,如果分支可以在不破坏任何自动化测试(包括验收测试和回归测试)的情况下合并到主干,则该分支是稳定的。因此,每个分支实际上都需要自己的部署流水线,以便团队可以确定哪些构建是好的,从而确定哪些版本的源代码可以在不违反策略的情况下合并到主线。任何此类版本都应该在构建启动之前将最新版本的主线合并到其中,以确保将分支合并到主线不会导致主线构建失败。
从持续集成(CI)的角度来看,这种策略有一些缺点。一个根本问题是,这种策略下的工作单元范围是整个分支,而不仅仅是特定的变更。换句话说,你不能将单个变更合并到主线—你必须合并整个分支,否则无法知道你是否违反了主线策略。如果团队在合并到主干后发现了一个错误,并且分支中还有其他变更,他们不能只合并修复。在这种情况下,团队要么必须让分支再次稳定,要么仅为修复创建另一个分支。
其中一些问题可以通过使用分布式版本控制系统(DVCS)来缓解。Linux内核开发团队使用这种模式的一个版本,为操作系统的不同部分保持逻辑分支—例如调度器和网络堆栈—在独立的存储库中。DVCS具有将选定的变更集从一个存储库发送到另一个存储库的能力,这个过程称为挑选(cherry-picking)。这意味着你可以只合并你想要的特性,而不是总是合并整个分支。现代DVCS还具有复杂的变基(rebasing)功能,因此你可以追溯性地将补丁应用于以前的变更集并将它们捆绑起来。因此,如果你在补丁中发现了错误,你可以将错误修复添加到补丁中,通过流水线运行此版本以验证它不会破坏主线,然后合并附加的补丁。在某些情况下,DVCS的使用将这种模式从我们不推荐的模式变成了我们可能推荐的模式,前提是团队定期合并到主线。
如果合并不够频繁,这种模式会遇到与所有团队不直接检入主干的模式相同的缺陷:真正的持续集成(Continuous Integration)会受到损害。这意味着始终存在频繁发生严重合并冲突的风险。因此,Kniberg建议每个团队在完成一个故事(Story)时就合并到主干,并且每天从主干合并。然而,即使有这些前提条件,由于需要保持每个分支与主线同步,总会存在持续的开销——可能是相当大的开销。如果分支之间出现显著分歧,例如在紧密耦合的代码库上执行重构(Refactoring),团队需要尽快同步这些更改以避免合并冲突。这反过来意味着需要针对分支的稳定版本执行重构,以便可以立即合并到主线。
在实践中,这种模式与按特性分支(Branch by Feature)并无太大区别。它的优势是分支较少,因此集成更频繁——至少在团队层面如此。它的劣势是分支分歧的速度要快得多,因为整个团队都在向每个分支检入代码。因此,合并可能会比按特性分支时复杂得多。主要风险在于团队在与主线进行更改合并时不够自律。团队分支会迅速偏离主线和彼此,合并冲突很快就会变得极其痛苦。在我们现实生活中见到这种模式的地方,这几乎不可避免地就是结果。
正如我们在第346页”保持应用程序可发布”一节中详细描述的那样,我们推荐采用增量开发方法以及特性隐藏(Feature Hiding)作为保持应用程序可发布的最佳方式,即使在开发新特性的过程中也是如此。总的来说,虽然需要更多的纪律,但这比管理多个分支、不断合并以及无法快速获得真正持续集成所提供的关于更改对整个应用程序影响的反馈要低风险得多。
然而,如果你正在处理一个大型的单体代码库,这种模式(连同按抽象分支(Branch by Abstraction))可以作为向松耦合组件迁移策略的有用部分。
我们参与过一个大型项目,其中一部分团队在印度工作。当时,开发站点之间的网络基础设施既缓慢又不可靠。每次提交的成本都很高。我们为印度团队创建了一个独立的本地仓库,他们频繁地向该仓库提交更改,使用正常的持续集成周期。他们运行本地的CruiseControl副本,因此拥有一个完全独立的本地持续集成周期。每天结束时,印度团队的一名幸运成员将团队的更改合并到位于英国的主线,并确保本地仓库与主线保持同步,以便第二天可以重新开始开发。
在软件开发过程中,有效控制你创建和依赖的资产对于任何规模项目的成功都至关重要。版本控制系统及其周围配置管理实践的演进是软件行业历史的重要组成部分。现代版本控制系统的成熟度及其易用性表明了它们对现代团队协作软件开发的核心重要性。
我们在这个可以说是外围话题上花费如此多时间的原因有两个:首先,版本控制模式是设计部署流水线(Deployment Pipeline)方式的核心。其次,根据我们的经验,糟糕的版本控制实践是快速、低风险发布的最常见障碍之一。这些版本控制系统的一些强大特性可能会以危及安全、可靠、低风险软件发布的方式应用。理解可用特性、选择正确的工具并恰当地使用它们是成功软件项目的重要属性。
我们花了一些时间比较不同的版本控制系统范式:标准的集中式模型、分布式模型和基于流的模型。我们相信分布式版本控制系统(Distributed Version Control System)特别会继续对软件交付方式产生巨大的积极影响。然而,使用标准模型仍然可以创建高效的流程。对于大多数团队来说,更重要的考虑是使用哪种分支策略。
在持续集成的愿望和分支的愿望之间存在根本的张力。每次你在基于持续集成的开发系统中决定分支时,都会在某种程度上做出妥协。选择使用哪种模式的问题应该基于识别对你的团队和软件项目最优的流程。一方面,持续集成的绝对观点认为每次更改都应该尽快提交到主干。主干始终是系统状态最完整和最新的描述,因为你将从中部署。更改与主干分离的时间越长——无论技术是什么,或合并工具有多复杂——最终合并时出现问题的风险就越大。另一方面,有一些因素,如网络不佳、构建缓慢或便利性,使得分支更有效率。
本章介绍了一系列选项来应对开发团队在某种程度上需要妥协持续集成(CI)会更有效率的情况。然而,重要的是每次创建分支时,你都要认识到这会带来相关成本。这种成本体现在风险的增加上,而降低风险的唯一方法就是确保无论出于何种原因创建的任何活跃分支,都应该每天或更频繁地合并回主线。否则,这个过程就不能再被认为是基于持续集成的。
正如我们所说,我们可以毫无保留地推荐的分支理由只有:发布、探索性开发,以及在万不得已的情况下,当没有其他合理方法能让应用程序达到可以通过其他方法进行进一步更改的状态时。
本书主要面向实践者。然而,实施持续交付不仅仅是购买一些工具和做一些自动化工作。它依赖于交付过程中所有相关人员之间的有效协作、高层赞助人的支持,以及一线人员做出改变的意愿。本章旨在为如何在组织内实现持续交付提供指导。首先,我们提出了一个配置和发布管理的成熟度模型。接下来,我们将探讨如何规划项目生命周期,包括发布。然后我们描述了一种软件项目构建和发布的风险管理方法。最后,我们审视了部署中常见的组织风险和反模式,以及帮助你避免这些问题的最佳实践和模式。
在开始之前,我们想介绍持续交付的整体价值主张。持续交付不仅仅是一种新的交付方法论。它是运营依赖软件的业务的全新范式。要理解为什么会这样,我们需要审视公司治理核心的一个基本矛盾。
CIMA将企业治理定义为”董事会和执行管理层行使的一系列责任和实践,目标是提供战略方向、确保目标达成、确定风险得到适当管理,并验证组织资源得到负责任的使用。“它进一步区分了公司治理和业务治理,前者关注合规性——换句话说,合规、保证、监督和负责任、透明的管理——后者关注业务的绩效和价值创造。
一方面,业务部门希望尽快将有价值的新软件推出,以持续增加收入。另一方面,负责公司治理的人员希望确保组织了解任何可能导致业务损失或被关闭的风险,如违反适用法规,并且有适当的流程来管理这些风险。
虽然业务中的每个人最终都有共同的目标,但绩效和合规性是可能经常发生冲突的力量。这可以从开发团队和运维团队的关系中看出,开发团队面临着尽快交付的压力,而运维团队则将任何变更都视为风险。
我们认为组织的这两个部分并非在进行零和博弈。同时实现合规性和绩效是可能的。这一原则正是持续交付的核心。部署流水线旨在通过确保交付团队获得关于应用程序生产就绪状态的持续反馈来实现绩效。
它还旨在通过使交付过程透明化来帮助团队实现合规性。IT部门和业务部门都可以随时试用应用程序,例如测试某些新功能,方法是自助将应用程序部署到UAT环境。出于审计目的,流水线提供了一个记录系统,准确记录每个应用程序的哪些版本经过了交付过程的哪些部分,以及能够从每个环境中的内容追溯到它在版本控制中的来源修订版本。该领域的许多工具都提供了锁定谁可以做什么的功能,以便只有授权人员才能执行部署。
本书中的实践,特别是增量交付以及构建、测试和部署过程的自动化,都旨在帮助管理发布新版本软件的风险。全面的测试自动化为应用程序质量提供了高度信心。部署自动化提供了按下按钮即可发布新变更和回滚的能力。诸如使用相同流程部署到每个环境、自动化环境、数据和基础设施管理等实践,旨在确保发布过程得到充分测试,将人为错误的可能性降至最低,并且任何问题——无论是功能性、非功能性还是配置相关的——都能在发布前及早发现。
通过采用这些实践,即使是拥有复杂应用的大型组织也能快速、可靠地交付新版本软件。这不仅意味着企业能更快获得投资回报,还意味着他们能以更低的风险实现这一目标,而不会产生漫长开发周期带来的机会成本——更糟的是交付不适用的软件。用精益制造(Lean Manufacturing)的类比来说,不经常交付的软件就像堆放在仓库里的库存。它已经花费了你的制造成本,却没有为你赚钱——事实上,存储它还在持续产生成本。
在讨论治理(Governance)主题时,对组织变革的目标有清晰的认识极为有用。在多年的咨询工作中——这个职业让我们有机会接触许多不同的组织并深入了解其工作实践的细节——我们和同事总结出了一个用于评估所服务组织的模型。这个模型有助于识别一个组织在流程和实践成熟度方面所处的位置,并定义了组织可以遵循的改进路径。
图15.1 成熟度模型
特别是,我们仔细考虑了组织中涉及软件交付的所有角色,以及他们如何协作。图15.1展示了这个模型。
最终目标是让你的组织得到改进。你期望的成果包括:
• 缩短周期时间,以便更快地为组织交付价值并提高盈利能力。
• 减少缺陷,从而提高效率并降低支持成本。
• 提高软件交付生命周期的可预测性,使规划更加有效。
• 能够采用并保持对任何适用监管制度的合规态度。
• 能够有效确定和管理与软件交付相关的风险。
• 通过更好的风险管理和更少的软件交付问题来降低成本。
我们相信这个成熟度模型可以作为指南,帮助你实现所有这些成果。一如既往,我们建议你应用戴明循环(Deming Cycle)——计划、执行、检查、行动。
使用该模型对你组织的配置和发布管理成熟度进行分类。你可能会发现组织的不同部分在各个不同类别中达到不同的级别。
选择一个你的不成熟状况特别痛苦的领域进行关注。价值流映射(Value Stream Mapping)将帮助你识别需要改进的领域。本书将帮助你了解每项改进带来的价值以及如何实施。你应该决定哪些改进对你的组织有意义,估算其成本和收益,并确定优先级。你应该定义验收标准来明确你期望的结果以及如何衡量它们,以便判断变革是否成功。
实施变革。首先,创建一个实施计划。从概念验证(Proof of Concept)开始可能是明智的。如果是这样,选择组织中真正陷入困境的部分——这些人会有最强的动力来实施变革,也是在这里你会看到最显著的变化。
一旦完成变革,使用你创建的验收标准来衡量变革是否产生了预期效果。召集所有利益相关者和参与者举行回顾会议,了解变革执行得如何以及潜在的改进领域在哪里。
重复这些步骤,在你的知识基础上不断积累。逐步推广改进,并在整个组织中推广。
组织变革是困难的,详细指南超出了本书的范围。我们能提供的最重要的建议是逐步实施变革,并随时衡量影响。如果你试图在一步之内让整个组织从一级跃升到五级,你会失败。改变大型组织可能需要数年时间。找出能带来最大价值的变革并制定执行方案应该被科学对待:提出假设,然后测试。重复这个过程,并在过程中学习。无论你有多优秀,总有改进的空间。如果某些方法不奏效,不要放弃这个过程;尝试其他方法。
每个软件开发项目都是不同的,但抽象出共同元素并不太难。特别是,我们可以有效地概括软件交付的生命周期。每个应用程序,就像每个团队一样,都有一条叙事弧线。谈论团队经历五个阶段已经变得很常见:形成(Forming)、震荡(Storming)、规范(Norming)、执行(Performing)和哀悼/重组(Mourning/Reforming)。同样,每个软件都会经历几个阶段。一个初步的高层次图景可能包括以下阶段:识别、启动、初始化、开发和部署、以及运营。在继续更详细地探讨构建和部署工程如何融入这幅图景之前,我们将简要介绍这些阶段。
信息技术基础架构库(ITIL)提供了一个软件服务交付框架,我们认为它与本书描述的交付方法基本兼容。我们都专注于通过将IT打造为业务的战略资产来为客户提供更高价值。正如ITIL关注服务的效用(utility,即目的适配性)和保证(warranty,即使用适配性),我们讨论的系统也需要满足明确定义的功能性和非功能性需求。
然而,ITIL的范围比本书要广泛得多。它旨在为服务生命周期的所有阶段提供最佳实践,从管理IT战略和服务组合的实践与职能,一直到如何管理服务台。相比之下,本书假设你已经有了一个战略,以及管理该战略的流程,并且对你想要提供的服务有一些高层次的想法。我们主要关注ITIL中被称为服务过渡(service transition)的阶段,并对服务运营(service operation)有一些讨论(特别是在[第11章]“管理基础设施和环境”中)。
在ITIL的背景下,本书的大部分内容可以被视为为发布和部署管理以及服务测试和验证流程提供最佳实践,包括它们与服务资产和配置管理以及变更管理流程的关系。然而,由于我们对交付采取整体视角,书中讨论的内容也对服务设计和服务运营有影响。
我们的方法与ITIL的主要区别在于我们对迭代和增量交付以及跨职能协作的关注。ITIL从服务设计和服务运营的角度认为这些很重要,但在讨论服务过渡——特别是开发、测试和部署时,这方面有所忽视。我们认为有价值、高质量软件的迭代和增量交付对企业创造和维持竞争优势的能力至关重要。
中型和大型组织会有治理战略。企业会确定其战略目标,从而识别出能够帮助企业实现战略目标的工作计划。这些计划又会被分解为项目。
然而,根据我们的经验,在没有商业案例的情况下启动IT项目是惊人地普遍。这很可能导致失败,因为如果没有商业案例,就无法知道成功是什么样子。你可能就像《南方公园》中的内裤侏儒,他们的战略是:
收集内裤。
?
