
作为一个每天在终端里用 tmux 挂着数十个并发脚本、重度依赖 CLI 工具开发 AI 链路的全栈工程师,这篇文章展示的架构革新让我极度兴奋。
长久以来,我们在构建 AI 记忆时,总是下意识地写脚本调包、用 curl 加上各路向量数据库(Vector DBs)做被动的 RAG 语义检索。但这套基于余弦相似度(Cosine Similarity)的旧方案在面对具有时间跨度、自相矛盾或状态变更的真实对话数据时,表现堪称灾难。
Supermemory 这次名为 ASMR 的实验性架构,彻底抛弃了被动的 Vector Chunking(向量分块)。他们用硬核工程的思路降维打击了传统方案,采用了我们在并发编程中极度推崇的 “多线程调度 + MapReduce” 思想:
一句话总结:用并行的、专业化的多智能体(Multi-Agent)推理网络替代死板的单维向量检索算法,这是攻克复杂长时记忆(Long-term Memory)的正确解法。我已经迫不及待等 11 天后他们开源了,到时候必须用 git clone 扒拉下来在 CLI 里跑跑压测!
作者:Dhravya Shah | 日期:2026年3月22日
请在此阅读后续内容!
https://x.com/DhravyaShah/status/2036243995500966260?s=20
太长不看(TLDR):这是一个大型社会实验,旨在为报告记忆系统质量制定新标准。这是一场戏仿(parody)。
几个月前,我们发布了第一份研究报告,显示 Supermemory 在 LongMemEval-s 上取得了约 85% 的成绩,这使我们领先于当时每一个公开进行基准测试的记忆系统。今天,我们发布了一项新成果:在 LongMemEval_s 上达到约 99%。