盈利。
没有商业案例,就很难进行需求收集,也不可能客观地对收集到的需求进行优先级排序(这也适用于内部提供的服务)。即使有了商业案例,你也可以确定,最终得到的应用或服务会与你在初始需求收集时脑海中的解决方案有很大不同。
在开始收集需求之前,另一个必不可少的事情是列出利益相关者(stakeholders)清单,其中最重要的是业务发起人(在PRINCE2中称为高级责任所有者)。每个项目应该只有一个业务发起人,否则,任何规模合理的项目在完成之前都会因政治内斗而崩溃。这个业务所有者在Scrum中被称为产品负责人(product owner),在其他敏捷方法中被称为客户。然而,除了业务所有者,每个项目都需要一个由利益相关方组成的指导委员会——在公司中,这将包括其他高管和服务用户代表;对于产品,可能包括知名或具有代表性的产品客户。IT项目的其他内部利益相关者包括运营、销售、营销和支持人员,当然还有开发和测试团队。所有这些利益相关者都应该在项目的下一个阶段得到代表:启动阶段。
最简单的描述是编写任何生产代码之前的阶段。通常,在此期间会收集和分析需求,对项目进行粗略的范围界定和规划。可能会倾向于认为这个阶段价值不高,但即使是你们的核心敏捷主义者作者也从痛苦的经验中认识到,这个阶段需要仔细规划和执行才能使软件项目成功。
启动阶段有许多交付成果,其中一些会因方法论和项目类型而异。然而,大多数启动阶段应包括以下内容:
• 商业案例,包括项目的估计价值。
• 高层次功能性和非功能性需求列表(特别要解决容量、可用性、服务连续性和安全性问题),只需足够的细节来估算所涉及的工作并规划项目。
• 发布计划,包括工作进度表和与项目相关的成本。为了获得这些信息,通常需要估算需求的相对规模、所需的编码工作量、每个需求相关的风险,以及人员配置计划。
• 测试策略。
• 发布策略(稍后详述)。
• 架构评估,从而决定要使用的平台和框架。
• 风险和问题日志。
• 开发生命周期描述。
• 执行此列表的计划描述。
这些交付物应包含足够的细节,使项目能够开始工作,目标是在最多几个月内交付成果,如果可能的话时间越短越好。根据我们的经验,一个合理的最大项目周期约为三到六个月——倾向于较短的时间限制。在启动(inception)过程之后,应根据项目的预估价值、预估成本和预测风险做出是否继续推进项目的决策。
启动过程中最重要的部分——确保项目有成功机会的关键——是让所有利益相关者面对面聚在一起。这意味着开发人员、客户、运维人员和管理层都要参与。这些人之间的对话会形成对要解决的问题和解决方法的共同理解,这才是真正的交付物。上述列表旨在构建这些对话的结构,以便讨论重要问题、识别风险并制定应对策略。
这些交付物应该被记录下来,但由于它们是活文档(living documents),我们预期每一项在整个项目过程中都会发生变化。为了以可靠的方式跟踪这些变化——让每个人都能轻松看到当前的情况——你应该将这些文档提交到版本控制系统中。
有一点需要警告:在项目的这个阶段,你做出的每一个决定都是基于推测的,并且会发生变化。你产出的是基于掌握的少量信息的最佳猜测。在项目的这个阶段——你对项目了解最少的阶段——投入过多精力是一个错误。这些是必要的规划讨论和方向设定,但要预期随着项目推进会不断细化和重新定义其中许多内容。成功的项目能够成功应对变化。那些试图避免变化的项目往往会失败。在项目的这个阶段进行详细规划、估算或设计都是浪费时间和金钱。只有基于大方向的决策在这个阶段才是持久的。
在启动之后,你应该建立初始的项目基础设施。这是初始化阶段,通常持续一到两周。以下列表描述了典型的初始化阶段活动。
• 确保团队(分析师、管理者以及开发人员)拥有开始工作所需的硬件和软件
• 确保基本基础设施到位——如互联网连接、白板、纸笔、打印机、食物和饮料
• 创建电子邮件账户并为人员分配访问资源的权限
• 设置版本控制
• 设置基本的持续集成环境
• 就角色、职责、工作时间和会议时间(例如站会、规划会议和演示会)达成一致
• 准备第一周的工作并就目标(不是截止日期)达成一致
• 创建简单的测试环境和测试数据
• 对预期系统设计进行更详细的审视:在这个阶段探索可能性才是真正的目标
• 通过进行探针(spike)(针对特定需求的一次性实现,作为概念验证)来识别和缓解任何分析、开发和测试风险
• 开发用户故事或需求待办列表(backlog)
• 设置项目结构,使用最简单的用户故事——相当于架构上的”hello world”——包括构建脚本和一些测试来启动持续集成
为这些任务分配足够的时间以舒适地完成它们至关重要。如果没有人知道正在开发的初始需求的验收标准,并且团队成员使用配置不良的计算机、糟糕的工具和不稳定的互联网连接,那么尝试开始工作是低效且令人沮丧的。
虽然项目的这个阶段真正针对的是建立基本项目基础设施,不应被视为真正的开发迭代,但使用一个真实世界的问题来让事情运转起来是极其有用的。当没有东西可测试时构建测试环境,或者当没有东西可存储时设置版本控制系统,这是一种毫无意义且低效的开始方式。选择你能找到的最简单的需求,但它仍然能解决一个真实问题并在设计方面建立一些初始方向。使用这个用户故事来确保你能正确地对结果进行版本控制,能在持续集成环境中运行测试,并能将结果部署到手动测试环境。目标是在初始化阶段结束时完成并演示这个用户故事,并建立所有支持性基础设施。
完成后,你就可以开始实际的开发了。
自然地,我们会推荐使用迭代和增量的过程来开发和发布软件。唯一可能不适用的情况是当你在处理涉及多方的大型国防项目时——但即使是航天飞机软件也是使用迭代过程实现的。1 尽管许多人认同迭代过程的好处,但我们经常看到声称在做迭代开发但实际上并没有做的团队。因此值得重申我们认为迭代过程的基本必要条件。
• 你的软件始终处于工作状态,通过自动化测试套件来证明,包括单元测试、组件测试和端到端验收测试,这些测试在你每次提交代码时都会运行。
• 在每次迭代中,将可工作的软件部署到类生产环境中,向用户展示(这使得过程不仅是迭代的,而且是增量的)。
• 迭代周期不超过两周。
使用迭代过程有几个原因:
• 如果你优先处理具有高业务价值的功能,你可能会发现软件在项目结束之前很早就开始变得有用。通常有充分的理由不在软件具备有用功能时立即发布——但没有什么比一个人们可以使用的工作系统更能将对项目最终成功的担忧转化为对新功能的兴奋。
• 你会定期从客户或发起人那里获得关于哪些功能有效、哪些需求需要澄清或更改的反馈,这反过来意味着你所做的事情更有可能是有用的。没有人在项目开始时就真正知道他们想要什么。
• 只有当客户签字确认时,事情才真正完成。定期进行展示是唯一相对可靠的跟踪进度的方式。
• 始终保持软件处于工作状态(因为你必须展示它)会在团队中培养纪律性,防止出现诸如长时间集成阶段、破坏一切的重构练习以及失去焦点、毫无结果的实验等问题。
• 也许最重要的是,迭代方法强调在每次迭代结束时拥有生产就绪的代码。这是衡量软件项目进度的唯一真正有用的标准,也是只有迭代方法才能提供的标准。
一个经常被引用的不进行迭代开发的理由是,当项目整体在完成大量功能之前不会产生任何价值时。虽然这个门槛对许多项目来说可能是真实存在的,但我们上面列表中的最后一点在这种情况下尤其适用。在管理没有采用迭代开发的大型项目时,所有进度衡量标准都是主观的,没有办法量化项目的实际进度。你在非迭代方法中看到的漂亮图表是基于对剩余时间的估计以及对后期集成、部署和测试的风险和成本的猜测。迭代开发基于开发团队生产用户认可的适用工作软件的速度,提供进度速率的客观衡量标准。只有生产就绪的工作代码,即使只在UAT环境中,你可以与之交互的代码,才能提供任何给定功能真正完成的任何保证。
至关重要的是,生产就绪还意味着软件在类生产环境中使用生产规模的数据集测试了其非功能需求(non-functional requirements)。你关心的任何非功能特性,如容量、可用性、安全性等,都应该使用现实的负载和使用模式进行测试。这些测试应该自动化,并针对通过验收测试的每个软件构建运行,这样你就知道你的软件始终适用。我们在第9章”测试非功能需求”中更详细地介绍了这一点。
迭代开发过程的关键是优先级排序(prioritization)和并行化(parallelization)。工作按优先级排序,以便分析师可以开始分析最有价值的功能,将工作提供给开发人员,然后提供给测试人员,并向真实用户或其代理展示。使用精益制造(lean manufacturing)的技术,这项工作可以并行化,并且可以改变每项任务的工作人员数量以消除瓶颈。这导致了一个非常高效的开发过程。
迭代和增量开发有许多方法。最流行的方法之一是Scrum,一种敏捷开发过程。我们已经看到Scrum在许多项目中取得成功,但我们也看到它失败。以下是失败的三个最常见原因:
• 缺乏承诺。向Scrum的过渡可能是一个令人恐惧的过程,尤其是对项目领导层而言。确保每个人定期会面讨论正在发生的事情,并建立定期的回顾会议(retrospective meetings)来分析绩效并寻求改进。敏捷过程依赖于透明度、协作、纪律和持续改进。当实施敏捷过程时出现的大量有用信息可能会将以前隐藏的不便真相推到聚光灯下。关键是要意识到这些问题一直存在。现在你知道了它们,你可以修复它们。
• 忽视良好的工程实践。Martin Fowler等人描述了如果遵循Scrum的人认为可以忽略测试驱动开发(test-driven development)、重构(refactoring)和持续集成(continuous integration)等技术实践会发生什么。被初级开发人员破坏的代码库不会仅靠任何开发过程自动修复。
• 适应直到过程不再是敏捷的。人们通常会”调整”敏捷过程,使其成为他们认为在其特定组织中更好的东西。毕竟,敏捷过程被设计为可以根据单个项目的需求进行裁剪。然而,敏捷过程的元素经常以微妙的方式相互作用,很容易误解价值所在,特别是对于没有这些迭代过程背景的人来说。我们怎么强调都不为过,重要的是首先假设所写的内容是正确的,并首先遵循所写的过程。只有在你看到它如何工作之后,你才应该开始使其适应你的组织。
最后一点对诺基亚来说非常令人不安,以至于他们创建了一个测试来评估他们的团队是否真正在进行Scrum。它分为两部分。
你在进行迭代开发吗?
• 迭代必须在四周以内完成(time-boxed)。[2]
• 软件功能必须在每次迭代结束时经过测试并可正常工作。
• 迭代必须在规格说明完成之前开始。
你在使用Scrum吗?
• 你知道谁是产品负责人(product owner)吗?
• 产品待办列表(product backlog)是否按业务价值排序?
• 产品待办列表是否有由团队创建的估算?
• 是否有项目经理(或其他人)干扰团队的工作?
关于最后一点需要说明的是,我们认为项目经理可以通过管理风险、移除障碍(如资源不足)以及促进高效交付来发挥有用的作用。但有些项目经理并不做这些事情。
通常,第一次发布不会是最后一次。接下来会发生什么在很大程度上取决于项目。开发和发布阶段可能会全速继续,或者团队规模可能会缩减。如果项目是试点,可能会出现相反的情况,团队可能会扩大。
真正迭代和敏捷流程的一个有趣方面是,在许多方面,项目的运营阶段与常规开发阶段并没有本质区别。正如我们所说,大多数项目不会在首次发布时就停止,而是会继续开发新功能。一些项目会有一系列维护版本,可能修复未预见的问题,可能调整项目以满足新发现的用户需求,也可能作为滚动开发计划的一部分。在所有这些情况下,新功能都会被识别、排序、分析、开发、测试和发布。这与项目的常规开发阶段没有区别。在这方面,让这些阶段融合在一起是消除风险的最佳方法之一,这也是本书其余部分所述持续交付(continuous delivery)的核心。
正如我们在本节前面提到的,将发布时间提前到对任何给定系统有意义的最早时点是非常有用的。你将获得的最佳反馈来自真实用户;关键是尽快发布你的软件供实际使用。然后你可以尽快对软件的可用性和实用性方面的任何问题或反馈做出反应。尽管如此,在系统发布供公众使用之前和之后的项目阶段之间还是有一些区别需要考虑。一旦首次公开发布,变更管理,特别是涉及应用程序生成的数据及其公共接口的变更管理,就会成为一个重要问题(参见[第12章],“数据管理”)。
风险管理是确保以下事项的过程:
• 已识别主要项目风险。
• 已制定适当的缓解策略来管理这些风险。
• 在整个项目过程中持续识别和管理风险。
风险管理流程应具备几个关键特征:
• 项目团队报告状态的标准结构
• 项目团队按照标准定期更新进展情况
• 项目经理可以跟踪所有项目当前状态和趋势的仪表板(dashboard)
• 由项目外部人员进行定期审计,以确保风险得到有效管理
需要注意的是,并非所有风险都需要制定缓解策略。某些事件具有灾难性,一旦发生,就无法采取任何措施来缓解。一颗巨大的小行星摧毁地球上所有生命就是一个极端例子,但你明白我们的意思。项目中经常存在一些真实的特定风险,会导致项目被取消,例如立法或经济变化、组织管理结构变更或关键项目赞助人的撤离。为成本过高或耗时过长而不值得实施的缓解策略做计划毫无意义——例如,为小公司的考勤和费用申请系统建立多站点多节点备份系统。
一个常见的风险管理模型(参见Tom DeMarco和Timothy Lister的Dancing with Bears)根据所有风险的影响——如果它们发生会造成多大损害——和可能性——它们发生的可能性有多大来分类。这两者结合起来评估每个风险的严重程度。最简单的方法是从财务角度考虑影响:如果风险发生会损失多少钱?然后可以将可能性建模为0(不可能)到1(确定)之间的概率。严重程度就是影响乘以概率,这样你就能以金额来估算风险的严重程度。这使你在决定采取何种策略来缓解风险时可以做出非常简单的计算:缓解策略的成本是否高于风险的严重程度?如果是,可能就不值得实施。
就本章前面介绍的项目生命周期模型而言,风险管理流程应该在启动阶段(inception phase)结束时开始,在初始化阶段(initiation phase)结束时重新审视,然后在整个开发和部署阶段定期重新审视。
启动阶段结束时
在这个阶段,应该准备好两个重要的交付成果。第一个是作为启动阶段的一部分而创建的发布策略。您应该验证我们在创建发布策略部分讨论的所有考虑因素是否都已被考虑在内。如果没有,团队计划如何管理相关风险?
第二个交付成果是启动阶段的计划。有时启动和开始阶段之间存在间隔,在这种情况下,这个计划可以推迟到开始阶段开始前几天。否则,它需要作为启动阶段结束的一部分来完成。
启动阶段结束
这里的关键是确保团队已准备好开始开发软件。他们应该已经有一个运行的持续集成服务器来编译代码(如果适用)并运行自动化测试套件。他们应该有一个类生产环境用于部署。应该制定测试策略,说明如何通过部署流水线中运行的自动化测试套件来测试应用程序的功能性和非功能性(特别是容量)需求。
开发和发布风险缓解
即使有最好的准备,开发和部署阶段也有很多可能严重出错的方式,有时比您想象的更快。我们都经历过或听说过关于项目在部署日期之后才交付代码的恐怖故事,或者系统部署后因容量问题而立即失败。在整个阶段,您需要问自己的问题是:“可能出什么问题?”因为如果您不问自己这个问题,当事情真的出错时,您将没有任何答案准备好。
在很多方面,风险管理的真正价值在于它为开发建立了一个背景,从而培养一种深思熟虑、具有风险意识的开发活动方法。作为团队一起考虑可能出什么问题的行为,可以成为可能被遗漏的具体需求的来源,但它也使我们能够在风险成为问题之前给予足够的关注来避免它。如果您认为第三方供应商可能会延误截止日期,您将提前监控他们的进度,从而有时间在截止日期到来之前计划和适应延误。
在这个阶段,您的目标是识别、跟踪和管理任何您能想到的可管理风险。有几种识别风险的方法:
• 查看部署计划。
• 在每次展示后定期进行项目小型回顾,并让团队在此会议期间进行风险头脑风暴。
• 将风险识别作为每日站立会议的一部分。
有几个常见的构建相关和部署相关风险需要注意—我们将在下一节中介绍这些。
重要的是不要打扰一个定期按计划交付可工作软件且缺陷很少的团队。然而,重要的是要快速发现是否有一个项目从外部看起来很好但实际上将要失败。幸运的是,迭代方法的一个巨大好处是,发现这种情况是否存在相对简单。如果您正在进行迭代开发,您应该在每次迭代结束时从类生产环境展示可工作的软件。这可能是切实进展的最佳证明。您的团队生产真正可工作代码的速度—足够好让真实用户使用,并将其部署到类生产主机环境中—速度(velocity)—是不会说谎的,即使估算会。
将这与非迭代方法进行比较—或者说,迭代周期太长的迭代方法。在这样的项目中,有必要深入了解团队的工作细节,深入研究各种项目文档和跟踪系统,以找出还剩多少工作要做以及已经完成了多少工作。一旦完成这个分析,就需要根据现实验证您的结果,这是一个极其困难和不可靠的过程,任何尝试过的人都可以证实。
分析任何项目的一个好起点是提出这些问题(这个列表在我们的几个项目中运作良好):
• 您如何跟踪进度?
• 您如何预防缺陷?
• 您如何发现缺陷?
• 您如何跟踪缺陷?
• 您如何知道一个故事已完成?
• 您如何管理环境?
• 您如何管理配置,如测试用例、部署脚本、环境和应用程序配置、数据库脚本和外部库?
• 您多久展示一次可工作的功能?
• 您多久做一次回顾?
• 您多久运行一次自动化测试?
• 您如何部署软件?
• 您如何构建软件?
• 您如何确保发布计划可行且运维团队可以接受?
• 您如何确保风险和问题日志是最新的?
这些问题不是规定性的,这很重要,因为每个团队需要有一定的灵活性来选择最适合其特定需求的流程。相反,它们是开放式的,确保您可以获得尽可能多的关于项目背景和方法的信息。然而,它们关注结果,因此您可以验证团队实际上能够交付,并且您将能够发现任何警告信号。
在本节中,我们描述了在构建、部署、测试和发布软件过程中出现的一些常见问题。虽然项目中几乎任何事情都可能出错,但有些问题比其他问题更容易发生。通常很难弄清楚项目到底出了什么问题——你所拥有的只是症状。当事情确实出错时,要弄清楚如何及早发现问题,并确保对这些症状进行监控。
一旦观察到症状,你需要找出根本原因。任何给定的症状都可能是多个潜在原因的表现。为此,我们使用一种叫做”根本原因分析”的技术。这是一个对非常简单程序的花哨名称。当面对一系列症状时,只需像小孩子一样反复问团队”为什么?“建议至少问五次”为什么?“虽然这个过程听起来几乎荒谬,但我们发现它非常有用且完全可靠。
一旦知道了根本原因,你就必须实际修复它。然而这超出了质量保证的职责范围。因此,话不多说,这里列出了常见症状清单,按其根本原因分组。
问题
部署构建需要很长时间,并且部署过程很脆弱。
症状
• 测试人员需要很长时间才能关闭缺陷。请注意,这个症状可能不完全是由部署不频繁引起的,但它是一个可能的根本原因。
• 故事需要很长时间才能被测试或由客户签收。
• 测试人员发现了开发人员很久以前就修复的缺陷。
• 没有人信任用户验收测试(UAT)、性能测试或持续集成(CI)环境,人们对何时可以发布版本持怀疑态度。
• 很少进行产品展示。
• 很少能够演示应用程序正常工作。
• 团队的速度(进度)比预期慢。
可能的原因
有许多可能的原因。以下是一些最常见的原因:
• 部署过程没有自动化。
• 没有足够的硬件可用。
• 硬件和操作系统的配置没有正确管理。
• 部署过程依赖于团队控制之外的系统。
• 没有足够多的人理解构建和部署过程。
• 测试人员、开发人员、分析师和运维人员在开发过程中没有充分协作。
• 开发人员没有通过进行小的增量更改来保持应用程序正常工作的纪律,因此经常破坏现有功能。
问题
交付团队未能实施有效的测试策略。
症状
• 回归缺陷不断出现。
• 即使团队将大部分时间花在修复缺陷上,缺陷数量仍在不断增加(当然,只有在有效的测试流程下,这种症状才会显现)。
• 客户抱怨产品质量差。
• 每当新功能请求到来时,开发人员都会呻吟并显得惊恐。
• 开发人员抱怨代码的可维护性,但情况从未好转。
• 实现新功能所需的时间不断增加,团队开始落后。
可能的原因
这个问题本质上有两个来源:测试人员与交付团队其他成员之间的协作效果不佳,以及自动化测试实施不当或不充分。
• 测试人员在功能开发过程中不与开发人员协作。
• 故事或功能在没有编写全面的自动化测试、没有得到测试人员签收或没有在类生产环境中向用户展示的情况下就被标记为”完成”。
• 缺陷通常被输入到待办事项中,而没有立即修复并编写自动化测试来检测回归问题。
• 开发人员或测试人员在开发自动化测试套件方面经验不足。
• 团队不了解针对他们所使用的技术或平台应该编写哪些最有效的测试类型。
• 开发人员在没有足够测试覆盖率的情况下工作,可能是因为项目管理没有给他们时间来实施自动化测试。
• 系统是一个将被丢弃的原型(尽管我们遇到过一些重要的生产系统,它们最初作为原型开发但从未被丢弃)。
请注意,自动化测试当然也可能过度——我们知道有一个项目,整个团队花了几周时间只编写测试。当客户发现没有可工作的软件时,团队被解雇了。然而,这个警示故事应该在具体情境中理解:到目前为止,最常见的失败模式是自动化测试太少,而不是太多。
问题
构建过程没有得到妥善管理。
症状
• 开发人员签入代码的频率不够(至少每天一次)。
• 提交阶段永久损坏。
• 缺陷数量很高。
• 每次发布前都有一个漫长的集成阶段。
可能的原因
• 自动化测试运行时间太长。
• 提交阶段运行时间太长(少于五分钟是理想的,超过十分钟是不可接受的)。
• 自动化测试间歇性失败,产生误报。
• 没有人有权限回滚签入。
• 没有足够多的人理解并能够对持续集成(CI)过程进行更改。
问题
无法使用自动化流程可靠地配置环境和安装应用程序。
症状
• 生产环境出现神秘故障。
• 新部署是紧张、令人恐惧的事件。
• 大型团队专门负责环境配置和管理。
• 生产部署经常需要回滚或打补丁。
• 生产环境出现不可接受的停机时间。
可能原因
• UAT 和生产环境不同。
• 对生产和预发布环境进行变更的变更管理流程不完善或执行不力。
• 运维、数据管理团队和交付团队之间协作不足。
• 对生产和预发布环境的监控不足,无法检测事件。
• 应用程序内置的监控工具和日志记录不足。
• 对应用程序的非功能性需求测试不足。
许多大型公司需要遵守管理其行业的具有法律约束力的法规。例如,所有在美国注册的上市公司都必须遵守 2002 年萨班斯-奥克斯利法案(Sarbanes-Oxley Act,通常缩写为 Sarbox 或 SOX)。美国医疗保健公司必须遵守 HIPAA 的规定。处理信用卡信息的系统必须符合 PCI DSS 标准。几乎每个领域都以某种方式受到监管,IT 系统经常需要在设计时考虑某些法规。
我们既没有空间也没有意愿去研究每个国家每个行业的法规,这些法规本身也在频繁变化。然而,我们想花一些时间讨论一般性的法规,特别是在对软件发布流程定义严格控制的环境中。许多此类监管制度要求审计追踪(audit trail),使得可以识别生产环境中的每一项变更,它来自哪些代码行,谁接触过它们,以及谁批准了流程中的步骤。此类法规在从金融到医疗保健的许多行业中都很常见。
以下是我们看到的一些用于执行此类法规的常见策略:
• 锁定能够访问”特权”环境的人员。
• 创建和维护有效且高效的变更管理流程,用于对特权环境进行变更。
• 在执行部署之前需要管理层批准。
• 要求记录从构建到发布的每个流程。
• 创建授权屏障(authorization barrier),确保创建软件的人无法将其部署到生产环境,作为防止潜在恶意干预的保护措施。
• 要求审计每个部署,以准确了解正在进行哪些变更。
这样的策略在受监管的组织中至关重要,可以大幅减少停机时间和缺陷数量。尽管如此,它们名声不佳,因为很容易以使变更更加困难的方式实施它们。然而,部署流水线(deployment pipeline)使得能够相当容易地执行这些策略,同时实现高效的交付流程。在本节中,我们提出一些原则和实践,以确保遵守此类监管制度,同时保持短周期时间。
许多公司坚持认为文档是审计的核心。我们不敢苟同。一张纸说你以某种方式做了某事,并不能保证你实际上做了那件事。咨询界充满了这样的故事:人们通过提供一堆”证明”他们已经实施的文档,以及指导员工在检查员询问时如何给出正确答案,从而通过了(例如)ISO 9001 审计。
文档还有一个讨厌的习惯,就是过时。文档越详细,就越可能很快过时。当它过时时,人们通常不会费心更新它。每个人至少听过一次以下对话:
操作员:“我遵循了你上个月发给我的部署流程,但它不起作用。”
开发人员:“哦,我们改变了部署方式。你需要复制这组新文件并设置权限 x。”或者更糟,“这很奇怪,让我看看……”然后花几个小时弄清楚发生了什么变化以及如何部署它。
自动化解决了所有这些问题。自动化脚本是你流程的文档,它必须有效。通过强制使用它们,你可以确保它们是最新的,并且流程完全按照你的意图执行。
通常需要能够追踪变更的历史,从生产环境中的内容到产生它的源代码控制版本。有两种实践可以帮助这个过程,我们想强调一下。
• 只创建一次二进制文件,并将你在构建流程第一阶段创建的相同二进制文件部署到生产环境。你可以通过对它们进行哈希处理(hash)(例如使用 MD5 或 SHA1)并将它们存储在安全数据库中来确保二进制文件相同。许多工具会自动为你执行此操作。
• 使用全自动化流程将你的二进制文件经过部署、测试和发布流程,并记录谁在何时做了什么。同样,市场上有几种工具可以帮助完成此操作。
即使采取了这些预防措施,在未经授权的更改可能被引入时仍然存在一个窗口期:当二进制文件首次从源代码创建时。只需要有人获得执行此操作的机器的访问权限,并在编译或组装过程中将文件插入文件系统,就可能发生这种情况。解决此问题的一种方法是使用自动化流程在一个受访问控制的机器上一步创建二进制文件。在这种情况下,能够自动配置和管理此环境至关重要,以便能够调试创建过程中的任何问题。