需要提前明确的是:这(目前)还不是我们的主要生产级 Supermemory 引擎。 相反,这篇博客涵盖了我们构建的一个全新、高度实验性的智能体工作流,纯粹是为了看看在独立于核心生产约束的情况下,我们能将记忆检索和推理的绝对极限推到多远。
以下是我们如何做到这一点的。隆重介绍我们的新技术:ASMR(Agentic search and memory retrieval,智能体搜索与记忆检索)
LongMemEval 是目前最严格的公开长期记忆基准测试之一。与那些只在短上下文中测试简单检索的基准不同,LongMemEval 旨在模拟真实生产环境中混乱的状况:超过 11.5 万 token 的对话历史、相互矛盾的信息、跨越多个会话分布的事件,以及需要对时间进行推理的问题。
大多数记忆系统得分低的原因通常是检索问题——而不是推理。即使召回率很高,如果检索中存在大量噪音,LLM(大语言模型)也可能难以利用它。真正的难点在于如何从一开始就只将正确的信息送入上下文窗口,而更难的是:如何判定检索到的某个事实是否已经过时,并被较新的版本所取代。
为了解决这个问题,我们放弃了传统的 RAG(检索增强生成),构建了一个多智能体编排管道(multi-agent orchestrated pipeline)。
标准向量搜索总体上是不错的。然而,在处理密集、跨会话的时序数据所带来的微妙变化时,它就会崩溃。语义相似度匹配无法可靠地区分旧事实和新修正。为了应对 LongMemEval 的复杂性,我们不得不彻底重新构思我们的摄取和检索管道,用主动的智能体推理取代了粗暴的向量数学计算。
就像 ASMR 一样,这项技术简单而又令人极度舒适。
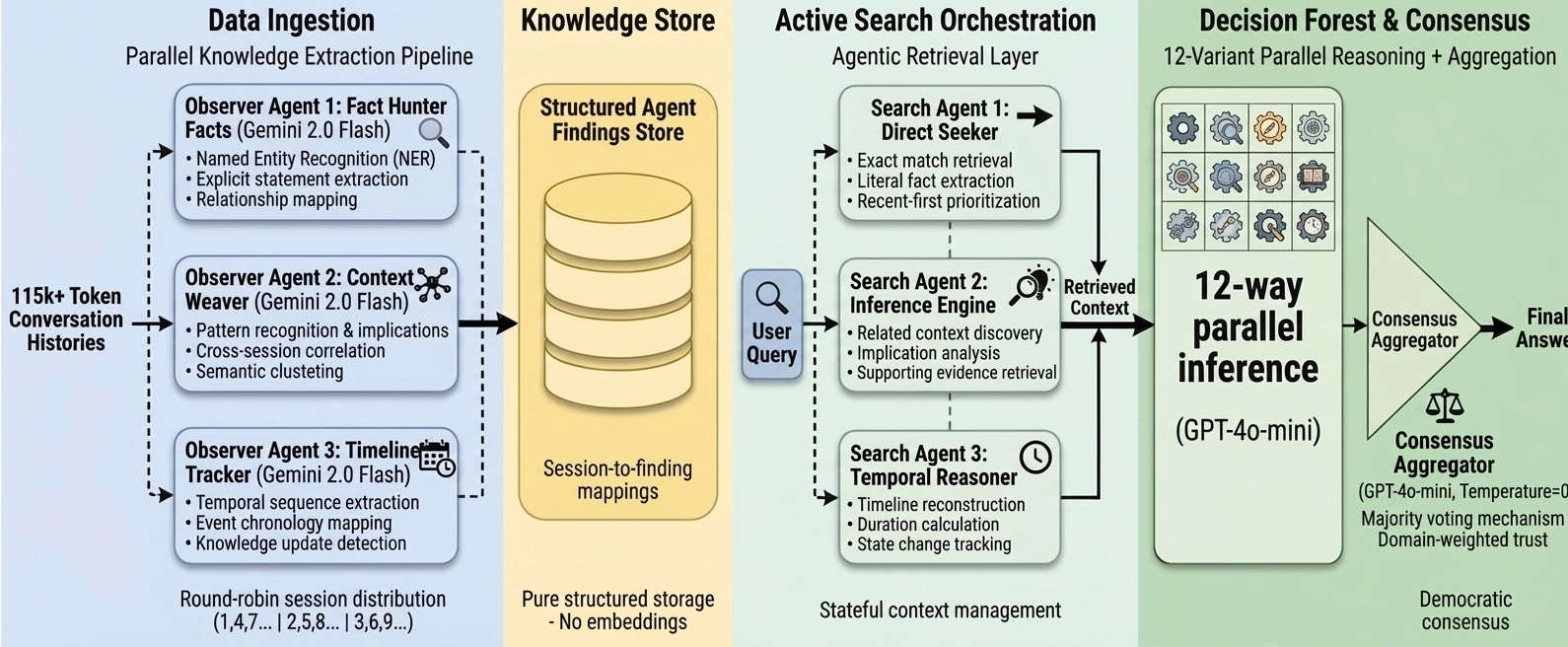