我们的一位同事Rolf Russell曾在一家金融服务公司工作,该公司对可追溯性要求特别严格,以保护其知识产权。为了确保部署到生产环境的代码确实与签入版本控制系统的代码相同,他们会反编译要部署的二进制文件。反编译的结果会与生产环境中内容的反编译版本进行比较,以查看正在进行哪些更改。
在同一家公司,只有CTO被授权将某些业务关键应用程序部署到生产环境。每周,CTO会留出几个小时用于发布,在此期间人们会来到她的办公室,以便她可以运行脚本执行部署。在撰写本文时,该公司正在转向一个系统,允许用户从需要ID卡访问的房间内的单个终端自行部署某些应用程序。这个房间配备了一个CCTV摄像头,24小时全天候记录所有活动。
大型组织通常为不同职能设立独立的部门。许多组织为开发、测试、运维、配置管理、数据管理和架构设立独立的团队。在本书的大部分内容中,我们提倡团队之间和团队内部的开放和自由的沟通与协作,因此在组织中负责软件创建和发布不同方面的部门之间建立障碍存在一些危险。然而,有些职责应该明确属于某个团队而不是另一个团队。在受监管的环境中,许多重要活动需要接受审计人员和安全团队的审查,他们的工作是确保组织不会面临任何形式的法律风险或安全漏洞。
这种职责分离,在正确的时机以正确的方式管理,不一定是坏事。理论上,为组织工作的每个人都会将该组织的最佳利益放在心上,这意味着他们将与其他部门有效合作。然而,实际情况往往并非如此。几乎无一例外,这种缺乏协作源于团队之间的沟通不畅。我们坚信,最有效的团队是在跨职能团队中开发软件,这些团队由来自定义、开发、测试和发布软件所需的所有不同学科的人员组成。这些团队应该坐在一起——当他们不在一起时,他们无法从彼此的知识中受益。
某些监管制度使得建立此类跨职能团队变得困难。如果您身处一个更加孤岛化的组织中,本书中描述的流程和技术——特别是实施部署流水线——有助于防止这些孤岛使交付过程变得低效。然而,最重要的解决方案是从项目一开始就在孤岛之间进行沟通。这应该采取以下几种形式:
• 参与项目交付的每个人,包括来自每个孤岛的人员,应该在每个项目开始时会面。我们将这群人称为发布工作组,因为他们的工作是保持发布过程的正常运作。他们的任务应该是为项目制定发布策略,详见第10章”部署和发布应用程序”。
• 发布工作组应该在整个项目期间定期会面。他们应该对自上次会议以来的项目进行回顾,计划如何改进,并执行计划。使用戴明循环(Deming cycle):计划、执行、检查、行动。
• 即使软件还没有用户,也应该尽可能频繁地发布到类生产环境——这意味着至少每次迭代一次。一些团队实践持续部署(continuous deployment),这意味着发布通过流水线所有阶段的每个更改。这是以下原则的应用:“如果它很痛苦,就更频繁地做它。”我们怎么强调这种实践的重要性都不为过。
• 项目状态,包括我们在第431页”风险管理流程”一节中提到的仪表板,应该对参与构建、部署、测试和发布过程的每个人可见,最好显示在每个人都能看到的大型监视器上。
在受监管的环境中,构建、部署、测试和发布流程的某些部分通常需要审批。特别是,手动测试环境、预发布环境和生产环境应始终处于严格的访问控制之下,以便只能通过组织的变更管理流程对其进行更改。这可能看起来过于官僚,但实际上研究表明,这样做的组织具有更低的平均故障间隔时间(MTBF)和平均修复时间(MTTR)(参见《The Visible Ops Handbook》第13页)。
如果您的组织由于对测试和生产环境的失控变更而难以满足其服务水平,我们建议采用以下流程来管理审批:
• 创建一个变更咨询委员会(Change Advisory Board),成员包括来自开发团队、运维团队、安全团队、变更管理团队和业务部门的代表。
• 决定哪些环境属于变更管理流程的管辖范围。确保这些环境受到访问控制,以便只能通过此流程进行更改。
• 建立一个自动化的变更请求管理系统,可用于提出变更请求和管理审批。任何人都应该能够查看每个变更请求的状态以及谁批准了它。
• 任何时候任何人想要对环境进行更改,无论是部署应用程序的新版本、创建新的虚拟环境还是进行配置更改,都必须通过变更请求来完成。
• 每次变更都需要补救策略(remediation strategy),例如回滚能力。
• 为变更的成功制定验收标准。理想情况下,创建一个现在失败但在变更成功后会通过的自动化测试。在运维管理仪表板上放置一个指示器,显示测试状态(参见第323页的”行为驱动监控”部分)。
• 建立一个自动化流程来应用变更,以便在变更获得批准后,可以通过按下按钮(或点击链接等)来执行。
最后一部分听起来很困难,但我们希望到现在为止它也听起来很熟悉,因为这一直是本书的主要焦点。将经过审核和授权的变更部署到生产环境的机制与将相同变更部署到任何其他环境相同,只是增加了授权:向部署流水线添加访问控制是一项微不足道的工作。这非常简单,以至于将审核和授权进一步扩展通常是有意义的:所有变更都由拥有该环境的人批准。这意味着您可以使用为测试环境创建的相同自动化来对属于变更管理流程的环境进行更改。这也意味着您已经测试了所创建的自动化流程。
变更咨询委员会如何决定是否应该执行变更?这只是风险管理的问题。进行变更的风险是什么?收益是什么?如果风险大于收益,则不应进行变更,或者应该进行另一个风险较小的变更。变更咨询委员会还应该能够对工单进行评论、请求更多信息或提出修改建议。所有这些流程都应该能够通过自动化工单系统进行管理。
最后,在实施和管理变更审批流程时,还应遵循三个原则:
• 保持系统的度量指标并使其可见。批准一项变更需要多长时间?有多少变更正在等待批准?有多少变更被拒绝?
• 保持验证系统成功的度量指标并使其可见。平均故障间隔时间和平均修复时间是多少?变更的周期时间是多少?ITIL文献中定义了更完整的度量指标列表。
• 定期对系统进行回顾,邀请组织各部门的代表参加,并根据这些回顾的反馈改进系统。
管理对每个项目的成功都至关重要。良好的管理创建了能够高效交付软件的流程,同时确保风险得到适当管理并遵守监管制度。然而,太多的组织——尽管出于良好的意图——创建了糟糕的管理结构,无法实现这些目标中的任何一个。本章旨在描述一种既处理合规性又处理绩效的管理方法。
我们的构建和发布成熟度模型旨在提高组织绩效。它允许您识别交付实践的有效性,并建议改进方法。这里描述的风险管理流程以及我们列出的常见反模式(antipatterns)列表,旨在帮助您制定策略,在问题发生时尽快识别它们,以便在容易修复时及早纠正。我们在本章(以及本书)中花费了大量篇幅讨论迭代式、增量式流程;这是因为迭代式、增量式交付是有效风险管理的关键。如果没有迭代式、增量式流程,您就没有客观的方法来衡量项目的进度或应用程序是否适合其目的。
最后,我们希望已经证明了迭代交付(iterative delivery),结合自动化的构建、部署、测试和发布流程(体现为部署流水线),不仅与合规性和性能目标兼容,而且是实现这些目标最有效的方式。这个过程促进了软件交付参与者之间更好的协作,提供快速反馈以便快速发现缺陷和不必要或实现不佳的功能,并为降低那个至关重要的指标——周期时间(cycle time)铺平了道路。这反过来意味着更快地交付有价值的高质量软件,从而以更低的风险实现更高的盈利能力。因此,良好治理的目标得以实现。
Adzic, Gojko, Bridging the Communication Gap: Specification by Example and Agile Acceptance Testing, Neuri, 2009.
Allspaw, John, The Art of Capacity Planning: Scaling Web Resources, O’Reilly, 2008.
Allspaw, John, Web Operations: Keeping the Web on Time, O’Reilly, 2010.
Ambler, Scott, and Pramodkumar Sadalage, Refactoring Databases: Evolutionary Database Design, Addison-Wesley, 2006.
Beck, Kent, and Cynthia Andres, Extreme Programming Explained: Embrace Change (2nd edition), Addison-Wesley, 2004.
Behr, Kevin, Gene Kim, and George Spafford, The Visible Ops Handbook: Implementing ITIL in 4 Practical and Auditable Steps, IT Process Institute, 2004.
Blank, Steven, The Four Steps to the Epiphany: Successful Strategies for Products That Win, CafePress, 2006.
Bowman, Ronald, Business Continuity Planning for Data Centers and Systems: A Strategic Implementation Guide, Wiley, 2008.
Chelimsky, Mark, The RSpec Book: Behaviour Driven Development with RSpec, Cucumber, and Friends, The Pragmatic Programmers, 2010.
Clark, Mike, Pragmatic Project Automation: How to Build, Deploy, and Monitor Java Applications, The Pragmatic Programmers, 2004.
Cohn, Mike, Succeeding with Agile: Software Development Using Scrum, Addison-Wesley, 2009.
Crispin, Lisa, and Janet Gregory, Agile Testing: A Practical Guide for Testers and Agile Teams, Addison-Wesley, 2009.
DeMarco, Tom, and Timothy Lister, Waltzing with Bears: Managing Risk on Software Projects, Dorset House, 2003.
Duvall, Paul, Steve Matyas, and Andrew Glover, Continuous Integration: Improving Software Quality and Reducing Risk, Addison-Wesley, 2007.
Evans, Eric, Domain-Driven Design, Addison-Wesley, 2003.
Feathers, Michael, Working Effectively with Legacy Code, Prentice Hall, 2004.
Fowler, Martin, Patterns of Enterprise Application Architecture, Addison-Wesley, 2002.
Freeman, Steve, and Nat Pryce, Growing Object-Oriented Software, Guided by Tests, Addison-Wesley, 2009.
Gregory, Peter, IT Disaster Recovery Planning for Dummies, For Dummies, 2007.
Kazman, Rick, and Mark Klein, Attribute-Based Architectural Styles, Carnegie Mellon Software Engineering Institute, 1999.
Kazman, Rick, Mark Klein, and Paul Clements, ATAM: Method for Architecture Evaluation, Carnegie Mellon Software Engineering Institute, 2000.
Meszaros, Gerard, xUnit Test Patterns: Refactoring Test Code, Addison-Wesley, 2007.
Nygard, Michael, Release It!: Design and Deploy Production-Ready Software, The Pragmatic Programmers, 2007.
Poppendieck, Mary, and Tom Poppendieck, Implementing Lean Software Development: From Concept to Cash, Addison-Wesley, 2006.
Poppendieck, Mary, and Tom Poppendieck, Lean Software Development: An Agile Toolkit, Addison-Wesley, 2003.
Sadalage, Pramod, Recipes for Continuous Database Integration, Pearson Education, 2007.
Sonatype Company, Maven: The Definitive Guide, O’Reilly, 2008.
ThoughtWorks, Inc., The ThoughtWorks Anthology: Essays on Software Technology and Innovation, The Pragmatic Programmers, 2008.
Wingerd, Laura, and Christopher Seiwald, “High-Level Best Practices in Software Configuration Management,” paper read at Eighth International Workshop on Software Configuration Management, Brussels, Belgium, July 1999.
A/B测试,264
Aardvarks,218
构建脚本中的绝对路径,164
抽象层
用于验收测试,198–204
用于数据库访问,335
用于针对UI的测试,88,201
在抽象分支中,349
验收标准
和非功能性需求,227–228
和测试数据,336
作为可执行规范,195–198
用于验收测试,85,89
用于自动化测试,93
用于变更管理,441
用于组织变革,420
管理,197
往返,200
验收测试阶段
和测试数据,339–341
作为部署流水线的一部分,110
工作流程,187
验收测试
针对UI,88
和分析,190
和异步性,200,207–210
和云计算,220–222,313
和外部系统,210
和团队规模,214
和测试替身(test doubles),210–212
和交付流程,99–101
和部署流水线,213–218
和超时,207–210
和虚拟化,310
应用驱动层,198–204
作为以下部分:
持续集成(CI),61
提交阶段,120
集成流水线,362
自动化,86–88,136
后门,206
定义,85
部署流水线门控,122–126
封装,206–207
失败,124
脆弱性,88,125,200,205
功能性,124
隔离性,205,220
分层,191
可维护性,190–192
手动,86,189
并行执行,199,220,336
性能,218–222
录制和回放,191,197
可靠性,200,219
在开发机器上运行,[62], [190]
屏幕录制,[136], [213–214]
共享资源,[219–220]
测试数据管理,[336], [339–341]
针对 UI 测试,[192–193]
转换为容量测试,[238]
UI 耦合,[125], [192], [201]
用例,[86]
验证,[192]
价值主张,[188–193], [351]
与单元测试对比,[188]
所有权归属,[125], [215]
窗口驱动模式,[201–204]
访问控制,[284], [438–439]
基础设施访问控制,[285–286]
AccuRev,[385], [399], [403]
ActiveDirectory,[290]
ActiveRecord 迁移,[328]
Actor 模型,[359]
适配敏捷流程,[427]
自适应测试,[336], [338]
敏捷开发,[427]
频繁发布,[131]
重构,[330]
演示展示,[90]
AgileDox,[201]
Albacore,[151]
警报,[281–282]
算法与应用性能,[230]
备选路径,[86]
Amazon,[316]
Amazon EC2,[221], [261], [312]
Amazon Web Services (AWS),[261], [312–315]
分析,[193–195]
与验收测试,[190]
与增量开发,[349]
与非功能性需求,[226–228]
分析师,[193]
Ant,[147–148]
AntHill Pro,[58], [126], [255], [373]
开发后部署,[7–9]
手动部署软件,[5–7]
长期分支,[411]
手动配置管理,[9–10]
非功能性需求的反模式,[230]
通过部署流水线解决,[105]
Apache,[320]
API(应用程序编程接口),[340], [357], [367], [369]
与测试,[46]
配置管理,[39]
应用驱动器,[191]
应用驱动模式,[198–204]
与发布策略,[250]
生命周期阶段,[421–429]
应用服务器,[296]
审批流程,[112], [250], [254], [267], [285], [437]
APT 仓库,[294]
Aptitude,[294]
Arch,[396]
与组件,[346]
与康威定律,[360]
与非功能性需求,[105], [226–228]
作为启动阶段的一部分,[423]
作为运维需求,[282]
作为发布策略的一部分,[251]
与部署,[256]
与流水线依赖,[366]
与部署流水线,[175–177], [374–375]
审计,[373]
在共享文件系统中实现,[375]
管理,[373–375]
组织特定仓库,[355]
清理,[175]
与版本控制对比,[166]
Artifactory,[111], [355], [361], [373], [375]
制品,[111]
与依赖管理,[353]
与标签,[374]
与可追溯性,[166]
与验收测试,[200], [207–210]
与容量测试,[239]
与单元测试,[180]
ATAM(架构权衡分析方法),[227]
原子提交,[383–384]
原子测试,[205], [337]
与验收标准,[198]
与数据归档,[282]
与部署,[273]
与分布式版本控制,[396]
与环境管理,[129]
与基础设施锁定,[286]
与低质量工具,[300]
与重建二进制文件,[114]
与部署流水线,[418]
作为非功能性需求,[227]
作为 IT 运维需求,[280–281]
作为交付的一部分,[429]
作为发布策略的一部分,[251]
管理,[436–441]
制品仓库审计,[373]
基础设施变更审计,[287]
手动流程审计,[6]
与持续部署,[266]
与运行时配置,[348]
与基于流的版本控制,[403]
作为项目启动的一部分,[430]
作为前置条件:
持续集成,[59–60]
合并,[390]
质量,[434]
失败测试的注释处理,[70]
基础设施测试,[323]
另见 [验收测试], [容量测试], [单元测试]
作为持续交付的原则,[25]
自动化的好处,[5–7]
对反馈的影响,[14]
降低风险,[418]
重要性,[12]
数据库初始化自动化,[326–327]
数据库迁移自动化,[327–331], [340]
部署自动化,[152–153]
与文档对比,[287], [437–438]
自主基础设施,[278], [292], [301]
可用性,[91], [314], [423]
Azure,[313], [317]
验收测试中的后门,[206]
回滚规划,[129], [251], [441]
回滚方式,[131–132]
缺陷待办事项,[99–101]
需求待办事项,[425]
作为发布计划的一部分,[251]
作为服务连续性规划的一部分,[282]
网络待办事项,[302]
向后兼容性,[371]
泥球(Ball of mud),[351], [359]
与版本控制,[166]
与虚拟化,[305]
环境基线,[51], [155]
Bash,[282]
批处理,[167]
Bazaar,[396]
Bcfg2,[291]
行为驱动开发,[195], [204], [323]
行为驱动监控,[322–323]
Bench,[243]
Beta 测试,[90]
大型可视化显示。见 [仪表板]
BigTable,[315]
与打包,[154]
与悲观锁,[387]
与版本控制,[35], [373]
构建,[438]
只构建一次,[113–115]
定义,[134]
环境特定二进制文件,[115]
在 CVS 中,[383]
管理,[373–375]
从版本控制重新创建,[33], [175], [354], [363], [373]
将配置与二进制文件分离,[50]
二进制文件共享文件系统,[166]
二进制文件格式,[300]
BitBucket,[394]
BitKeeper,[386], [395]
BizTalk,[311]
BladeLogic,[161], [287], [289], [291], [296]
蓝绿部署,[261–262], [301], [332–333]
BMC,[156], [161], [289], [291], [318]
引导问题,[372]
瓶颈,[106], [138]
边界值分析,[86]
抽象分支,[334–335], [349–351], [360], [415]
集成分支,[389]
维护分支,[389]
发布分支,[389]
与持续集成,[59], [390–393]
按特性分支,[36], [81], [349], [405], [410–412]
按团队分支,[412–415]
为发布分支,[346], [367]
延迟分支,[390]
分支定义,[388–393]
早期分支,[390]
C/C++
使用 Make 和 SCons 构建,[147]
编译,[146]
C#,[282]
CA,[318]
CAB(变更咨询委员会),[280],[440]
金丝雀发布,[235],[262–265]
与持续部署,[267]
与数据库迁移,[333]
容量
与云计算,[314]
作为项目失败的原因,[431]
定义,[225]
设计,[230]
度量,[232–234]
规划,[251],[317],[423]
容量测试
与金丝雀发布,[264]
与云计算,[313]
与虚拟化,[310]
作为测试策略的一部分,[91]
自动化,[238–244]
环境,[234–237]
推算,[234]
在部署流水线中,[112],[244–246]
交互模板,[241–244]
度量指标,[232–234]
分布式系统的,[240]
性能,[238]
场景,[238]
模拟,[239]
阈值,[238]
通过服务层,[239]
通过 API,[239]
通过 UI,[240–241]
预热期,[245]
测试数据管理,[341–342]
Capistrano,[162]
谨慎乐观,[370–371]
CCTV(闭路电视),[273]
CfEngine,[51],[53],[155],[161],[284],[287],[291]
变更管理,[9],[53–54],[280],[287],[421],[429],[436–437],[440–441]
变更请求,[440]
变更集。参见 [修订版本]
检查点,[394]
签入
与提交测试持续时间,[185]
频率,[435]
在构建失败时,[66]
CheckStyle,[74],[158]
Chef,[291]
挑选合并,[394],[409],[414]
数小鸡,[254]
CIM(通用信息模型),[319]
CIMA(英国特许管理会计师公会),[417]
断路器模式,[98],[211]
循环依赖,[371–373]
类加载器,[354]
ClearCase,[385–386],[399],[404],[409]
云计算
与架构,[313],[315]
与合规性,[314]
与非功能性需求,[314]
与性能,[314]
与安全,[313]
与服务级别协议,[314]
与供应商锁定,[315]
批评,[316–317]
定义,[312]
用于验收测试,[220–222]
云中的基础设施,[313–314]
云中的平台,[314–315]
CMS(配置管理系统),[290]
Cobbler,[289]
代码分析,[120],[135]
代码覆盖率,[135],[172]
代码重复,[121]
代码冻结,[408]
代码风格,[121]
协作
临时协作,[8]
与验收测试,[99],[190]
与分布式版本控制,[395]
与部署流水线,[107]
作为以下目标:
组件,[346]
版本控制,[32],[381]
交付团队之间的,[18],[434],[434],[436]
在孤岛式组织中,[439]
COM(组件对象模型),[353]
商业现货软件。参见 [COTS]
提交信息,[37–38]
提交阶段
与增量开发,[347]
与测试数据,[338–339]
作为以下部分:
CI,[61]
部署流水线,[110],[120–122]
脚本编写,[152]
工作流,[169]
提交测试
特征,[14]
失败,[73],[171]
原则和实践,[177–185]
签入前运行,[66–67]
速度,[60–62],[73],[435]
测试数据管理,[338–339]
另见 [单元测试]
兼容性测试,[342]
编译
作为提交阶段的一部分,[120]
增量编译,[146]
优化,[146]
静态编译,[353]
警告,[74]
合规性
与云计算,[314]
与持续交付,[267]
与库管理,[160]
与组织成熟度,[420]
作为版本控制的目标,[31]
管理,[436–441]
组件测试,[89]
与 CI,[60]
组件
与部署,[156]
与项目结构,[160]
与部署流水线,[360–361]
配置管理,[39],[356–360],[363]
创建,[356–360]
定义,[345]
依赖管理,[39],[375]
用于按版本分支,[409]
与库的区别,[352]
Concordion,[85],[191],[196]
配置管理
与部署,[154]
与部署脚本,[155]
与紧急修复,[266]
与基础设施,[283–287],[290–295]
与服务资产,[421]
作为发布策略的一部分,[250]
不良配置管理,[435–436]
定义,[31]
用于部署时,[42]
重要性,[18–20]
手动配置管理反模式,[9–10]
成熟度模型,[419–421]
迁移,[129]
二进制文件的,[373]
数据库的,[328–329]
环境的,[277],[288],[308]
中间件的,[295–300]
服务器的,[288–295]
软件的,[39]
虚拟环境的,[305–307]
升级,[257]
运行时配置,[42],[348],[351]
版本控制实践。参见 [版本控制实践]
配置管理系统。参见 [CMS]
符合性,[417]
一致性,[290]
控制台输出,[171]
整合
提供 CI 作为中心服务,[76]
通过虚拟化,[304]
情境调查(Contextual enquiry),[90]
持续部署,[126],[266–270],[279],[440]
持续改进,[15],[28–29],[441]
持续集成流水线(Continuous integation pipeline),[110]
和分支,[36],[390–393],[410],[414]
和数据库脚本化,[326–327]
和主线开发,[405]
和测试数据管理,[339]
作为中心化服务,[75–76]
作为项目启动的一部分,[424],[430]
作为质量的先决条件,[427]
糟糕的持续集成,[435]
基本实践,[57–59]
定义,[55]
基本实践,[66–71]
反馈机制,[63–65]
管理环境,[289]
使用基于流的版本控制,[403–404]
ControlTier,[161]
康威定律(Conway’s Law),[359]
Maven 中的坐标,[375]
企业治理。参见 [治理]
成本效益分析,[420]
COTS(商业现成软件),[284],[295],[307]
耦合分析,[121],[135],[139],[174]
和松耦合架构,[315]
和主线开发,[392]
数据库迁移与应用变更的耦合,[329],[333–334]
外部系统与验收测试的耦合,[211]
在容量测试中的耦合,[242]
测试与数据的耦合,[336]
UI 与验收测试的耦合,[125],[192],[201]
在发布流程中的耦合,[261],[325]
CPAN(Perl 综合存档网络),[155]
崩溃报告,[267–270]
Crontab,[294]
横切关注点(Crosscutting concerns),[227]
跨功能需求,[226]
跨功能团队,[105],[358]
跨功能测试。参见 [非功能测试]
CruiseControl 系列,[58],[127]
Cucumber,[85–86],[191],[196],[200],[323]
Cucumber-Nagios,[323]
客户,[422]
CVS(并发版本系统),[32],[382–383],[409]
和金丝雀发布,[263]
和合规性,[437]
和紧急修复,[266]
和组织成熟度,[419]
基础设施变更的周期时间,[287],[441]
重要性,[11],[138]
衡量,[137]
圈复杂度(Cyclomatic complexity),[121],[135],[139],[174]
DAG(有向无环图),[363],[400]
Darcs(Darcs 高级版本控制系统),[396]
Darwin Ports,[294]
和 CI,[82]
用于运维,[320–322]
用于跟踪交付状态,[429],[440]
重要性,[16]
和回滚,[259]
在生产环境中归档,[282],[343]
在验收测试中,[204]
数据的生命周期,[325]