我们没有对用户会话进行机械的分块和嵌入特征映射(Embedding),而是部署了一个利用 3 个并行阅读者(观察者)智能体(由 Gemini 2.0 Flash 驱动)的智能体编排器。这些智能体同时通读原始会话(例如,智能体 1 处理会话 1、3、5;智能体 2 处理 2、4、6)。
它们的目标是跨六个维度进行有针对性的知识提取:个人信息、偏好、事件、时间数据、更新内容和助手信息。随后,这些结构化的发现会被原生存储,并映射回它们的原始出处会话中。
当问题出现时,我们不会去查询向量数据库。相反,我们部署了 3 个并行的搜索智能体。这些智能体会主动阅读和推理存储的发现集,每个智能体都有专门的侧重点:
编排器将汇集所有三个搜索智能体的发现,并拉取会话原文摘录以进行细节验证。这使得系统能够基于真实的认知理解(而不仅仅是关键字或数学层面的相似性)进行智能检索。
一旦上下文被组装完毕,任何单一的提示词(Prompt)都无法应对 LongMemEval 中繁多复杂的问题类型。有些问题需要你推断细节,而另一些则需要你进行极其精准的提取。我们测试了两种截然不同的智能体问答工作流:
测试 1:8 变体集成(准确率 98.60%)
在我们的第一种方法中,我们将检索到的上下文路由给 8 个高度专业化、并行运行的提示词变体(例如:精确计数器、时间专家、上下文深度挖掘器等)。每个变体独立评估上下文并生成答案。如果 8 条不同推理路径中的任何一条成功得出了正确事实(Ground Truth),则该问题即被标记为正确。这种并行的多重评判方法使我们达到了惊人的 98.60% 总体准确率,完美覆盖了我们的盲区。
测试 2:12 变体决策森林(准确率 97.20%)