数据中心自动化工具,[284]
数据中心管理,[290–295]
数据迁移,[118],[129],[262],[264]
作为测试的一部分,[257]
作为发布计划的一部分,[252]
和应用性能,[230]
和测试,[184]
数据库管理员,[326],[329]
和编排,[329–331],[333]
和测试原子性,[205]
和单元测试,[179–180],[335–336]
用于中间件配置,[299]
数据库的前向和后向兼容性,[334]
增量变更,[327–331]
初始化,[326–327]
内存数据库,[154]
迁移,[327–334]
监控,[318]
规范化和反规范化,[331]
主键,[329]
重构,[334],[341]
引用约束,[329]
回滚,[328],[331–334]
前滚,[328]
模式(schemas),[327]
临时表,[329],[332]
事务记录和回放,[332]
升级,[261]
版本管理,[328–329]
DbDeploy,[328],[331],[344]
DbDeploy.NET,[328]
DbDiff,[328]
Dbmigrate,[328]
死锁,[136]
Debian,[154],[283–284],[353]
声明式部署工具,[161]
声明式基础设施管理,[290]
和发布策略,[251]
作为糟糕 CI 的症状,[435]
关键缺陷,[131],[265–266],[409]
在待办事项中,[99–101]
衡量,[138]
重现,[247]
零缺陷,[100]
戴明循环(Deming cycle),[28],[420],[440]
戴明,W. Edwards,[27],[83]
使用 Maven 分析,[378]
和集成,[370]
和可追溯性,[363]
分支之间的依赖,[391]
构建时依赖,[352]
循环依赖,[371–373]
下游依赖,[364]
流动依赖(fluid),[370]
受保护的依赖(guarded),[370]
在构建工具中,[146]
在软件中,[351–356]
在项目计划中,[348]
使用 Maven 管理,[375–378]
重构,[377]
运行时依赖,[352]
静态依赖,[370]
传递性依赖,[355]
上游依赖,[364]
保持浅层,[371]
管理,[355],[363–373]
使用部署流水线建模,[365–369]
依赖地狱(Dependency hell),[352–354],[365]
和按抽象分支,[351]
和模拟时间,[184]
和 Maven,[149]
和单元测试,[179–180]
依赖管理,[38–39],[149],[353]
和信任,[369]
应用和基础设施之间的依赖管理,[285]
依赖网络和构建工具,[144]
和组件,[357]
和幂等性,[155–156]
自动化,[152–153]
蓝绿部署。参见 蓝绿部署
定义,[25]
从头部署所有内容,[156]
一起部署所有内容,[156]
快速失败,[272–273]
部署失败,[117]
增量实施,[156–157]
延迟部署反模式,[7–9]
日志记录,[270–271]
管理,[421]
手动部署,[5–7],[116],[165]
编排,[161]
规划和实施,[253–254]
脚本化,[160–164]
脚本化升级,[153]
冒烟测试,[117],[163]
通过自动化测试,[130],[153]
部署到远程机器,[161]
对每个环境使用相同的流程,[22],[115–117],[153–154],[253],[279],[283],[286],[308],[438]
验证环境,[155]
验收测试阶段,[213–218]
和制品仓库,[374–375]
和发布分支,[409]
和容量测试,[244–246]
和合规性,[437]
和组件,[360–361],[361–363]
和持续部署,[267]
和数据库,[326]
和依赖图,[365–369]
紧急修复,[266]
治理,[418], [442]
集成测试,[212]
主干开发,[405]
测试数据,[338–343]
版本控制,[404], [416]
虚拟化,[304], [307–310]
虚拟机模板,[309]
作为项目启动的一部分,[430]
定义,[106–113]
演进,[136–137]
失败,[119–120]
实施,[133–137]
在孤岛式组织中,[439]
术语起源,[122]
脚本化,[152]
部署生产线,[110]
部署测试,[89], [216–218], [285]
开发和发布,[425–428]
开发环境
验收测试,[125]
部署脚本,[154]
测试数据,[343]
配置管理,[33], [50], [289]
作为开发的一部分进行管理,[62]
GUI测试的设备驱动程序,[202]
DevOps,[28]
敏捷基础设施,[279]
创建部署流程,[270]
构建系统的所有权,[174]
另见 [运维]
DHCP(动态主机配置协议),[285], [289]
诊断,[139]
菱形依赖,[354], [365]
有向无环图。见 [DAG]
目录服务,[300]
灾难恢复,[250], [282]
纪律
验收测试,[214]
持续集成,[57]
增量开发,[349], [392], [426], [434]
磁盘镜像,[305]
显示。见 [仪表板]
分布式开发
持续集成,[75–78]
流水线组件,[360]
版本控制,[78]
沟通,[75]
分布式团队,[143]
分布式版本控制,[79–81], [393–399], [411], [414]
DLL(动态链接库),[352], [356]
DLL地狱,[352]
DNS,[300]
DNS区域文件,[285]
文档
自文档化基础设施,[292]
作为IT运维的要求,[280–281]
作为以下内容的一部分:
合规和审计,[437]
发布计划,[252]
从验收测试生成,[86]
对比自动化,[287], [437–438]
领域语言,[198]
领域驱动设计,[152]
领域特定语言(DSL)
构建工具,[144–151]
定义,[198]
在验收测试中,[198–204]
另见 [Puppet]
不要重复自己,[358]
完成
验收测试,[85]
测试,[101]
定义,[27–28]
作为项目生命周期的一部分进行签收,[426], [434]
停机时间,[260], [436]
Dpkg,[294]
虚拟对象,[92]
另见 [测试替身]
重复,[139]
动态链接,[357]
动态视图,[403]
EAR文件,[159]
EasyMock,[181]
EC2,[221]
Eclipse,[350]
效率,[419]
Egg包,[155]
ElectricCommander,[58]
Ellison, Larry,[316]
嵌入式软件,[256], [277]
紧急修复,[265–266]
封装
组件,[358]
主干开发,[392]
单体系统,[345]
单元测试,[180]
在验收测试中,[206–207]
端到端测试
验收测试,[205]
容量测试,[241]
企业治理。见 [治理]
环境
作为发布策略的一部分,[250]
基线,[51], [155]
容量测试,[234–237], [258]
定义,[277]
管理,[49–54], [130], [277], [288–295], [308]
类生产环境,[107], [117], [129], [254], [308]
供应,[288–290]
从版本控制可重建,[33]
共享,[258]
预发布环境,[258–259], [330]
系统集成测试(SIT),[330]
等价类划分,[86]
逃逸,[44], [47], [257]
估算,[428]
Eucalyptus,[312], [316]
事件驱动系统
组件,[359]
容量测试,[241]
可执行规范,[195–198], [246], [339], [342]
探索性测试,[87], [90], [128], [255], [343]
外部系统
验收测试,[125], [210]
集成测试,[96–98]
日志记录,[320]
发布策略,[250]
配置,[50]
升级,[261]
外部引用(SVN),[384]
容量测试中的外推,[234]
极限编程,[26], [266]
持续集成,[55], [71]
Fabric,[162]
外观模式,[351]
Facter,[291]
快速失败
提交阶段,[171]
部署,[272–273]
故障转移,作为发布策略的一部分,[251]
伪造对象,[92]
特性分支。见 [版本控制实践]
特性小组,[411]
反馈
自动化验收测试,[86]
金丝雀发布,[263]
依赖管理,[369–370]
度量指标,[137–140]
监控,[317]
集成流水线,[362]
作为项目生命周期的一部分,[426]
由部署流水线创建,[106]
重要性,[12–16]
在提交阶段,[120]
通过虚拟化改进,[310]
建模依赖时,[365]
流水线组件时,[360]
文件系统层次标准,[165]
用于存储二进制文件的共享文件系统,[166]
FindBugs,[74], [158]
救火,[286]
防火墙
云计算,[313]
集成测试,[96]
配置,[118], [284], [300]
Fit,[201]
适用性,[421], [426], [442]
可用性,[421], [427]
FitNesse,[191], [196], [201]
Flapjack,[318]
Flex,[192]
Force.com,[314]
取证工具,[301]
派生。见 [版本控制实践]
向前兼容性,[334]
脆弱性。见 [验收测试]
Func,[162]
功能测试。见 [验收测试]
FxCop,[74]
Gantt,[151]
甘特图,[280]
垃圾回收,[247]
关卡。见 [审批流程]
GAV,[375]
Gem包,[155]
Gentoo,[353]
Git,[32], [79–81], [374], [393], [396], [403]
GitHub,[79], [394], [411]
给定,当,那么,[86], [195], [336]
全局程序集缓存,[353]
全局优化,[138]
Gmail,[313]
Go,[58], [113], [126], [255], [373]
通过/不通过,[423]
Google App Engine,[314–315], [317]
Google Code,[394]
治理
业务治理,[417]
公司治理,[417]
企业治理,[417]
良好治理,[442]
GPG(GNU隐私卫士),[294]
GPL(通用公共许可证),[355]
Gradle,[151]
绿地项目,[92–94]
保护测试,[245]
GUI(图形用户界面)
和验收测试,[192–193]
用于部署,[165]
分层,[192]
另见 [UI]
Gump,[371]
H2,[336]
Handle,[301]
Happy path(正常路径),[85],[87–88],[94]
加固,[284]
硬件
和容量测试,[236]
虚拟化以实现标准化,[304]
哈希,[114],[166],[175],[373],[438]
霍桑效应,[137]
Hibernate,[159]
隐藏功能,[347–349]
高可用性
和业务连续性规划,[282]
和多宿主服务器,[302]
作为发布策略的一部分,[251]
HIPAA,[314],[436]
热部署。见 零停机发布
HP(惠普),[156],[291],[318]
HP Operations Center,[287],[296]
Hudson,[58],[63],[127],[289]
过度活跃的构建,[370]
Hyper-V,[290]
IANA(互联网号码分配机构),[320]
IBM,[156],[291],[303],[316],[318]
IDE(集成开发环境),[57],[143],[160]
幂等性
和部署工具,[161]
和基础设施管理,[290–291],[295]
应用程序部署的,[155–156]
识别,[422]
IIS(Internet Information Services),[299]
影响,[430]
启动阶段,[283],[422–424]
增量编译,[146]
增量交付,[331],[346–351],[418],[420],[442]
增量开发,[36],[326],[346–351],[367],[405–406],[425],[434],[442]
知情的悲观,[371]
基础设施
作为项目启动的一部分,[424]
可审计性,[287]
定义,[277]
演化,[317]
管理,[283–287]
测试变更,[287]
云中的基础设施,[313–314]
启动,[424–425]
内存数据库,[154],[180],[336]
安装程序,[51]
InstallShield,[118]
即时通讯,[75]
集成开发环境。见 [IDE]
集成
和验收测试,[210]
和数据库,[329]
和依赖关系,[369–370]
和基础设施管理,[301]
集成阶段,[55],[348],[405],[426],[435]
集成流水线,[361–363]
集成团队,[358]
集成测试,[96–98]
意图编程,[198]
交互模板,[241–244],[342]
间歇性失败
在验收测试中,[200],[207]
在容量测试中,[233],[245]
互操作性,[316]
库存,[391],[418]
控制反转。见 依赖注入
INVEST原则,[93],[190]
IPMI(智能平台管理接口),[288],[318]
ISO 9001,[437]
验收测试中的隔离,[205],[220]
问题,[431]
第一次迭代,[253]
第零次迭代,[134]
迭代交付,[442]
和分析,[193–195]
迭代开发,[425]
ITIL(信息技术基础设施库),[421–422]
Ivy,[150],[154],[160],[166],[355],[375]
J2EE(Java 2平台企业版),[359]
JAR包,[159],[356],[374]
Java
使用Ant构建,[147]
类加载器,[354]
组件,[345]
数据库迁移,[328]
命名约定,[158]
项目结构,[157–160]
运行时依赖,[354]
Javac,[146]
JavaDB,[336]
Javadoc,[149]
JBehave,[85],[191],[196]
JDepend,[74]
Jikes,[146]
JMeter,[243]
JMock,[181]
JMX,[319]
JRuby,[151]
Jumpstart,[284],[289]
即时编译器,[146]
改善。见 持续改进
看板,[411]
启动会议,[194]
Kickstart,[284],[289]
Knuth,Donald,[228]
标签,[374]
大型团队
和主干开发,[392],[405]
按团队分支,[412]
发布分支,[409]
通过组件协作,[346]
另见 [团队规模]
迪米特法则,[345],[358],[406]
分层
在验收测试中,[190]
在软件中,[359]
LCFG,[291]
LDAP(轻量级目录访问协议),[44],[291]
精益
和项目管理,[427]
作为持续交付的原则,[27]
对本书的影响,[16]
不持续交付的成本,[418]
遗留系统,[95–96],[306]
类库
配置管理,[38–39],[354–356],[363]
定义,[352]
依赖管理,[375]
作为开发的一部分进行管理,[62]
许可
作为发布计划的一部分,[252]
中间件的,[300]
生命周期,[421–429]
可能性,[430]
代码行数,[137]
Linux,[154],[310],[395]
Live-live发布。见 蓝绿部署
活动构建,[110]
负载测试,[231]
锁定。见 [版本控制实践]
日志记录
和基础设施管理,[301]
和发布策略,[250]
作为运维团队的需求,[281]
重要性,[436]
部署的,[270–271]
基础设施变更的,[287]
LOM(熄灯管理),[288],[318]
长期运行测试,[231],[238]
Lsof,[301]
Mac OS,[310]
主干开发,[35–37],[59],[346–351],[392],[405–408]
可维护性
和主干开发,[406]
和质量,[434]
验收测试的,[190–192]
容量测试的,[240]
维护
作为发布策略的一部分,[250],[409]
构建系统的,[174]
Make,[144],[146–147]
Makefile,[146]
受管设备,[319]
管理信息库,[320]
清单
和可追溯性,[166]
硬件的,[271]
手动测试,[110],[126],[189],[223],[343]
Marathon,[243]
Marick,Brian,[84]
Marimba,[155]
Marionette Collective,[161],[291]
营销,[252]
成熟度模型,[419–421]
Maven,[38],[148–150],[154],[157],[160],[166],[355],[375–378]
使用它分析依赖,[378]
与Buildr的比较,[151]
坐标,[375]
仓库,[375]
快照,[377]
子项目,[158]
Maven标准目录布局,[157]
McCarthy,John,[312]
平均故障间隔时间。见 [MTBF]
平均修复时间。见 [MTTR]
度量,[264],[420]
内存泄漏,[247]
Mercurial, [32], [79–81], [374], [393], [396], [398], [403]
合并冲突, [386], [390], [415]
合并团队, [407]
合并
定义, [389–390]
在按特性分支中, [349], [410]
在按团队分支中, [413]
在ClearCase中, [404]
在基于流的系统中, [402]
在集成阶段, [406]
跟踪, [385]
使用分布式版本控制, [399]
使用乐观锁, [386]
消息队列
作为API, [357]
容量测试, [241]
配置管理, [296]
Metabase, [299]
度量指标, [106], [172], [287], [441]
作为部署流水线的一部分, [137–140]
Microsoft, [316], [359]
中间件
与应用部署, [155]
配置管理, [295–300]
管理, [130], [284]
监控, [318]
缓解, [430]
Mocha, [181]
Mockito, [181]
模拟对象, [92], [178]
另见 [测试替身]
监控
与商业智能, [317]
应用, [318]
作为发布策略的一部分, [250]
重要性, [436]
基础设施和环境, [317–323]
中间件, [318]
网络, [302]
操作系统, [318]
需求, [281–282]
用户行为, [318]
单体架构, [345], [357]
Monotone, [396]
MSBuild, [148]
MTBF(平均故障间隔时间), [280], [286], [440]
MTTR(平均修复时间), [278], [280], [286], [440]
多宿主系统, [301–303]
神话英雄, [108]
Nabaztag, [63]
Nagios, [257], [281], [301], [318], [321]
Nant, [148]
NDepend, [74]
.NET
验收测试, [197]
与依赖地狱, [353]
数据库迁移, [328]
项目结构, [157–160]
技巧和诀窍, [167]
网络启动, [289]
网络管理系统, [319]
网络
管理, [302]
与非功能性需求, [229]
配置管理, [300]
拓扑结构, [118]
虚拟网络, [311]
Nexus, [111], [166], [175], [355], [361], [373], [375]
NIC(网络接口卡), [302]
每夜构建, [65], [127]
NMock, [181]
非功能性需求
分析, [226–228]
与验收标准, [227–228]
与云计算, [314]
与部署流水线, [136]
日志记录, [320]
管理, [226–228], [436]
作为发布策略的来源, [251]
权衡, [227]
虚拟化测试, [305]
非功能性测试
定义, [91]
在部署流水线中, [128]
NoSQL, [326]
通知
与持续集成, [63–65]
作为监控的一部分, [317]
N层架构
与组件, [359]
与部署, [155]
冒烟测试, [164]
面向对象设计, [350]
开源, [143]
与分布式版本控制, [81]
与Maven, [375]
OpenNMS, [281], [301], [318]
操作系统
配置, [118]
监控, [318]
运维, [105], [279–283], [428–429]
另见 [DevOps]
Operations Center, [291]
Operations Manager, [281], [301], [318]
机会成本, [300]
乐观锁, [386–387]
Oracle, [154], [320]
编排(Orchestration), [257–258], [329–331], [333]
组织变革, [419]
OSGi, [350], [354–356]
带外管理, [288], [318]
过度设计, [228]
打包
与配置, [41]
作为以下部分:
部署流水线, [135], [283]
集成, [361]
工具, [154–155]
Panopticode, [139]
密码. 见 [安全]
补丁, [251]
模式与非功能性需求, [230]
PCI DSS, [314], [436]
峰值需求, [244]
Perforce, [385]
性能
与治理, [417]
定义, [225]
验收测试的性能, [218–222]
调优, [247]
Perl, [155], [283], [356]
悲观锁, [386–387]
试点项目, [428]
计划、执行、检查、行动. 见 [戴明循环]
云中的平台, [314–315]
POM, [375]
Postfix, [293]
波将金村庄, [351]
PowerBuilder, [271]
PowerShell, [162], [282], [299]
验收测试中的前置条件, [206]
可预测性, [419]
过早优化, [228]
Preseed, [284], [289]
预测试提交, [37], [67], [120], [171]
定价, [252]
主键, [329]
优先级排序
作为项目生命周期的一部分, [427]
缺陷, [101]
非功能性需求, [226]
需求, [422]
进程边界
与验收测试, [206]
与非功能性需求, [229]
流程建模, [133]
采购, [283]
产品负责人, [422]
生产环境
与不受控的变更, [273]
登录, [160]
生产就绪, [346–351], [426]
生产规模, [251]
类生产环境, [107], [117], [129], [308]
特征, [254]
生产力, [50], [82], [173]
面向产品的构建工具, [145]
性能分析工具, [231]
盈利能力, [419]
项目期限, [423]
项目经理, [428]
JVM和.NET项目的项目结构, [157–160]
混杂集成, [81]
晋升, [46], [254–257], [402], [406]
概念验证, [420]
供应, [288], [290–295], [303]
Psake, [151]
PsExec, [162]
拉动式系统, [17], [106], [255]
Pulse, [58]
Puppet, [51], [53], [118], [155–156], [161], [284], [287–288], [290–296], [300], [306], [323]
按钮式部署, [17], [112], [126], [135], [157], [255], [315]
PVCS(Polytron版本控制系统), [386]
PXE(预启动执行环境), [288–290]
Python, [147], [155], [283]
质量, [12], [62], [418], [422], [434–435]
属性, [227]
质量分析师. 见 [测试人员]
量词, [376]
竞态条件, [136]
RAID, [374]
Rake, [150], [150–151]
rBuilder, [305]
RCS(修订控制系统), [32], [382]
RDBMS(关系数据库管理系统), [314], [326]
变基, [394], [414]
录制与回放
用于验收测试, [191], [197]
用于容量测试, [239], [241]
数据库事务, [332]
恢复点目标, [282]
恢复时间目标, [282]
回滚作为撤销变更的方式,[132],[259–260]
RedHat Linux,[154],[284]
重构(Refactoring)
验收测试,[192],[218–219]
与抽象分支,[350]
与团队分支,[415]
与CI,[72]
与主线开发,[406]
与版本控制,[36]
作为项目生命周期的一部分,[426]
作为质量的前提条件,[427]
由回归测试启用,[87]
引用完整性约束,[329]
回归缺陷(Regression bugs)
与持续交付,[349]
作为应用程序质量不佳的症状,[434]
由不受控的变更导致,[265]
在遗留系统上,[96]
回归测试,[87],[124],[128],[189]
构建脚本中的相对路径,[164]
发布(Release)
作为部署流水线的一部分,[110]
自动化,[129]
维护,[409]
管理,[107],[419–421]
建模流程,[254–257]
零停机时间,[260–261]
发布分支。参见 [版本控制实践]
发布候选版本(Release candidate)
与验收测试门控,[124]
与手动测试阶段,[127]
定义,[22–24]
生命周期,[132]
发布计划,[129],[251–252],[281],[283],[423]
发布策略,[250–252],[423],[430]
修复(Remediation),[441]
远程安装,[288]
可重复性(Repeatability),[354]
状态报告,[429]
仓储模式(Repository pattern),[335]
可复现性(Reproduceability),[373]
需求(Requirements)
运维团队的需求,[279–283]
发布策略作为需求来源,[251]
弹性(Resilience),[316]
资源状态,[136]
职责(Responsibility)
部署职责,[271]
修复构建的职责,[70–71],[174]
开发人员理解运维的职责,[281]
Rest,[197]
回顾会议(Retrospectives),[16]
作为以下内容的一部分:
持续改进,[28],[420],[441]
风险管理,[431]
促进协作,[440]
收入,[264],[316–317]
反向代理,[271]
逆向工程,[299]
回退(Reverting),[435]
当构建损坏时,[69]
修订控制。参见 [版本控制]
二进制文件的修订版本,[166]
Rhino,[181]
风险(Risk)
与金丝雀发布,[263]
与问题日志,[423]
与非功能性需求,[225]
与组织成熟度,[420]
管理,[417],[429–432],[442]
部署风险,[278]
开发风险,[430–431]
发布风险,[4–11],[279]
降低风险:
通过持续交付,[279]
通过持续部署,[267]
通过回顾会议,[431]
通过虚拟化,[303]
角色(Roles),[424]
回滚(Roll back)
与制品,[373]
与遗留系统,[252]
自动化,[10]
频繁回滚与糟糕的配置管理,[436]
数据库回滚,[328],[331–334]
通过回滚降低发布风险,[109]
策略,[132],[259–265]
对比紧急修复,[266]
数据库前滚(Roll forward),[328]
滚动构建,[65]
根本原因分析,[433]
路由器(Routers),[263]
与蓝绿部署,[261]
配置管理,[300]
rPath,[305]
RPM,[294],[299]
RSA,[273]
Rsync,[156],[162]
Ruby,[155],[283]
Ruby Gems,[355]
Ruby on Rails,[328],[354]
RubyGems,[38],[151],[294]
运行时优化,[245]
异常路径(Sad path),[88]
Sahi,[134],[197]
SalesForce,[313]
SAN,[374]
萨班斯-奥克斯利法案。参见 [SOX]
可扩展性测试,[231]
扩展(Scaling)
用于容量测试,[236]
通过云计算,[313]
SCCS(源代码控制系统),[32],[382]
场景(Scenarios),在容量测试中,[238]
SCons,[147]
Scp,[162]
屏幕录制,[136],[213–214]
脚本与部署流水线,[152]
Scrum,[422],[427]
接缝(Seams),[350]
安全性(Security)
与云计算,[313]
与配置管理,[43]
与监控,[322]
与网络路由,[303]
作为非功能性需求,[423]
作为测试策略的一部分,[91]
安全漏洞,[131]
基础设施的安全性,[285–286]
Selenium,[197]
Selenium Grid,[221],[310]
Selenium Remoting,[221]
自助式部署,[112],[255]
高级责任人,[422]
服务资产和配置管理,[421]
服务连续性规划,[282]
服务设计,[421]
服务中断,[286]
服务运营,[421]
服务包,[290]
服务测试与验证,[421]
服务转换,[421]
服务级别协议。参见 [SLA]
面向服务的架构(Service-oriented architectures)
与数据库,[329]
与部署,[156],[258]
与环境,[278]
容量测试,[239],[241]
推广,[257]
SETI@Home,[313]
严重性(Severity),[430]
服务连续性规划,[423]
影子域(Shadow domains)。参见 蓝绿部署
共享文件系统作为制品仓库,[375]
共享库,[352]
无共享架构(Shared-nothing architectures),[264],[313]
共享资源,[261]
共同理解,[423]
演示(Showcases),[128],[426]
作为手动测试的一种形式,[90]
作为风险缓解策略,[433]
Shuttleworth, Mark,[394]
并行部署,[262]
孤岛(Silos)
与组件,[358]
与部署,[8]
开发与运维孤岛,[279]
管理交付,[439–440]
Simian,[74]
简单性与非功能性需求,[229]
容量测试的模拟,[239]
Skype,[75]
SLA(服务级别协议),[128],[251],[280],[314],[331]
慢速测试(Slow tests)
构建失败,[73]
单元测试与测试替身,[89]
冒烟测试(Smoke tests)
与行为驱动监控,[323]
与基础设施管理,[301]
与遗留系统,[95]
与编排,[258]
作为以下内容的一部分:
验收测试套件,[217]
集成流水线,[361]
发布计划,[251]
用于蓝绿部署,[261]
用于部署,[273]
用于部署脚本,[167],[255]
SMTP(简单邮件传输协议),[285],[300]
快照(Snapshots)
在Maven中,[377]
虚拟机快照,[305]
SNMP(简单网络管理协议),[302],[319]
软件工程研究所,[227]
Solaris,[284]
源代码控制。参见 [版本控制]
SOX(萨班斯-奥克斯利法案),[280],[436]
规格说明。参见 [验收标准]
间谍(Spies),[92]
另见 [测试替身]
探针(Spikes),[382],[425]
Splunk,[318]
SqlLite,[336]
Ssh,[162],[302]
稳定性(Stability),[230],[369]
稳定化阶段,[347]
稳定患者,[129],[286]
预发布环境(Staging environment),[258–259],[290]