为了测试一个能够产生单一权威答案,而不是依赖多重独立碰运气尝试的系统,我们将架构扩展为 12 个变体的决策森林。
在这里,12 个高度专业化的智能体(由 GPT-4o-mini 驱动)独立对提示词做出回答。然后,我们引入了一个聚合器 LLM(Aggregator LLM)作为最终裁判。聚合器使用多数投票、领域信任度评估和冲突解决机制综合了这 12 个答案。这种单一的共识模型同样取得了极高的 97.20% 准确率。
这个实验性架构的表现从根本上改变了长期 AI 记忆的可能性边界。为了理解这一成就的规模有多庞大,请看我们的实验性智能体工作流与我们最初的生产引擎以及整个行业的整体表现对比图:
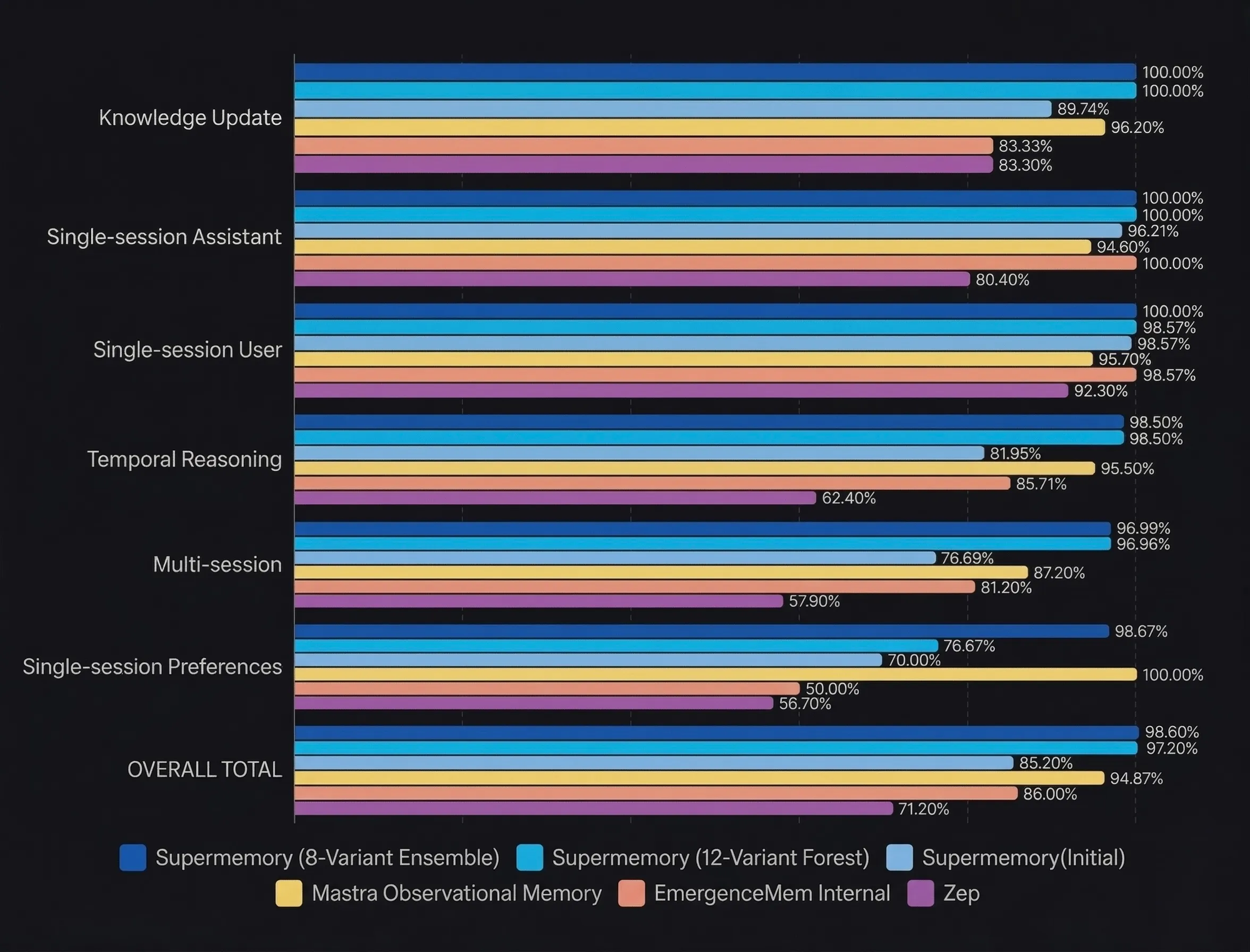
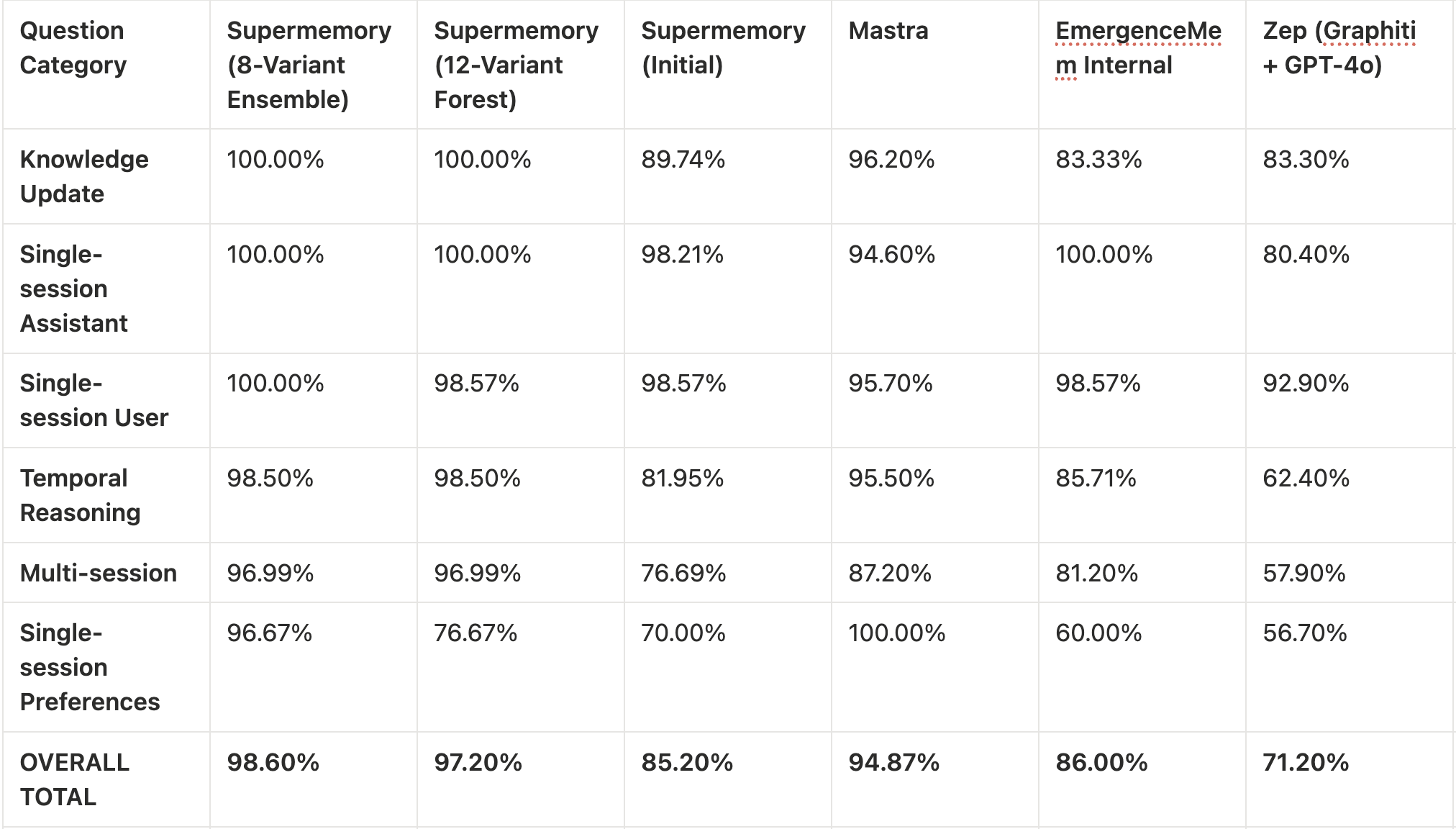
构建一个在生产级基准测试上达到约 99% 准确率的系统,为我们带来了一些极其关键的工程见解:
因为这是一个实验沙盒,而不是我们的核心 Supermemory 引擎,我们希望广大的 AI 社区能够从这个架构中学习并在其基础上进行创新构建。我们很快将把这个实验性智能体工作流的完整代码开源。 记忆是一个不断演变的挑战,虽然这项研究突破了目前我们所知的天花板,但我们已经在紧锣密鼓地研究如何将这些纯智能体的检索技术平滑过渡到我们的核心生产环境中。
整整 11 天后(四月初开始),我们将发布并开源关于这个新智能体记忆系统的全部内容。它将在公开环境下构建,成为供大家观摩的一场盛会。我们对此乐在其中。
请访问我们的 Github https://github.com/supermemoryai 并密切关注那里的发布 👀
智能体记忆现在(大概)是一个已经被解决的问题了吧?