利益相关者(Stakeholders),[422]
Stallman,Richard,[316]
StarTeam,[386],[409]
状态
在验收测试中,[204–206]
在中间件中,[298–299]
在单元测试中,[179],[183]
静态分析,[331]
静态编译,[353]
静态链接,[357]
静态视图,[403]
停止生产线(Stop the line),[119–120]
存储过程,[334]
用户故事(Stories)
和验收标准,[195]
和验收测试,[85],[99],[188],[193]
和组件,[358]
和缺陷,[101]
和遗留系统,[95]
和非功能性需求,[227–228]
和吞吐量,[138]
INVEST,[93]
策略模式(Strategy pattern),[351]
流媒体视频,[315]
桩(Stubs),[92],[178]
用于开发容量测试,[244]
Subversion,[32],[383–385],[397]
Sun,[294],[359]
沉没成本,[300],[349]
支持
和数据归档,[282]
作为以下部分:
发布计划,[252]
发布策略,[251]
降低成本,[419]
SuSE Linux,[154]
掩盖问题(Sweeping it under the rug),[351]
符号链接,[260],[269],[271],[294]
Sysinternals,[301]
System Center Configuration Manager,[291],[296]
系统特性,[226]
记录系统(System of record),[381],[418]
标记(Tagging)
和发布,[409]
在ClearCase中,[404]
在CVS中,[383]
在Subversion中,[384]
另见 [版本控制实践]
Tarantino,[328]
面向任务的构建工具,[145]
TC3,[314]
TCP/IP,[300]
Tcpdump,[301]
TCPView,[301]
Team Foundation Server,[386]
团队规模
和验收测试,[214]
和组件,[357]
持续交付是否可扩展?,[16]
使用构建管理员,[174]
另见 [大型团队]
TeamCity,[58]
技术债务(Technical debt),[330],[406]
模板,[305],[309–310]
临时表,[329],[332]
测试自动化金字塔,[178]
测试覆盖率,[87],[121],[174],[435]
测试数据
和数据库转储,[340],[343]
应用参考数据,[340],[343]
从测试中解耦,[336]
功能分区,[337]
在验收测试中,[339–341]
在容量测试中,[243],[341–342]
在提交测试中,[338–339]
管理,[334–338]
测试参考数据,[340],[343]
测试专用数据,[340]
测试替身(Test doubles),[89],[91],[178]
和验收测试,[210–212]
和单元测试,[180–183],[335]
速度,[89]
测试性能
和数据库,[335–336]
伪造时间,[184]
通过虚拟化提高性能,[305],[310]
测试排序,[336]
测试驱动开发(Test-driven development),[71],[178],[427]
另见 [行为驱动开发(Behavior-driven development)]
测试人员,[193]
测试象限图,[84],[178]
测试策略
作为项目启动的一部分,[423]
绿地项目,[92–94]
重要性,[434]
遗留系统,[95–96]
项目中期,[94–95]
测试,[105]
自适应的,[336],[338]
失败的,[308]
隔离性,[336–337]
手动的,[126],[128],[138],[189],[223],[343]
排序,[336]
设置和清理,[337],[340]
类型,[84]
另见 自动化测试,[手动测试]
TFTP(简单文件传输协议),[289]
约束理论(Theory of Constraints),[138]
线程池,[318]
线程
和应用性能,[230]
通过验收测试捕获问题,[189]
容量测试中的阈值,[238]
吞吐量,[225],[231]
单元测试中的时间,[184]
时间盒迭代(Time-boxed iterations),[428]
超时和验收测试,[207–210]
Tivoli,[287],[291],[318]
待办事项(TODOs),[74]
工具链
和测试环境,[254]
和部署流水线,[114]
版本控制,[34],[355]
Torvalds,Linus,[385],[395]
触摸屏,[204]
可追溯性(Traceability)
和制品仓库,[373]
和依赖关系,[363]
和部署流水线,[114]
和集成流水线,[362]
从二进制文件到版本控制,[165–166],[418]
管理和强制执行,[438–439]
当流水线化组件时,[360],[366]
非功能性需求的权衡,[227]
红绿灯,[172],[322]
用于管理测试状态的事务,[337]
主干。见 [主线开发]
信任和依赖管理,[369]
元组(Tuple),[43]
图灵完备性(Turing completeness),[198]
Twist,[85–86],[191],[196]
双因素认证,[273]
通用语言(Ubiquitous language),[125]
Ubuntu,[154],[353],[394]
用户界面(UI)
和容量测试,[240–241]
和单元测试,[178–179]
另见 [图形用户界面(GUI)]
不受控的变更,[20],[265],[273],[288],[290],[306]
不可部署的软件,[105],[391]
联合文件系统(Union filesystem),[400]
单元测试,[89]
和异步性,[180]
和持续集成,[60]
和数据库,[179–180],[335–336]
和依赖注入,[179]
和状态,[183]
和测试替身,[180–183]
和用户界面,[178–179]
作为提交阶段的一部分,[120]
自动化,[135]
伪造时间,[184]
原则和实践,[177–185]
速度,[89],[177]
与验收测试的对比,[188]
另见 [提交测试]
升级,[261]
和部署脚本,[153]
和用户安装的软件,[267–270]
作为以下部分:
发布计划,[252]
发布策略,[251]
可用性
和非功能性需求,[228]
测试,[87],[90],[128],[255]
用例和验收测试,[86]
用户验收测试,[86],[135]
和测试数据,[343]
在部署流水线中,[112]
用户安装的软件
和验收测试,[125]
和金丝雀发布,[264]
和持续交付,[267–270]
和部署自动化,[129]
崩溃报告,[267–270]
使用虚拟化测试,[310]
升级,[267–270]
效用(Utility),[421]
效用计算(Utility computing),[312],[316]
价值创造,[417],[419],[442]
价值流(Value stream),[106–113],[133],[254],[420]
速率(Velocity),[139],[431],[433]
供应商锁定,[315],[317]
版本控制
和中间件配置,[296],[298],[301]
作为持续交付的原则,[25–26]
作为项目启动的一部分,[424]
作为持续集成的先决条件,[56–57]
定义,[32]
分布式。参见 [分布式版本控制]
用于数据库脚本,[327]
用于库,[38],[354]
基于流的,[388],[399–404]
版本控制实践
分支。参见 分支
控制一切,[33–35]
派生(forking),[81]
定期检入的重要性,[36],[59],[405]
锁定,[383]
主线。参见 [主线开发]
合并。参见 合并
基于流的开发,[405]
视图,[334],[403]
与蓝绿部署,[262]
与部署脚本,[155]
与编排(orchestration),[258]
与服务器配置,[303]
与部署流水线,[304],[307–310]
基线,[53],[305]
定义,[303]
用于验收测试,[217],[220]
用于创建测试环境,[254]
用于环境管理,[118]
用于基础设施整合,[304]
用于管理遗留系统,[306]
用于加速测试,[305],[310]
用于测试非功能性需求,[305]
用于测试用户安装的软件,[310]
管理虚拟环境,[305–307]
网络虚拟化,[311]
通过虚拟化降低交付风险,[303]
快照,[305]
模板,[305]
可见性,[4],[113],[362]
Visual Basic,[271],[345]
Visual SourceSafe,[386]
可视化,[140],[366]
Vnc2swf,[136],[213]
行走骨架(Walking skeleton),[134]
预热期,[245],[259],[261],[272]
保修,[421]
WARs,[159]
浪费,[105],[391]
Web服务器,[296]
Web服务
作为API,[357]
容量测试,[241]
WebDriver,[134],[197]
WebLogic,[320]
WebSphere,[153]
White,[197]
整个团队
与验收测试,[125]
与交付,[28]
与部署,[271]
与提交阶段,[172]
Wikipedia,[313]
窗口驱动模式,[201–204]
Windows,[154],[310],[352]
Windows Deployment Services,[288–290]
Windows Preinstallation Environment,[290]
Wireshark,[301]
WiX,[283]
WordPress,[313]
与分布式版本控制,[396]
与部署流水线,[111]
验收测试阶段的工作流,[187]
可工作的软件,[56],[425]
艺术品,[49],[288–289],[306]
在我机器上可以运行综合症,[116]
工作区管理,[62]
WPKG,[291]
Wsadmin,[153]
Xcopy部署,[353]
XDoclet,[158]
XML(可扩展标记语言),[43],[147],[297]
XUnit,[135],[191],[200]
YAGNI(你不会需要它!),[245]
YAML,[43]
Yum,[294]
Zenoss,[318]
零缺陷,[100]
零停机时间发布,[260–261],[331–334]
zone文件,[300]
[1]. 实施精益软件开发,第59页。
[1]. 技术上讲,配置信息可以看作是一组元组(tuple)。
[1]. 例如,James Shore [dsyXYv]。
[2]. “探索性测试解释”,James Bach [9BRHOz],第2页。
[3]. 第5.7节,第136–140页。
[1]. Inspired by Marty Cagan和The Four Steps to the Epiphany by Steven Gary Blank等书强调了在产品开发过程中基于客户反馈进行迭代发现的重要性。
[2]. Chris Read提出了这个想法[9EIHHS]。
[3]. Evans,2004年。
[4]. 实施精益软件开发,第59页。
[1]. 在撰写本文时,Buildr还能无缝处理Scala、Groovy和Ruby——当你读到这里时,我们预计它将支持更多面向JVM的语言。
[2]. 在Java中情况稍微复杂一些。在撰写本文时,Sun的Javac编译器不支持增量构建(因此有了Ant任务),但IBM的Jikes编译器可以。然而,Ant中的javac任务会执行增量编译。
[3]. 参见Evans (2003)。
[4]. 本书网站上有Ant、Maven、MSBuild和Psake的提交脚本示例[dzMeNE]。
[5]. CPAN是设计较好的平台打包系统之一,因为它可以以完全自动化的方式将Perl模块转换为RedHat或Debian包。如果所有平台包格式都设计为允许自动转换为系统包格式,这种冲突就不会存在。
[6]. 与Rails不同,Rails强制执行目录结构,.NET工具链也会为你处理其中一些问题。
[7]. 查看Jean-Paul Boodhoo的博客文章[ahdDZO]。
[1]. James Carr有一篇关于TDD模式的好博客文章[cX6V1k]。
[1]. Bob Martin阐述了为什么自动化验收测试很重要且不应外包的一些原因[dB6JQ1]。
[2]. 这种方法的倡导者包括J. B. Rainsberger,在他的”集成测试是骗局”博客文章[a0tjh0]中描述,以及James Shore在他的”验收测试的问题”博客文章[dsyXYv]中提到。
[3]. 也就是说,它们必须是独立的(independent)、可协商的(negotiable)、有价值的(valuable)、可估算的(estimable)、小的(small)和可测试的(testable)。
[4]. 在撰写本文时,Flex属于这一类别——希望当你读到这里时,新的测试框架将会出现,以通过Flex驱动测试。
[5]. Twist 是一个由 Jez 雇主创建的商业工具,它允许你直接在验收标准脚本上使用 Eclipse 的自动完成功能和参数查找,并允许你重构脚本和底层测试实现层,同时保持两者同步。
[6]. Nygard, 2007, p. 115.
[1]. Nygard, 2007, p. 151.
[2]. Nygard, 2007, p. 76.
[3]. Nygard, 2007, p. 142.
[4]. Nygard, 2007, p. 61.
[1]. Unity 3D 网页播放器软件在其网站上发布统计数据 [cFI7XI]。
[2]. 要了解亚马逊购物车演变的精彩分析,请查看 [blrMWp]。
[3]. 谷歌为其所有内部服务创建了一个名为 Protocol Buffers 的框架,旨在处理版本控制 [beffuK]。
[1]. 其中一些灵感来自 James White [9QRI77]。
[2]. 就本章而言,我们将支持视为运维工作的一部分,尽管情况并非总是如此。
[3]. Nygard, 2007, p. 222.
[4]. 微软的 Azure 提供了一些算作云基础设施的服务。然而,他们的虚拟机产品具有云平台的一些特征,因为在撰写本文时,你无法管理员访问虚拟机,因此无法更改其配置或安装需要提升权限的软件。
[1]. 我们将在下一章”高级版本控制”中讨论分支策略。
[2]. 关于分布式版本控制系统的使用,这里有一些注意事项,我们将在下一章讨论。
[3]. 在 Windows XP 中,免注册 COM 的引入允许应用程序将所需的 DLL 存储在自己的目录中。
[4]. Melvin E. Conway, How Do Committees Invent, Datamation 14:5:28–31.
[5]. MacCormack, Rusnak, Baldwin, Exploring the Duality between Product and Organizational Architectures: A Test of the Mirroring Hypothesis, Harvard Business School [8XYofQ]。
[6]. 本地仓库会定期从远程仓库更新——虽然可以在远程仓库中存储快照,但这不是一个好主意。
[1]. 虽然开源系统和商业系统之间的区别对消费者的自由很重要,但值得注意的是,Subversion 由商业组织 Collabnet 维护,该组织提供付费支持。
[2]. 要以幽默的方式了解主要的开源版本控制系统,请参阅 [bnb6MF]。
[3]. RCS 与 SCCS 一样,仅适用于本地文件系统。
[4]. 我们更喜欢使用更通用的术语”变更集”而不是”修订版”,但 Subversion 专门使用”修订版”。
[5]. 实际上,VSS 建议在运行 VSS 时至少每周运行一次数据库完整性检查器 [c2M8mf]。
[6]. 摘自 Appleton et al., 1998 [dAI5I4]。
[7]. 如 Henrik Kniberg 在《多个敏捷团队的版本控制》中所述 [ctlRvc]。
[1]. ACM, 1984, vol. 27 issue 9.
[2]. 如上所述,我们认为迭代应该限定为两周,而不是四周。